diff --git a/CODE_OF_CONDUCT.md b/CODE_OF_CONDUCT.md
deleted file mode 100644
index 5d8023ba..00000000
--- a/CODE_OF_CONDUCT.md
+++ /dev/null
@@ -1,74 +0,0 @@
-
-# Contributor Covenant Code of Conduct
-
-## Our Pledge
-
-In the interest of fostering an open and welcoming environment, we as
-contributors and maintainers pledge to making participation in our project, and
-our community a harassment-free experience for everyone, regardless of age, body
-size, disability, ethnicity, gender identity and expression, level of experience,
-education, socio-economic status, nationality, personal appearance, race,
-religion, or sexual identity and orientation.
-
-## Our Standards
-
-Examples of behavior that contributes to creating a positive environment
-include:
-
-* Using welcoming and inclusive language
-* Being respectful of differing viewpoints and experiences
-* Gracefully accepting constructive criticism
-* Focusing on what is best for the community
-* Showing empathy towards other community members
-
-Examples of unacceptable behavior by participants include:
-
-* The use of sexualized language or imagery and unwelcome sexual attention or
- advances
-* Trolling, insulting/derogatory comments, and personal or political attacks
-* Public or private harassment
-* Publishing others' private information, such as a physical or electronic
- address, without explicit permission
-* Other conduct which could reasonably be considered inappropriate in a
- professional setting
-
-## Our Responsibilities
-
-Project maintainers are responsible for clarifying the standards of acceptable
-behavior and are expected to take appropriate and fair corrective action in
-response to any instances of unacceptable behavior.
-
-Project maintainers have the right and responsibility to remove, edit, or
-reject comments, commits, code, wiki edits, issues, and other contributions
-that are not aligned to this Code of Conduct, or to ban temporarily or
-permanently any contributor for other behaviors that they deem inappropriate,
-threatening, offensive, or harmful.
-
-## Scope
-
-This Code of Conduct applies both within project spaces and in public spaces
-when an individual is representing the project or its community. Examples of
-representing a project or community include using an official project e-mail
-address, posting via an official social media account, or acting as an appointed
-representative at an online or offline event. Representation of a project may be
-further defined and clarified by project maintainers.
-
-## Enforcement
-
-Instances of abusive, harassing, or otherwise unacceptable behavior may be
-reported by contacting the project team at https://knowstreaming.com/support-center . All
-complaints will be reviewed and investigated and will result in a response that
-is deemed necessary and appropriate to the circumstances. The project team is
-obligated to maintain confidentiality with regard to the reporter of an incident.
-Further details of specific enforcement policies may be posted separately.
-
-Project maintainers who do not follow or enforce the Code of Conduct in good
-faith may face temporary or permanent repercussions as determined by other
-members of the project's leadership.
-
-## Attribution
-
-This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
-available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
-
-[homepage]: https://www.contributor-covenant.org
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
deleted file mode 100644
index 06577128..00000000
--- a/CONTRIBUTING.md
+++ /dev/null
@@ -1,150 +0,0 @@
-
-
-
-# 为KnowStreaming做贡献
-
-
-欢迎👏🏻来到KnowStreaming!本文档是关于如何为KnowStreaming做出贡献的指南。
-
-如果您发现不正确或遗漏的内容, 请留下意见/建议。
-
-## 行为守则
-请务必阅读并遵守我们的 [行为准则](./CODE_OF_CONDUCT.md).
-
-
-
-## 贡献
-
-**KnowStreaming** 欢迎任何角色的新参与者,包括 **User** 、**Contributor**、**Committer**、**PMC** 。
-
-我们鼓励新人积极加入 **KnowStreaming** 项目,从User到Contributor、Committer ,甚至是 PMC 角色。
-
-为了做到这一点,新人需要积极地为 **KnowStreaming** 项目做出贡献。以下介绍如何对 **KnowStreaming** 进行贡献。
-
-
-### 创建/打开 Issue
-
-如果您在文档中发现拼写错误、在代码中**发现错误**或想要**新功能**或想要**提供建议**,您可以在 GitHub 上[创建一个Issue](https://github.com/didi/KnowStreaming/issues/new/choose) 进行报告。
-
-
-如果您想直接贡献, 您可以选择下面标签的问题。
-
-- [contribution welcome](https://github.com/didi/KnowStreaming/labels/contribution%20welcome) : 非常需要解决/新增 的Issues
-- [good first issue](https://github.com/didi/KnowStreaming/labels/good%20first%20issue): 对新人比较友好, 新人可以拿这个Issue来练练手热热身。
-
- 请注意,任何 PR 都必须与有效issue相关联。否则,PR 将被拒绝。
-
-
-
-### 开始你的贡献
-
-**分支介绍**
-
-我们将 `dev`分支作为开发分支, 说明这是一个不稳定的分支。
-
-此外,我们的分支模型符合 [https://nvie.com/posts/a-successful-git-branching-model/](https://nvie.com/posts/a-successful-git-branching-model/). 我们强烈建议新人在创建PR之前先阅读上述文章。
-
-
-
-**贡献流程**
-
-为方便描述,我们这里定义一下2个名词:
-
-自己Fork出来的仓库是私人仓库, 我们这里称之为 :**分叉仓库**
-Fork的源项目,我们称之为:**源仓库**
-
-
-现在,如果您准备好创建PR, 以下是贡献者的工作流程:
-
-1. Fork [KnowStreaming](https://github.com/didi/KnowStreaming) 项目到自己的仓库
-
-2. 从源仓库的`dev`拉取并创建自己的本地分支,例如: `dev`
-3. 在本地分支上对代码进行修改
-4. Rebase 开发分支, 并解决冲突
-5. commit 并 push 您的更改到您自己的**分叉仓库**
-6. 创建一个 Pull Request 到**源仓库**的`dev`分支中。
-7. 等待回复。如果回复的慢,请无情的催促。
-
-
-更为详细的贡献流程请看:[贡献流程](./docs/contributer_guide/贡献流程.md)
-
-创建Pull Request时:
-
-1. 请遵循 PR的 [模板](./.github/PULL_REQUEST_TEMPLATE.md)
-2. 请确保 PR 有相应的issue。
-3. 如果您的 PR 包含较大的更改,例如组件重构或新组件,请编写有关其设计和使用的详细文档(在对应的issue中)。
-4. 注意单个 PR 不能太大。如果需要进行大量更改,最好将更改分成几个单独的 PR。
-5. 在合并PR之前,尽量的将最终的提交信息清晰简洁, 将多次修改的提交尽可能的合并为一次提交。
-6. 创建 PR 后,将为PR分配一个或多个reviewers。
-
-
-如果您的 PR 包含较大的更改,例如组件重构或新组件,请编写有关其设计和使用的详细文档。
-
-
-# 代码审查指南
-
-Commiter将轮流review代码,以确保在合并前至少有一名Commiter
-
-一些原则:
-
-- 可读性——重要的代码应该有详细的文档。API 应该有 Javadoc。代码风格应与现有风格保持一致。
-- 优雅:新的函数、类或组件应该设计得很好。
-- 可测试性——单元测试用例应该覆盖 80% 的新代码。
-- 可维护性 - 遵守我们的编码规范。
-
-
-# 开发者
-
-## 成为Contributor
-
-只要成功提交并合并PR , 则为Contributor
-
-贡献者名单请看:[贡献者名单](./docs/contributer_guide/开发者名单.md)
-
-## 尝试成为Commiter
-
-一般来说, 贡献8个重要的补丁并至少让三个不同的人来Review他们(您需要3个Commiter的支持)。
-然后请人给你提名, 您需要展示您的
-
-1. 至少8个重要的PR和项目的相关问题
-2. 与团队合作的能力
-3. 了解项目的代码库和编码风格
-4. 编写好代码的能力
-
-当前的Commiter可以通过在KnowStreaming中的Issue标签 `nomination`(提名)来提名您
-
-1. 你的名字和姓氏
-2. 指向您的Git个人资料的链接
-3. 解释为什么你应该成为Commiter
-4. 详细说明提名人与您合作的3个PR以及相关问题,这些问题可以证明您的能力。
-
-另外2个Commiter需要支持您的**提名**,如果5个工作日内没有人反对,您就是提交者,如果有人反对或者想要更多的信息,Commiter会讨论并通常达成共识(5个工作日内) 。
-
-
-# 开源奖励计划
-
-
-我们非常欢迎开发者们为KnowStreaming开源项目贡献一份力量,相应也将给予贡献者激励以表认可与感谢。
-
-
-## 参与贡献
-
-1. 积极参与 Issue 的讨论,如答疑解惑、提供想法或报告无法解决的错误(Issue)
-2. 撰写和改进项目的文档(Wiki)
-3. 提交补丁优化代码(Coding)
-
-
-## 你将获得
-
-1. 加入KnowStreaming开源项目贡献者名单并展示
-2. KnowStreaming开源贡献者证书(纸质&电子版)
-3. KnowStreaming贡献者精美大礼包(KnowStreamin/滴滴 周边)
-
-
-## 相关规则
-
-- Contributer和Commiter都会有对应的证书和对应的礼包
-- 每季度有KnowStreaming项目团队评选出杰出贡献者,颁发相应证书。
-- 年末进行年度评选
-
-贡献者名单请看:[贡献者名单](./docs/contributer_guide/开发者名单.md)
\ No newline at end of file
diff --git a/README.md b/README.md
deleted file mode 100644
index 8f526268..00000000
--- a/README.md
+++ /dev/null
@@ -1,157 +0,0 @@
-
-
- -
-
-
-
-
-
- 产品官网 |
- 下载地址 |
- 文档资源 |
- 体验环境
-
-
-
-
-
-  -
-
-
-
-
-
-
-
-
-  -
-
-
-
-
-
-
-
-
-  -
-
-
-
-
-
-
-
-
-  -
-
-
-
-
-
-
-
-
-  -
-
-
-
-
-
-
-
----
-
-
-## `Know Streaming` 简介
-
-`Know Streaming`是一套云原生的Kafka管控平台,脱胎于众多互联网内部多年的Kafka运营实践经验,专注于Kafka运维管控、监控告警、资源治理、多活容灾等核心场景。在用户体验、监控、运维管控上进行了平台化、可视化、智能化的建设,提供一系列特色的功能,极大地方便了用户和运维人员的日常使用,让普通运维人员都能成为Kafka专家。
-
-我们现在正在收集 Know Streaming 用户信息,以帮助我们进一步改进 Know Streaming。
-请在 [issue#663](https://github.com/didi/KnowStreaming/issues/663) 上提供您的使用信息来支持我们:[谁在使用 Know Streaming](https://github.com/didi/KnowStreaming/issues/663)
-
-
-
-整体具有以下特点:
-
-- 👀 **零侵入、全覆盖**
- - 无需侵入改造 `Apache Kafka` ,一键便能纳管 `0.10.x` ~ `3.x.x` 众多版本的Kafka,包括 `ZK` 或 `Raft` 运行模式的版本,同时在兼容架构上具备良好的扩展性,帮助您提升集群管理水平;
-
-- 🌪️ **零成本、界面化**
- - 提炼高频 CLI 能力,设计合理的产品路径,提供清新美观的 GUI 界面,支持 Cluster、Broker、Zookeeper、Topic、ConsumerGroup、Message、ACL、Connect 等组件 GUI 管理,普通用户5分钟即可上手;
-
-- 👏 **云原生、插件化**
- - 基于云原生构建,具备水平扩展能力,只需要增加节点即可获取更强的采集及对外服务能力,提供众多可热插拔的企业级特性,覆盖可观测性生态整合、资源治理、多活容灾等核心场景;
-
-- 🚀 **专业能力**
- - 集群管理:支持一键纳管,健康分析、核心组件观测 等功能;
- - 观测提升:多维度指标观测大盘、观测指标最佳实践 等功能;
- - 异常巡检:集群多维度健康巡检、集群多维度健康分 等功能;
- - 能力增强:集群负载均衡、Topic扩缩副本、Topic副本迁移 等功能;
-
-
-
-**产品图**
-
-
-
- -
-
-
-
-
-
-
-
-## 文档资源
-
-**`开发相关手册`**
-
-- [打包编译手册](docs/install_guide/源码编译打包手册.md)
-- [单机部署手册](docs/install_guide/单机部署手册.md)
-- [版本升级手册](docs/install_guide/版本升级手册.md)
-- [本地源码启动手册](docs/dev_guide/本地源码启动手册.md)
-
-**`产品相关手册`**
-
-- [产品使用指南](docs/user_guide/用户使用手册.md)
-- [2.x与3.x新旧对比手册](docs/user_guide/新旧对比手册.md)
-- [FAQ](docs/user_guide/faq.md)
-
-
-**点击 [这里](https://doc.knowstreaming.com/product),也可以从官网获取到更多文档**
-
-
-
-
-
-## 成为社区贡献者
-
-1. [贡献源码](https://doc.knowstreaming.com/product/10-contribution) 了解如何成为 Know Streaming 的贡献者
-2. [具体贡献流程](https://doc.knowstreaming.com/product/10-contribution#102-贡献流程)
-3. [开源激励计划](https://doc.knowstreaming.com/product/10-contribution#105-开源激励计划)
-4. [贡献者名单](https://doc.knowstreaming.com/product/10-contribution#106-贡献者名单)
-
-
-获取KnowStreaming开源社区证书。
-
-## 加入技术交流群
-
-**`1、知识星球`**
-
-
- -
-
-
-
-
-
-
-
-
-
-
-
-👍 我们正在组建国内最大,最权威的 **[Kafka中文社区](https://z.didi.cn/5gSF9)**
-
-在这里你可以结交各大互联网的 Kafka大佬 以及 4000+ Kafka爱好者,一起实现知识共享,实时掌控最新行业资讯,期待 👏 您的加入中~ https://z.didi.cn/5gSF9
-
-有问必答~! 互动有礼~!
-
-PS: 提问请尽量把问题一次性描述清楚,并告知环境信息情况~!如使用版本、操作步骤、报错/警告信息等,方便大V们快速解答~
-
-
-
-**`2、微信群`**
-
-微信加群:添加`mike_zhangliang`、`PenceXie` 、`szzdzhp001`的微信号备注KnowStreaming加群。
-
-
-加群之前有劳点一下 star,一个小小的 star 是对KnowStreaming作者们努力建设社区的动力。
-
-感谢感谢!!!
-
- -
-## Star History
-
-[](https://star-history.com/#didi/KnowStreaming&Date)
diff --git a/Releases_Notes.md b/Releases_Notes.md
deleted file mode 100644
index a606ef72..00000000
--- a/Releases_Notes.md
+++ /dev/null
@@ -1,572 +0,0 @@
-
-## v3.3.0
-
-**问题修复**
-- 修复 Connect 的 JMX-Port 配置未生效问题;
-- 修复 不存在 Connector 时,OverView 页面的数据一直处于加载中的问题;
-- 修复 Group 分区信息,分页时展示不全的问题;
-- 修复采集副本指标时,参数传递错误的问题;
-- 修复用户信息修改后,用户列表会抛出空指针异常的问题;
-- 修复 Topic 详情页面,查看消息时,选择分区不生效问题;
-- 修复对 ZK 客户端进行配置后不生效的问题;
-- 修复 connect 模块,指标中缺少健康巡检项通过数的问题;
-- 修复 connect 模块,指标获取方法存在映射错误的问题;
-- 修复 connect 模块,max 纬度指标获取错误的问题;
-- 修复 Topic 指标大盘 TopN 指标显示信息错误的问题;
-- 修复 Broker Similar Config 显示错误的问题;
-- 修复解析 ZK 四字命令时,数据类型设置错误导致空指针的问题;
-- 修复新增 Topic 时,清理策略选项版本控制错误的问题;
-- 修复新接入集群时 Controller-Host 信息不显示的问题;
-- 修复 Connector 和 MM2 列表搜索不生效的问题;
-- 修复 Zookeeper 页面,Leader 显示存在异常的问题;
-- 修复前端打包失败的问题;
-
-
-**产品优化**
-- ZK Overview 页面补充默认展示的指标;
-- 统一初始化 ES 索引模版的脚本为 init_es_template.sh,同时新增缺失的 connect 索引模版初始化脚本,去除多余的 replica 和 zookeper 索引模版初始化脚本;
-- 指标大盘页面,优化指标筛选操作后,无指标数据的指标卡片由不显示改为显示,并增加无数据的兜底;
-- 删除从 ES 读写 replica 指标的相关代码;
-- 优化 Topic 健康巡检的日志,明确错误的原因;
-- 优化无 ZK 模块时,巡检详情忽略对 ZK 的展示;
-- 优化本地缓存大小为可配置;
-- Task 模块中的返回中,补充任务的分组信息;
-- FAQ 补充 Ldap 的配置说明;
-- FAQ 补充接入 Kerberos 认证的 Kafka 集群的配置说明;
-- ks_km_kafka_change_record 表增加时间纬度的索引,优化查询性能;
-- 优化 ZK 健康巡检的日志,便于问题的排查;
-
-**功能新增**
-- 新增基于滴滴 Kafka 的 Topic 复制功能(需使用滴滴 Kafka 才可具备该能力);
-- Topic 指标大盘,新增 Topic 复制相关的指标;
-- 新增基于 TestContainers 的单测;
-
-
-**Kafka MM2 Beta版 (v3.3.0版本新增发布)**
-- MM2 任务的增删改查;
-- MM2 任务的指标大盘;
-- MM2 任务的健康状态;
-
----
-
-
-## v3.2.0
-
-**问题修复**
-- 修复健康巡检结果更新至 DB 时,出现死锁问题;
-- 修复 KafkaJMXClient 类中,logger错误的问题;
-- 后端修复 Topic 过期策略在 0.10.1.0 版本能多选的问题,实际应该只能二选一;
-- 修复接入集群时,不填写集群配置会报错的问题;
-- 升级 spring-context 至 5.3.19 版本,修复安全漏洞;
-- 修复 Broker & Topic 修改配置时,多版本兼容配置的版本信息错误的问题;
-- 修复 Topic 列表的健康分为健康状态;
-- 修复 Broker LogSize 指标存储名称错误导致查询不到的问题;
-- 修复 Prometheus 中,缺少 Group 部分指标的问题;
-- 修复因缺少健康状态指标导致集群数错误的问题;
-- 修复后台任务记录操作日志时,因缺少操作用户信息导致出现异常的问题;
-- 修复 Replica 指标查询时,DSL 错误的问题;
-- 关闭 errorLogger,修复错误日志重复输出的问题;
-- 修复系统管理更新用户信息失败的问题;
-- 修复因原AR信息丢失,导致迁移任务一直处于执行中的错误;
-- 修复集群 Topic 列表实时数据查询时,出现失败的问题;
-- 修复集群 Topic 列表,页面白屏问题;
-- 修复副本变更时,因AR数据异常,导致数组访问越界的问题;
-
-
-**产品优化**
-- 优化健康巡检为按照资源维度多线程并发处理;
-- 统一日志输出格式,并优化部分输出的日志;
-- 优化 ZK 四字命令结果解析过程中,容易引起误解的 WARN 日志;
-- 优化 Zookeeper 详情中,目录结构的搜索文案;
-- 优化线程池的名称,方便第三方系统进行相关问题的分析;
-- 去除 ESClient 的并发访问控制,降低 ESClient 创建数及提升利用率;
-- 优化 Topic Messages 抽屉文案;
-- 优化 ZK 健康巡检失败时的错误日志信息;
-- 提高 Offset 信息获取的超时时间,降低并发过高时出现请求超时的概率;
-- 优化 Topic & Partition 元信息的更新策略,降低对 DB 连接的占用;
-- 优化 Sonar 代码扫码问题;
-- 优化分区 Offset 指标的采集;
-- 优化前端图表相关组件逻辑;
-- 优化产品主题色;
-- Consumer 列表刷新按钮新增 hover 提示;
-- 优化配置 Topic 的消息大小时的测试弹框体验;
-- 优化 Overview 页面 TopN 查询的流程;
-
-
-**功能新增**
-- 新增页面无数据排查文档;
-- 增加 ES 索引删除的功能;
-- 支持拆分API服务和Job服务部署;
-
-
-**Kafka Connect Beta版 (v3.2.0版本新增发布)**
-- Connect 集群的纳管;
-- Connector 的增删改查;
-- Connect 集群 & Connector 的指标大盘;
-
-
----
-
-
-## v3.1.0
-
-**Bug修复**
-- 修复重置 Group Offset 的提示信息中,缺少Dead状态也可进行重置的描述;
-- 修复新建 Topic 后,立即查看 Topic Messages 信息时,会提示 Topic 不存在的问题;
-- 修复副本变更时,优先副本选举未被正常处罚执行的问题;
-- 修复 git 目录不存在时,打包不能正常进行的问题;
-- 修复 KRaft 模式的 Kafka 集群,JMX PORT 显示 -1 的问题;
-
-
-**体验优化**
-- 优化Cluster、Broker、Topic、Group的健康分为健康状态;
-- 去除健康巡检配置中的权重信息;
-- 错误提示页面展示优化;
-- 前端打包编译依赖默认使用 taobao 镜像;
-- 重新设计优化导航栏的 icon ;
-
-
-**新增**
-- 个人头像下拉信息中,新增产品版本信息;
-- 多集群列表页面,新增集群健康状态分布信息;
-
-
-**Kafka ZK 部分 (v3.1.0版本正式发布)**
-- 新增 ZK 集群的指标大盘信息;
-- 新增 ZK 集群的服务状态概览信息;
-- 新增 ZK 集群的服务节点列表信息;
-- 新增 Kafka 在 ZK 的存储数据查看功能;
-- 新增 ZK 的健康巡检及健康状态计算;
-
-
-
----
-
-
-## v3.0.1
-
-**Bug修复**
-- 修复重置 Group Offset 时,提示信息中缺少 Dead 状态也可进行重置的信息;
-- 修复 Ldap 某个属性不存在时,会直接抛出空指针导致登陆失败的问题;
-- 修复集群 Topic 列表页,健康分详情信息中,检查时间展示错误的问题;
-- 修复更新健康检查结果时,出现死锁的问题;
-- 修复 Replica 索引模版错误的问题;
-- 修复 FAQ 文档中的错误链接;
-- 修复 Broker 的 TopN 指标不存在时,页面数据不展示的问题;
-- 修复 Group 详情页,图表时间范围选择不生效的问题;
-
-
-**体验优化**
-- 集群 Group 列表按照 Group 维度进行展示;
-- 优化避免因 ES 中该指标不存在,导致日志中出现大量空指针的问题;
-- 优化全局 Message & Notification 展示效果;
-- 优化 Topic 扩分区名称 & 描述展示;
-
-
-**新增**
-- Broker 列表页面,新增 JMX 是否成功连接的信息;
-
-
-**ZK 部分(未完全发布)**
-- 后端补充 Kafka ZK 指标采集,Kafka ZK 信息获取相关功能;
-- 增加本地缓存,避免同一采集周期内 ZK 指标重复采集;
-- 增加 ZK 节点采集失败跳过策略,避免不断对存在问题的节点不断尝试;
-- 修复 zkAvgLatency 指标转 Long 时抛出异常问题;
-- 修复 ks_km_zookeeper 表中,role 字段类型错误问题;
-
----
-
-## v3.0.0
-
-**Bug修复**
-- 修复 Group 指标防重复采集不生效问题
-- 修复自动创建 ES 索引模版失败问题
-- 修复 Group+Topic 列表中存在已删除Topic的问题
-- 修复使用 MySQL-8 ,因兼容问题, start_time 信息为 NULL 时,会导致创建任务失败的问题
-- 修复 Group 信息表更新时,出现死锁的问题
-- 修复图表补点逻辑与图表时间范围不适配的问题
-
-
-**体验优化**
-- 按照资源类别,拆分健康巡检任务
-- 优化 Group 详情页的指标为实时获取
-- 图表拖拽排序支持用户级存储
-- 多集群列表 ZK 信息展示兼容无 ZK 情况
-- Topic 详情消息预览支持复制功能
-- 部分内容大数字支持千位分割符展示
-
-
-**新增**
-- 集群信息中,新增 Zookeeper 客户端配置字段
-- 集群信息中,新增 Kafka 集群运行模式字段
-- 新增 docker-compose 的部署方式
-
----
-
-## v3.0.0-beta.3
-
-**文档**
-- FAQ 补充权限识别失败问题的说明
-- 同步更新文档,保持与官网一致
-
-
-**Bug修复**
-- Offset 信息获取时,过滤掉无 Leader 的分区
-- 升级 oshi-core 版本至 5.6.1 版本,修复 Windows 系统获取系统指标失败问题
-- 修复 JMX 连接被关闭后,未进行重建的问题
-- 修复因 DB 中 Broker 信息不存在导致 TotalLogSize 指标获取时抛空指针问题
-- 修复 dml-logi.sql 中,SQL 注释错误的问题
-- 修复 startup.sh 中,识别操作系统类型错误的问题
-- 修复配置管理页面删除配置失败的问题
-- 修复系统管理应用文件引用路径
-- 修复 Topic Messages 详情提示信息点击跳转 404 的问题
-- 修复扩副本时,当前副本数不显示问题
-
-
-**体验优化**
-- Topic-Messages 页面,增加返回数据的排序以及按照Earliest/Latest的获取方式
-- 优化 GroupOffsetResetEnum 类名为 OffsetTypeEnum,使得类名含义更准确
-- 移动 KafkaZKDAO 类,及 Kafka Znode 实体类的位置,使得 Kafka Zookeeper DAO 更加内聚及便于识别
-- 后端补充 Overview 页面指标排序的功能
-- 前端 Webpack 配置优化
-- Cluster Overview 图表取消放大展示功能
-- 列表页增加手动刷新功能
-- 接入/编辑集群,优化 JMX-PORT,Version 信息的回显,优化JMX信息的展示
-- 提高登录页面图片展示清晰度
-- 部分样式和文案优化
-
----
-
-## v3.0.0-beta.2
-
-**文档**
-- 新增登录系统对接文档
-- 优化前端工程打包构建部分文档说明
-- FAQ补充KnowStreaming连接特定JMX IP的说明
-
-
-**Bug修复**
-- 修复logi_security_oplog表字段过短,导致删除Topic等操作无法记录的问题
-- 修复ES查询时,抛java.lang.NumberFormatException: For input string: "{"value":0,"relation":"eq"}" 问题
-- 修复LogStartOffset和LogEndOffset指标单位错误问题
-- 修复进行副本变更时,旧副本数为NULL的问题
-- 修复集群Group列表,在第二页搜索时,搜索时返回的分页信息错误问题
-- 修复重置Offset时,返回的错误信息提示不一致的问题
-- 修复集群查看,系统查看,LoadRebalance等页面权限点缺失问题
-- 修复查询不存在的Topic时,错误信息提示不明显的问题
-- 修复Windows用户打包前端工程报错的问题
-- package-lock.json锁定前端依赖版本号,修复因依赖自动升级导致打包失败等问题
-- 系统管理子应用,补充后端返回的Code码拦截,解决后端接口返回报错不展示的问题
-- 修复用户登出后,依旧可以访问系统的问题
-- 修复巡检任务配置时,数值显示错误的问题
-- 修复Broker/Topic Overview 图表和图表详情问题
-- 修复Job扩缩副本任务明细数据错误的问题
-- 修复重置Offset时,分区ID,Offset数值无限制问题
-- 修复扩缩/迁移副本时,无法选中Kafka系统Topic的问题
-- 修复Topic的Config页面,编辑表单时不能正确回显当前值的问题
-- 修复Broker Card返回数据后依旧展示加载态的问题
-
-
-
-**体验优化**
-- 优化默认用户密码为 admin/admin
-- 缩短新增集群后,集群信息加载的耗时
-- 集群Broker列表,增加Controller角色信息
-- 副本变更任务结束后,增加进行优先副本选举的操作
-- Task模块任务分为Metrics、Common、Metadata三类任务,每类任务配备独立线程池,减少对Job模块的线程池,以及不同类任务之间的相互影响
-- 删除代码中存在的多余无用文件
-- 自动新增ES索引模版及近7天索引,减少用户搭建时需要做的事项
-- 优化前端工程打包流程
-- 优化登录页文案,页面左侧栏内容,单集群详情样式,Topic列表趋势图等
-- 首次进入Broker/Topic图表详情时,进行预缓存数据从而优化体验
-- 优化Topic详情Partition Tab的展示
-- 多集群列表页增加编辑功能
-- 优化副本变更时,迁移时间支持分钟级别粒度
-- logi-security版本升级至2.10.13
-- logi-elasticsearch-client版本升级至1.0.24
-
-
-**能力提升**
-- 支持Ldap登录认证
-
----
-
-## v3.0.0-beta.1
-
-**文档**
-- 新增Task模块说明文档
-- FAQ补充 `Specified key was too long; max key length is 767 bytes ` 错误说明
-- FAQ补充 `出现ESIndexNotFoundException报错` 错误说明
-
-
-**Bug修复**
-- 修复 Consumer 点击 Stop 未停止检索的问题
-- 修复创建/编辑角色权限报错问题
-- 修复多集群管理/单集群详情均衡卡片状态错误问题
-- 修复版本列表未排序问题
-- 修复Raft集群Controller信息不断记录问题
-- 修复部分版本消费组描述信息获取失败问题
-- 修复分区Offset获取失败的日志中,缺少Topic名称信息问题
-- 修复GitHub图地址错误,及图裂问题
-- 修复Broker默认使用的地址和注释不一致问题
-- 修复 Consumer 列表分页不生效问题
-- 修复操作记录表operation_methods字段缺少默认值问题
-- 修复集群均衡表中move_broker_list字段无效的问题
-- 修复KafkaUser、KafkaACL信息获取时,日志一直重复提示不支持问题
-- 修复指标缺失时,曲线出现掉底的问题
-
-
-**体验优化**
-- 优化前端构建时间和打包体积,增加依赖打包的分包策略
-- 优化产品样式和文案展示
-- 优化ES客户端数为可配置
-- 优化日志中大量出现的MySQL Key冲突日志
-
-
-**能力提升**
-- 增加周期任务,用于主动创建缺少的ES模版及索引的能力,减少额外的脚本操作
-- 增加JMX连接的Broker地址可选择的能力
-
----
-
-## v3.0.0-beta.0
-
-**1、多集群管理**
-
-- 增加健康监测体系、关键组件&指标 GUI 展示
-- 增加 2.8.x 以上 Kafka 集群接入,覆盖 0.10.x-3.x
-- 删除逻辑集群、共享集群、Region 概念
-
-**2、Cluster 管理**
-
-- 增加集群概览信息、集群配置变更记录
-- 增加 Cluster 健康分,健康检查规则支持自定义配置
-- 增加 Cluster 关键指标统计和 GUI 展示,支持自定义配置
-- 增加 Cluster 层 I/O、Disk 的 Load Reblance 功能,支持定时均衡任务(企业版)
-- 删除限流、鉴权功能
-- 删除 APPID 概念
-
-**3、Broker 管理**
-
-- 增加 Broker 健康分
-- 增加 Broker 关键指标统计和 GUI 展示,支持自定义配置
-- 增加 Broker 参数配置功能,需重启生效
-- 增加 Controller 变更记录
-- 增加 Broker Datalogs 记录
-- 删除 Leader Rebalance 功能
-- 删除 Broker 优先副本选举
-
-**4、Topic 管理**
-
-- 增加 Topic 健康分
-- 增加 Topic 关键指标统计和 GUI 展示,支持自定义配置
-- 增加 Topic 参数配置功能,可实时生效
-- 增加 Topic 批量迁移、Topic 批量扩缩副本功能
-- 增加查看系统 Topic 功能
-- 优化 Partition 分布的 GUI 展示
-- 优化 Topic Message 数据采样
-- 删除 Topic 过期概念
-- 删除 Topic 申请配额功能
-
-**5、Consumer 管理**
-
-- 优化了 ConsumerGroup 展示形式,增加 Consumer Lag 的 GUI 展示
-
-**6、ACL 管理**
-
-- 增加原生 ACL GUI 配置功能,可配置生产、消费、自定义多种组合权限
-- 增加 KafkaUser 功能,可自定义新增 KafkaUser
-
-**7、消息测试(企业版)**
-
-- 增加生产者消息模拟器,支持 Data、Flow、Header、Options 自定义配置(企业版)
-- 增加消费者消息模拟器,支持 Data、Flow、Header、Options 自定义配置(企业版)
-
-**8、Job**
-
-- 优化 Job 模块,支持任务进度管理
-
-**9、系统管理**
-
-- 优化用户、角色管理体系,支持自定义角色配置页面及操作权限
-- 优化审计日志信息
-- 删除多租户体系
-- 删除工单流程
-
----
-
-## v2.6.0
-
-版本上线时间:2022-01-24
-
-### 能力提升
-- 增加简单回退工具类
-
-### 体验优化
-- 补充周期任务说明文档
-- 补充集群安装部署使用说明文档
-- 升级Swagger、SpringFramework、SpringBoot、EChats版本
-- 优化Task模块的日志输出
-- 优化corn表达式解析失败后退出无任何日志提示问题
-- Ldap用户接入时,增加部门及邮箱信息等
-- 对Jmx模块,增加连接失败后的回退机制及错误日志优化
-- 增加线程池、客户端池可配置
-- 删除无用的jmx_prometheus_javaagent-0.14.0.jar
-- 优化迁移任务名称
-- 优化创建Region时,Region容量信息不能立即被更新问题
-- 引入lombok
-- 更新视频教程
-- 优化kcm_script.sh脚本中的LogiKM地址为可通过程序传入
-- 第三方接口及网关接口,增加是否跳过登录的开关
-- extends模块相关配置调整为非必须在application.yml中配置
-
-### bug修复
-- 修复批量往DB写入空指标数组时报SQL语法异常的问题
-- 修复网关增加配置及修改配置时,version不变化问题
-- 修复集群列表页,提示框遮挡问题
-- 修复对高版本Broker元信息协议解析失败的问题
-- 修复Dockerfile执行时提示缺少application.yml文件的问题
-- 修复逻辑集群更新时,会报空指针的问题
-
-
-## v2.5.0
-
-版本上线时间:2021-07-10
-
-### 体验优化
-- 更改产品名为LogiKM
-- 更新产品图标
-
-
-## v2.4.1+
-
-版本上线时间:2021-05-21
-
-### 能力提升
-- 增加直接增加权限和配额的接口(v2.4.1)
-- 增加接口调用可绕过登录的功能(v2.4.1)
-
-### 体验优化
-- Tomcat 版本提升至8.5.66(v2.4.2)
-- op接口优化,拆分util接口为topic、leader两类接口(v2.4.1)
-- 简化Gateway配置的Key长度(v2.4.1)
-
-### bug修复
-- 修复页面展示版本错误问题(v2.4.2)
-
-
-## v2.4.0
-
-版本上线时间:2021-05-18
-
-
-### 能力提升
-
-- 增加App与Topic自动化审批开关
-- Broker元信息中增加Rack信息
-- 升级MySQL 驱动,支持MySQL 8+
-- 增加操作记录查询界面
-
-### 体验优化
-
-- FAQ告警组说明优化
-- 用户手册共享及 独享集群概念优化
-- 用户管理界面,前端限制用户删除自己
-
-### bug修复
-
-- 修复op-util类中创建Topic失败的接口
-- 周期同步Topic到DB的任务修复,将Topic列表查询从缓存调整为直接查DB
-- 应用下线审批失败的功能修复,将权限为0(无权限)的数据进行过滤
-- 修复登录及权限绕过的漏洞
-- 修复研发角色展示接入集群、暂停监控等按钮的问题
-
-
-## v2.3.0
-
-版本上线时间:2021-02-08
-
-
-### 能力提升
-
-- 新增支持docker化部署
-- 可指定Broker作为候选controller
-- 可新增并管理网关配置
-- 可获取消费组状态
-- 增加集群的JMX认证
-
-### 体验优化
-
-- 优化编辑用户角色、修改密码的流程
-- 新增consumerID的搜索功能
-- 优化“Topic连接信息”、“消费组重置消费偏移”、“修改Topic保存时间”的文案提示
-- 在相应位置增加《资源申请文档》链接
-
-### bug修复
-
-- 修复Broker监控图表时间轴展示错误的问题
-- 修复创建夜莺监控告警规则时,使用的告警周期的单位不正确的问题
-
-
-
-## v2.2.0
-
-版本上线时间:2021-01-25
-
-
-
-### 能力提升
-
-- 优化工单批量操作流程
-- 增加获取Topic75分位/99分位的实时耗时数据
-- 增加定时任务,可将无主未落DB的Topic定期写入DB
-
-### 体验优化
-
-- 在相应位置增加《集群接入文档》链接
-- 优化物理集群、逻辑集群含义
-- 在Topic详情页、Topic扩分区操作弹窗增加展示Topic所属Region的信息
-- 优化Topic审批时,Topic数据保存时间的配置流程
-- 优化Topic/应用申请、审批时的错误提示文案
-- 优化Topic数据采样的操作项文案
-- 优化运维人员删除Topic时的提示文案
-- 优化运维人员删除Region的删除逻辑与提示文案
-- 优化运维人员删除逻辑集群的提示文案
-- 优化上传集群配置文件时的文件类型限制条件
-
-### bug修复
-
-- 修复填写应用名称时校验特殊字符出错的问题
-- 修复普通用户越权访问应用详情的问题
-- 修复由于Kafka版本升级,导致的数据压缩格式无法获取的问题
-- 修复删除逻辑集群或Topic之后,界面依旧展示的问题
-- 修复进行Leader rebalance操作时执行结果重复提示的问题
-
-
-## v2.1.0
-
-版本上线时间:2020-12-19
-
-
-
-### 体验优化
-
-- 优化页面加载时的背景样式
-- 优化普通用户申请Topic权限的流程
-- 优化Topic申请配额、申请分区的权限限制
-- 优化取消Topic权限的文案提示
-- 优化申请配额表单的表单项名称
-- 优化重置消费偏移的操作流程
-- 优化创建Topic迁移任务的表单内容
-- 优化Topic扩分区操作的弹窗界面样式
-- 优化集群Broker监控可视化图表样式
-- 优化创建逻辑集群的表单内容
-- 优化集群安全协议的提示文案
-
-### bug修复
-
-- 修复偶发性重置消费偏移失败的问题
-
-
-
-
diff --git a/bin/init_es_template.sh b/bin/init_es_template.sh
deleted file mode 100644
index e570d285..00000000
--- a/bin/init_es_template.sh
+++ /dev/null
@@ -1,1036 +0,0 @@
-esaddr=127.0.0.1
-port=8060
-curl -s --connect-timeout 10 -o /dev/null http://${esaddr}:${port}/_cat/nodes >/dev/null 2>&1
-if [ "$?" != "0" ];then
- echo "Elasticserach 访问失败, 请安装完后检查并重新执行该脚本 "
- exit
-fi
-
-curl -s --connect-timeout 10 -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${esaddr}:${port}/_template/ks_kafka_broker_metric -d '{
- "order" : 10,
- "index_patterns" : [
- "ks_kafka_broker_metric*"
- ],
- "settings" : {
- "index" : {
- "number_of_shards" : "2"
- }
- },
- "mappings" : {
- "properties" : {
- "brokerId" : {
- "type" : "long"
- },
- "routingValue" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "clusterPhyId" : {
- "type" : "long"
- },
- "metrics" : {
- "properties" : {
- "NetworkProcessorAvgIdle" : {
- "type" : "float"
- },
- "UnderReplicatedPartitions" : {
- "type" : "float"
- },
- "BytesIn_min_15" : {
- "type" : "float"
- },
- "HealthCheckTotal" : {
- "type" : "float"
- },
- "RequestHandlerAvgIdle" : {
- "type" : "float"
- },
- "connectionsCount" : {
- "type" : "float"
- },
- "BytesIn_min_5" : {
- "type" : "float"
- },
- "HealthScore" : {
- "type" : "float"
- },
- "BytesOut" : {
- "type" : "float"
- },
- "BytesOut_min_15" : {
- "type" : "float"
- },
- "BytesIn" : {
- "type" : "float"
- },
- "BytesOut_min_5" : {
- "type" : "float"
- },
- "TotalRequestQueueSize" : {
- "type" : "float"
- },
- "MessagesIn" : {
- "type" : "float"
- },
- "TotalProduceRequests" : {
- "type" : "float"
- },
- "HealthCheckPassed" : {
- "type" : "float"
- },
- "TotalResponseQueueSize" : {
- "type" : "float"
- }
- }
- },
- "key" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "timestamp" : {
- "format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
- "index" : true,
- "type" : "date",
- "doc_values" : true
- }
- }
- },
- "aliases" : { }
- }'
-
-curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${esaddr}:${port}/_template/ks_kafka_cluster_metric -d '{
- "order" : 10,
- "index_patterns" : [
- "ks_kafka_cluster_metric*"
- ],
- "settings" : {
- "index" : {
- "number_of_shards" : "2"
- }
- },
- "mappings" : {
- "properties" : {
- "routingValue" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "clusterPhyId" : {
- "type" : "long"
- },
- "metrics" : {
- "properties" : {
- "Connections" : {
- "type" : "double"
- },
- "BytesIn_min_15" : {
- "type" : "double"
- },
- "PartitionURP" : {
- "type" : "double"
- },
- "HealthScore_Topics" : {
- "type" : "double"
- },
- "EventQueueSize" : {
- "type" : "double"
- },
- "ActiveControllerCount" : {
- "type" : "double"
- },
- "GroupDeads" : {
- "type" : "double"
- },
- "BytesIn_min_5" : {
- "type" : "double"
- },
- "HealthCheckTotal_Topics" : {
- "type" : "double"
- },
- "Partitions" : {
- "type" : "double"
- },
- "BytesOut" : {
- "type" : "double"
- },
- "Groups" : {
- "type" : "double"
- },
- "BytesOut_min_15" : {
- "type" : "double"
- },
- "TotalRequestQueueSize" : {
- "type" : "double"
- },
- "HealthCheckPassed_Groups" : {
- "type" : "double"
- },
- "TotalProduceRequests" : {
- "type" : "double"
- },
- "HealthCheckPassed" : {
- "type" : "double"
- },
- "TotalLogSize" : {
- "type" : "double"
- },
- "GroupEmptys" : {
- "type" : "double"
- },
- "PartitionNoLeader" : {
- "type" : "double"
- },
- "HealthScore_Brokers" : {
- "type" : "double"
- },
- "Messages" : {
- "type" : "double"
- },
- "Topics" : {
- "type" : "double"
- },
- "PartitionMinISR_E" : {
- "type" : "double"
- },
- "HealthCheckTotal" : {
- "type" : "double"
- },
- "Brokers" : {
- "type" : "double"
- },
- "Replicas" : {
- "type" : "double"
- },
- "HealthCheckTotal_Groups" : {
- "type" : "double"
- },
- "GroupRebalances" : {
- "type" : "double"
- },
- "MessageIn" : {
- "type" : "double"
- },
- "HealthScore" : {
- "type" : "double"
- },
- "HealthCheckPassed_Topics" : {
- "type" : "double"
- },
- "HealthCheckTotal_Brokers" : {
- "type" : "double"
- },
- "PartitionMinISR_S" : {
- "type" : "double"
- },
- "BytesIn" : {
- "type" : "double"
- },
- "BytesOut_min_5" : {
- "type" : "double"
- },
- "GroupActives" : {
- "type" : "double"
- },
- "MessagesIn" : {
- "type" : "double"
- },
- "GroupReBalances" : {
- "type" : "double"
- },
- "HealthCheckPassed_Brokers" : {
- "type" : "double"
- },
- "HealthScore_Groups" : {
- "type" : "double"
- },
- "TotalResponseQueueSize" : {
- "type" : "double"
- },
- "Zookeepers" : {
- "type" : "double"
- },
- "LeaderMessages" : {
- "type" : "double"
- },
- "HealthScore_Cluster" : {
- "type" : "double"
- },
- "HealthCheckPassed_Cluster" : {
- "type" : "double"
- },
- "HealthCheckTotal_Cluster" : {
- "type" : "double"
- }
- }
- },
- "key" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "timestamp" : {
- "format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
- "type" : "date"
- }
- }
- },
- "aliases" : { }
- }'
-
-curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${esaddr}:${port}/_template/ks_kafka_group_metric -d '{
- "order" : 10,
- "index_patterns" : [
- "ks_kafka_group_metric*"
- ],
- "settings" : {
- "index" : {
- "number_of_shards" : "6"
- }
- },
- "mappings" : {
- "properties" : {
- "group" : {
- "type" : "keyword"
- },
- "partitionId" : {
- "type" : "long"
- },
- "routingValue" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "clusterPhyId" : {
- "type" : "long"
- },
- "topic" : {
- "type" : "keyword"
- },
- "metrics" : {
- "properties" : {
- "HealthScore" : {
- "type" : "float"
- },
- "Lag" : {
- "type" : "float"
- },
- "OffsetConsumed" : {
- "type" : "float"
- },
- "HealthCheckTotal" : {
- "type" : "float"
- },
- "HealthCheckPassed" : {
- "type" : "float"
- }
- }
- },
- "groupMetric" : {
- "type" : "keyword"
- },
- "key" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "timestamp" : {
- "format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
- "index" : true,
- "type" : "date",
- "doc_values" : true
- }
- }
- },
- "aliases" : { }
- }'
-
-curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${esaddr}:${port}/_template/ks_kafka_partition_metric -d '{
- "order" : 10,
- "index_patterns" : [
- "ks_kafka_partition_metric*"
- ],
- "settings" : {
- "index" : {
- "number_of_shards" : "6"
- }
- },
- "mappings" : {
- "properties" : {
- "brokerId" : {
- "type" : "long"
- },
- "partitionId" : {
- "type" : "long"
- },
- "routingValue" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "clusterPhyId" : {
- "type" : "long"
- },
- "topic" : {
- "type" : "keyword"
- },
- "metrics" : {
- "properties" : {
- "LogStartOffset" : {
- "type" : "float"
- },
- "Messages" : {
- "type" : "float"
- },
- "LogEndOffset" : {
- "type" : "float"
- }
- }
- },
- "key" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "timestamp" : {
- "format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
- "index" : true,
- "type" : "date",
- "doc_values" : true
- }
- }
- },
- "aliases" : { }
- }'
-
-curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${esaddr}:${port}/_template/ks_kafka_topic_metric -d '{
- "order" : 10,
- "index_patterns" : [
- "ks_kafka_topic_metric*"
- ],
- "settings" : {
- "index" : {
- "number_of_shards" : "6"
- }
- },
- "mappings" : {
- "properties" : {
- "brokerId" : {
- "type" : "long"
- },
- "routingValue" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "topic" : {
- "type" : "keyword"
- },
- "clusterPhyId" : {
- "type" : "long"
- },
- "metrics" : {
- "properties" : {
- "BytesIn_min_15" : {
- "type" : "float"
- },
- "Messages" : {
- "type" : "float"
- },
- "BytesRejected" : {
- "type" : "float"
- },
- "PartitionURP" : {
- "type" : "float"
- },
- "HealthCheckTotal" : {
- "type" : "float"
- },
- "ReplicationCount" : {
- "type" : "float"
- },
- "ReplicationBytesOut" : {
- "type" : "float"
- },
- "ReplicationBytesIn" : {
- "type" : "float"
- },
- "FailedFetchRequests" : {
- "type" : "float"
- },
- "BytesIn_min_5" : {
- "type" : "float"
- },
- "HealthScore" : {
- "type" : "float"
- },
- "LogSize" : {
- "type" : "float"
- },
- "BytesOut" : {
- "type" : "float"
- },
- "BytesOut_min_15" : {
- "type" : "float"
- },
- "FailedProduceRequests" : {
- "type" : "float"
- },
- "BytesIn" : {
- "type" : "float"
- },
- "BytesOut_min_5" : {
- "type" : "float"
- },
- "MessagesIn" : {
- "type" : "float"
- },
- "TotalProduceRequests" : {
- "type" : "float"
- },
- "HealthCheckPassed" : {
- "type" : "float"
- }
- }
- },
- "brokerAgg" : {
- "type" : "keyword"
- },
- "key" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "timestamp" : {
- "format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
- "index" : true,
- "type" : "date",
- "doc_values" : true
- }
- }
- },
- "aliases" : { }
- }'
-
-curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${SERVER_ES_ADDRESS}/_template/ks_kafka_zookeeper_metric -d '{
- "order" : 10,
- "index_patterns" : [
- "ks_kafka_zookeeper_metric*"
- ],
- "settings" : {
- "index" : {
- "number_of_shards" : "2"
- }
- },
- "mappings" : {
- "properties" : {
- "routingValue" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "clusterPhyId" : {
- "type" : "long"
- },
- "metrics" : {
- "properties" : {
- "AvgRequestLatency" : {
- "type" : "double"
- },
- "MinRequestLatency" : {
- "type" : "double"
- },
- "MaxRequestLatency" : {
- "type" : "double"
- },
- "OutstandingRequests" : {
- "type" : "double"
- },
- "NodeCount" : {
- "type" : "double"
- },
- "WatchCount" : {
- "type" : "double"
- },
- "NumAliveConnections" : {
- "type" : "double"
- },
- "PacketsReceived" : {
- "type" : "double"
- },
- "PacketsSent" : {
- "type" : "double"
- },
- "EphemeralsCount" : {
- "type" : "double"
- },
- "ApproximateDataSize" : {
- "type" : "double"
- },
- "OpenFileDescriptorCount" : {
- "type" : "double"
- },
- "MaxFileDescriptorCount" : {
- "type" : "double"
- }
- }
- },
- "key" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "timestamp" : {
- "format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
- "type" : "date"
- }
- }
- },
- "aliases" : { }
- }'
-
-curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${SERVER_ES_ADDRESS}/_template/ks_kafka_connect_cluster_metric -d '{
- "order" : 10,
- "index_patterns" : [
- "ks_kafka_connect_cluster_metric*"
- ],
- "settings" : {
- "index" : {
- "number_of_shards" : "2"
- }
- },
- "mappings" : {
- "properties" : {
- "connectClusterId" : {
- "type" : "long"
- },
- "routingValue" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "clusterPhyId" : {
- "type" : "long"
- },
- "metrics" : {
- "properties" : {
- "ConnectorCount" : {
- "type" : "float"
- },
- "TaskCount" : {
- "type" : "float"
- },
- "ConnectorStartupAttemptsTotal" : {
- "type" : "float"
- },
- "ConnectorStartupFailurePercentage" : {
- "type" : "float"
- },
- "ConnectorStartupFailureTotal" : {
- "type" : "float"
- },
- "ConnectorStartupSuccessPercentage" : {
- "type" : "float"
- },
- "ConnectorStartupSuccessTotal" : {
- "type" : "float"
- },
- "TaskStartupAttemptsTotal" : {
- "type" : "float"
- },
- "TaskStartupFailurePercentage" : {
- "type" : "float"
- },
- "TaskStartupFailureTotal" : {
- "type" : "float"
- },
- "TaskStartupSuccessPercentage" : {
- "type" : "float"
- },
- "TaskStartupSuccessTotal" : {
- "type" : "float"
- }
- }
- },
- "key" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "timestamp" : {
- "format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
- "index" : true,
- "type" : "date",
- "doc_values" : true
- }
- }
- },
- "aliases" : { }
- }'
-
-curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${SERVER_ES_ADDRESS}/_template/ks_kafka_connect_connector_metric -d '{
- "order" : 10,
- "index_patterns" : [
- "ks_kafka_connect_connector_metric*"
- ],
- "settings" : {
- "index" : {
- "number_of_shards" : "2"
- }
- },
- "mappings" : {
- "properties" : {
- "connectClusterId" : {
- "type" : "long"
- },
- "routingValue" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "connectorName" : {
- "type" : "keyword"
- },
- "connectorNameAndClusterId" : {
- "type" : "keyword"
- },
- "clusterPhyId" : {
- "type" : "long"
- },
- "metrics" : {
- "properties" : {
- "HealthState" : {
- "type" : "float"
- },
- "ConnectorTotalTaskCount" : {
- "type" : "float"
- },
- "HealthCheckPassed" : {
- "type" : "float"
- },
- "HealthCheckTotal" : {
- "type" : "float"
- },
- "ConnectorRunningTaskCount" : {
- "type" : "float"
- },
- "ConnectorPausedTaskCount" : {
- "type" : "float"
- },
- "ConnectorFailedTaskCount" : {
- "type" : "float"
- },
- "ConnectorUnassignedTaskCount" : {
- "type" : "float"
- },
- "BatchSizeAvg" : {
- "type" : "float"
- },
- "BatchSizeMax" : {
- "type" : "float"
- },
- "OffsetCommitAvgTimeMs" : {
- "type" : "float"
- },
- "OffsetCommitMaxTimeMs" : {
- "type" : "float"
- },
- "OffsetCommitFailurePercentage" : {
- "type" : "float"
- },
- "OffsetCommitSuccessPercentage" : {
- "type" : "float"
- },
- "PollBatchAvgTimeMs" : {
- "type" : "float"
- },
- "PollBatchMaxTimeMs" : {
- "type" : "float"
- },
- "SourceRecordActiveCount" : {
- "type" : "float"
- },
- "SourceRecordActiveCountAvg" : {
- "type" : "float"
- },
- "SourceRecordActiveCountMax" : {
- "type" : "float"
- },
- "SourceRecordPollRate" : {
- "type" : "float"
- },
- "SourceRecordPollTotal" : {
- "type" : "float"
- },
- "SourceRecordWriteRate" : {
- "type" : "float"
- },
- "SourceRecordWriteTotal" : {
- "type" : "float"
- },
- "OffsetCommitCompletionRate" : {
- "type" : "float"
- },
- "OffsetCommitCompletionTotal" : {
- "type" : "float"
- },
- "OffsetCommitSkipRate" : {
- "type" : "float"
- },
- "OffsetCommitSkipTotal" : {
- "type" : "float"
- },
- "PartitionCount" : {
- "type" : "float"
- },
- "PutBatchAvgTimeMs" : {
- "type" : "float"
- },
- "PutBatchMaxTimeMs" : {
- "type" : "float"
- },
- "SinkRecordActiveCount" : {
- "type" : "float"
- },
- "SinkRecordActiveCountAvg" : {
- "type" : "float"
- },
- "SinkRecordActiveCountMax" : {
- "type" : "float"
- },
- "SinkRecordLagMax" : {
- "type" : "float"
- },
- "SinkRecordReadRate" : {
- "type" : "float"
- },
- "SinkRecordReadTotal" : {
- "type" : "float"
- },
- "SinkRecordSendRate" : {
- "type" : "float"
- },
- "SinkRecordSendTotal" : {
- "type" : "float"
- },
- "DeadletterqueueProduceFailures" : {
- "type" : "float"
- },
- "DeadletterqueueProduceRequests" : {
- "type" : "float"
- },
- "LastErrorTimestamp" : {
- "type" : "float"
- },
- "TotalErrorsLogged" : {
- "type" : "float"
- },
- "TotalRecordErrors" : {
- "type" : "float"
- },
- "TotalRecordFailures" : {
- "type" : "float"
- },
- "TotalRecordsSkipped" : {
- "type" : "float"
- },
- "TotalRetries" : {
- "type" : "float"
- }
- }
- },
- "key" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "timestamp" : {
- "format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
- "index" : true,
- "type" : "date",
- "doc_values" : true
- }
- }
- },
- "aliases" : { }
- }'
-
-curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${SERVER_ES_ADDRESS}/_template/ks_kafka_connect_mirror_maker_metric -d '{
- "order" : 10,
- "index_patterns" : [
- "ks_kafka_connect_mirror_maker_metric*"
- ],
- "settings" : {
- "index" : {
- "number_of_shards" : "2"
- }
- },
- "mappings" : {
- "properties" : {
- "connectClusterId" : {
- "type" : "long"
- },
- "routingValue" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "connectorName" : {
- "type" : "keyword"
- },
- "connectorNameAndClusterId" : {
- "type" : "keyword"
- },
- "clusterPhyId" : {
- "type" : "long"
- },
- "metrics" : {
- "properties" : {
- "HealthState" : {
- "type" : "float"
- },
- "HealthCheckTotal" : {
- "type" : "float"
- },
- "ByteCount" : {
- "type" : "float"
- },
- "ByteRate" : {
- "type" : "float"
- },
- "RecordAgeMs" : {
- "type" : "float"
- },
- "RecordAgeMsAvg" : {
- "type" : "float"
- },
- "RecordAgeMsMax" : {
- "type" : "float"
- },
- "RecordAgeMsMin" : {
- "type" : "float"
- },
- "RecordCount" : {
- "type" : "float"
- },
- "RecordRate" : {
- "type" : "float"
- },
- "ReplicationLatencyMs" : {
- "type" : "float"
- },
- "ReplicationLatencyMsAvg" : {
- "type" : "float"
- },
- "ReplicationLatencyMsMax" : {
- "type" : "float"
- },
- "ReplicationLatencyMsMin" : {
- "type" : "float"
- }
- }
- },
- "key" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "timestamp" : {
- "format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
- "index" : true,
- "type" : "date",
- "doc_values" : true
- }
- }
- },
- "aliases" : { }
- }'
-
-
-for i in {0..6};
-do
- logdate=_$(date -d "${i} day ago" +%Y-%m-%d)
- curl -s --connect-timeout 10 -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_broker_metric${logdate} && \
- curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_cluster_metric${logdate} && \
- curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_group_metric${logdate} && \
- curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_partition_metric${logdate} && \
- curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_zookeeper_metric${logdate} && \
- curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_connect_cluster_metric${logdate} && \
- curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_connect_connector_metric${logdate} && \
- curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_connect_mirror_maker_metric${logdate} && \
- curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_topic_metric${logdate} || \
- exit 2
-done
diff --git a/bin/shutdown.sh b/bin/shutdown.sh
deleted file mode 100644
index c5317df8..00000000
--- a/bin/shutdown.sh
+++ /dev/null
@@ -1,16 +0,0 @@
-#!/bin/bash
-
-cd `dirname $0`/../libs
-target_dir=`pwd`
-
-pid=`ps ax | grep -i 'ks-km' | grep ${target_dir} | grep java | grep -v grep | awk '{print $1}'`
-if [ -z "$pid" ] ; then
- echo "No ks-km running."
- exit -1;
-fi
-
-echo "The ks-km (${pid}) is running..."
-
-kill ${pid}
-
-echo "Send shutdown request to ks-km (${pid}) OK"
diff --git a/bin/startup.sh b/bin/startup.sh
deleted file mode 100644
index cbde7c56..00000000
--- a/bin/startup.sh
+++ /dev/null
@@ -1,82 +0,0 @@
-error_exit ()
-{
- echo "ERROR: $1 !!"
- exit 1
-}
-
-[ ! -e "$JAVA_HOME/bin/java" ] && JAVA_HOME=$HOME/jdk/java
-[ ! -e "$JAVA_HOME/bin/java" ] && JAVA_HOME=/usr/java
-[ ! -e "$JAVA_HOME/bin/java" ] && unset JAVA_HOME
-
-if [ -z "$JAVA_HOME" ]; then
- if [ "Darwin" = "$(uname -s)" ]; then
-
- if [ -x '/usr/libexec/java_home' ] ; then
- export JAVA_HOME=`/usr/libexec/java_home`
-
- elif [ -d "/System/Library/Frameworks/JavaVM.framework/Versions/CurrentJDK/Home" ]; then
- export JAVA_HOME="/System/Library/Frameworks/JavaVM.framework/Versions/CurrentJDK/Home"
- fi
- else
- JAVA_PATH=`dirname $(readlink -f $(which javac))`
- if [ "x$JAVA_PATH" != "x" ]; then
- export JAVA_HOME=`dirname $JAVA_PATH 2>/dev/null`
- fi
- fi
- if [ -z "$JAVA_HOME" ]; then
- error_exit "Please set the JAVA_HOME variable in your environment, We need java(x64)! jdk8 or later is better!"
- fi
-fi
-
-
-
-
-export WEB_SERVER="ks-km"
-export JAVA_HOME
-export JAVA="$JAVA_HOME/bin/java"
-export BASE_DIR=`cd $(dirname $0)/..; pwd`
-export CUSTOM_SEARCH_LOCATIONS=file:${BASE_DIR}/conf/
-
-
-#===========================================================================================
-# JVM Configuration
-#===========================================================================================
-
-JAVA_OPT="${JAVA_OPT} -server -Xms2g -Xmx2g -Xmn1g -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=320m"
-JAVA_OPT="${JAVA_OPT} -XX:-OmitStackTraceInFastThrow -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${BASE_DIR}/logs/java_heapdump.hprof"
-
-## jdk版本高的情况 有些 参数废弃了
-JAVA_MAJOR_VERSION=$($JAVA -version 2>&1 | sed -E -n 's/.* version "([0-9]*).*$/\1/p')
-if [[ "$JAVA_MAJOR_VERSION" -ge "9" ]] ; then
- JAVA_OPT="${JAVA_OPT} -Xlog:gc*:file=${BASE_DIR}/logs/km_gc.log:time,tags:filecount=10,filesize=102400"
-else
- JAVA_OPT="${JAVA_OPT} -Djava.ext.dirs=${JAVA_HOME}/jre/lib/ext:${JAVA_HOME}/lib/ext"
- JAVA_OPT="${JAVA_OPT} -Xloggc:${BASE_DIR}/logs/km_gc.log -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=100M"
-
-fi
-
-JAVA_OPT="${JAVA_OPT} -jar ${BASE_DIR}/libs/${WEB_SERVER}.jar"
-JAVA_OPT="${JAVA_OPT} --spring.config.additional-location=${CUSTOM_SEARCH_LOCATIONS}"
-JAVA_OPT="${JAVA_OPT} --logging.config=${BASE_DIR}/conf/logback-spring.xml"
-JAVA_OPT="${JAVA_OPT} --server.max-http-header-size=524288"
-
-
-
-if [ ! -d "${BASE_DIR}/logs" ]; then
- mkdir ${BASE_DIR}/logs
-fi
-
-echo "$JAVA ${JAVA_OPT}"
-
-# check the start.out log output file
-if [ ! -f "${BASE_DIR}/logs/start.out" ]; then
- touch "${BASE_DIR}/logs/start.out"
-fi
-
-# start
-echo -e "---- 启动脚本 ------\n $JAVA ${JAVA_OPT}" > ${BASE_DIR}/logs/start.out 2>&1 &
-
-
-nohup $JAVA ${JAVA_OPT} >> ${BASE_DIR}/logs/start.out 2>&1 &
-
-echo "${WEB_SERVER} is starting,you can check the ${BASE_DIR}/logs/start.out"
diff --git a/docs/contribute_guide/assets/分支管理.drawio b/docs/contribute_guide/assets/分支管理.drawio
deleted file mode 100644
index 0e7e3d37..00000000
--- a/docs/contribute_guide/assets/分支管理.drawio
+++ /dev/null
@@ -1,111 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/docs/contribute_guide/assets/分支管理.png b/docs/contribute_guide/assets/分支管理.png
deleted file mode 100644
index 867fecd4..00000000
Binary files a/docs/contribute_guide/assets/分支管理.png and /dev/null differ
diff --git a/docs/contribute_guide/assets/环境初始化.jpg b/docs/contribute_guide/assets/环境初始化.jpg
deleted file mode 100644
index 31ff5f28..00000000
Binary files a/docs/contribute_guide/assets/环境初始化.jpg and /dev/null differ
diff --git a/docs/contribute_guide/assets/申请合并.jpg b/docs/contribute_guide/assets/申请合并.jpg
deleted file mode 100644
index d02a7f50..00000000
Binary files a/docs/contribute_guide/assets/申请合并.jpg and /dev/null differ
diff --git a/docs/contribute_guide/assets/问题认领.jpg b/docs/contribute_guide/assets/问题认领.jpg
deleted file mode 100644
index 62da4728..00000000
Binary files a/docs/contribute_guide/assets/问题认领.jpg and /dev/null differ
diff --git a/docs/contribute_guide/代码规范.md b/docs/contribute_guide/代码规范.md
deleted file mode 100644
index be0bcfd2..00000000
--- a/docs/contribute_guide/代码规范.md
+++ /dev/null
@@ -1 +0,0 @@
-TODO.
\ No newline at end of file
diff --git a/docs/contribute_guide/贡献名单.md b/docs/contribute_guide/贡献名单.md
deleted file mode 100644
index 41481787..00000000
--- a/docs/contribute_guide/贡献名单.md
+++ /dev/null
@@ -1,100 +0,0 @@
-# 贡献名单
-
-- [贡献名单](#贡献名单)
- - [1、贡献者角色](#1贡献者角色)
- - [1.1、Maintainer](#11maintainer)
- - [1.2、Committer](#12committer)
- - [1.3、Contributor](#13contributor)
- - [2、贡献者名单](#2贡献者名单)
-
-
-## 1、贡献者角色
-
-KnowStreaming 开发者包含 Maintainer、Committer、Contributor 三种角色,每种角色的标准定义如下。
-
-### 1.1、Maintainer
-
-Maintainer 是对 KnowStreaming 项目的演进和发展做出显著贡献的个人。具体包含以下的标准:
-
-- 完成多个关键模块或者工程的设计与开发,是项目的核心开发人员;
-- 持续的投入和激情,能够积极参与社区、官网、issue、PR 等项目相关事项的维护;
-- 在社区中具有有目共睹的影响力,能够代表 KnowStreaming 参加重要的社区会议和活动;
-- 具有培养 Committer 和 Contributor 的意识和能力;
-
-### 1.2、Committer
-
-Committer 是具有 KnowStreaming 仓库写权限的个人,包含以下的标准:
-
-- 能够在长时间内做持续贡献 issue、PR 的个人;
-- 参与 issue 列表的维护及重要 feature 的讨论;
-- 参与 code review;
-
-### 1.3、Contributor
-
-Contributor 是对 KnowStreaming 项目有贡献的个人,标准为:
-
-- 提交过 PR 并被合并;
-
----
-
-## 2、贡献者名单
-
-开源贡献者名单(不定期更新)
-
-在名单内,但是没有收到贡献者礼品的同学,可以联系:szzdzhp001
-
-| 姓名 | Github | 角色 | 公司 |
-| ------------------- | ---------------------------------------------------------- | ----------- | -------- |
-| 张亮 | [@zhangliangboy](https://github.com/zhangliangboy) | Maintainer | 滴滴出行 |
-| 谢鹏 | [@PenceXie](https://github.com/PenceXie) | Maintainer | 滴滴出行 |
-| 赵情融 | [@zqrferrari](https://github.com/zqrferrari) | Maintainer | 滴滴出行 |
-| 石臻臻 | [@shirenchuang](https://github.com/shirenchuang) | Maintainer | 滴滴出行 |
-| 曾巧 | [@ZQKC](https://github.com/ZQKC) | Maintainer | 滴滴出行 |
-| 孙超 | [@lucasun](https://github.com/lucasun) | Maintainer | 滴滴出行 |
-| 洪华驰 | [@brodiehong](https://github.com/brodiehong) | Maintainer | 滴滴出行 |
-| 许喆 | [@potaaaaaato](https://github.com/potaaaaaato) | Committer | 滴滴出行 |
-| 郭宇航 | [@GraceWalk](https://github.com/GraceWalk) | Committer | 滴滴出行 |
-| 李伟 | [@velee](https://github.com/velee) | Committer | 滴滴出行 |
-| 张占昌 | [@zzccctv](https://github.com/zzccctv) | Committer | 滴滴出行 |
-| 王东方 | [@wangdongfang-aden](https://github.com/wangdongfang-aden) | Committer | 滴滴出行 |
-| 王耀波 | [@WYAOBO](https://github.com/WYAOBO) | Committer | 滴滴出行 |
-| 赵寅锐 | [@ZHAOYINRUI](https://github.com/ZHAOYINRUI) | Maintainer | 字节跳动 |
-| haoqi123 | [@haoqi123](https://github.com/haoqi123) | Contributor | 前程无忧 |
-| chaixiaoxue | [@chaixiaoxue](https://github.com/chaixiaoxue) | Contributor | SYNNEX |
-| 陆晗 | [@luhea](https://github.com/luhea) | Contributor | 竞技世界 |
-| Mengqi777 | [@Mengqi777](https://github.com/Mengqi777) | Contributor | 腾讯 |
-| ruanliang-hualun | [@ruanliang-hualun](https://github.com/ruanliang-hualun) | Contributor | 网易 |
-| 17hao | [@17hao](https://github.com/17hao) | Contributor | |
-| Huyueeer | [@Huyueeer](https://github.com/Huyueeer) | Contributor | INVENTEC |
-| lomodays207 | [@lomodays207](https://github.com/lomodays207) | Contributor | 建信金科 |
-| Super .Wein(星痕) | [@superspeedone](https://github.com/superspeedone) | Contributor | 韵达 |
-| Hongten | [@Hongten](https://github.com/Hongten) | Contributor | Shopee |
-| 徐正熙 | [@hyper-xx)](https://github.com/hyper-xx) | Contributor | 滴滴出行 |
-| RichardZhengkay | [@RichardZhengkay](https://github.com/RichardZhengkay) | Contributor | 趣街 |
-| 罐子里的茶 | [@gzldc](https://github.com/gzldc) | Contributor | 道富 |
-| 陈忠玉 | [@paula](https://github.com/chenzhongyu11) | Contributor | 平安产险 |
-| 杨光 | [@yaangvipguang](https://github.com/yangvipguang) | Contributor |
-| 王亚聪 | [@wangyacongi](https://github.com/wangyacongi) | Contributor |
-| Yang Jing | [@yangbajing](https://github.com/yangbajing) | Contributor | |
-| 刘新元 Liu XinYuan | [@Liu-XinYuan](https://github.com/Liu-XinYuan) | Contributor | |
-| Joker | [@LiubeyJokerQueue](https://github.com/JokerQueue) | Contributor | 丰巢 |
-| Eason Lau | [@Liubey](https://github.com/Liubey) | Contributor | |
-| hailanxin | [@hailanxin](https://github.com/hailanxin) | Contributor | |
-| Qi Zhang | [@zzzhangqi](https://github.com/zzzhangqi) | Contributor | 好雨科技 |
-| fengxsong | [@fengxsong](https://github.com/fengxsong) | Contributor | |
-| 谢晓东 | [@Strangevy](https://github.com/Strangevy) | Contributor | 花生日记 |
-| ZhaoXinlong | [@ZhaoXinlong](https://github.com/ZhaoXinlong) | Contributor | |
-| xuehaipeng | [@xuehaipeng](https://github.com/xuehaipeng) | Contributor | |
-| 孔令续 | [@mrazkong](https://github.com/mrazkong) | Contributor | |
-| pierre xiong | [@pierre94](https://github.com/pierre94) | Contributor | |
-| PengShuaixin | [@PengShuaixin](https://github.com/PengShuaixin) | Contributor | |
-| 梁壮 | [@lz](https://github.com/silent-night-no-trace) | Contributor | |
-| 张晓寅 | [@ahu0605](https://github.com/ahu0605) | Contributor | 电信数智 |
-| 黄海婷 | [@Huanghaiting](https://github.com/Huanghaiting) | Contributor | 云徙科技 |
-| 任祥德 | [@RenChauncy](https://github.com/RenChauncy) | Contributor | 探马企服 |
-| 胡圣林 | [@slhu997](https://github.com/slhu997) | Contributor | |
-| 史泽颖 | [@shizeying](https://github.com/shizeying) | Contributor | |
-| 王玉博 | [@Wyb7290](https://github.com/Wyb7290) | Committer | |
-| 伍璇 | [@Luckywustone](https://github.com/Luckywustone) | Contributor ||
-| 邓苑 | [@CatherineDY](https://github.com/CatherineDY) | Contributor ||
-| 封琼凤 | [@Luckywustone](https://github.com/fengqiongfeng) | Committer ||
diff --git a/docs/contribute_guide/贡献指南.md b/docs/contribute_guide/贡献指南.md
deleted file mode 100644
index 37cf89bc..00000000
--- a/docs/contribute_guide/贡献指南.md
+++ /dev/null
@@ -1,167 +0,0 @@
-# 贡献指南
-
-- [贡献指南](#贡献指南)
- - [1、行为准则](#1行为准则)
- - [2、仓库规范](#2仓库规范)
- - [2.1、Issue 规范](#21issue-规范)
- - [2.2、Commit-Log 规范](#22commit-log-规范)
- - [2.3、Pull-Request 规范](#23pull-request-规范)
- - [3、操作示例](#3操作示例)
- - [3.1、初始化环境](#31初始化环境)
- - [3.2、认领问题](#32认领问题)
- - [3.3、处理问题 \& 提交解决](#33处理问题--提交解决)
- - [3.4、请求合并](#34请求合并)
- - [4、常见问题](#4常见问题)
- - [4.1、如何将多个 Commit-Log 合并为一个?](#41如何将多个-commit-log-合并为一个)
-
-
----
-
-
-欢迎 👏🏻 👏🏻 👏🏻 来到 `KnowStreaming`。本文档是关于如何为 `KnowStreaming` 做出贡献的指南。如果您发现不正确或遗漏的内容, 请留下您的意见/建议。
-
-
----
-
-
-## 1、行为准则
-
-请务必阅读并遵守我们的:[行为准则](https://github.com/didi/KnowStreaming/blob/master/CODE_OF_CONDUCT.md)。
-
-
-## 2、仓库规范
-
-### 2.1、Issue 规范
-
-按要求,在 [创建Issue](https://github.com/didi/KnowStreaming/issues/new/choose) 中创建ISSUE即可。
-
-需要重点说明的是:
-- 提供出现问题的环境信息,包括使用的系统,使用的KS版本等;
-- 提供出现问题的复现方式;
-
-
-### 2.2、Commit-Log 规范
-
-`Commit-Log` 包含三部分 `Header`、`Body`、`Footer`。其中 `Header` 是必须的,格式固定,`Body` 在变更有必要详细解释时使用。
-
-
-**1、`Header` 规范**
-
-`Header` 格式为 `[Type]Message(#IssueID)`, 主要有三部分组成,分别是`Type`、`Message`、`IssueID`,
-
-- `Type`:说明这个提交是哪一个类型的,比如有 Bugfix、Feature、Optimize等;
-- `Message`:说明提交的信息,比如修复xx问题;
-- `IssueID`:该提交,关联的Issue的编号;
-
-
-实际例子:[`[Bugfix]修复新接入的集群,Controller-Host不显示的问题(#927)`](https://github.com/didi/KnowStreaming/pull/933/commits)
-
-
-
-**2、`Body` 规范**
-
-一般不需要,如果解决了较复杂问题,或者代码较多,需要 `Body` 说清楚解决的问题,解决的思路等信息。
-
----
-
-**3、实际例子**
-
-```
-[Optimize]优化 MySQL & ES 测试容器的初始化(#906)
-
-主要的变更
-1、knowstreaming/knowstreaming-manager 容器;
-2、knowstreaming/knowstreaming-mysql 容器调整为使用 mysql:5.7 容器;
-3、初始化 mysql:5.7 容器后,增加初始化 MySQL 表及数据的动作;
-
-被影响的变更:
-1、移动 km-dist/init/sql 下的MySQL初始化脚本至 km-persistence/src/main/resource/sql 下,以便项目测试时加载到所需的初始化 SQL;
-2、删除无用的 km-dist/init/template 目录;
-3、因为 km-dist/init/sql 和 km-dist/init/template 目录的调整,因此也调整 ReleaseKnowStreaming.xml 内的文件内容;
-```
-
-
-**TODO : 后续有兴趣的同学,可以考虑引入 Git 的 Hook 进行更好的 Commit-Log 的管理。**
-
-
-### 2.3、Pull-Request 规范
-
-详细见:[PULL-REQUEST 模版](../../.github/PULL_REQUEST_TEMPLATE.md)
-
-需要重点说明的是:
-
-- 任何 PR 都必须与有效 ISSUE 相关联。否则, PR 将被拒绝;
-- 一个分支只修改一件事,一个 PR 只修改一件事;
-
----
-
-
-## 3、操作示例
-
-本节主要介绍对 `KnowStreaming` 进行代码贡献时,相关的操作方式及操作命令。
-
-名词说明:
-- 主仓库:https://github.com/didi/KnowStreaming 这个仓库为主仓库。
-- 分仓库:Fork 到自己账号下的 KnowStreaming 仓库为分仓库;
-
-
-### 3.1、初始化环境
-
-1. `Fork KnowStreaming` 主仓库至自己账号下,见 https://github.com/didi/KnowStreaming 地址右上角的 `Fork` 按钮;
-2. 克隆分仓库至本地:`git clone git@github.com:xxxxxxx/KnowStreaming.git`,该仓库的简写名通常是`origin`;
-3. 添加主仓库至本地:`git remote add upstream https://github.com/didi/KnowStreaming`,`upstream`是主仓库在本地的简写名,可以随意命名,前后保持一致即可;
-4. 拉取主仓库代码:`git fetch upstream`;
-5. 拉取分仓库代码:`git fetch origin`;
-6. 将主仓库的`master`分支,拉取到本地并命名为`github_master`:`git checkout -b upstream/master`;
-
-最后,我们来看一下初始化完成之后的大致效果,具体如下图所示:
-
-
-
-至此,我们的环境就初始化好了。后续,`github_master` 分支就是主仓库的`master`分支,我们可以使用`git pull`拉取该分支的最新代码,还可以使用`git checkout -b xxx`拉取我们想要的分支。
-
-
-
-### 3.2、认领问题
-
-在文末评论说明自己要处理该问题即可,具体如下图所示:
-
-
-
-
-### 3.3、处理问题 & 提交解决
-
-本节主要介绍一下处理问题 & 提交解决过程中的分支管理,具体如下图所示:
-
-
-
-1. 切换到主分支:`git checkout github_master`;
-2. 主分支拉最新代码:`git pull`;
-3. 基于主分支拉新分支:`git checkout -b fix_928`;
-4. 提交代码,安装commit的规范进行提交,例如:`git commit -m "[Optimize]优化xxx问题(#928)"`;
-5. 提交到自己远端仓库:`git push --set-upstream origin fix_928`;
-6. `GitHub` 页面发起 `Pull Request` 请求,管理员合入主仓库。这部分详细见下一节;
-
-
-### 3.4、请求合并
-
-代码在提交到 `GitHub` 分仓库之后,就可以在 `GitHub` 的网站创建 `Pull Request`,申请将代码合入主仓库了。 `Pull Request` 具体见下图所示:
-
-
-
-
-
-[Pull Request 创建的例子](https://github.com/didi/KnowStreaming/pull/945)
-
-
-
----
-
-
-## 4、常见问题
-
-### 4.1、如何将多个 Commit-Log 合并为一个?
