mirror of
https://github.com/didi/KnowStreaming.git
synced 2026-01-18 14:38:06 +08:00
Add km module kafka
This commit is contained in:
289
docs/zh/Kafka分享/Kafka Controller /Controller中的状态机.md
Normal file
289
docs/zh/Kafka分享/Kafka Controller /Controller中的状态机.md
Normal file
@@ -0,0 +1,289 @@
|
||||
|
||||
|
||||
前言
|
||||
>Controller中有两个状态机分别是`ReplicaStateMachine 副本状态机`和`PartitionStateMachine分区状态机` ; 他们的作用是负责处理每个分区和副本在状态变更过程中要处理的事情; 并且确保从上一个状态变更到下一个状态是合法的; 源码中你能看到很多地方只是进行状态流转; 所以我们要清楚每个流转都做了哪些事情;对我们阅读源码更清晰
|
||||
>
|
||||
>----
|
||||
>在之前的文章 [【kafka源码】Controller启动过程以及选举流程源码分析]() 中,我们有分析到,
|
||||
>`replicaStateMachine.startup()` 和 `partitionStateMachine.startup()`
|
||||
>副本专状态机和分区状态机的启动; 那我们就从这里开始好好讲下两个状态机
|
||||
|
||||
|
||||
## 源码解析
|
||||
<font color="red">如果觉得阅读源码解析太枯燥,请直接看 源码总结及其后面部分</font>
|
||||
|
||||
### ReplicaStateMachine 副本状态机
|
||||
Controller 选举成功之后 调用`ReplicaStateMachine.startup`启动副本状态机
|
||||
```scala
|
||||
|
||||
def startup(): Unit = {
|
||||
//初始化所有副本的状态
|
||||
initializeReplicaState()
|
||||
val (onlineReplicas, offlineReplicas) = controllerContext.onlineAndOfflineReplicas
|
||||
handleStateChanges(onlineReplicas.toSeq, OnlineReplica)
|
||||
handleStateChanges(offlineReplicas.toSeq, OfflineReplica)
|
||||
}
|
||||
|
||||
```
|
||||
1. 初始化所有副本的状态,如果副本在线则状态变更为`OnlineReplica` ;否则变更为`ReplicaDeletionIneligible`副本删除失败状态; 判断副本是否在线的条件是 副本所在Broker需要在线&&副本没有被标记为已下线状态(Map `replicasOnOfflineDirs`用于维护副本失败在线),一般情况下这个里面是被标记为删除的Topic
|
||||
2. 执行状态变更处理器
|
||||
|
||||
#### ReplicaStateMachine状态变更处理器
|
||||
>它确保每个状态转换都发生从合法的先前状态到目标状态。有效的状态转换是:
|
||||
>1. `NonExistentReplica --> NewReplica: `-- 将 LeaderAndIsr 请求与当前领导者和 isr 发送到新副本,并将分区的 UpdateMetadata 请求发送到每个实时代理
|
||||
>2. `NewReplica -> OnlineReplica` --如果需要,将新副本添加到分配的副本列表中
|
||||
>3. `OnlineReplica,OfflineReplica -> OnlineReplica:`--将带有当前领导者和 isr 的 LeaderAndIsr 请求发送到新副本,并将分区的 UpdateMetadata 请求发送到每个实时代理
|
||||
>4. `NewReplica,OnlineReplica,OfflineReplica,ReplicaDeletionIneligible -> OfflineReplica:`:-- 向副本发送 `StopReplicaRequest` ;
|
||||
> -- 从 isr 中删除此副本并将 LeaderAndIsr 请求(带有新的 isr)发送到领导副本,并将分区的 UpdateMetadata 请求发送到每个实时代理。
|
||||
> 5. `OfflineReplica -> ReplicaDeletionStarted:` -- 向副本发送 `StopReplicaRequest` (带 删除参数);
|
||||
> 6. `ReplicaDeletionStarted -> ReplicaDeletionSuccessful:` --在状态机中标记副本的状态
|
||||
> 7. `ReplicaDeletionStarted -> ReplicaDeletionIneligible:` --在状态机中标记副本的状态
|
||||
> 8. `ReplicaDeletionSuccessful -> NonExistentReplica:`--从内存分区副本分配缓存中删除副本
|
||||
```scala
|
||||
private def doHandleStateChanges(replicaId: Int, replicas: Seq[PartitionAndReplica], targetState: ReplicaState): Unit = {
|
||||
//如果有副本没有设置状态,则初始化为`NonExistentReplica`
|
||||
replicas.foreach(replica => controllerContext.putReplicaStateIfNotExists(replica, NonExistentReplica))
|
||||
//校验状态流转是不是正确
|
||||
val (validReplicas, invalidReplicas) = controllerContext.checkValidReplicaStateChange(replicas, targetState)
|
||||