-
-可以使用 `git rebase -i` 命令进行解决。
-
-
diff --git a/docs/dev_guide/Task模块简介.md b/docs/dev_guide/Task模块简介.md
deleted file mode 100644
index 688e033b..00000000
--- a/docs/dev_guide/Task模块简介.md
+++ /dev/null
@@ -1,264 +0,0 @@
-# Task模块简介
-
-## 1、Task简介
-
-在 KnowStreaming 中(下面简称KS),Task模块主要是用于执行一些周期任务,包括Cluster、Broker、Topic等指标的定时采集,集群元数据定时更新至DB,集群状态的健康巡检等。在KS中,与Task模块相关的代码,我们都统一存放在km-task模块中。
-
-Task模块是基于 LogiCommon 中的Logi-Job组件实现的任务周期执行,Logi-Job 的功能类似 XXX-Job,它是 XXX-Job 在 KnowStreaming 的内嵌实现,主要用于简化 KnowStreaming 的部署。
-Logi-Job 的任务总共有两种执行模式,分别是:
-
-+ 广播模式:同一KS集群下,同一任务周期中,所有KS主机都会执行该定时任务。
-+ 抢占模式:同一KS集群下,同一任务周期中,仅有某一台KS主机会执行该任务。
-
-KS集群范围定义:连接同一个DB,且application.yml中的spring.logi-job.app-name的名称一样的KS主机为同一KS集群。
-
-## 2、使用指南
-
-Task模块基于Logi-Job的广播模式与抢占模式,分别实现了任务的抢占执行、重复执行以及均衡执行,他们之间的差别是:
-
-+ 抢占执行:同一个KS集群,同一个任务执行周期中,仅有一台KS主机执行该任务;
-+ 重复执行:同一个KS集群,同一个任务执行周期中,所有KS主机都执行该任务。比如3台KS主机,3个Kafka集群,此时每台KS主机都会去采集这3个Kafka集群的指标;
-+ 均衡执行:同一个KS集群,同一个任务执行周期中,每台KS主机仅执行该任务的一部分,所有的KS主机共同协作完成了任务。比如3台KS主机,3个Kafka集群,稳定运行情况下,每台KS主机将仅采集1个Kafka集群的指标,3台KS主机共同完成3个Kafka集群指标的采集。
-
-下面我们看一下具体例子。
-
-### 2.1、抢占模式——抢占执行
-
-功能说明:
-
-+ 同一个KS集群,同一个任务执行周期中,仅有一台KS主机执行该任务。
-
-代码例子:
-
-```java
-// 1、实现Job接口,重写excute方法;
-// 2、在类上添加@Task注解,并且配置好信息,指定为随机抢占模式;
-// 效果:KS集群中,每5秒,会有一台KS主机输出 "测试定时任务运行中";
-@Task(name = "TestJob",
- description = "测试定时任务",
- cron = "*/5 * * * * ?",
- autoRegister = true,
- consensual = ConsensualEnum.RANDOM, // 这里一定要设置为RANDOM
- timeout = 6 * 60)
-public class TestJob implements Job {
-
- @Override
- public TaskResult execute(JobContext jobContext) throws Exception {
-
- System.out.println("测试定时任务运行中");
- return new TaskResult();
-
- }
-
-}
-```
-
-
-
-### 2.2、广播模式——重复执行
-
-功能说明:
-
-+ 同一个KS集群,同一个任务执行周期中,所有KS主机都执行该任务。比如3台KS主机,3个Kafka集群,此时每台KS主机都会去重复采集这3个Kafka集群的指标。
-
-代码例子:
-
-```java
-// 1、实现Job接口,重写excute方法;
-// 2、在类上添加@Task注解,并且配置好信息,指定为广播抢占模式;
-// 效果:KS集群中,每5秒,每台KS主机都会输出 "测试定时任务运行中";
-@Task(name = "TestJob",
- description = "测试定时任务",
- cron = "*/5 * * * * ?",
- autoRegister = true,
- consensual = ConsensualEnum.BROADCAST, // 这里一定要设置为BROADCAST
- timeout = 6 * 60)
-public class TestJob implements Job {
-
- @Override
- public TaskResult execute(JobContext jobContext) throws Exception {
-
- System.out.println("测试定时任务运行中");
- return new TaskResult();
-
- }
-
-}
-```
-
-
-
-### 2.3、广播模式——均衡执行
-
-功能说明:
-
-+ 同一个KS集群,同一个任务执行周期中,每台KS主机仅执行该任务的一部分,所有的KS主机共同协作完成了任务。比如3台KS主机,3个Kafka集群,稳定运行情况下,每台KS主机将仅采集1个Kafka集群的指标,3台KS主机共同完成3个Kafka集群指标的采集。
-
-代码例子:
-
-+ 该模式有点特殊,是KS基于Logi-Job的广播模式,做的一个扩展,以下为一个使用例子:
-
-```java
-// 1、继承AbstractClusterPhyDispatchTask,实现processSubTask方法;
-// 2、在类上添加@Task注解,并且配置好信息,指定为广播模式;
-// 效果:在本样例中,每隔1分钟ks会将所有的kafka集群列表在ks集群主机内均衡拆分,每台主机会将分发到自身的Kafka集群依次执行processSubTask方法,实现KS集群的任务协同处理。
-@Task(name = "kmJobTask",
- description = "km job 模块调度执行任务",
- cron = "0 0/1 * * * ? *",
- autoRegister = true,
- consensual = ConsensualEnum.BROADCAST,
- timeout = 6 * 60)
-public class KMJobTask extends AbstractClusterPhyDispatchTask {
-
- @Autowired
- private JobService jobService;
-
- @Override
- protected TaskResult processSubTask(ClusterPhy clusterPhy, long triggerTimeUnitMs) throws Exception {
- jobService.scheduleJobByClusterId(clusterPhy.getId());
- return TaskResult.SUCCESS;
- }
-}
-```
-
-
-
-## 3、原理简介
-
-### 3.1、Task注解说明
-
-```java
-public @interface Task {
- String name() default ""; //任务名称
- String description() default ""; //任务描述
- String owner() default "system"; //拥有者
- String cron() default ""; //定时执行的时间策略
- int retryTimes() default 0; //失败以后所能重试的最大次数
- long timeout() default 0; //在超时时间里重试
- //是否自动注册任务到数据库中
- //如果设置为false,需要手动去数据库km_task表注册定时任务信息。数据库记录和@Task注解缺一不可
- boolean autoRegister() default false;
- //执行模式:广播、随机抢占
- //广播模式:同一集群下的所有服务器都会执行该定时任务
- //随机抢占模式:同一集群下随机一台服务器执行该任务
- ConsensualEnum consensual() default ConsensualEnum.RANDOM;
- }
-```
-
-### 3.2、数据库表介绍
-
-+ logi_task:记录项目中的定时任务信息,一个定时任务对应一条记录。
-+ logi_job:具体任务执行信息。
-+ logi_job_log:定时任务的执行日志。
-+ logi_worker:记录机器信息,实现集群控制。
-
-### 3.3、均衡执行简介
-
-#### 3.3.1、类关系图
-
-这里以KMJobTask为例,简单介绍KM中的定时任务实现逻辑。
-
- 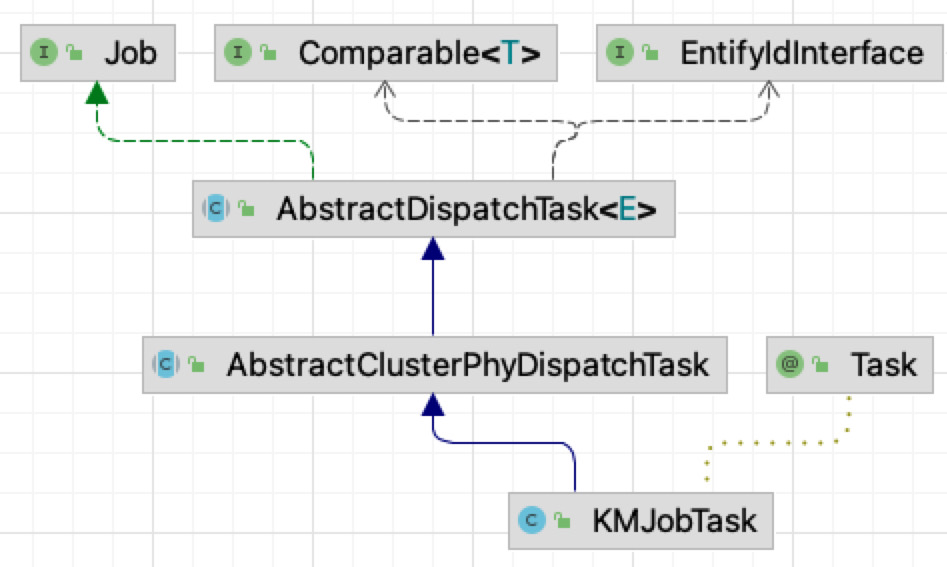
-
-+ Job:使用logi组件实现定时任务,必须实现该接口。
-+ Comparable & EntufyIdInterface:比较接口,实现任务的排序逻辑。
-+ AbstractDispatchTask:实现广播模式下,任务的均衡分发。
-+ AbstractClusterPhyDispatchTask:对分发到当前服务器的集群列表进行枚举。
-+ KMJobTask:实现对单个集群的定时任务处理。
-
-#### 3.3.2、关键类代码
-
-+ **AbstractDispatchTask类**
-
-```java
-// 实现Job接口的抽象类,进行任务的负载均衡执行
-public abstract class AbstractDispatchTask implements Job {
-
- // 罗列所有的任务
- protected abstract List listAllTasks();
-
- // 执行被分配给该KS主机的任务
- protected abstract TaskResult processTask(List subTaskList, long triggerTimeUnitMs);
-
- // 被Logi-Job触发执行该方法
- // 该方法进行任务的分配
- @Override
- public TaskResult execute(JobContext jobContext) {
- try {
-
- long triggerTimeUnitMs = System.currentTimeMillis();
-
- // 获取所有的任务
- List allTaskList = this.listAllTasks();
-
- // 计算当前KS机器需要执行的任务
- List subTaskList = this.selectTask(allTaskList, jobContext.getAllWorkerCodes(), jobContext.getCurrentWorkerCode());
-
- // 进行任务处理
- return this.processTask(subTaskList, triggerTimeUnitMs);
- } catch (Exception e) {
- // ...
- }
- }
-}
-```
-
-+ **AbstractClusterPhyDispatchTask类**
-
-```java
-// 继承AbstractDispatchTask的抽象类,对Kafka集群进行负载均衡执行
-public abstract class AbstractClusterPhyDispatchTask extends AbstractDispatchTask {
-
- // 执行被分配的任务,具体由子类实现
- protected abstract TaskResult processSubTask(ClusterPhy clusterPhy, long triggerTimeUnitMs) throws Exception;
-
- // 返回所有的Kafka集群
- @Override
- public List listAllTasks() {
- return clusterPhyService.listAllClusters();
- }
-
- // 执行被分配给该KS主机的Kafka集群任务
- @Override
- public TaskResult processTask(List subTaskList, long triggerTimeUnitMs) { // ... }
-
-}
-```
-
-+ **KMJobTask类**
-
-```java
-// 加上@Task注解,并配置任务执行信息
-@Task(name = "kmJobTask",
- description = "km job 模块调度执行任务",
- cron = "0 0/1 * * * ? *",
- autoRegister = true,
- consensual = ConsensualEnum.BROADCAST,
- timeout = 6 * 60)
-// 继承AbstractClusterPhyDispatchTask类
-public class KMJobTask extends AbstractClusterPhyDispatchTask {
-
- @Autowired
- private JobService jobService;
-
- // 执行该Kafka集群的Job模块的任务
- @Override
- protected TaskResult processSubTask(ClusterPhy clusterPhy, long triggerTimeUnitMs) throws Exception {
- jobService.scheduleJobByClusterId(clusterPhy.getId());
- return TaskResult.SUCCESS;
- }
-}
-```
-
-#### 3.3.3、均衡执行总结
-
-均衡执行的实现原理总结起来就是以下几点:
-
-+ Logi-Job设置为广播模式,触发所有的KS主机执行任务;
-+ 每台KS主机,被触发执行后,按照统一的规则,对任务列表,KS集群主机列表进行排序。然后按照顺序将任务列表均衡的分配给排序后的KS集群主机。KS集群稳定运行情况下,这一步保证了每台KS主机之间分配到的任务列表不重复,不丢失。
-+ 最后每台KS主机,执行被分配到的任务。
-
-## 4、注意事项
-
-+ 不能100%保证任务在一个周期内,且仅且执行一次,可能出现重复执行或丢失的情况,所以必须严格是且仅且执行一次的任务,不建议基于Logi-Job进行任务控制。
-+ 尽量让Logi-Job仅负责任务的触发,后续的执行建议放到自己创建的线程池中进行。
diff --git a/docs/dev_guide/assets/connect_jmx_failed/check_jmx_opened.jpg b/docs/dev_guide/assets/connect_jmx_failed/check_jmx_opened.jpg
deleted file mode 100644
index 1890983c..00000000
Binary files a/docs/dev_guide/assets/connect_jmx_failed/check_jmx_opened.jpg and /dev/null differ
diff --git a/docs/dev_guide/assets/support_kerberos_zk/need_modify_code.png b/docs/dev_guide/assets/support_kerberos_zk/need_modify_code.png
deleted file mode 100644
index c51c1c00..00000000
Binary files a/docs/dev_guide/assets/support_kerberos_zk/need_modify_code.png and /dev/null differ
diff --git a/docs/dev_guide/assets/support_kerberos_zk/success_1.png b/docs/dev_guide/assets/support_kerberos_zk/success_1.png
deleted file mode 100644
index f15ed55e..00000000
Binary files a/docs/dev_guide/assets/support_kerberos_zk/success_1.png and /dev/null differ
diff --git a/docs/dev_guide/assets/support_kerberos_zk/success_2.png b/docs/dev_guide/assets/support_kerberos_zk/success_2.png
deleted file mode 100644
index f15ed55e..00000000
Binary files a/docs/dev_guide/assets/support_kerberos_zk/success_2.png and /dev/null differ
diff --git a/docs/dev_guide/assets/support_kerberos_zk/watch_user_acl.png b/docs/dev_guide/assets/support_kerberos_zk/watch_user_acl.png
deleted file mode 100644
index b076316b..00000000
Binary files a/docs/dev_guide/assets/support_kerberos_zk/watch_user_acl.png and /dev/null differ
diff --git a/docs/dev_guide/多版本兼容方案.md b/docs/dev_guide/多版本兼容方案.md
deleted file mode 100644
index f41c01d4..00000000
--- a/docs/dev_guide/多版本兼容方案.md
+++ /dev/null
@@ -1,43 +0,0 @@
-
-## 4.2、Kafka 多版本兼容方案
-
- 当前 KnowStreaming 支持纳管多个版本的 kafka 集群,由于不同版本的 kafka 在指标采集、接口查询、行为操作上有些不一致,因此 KnowStreaming 需要一套机制来解决多 kafka 版本的纳管兼容性问题。
-
-### 4.2.1、整体思路
-
- 由于需要纳管多个 kafka 版本,而且未来还可能会纳管非 kafka 官方的版本,kafka 的版本号会存在着多种情况,所以首先要明确一个核心思想:KnowStreaming 提供尽可能多的纳管能力,但是不提供无限的纳管能力,每一个版本的 KnowStreaming 只纳管其自身声明的 kafka 版本,后续随着 KnowStreaming 自身版本的迭代,会逐步支持更多 kafka 版本的纳管接入。
-
-### 4.2.2、构建版本兼容列表
-
- 每一个版本的 KnowStreaming 都声明一个自身支持纳管的 kafka 版本列表,并且对 kafka 的版本号进行归一化处理,后续所有 KnowStreaming 对不同 kafka 集群的操作都和这个集群对应的版本号严格相关。
-
- KnowStreaming 对外提供自身所支持的 kafka 版本兼容列表,用以声明自身支持的版本范围。
-
- 对于在集群接入过程中,如果希望接入当前 KnowStreaming 不支持的 kafka 版本的集群,KnowStreaming 建议在于的过程中选择相近的版本号接入。
-
-### 4.2.3、构建版本兼容性字典
-
- 在构建了 KnowStreaming 支持的 kafka 版本列表的基础上,KnowStreaming 在实现过程中,还会声明自身支持的所有兼容性,构建兼容性字典。
-
- 当前 KnowStreaming 支持的 kafka 版本兼容性字典包括三个维度:
-
-- 指标采集:同一个指标在不同 kafka 版本下可能获取的方式不一样,不同版本的 kafka 可能会有不同的指标,因此对于指标采集的处理需要构建兼容性字典。
-- kafka api:同一个 kafka 的操作处理的方式在不同 kafka 版本下可能存在不一致,如:topic 的创建,因此 KnowStreaming 针对不同 kafka-api 的处理需要构建兼容性字典。
-- 平台操作:KnowStreaming 在接入不同版本的 kafka 集群的时候,在平台页面上会根据不同的 kafka 版。
-
-兼容性字典的核心设计字段如下:
-
-| 兼容性维度 | 兼容项名称 | 最小 Kafka 版本号(归一化) | 最大 Kafka 版本号(归一化) | 处理器 |
-| ---------- | ---------- | --------------------------- | --------------------------- | ------ |
-
-KS-KM 根据其需要纳管的 kafka 版本,按照上述三个维度构建了完善了兼容性字典。
-
-### 4.2.4、兼容性问题
-
- KS-KM 的每个版本针对需要纳管的 kafka 版本列表,事先分析各个版本的差异性和产品需求,同时 KS-KM 构建了一套专门处理兼容性的服务,来进行兼容性的注册、字典构建、处理器分发等操作,其中版本兼容性处理器是来具体处理不同 kafka 版本差异性的地方。
-
- 
-
- 如上图所示,KS-KM 的 topic 服务在面对不同 kafka 版本时,其 topic 的创建、删除、扩容由于 kafka 版本自身的差异,导致 KnowStreaming 的处理也不一样,所以需要根据不同的 kafka 版本来实现不同的兼容性处理器,同时向 KnowStreaming 的兼容服务进行兼容性的注册,构建兼容性字典,后续在 KnowStreaming 的运行过程中,针对不同的 kafka 版本即可分发到不同的处理器中执行。
-
- 后续随着 KnowStreaming 产品的发展,如果有新的兼容性的地方需要增加,只需要实现新版本的处理器,增加注册项即可。
diff --git a/docs/dev_guide/指标说明.md b/docs/dev_guide/指标说明.md
deleted file mode 100644
index 1eb9a94b..00000000
--- a/docs/dev_guide/指标说明.md
+++ /dev/null
@@ -1,152 +0,0 @@
-## 3.3、指标说明
-
-当前 KnowStreaming 支持针对 kafka 集群的多维度指标的采集和展示,同时也支持多个 kafka 版本的指标进行兼容,以下是 KnowStreaming 支持的指标说明。
-
-现在对当前 KnowStreaming 支持的指标从指标名称、指标单位、指标说明、kafka 版本、企业/开源版指标 五个维度进行说明。
-
-### 3.3.1、Cluster 指标
-
-| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
-| ------------------------- | -------- | ------------------------------------ | ---------------- | --------------- |
-| HealthScore | 分 | 集群总体的健康分 | 全部版本 | 开源版 |
-| HealthCheckPassed | 个 | 集群总体健康检查通过数 | 全部版本 | 开源版 |
-| HealthCheckTotal | 个 | 集群总体健康检查总数 | 全部版本 | 开源版 |
-| HealthScore_Topics | 分 | 集群 Topics 的健康分 | 全部版本 | 开源版 |
-| HealthCheckPassed_Topics | 个 | 集群 Topics 健康检查通过数 | 全部版本 | 开源版 |
-| HealthCheckTotal_Topics | 个 | 集群 Topics 健康检查总数 | 全部版本 | 开源版 |
-| HealthScore_Brokers | 分 | 集群 Brokers 的健康分 | 全部版本 | 开源版 |
-| HealthCheckPassed_Brokers | 个 | 集群 Brokers 健康检查通过数 | 全部版本 | 开源版 |
-| HealthCheckTotal_Brokers | 个 | 集群 Brokers 健康检查总数 | 全部版本 | 开源版 |
-| HealthScore_Groups | 分 | 集群 Groups 的健康分 | 全部版本 | 开源版 |
-| HealthCheckPassed_Groups | 个 | 集群 Groups 健康检查总数 | 全部版本 | 开源版 |
-| HealthCheckTotal_Groups | 个 | 集群 Groups 健康检查总数 | 全部版本 | 开源版 |
-| HealthScore_Cluster | 分 | 集群自身的健康分 | 全部版本 | 开源版 |
-| HealthCheckPassed_Cluster | 个 | 集群自身健康检查通过数 | 全部版本 | 开源版 |
-| HealthCheckTotal_Cluster | 个 | 集群自身健康检查总数 | 全部版本 | 开源版 |
-| TotalRequestQueueSize | 个 | 集群中总的请求队列数 | 全部版本 | 开源版 |
-| TotalResponseQueueSize | 个 | 集群中总的响应队列数 | 全部版本 | 开源版 |
-| EventQueueSize | 个 | 集群中 Controller 的 EventQueue 大小 | 2.0.0 及以上版本 | 开源版 |
-| ActiveControllerCount | 个 | 集群中存活的 Controller 数 | 全部版本 | 开源版 |
-| TotalProduceRequests | 个 | 集群中的 Produce 每秒请求数 | 全部版本 | 开源版 |
-| TotalLogSize | byte | 集群总的已使用的磁盘大小 | 全部版本 | 开源版 |
-| ConnectionsCount | 个 | 集群的连接(Connections)个数 | 全部版本 | 开源版 |
-| Zookeepers | 个 | 集群中存活的 zk 节点个数 | 全部版本 | 开源版 |
-| ZookeepersAvailable | 是/否 | ZK 地址是否合法 | 全部版本 | 开源版 |
-| Brokers | 个 | 集群的 broker 的总数 | 全部版本 | 开源版 |
-| BrokersAlive | 个 | 集群的 broker 的存活数 | 全部版本 | 开源版 |
-| BrokersNotAlive | 个 | 集群的 broker 的未存活数 | 全部版本 | 开源版 |
-| Replicas | 个 | 集群中 Replica 的总数 | 全部版本 | 开源版 |
-| Topics | 个 | 集群中 Topic 的总数 | 全部版本 | 开源版 |
-| Partitions | 个 | 集群的 Partitions 总数 | 全部版本 | 开源版 |
-| PartitionNoLeader | 个 | 集群中的 PartitionNoLeader 总数 | 全部版本 | 开源版 |
-| PartitionMinISR_S | 个 | 集群中的小于 PartitionMinISR 总数 | 全部版本 | 开源版 |
-| PartitionMinISR_E | 个 | 集群中的等于 PartitionMinISR 总数 | 全部版本 | 开源版 |
-| PartitionURP | 个 | 集群中的未同步的 Partition 总数 | 全部版本 | 开源版 |
-| MessagesIn | 条/s | 集群每条消息写入条数 | 全部版本 | 开源版 |
-| Messages | 条 | 集群总的消息条数 | 全部版本 | 开源版 |
-| LeaderMessages | 条 | 集群中 leader 总的消息条数 | 全部版本 | 开源版 |
-| BytesIn | byte/s | 集群的每秒写入字节数 | 全部版本 | 开源版 |
-| BytesIn_min_5 | byte/s | 集群的每秒写入字节数,5 分钟均值 | 全部版本 | 开源版 |
-| BytesIn_min_15 | byte/s | 集群的每秒写入字节数,15 分钟均值 | 全部版本 | 开源版 |
-| BytesOut | byte/s | 集群的每秒流出字节数 | 全部版本 | 开源版 |
-| BytesOut_min_5 | byte/s | 集群的每秒流出字节数,5 分钟均值 | 全部版本 | 开源版 |
-| BytesOut_min_15 | byte/s | 集群的每秒流出字节数,15 分钟均值 | 全部版本 | 开源版 |
-| Groups | 个 | 集群中 Group 的总数 | 全部版本 | 开源版 |
-| GroupActives | 个 | 集群中 ActiveGroup 的总数 | 全部版本 | 开源版 |
-| GroupEmptys | 个 | 集群中 EmptyGroup 的总数 | 全部版本 | 开源版 |
-| GroupRebalances | 个 | 集群中 RebalanceGroup 的总数 | 全部版本 | 开源版 |
-| GroupDeads | 个 | 集群中 DeadGroup 的总数 | 全部版本 | 开源版 |
-| Alive | 是/否 | 集群是否存活,1:存活;0:没有存活 | 全部版本 | 开源版 |
-| AclEnable | 是/否 | 集群是否开启 Acl,1:是;0:否 | 全部版本 | 开源版 |
-| Acls | 个 | ACL 数 | 全部版本 | 开源版 |
-| AclUsers | 个 | ACL-KafkaUser 数 | 全部版本 | 开源版 |
-| AclTopics | 个 | ACL-Topic 数 | 全部版本 | 开源版 |
-| AclGroups | 个 | ACL-Group 数 | 全部版本 | 开源版 |
-| Jobs | 个 | 集群任务总数 | 全部版本 | 开源版 |
-| JobsRunning | 个 | 集群 running 任务总数 | 全部版本 | 开源版 |
-| JobsWaiting | 个 | 集群 waiting 任务总数 | 全部版本 | 开源版 |
-| JobsSuccess | 个 | 集群 success 任务总数 | 全部版本 | 开源版 |
-| JobsFailed | 个 | 集群 failed 任务总数 | 全部版本 | 开源版 |
-| LoadReBalanceEnable | 是/否 | 是否开启均衡, 1:是;0:否 | 全部版本 | 企业版 |
-| LoadReBalanceCpu | 是/否 | CPU 是否均衡, 1:是;0:否 | 全部版本 | 企业版 |
-| LoadReBalanceNwIn | 是/否 | BytesIn 是否均衡, 1:是;0:否 | 全部版本 | 企业版 |
-| LoadReBalanceNwOut | 是/否 | BytesOut 是否均衡, 1:是;0:否 | 全部版本 | 企业版 |
-| LoadReBalanceDisk | 是/否 | Disk 是否均衡, 1:是;0:否 | 全部版本 | 企业版 |
-
-### 3.3.2、Broker 指标
-
-| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
-| ----------------------- | -------- | ------------------------------------- | ---------- | --------------- |
-| HealthScore | 分 | Broker 健康分 | 全部版本 | 开源版 |
-| HealthCheckPassed | 个 | Broker 健康检查通过数 | 全部版本 | 开源版 |
-| HealthCheckTotal | 个 | Broker 健康检查总数 | 全部版本 | 开源版 |
-| TotalRequestQueueSize | 个 | Broker 的请求队列大小 | 全部版本 | 开源版 |
-| TotalResponseQueueSize | 个 | Broker 的应答队列大小 | 全部版本 | 开源版 |
-| ReplicationBytesIn | byte/s | Broker 的副本流入流量 | 全部版本 | 开源版 |
-| ReplicationBytesOut | byte/s | Broker 的副本流出流量 | 全部版本 | 开源版 |
-| MessagesIn | 条/s | Broker 的每秒消息流入条数 | 全部版本 | 开源版 |
-| TotalProduceRequests | 个/s | Broker 上 Produce 的每秒请求数 | 全部版本 | 开源版 |
-| NetworkProcessorAvgIdle | % | Broker 的网络处理器的空闲百分比 | 全部版本 | 开源版 |
-| RequestHandlerAvgIdle | % | Broker 上请求处理器的空闲百分比 | 全部版本 | 开源版 |
-| PartitionURP | 个 | Broker 上的未同步的副本的个数 | 全部版本 | 开源版 |
-| ConnectionsCount | 个 | Broker 上网络链接的个数 | 全部版本 | 开源版 |
-| BytesIn | byte/s | Broker 的每秒数据写入量 | 全部版本 | 开源版 |
-| BytesIn_min_5 | byte/s | Broker 的每秒数据写入量,5 分钟均值 | 全部版本 | 开源版 |
-| BytesIn_min_15 | byte/s | Broker 的每秒数据写入量,15 分钟均值 | 全部版本 | 开源版 |
-| BytesOut | byte/s | Broker 的每秒数据流出量 | 全部版本 | 开源版 |
-| BytesOut_min_5 | byte/s | Broker 的每秒数据流出量,5 分钟均值 | 全部版本 | 开源版 |
-| BytesOut_min_15 | byte/s | Broker 的每秒数据流出量,15 分钟均值 | 全部版本 | 开源版 |
-| ReassignmentBytesIn | byte/s | Broker 的每秒数据迁移写入量 | 全部版本 | 开源版 |
-| ReassignmentBytesOut | byte/s | Broker 的每秒数据迁移流出量 | 全部版本 | 开源版 |
-| Partitions | 个 | Broker 上的 Partition 个数 | 全部版本 | 开源版 |
-| PartitionsSkew | % | Broker 上的 Partitions 倾斜度 | 全部版本 | 开源版 |
-| Leaders | 个 | Broker 上的 Leaders 个数 | 全部版本 | 开源版 |
-| LeadersSkew | % | Broker 上的 Leaders 倾斜度 | 全部版本 | 开源版 |
-| LogSize | byte | Broker 上的消息容量大小 | 全部版本 | 开源版 |
-| Alive | 是/否 | Broker 是否存活,1:存活;0:没有存活 | 全部版本 | 开源版 |
-
-### 3.3.3、Topic 指标
-
-| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
-| --------------------- | -------- | ------------------------------------- | ---------- | --------------- |
-| HealthScore | 分 | 健康分 | 全部版本 | 开源版 |
-| HealthCheckPassed | 个 | 健康项检查通过数 | 全部版本 | 开源版 |
-| HealthCheckTotal | 个 | 健康项检查总数 | 全部版本 | 开源版 |
-| TotalProduceRequests | 条/s | Topic 的 TotalProduceRequests | 全部版本 | 开源版 |
-| BytesRejected | 个/s | Topic 的每秒写入拒绝量 | 全部版本 | 开源版 |
-| FailedFetchRequests | 个/s | Topic 的 FailedFetchRequests | 全部版本 | 开源版 |
-| FailedProduceRequests | 个/s | Topic 的 FailedProduceRequests | 全部版本 | 开源版 |
-| ReplicationCount | 个 | Topic 总的副本数 | 全部版本 | 开源版 |
-| Messages | 条 | Topic 总的消息数 | 全部版本 | 开源版 |
-| MessagesIn | 条/s | Topic 每秒消息条数 | 全部版本 | 开源版 |
-| BytesIn | byte/s | Topic 每秒消息写入字节数 | 全部版本 | 开源版 |
-| BytesIn_min_5 | byte/s | Topic 每秒消息写入字节数,5 分钟均值 | 全部版本 | 开源版 |
-| BytesIn_min_15 | byte/s | Topic 每秒消息写入字节数,15 分钟均值 | 全部版本 | 开源版 |
-| BytesOut | byte/s | Topic 每秒消息流出字节数 | 全部版本 | 开源版 |
-| BytesOut_min_5 | byte/s | Topic 每秒消息流出字节数,5 分钟均值 | 全部版本 | 开源版 |
-| BytesOut_min_15 | byte/s | Topic 每秒消息流出字节数,15 分钟均值 | 全部版本 | 开源版 |
-| LogSize | byte | Topic 的大小 | 全部版本 | 开源版 |
-| PartitionURP | 个 | Topic 未同步的副本数 | 全部版本 | 开源版 |
-
-### 3.3.4、Partition 指标
-
-| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
-| -------------- | -------- | ----------------------------------------- | ---------- | --------------- |
-| LogEndOffset | 条 | Partition 中 leader 副本的 LogEndOffset | 全部版本 | 开源版 |
-| LogStartOffset | 条 | Partition 中 leader 副本的 LogStartOffset | 全部版本 | 开源版 |
-| Messages | 条 | Partition 总的消息数 | 全部版本 | 开源版 |
-| BytesIn | byte/s | Partition 的每秒消息流入字节数 | 全部版本 | 开源版 |
-| BytesOut | byte/s | Partition 的每秒消息流出字节数 | 全部版本 | 开源版 |
-| LogSize | byte | Partition 的大小 | 全部版本 | 开源版 |
-
-### 3.3.5、Group 指标
-
-| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
-| ----------------- | -------- | -------------------------- | ---------- | --------------- |
-| HealthScore | 分 | 健康分 | 全部版本 | 开源版 |
-| HealthCheckPassed | 个 | 健康检查通过数 | 全部版本 | 开源版 |
-| HealthCheckTotal | 个 | 健康检查总数 | 全部版本 | 开源版 |
-| OffsetConsumed | 条 | Consumer 的 CommitedOffset | 全部版本 | 开源版 |
-| LogEndOffset | 条 | Consumer 的 LogEndOffset | 全部版本 | 开源版 |
-| Lag | 条 | Group 消费者的 Lag 数 | 全部版本 | 开源版 |
-| State | 个 | Group 组的状态 | 全部版本 | 开源版 |
diff --git a/docs/dev_guide/支持Kerberos认证的ZK.md b/docs/dev_guide/支持Kerberos认证的ZK.md
deleted file mode 100644
index 116643ba..00000000
--- a/docs/dev_guide/支持Kerberos认证的ZK.md
+++ /dev/null
@@ -1,69 +0,0 @@
-
-## 支持Kerberos认证的ZK
-
-
-### 1、修改 KnowStreaming 代码
-
-代码位置:`src/main/java/com/xiaojukeji/know/streaming/km/persistence/kafka/KafkaAdminZKClient.java`
-
-将 `createZKClient` 的 `135行 的 false 改为 true
-
-
-
-修改完后重新进行打包编译,打包编译见:[打包编译](https://github.com/didi/KnowStreaming/blob/master/docs/install_guide/%E6%BA%90%E7%A0%81%E7%BC%96%E8%AF%91%E6%89%93%E5%8C%85%E6%89%8B%E5%86%8C.md
-)
-
-
-
-### 2、查看用户在ZK的ACL
-
-假设我们使用的用户是 `kafka` 这个用户。
-
-- 1、查看 server.properties 的配置的 zookeeper.connect 的地址;
-- 2、使用 `zkCli.sh -serve zookeeper.connect的地址` 登录到ZK页面;
-- 3、ZK页面上,执行命令 `getAcl /kafka` 查看 `kafka` 用户的权限;
-
-此时,我们可以看到如下信息:
-
-
-`kafka` 用户需要的权限是 `cdrwa`。如果用户没有 `cdrwa` 权限的话,需要创建用户并授权,授权命令为:`setAcl`
-
-
-### 3、创建Kerberos的keytab并修改 KnowStreaming 主机
-
-- 1、在 Kerberos 的域中创建 `kafka/_HOST` 的 `keytab`,并导出。例如:`kafka/dbs-kafka-test-8-53`;
-- 2、导出 keytab 后上传到安装 KS 的机器的 `/etc/keytab` 下;
-- 3、在 KS 机器上,执行 `kinit -kt zookeepe.keytab kafka/dbs-kafka-test-8-53` 看是否能进行 `Kerberos` 登录;
-- 4、可以登录后,配置 `/opt/zookeeper.jaas` 文件,例子如下:
-```sql
-Client {
- com.sun.security.auth.module.Krb5LoginModule required
- useKeyTab=true
- storeKey=false
- serviceName="zookeeper"
- keyTab="/etc/keytab/zookeeper.keytab"
- principal="kafka/dbs-kafka-test-8-53@XXX.XXX.XXX";
-};
-```
-- 5、需要配置 `KDC-Server` 对 `KnowStreaming` 的机器开通防火墙,并在KS的机器 `/etc/host/` 配置 `kdc-server` 的 `hostname`。并将 `krb5.conf` 导入到 `/etc` 下;
-
-
-### 4、修改 KnowStreaming 的配置
-
-- 1、在 `/usr/local/KnowStreaming/KnowStreaming/bin/startup.sh` 中的47行的JAVA_OPT中追加如下设置
-```bash
--Dsun.security.krb5.debug=true -Djava.security.krb5.conf=/etc/krb5.conf -Djava.security.auth.login.config=/opt/zookeeper.jaas
-```
-
-- 2、重启KS集群后再 start.out 中看到如下信息,则证明Kerberos配置成功;
-
-
-
-
-
-
-### 5、补充说明
-
-- 1、多Kafka集群如果用的是一样的Kerberos域的话,只需在每个`ZK`中给`kafka`用户配置`crdwa`权限即可,这样集群初始化的时候`zkclient`是都可以认证;
-- 2、当前需要修改代码重新打包才可以支持,后续考虑通过页面支持Kerberos认证的ZK接入;
-- 3、多个Kerberos域暂时未适配;
\ No newline at end of file
diff --git a/docs/dev_guide/无数据排查文档.md b/docs/dev_guide/无数据排查文档.md
deleted file mode 100644
index fd7886bc..00000000
--- a/docs/dev_guide/无数据排查文档.md
+++ /dev/null
@@ -1,285 +0,0 @@
-## 1、集群接入错误
-
-### 1.1、异常现象
-
-如下图所示,集群非空时,大概率为地址配置错误导致。
-
-
-
-## Star History
-
-[](https://star-history.com/#didi/KnowStreaming&Date)
diff --git a/Releases_Notes.md b/Releases_Notes.md
deleted file mode 100644
index a606ef72..00000000
--- a/Releases_Notes.md
+++ /dev/null
@@ -1,572 +0,0 @@
-
-## v3.3.0
-
-**问题修复**
-- 修复 Connect 的 JMX-Port 配置未生效问题;
-- 修复 不存在 Connector 时,OverView 页面的数据一直处于加载中的问题;
-- 修复 Group 分区信息,分页时展示不全的问题;
-- 修复采集副本指标时,参数传递错误的问题;
-- 修复用户信息修改后,用户列表会抛出空指针异常的问题;
-- 修复 Topic 详情页面,查看消息时,选择分区不生效问题;
-- 修复对 ZK 客户端进行配置后不生效的问题;
-- 修复 connect 模块,指标中缺少健康巡检项通过数的问题;
-- 修复 connect 模块,指标获取方法存在映射错误的问题;
-- 修复 connect 模块,max 纬度指标获取错误的问题;
-- 修复 Topic 指标大盘 TopN 指标显示信息错误的问题;
-- 修复 Broker Similar Config 显示错误的问题;
-- 修复解析 ZK 四字命令时,数据类型设置错误导致空指针的问题;
-- 修复新增 Topic 时,清理策略选项版本控制错误的问题;
-- 修复新接入集群时 Controller-Host 信息不显示的问题;
-- 修复 Connector 和 MM2 列表搜索不生效的问题;
-- 修复 Zookeeper 页面,Leader 显示存在异常的问题;
-- 修复前端打包失败的问题;
-
-
-**产品优化**
-- ZK Overview 页面补充默认展示的指标;
-- 统一初始化 ES 索引模版的脚本为 init_es_template.sh,同时新增缺失的 connect 索引模版初始化脚本,去除多余的 replica 和 zookeper 索引模版初始化脚本;
-- 指标大盘页面,优化指标筛选操作后,无指标数据的指标卡片由不显示改为显示,并增加无数据的兜底;
-- 删除从 ES 读写 replica 指标的相关代码;
-- 优化 Topic 健康巡检的日志,明确错误的原因;
-- 优化无 ZK 模块时,巡检详情忽略对 ZK 的展示;
-- 优化本地缓存大小为可配置;
-- Task 模块中的返回中,补充任务的分组信息;
-- FAQ 补充 Ldap 的配置说明;
-- FAQ 补充接入 Kerberos 认证的 Kafka 集群的配置说明;
-- ks_km_kafka_change_record 表增加时间纬度的索引,优化查询性能;
-- 优化 ZK 健康巡检的日志,便于问题的排查;
-
-**功能新增**
-- 新增基于滴滴 Kafka 的 Topic 复制功能(需使用滴滴 Kafka 才可具备该能力);
-- Topic 指标大盘,新增 Topic 复制相关的指标;
-- 新增基于 TestContainers 的单测;
-
-
-**Kafka MM2 Beta版 (v3.3.0版本新增发布)**
-- MM2 任务的增删改查;
-- MM2 任务的指标大盘;
-- MM2 任务的健康状态;
-
----
-
-
-## v3.2.0
-
-**问题修复**
-- 修复健康巡检结果更新至 DB 时,出现死锁问题;
-- 修复 KafkaJMXClient 类中,logger错误的问题;
-- 后端修复 Topic 过期策略在 0.10.1.0 版本能多选的问题,实际应该只能二选一;
-- 修复接入集群时,不填写集群配置会报错的问题;
-- 升级 spring-context 至 5.3.19 版本,修复安全漏洞;
-- 修复 Broker & Topic 修改配置时,多版本兼容配置的版本信息错误的问题;
-- 修复 Topic 列表的健康分为健康状态;
-- 修复 Broker LogSize 指标存储名称错误导致查询不到的问题;
-- 修复 Prometheus 中,缺少 Group 部分指标的问题;
-- 修复因缺少健康状态指标导致集群数错误的问题;
-- 修复后台任务记录操作日志时,因缺少操作用户信息导致出现异常的问题;
-- 修复 Replica 指标查询时,DSL 错误的问题;
-- 关闭 errorLogger,修复错误日志重复输出的问题;
-- 修复系统管理更新用户信息失败的问题;
-- 修复因原AR信息丢失,导致迁移任务一直处于执行中的错误;
-- 修复集群 Topic 列表实时数据查询时,出现失败的问题;
-- 修复集群 Topic 列表,页面白屏问题;
-- 修复副本变更时,因AR数据异常,导致数组访问越界的问题;
-
-
-**产品优化**
-- 优化健康巡检为按照资源维度多线程并发处理;
-- 统一日志输出格式,并优化部分输出的日志;
-- 优化 ZK 四字命令结果解析过程中,容易引起误解的 WARN 日志;
-- 优化 Zookeeper 详情中,目录结构的搜索文案;
-- 优化线程池的名称,方便第三方系统进行相关问题的分析;
-- 去除 ESClient 的并发访问控制,降低 ESClient 创建数及提升利用率;
-- 优化 Topic Messages 抽屉文案;
-- 优化 ZK 健康巡检失败时的错误日志信息;
-- 提高 Offset 信息获取的超时时间,降低并发过高时出现请求超时的概率;
-- 优化 Topic & Partition 元信息的更新策略,降低对 DB 连接的占用;
-- 优化 Sonar 代码扫码问题;
-- 优化分区 Offset 指标的采集;
-- 优化前端图表相关组件逻辑;
-- 优化产品主题色;
-- Consumer 列表刷新按钮新增 hover 提示;
-- 优化配置 Topic 的消息大小时的测试弹框体验;
-- 优化 Overview 页面 TopN 查询的流程;
-
-
-**功能新增**
-- 新增页面无数据排查文档;
-- 增加 ES 索引删除的功能;
-- 支持拆分API服务和Job服务部署;
-
-
-**Kafka Connect Beta版 (v3.2.0版本新增发布)**
-- Connect 集群的纳管;
-- Connector 的增删改查;
-- Connect 集群 & Connector 的指标大盘;
-
-
----
-
-
-## v3.1.0
-
-**Bug修复**
-- 修复重置 Group Offset 的提示信息中,缺少Dead状态也可进行重置的描述;
-- 修复新建 Topic 后,立即查看 Topic Messages 信息时,会提示 Topic 不存在的问题;
-- 修复副本变更时,优先副本选举未被正常处罚执行的问题;
-- 修复 git 目录不存在时,打包不能正常进行的问题;
-- 修复 KRaft 模式的 Kafka 集群,JMX PORT 显示 -1 的问题;
-
-
-**体验优化**
-- 优化Cluster、Broker、Topic、Group的健康分为健康状态;
-- 去除健康巡检配置中的权重信息;
-- 错误提示页面展示优化;
-- 前端打包编译依赖默认使用 taobao 镜像;
-- 重新设计优化导航栏的 icon ;
-
-
-**新增**
-- 个人头像下拉信息中,新增产品版本信息;
-- 多集群列表页面,新增集群健康状态分布信息;
-
-
-**Kafka ZK 部分 (v3.1.0版本正式发布)**
-- 新增 ZK 集群的指标大盘信息;
-- 新增 ZK 集群的服务状态概览信息;
-- 新增 ZK 集群的服务节点列表信息;
-- 新增 Kafka 在 ZK 的存储数据查看功能;
-- 新增 ZK 的健康巡检及健康状态计算;
-
-
-
----
-
-
-## v3.0.1
-
-**Bug修复**
-- 修复重置 Group Offset 时,提示信息中缺少 Dead 状态也可进行重置的信息;
-- 修复 Ldap 某个属性不存在时,会直接抛出空指针导致登陆失败的问题;
-- 修复集群 Topic 列表页,健康分详情信息中,检查时间展示错误的问题;
-- 修复更新健康检查结果时,出现死锁的问题;
-- 修复 Replica 索引模版错误的问题;
-- 修复 FAQ 文档中的错误链接;
-- 修复 Broker 的 TopN 指标不存在时,页面数据不展示的问题;
-- 修复 Group 详情页,图表时间范围选择不生效的问题;
-
-
-**体验优化**
-- 集群 Group 列表按照 Group 维度进行展示;
-- 优化避免因 ES 中该指标不存在,导致日志中出现大量空指针的问题;
-- 优化全局 Message & Notification 展示效果;
-- 优化 Topic 扩分区名称 & 描述展示;
-
-
-**新增**
-- Broker 列表页面,新增 JMX 是否成功连接的信息;
-
-
-**ZK 部分(未完全发布)**
-- 后端补充 Kafka ZK 指标采集,Kafka ZK 信息获取相关功能;
-- 增加本地缓存,避免同一采集周期内 ZK 指标重复采集;
-- 增加 ZK 节点采集失败跳过策略,避免不断对存在问题的节点不断尝试;
-- 修复 zkAvgLatency 指标转 Long 时抛出异常问题;
-- 修复 ks_km_zookeeper 表中,role 字段类型错误问题;
-
----
-
-## v3.0.0
-
-**Bug修复**
-- 修复 Group 指标防重复采集不生效问题
-- 修复自动创建 ES 索引模版失败问题
-- 修复 Group+Topic 列表中存在已删除Topic的问题
-- 修复使用 MySQL-8 ,因兼容问题, start_time 信息为 NULL 时,会导致创建任务失败的问题
-- 修复 Group 信息表更新时,出现死锁的问题
-- 修复图表补点逻辑与图表时间范围不适配的问题
-
-
-**体验优化**
-- 按照资源类别,拆分健康巡检任务
-- 优化 Group 详情页的指标为实时获取
-- 图表拖拽排序支持用户级存储
-- 多集群列表 ZK 信息展示兼容无 ZK 情况
-- Topic 详情消息预览支持复制功能
-- 部分内容大数字支持千位分割符展示
-
-
-**新增**
-- 集群信息中,新增 Zookeeper 客户端配置字段
-- 集群信息中,新增 Kafka 集群运行模式字段
-- 新增 docker-compose 的部署方式
-
----
-
-## v3.0.0-beta.3
-
-**文档**
-- FAQ 补充权限识别失败问题的说明
-- 同步更新文档,保持与官网一致
-
-
-**Bug修复**
-- Offset 信息获取时,过滤掉无 Leader 的分区
-- 升级 oshi-core 版本至 5.6.1 版本,修复 Windows 系统获取系统指标失败问题
-- 修复 JMX 连接被关闭后,未进行重建的问题
-- 修复因 DB 中 Broker 信息不存在导致 TotalLogSize 指标获取时抛空指针问题
-- 修复 dml-logi.sql 中,SQL 注释错误的问题
-- 修复 startup.sh 中,识别操作系统类型错误的问题
-- 修复配置管理页面删除配置失败的问题
-- 修复系统管理应用文件引用路径
-- 修复 Topic Messages 详情提示信息点击跳转 404 的问题
-- 修复扩副本时,当前副本数不显示问题
-
-
-**体验优化**
-- Topic-Messages 页面,增加返回数据的排序以及按照Earliest/Latest的获取方式
-- 优化 GroupOffsetResetEnum 类名为 OffsetTypeEnum,使得类名含义更准确
-- 移动 KafkaZKDAO 类,及 Kafka Znode 实体类的位置,使得 Kafka Zookeeper DAO 更加内聚及便于识别
-- 后端补充 Overview 页面指标排序的功能
-- 前端 Webpack 配置优化
-- Cluster Overview 图表取消放大展示功能
-- 列表页增加手动刷新功能
-- 接入/编辑集群,优化 JMX-PORT,Version 信息的回显,优化JMX信息的展示
-- 提高登录页面图片展示清晰度
-- 部分样式和文案优化
-
----
-
-## v3.0.0-beta.2
-
-**文档**
-- 新增登录系统对接文档
-- 优化前端工程打包构建部分文档说明
-- FAQ补充KnowStreaming连接特定JMX IP的说明
-
-
-**Bug修复**
-- 修复logi_security_oplog表字段过短,导致删除Topic等操作无法记录的问题
-- 修复ES查询时,抛java.lang.NumberFormatException: For input string: "{"value":0,"relation":"eq"}" 问题
-- 修复LogStartOffset和LogEndOffset指标单位错误问题
-- 修复进行副本变更时,旧副本数为NULL的问题
-- 修复集群Group列表,在第二页搜索时,搜索时返回的分页信息错误问题
-- 修复重置Offset时,返回的错误信息提示不一致的问题
-- 修复集群查看,系统查看,LoadRebalance等页面权限点缺失问题
-- 修复查询不存在的Topic时,错误信息提示不明显的问题
-- 修复Windows用户打包前端工程报错的问题
-- package-lock.json锁定前端依赖版本号,修复因依赖自动升级导致打包失败等问题
-- 系统管理子应用,补充后端返回的Code码拦截,解决后端接口返回报错不展示的问题
-- 修复用户登出后,依旧可以访问系统的问题
-- 修复巡检任务配置时,数值显示错误的问题
-- 修复Broker/Topic Overview 图表和图表详情问题
-- 修复Job扩缩副本任务明细数据错误的问题
-- 修复重置Offset时,分区ID,Offset数值无限制问题
-- 修复扩缩/迁移副本时,无法选中Kafka系统Topic的问题
-- 修复Topic的Config页面,编辑表单时不能正确回显当前值的问题
-- 修复Broker Card返回数据后依旧展示加载态的问题
-
-
-
-**体验优化**
-- 优化默认用户密码为 admin/admin
-- 缩短新增集群后,集群信息加载的耗时
-- 集群Broker列表,增加Controller角色信息
-- 副本变更任务结束后,增加进行优先副本选举的操作
-- Task模块任务分为Metrics、Common、Metadata三类任务,每类任务配备独立线程池,减少对Job模块的线程池,以及不同类任务之间的相互影响
-- 删除代码中存在的多余无用文件
-- 自动新增ES索引模版及近7天索引,减少用户搭建时需要做的事项
-- 优化前端工程打包流程
-- 优化登录页文案,页面左侧栏内容,单集群详情样式,Topic列表趋势图等
-- 首次进入Broker/Topic图表详情时,进行预缓存数据从而优化体验
-- 优化Topic详情Partition Tab的展示
-- 多集群列表页增加编辑功能
-- 优化副本变更时,迁移时间支持分钟级别粒度
-- logi-security版本升级至2.10.13
-- logi-elasticsearch-client版本升级至1.0.24
-
-
-**能力提升**
-- 支持Ldap登录认证
-
----
-
-## v3.0.0-beta.1
-
-**文档**
-- 新增Task模块说明文档
-- FAQ补充 `Specified key was too long; max key length is 767 bytes ` 错误说明
-- FAQ补充 `出现ESIndexNotFoundException报错` 错误说明
-
-
-**Bug修复**
-- 修复 Consumer 点击 Stop 未停止检索的问题
-- 修复创建/编辑角色权限报错问题
-- 修复多集群管理/单集群详情均衡卡片状态错误问题
-- 修复版本列表未排序问题
-- 修复Raft集群Controller信息不断记录问题
-- 修复部分版本消费组描述信息获取失败问题
-- 修复分区Offset获取失败的日志中,缺少Topic名称信息问题
-- 修复GitHub图地址错误,及图裂问题
-- 修复Broker默认使用的地址和注释不一致问题
-- 修复 Consumer 列表分页不生效问题
-- 修复操作记录表operation_methods字段缺少默认值问题
-- 修复集群均衡表中move_broker_list字段无效的问题
-- 修复KafkaUser、KafkaACL信息获取时,日志一直重复提示不支持问题
-- 修复指标缺失时,曲线出现掉底的问题
-
-
-**体验优化**
-- 优化前端构建时间和打包体积,增加依赖打包的分包策略
-- 优化产品样式和文案展示
-- 优化ES客户端数为可配置
-- 优化日志中大量出现的MySQL Key冲突日志
-
-
-**能力提升**
-- 增加周期任务,用于主动创建缺少的ES模版及索引的能力,减少额外的脚本操作
-- 增加JMX连接的Broker地址可选择的能力
-
----
-
-## v3.0.0-beta.0
-
-**1、多集群管理**
-
-- 增加健康监测体系、关键组件&指标 GUI 展示
-- 增加 2.8.x 以上 Kafka 集群接入,覆盖 0.10.x-3.x
-- 删除逻辑集群、共享集群、Region 概念
-
-**2、Cluster 管理**
-
-- 增加集群概览信息、集群配置变更记录
-- 增加 Cluster 健康分,健康检查规则支持自定义配置
-- 增加 Cluster 关键指标统计和 GUI 展示,支持自定义配置
-- 增加 Cluster 层 I/O、Disk 的 Load Reblance 功能,支持定时均衡任务(企业版)
-- 删除限流、鉴权功能
-- 删除 APPID 概念
-
-**3、Broker 管理**
-
-- 增加 Broker 健康分
-- 增加 Broker 关键指标统计和 GUI 展示,支持自定义配置
-- 增加 Broker 参数配置功能,需重启生效
-- 增加 Controller 变更记录
-- 增加 Broker Datalogs 记录
-- 删除 Leader Rebalance 功能
-- 删除 Broker 优先副本选举
-
-**4、Topic 管理**
-
-- 增加 Topic 健康分
-- 增加 Topic 关键指标统计和 GUI 展示,支持自定义配置
-- 增加 Topic 参数配置功能,可实时生效
-- 增加 Topic 批量迁移、Topic 批量扩缩副本功能
-- 增加查看系统 Topic 功能
-- 优化 Partition 分布的 GUI 展示
-- 优化 Topic Message 数据采样
-- 删除 Topic 过期概念
-- 删除 Topic 申请配额功能
-
-**5、Consumer 管理**
-
-- 优化了 ConsumerGroup 展示形式,增加 Consumer Lag 的 GUI 展示
-
-**6、ACL 管理**
-
-- 增加原生 ACL GUI 配置功能,可配置生产、消费、自定义多种组合权限
-- 增加 KafkaUser 功能,可自定义新增 KafkaUser
-
-**7、消息测试(企业版)**
-
-- 增加生产者消息模拟器,支持 Data、Flow、Header、Options 自定义配置(企业版)
-- 增加消费者消息模拟器,支持 Data、Flow、Header、Options 自定义配置(企业版)
-
-**8、Job**
-
-- 优化 Job 模块,支持任务进度管理
-
-**9、系统管理**
-
-- 优化用户、角色管理体系,支持自定义角色配置页面及操作权限
-- 优化审计日志信息
-- 删除多租户体系
-- 删除工单流程
-
----
-
-## v2.6.0
-
-版本上线时间:2022-01-24
-
-### 能力提升
-- 增加简单回退工具类
-
-### 体验优化
-- 补充周期任务说明文档
-- 补充集群安装部署使用说明文档
-- 升级Swagger、SpringFramework、SpringBoot、EChats版本
-- 优化Task模块的日志输出
-- 优化corn表达式解析失败后退出无任何日志提示问题
-- Ldap用户接入时,增加部门及邮箱信息等
-- 对Jmx模块,增加连接失败后的回退机制及错误日志优化
-- 增加线程池、客户端池可配置
-- 删除无用的jmx_prometheus_javaagent-0.14.0.jar
-- 优化迁移任务名称
-- 优化创建Region时,Region容量信息不能立即被更新问题
-- 引入lombok
-- 更新视频教程
-- 优化kcm_script.sh脚本中的LogiKM地址为可通过程序传入
-- 第三方接口及网关接口,增加是否跳过登录的开关
-- extends模块相关配置调整为非必须在application.yml中配置
-
-### bug修复
-- 修复批量往DB写入空指标数组时报SQL语法异常的问题
-- 修复网关增加配置及修改配置时,version不变化问题
-- 修复集群列表页,提示框遮挡问题
-- 修复对高版本Broker元信息协议解析失败的问题
-- 修复Dockerfile执行时提示缺少application.yml文件的问题
-- 修复逻辑集群更新时,会报空指针的问题
-
-
-## v2.5.0
-
-版本上线时间:2021-07-10
-
-### 体验优化
-- 更改产品名为LogiKM
-- 更新产品图标
-
-
-## v2.4.1+
-
-版本上线时间:2021-05-21
-
-### 能力提升
-- 增加直接增加权限和配额的接口(v2.4.1)
-- 增加接口调用可绕过登录的功能(v2.4.1)
-
-### 体验优化
-- Tomcat 版本提升至8.5.66(v2.4.2)
-- op接口优化,拆分util接口为topic、leader两类接口(v2.4.1)
-- 简化Gateway配置的Key长度(v2.4.1)
-
-### bug修复
-- 修复页面展示版本错误问题(v2.4.2)
-
-
-## v2.4.0
-
-版本上线时间:2021-05-18
-
-
-### 能力提升
-
-- 增加App与Topic自动化审批开关
-- Broker元信息中增加Rack信息
-- 升级MySQL 驱动,支持MySQL 8+
-- 增加操作记录查询界面
-
-### 体验优化
-
-- FAQ告警组说明优化
-- 用户手册共享及 独享集群概念优化
-- 用户管理界面,前端限制用户删除自己
-
-### bug修复
-
-- 修复op-util类中创建Topic失败的接口
-- 周期同步Topic到DB的任务修复,将Topic列表查询从缓存调整为直接查DB
-- 应用下线审批失败的功能修复,将权限为0(无权限)的数据进行过滤
-- 修复登录及权限绕过的漏洞
-- 修复研发角色展示接入集群、暂停监控等按钮的问题
-
-
-## v2.3.0
-
-版本上线时间:2021-02-08
-
-
-### 能力提升
-
-- 新增支持docker化部署
-- 可指定Broker作为候选controller
-- 可新增并管理网关配置
-- 可获取消费组状态
-- 增加集群的JMX认证
-
-### 体验优化
-
-- 优化编辑用户角色、修改密码的流程
-- 新增consumerID的搜索功能
-- 优化“Topic连接信息”、“消费组重置消费偏移”、“修改Topic保存时间”的文案提示
-- 在相应位置增加《资源申请文档》链接
-
-### bug修复
-
-- 修复Broker监控图表时间轴展示错误的问题
-- 修复创建夜莺监控告警规则时,使用的告警周期的单位不正确的问题
-
-
-
-## v2.2.0
-
-版本上线时间:2021-01-25
-
-
-
-### 能力提升
-
-- 优化工单批量操作流程
-- 增加获取Topic75分位/99分位的实时耗时数据
-- 增加定时任务,可将无主未落DB的Topic定期写入DB
-
-### 体验优化
-
-- 在相应位置增加《集群接入文档》链接
-- 优化物理集群、逻辑集群含义
-- 在Topic详情页、Topic扩分区操作弹窗增加展示Topic所属Region的信息
-- 优化Topic审批时,Topic数据保存时间的配置流程
-- 优化Topic/应用申请、审批时的错误提示文案
-- 优化Topic数据采样的操作项文案
-- 优化运维人员删除Topic时的提示文案
-- 优化运维人员删除Region的删除逻辑与提示文案
-- 优化运维人员删除逻辑集群的提示文案
-- 优化上传集群配置文件时的文件类型限制条件
-
-### bug修复
-
-- 修复填写应用名称时校验特殊字符出错的问题
-- 修复普通用户越权访问应用详情的问题
-- 修复由于Kafka版本升级,导致的数据压缩格式无法获取的问题
-- 修复删除逻辑集群或Topic之后,界面依旧展示的问题
-- 修复进行Leader rebalance操作时执行结果重复提示的问题
-
-
-## v2.1.0
-
-版本上线时间:2020-12-19
-
-
-
-### 体验优化
-
-- 优化页面加载时的背景样式
-- 优化普通用户申请Topic权限的流程
-- 优化Topic申请配额、申请分区的权限限制
-- 优化取消Topic权限的文案提示
-- 优化申请配额表单的表单项名称
-- 优化重置消费偏移的操作流程
-- 优化创建Topic迁移任务的表单内容
-- 优化Topic扩分区操作的弹窗界面样式
-- 优化集群Broker监控可视化图表样式
-- 优化创建逻辑集群的表单内容
-- 优化集群安全协议的提示文案
-
-### bug修复
-
-- 修复偶发性重置消费偏移失败的问题
-
-
-
-
diff --git a/bin/init_es_template.sh b/bin/init_es_template.sh
deleted file mode 100644
index e570d285..00000000
--- a/bin/init_es_template.sh
+++ /dev/null
@@ -1,1036 +0,0 @@
-esaddr=127.0.0.1
-port=8060
-curl -s --connect-timeout 10 -o /dev/null http://${esaddr}:${port}/_cat/nodes >/dev/null 2>&1
-if [ "$?" != "0" ];then
- echo "Elasticserach 访问失败, 请安装完后检查并重新执行该脚本 "
- exit
-fi
-
-curl -s --connect-timeout 10 -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${esaddr}:${port}/_template/ks_kafka_broker_metric -d '{
- "order" : 10,
- "index_patterns" : [
- "ks_kafka_broker_metric*"
- ],
- "settings" : {
- "index" : {
- "number_of_shards" : "2"
- }
- },
- "mappings" : {
- "properties" : {
- "brokerId" : {
- "type" : "long"
- },
- "routingValue" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "clusterPhyId" : {
- "type" : "long"
- },
- "metrics" : {
- "properties" : {
- "NetworkProcessorAvgIdle" : {
- "type" : "float"
- },
- "UnderReplicatedPartitions" : {
- "type" : "float"
- },
- "BytesIn_min_15" : {
- "type" : "float"
- },
- "HealthCheckTotal" : {
- "type" : "float"
- },
- "RequestHandlerAvgIdle" : {
- "type" : "float"
- },
- "connectionsCount" : {
- "type" : "float"
- },
- "BytesIn_min_5" : {
- "type" : "float"
- },
- "HealthScore" : {
- "type" : "float"
- },
- "BytesOut" : {
- "type" : "float"
- },
- "BytesOut_min_15" : {
- "type" : "float"
- },
- "BytesIn" : {
- "type" : "float"
- },
- "BytesOut_min_5" : {
- "type" : "float"
- },
- "TotalRequestQueueSize" : {
- "type" : "float"
- },
- "MessagesIn" : {
- "type" : "float"
- },
- "TotalProduceRequests" : {
- "type" : "float"
- },
- "HealthCheckPassed" : {
- "type" : "float"
- },
- "TotalResponseQueueSize" : {
- "type" : "float"
- }
- }
- },
- "key" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "timestamp" : {
- "format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
- "index" : true,
- "type" : "date",
- "doc_values" : true
- }
- }
- },
- "aliases" : { }
- }'
-
-curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${esaddr}:${port}/_template/ks_kafka_cluster_metric -d '{
- "order" : 10,
- "index_patterns" : [
- "ks_kafka_cluster_metric*"
- ],
- "settings" : {
- "index" : {
- "number_of_shards" : "2"
- }
- },
- "mappings" : {
- "properties" : {
- "routingValue" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "clusterPhyId" : {
- "type" : "long"
- },
- "metrics" : {
- "properties" : {
- "Connections" : {
- "type" : "double"
- },
- "BytesIn_min_15" : {
- "type" : "double"
- },
- "PartitionURP" : {
- "type" : "double"
- },
- "HealthScore_Topics" : {
- "type" : "double"
- },
- "EventQueueSize" : {
- "type" : "double"
- },
- "ActiveControllerCount" : {
- "type" : "double"
- },
- "GroupDeads" : {
- "type" : "double"
- },
- "BytesIn_min_5" : {
- "type" : "double"
- },
- "HealthCheckTotal_Topics" : {
- "type" : "double"
- },
- "Partitions" : {
- "type" : "double"
- },
- "BytesOut" : {
- "type" : "double"
- },
- "Groups" : {
- "type" : "double"
- },
- "BytesOut_min_15" : {
- "type" : "double"
- },
- "TotalRequestQueueSize" : {
- "type" : "double"
- },
- "HealthCheckPassed_Groups" : {
- "type" : "double"
- },
- "TotalProduceRequests" : {
- "type" : "double"
- },
- "HealthCheckPassed" : {
- "type" : "double"
- },
- "TotalLogSize" : {
- "type" : "double"
- },
- "GroupEmptys" : {
- "type" : "double"
- },
- "PartitionNoLeader" : {
- "type" : "double"
- },
- "HealthScore_Brokers" : {
- "type" : "double"
- },
- "Messages" : {
- "type" : "double"
- },
- "Topics" : {
- "type" : "double"
- },
- "PartitionMinISR_E" : {
- "type" : "double"
- },
- "HealthCheckTotal" : {
- "type" : "double"
- },
- "Brokers" : {
- "type" : "double"
- },
- "Replicas" : {
- "type" : "double"
- },
- "HealthCheckTotal_Groups" : {
- "type" : "double"
- },
- "GroupRebalances" : {
- "type" : "double"
- },
- "MessageIn" : {
- "type" : "double"
- },
- "HealthScore" : {
- "type" : "double"
- },
- "HealthCheckPassed_Topics" : {
- "type" : "double"
- },
- "HealthCheckTotal_Brokers" : {
- "type" : "double"
- },
- "PartitionMinISR_S" : {
- "type" : "double"
- },
- "BytesIn" : {
- "type" : "double"
- },
- "BytesOut_min_5" : {
- "type" : "double"
- },
- "GroupActives" : {
- "type" : "double"
- },
- "MessagesIn" : {
- "type" : "double"
- },
- "GroupReBalances" : {
- "type" : "double"
- },
- "HealthCheckPassed_Brokers" : {
- "type" : "double"
- },
- "HealthScore_Groups" : {
- "type" : "double"
- },
- "TotalResponseQueueSize" : {
- "type" : "double"
- },
- "Zookeepers" : {
- "type" : "double"
- },
- "LeaderMessages" : {
- "type" : "double"
- },
- "HealthScore_Cluster" : {
- "type" : "double"
- },
- "HealthCheckPassed_Cluster" : {
- "type" : "double"
- },
- "HealthCheckTotal_Cluster" : {
- "type" : "double"
- }
- }
- },
- "key" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "timestamp" : {
- "format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
- "type" : "date"
- }
- }
- },
- "aliases" : { }
- }'
-
-curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${esaddr}:${port}/_template/ks_kafka_group_metric -d '{
- "order" : 10,
- "index_patterns" : [
- "ks_kafka_group_metric*"
- ],
- "settings" : {
- "index" : {
- "number_of_shards" : "6"
- }
- },
- "mappings" : {
- "properties" : {
- "group" : {
- "type" : "keyword"
- },
- "partitionId" : {
- "type" : "long"
- },
- "routingValue" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "clusterPhyId" : {
- "type" : "long"
- },
- "topic" : {
- "type" : "keyword"
- },
- "metrics" : {
- "properties" : {
- "HealthScore" : {
- "type" : "float"
- },
- "Lag" : {
- "type" : "float"
- },
- "OffsetConsumed" : {
- "type" : "float"
- },
- "HealthCheckTotal" : {
- "type" : "float"
- },
- "HealthCheckPassed" : {
- "type" : "float"
- }
- }
- },
- "groupMetric" : {
- "type" : "keyword"
- },
- "key" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "timestamp" : {
- "format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
- "index" : true,
- "type" : "date",
- "doc_values" : true
- }
- }
- },
- "aliases" : { }
- }'
-
-curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${esaddr}:${port}/_template/ks_kafka_partition_metric -d '{
- "order" : 10,
- "index_patterns" : [
- "ks_kafka_partition_metric*"
- ],
- "settings" : {
- "index" : {
- "number_of_shards" : "6"
- }
- },
- "mappings" : {
- "properties" : {
- "brokerId" : {
- "type" : "long"
- },
- "partitionId" : {
- "type" : "long"
- },
- "routingValue" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "clusterPhyId" : {
- "type" : "long"
- },
- "topic" : {
- "type" : "keyword"
- },
- "metrics" : {
- "properties" : {
- "LogStartOffset" : {
- "type" : "float"
- },
- "Messages" : {
- "type" : "float"
- },
- "LogEndOffset" : {
- "type" : "float"
- }
- }
- },
- "key" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "timestamp" : {
- "format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
- "index" : true,
- "type" : "date",
- "doc_values" : true
- }
- }
- },
- "aliases" : { }
- }'
-
-curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${esaddr}:${port}/_template/ks_kafka_topic_metric -d '{
- "order" : 10,
- "index_patterns" : [
- "ks_kafka_topic_metric*"
- ],
- "settings" : {
- "index" : {
- "number_of_shards" : "6"
- }
- },
- "mappings" : {
- "properties" : {
- "brokerId" : {
- "type" : "long"
- },
- "routingValue" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "topic" : {
- "type" : "keyword"
- },
- "clusterPhyId" : {
- "type" : "long"
- },
- "metrics" : {
- "properties" : {
- "BytesIn_min_15" : {
- "type" : "float"
- },
- "Messages" : {
- "type" : "float"
- },
- "BytesRejected" : {
- "type" : "float"
- },
- "PartitionURP" : {
- "type" : "float"
- },
- "HealthCheckTotal" : {
- "type" : "float"
- },
- "ReplicationCount" : {
- "type" : "float"
- },
- "ReplicationBytesOut" : {
- "type" : "float"
- },
- "ReplicationBytesIn" : {
- "type" : "float"
- },
- "FailedFetchRequests" : {
- "type" : "float"
- },
- "BytesIn_min_5" : {
- "type" : "float"
- },
- "HealthScore" : {
- "type" : "float"
- },
- "LogSize" : {
- "type" : "float"
- },
- "BytesOut" : {
- "type" : "float"
- },
- "BytesOut_min_15" : {
- "type" : "float"
- },
- "FailedProduceRequests" : {
- "type" : "float"
- },
- "BytesIn" : {
- "type" : "float"
- },
- "BytesOut_min_5" : {
- "type" : "float"
- },
- "MessagesIn" : {
- "type" : "float"
- },
- "TotalProduceRequests" : {
- "type" : "float"
- },
- "HealthCheckPassed" : {
- "type" : "float"
- }
- }
- },
- "brokerAgg" : {
- "type" : "keyword"
- },
- "key" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "timestamp" : {
- "format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
- "index" : true,
- "type" : "date",
- "doc_values" : true
- }
- }
- },
- "aliases" : { }
- }'
-
-curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${SERVER_ES_ADDRESS}/_template/ks_kafka_zookeeper_metric -d '{
- "order" : 10,
- "index_patterns" : [
- "ks_kafka_zookeeper_metric*"
- ],
- "settings" : {
- "index" : {
- "number_of_shards" : "2"
- }
- },
- "mappings" : {
- "properties" : {
- "routingValue" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "clusterPhyId" : {
- "type" : "long"
- },
- "metrics" : {
- "properties" : {
- "AvgRequestLatency" : {
- "type" : "double"
- },
- "MinRequestLatency" : {
- "type" : "double"
- },
- "MaxRequestLatency" : {
- "type" : "double"
- },
- "OutstandingRequests" : {
- "type" : "double"
- },
- "NodeCount" : {
- "type" : "double"
- },
- "WatchCount" : {
- "type" : "double"
- },
- "NumAliveConnections" : {
- "type" : "double"
- },
- "PacketsReceived" : {
- "type" : "double"
- },
- "PacketsSent" : {
- "type" : "double"
- },
- "EphemeralsCount" : {
- "type" : "double"
- },
- "ApproximateDataSize" : {
- "type" : "double"
- },
- "OpenFileDescriptorCount" : {
- "type" : "double"
- },
- "MaxFileDescriptorCount" : {
- "type" : "double"
- }
- }
- },
- "key" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "timestamp" : {
- "format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
- "type" : "date"
- }
- }
- },
- "aliases" : { }
- }'
-
-curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${SERVER_ES_ADDRESS}/_template/ks_kafka_connect_cluster_metric -d '{
- "order" : 10,
- "index_patterns" : [
- "ks_kafka_connect_cluster_metric*"
- ],
- "settings" : {
- "index" : {
- "number_of_shards" : "2"
- }
- },
- "mappings" : {
- "properties" : {
- "connectClusterId" : {
- "type" : "long"
- },
- "routingValue" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "clusterPhyId" : {
- "type" : "long"
- },
- "metrics" : {
- "properties" : {
- "ConnectorCount" : {
- "type" : "float"
- },
- "TaskCount" : {
- "type" : "float"
- },
- "ConnectorStartupAttemptsTotal" : {
- "type" : "float"
- },
- "ConnectorStartupFailurePercentage" : {
- "type" : "float"
- },
- "ConnectorStartupFailureTotal" : {
- "type" : "float"
- },
- "ConnectorStartupSuccessPercentage" : {
- "type" : "float"
- },
- "ConnectorStartupSuccessTotal" : {
- "type" : "float"
- },
- "TaskStartupAttemptsTotal" : {
- "type" : "float"
- },
- "TaskStartupFailurePercentage" : {
- "type" : "float"
- },
- "TaskStartupFailureTotal" : {
- "type" : "float"
- },
- "TaskStartupSuccessPercentage" : {
- "type" : "float"
- },
- "TaskStartupSuccessTotal" : {
- "type" : "float"
- }
- }
- },
- "key" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "timestamp" : {
- "format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
- "index" : true,
- "type" : "date",
- "doc_values" : true
- }
- }
- },
- "aliases" : { }
- }'
-
-curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${SERVER_ES_ADDRESS}/_template/ks_kafka_connect_connector_metric -d '{
- "order" : 10,
- "index_patterns" : [
- "ks_kafka_connect_connector_metric*"
- ],
- "settings" : {
- "index" : {
- "number_of_shards" : "2"
- }
- },
- "mappings" : {
- "properties" : {
- "connectClusterId" : {
- "type" : "long"
- },
- "routingValue" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "connectorName" : {
- "type" : "keyword"
- },
- "connectorNameAndClusterId" : {
- "type" : "keyword"
- },
- "clusterPhyId" : {
- "type" : "long"
- },
- "metrics" : {
- "properties" : {
- "HealthState" : {
- "type" : "float"
- },
- "ConnectorTotalTaskCount" : {
- "type" : "float"
- },
- "HealthCheckPassed" : {
- "type" : "float"
- },
- "HealthCheckTotal" : {
- "type" : "float"
- },
- "ConnectorRunningTaskCount" : {
- "type" : "float"
- },
- "ConnectorPausedTaskCount" : {
- "type" : "float"
- },
- "ConnectorFailedTaskCount" : {
- "type" : "float"
- },
- "ConnectorUnassignedTaskCount" : {
- "type" : "float"
- },
- "BatchSizeAvg" : {
- "type" : "float"
- },
- "BatchSizeMax" : {
- "type" : "float"
- },
- "OffsetCommitAvgTimeMs" : {
- "type" : "float"
- },
- "OffsetCommitMaxTimeMs" : {
- "type" : "float"
- },
- "OffsetCommitFailurePercentage" : {
- "type" : "float"
- },
- "OffsetCommitSuccessPercentage" : {
- "type" : "float"
- },
- "PollBatchAvgTimeMs" : {
- "type" : "float"
- },
- "PollBatchMaxTimeMs" : {
- "type" : "float"
- },
- "SourceRecordActiveCount" : {
- "type" : "float"
- },
- "SourceRecordActiveCountAvg" : {
- "type" : "float"
- },
- "SourceRecordActiveCountMax" : {
- "type" : "float"
- },
- "SourceRecordPollRate" : {
- "type" : "float"
- },
- "SourceRecordPollTotal" : {
- "type" : "float"
- },
- "SourceRecordWriteRate" : {
- "type" : "float"
- },
- "SourceRecordWriteTotal" : {
- "type" : "float"
- },
- "OffsetCommitCompletionRate" : {
- "type" : "float"
- },
- "OffsetCommitCompletionTotal" : {
- "type" : "float"
- },
- "OffsetCommitSkipRate" : {
- "type" : "float"
- },
- "OffsetCommitSkipTotal" : {
- "type" : "float"
- },
- "PartitionCount" : {
- "type" : "float"
- },
- "PutBatchAvgTimeMs" : {
- "type" : "float"
- },
- "PutBatchMaxTimeMs" : {
- "type" : "float"
- },
- "SinkRecordActiveCount" : {
- "type" : "float"
- },
- "SinkRecordActiveCountAvg" : {
- "type" : "float"
- },
- "SinkRecordActiveCountMax" : {
- "type" : "float"
- },
- "SinkRecordLagMax" : {
- "type" : "float"
- },
- "SinkRecordReadRate" : {
- "type" : "float"
- },
- "SinkRecordReadTotal" : {
- "type" : "float"
- },
- "SinkRecordSendRate" : {
- "type" : "float"
- },
- "SinkRecordSendTotal" : {
- "type" : "float"
- },
- "DeadletterqueueProduceFailures" : {
- "type" : "float"
- },
- "DeadletterqueueProduceRequests" : {
- "type" : "float"
- },
- "LastErrorTimestamp" : {
- "type" : "float"
- },
- "TotalErrorsLogged" : {
- "type" : "float"
- },
- "TotalRecordErrors" : {
- "type" : "float"
- },
- "TotalRecordFailures" : {
- "type" : "float"
- },
- "TotalRecordsSkipped" : {
- "type" : "float"
- },
- "TotalRetries" : {
- "type" : "float"
- }
- }
- },
- "key" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "timestamp" : {
- "format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
- "index" : true,
- "type" : "date",
- "doc_values" : true
- }
- }
- },
- "aliases" : { }
- }'
-
-curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${SERVER_ES_ADDRESS}/_template/ks_kafka_connect_mirror_maker_metric -d '{
- "order" : 10,
- "index_patterns" : [
- "ks_kafka_connect_mirror_maker_metric*"
- ],
- "settings" : {
- "index" : {
- "number_of_shards" : "2"
- }
- },
- "mappings" : {
- "properties" : {
- "connectClusterId" : {
- "type" : "long"
- },
- "routingValue" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "connectorName" : {
- "type" : "keyword"
- },
- "connectorNameAndClusterId" : {
- "type" : "keyword"
- },
- "clusterPhyId" : {
- "type" : "long"
- },
- "metrics" : {
- "properties" : {
- "HealthState" : {
- "type" : "float"
- },
- "HealthCheckTotal" : {
- "type" : "float"
- },
- "ByteCount" : {
- "type" : "float"
- },
- "ByteRate" : {
- "type" : "float"
- },
- "RecordAgeMs" : {
- "type" : "float"
- },
- "RecordAgeMsAvg" : {
- "type" : "float"
- },
- "RecordAgeMsMax" : {
- "type" : "float"
- },
- "RecordAgeMsMin" : {
- "type" : "float"
- },
- "RecordCount" : {
- "type" : "float"
- },
- "RecordRate" : {
- "type" : "float"
- },
- "ReplicationLatencyMs" : {
- "type" : "float"
- },
- "ReplicationLatencyMsAvg" : {
- "type" : "float"
- },
- "ReplicationLatencyMsMax" : {
- "type" : "float"
- },
- "ReplicationLatencyMsMin" : {
- "type" : "float"
- }
- }
- },
- "key" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "timestamp" : {
- "format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
- "index" : true,
- "type" : "date",
- "doc_values" : true
- }
- }
- },
- "aliases" : { }
- }'
-
-
-for i in {0..6};
-do
- logdate=_$(date -d "${i} day ago" +%Y-%m-%d)
- curl -s --connect-timeout 10 -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_broker_metric${logdate} && \
- curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_cluster_metric${logdate} && \
- curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_group_metric${logdate} && \
- curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_partition_metric${logdate} && \
- curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_zookeeper_metric${logdate} && \
- curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_connect_cluster_metric${logdate} && \
- curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_connect_connector_metric${logdate} && \
- curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_connect_mirror_maker_metric${logdate} && \
- curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_topic_metric${logdate} || \
- exit 2
-done
diff --git a/bin/shutdown.sh b/bin/shutdown.sh
deleted file mode 100644
index c5317df8..00000000
--- a/bin/shutdown.sh
+++ /dev/null
@@ -1,16 +0,0 @@
-#!/bin/bash
-
-cd `dirname $0`/../libs
-target_dir=`pwd`
-
-pid=`ps ax | grep -i 'ks-km' | grep ${target_dir} | grep java | grep -v grep | awk '{print $1}'`
-if [ -z "$pid" ] ; then
- echo "No ks-km running."
- exit -1;
-fi
-
-echo "The ks-km (${pid}) is running..."
-
-kill ${pid}
-
-echo "Send shutdown request to ks-km (${pid}) OK"
diff --git a/bin/startup.sh b/bin/startup.sh
deleted file mode 100644
index cbde7c56..00000000
--- a/bin/startup.sh
+++ /dev/null
@@ -1,82 +0,0 @@
-error_exit ()
-{
- echo "ERROR: $1 !!"
- exit 1
-}
-
-[ ! -e "$JAVA_HOME/bin/java" ] && JAVA_HOME=$HOME/jdk/java
-[ ! -e "$JAVA_HOME/bin/java" ] && JAVA_HOME=/usr/java
-[ ! -e "$JAVA_HOME/bin/java" ] && unset JAVA_HOME
-
-if [ -z "$JAVA_HOME" ]; then
- if [ "Darwin" = "$(uname -s)" ]; then
-
- if [ -x '/usr/libexec/java_home' ] ; then
- export JAVA_HOME=`/usr/libexec/java_home`
-
- elif [ -d "/System/Library/Frameworks/JavaVM.framework/Versions/CurrentJDK/Home" ]; then
- export JAVA_HOME="/System/Library/Frameworks/JavaVM.framework/Versions/CurrentJDK/Home"
- fi
- else
- JAVA_PATH=`dirname $(readlink -f $(which javac))`
- if [ "x$JAVA_PATH" != "x" ]; then
- export JAVA_HOME=`dirname $JAVA_PATH 2>/dev/null`
- fi
- fi
- if [ -z "$JAVA_HOME" ]; then
- error_exit "Please set the JAVA_HOME variable in your environment, We need java(x64)! jdk8 or later is better!"
- fi
-fi
-
-
-
-
-export WEB_SERVER="ks-km"
-export JAVA_HOME
-export JAVA="$JAVA_HOME/bin/java"
-export BASE_DIR=`cd $(dirname $0)/..; pwd`
-export CUSTOM_SEARCH_LOCATIONS=file:${BASE_DIR}/conf/
-
-
-#===========================================================================================
-# JVM Configuration
-#===========================================================================================
-
-JAVA_OPT="${JAVA_OPT} -server -Xms2g -Xmx2g -Xmn1g -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=320m"
-JAVA_OPT="${JAVA_OPT} -XX:-OmitStackTraceInFastThrow -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${BASE_DIR}/logs/java_heapdump.hprof"
-
-## jdk版本高的情况 有些 参数废弃了
-JAVA_MAJOR_VERSION=$($JAVA -version 2>&1 | sed -E -n 's/.* version "([0-9]*).*$/\1/p')
-if [[ "$JAVA_MAJOR_VERSION" -ge "9" ]] ; then
- JAVA_OPT="${JAVA_OPT} -Xlog:gc*:file=${BASE_DIR}/logs/km_gc.log:time,tags:filecount=10,filesize=102400"
-else
- JAVA_OPT="${JAVA_OPT} -Djava.ext.dirs=${JAVA_HOME}/jre/lib/ext:${JAVA_HOME}/lib/ext"
- JAVA_OPT="${JAVA_OPT} -Xloggc:${BASE_DIR}/logs/km_gc.log -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=100M"
-
-fi
-
-JAVA_OPT="${JAVA_OPT} -jar ${BASE_DIR}/libs/${WEB_SERVER}.jar"
-JAVA_OPT="${JAVA_OPT} --spring.config.additional-location=${CUSTOM_SEARCH_LOCATIONS}"
-JAVA_OPT="${JAVA_OPT} --logging.config=${BASE_DIR}/conf/logback-spring.xml"
-JAVA_OPT="${JAVA_OPT} --server.max-http-header-size=524288"
-
-
-
-if [ ! -d "${BASE_DIR}/logs" ]; then
- mkdir ${BASE_DIR}/logs
-fi
-
-echo "$JAVA ${JAVA_OPT}"
-
-# check the start.out log output file
-if [ ! -f "${BASE_DIR}/logs/start.out" ]; then
- touch "${BASE_DIR}/logs/start.out"
-fi
-
-# start
-echo -e "---- 启动脚本 ------\n $JAVA ${JAVA_OPT}" > ${BASE_DIR}/logs/start.out 2>&1 &
-
-
-nohup $JAVA ${JAVA_OPT} >> ${BASE_DIR}/logs/start.out 2>&1 &
-
-echo "${WEB_SERVER} is starting,you can check the ${BASE_DIR}/logs/start.out"
diff --git a/docs/contribute_guide/assets/分支管理.drawio b/docs/contribute_guide/assets/分支管理.drawio
deleted file mode 100644
index 0e7e3d37..00000000
--- a/docs/contribute_guide/assets/分支管理.drawio
+++ /dev/null
@@ -1,111 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/docs/contribute_guide/assets/分支管理.png b/docs/contribute_guide/assets/分支管理.png
deleted file mode 100644
index 867fecd4..00000000
Binary files a/docs/contribute_guide/assets/分支管理.png and /dev/null differ
diff --git a/docs/contribute_guide/assets/环境初始化.jpg b/docs/contribute_guide/assets/环境初始化.jpg
deleted file mode 100644
index 31ff5f28..00000000
Binary files a/docs/contribute_guide/assets/环境初始化.jpg and /dev/null differ
diff --git a/docs/contribute_guide/assets/申请合并.jpg b/docs/contribute_guide/assets/申请合并.jpg
deleted file mode 100644
index d02a7f50..00000000
Binary files a/docs/contribute_guide/assets/申请合并.jpg and /dev/null differ
diff --git a/docs/contribute_guide/assets/问题认领.jpg b/docs/contribute_guide/assets/问题认领.jpg
deleted file mode 100644
index 62da4728..00000000
Binary files a/docs/contribute_guide/assets/问题认领.jpg and /dev/null differ
diff --git a/docs/contribute_guide/代码规范.md b/docs/contribute_guide/代码规范.md
deleted file mode 100644
index be0bcfd2..00000000
--- a/docs/contribute_guide/代码规范.md
+++ /dev/null
@@ -1 +0,0 @@
-TODO.
\ No newline at end of file
diff --git a/docs/contribute_guide/贡献名单.md b/docs/contribute_guide/贡献名单.md
deleted file mode 100644
index 41481787..00000000
--- a/docs/contribute_guide/贡献名单.md
+++ /dev/null
@@ -1,100 +0,0 @@
-# 贡献名单
-
-- [贡献名单](#贡献名单)
- - [1、贡献者角色](#1贡献者角色)
- - [1.1、Maintainer](#11maintainer)
- - [1.2、Committer](#12committer)
- - [1.3、Contributor](#13contributor)
- - [2、贡献者名单](#2贡献者名单)
-
-
-## 1、贡献者角色
-
-KnowStreaming 开发者包含 Maintainer、Committer、Contributor 三种角色,每种角色的标准定义如下。
-
-### 1.1、Maintainer
-
-Maintainer 是对 KnowStreaming 项目的演进和发展做出显著贡献的个人。具体包含以下的标准:
-
-- 完成多个关键模块或者工程的设计与开发,是项目的核心开发人员;
-- 持续的投入和激情,能够积极参与社区、官网、issue、PR 等项目相关事项的维护;
-- 在社区中具有有目共睹的影响力,能够代表 KnowStreaming 参加重要的社区会议和活动;
-- 具有培养 Committer 和 Contributor 的意识和能力;
-
-### 1.2、Committer
-
-Committer 是具有 KnowStreaming 仓库写权限的个人,包含以下的标准:
-
-- 能够在长时间内做持续贡献 issue、PR 的个人;
-- 参与 issue 列表的维护及重要 feature 的讨论;
-- 参与 code review;
-
-### 1.3、Contributor
-
-Contributor 是对 KnowStreaming 项目有贡献的个人,标准为:
-
-- 提交过 PR 并被合并;
-
----
-
-## 2、贡献者名单
-
-开源贡献者名单(不定期更新)
-
-在名单内,但是没有收到贡献者礼品的同学,可以联系:szzdzhp001
-
-| 姓名 | Github | 角色 | 公司 |
-| ------------------- | ---------------------------------------------------------- | ----------- | -------- |
-| 张亮 | [@zhangliangboy](https://github.com/zhangliangboy) | Maintainer | 滴滴出行 |
-| 谢鹏 | [@PenceXie](https://github.com/PenceXie) | Maintainer | 滴滴出行 |
-| 赵情融 | [@zqrferrari](https://github.com/zqrferrari) | Maintainer | 滴滴出行 |
-| 石臻臻 | [@shirenchuang](https://github.com/shirenchuang) | Maintainer | 滴滴出行 |
-| 曾巧 | [@ZQKC](https://github.com/ZQKC) | Maintainer | 滴滴出行 |
-| 孙超 | [@lucasun](https://github.com/lucasun) | Maintainer | 滴滴出行 |
-| 洪华驰 | [@brodiehong](https://github.com/brodiehong) | Maintainer | 滴滴出行 |
-| 许喆 | [@potaaaaaato](https://github.com/potaaaaaato) | Committer | 滴滴出行 |
-| 郭宇航 | [@GraceWalk](https://github.com/GraceWalk) | Committer | 滴滴出行 |
-| 李伟 | [@velee](https://github.com/velee) | Committer | 滴滴出行 |
-| 张占昌 | [@zzccctv](https://github.com/zzccctv) | Committer | 滴滴出行 |
-| 王东方 | [@wangdongfang-aden](https://github.com/wangdongfang-aden) | Committer | 滴滴出行 |
-| 王耀波 | [@WYAOBO](https://github.com/WYAOBO) | Committer | 滴滴出行 |
-| 赵寅锐 | [@ZHAOYINRUI](https://github.com/ZHAOYINRUI) | Maintainer | 字节跳动 |
-| haoqi123 | [@haoqi123](https://github.com/haoqi123) | Contributor | 前程无忧 |
-| chaixiaoxue | [@chaixiaoxue](https://github.com/chaixiaoxue) | Contributor | SYNNEX |
-| 陆晗 | [@luhea](https://github.com/luhea) | Contributor | 竞技世界 |
-| Mengqi777 | [@Mengqi777](https://github.com/Mengqi777) | Contributor | 腾讯 |
-| ruanliang-hualun | [@ruanliang-hualun](https://github.com/ruanliang-hualun) | Contributor | 网易 |
-| 17hao | [@17hao](https://github.com/17hao) | Contributor | |
-| Huyueeer | [@Huyueeer](https://github.com/Huyueeer) | Contributor | INVENTEC |
-| lomodays207 | [@lomodays207](https://github.com/lomodays207) | Contributor | 建信金科 |
-| Super .Wein(星痕) | [@superspeedone](https://github.com/superspeedone) | Contributor | 韵达 |
-| Hongten | [@Hongten](https://github.com/Hongten) | Contributor | Shopee |
-| 徐正熙 | [@hyper-xx)](https://github.com/hyper-xx) | Contributor | 滴滴出行 |
-| RichardZhengkay | [@RichardZhengkay](https://github.com/RichardZhengkay) | Contributor | 趣街 |
-| 罐子里的茶 | [@gzldc](https://github.com/gzldc) | Contributor | 道富 |
-| 陈忠玉 | [@paula](https://github.com/chenzhongyu11) | Contributor | 平安产险 |
-| 杨光 | [@yaangvipguang](https://github.com/yangvipguang) | Contributor |
-| 王亚聪 | [@wangyacongi](https://github.com/wangyacongi) | Contributor |
-| Yang Jing | [@yangbajing](https://github.com/yangbajing) | Contributor | |
-| 刘新元 Liu XinYuan | [@Liu-XinYuan](https://github.com/Liu-XinYuan) | Contributor | |
-| Joker | [@LiubeyJokerQueue](https://github.com/JokerQueue) | Contributor | 丰巢 |
-| Eason Lau | [@Liubey](https://github.com/Liubey) | Contributor | |
-| hailanxin | [@hailanxin](https://github.com/hailanxin) | Contributor | |
-| Qi Zhang | [@zzzhangqi](https://github.com/zzzhangqi) | Contributor | 好雨科技 |
-| fengxsong | [@fengxsong](https://github.com/fengxsong) | Contributor | |
-| 谢晓东 | [@Strangevy](https://github.com/Strangevy) | Contributor | 花生日记 |
-| ZhaoXinlong | [@ZhaoXinlong](https://github.com/ZhaoXinlong) | Contributor | |
-| xuehaipeng | [@xuehaipeng](https://github.com/xuehaipeng) | Contributor | |
-| 孔令续 | [@mrazkong](https://github.com/mrazkong) | Contributor | |
-| pierre xiong | [@pierre94](https://github.com/pierre94) | Contributor | |
-| PengShuaixin | [@PengShuaixin](https://github.com/PengShuaixin) | Contributor | |
-| 梁壮 | [@lz](https://github.com/silent-night-no-trace) | Contributor | |
-| 张晓寅 | [@ahu0605](https://github.com/ahu0605) | Contributor | 电信数智 |
-| 黄海婷 | [@Huanghaiting](https://github.com/Huanghaiting) | Contributor | 云徙科技 |
-| 任祥德 | [@RenChauncy](https://github.com/RenChauncy) | Contributor | 探马企服 |
-| 胡圣林 | [@slhu997](https://github.com/slhu997) | Contributor | |
-| 史泽颖 | [@shizeying](https://github.com/shizeying) | Contributor | |
-| 王玉博 | [@Wyb7290](https://github.com/Wyb7290) | Committer | |
-| 伍璇 | [@Luckywustone](https://github.com/Luckywustone) | Contributor ||
-| 邓苑 | [@CatherineDY](https://github.com/CatherineDY) | Contributor ||
-| 封琼凤 | [@Luckywustone](https://github.com/fengqiongfeng) | Committer ||
diff --git a/docs/contribute_guide/贡献指南.md b/docs/contribute_guide/贡献指南.md
deleted file mode 100644
index 37cf89bc..00000000
--- a/docs/contribute_guide/贡献指南.md
+++ /dev/null
@@ -1,167 +0,0 @@
-# 贡献指南
-
-- [贡献指南](#贡献指南)
- - [1、行为准则](#1行为准则)
- - [2、仓库规范](#2仓库规范)
- - [2.1、Issue 规范](#21issue-规范)
- - [2.2、Commit-Log 规范](#22commit-log-规范)
- - [2.3、Pull-Request 规范](#23pull-request-规范)
- - [3、操作示例](#3操作示例)
- - [3.1、初始化环境](#31初始化环境)
- - [3.2、认领问题](#32认领问题)
- - [3.3、处理问题 \& 提交解决](#33处理问题--提交解决)
- - [3.4、请求合并](#34请求合并)
- - [4、常见问题](#4常见问题)
- - [4.1、如何将多个 Commit-Log 合并为一个?](#41如何将多个-commit-log-合并为一个)
-
-
----
-
-
-欢迎 👏🏻 👏🏻 👏🏻 来到 `KnowStreaming`。本文档是关于如何为 `KnowStreaming` 做出贡献的指南。如果您发现不正确或遗漏的内容, 请留下您的意见/建议。
-
-
----
-
-
-## 1、行为准则
-
-请务必阅读并遵守我们的:[行为准则](https://github.com/didi/KnowStreaming/blob/master/CODE_OF_CONDUCT.md)。
-
-
-## 2、仓库规范
-
-### 2.1、Issue 规范
-
-按要求,在 [创建Issue](https://github.com/didi/KnowStreaming/issues/new/choose) 中创建ISSUE即可。
-
-需要重点说明的是:
-- 提供出现问题的环境信息,包括使用的系统,使用的KS版本等;
-- 提供出现问题的复现方式;
-
-
-### 2.2、Commit-Log 规范
-
-`Commit-Log` 包含三部分 `Header`、`Body`、`Footer`。其中 `Header` 是必须的,格式固定,`Body` 在变更有必要详细解释时使用。
-
-
-**1、`Header` 规范**
-
-`Header` 格式为 `[Type]Message(#IssueID)`, 主要有三部分组成,分别是`Type`、`Message`、`IssueID`,
-
-- `Type`:说明这个提交是哪一个类型的,比如有 Bugfix、Feature、Optimize等;
-- `Message`:说明提交的信息,比如修复xx问题;
-- `IssueID`:该提交,关联的Issue的编号;
-
-
-实际例子:[`[Bugfix]修复新接入的集群,Controller-Host不显示的问题(#927)`](https://github.com/didi/KnowStreaming/pull/933/commits)
-
-
-
-**2、`Body` 规范**
-
-一般不需要,如果解决了较复杂问题,或者代码较多,需要 `Body` 说清楚解决的问题,解决的思路等信息。
-
----
-
-**3、实际例子**
-
-```
-[Optimize]优化 MySQL & ES 测试容器的初始化(#906)
-
-主要的变更
-1、knowstreaming/knowstreaming-manager 容器;
-2、knowstreaming/knowstreaming-mysql 容器调整为使用 mysql:5.7 容器;
-3、初始化 mysql:5.7 容器后,增加初始化 MySQL 表及数据的动作;
-
-被影响的变更:
-1、移动 km-dist/init/sql 下的MySQL初始化脚本至 km-persistence/src/main/resource/sql 下,以便项目测试时加载到所需的初始化 SQL;
-2、删除无用的 km-dist/init/template 目录;
-3、因为 km-dist/init/sql 和 km-dist/init/template 目录的调整,因此也调整 ReleaseKnowStreaming.xml 内的文件内容;
-```
-
-
-**TODO : 后续有兴趣的同学,可以考虑引入 Git 的 Hook 进行更好的 Commit-Log 的管理。**
-
-
-### 2.3、Pull-Request 规范
-
-详细见:[PULL-REQUEST 模版](../../.github/PULL_REQUEST_TEMPLATE.md)
-
-需要重点说明的是:
-
-- 任何 PR 都必须与有效 ISSUE 相关联。否则, PR 将被拒绝;
-- 一个分支只修改一件事,一个 PR 只修改一件事;
-
----
-
-
-## 3、操作示例
-
-本节主要介绍对 `KnowStreaming` 进行代码贡献时,相关的操作方式及操作命令。
-
-名词说明:
-- 主仓库:https://github.com/didi/KnowStreaming 这个仓库为主仓库。
-- 分仓库:Fork 到自己账号下的 KnowStreaming 仓库为分仓库;
-
-
-### 3.1、初始化环境
-
-1. `Fork KnowStreaming` 主仓库至自己账号下,见 https://github.com/didi/KnowStreaming 地址右上角的 `Fork` 按钮;
-2. 克隆分仓库至本地:`git clone git@github.com:xxxxxxx/KnowStreaming.git`,该仓库的简写名通常是`origin`;
-3. 添加主仓库至本地:`git remote add upstream https://github.com/didi/KnowStreaming`,`upstream`是主仓库在本地的简写名,可以随意命名,前后保持一致即可;
-4. 拉取主仓库代码:`git fetch upstream`;
-5. 拉取分仓库代码:`git fetch origin`;
-6. 将主仓库的`master`分支,拉取到本地并命名为`github_master`:`git checkout -b upstream/master`;
-
-最后,我们来看一下初始化完成之后的大致效果,具体如下图所示:
-
-
-
-至此,我们的环境就初始化好了。后续,`github_master` 分支就是主仓库的`master`分支,我们可以使用`git pull`拉取该分支的最新代码,还可以使用`git checkout -b xxx`拉取我们想要的分支。
-
-
-
-### 3.2、认领问题
-
-在文末评论说明自己要处理该问题即可,具体如下图所示:
-
-
-
-
-### 3.3、处理问题 & 提交解决
-
-本节主要介绍一下处理问题 & 提交解决过程中的分支管理,具体如下图所示:
-
-
-
-1. 切换到主分支:`git checkout github_master`;
-2. 主分支拉最新代码:`git pull`;
-3. 基于主分支拉新分支:`git checkout -b fix_928`;
-4. 提交代码,安装commit的规范进行提交,例如:`git commit -m "[Optimize]优化xxx问题(#928)"`;
-5. 提交到自己远端仓库:`git push --set-upstream origin fix_928`;
-6. `GitHub` 页面发起 `Pull Request` 请求,管理员合入主仓库。这部分详细见下一节;
-
-
-### 3.4、请求合并
-
-代码在提交到 `GitHub` 分仓库之后,就可以在 `GitHub` 的网站创建 `Pull Request`,申请将代码合入主仓库了。 `Pull Request` 具体见下图所示:
-
-
-
-
-
-[Pull Request 创建的例子](https://github.com/didi/KnowStreaming/pull/945)
-
-
-
----
-
-
-## 4、常见问题
-
-### 4.1、如何将多个 Commit-Log 合并为一个?
-
-可以使用 `git rebase -i` 命令进行解决。
-
-
diff --git a/docs/dev_guide/Task模块简介.md b/docs/dev_guide/Task模块简介.md
deleted file mode 100644
index 688e033b..00000000
--- a/docs/dev_guide/Task模块简介.md
+++ /dev/null
@@ -1,264 +0,0 @@
-# Task模块简介
-
-## 1、Task简介
-
-在 KnowStreaming 中(下面简称KS),Task模块主要是用于执行一些周期任务,包括Cluster、Broker、Topic等指标的定时采集,集群元数据定时更新至DB,集群状态的健康巡检等。在KS中,与Task模块相关的代码,我们都统一存放在km-task模块中。
-
-Task模块是基于 LogiCommon 中的Logi-Job组件实现的任务周期执行,Logi-Job 的功能类似 XXX-Job,它是 XXX-Job 在 KnowStreaming 的内嵌实现,主要用于简化 KnowStreaming 的部署。
-Logi-Job 的任务总共有两种执行模式,分别是:
-
-+ 广播模式:同一KS集群下,同一任务周期中,所有KS主机都会执行该定时任务。
-+ 抢占模式:同一KS集群下,同一任务周期中,仅有某一台KS主机会执行该任务。
-
-KS集群范围定义:连接同一个DB,且application.yml中的spring.logi-job.app-name的名称一样的KS主机为同一KS集群。
-
-## 2、使用指南
-
-Task模块基于Logi-Job的广播模式与抢占模式,分别实现了任务的抢占执行、重复执行以及均衡执行,他们之间的差别是:
-
-+ 抢占执行:同一个KS集群,同一个任务执行周期中,仅有一台KS主机执行该任务;
-+ 重复执行:同一个KS集群,同一个任务执行周期中,所有KS主机都执行该任务。比如3台KS主机,3个Kafka集群,此时每台KS主机都会去采集这3个Kafka集群的指标;
-+ 均衡执行:同一个KS集群,同一个任务执行周期中,每台KS主机仅执行该任务的一部分,所有的KS主机共同协作完成了任务。比如3台KS主机,3个Kafka集群,稳定运行情况下,每台KS主机将仅采集1个Kafka集群的指标,3台KS主机共同完成3个Kafka集群指标的采集。
-
-下面我们看一下具体例子。
-
-### 2.1、抢占模式——抢占执行
-
-功能说明:
-
-+ 同一个KS集群,同一个任务执行周期中,仅有一台KS主机执行该任务。
-
-代码例子:
-
-```java
-// 1、实现Job接口,重写excute方法;
-// 2、在类上添加@Task注解,并且配置好信息,指定为随机抢占模式;
-// 效果:KS集群中,每5秒,会有一台KS主机输出 "测试定时任务运行中";
-@Task(name = "TestJob",
- description = "测试定时任务",
- cron = "*/5 * * * * ?",
- autoRegister = true,
- consensual = ConsensualEnum.RANDOM, // 这里一定要设置为RANDOM
- timeout = 6 * 60)
-public class TestJob implements Job {
-
- @Override
- public TaskResult execute(JobContext jobContext) throws Exception {
-
- System.out.println("测试定时任务运行中");
- return new TaskResult();
-
- }
-
-}
-```
-
-
-
-### 2.2、广播模式——重复执行
-
-功能说明:
-
-+ 同一个KS集群,同一个任务执行周期中,所有KS主机都执行该任务。比如3台KS主机,3个Kafka集群,此时每台KS主机都会去重复采集这3个Kafka集群的指标。
-
-代码例子:
-
-```java
-// 1、实现Job接口,重写excute方法;
-// 2、在类上添加@Task注解,并且配置好信息,指定为广播抢占模式;
-// 效果:KS集群中,每5秒,每台KS主机都会输出 "测试定时任务运行中";
-@Task(name = "TestJob",
- description = "测试定时任务",
- cron = "*/5 * * * * ?",
- autoRegister = true,
- consensual = ConsensualEnum.BROADCAST, // 这里一定要设置为BROADCAST
- timeout = 6 * 60)
-public class TestJob implements Job {
-
- @Override
- public TaskResult execute(JobContext jobContext) throws Exception {
-
- System.out.println("测试定时任务运行中");
- return new TaskResult();
-
- }
-
-}
-```
-
-
-
-### 2.3、广播模式——均衡执行
-
-功能说明:
-
-+ 同一个KS集群,同一个任务执行周期中,每台KS主机仅执行该任务的一部分,所有的KS主机共同协作完成了任务。比如3台KS主机,3个Kafka集群,稳定运行情况下,每台KS主机将仅采集1个Kafka集群的指标,3台KS主机共同完成3个Kafka集群指标的采集。
-
-代码例子:
-
-+ 该模式有点特殊,是KS基于Logi-Job的广播模式,做的一个扩展,以下为一个使用例子:
-
-```java
-// 1、继承AbstractClusterPhyDispatchTask,实现processSubTask方法;
-// 2、在类上添加@Task注解,并且配置好信息,指定为广播模式;
-// 效果:在本样例中,每隔1分钟ks会将所有的kafka集群列表在ks集群主机内均衡拆分,每台主机会将分发到自身的Kafka集群依次执行processSubTask方法,实现KS集群的任务协同处理。
-@Task(name = "kmJobTask",
- description = "km job 模块调度执行任务",
- cron = "0 0/1 * * * ? *",
- autoRegister = true,
- consensual = ConsensualEnum.BROADCAST,
- timeout = 6 * 60)
-public class KMJobTask extends AbstractClusterPhyDispatchTask {
-
- @Autowired
- private JobService jobService;
-
- @Override
- protected TaskResult processSubTask(ClusterPhy clusterPhy, long triggerTimeUnitMs) throws Exception {
- jobService.scheduleJobByClusterId(clusterPhy.getId());
- return TaskResult.SUCCESS;
- }
-}
-```
-
-
-
-## 3、原理简介
-
-### 3.1、Task注解说明
-
-```java
-public @interface Task {
- String name() default ""; //任务名称
- String description() default ""; //任务描述
- String owner() default "system"; //拥有者
- String cron() default ""; //定时执行的时间策略
- int retryTimes() default 0; //失败以后所能重试的最大次数
- long timeout() default 0; //在超时时间里重试
- //是否自动注册任务到数据库中
- //如果设置为false,需要手动去数据库km_task表注册定时任务信息。数据库记录和@Task注解缺一不可
- boolean autoRegister() default false;
- //执行模式:广播、随机抢占
- //广播模式:同一集群下的所有服务器都会执行该定时任务
- //随机抢占模式:同一集群下随机一台服务器执行该任务
- ConsensualEnum consensual() default ConsensualEnum.RANDOM;
- }
-```
-
-### 3.2、数据库表介绍
-
-+ logi_task:记录项目中的定时任务信息,一个定时任务对应一条记录。
-+ logi_job:具体任务执行信息。
-+ logi_job_log:定时任务的执行日志。
-+ logi_worker:记录机器信息,实现集群控制。
-
-### 3.3、均衡执行简介
-
-#### 3.3.1、类关系图
-
-这里以KMJobTask为例,简单介绍KM中的定时任务实现逻辑。
-
- 
-
-+ Job:使用logi组件实现定时任务,必须实现该接口。
-+ Comparable & EntufyIdInterface:比较接口,实现任务的排序逻辑。
-+ AbstractDispatchTask:实现广播模式下,任务的均衡分发。
-+ AbstractClusterPhyDispatchTask:对分发到当前服务器的集群列表进行枚举。
-+ KMJobTask:实现对单个集群的定时任务处理。
-
-#### 3.3.2、关键类代码
-
-+ **AbstractDispatchTask类**
-
-```java
-// 实现Job接口的抽象类,进行任务的负载均衡执行
-public abstract class AbstractDispatchTask implements Job {
-
- // 罗列所有的任务
- protected abstract List listAllTasks();
-
- // 执行被分配给该KS主机的任务
- protected abstract TaskResult processTask(List subTaskList, long triggerTimeUnitMs);
-
- // 被Logi-Job触发执行该方法
- // 该方法进行任务的分配
- @Override
- public TaskResult execute(JobContext jobContext) {
- try {
-
- long triggerTimeUnitMs = System.currentTimeMillis();
-
- // 获取所有的任务
- List allTaskList = this.listAllTasks();
-
- // 计算当前KS机器需要执行的任务
- List subTaskList = this.selectTask(allTaskList, jobContext.getAllWorkerCodes(), jobContext.getCurrentWorkerCode());
-
- // 进行任务处理
- return this.processTask(subTaskList, triggerTimeUnitMs);
- } catch (Exception e) {
- // ...
- }
- }
-}
-```
-
-+ **AbstractClusterPhyDispatchTask类**
-
-```java
-// 继承AbstractDispatchTask的抽象类,对Kafka集群进行负载均衡执行
-public abstract class AbstractClusterPhyDispatchTask extends AbstractDispatchTask {
-
- // 执行被分配的任务,具体由子类实现
- protected abstract TaskResult processSubTask(ClusterPhy clusterPhy, long triggerTimeUnitMs) throws Exception;
-
- // 返回所有的Kafka集群
- @Override
- public List listAllTasks() {
- return clusterPhyService.listAllClusters();
- }
-
- // 执行被分配给该KS主机的Kafka集群任务
- @Override
- public TaskResult processTask(List subTaskList, long triggerTimeUnitMs) { // ... }
-
-}
-```
-
-+ **KMJobTask类**
-
-```java
-// 加上@Task注解,并配置任务执行信息
-@Task(name = "kmJobTask",
- description = "km job 模块调度执行任务",
- cron = "0 0/1 * * * ? *",
- autoRegister = true,
- consensual = ConsensualEnum.BROADCAST,
- timeout = 6 * 60)
-// 继承AbstractClusterPhyDispatchTask类
-public class KMJobTask extends AbstractClusterPhyDispatchTask {
-
- @Autowired
- private JobService jobService;
-
- // 执行该Kafka集群的Job模块的任务
- @Override
- protected TaskResult processSubTask(ClusterPhy clusterPhy, long triggerTimeUnitMs) throws Exception {
- jobService.scheduleJobByClusterId(clusterPhy.getId());
- return TaskResult.SUCCESS;
- }
-}
-```
-
-#### 3.3.3、均衡执行总结
-
-均衡执行的实现原理总结起来就是以下几点:
-
-+ Logi-Job设置为广播模式,触发所有的KS主机执行任务;
-+ 每台KS主机,被触发执行后,按照统一的规则,对任务列表,KS集群主机列表进行排序。然后按照顺序将任务列表均衡的分配给排序后的KS集群主机。KS集群稳定运行情况下,这一步保证了每台KS主机之间分配到的任务列表不重复,不丢失。
-+ 最后每台KS主机,执行被分配到的任务。
-
-## 4、注意事项
-
-+ 不能100%保证任务在一个周期内,且仅且执行一次,可能出现重复执行或丢失的情况,所以必须严格是且仅且执行一次的任务,不建议基于Logi-Job进行任务控制。
-+ 尽量让Logi-Job仅负责任务的触发,后续的执行建议放到自己创建的线程池中进行。
diff --git a/docs/dev_guide/assets/connect_jmx_failed/check_jmx_opened.jpg b/docs/dev_guide/assets/connect_jmx_failed/check_jmx_opened.jpg
deleted file mode 100644
index 1890983c..00000000
Binary files a/docs/dev_guide/assets/connect_jmx_failed/check_jmx_opened.jpg and /dev/null differ
diff --git a/docs/dev_guide/assets/support_kerberos_zk/need_modify_code.png b/docs/dev_guide/assets/support_kerberos_zk/need_modify_code.png
deleted file mode 100644
index c51c1c00..00000000
Binary files a/docs/dev_guide/assets/support_kerberos_zk/need_modify_code.png and /dev/null differ
diff --git a/docs/dev_guide/assets/support_kerberos_zk/success_1.png b/docs/dev_guide/assets/support_kerberos_zk/success_1.png
deleted file mode 100644
index f15ed55e..00000000
Binary files a/docs/dev_guide/assets/support_kerberos_zk/success_1.png and /dev/null differ
diff --git a/docs/dev_guide/assets/support_kerberos_zk/success_2.png b/docs/dev_guide/assets/support_kerberos_zk/success_2.png
deleted file mode 100644
index f15ed55e..00000000
Binary files a/docs/dev_guide/assets/support_kerberos_zk/success_2.png and /dev/null differ
diff --git a/docs/dev_guide/assets/support_kerberos_zk/watch_user_acl.png b/docs/dev_guide/assets/support_kerberos_zk/watch_user_acl.png
deleted file mode 100644
index b076316b..00000000
Binary files a/docs/dev_guide/assets/support_kerberos_zk/watch_user_acl.png and /dev/null differ
diff --git a/docs/dev_guide/多版本兼容方案.md b/docs/dev_guide/多版本兼容方案.md
deleted file mode 100644
index f41c01d4..00000000
--- a/docs/dev_guide/多版本兼容方案.md
+++ /dev/null
@@ -1,43 +0,0 @@
-
-## 4.2、Kafka 多版本兼容方案
-
- 当前 KnowStreaming 支持纳管多个版本的 kafka 集群,由于不同版本的 kafka 在指标采集、接口查询、行为操作上有些不一致,因此 KnowStreaming 需要一套机制来解决多 kafka 版本的纳管兼容性问题。
-
-### 4.2.1、整体思路
-
- 由于需要纳管多个 kafka 版本,而且未来还可能会纳管非 kafka 官方的版本,kafka 的版本号会存在着多种情况,所以首先要明确一个核心思想:KnowStreaming 提供尽可能多的纳管能力,但是不提供无限的纳管能力,每一个版本的 KnowStreaming 只纳管其自身声明的 kafka 版本,后续随着 KnowStreaming 自身版本的迭代,会逐步支持更多 kafka 版本的纳管接入。
-
-### 4.2.2、构建版本兼容列表
-
- 每一个版本的 KnowStreaming 都声明一个自身支持纳管的 kafka 版本列表,并且对 kafka 的版本号进行归一化处理,后续所有 KnowStreaming 对不同 kafka 集群的操作都和这个集群对应的版本号严格相关。
-
- KnowStreaming 对外提供自身所支持的 kafka 版本兼容列表,用以声明自身支持的版本范围。
-
- 对于在集群接入过程中,如果希望接入当前 KnowStreaming 不支持的 kafka 版本的集群,KnowStreaming 建议在于的过程中选择相近的版本号接入。
-
-### 4.2.3、构建版本兼容性字典
-
- 在构建了 KnowStreaming 支持的 kafka 版本列表的基础上,KnowStreaming 在实现过程中,还会声明自身支持的所有兼容性,构建兼容性字典。
-
- 当前 KnowStreaming 支持的 kafka 版本兼容性字典包括三个维度:
-
-- 指标采集:同一个指标在不同 kafka 版本下可能获取的方式不一样,不同版本的 kafka 可能会有不同的指标,因此对于指标采集的处理需要构建兼容性字典。
-- kafka api:同一个 kafka 的操作处理的方式在不同 kafka 版本下可能存在不一致,如:topic 的创建,因此 KnowStreaming 针对不同 kafka-api 的处理需要构建兼容性字典。
-- 平台操作:KnowStreaming 在接入不同版本的 kafka 集群的时候,在平台页面上会根据不同的 kafka 版。
-
-兼容性字典的核心设计字段如下:
-
-| 兼容性维度 | 兼容项名称 | 最小 Kafka 版本号(归一化) | 最大 Kafka 版本号(归一化) | 处理器 |
-| ---------- | ---------- | --------------------------- | --------------------------- | ------ |
-
-KS-KM 根据其需要纳管的 kafka 版本,按照上述三个维度构建了完善了兼容性字典。
-
-### 4.2.4、兼容性问题
-
- KS-KM 的每个版本针对需要纳管的 kafka 版本列表,事先分析各个版本的差异性和产品需求,同时 KS-KM 构建了一套专门处理兼容性的服务,来进行兼容性的注册、字典构建、处理器分发等操作,其中版本兼容性处理器是来具体处理不同 kafka 版本差异性的地方。
-
- 
-
- 如上图所示,KS-KM 的 topic 服务在面对不同 kafka 版本时,其 topic 的创建、删除、扩容由于 kafka 版本自身的差异,导致 KnowStreaming 的处理也不一样,所以需要根据不同的 kafka 版本来实现不同的兼容性处理器,同时向 KnowStreaming 的兼容服务进行兼容性的注册,构建兼容性字典,后续在 KnowStreaming 的运行过程中,针对不同的 kafka 版本即可分发到不同的处理器中执行。
-
- 后续随着 KnowStreaming 产品的发展,如果有新的兼容性的地方需要增加,只需要实现新版本的处理器,增加注册项即可。
diff --git a/docs/dev_guide/指标说明.md b/docs/dev_guide/指标说明.md
deleted file mode 100644
index 1eb9a94b..00000000
--- a/docs/dev_guide/指标说明.md
+++ /dev/null
@@ -1,152 +0,0 @@
-## 3.3、指标说明
-
-当前 KnowStreaming 支持针对 kafka 集群的多维度指标的采集和展示,同时也支持多个 kafka 版本的指标进行兼容,以下是 KnowStreaming 支持的指标说明。
-
-现在对当前 KnowStreaming 支持的指标从指标名称、指标单位、指标说明、kafka 版本、企业/开源版指标 五个维度进行说明。
-
-### 3.3.1、Cluster 指标
-
-| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
-| ------------------------- | -------- | ------------------------------------ | ---------------- | --------------- |
-| HealthScore | 分 | 集群总体的健康分 | 全部版本 | 开源版 |
-| HealthCheckPassed | 个 | 集群总体健康检查通过数 | 全部版本 | 开源版 |
-| HealthCheckTotal | 个 | 集群总体健康检查总数 | 全部版本 | 开源版 |
-| HealthScore_Topics | 分 | 集群 Topics 的健康分 | 全部版本 | 开源版 |
-| HealthCheckPassed_Topics | 个 | 集群 Topics 健康检查通过数 | 全部版本 | 开源版 |
-| HealthCheckTotal_Topics | 个 | 集群 Topics 健康检查总数 | 全部版本 | 开源版 |
-| HealthScore_Brokers | 分 | 集群 Brokers 的健康分 | 全部版本 | 开源版 |
-| HealthCheckPassed_Brokers | 个 | 集群 Brokers 健康检查通过数 | 全部版本 | 开源版 |
-| HealthCheckTotal_Brokers | 个 | 集群 Brokers 健康检查总数 | 全部版本 | 开源版 |
-| HealthScore_Groups | 分 | 集群 Groups 的健康分 | 全部版本 | 开源版 |
-| HealthCheckPassed_Groups | 个 | 集群 Groups 健康检查总数 | 全部版本 | 开源版 |
-| HealthCheckTotal_Groups | 个 | 集群 Groups 健康检查总数 | 全部版本 | 开源版 |
-| HealthScore_Cluster | 分 | 集群自身的健康分 | 全部版本 | 开源版 |
-| HealthCheckPassed_Cluster | 个 | 集群自身健康检查通过数 | 全部版本 | 开源版 |
-| HealthCheckTotal_Cluster | 个 | 集群自身健康检查总数 | 全部版本 | 开源版 |
-| TotalRequestQueueSize | 个 | 集群中总的请求队列数 | 全部版本 | 开源版 |
-| TotalResponseQueueSize | 个 | 集群中总的响应队列数 | 全部版本 | 开源版 |
-| EventQueueSize | 个 | 集群中 Controller 的 EventQueue 大小 | 2.0.0 及以上版本 | 开源版 |
-| ActiveControllerCount | 个 | 集群中存活的 Controller 数 | 全部版本 | 开源版 |
-| TotalProduceRequests | 个 | 集群中的 Produce 每秒请求数 | 全部版本 | 开源版 |
-| TotalLogSize | byte | 集群总的已使用的磁盘大小 | 全部版本 | 开源版 |
-| ConnectionsCount | 个 | 集群的连接(Connections)个数 | 全部版本 | 开源版 |
-| Zookeepers | 个 | 集群中存活的 zk 节点个数 | 全部版本 | 开源版 |
-| ZookeepersAvailable | 是/否 | ZK 地址是否合法 | 全部版本 | 开源版 |
-| Brokers | 个 | 集群的 broker 的总数 | 全部版本 | 开源版 |
-| BrokersAlive | 个 | 集群的 broker 的存活数 | 全部版本 | 开源版 |
-| BrokersNotAlive | 个 | 集群的 broker 的未存活数 | 全部版本 | 开源版 |
-| Replicas | 个 | 集群中 Replica 的总数 | 全部版本 | 开源版 |
-| Topics | 个 | 集群中 Topic 的总数 | 全部版本 | 开源版 |
-| Partitions | 个 | 集群的 Partitions 总数 | 全部版本 | 开源版 |
-| PartitionNoLeader | 个 | 集群中的 PartitionNoLeader 总数 | 全部版本 | 开源版 |
-| PartitionMinISR_S | 个 | 集群中的小于 PartitionMinISR 总数 | 全部版本 | 开源版 |
-| PartitionMinISR_E | 个 | 集群中的等于 PartitionMinISR 总数 | 全部版本 | 开源版 |
-| PartitionURP | 个 | 集群中的未同步的 Partition 总数 | 全部版本 | 开源版 |
-| MessagesIn | 条/s | 集群每条消息写入条数 | 全部版本 | 开源版 |
-| Messages | 条 | 集群总的消息条数 | 全部版本 | 开源版 |
-| LeaderMessages | 条 | 集群中 leader 总的消息条数 | 全部版本 | 开源版 |
-| BytesIn | byte/s | 集群的每秒写入字节数 | 全部版本 | 开源版 |
-| BytesIn_min_5 | byte/s | 集群的每秒写入字节数,5 分钟均值 | 全部版本 | 开源版 |
-| BytesIn_min_15 | byte/s | 集群的每秒写入字节数,15 分钟均值 | 全部版本 | 开源版 |
-| BytesOut | byte/s | 集群的每秒流出字节数 | 全部版本 | 开源版 |
-| BytesOut_min_5 | byte/s | 集群的每秒流出字节数,5 分钟均值 | 全部版本 | 开源版 |
-| BytesOut_min_15 | byte/s | 集群的每秒流出字节数,15 分钟均值 | 全部版本 | 开源版 |
-| Groups | 个 | 集群中 Group 的总数 | 全部版本 | 开源版 |
-| GroupActives | 个 | 集群中 ActiveGroup 的总数 | 全部版本 | 开源版 |
-| GroupEmptys | 个 | 集群中 EmptyGroup 的总数 | 全部版本 | 开源版 |
-| GroupRebalances | 个 | 集群中 RebalanceGroup 的总数 | 全部版本 | 开源版 |
-| GroupDeads | 个 | 集群中 DeadGroup 的总数 | 全部版本 | 开源版 |
-| Alive | 是/否 | 集群是否存活,1:存活;0:没有存活 | 全部版本 | 开源版 |
-| AclEnable | 是/否 | 集群是否开启 Acl,1:是;0:否 | 全部版本 | 开源版 |
-| Acls | 个 | ACL 数 | 全部版本 | 开源版 |
-| AclUsers | 个 | ACL-KafkaUser 数 | 全部版本 | 开源版 |
-| AclTopics | 个 | ACL-Topic 数 | 全部版本 | 开源版 |
-| AclGroups | 个 | ACL-Group 数 | 全部版本 | 开源版 |
-| Jobs | 个 | 集群任务总数 | 全部版本 | 开源版 |
-| JobsRunning | 个 | 集群 running 任务总数 | 全部版本 | 开源版 |
-| JobsWaiting | 个 | 集群 waiting 任务总数 | 全部版本 | 开源版 |
-| JobsSuccess | 个 | 集群 success 任务总数 | 全部版本 | 开源版 |
-| JobsFailed | 个 | 集群 failed 任务总数 | 全部版本 | 开源版 |
-| LoadReBalanceEnable | 是/否 | 是否开启均衡, 1:是;0:否 | 全部版本 | 企业版 |
-| LoadReBalanceCpu | 是/否 | CPU 是否均衡, 1:是;0:否 | 全部版本 | 企业版 |
-| LoadReBalanceNwIn | 是/否 | BytesIn 是否均衡, 1:是;0:否 | 全部版本 | 企业版 |
-| LoadReBalanceNwOut | 是/否 | BytesOut 是否均衡, 1:是;0:否 | 全部版本 | 企业版 |
-| LoadReBalanceDisk | 是/否 | Disk 是否均衡, 1:是;0:否 | 全部版本 | 企业版 |
-
-### 3.3.2、Broker 指标
-
-| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
-| ----------------------- | -------- | ------------------------------------- | ---------- | --------------- |
-| HealthScore | 分 | Broker 健康分 | 全部版本 | 开源版 |
-| HealthCheckPassed | 个 | Broker 健康检查通过数 | 全部版本 | 开源版 |
-| HealthCheckTotal | 个 | Broker 健康检查总数 | 全部版本 | 开源版 |
-| TotalRequestQueueSize | 个 | Broker 的请求队列大小 | 全部版本 | 开源版 |
-| TotalResponseQueueSize | 个 | Broker 的应答队列大小 | 全部版本 | 开源版 |
-| ReplicationBytesIn | byte/s | Broker 的副本流入流量 | 全部版本 | 开源版 |
-| ReplicationBytesOut | byte/s | Broker 的副本流出流量 | 全部版本 | 开源版 |
-| MessagesIn | 条/s | Broker 的每秒消息流入条数 | 全部版本 | 开源版 |
-| TotalProduceRequests | 个/s | Broker 上 Produce 的每秒请求数 | 全部版本 | 开源版 |
-| NetworkProcessorAvgIdle | % | Broker 的网络处理器的空闲百分比 | 全部版本 | 开源版 |
-| RequestHandlerAvgIdle | % | Broker 上请求处理器的空闲百分比 | 全部版本 | 开源版 |
-| PartitionURP | 个 | Broker 上的未同步的副本的个数 | 全部版本 | 开源版 |
-| ConnectionsCount | 个 | Broker 上网络链接的个数 | 全部版本 | 开源版 |
-| BytesIn | byte/s | Broker 的每秒数据写入量 | 全部版本 | 开源版 |
-| BytesIn_min_5 | byte/s | Broker 的每秒数据写入量,5 分钟均值 | 全部版本 | 开源版 |
-| BytesIn_min_15 | byte/s | Broker 的每秒数据写入量,15 分钟均值 | 全部版本 | 开源版 |
-| BytesOut | byte/s | Broker 的每秒数据流出量 | 全部版本 | 开源版 |
-| BytesOut_min_5 | byte/s | Broker 的每秒数据流出量,5 分钟均值 | 全部版本 | 开源版 |
-| BytesOut_min_15 | byte/s | Broker 的每秒数据流出量,15 分钟均值 | 全部版本 | 开源版 |
-| ReassignmentBytesIn | byte/s | Broker 的每秒数据迁移写入量 | 全部版本 | 开源版 |
-| ReassignmentBytesOut | byte/s | Broker 的每秒数据迁移流出量 | 全部版本 | 开源版 |
-| Partitions | 个 | Broker 上的 Partition 个数 | 全部版本 | 开源版 |
-| PartitionsSkew | % | Broker 上的 Partitions 倾斜度 | 全部版本 | 开源版 |
-| Leaders | 个 | Broker 上的 Leaders 个数 | 全部版本 | 开源版 |
-| LeadersSkew | % | Broker 上的 Leaders 倾斜度 | 全部版本 | 开源版 |
-| LogSize | byte | Broker 上的消息容量大小 | 全部版本 | 开源版 |
-| Alive | 是/否 | Broker 是否存活,1:存活;0:没有存活 | 全部版本 | 开源版 |
-
-### 3.3.3、Topic 指标
-
-| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
-| --------------------- | -------- | ------------------------------------- | ---------- | --------------- |
-| HealthScore | 分 | 健康分 | 全部版本 | 开源版 |
-| HealthCheckPassed | 个 | 健康项检查通过数 | 全部版本 | 开源版 |
-| HealthCheckTotal | 个 | 健康项检查总数 | 全部版本 | 开源版 |
-| TotalProduceRequests | 条/s | Topic 的 TotalProduceRequests | 全部版本 | 开源版 |
-| BytesRejected | 个/s | Topic 的每秒写入拒绝量 | 全部版本 | 开源版 |
-| FailedFetchRequests | 个/s | Topic 的 FailedFetchRequests | 全部版本 | 开源版 |
-| FailedProduceRequests | 个/s | Topic 的 FailedProduceRequests | 全部版本 | 开源版 |
-| ReplicationCount | 个 | Topic 总的副本数 | 全部版本 | 开源版 |
-| Messages | 条 | Topic 总的消息数 | 全部版本 | 开源版 |
-| MessagesIn | 条/s | Topic 每秒消息条数 | 全部版本 | 开源版 |
-| BytesIn | byte/s | Topic 每秒消息写入字节数 | 全部版本 | 开源版 |
-| BytesIn_min_5 | byte/s | Topic 每秒消息写入字节数,5 分钟均值 | 全部版本 | 开源版 |
-| BytesIn_min_15 | byte/s | Topic 每秒消息写入字节数,15 分钟均值 | 全部版本 | 开源版 |
-| BytesOut | byte/s | Topic 每秒消息流出字节数 | 全部版本 | 开源版 |
-| BytesOut_min_5 | byte/s | Topic 每秒消息流出字节数,5 分钟均值 | 全部版本 | 开源版 |
-| BytesOut_min_15 | byte/s | Topic 每秒消息流出字节数,15 分钟均值 | 全部版本 | 开源版 |
-| LogSize | byte | Topic 的大小 | 全部版本 | 开源版 |
-| PartitionURP | 个 | Topic 未同步的副本数 | 全部版本 | 开源版 |
-
-### 3.3.4、Partition 指标
-
-| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
-| -------------- | -------- | ----------------------------------------- | ---------- | --------------- |
-| LogEndOffset | 条 | Partition 中 leader 副本的 LogEndOffset | 全部版本 | 开源版 |
-| LogStartOffset | 条 | Partition 中 leader 副本的 LogStartOffset | 全部版本 | 开源版 |
-| Messages | 条 | Partition 总的消息数 | 全部版本 | 开源版 |
-| BytesIn | byte/s | Partition 的每秒消息流入字节数 | 全部版本 | 开源版 |
-| BytesOut | byte/s | Partition 的每秒消息流出字节数 | 全部版本 | 开源版 |
-| LogSize | byte | Partition 的大小 | 全部版本 | 开源版 |
-
-### 3.3.5、Group 指标
-
-| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
-| ----------------- | -------- | -------------------------- | ---------- | --------------- |
-| HealthScore | 分 | 健康分 | 全部版本 | 开源版 |
-| HealthCheckPassed | 个 | 健康检查通过数 | 全部版本 | 开源版 |
-| HealthCheckTotal | 个 | 健康检查总数 | 全部版本 | 开源版 |
-| OffsetConsumed | 条 | Consumer 的 CommitedOffset | 全部版本 | 开源版 |
-| LogEndOffset | 条 | Consumer 的 LogEndOffset | 全部版本 | 开源版 |
-| Lag | 条 | Group 消费者的 Lag 数 | 全部版本 | 开源版 |
-| State | 个 | Group 组的状态 | 全部版本 | 开源版 |
diff --git a/docs/dev_guide/支持Kerberos认证的ZK.md b/docs/dev_guide/支持Kerberos认证的ZK.md
deleted file mode 100644
index 116643ba..00000000
--- a/docs/dev_guide/支持Kerberos认证的ZK.md
+++ /dev/null
@@ -1,69 +0,0 @@
-
-## 支持Kerberos认证的ZK
-
-
-### 1、修改 KnowStreaming 代码
-
-代码位置:`src/main/java/com/xiaojukeji/know/streaming/km/persistence/kafka/KafkaAdminZKClient.java`
-
-将 `createZKClient` 的 `135行 的 false 改为 true
-
-
-
-修改完后重新进行打包编译,打包编译见:[打包编译](https://github.com/didi/KnowStreaming/blob/master/docs/install_guide/%E6%BA%90%E7%A0%81%E7%BC%96%E8%AF%91%E6%89%93%E5%8C%85%E6%89%8B%E5%86%8C.md
-)
-
-
-
-### 2、查看用户在ZK的ACL
-
-假设我们使用的用户是 `kafka` 这个用户。
-
-- 1、查看 server.properties 的配置的 zookeeper.connect 的地址;
-- 2、使用 `zkCli.sh -serve zookeeper.connect的地址` 登录到ZK页面;
-- 3、ZK页面上,执行命令 `getAcl /kafka` 查看 `kafka` 用户的权限;
-
-此时,我们可以看到如下信息:
-
-
-`kafka` 用户需要的权限是 `cdrwa`。如果用户没有 `cdrwa` 权限的话,需要创建用户并授权,授权命令为:`setAcl`
-
-
-### 3、创建Kerberos的keytab并修改 KnowStreaming 主机
-
-- 1、在 Kerberos 的域中创建 `kafka/_HOST` 的 `keytab`,并导出。例如:`kafka/dbs-kafka-test-8-53`;
-- 2、导出 keytab 后上传到安装 KS 的机器的 `/etc/keytab` 下;
-- 3、在 KS 机器上,执行 `kinit -kt zookeepe.keytab kafka/dbs-kafka-test-8-53` 看是否能进行 `Kerberos` 登录;
-- 4、可以登录后,配置 `/opt/zookeeper.jaas` 文件,例子如下:
-```sql
-Client {
- com.sun.security.auth.module.Krb5LoginModule required
- useKeyTab=true
- storeKey=false
- serviceName="zookeeper"
- keyTab="/etc/keytab/zookeeper.keytab"
- principal="kafka/dbs-kafka-test-8-53@XXX.XXX.XXX";
-};
-```
-- 5、需要配置 `KDC-Server` 对 `KnowStreaming` 的机器开通防火墙,并在KS的机器 `/etc/host/` 配置 `kdc-server` 的 `hostname`。并将 `krb5.conf` 导入到 `/etc` 下;
-
-
-### 4、修改 KnowStreaming 的配置
-
-- 1、在 `/usr/local/KnowStreaming/KnowStreaming/bin/startup.sh` 中的47行的JAVA_OPT中追加如下设置
-```bash
--Dsun.security.krb5.debug=true -Djava.security.krb5.conf=/etc/krb5.conf -Djava.security.auth.login.config=/opt/zookeeper.jaas
-```
-
-- 2、重启KS集群后再 start.out 中看到如下信息,则证明Kerberos配置成功;
-
-
-
-
-
-
-### 5、补充说明
-
-- 1、多Kafka集群如果用的是一样的Kerberos域的话,只需在每个`ZK`中给`kafka`用户配置`crdwa`权限即可,这样集群初始化的时候`zkclient`是都可以认证;
-- 2、当前需要修改代码重新打包才可以支持,后续考虑通过页面支持Kerberos认证的ZK接入;
-- 3、多个Kerberos域暂时未适配;
\ No newline at end of file
diff --git a/docs/dev_guide/无数据排查文档.md b/docs/dev_guide/无数据排查文档.md
deleted file mode 100644
index fd7886bc..00000000
--- a/docs/dev_guide/无数据排查文档.md
+++ /dev/null
@@ -1,285 +0,0 @@
-## 1、集群接入错误
-
-### 1.1、异常现象
-
-如下图所示,集群非空时,大概率为地址配置错误导致。
-
- -
-
-
-### 1.2、解决方案
-
-接入集群时,依据提示的错误,进行相应的解决。例如:
-
-
-
-
-
-### 1.2、解决方案
-
-接入集群时,依据提示的错误,进行相应的解决。例如:
-
-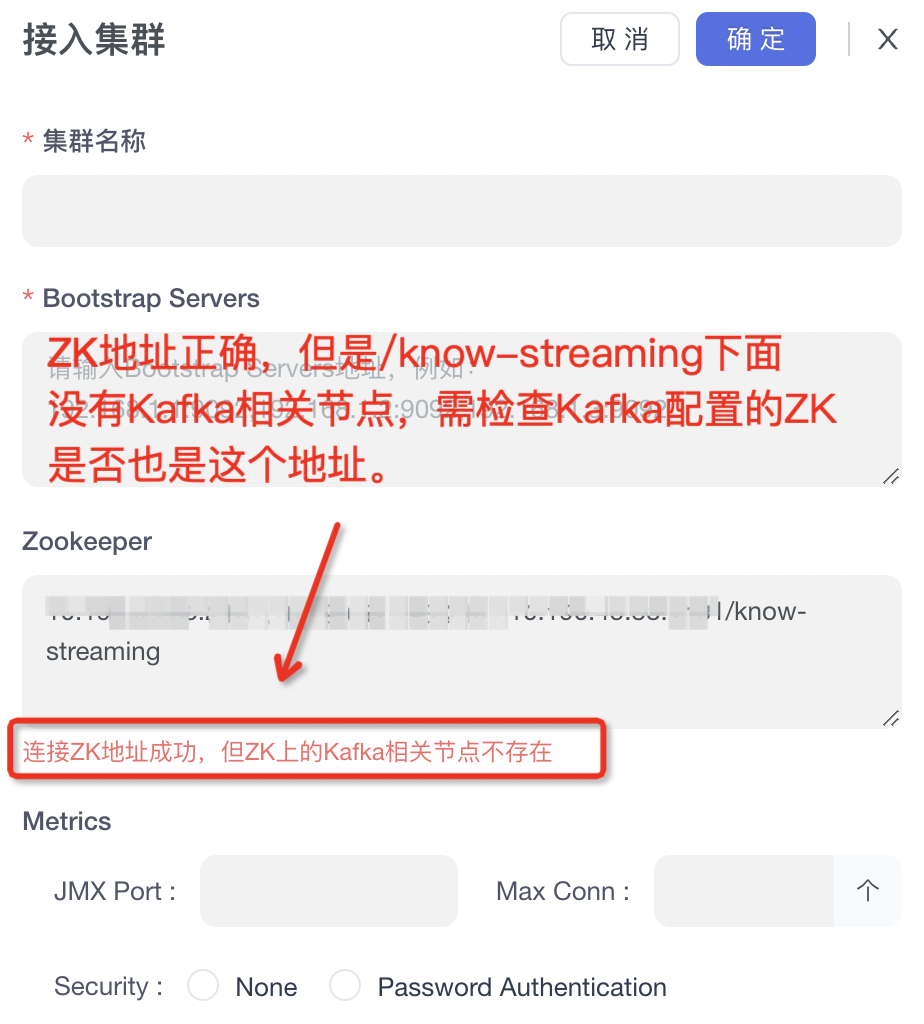 -
-### 1.3、正常情况
-
-接入集群时,页面信息都自动正常出现,没有提示错误。
-
-
-
-## 2、JMX连接失败(需使用3.0.1及以上版本)
-
-### 2.1异常现象
-
-Broker列表的JMX Port列出现红色感叹号,则该Broker的JMX连接异常。
-
-
-
-### 1.3、正常情况
-
-接入集群时,页面信息都自动正常出现,没有提示错误。
-
-
-
-## 2、JMX连接失败(需使用3.0.1及以上版本)
-
-### 2.1异常现象
-
-Broker列表的JMX Port列出现红色感叹号,则该Broker的JMX连接异常。
-
-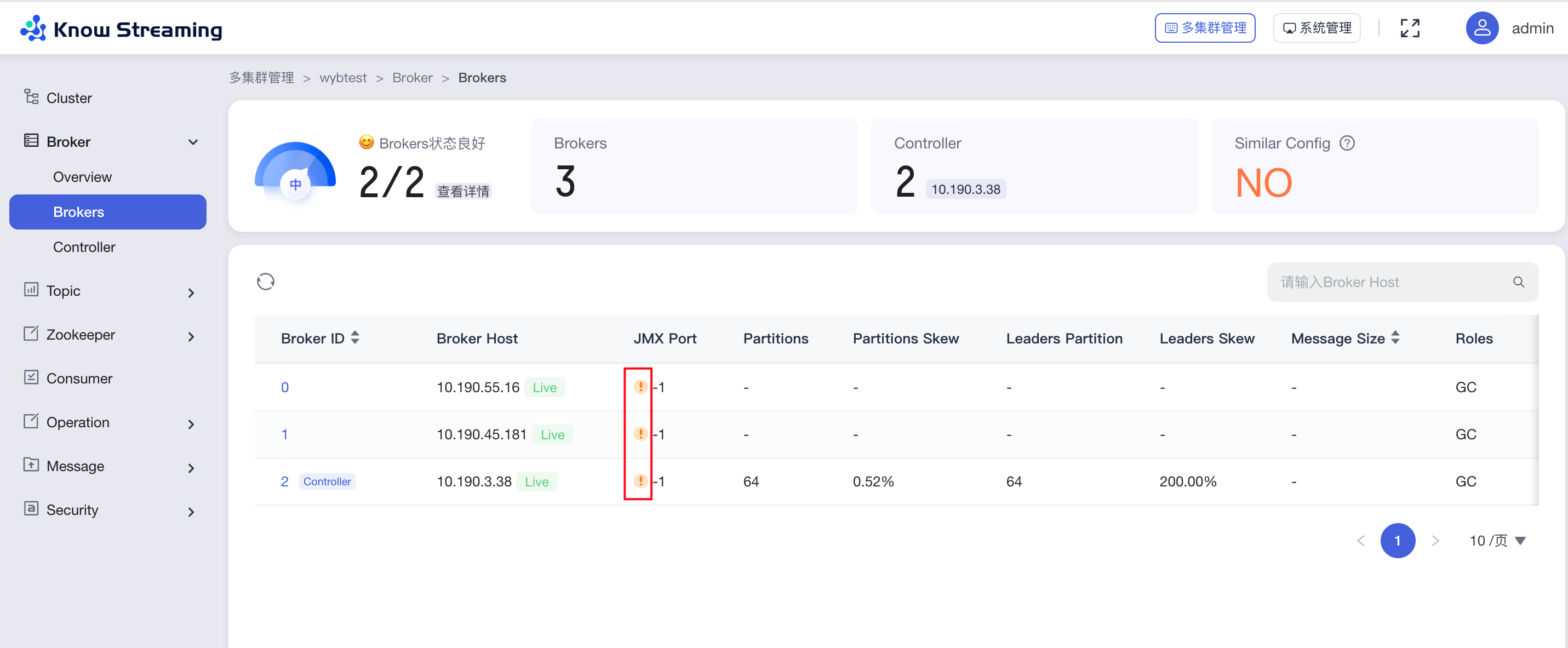 -
-
-
-#### 2.1.1、原因一:JMX未开启
-
-##### 2.1.1.1、异常现象
-
-broker列表的JMX Port值为-1,对应Broker的JMX未开启。
-
-
-
-
-
-#### 2.1.1、原因一:JMX未开启
-
-##### 2.1.1.1、异常现象
-
-broker列表的JMX Port值为-1,对应Broker的JMX未开启。
-
-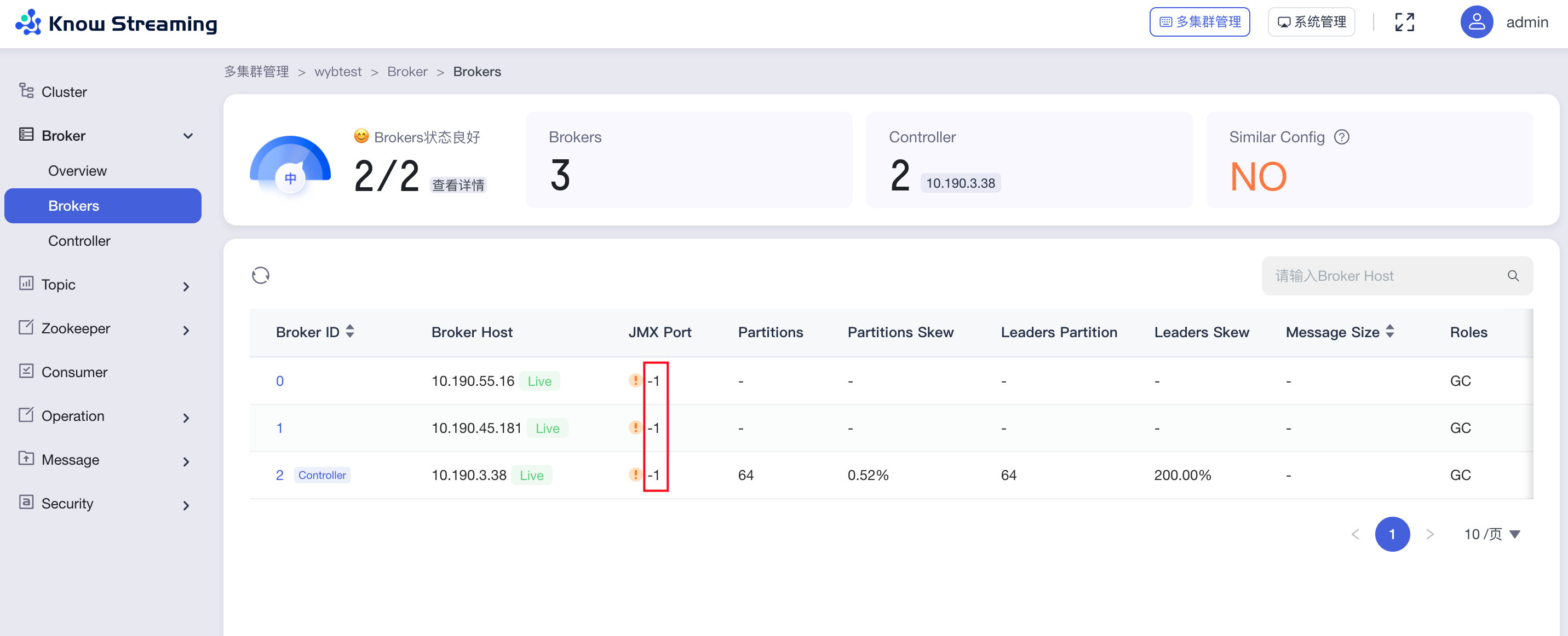 -
-##### 2.1.1.2、解决方案
-
-开启JMX,开启流程如下:
-
-1、修改kafka的bin目录下面的:`kafka-server-start.sh`文件
-
-```
-# 在这个下面增加JMX端口的配置
-if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
- export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
- export JMX_PORT=9999 # 增加这个配置, 这里的数值并不一定是要9999
-fi
-```
-
-
-
-2、修改kafka的bin目录下面对的:`kafka-run-class.sh`文件
-
-```
-# JMX settings
-if [ -z "$KAFKA_JMX_OPTS" ]; then
- KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false
- -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=${当前机器的IP}"
-fi
-
-# JMX port to use
-if [ $JMX_PORT ]; then
- KAFKA_JMX_OPTS="$KAFKA_JMX_OPTS -Dcom.sun.management.jmxremote.port=$JMX_PORT - Dcom.sun.management.jmxremote.rmi.port=$JMX_PORT"
-fi
-```
-
-
-
-3、重启Kafka-Broker。
-
-
-
-#### 2.1.2、原因二:JMX配置错误
-
-##### 2.1.2.1、异常现象
-
-错误日志:
-
-```
-# 错误一: 错误提示的是真实的IP,这样的话基本就是JMX配置的有问题了。
-2021-01-27 10:06:20.730 ERROR 50901 --- [ics-Thread-1-62] c.x.k.m.c.utils.jmx.JmxConnectorWrap : JMX connect exception, host:192.168.0.1 port:9999. java.rmi.ConnectException: Connection refused to host: 192.168.0.1; nested exception is:
-
-# 错误二:错误提示的是127.0.0.1这个IP,这个是机器的hostname配置的可能有问题。
-2021-01-27 10:06:20.730 ERROR 50901 --- [ics-Thread-1-62] c.x.k.m.c.utils.jmx.JmxConnectorWrap : JMX connect exception, host:127.0.0.1 port:9999. java.rmi.ConnectException: Connection refused to host: 127.0.0.1;; nested exception is:
-```
-
-
-
-##### 2.1.2.2、解决方案
-
-开启JMX,开启流程如下:
-
-1、修改kafka的bin目录下面的:`kafka-server-start.sh`文件
-
-```
-# 在这个下面增加JMX端口的配置
-if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
- export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
- export JMX_PORT=9999 # 增加这个配置, 这里的数值并不一定是要9999
-fi
-```
-
-
-
-2、修改kafka的bin目录下面对的:`kafka-run-class.sh`文件
-
-```
-# JMX settings
-if [ -z "$KAFKA_JMX_OPTS" ]; then
- KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false
- -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=${当前机器的IP}"
-fi
-
-# JMX port to use
-if [ $JMX_PORT ]; then
- KAFKA_JMX_OPTS="$KAFKA_JMX_OPTS -Dcom.sun.management.jmxremote.port=$JMX_PORT - Dcom.sun.management.jmxremote.rmi.port=$JMX_PORT"
-fi
-```
-
-
-
-3、重启Kafka-Broker。
-
-
-
-#### 2.1.3、原因三:JMX开启SSL
-
-##### 2.1.3.1、解决方案
-
-
-
-##### 2.1.1.2、解决方案
-
-开启JMX,开启流程如下:
-
-1、修改kafka的bin目录下面的:`kafka-server-start.sh`文件
-
-```
-# 在这个下面增加JMX端口的配置
-if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
- export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
- export JMX_PORT=9999 # 增加这个配置, 这里的数值并不一定是要9999
-fi
-```
-
-
-
-2、修改kafka的bin目录下面对的:`kafka-run-class.sh`文件
-
-```
-# JMX settings
-if [ -z "$KAFKA_JMX_OPTS" ]; then
- KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false
- -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=${当前机器的IP}"
-fi
-
-# JMX port to use
-if [ $JMX_PORT ]; then
- KAFKA_JMX_OPTS="$KAFKA_JMX_OPTS -Dcom.sun.management.jmxremote.port=$JMX_PORT - Dcom.sun.management.jmxremote.rmi.port=$JMX_PORT"
-fi
-```
-
-
-
-3、重启Kafka-Broker。
-
-
-
-#### 2.1.2、原因二:JMX配置错误
-
-##### 2.1.2.1、异常现象
-
-错误日志:
-
-```
-# 错误一: 错误提示的是真实的IP,这样的话基本就是JMX配置的有问题了。
-2021-01-27 10:06:20.730 ERROR 50901 --- [ics-Thread-1-62] c.x.k.m.c.utils.jmx.JmxConnectorWrap : JMX connect exception, host:192.168.0.1 port:9999. java.rmi.ConnectException: Connection refused to host: 192.168.0.1; nested exception is:
-
-# 错误二:错误提示的是127.0.0.1这个IP,这个是机器的hostname配置的可能有问题。
-2021-01-27 10:06:20.730 ERROR 50901 --- [ics-Thread-1-62] c.x.k.m.c.utils.jmx.JmxConnectorWrap : JMX connect exception, host:127.0.0.1 port:9999. java.rmi.ConnectException: Connection refused to host: 127.0.0.1;; nested exception is:
-```
-
-
-
-##### 2.1.2.2、解决方案
-
-开启JMX,开启流程如下:
-
-1、修改kafka的bin目录下面的:`kafka-server-start.sh`文件
-
-```
-# 在这个下面增加JMX端口的配置
-if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
- export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
- export JMX_PORT=9999 # 增加这个配置, 这里的数值并不一定是要9999
-fi
-```
-
-
-
-2、修改kafka的bin目录下面对的:`kafka-run-class.sh`文件
-
-```
-# JMX settings
-if [ -z "$KAFKA_JMX_OPTS" ]; then
- KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false
- -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=${当前机器的IP}"
-fi
-
-# JMX port to use
-if [ $JMX_PORT ]; then
- KAFKA_JMX_OPTS="$KAFKA_JMX_OPTS -Dcom.sun.management.jmxremote.port=$JMX_PORT - Dcom.sun.management.jmxremote.rmi.port=$JMX_PORT"
-fi
-```
-
-
-
-3、重启Kafka-Broker。
-
-
-
-#### 2.1.3、原因三:JMX开启SSL
-
-##### 2.1.3.1、解决方案
-
-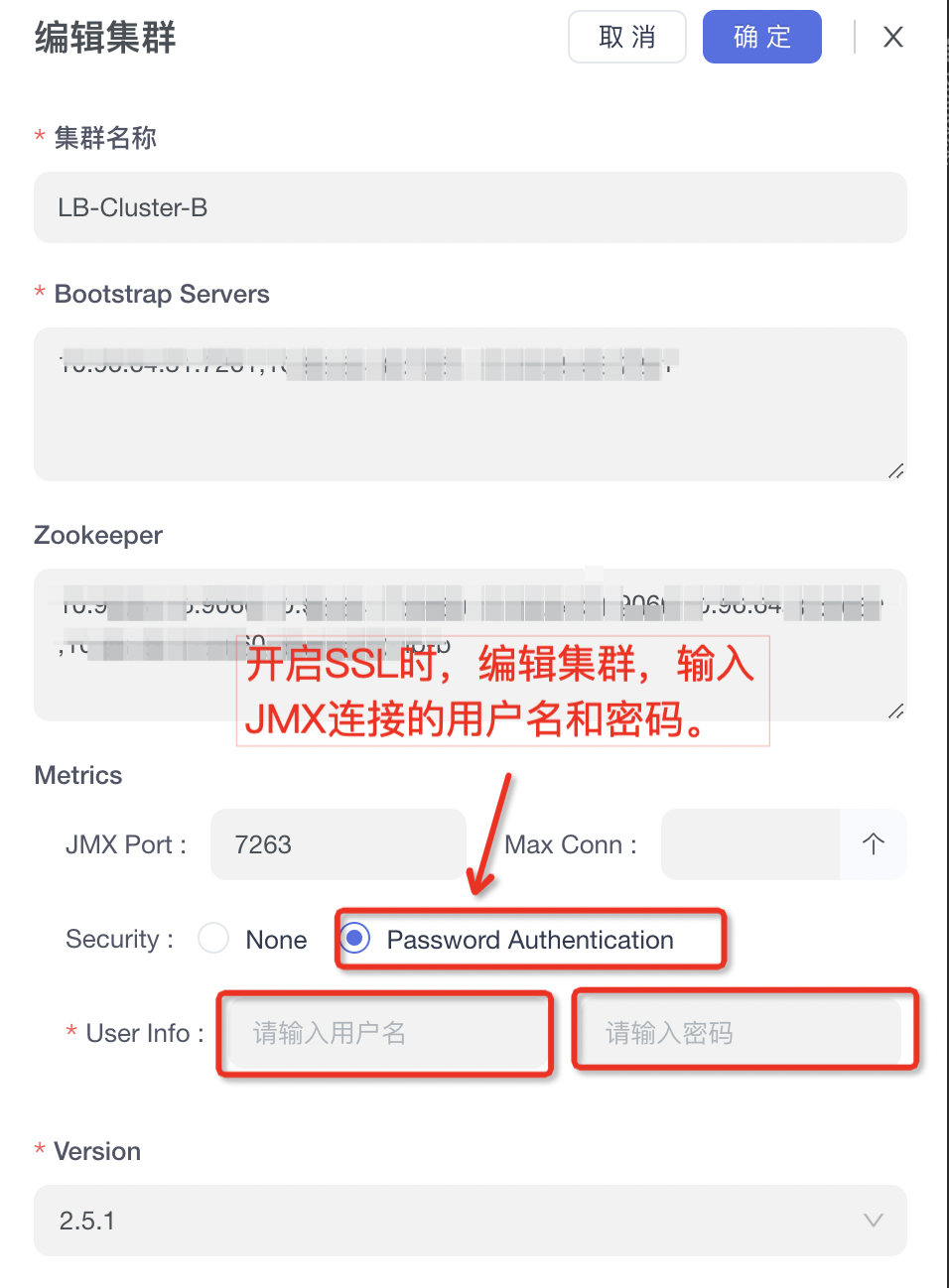 -
-#### 2.1.4、原因四:连接了错误IP
-
-##### 2.1.4.1、异常现象
-
-Broker 配置了内外网,而JMX在配置时,可能配置了内网IP或者外网IP,此时`KnowStreaming` 需要连接到特定网络的IP才可以进行访问。
-
- 比如:Broker在ZK的存储结构如下所示,我们期望连接到 `endpoints` 中标记为 `INTERNAL` 的地址,但是 `KnowStreaming` 却连接了 `EXTERNAL` 的地址。
-
-```json
-{
- "listener_security_protocol_map": {
- "EXTERNAL": "SASL_PLAINTEXT",
- "INTERNAL": "SASL_PLAINTEXT"
- },
- "endpoints": [
- "EXTERNAL://192.168.0.1:7092",
- "INTERNAL://192.168.0.2:7093"
- ],
- "jmx_port": 8099,
- "host": "192.168.0.1",
- "timestamp": "1627289710439",
- "port": -1,
- "version": 4
-}
-```
-
-##### 2.1.4.2、解决方案
-
-可以手动往`ks_km_physical_cluster`表的`jmx_properties`字段增加一个`useWhichEndpoint`字段,从而控制 `KnowStreaming` 连接到特定的JMX IP及PORT。
-
-`jmx_properties`格式:
-
-```json
-{
- "maxConn": 100, // KM对单台Broker的最大JMX连接数
- "username": "xxxxx", //用户名,可以不填写
- "password": "xxxx", // 密码,可以不填写
- "openSSL": true, //开启SSL, true表示开启ssl, false表示关闭
- "useWhichEndpoint": "EXTERNAL" //指定要连接的网络名称,填写EXTERNAL就是连接endpoints里面的EXTERNAL地址
-}
-```
-
-
-
-SQL例子:
-
-```sql
-UPDATE ks_km_physical_cluster SET jmx_properties='{ "maxConn": 10, "username": "xxxxx", "password": "xxxx", "openSSL": false , "useWhichEndpoint": "xxx"}' where id={xxx};
-```
-
-### 2.2、正常情况
-
-修改完成后,如果看到 JMX PORT这一列全部为绿色,则表示JMX已正常。
-
-
-
-#### 2.1.4、原因四:连接了错误IP
-
-##### 2.1.4.1、异常现象
-
-Broker 配置了内外网,而JMX在配置时,可能配置了内网IP或者外网IP,此时`KnowStreaming` 需要连接到特定网络的IP才可以进行访问。
-
- 比如:Broker在ZK的存储结构如下所示,我们期望连接到 `endpoints` 中标记为 `INTERNAL` 的地址,但是 `KnowStreaming` 却连接了 `EXTERNAL` 的地址。
-
-```json
-{
- "listener_security_protocol_map": {
- "EXTERNAL": "SASL_PLAINTEXT",
- "INTERNAL": "SASL_PLAINTEXT"
- },
- "endpoints": [
- "EXTERNAL://192.168.0.1:7092",
- "INTERNAL://192.168.0.2:7093"
- ],
- "jmx_port": 8099,
- "host": "192.168.0.1",
- "timestamp": "1627289710439",
- "port": -1,
- "version": 4
-}
-```
-
-##### 2.1.4.2、解决方案
-
-可以手动往`ks_km_physical_cluster`表的`jmx_properties`字段增加一个`useWhichEndpoint`字段,从而控制 `KnowStreaming` 连接到特定的JMX IP及PORT。
-
-`jmx_properties`格式:
-
-```json
-{
- "maxConn": 100, // KM对单台Broker的最大JMX连接数
- "username": "xxxxx", //用户名,可以不填写
- "password": "xxxx", // 密码,可以不填写
- "openSSL": true, //开启SSL, true表示开启ssl, false表示关闭
- "useWhichEndpoint": "EXTERNAL" //指定要连接的网络名称,填写EXTERNAL就是连接endpoints里面的EXTERNAL地址
-}
-```
-
-
-
-SQL例子:
-
-```sql
-UPDATE ks_km_physical_cluster SET jmx_properties='{ "maxConn": 10, "username": "xxxxx", "password": "xxxx", "openSSL": false , "useWhichEndpoint": "xxx"}' where id={xxx};
-```
-
-### 2.2、正常情况
-
-修改完成后,如果看到 JMX PORT这一列全部为绿色,则表示JMX已正常。
-
-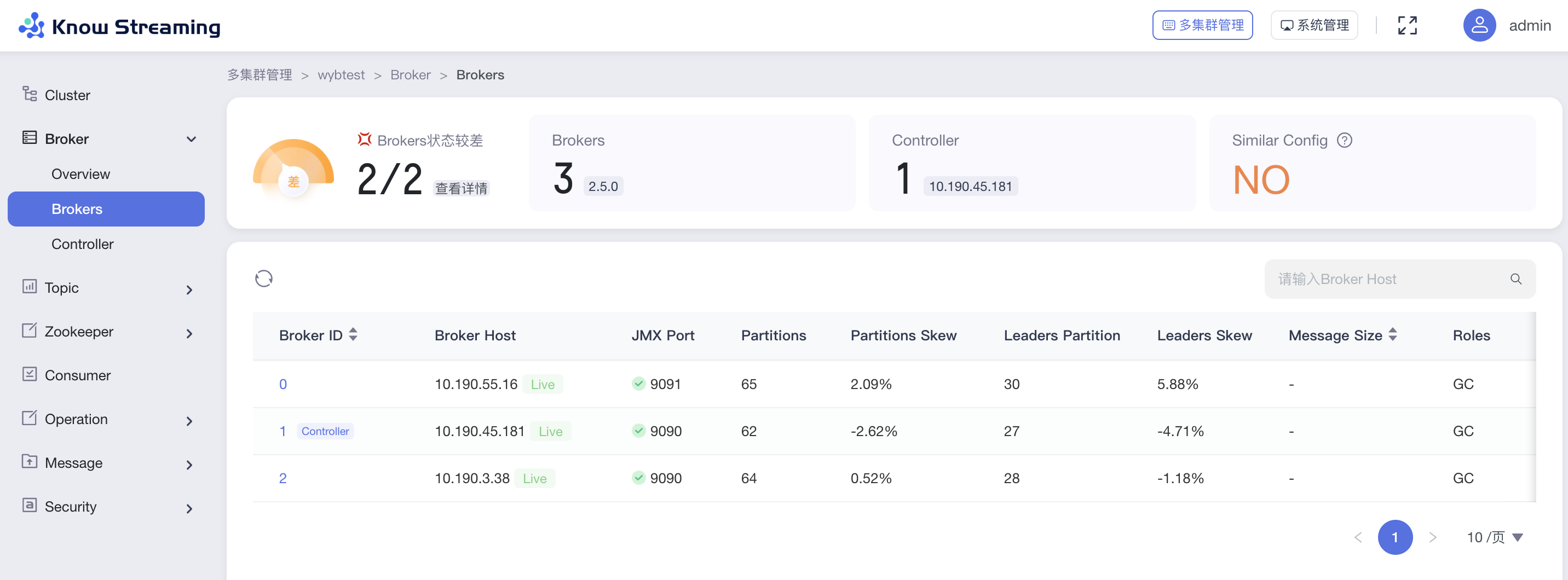 -
-
-
-## 3、Elasticsearch问题
-
-注意:mac系统在执行curl指令时,可能报zsh错误。可参考以下操作。
-
-```
-1 进入.zshrc 文件 vim ~/.zshrc
-2.在.zshrc中加入 setopt no_nomatch
-3.更新配置 source ~/.zshrc
-```
-
-### 3.1、原因一:缺少索引
-
-#### 3.1.1、异常现象
-
-报错信息
-
-```
-com.didiglobal.logi.elasticsearch.client.model.exception.ESIndexNotFoundException: method [GET], host[http://127.0.0.1:9200], URI [/ks_kafka_broker_metric_2022-10-21,ks_kafka_broker_metric_2022-10-22/_search], status line [HTTP/1.1 404 Not Found]
-```
-
-curl http://{ES的IP地址}:{ES的端口号}/_cat/indices/ks_kafka* 查看KS索引列表,发现没有索引。
-
-#### 3.1.2、解决方案
-
-执行 [ES索引及模版初始化](https://github.com/didi/KnowStreaming/blob/master/bin/init_es_template.sh) 脚本,来创建索引及模版。
-
-
-
-### 3.2、原因二:索引模板错误
-
-#### 3.2.1、异常现象
-
-多集群列表有数据,集群详情页图标无数据。查询KS索引模板列表,发现不存在。
-
-```
-curl {ES的IP地址}:{ES的端口号}/_cat/templates/ks_kafka*?v&h=name
-```
-
-正常KS模板如下图所示。
-
-
-
-
-
-## 3、Elasticsearch问题
-
-注意:mac系统在执行curl指令时,可能报zsh错误。可参考以下操作。
-
-```
-1 进入.zshrc 文件 vim ~/.zshrc
-2.在.zshrc中加入 setopt no_nomatch
-3.更新配置 source ~/.zshrc
-```
-
-### 3.1、原因一:缺少索引
-
-#### 3.1.1、异常现象
-
-报错信息
-
-```
-com.didiglobal.logi.elasticsearch.client.model.exception.ESIndexNotFoundException: method [GET], host[http://127.0.0.1:9200], URI [/ks_kafka_broker_metric_2022-10-21,ks_kafka_broker_metric_2022-10-22/_search], status line [HTTP/1.1 404 Not Found]
-```
-
-curl http://{ES的IP地址}:{ES的端口号}/_cat/indices/ks_kafka* 查看KS索引列表,发现没有索引。
-
-#### 3.1.2、解决方案
-
-执行 [ES索引及模版初始化](https://github.com/didi/KnowStreaming/blob/master/bin/init_es_template.sh) 脚本,来创建索引及模版。
-
-
-
-### 3.2、原因二:索引模板错误
-
-#### 3.2.1、异常现象
-
-多集群列表有数据,集群详情页图标无数据。查询KS索引模板列表,发现不存在。
-
-```
-curl {ES的IP地址}:{ES的端口号}/_cat/templates/ks_kafka*?v&h=name
-```
-
-正常KS模板如下图所示。
-
- -
-
-
-#### 3.2.2、解决方案
-
-删除KS索引模板和索引
-
-```
-curl -XDELETE {ES的IP地址}:{ES的端口号}/ks_kafka*
-curl -XDELETE {ES的IP地址}:{ES的端口号}/_template/ks_kafka*
-```
-
-执行 [ES索引及模版初始化](https://github.com/didi/KnowStreaming/blob/master/bin/init_es_template.sh) 脚本,来创建索引及模版。
-
-
-### 3.3、原因三:集群Shard满
-
-#### 3.3.1、异常现象
-
-报错信息
-
-```
-com.didiglobal.logi.elasticsearch.client.model.exception.ESIndexNotFoundException: method [GET], host[http://127.0.0.1:9200], URI [/ks_kafka_broker_metric_2022-10-21,ks_kafka_broker_metric_2022-10-22/_search], status line [HTTP/1.1 404 Not Found]
-```
-
-尝试手动创建索引失败。
-
-```
-#创建ks_kafka_cluster_metric_test索引的指令
-curl -s -XPUT http://{ES的IP地址}:{ES的端口号}/ks_kafka_cluster_metric_test
-```
-
-#### 3.3.2、解决方案
-
-ES索引的默认分片数量为1000,达到数量以后,索引创建失败。
-
-+ 扩大ES索引数量上限,执行指令
-
-```
-curl -XPUT -H"content-type:application/json" http://{ES的IP地址}:{ES的端口号}/_cluster/settings -d '
-{
- "persistent": {
- "cluster": {
- "max_shards_per_node":{索引上限,默认为1000}
- }
- }
-}'
-```
-
-执行 [ES索引及模版初始化](https://github.com/didi/KnowStreaming/blob/master/bin/init_es_template.sh) 脚本,来补全索引。
diff --git a/docs/dev_guide/本地源码启动手册.md b/docs/dev_guide/本地源码启动手册.md
deleted file mode 100644
index c37fb165..00000000
--- a/docs/dev_guide/本地源码启动手册.md
+++ /dev/null
@@ -1,90 +0,0 @@
-## 6.1、本地源码启动手册
-
-### 6.1.1、打包方式
-
-`Know Streaming` 采用前后端分离的开发模式,使用 Maven 对项目进行统一的构建管理。maven 在打包构建过程中,会将前后端代码一并打包生成最终的安装包。
-
-`Know Streaming` 除了使用安装包启动之外,还可以通过本地源码启动完整的带前端页面的项目,下面我们正式开始介绍本地源码如何启动 `Know Streaming`。
-
-### 6.1.2、环境要求
-
-**系统支持**
-
-`windows7+`、`Linux`、`Mac`
-
-**环境依赖**
-
-- Maven 3.6.3
-- Node v12.20.0
-- Java 8+
-- MySQL 5.7
-- Idea
-- Elasticsearch 7.6
-- Git
-
-### 6.1.3、环境初始化
-
-安装好环境信息之后,还需要初始化 MySQL 与 Elasticsearch 信息,包括:
-
-- 初始化 MySQL 表及数据
-- 初始化 Elasticsearch 索引
-
-具体见:[单机部署手册](../install_guide/单机部署手册.md) 中的最后一步,部署 KnowStreaming 服务中的初始化相关工作。
-
-### 6.1.4、本地启动
-
-**第一步:本地打包**
-
-执行 `mvn install` 可对项目进行前后端同时进行打包,通过该命令,除了可以对后端进行打包之外,还可以将前端相关的静态资源文件也一并打包出来。
-
-**第二步:修改配置**
-
-```yaml
-# 修改 km-rest/src/main/resources/application.yml 中相关的配置
-
-# 修改MySQL的配置,中间省略了一些非必需修改的配置
-spring:
- datasource:
- know-streaming:
- jdbc-url: 修改为实际MYSQL地址
- username: 修改为实际MYSQL用户名
- password: 修改为实际MYSQL密码
- logi-job:
- jdbc-url: 修改为实际MYSQL地址
- username: 修改为实际MYSQL用户名
- password: 修改为实际MYSQL密码
- logi-security:
- jdbc-url: 修改为实际MYSQL地址
- username: 修改为实际MYSQL用户名
- password: 修改为实际MYSQL密码
-
-# 修改ES的配置,中间省略了一些非必需修改的配置
-es.client.address: 修改为实际ES地址
-```
-
-**第三步:配置 IDEA**
-
-`Know Streaming`的 Main 方法在:
-
-```java
-km-rest/src/main/java/com/xiaojukeji/know/streaming/km/rest/KnowStreaming.java
-```
-
-IDEA 更多具体的配置如下图所示:
-
-
-
-
-
-#### 3.2.2、解决方案
-
-删除KS索引模板和索引
-
-```
-curl -XDELETE {ES的IP地址}:{ES的端口号}/ks_kafka*
-curl -XDELETE {ES的IP地址}:{ES的端口号}/_template/ks_kafka*
-```
-
-执行 [ES索引及模版初始化](https://github.com/didi/KnowStreaming/blob/master/bin/init_es_template.sh) 脚本,来创建索引及模版。
-
-
-### 3.3、原因三:集群Shard满
-
-#### 3.3.1、异常现象
-
-报错信息
-
-```
-com.didiglobal.logi.elasticsearch.client.model.exception.ESIndexNotFoundException: method [GET], host[http://127.0.0.1:9200], URI [/ks_kafka_broker_metric_2022-10-21,ks_kafka_broker_metric_2022-10-22/_search], status line [HTTP/1.1 404 Not Found]
-```
-
-尝试手动创建索引失败。
-
-```
-#创建ks_kafka_cluster_metric_test索引的指令
-curl -s -XPUT http://{ES的IP地址}:{ES的端口号}/ks_kafka_cluster_metric_test
-```
-
-#### 3.3.2、解决方案
-
-ES索引的默认分片数量为1000,达到数量以后,索引创建失败。
-
-+ 扩大ES索引数量上限,执行指令
-
-```
-curl -XPUT -H"content-type:application/json" http://{ES的IP地址}:{ES的端口号}/_cluster/settings -d '
-{
- "persistent": {
- "cluster": {
- "max_shards_per_node":{索引上限,默认为1000}
- }
- }
-}'
-```
-
-执行 [ES索引及模版初始化](https://github.com/didi/KnowStreaming/blob/master/bin/init_es_template.sh) 脚本,来补全索引。
diff --git a/docs/dev_guide/本地源码启动手册.md b/docs/dev_guide/本地源码启动手册.md
deleted file mode 100644
index c37fb165..00000000
--- a/docs/dev_guide/本地源码启动手册.md
+++ /dev/null
@@ -1,90 +0,0 @@
-## 6.1、本地源码启动手册
-
-### 6.1.1、打包方式
-
-`Know Streaming` 采用前后端分离的开发模式,使用 Maven 对项目进行统一的构建管理。maven 在打包构建过程中,会将前后端代码一并打包生成最终的安装包。
-
-`Know Streaming` 除了使用安装包启动之外,还可以通过本地源码启动完整的带前端页面的项目,下面我们正式开始介绍本地源码如何启动 `Know Streaming`。
-
-### 6.1.2、环境要求
-
-**系统支持**
-
-`windows7+`、`Linux`、`Mac`
-
-**环境依赖**
-
-- Maven 3.6.3
-- Node v12.20.0
-- Java 8+
-- MySQL 5.7
-- Idea
-- Elasticsearch 7.6
-- Git
-
-### 6.1.3、环境初始化
-
-安装好环境信息之后,还需要初始化 MySQL 与 Elasticsearch 信息,包括:
-
-- 初始化 MySQL 表及数据
-- 初始化 Elasticsearch 索引
-
-具体见:[单机部署手册](../install_guide/单机部署手册.md) 中的最后一步,部署 KnowStreaming 服务中的初始化相关工作。
-
-### 6.1.4、本地启动
-
-**第一步:本地打包**
-
-执行 `mvn install` 可对项目进行前后端同时进行打包,通过该命令,除了可以对后端进行打包之外,还可以将前端相关的静态资源文件也一并打包出来。
-
-**第二步:修改配置**
-
-```yaml
-# 修改 km-rest/src/main/resources/application.yml 中相关的配置
-
-# 修改MySQL的配置,中间省略了一些非必需修改的配置
-spring:
- datasource:
- know-streaming:
- jdbc-url: 修改为实际MYSQL地址
- username: 修改为实际MYSQL用户名
- password: 修改为实际MYSQL密码
- logi-job:
- jdbc-url: 修改为实际MYSQL地址
- username: 修改为实际MYSQL用户名
- password: 修改为实际MYSQL密码
- logi-security:
- jdbc-url: 修改为实际MYSQL地址
- username: 修改为实际MYSQL用户名
- password: 修改为实际MYSQL密码
-
-# 修改ES的配置,中间省略了一些非必需修改的配置
-es.client.address: 修改为实际ES地址
-```
-
-**第三步:配置 IDEA**
-
-`Know Streaming`的 Main 方法在:
-
-```java
-km-rest/src/main/java/com/xiaojukeji/know/streaming/km/rest/KnowStreaming.java
-```
-
-IDEA 更多具体的配置如下图所示:
-
-
- -
-
-
-**第四步:启动项目**
-
-最后就是启动项目,在本地 console 中输出了 `KnowStreaming-KM started` 则表示我们已经成功启动 `Know Streaming` 了。
-
-### 6.1.5、本地访问
-
-`Know Streaming` 启动之后,可以访问一些信息,包括:
-
-- 产品页面:http://localhost:8080 ,默认账号密码:`admin` / `admin2022_` 进行登录。`v3.0.0-beta.2`版本开始,默认账号密码为`admin` / `admin`;
-- 接口地址:http://localhost:8080/swagger-ui.html 查看后端提供的相关接口。
-
-更多信息,详见:[KnowStreaming 官网](https://knowstreaming.com/)
\ No newline at end of file
diff --git a/docs/dev_guide/登录系统对接.md b/docs/dev_guide/登录系统对接.md
deleted file mode 100644
index e1038c63..00000000
--- a/docs/dev_guide/登录系统对接.md
+++ /dev/null
@@ -1,199 +0,0 @@
-
-
-
-
-## 登录系统对接
-
-[KnowStreaming](https://github.com/didi/KnowStreaming)(以下简称KS) 除了实现基于本地MySQL的用户登录认证方式外,还已经实现了基于Ldap的登录认证。
-
-但是,登录认证系统并非仅此两种。因此,为了具有更好的拓展性,KS具有自定义登陆认证逻辑,快速对接已有系统的特性。
-
-在KS中,我们将登陆认证相关的一些文件放在[km-extends](https://github.com/didi/KnowStreaming/tree/master/km-extends)模块下的[km-account](https://github.com/didi/KnowStreaming/tree/master/km-extends/km-account)模块里。
-
-本文将介绍KS如何快速对接自有的用户登录认证系统。
-
-### 对接步骤
-
-- 创建一个登陆认证类,实现[LogiCommon](https://github.com/didi/LogiCommon)的LoginExtend接口;
-- 将[application.yml](https://github.com/didi/KnowStreaming/blob/master/km-rest/src/main/resources/application.yml)中的spring.logi-security.login-extend-bean-name字段改为登陆认证类的bean名称;
-
-```Java
-//LoginExtend 接口
-public interface LoginExtend {
-
- /**
- * 验证登录信息,同时记住登录状态
- */
- UserBriefVO verifyLogin(AccountLoginDTO var1, HttpServletRequest var2, HttpServletResponse var3) throws LogiSecurityException;
-
- /**
- * 登出接口,清楚登录状态
- */
- Result logout(HttpServletRequest var1, HttpServletResponse var2);
-
- /**
- * 检查是否已经登录
- */
- boolean interceptorCheck(HttpServletRequest var1, HttpServletResponse var2, String var3, List var4) throws IOException;
-
-}
-
-```
-
-
-
-### 对接例子
-
-我们以Ldap对接为例,说明KS如何对接登录认证系统。
-
-+ 编写[LdapLoginServiceImpl](https://github.com/didi/KnowStreaming/blob/master/km-extends/km-account/src/main/java/com/xiaojukeji/know/streaming/km/account/login/ldap/LdapLoginServiceImpl.java)类,实现LoginExtend接口。
-+ 设置[application.yml](https://github.com/didi/KnowStreaming/blob/master/km-rest/src/main/resources/application.yml)中的spring.logi-security.login-extend-bean-name=ksLdapLoginService。
-
-完成上述两步即可实现KS对接Ldap认证登陆。
-
-```Java
-@Service("ksLdapLoginService")
-public class LdapLoginServiceImpl implements LoginExtend {
-
-
- @Override
- public UserBriefVO verifyLogin(AccountLoginDTO loginDTO,
- HttpServletRequest request,
- HttpServletResponse response) throws LogiSecurityException {
- String decodePasswd = AESUtils.decrypt(loginDTO.getPw());
-
- // 去LDAP验证账密
- LdapPrincipal ldapAttrsInfo = ldapAuthentication.authenticate(loginDTO.getUserName(), decodePasswd);
- if (ldapAttrsInfo == null) {
- // 用户不存在,正常来说上如果有问题,上一步会直接抛出异常
- throw new LogiSecurityException(ResultCode.USER_NOT_EXISTS);
- }
-
- // 进行业务相关操作
-
- // 记录登录状态,Ldap因为无法记录登录状态,因此有KnowStreaming进行记录
- initLoginContext(request, response, loginDTO.getUserName(), user.getId());
- return CopyBeanUtil.copy(user, UserBriefVO.class);
- }
-
- @Override
- public Result logout(HttpServletRequest request, HttpServletResponse response) {
-
- //清理cookie和session
-
- return Result.buildSucc(Boolean.TRUE);
- }
-
- @Override
- public boolean interceptorCheck(HttpServletRequest request, HttpServletResponse response, String requestMappingValue, List whiteMappingValues) throws IOException {
-
- // 检查是否已经登录
- String userName = HttpRequestUtil.getOperator(request);
- if (StringUtils.isEmpty(userName)) {
- // 未登录,则进行登出
- logout(request, response);
- return Boolean.FALSE;
- }
-
- return Boolean.TRUE;
- }
-}
-
-```
-
-
-
-### 实现原理
-
-因为登陆和登出整体实现逻辑是一致的,所以我们以登陆逻辑为例进行介绍。
-
-+ 登陆原理
-
-登陆走的是[LogiCommon](https://github.com/didi/LogiCommon)自带的LoginController。
-
-```java
-@RestController
-public class LoginController {
-
-
- //登陆接口
- @PostMapping({"/login"})
- public Result login(HttpServletRequest request, HttpServletResponse response, @RequestBody AccountLoginDTO loginDTO) {
- try {
- //登陆认证
- UserBriefVO userBriefVO = this.loginService.verifyLogin(loginDTO, request, response);
- return Result.success(userBriefVO);
-
- } catch (LogiSecurityException var5) {
- return Result.fail(var5);
- }
- }
-
-}
-```
-
-而登陆操作是调用LoginServiceImpl类来实现,但是具体由哪个登陆认证类来执行登陆操作却由loginExtendBeanTool来指定。
-
-```java
-//LoginServiceImpl类
-@Service
-public class LoginServiceImpl implements LoginService {
-
- //实现登陆操作,但是具体哪个登陆类由loginExtendBeanTool来管理
- public UserBriefVO verifyLogin(AccountLoginDTO loginDTO, HttpServletRequest request, HttpServletResponse response) throws LogiSecurityException {
-
- return this.loginExtendBeanTool.getLoginExtendImpl().verifyLogin(loginDTO, request, response);
- }
-
-
-}
-```
-
-而loginExtendBeanTool类会优先去查找用户指定的登陆认证类,如果失败则调用默认的登陆认证函数。
-
-```java
-//LoginExtendBeanTool类
-@Component("logiSecurityLoginExtendBeanTool")
-public class LoginExtendBeanTool {
-
- public LoginExtend getLoginExtendImpl() {
- LoginExtend loginExtend;
- //先调用用户指定登陆类,如果失败则调用系统默认登陆认证
- try {
- //调用的类由spring.logi-security.login-extend-bean-name指定
- loginExtend = this.getCustomLoginExtendImplBean();
- } catch (UnsupportedOperationException var3) {
- loginExtend = this.getDefaultLoginExtendImplBean();
- }
-
- return loginExtend;
- }
-}
-```
-
-+ 认证原理
-
-认证的实现则比较简单,向Spring中注册我们的拦截器PermissionInterceptor。
-
-拦截器会调用LoginServiceImpl类的拦截方法,LoginServiceImpl后续处理逻辑就和前面登陆是一致的。
-
-```java
-public class PermissionInterceptor implements HandlerInterceptor {
-
-
- /**
- * 拦截预处理
- * @return boolean false:拦截, 不向下执行, true:放行
- */
- @Override
- public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
-
- //免登录相关校验,如果验证通过,提前返回
-
- //走拦截函数,进行普通用户验证
- return loginService.interceptorCheck(request, response, classRequestMappingValue, whiteMappingValues);
- }
-
-}
-```
-
diff --git a/docs/dev_guide/解决连接JMX失败.md b/docs/dev_guide/解决连接JMX失败.md
deleted file mode 100644
index 03271837..00000000
--- a/docs/dev_guide/解决连接JMX失败.md
+++ /dev/null
@@ -1,126 +0,0 @@
-
-
-
-
-## JMX-连接失败问题解决
-
-集群正常接入`KnowStreaming`之后,即可以看到集群的Broker列表,此时如果查看不了Topic的实时流量,或者是Broker的实时流量信息时,那么大概率就是`JMX`连接的问题了。
-
-下面我们按照步骤来一步一步的检查。
-
-### 1、问题说明
-
-**类型一:JMX配置未开启**
-
-未开启时,直接到`2、解决方法`查看如何开启即可。
-
-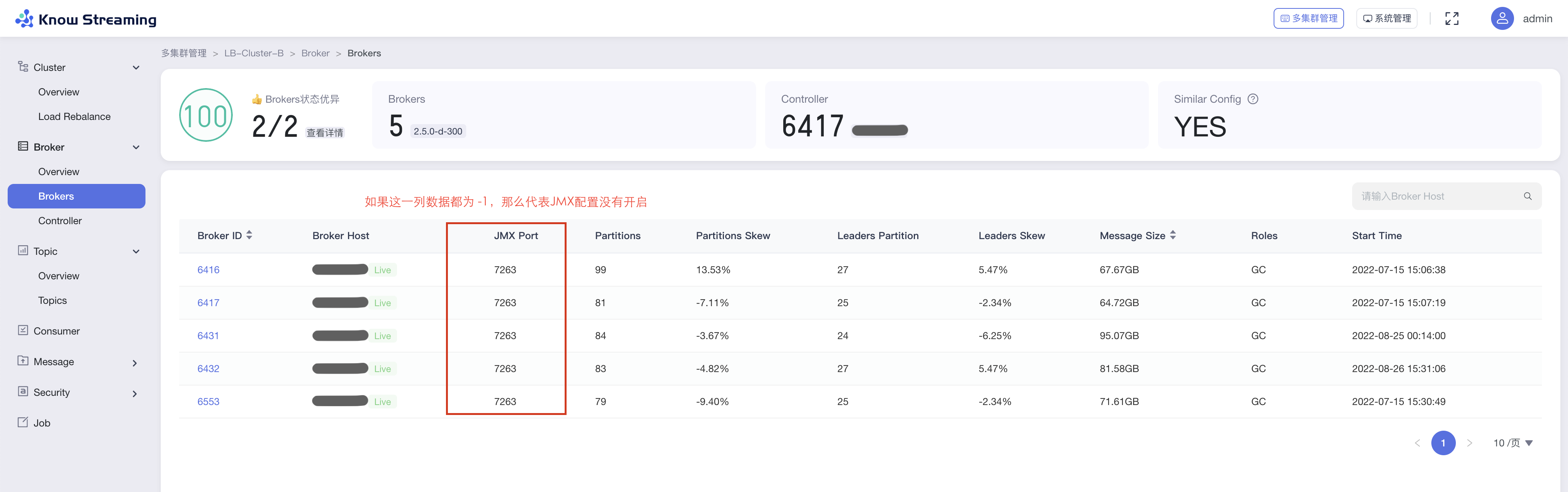
-
-
-**类型二:配置错误**
-
-`JMX`端口已经开启的情况下,有的时候开启的配置不正确,此时也会导致出现连接失败的问题。这里大概列举几种原因:
-
-- `JMX`配置错误:见`2、解决方法`。
-- 存在防火墙或者网络限制:网络通的另外一台机器`telnet`试一下看是否可以连接上。
-- 需要进行用户名及密码的认证:见`3、解决方法 —— 认证的JMX`。
-
-
-错误日志例子:
-```
-# 错误一: 错误提示的是真实的IP,这样的话基本就是JMX配置的有问题了。
-2021-01-27 10:06:20.730 ERROR 50901 --- [ics-Thread-1-62] c.x.k.m.c.utils.jmx.JmxConnectorWrap : JMX connect exception, host:192.168.0.1 port:9999.