invalidReplicas.foreach(replica => logInvalidTransition(replica, targetState))
|
||||
|
||||
//代码省略,在下面细细说来
|
||||
}
|
||||
```
|
||||
```scala
|
||||
controllerBrokerRequestBatch.sendRequestsToBrokers(controllerContext.epoch)
|
||||
```
|
||||
1. 如果有副本没有设置状态,则初始化为`NonExistentReplica`
|
||||
2. 校验状态流转是不是正确
|
||||
3. 执行完了之后,还会可能尝试发一次`UPDATA_METADATA`
|
||||
|
||||
##### 先前状态 ==> OnlineReplica
|
||||
可流转的状态有
|
||||
1. `NewReplica`
|
||||
2. `OnlineReplica`
|
||||
3. `OfflineReplica`
|
||||
4. `ReplicaDeletionIneligible`
|
||||
|
||||
###### NewReplica ==》OnlineReplica
|
||||
>如果有需要,将新副本添加到分配的副本列表中;
|
||||
>比如[【kafka源码】TopicCommand之创建Topic源码解析]()
|
||||
|
||||
```scala
|
||||
case NewReplica =>
|
||||
val assignment = controllerContext.partitionFullReplicaAssignment(partition)
|
||||
if (!assignment.replicas.contains(replicaId)) {
|
||||
error(s"Adding replica ($replicaId) that is not part of the assignment $assignment")
|
||||
val newAssignment = assignment.copy(replicas = assignment.replicas :+ replicaId)
|
||||
controllerContext.updatePartitionFullReplicaAssignment(partition, newAssignment)
|
||||
}
|
||||
```
|
||||
|
||||
###### 其他状态 ==》OnlineReplica
|
||||
> 将带有当前领导者和 isr 的 LeaderAndIsr 请求发送到新副本,并将分区的 UpdateMetadata 请求发送到每个实时代理
|
||||
```scala
|
||||
case _ =>
|
||||
controllerContext.partitionLeadershipInfo.get(partition) match {
|
||||
case Some(leaderIsrAndControllerEpoch) =>
|
||||
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(Seq(replicaId),
|
||||
replica.topicPartition,
|
||||
leaderIsrAndControllerEpoch,
|
||||
controllerContext.partitionFullReplicaAssignment(partition), isNew = false)
|
||||
case None =>
|
||||
}
|
||||
```
|
||||
##### 先前状态 ==> ReplicaDeletionIneligible
|
||||
> 在内存`replicaStates`中更新一下副本状态为`ReplicaDeletionIneligible`
|
||||
##### 先前状态 ==》OfflinePartition
|
||||
>-- 向副本发送 StopReplicaRequest ;
|
||||
– 从 isr 中删除此副本并将 LeaderAndIsr 请求(带有新的 isr)发送到领导副本,并将分区的 UpdateMetadata 请求发送到每个实时代理。
|
||||
|
||||
```scala
|
||||
|
||||
case OfflineReplica =>
|
||||
// 添加构建StopReplicaRequest请求的擦书,deletePartition = false表示还不删除分区
|
||||
validReplicas.foreach { replica =>
|
||||
controllerBrokerRequestBatch.addStopReplicaRequestForBrokers(Seq(replicaId), replica.topicPartition, deletePartition = false)
|
||||
}
|
||||
val (replicasWithLeadershipInfo, replicasWithoutLeadershipInfo) = validReplicas.partition { replica =>
|
||||
controllerContext.partitionLeadershipInfo.contains(replica.topicPartition)
|
||||
}
|
||||
//尝试从多个分区的 isr 中删除副本。从 isr 中删除副本会更新 Zookeeper 中的分区状态
|
||||
//反复尝试从多个分区的 isr 中删除副本,直到没有更多剩余的分区可以重试。
|
||||
//从/brokers/topics/test_create_topic13/partitions获取分区相关数据
|
||||
//移除副本之后,重新写入到zk中
|
||||
val updatedLeaderIsrAndControllerEpochs = removeReplicasFromIsr(replicaId, replicasWithLeadershipInfo.map(_.topicPartition))
|
||||
updatedLeaderIsrAndControllerEpochs.foreach { case (partition, leaderIsrAndControllerEpoch) =>
|
||||
if (!controllerContext.isTopicQueuedUpForDeletion(partition.topic)) {