-java.rmi.ConnectException: Connection refused to host: 192.168.0.1; nested exception is:
-
-
-# 错误二:错误提示的是127.0.0.1这个IP,这个是机器的hostname配置的可能有问题。
-2021-01-27 10:06:20.730 ERROR 50901 --- [ics-Thread-1-62] c.x.k.m.c.utils.jmx.JmxConnectorWrap : JMX connect exception, host:127.0.0.1 port:9999.
-java.rmi.ConnectException: Connection refused to host: 127.0.0.1;; nested exception is:
-```
-
-**类型三:连接特定IP**
-
-Broker 配置了内外网,而JMX在配置时,可能配置了内网IP或者外网IP,此时 `KnowStreaming` 需要连接到特定网络的IP才可以进行访问。
-
-比如:
-
-Broker在ZK的存储结构如下所示,我们期望连接到 `endpoints` 中标记为 `INTERNAL` 的地址,但是 `KnowStreaming` 却连接了 `EXTERNAL` 的地址,此时可以看 `4、解决方法 —— JMX连接特定网络` 进行解决。
-
-```json
- {
- "listener_security_protocol_map": {"EXTERNAL":"SASL_PLAINTEXT","INTERNAL":"SASL_PLAINTEXT"},
- "endpoints": ["EXTERNAL://192.168.0.1:7092","INTERNAL://192.168.0.2:7093"],
- "jmx_port": 8099,
- "host": "192.168.0.1",
- "timestamp": "1627289710439",
- "port": -1,
- "version": 4
- }
-```
-
-### 2、解决方法
-
-这里仅介绍一下比较通用的解决方式,如若有更好的方式,欢迎大家指导告知一下。
-
-修改`kafka-server-start.sh`文件:
-```
-# 在这个下面增加JMX端口的配置
-if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
- export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
- export JMX_PORT=9999 # 增加这个配置, 这里的数值并不一定是要9999
-fi
-```
-
-
-
-修改`kafka-run-class.sh`文件
-```
-# JMX settings
-if [ -z "$KAFKA_JMX_OPTS" ]; then
- KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=${当前机器的IP}"
-fi
-
-# JMX port to use
-if [ $JMX_PORT ]; then
- KAFKA_JMX_OPTS="$KAFKA_JMX_OPTS -Dcom.sun.management.jmxremote.port=$JMX_PORT -Dcom.sun.management.jmxremote.rmi.port=$JMX_PORT"
-fi
-```
-
-
-### 3、解决方法 —— 认证的JMX
-
-如果您是直接看的这个部分,建议先看一下上一节:`2、解决方法`以确保`JMX`的配置没有问题了。
-
-在`JMX`的配置等都没有问题的情况下,如果是因为认证的原因导致连接不了的,可以在集群接入界面配置你的`JMX`认证信息。
-
-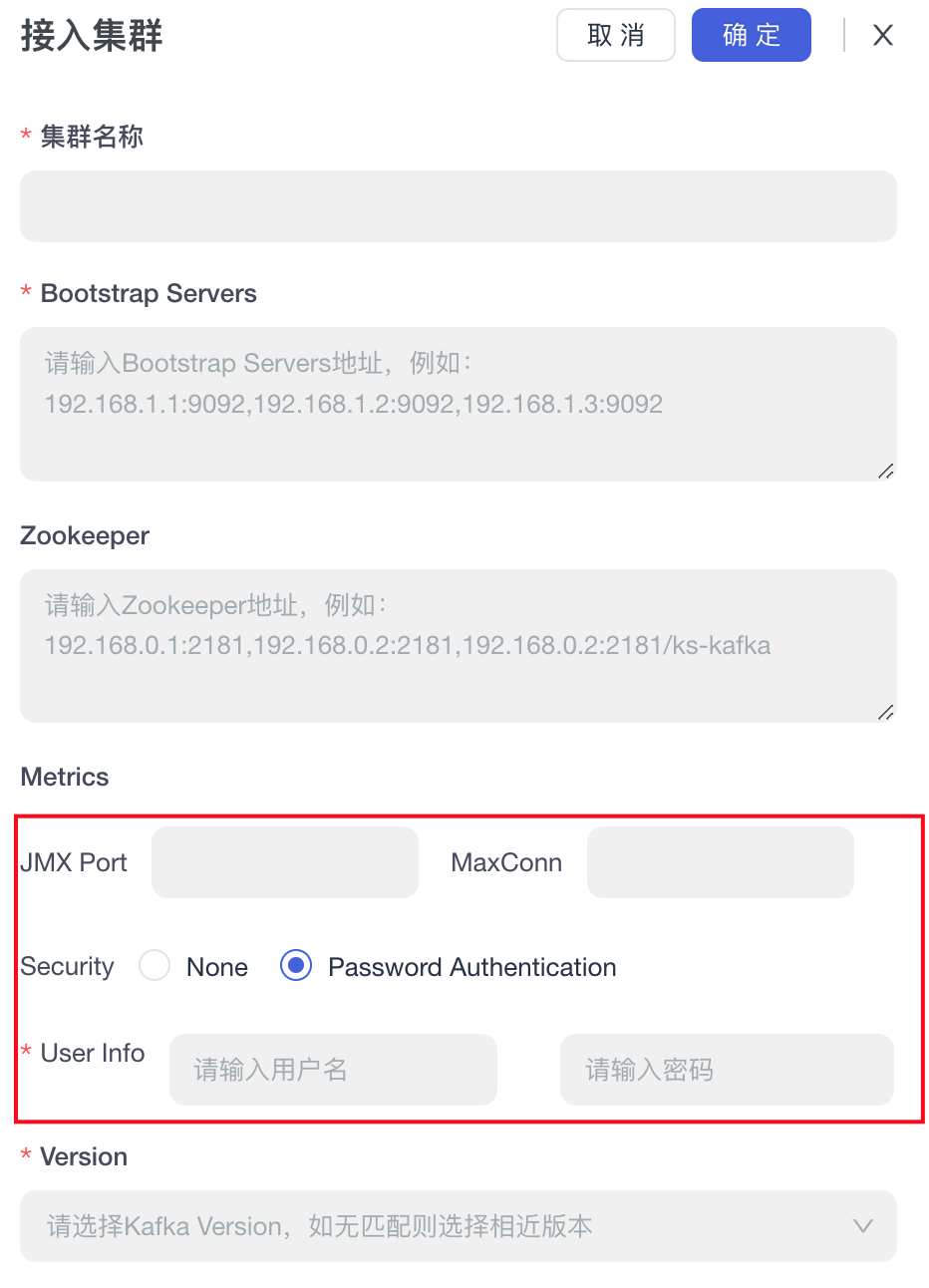 -
-
-
-### 4、解决方法 —— JMX连接特定网络
-
-可以手动往`ks_km_physical_cluster`表的`jmx_properties`字段增加一个`useWhichEndpoint`字段,从而控制 `KnowStreaming` 连接到特定的JMX IP及PORT。
-
-`jmx_properties`格式:
-```json
-{
- "maxConn": 100, # KM对单台Broker的最大JMX连接数
- "username": "xxxxx", # 用户名,可以不填写
- "password": "xxxx", # 密码,可以不填写
- "openSSL": true, # 开启SSL, true表示开启ssl, false表示关闭
- "useWhichEndpoint": "EXTERNAL" #指定要连接的网络名称,填写EXTERNAL就是连接endpoints里面的EXTERNAL地址
-}
-```
-
-
-
-SQL例子:
-```sql
-UPDATE ks_km_physical_cluster SET jmx_properties='{ "maxConn": 10, "username": "xxxxx", "password": "xxxx", "openSSL": false , "useWhichEndpoint": "xxx"}' where id={xxx};
-```
-
-注意:
-
-+ 目前此功能只支持采用 `ZK` 做分布式协调的kafka集群。
-
-
\ No newline at end of file
diff --git a/docs/install_guide/单机部署手册.md b/docs/install_guide/单机部署手册.md
deleted file mode 100644
index c42e6318..00000000
--- a/docs/install_guide/单机部署手册.md
+++ /dev/null
@@ -1,417 +0,0 @@
-## 2.1、单机部署
-
-**风险提示**
-
-⚠️ 脚本全自动安装,会将所部署机器上的 MySQL、JDK、ES 等进行删除重装,请注意原有服务丢失风险。
-
-### 2.1.1、安装说明
-
-- 以 `v3.0.0-beta.1` 版本为例进行部署;
-- 以 CentOS-7 为例,系统基础配置要求 4C-8G;
-- 部署完成后,可通过浏览器:`IP:PORT` 进行访问,默认端口是 `8080`,系统默认账号密码: `admin` / `admin2022_`。
-- `v3.0.0-beta.2`版本开始,默认账号密码为`admin` / `admin`;
-- 本文为单机部署,如需分布式部署,[请联系我们](https://knowstreaming.com/support-center)
-
-**软件依赖**
-
-| 软件名 | 版本要求 | 默认端口 |
-| ------------- | ------------ | -------- |
-| MySQL | v5.7 或 v8.0 | 3306 |
-| ElasticSearch | v7.6+ | 8060 |
-| JDK | v8+ | - |
-| CentOS | v6+ | - |
-| Ubuntu | v16+ | - |
-
-
-
-### 2.1.2、脚本部署
-
-**在线安装**
-
-```bash
-# 在服务器中下载安装脚本, 该脚本中会在当前目录下,重新安装MySQL。重装后的mysql密码存放在当前目录的mysql.password文件中。
-wget https://s3-gzpu.didistatic.com/pub/knowstreaming/deploy_KnowStreaming-3.0.0-beta.1.sh
-
-# 执行脚本
-sh deploy_KnowStreaming.sh
-
-# 访问地址
-127.0.0.1:8080
-```
-
-**离线安装**
-
-```bash
-# 将安装包下载到本地且传输到目标服务器
-wget https://s3-gzpu.didistatic.com/pub/knowstreaming/KnowStreaming-3.0.0-beta.1-offline.tar.gz
-
-# 解压安装包
-tar -zxf KnowStreaming-3.0.0-beta.1-offline.tar.gz
-
-# 执行安装脚本
-sh deploy_KnowStreaming-offline.sh
-
-# 访问地址
-127.0.0.1:8080
-```
-
-
-
-### 2.1.3、容器部署
-
-#### 2.1.3.1、Helm
-
-**环境依赖**
-
-- Kubernetes >= 1.14 ,Helm >= 2.17.0
-
-- 默认依赖全部安装,ElasticSearch(3 节点集群模式) + MySQL(单机) + KnowStreaming-manager + KnowStreaming-ui
-
-- 使用已有的 ElasticSearch(7.6.x) 和 MySQL(5.7) 只需调整 values.yaml 部分参数即可
-
-**安装命令**
-
-```bash
-# 相关镜像在Docker Hub都可以下载
-# 快速安装(NAMESPACE需要更改为已存在的,安装启动需要几分钟初始化请稍等~)
-helm install -n [NAMESPACE] [NAME] http://download.knowstreaming.com/charts/knowstreaming-manager-0.1.5.tgz
-
-# 获取KnowStreaming前端ui的service. 默认nodeport方式.
-# (http://nodeIP:nodeport,默认用户名密码:admin/admin2022_)
-# `v3.0.0-beta.2`版本开始(helm chart包版本0.1.4开始),默认账号密码为`admin` / `admin`;
-
-# 添加仓库
-helm repo add knowstreaming http://download.knowstreaming.com/charts
-
-# 拉取最新版本
-helm pull knowstreaming/knowstreaming-manager
-```
-
-
-
-#### 2.1.3.2、Docker Compose
-**环境依赖**
-
-- [Docker](https://docs.docker.com/engine/install/)
-- [Docker Compose](https://docs.docker.com/compose/install/)
-
-
-**安装命令**
-```bash
-# `v3.0.0-beta.2`版本开始(docker镜像为0.2.0版本开始),默认账号密码为`admin` / `admin`;
-# https://hub.docker.com/u/knowstreaming 在此处寻找最新镜像版本
-# mysql与es可以使用自己搭建的服务,调整对应配置即可
-
-# 复制docker-compose.yml到指定位置后执行下方命令即可启动
-docker-compose up -d
-```
-
-**验证安装**
-```shell
-docker-compose ps
-# 验证启动 - 状态为 UP 则表示成功
- Name Command State Ports
-----------------------------------------------------------------------------------------------------
-elasticsearch-single /usr/local/bin/docker-entr ... Up 9200/tcp, 9300/tcp
-knowstreaming-init /bin/bash /es_template_cre ... Up
-knowstreaming-manager /bin/sh /ks-start.sh Up 80/tcp
-knowstreaming-mysql /entrypoint.sh mysqld Up (health: starting) 3306/tcp, 33060/tcp
-knowstreaming-ui /docker-entrypoint.sh ngin ... Up 0.0.0.0:80->80/tcp
-
-# 稍等一分钟左右 knowstreaming-init 会退出,表示es初始化完成,可以访问页面
- Name Command State Ports
--------------------------------------------------------------------------------------------
-knowstreaming-init /bin/bash /es_template_cre ... Exit 0
-knowstreaming-mysql /entrypoint.sh mysqld Up (healthy) 3306/tcp, 33060/tcp
-```
-
-**访问**
-```http request
-http://127.0.0.1:80/
-```
-
-
-**docker-compose.yml**
-```yml
-version: "2"
-services:
- # *不要调整knowstreaming-manager服务名称,ui中会用到
- knowstreaming-manager:
- image: knowstreaming/knowstreaming-manager:latest
- container_name: knowstreaming-manager
- privileged: true
- restart: always
- depends_on:
- - elasticsearch-single
- - knowstreaming-mysql
- expose:
- - 80
- command:
- - /bin/sh
- - /ks-start.sh
- environment:
- TZ: Asia/Shanghai
- # mysql服务地址
- SERVER_MYSQL_ADDRESS: knowstreaming-mysql:3306
- # mysql数据库名
- SERVER_MYSQL_DB: know_streaming
- # mysql用户名
- SERVER_MYSQL_USER: root
- # mysql用户密码
- SERVER_MYSQL_PASSWORD: admin2022_
- # es服务地址
- SERVER_ES_ADDRESS: elasticsearch-single:9200
- # 服务JVM参数
- JAVA_OPTS: -Xmx1g -Xms1g
- # 对于kafka中ADVERTISED_LISTENERS填写的hostname可以通过该方式完成
-# extra_hosts:
-# - "hostname:x.x.x.x"
- # 服务日志路径
-# volumes:
-# - /ks/manage/log:/logs
- knowstreaming-ui:
- image: knowstreaming/knowstreaming-ui:latest
- container_name: knowstreaming-ui
- restart: always
- ports:
- - '80:80'
- environment:
- TZ: Asia/Shanghai
- depends_on:
- - knowstreaming-manager
-# extra_hosts:
-# - "hostname:x.x.x.x"
- elasticsearch-single:
- image: docker.io/library/elasticsearch:7.6.2
- container_name: elasticsearch-single
- restart: always
- expose:
- - 9200
- - 9300
-# ports:
-# - '9200:9200'
-# - '9300:9300'
- environment:
- TZ: Asia/Shanghai
- # es的JVM参数
- ES_JAVA_OPTS: -Xms512m -Xmx512m
- # 单节点配置,多节点集群参考 https://www.elastic.co/guide/en/elasticsearch/reference/7.6/docker.html#docker-compose-file
- discovery.type: single-node
- # 数据持久化路径
-# volumes:
-# - /ks/es/data:/usr/share/elasticsearch/data
-
- # es初始化服务,与manager使用同一镜像
- # 首次启动es需初始化模版和索引,后续会自动创建
- knowstreaming-init:
- image: knowstreaming/knowstreaming-manager:latest
- container_name: knowstreaming-init
- depends_on:
- - elasticsearch-single
- command:
- - /bin/bash
- - /es_template_create.sh
- environment:
- TZ: Asia/Shanghai
- # es服务地址
- SERVER_ES_ADDRESS: elasticsearch-single:9200
-
- knowstreaming-mysql:
- image: knowstreaming/knowstreaming-mysql:latest
- container_name: knowstreaming-mysql
- restart: always
- environment:
- TZ: Asia/Shanghai
- # root 用户密码
- MYSQL_ROOT_PASSWORD: admin2022_
- # 初始化时创建的数据库名称
- MYSQL_DATABASE: know_streaming
- # 通配所有host,可以访问远程
- MYSQL_ROOT_HOST: '%'
- expose:
- - 3306
-# ports:
-# - '3306:3306'
- # 数据持久化路径
-# volumes:
-# - /ks/mysql/data:/data/mysql
-```
-
-
-
-### 2.1.4、手动部署
-
-**部署流程**
-
-1. 安装 `JDK-11`、`MySQL`、`ElasticSearch` 等依赖服务
-2. 安装 KnowStreaming
-
-
-
-#### 2.1.4.1、安装 MySQL 服务
-
-**yum 方式安装**
-
-```bash
-# 配置yum源
-wget https://dev.mysql.com/get/mysql57-community-release-el7-9.noarch.rpm
-rpm -ivh mysql57-community-release-el7-9.noarch.rpm
-
-# 执行安装
-yum -y install mysql-server mysql-client
-
-# 服务启动
-systemctl start mysqld
-
-# 获取初始密码并修改
-old_pass=`grep 'temporary password' /var/log/mysqld.log | awk '{print $NF}' | tail -n 1`
-
-mysql -NBe "alter user USER() identified by 'Didi_km_678';" --connect-expired-password -uroot -p$old_pass
-```
-
-**rpm 方式安装**
-
-```bash
-# 下载安装包
-wget https://s3-gzpu.didistatic.com/knowsearch/mysql5.7.tar.gz
-
-# 解压到指定目录
-tar -zxf mysql5.7.tar.gz -C /tmp/
-
-# 执行安装
-yum -y localinstall /tmp/libaio-*.rpm /tmp/mysql-*.rpm
-
-# 服务启动
-systemctl start mysqld
-
-
-# 获取初始密码并修改
-old_pass=`grep 'temporary password' /var/log/mysqld.log | awk '{print $NF}' | tail -n 1`
-
-mysql -NBe "alter user USER() identified by 'Didi_km_678';" --connect-expired-password -uroot -p$old_pass
-
-```
-
-
-
-#### 2.1.4.2、配置 JDK 环境
-
-```bash
-# 下载安装包
-wget https://s3-gzpu.didistatic.com/pub/jdk11.tar.gz
-
-# 解压到指定目录
-tar -zxf jdk11.tar.gz -C /usr/local/
-
-# 更改目录名
-mv /usr/local/jdk-11.0.2 /usr/local/java11
-
-# 添加到环境变量
-echo "export JAVA_HOME=/usr/local/java11" >> ~/.bashrc
-echo "export CLASSPATH=/usr/java/java11/lib" >> ~/.bashrc
-echo "export PATH=$JAVA_HOME/bin:$PATH:$HOME/bin" >> ~/.bashrc
-
-source ~/.bashrc
-
-```
-
-
-
-#### 2.1.4.3、ElasticSearch 实例搭建
-
-- ElasticSearch 用于存储平台采集的 Kafka 指标;
-- 以下安装示例为单节点模式,如需集群部署可以参考:[Elasticsearch 官方文档](https://www.elastic.co/guide/en/elasticsearch/reference/7.6/elasticsearch-intro.html)
-
-```bash
-# 下载安装包
-wget https://s3-gzpu.didistatic.com/pub/elasticsearch.tar.gz
-
-# 创建ES数据存储目录
-mkdir -p /data/es_data
-
-# 创建ES所属用户
-useradd arius
-
-# 配置用户的打开文件数
-echo "arius soft nofile 655350" >> /etc/security/limits.conf
-echo "arius hard nofile 655350" >> /etc/security/limits.conf
-echo "vm.max_map_count = 655360" >> /etc/sysctl.conf
-sysctl -p
-
-# 解压安装包
-tar -zxf elasticsearch.tar.gz -C /data/
-
-# 更改目录所属组
-chown -R arius:arius /data/
-
-# 修改配置文件(参考以下配置)
-vim /data/elasticsearch/config/elasticsearch.yml
- cluster.name: km_es
- node.name: es-node1
- node.master: true
- node.data: true
- path.data: /data/es_data
- http.port: 8060
- discovery.seed_hosts: ["127.0.0.1:9300"]
-
-# 修改内存配置
-vim /data/elasticsearch/config/jvm.options
- -Xms2g
- -Xmx2g
-
-# 启动服务
-su - arius
-export JAVA_HOME=/usr/local/java11
-sh /data/elasticsearch/control.sh start
-
-# 确认状态
-sh /data/elasticsearch/control.sh status
-```
-
-
-
-#### 2.1.4.4、KnowStreaming 实例搭建
-
-```bash
-# 下载安装包
-wget https://s3-gzpu.didistatic.com/pub/knowstreaming/KnowStreaming-3.0.0-beta.1.tar.gz
-
-# 解压安装包到指定目录
-tar -zxf KnowStreaming-3.0.0-beta.1.tar.gz -C /data/
-
-# 修改启动脚本并加入systemd管理
-cd /data/KnowStreaming/
-
-# 创建相应的库和导入初始化数据
-mysql -uroot -pDidi_km_678 -e "create database know_streaming;"
-mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/ddl-ks-km.sql
-mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/ddl-logi-job.sql
-mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/ddl-logi-security.sql
-mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/dml-ks-km.sql
-mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/dml-logi.sql
-
-# 创建elasticsearch初始化数据
-sh ./bin/init_es_template.sh
-
-# 修改配置文件
-vim ./conf/application.yml
-
-# 监听端口
-server:
- port: 8080 # web 服务端口
- tomcat:
- accept-count: 1000
- max-connections: 10000
-
-# ES地址
-es.client.address: 127.0.0.1:8060
-
-# 数据库配置(一共三处地方,修改正确的mysql地址和数据库名称以及用户名密码)
-jdbc-url: jdbc:mariadb://127.0.0.1:3306/know_streaming?.....
-username: root
-password: Didi_km_678
-
-# 启动服务
-cd /data/KnowStreaming/bin/
-sh startup.sh
-```
diff --git a/docs/install_guide/源码编译打包手册.md b/docs/install_guide/源码编译打包手册.md
deleted file mode 100644
index d6ff6572..00000000
--- a/docs/install_guide/源码编译打包手册.md
+++ /dev/null
@@ -1,62 +0,0 @@
-
-
-# `Know Streaming` 源码编译打包手册
-
-## 1、环境信息
-
-**系统支持**
-
-`windows7+`、`Linux`、`Mac`
-
-**环境依赖**
-
-- Maven 3.6.3 (后端)
-- Node v12.20.0/v14.17.3 (前端)
-- Java 8+ (后端)
-- Git
-
-## 2、编译打包
-
-整个工程中,除了`km-console`为前端模块之外,其他模块都是后端工程相关模块。
-
-因此,如果前后端合并打包,则打对整个工程进行打包;如果前端单独打包,则仅打包 `km-console` 中的代码;如果是仅需要后端打包,则在顶层 `pom.xml` 中去掉 `km-console`模块,然后进行打包。
-
-具体见下面描述。
-
-### 2.1、前后端合并打包
-
-1. 下载源码;
-2. 进入 `KS-KM` 工程目录,执行 `mvn -Prelease-package -Dmaven.test.skip=true clean install -U` 命令;
-3. 打包命令执行完成后,会在 `km-dist/target` 目录下面生成一个 `KnowStreaming-*.tar.gz` 的安装包。
-
-### 2.2、前端单独打包
-
-1. 下载源码;
-2. 跳转到 [前端打包构建文档](https://github.com/didi/KnowStreaming/blob/master/km-console/README.md) 按步骤进行。打包成功后,会在 `km-rest/src/main/resources` 目录下生成名为 `templates` 的前端静态资源包;
-3. 如果上一步过程中报错,请查看 [FAQ](https://github.com/didi/KnowStreaming/blob/master/docs/user_guide/faq.md) 第 8.10 条;
-
-### 2.3、后端单独打包
-
-1. 下载源码;
-2. 修改顶层 `pom.xml` ,去掉其中的 `km-console` 模块,如下所示;
-
-```xml
-
-
- km-common
- km-persistence
- km-core
- km-biz
- km-extends/km-account
- km-extends/km-monitor
- km-extends/km-license
- km-extends/km-rebalance
- km-task
- km-collector
- km-rest
- km-dist
-
-```
-
-3. 执行 `mvn -U clean package -Dmaven.test.skip=true`命令;
-4. 执行完成之后会在 `KS-KM/km-rest/target` 目录下面生成一个 `ks-km.jar` 即为 KS 的后端部署的 Jar 包,也可以执行 `mvn -Prelease-package -Dmaven.test.skip=true clean install -U` 生成的 tar 包也仅有后端服务的功能;
diff --git a/docs/install_guide/版本升级手册.md b/docs/install_guide/版本升级手册.md
deleted file mode 100644
index 061c080d..00000000
--- a/docs/install_guide/版本升级手册.md
+++ /dev/null
@@ -1,463 +0,0 @@
-## 6.2、版本升级手册
-
-注意:
-- 如果想升级至具体版本,需要将你当前版本至你期望使用版本的变更统统执行一遍,然后才能正常使用。
-- 如果中间某个版本没有升级信息,则表示该版本直接替换安装包即可从前一个版本升级至当前版本。
-
-### 升级至 `master` 版本
-
-
-### 升级至 `3.3.0` 版本
-
-**SQL 变更**
-```sql
-ALTER TABLE `logi_security_user`
- CHANGE COLUMN `phone` `phone` VARCHAR(20) NOT NULL DEFAULT '' COMMENT 'mobile' ;
-
-ALTER TABLE ks_kc_connector ADD `heartbeat_connector_name` varchar(512) DEFAULT '' COMMENT '心跳检测connector名称';
-ALTER TABLE ks_kc_connector ADD `checkpoint_connector_name` varchar(512) DEFAULT '' COMMENT '进度确认connector名称';
-
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_MIRROR_MAKER_TOTAL_RECORD_ERRORS', '{\"value\" : 1}', 'MirrorMaker消息处理错误的次数', 'admin');
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_MIRROR_MAKER_REPLICATION_LATENCY_MS_MAX', '{\"value\" : 6000}', 'MirrorMaker消息复制最大延迟时间', 'admin');
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_MIRROR_MAKER_UNASSIGNED_TASK_COUNT', '{\"value\" : 20}', 'MirrorMaker未被分配的任务数量', 'admin');
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_MIRROR_MAKER_FAILED_TASK_COUNT', '{\"value\" : 10}', 'MirrorMaker失败状态的任务数量', 'admin');
-
-
--- 多集群管理权限2023-01-05新增
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2012', 'Topic-新增Topic复制', '1593', '1', '2', 'Topic-新增Topic复制', '0', 'know-streaming');
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2014', 'Topic-详情-取消Topic复制', '1593', '1', '2', 'Topic-详情-取消Topic复制', '0', 'know-streaming');
-
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2012', '0', 'know-streaming');
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2014', '0', 'know-streaming');
-
-
--- 多集群管理权限2023-01-18新增
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2016', 'MM2-新增', '1593', '1', '2', 'MM2-新增', '0', 'know-streaming');
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2018', 'MM2-编辑', '1593', '1', '2', 'MM2-编辑', '0', 'know-streaming');
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2020', 'MM2-删除', '1593', '1', '2', 'MM2-删除', '0', 'know-streaming');
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2022', 'MM2-重启', '1593', '1', '2', 'MM2-重启', '0', 'know-streaming');
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2024', 'MM2-暂停&恢复', '1593', '1', '2', 'MM2-暂停&恢复', '0', 'know-streaming');
-
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2016', '0', 'know-streaming');
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2018', '0', 'know-streaming');
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2020', '0', 'know-streaming');
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2022', '0', 'know-streaming');
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2024', '0', 'know-streaming');
-
-
-DROP TABLE IF EXISTS `ks_ha_active_standby_relation`;
-CREATE TABLE `ks_ha_active_standby_relation` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
- `active_cluster_phy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '主集群ID',
- `standby_cluster_phy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '备集群ID',
- `res_name` varchar(192) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT '资源名称',
- `res_type` int(11) NOT NULL DEFAULT '-1' COMMENT '资源类型,0:集群,1:镜像Topic,2:主备Topic',
- `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
- `modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
- `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
- PRIMARY KEY (`id`),
- UNIQUE KEY `uniq_cluster_res` (`res_type`,`active_cluster_phy_id`,`standby_cluster_phy_id`,`res_name`),
- UNIQUE KEY `uniq_res_type_standby_cluster_res_name` (`res_type`,`standby_cluster_phy_id`,`res_name`)
-) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='HA主备关系表';
-
-
--- 删除idx_cluster_phy_id 索引并新增idx_cluster_update_time索引
-ALTER TABLE `ks_km_kafka_change_record` DROP INDEX `idx_cluster_phy_id` ,
-ADD INDEX `idx_cluster_update_time` (`cluster_phy_id` ASC, `update_time` ASC);
-```
-
-### 升级至 `3.2.0` 版本
-
-**配置变更**
-
-```yaml
-# 新增如下配置
-
-spring:
- logi-job: # know-streaming 依赖的 logi-job 模块的数据库的配置,默认与 know-streaming 的数据库配置保持一致即可
- enable: true # true表示开启job任务, false表关闭。KS在部署上可以考虑部署两套服务,一套处理前端请求,一套执行job任务,此时可以通过该字段进行控制
-
-# 线程池大小相关配置
-thread-pool:
- es:
- search: # es查询线程池
- thread-num: 20 # 线程池大小
- queue-size: 10000 # 队列大小
-
-# 客户端池大小相关配置
-client-pool:
- kafka-admin:
- client-cnt: 1 # 每个Kafka集群创建的KafkaAdminClient数
-
-# ES客户端配置
-es:
- index:
- expire: 15 # 索引过期天数,15表示超过15天的索引会被KS过期删除
-```
-
-**SQL 变更**
-```sql
-DROP TABLE IF EXISTS `ks_kc_connect_cluster`;
-CREATE TABLE `ks_kc_connect_cluster` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'Connect集群ID',
- `kafka_cluster_phy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'Kafka集群ID',
- `name` varchar(128) NOT NULL DEFAULT '' COMMENT '集群名称',
- `group_name` varchar(128) NOT NULL DEFAULT '' COMMENT '集群Group名称',
- `cluster_url` varchar(1024) NOT NULL DEFAULT '' COMMENT '集群地址',
- `member_leader_url` varchar(1024) NOT NULL DEFAULT '' COMMENT 'URL地址',
- `version` varchar(64) NOT NULL DEFAULT '' COMMENT 'connect版本',
- `jmx_properties` text COMMENT 'JMX配置',
- `state` tinyint(4) NOT NULL DEFAULT '1' COMMENT '集群使用的消费组状态,也表示集群状态:-1 Unknown,0 ReBalance,1 Active,2 Dead,3 Empty',
- `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '接入时间',
- `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
- PRIMARY KEY (`id`),
- UNIQUE KEY `uniq_id_group_name` (`id`,`group_name`),
- UNIQUE KEY `uniq_name_kafka_cluster` (`name`,`kafka_cluster_phy_id`),
- KEY `idx_kafka_cluster_phy_id` (`kafka_cluster_phy_id`)
-) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='Connect集群信息表';
-
-
-DROP TABLE IF EXISTS `ks_kc_connector`;
-CREATE TABLE `ks_kc_connector` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
- `kafka_cluster_phy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'Kafka集群ID',
- `connect_cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'Connect集群ID',
- `connector_name` varchar(512) NOT NULL DEFAULT '' COMMENT 'Connector名称',
- `connector_class_name` varchar(512) NOT NULL DEFAULT '' COMMENT 'Connector类',
- `connector_type` varchar(32) NOT NULL DEFAULT '' COMMENT 'Connector类型',
- `state` varchar(45) NOT NULL DEFAULT '' COMMENT '状态',
- `topics` text COMMENT '访问过的Topics',
- `task_count` int(11) NOT NULL DEFAULT '0' COMMENT '任务数',
- `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
- `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
- PRIMARY KEY (`id`),
- UNIQUE KEY `uniq_connect_cluster_id_connector_name` (`connect_cluster_id`,`connector_name`)
-) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='Connector信息表';
-
-
-DROP TABLE IF EXISTS `ks_kc_worker`;
-CREATE TABLE `ks_kc_worker` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
- `kafka_cluster_phy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'Kafka集群ID',
- `connect_cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'Connect集群ID',
- `member_id` varchar(512) NOT NULL DEFAULT '' COMMENT '成员ID',
- `host` varchar(128) NOT NULL DEFAULT '' COMMENT '主机名',
- `jmx_port` int(16) NOT NULL DEFAULT '-1' COMMENT 'Jmx端口',
- `url` varchar(1024) NOT NULL DEFAULT '' COMMENT 'URL信息',
- `leader_url` varchar(1024) NOT NULL DEFAULT '' COMMENT 'leaderURL信息',
- `leader` int(16) NOT NULL DEFAULT '0' COMMENT '状态: 1是leader,0不是leader',
- `worker_id` varchar(128) NOT NULL COMMENT 'worker地址',
- `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
- `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
- PRIMARY KEY (`id`),
- UNIQUE KEY `uniq_cluster_id_member_id` (`connect_cluster_id`,`member_id`)
-) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='worker信息表';
-
-
-DROP TABLE IF EXISTS `ks_kc_worker_connector`;
-CREATE TABLE `ks_kc_worker_connector` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
- `kafka_cluster_phy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'Kafka集群ID',
- `connect_cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'Connect集群ID',
- `connector_name` varchar(512) NOT NULL DEFAULT '' COMMENT 'Connector名称',
- `worker_member_id` varchar(256) NOT NULL DEFAULT '',
- `task_id` int(16) NOT NULL DEFAULT '-1' COMMENT 'Task的ID',
- `state` varchar(128) DEFAULT NULL COMMENT '任务状态',
- `worker_id` varchar(128) DEFAULT NULL COMMENT 'worker信息',
- `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
- `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
- PRIMARY KEY (`id`),
- UNIQUE KEY `uniq_relation` (`connect_cluster_id`,`connector_name`,`task_id`,`worker_member_id`)
-) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='Worker和Connector关系表';
-
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_CONNECTOR_FAILED_TASK_COUNT', '{\"value\" : 1}', 'connector失败状态的任务数量', 'admin');
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_CONNECTOR_UNASSIGNED_TASK_COUNT', '{\"value\" : 1}', 'connector未被分配的任务数量', 'admin');
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_CONNECT_CLUSTER_TASK_STARTUP_FAILURE_PERCENTAGE', '{\"value\" : 0.05}', 'Connect集群任务启动失败概率', 'admin');
-```
-
----
-
-### 升级至 `v3.1.0` 版本
-
-```sql
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_ZK_BRAIN_SPLIT', '{ \"value\": 1} ', 'ZK 脑裂', 'admin');
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_ZK_OUTSTANDING_REQUESTS', '{ \"amount\": 100, \"ratio\":0.8} ', 'ZK Outstanding 请求堆积数', 'admin');
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_ZK_WATCH_COUNT', '{ \"amount\": 100000, \"ratio\": 0.8 } ', 'ZK WatchCount 数', 'admin');
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_ZK_ALIVE_CONNECTIONS', '{ \"amount\": 10000, \"ratio\": 0.8 } ', 'ZK 连接数', 'admin');
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_ZK_APPROXIMATE_DATA_SIZE', '{ \"amount\": 524288000, \"ratio\": 0.8 } ', 'ZK 数据大小(Byte)', 'admin');
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_ZK_SENT_RATE', '{ \"amount\": 500000, \"ratio\": 0.8 } ', 'ZK 发包数', 'admin');
-
-```
-
-### 升级至 `v3.0.1` 版本
-
-**ES 索引模版**
-```bash
-# 新增 ks_kafka_zookeeper_metric 索引模版。
-# 可通过再次执行 bin/init_es_template.sh 脚本,创建该索引模版。
-
-# 索引模版内容
-PUT _template/ks_kafka_zookeeper_metric
-{
- "order" : 10,
- "index_patterns" : [
- "ks_kafka_zookeeper_metric*"
- ],
- "settings" : {
- "index" : {
- "number_of_shards" : "10"
- }
- },
- "mappings" : {
- "properties" : {
- "routingValue" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "clusterPhyId" : {
- "type" : "long"
- },
- "metrics" : {
- "properties" : {
- "AvgRequestLatency" : {
- "type" : "double"
- },
- "MinRequestLatency" : {
- "type" : "double"
- },
- "MaxRequestLatency" : {
- "type" : "double"
- },
- "OutstandingRequests" : {
- "type" : "double"
- },
- "NodeCount" : {
- "type" : "double"
- },
- "WatchCount" : {
- "type" : "double"
- },
- "NumAliveConnections" : {
- "type" : "double"
- },
- "PacketsReceived" : {
- "type" : "double"
- },
- "PacketsSent" : {
- "type" : "double"
- },
- "EphemeralsCount" : {
- "type" : "double"
- },
- "ApproximateDataSize" : {
- "type" : "double"
- },
- "OpenFileDescriptorCount" : {
- "type" : "double"
- },
- "MaxFileDescriptorCount" : {
- "type" : "double"
- }
- }
- },
- "key" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "timestamp" : {
- "format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
- "type" : "date"
- }
- }
- },
- "aliases" : { }
- }
-```
-
-
-**SQL 变更**
-
-```sql
-DROP TABLE IF EXISTS `ks_km_zookeeper`;
-CREATE TABLE `ks_km_zookeeper` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
- `cluster_phy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '物理集群ID',
- `host` varchar(128) NOT NULL DEFAULT '' COMMENT 'zookeeper主机名',
- `port` int(16) NOT NULL DEFAULT '-1' COMMENT 'zookeeper端口',
- `role` varchar(16) NOT NULL DEFAULT '' COMMENT '角色, leader follower observer',
- `version` varchar(128) NOT NULL DEFAULT '' COMMENT 'zookeeper版本',
- `status` int(16) NOT NULL DEFAULT '0' COMMENT '状态: 1存活,0未存活,11存活但是4字命令使用不了',
- `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
- `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
- PRIMARY KEY (`id`),
- UNIQUE KEY `uniq_cluster_phy_id_host_port` (`cluster_phy_id`,`host`, `port`)
-) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='Zookeeper信息表';
-
-
-DROP TABLE IF EXISTS `ks_km_group`;
-CREATE TABLE `ks_km_group` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
- `cluster_phy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
- `name` varchar(192) COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'Group名称',
- `member_count` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '成员数',
- `topic_members` text CHARACTER SET utf8 COMMENT 'group消费的topic列表',
- `partition_assignor` varchar(255) CHARACTER SET utf8 NOT NULL COMMENT '分配策略',
- `coordinator_id` int(11) NOT NULL COMMENT 'group协调器brokerId',
- `type` int(11) NOT NULL COMMENT 'group类型 0:consumer 1:connector',
- `state` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '' COMMENT '状态',
- `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
- `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
- PRIMARY KEY (`id`),
- UNIQUE KEY `uniq_cluster_phy_id_name` (`cluster_phy_id`,`name`)
-) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='Group信息表';
-
-```
-
-
-### 升级至 `v3.0.0` 版本
-
-**SQL 变更**
-
-```sql
-ALTER TABLE `ks_km_physical_cluster`
-ADD COLUMN `zk_properties` TEXT NULL COMMENT 'ZK配置' AFTER `jmx_properties`;
-```
-
----
-
-
-### 升级至 `v3.0.0-beta.2`版本
-
-**配置变更**
-
-```yaml
-
-# 新增配置
-spring:
- logi-security: # know-streaming 依赖的 logi-security 模块的数据库的配置,默认与 know-streaming 的数据库配置保持一致即可
- login-extend-bean-name: logiSecurityDefaultLoginExtendImpl # 使用的登录系统Service的Bean名称,无需修改
-
-# 线程池大小相关配置,在task模块中,新增了三类线程池,
-# 从而减少不同类型任务之间的相互影响,以及减少对logi-job内的线程池的影响
-thread-pool:
- task: # 任务模块的配置
- metrics: # metrics采集任务配置
- thread-num: 18 # metrics采集任务线程池核心线程数
- queue-size: 180 # metrics采集任务线程池队列大小
- metadata: # metadata同步任务配置
- thread-num: 27 # metadata同步任务线程池核心线程数
- queue-size: 270 # metadata同步任务线程池队列大小
- common: # 剩余其他任务配置
- thread-num: 15 # 剩余其他任务线程池核心线程数
- queue-size: 150 # 剩余其他任务线程池队列大小
-
-# 删除配置,下列配置将不再使用
-thread-pool:
- task: # 任务模块的配置
- heaven: # 采集任务配置
- thread-num: 20 # 采集任务线程池核心线程数
- queue-size: 1000 # 采集任务线程池队列大小
-
-```
-
-**SQL 变更**
-
-```sql
--- 多集群管理权限2022-09-06新增
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2000', '多集群管理查看', '1593', '1', '2', '多集群管理查看', '0', 'know-streaming');
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2002', 'Topic-迁移副本', '1593', '1', '2', 'Topic-迁移副本', '0', 'know-streaming');
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2004', 'Topic-扩缩副本', '1593', '1', '2', 'Topic-扩缩副本', '0', 'know-streaming');
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2006', 'Cluster-LoadReBalance-周期均衡', '1593', '1', '2', 'Cluster-LoadReBalance-周期均衡', '0', 'know-streaming');
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2008', 'Cluster-LoadReBalance-立即均衡', '1593', '1', '2', 'Cluster-LoadReBalance-立即均衡', '0', 'know-streaming');
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2010', 'Cluster-LoadReBalance-设置集群规格', '1593', '1', '2', 'Cluster-LoadReBalance-设置集群规格', '0', 'know-streaming');
-
-
--- 系统管理权限2022-09-06新增
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('3000', '系统管理查看', '1595', '1', '2', '系统管理查看', '0', 'know-streaming');
-
-
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2000', '0', 'know-streaming');
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2002', '0', 'know-streaming');
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2004', '0', 'know-streaming');
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2006', '0', 'know-streaming');
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2008', '0', 'know-streaming');
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2010', '0', 'know-streaming');
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '3000', '0', 'know-streaming');
-
--- 修改字段长度
-ALTER TABLE `logi_security_oplog`
- CHANGE COLUMN `operator_ip` `operator_ip` VARCHAR(64) NOT NULL COMMENT '操作者ip' ,
- CHANGE COLUMN `operator` `operator` VARCHAR(64) NULL DEFAULT NULL COMMENT '操作者账号' ,
- CHANGE COLUMN `operate_page` `operate_page` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '操作页面' ,
- CHANGE COLUMN `operate_type` `operate_type` VARCHAR(64) NOT NULL COMMENT '操作类型' ,
- CHANGE COLUMN `target_type` `target_type` VARCHAR(64) NOT NULL COMMENT '对象分类' ,
- CHANGE COLUMN `target` `target` VARCHAR(1024) NOT NULL COMMENT '操作对象' ,
- CHANGE COLUMN `operation_methods` `operation_methods` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '操作方式' ;
-```
-
----
-
-### 升级至 `v3.0.0-beta.1`版本
-
-**SQL 变更**
-
-1、在`ks_km_broker`表增加了一个监听信息字段。
-2、为`logi_security_oplog`表 operation_methods 字段设置默认值''。
-因此需要执行下面的 sql 对数据库表进行更新。
-
-```sql
-ALTER TABLE `ks_km_broker`
-ADD COLUMN `endpoint_map` VARCHAR(1024) NOT NULL DEFAULT '' COMMENT '监听信息' AFTER `update_time`;
-
-ALTER TABLE `logi_security_oplog`
-ALTER COLUMN `operation_methods` set default '';
-
-```
-
----
-
-### `2.x`版本 升级至 `v3.0.0-beta.0`版本
-
-**升级步骤:**
-
-1. 依旧使用**`2.x 版本的 DB`**,在上面初始化 3.0.0 版本所需数据库表结构及数据;
-2. 将 2.x 版本中的集群,在 3.0.0 版本,手动逐一接入;
-3. 将 Topic 业务数据,迁移至 3.0.0 表中,详见下方 SQL;
-
-**注意事项**
-
-- 建议升级 3.0.0 版本过程中,保留 2.x 版本的使用,待 3.0.0 版本稳定使用后,再下线 2.x 版本;
-- 3.0.0 版本仅需要`集群信息`及`Topic的描述信息`。2.x 版本的 DB 的其他数据 3.0.0 版本都不需要;
-- 部署 3.0.0 版本之后,集群、Topic 等指标数据都为空,3.0.0 版本会周期进行采集,运行一段时间之后就会有该数据了,因此不会将 2.x 中的指标数据进行迁移;
-
-**迁移数据**
-
-```sql
--- 迁移Topic的备注信息。
--- 需在 3.0.0 部署完成后,再执行该SQL。
--- 考虑到 2.x 版本中还存在增量数据,因此建议改SQL周期执行,是的增量数据也能被迁移至 3.0.0 版本中。
-
-UPDATE ks_km_topic
- INNER JOIN
- (SELECT
- topic.cluster_id AS cluster_id,
- topic.topic_name AS topic_name,
- topic.description AS description
- FROM topic WHERE description != ''
- ) AS t
-
-ON ks_km_topic.cluster_phy_id = t.cluster_id
- AND ks_km_topic.topic_name = t.topic_name
- AND ks_km_topic.id > 0
- SET ks_km_topic.description = t.description;
-```
\ No newline at end of file
diff --git a/docs/user_guide/faq.md b/docs/user_guide/faq.md
deleted file mode 100644
index 1656ec37..00000000
--- a/docs/user_guide/faq.md
+++ /dev/null
@@ -1,228 +0,0 @@
-# FAQ
-
-## 8.1、支持哪些 Kafka 版本?
-
-- 支持 0.10+ 的 Kafka 版本;
-- 支持 ZK 及 Raft 运行模式的 Kafka 版本;
-
-
-
-## 8.1、2.x 版本和 3.0 版本有什么差异?
-
-**全新设计理念**
-
-- 在 0 侵入、0 门槛的前提下提供直观 GUI 用于管理和观测 Apache Kafka®,帮助用户降低 Kafka CLI 操作门槛,轻松实现对原生 Kafka 集群的可管、可见、可掌控,提升 Kafka 使用体验和降低管理成本。
-- 支持海量集群一键接入,无需任何改造,即可实现集群深度纳管,真正的 0 侵入、插件化系统设计,覆盖 0.10.x-3.x.x 众多 Kafka 版本无缝纳管。
-
-**开源协议调整**
-
-- 3.x:AGPL 3.0
-- 2.x:Apache License 2.0
-
-更多具体内容见:[新旧版本对比](https://doc.knowstreaming.com/product/9-attachment#92%E6%96%B0%E6%97%A7%E7%89%88%E6%9C%AC%E5%AF%B9%E6%AF%94)
-
-
-
-## 8.3、页面流量信息等无数据?
-
-- 1、`Broker JMX`未正确开启
-
-可以参看:[Jmx 连接配置&问题解决](https://doc.knowstreaming.com/product/9-attachment#91jmx-%E8%BF%9E%E6%8E%A5%E5%A4%B1%E8%B4%A5%E9%97%AE%E9%A2%98%E8%A7%A3%E5%86%B3)
-
-- 2、`ES` 存在问题
-
-建议使用`ES 7.6`版本,同时创建近 7 天的索引,具体见:[快速开始](./1-quick-start.md) 中的 ES 索引模版及索引创建。
-
-
-
-## 8.4、`Jmx`连接失败如何解决?
-
-- 参看 [Jmx 连接配置&问题解决](https://doc.knowstreaming.com/product/9-attachment#91jmx-%E8%BF%9E%E6%8E%A5%E5%A4%B1%E8%B4%A5%E9%97%AE%E9%A2%98%E8%A7%A3%E5%86%B3) 说明。
-
-
-
-## 8.5、有没有 API 文档?
-
-`KnowStreaming` 采用 Swagger 进行 API 说明,在启动 KnowStreaming 服务之后,就可以从下面地址看到。
-
-Swagger-API 地址: [http://IP:PORT/swagger-ui.html#/](http://IP:PORT/swagger-ui.html#/)
-
-
-
-## 8.6、删除 Topic 成功后,为何过段时间又出现了?
-
-**原因说明:**
-
-`KnowStreaming` 会去请求 Topic 的 endoffset 信息,要获取这个信息就需要发送 metadata 请求,发送 metadata 请求的时候,如果集群允许自动创建 Topic,那么当 Topic 不存在时,就会自动将该 Topic 创建出来。
-
-**问题解决:**
-
-因为在 `KnowStreaming` 上,禁止 Kafka 客户端内部元信息获取这个动作非常的难做到,因此短时间内这个问题不好从 `KnowStreaming` 上解决。
-
-当然,对于不存在的 Topic,`KnowStreaming` 是不会进行元信息请求的,因此也不用担心会莫名其妙的创建一个 Topic 出来。
-
-但是,另外一点,对于开启允许 Topic 自动创建的集群,建议是关闭该功能,开启是非常危险的,如果关闭之后,`KnowStreaming` 也不会有这个问题。
-
-最后这里举个开启这个配置后,非常危险的代码例子吧:
-
-```java
-for (int i= 0; i < 100000; ++i) {
- // 如果是客户端类似这样写的,那么一启动,那么将创建10万个Topic出来,集群元信息瞬间爆炸,controller可能就不可服务了。
- producer.send(new ProducerRecord("know_streaming" + i,"hello logi_km"));
-}
-```
-
-
-
-## 8.7、如何在不登录的情况下,调用接口?
-
-步骤一:接口调用时,在 header 中,增加如下信息:
-
-```shell
-# 表示开启登录绕过
-Trick-Login-Switch : on
-
-# 登录绕过的用户, 这里可以是admin, 或者是其他的, 但是必须在系统管理->用户管理中设置了该用户。
-Trick-Login-User : admin
-```
-
-
-
-步骤二:点击右上角"系统管理",选择配置管理,在页面中添加以下键值对。
-
-```shell
-# 模块选择
-SECURITY.LOGIN
-
-# 设置的配置键,必须是这个
-SECURITY.TRICK_USERS
-
-# 设置的value,是json数组的格式,包含步骤一header中设置的用户名,例如
-[ "admin", "logi"]
-```
-
-
-
-步骤三:解释说明
-
-设置完成上面两步之后,就可以直接调用需要登录的接口了。
-
-但是还有一点需要注意,绕过的用户仅能调用他有权限的接口,比如一个普通用户,那么他就只能调用普通的接口,不能去调用运维人员的接口。
-
-## 8.8、Specified key was too long; max key length is 767 bytes
-
-**原因:** 不同版本的 InoDB 引擎,参数‘innodb_large_prefix’默认值不同,即在 5.6 默认值为 OFF,5.7 默认值为 ON。
-
-对于引擎为 InnoDB,innodb_large_prefix=OFF,且行格式为 Antelope 即支持 REDUNDANT 或 COMPACT 时,索引键前缀长度最大为 767 字节。innodb_large_prefix=ON,且行格式为 Barracuda 即支持 DYNAMIC 或 COMPRESSED 时,索引键前缀长度最大为 3072 字节。
-
-**解决方案:**
-
-- 减少 varchar 字符大小低于 767/4=191。
-- 将字符集改为 latin1(一个字符=一个字节)。
-- 开启‘innodb_large_prefix’,修改默认行格式‘innodb_file_format’为 Barracuda,并设置 row_format=dynamic。
-
-## 8.9、出现 ESIndexNotFoundEXception 报错
-
-**原因 :**没有创建 ES 索引模版
-
-**解决方案:**执行 init_es_template.sh 脚本,创建 ES 索引模版即可。
-
-## 8.10、km-console 打包构建失败
-
-首先,**请确保您正在使用最新版本**,版本列表见 [Tags](https://github.com/didi/KnowStreaming/tags)。如果不是最新版本,请升级后再尝试有无问题。
-
-常见的原因是由于工程依赖没有正常安装,导致在打包过程中缺少依赖,造成打包失败。您可以检查是否有以下文件夹,且文件夹内是否有内容
-
-```
-KnowStreaming/km-console/node_modules
-KnowStreaming/km-console/packages/layout-clusters-fe/node_modules
-KnowStreaming/km-console/packages/config-manager-fe/node_modules
-```
-
-如果发现没有对应的 `node_modules` 目录或着目录内容为空,说明依赖没有安装成功。请按以下步骤操作,
-
-1. 手动删除上述三个文件夹(如果有)
-
-2. 如果之前是通过 `mvn install` 打包 `km-console`,请到项目根目录(KnowStreaming)下重新输入该指令进行打包。观察打包过程有无报错。如有报错,请见步骤 4。
-
-3. 如果是通过本地独立构建前端工程的方式(指直接执行 `npm run build`),请进入 `KnowStreaming/km-console` 目录,执行下述步骤(注意:执行时请确保您在使用 `node v12` 版本)
-
- a. 执行 `npm run i`。如有报错,请见步骤 4。
-
- b. 执行 `npm run build`。如有报错,请见步骤 4。
-
-4. 麻烦联系我们协助解决。推荐提供以下信息,方面我们快速定位问题,示例如下。
-
-```
-操作系统: Mac
-命令行终端:bash
-Node 版本: v12.22.12
-复现步骤: 1. -> 2.
-错误截图:
-```
-
-## 8.11、在 `km-console` 目录下执行 `npm run start` 时看不到应用构建和热加载过程?如何启动单个应用?
-
-需要到具体的应用中执行 `npm run start`,例如 `cd packages/layout-clusters-fe` 后,执行 `npm run start`。
-
-应用启动后需要到基座应用中查看(需要启动基座应用,即 layout-clusters-fe)。
-
-
-## 8.12、权限识别失败问题
-1、使用admin账号登陆KnowStreaming时,点击系统管理-用户管理-角色管理-新增角色,查看页面是否正常。
-
-
-
-
-
-### 4、解决方法 —— JMX连接特定网络
-
-可以手动往`ks_km_physical_cluster`表的`jmx_properties`字段增加一个`useWhichEndpoint`字段,从而控制 `KnowStreaming` 连接到特定的JMX IP及PORT。
-
-`jmx_properties`格式:
-```json
-{
- "maxConn": 100, # KM对单台Broker的最大JMX连接数
- "username": "xxxxx", # 用户名,可以不填写
- "password": "xxxx", # 密码,可以不填写
- "openSSL": true, # 开启SSL, true表示开启ssl, false表示关闭
- "useWhichEndpoint": "EXTERNAL" #指定要连接的网络名称,填写EXTERNAL就是连接endpoints里面的EXTERNAL地址
-}
-```
-
-
-
-SQL例子:
-```sql
-UPDATE ks_km_physical_cluster SET jmx_properties='{ "maxConn": 10, "username": "xxxxx", "password": "xxxx", "openSSL": false , "useWhichEndpoint": "xxx"}' where id={xxx};
-```
-
-注意:
-
-+ 目前此功能只支持采用 `ZK` 做分布式协调的kafka集群。
-
-
\ No newline at end of file
diff --git a/docs/install_guide/单机部署手册.md b/docs/install_guide/单机部署手册.md
deleted file mode 100644
index c42e6318..00000000
--- a/docs/install_guide/单机部署手册.md
+++ /dev/null
@@ -1,417 +0,0 @@
-## 2.1、单机部署
-
-**风险提示**
-
-⚠️ 脚本全自动安装,会将所部署机器上的 MySQL、JDK、ES 等进行删除重装,请注意原有服务丢失风险。
-
-### 2.1.1、安装说明
-
-- 以 `v3.0.0-beta.1` 版本为例进行部署;
-- 以 CentOS-7 为例,系统基础配置要求 4C-8G;
-- 部署完成后,可通过浏览器:`IP:PORT` 进行访问,默认端口是 `8080`,系统默认账号密码: `admin` / `admin2022_`。
-- `v3.0.0-beta.2`版本开始,默认账号密码为`admin` / `admin`;
-- 本文为单机部署,如需分布式部署,[请联系我们](https://knowstreaming.com/support-center)
-
-**软件依赖**
-
-| 软件名 | 版本要求 | 默认端口 |
-| ------------- | ------------ | -------- |
-| MySQL | v5.7 或 v8.0 | 3306 |
-| ElasticSearch | v7.6+ | 8060 |
-| JDK | v8+ | - |
-| CentOS | v6+ | - |
-| Ubuntu | v16+ | - |
-
-
-
-### 2.1.2、脚本部署
-
-**在线安装**
-
-```bash
-# 在服务器中下载安装脚本, 该脚本中会在当前目录下,重新安装MySQL。重装后的mysql密码存放在当前目录的mysql.password文件中。
-wget https://s3-gzpu.didistatic.com/pub/knowstreaming/deploy_KnowStreaming-3.0.0-beta.1.sh
-
-# 执行脚本
-sh deploy_KnowStreaming.sh
-
-# 访问地址
-127.0.0.1:8080
-```
-
-**离线安装**
-
-```bash
-# 将安装包下载到本地且传输到目标服务器
-wget https://s3-gzpu.didistatic.com/pub/knowstreaming/KnowStreaming-3.0.0-beta.1-offline.tar.gz
-
-# 解压安装包
-tar -zxf KnowStreaming-3.0.0-beta.1-offline.tar.gz
-
-# 执行安装脚本
-sh deploy_KnowStreaming-offline.sh
-
-# 访问地址
-127.0.0.1:8080
-```
-
-
-
-### 2.1.3、容器部署
-
-#### 2.1.3.1、Helm
-
-**环境依赖**
-
-- Kubernetes >= 1.14 ,Helm >= 2.17.0
-
-- 默认依赖全部安装,ElasticSearch(3 节点集群模式) + MySQL(单机) + KnowStreaming-manager + KnowStreaming-ui
-
-- 使用已有的 ElasticSearch(7.6.x) 和 MySQL(5.7) 只需调整 values.yaml 部分参数即可
-
-**安装命令**
-
-```bash
-# 相关镜像在Docker Hub都可以下载
-# 快速安装(NAMESPACE需要更改为已存在的,安装启动需要几分钟初始化请稍等~)
-helm install -n [NAMESPACE] [NAME] http://download.knowstreaming.com/charts/knowstreaming-manager-0.1.5.tgz
-
-# 获取KnowStreaming前端ui的service. 默认nodeport方式.