|
||||
val recipients = controllerContext.partitionReplicaAssignment(partition).filterNot(_ == replicaId)
|
||||
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(recipients,
|
||||
partition,
|
||||
leaderIsrAndControllerEpoch,
|
||||
controllerContext.partitionFullReplicaAssignment(partition), isNew = false)
|
||||
}
|
||||
val replica = PartitionAndReplica(partition, replicaId)
|
||||
val currentState = controllerContext.replicaState(replica)
|
||||
logSuccessfulTransition(replicaId, partition, currentState, OfflineReplica)
|
||||
controllerContext.putReplicaState(replica, OfflineReplica)
|
||||
}
|
||||
|
||||
replicasWithoutLeadershipInfo.foreach { replica =>
|
||||
val currentState = controllerContext.replicaState(replica)
|
||||
logSuccessfulTransition(replicaId, replica.topicPartition, currentState, OfflineReplica)
|
||||
controllerBrokerRequestBatch.addUpdateMetadataRequestForBrokers(controllerContext.liveOrShuttingDownBrokerIds.toSeq, Set(replica.topicPartition))
|
||||
controllerContext.putReplicaState(replica, OfflineReplica)
|
||||
}
|
||||
```
|
||||
1. 添加构建StopReplicaRequest请求的参数,`deletePartition = false`表示还不删除分区
|
||||
2. 反复尝试从多个分区的 isr 中删除副本,直到没有更多剩余的分区可以重试。从`/brokers/topics/{TOPICNAME}/partitions`获取分区相关数据,进过计算然后重新写入到zk中`/brokers/topics/{TOPICNAME}/partitions/state/`; 当然内存中的副本状态机的状态也会变更成 `OfflineReplica` ;
|
||||
3. 根据条件判断是否需要发送`LeaderAndIsrRequest`、`UpdateMetadataRequest`
|
||||
4. 发送`StopReplicaRequests`请求;
|
||||
|
||||
|
||||
##### 先前状态==>ReplicaDeletionStarted
|
||||
> 向指定的副本发送 [StopReplicaRequest 请求]()(带 删除参数);
|
||||
|
||||
```scala
|
||||
controllerBrokerRequestBatch.addStopReplicaRequestForBrokers(Seq(replicaId), replica.topicPartition, deletePartition = true)
|
||||
|
||||
```
|
||||
|
||||
##### 当前状态 ==> NewReplica
|
||||
>一般情况下,创建Topic的时候会触发这个流转;
|
||||
|
||||
```scala
|
||||
case NewReplica =>
|
||||
validReplicas.foreach { replica =>
|
||||
val partition = replica.topicPartition
|
||||
val currentState = controllerContext.replicaState(replica)
|
||||
|
||||
controllerContext.partitionLeadershipInfo.get(partition) match {
|
||||
case Some(leaderIsrAndControllerEpoch) =>
|
||||
if (leaderIsrAndControllerEpoch.leaderAndIsr.leader == replicaId) {
|
||||
val exception = new StateChangeFailedException(s"Replica $replicaId for partition $partition cannot be moved to NewReplica state as it is being requested to become leader")
|
||||
logFailedStateChange(replica, currentState, OfflineReplica, exception)
|
||||
} else {
|
||||
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(Seq(replicaId),
|
||||
replica.topicPartition,
|
||||
leaderIsrAndControllerEpoch,
|
||||
controllerContext.partitionFullReplicaAssignment(replica.topicPartition),
|
||||
isNew = true)
|
||||
logSuccessfulTransition(replicaId, partition, currentState, NewReplica)
|
||||
controllerContext.putReplicaState(replica, NewReplica)
|
||||
}
|
||||
case None =>
|
||||
logSuccessfulTransition(replicaId, partition, currentState, NewReplica)
|
||||
controllerContext.putReplicaState(replica, NewReplica)
|
||||
}
|
||||
}
|
||||
```
|
||||
1. 在内存中更新 副本状态;
|
||||
2. 在某些情况下,将带有当前领导者和 isr 的 LeaderAndIsr 请求发送到新副本,并将分区的 UpdateMetadata 请求发送到每个实时代理
|
||||
|
||||
##### 当前状态 ==> NonExistentPartition
|
||||
1. `OfflinePartition`
|
||||
|
||||
##### 当前状态 ==> NonExistentPartition
|
||||
|
||||
|
||||
### PartitionStateMachine分区状态机
|
||||
`PartitionStateMachine.startup`
|
||||
```scala
|
||||
def startup(): Unit = {
|
||||
initializePartitionState()
|
||||
triggerOnlinePartitionStateChange()
|
||||
}
|
||||
```
|
||||
`PartitionStateMachine.initializePartitionState()`
|
||||
> 初始化分区状态
|
||||
```scala
|
||||
/**
|
||||
* Invoked on startup of the partition's state machine to set the initial state for all existing partitions in
|
||||
* zookeeper
|
||||
*/
|
||||
private def initializePartitionState(): Unit = {
|
||||
for (topicPartition <- controllerContext.allPartitions) {
|
||||
// check if leader and isr path exists for partition. If not, then it is in NEW state
|
||||
//检查leader和isr路径是否存在
|
||||
controllerContext.partitionLeadershipInfo.get(topicPartition) match {
|
||||
case Some(currentLeaderIsrAndEpoch) =>
|
||||
if (controllerContext.isReplicaOnline(currentLeaderIsrAndEpoch.leaderAndIsr.leader, topicPartition))
|
||||
// leader is alive
|
||||
controllerContext.putPartitionState(topicPartition, OnlinePartition)
|
||||
else
|
||||
controllerContext.putPartitionState(topicPartition, OfflinePartition)
|
||||
case None =>
|
||||
controllerContext.putPartitionState(topicPartition, NewPartition)
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
1. 如果分区不存在`LeaderIsr`,则状态是`NewPartition`
|
||||
2. 如果分区存在`LeaderIsr`,就判断一下Leader是否存活
|
||||
2.1 如果存活的话,状态是`OnlinePartition`
|
||||
2.2 否则是`OfflinePartition`
|
||||
|
||||
|
||||
`PartitionStateMachine. triggerOnlinePartitionStateChange()`
|
||||
>尝试将所有处于 `NewPartition `或 `OfflinePartition `状态的分区移动到 `OnlinePartition` 状态,但属于要删除的主题的分区除外
|
||||
|
||||
```scala
|
||||
def triggerOnlinePartitionStateChange(): Unit = {
|
||||
val partitions = controllerContext.partitionsInStates(Set(OfflinePartition, NewPartition))
|
||||
triggerOnlineStateChangeForPartitions(partitions)
|
||||
}
|
||||
|
||||
private def triggerOnlineStateChangeForPartitions(partitions: collection.Set[TopicPartition]): Unit = {
|
||||
// try to move all partitions in NewPartition or OfflinePartition state to OnlinePartition state except partitions
|
||||
// that belong to topics to be deleted
|
||||
val partitionsToTrigger = partitions.filter { partition =>
|
||||
!controllerContext.isTopicQueuedUpForDeletion(partition.topic)
|
||||
}.toSeq
|
||||
|
||||
handleStateChanges(partitionsToTrigger, OnlinePartition, Some(OfflinePartitionLeaderElectionStrategy(false)))
|
||||
// TODO: If handleStateChanges catches an exception, it is not enough to bail out and log an error.