-# (http://nodeIP:nodeport,默认用户名密码:admin/admin2022_)
-# `v3.0.0-beta.2`版本开始(helm chart包版本0.1.4开始),默认账号密码为`admin` / `admin`;
-
-# 添加仓库
-helm repo add knowstreaming http://download.knowstreaming.com/charts
-
-# 拉取最新版本
-helm pull knowstreaming/knowstreaming-manager
-```
-
-
-
-#### 2.1.3.2、Docker Compose
-**环境依赖**
-
-- [Docker](https://docs.docker.com/engine/install/)
-- [Docker Compose](https://docs.docker.com/compose/install/)
-
-
-**安装命令**
-```bash
-# `v3.0.0-beta.2`版本开始(docker镜像为0.2.0版本开始),默认账号密码为`admin` / `admin`;
-# https://hub.docker.com/u/knowstreaming 在此处寻找最新镜像版本
-# mysql与es可以使用自己搭建的服务,调整对应配置即可
-
-# 复制docker-compose.yml到指定位置后执行下方命令即可启动
-docker-compose up -d
-```
-
-**验证安装**
-```shell
-docker-compose ps
-# 验证启动 - 状态为 UP 则表示成功
- Name Command State Ports
-----------------------------------------------------------------------------------------------------
-elasticsearch-single /usr/local/bin/docker-entr ... Up 9200/tcp, 9300/tcp
-knowstreaming-init /bin/bash /es_template_cre ... Up
-knowstreaming-manager /bin/sh /ks-start.sh Up 80/tcp
-knowstreaming-mysql /entrypoint.sh mysqld Up (health: starting) 3306/tcp, 33060/tcp
-knowstreaming-ui /docker-entrypoint.sh ngin ... Up 0.0.0.0:80->80/tcp
-
-# 稍等一分钟左右 knowstreaming-init 会退出,表示es初始化完成,可以访问页面
- Name Command State Ports
--------------------------------------------------------------------------------------------
-knowstreaming-init /bin/bash /es_template_cre ... Exit 0
-knowstreaming-mysql /entrypoint.sh mysqld Up (healthy) 3306/tcp, 33060/tcp
-```
-
-**访问**
-```http request
-http://127.0.0.1:80/
-```
-
-
-**docker-compose.yml**
-```yml
-version: "2"
-services:
- # *不要调整knowstreaming-manager服务名称,ui中会用到
- knowstreaming-manager:
- image: knowstreaming/knowstreaming-manager:latest
- container_name: knowstreaming-manager
- privileged: true
- restart: always
- depends_on:
- - elasticsearch-single
- - knowstreaming-mysql
- expose:
- - 80
- command:
- - /bin/sh
- - /ks-start.sh
- environment:
- TZ: Asia/Shanghai
- # mysql服务地址
- SERVER_MYSQL_ADDRESS: knowstreaming-mysql:3306
- # mysql数据库名
- SERVER_MYSQL_DB: know_streaming
- # mysql用户名
- SERVER_MYSQL_USER: root
- # mysql用户密码
- SERVER_MYSQL_PASSWORD: admin2022_
- # es服务地址
- SERVER_ES_ADDRESS: elasticsearch-single:9200
- # 服务JVM参数
- JAVA_OPTS: -Xmx1g -Xms1g
- # 对于kafka中ADVERTISED_LISTENERS填写的hostname可以通过该方式完成
-# extra_hosts:
-# - "hostname:x.x.x.x"
- # 服务日志路径
-# volumes:
-# - /ks/manage/log:/logs
- knowstreaming-ui:
- image: knowstreaming/knowstreaming-ui:latest
- container_name: knowstreaming-ui
- restart: always
- ports:
- - '80:80'
- environment:
- TZ: Asia/Shanghai
- depends_on:
- - knowstreaming-manager
-# extra_hosts:
-# - "hostname:x.x.x.x"
- elasticsearch-single:
- image: docker.io/library/elasticsearch:7.6.2
- container_name: elasticsearch-single
- restart: always
- expose:
- - 9200
- - 9300
-# ports:
-# - '9200:9200'
-# - '9300:9300'
- environment:
- TZ: Asia/Shanghai
- # es的JVM参数
- ES_JAVA_OPTS: -Xms512m -Xmx512m
- # 单节点配置,多节点集群参考 https://www.elastic.co/guide/en/elasticsearch/reference/7.6/docker.html#docker-compose-file
- discovery.type: single-node
- # 数据持久化路径
-# volumes:
-# - /ks/es/data:/usr/share/elasticsearch/data
-
- # es初始化服务,与manager使用同一镜像
- # 首次启动es需初始化模版和索引,后续会自动创建
- knowstreaming-init:
- image: knowstreaming/knowstreaming-manager:latest
- container_name: knowstreaming-init
- depends_on:
- - elasticsearch-single
- command:
- - /bin/bash
- - /es_template_create.sh
- environment:
- TZ: Asia/Shanghai
- # es服务地址
- SERVER_ES_ADDRESS: elasticsearch-single:9200
-
- knowstreaming-mysql:
- image: knowstreaming/knowstreaming-mysql:latest
- container_name: knowstreaming-mysql
- restart: always
- environment:
- TZ: Asia/Shanghai
- # root 用户密码
- MYSQL_ROOT_PASSWORD: admin2022_
- # 初始化时创建的数据库名称
- MYSQL_DATABASE: know_streaming
- # 通配所有host,可以访问远程
- MYSQL_ROOT_HOST: '%'
- expose:
- - 3306
-# ports:
-# - '3306:3306'
- # 数据持久化路径
-# volumes:
-# - /ks/mysql/data:/data/mysql
-```
-
-
-
-### 2.1.4、手动部署
-
-**部署流程**
-
-1. 安装 `JDK-11`、`MySQL`、`ElasticSearch` 等依赖服务
-2. 安装 KnowStreaming
-
-
-
-#### 2.1.4.1、安装 MySQL 服务
-
-**yum 方式安装**
-
-```bash
-# 配置yum源
-wget https://dev.mysql.com/get/mysql57-community-release-el7-9.noarch.rpm
-rpm -ivh mysql57-community-release-el7-9.noarch.rpm
-
-# 执行安装
-yum -y install mysql-server mysql-client
-
-# 服务启动
-systemctl start mysqld
-
-# 获取初始密码并修改
-old_pass=`grep 'temporary password' /var/log/mysqld.log | awk '{print $NF}' | tail -n 1`
-
-mysql -NBe "alter user USER() identified by 'Didi_km_678';" --connect-expired-password -uroot -p$old_pass
-```
-
-**rpm 方式安装**
-
-```bash
-# 下载安装包
-wget https://s3-gzpu.didistatic.com/knowsearch/mysql5.7.tar.gz
-
-# 解压到指定目录
-tar -zxf mysql5.7.tar.gz -C /tmp/
-
-# 执行安装
-yum -y localinstall /tmp/libaio-*.rpm /tmp/mysql-*.rpm
-
-# 服务启动
-systemctl start mysqld
-
-
-# 获取初始密码并修改
-old_pass=`grep 'temporary password' /var/log/mysqld.log | awk '{print $NF}' | tail -n 1`
-
-mysql -NBe "alter user USER() identified by 'Didi_km_678';" --connect-expired-password -uroot -p$old_pass
-
-```
-
-
-
-#### 2.1.4.2、配置 JDK 环境
-
-```bash
-# 下载安装包
-wget https://s3-gzpu.didistatic.com/pub/jdk11.tar.gz
-
-# 解压到指定目录
-tar -zxf jdk11.tar.gz -C /usr/local/
-
-# 更改目录名
-mv /usr/local/jdk-11.0.2 /usr/local/java11
-
-# 添加到环境变量
-echo "export JAVA_HOME=/usr/local/java11" >> ~/.bashrc
-echo "export CLASSPATH=/usr/java/java11/lib" >> ~/.bashrc
-echo "export PATH=$JAVA_HOME/bin:$PATH:$HOME/bin" >> ~/.bashrc
-
-source ~/.bashrc
-
-```
-
-
-
-#### 2.1.4.3、ElasticSearch 实例搭建
-
-- ElasticSearch 用于存储平台采集的 Kafka 指标;
-- 以下安装示例为单节点模式,如需集群部署可以参考:[Elasticsearch 官方文档](https://www.elastic.co/guide/en/elasticsearch/reference/7.6/elasticsearch-intro.html)
-
-```bash
-# 下载安装包
-wget https://s3-gzpu.didistatic.com/pub/elasticsearch.tar.gz
-
-# 创建ES数据存储目录
-mkdir -p /data/es_data
-
-# 创建ES所属用户
-useradd arius
-
-# 配置用户的打开文件数
-echo "arius soft nofile 655350" >> /etc/security/limits.conf
-echo "arius hard nofile 655350" >> /etc/security/limits.conf
-echo "vm.max_map_count = 655360" >> /etc/sysctl.conf
-sysctl -p
-
-# 解压安装包
-tar -zxf elasticsearch.tar.gz -C /data/
-
-# 更改目录所属组
-chown -R arius:arius /data/
-
-# 修改配置文件(参考以下配置)
-vim /data/elasticsearch/config/elasticsearch.yml
- cluster.name: km_es
- node.name: es-node1
- node.master: true
- node.data: true
- path.data: /data/es_data
- http.port: 8060
- discovery.seed_hosts: ["127.0.0.1:9300"]
-
-# 修改内存配置
-vim /data/elasticsearch/config/jvm.options
- -Xms2g
- -Xmx2g
-
-# 启动服务
-su - arius
-export JAVA_HOME=/usr/local/java11
-sh /data/elasticsearch/control.sh start
-
-# 确认状态
-sh /data/elasticsearch/control.sh status
-```
-
-
-
-#### 2.1.4.4、KnowStreaming 实例搭建
-
-```bash
-# 下载安装包
-wget https://s3-gzpu.didistatic.com/pub/knowstreaming/KnowStreaming-3.0.0-beta.1.tar.gz
-
-# 解压安装包到指定目录
-tar -zxf KnowStreaming-3.0.0-beta.1.tar.gz -C /data/
-
-# 修改启动脚本并加入systemd管理
-cd /data/KnowStreaming/
-
-# 创建相应的库和导入初始化数据
-mysql -uroot -pDidi_km_678 -e "create database know_streaming;"
-mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/ddl-ks-km.sql
-mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/ddl-logi-job.sql
-mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/ddl-logi-security.sql
-mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/dml-ks-km.sql
-mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/dml-logi.sql
-
-# 创建elasticsearch初始化数据
-sh ./bin/init_es_template.sh
-
-# 修改配置文件
-vim ./conf/application.yml
-
-# 监听端口
-server:
- port: 8080 # web 服务端口
- tomcat:
- accept-count: 1000
- max-connections: 10000
-
-# ES地址
-es.client.address: 127.0.0.1:8060
-
-# 数据库配置(一共三处地方,修改正确的mysql地址和数据库名称以及用户名密码)
-jdbc-url: jdbc:mariadb://127.0.0.1:3306/know_streaming?.....
-username: root
-password: Didi_km_678
-
-# 启动服务
-cd /data/KnowStreaming/bin/
-sh startup.sh
-```
diff --git a/docs/install_guide/源码编译打包手册.md b/docs/install_guide/源码编译打包手册.md
deleted file mode 100644
index d6ff6572..00000000
--- a/docs/install_guide/源码编译打包手册.md
+++ /dev/null
@@ -1,62 +0,0 @@
-
-
-# `Know Streaming` 源码编译打包手册
-
-## 1、环境信息
-
-**系统支持**
-
-`windows7+`、`Linux`、`Mac`
-
-**环境依赖**
-
-- Maven 3.6.3 (后端)
-- Node v12.20.0/v14.17.3 (前端)
-- Java 8+ (后端)
-- Git
-
-## 2、编译打包
-
-整个工程中,除了`km-console`为前端模块之外,其他模块都是后端工程相关模块。
-
-因此,如果前后端合并打包,则打对整个工程进行打包;如果前端单独打包,则仅打包 `km-console` 中的代码;如果是仅需要后端打包,则在顶层 `pom.xml` 中去掉 `km-console`模块,然后进行打包。
-
-具体见下面描述。
-
-### 2.1、前后端合并打包
-
-1. 下载源码;
-2. 进入 `KS-KM` 工程目录,执行 `mvn -Prelease-package -Dmaven.test.skip=true clean install -U` 命令;
-3. 打包命令执行完成后,会在 `km-dist/target` 目录下面生成一个 `KnowStreaming-*.tar.gz` 的安装包。
-
-### 2.2、前端单独打包
-
-1. 下载源码;
-2. 跳转到 [前端打包构建文档](https://github.com/didi/KnowStreaming/blob/master/km-console/README.md) 按步骤进行。打包成功后,会在 `km-rest/src/main/resources` 目录下生成名为 `templates` 的前端静态资源包;
-3. 如果上一步过程中报错,请查看 [FAQ](https://github.com/didi/KnowStreaming/blob/master/docs/user_guide/faq.md) 第 8.10 条;
-
-### 2.3、后端单独打包
-
-1. 下载源码;
-2. 修改顶层 `pom.xml` ,去掉其中的 `km-console` 模块,如下所示;
-
-```xml
-
-
- km-common
- km-persistence
- km-core
- km-biz
- km-extends/km-account
- km-extends/km-monitor
- km-extends/km-license
- km-extends/km-rebalance
- km-task
- km-collector
- km-rest
- km-dist
-
-```
-
-3. 执行 `mvn -U clean package -Dmaven.test.skip=true`命令;
-4. 执行完成之后会在 `KS-KM/km-rest/target` 目录下面生成一个 `ks-km.jar` 即为 KS 的后端部署的 Jar 包,也可以执行 `mvn -Prelease-package -Dmaven.test.skip=true clean install -U` 生成的 tar 包也仅有后端服务的功能;
diff --git a/docs/install_guide/版本升级手册.md b/docs/install_guide/版本升级手册.md
deleted file mode 100644
index 061c080d..00000000
--- a/docs/install_guide/版本升级手册.md
+++ /dev/null
@@ -1,463 +0,0 @@
-## 6.2、版本升级手册
-
-注意:
-- 如果想升级至具体版本,需要将你当前版本至你期望使用版本的变更统统执行一遍,然后才能正常使用。
-- 如果中间某个版本没有升级信息,则表示该版本直接替换安装包即可从前一个版本升级至当前版本。
-
-### 升级至 `master` 版本
-
-
-### 升级至 `3.3.0` 版本
-
-**SQL 变更**
-```sql
-ALTER TABLE `logi_security_user`
- CHANGE COLUMN `phone` `phone` VARCHAR(20) NOT NULL DEFAULT '' COMMENT 'mobile' ;
-
-ALTER TABLE ks_kc_connector ADD `heartbeat_connector_name` varchar(512) DEFAULT '' COMMENT '心跳检测connector名称';
-ALTER TABLE ks_kc_connector ADD `checkpoint_connector_name` varchar(512) DEFAULT '' COMMENT '进度确认connector名称';
-
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_MIRROR_MAKER_TOTAL_RECORD_ERRORS', '{\"value\" : 1}', 'MirrorMaker消息处理错误的次数', 'admin');
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_MIRROR_MAKER_REPLICATION_LATENCY_MS_MAX', '{\"value\" : 6000}', 'MirrorMaker消息复制最大延迟时间', 'admin');
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_MIRROR_MAKER_UNASSIGNED_TASK_COUNT', '{\"value\" : 20}', 'MirrorMaker未被分配的任务数量', 'admin');
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_MIRROR_MAKER_FAILED_TASK_COUNT', '{\"value\" : 10}', 'MirrorMaker失败状态的任务数量', 'admin');
-
-
--- 多集群管理权限2023-01-05新增
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2012', 'Topic-新增Topic复制', '1593', '1', '2', 'Topic-新增Topic复制', '0', 'know-streaming');
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2014', 'Topic-详情-取消Topic复制', '1593', '1', '2', 'Topic-详情-取消Topic复制', '0', 'know-streaming');
-
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2012', '0', 'know-streaming');
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2014', '0', 'know-streaming');
-
-
--- 多集群管理权限2023-01-18新增
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2016', 'MM2-新增', '1593', '1', '2', 'MM2-新增', '0', 'know-streaming');
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2018', 'MM2-编辑', '1593', '1', '2', 'MM2-编辑', '0', 'know-streaming');
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2020', 'MM2-删除', '1593', '1', '2', 'MM2-删除', '0', 'know-streaming');
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2022', 'MM2-重启', '1593', '1', '2', 'MM2-重启', '0', 'know-streaming');
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2024', 'MM2-暂停&恢复', '1593', '1', '2', 'MM2-暂停&恢复', '0', 'know-streaming');
-
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2016', '0', 'know-streaming');
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2018', '0', 'know-streaming');
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2020', '0', 'know-streaming');
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2022', '0', 'know-streaming');
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2024', '0', 'know-streaming');
-
-
-DROP TABLE IF EXISTS `ks_ha_active_standby_relation`;
-CREATE TABLE `ks_ha_active_standby_relation` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
- `active_cluster_phy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '主集群ID',
- `standby_cluster_phy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '备集群ID',
- `res_name` varchar(192) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT '资源名称',
- `res_type` int(11) NOT NULL DEFAULT '-1' COMMENT '资源类型,0:集群,1:镜像Topic,2:主备Topic',
- `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
- `modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
- `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
- PRIMARY KEY (`id`),
- UNIQUE KEY `uniq_cluster_res` (`res_type`,`active_cluster_phy_id`,`standby_cluster_phy_id`,`res_name`),
- UNIQUE KEY `uniq_res_type_standby_cluster_res_name` (`res_type`,`standby_cluster_phy_id`,`res_name`)
-) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='HA主备关系表';
-
-
--- 删除idx_cluster_phy_id 索引并新增idx_cluster_update_time索引
-ALTER TABLE `ks_km_kafka_change_record` DROP INDEX `idx_cluster_phy_id` ,
-ADD INDEX `idx_cluster_update_time` (`cluster_phy_id` ASC, `update_time` ASC);
-```
-
-### 升级至 `3.2.0` 版本
-
-**配置变更**
-
-```yaml
-# 新增如下配置
-
-spring:
- logi-job: # know-streaming 依赖的 logi-job 模块的数据库的配置,默认与 know-streaming 的数据库配置保持一致即可
- enable: true # true表示开启job任务, false表关闭。KS在部署上可以考虑部署两套服务,一套处理前端请求,一套执行job任务,此时可以通过该字段进行控制
-
-# 线程池大小相关配置
-thread-pool:
- es:
- search: # es查询线程池
- thread-num: 20 # 线程池大小
- queue-size: 10000 # 队列大小
-
-# 客户端池大小相关配置
-client-pool:
- kafka-admin:
- client-cnt: 1 # 每个Kafka集群创建的KafkaAdminClient数
-
-# ES客户端配置
-es:
- index:
- expire: 15 # 索引过期天数,15表示超过15天的索引会被KS过期删除
-```
-
-**SQL 变更**
-```sql
-DROP TABLE IF EXISTS `ks_kc_connect_cluster`;
-CREATE TABLE `ks_kc_connect_cluster` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'Connect集群ID',
- `kafka_cluster_phy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'Kafka集群ID',
- `name` varchar(128) NOT NULL DEFAULT '' COMMENT '集群名称',
- `group_name` varchar(128) NOT NULL DEFAULT '' COMMENT '集群Group名称',
- `cluster_url` varchar(1024) NOT NULL DEFAULT '' COMMENT '集群地址',
- `member_leader_url` varchar(1024) NOT NULL DEFAULT '' COMMENT 'URL地址',
- `version` varchar(64) NOT NULL DEFAULT '' COMMENT 'connect版本',
- `jmx_properties` text COMMENT 'JMX配置',
- `state` tinyint(4) NOT NULL DEFAULT '1' COMMENT '集群使用的消费组状态,也表示集群状态:-1 Unknown,0 ReBalance,1 Active,2 Dead,3 Empty',
- `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '接入时间',
- `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
- PRIMARY KEY (`id`),
- UNIQUE KEY `uniq_id_group_name` (`id`,`group_name`),
- UNIQUE KEY `uniq_name_kafka_cluster` (`name`,`kafka_cluster_phy_id`),
- KEY `idx_kafka_cluster_phy_id` (`kafka_cluster_phy_id`)
-) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='Connect集群信息表';
-
-
-DROP TABLE IF EXISTS `ks_kc_connector`;
-CREATE TABLE `ks_kc_connector` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
- `kafka_cluster_phy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'Kafka集群ID',
- `connect_cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'Connect集群ID',
- `connector_name` varchar(512) NOT NULL DEFAULT '' COMMENT 'Connector名称',
- `connector_class_name` varchar(512) NOT NULL DEFAULT '' COMMENT 'Connector类',
- `connector_type` varchar(32) NOT NULL DEFAULT '' COMMENT 'Connector类型',
- `state` varchar(45) NOT NULL DEFAULT '' COMMENT '状态',
- `topics` text COMMENT '访问过的Topics',
- `task_count` int(11) NOT NULL DEFAULT '0' COMMENT '任务数',
- `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
- `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
- PRIMARY KEY (`id`),
- UNIQUE KEY `uniq_connect_cluster_id_connector_name` (`connect_cluster_id`,`connector_name`)
-) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='Connector信息表';
-
-
-DROP TABLE IF EXISTS `ks_kc_worker`;
-CREATE TABLE `ks_kc_worker` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
- `kafka_cluster_phy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'Kafka集群ID',
- `connect_cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'Connect集群ID',
- `member_id` varchar(512) NOT NULL DEFAULT '' COMMENT '成员ID',
- `host` varchar(128) NOT NULL DEFAULT '' COMMENT '主机名',
- `jmx_port` int(16) NOT NULL DEFAULT '-1' COMMENT 'Jmx端口',
- `url` varchar(1024) NOT NULL DEFAULT '' COMMENT 'URL信息',
- `leader_url` varchar(1024) NOT NULL DEFAULT '' COMMENT 'leaderURL信息',
- `leader` int(16) NOT NULL DEFAULT '0' COMMENT '状态: 1是leader,0不是leader',
- `worker_id` varchar(128) NOT NULL COMMENT 'worker地址',
- `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
- `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
- PRIMARY KEY (`id`),
- UNIQUE KEY `uniq_cluster_id_member_id` (`connect_cluster_id`,`member_id`)
-) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='worker信息表';
-
-
-DROP TABLE IF EXISTS `ks_kc_worker_connector`;
-CREATE TABLE `ks_kc_worker_connector` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
- `kafka_cluster_phy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'Kafka集群ID',
- `connect_cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'Connect集群ID',
- `connector_name` varchar(512) NOT NULL DEFAULT '' COMMENT 'Connector名称',
- `worker_member_id` varchar(256) NOT NULL DEFAULT '',
- `task_id` int(16) NOT NULL DEFAULT '-1' COMMENT 'Task的ID',
- `state` varchar(128) DEFAULT NULL COMMENT '任务状态',
- `worker_id` varchar(128) DEFAULT NULL COMMENT 'worker信息',
- `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
- `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
- PRIMARY KEY (`id`),
- UNIQUE KEY `uniq_relation` (`connect_cluster_id`,`connector_name`,`task_id`,`worker_member_id`)
-) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='Worker和Connector关系表';
-
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_CONNECTOR_FAILED_TASK_COUNT', '{\"value\" : 1}', 'connector失败状态的任务数量', 'admin');
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_CONNECTOR_UNASSIGNED_TASK_COUNT', '{\"value\" : 1}', 'connector未被分配的任务数量', 'admin');
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_CONNECT_CLUSTER_TASK_STARTUP_FAILURE_PERCENTAGE', '{\"value\" : 0.05}', 'Connect集群任务启动失败概率', 'admin');
-```
-
----
-
-### 升级至 `v3.1.0` 版本
-
-```sql
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_ZK_BRAIN_SPLIT', '{ \"value\": 1} ', 'ZK 脑裂', 'admin');
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_ZK_OUTSTANDING_REQUESTS', '{ \"amount\": 100, \"ratio\":0.8} ', 'ZK Outstanding 请求堆积数', 'admin');
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_ZK_WATCH_COUNT', '{ \"amount\": 100000, \"ratio\": 0.8 } ', 'ZK WatchCount 数', 'admin');
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_ZK_ALIVE_CONNECTIONS', '{ \"amount\": 10000, \"ratio\": 0.8 } ', 'ZK 连接数', 'admin');
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_ZK_APPROXIMATE_DATA_SIZE', '{ \"amount\": 524288000, \"ratio\": 0.8 } ', 'ZK 数据大小(Byte)', 'admin');
-INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_ZK_SENT_RATE', '{ \"amount\": 500000, \"ratio\": 0.8 } ', 'ZK 发包数', 'admin');
-
-```
-
-### 升级至 `v3.0.1` 版本
-
-**ES 索引模版**
-```bash
-# 新增 ks_kafka_zookeeper_metric 索引模版。
-# 可通过再次执行 bin/init_es_template.sh 脚本,创建该索引模版。
-
-# 索引模版内容
-PUT _template/ks_kafka_zookeeper_metric
-{
- "order" : 10,
- "index_patterns" : [
- "ks_kafka_zookeeper_metric*"
- ],
- "settings" : {
- "index" : {
- "number_of_shards" : "10"
- }
- },
- "mappings" : {
- "properties" : {
- "routingValue" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "clusterPhyId" : {
- "type" : "long"
- },
- "metrics" : {
- "properties" : {
- "AvgRequestLatency" : {
- "type" : "double"
- },
- "MinRequestLatency" : {
- "type" : "double"
- },
- "MaxRequestLatency" : {
- "type" : "double"
- },
- "OutstandingRequests" : {
- "type" : "double"
- },
- "NodeCount" : {
- "type" : "double"
- },
- "WatchCount" : {
- "type" : "double"
- },
- "NumAliveConnections" : {
- "type" : "double"
- },
- "PacketsReceived" : {
- "type" : "double"
- },
- "PacketsSent" : {
- "type" : "double"
- },
- "EphemeralsCount" : {
- "type" : "double"
- },
- "ApproximateDataSize" : {
- "type" : "double"
- },
- "OpenFileDescriptorCount" : {
- "type" : "double"
- },
- "MaxFileDescriptorCount" : {
- "type" : "double"
- }
- }
- },
- "key" : {
- "type" : "text",
- "fields" : {
- "keyword" : {
- "ignore_above" : 256,
- "type" : "keyword"
- }
- }
- },
- "timestamp" : {
- "format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
- "type" : "date"
- }
- }
- },
- "aliases" : { }
- }
-```
-
-
-**SQL 变更**
-
-```sql
-DROP TABLE IF EXISTS `ks_km_zookeeper`;
-CREATE TABLE `ks_km_zookeeper` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
- `cluster_phy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '物理集群ID',
- `host` varchar(128) NOT NULL DEFAULT '' COMMENT 'zookeeper主机名',
- `port` int(16) NOT NULL DEFAULT '-1' COMMENT 'zookeeper端口',
- `role` varchar(16) NOT NULL DEFAULT '' COMMENT '角色, leader follower observer',
- `version` varchar(128) NOT NULL DEFAULT '' COMMENT 'zookeeper版本',
- `status` int(16) NOT NULL DEFAULT '0' COMMENT '状态: 1存活,0未存活,11存活但是4字命令使用不了',
- `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
- `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
- PRIMARY KEY (`id`),
- UNIQUE KEY `uniq_cluster_phy_id_host_port` (`cluster_phy_id`,`host`, `port`)
-) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='Zookeeper信息表';
-
-
-DROP TABLE IF EXISTS `ks_km_group`;
-CREATE TABLE `ks_km_group` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
- `cluster_phy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
- `name` varchar(192) COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'Group名称',
- `member_count` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '成员数',
- `topic_members` text CHARACTER SET utf8 COMMENT 'group消费的topic列表',
- `partition_assignor` varchar(255) CHARACTER SET utf8 NOT NULL COMMENT '分配策略',
- `coordinator_id` int(11) NOT NULL COMMENT 'group协调器brokerId',
- `type` int(11) NOT NULL COMMENT 'group类型 0:consumer 1:connector',
- `state` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '' COMMENT '状态',
- `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
- `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
- PRIMARY KEY (`id`),
- UNIQUE KEY `uniq_cluster_phy_id_name` (`cluster_phy_id`,`name`)
-) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='Group信息表';
-
-```
-
-
-### 升级至 `v3.0.0` 版本
-
-**SQL 变更**
-
-```sql
-ALTER TABLE `ks_km_physical_cluster`
-ADD COLUMN `zk_properties` TEXT NULL COMMENT 'ZK配置' AFTER `jmx_properties`;
-```
-
----
-
-
-### 升级至 `v3.0.0-beta.2`版本
-
-**配置变更**
-
-```yaml
-
-# 新增配置
-spring:
- logi-security: # know-streaming 依赖的 logi-security 模块的数据库的配置,默认与 know-streaming 的数据库配置保持一致即可
- login-extend-bean-name: logiSecurityDefaultLoginExtendImpl # 使用的登录系统Service的Bean名称,无需修改
-
-# 线程池大小相关配置,在task模块中,新增了三类线程池,
-# 从而减少不同类型任务之间的相互影响,以及减少对logi-job内的线程池的影响
-thread-pool:
- task: # 任务模块的配置
- metrics: # metrics采集任务配置
- thread-num: 18 # metrics采集任务线程池核心线程数
- queue-size: 180 # metrics采集任务线程池队列大小
- metadata: # metadata同步任务配置
- thread-num: 27 # metadata同步任务线程池核心线程数
- queue-size: 270 # metadata同步任务线程池队列大小
- common: # 剩余其他任务配置
- thread-num: 15 # 剩余其他任务线程池核心线程数
- queue-size: 150 # 剩余其他任务线程池队列大小
-
-# 删除配置,下列配置将不再使用
-thread-pool:
- task: # 任务模块的配置
- heaven: # 采集任务配置
- thread-num: 20 # 采集任务线程池核心线程数
- queue-size: 1000 # 采集任务线程池队列大小
-
-```
-
-**SQL 变更**
-
-```sql
--- 多集群管理权限2022-09-06新增
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2000', '多集群管理查看', '1593', '1', '2', '多集群管理查看', '0', 'know-streaming');
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2002', 'Topic-迁移副本', '1593', '1', '2', 'Topic-迁移副本', '0', 'know-streaming');
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2004', 'Topic-扩缩副本', '1593', '1', '2', 'Topic-扩缩副本', '0', 'know-streaming');
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2006', 'Cluster-LoadReBalance-周期均衡', '1593', '1', '2', 'Cluster-LoadReBalance-周期均衡', '0', 'know-streaming');
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2008', 'Cluster-LoadReBalance-立即均衡', '1593', '1', '2', 'Cluster-LoadReBalance-立即均衡', '0', 'know-streaming');
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2010', 'Cluster-LoadReBalance-设置集群规格', '1593', '1', '2', 'Cluster-LoadReBalance-设置集群规格', '0', 'know-streaming');
-
-
--- 系统管理权限2022-09-06新增
-INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('3000', '系统管理查看', '1595', '1', '2', '系统管理查看', '0', 'know-streaming');
-
-
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2000', '0', 'know-streaming');
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2002', '0', 'know-streaming');
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2004', '0', 'know-streaming');
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2006', '0', 'know-streaming');
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2008', '0', 'know-streaming');
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2010', '0', 'know-streaming');
-INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '3000', '0', 'know-streaming');
-
--- 修改字段长度
-ALTER TABLE `logi_security_oplog`
- CHANGE COLUMN `operator_ip` `operator_ip` VARCHAR(64) NOT NULL COMMENT '操作者ip' ,
- CHANGE COLUMN `operator` `operator` VARCHAR(64) NULL DEFAULT NULL COMMENT '操作者账号' ,
- CHANGE COLUMN `operate_page` `operate_page` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '操作页面' ,
- CHANGE COLUMN `operate_type` `operate_type` VARCHAR(64) NOT NULL COMMENT '操作类型' ,
- CHANGE COLUMN `target_type` `target_type` VARCHAR(64) NOT NULL COMMENT '对象分类' ,
- CHANGE COLUMN `target` `target` VARCHAR(1024) NOT NULL COMMENT '操作对象' ,
- CHANGE COLUMN `operation_methods` `operation_methods` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '操作方式' ;
-```
-
----
-
-### 升级至 `v3.0.0-beta.1`版本
-
-**SQL 变更**
-
-1、在`ks_km_broker`表增加了一个监听信息字段。
-2、为`logi_security_oplog`表 operation_methods 字段设置默认值''。
-因此需要执行下面的 sql 对数据库表进行更新。
-
-```sql
-ALTER TABLE `ks_km_broker`
-ADD COLUMN `endpoint_map` VARCHAR(1024) NOT NULL DEFAULT '' COMMENT '监听信息' AFTER `update_time`;
-
-ALTER TABLE `logi_security_oplog`
-ALTER COLUMN `operation_methods` set default '';
-
-```
-
----
-
-### `2.x`版本 升级至 `v3.0.0-beta.0`版本
-
-**升级步骤:**
-
-1. 依旧使用**`2.x 版本的 DB`**,在上面初始化 3.0.0 版本所需数据库表结构及数据;
-2. 将 2.x 版本中的集群,在 3.0.0 版本,手动逐一接入;
-3. 将 Topic 业务数据,迁移至 3.0.0 表中,详见下方 SQL;
-
-**注意事项**
-
-- 建议升级 3.0.0 版本过程中,保留 2.x 版本的使用,待 3.0.0 版本稳定使用后,再下线 2.x 版本;
-- 3.0.0 版本仅需要`集群信息`及`Topic的描述信息`。2.x 版本的 DB 的其他数据 3.0.0 版本都不需要;
-- 部署 3.0.0 版本之后,集群、Topic 等指标数据都为空,3.0.0 版本会周期进行采集,运行一段时间之后就会有该数据了,因此不会将 2.x 中的指标数据进行迁移;
-
-**迁移数据**
-
-```sql
--- 迁移Topic的备注信息。
--- 需在 3.0.0 部署完成后,再执行该SQL。
--- 考虑到 2.x 版本中还存在增量数据,因此建议改SQL周期执行,是的增量数据也能被迁移至 3.0.0 版本中。
-
-UPDATE ks_km_topic
- INNER JOIN
- (SELECT
- topic.cluster_id AS cluster_id,
- topic.topic_name AS topic_name,
- topic.description AS description
- FROM topic WHERE description != ''
- ) AS t
-
-ON ks_km_topic.cluster_phy_id = t.cluster_id
- AND ks_km_topic.topic_name = t.topic_name
- AND ks_km_topic.id > 0
- SET ks_km_topic.description = t.description;
-```
\ No newline at end of file
diff --git a/docs/user_guide/faq.md b/docs/user_guide/faq.md
deleted file mode 100644
index 1656ec37..00000000
--- a/docs/user_guide/faq.md
+++ /dev/null
@@ -1,228 +0,0 @@
-# FAQ
-
-## 8.1、支持哪些 Kafka 版本?
-
-- 支持 0.10+ 的 Kafka 版本;
-- 支持 ZK 及 Raft 运行模式的 Kafka 版本;
-
-
-
-## 8.1、2.x 版本和 3.0 版本有什么差异?
-
-**全新设计理念**
-
-- 在 0 侵入、0 门槛的前提下提供直观 GUI 用于管理和观测 Apache Kafka®,帮助用户降低 Kafka CLI 操作门槛,轻松实现对原生 Kafka 集群的可管、可见、可掌控,提升 Kafka 使用体验和降低管理成本。
-- 支持海量集群一键接入,无需任何改造,即可实现集群深度纳管,真正的 0 侵入、插件化系统设计,覆盖 0.10.x-3.x.x 众多 Kafka 版本无缝纳管。
-
-**开源协议调整**
-
-- 3.x:AGPL 3.0
-- 2.x:Apache License 2.0
-
-更多具体内容见:[新旧版本对比](https://doc.knowstreaming.com/product/9-attachment#92%E6%96%B0%E6%97%A7%E7%89%88%E6%9C%AC%E5%AF%B9%E6%AF%94)
-
-
-
-## 8.3、页面流量信息等无数据?
-
-- 1、`Broker JMX`未正确开启
-
-可以参看:[Jmx 连接配置&问题解决](https://doc.knowstreaming.com/product/9-attachment#91jmx-%E8%BF%9E%E6%8E%A5%E5%A4%B1%E8%B4%A5%E9%97%AE%E9%A2%98%E8%A7%A3%E5%86%B3)
-
-- 2、`ES` 存在问题
-
-建议使用`ES 7.6`版本,同时创建近 7 天的索引,具体见:[快速开始](./1-quick-start.md) 中的 ES 索引模版及索引创建。
-
-
-
-## 8.4、`Jmx`连接失败如何解决?
-
-- 参看 [Jmx 连接配置&问题解决](https://doc.knowstreaming.com/product/9-attachment#91jmx-%E8%BF%9E%E6%8E%A5%E5%A4%B1%E8%B4%A5%E9%97%AE%E9%A2%98%E8%A7%A3%E5%86%B3) 说明。
-
-
-
-## 8.5、有没有 API 文档?
-
-`KnowStreaming` 采用 Swagger 进行 API 说明,在启动 KnowStreaming 服务之后,就可以从下面地址看到。
-
-Swagger-API 地址: [http://IP:PORT/swagger-ui.html#/](http://IP:PORT/swagger-ui.html#/)
-
-
-
-## 8.6、删除 Topic 成功后,为何过段时间又出现了?
-
-**原因说明:**
-
-`KnowStreaming` 会去请求 Topic 的 endoffset 信息,要获取这个信息就需要发送 metadata 请求,发送 metadata 请求的时候,如果集群允许自动创建 Topic,那么当 Topic 不存在时,就会自动将该 Topic 创建出来。
-
-**问题解决:**
-
-因为在 `KnowStreaming` 上,禁止 Kafka 客户端内部元信息获取这个动作非常的难做到,因此短时间内这个问题不好从 `KnowStreaming` 上解决。
-
-当然,对于不存在的 Topic,`KnowStreaming` 是不会进行元信息请求的,因此也不用担心会莫名其妙的创建一个 Topic 出来。
-
-但是,另外一点,对于开启允许 Topic 自动创建的集群,建议是关闭该功能,开启是非常危险的,如果关闭之后,`KnowStreaming` 也不会有这个问题。
-
-最后这里举个开启这个配置后,非常危险的代码例子吧:
-
-```java
-for (int i= 0; i < 100000; ++i) {
- // 如果是客户端类似这样写的,那么一启动,那么将创建10万个Topic出来,集群元信息瞬间爆炸,controller可能就不可服务了。
- producer.send(new ProducerRecord("know_streaming" + i,"hello logi_km"));
-}
-```
-
-
-
-## 8.7、如何在不登录的情况下,调用接口?
-
-步骤一:接口调用时,在 header 中,增加如下信息:
-
-```shell
-# 表示开启登录绕过
-Trick-Login-Switch : on
-
-# 登录绕过的用户, 这里可以是admin, 或者是其他的, 但是必须在系统管理->用户管理中设置了该用户。
-Trick-Login-User : admin
-```
-
-
-
-步骤二:点击右上角"系统管理",选择配置管理,在页面中添加以下键值对。
-
-```shell
-# 模块选择
-SECURITY.LOGIN
-
-# 设置的配置键,必须是这个
-SECURITY.TRICK_USERS
-
-# 设置的value,是json数组的格式,包含步骤一header中设置的用户名,例如
-[ "admin", "logi"]
-```
-
-
-
-步骤三:解释说明
-
-设置完成上面两步之后,就可以直接调用需要登录的接口了。
-
-但是还有一点需要注意,绕过的用户仅能调用他有权限的接口,比如一个普通用户,那么他就只能调用普通的接口,不能去调用运维人员的接口。
-
-## 8.8、Specified key was too long; max key length is 767 bytes
-
-**原因:** 不同版本的 InoDB 引擎,参数‘innodb_large_prefix’默认值不同,即在 5.6 默认值为 OFF,5.7 默认值为 ON。
-
-对于引擎为 InnoDB,innodb_large_prefix=OFF,且行格式为 Antelope 即支持 REDUNDANT 或 COMPACT 时,索引键前缀长度最大为 767 字节。innodb_large_prefix=ON,且行格式为 Barracuda 即支持 DYNAMIC 或 COMPRESSED 时,索引键前缀长度最大为 3072 字节。
-
-**解决方案:**
-
-- 减少 varchar 字符大小低于 767/4=191。
-- 将字符集改为 latin1(一个字符=一个字节)。
-- 开启‘innodb_large_prefix’,修改默认行格式‘innodb_file_format’为 Barracuda,并设置 row_format=dynamic。
-
-## 8.9、出现 ESIndexNotFoundEXception 报错
-
-**原因 :**没有创建 ES 索引模版
-
-**解决方案:**执行 init_es_template.sh 脚本,创建 ES 索引模版即可。
-
-## 8.10、km-console 打包构建失败
-
-首先,**请确保您正在使用最新版本**,版本列表见 [Tags](https://github.com/didi/KnowStreaming/tags)。如果不是最新版本,请升级后再尝试有无问题。
-
-常见的原因是由于工程依赖没有正常安装,导致在打包过程中缺少依赖,造成打包失败。您可以检查是否有以下文件夹,且文件夹内是否有内容
-
-```
-KnowStreaming/km-console/node_modules
-KnowStreaming/km-console/packages/layout-clusters-fe/node_modules
-KnowStreaming/km-console/packages/config-manager-fe/node_modules
-```
-
-如果发现没有对应的 `node_modules` 目录或着目录内容为空,说明依赖没有安装成功。请按以下步骤操作,
-
-1. 手动删除上述三个文件夹(如果有)
-
-2. 如果之前是通过 `mvn install` 打包 `km-console`,请到项目根目录(KnowStreaming)下重新输入该指令进行打包。观察打包过程有无报错。如有报错,请见步骤 4。
-
-3. 如果是通过本地独立构建前端工程的方式(指直接执行 `npm run build`),请进入 `KnowStreaming/km-console` 目录,执行下述步骤(注意:执行时请确保您在使用 `node v12` 版本)
-
- a. 执行 `npm run i`。如有报错,请见步骤 4。
-
- b. 执行 `npm run build`。如有报错,请见步骤 4。
-
-4. 麻烦联系我们协助解决。推荐提供以下信息,方面我们快速定位问题,示例如下。
-
-```
-操作系统: Mac
-命令行终端:bash
-Node 版本: v12.22.12
-复现步骤: 1. -> 2.
-错误截图:
-```
-
-## 8.11、在 `km-console` 目录下执行 `npm run start` 时看不到应用构建和热加载过程?如何启动单个应用?
-
-需要到具体的应用中执行 `npm run start`,例如 `cd packages/layout-clusters-fe` 后,执行 `npm run start`。
-
-应用启动后需要到基座应用中查看(需要启动基座应用,即 layout-clusters-fe)。
-
-
-## 8.12、权限识别失败问题
-1、使用admin账号登陆KnowStreaming时,点击系统管理-用户管理-角色管理-新增角色,查看页面是否正常。
-
- -
-2、查看'/logi-security/api/v1/permission/tree'接口返回值,出现如下图所示乱码现象。
-
-
-3、查看logi_security_permission表,看看是否出现了中文乱码现象。
-
-根据以上几点,我们可以确定是由于数据库乱码造成的权限识别失败问题。
-
-+ 原因:由于数据库编码和我们提供的脚本不一致,数据库里的数据发生了乱码,因此出现权限识别失败问题。
-+ 解决方案:清空数据库数据,将数据库字符集调整为utf8,最后重新执行[dml-logi.sql](https://github.com/didi/KnowStreaming/blob/master/km-dist/init/sql/dml-logi.sql)脚本导入数据即可。
-
-
-## 8.13、接入开启kerberos认证的kafka集群
-
-1. 部署KnowStreaming的机器上安装krb客户端;
-2. 替换/etc/krb5.conf配置文件;
-3. 把kafka对应的keytab复制到改机器目录下;
-4. 接入集群时认证配置,配置信息根据实际情况填写;
-```json
-{
- "security.protocol": "SASL_PLAINTEXT",
- "sasl.mechanism": "GSSAPI",
- "sasl.jaas.config": "com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true keyTab=\"/etc/keytab/kafka.keytab\" storeKey=true useTicketCache=false principal=\"kafka/kafka@TEST.COM\";",
- "sasl.kerberos.service.name": "kafka"
-}
-```
-
-
-## 8.14、对接Ldap的配置
-
-```yaml
-# 需要在application.yml中增加如下配置。相关配置的信息,按实际情况进行调整
-account:
- ldap:
- url: ldap://127.0.0.1:8080/
- basedn: DC=senz,DC=local
- factory: com.sun.jndi.ldap.LdapCtxFactory
- filter: sAMAccountName
- security:
- authentication: simple
- principal: CN=search,DC=senz,DC=local
- credentials: xxxxxxx
- auth-user-registration: false # 是否注册到mysql,默认false
- auth-user-registration-role: 1677 # 1677是超级管理员角色的id,如果赋予想默认赋予普通角色,可以到ks新建一个。
-
-# 需要在application.yml中修改如下配置
-spring:
- logi-security:
- login-extend-bean-name: ksLdapLoginService # 表示使用ldap的service
-```
-
-## 8.15、测试时使用Testcontainers的说明
-1. 需要docker运行环境 [Testcontainers运行环境说明](https://www.testcontainers.org/supported_docker_environment/)
-2. 如果本机没有docker,可以使用[远程访问docker](https://docs.docker.com/config/daemon/remote-access/) [Testcontainers配置说明](https://www.testcontainers.org/features/configuration/#customizing-docker-host-detection)
\ No newline at end of file
diff --git a/docs/user_guide/新旧对比手册.md b/docs/user_guide/新旧对比手册.md
deleted file mode 100644
index d934e41f..00000000
--- a/docs/user_guide/新旧对比手册.md
+++ /dev/null
@@ -1,92 +0,0 @@
-## 9.2、新旧版本对比
-
-### 9.2.1、全新的设计理念
-
-- 在 0 侵入、0 门槛的前提下提供直观 GUI 用于管理和观测 Apache Kafka®,帮助用户降低 Kafka CLI 操作门槛,轻松实现对原生 Kafka 集群的可管、可见、可掌控,提升 Kafka 使用体验和降低管理成本。
-- 支持海量集群一键接入,无需任何改造,即可实现集群深度纳管,真正的 0 侵入、插件化系统设计,覆盖 0.10.x-3.x.x 众多 Kafka 版本无缝纳管。
-
-### 9.2.2、产品名称&协议
-
-- Know Streaming V3.0
-
- - 名称:Know Streaming
- - 协议:AGPL 3.0
-
-- Logi-KM V2.x
-
- - 名称:Logi-KM
- - 协议:Apache License 2.0
-
-### 9.2.3、功能架构
-
-- Know Streaming V3.0
-
-
-
-- Logi-KM V2.x
-
-
-
-### 9.2.4、功能变更
-
-- 多集群管理
-
- - 增加健康监测体系、关键组件&指标 GUI 展示
- - 增加 2.8.x 以上 Kafka 集群接入,覆盖 0.10.x-3.x
- - 删除逻辑集群、共享集群、Region 概念
-
-- Cluster 管理
-
- - 增加集群概览信息、集群配置变更记录
- - 增加 Cluster 健康分,健康检查规则支持自定义配置
- - 增加 Cluster 关键指标统计和 GUI 展示,支持自定义配置
- - 增加 Cluster 层 I/O、Disk 的 Load Reblance 功能,支持定时均衡任务(企业版)
- - 删除限流、鉴权功能
- - 删除 APPID 概念
-
-- Broker 管理
-
- - 增加 Broker 健康分
- - 增加 Broker 关键指标统计和 GUI 展示,支持自定义配置
- - 增加 Broker 参数配置功能,需重启生效
- - 增加 Controller 变更记录
- - 增加 Broker Datalogs 记录
- - 删除 Leader Rebalance 功能
- - 删除 Broker 优先副本选举
-
-- Topic 管理
-
- - 增加 Topic 健康分
- - 增加 Topic 关键指标统计和 GUI 展示,支持自定义配置
- - 增加 Topic 参数配置功能,可实时生效
- - 增加 Topic 批量迁移、Topic 批量扩缩副本功能
- - 增加查看系统 Topic 功能
- - 优化 Partition 分布的 GUI 展示
- - 优化 Topic Message 数据采样
- - 删除 Topic 过期概念
- - 删除 Topic 申请配额功能
-
-- Consumer 管理
-
- - 优化了 ConsumerGroup 展示形式,增加 Consumer Lag 的 GUI 展示
-
-- ACL 管理
-
- - 增加原生 ACL GUI 配置功能,可配置生产、消费、自定义多种组合权限
- - 增加 KafkaUser 功能,可自定义新增 KafkaUser
-
-- 消息测试(企业版)
-
- - 增加生产者消息模拟器,支持 Data、Flow、Header、Options 自定义配置(企业版)
- - 增加消费者消息模拟器,支持 Data、Flow、Header、Options 自定义配置(企业版)
-
-- Job
-
- - 优化 Job 模块,支持任务进度管理
-
-- 系统管理
-
- - 优化用户、角色管理体系,支持自定义角色配置页面及操作权限
- - 优化审计日志信息
- - 删除多租户体系
- - 删除工单流程
\ No newline at end of file
diff --git a/docs/user_guide/用户使用手册.md b/docs/user_guide/用户使用手册.md
deleted file mode 100644
index 6179cb3b..00000000
--- a/docs/user_guide/用户使用手册.md
+++ /dev/null
@@ -1,848 +0,0 @@
-
-## 5.0、产品简介
-
-`Know Streaming` 是一套云原生的 Kafka 管控平台,脱胎于众多互联网内部多年的 Kafka 运营实践经验,专注于 Kafka 运维管控、监控告警、资源治理、多活容灾等核心场景,在用户体验、监控、运维管控上进行了平台化、可视化、智能化的建设,提供一系列特色的功能,极大地方便了用户和运维人员的日常使用,让普通运维人员都能成为 Kafka 专家。
-
-## 5.1、功能架构
-
-
-
-## 5.2、体验路径
-
-下面是用户第一次使用我们产品的典型体验路径:
-
-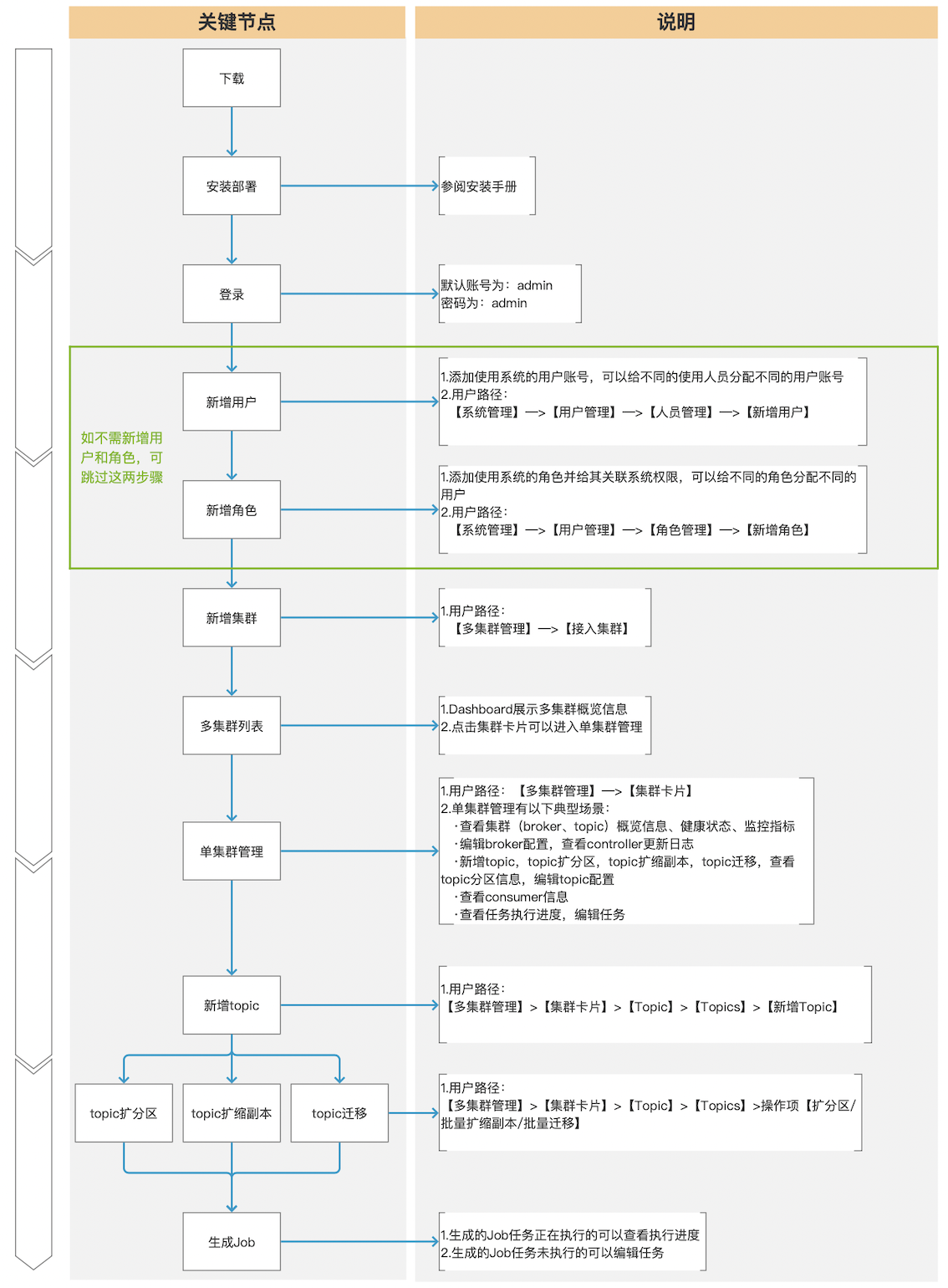
-
-## 5.3、常用功能
-
-### 5.3.1、用户管理
-
-用户管理是提供给管理员进行人员管理和用户角色管理的功能模块,可以进行新增用户和分配角色。下面是一个典型的场景:
-eg:团队加入了新成员,需要给这位成员分配一个使用系统的账号,需要以下几个步骤
-
-- 步骤 1:点击“系统管理”>“用户管理”>“人员管理”>“新增用户”,输入“账号”、“实名”、“密码”,根据此账号所需要的权限,选择此账号所对应的角色。如果有满足权限的角色,则用户新增成功。如果没有满足权限的角色,则需要新增角色(步骤 2)
-- 步骤 2:点击“系统管理”>“用户管理”>“角色管理”>“新增角色”。输入角色名称和描述,给此角色分配权限,点击“确定”,角色新增成功
-
-- 步骤 3:根据此新增的角色,参考步骤 1,重新新增用户
-
-- 步骤 4:此用户账号新增成功,可以进行登录产品使用
-
-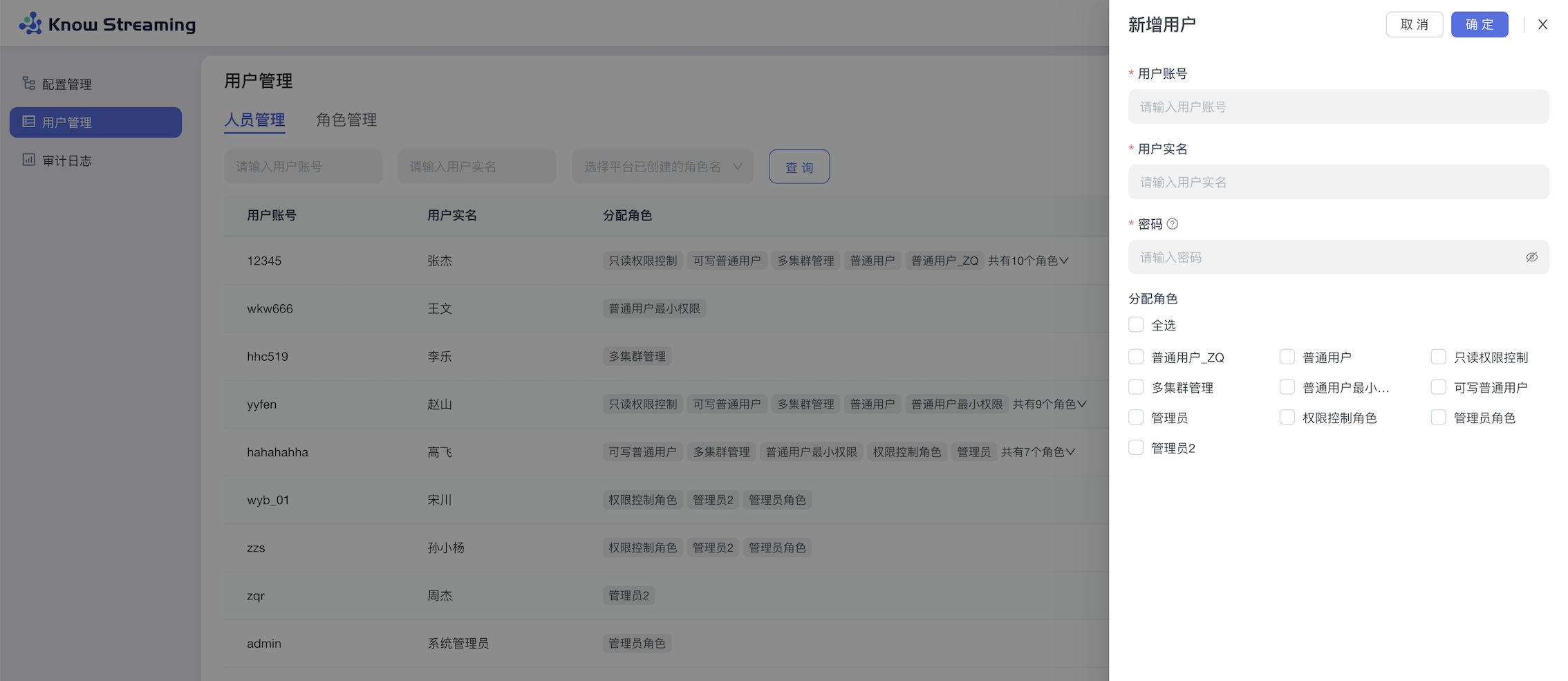
-
-### 5.3.2、接入集群
-
-- 步骤 1:点击“多集群管理”>“接入集群”
-
-- 步骤 2:填写相关集群信息
-
-- 集群名称:支持中英文、下划线、短划线(-),最长 128 字符。平台内不能重复
- - Bootstrap Servers:输入 Bootstrap Servers 地址。输入完成之后会进行连接测试,测试完成之后会给出测试结果连接成功 or 连接失败(以及失败的原因)。
- - Zookeeper:输入 zookeeper 地址,输入完成之后会进行连接测试,测试完成之后会给出测试结果连接成功 or 连接失败(以及失败的原因)
- - Metrics 选填:JMX Port,输入 JMX 端口号;MaxConn,输入服务端最大允许的连接数
- - Security:若有 JMX 账号密码,则输入账号密码
- - Version:选择所支持的 kafka 版本,如果没有匹配则可以选择相近版本
- - 集群配置选填:输入用户创建 kafka 客户端进行信息获取的相关配置
- - 集群描述:最多 200 字符
-
-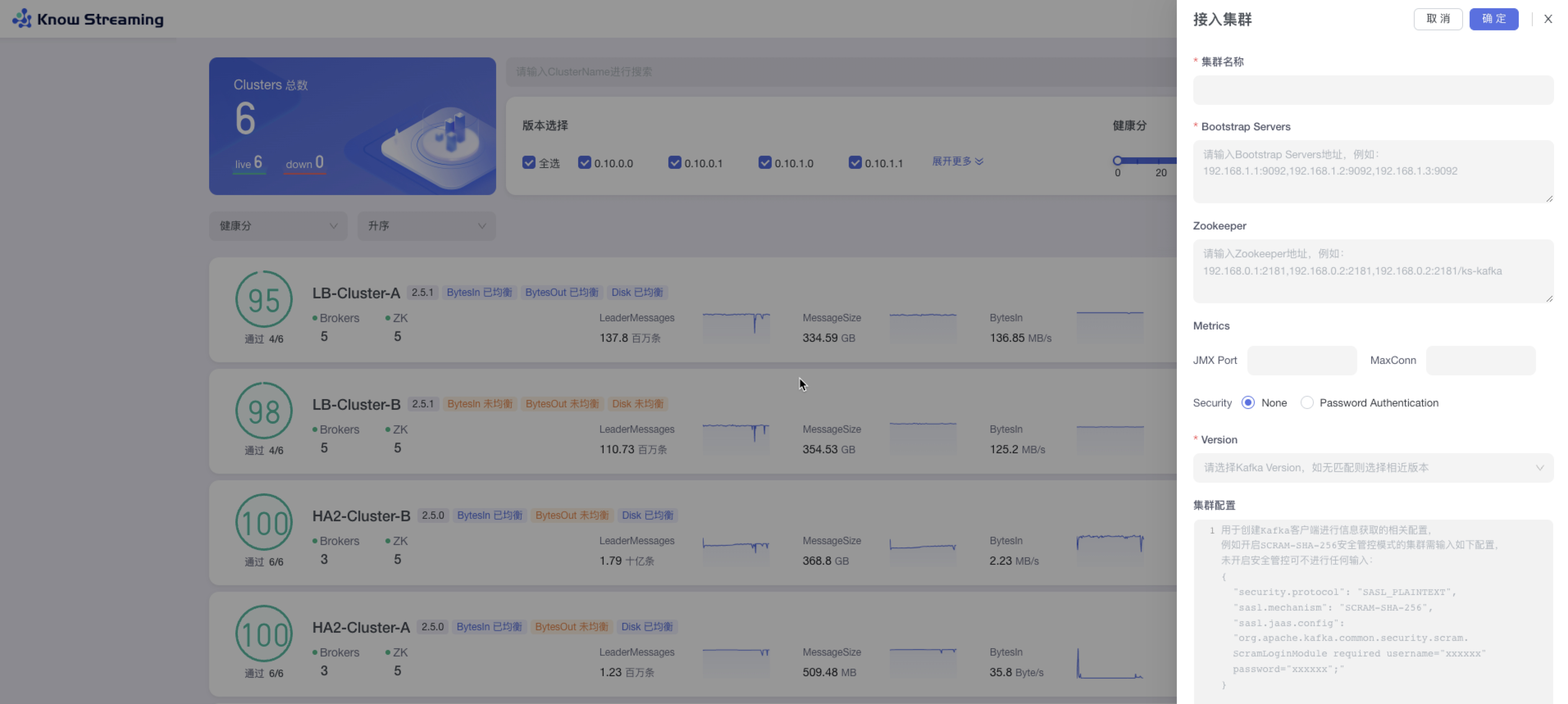
-
-### 5.3.3、新增 Topic
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“新增 Topic”按钮>“创建 Topic“抽屉
-
-- 步骤 2:输入“Topic 名称(不能重复)”、“Topic 描述”、“分区数”、“副本数”、“数据保存时间”、“清理策略(删除或压缩)”
-
-- 步骤 3:展开“更多配置”可以打开高级配置选项,根据自己需要输入相应配置参数
-
-- 步骤 4:点击“确定”,创建 Topic 完成
-
-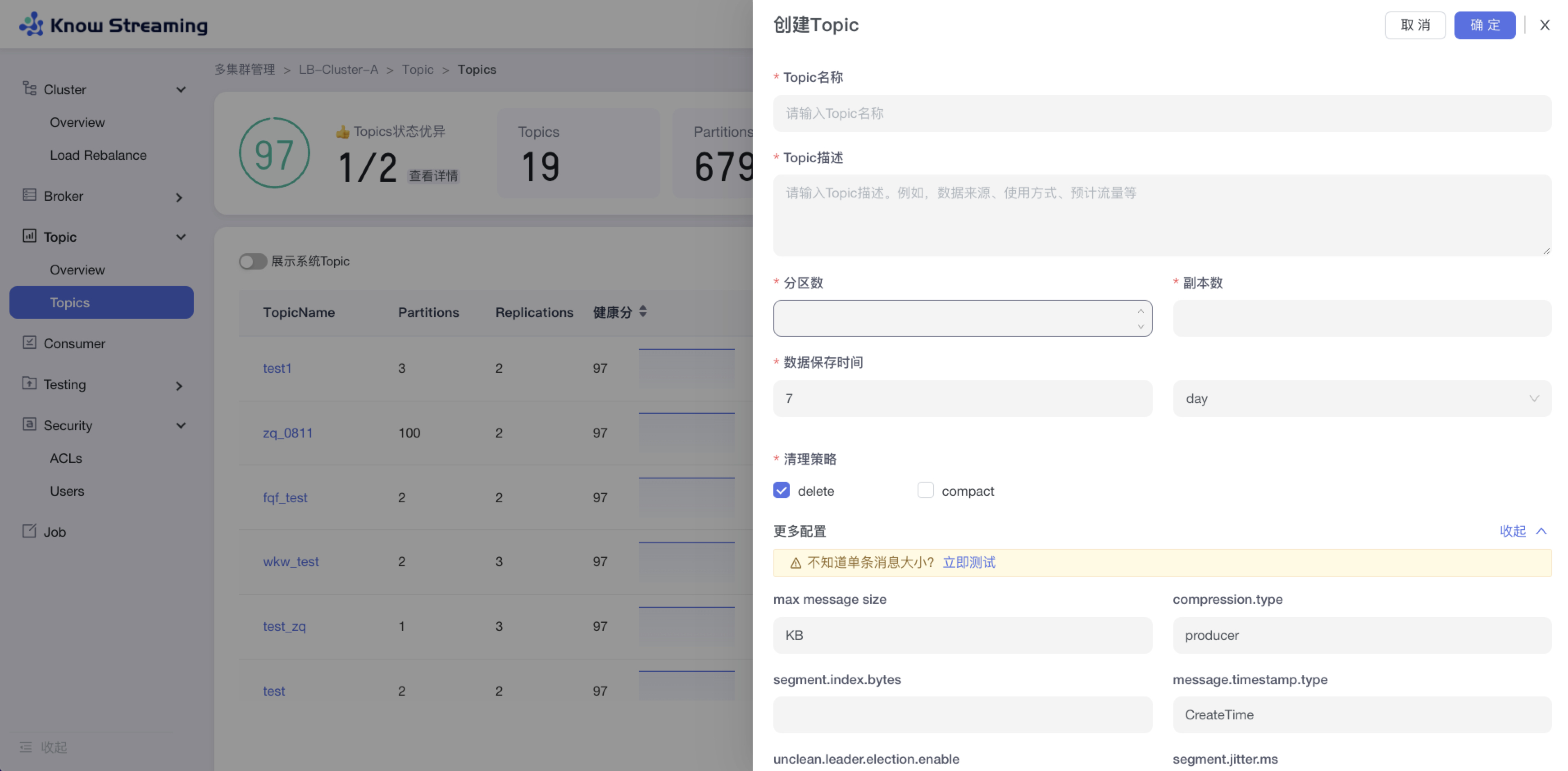
-
-### 5.3.4、Topic 扩分区
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“Topic 列表“>操作项”扩分区“>“扩分区”抽屉
-
-- 步骤 2:扩分区抽屉展示内容为“流量的趋势图”、“当前分区数及支持的最低消息写入速率”、“扩分区后支持的最低消息写入速率”
-
-- 步骤 3:输入所需的分区总数,自动计算出扩分区后支持的最低消息写入速率
-
-- 步骤 4:点击确定,扩分区完成
-
-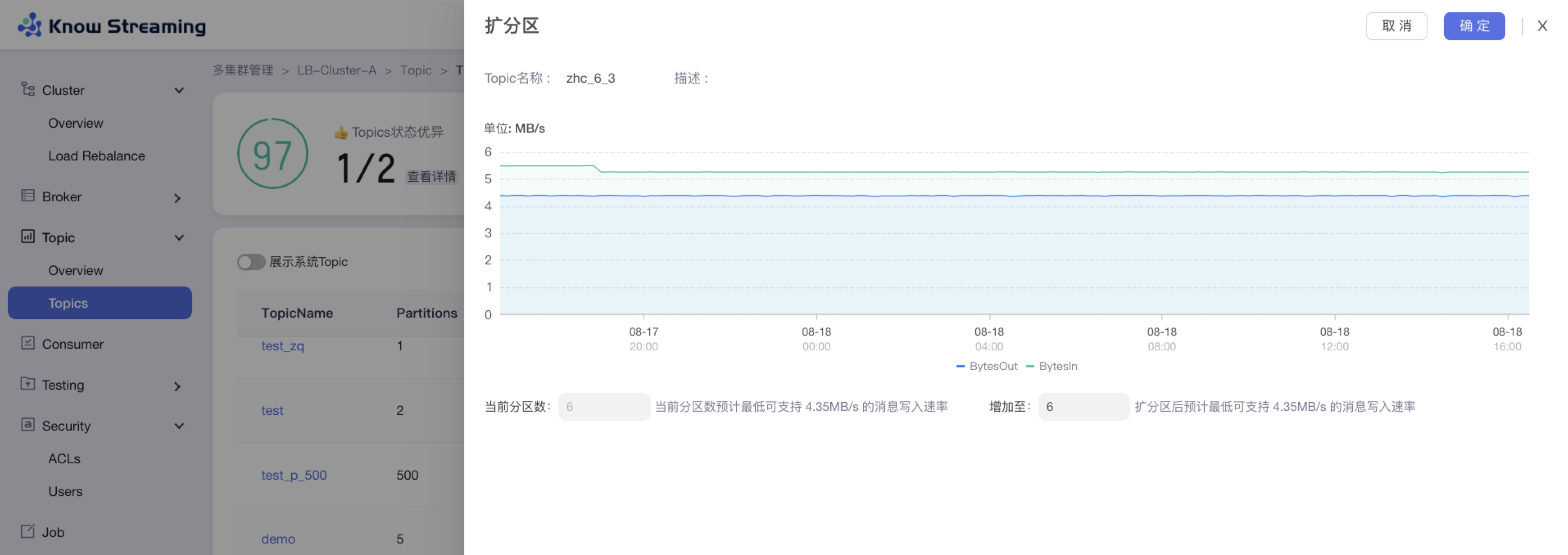
-
-### 5.3.5、Topic 批量扩缩副本
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“批量操作下拉“>“批量扩缩副本“>“批量扩缩容”抽屉
-
-- 步骤 2:选择所需要进行扩缩容的 Topic,可多选,所选择的 Topic 出现在下方 Topic 列表中
-
-- 步骤 3:Topic 列表展示 Topic“近三天平均流量”、“近三天峰值流量及时间”、“Partition 数”、”当前副本数“、“新副本数”
-
-- 步骤 4:扩容时,选择目标节点,新增的副本会在选择的目标节点上;缩容时不需要选择目标节点,自动删除最后一个(或几个)副本
-
-- 步骤 5:输入迁移任务配置参数,包含限流值和任务执行时间
-
-- 步骤 6:输入任务描述
-
-- 步骤 7:点击“确定”,创建 Topic 扩缩副本任务
-
-- 步骤 8:去“Job”模块的 Job 列表查看创建的任务,如果已经执行则可以查看执行进度;如果未开始执行则可以编辑任务
-
-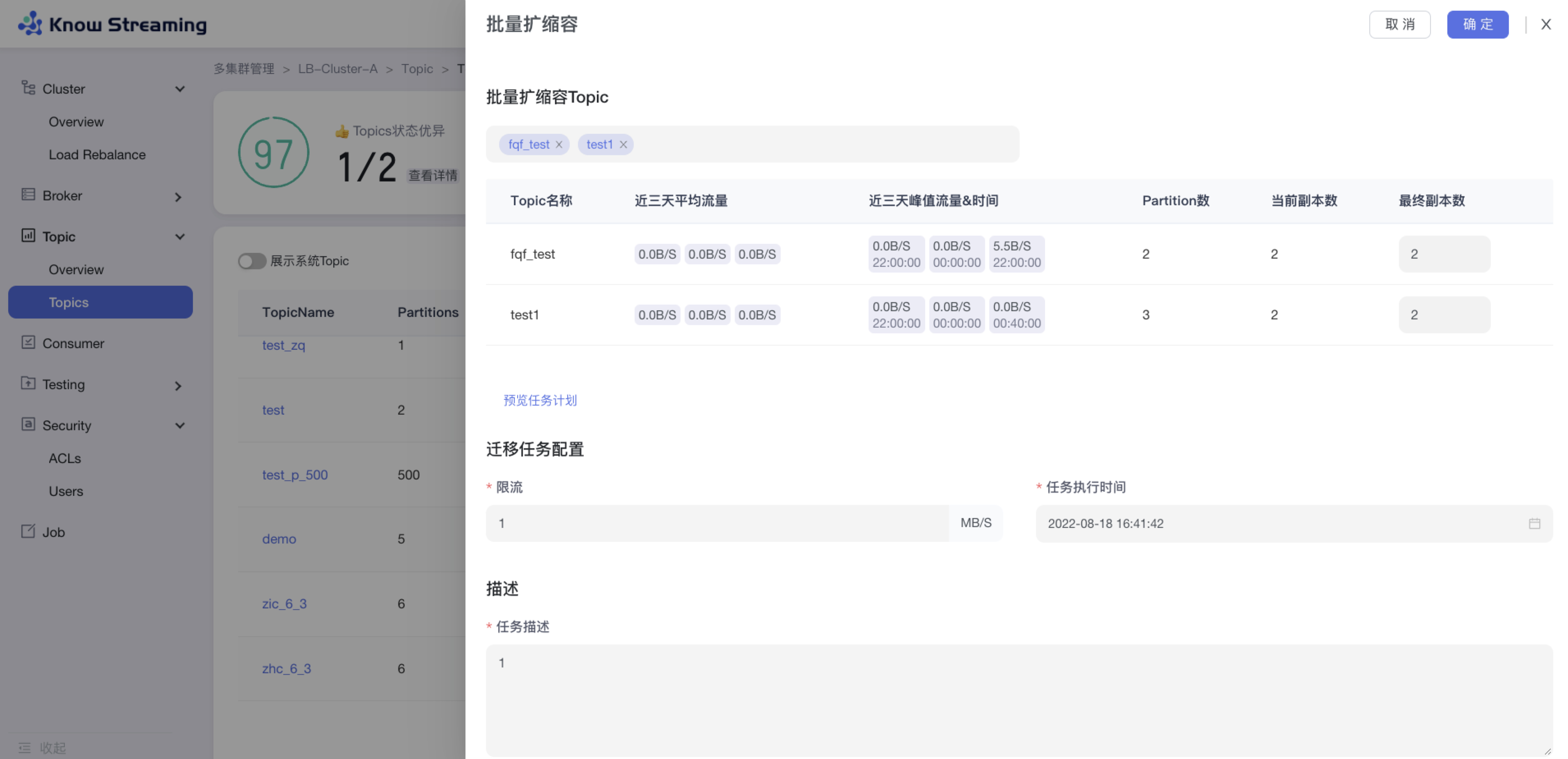
-
-### 5.3.6、Topic 批量迁移
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“批量操作下拉“>“批量迁移“>“批量迁移”抽屉
-
-- 步骤 2:选择所需要进行迁移的 Topic,可多选,所选择的 Topic 出现在下方 Topic 列表中
-
-- 步骤 3:选择所需要迁移的 partition 和迁移数据的时间范围
-
-- 步骤 4:选择目标节点(节点数必须不小于最大副本数)
-
-- 步骤 5:点击“预览任务计划”,打开“任务计划”二次抽屉,可对目标 Broker ID 进行编辑
-
-- 步骤 6:输入迁移任务配置参数,包含限流值和任务执行时间
-
-- 步骤 7:输入任务描述
-
-- 步骤 8:点击“确定”,创建 Topic 迁移任务
-
-- 步骤 9:去“Job”模块的 Job 列表查看创建的任务,如果已经执行则可以查看执行进度;如果未开始执行则可以编辑任务
-
-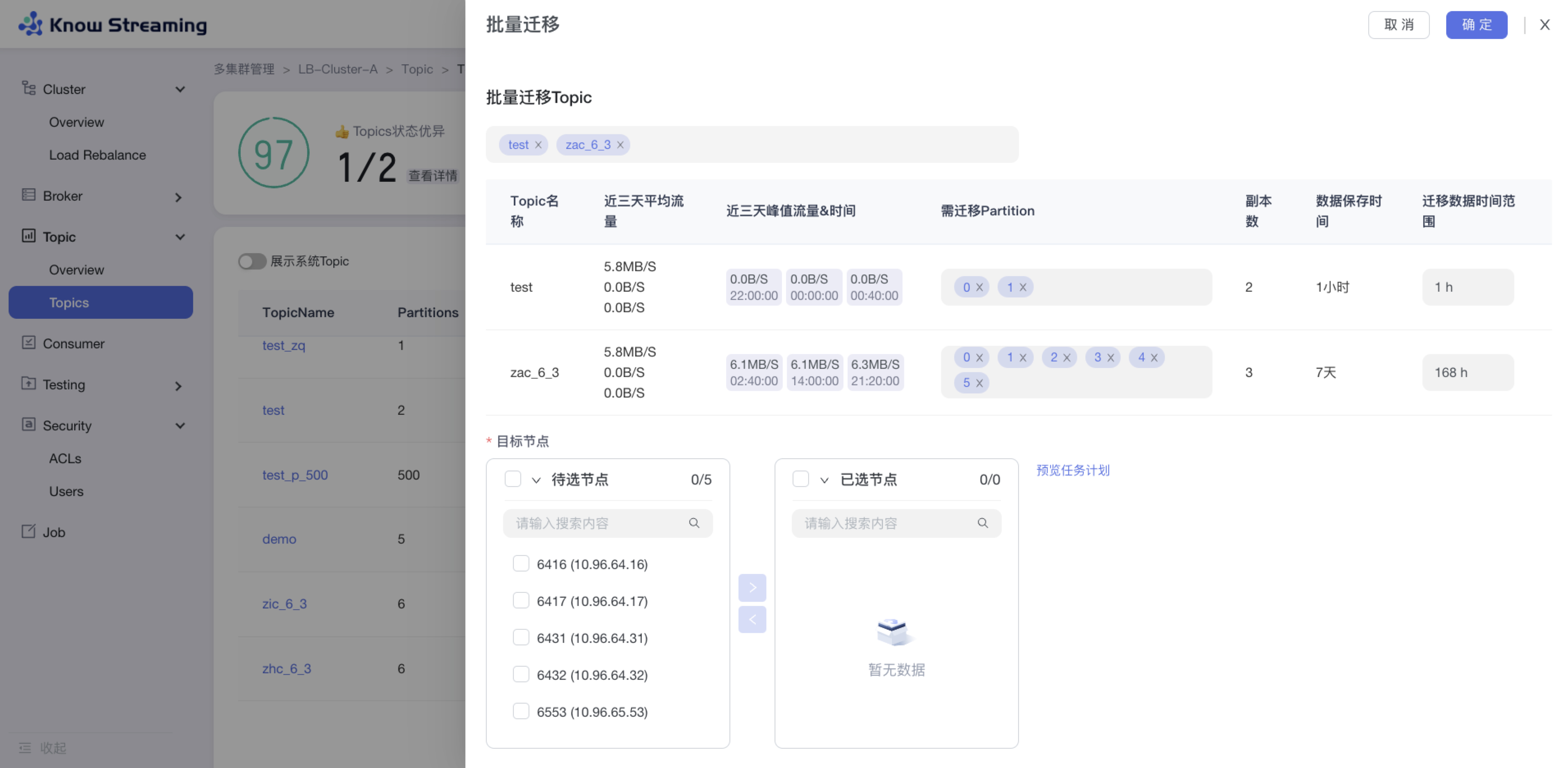
-
-### 5.3.7、设置 Cluster 健康检查规则
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“集群健康状态旁边 icon”>“健康度设置抽屉”
-
-- 步骤 2:健康度设置抽屉展示出了检查项和其对应的权重,可以修改检查项的检查规则
-
-- 步骤 3:检查规则可配置,分别为
-
- - Cluster:集群 controller 数不等于 1(数字不可配置)不通过
- - Broker:RequestQueueSize 大于等于 10(默认为 10,可配置数字)不通过
- - Broker:NetworkProcessorAvgIdlePercent 的 Idle 小于等于 0.8%(默认为 0.8%,可配置数字)不通过
- - Topic:无 leader 的 Topic 数量,大于等于 1(默认为 1,数字可配置)不通过
- - Topic:Topic 在 10(默认为 10,数字可配置)个周期内 8(默认为 8,数字可配置)个周期内处于未同步的状态则不通过
- - ConsumerGroup:Group 在 10(默认为 10,数字可配置)个周期内进行 8(默认为 8,数字可配置)次 re-balance 不通过
-
-- 步骤 4:设置完成后,点击“确认”,健康检查规则设置成功
-
-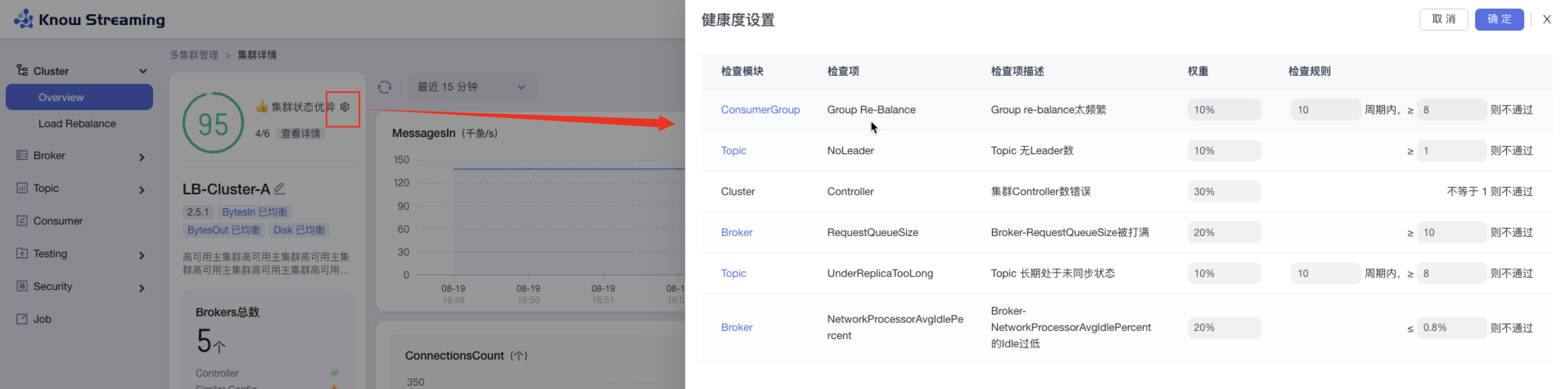
-
-### 5.3.8、图表指标筛选
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“指标筛选 icon”>“指标筛选抽屉”
-
-- 步骤 2:指标筛选抽屉展示信息为以下几类“Health”、“Cluster”、“Broker”、“Consumer”、“Security”、“Job”
-
-- 步骤 3:默认勾选比较重要的指标进行展示。根据需要选中/取消选中相应指标,点击”确认“,指标筛选成功,展示的图表随之变化
-
-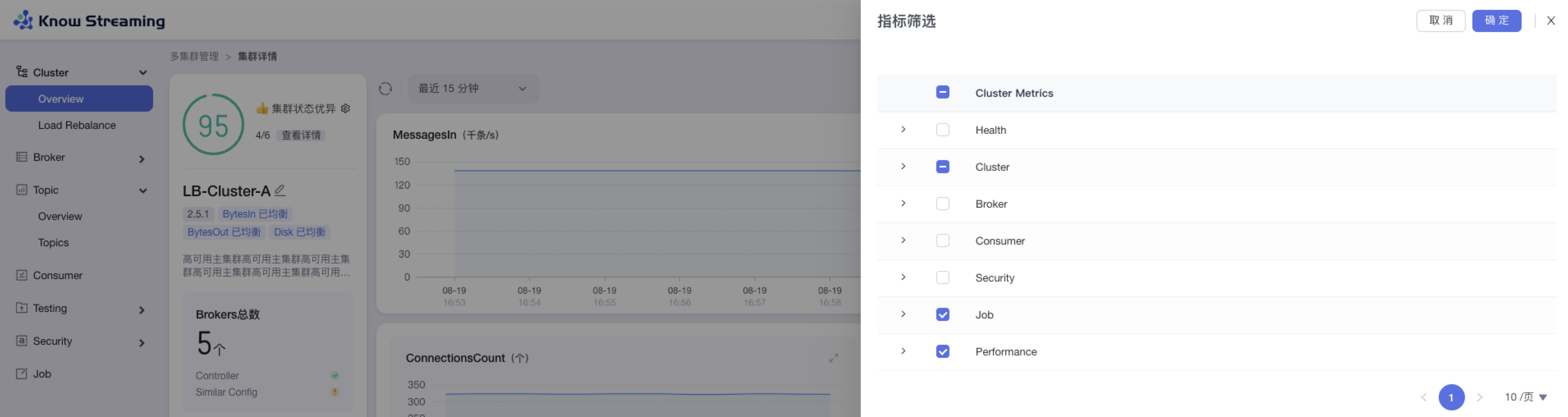
-
-### 5.3.9、编辑 Broker 配置
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Brokers”>“Broker ID”>“Configuration”TAB>“编辑”按钮
-
-- 步骤 2:输入配置项的新配置内容
-
-- 步骤 3:(选填)点击“应用于全部 Broker”,将此配置项的修改应用于全部的 Broker
-
-- 步骤 4:点击“确认”,Broker 配置修改成功
-
-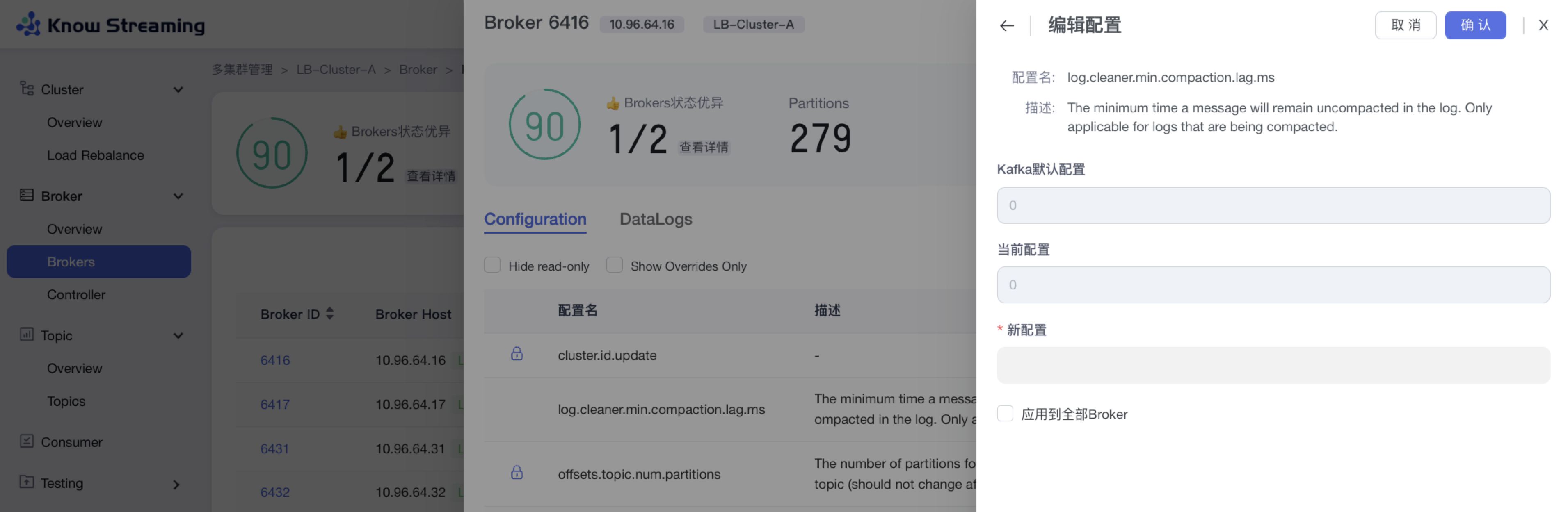
-
-### 5.3.10、重置 consumer Offset
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Consumer”>“Consumer Group”名称>“Consumer Group 详情”抽屉>“重置 Offset”按钮>“重置 Offset”抽屉
-
-- 步骤 2:选择重置 Offset 的类型,可“重置到指定时间”或“重置分区”
-
-- 步骤 3:重置到指定时间,可选择“最新 Offset”或“自定义时间”
-
-- 步骤 4:重置分区,可选择 partition 和其重置的 offset
-
-- 步骤 5:点击“确认”,重置 Offset 开始执行
-
-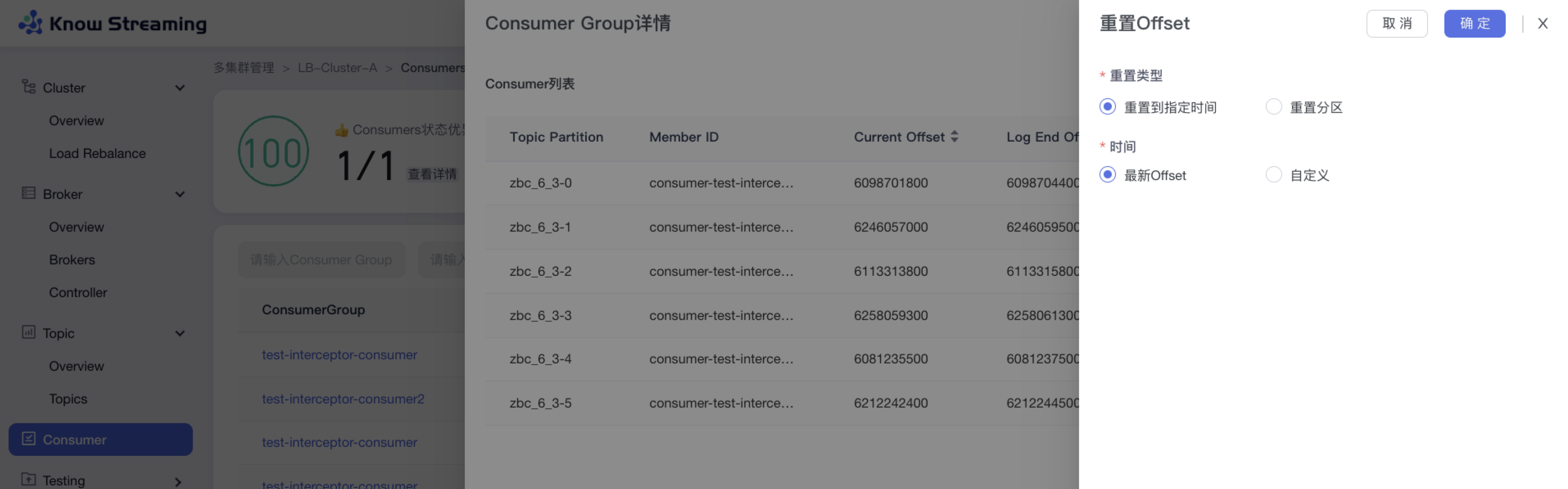
-
-### 5.3.11、新增 ACL
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Security”>“Users”>“新增 ACL”
-
-- 步骤 2:输入 ACL 配置参数
-
- - ACL 用途:生产权限、消费权限、自定义权限
- - 生产权限时:可选择应用于所有 Kafka User 或者特定 Kafka User;可选择应用于所有 Topic 或者特定 Topic
- - 消费权限时:可选择应用于所有 Kafka User 或者特定 Kafka User;可选择应用于所有 Topic 或者特定 Topic;可选择应用于所有 Consumer Group 或者特定 Consumer Group
-
-- 步骤 3:点击“确定”,新增 ACL 成功
-
-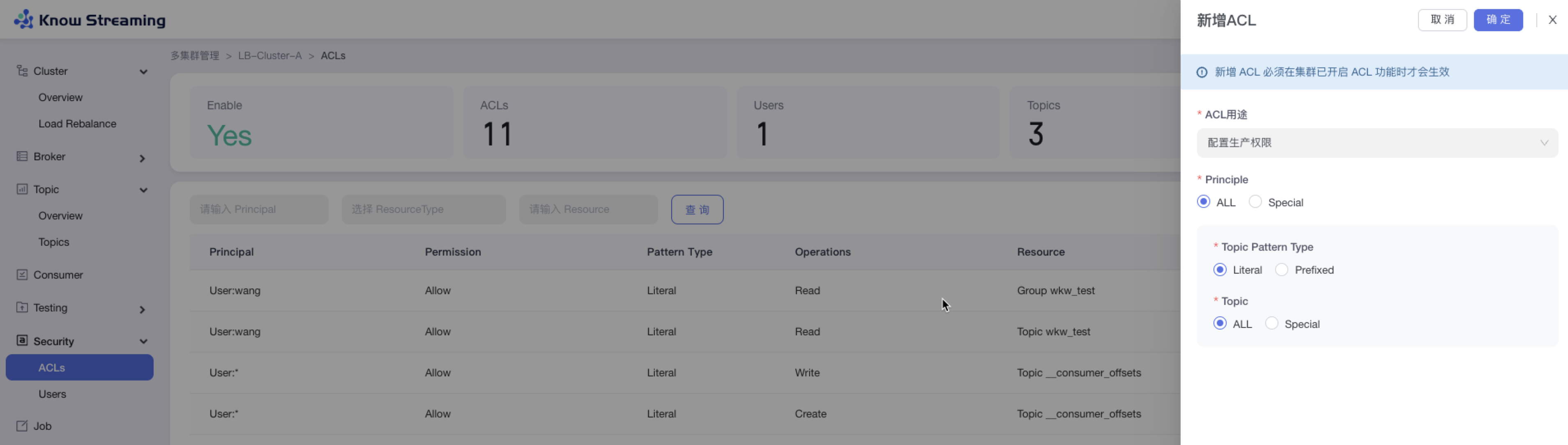
-
-## 5.4、全部功能
-
-### 5.4.1、登录/退出登录
-
-- 登录:输入账号密码,点击登录
-
-- 退出登录:鼠标悬停右上角“头像”或者“用户名”,出现小弹窗“登出”,点击“登出”,退出登录
-
-### 5.4.2、系统管理
-
-用户登录完成之后,点击页面右上角【系统管理】按钮,切换到系统管理的视角,可以进行配置管理、用户管理、审计日志查看。
-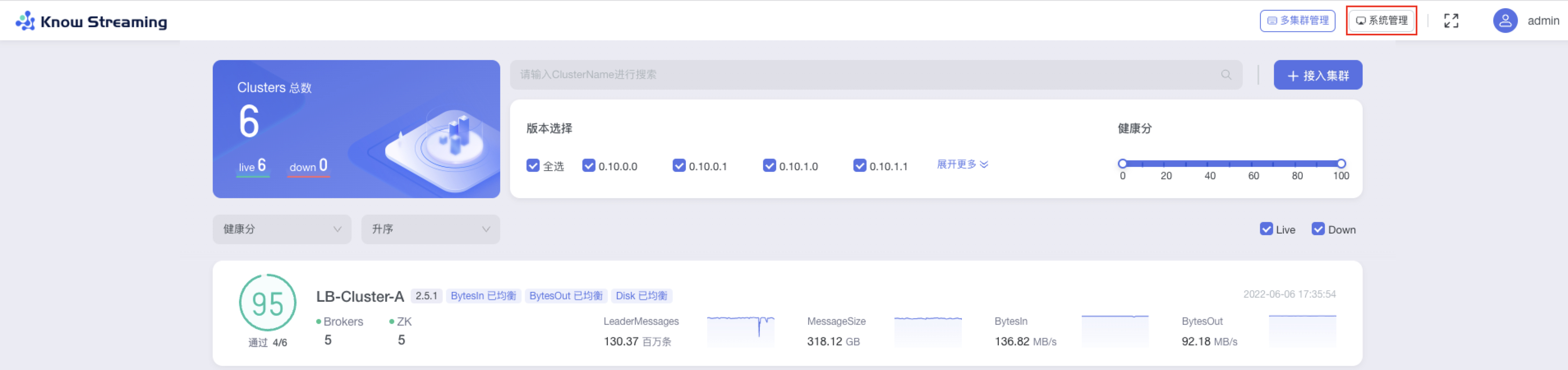
-
-#### 5.4.2.1、配置管理
-
-配置管理是提供给管理员一个快速配置配置文件的能力,所配置的配置文件将会在对应模块生效。
-
-#### 5.4.2.2、查看配置列表
-
-- 步骤 1:点击”系统管理“>“配置管理”
-
-- 步骤 2:列表展示配置所属模块、配置键、配置值、启用状态、更新时间、更新人。列表有操作项编辑、删除,可对配置模块、配置键、配置值、描述、启用状态进行配置,也可删除此条配置
-
-
-
-#### 5.4.2.3、新增配置
-
-- 步骤 1:点击“系统管理”>“配置管理”>“新增配置”
-
-- 步骤 2:模块:下拉选择所有可配置的模块;配置键:不限制输入内容,500 字以内;配置值:代码编辑器样式,不限内容不限长度;启用状态开关:可以启用/禁用此项配置
-
-
-
-#### 5.4.2.4、编辑配置
-
-可对配置模块、配置键、配置值、描述、启用状态进行配置。
-
-#### 5.4.2.5、用户管理
-
-用户管理是提供给管理员进行人员管理和用户角色管理的功能模块,可以进行新增用户和分配角色。
-
-#### 5.4.2.6、人员管理列表
-
-- 步骤 1:点击“系统管理”>“用户管理”>“人员管理”
-
-- 步骤 2:人员管理列表展示用户角色、用户实名、用户分配的角色、更新时间、编辑操作。
-
-- 步骤 3:列表支持”用户账号“、“用户实名”、“角色名”筛选。
-
-
-
-#### 5.4.2.7、新增用户
-
-- 步骤 1:点击“系统管理”>“用户管理”>“人员管理”>“新增用户”
-
-- 步骤 2:填写“用户账号”、“用户实名”、“用户密码”这些必填参数,可以对此账号分配已经存在的角色。
-
-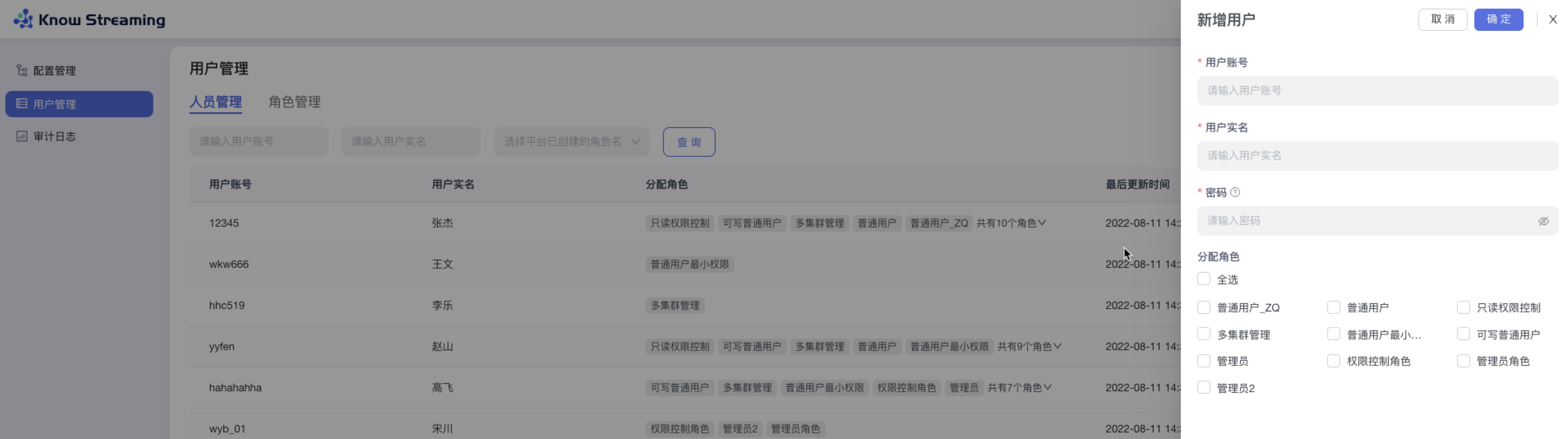
-
-#### 5.4.2.8、编辑用户
-
-- 步骤 1:点击“系统管理”>“用户管理”>“人员管理”>列表操作项“编辑”
-
-- 步骤 2:用户账号不可编辑;可以编辑“用户实名”,修改“用户密码”,重新分配“用户角色“
-
-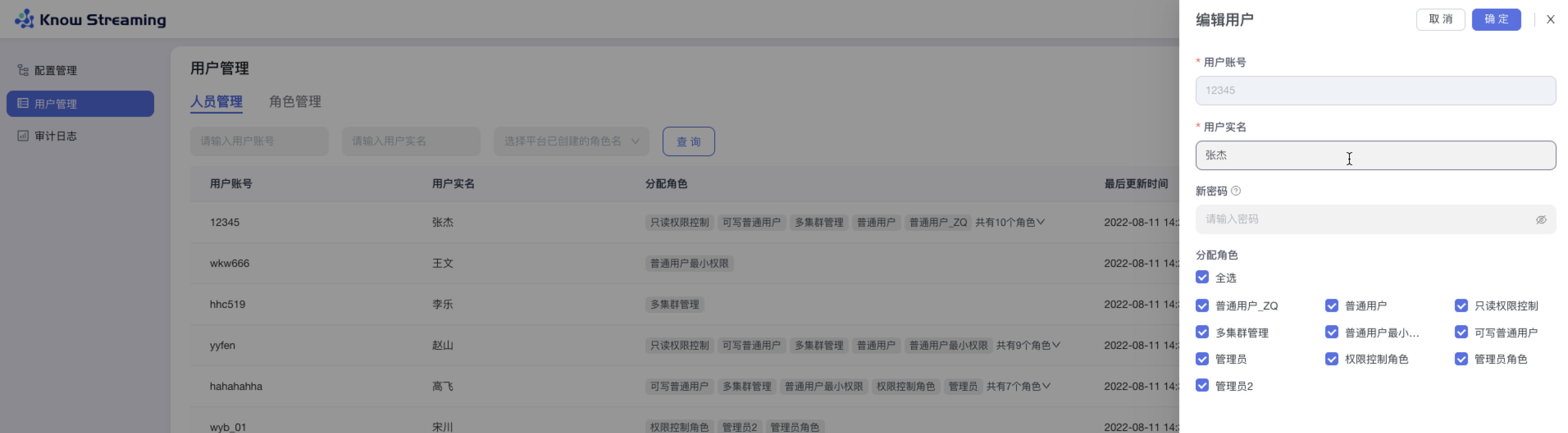
-
-#### 5.4.2.9、角色管理列表
-
-- 步骤 1:点击“系统管理”>“用户管理”>“角色管理”
-
-- 步骤 2:角色列表展示信息为“角色 ID”、“名称”、“描述”、“分配用户数”、“最后修改人”、“最后更新时间”、操作项“查看详情”、操作项”分配用户“
-
-- 步骤 3:列表有筛选框,可对“角色名称”进行筛选
-
-- 步骤 4:列表操作项,“查看详情”可查看到角色绑定的权限项,”分配用户“可对此项角色下绑定的用户进行增减
-
-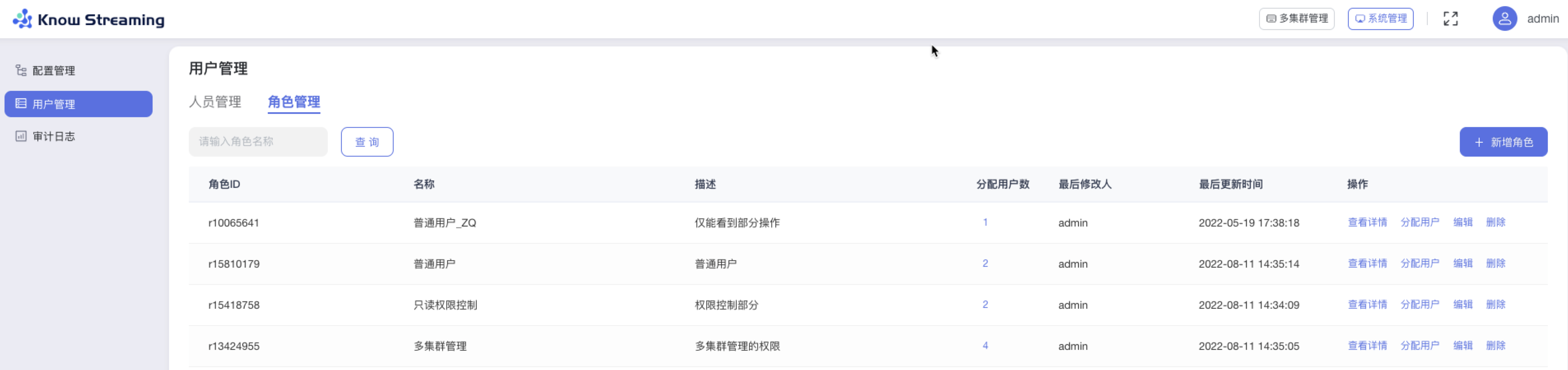
-
-#### 5.4.2.10、新增角色
-
-- 步骤 1:点击“系统管理”>“用户管理”>“角色管理”>“新增角色”
-
-- 步骤 2:输入“角色名称”(角色名称只能由中英文大小写、数字、下划线\_组成,长度限制在 3 ~ 128 字符)、“角色描述“(不能为空)、“分配权限“(至少需要分配一项权限),点击确认,新增角色成功添加到角色列表
-
-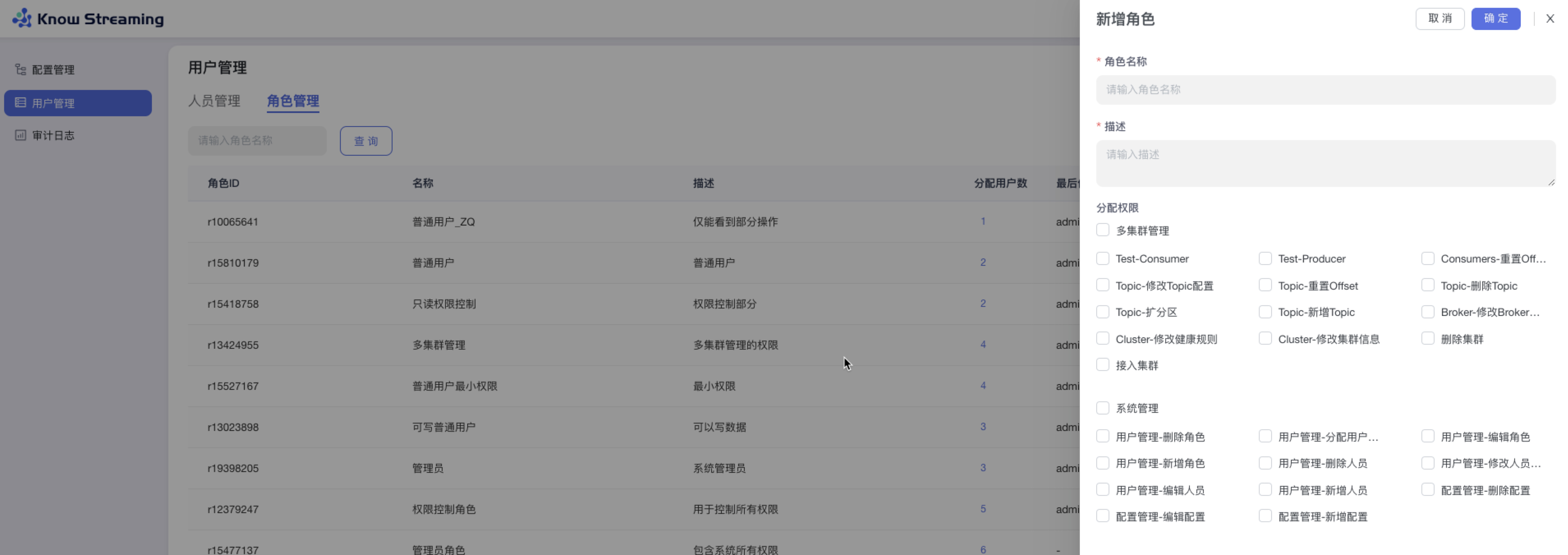
-
-#### 5.4.2.11、审计日志
-
-- 步骤 1:点击“系统管理”>“审计日志“
-- 步骤 2:审计日志包含所有对于系统的操作记录,操作记录列表展示信息为下
-
- - “模块”:操作对象所属的功能模块
- - “操作对象”:具体哪一个集群、任务 ID、topic、broker、角色等
- - “行为”:操作记录的行为,包含“新增”、“替换”、“读取”、“禁用”、“修改”、“删除”、“编辑”等
- - “操作内容”:具体操作的内容是什么
- - “操作时间”:操作发生的时间
- - “操作人”:此项操作所属的用户
-
-- 步骤 3:操作记录列表可以对“模块“、”操作对象“、“操作内容”、”操作时间“进行筛选
-
-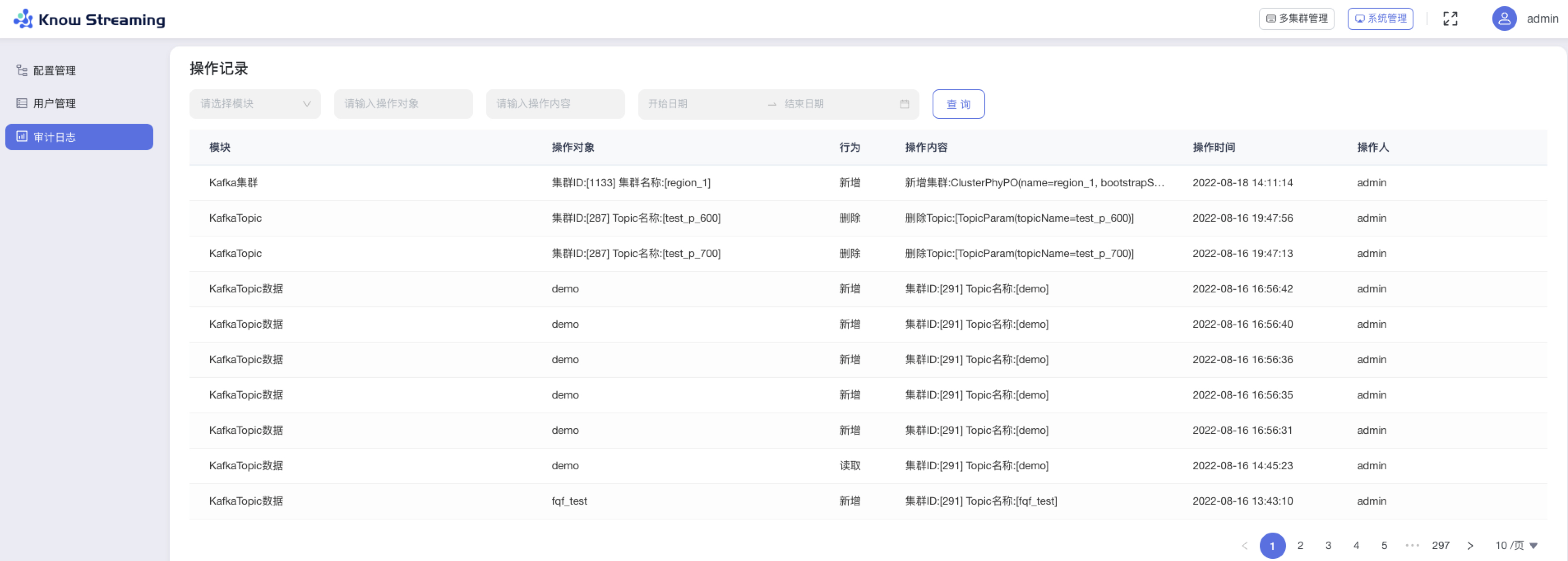
-
-### 5.4.3、多集群管理
-
-#### 5.4.3.1、多集群列表
-
-- 步骤 1:点击顶部导航栏“多集群管理”
-
-- 步骤 2:多集群管理页面包含的信息为:”集群信息总览“、“集群列表”、“列表筛选项”、“接入集群”
-
-- 步骤 3:集群列表筛选项为
-
- - 集群信息总览:cluster 总数、live 数、down 数
- - 版本筛选:包含所有存在的集群版本
- - 健康分筛选:筛选项为 0、10、20、30、40、50、60、70、80、90、100
- - live、down 筛选:多选
- - 下拉框筛选排序,选项维度为“接入时间”、“健康分“、”Messages“、”MessageSize“、”BytesIn“、”BytesOut“、”Brokers“;可对这些维度进行“升序”、“降序”排序
-
-- 步骤 4:每个卡片代表一个集群,其所展示的集群概览信息包括“健康分及健康检查项通过数”、“broker 数量”、“ZK 数量”、“版本号”、“BytesIn 均衡状态”、“BytesOut 均衡状态”、“Disk 均衡状态”、”Messages“、“MessageSize”、“BytesIn”、“BytesOut”、“接入时间”
-
-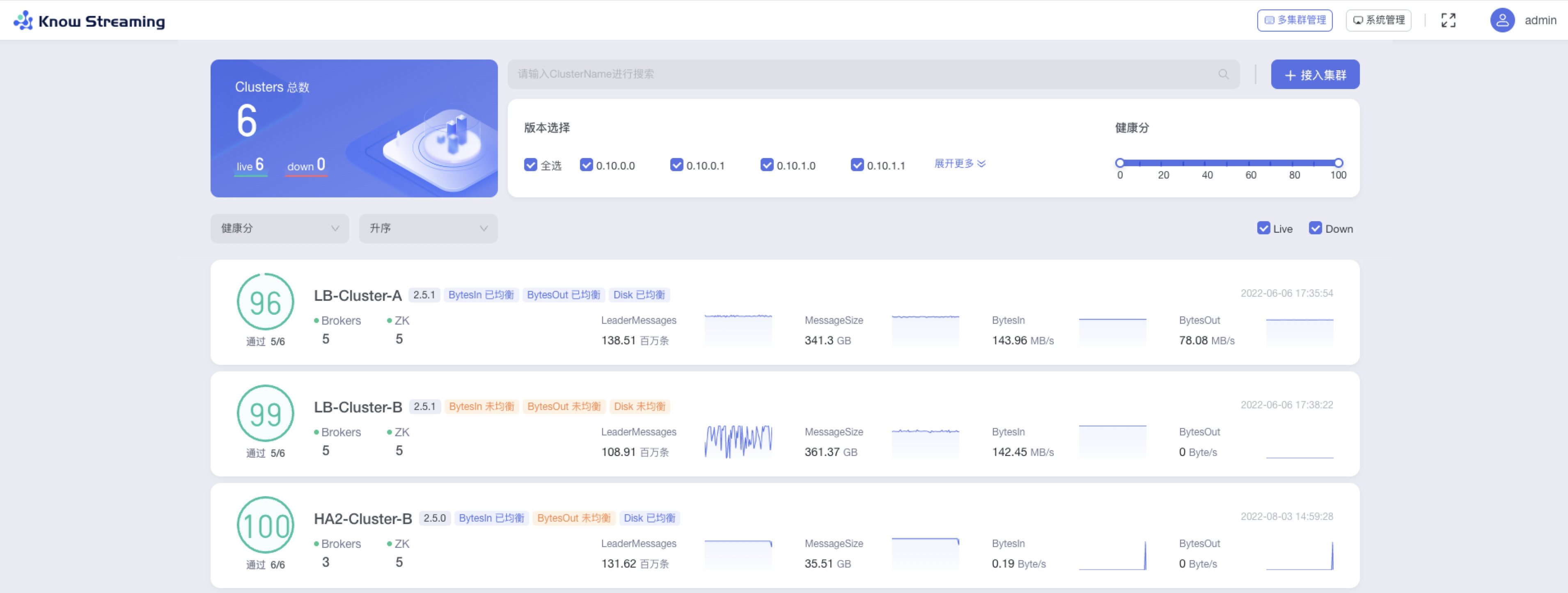
-
-#### 5.4.3.2、接入集群
-
-- 步骤 1:点击“多集群管理”>“接入集群”
-
-- 步骤 2:填写相关集群信息
- - 集群名称:平台内不能重复
- - Bootstrap Servers:输入 Bootstrap Servers 地址,输入完成之后会进行连接测试,测试完成之后会给出测试结果连接成功 or 连接失败(以及失败的原因)。
- - Zookeeper:输入 zookeeper 地址,输入完成之后会进行连接测试,测试完成之后会给出测试结果连接成功 or 连接失败(以及失败的原因)
- - Metrics 选填:JMX Port,输入 JMX 端口号;MaxConn,输入服务端最大允许的连接数
- - Security:若有 JMX 账号密码,则输入账号密码
- - Version:kafka 版本,如果没有匹配则可以选择相近版本
- - 集群配置选填:用户创建 kafka 客户端进行信息获取的相关配置
-
-
-
-#### 5.4.3.3、删除集群
-
-- 步骤 1:点击“多集群管理”>鼠标悬浮集群卡片>点击卡片右上角“删除 icon”>打开“删除弹窗”
-
-- 步骤 2:在删除弹窗中的“集群名称”输入框,输入所要删除集群的集群名称,点击“删除”,成功删除集群,解除平台的纳管关系(集群资源不会删除)
-
-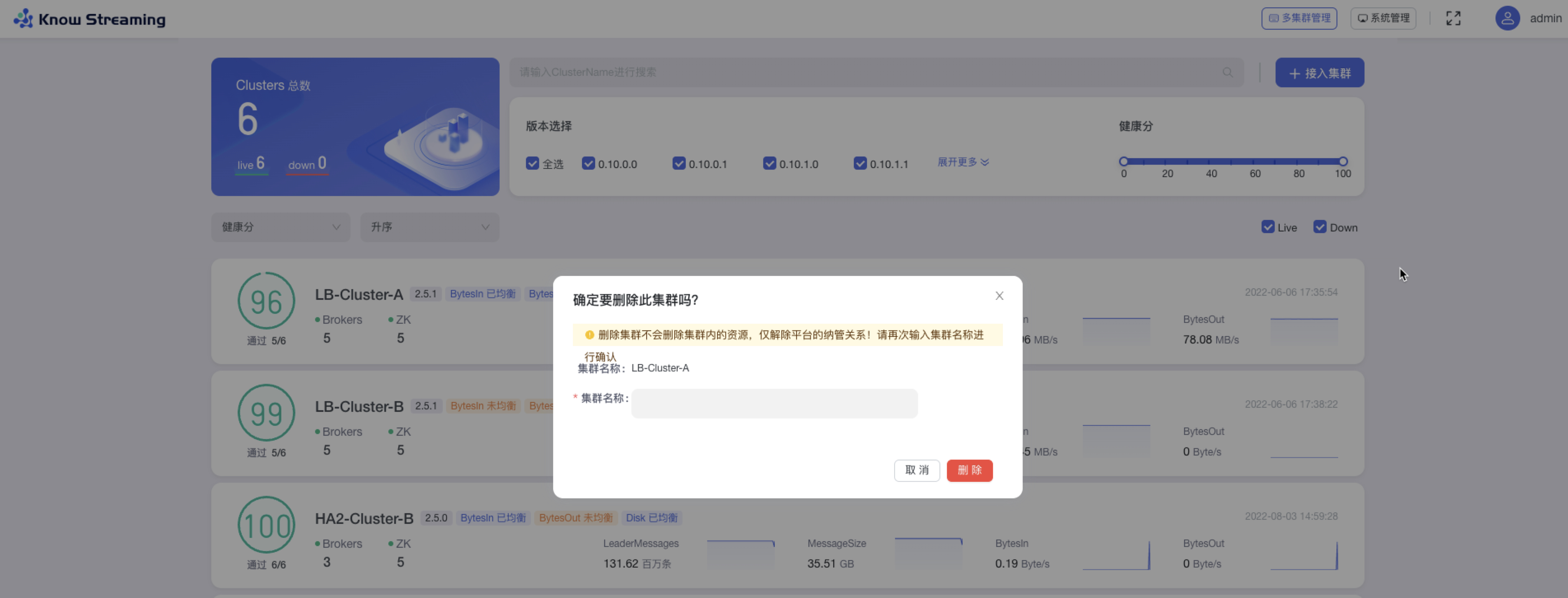
-
-### 5.4.4、Cluster 管理
-
-#### 5.4.4.1、Cluster Overview
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>进入单集群管理界面
-
-- 步骤 2:左侧导航栏
-
- - 一级导航:Cluster;二级导航:Overview、Load Rebalance
- - 一级导航:Broker;二级导航:Overview、Brokers、Controller
- - 一级导航:Topic;二级导航:Overview、Topics
- - 一级导航:Consumer
- - 一级导航:Testing;二级导航:Produce、Consume
- - 一级导航:Security;二级导航:ACLs、Users
- - 一级导航:Job
-
-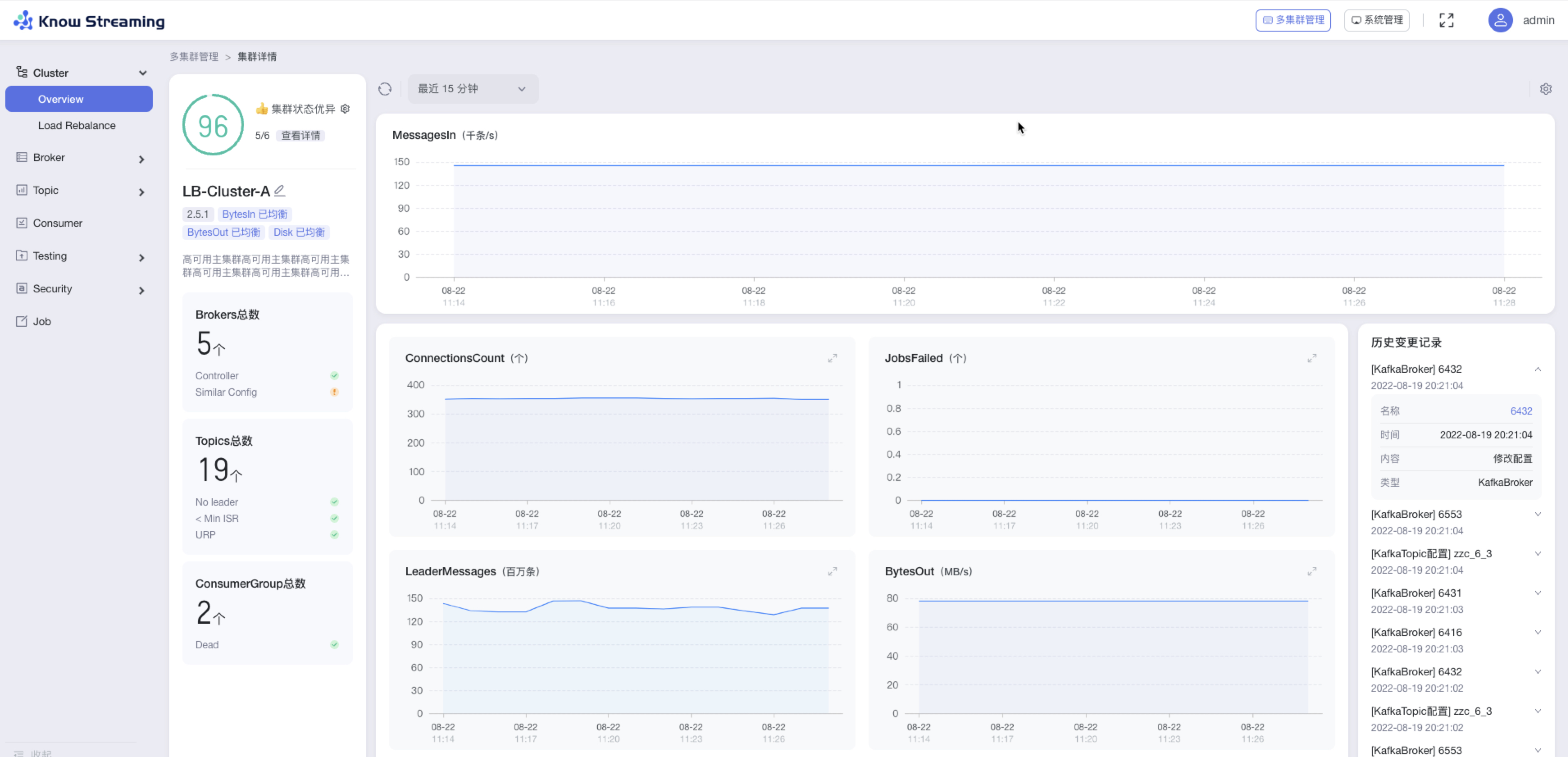
-
-#### 5.4.4.2、查看 Cluster 概览信息
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”
-
-- 步骤 2:cluster 概览信息包括以下内容
-
- - 集群健康分,健康检查通过项
- - Cluster 信息:包含名称、版本、均衡状态
- - Broker 信息:Broker 总数、controller 信息、similar config 信息
- - Topic 信息:Topic 总数、No Leader、“集群卡片”>“Cluster”>“Overview”>“集群健康状态旁边 icon”>“健康度设置抽屉”
-
-- 步骤 2:健康度设置抽屉展示出了检查项和其对应的权重,可以修改检查项的检查规则
-
-- 步骤 3:检查规则可配置,分别为
-
- - Cluster:集群 controller 数不等于 1(数字不可配置)不通过
- - Broker:RequestQueueSize 大于等于 10(默认为 10,可配置数字)不通过
- - Broker:NetworkProcessorAvgIdlePercent 的 Idle 小于等于 0.8%(默认为 0.8%,可配置数字)不通过
- - Topic:无 leader 的 Topic 数量,大于等于 1(默认为 1,数字可配置)不通过
- - Topic:Topic 在 10(默认为 10,数字可配置)个周期内 8(默认为 8,数字可配置)个周期内处于未同步的状态
- - ConsumerGroup:Group 在 10(默认为 10,数字可配置)个周期内进行 8(默认为 8,数字可配置)次 re-balance 不通过
-
-- 步骤 4:设置完成后,点击“确认”,健康检查规则设置成功
-
-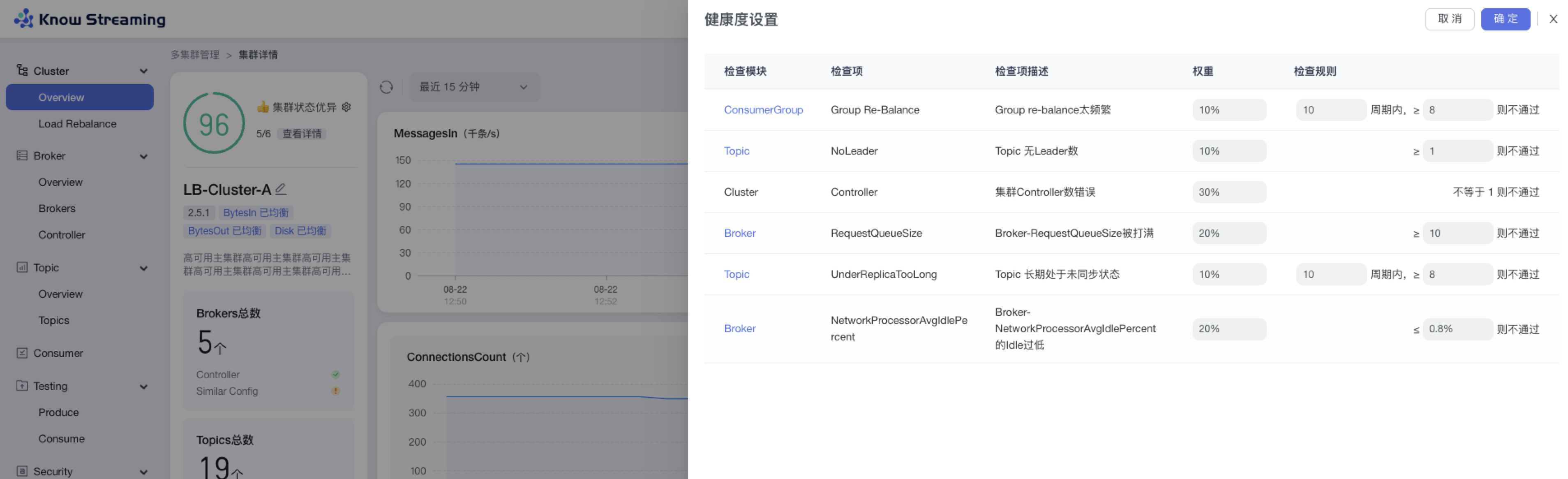
-
-#### 5.4.4.4、查看 Cluster 健康检查详情
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“集群健康状态旁边【查看详情】”>“健康检查详情抽屉”
-
-- 步骤 2:健康检查详情抽屉展示信息为:“检查模块”、“检查项”、“权重”、“得分”、“检查时间”、“检查结果是否通过”,若未通过会展示未通过的对象
-
-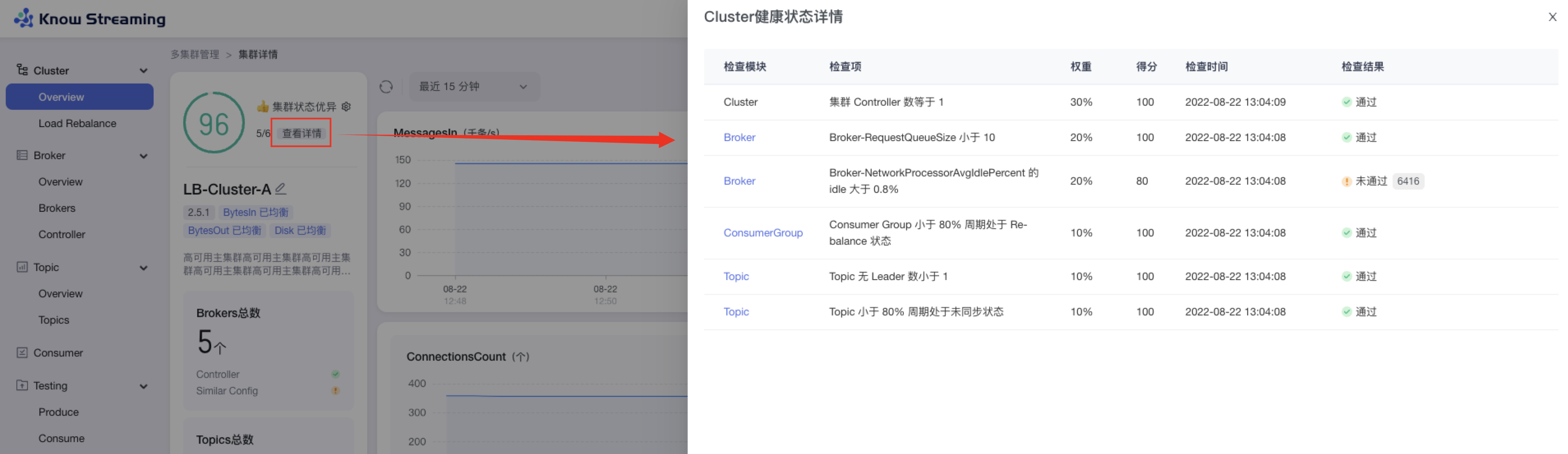
-
-#### 5.4.4.5、编辑 Cluster 信息
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“Cluster 名称旁边编辑 icon”>“编辑集群抽屉”
-
-- 步骤 2:可编辑的信息包括“集群名称”、“Bootstrap Servers”、“Zookeeper”、“JMX Port”、“Maxconn(最大连接数)”、“Security(认证措施)”、“Version(版本号)”、“集群配置”、“集群描述”
-
-- 步骤 3:点击“确定”,成功编辑集群信息
-
-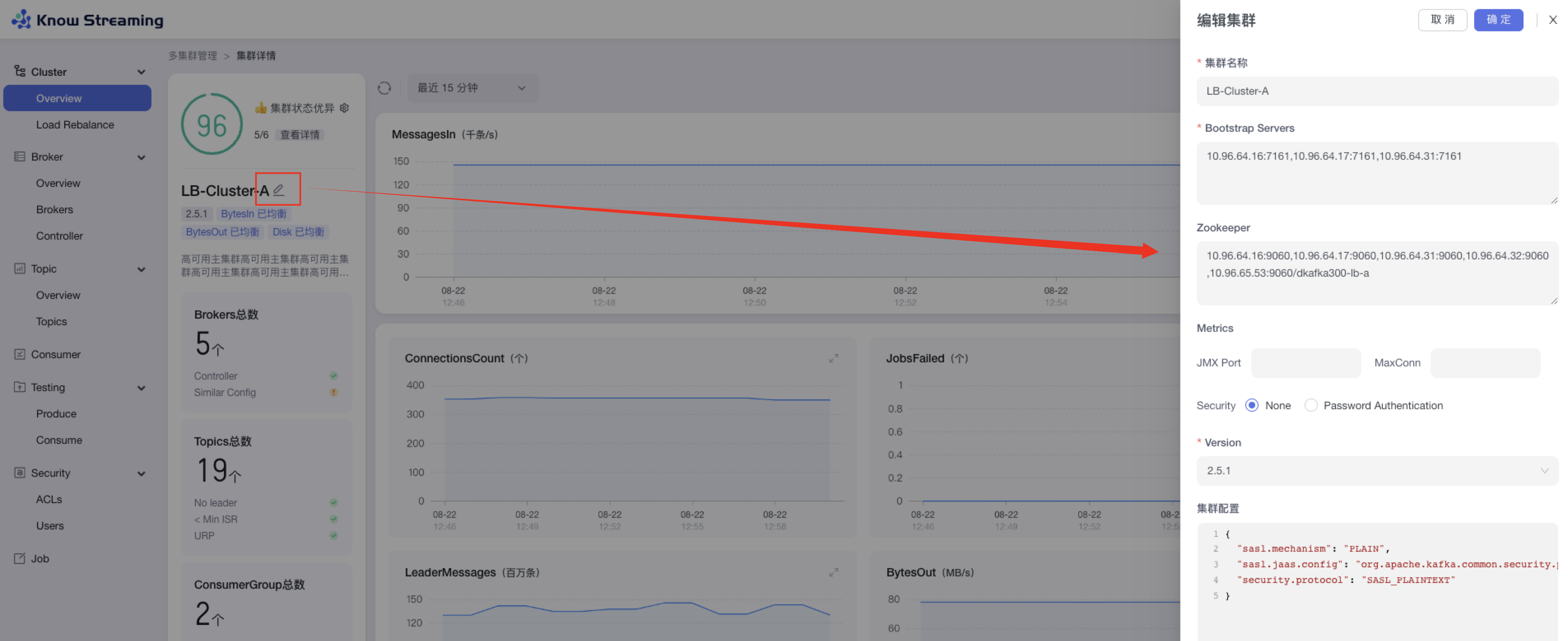
-
-#### 5.4.4.6、图表指标筛选
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“指标筛选 icon”>“指标筛选抽屉”
-
-- 步骤 2:指标筛选抽屉展示信息为以下几类“Health”、“Cluster”、“Broker”、“Consumer”、“Security”、“Job”
-
-- 步骤 3:默认勾选比较重要的指标进行展示。根据需要选中/取消选中相应指标,点击”确认“,指标筛选成功,展示的图表随之变化
-
-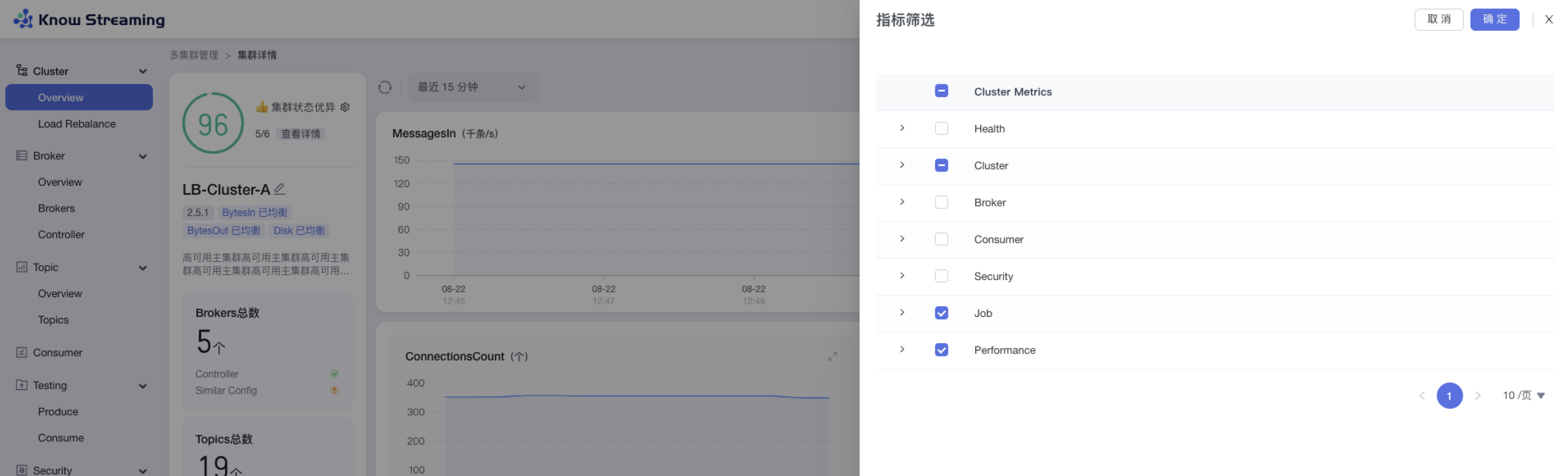
-
-#### 5.4.4.7、图表时间筛选
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“时间选择下拉框”>“时间选择弹窗”
-
-- 步骤 2:选择时间“最近 15 分钟”、“最近 1 小时”、“最近 6 小时”、“最近 12 小时”、“最近 1 天”,也可以自定义时间段范围
-
-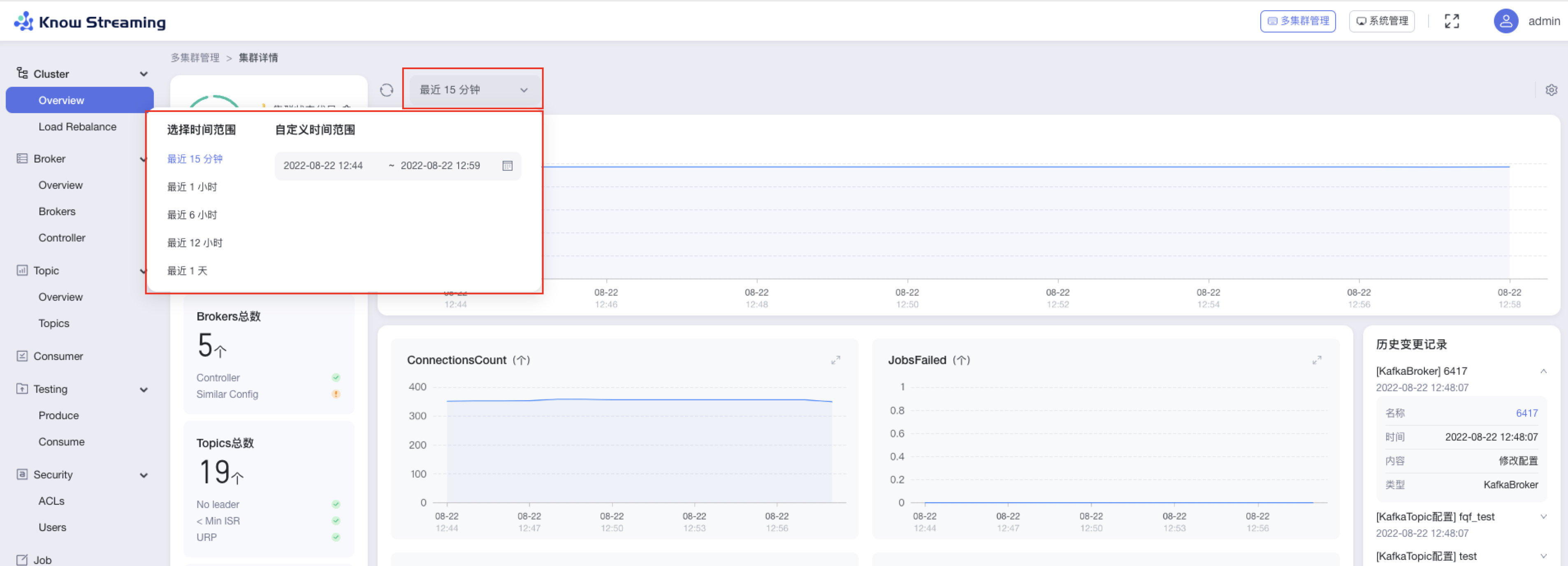
-
-#### 5.4.4.8、查看集群历史变更记录
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“历史变更记录”区域
-
-- 步骤 2:历史变更记录区域展示了历史的配置变更,每条记录可展开收起。包含“配置对象”、“变更时间”、“变更内容”、“配置类型”
-
-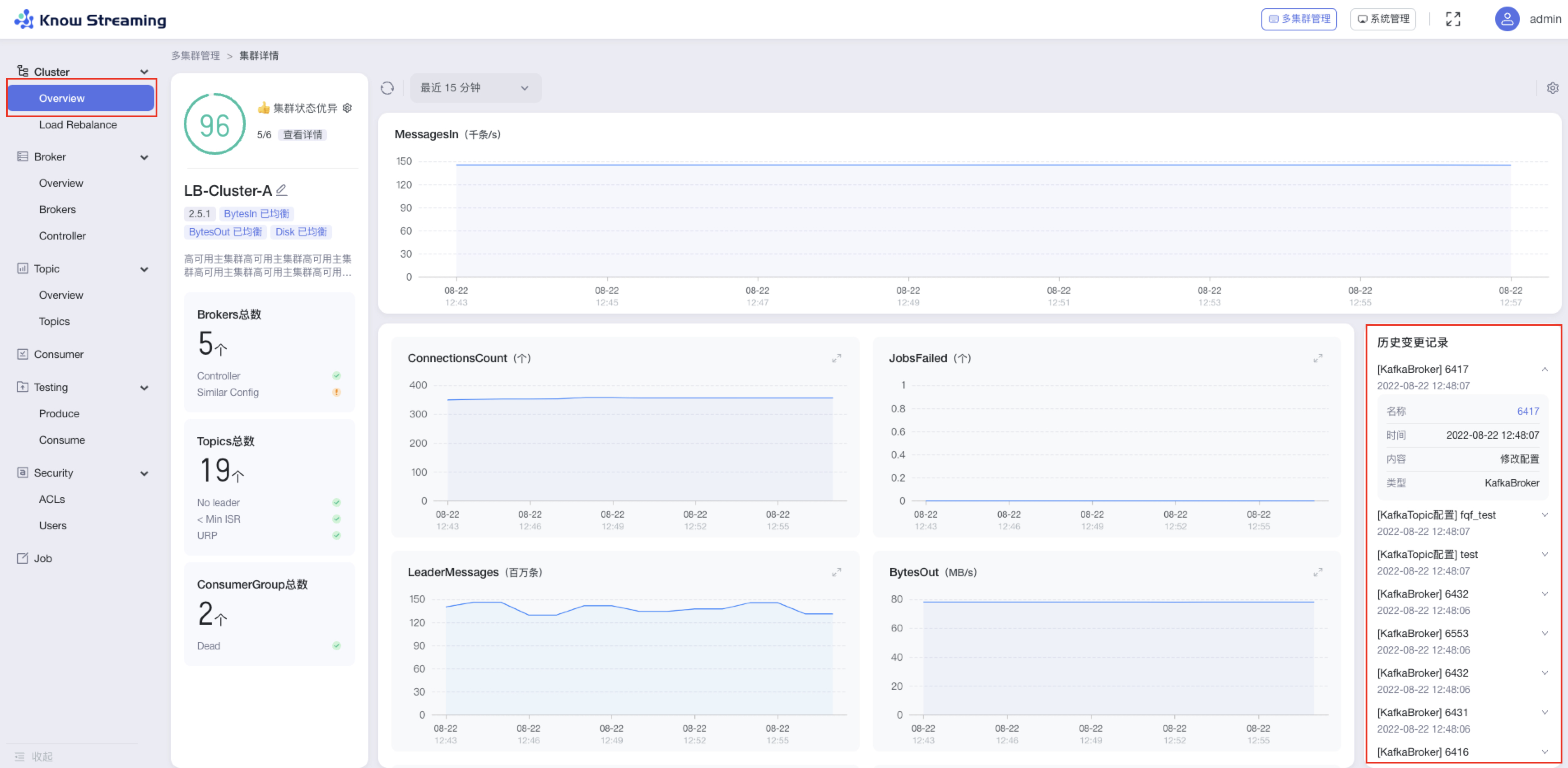
-
-### 5.4.5、Load Rebalance(企业版)
-
-#### 5.4.5.1、查看 Load Rebalance 概览信息
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Load Rebalance”
-
-- 步骤 2:Load Rebalance 概览信息包含“均衡状态卡片”、“Disk 信息卡片”、“BytesIn 信息卡片”、“BytesOut 信息卡片”、“Broker 均衡状态列表”
-
-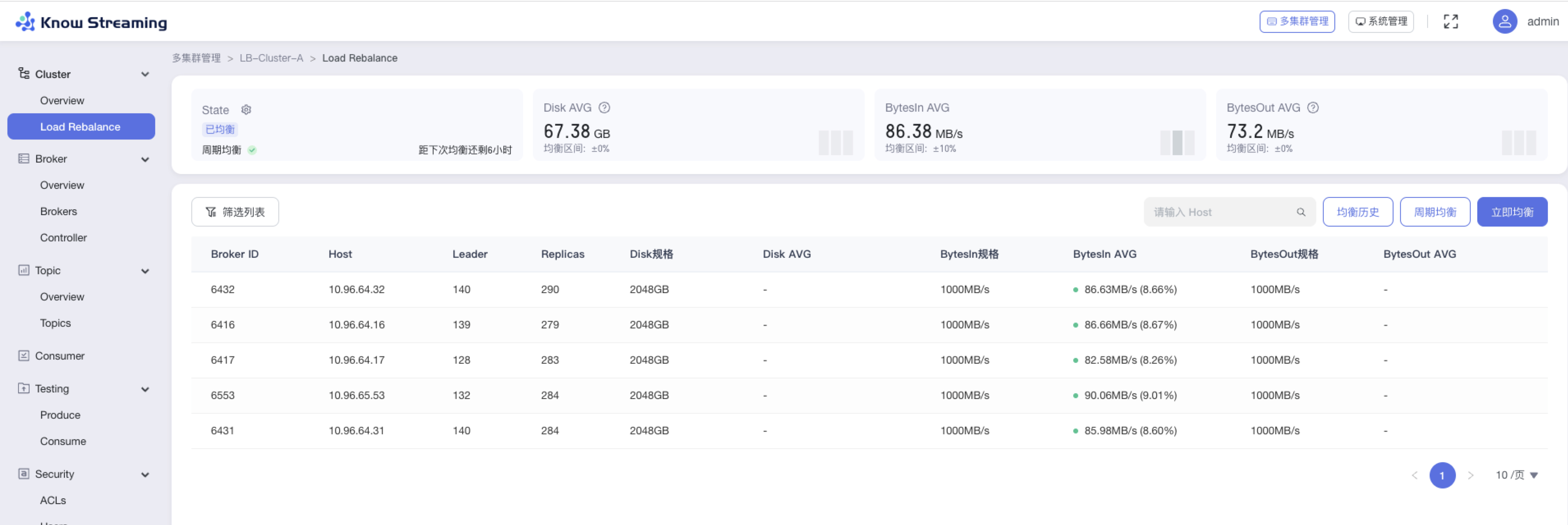
-
-#### 5.4.5.2、设置集群规格
-
-提供对集群的每个节点的 Disk、BytesIn、BytesOut 的规格进行设置的功能
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Load Rebalance”>“State 卡片 icon“>”设置集群规格抽屉“
-
-- 步骤 2:穿梭框左侧展示集群中的待选节点,穿梭框右侧展示已经选中的节点,选择自己所需设置规格的节点
-
-- 步骤 3:设置“单机核数”、“单机磁盘”、“单机网络”,点击确定,完成设置
-
-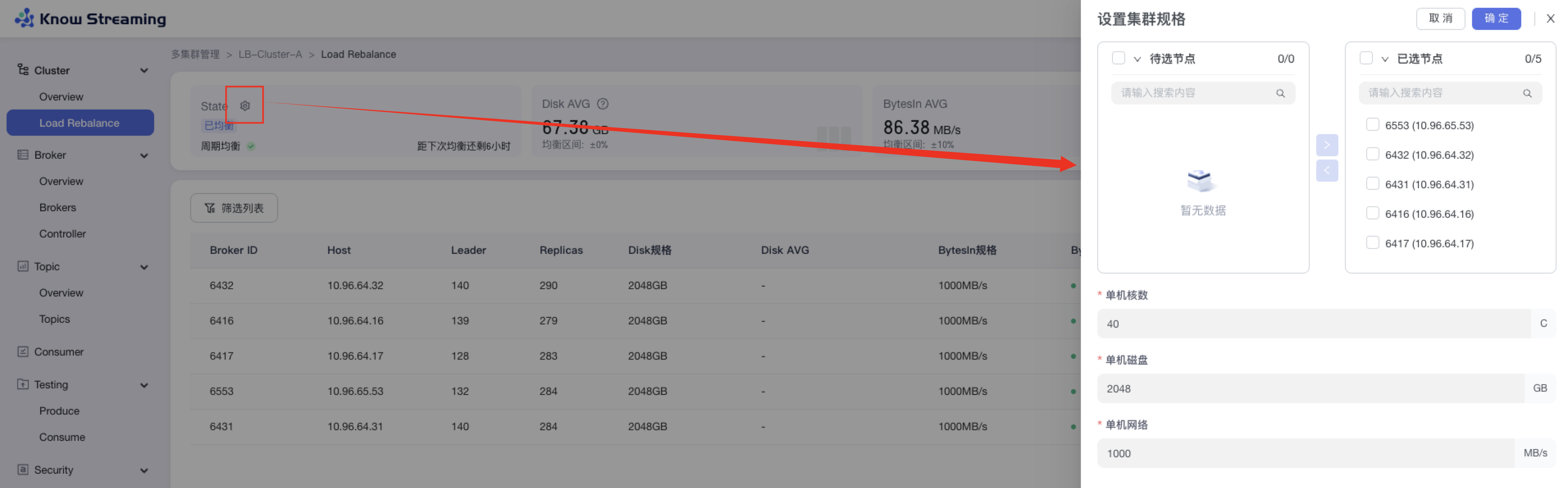
-
-#### 5.4.5.3、均衡状态列表筛选
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Load Rebalance”>“筛选列表”按钮>筛选弹窗
-
-- 步骤 2:可选择“Disk”、“BytesIn”、“BytesOut”三种维度,其各自对应“已均衡”、“未均衡”两种状态,可以组合进行筛选
-
-- 步骤 3:点击“确认”,执行筛选操作
-
-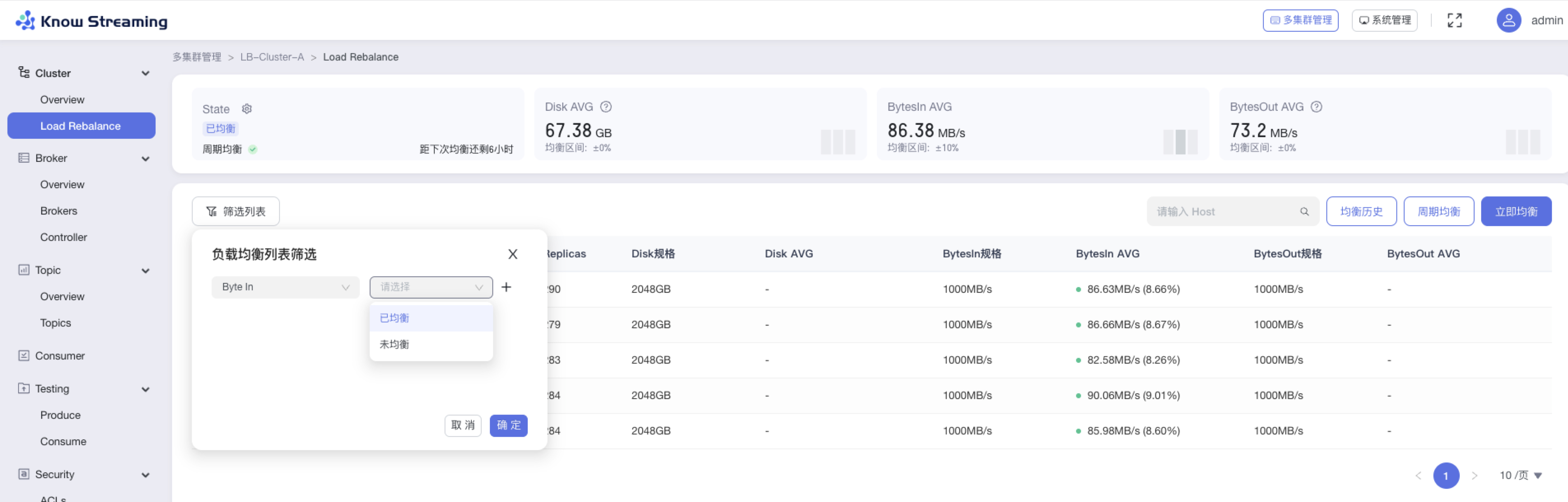
-
-#### 5.4.5.4、立即均衡
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Load Rebalance”>“立即均衡”按钮>“立即均衡抽屉”
-
-- 步骤 2:配置均衡策略
-
- - 指标计算周期:默认近 10mins,可选择
- - 均衡维度:默认 Disk、BytesIn、BytesOut,可选择
- - 均衡区间:在表格内自定义配置均衡区间范围(单位:%,大于 0,小于 100)
- - Topic 黑名单:选择 topic 黑名单。通过穿梭框(支持模糊选择)选出目标 topic(本次均衡,略过已选的 topic)
-
-- 步骤 3:配置运行参数
-
- - 吞吐量优先:并行度 0(无限制), 策略是优先执行大小最大副本
- - 稳定性优先: 并行度 1 ,策略是优先执行大小最小副本
- - 自定义:可以自由设置并行度和优先执行的副本策略
- - 限流值:流量最大值,0-99999 自定义
-
-- 步骤 4:点击“预览计划”按钮,打开执行计划弹窗。可以看到计划概览信息、计划明细信息
-
-- 步骤 5:点击“预览计划弹窗”的“执行文件”,可以下载 json 格式的执行文件
-
-- 步骤 6:点击“预览计划弹窗”的“立即均衡”按钮,开始执行均衡任务
-
-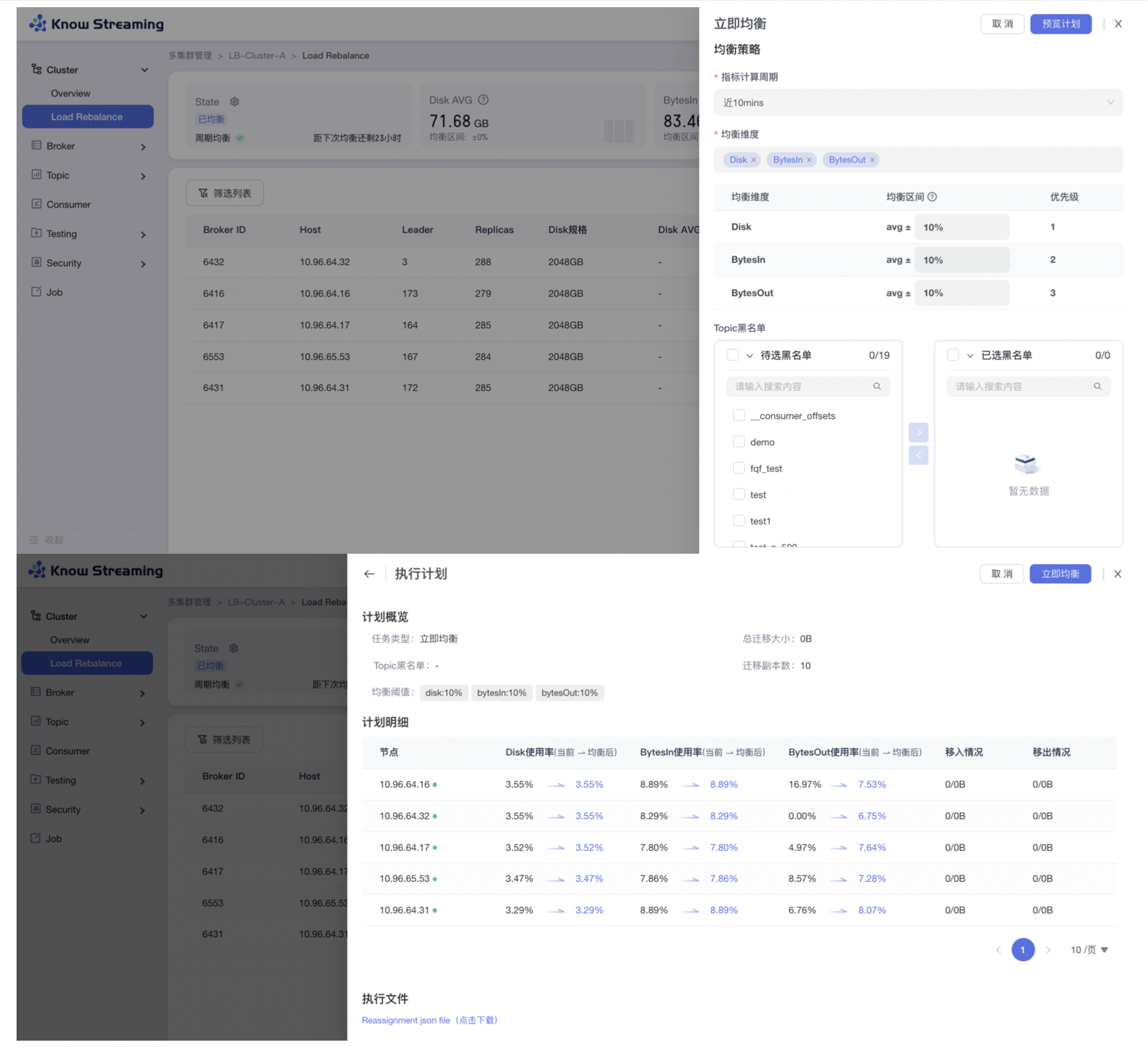
-
-#### 5.4.5.5、周期均衡
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Load Rebalance”>“周期均衡”按钮>“周期均衡抽屉”
-
-- 步骤 2:配置均衡策略
-
- - 指标计算周期:默认近 10mins,可选择
- - 均衡维度:默认 Disk、BytesIn、BytesOut,可选择
- - 均衡区间:在表格内自定义配置均衡区间范围(单位:%,大于 0,小于 100)
- - Topic 黑名单:选择 topic 黑名单。通过穿梭框(支持模糊选择)选出目标 topic(本次均衡,略过已选的 topic)
-
-- 步骤 3:配置运行参数
-
- - 任务并行度:每个节点同时迁移的副本数量
- - 任务周期:时间选择器,自定义选择运行周期
- - 稳定性优先: 并行度 1 ,策略是优先执行大小最小副本
- - 自定义:可以自由设置并行度和优先执行的副本策略
- - 限流值:流量最大值,0-99999 自定义
-
-- 步骤 4:点击“预览计划”按钮,打开执行计划弹窗。可以看到计划概览信息、计划明细信息
-
-- 步骤 5:点击“预览计划弹窗”的“执行文件”,可以下载 json 格式的执行文件
-
-- 步骤 6:点击“预览计划弹窗”的“立即均衡”按钮,开始执行均衡任务
-
-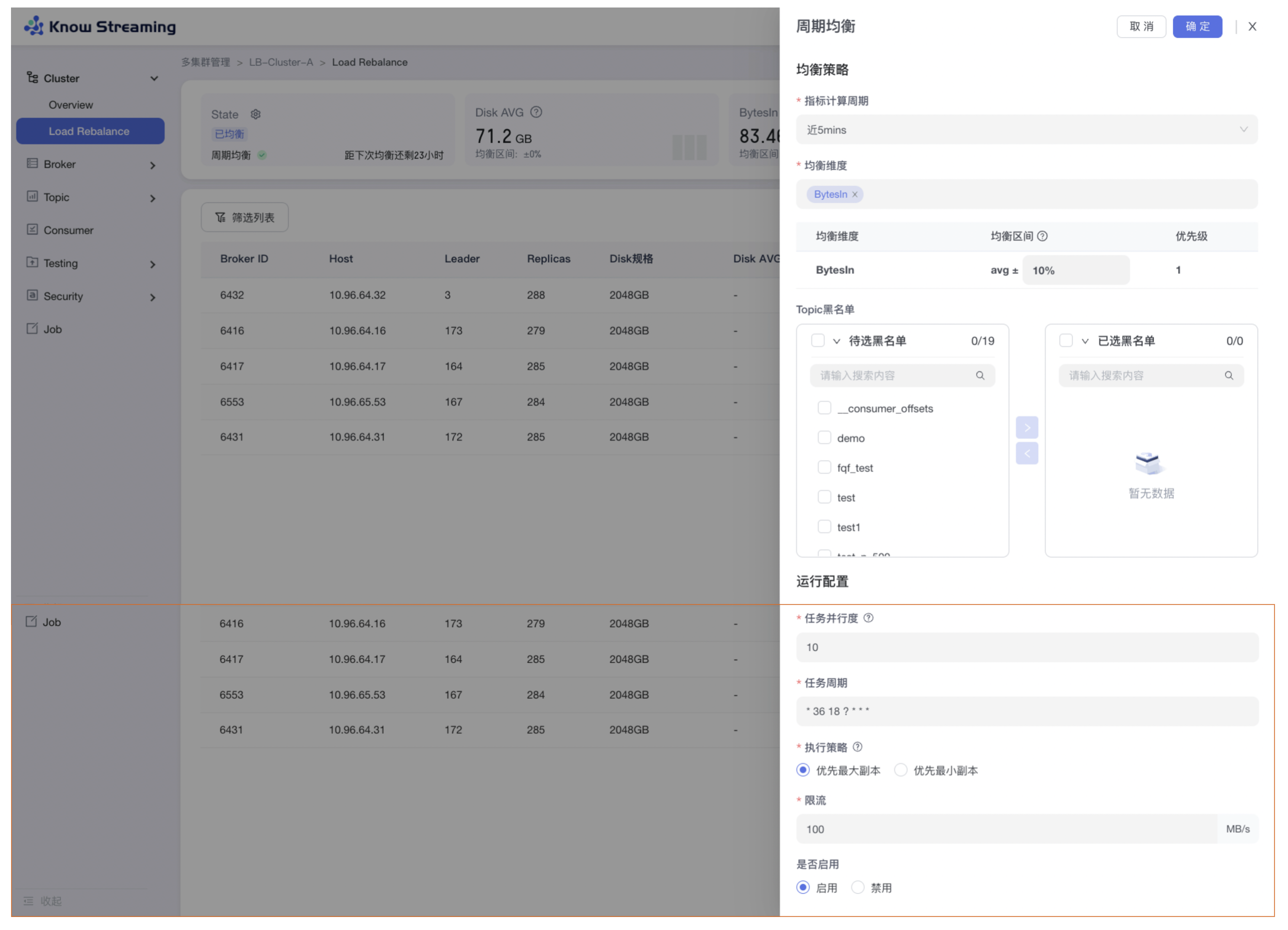
-
-### 5.4.6、Broker
-
-#### 5.4.6.1、查看 Broker 概览信息
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Broker”>“Overview”
-
-- 步骤 2:Broker 概览信息包括以下内容
-
- - 集群健康分,健康检查通过项
- - Broker 信息:包含名称、版本、均衡状态
- - Broker 信息:Broker 总数、controller 信息、similar config 信息
- - Topic 信息:Topic 总数、No Leader、“集群卡片”>“Brokers”>“Broker ID”>“Configuration”TAB>“编辑”按钮
-
-- 步骤 2:输入配置项的新配置内容
-
-- 步骤 3:(选填)点击“应用于全部 Broker”,将此配置项的修改应用于全部的 Broker
-
-- 步骤 4:点击“确认”,Broker 配置修改成功
-
-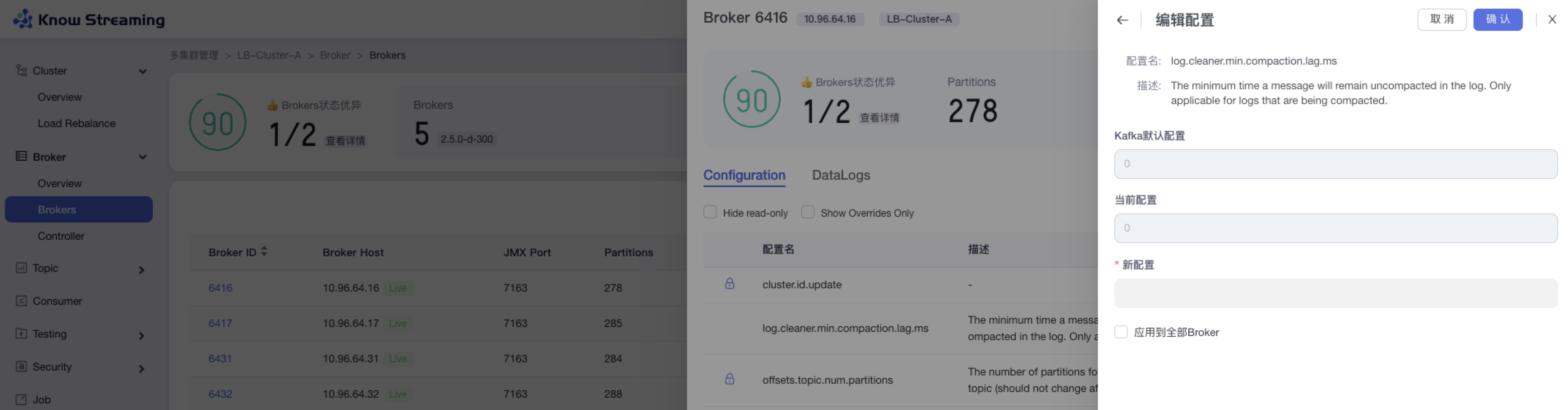
-
-#### 5.4.6.3、查看 Broker DataLogs
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Brokers”>“Broker ID”>“Data Logs”TAB>“编辑”按钮
-
-- 步骤 2:Broker DataLogs 列表展示的信息为“Folder”、“topic”、“Partition”、“Offset Lag”、“Size”
-
-- 步骤 3:输入框输入”Topic Name“可以筛选结果
-
-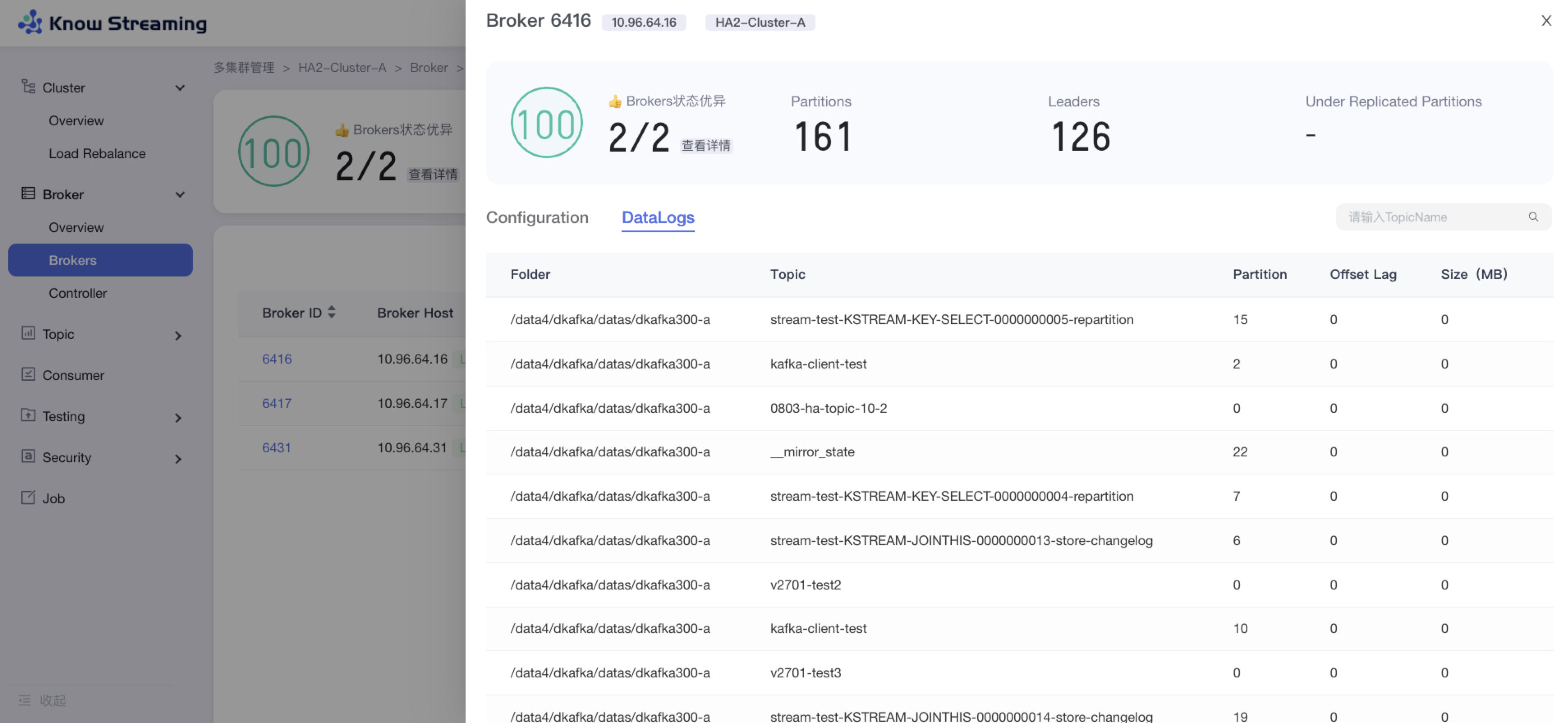
-
-#### 5.4.6.4、查看 Controller 列表
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Broker”>“Controller”
-
-- 步骤 2:Controller 列表展示的信息为“Change Time”、“Broker ID”、“Broker Host”
-
-- 步骤 3:输入框输入“Broker Host“可以筛选结果
-
-- 步骤 4:点击 Broker ID 可以打开 Broker 详情,进行修改配置或者查看 DataLogs
-
-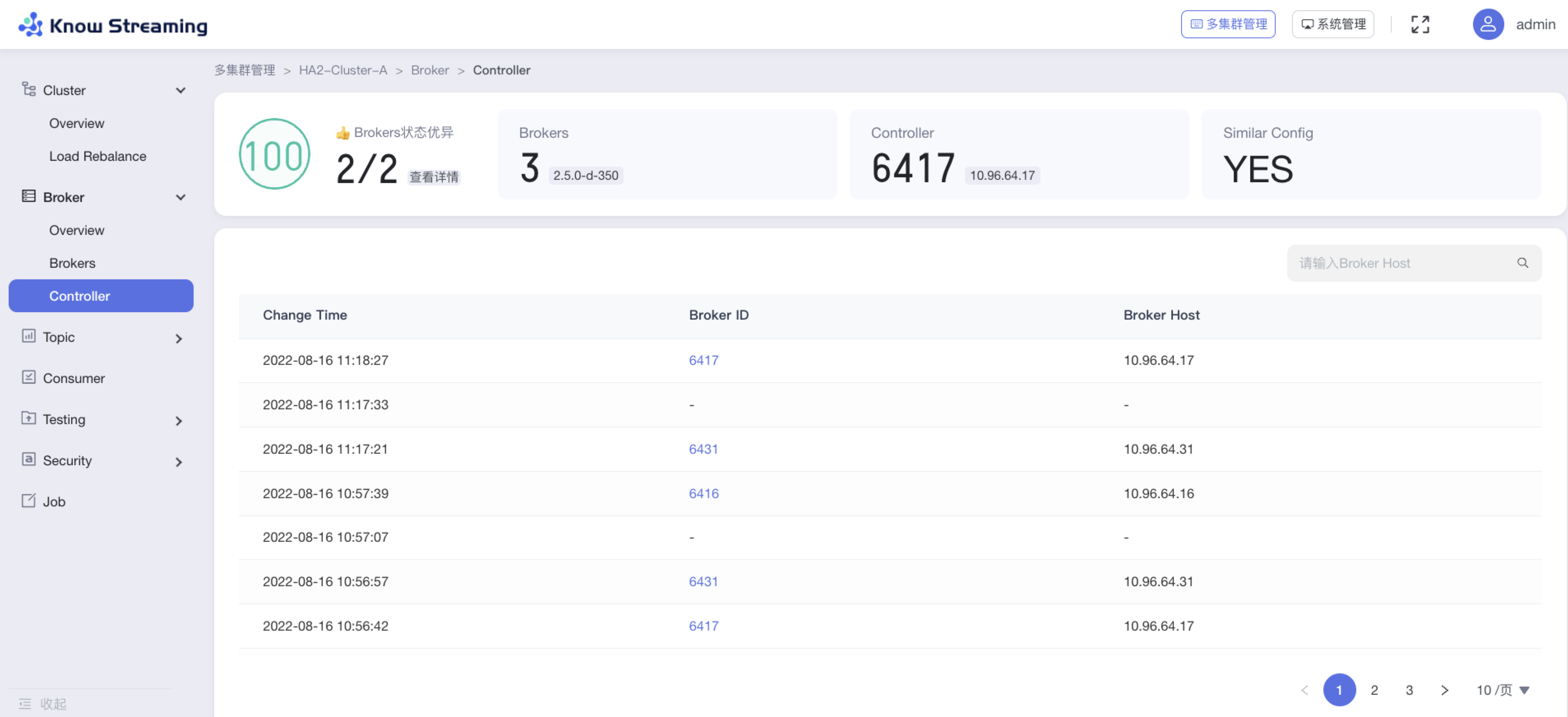
-
-### 5.4.7、Topic
-
-#### 5.4.7.1、查看 Topic 概览信息
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Overview”
-
-- 步骤 2:Topic 概览信息包括以下内容
-
- - 集群健康分,健康检查通过项
- - Topics:Topic 总数
- - Partitions:Partition 总数
- - PartitionNoLeader:没有 leader 的 partition 个数
- - < Min ISR:同步副本数小于 Min ISR
- - =Min ISR:同步副本数等于 Min ISR
- - Topic 指标图表
-
-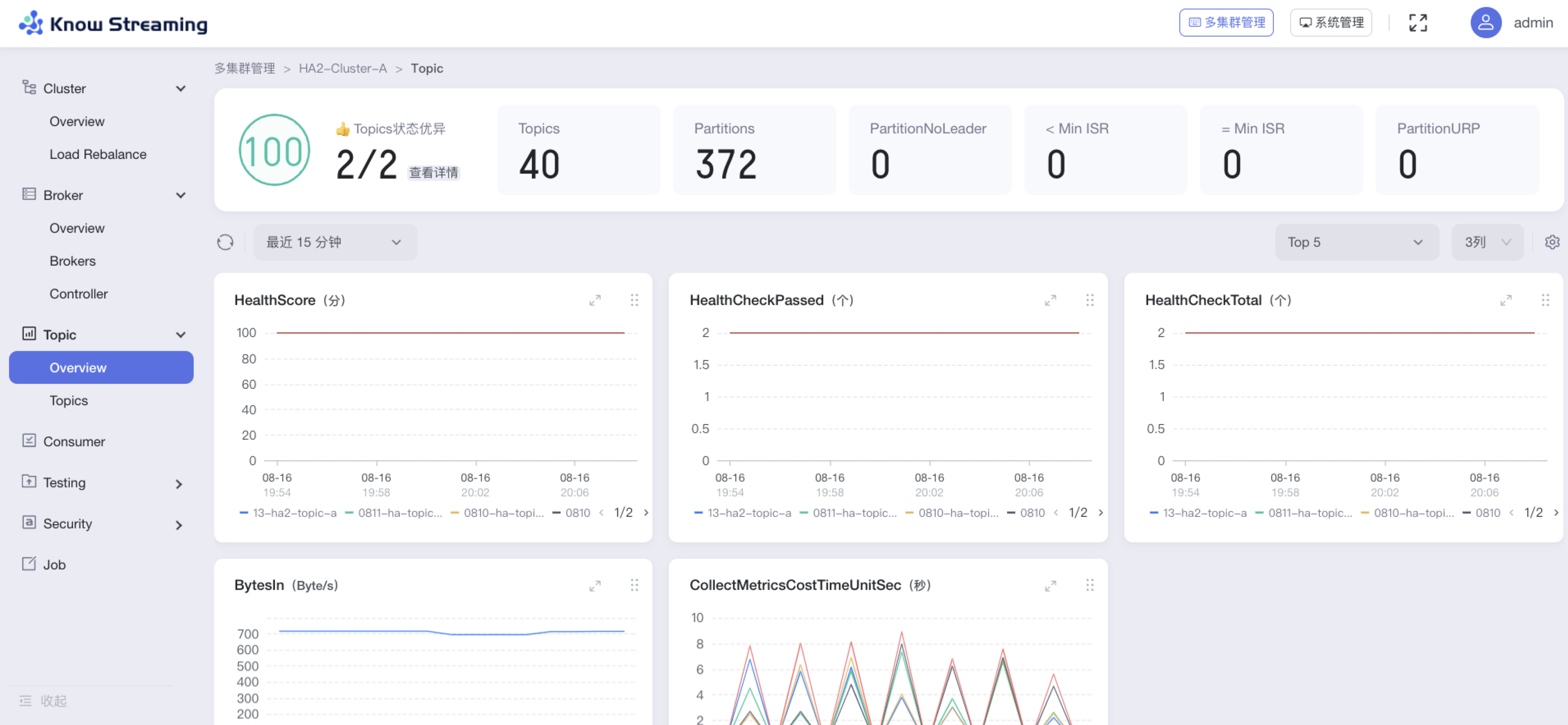
-
-#### 5.4.7.2、查看 Topic 健康检查详情
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Overview”>“集群健康状态旁边【查看详情】”>“健康检查详情抽屉”
-
-- 步骤 2:健康检查详情抽屉展示信息为:“检查项”、“权重”、“得分”、“检查时间”、“检查结果是否通过”,若未通过会展示未通过的对象
-
-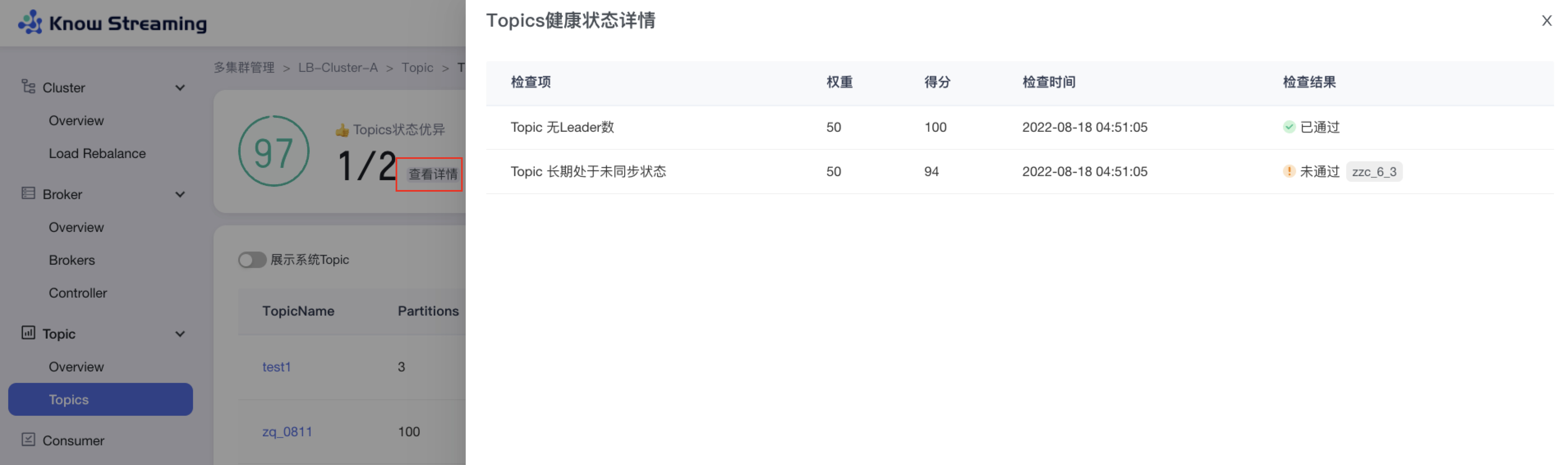
-
-#### 5.4.7.3、查看 Topic 列表
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”
-
-- 步骤 2:Topic 列表展示内容为“TopicName”、“Partitions”、“Replications”、“健康分”、“BytesIn”、“BytesOut”、“MessageSize”、“保存时间”、“描述”、操作项”扩分区“、操作项”删除“
-
-- 步骤 3:筛选框输入“TopicName”可以对列表进行筛选;点击“展示系统 Topic”开关,可以筛选系统 topic
-
-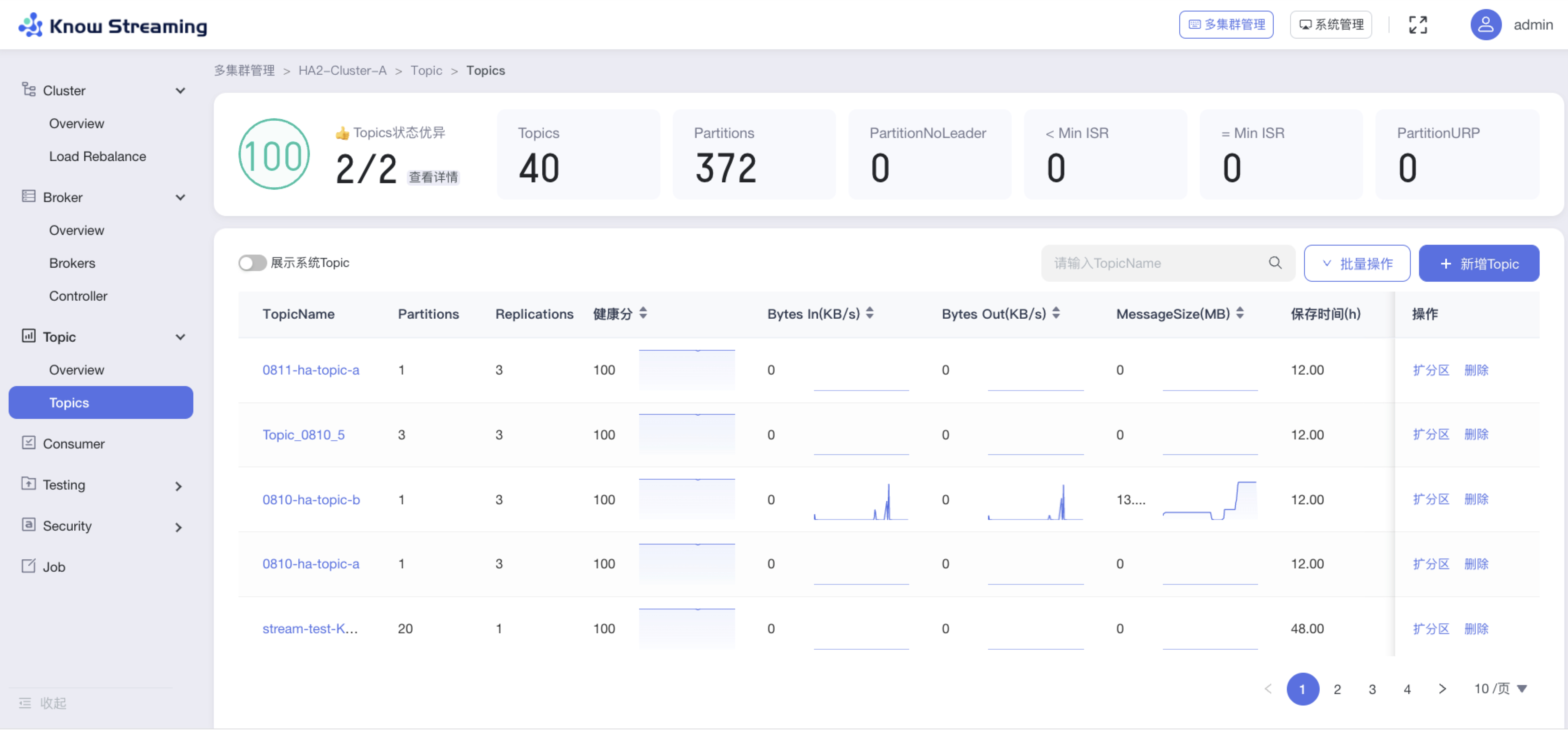
-
-#### 5.4.7.4、新增 Topic
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“新增 Topic”按钮>“创建 Topic“抽屉
-
-- 步骤 2:输入“Topic 名称(不能重复)”、“Topic 描述”、“分区数”、“副本数”、“数据保存时间”、“清理策略(删除或压缩)”
-
-- 步骤 3:展开“更多配置”可以打开高级配置选项,根据自己需要输入相应配置参数
-
-- 步骤 4:点击“确定”,创建 Topic 完成
-
-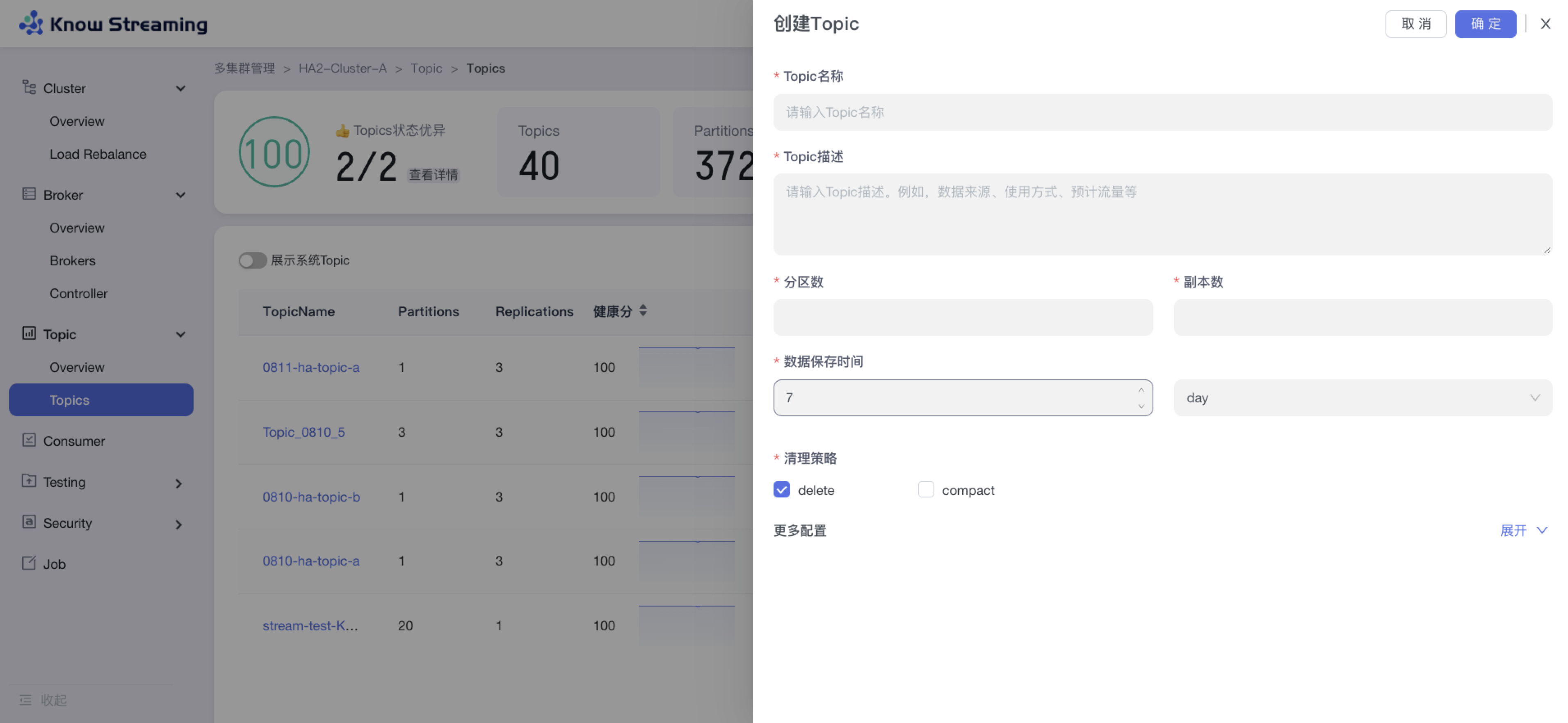
-
-#### 5.4.7.5、Topic 扩分区
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“Topic 列表“>操作项”扩分区“>“扩分区”抽屉
-
-- 步骤 2:扩分区抽屉展示内容为“流量的趋势图”、“当前分区数及支持的最低消息写入速率”、“扩分区后支持的最低消息写入速率”
-
-- 步骤 3:输入所需的分区总数,自动计算出扩分区后支持的最低消息写入速率
-
-- 步骤 4:点击确定,扩分区完成
-
-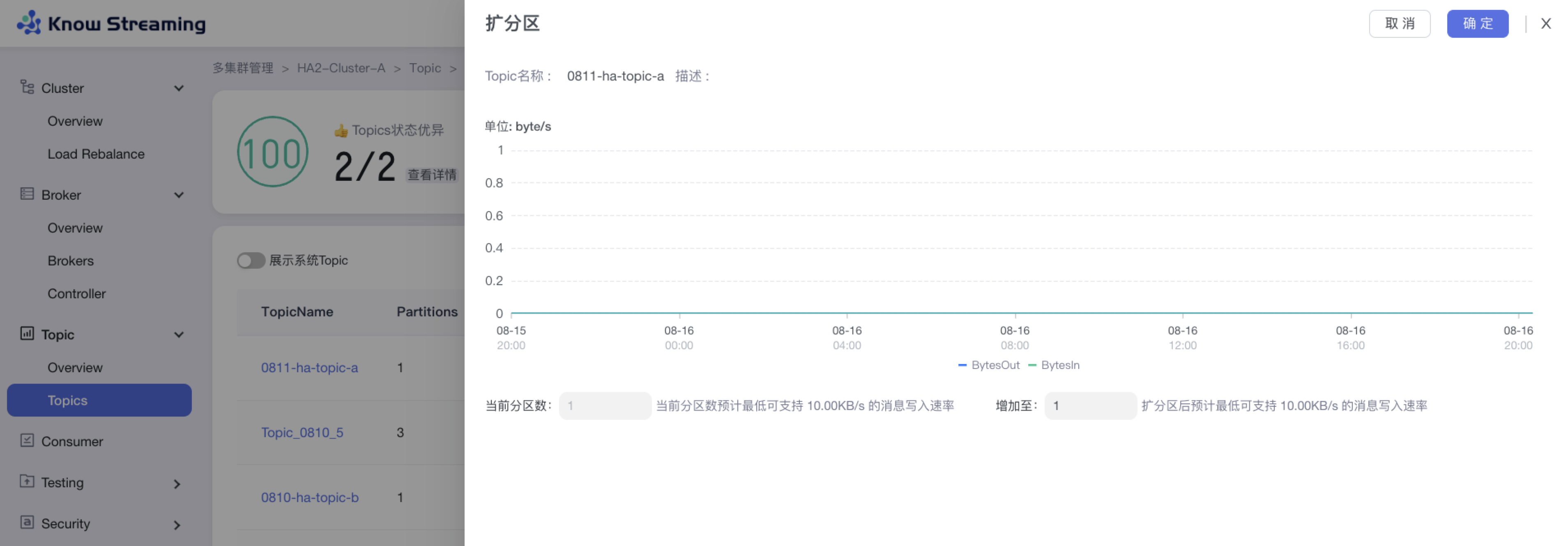
-
-#### 5.4.7.6、删除 Topic
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“Topic 列表“>操作项”删除“>“删除 Topic”弹窗
-
-- 步骤 2:输入“TopicName”进行二次确认
-
-- 步骤 3:点击“删除”,删除 Topic 完成
-
-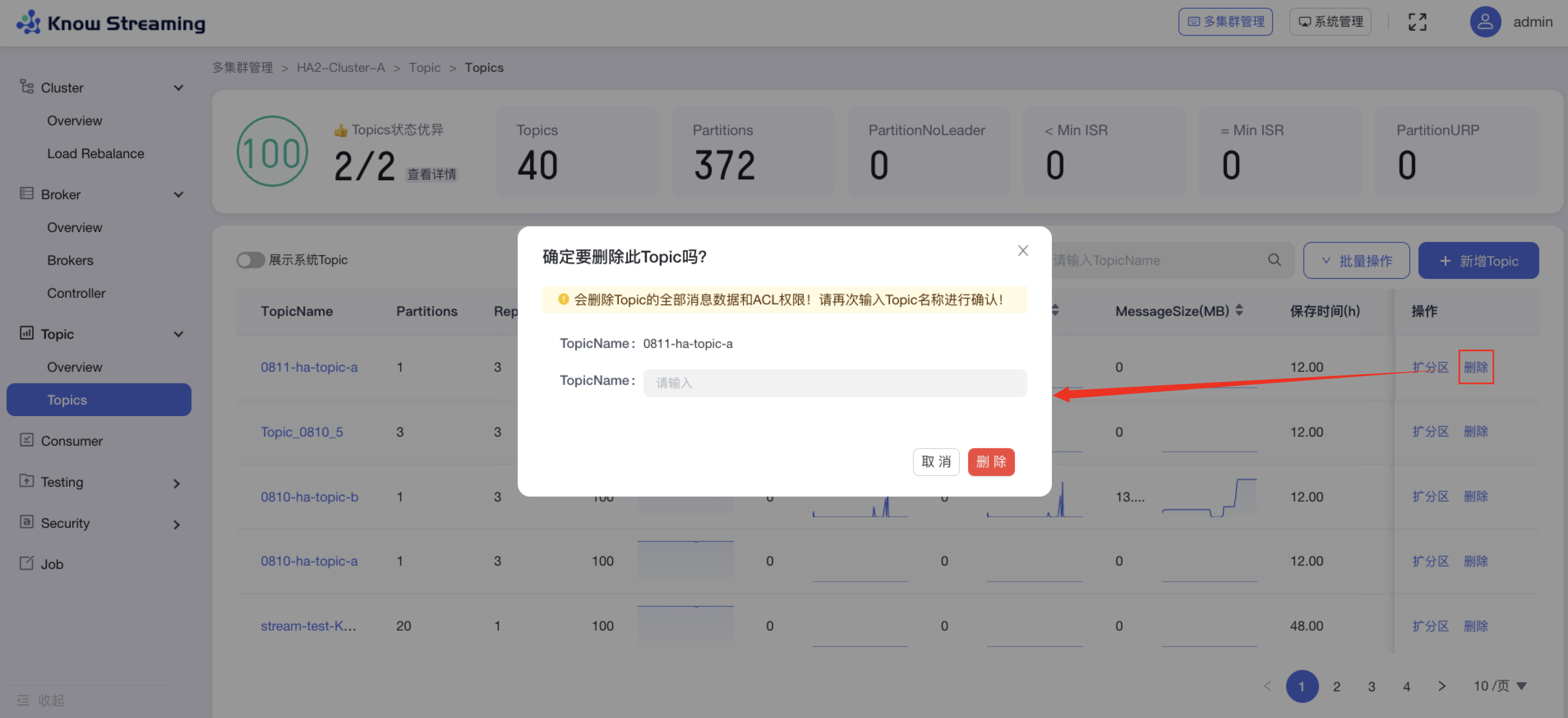
-
-#### 5.4.7.7、Topic 批量扩缩副本
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“批量操作下拉“>“批量扩缩副本“>“批量扩缩容”抽屉
-
-- 步骤 2:选择所需要进行扩缩容的 Topic,可多选,所选择的 Topic 出现在下方 Topic 列表中
-
-- 步骤 3:Topic 列表展示 Topic“近三天平均流量”、“近三天峰值流量及时间”、“Partition 数”、”当前副本数“、“新副本数”
-
-- 步骤 4:扩容时,选择目标节点,新增的副本会在选择的目标节点上;缩容时不需要选择目标节点,自动删除最后一个(或几个)副本
-
-- 步骤 5:输入迁移任务配置参数,包含限流值和任务执行时间
-
-- 步骤 6:输入任务描述
-
-- 步骤 7:点击“确定”,执行 Topic 扩缩容任务
-
-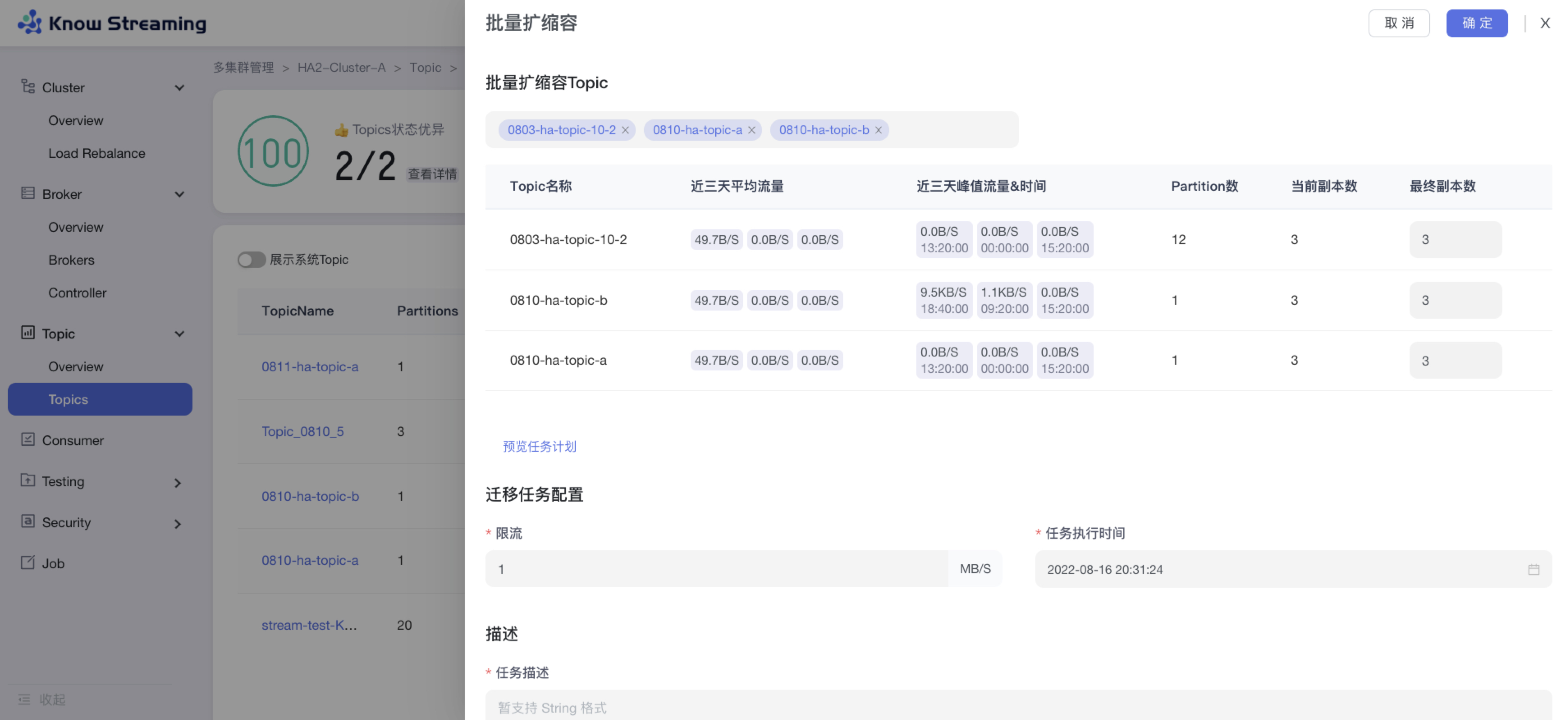
-
-#### 5.4.7.8、Topic 批量迁移
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“批量操作下拉“>“批量迁移“>“批量迁移”抽屉
-
-- 步骤 2:选择所需要进行迁移的 Topic,可多选,所选择的 Topic 出现在下方 Topic 列表中
-
-- 步骤 3:选择所需要迁移的 partition 和迁移数据的时间范围
-
-- 步骤 4:选择目标节点(节点数必须不小于最大副本数)
-
-- 步骤 5:点击“预览任务计划”,打开“任务计划”二次抽屉,可对每个 partition 的目标 Broker ID 进行编辑,目标 broker 应该等于副本数
-
-- 步骤 6:输入迁移任务配置参数,包含限流值和任务执行时间
-
-- 步骤 7:输入任务描述
-
-- 步骤 8:点击“确定”,执行 Topic 迁移任务
-
-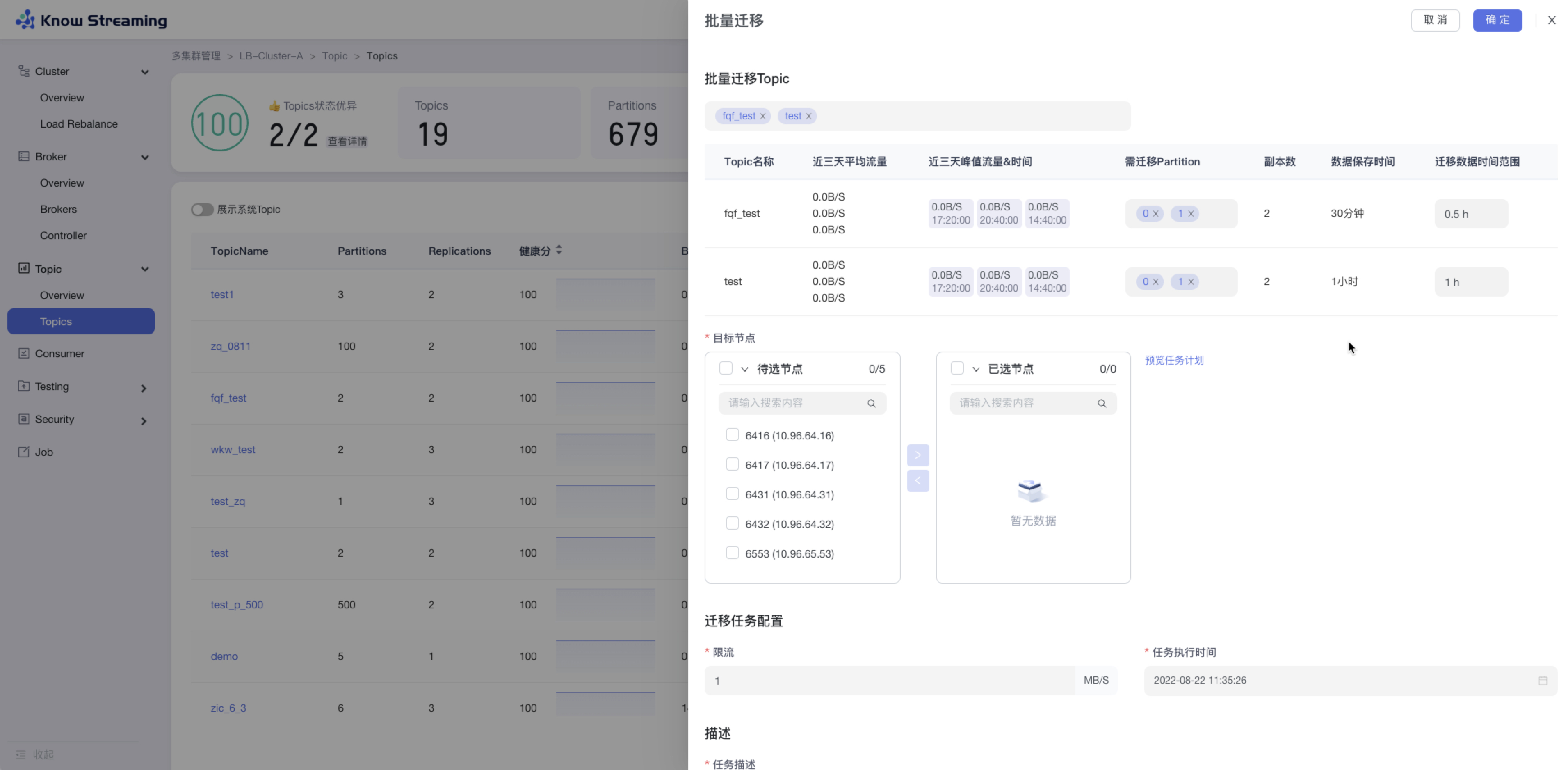
-
-### 5.4.8、Consumer
-
-#### 5.4.8.1、Consumer Overview
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Consumer”
-
-- 步骤 2:Consumer 概览信息包括以下内容
-
- - 集群健康分,健康检查通过项
- - Groups:Consumer Group 总数
- - GroupsActives:活跃的 Group 总数
- - GroupsEmptys:Empty 的 Group 总数
- - GroupRebalance:进行 Rebalance 的 Group 总数
- - GroupDeads:Dead 的 Group 总数
- - Consumer Group 列表
-
-- 步骤 3:输入“Consumer Group”、“Topic Name‘,可对列表进行筛选
-
-- 步骤 4:点击列表“Consumer Group”名称,可以查看 Comsuer Group 详情
-
-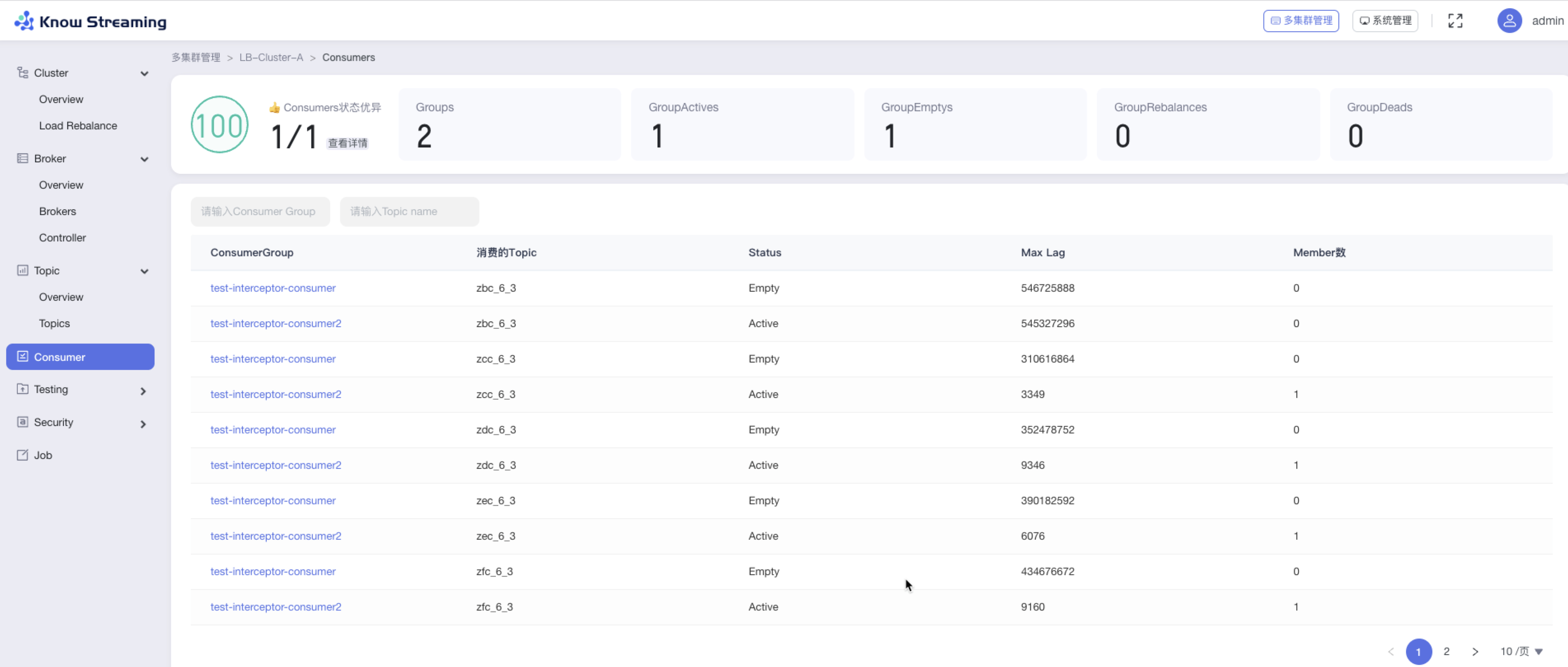
-
-#### 5.4.8.2、查看 Consumer 列表
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Consumer”>“Consumer Group”名称>“Consumer Group 详情”抽屉
-
-- 步骤 2:Consumer Group 详情有列表视图和图表视图
-
-- 步骤 3:列表视图展示信息为 Consumer 列表,包含”Topic Partition“、”Member ID“、”Current Offset“、“Log End Offset”、”Lag“、”Host“、”Client ID“
-
-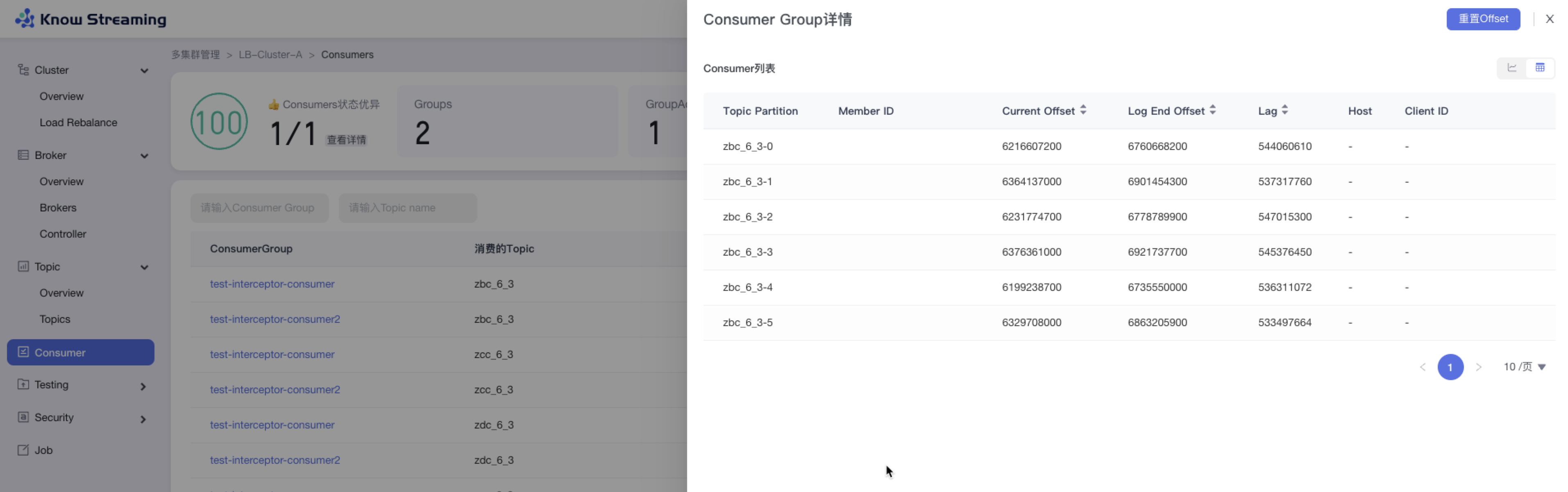
-
-#### 5.4.8.3、重置 Offset
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Consumer”>“Consumer Group”名称>“Consumer Group 详情”抽屉>“重置 Offset”按钮>“重置 Offset”抽屉
-
-- 步骤 2:选择重置 Offset 的类型,可“重置到指定时间”或“重置分区”
-
-- 步骤 3:重置到指定时间,可选择“最新 Offset”或“自定义时间”
-
-- 步骤 4:重置分区,可选择 partition 和其重置的 offset
-
-- 步骤 5:点击“确认”,重置 Offset 开始执行
-
-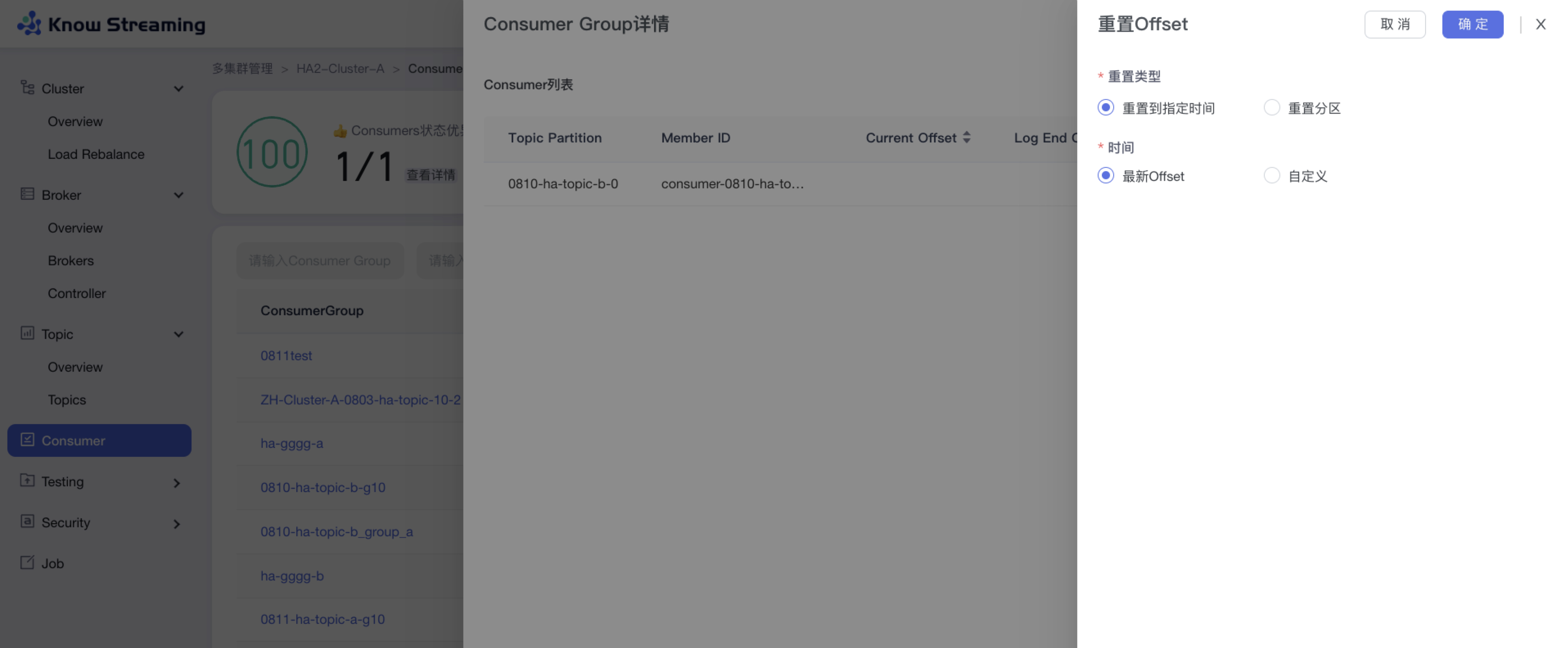
-
-### 5.4.9、Testing(企业版)
-
-#### 5.4.9.1、生产测试
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Testing”>“Produce”
-
-- 步骤 2:生产配置
-
- - Data:选择数据写入的 topic,输入写入数据的 key(暂只支持 string 格式),输入写入数据的 value(暂只支持 string 格式)。其中 key 和 value 可以随机生成
- - Flow:输入单次发送的消息数量,默认为 1,可以手动修改。选择手动生产模式,代表每次点击按钮【Run】执行生产;选择周期生产模式,需要填写运行总时间和运行时间间隔。
- - Header:输入 Header 的 key,value
- - Options:选择 Froce Partition,代表消息仅发送到这些选择的 Partition。选择数据压缩格式。选择 Acks 参数,none 意思是消息发送了就认为发送成功;leader 意思是 leader 接收到消息(不管 follower 有没有同步成功)认为消息发送成功;all 意思是所有的 follower 消息同步成功认为是消息发送成功
-
-- 步骤 3:点击按钮【Run】,生产测试开始,可以从右侧看到生产测试的信息
-
-
-
-#### 5.4.9.2、消费测试
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Testing”>“Consume”
-
-- 步骤 2:消费配置
-
- - Topic:选择数据从哪个 topic 进行消费
- - Start From:选择数据从什么地方开始消费,可以根据时间选择或者根据 Offset 进行选择
- - Until:选择消费截止到什么地方,可以根据时间或者 offset 或者消息数等进行选择
- - Filter:选择过滤器的规则。包含/不包含某【key,value】;等于/大于/小于多少条消息
-
-- 步骤 3:点击按钮【Run】,消费测试开始,可以在右边看到消费的明细信息
-
-
-
-### 5.4.10、Security
-
-注意:只有在开启集群认证的情况下才能够使用 Security 功能
-
-#### 5.4.10.1、查看 ACL 概览信息
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Security”>“ACLs”
-
-- 步骤 2:ACL 概览信息包括以下内容
-
- - Enable:是否可用
- - ACLs:ACL 总数
- - Users:User 总数
- - Topics:Topic 总数
- - Consumer Groups:Consumer Group 总数
- - ACL 列表
-
-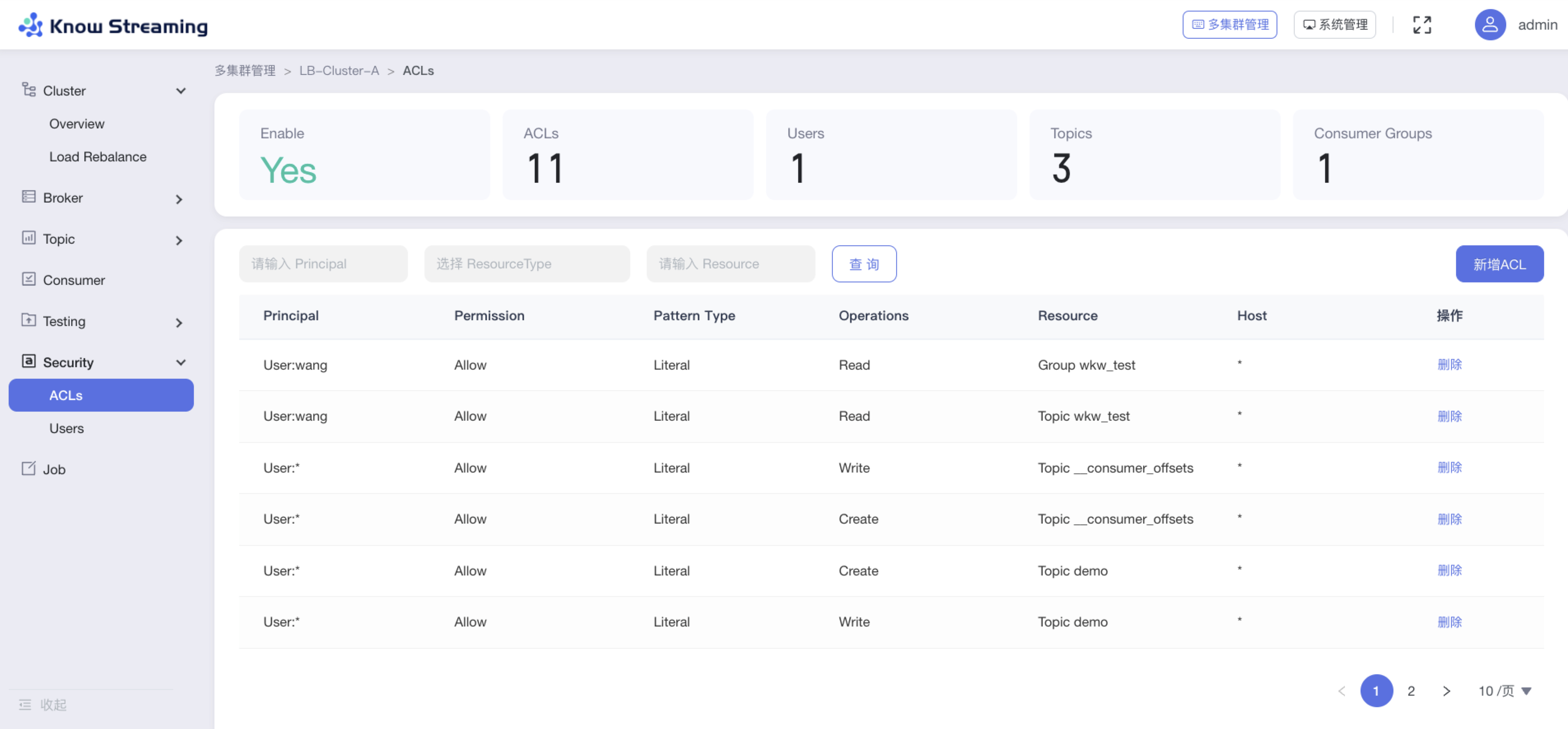
-
-#### 5.4.10.2、新增 ACl
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Security”>“Users”>“新增 ACL”
-
-- 步骤 2:输入 ACL 配置参数
-
- - ACL 用途:生产权限、消费权限、自定义权限
- - 生产权限时:可选择应用于所有 Kafka User 或者特定 Kafka User;可选择应用于所有 Topic 或者特定 Topic
- - 消费权限时:可选择应用于所有 Kafka User 或者特定 Kafka User;可选择应用于所有 Topic 或者特定 Topic;可选择应用于所有 Consumer Group 或者特定 Consumer Group
-
-- 步骤 3:点击“确定”,新增 ACL 成功
-
-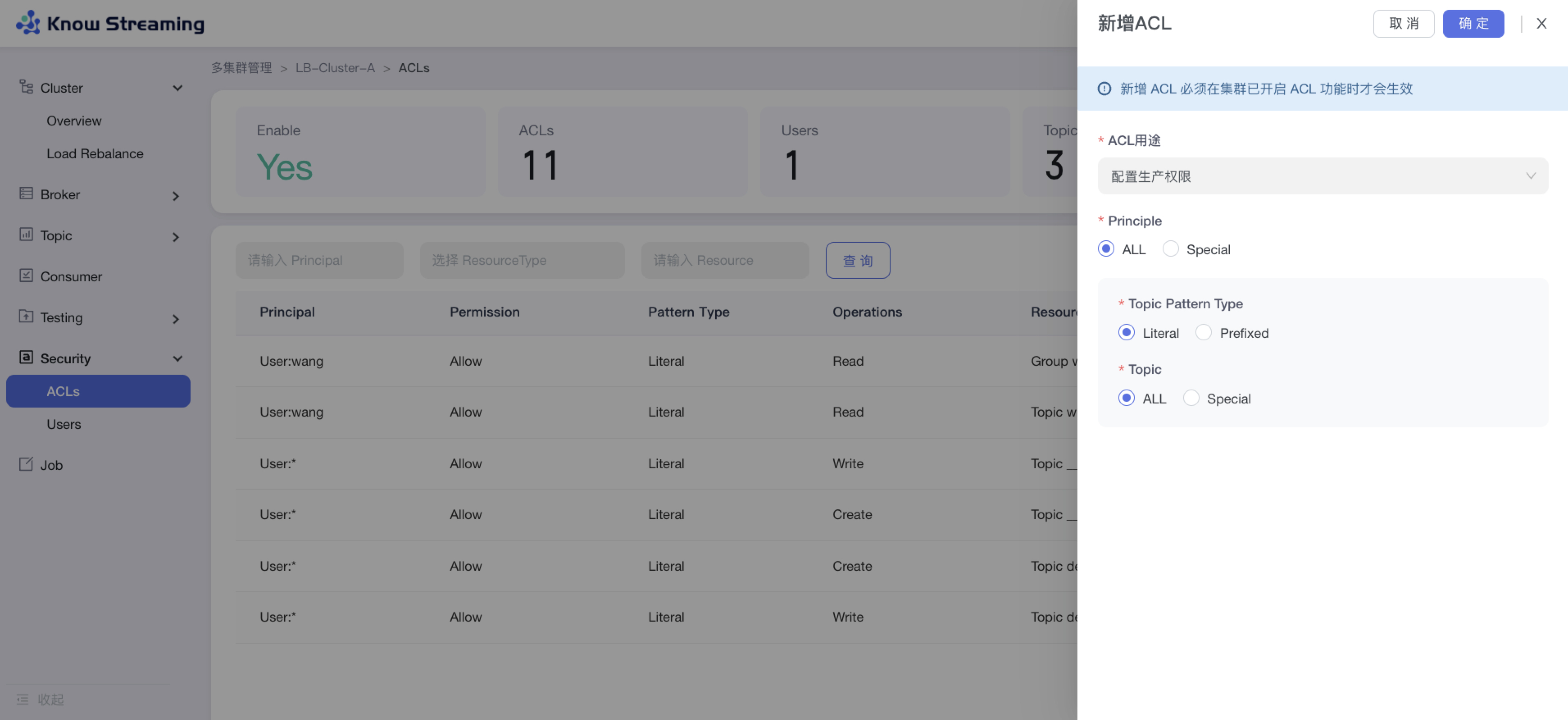
-
-#### 5.4.10.3、查看 User 信息
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Security”>“ACLs”
-
-- 步骤 2:User 列表展示内容包括“Kafka User 名称”、“认证方式”、“passwprd”、操作项”修改密码“、”操作项“删除”
-
-- 步骤 3:筛选框输入“Kafka User”可筛选出列表中相关 Kafka User
-
-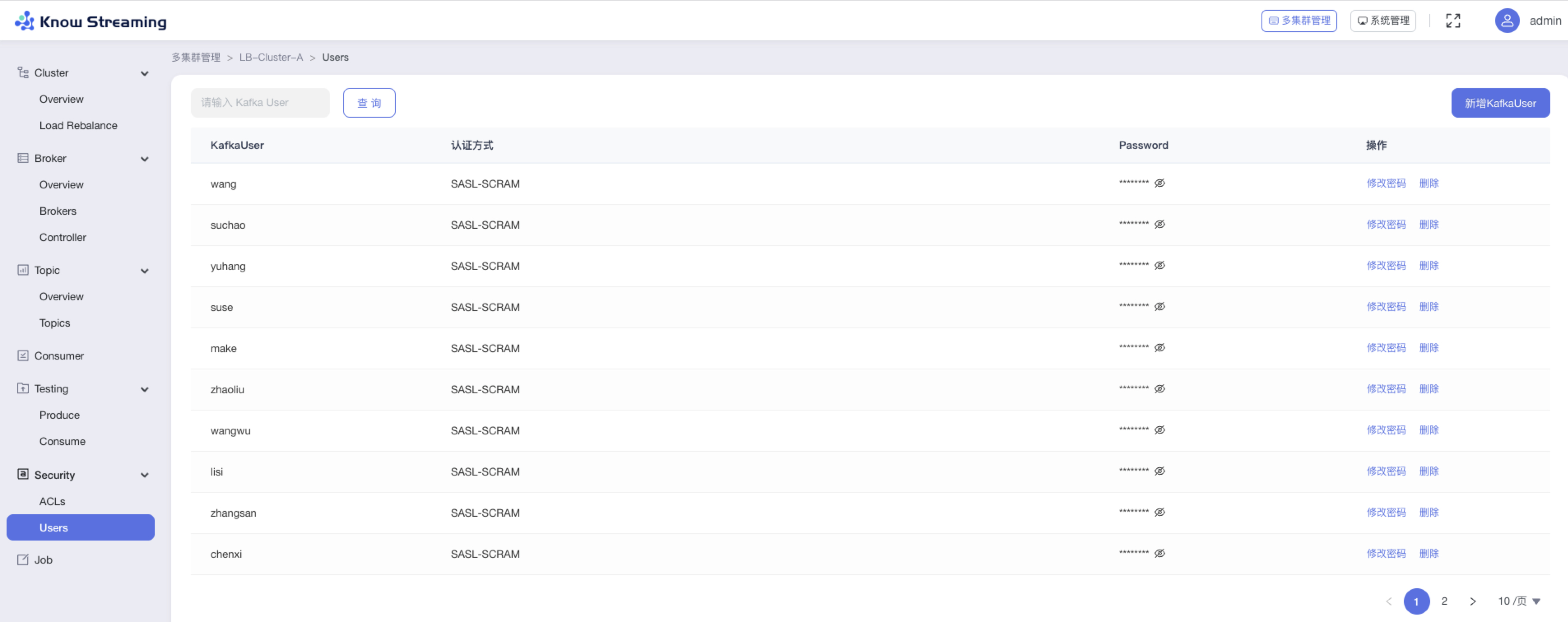
-
-#### 5.4.10.4、新增 Kafka User
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Security”>“Users”>“新增 Kafka User”
-
-- 步骤 2:输入 Kafka User 名称、认证方式、密码
-
-- 步骤 3:点击“确定”,新增 Kafka User 成功
-
-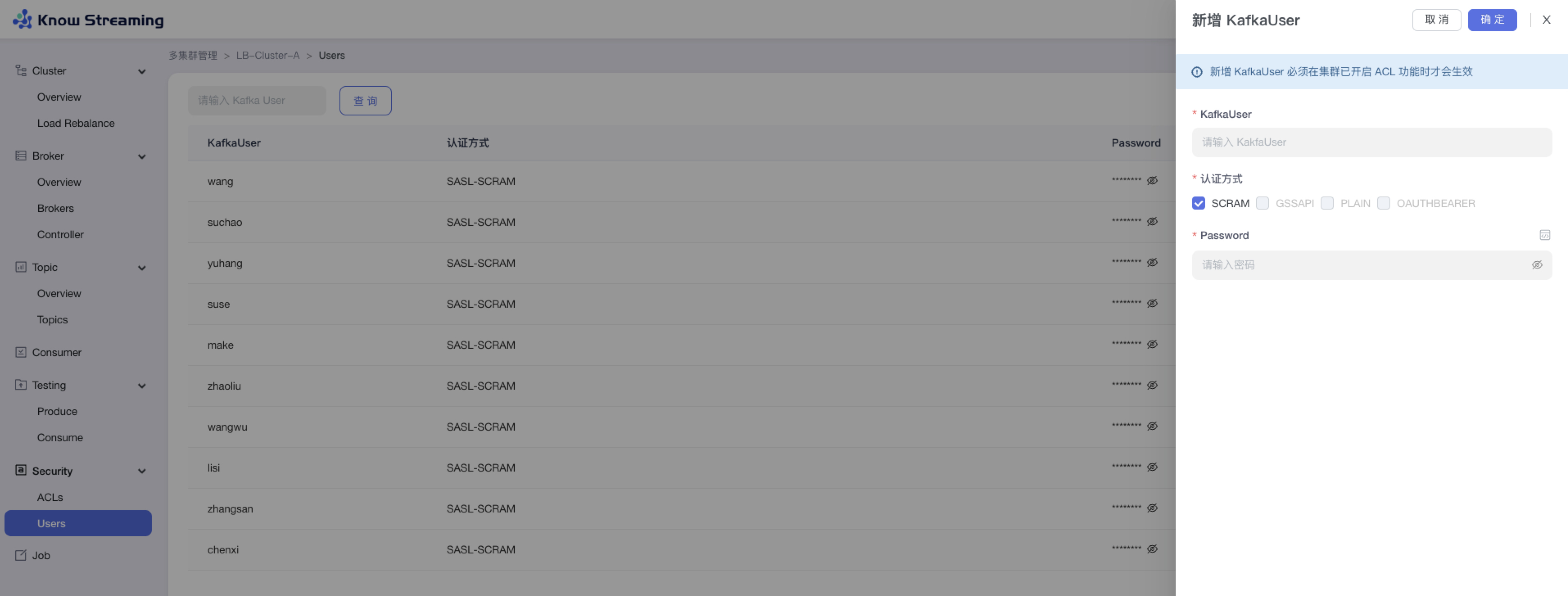
-
-### 5.4.11、Job
-
-#### 5.4.11.1、查看 Job 概览信息
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Job“
-
-- 步骤 2:Job 概览信息包括以下内容
-
- - Jobs:Job 总数
- - Doing:正在运行的 Job 总数
- - Prepare:准备运行的 Job 总数
- - Success:运行成功的 Job 总数
- - Fail:运行失败的 Job 总数
- - Job 列表
-
-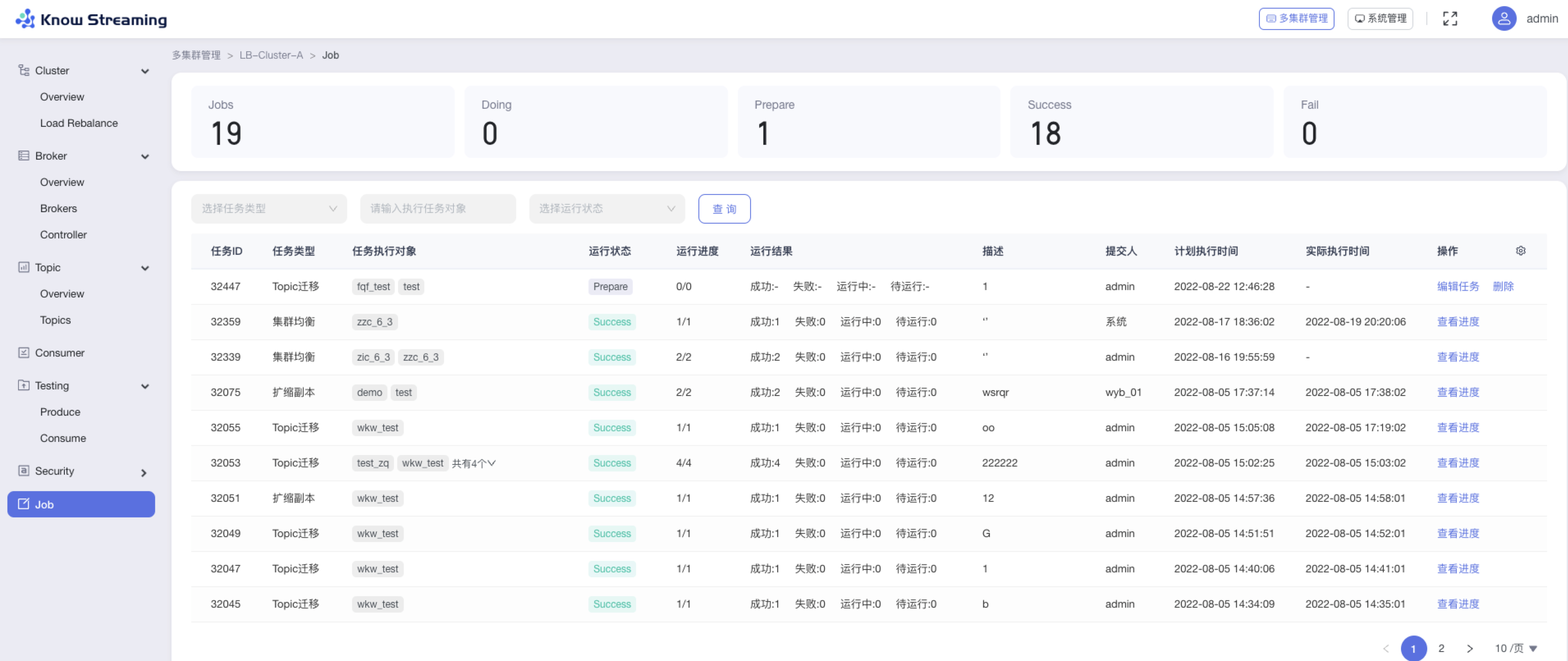
-
-#### 5.4.11.2、Job 查看进度
-
-Doing 状态下的任务可以查看进度
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Job”>“Job”列表>操作项“查看进度”>“查看进度”抽屉
-
-- 步骤 2:
-
- - 均衡任务:任务基本信息、均衡计划、任务执行明细信息
- - 扩缩副本:任务基本信息、任务执行明细信息、节点流量情况
- - Topic 迁移:任务基本信息、任务执行明细信息、节点流量情况
-
-
-
-#### 5.4.11.3、Job 编辑任务
-
-Prepare 状态下的任务可以进行编辑
-
-- 点击“多集群管理”>“集群卡片”>“Job”>“Job”列表>操作项“编辑”
-
-- 对任务执行的参数进行重新配置
-
- - 集群均衡:可以对指标计算周期、均衡维度、topic 黑名单、运行配置等参数重新设置
- - Topic 迁移:可以对 topic 需要迁移的 partition、迁移数据的时间范围、目标 broker 节点、限流值、执行时间、描述等参数重新配置
- - topic 扩缩副本:可以对最终副本数、限流值、任务执行时间、描述等参数重新配置
-
-- 点击“确定”,编辑任务成功
-
-
diff --git a/km-biz/pom.xml b/km-biz/pom.xml
deleted file mode 100644
index b8c3457b..00000000
--- a/km-biz/pom.xml
+++ /dev/null
@@ -1,94 +0,0 @@
-
-
- 4.0.0
- com.xiaojukeji.kafka
- km-biz
- ${km.revision}
- jar
-
-
- km
- com.xiaojukeji.kafka
- ${km.revision}
-
-
-
-
- true
- true
-
- UTF-8
- UTF-8
-
-
-
-
- com.xiaojukeji.kafka
- km-core
- ${project.parent.version}
-
-
-
-
- org.springframework
- spring-web
- ${spring.version}
-
-
- org.springframework
- spring-test
- ${spring.version}
-
-
-
-
- javax.servlet
- javax.servlet-api
-
-
- javax.annotation
- javax.annotation-api
-
-
-
- org.apache.kafka
- kafka-clients
- ${kafka-clients.version}
-
-
-
- commons-lang
- commons-lang
-
-
-
- commons-codec
- commons-codec
-
-
- org.eclipse.jetty
- jetty-util
-
-
-
- com.github.ben-manes.caffeine
- caffeine
-
-
-
-
- com.alibaba
- fastjson
-
-
- com.fasterxml.jackson.core
- jackson-databind
-
-
- org.springframework
- spring-context
-
-
-
\ No newline at end of file
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/BrokerConfigManager.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/BrokerConfigManager.java
deleted file mode 100644
index 4c583dc4..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/BrokerConfigManager.java
+++ /dev/null
@@ -1,19 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.broker;
-
-import com.xiaojukeji.know.streaming.km.common.bean.entity.param.config.KafkaBrokerConfigModifyParam;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.config.kafka.KafkaBrokerConfigVO;
-
-import java.util.List;
-
-public interface BrokerConfigManager {
- /**
- * 获取Broker配置详细信息
- * @param clusterPhyId 物理集群ID
- * @param brokerId brokerId
- * @return
- */
- Result> getBrokerConfigDetail(Long clusterPhyId, Integer brokerId);
-
- Result modifyBrokerConfig(KafkaBrokerConfigModifyParam modifyParam, String operator);
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/BrokerManager.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/BrokerManager.java
deleted file mode 100644
index e135bcd9..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/BrokerManager.java
+++ /dev/null
@@ -1,13 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.broker;
-
-import com.xiaojukeji.know.streaming.km.common.bean.dto.pagination.PaginationBaseDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.broker.BrokerBasicVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.log.LogDirVO;
-
-public interface BrokerManager {
- Result getBrokerBasic(Long clusterPhyId, Integer brokerId);
-
- PaginationResult getBrokerLogDirs(Long clusterPhyId, Integer brokerId, PaginationBaseDTO dto);
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/impl/BrokerConfigManagerImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/impl/BrokerConfigManagerImpl.java
deleted file mode 100644
index d670a8a5..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/impl/BrokerConfigManagerImpl.java
+++ /dev/null
@@ -1,97 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.broker.impl;
-
-import com.xiaojukeji.know.streaming.km.biz.broker.BrokerConfigManager;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.broker.Broker;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.config.kafkaconfig.KafkaConfigDetail;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.param.config.KafkaBrokerConfigModifyParam;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.po.broker.BrokerConfigPO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.config.kafka.KafkaBrokerConfigVO;
-import com.xiaojukeji.know.streaming.km.common.constant.KafkaConstant;
-import com.xiaojukeji.know.streaming.km.common.enums.config.ConfigDiffTypeEnum;
-import com.xiaojukeji.know.streaming.km.common.utils.ConvertUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.ValidateUtils;
-import com.xiaojukeji.know.streaming.km.core.service.broker.BrokerConfigService;
-import com.xiaojukeji.know.streaming.km.core.service.broker.BrokerService;
-import org.apache.kafka.common.config.ConfigDef;
-import org.springframework.beans.factory.annotation.Autowired;
-import org.springframework.stereotype.Component;
-
-import java.util.*;
-import java.util.function.Function;
-import java.util.stream.Collectors;
-
-@Component
-public class BrokerConfigManagerImpl implements BrokerConfigManager {
- @Autowired
- private BrokerService brokerService;
-
- @Autowired
- private BrokerConfigService brokerConfigService;
-
- @Override
- public Result> getBrokerConfigDetail(Long clusterPhyId, Integer brokerId) {
- // 获取当前broker配置
- Result> configResult = brokerConfigService.getBrokerConfigDetailFromKafka(clusterPhyId, brokerId);
- if (configResult.failed()) {
- return Result.buildFromIgnoreData(configResult);
- }
-
- // 获取差异的配置
- List diffPOList = brokerConfigService.getBrokerConfigDiffFromDB(clusterPhyId, brokerId);
-
- // 组装数据
- return Result.buildSuc(this.convert2KafkaBrokerConfigVOList(configResult.getData(), diffPOList));
- }
-
- private List convert2KafkaBrokerConfigVOList(List configList, List diffPOList) {
- if (ValidateUtils.isEmptyList(configList)) {
- return new ArrayList<>();
- }
-
- Map poMap = diffPOList.stream().collect(Collectors.toMap(BrokerConfigPO::getConfigName, Function.identity()));
-
- List voList = ConvertUtil.list2List(configList, KafkaBrokerConfigVO.class);
- for (KafkaBrokerConfigVO vo: voList) {
- BrokerConfigPO po = poMap.get(vo.getName());
- if (po != null) {
- vo.setExclusive(po.getDiffType().equals(ConfigDiffTypeEnum.ALONE_POSSESS.getCode()));
- vo.setDifferentiated(po.getDiffType().equals(ConfigDiffTypeEnum.UN_EQUAL.getCode()));
- } else {
- vo.setExclusive(false);
- vo.setDifferentiated(false);
- }
-
- ConfigDef.ConfigKey configKey = KafkaConstant.KAFKA_ALL_CONFIG_DEF_MAP.get(vo.getName());
- if (configKey == null) {
- continue;
- }
-
- try {
- vo.setDocumentation(configKey.documentation);
- vo.setDefaultValue(configKey.defaultValue.toString());
- } catch (Exception e) {
- // ignore
- }
- }
- return voList;
- }
-
- @Override
- public Result modifyBrokerConfig(KafkaBrokerConfigModifyParam modifyParam, String operator) {
- if (modifyParam.getApplyAll() == null || !modifyParam.getApplyAll()) {
- return brokerConfigService.modifyBrokerConfig(modifyParam, operator);
- }
-
- List brokerList = brokerService.listAliveBrokersFromDB(modifyParam.getClusterPhyId());
- for (Broker broker: brokerList) {
- modifyParam.setBrokerId(broker.getBrokerId());
- Result rv = brokerConfigService.modifyBrokerConfig(modifyParam, operator);
- if (rv.failed()) {
- return rv;
- }
- }
-
- return Result.buildSuc();
- }
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/impl/BrokerManagerImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/impl/BrokerManagerImpl.java
deleted file mode 100644
index 8fd9a411..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/impl/BrokerManagerImpl.java
+++ /dev/null
@@ -1,75 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.broker.impl;
-
-import com.xiaojukeji.know.streaming.km.biz.broker.BrokerManager;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.pagination.PaginationBaseDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.broker.Broker;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.cluster.ClusterPhy;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.ResultStatus;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.broker.BrokerBasicVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.log.LogDirVO;
-import com.xiaojukeji.know.streaming.km.common.constant.MsgConstant;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationUtil;
-import com.xiaojukeji.know.streaming.km.core.service.broker.BrokerService;
-import com.xiaojukeji.know.streaming.km.core.service.cluster.ClusterPhyService;
-import org.apache.kafka.clients.admin.LogDirDescription;
-import org.springframework.beans.factory.annotation.Autowired;
-import org.springframework.stereotype.Component;
-
-import java.util.*;
-
-@Component
-public class BrokerManagerImpl implements BrokerManager {
- @Autowired
- private BrokerService brokerService;
-
- @Autowired
- private ClusterPhyService clusterPhyService;
-
- @Override
- public Result getBrokerBasic(Long clusterPhyId, Integer brokerId) {
- ClusterPhy clusterPhy = clusterPhyService.getClusterByCluster(clusterPhyId);
- if (clusterPhy == null) {
- return Result.buildFromRSAndMsg(ResultStatus.NOT_EXIST, MsgConstant.getClusterPhyNotExist(clusterPhyId));
- }
-
- Broker broker = brokerService.getBroker(clusterPhyId, brokerId);
- if (broker == null) {
- return Result.buildFromRSAndMsg(ResultStatus.NOT_EXIST, MsgConstant.getBrokerNotExist(clusterPhyId, brokerId));
- }
-
- return Result.buildSuc(new BrokerBasicVO(brokerId, broker.getHost(), clusterPhy.getName()));
- }
-
- @Override
- public PaginationResult getBrokerLogDirs(Long clusterPhyId, Integer brokerId, PaginationBaseDTO dto) {
- Result> dirDescResult = brokerService.getBrokerLogDirDescFromKafka(clusterPhyId, brokerId);
- if (dirDescResult.failed()) {
- return PaginationResult.buildFailure(dirDescResult, dto);
- }
-
- Map dirDescMap = dirDescResult.hasData()? dirDescResult.getData(): new HashMap<>();
-
- List voList = new ArrayList<>();
- for (Map.Entry entry: dirDescMap.entrySet()) {
- entry.getValue().replicaInfos().entrySet().stream().forEach(elem -> {
- LogDirVO vo = new LogDirVO();
- vo.setDir(entry.getKey());
- vo.setTopicName(elem.getKey().topic());
- vo.setPartitionId(elem.getKey().partition());
- vo.setOffsetLag(elem.getValue().offsetLag());
- vo.setLogSizeUnitB(elem.getValue().size());
- voList.add(vo);
- });
- }
-
- return PaginationUtil.pageBySubData(
- PaginationUtil.pageByFuzzyFilter(voList, dto.getSearchKeywords(), Arrays.asList("topicName")),
- dto
- );
- }
-
- /**************************************************** private method ****************************************************/
-
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterBrokersManager.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterBrokersManager.java
deleted file mode 100644
index 8427c1ef..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterBrokersManager.java
+++ /dev/null
@@ -1,26 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.cluster;
-
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterBrokersOverviewDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.res.ClusterBrokersOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.res.ClusterBrokersStateVO;
-
-/**
- * 多集群总体状态
- */
-public interface ClusterBrokersManager {
- /**
- * 获取缓存查询结果 & broker 表查询结果并集
- * @param clusterPhyId kafka 物理集群 id
- * @param dto 封装分页查询参数对象
- * @return 返回获取到的缓存查询结果 & broker 表查询结果并集
- */
- PaginationResult getClusterPhyBrokersOverview(Long clusterPhyId, ClusterBrokersOverviewDTO dto);
-
- /**
- * 根据物理集群id获取集群对应broker状态信息
- * @param clusterPhyId 物理集群 id
- * @return 返回根据物理集群id获取到的集群对应broker状态信息
- */
- ClusterBrokersStateVO getClusterPhyBrokersState(Long clusterPhyId);
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterConnectorsManager.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterConnectorsManager.java
deleted file mode 100644
index c20c5c77..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterConnectorsManager.java
+++ /dev/null
@@ -1,15 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.cluster;
-
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterConnectorsOverviewDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.connect.ConnectStateVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.connector.ClusterConnectorOverviewVO;
-
-/**
- * Kafka集群Connector概览
- */
-public interface ClusterConnectorsManager {
- PaginationResult getClusterConnectorsOverview(Long clusterPhyId, ClusterConnectorsOverviewDTO dto);
-
- ConnectStateVO getClusterConnectorsState(Long clusterPhyId);
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterTopicsManager.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterTopicsManager.java
deleted file mode 100644
index 928d5d36..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterTopicsManager.java
+++ /dev/null
@@ -1,12 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.cluster;
-
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterTopicsOverviewDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.res.ClusterPhyTopicsOverviewVO;
-
-/**
- * 多集群总体状态
- */
-public interface ClusterTopicsManager {
- PaginationResult getClusterPhyTopicsOverview(Long clusterPhyId, ClusterTopicsOverviewDTO dto);
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterZookeepersManager.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterZookeepersManager.java
deleted file mode 100644
index 8219cd7e..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterZookeepersManager.java
+++ /dev/null
@@ -1,19 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.cluster;
-
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterZookeepersOverviewDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.zookeeper.ClusterZookeepersOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.zookeeper.ClusterZookeepersStateVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.zookeeper.ZnodeVO;
-
-/**
- * 多集群总体状态
- */
-public interface ClusterZookeepersManager {
- Result getClusterPhyZookeepersState(Long clusterPhyId);
-
- PaginationResult getClusterPhyZookeepersOverview(Long clusterPhyId, ClusterZookeepersOverviewDTO dto);
-
- Result getZnodeVO(Long clusterPhyId, String path);
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/MultiClusterPhyManager.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/MultiClusterPhyManager.java
deleted file mode 100644
index 2d57d719..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/MultiClusterPhyManager.java
+++ /dev/null
@@ -1,33 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.cluster;
-
-import com.xiaojukeji.know.streaming.km.common.bean.entity.cluster.ClusterPhysHealthState;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.cluster.ClusterPhysState;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.MultiClusterDashboardDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.ClusterPhyBaseVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.ClusterPhyDashboardVO;
-
-import java.util.List;
-
-/**
- * 多集群总体状态
- */
-public interface MultiClusterPhyManager {
- /**
- * 获取所有集群的状态
- * @return
- */
- ClusterPhysState getClusterPhysState();
-
- ClusterPhysHealthState getClusterPhysHealthState();
-
- /**
- * 查询多集群大盘
- * @param dto 分页信息
- * @return
- */
- PaginationResult getClusterPhysDashboard(MultiClusterDashboardDTO dto);
-
- Result> getClusterPhysBasic();
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterBrokersManagerImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterBrokersManagerImpl.java
deleted file mode 100644
index ab5d6a6d..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterBrokersManagerImpl.java
+++ /dev/null
@@ -1,257 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.cluster.impl;
-
-import com.didiglobal.logi.log.ILog;
-import com.didiglobal.logi.log.LogFactory;
-import com.xiaojukeji.know.streaming.km.biz.cluster.ClusterBrokersManager;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterBrokersOverviewDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.pagination.PaginationSortDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.broker.Broker;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.cluster.ClusterPhy;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.config.JmxConfig;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.kafkacontroller.KafkaController;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.metrics.BrokerMetrics;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.topic.Topic;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.res.ClusterBrokersOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.res.ClusterBrokersStateVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.kafkacontroller.KafkaControllerVO;
-import com.xiaojukeji.know.streaming.km.common.constant.KafkaConstant;
-import com.xiaojukeji.know.streaming.km.common.enums.SortTypeEnum;
-import com.xiaojukeji.know.streaming.km.common.enums.cluster.ClusterRunStateEnum;
-import com.xiaojukeji.know.streaming.km.common.utils.ConvertUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationMetricsUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.ValidateUtils;
-import com.xiaojukeji.know.streaming.km.core.service.broker.BrokerConfigService;
-import com.xiaojukeji.know.streaming.km.core.service.broker.BrokerMetricService;
-import com.xiaojukeji.know.streaming.km.core.service.broker.BrokerService;
-import com.xiaojukeji.know.streaming.km.core.service.kafkacontroller.KafkaControllerService;
-import com.xiaojukeji.know.streaming.km.core.service.topic.TopicService;
-import com.xiaojukeji.know.streaming.km.persistence.cache.LoadedClusterPhyCache;
-import com.xiaojukeji.know.streaming.km.persistence.kafka.KafkaJMXClient;
-import org.springframework.beans.factory.annotation.Autowired;
-import org.springframework.stereotype.Service;
-
-import java.util.*;
-import java.util.function.Function;
-import java.util.stream.Collectors;
-
-
-@Service
-public class ClusterBrokersManagerImpl implements ClusterBrokersManager {
- private static final ILog log = LogFactory.getLog(ClusterBrokersManagerImpl.class);
-
- @Autowired
- private TopicService topicService;
-
- @Autowired
- private BrokerService brokerService;
-
- @Autowired
- private BrokerConfigService brokerConfigService;
-
- @Autowired
- private BrokerMetricService brokerMetricService;
-
- @Autowired
- private KafkaControllerService kafkaControllerService;
-
- @Autowired
- private KafkaJMXClient kafkaJMXClient;
-
- @Override
- public PaginationResult getClusterPhyBrokersOverview(Long clusterPhyId, ClusterBrokersOverviewDTO dto) {
- // 获取集群Broker列表
- List brokerList = brokerService.listAllBrokersFromDB(clusterPhyId);
-
- // 搜索
- brokerList = PaginationUtil.pageByFuzzyFilter(brokerList, dto.getSearchKeywords(), Arrays.asList("host"));
-
- // 获取指标
- Result> metricsResult = brokerMetricService.getLatestMetricsFromES(
- clusterPhyId,
- brokerList.stream().filter(elem1 -> elem1.alive()).map(elem2 -> elem2.getBrokerId()).collect(Collectors.toList())
- );
-
- // 分页 + 搜索
- PaginationResult paginationResult = this.pagingBrokers(brokerList, metricsResult.hasData()? metricsResult.getData(): new ArrayList<>(), dto);
-
- // 获取__consumer_offsetsTopic的分布
- Topic groupTopic = topicService.getTopic(clusterPhyId, org.apache.kafka.common.internals.Topic.GROUP_METADATA_TOPIC_NAME);
- Topic transactionTopic = topicService.getTopic(clusterPhyId, org.apache.kafka.common.internals.Topic.TRANSACTION_STATE_TOPIC_NAME);