|
||||
// It is important to trigger leader election for those partitions.
|
||||
}
|
||||
```
|
||||
|
||||
#### PartitionStateMachine 分区状态机
|
||||
|
||||
`PartitionStateMachine.doHandleStateChanges `
|
||||
` controllerBrokerRequestBatch.sendRequestsToBrokers(controllerContext.epoch)
|
||||
`
|
||||
|
||||
>它确保每个状态转换都发生从合法的先前状态到目标状态。有效的状态转换是:
|
||||
>1. `NonExistentPartition -> NewPartition:` 将分配的副本从 ZK 加载到控制器缓存
|
||||
>2. `NewPartition -> OnlinePartition:` 将第一个活动副本指定为领导者,将所有活动副本指定为 isr;将此分区的leader和isr写入ZK ;向每个实时副本发送 LeaderAndIsr 请求,向每个实时代理发送 UpdateMetadata 请求
|
||||
>3. `OnlinePartition,OfflinePartition -> OnlinePartition:` 为这个分区选择新的leader和isr以及一组副本来接收LeaderAndIsr请求,并将leader和isr写入ZK;
|
||||
> 对于这个分区,向每个接收副本发送LeaderAndIsr请求,向每个live broker发送UpdateMetadata请求
|
||||
> 4. `NewPartition,OnlinePartition,OfflinePartition -> OfflinePartition:` 将分区状态标记为 Offline
|
||||
> 5. `OfflinePartition -> NonExistentPartition:` 将分区状态标记为 NonExistentPartition
|
||||
>
|
||||
##### 先前状态==》NewPartition
|
||||
>将分配的副本从 ZK 加载到控制器缓存
|
||||
|
||||
##### 先前状态==》OnlinePartition
|
||||