-
- //获取controller信息
- KafkaController kafkaController = kafkaControllerService.getKafkaControllerFromDB(clusterPhyId);
-
- //获取jmx状态信息
- Map jmxConnectedMap = new HashMap<>();
- brokerList.forEach(elem -> jmxConnectedMap.put(elem.getBrokerId(), kafkaJMXClient.getClientWithCheck(clusterPhyId, elem.getBrokerId()) != null));
-
-
- ClusterPhy clusterPhy = LoadedClusterPhyCache.getByPhyId(clusterPhyId);
-
- // 格式转换
- return PaginationResult.buildSuc(
- this.convert2ClusterBrokersOverviewVOList(
- clusterPhy,
- paginationResult.getData().getBizData(),
- brokerList,
- metricsResult.getData(),
- groupTopic,
- transactionTopic,
- kafkaController,
- jmxConnectedMap
- ),
- paginationResult
- );
- }
-
- @Override
- public ClusterBrokersStateVO getClusterPhyBrokersState(Long clusterPhyId) {
- ClusterBrokersStateVO clusterBrokersStateVO = new ClusterBrokersStateVO();
-
- // 获取集群Broker列表
- List allBrokerList = brokerService.listAllBrokersFromDB(clusterPhyId);
- if (allBrokerList == null) {
- allBrokerList = new ArrayList<>();
- }
-
- // 设置broker数
- clusterBrokersStateVO.setBrokerCount(allBrokerList.size());
-
- // 设置版本信息
- clusterBrokersStateVO.setBrokerVersionList(
- this.getBrokerVersionList(clusterPhyId, allBrokerList.stream().filter(elem -> elem.alive()).collect(Collectors.toList()))
- );
-
- // 获取controller信息
- KafkaController kafkaController = kafkaControllerService.getKafkaControllerFromDB(clusterPhyId);
-
- // 设置kafka-controller信息
- clusterBrokersStateVO.setKafkaControllerAlive(false);
- if(null != kafkaController) {
- clusterBrokersStateVO.setKafkaController(
- this.convert2KafkaControllerVO(
- kafkaController,
- brokerService.getBroker(clusterPhyId, kafkaController.getBrokerId())
- )
- );
- clusterBrokersStateVO.setKafkaControllerAlive(true);
- }
-
- clusterBrokersStateVO.setConfigSimilar(brokerConfigService.countBrokerConfigDiffsFromDB(clusterPhyId, KafkaConstant.CONFIG_SIMILAR_IGNORED_CONFIG_KEY_LIST) <= 0
- );
-
- return clusterBrokersStateVO;
- }
-
- /**************************************************** private method ****************************************************/
-
- private PaginationResult pagingBrokers(List brokerList, List metricsList, PaginationSortDTO dto) {
- if (ValidateUtils.isBlank(dto.getSortField())) {
- // 默认排序
- return PaginationUtil.pageBySubData(
- PaginationUtil.pageBySort(brokerList, "brokerId", SortTypeEnum.ASC.getSortType()).stream().map(elem -> elem.getBrokerId()).collect(Collectors.toList()),
- dto
- );
- }
- if (!brokerMetricService.isMetricName(dto.getSortField())) {
- // 非指标字段进行排序,分页
- return PaginationUtil.pageBySubData(
- PaginationUtil.pageBySort(brokerList, dto.getSortField(), dto.getSortType()).stream().map(elem -> elem.getBrokerId()).collect(Collectors.toList()),
- dto
- );
- }
-
- // 指标字段进行排序及分页
- Map metricsMap = metricsList.stream().collect(Collectors.toMap(BrokerMetrics::getBrokerId, Function.identity()));
- brokerList.stream().forEach(elem -> {
- metricsMap.putIfAbsent(elem.getBrokerId(), new BrokerMetrics(elem.getClusterPhyId(), elem.getBrokerId()));
- });
-
- // 排序
- metricsList = (List) PaginationMetricsUtil.sortMetrics(new ArrayList<>(metricsMap.values()), dto.getSortField(), "brokerId", dto.getSortType());
-
- return PaginationUtil.pageBySubData(
- metricsList.stream().map(elem -> elem.getBrokerId()).collect(Collectors.toList()),
- dto
- );
- }
-
- private List convert2ClusterBrokersOverviewVOList(ClusterPhy clusterPhy,
- List pagedBrokerIdList,
- List brokerList,
- List metricsList,
- Topic groupTopic,
- Topic transactionTopic,
- KafkaController kafkaController,
- Map jmxConnectedMap) {
- Map metricsMap = metricsList == null ? new HashMap<>() : metricsList.stream().collect(Collectors.toMap(BrokerMetrics::getBrokerId, Function.identity()));
-
- Map brokerMap = brokerList == null ? new HashMap<>() : brokerList.stream().collect(Collectors.toMap(Broker::getBrokerId, Function.identity()));
-
- List voList = new ArrayList<>(pagedBrokerIdList.size());
- for (Integer brokerId : pagedBrokerIdList) {
- Broker broker = brokerMap.get(brokerId);
- BrokerMetrics brokerMetrics = metricsMap.get(brokerId);
- Boolean jmxConnected = jmxConnectedMap.get(brokerId);
- voList.add(this.convert2ClusterBrokersOverviewVO(brokerId, broker, brokerMetrics, groupTopic, transactionTopic, kafkaController, jmxConnected));
- }
-
- //补充非zk模式的JMXPort信息
- if (!clusterPhy.getRunState().equals(ClusterRunStateEnum.RUN_ZK.getRunState())) {
- JmxConfig jmxConfig = ConvertUtil.str2ObjByJson(clusterPhy.getJmxProperties(), JmxConfig.class);
- voList.forEach(elem -> elem.setJmxPort(jmxConfig.getJmxPort() == null ? -1 : jmxConfig.getJmxPort()));
- }
-
- return voList;
- }
-
- private ClusterBrokersOverviewVO convert2ClusterBrokersOverviewVO(Integer brokerId, Broker broker, BrokerMetrics brokerMetrics, Topic groupTopic, Topic transactionTopic, KafkaController kafkaController, Boolean jmxConnected) {
- ClusterBrokersOverviewVO clusterBrokersOverviewVO = new ClusterBrokersOverviewVO();
- clusterBrokersOverviewVO.setBrokerId(brokerId);
- if (broker != null) {
- clusterBrokersOverviewVO.setHost(broker.getHost());
- clusterBrokersOverviewVO.setRack(broker.getRack());
- clusterBrokersOverviewVO.setJmxPort(broker.getJmxPort());
- clusterBrokersOverviewVO.setAlive(broker.alive());
- clusterBrokersOverviewVO.setStartTimeUnitMs(broker.getStartTimestamp());
- }
- clusterBrokersOverviewVO.setKafkaRoleList(new ArrayList<>());
-
- if (groupTopic != null && groupTopic.getBrokerIdSet().contains(brokerId)) {
- clusterBrokersOverviewVO.getKafkaRoleList().add(groupTopic.getTopicName());
- }
- if (transactionTopic != null && transactionTopic.getBrokerIdSet().contains(brokerId)) {
- clusterBrokersOverviewVO.getKafkaRoleList().add(transactionTopic.getTopicName());
- }
- if (kafkaController != null && kafkaController.getBrokerId().equals(brokerId)) {
- clusterBrokersOverviewVO.getKafkaRoleList().add(KafkaConstant.CONTROLLER_ROLE);
- }
-
- clusterBrokersOverviewVO.setLatestMetrics(brokerMetrics);
- clusterBrokersOverviewVO.setJmxConnected(jmxConnected);
- return clusterBrokersOverviewVO;
- }
-
- private KafkaControllerVO convert2KafkaControllerVO(KafkaController kafkaController, Broker kafkaControllerBroker) {
- if(null != kafkaController && null != kafkaControllerBroker) {
- KafkaControllerVO kafkaControllerVO = new KafkaControllerVO();
- kafkaControllerVO.setBrokerId(kafkaController.getBrokerId());
- kafkaControllerVO.setBrokerHost(kafkaControllerBroker.getHost());
- return kafkaControllerVO;
- }
-
- return null;
- }
-
- private List getBrokerVersionList(Long clusterPhyId, List brokerList) {
- Set brokerVersionList = new HashSet<>();
- for (Broker broker : brokerList) {
- brokerVersionList.add(brokerService.getBrokerVersionFromKafkaWithCacheFirst(broker.getClusterPhyId(),broker.getBrokerId(),broker.getStartTimestamp()));
- }
- brokerVersionList.remove("");
- return new ArrayList<>(brokerVersionList);
- }
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterConnectorsManagerImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterConnectorsManagerImpl.java
deleted file mode 100644
index e982c588..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterConnectorsManagerImpl.java
+++ /dev/null
@@ -1,152 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.cluster.impl;
-
-import com.didiglobal.logi.log.ILog;
-import com.didiglobal.logi.log.LogFactory;
-import com.xiaojukeji.know.streaming.km.biz.cluster.ClusterConnectorsManager;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterConnectorsOverviewDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.connect.ClusterConnectorDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.metrices.MetricDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.metrices.connect.MetricsConnectorsDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.ConnectCluster;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.ConnectWorker;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.WorkerConnector;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.metrics.connect.ConnectorMetrics;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.po.connect.ConnectorPO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.connect.ConnectStateVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.connector.ClusterConnectorOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.metrics.line.MetricMultiLinesVO;
-import com.xiaojukeji.know.streaming.km.common.converter.ConnectConverter;
-import com.xiaojukeji.know.streaming.km.common.utils.ConvertUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationMetricsUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationUtil;
-import com.xiaojukeji.know.streaming.km.core.service.connect.cluster.ConnectClusterService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.connector.ConnectorMetricService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.connector.ConnectorService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.worker.WorkerConnectorService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.worker.WorkerService;
-import org.apache.kafka.connect.runtime.AbstractStatus;
-import org.springframework.beans.factory.annotation.Autowired;
-import org.springframework.stereotype.Service;
-
-import java.util.ArrayList;
-import java.util.Arrays;
-import java.util.List;
-import java.util.stream.Collectors;
-
-
-@Service
-public class ClusterConnectorsManagerImpl implements ClusterConnectorsManager {
- private static final ILog LOGGER = LogFactory.getLog(ClusterConnectorsManagerImpl.class);
-
- @Autowired
- private ConnectorService connectorService;
-
- @Autowired
- private ConnectClusterService connectClusterService;
-
- @Autowired
- private ConnectorMetricService connectorMetricService;
-
- @Autowired
- private WorkerService workerService;
-
- @Autowired
- private WorkerConnectorService workerConnectorService;
-
- @Override
- public PaginationResult getClusterConnectorsOverview(Long clusterPhyId, ClusterConnectorsOverviewDTO dto) {
- List clusterList = connectClusterService.listByKafkaCluster(clusterPhyId);
-
- List poList = connectorService.listByKafkaClusterIdFromDB(clusterPhyId);
-
- // 查询实时指标
- Result> latestMetricsResult = connectorMetricService.getLatestMetricsFromES(
- clusterPhyId,
- poList.stream().map(elem -> new ClusterConnectorDTO(elem.getConnectClusterId(), elem.getConnectorName())).collect(Collectors.toList()),
- dto.getLatestMetricNames()
- );
-
- if (latestMetricsResult.failed()) {
- LOGGER.error("method=getClusterConnectorsOverview||clusterPhyId={}||result={}||errMsg=get latest metric failed", clusterPhyId, latestMetricsResult);
- return PaginationResult.buildFailure(latestMetricsResult, dto);
- }
-
- // 转换成vo
- List voList = ConnectConverter.convert2ClusterConnectorOverviewVOList(clusterList, poList,latestMetricsResult.getData());
-
- // 请求分页信息
- PaginationResult voPaginationResult = this.pagingConnectorInLocal(voList, dto);
- if (voPaginationResult.failed()) {
- LOGGER.error("method=getClusterConnectorsOverview||clusterPhyId={}||result={}||errMsg=pagination in local failed", clusterPhyId, voPaginationResult);
-
- return PaginationResult.buildFailure(voPaginationResult, dto);
- }
-
- // 查询历史指标
- Result> lineMetricsResult = connectorMetricService.listConnectClusterMetricsFromES(
- clusterPhyId,
- this.buildMetricsConnectorsDTO(
- voPaginationResult.getData().getBizData().stream().map(elem -> new ClusterConnectorDTO(elem.getConnectClusterId(), elem.getConnectorName())).collect(Collectors.toList()),
- dto.getMetricLines()
- )
- );
-
-
- return PaginationResult.buildSuc(
- ConnectConverter.supplyData2ClusterConnectorOverviewVOList(
- voPaginationResult.getData().getBizData(),
- lineMetricsResult.getData()
- ),
- voPaginationResult
- );
- }
-
- @Override
- public ConnectStateVO getClusterConnectorsState(Long clusterPhyId) {
- //获取Connect集群Id列表
- List connectClusterList = connectClusterService.listByKafkaCluster(clusterPhyId);
- List connectorPOList = connectorService.listByKafkaClusterIdFromDB(clusterPhyId);
- List workerConnectorList = workerConnectorService.listByKafkaClusterIdFromDB(clusterPhyId);
- List connectWorkerList = workerService.listByKafkaClusterIdFromDB(clusterPhyId);
-
- return convert2ConnectStateVO(connectClusterList, connectorPOList, workerConnectorList, connectWorkerList);
- }
-
- /**************************************************** private method ****************************************************/
-
- private MetricsConnectorsDTO buildMetricsConnectorsDTO(List connectorDTOList, MetricDTO metricDTO) {
- MetricsConnectorsDTO dto = ConvertUtil.obj2Obj(metricDTO, MetricsConnectorsDTO.class);
- dto.setConnectorNameList(connectorDTOList == null? new ArrayList<>(): connectorDTOList);
-
- return dto;
- }
-
- private ConnectStateVO convert2ConnectStateVO(List connectClusterList, List connectorPOList, List workerConnectorList, List connectWorkerList) {
- ConnectStateVO connectStateVO = new ConnectStateVO();
- connectStateVO.setConnectClusterCount(connectClusterList.size());
- connectStateVO.setTotalConnectorCount(connectorPOList.size());
- connectStateVO.setAliveConnectorCount(connectorPOList.stream().filter(elem -> elem.getState().equals(AbstractStatus.State.RUNNING.name())).collect(Collectors.toList()).size());
- connectStateVO.setWorkerCount(connectWorkerList.size());
- connectStateVO.setTotalTaskCount(workerConnectorList.size());
- connectStateVO.setAliveTaskCount(workerConnectorList.stream().filter(elem -> elem.getState().equals(AbstractStatus.State.RUNNING.name())).collect(Collectors.toList()).size());
- return connectStateVO;
- }
-
- private PaginationResult pagingConnectorInLocal(List connectorVOList, ClusterConnectorsOverviewDTO dto) {
- //模糊匹配
- connectorVOList = PaginationUtil.pageByFuzzyFilter(connectorVOList, dto.getSearchKeywords(), Arrays.asList("connectorName"));
-
- //排序
- if (!dto.getLatestMetricNames().isEmpty()) {
- PaginationMetricsUtil.sortMetrics(connectorVOList, "latestMetrics", dto.getSortMetricNameList(), "connectorName", dto.getSortType());
- } else {
- PaginationUtil.pageBySort(connectorVOList, dto.getSortField(), dto.getSortType(), "connectorName", dto.getSortType());
- }
-
- //分页
- return PaginationUtil.pageBySubData(connectorVOList, dto);
- }
-
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterTopicsManagerImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterTopicsManagerImpl.java
deleted file mode 100644
index 3a2b11ef..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterTopicsManagerImpl.java
+++ /dev/null
@@ -1,120 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.cluster.impl;
-
-import com.didiglobal.logi.log.ILog;
-import com.didiglobal.logi.log.LogFactory;
-import com.xiaojukeji.know.streaming.km.biz.cluster.ClusterTopicsManager;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterTopicsOverviewDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.metrices.MetricDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.metrices.MetricsTopicDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.metrics.TopicMetrics;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.topic.Topic;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.res.ClusterPhyTopicsOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.metrics.line.MetricMultiLinesVO;
-import com.xiaojukeji.know.streaming.km.common.constant.KafkaConstant;
-import com.xiaojukeji.know.streaming.km.common.converter.TopicVOConverter;
-import com.xiaojukeji.know.streaming.km.common.enums.ha.HaResTypeEnum;
-import com.xiaojukeji.know.streaming.km.common.utils.ConvertUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationMetricsUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.ValidateUtils;
-import com.xiaojukeji.know.streaming.km.core.service.ha.HaActiveStandbyRelationService;
-import com.xiaojukeji.know.streaming.km.core.service.topic.TopicMetricService;
-import com.xiaojukeji.know.streaming.km.core.service.topic.TopicService;
-import org.springframework.beans.factory.annotation.Autowired;
-import org.springframework.stereotype.Service;
-
-import java.util.*;
-import java.util.stream.Collectors;
-
-
-
-@Service
-public class ClusterTopicsManagerImpl implements ClusterTopicsManager {
- private static final ILog log = LogFactory.getLog(ClusterTopicsManagerImpl.class);
-
- @Autowired
- private TopicService topicService;
-
- @Autowired
- private TopicMetricService topicMetricService;
-
- @Autowired
- private HaActiveStandbyRelationService haActiveStandbyRelationService;
-
- @Override
- public PaginationResult getClusterPhyTopicsOverview(Long clusterPhyId, ClusterTopicsOverviewDTO dto) {
- // 获取集群所有的Topic信息
- List topicList = topicService.listTopicsFromDB(clusterPhyId);
-
- // 获取集群所有Topic的指标
- Map metricsMap = topicMetricService.getLatestMetricsFromCache(clusterPhyId);
-
- // 获取HA信息
- Set haTopicNameSet = haActiveStandbyRelationService.listByClusterAndType(clusterPhyId, HaResTypeEnum.MIRROR_TOPIC).stream().map(elem -> elem.getResName()).collect(Collectors.toSet());
-
- // 转换成vo
- List voList = TopicVOConverter.convert2ClusterPhyTopicsOverviewVOList(topicList, metricsMap, haTopicNameSet);
-
- // 请求分页信息
- PaginationResult voPaginationResult = this.pagingTopicInLocal(voList, dto);
- if (voPaginationResult.failed()) {
- log.error("method=getClusterPhyTopicsOverview||clusterPhyId={}||result={}||errMsg=pagination in local failed", clusterPhyId, voPaginationResult);
-
- return PaginationResult.buildFailure(voPaginationResult, dto);
- }
-
- // 查询指标
- Result> metricMultiLinesResult = topicMetricService.listTopicMetricsFromES(
- clusterPhyId,
- this.buildTopicOverviewMetricsDTO(voPaginationResult.getData().getBizData().stream().map(elem -> elem.getTopicName()).collect(Collectors.toList()), dto.getMetricLines())
- );
-
- if (metricMultiLinesResult.failed()) {
- // 查询ES失败或者ES无数据,则ES可能存在问题,此时降级返回Topic的基本信息数据
- log.error("method=getClusterPhyTopicsOverview||clusterPhyId={}||result={}||errMsg=get metrics from es failed", clusterPhyId, metricMultiLinesResult);
- }
-
- return PaginationResult.buildSuc(
- TopicVOConverter.supplyMetricLines(
- voPaginationResult.getData().getBizData(),
- metricMultiLinesResult.getData() == null? new ArrayList<>(): metricMultiLinesResult.getData()
- ),
- voPaginationResult
- );
- }
-
- /**************************************************** private method ****************************************************/
-
- private MetricsTopicDTO buildTopicOverviewMetricsDTO(List topicNameList, MetricDTO metricDTO) {
- MetricsTopicDTO dto = ConvertUtil.obj2Obj(metricDTO, MetricsTopicDTO.class);
- dto.setTopics(topicNameList == null? new ArrayList<>(): topicNameList);
- return dto;
- }
-
- private PaginationResult pagingTopicInLocal(List voList, ClusterTopicsOverviewDTO dto) {
- List metricsList = voList.stream().filter(elem -> {
- if (dto.getShowInternalTopics() != null && dto.getShowInternalTopics()) {
- // 仅展示系统Topic
- return KafkaConstant.KAFKA_INTERNAL_TOPICS.contains(elem.getTopicName());
- } else {
- // 仅展示用户Topic
- return !KafkaConstant.KAFKA_INTERNAL_TOPICS.contains(elem.getTopicName());
- }
- }).collect(Collectors.toList());
-
- // 名称搜索
- metricsList = PaginationUtil.pageByFuzzyFilter(metricsList, dto.getSearchKeywords(), Arrays.asList("topicName"));
-
- if (!ValidateUtils.isBlank(dto.getSortField()) && !"createTime".equals(dto.getSortField())) {
- // 指标排序
- PaginationMetricsUtil.sortMetrics(metricsList, "latestMetrics", dto.getSortField(), "topicName", dto.getSortType());
- } else {
- // 信息排序
- PaginationUtil.pageBySort(metricsList, dto.getSortField(), dto.getSortType(), "topicName", dto.getSortType());
- }
-
- return PaginationUtil.pageBySubData(metricsList, dto);
- }
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterZookeepersManagerImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterZookeepersManagerImpl.java
deleted file mode 100644
index aca30269..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterZookeepersManagerImpl.java
+++ /dev/null
@@ -1,137 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.cluster.impl;
-
-import com.didiglobal.logi.log.ILog;
-import com.didiglobal.logi.log.LogFactory;
-import com.xiaojukeji.know.streaming.km.biz.cluster.ClusterZookeepersManager;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterZookeepersOverviewDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.cluster.ClusterPhy;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.metrics.ZookeeperMetrics;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.ResultStatus;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.zookeeper.Znode;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.zookeeper.ZookeeperInfo;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.zookeeper.ClusterZookeepersOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.zookeeper.ClusterZookeepersStateVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.zookeeper.ZnodeVO;
-import com.xiaojukeji.know.streaming.km.common.constant.MsgConstant;
-import com.xiaojukeji.know.streaming.km.common.enums.zookeeper.ZKRoleEnum;
-import com.xiaojukeji.know.streaming.km.common.utils.ConvertUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationUtil;
-import com.xiaojukeji.know.streaming.km.core.service.cluster.ClusterPhyService;
-import com.xiaojukeji.know.streaming.km.core.service.version.metrics.kafka.ZookeeperMetricVersionItems;
-import com.xiaojukeji.know.streaming.km.core.service.zookeeper.ZnodeService;
-import com.xiaojukeji.know.streaming.km.core.service.zookeeper.ZookeeperMetricService;
-import com.xiaojukeji.know.streaming.km.core.service.zookeeper.ZookeeperService;
-import org.springframework.beans.factory.annotation.Autowired;
-import org.springframework.stereotype.Service;
-import java.util.Arrays;
-import java.util.List;
-
-
-@Service
-public class ClusterZookeepersManagerImpl implements ClusterZookeepersManager {
- private static final ILog LOGGER = LogFactory.getLog(ClusterZookeepersManagerImpl.class);
-
- @Autowired
- private ClusterPhyService clusterPhyService;
-
- @Autowired
- private ZookeeperService zookeeperService;
-
- @Autowired
- private ZookeeperMetricService zookeeperMetricService;
-
- @Autowired
- private ZnodeService znodeService;
-
- @Override
- public Result getClusterPhyZookeepersState(Long clusterPhyId) {
- ClusterPhy clusterPhy = clusterPhyService.getClusterByCluster(clusterPhyId);
- if (clusterPhy == null) {
- return Result.buildFromRSAndMsg(ResultStatus.CLUSTER_NOT_EXIST, MsgConstant.getClusterPhyNotExist(clusterPhyId));
- }
-
- List infoList = zookeeperService.listFromDBByCluster(clusterPhyId);
-
- ClusterZookeepersStateVO vo = new ClusterZookeepersStateVO();
- vo.setTotalServerCount(infoList.size());
- vo.setAliveFollowerCount(0);
- vo.setTotalFollowerCount(0);
- vo.setAliveObserverCount(0);
- vo.setTotalObserverCount(0);
- vo.setAliveServerCount(0);
- for (ZookeeperInfo info: infoList) {
- if (info.getRole().equals(ZKRoleEnum.LEADER.getRole())) {
- vo.setLeaderNode(info.getHost());
- }
-
- if (info.getRole().equals(ZKRoleEnum.FOLLOWER.getRole())) {
- vo.setTotalFollowerCount(vo.getTotalFollowerCount() + 1);
- vo.setAliveFollowerCount(info.alive()? vo.getAliveFollowerCount() + 1: vo.getAliveFollowerCount());
- }
-
- if (info.getRole().equals(ZKRoleEnum.OBSERVER.getRole())) {
- vo.setTotalObserverCount(vo.getTotalObserverCount() + 1);
- vo.setAliveObserverCount(info.alive()? vo.getAliveObserverCount() + 1: vo.getAliveObserverCount());
- }
-
- if (info.alive()) {
- vo.setAliveServerCount(vo.getAliveServerCount() + 1);
- }
- }
-
- // 指标获取
- Result metricsResult = zookeeperMetricService.batchCollectMetricsFromZookeeper(
- clusterPhyId,
- Arrays.asList(
- ZookeeperMetricVersionItems.ZOOKEEPER_METRIC_WATCH_COUNT,
- ZookeeperMetricVersionItems.ZOOKEEPER_METRIC_HEALTH_STATE,
- ZookeeperMetricVersionItems.ZOOKEEPER_METRIC_HEALTH_CHECK_PASSED,
- ZookeeperMetricVersionItems.ZOOKEEPER_METRIC_HEALTH_CHECK_TOTAL
- )
-
- );
- if (metricsResult.failed()) {
- LOGGER.error(
- "method=getClusterPhyZookeepersState||clusterPhyId={}||errMsg={}",
- clusterPhyId, metricsResult.getMessage()
- );
- return Result.buildSuc(vo);
- }
-
- ZookeeperMetrics metrics = metricsResult.getData();
- vo.setWatchCount(ConvertUtil.float2Integer(metrics.getMetrics().get(ZookeeperMetricVersionItems.ZOOKEEPER_METRIC_WATCH_COUNT)));
- vo.setHealthState(ConvertUtil.float2Integer(metrics.getMetrics().get(ZookeeperMetricVersionItems.ZOOKEEPER_METRIC_HEALTH_STATE)));
- vo.setHealthCheckPassed(ConvertUtil.float2Integer(metrics.getMetrics().get(ZookeeperMetricVersionItems.ZOOKEEPER_METRIC_HEALTH_CHECK_PASSED)));
- vo.setHealthCheckTotal(ConvertUtil.float2Integer(metrics.getMetrics().get(ZookeeperMetricVersionItems.ZOOKEEPER_METRIC_HEALTH_CHECK_TOTAL)));
-
- return Result.buildSuc(vo);
- }
-
- @Override
- public PaginationResult getClusterPhyZookeepersOverview(Long clusterPhyId, ClusterZookeepersOverviewDTO dto) {
- //获取集群zookeeper列表
- List clusterZookeepersOverviewVOList = ConvertUtil.list2List(zookeeperService.listFromDBByCluster(clusterPhyId), ClusterZookeepersOverviewVO.class);
-
- //搜索
- clusterZookeepersOverviewVOList = PaginationUtil.pageByFuzzyFilter(clusterZookeepersOverviewVOList, dto.getSearchKeywords(), Arrays.asList("host"));
-
- //分页
- PaginationResult paginationResult = PaginationUtil.pageBySubData(clusterZookeepersOverviewVOList, dto);
-
- return paginationResult;
- }
-
- @Override
- public Result getZnodeVO(Long clusterPhyId, String path) {
- Result result = znodeService.getZnode(clusterPhyId, path);
- if (result.failed()) {
- return Result.buildFromIgnoreData(result);
- }
- return Result.buildSuc(ConvertUtil.obj2ObjByJSON(result.getData(), ZnodeVO.class));
- }
-
- /**************************************************** private method ****************************************************/
-
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/MultiClusterPhyManagerImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/MultiClusterPhyManagerImpl.java
deleted file mode 100644
index 7e379c99..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/MultiClusterPhyManagerImpl.java
+++ /dev/null
@@ -1,177 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.cluster.impl;
-
-import com.didiglobal.logi.log.ILog;
-import com.didiglobal.logi.log.LogFactory;
-import com.xiaojukeji.know.streaming.km.biz.cluster.MultiClusterPhyManager;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.metrices.MetricDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.metrices.MetricsClusterPhyDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.cluster.ClusterPhysHealthState;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.cluster.ClusterPhysState;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.cluster.ClusterPhy;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.MultiClusterDashboardDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.metrics.ClusterMetrics;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.ClusterPhyBaseVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.ClusterPhyDashboardVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.metrics.line.MetricMultiLinesVO;
-import com.xiaojukeji.know.streaming.km.common.converter.ClusterVOConverter;
-import com.xiaojukeji.know.streaming.km.common.enums.health.HealthStateEnum;
-import com.xiaojukeji.know.streaming.km.common.utils.ConvertUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationMetricsUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.ValidateUtils;
-import com.xiaojukeji.know.streaming.km.core.service.cluster.ClusterMetricService;
-import com.xiaojukeji.know.streaming.km.core.service.cluster.ClusterPhyService;
-import com.xiaojukeji.know.streaming.km.core.service.version.metrics.kafka.ClusterMetricVersionItems;
-import org.springframework.beans.factory.annotation.Autowired;
-import org.springframework.stereotype.Service;
-
-import java.util.*;
-import java.util.stream.Collectors;
-
-@Service
-public class MultiClusterPhyManagerImpl implements MultiClusterPhyManager {
- private static final ILog log = LogFactory.getLog(MultiClusterPhyManagerImpl.class);
-
- @Autowired
- private ClusterPhyService clusterPhyService;
-
- @Autowired
- private ClusterMetricService clusterMetricService;
-
- @Override
- public ClusterPhysState getClusterPhysState() {
- List clusterPhyList = clusterPhyService.listAllClusters();
- ClusterPhysState physState = new ClusterPhysState(0, 0, 0, clusterPhyList.size());
-
- for (ClusterPhy clusterPhy : clusterPhyList) {
- ClusterMetrics metrics = clusterMetricService.getLatestMetricsFromCache(clusterPhy.getId());
- Float state = metrics.getMetric(ClusterMetricVersionItems.CLUSTER_METRIC_HEALTH_STATE);
- if (state == null) {
- physState.setUnknownCount(physState.getUnknownCount() + 1);
- } else if (state.intValue() == HealthStateEnum.DEAD.getDimension()) {
- physState.setDownCount(physState.getDownCount() + 1);
- } else {
- physState.setLiveCount(physState.getLiveCount() + 1);
- }
- }
- return physState;
- }
-
-
- @Override
- public ClusterPhysHealthState getClusterPhysHealthState() {
- List clusterPhyList = clusterPhyService.listAllClusters();
-
- ClusterPhysHealthState physState = new ClusterPhysHealthState(clusterPhyList.size());
- for (ClusterPhy clusterPhy: clusterPhyList) {
- ClusterMetrics metrics = clusterMetricService.getLatestMetricsFromCache(clusterPhy.getId());
- Float state = metrics.getMetric(ClusterMetricVersionItems.CLUSTER_METRIC_HEALTH_STATE);
- if (state == null) {
- physState.setUnknownCount(physState.getUnknownCount() + 1);
- } else if (state.intValue() == HealthStateEnum.GOOD.getDimension()) {
- physState.setGoodCount(physState.getGoodCount() + 1);
- } else if (state.intValue() == HealthStateEnum.MEDIUM.getDimension()) {
- physState.setMediumCount(physState.getMediumCount() + 1);
- } else if (state.intValue() == HealthStateEnum.POOR.getDimension()) {
- physState.setPoorCount(physState.getPoorCount() + 1);
- } else if (state.intValue() == HealthStateEnum.DEAD.getDimension()) {
- physState.setDeadCount(physState.getDeadCount() + 1);
- } else {
- physState.setUnknownCount(physState.getUnknownCount() + 1);
- }
- }
-
- return physState;
- }
-
- @Override
- public PaginationResult getClusterPhysDashboard(MultiClusterDashboardDTO dto) {
- // 获取集群
- List clusterPhyList = clusterPhyService.listAllClusters();
-
- // 转为vo格式,方便后续进行分页筛选等
- List voList = ConvertUtil.list2List(clusterPhyList, ClusterPhyDashboardVO.class);
-
- // 本地分页过滤
- voList = this.getAndPagingDataInLocal(voList, dto);
-
- // ES分页过滤
- PaginationResult latestMetricsResult = this.getAndPagingClusterWithLatestMetricsFromCache(voList, dto);
- if (latestMetricsResult.failed()) {
- log.error("method=getClusterPhysDashboard||pagingData={}||result={}||errMsg=search es data failed.", dto, latestMetricsResult);
- return PaginationResult.buildFailure(latestMetricsResult, dto);
- }
-
- // 获取历史指标
- Result> linesMetricResult = clusterMetricService.listClusterMetricsFromES(
- this.buildMetricsClusterPhyDTO(
- latestMetricsResult.getData().getBizData().stream().map(elem -> elem.getClusterPhyId()).collect(Collectors.toList()),
- dto.getMetricLines()
- ));
-
- // 组装最终数据
- return PaginationResult.buildSuc(
- ClusterVOConverter.convert2ClusterPhyDashboardVOList(voList, linesMetricResult.getData(), latestMetricsResult.getData().getBizData()),
- latestMetricsResult
- );
- }
-
- @Override
- public Result> getClusterPhysBasic() {
- // 获取集群
- List clusterPhyList = clusterPhyService.listAllClusters();
-
- // 转为vo格式,方便后续进行分页筛选等
- return Result.buildSuc(ConvertUtil.list2List(clusterPhyList, ClusterPhyBaseVO.class));
- }
-
-
- /**************************************************** private method ****************************************************/
-
-
- private List getAndPagingDataInLocal(List voList, MultiClusterDashboardDTO dto) {
- // 时间排序
- if ("createTime".equals(dto.getSortField())) {
- voList = PaginationUtil.pageBySort(voList, "createTime", dto.getSortType(), "name", dto.getSortType());
- }
-
- // 名称搜索
- if (!ValidateUtils.isBlank(dto.getSearchKeywords())) {
- voList = PaginationUtil.pageByFuzzyFilter(voList, dto.getSearchKeywords(), Arrays.asList("name"));
- }
-
- // 精确搜索
- return PaginationUtil.pageByPreciseFilter(voList, dto.getPreciseFilterDTOList());
- }
-
- private PaginationResult getAndPagingClusterWithLatestMetricsFromCache(List voList, MultiClusterDashboardDTO dto) {
- // 获取所有的metrics
- List metricsList = new ArrayList<>();
- for (ClusterPhyDashboardVO vo: voList) {
- ClusterMetrics clusterMetrics = clusterMetricService.getLatestMetricsFromCache(vo.getId());
- clusterMetrics.getMetrics().putIfAbsent(ClusterMetricVersionItems.CLUSTER_METRIC_HEALTH_STATE, (float) HealthStateEnum.UNKNOWN.getDimension());
-
- metricsList.add(clusterMetrics);
- }
-
- // 范围搜索
- metricsList = (List) PaginationMetricsUtil.rangeFilterMetrics(metricsList, dto.getRangeFilterDTOList());
-
- // 精确搜索
- metricsList = (List) PaginationMetricsUtil.preciseFilterMetrics(metricsList, dto.getPreciseFilterDTOList());
-
- // 排序
- PaginationMetricsUtil.sortMetrics(metricsList, dto.getSortField(), "clusterPhyId", dto.getSortType());
-
- // 分页
- return PaginationUtil.pageBySubData(metricsList, dto);
- }
-
- private MetricsClusterPhyDTO buildMetricsClusterPhyDTO(List clusterIdList, MetricDTO metricDTO) {
- MetricsClusterPhyDTO dto = ConvertUtil.obj2Obj(metricDTO, MetricsClusterPhyDTO.class);
- dto.setClusterPhyIds(clusterIdList);
- return dto;
- }
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/ConnectorManager.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/ConnectorManager.java
deleted file mode 100644
index 3752504d..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/ConnectorManager.java
+++ /dev/null
@@ -1,16 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.connect.connector;
-
-import com.xiaojukeji.know.streaming.km.common.bean.dto.connect.connector.ConnectorCreateDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.connect.connector.ConnectorStateVO;
-
-import java.util.Properties;
-
-public interface ConnectorManager {
- Result updateConnectorConfig(Long connectClusterId, String connectorName, Properties configs, String operator);
-
- Result createConnector(ConnectorCreateDTO dto, String operator);
- Result createConnector(ConnectorCreateDTO dto, String heartbeatName, String checkpointName, String operator);
-
- Result getConnectorStateVO(Long connectClusterId, String connectorName);
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/WorkerConnectorManager.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/WorkerConnectorManager.java
deleted file mode 100644
index eaf82423..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/WorkerConnectorManager.java
+++ /dev/null
@@ -1,16 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.connect.connector;
-
-
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.connect.task.KCTaskOverviewVO;
-
-import java.util.List;
-
-/**
- * @author wyb
- * @date 2022/11/14
- */
-public interface WorkerConnectorManager {
- Result> getTaskOverview(Long connectClusterId, String connectorName);
-
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/impl/ConnectorManagerImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/impl/ConnectorManagerImpl.java
deleted file mode 100644
index 5800b26f..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/impl/ConnectorManagerImpl.java
+++ /dev/null
@@ -1,115 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.connect.connector.impl;
-
-import com.xiaojukeji.know.streaming.km.biz.connect.connector.ConnectorManager;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.connect.connector.ConnectorCreateDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.WorkerConnector;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.config.ConnectConfigInfos;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.connector.KSConnector;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.connector.KSConnectorInfo;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.ResultStatus;
-import com.xiaojukeji.know.streaming.km.common.bean.po.connect.ConnectorPO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.connect.connector.ConnectorStateVO;
-import com.xiaojukeji.know.streaming.km.common.constant.connect.KafkaConnectConstant;
-import com.xiaojukeji.know.streaming.km.core.service.connect.connector.ConnectorService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.plugin.PluginService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.worker.WorkerConnectorService;
-import org.apache.kafka.connect.runtime.AbstractStatus;
-import org.springframework.beans.factory.annotation.Autowired;
-import org.springframework.stereotype.Service;
-
-import java.util.List;
-import java.util.Properties;
-import java.util.stream.Collectors;
-
-@Service
-public class ConnectorManagerImpl implements ConnectorManager {
- @Autowired
- private PluginService pluginService;
-
- @Autowired
- private ConnectorService connectorService;
-
- @Autowired
- private WorkerConnectorService workerConnectorService;
-
- @Override
- public Result updateConnectorConfig(Long connectClusterId, String connectorName, Properties configs, String operator) {
- Result infosResult = pluginService.validateConfig(connectClusterId, configs);
- if (infosResult.failed()) {
- return Result.buildFromIgnoreData(infosResult);