> 将第一个活动副本指定为领导者,将所有活动副本指定为 isr;将此分区的leader和isr写入ZK ;向每个实时副本发送 LeaderAndIsr 请求,向每个实时Broker发送 UpdateMetadata 请求
|
||||
|
||||
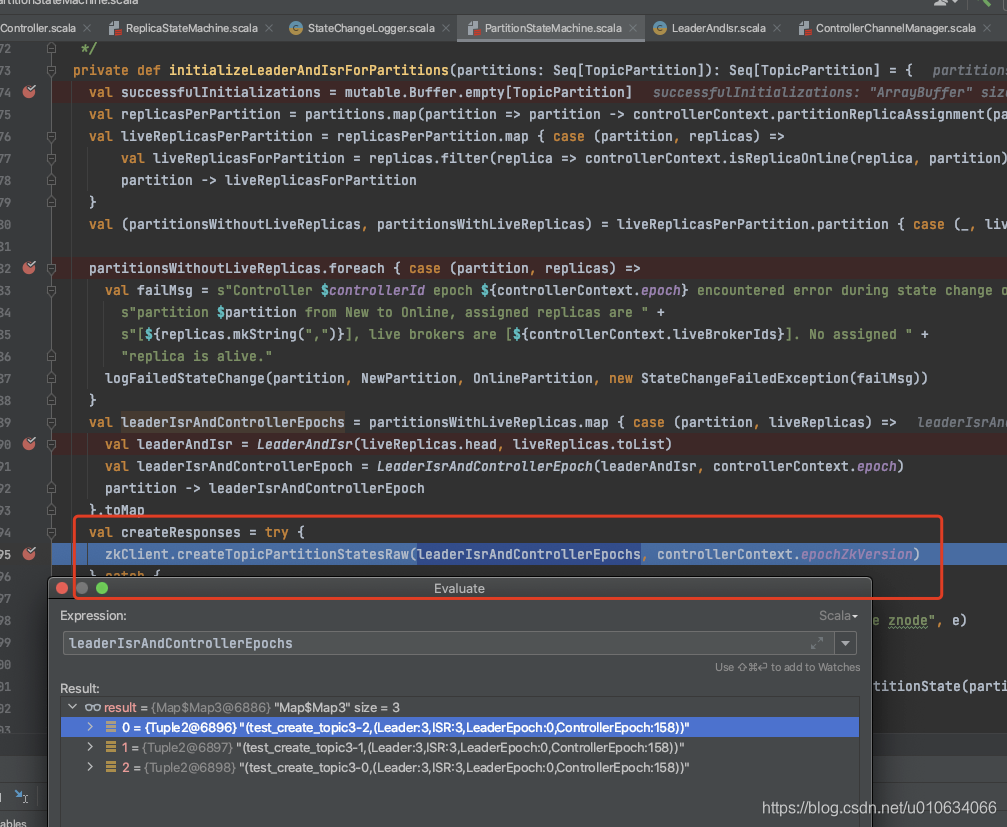
创建一个新的Topic的时候,我们主要看下面这个接口`initializeLeaderAndIsrForPartitions`
|
||||
|
||||
|
||||
0. 获取`leaderIsrAndControllerEpochs`; Leader为副本的第一个;
|
||||
1. 向zk中写入`/brokers/topics/{topicName}/partitions/` 持久节点; 无数据
|
||||
2. 向zk中写入`/brokers/topics/{topicName}/partitions/{分区号}` 持久节点; 无数据
|
||||
3. 向zk中写入`/brokers/topics/{topicName}/partitions/{分区号}/state` 持久节点; 数据为`leaderIsrAndControllerEpoch`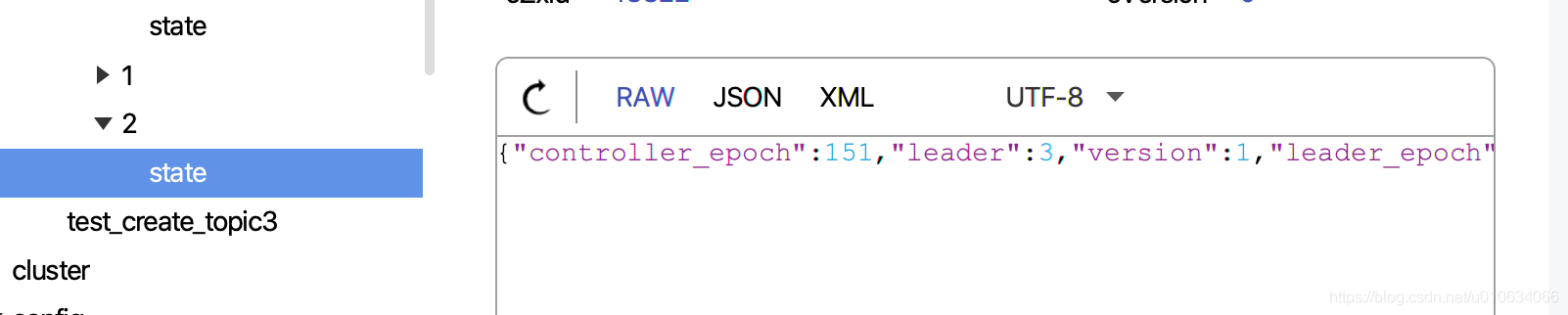
|
||||
4. 向副本所属Broker发送[`leaderAndIsrRequest`]()请求
|
||||
5. 向所有Broker发送[`UPDATE_METADATA` ]()请求
|
||||
|
||||
|
||||
##### 先前状态==》OfflinePartition
|
||||
>将分区状态标记为 Offline ; 在Map对象`partitionStates`中维护的; `NewPartition,OnlinePartition,OfflinePartition ` 可转;
|
||||
##### 先前状态==》NonExistentPartition
|
||||
|
||||
>将分区状态标记为 Offline ; 在Map对象`partitionStates`中维护的; `OfflinePartition ` 可转;
|
||||
|
||||
|
||||
|
||||
## 源码总结
|
||||
|
||||
## Q&A
|
||||
Reference in New Issue
Block a user