- }
-
- if (infosResult.getData().getErrorCount() > 0) {
- return Result.buildFromRSAndMsg(ResultStatus.PARAM_ILLEGAL, "Connector参数错误");
- }
-
- return connectorService.updateConnectorConfig(connectClusterId, connectorName, configs, operator);
- }
-
- @Override
- public Result createConnector(ConnectorCreateDTO dto, String operator) {
- dto.getConfigs().put(KafkaConnectConstant.MIRROR_MAKER_NAME_FIELD_NAME, dto.getConnectorName());
-
- Result createResult = connectorService.createConnector(dto.getConnectClusterId(), dto.getConnectorName(), dto.getConfigs(), operator);
- if (createResult.failed()) {
- return Result.buildFromIgnoreData(createResult);
- }
-
- Result ksConnectorResult = connectorService.getAllConnectorInfoFromCluster(dto.getConnectClusterId(), dto.getConnectorName());
- if (ksConnectorResult.failed()) {
- return Result.buildFromRSAndMsg(ResultStatus.SUCCESS, "创建成功,但是获取元信息失败,页面元信息会存在1分钟延迟");
- }
-
- connectorService.addNewToDB(ksConnectorResult.getData());
- return Result.buildSuc();
- }
-
- @Override
- public Result createConnector(ConnectorCreateDTO dto, String heartbeatName, String checkpointName, String operator) {
- dto.getConfigs().put(KafkaConnectConstant.MIRROR_MAKER_NAME_FIELD_NAME, dto.getConnectorName());
-
- Result createResult = connectorService.createConnector(dto.getConnectClusterId(), dto.getConnectorName(), dto.getConfigs(), operator);
- if (createResult.failed()) {
- return Result.buildFromIgnoreData(createResult);
- }
-
- Result ksConnectorResult = connectorService.getAllConnectorInfoFromCluster(dto.getConnectClusterId(), dto.getConnectorName());
- if (ksConnectorResult.failed()) {
- return Result.buildFromRSAndMsg(ResultStatus.SUCCESS, "创建成功,但是获取元信息失败,页面元信息会存在1分钟延迟");
- }
-
- KSConnector connector = ksConnectorResult.getData();
- connector.setCheckpointConnectorName(checkpointName);
- connector.setHeartbeatConnectorName(heartbeatName);
-
- connectorService.addNewToDB(connector);
- return Result.buildSuc();
- }
-
-
- @Override
- public Result getConnectorStateVO(Long connectClusterId, String connectorName) {
- ConnectorPO connectorPO = connectorService.getConnectorFromDB(connectClusterId, connectorName);
-
- if (connectorPO == null) {
- return Result.buildFailure(ResultStatus.NOT_EXIST);
- }
-
- List workerConnectorList = workerConnectorService.listFromDB(connectClusterId).stream().filter(elem -> elem.getConnectorName().equals(connectorName)).collect(Collectors.toList());
-
- return Result.buildSuc(convert2ConnectorOverviewVO(connectorPO, workerConnectorList));
- }
-
- private ConnectorStateVO convert2ConnectorOverviewVO(ConnectorPO connectorPO, List workerConnectorList) {
- ConnectorStateVO connectorStateVO = new ConnectorStateVO();
- connectorStateVO.setConnectClusterId(connectorPO.getConnectClusterId());
- connectorStateVO.setName(connectorPO.getConnectorName());
- connectorStateVO.setType(connectorPO.getConnectorType());
- connectorStateVO.setState(connectorPO.getState());
- connectorStateVO.setTotalTaskCount(workerConnectorList.size());
- connectorStateVO.setAliveTaskCount(workerConnectorList.stream().filter(elem -> elem.getState().equals(AbstractStatus.State.RUNNING.name())).collect(Collectors.toList()).size());
- connectorStateVO.setTotalWorkerCount(workerConnectorList.stream().map(elem -> elem.getWorkerId()).collect(Collectors.toSet()).size());
- return connectorStateVO;
- }
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/impl/WorkerConnectorManageImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/impl/WorkerConnectorManageImpl.java
deleted file mode 100644
index 4d0cd317..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/impl/WorkerConnectorManageImpl.java
+++ /dev/null
@@ -1,37 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.connect.connector.impl;
-
-import com.didiglobal.logi.log.ILog;
-import com.didiglobal.logi.log.LogFactory;
-import com.xiaojukeji.know.streaming.km.biz.connect.connector.WorkerConnectorManager;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.ConnectCluster;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.WorkerConnector;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.connect.task.KCTaskOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.utils.ConvertUtil;
-import com.xiaojukeji.know.streaming.km.core.service.connect.worker.WorkerConnectorService;
-import com.xiaojukeji.know.streaming.km.persistence.connect.cache.LoadedConnectClusterCache;
-import org.springframework.beans.factory.annotation.Autowired;
-import org.springframework.stereotype.Service;
-
-import java.util.List;
-
-/**
- * @author wyb
- * @date 2022/11/14
- */
-@Service
-public class WorkerConnectorManageImpl implements WorkerConnectorManager {
-
- private static final ILog LOGGER = LogFactory.getLog(WorkerConnectorManageImpl.class);
-
- @Autowired
- private WorkerConnectorService workerConnectorService;
-
- @Override
- public Result> getTaskOverview(Long connectClusterId, String connectorName) {
- ConnectCluster connectCluster = LoadedConnectClusterCache.getByPhyId(connectClusterId);
- List workerConnectorList = workerConnectorService.getWorkerConnectorListFromCluster(connectCluster, connectorName);
-
- return Result.buildSuc(ConvertUtil.list2List(workerConnectorList, KCTaskOverviewVO.class));
- }
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/mm2/MirrorMakerManager.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/mm2/MirrorMakerManager.java
deleted file mode 100644
index 6851ca5e..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/mm2/MirrorMakerManager.java
+++ /dev/null
@@ -1,43 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.connect.mm2;
-
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterMirrorMakersOverviewDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.connect.mm2.MirrorMakerCreateDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.mm2.ClusterMirrorMakerOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.mm2.MirrorMakerBaseStateVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.mm2.MirrorMakerStateVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.connect.plugin.ConnectConfigInfosVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.connect.task.KCTaskOverviewVO;
-
-import java.util.List;
-import java.util.Map;
-import java.util.Properties;
-
-/**
- * @author wyb
- * @date 2022/12/26
- */
-public interface MirrorMakerManager {
- Result createMirrorMaker(MirrorMakerCreateDTO dto, String operator);
-
- Result deleteMirrorMaker(Long connectClusterId, String sourceConnectorName, String operator);
-
- Result modifyMirrorMakerConfig(MirrorMakerCreateDTO dto, String operator);
-
- Result restartMirrorMaker(Long connectClusterId, String sourceConnectorName, String operator);
- Result stopMirrorMaker(Long connectClusterId, String sourceConnectorName, String operator);
- Result resumeMirrorMaker(Long connectClusterId, String sourceConnectorName, String operator);
-
- Result getMirrorMakerStateVO(Long clusterPhyId);
-
- PaginationResult getClusterMirrorMakersOverview(Long clusterPhyId, ClusterMirrorMakersOverviewDTO dto);
-
-
- Result getMirrorMakerState(Long connectId, String connectName);
-
- Result>> getTaskOverview(Long connectClusterId, String connectorName);
- Result> getMM2Configs(Long connectClusterId, String connectorName);
-
- Result> validateConnectors(MirrorMakerCreateDTO dto);
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/mm2/impl/MirrorMakerManagerImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/mm2/impl/MirrorMakerManagerImpl.java
deleted file mode 100644
index 803daa26..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/mm2/impl/MirrorMakerManagerImpl.java
+++ /dev/null
@@ -1,652 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.connect.mm2.impl;
-
-import com.didiglobal.logi.log.ILog;
-import com.didiglobal.logi.log.LogFactory;
-import com.xiaojukeji.know.streaming.km.biz.connect.connector.ConnectorManager;
-import com.xiaojukeji.know.streaming.km.biz.connect.mm2.MirrorMakerManager;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterMirrorMakersOverviewDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.connect.ClusterConnectorDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.connect.connector.ConnectorCreateDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.connect.mm2.MirrorMakerCreateDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.metrices.MetricDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.metrices.mm2.MetricsMirrorMakersDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.cluster.ClusterPhy;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.ConnectCluster;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.ConnectWorker;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.WorkerConnector;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.config.ConnectConfigInfos;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.connector.KSConnectorInfo;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.metrics.mm2.MirrorMakerMetrics;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.ResultStatus;
-import com.xiaojukeji.know.streaming.km.common.bean.po.connect.ConnectorPO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.mm2.ClusterMirrorMakerOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.mm2.MirrorMakerBaseStateVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.mm2.MirrorMakerStateVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.connect.plugin.ConnectConfigInfosVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.metrics.line.MetricLineVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.metrics.line.MetricMultiLinesVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.connect.task.KCTaskOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.constant.MsgConstant;
-import com.xiaojukeji.know.streaming.km.common.utils.*;
-import com.xiaojukeji.know.streaming.km.common.constant.connect.KafkaConnectConstant;
-import com.xiaojukeji.know.streaming.km.common.utils.ConvertUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.MirrorMakerUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.ValidateUtils;
-import com.xiaojukeji.know.streaming.km.core.service.cluster.ClusterPhyService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.cluster.ConnectClusterService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.connector.ConnectorService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.mm2.MirrorMakerMetricService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.plugin.PluginService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.worker.WorkerConnectorService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.worker.WorkerService;
-import com.xiaojukeji.know.streaming.km.core.utils.ApiCallThreadPoolService;
-import com.xiaojukeji.know.streaming.km.persistence.cache.LoadedClusterPhyCache;
-import org.apache.commons.lang.StringUtils;
-import org.springframework.beans.factory.annotation.Autowired;
-import org.springframework.stereotype.Service;
-
-import java.util.*;
-import java.util.function.Function;
-import java.util.stream.Collectors;
-
-import static org.apache.kafka.connect.runtime.AbstractStatus.State.RUNNING;
-import static com.xiaojukeji.know.streaming.km.common.constant.connect.KafkaConnectConstant.*;
-
-
-/**
- * @author wyb
- * @date 2022/12/26
- */
-@Service
-public class MirrorMakerManagerImpl implements MirrorMakerManager {
- private static final ILog LOGGER = LogFactory.getLog(MirrorMakerManagerImpl.class);
-
- @Autowired
- private ConnectorService connectorService;
-
- @Autowired
- private WorkerConnectorService workerConnectorService;
-
- @Autowired
- private WorkerService workerService;
-
- @Autowired
- private ConnectorManager connectorManager;
-
- @Autowired
- private ClusterPhyService clusterPhyService;
-
- @Autowired
- private MirrorMakerMetricService mirrorMakerMetricService;
-
- @Autowired
- private ConnectClusterService connectClusterService;
-
- @Autowired
- private PluginService pluginService;
-
- @Override
- public Result createMirrorMaker(MirrorMakerCreateDTO dto, String operator) {
- // 检查基本参数
- Result rv = this.checkCreateMirrorMakerParamAndUnifyData(dto);
- if (rv.failed()) {
- return rv;
- }
-
- // 创建MirrorSourceConnector
- Result sourceConnectResult = connectorManager.createConnector(
- dto,
- dto.getCheckpointConnectorConfigs() != null? MirrorMakerUtil.genCheckpointName(dto.getConnectorName()): "",
- dto.getHeartbeatConnectorConfigs() != null? MirrorMakerUtil.genHeartbeatName(dto.getConnectorName()): "",
- operator
- );
- if (sourceConnectResult.failed()) {
- // 创建失败, 直接返回
- return Result.buildFromIgnoreData(sourceConnectResult);
- }
-
- // 创建 checkpoint 任务
- Result checkpointResult = Result.buildSuc();
- if (dto.getCheckpointConnectorConfigs() != null) {
- checkpointResult = connectorManager.createConnector(
- new ConnectorCreateDTO(dto.getConnectClusterId(), MirrorMakerUtil.genCheckpointName(dto.getConnectorName()), dto.getCheckpointConnectorConfigs()),
- operator
- );
- }
-
- // 创建 heartbeat 任务
- Result heartbeatResult = Result.buildSuc();
- if (dto.getHeartbeatConnectorConfigs() != null) {
- heartbeatResult = connectorManager.createConnector(
- new ConnectorCreateDTO(dto.getConnectClusterId(), MirrorMakerUtil.genHeartbeatName(dto.getConnectorName()), dto.getHeartbeatConnectorConfigs()),
- operator
- );
- }
-
- // 全都成功
- if (checkpointResult.successful() && checkpointResult.successful()) {
- return Result.buildSuc();
- } else if (checkpointResult.failed() && checkpointResult.failed()) {
- return Result.buildFromRSAndMsg(
- ResultStatus.KAFKA_CONNECTOR_OPERATE_FAILED,
- String.format("创建 checkpoint & heartbeat 失败.\n失败信息分别为:%s\n\n%s", checkpointResult.getMessage(), heartbeatResult.getMessage())
- );
- } else if (checkpointResult.failed()) {
- return Result.buildFromRSAndMsg(
- ResultStatus.KAFKA_CONNECTOR_OPERATE_FAILED,
- String.format("创建 checkpoint 失败.\n失败信息分别为:%s", checkpointResult.getMessage())
- );
- } else{
- return Result.buildFromRSAndMsg(
- ResultStatus.KAFKA_CONNECTOR_OPERATE_FAILED,
- String.format("创建 heartbeat 失败.\n失败信息分别为:%s", heartbeatResult.getMessage())
- );
- }
- }
-
- @Override
- public Result deleteMirrorMaker(Long connectClusterId, String sourceConnectorName, String operator) {
- ConnectorPO connectorPO = connectorService.getConnectorFromDB(connectClusterId, sourceConnectorName);
- if (connectorPO == null) {
- return Result.buildFromRSAndMsg(ResultStatus.NOT_EXIST, MsgConstant.getConnectorNotExist(connectClusterId, sourceConnectorName));
- }
-
- Result rv = Result.buildSuc();
- if (!ValidateUtils.isBlank(connectorPO.getCheckpointConnectorName())) {
- rv = connectorService.deleteConnector(connectClusterId, connectorPO.getCheckpointConnectorName(), operator);
- }
- if (rv.failed()) {
- return rv;
- }
-
- if (!ValidateUtils.isBlank(connectorPO.getHeartbeatConnectorName())) {
- rv = connectorService.deleteConnector(connectClusterId, connectorPO.getHeartbeatConnectorName(), operator);
- }
- if (rv.failed()) {
- return rv;
- }
-
- return connectorService.deleteConnector(connectClusterId, sourceConnectorName, operator);
- }
-
- @Override
- public Result modifyMirrorMakerConfig(MirrorMakerCreateDTO dto, String operator) {
- ConnectorPO connectorPO = connectorService.getConnectorFromDB(dto.getConnectClusterId(), dto.getConnectorName());
- if (connectorPO == null) {
- return Result.buildFromRSAndMsg(ResultStatus.NOT_EXIST, MsgConstant.getConnectorNotExist(dto.getConnectClusterId(), dto.getConnectorName()));
- }
-
- Result rv = Result.buildSuc();
- if (!ValidateUtils.isBlank(connectorPO.getCheckpointConnectorName()) && dto.getCheckpointConnectorConfigs() != null) {
- rv = connectorService.updateConnectorConfig(dto.getConnectClusterId(), connectorPO.getCheckpointConnectorName(), dto.getCheckpointConnectorConfigs(), operator);
- }
- if (rv.failed()) {
- return rv;
- }
-
- if (!ValidateUtils.isBlank(connectorPO.getHeartbeatConnectorName()) && dto.getHeartbeatConnectorConfigs() != null) {
- rv = connectorService.updateConnectorConfig(dto.getConnectClusterId(), connectorPO.getHeartbeatConnectorName(), dto.getHeartbeatConnectorConfigs(), operator);
- }
- if (rv.failed()) {
- return rv;
- }
-
- return connectorService.updateConnectorConfig(dto.getConnectClusterId(), dto.getConnectorName(), dto.getConfigs(), operator);
- }
-
- @Override
- public Result restartMirrorMaker(Long connectClusterId, String sourceConnectorName, String operator) {
- ConnectorPO connectorPO = connectorService.getConnectorFromDB(connectClusterId, sourceConnectorName);
- if (connectorPO == null) {
- return Result.buildFromRSAndMsg(ResultStatus.NOT_EXIST, MsgConstant.getConnectorNotExist(connectClusterId, sourceConnectorName));
- }
-
- Result rv = Result.buildSuc();
- if (!ValidateUtils.isBlank(connectorPO.getCheckpointConnectorName())) {
- rv = connectorService.restartConnector(connectClusterId, connectorPO.getCheckpointConnectorName(), operator);
- }
- if (rv.failed()) {
- return rv;
- }
-
- if (!ValidateUtils.isBlank(connectorPO.getHeartbeatConnectorName())) {
- rv = connectorService.restartConnector(connectClusterId, connectorPO.getHeartbeatConnectorName(), operator);
- }
- if (rv.failed()) {
- return rv;
- }
-
- return connectorService.restartConnector(connectClusterId, sourceConnectorName, operator);
- }
-
- @Override
- public Result stopMirrorMaker(Long connectClusterId, String sourceConnectorName, String operator) {
- ConnectorPO connectorPO = connectorService.getConnectorFromDB(connectClusterId, sourceConnectorName);
- if (connectorPO == null) {
- return Result.buildFromRSAndMsg(ResultStatus.NOT_EXIST, MsgConstant.getConnectorNotExist(connectClusterId, sourceConnectorName));
- }
-
- Result rv = Result.buildSuc();
- if (!ValidateUtils.isBlank(connectorPO.getCheckpointConnectorName())) {
- rv = connectorService.stopConnector(connectClusterId, connectorPO.getCheckpointConnectorName(), operator);
- }
- if (rv.failed()) {
- return rv;
- }
-
- if (!ValidateUtils.isBlank(connectorPO.getHeartbeatConnectorName())) {
- rv = connectorService.stopConnector(connectClusterId, connectorPO.getHeartbeatConnectorName(), operator);
- }
- if (rv.failed()) {
- return rv;
- }
-
- return connectorService.stopConnector(connectClusterId, sourceConnectorName, operator);
- }
-
- @Override
- public Result resumeMirrorMaker(Long connectClusterId, String sourceConnectorName, String operator) {
- ConnectorPO connectorPO = connectorService.getConnectorFromDB(connectClusterId, sourceConnectorName);
- if (connectorPO == null) {
- return Result.buildFromRSAndMsg(ResultStatus.NOT_EXIST, MsgConstant.getConnectorNotExist(connectClusterId, sourceConnectorName));
- }
-
- Result rv = Result.buildSuc();
- if (!ValidateUtils.isBlank(connectorPO.getCheckpointConnectorName())) {
- rv = connectorService.resumeConnector(connectClusterId, connectorPO.getCheckpointConnectorName(), operator);
- }
- if (rv.failed()) {
- return rv;
- }
-
- if (!ValidateUtils.isBlank(connectorPO.getHeartbeatConnectorName())) {
- rv = connectorService.resumeConnector(connectClusterId, connectorPO.getHeartbeatConnectorName(), operator);
- }
- if (rv.failed()) {
- return rv;
- }
-
- return connectorService.resumeConnector(connectClusterId, sourceConnectorName, operator);
- }
-
- @Override
- public Result getMirrorMakerStateVO(Long clusterPhyId) {
- List connectorPOList = connectorService.listByKafkaClusterIdFromDB(clusterPhyId);
- List workerConnectorList = workerConnectorService.listByKafkaClusterIdFromDB(clusterPhyId);
- List workerList = workerService.listByKafkaClusterIdFromDB(clusterPhyId);
-
- return Result.buildSuc(convert2MirrorMakerStateVO(connectorPOList, workerConnectorList, workerList));
- }
-
- @Override
- public PaginationResult getClusterMirrorMakersOverview(Long clusterPhyId, ClusterMirrorMakersOverviewDTO dto) {
- List mirrorMakerList = connectorService.listByKafkaClusterIdFromDB(clusterPhyId).stream().filter(elem -> elem.getConnectorClassName().equals(MIRROR_MAKER_SOURCE_CONNECTOR_TYPE)).collect(Collectors.toList());
- List connectClusterList = connectClusterService.listByKafkaCluster(clusterPhyId);
-
-
- Result> latestMetricsResult = mirrorMakerMetricService.getLatestMetricsFromES(clusterPhyId,
- mirrorMakerList.stream().map(elem -> new Tuple<>(elem.getConnectClusterId(), elem.getConnectorName())).collect(Collectors.toList()),
- dto.getLatestMetricNames());
-
- if (latestMetricsResult.failed()) {
- LOGGER.error("method=getClusterMirrorMakersOverview||clusterPhyId={}||result={}||errMsg=get latest metric failed", clusterPhyId, latestMetricsResult);
- return PaginationResult.buildFailure(latestMetricsResult, dto);
- }
-
- List mirrorMakerOverviewVOList = this.convert2ClusterMirrorMakerOverviewVO(mirrorMakerList, connectClusterList, latestMetricsResult.getData());
-
- List mirrorMakerVOList = this.completeClusterInfo(mirrorMakerOverviewVOList);
-
- PaginationResult voPaginationResult = this.pagingMirrorMakerInLocal(mirrorMakerVOList, dto);
-
- if (voPaginationResult.failed()) {
- LOGGER.error("method=ClusterMirrorMakerOverviewVO||clusterPhyId={}||result={}||errMsg=pagination in local failed", clusterPhyId, voPaginationResult);
-
- return PaginationResult.buildFailure(voPaginationResult, dto);
- }
-
- // 查询历史指标
- Result> lineMetricsResult = mirrorMakerMetricService.listMirrorMakerClusterMetricsFromES(
- clusterPhyId,
- this.buildMetricsConnectorsDTO(
- voPaginationResult.getData().getBizData().stream().map(elem -> new ClusterConnectorDTO(elem.getConnectClusterId(), elem.getConnectorName())).collect(Collectors.toList()),
- dto.getMetricLines()
- ));
-
- return PaginationResult.buildSuc(
- this.supplyData2ClusterMirrorMakerOverviewVOList(
- voPaginationResult.getData().getBizData(),
- lineMetricsResult.getData()
- ),
- voPaginationResult
- );
- }
-
- @Override
- public Result getMirrorMakerState(Long connectClusterId, String connectName) {
- //mm2任务
- ConnectorPO connectorPO = connectorService.getConnectorFromDB(connectClusterId, connectName);
- if (connectorPO == null){
- return Result.buildFrom(ResultStatus.NOT_EXIST);
- }
-
- List workerConnectorList = workerConnectorService.listFromDB(connectClusterId).stream()
- .filter(workerConnector -> workerConnector.getConnectorName().equals(connectorPO.getConnectorName())
- || (!StringUtils.isBlank(connectorPO.getCheckpointConnectorName()) && workerConnector.getConnectorName().equals(connectorPO.getCheckpointConnectorName()))
- || (!StringUtils.isBlank(connectorPO.getHeartbeatConnectorName()) && workerConnector.getConnectorName().equals(connectorPO.getHeartbeatConnectorName())))
- .collect(Collectors.toList());
-
- MirrorMakerBaseStateVO mirrorMakerBaseStateVO = new MirrorMakerBaseStateVO();
- mirrorMakerBaseStateVO.setTotalTaskCount(workerConnectorList.size());
- mirrorMakerBaseStateVO.setAliveTaskCount(workerConnectorList.stream().filter(elem -> elem.getState().equals(RUNNING.name())).collect(Collectors.toList()).size());
- mirrorMakerBaseStateVO.setWorkerCount(workerConnectorList.stream().collect(Collectors.groupingBy(WorkerConnector::getWorkerId)).size());
- return Result.buildSuc(mirrorMakerBaseStateVO);
- }
-
- @Override
- public Result>> getTaskOverview(Long connectClusterId, String connectorName) {
- ConnectorPO connectorPO = connectorService.getConnectorFromDB(connectClusterId, connectorName);
- if (connectorPO == null){
- return Result.buildFrom(ResultStatus.NOT_EXIST);
- }
-
- Map> listMap = new HashMap<>();
- List workerConnectorList = workerConnectorService.listFromDB(connectClusterId);
- if (workerConnectorList.isEmpty()){
- return Result.buildSuc(listMap);
- }
- workerConnectorList.forEach(workerConnector -> {
- if (workerConnector.getConnectorName().equals(connectorPO.getConnectorName())){
- listMap.putIfAbsent(KafkaConnectConstant.MIRROR_MAKER_SOURCE_CONNECTOR_TYPE, new ArrayList<>());
- listMap.get(MIRROR_MAKER_SOURCE_CONNECTOR_TYPE).add(ConvertUtil.obj2Obj(workerConnector, KCTaskOverviewVO.class));
- } else if (workerConnector.getConnectorName().equals(connectorPO.getCheckpointConnectorName())) {
- listMap.putIfAbsent(KafkaConnectConstant.MIRROR_MAKER_HEARTBEAT_CONNECTOR_TYPE, new ArrayList<>());
- listMap.get(MIRROR_MAKER_HEARTBEAT_CONNECTOR_TYPE).add(ConvertUtil.obj2Obj(workerConnector, KCTaskOverviewVO.class));
- } else if (workerConnector.getConnectorName().equals(connectorPO.getHeartbeatConnectorName())) {
- listMap.putIfAbsent(KafkaConnectConstant.MIRROR_MAKER_CHECKPOINT_CONNECTOR_TYPE, new ArrayList<>());
- listMap.get(MIRROR_MAKER_CHECKPOINT_CONNECTOR_TYPE).add(ConvertUtil.obj2Obj(workerConnector, KCTaskOverviewVO.class));
- }
-
- });
-
- return Result.buildSuc(listMap);
- }
-
- @Override
- public Result> getMM2Configs(Long connectClusterId, String connectorName) {
- ConnectorPO connectorPO = connectorService.getConnectorFromDB(connectClusterId, connectorName);
- if (connectorPO == null){
- return Result.buildFrom(ResultStatus.NOT_EXIST);
- }
-
- List propList = new ArrayList<>();
-
- // source
- Result connectorResult = connectorService.getConnectorInfoFromCluster(connectClusterId, connectorPO.getConnectorName());
- if (connectorResult.failed()) {
- return Result.buildFromIgnoreData(connectorResult);
- }
-
- Properties props = new Properties();
- props.putAll(connectorResult.getData().getConfig());
- propList.add(props);
-
- // checkpoint
- if (!ValidateUtils.isBlank(connectorPO.getCheckpointConnectorName())) {
- connectorResult = connectorService.getConnectorInfoFromCluster(connectClusterId, connectorPO.getCheckpointConnectorName());
- if (connectorResult.failed()) {
- return Result.buildFromIgnoreData(connectorResult);
- }
-
- props = new Properties();
- props.putAll(connectorResult.getData().getConfig());
- propList.add(props);
- }
-
-
- // heartbeat
- if (!ValidateUtils.isBlank(connectorPO.getHeartbeatConnectorName())) {
- connectorResult = connectorService.getConnectorInfoFromCluster(connectClusterId, connectorPO.getHeartbeatConnectorName());
- if (connectorResult.failed()) {
- return Result.buildFromIgnoreData(connectorResult);
- }
-
- props = new Properties();
- props.putAll(connectorResult.getData().getConfig());
- propList.add(props);
- }
-
- return Result.buildSuc(propList);
- }
-
- @Override
- public Result> validateConnectors(MirrorMakerCreateDTO dto) {
- List voList = new ArrayList<>();
-
- Result infoResult = pluginService.validateConfig(dto.getConnectClusterId(), dto.getConfigs());
- if (infoResult.failed()) {
- return Result.buildFromIgnoreData(infoResult);
- }
-
- voList.add(ConvertUtil.obj2Obj(infoResult.getData(), ConnectConfigInfosVO.class));
-
- if (dto.getHeartbeatConnectorConfigs() != null) {
- infoResult = pluginService.validateConfig(dto.getConnectClusterId(), dto.getHeartbeatConnectorConfigs());
- if (infoResult.failed()) {
- return Result.buildFromIgnoreData(infoResult);
- }
-
- voList.add(ConvertUtil.obj2Obj(infoResult.getData(), ConnectConfigInfosVO.class));
- }
-
- if (dto.getCheckpointConnectorConfigs() != null) {
- infoResult = pluginService.validateConfig(dto.getConnectClusterId(), dto.getCheckpointConnectorConfigs());
- if (infoResult.failed()) {
- return Result.buildFromIgnoreData(infoResult);
- }
-
- voList.add(ConvertUtil.obj2Obj(infoResult.getData(), ConnectConfigInfosVO.class));
- }
-
- return Result.buildSuc(voList);
- }
-
-
- /**************************************************** private method ****************************************************/
-
- private MetricsMirrorMakersDTO buildMetricsConnectorsDTO(List connectorDTOList, MetricDTO metricDTO) {
- MetricsMirrorMakersDTO dto = ConvertUtil.obj2Obj(metricDTO, MetricsMirrorMakersDTO.class);
- dto.setConnectorNameList(connectorDTOList == null? new ArrayList<>(): connectorDTOList);
-
- return dto;
- }
-
- public Result checkCreateMirrorMakerParamAndUnifyData(MirrorMakerCreateDTO dto) {
- ClusterPhy sourceClusterPhy = clusterPhyService.getClusterByCluster(dto.getSourceKafkaClusterId());
- if (sourceClusterPhy == null) {
- return Result.buildFromRSAndMsg(ResultStatus.CLUSTER_NOT_EXIST, MsgConstant.getClusterPhyNotExist(dto.getSourceKafkaClusterId()));
- }
-
- ConnectCluster connectCluster = connectClusterService.getById(dto.getConnectClusterId());
- if (connectCluster == null) {
- return Result.buildFromRSAndMsg(ResultStatus.CLUSTER_NOT_EXIST, MsgConstant.getConnectClusterNotExist(dto.getConnectClusterId()));
- }
-
- ClusterPhy targetClusterPhy = clusterPhyService.getClusterByCluster(connectCluster.getKafkaClusterPhyId());
- if (targetClusterPhy == null) {
- return Result.buildFromRSAndMsg(ResultStatus.CLUSTER_NOT_EXIST, MsgConstant.getClusterPhyNotExist(connectCluster.getKafkaClusterPhyId()));
- }
-
- if (!dto.getConfigs().containsKey(CONNECTOR_CLASS_FILED_NAME)) {
- return Result.buildFromRSAndMsg(ResultStatus.PARAM_ILLEGAL, "SourceConnector缺少connector.class");
- }
-
- if (!MIRROR_MAKER_SOURCE_CONNECTOR_TYPE.equals(dto.getConfigs().getProperty(CONNECTOR_CLASS_FILED_NAME))) {
- return Result.buildFromRSAndMsg(ResultStatus.PARAM_ILLEGAL, "SourceConnector的connector.class类型错误");
- }
-
- if (dto.getCheckpointConnectorConfigs() != null) {
- if (!dto.getCheckpointConnectorConfigs().containsKey(CONNECTOR_CLASS_FILED_NAME)) {
- return Result.buildFromRSAndMsg(ResultStatus.PARAM_ILLEGAL, "CheckpointConnector缺少connector.class");
- }
-
- if (!MIRROR_MAKER_CHECKPOINT_CONNECTOR_TYPE.equals(dto.getCheckpointConnectorConfigs().getProperty(CONNECTOR_CLASS_FILED_NAME))) {
- return Result.buildFromRSAndMsg(ResultStatus.PARAM_ILLEGAL, "Checkpoint的connector.class类型错误");
- }
- }
-
- if (dto.getHeartbeatConnectorConfigs() != null) {
- if (!dto.getHeartbeatConnectorConfigs().containsKey(CONNECTOR_CLASS_FILED_NAME)) {
- return Result.buildFromRSAndMsg(ResultStatus.PARAM_ILLEGAL, "HeartbeatConnector缺少connector.class");
- }
-
- if (!MIRROR_MAKER_HEARTBEAT_CONNECTOR_TYPE.equals(dto.getHeartbeatConnectorConfigs().getProperty(CONNECTOR_CLASS_FILED_NAME))) {
- return Result.buildFromRSAndMsg(ResultStatus.PARAM_ILLEGAL, "Heartbeat的connector.class类型错误");
- }
- }
-
- dto.unifyData(
- sourceClusterPhy.getId(), sourceClusterPhy.getBootstrapServers(), ConvertUtil.str2ObjByJson(sourceClusterPhy.getClientProperties(), Properties.class),
- targetClusterPhy.getId(), targetClusterPhy.getBootstrapServers(), ConvertUtil.str2ObjByJson(targetClusterPhy.getClientProperties(), Properties.class)
- );
-
- return Result.buildSuc();
- }
-
- private MirrorMakerStateVO convert2MirrorMakerStateVO(List connectorPOList,List workerConnectorList,List workerList){
- MirrorMakerStateVO mirrorMakerStateVO = new MirrorMakerStateVO();
-
- List sourceSet = connectorPOList.stream().filter(elem -> elem.getConnectorClassName().equals(MIRROR_MAKER_SOURCE_CONNECTOR_TYPE)).collect(Collectors.toList());
- mirrorMakerStateVO.setMirrorMakerCount(sourceSet.size());
-
- Set connectClusterIdSet = sourceSet.stream().map(ConnectorPO::getConnectClusterId).collect(Collectors.toSet());
- mirrorMakerStateVO.setWorkerCount(workerList.stream().filter(elem -> connectClusterIdSet.contains(elem.getConnectClusterId())).collect(Collectors.toList()).size());
-
- List mirrorMakerConnectorList = new ArrayList<>();
- mirrorMakerConnectorList.addAll(sourceSet);
- mirrorMakerConnectorList.addAll(connectorPOList.stream().filter(elem -> elem.getConnectorClassName().equals(MIRROR_MAKER_CHECKPOINT_CONNECTOR_TYPE)).collect(Collectors.toList()));
- mirrorMakerConnectorList.addAll(connectorPOList.stream().filter(elem -> elem.getConnectorClassName().equals(MIRROR_MAKER_HEARTBEAT_CONNECTOR_TYPE)).collect(Collectors.toList()));
- mirrorMakerStateVO.setTotalConnectorCount(mirrorMakerConnectorList.size());
- mirrorMakerStateVO.setAliveConnectorCount(mirrorMakerConnectorList.stream().filter(elem -> elem.getState().equals(RUNNING.name())).collect(Collectors.toList()).size());
-
- Set connectorNameSet = mirrorMakerConnectorList.stream().map(elem -> elem.getConnectorName()).collect(Collectors.toSet());
- List taskList = workerConnectorList.stream().filter(elem -> connectorNameSet.contains(elem.getConnectorName())).collect(Collectors.toList());
- mirrorMakerStateVO.setTotalTaskCount(taskList.size());
- mirrorMakerStateVO.setAliveTaskCount(taskList.stream().filter(elem -> elem.getState().equals(RUNNING.name())).collect(Collectors.toList()).size());
-
- return mirrorMakerStateVO;
- }
-
- private List convert2ClusterMirrorMakerOverviewVO(List mirrorMakerList, List connectClusterList, List latestMetric) {
- List clusterMirrorMakerOverviewVOList = new ArrayList<>();
- Map metricsMap = latestMetric.stream().collect(Collectors.toMap(elem -> elem.getConnectClusterId() + "@" + elem.getConnectorName(), Function.identity()));
- Map connectClusterMap = connectClusterList.stream().collect(Collectors.toMap(elem -> elem.getId(), Function.identity()));
-
- for (ConnectorPO mirrorMaker : mirrorMakerList) {
- ClusterMirrorMakerOverviewVO clusterMirrorMakerOverviewVO = new ClusterMirrorMakerOverviewVO();
- clusterMirrorMakerOverviewVO.setConnectClusterId(mirrorMaker.getConnectClusterId());
- clusterMirrorMakerOverviewVO.setConnectClusterName(connectClusterMap.get(mirrorMaker.getConnectClusterId()).getName());
- clusterMirrorMakerOverviewVO.setConnectorName(mirrorMaker.getConnectorName());
- clusterMirrorMakerOverviewVO.setState(mirrorMaker.getState());
- clusterMirrorMakerOverviewVO.setCheckpointConnector(mirrorMaker.getCheckpointConnectorName());
- clusterMirrorMakerOverviewVO.setTaskCount(mirrorMaker.getTaskCount());
- clusterMirrorMakerOverviewVO.setHeartbeatConnector(mirrorMaker.getHeartbeatConnectorName());
- clusterMirrorMakerOverviewVO.setLatestMetrics(metricsMap.getOrDefault(mirrorMaker.getConnectClusterId() + "@" + mirrorMaker.getConnectorName(), new MirrorMakerMetrics(mirrorMaker.getConnectClusterId(), mirrorMaker.getConnectorName())));
- clusterMirrorMakerOverviewVOList.add(clusterMirrorMakerOverviewVO);
- }
- return clusterMirrorMakerOverviewVOList;
- }
-
- PaginationResult pagingMirrorMakerInLocal(List mirrorMakerOverviewVOList, ClusterMirrorMakersOverviewDTO dto) {
- List mirrorMakerVOList = PaginationUtil.pageByFuzzyFilter(mirrorMakerOverviewVOList, dto.getSearchKeywords(), Arrays.asList("connectorName"));
-
- //排序
- if (!dto.getLatestMetricNames().isEmpty()) {
- PaginationMetricsUtil.sortMetrics(mirrorMakerVOList, "latestMetrics", dto.getSortMetricNameList(), "connectorName", dto.getSortType());
- } else {
- PaginationUtil.pageBySort(mirrorMakerVOList, dto.getSortField(), dto.getSortType(), "connectorName", dto.getSortType());
- }
-
- //分页
- return PaginationUtil.pageBySubData(mirrorMakerVOList, dto);
- }
-
- public static List supplyData2ClusterMirrorMakerOverviewVOList(List voList,
- List metricLineVOList) {
- Map> metricLineMap = new HashMap<>();
- if (metricLineVOList != null) {
- for (MetricMultiLinesVO metricMultiLinesVO : metricLineVOList) {
- metricMultiLinesVO.getMetricLines()
- .forEach(metricLineVO -> {
- String key = metricLineVO.getName();
- List metricLineVOS = metricLineMap.getOrDefault(key, new ArrayList<>());
- metricLineVOS.add(metricLineVO);
- metricLineMap.put(key, metricLineVOS);
- });
- }
- }
-
- voList.forEach(elem -> {
- elem.setMetricLines(metricLineMap.get(elem.getConnectClusterId() + "#" + elem.getConnectorName()));
- });
-
- return voList;
- }
-
- private List completeClusterInfo(List mirrorMakerVOList) {
-
- Map connectorInfoMap = new HashMap<>();
-
- for (ClusterMirrorMakerOverviewVO mirrorMakerVO : mirrorMakerVOList) {
- ApiCallThreadPoolService.runnableTask(String.format("method=completeClusterInfo||connectClusterId=%d||connectorName=%s||getMirrorMakerInfo", mirrorMakerVO.getConnectClusterId(), mirrorMakerVO.getConnectorName()),
- 3000
- , () -> {
- Result connectorInfoRet = connectorService.getConnectorInfoFromCluster(mirrorMakerVO.getConnectClusterId(), mirrorMakerVO.getConnectorName());
- if (connectorInfoRet.hasData()) {
- connectorInfoMap.put(mirrorMakerVO.getConnectClusterId() + mirrorMakerVO.getConnectorName(), connectorInfoRet.getData());
- }
-
- return connectorInfoRet.getData();
- });
- }
-
- ApiCallThreadPoolService.waitResult(1000);
-
- List newMirrorMakerVOList = new ArrayList<>();
- for (ClusterMirrorMakerOverviewVO mirrorMakerVO : mirrorMakerVOList) {
- KSConnectorInfo connectorInfo = connectorInfoMap.get(mirrorMakerVO.getConnectClusterId() + mirrorMakerVO.getConnectorName());
- if (connectorInfo == null) {
- continue;
- }
-
- String sourceClusterAlias = connectorInfo.getConfig().get(MIRROR_MAKER_SOURCE_CLUSTER_ALIAS_FIELD_NAME);
- String targetClusterAlias = connectorInfo.getConfig().get(MIRROR_MAKER_TARGET_CLUSTER_ALIAS_FIELD_NAME);
- //先默认设置为集群别名
- mirrorMakerVO.setSourceKafkaClusterName(sourceClusterAlias);
- mirrorMakerVO.setDestKafkaClusterName(targetClusterAlias);
-
- if (!ValidateUtils.isBlank(sourceClusterAlias) && CommonUtils.isNumeric(sourceClusterAlias)) {
- ClusterPhy clusterPhy = LoadedClusterPhyCache.getByPhyId(Long.valueOf(sourceClusterAlias));
- if (clusterPhy != null) {
- mirrorMakerVO.setSourceKafkaClusterId(clusterPhy.getId());
- mirrorMakerVO.setSourceKafkaClusterName(clusterPhy.getName());
- }
- }
-
- if (!ValidateUtils.isBlank(targetClusterAlias) && CommonUtils.isNumeric(targetClusterAlias)) {
- ClusterPhy clusterPhy = LoadedClusterPhyCache.getByPhyId(Long.valueOf(targetClusterAlias));
- if (clusterPhy != null) {
- mirrorMakerVO.setDestKafkaClusterId(clusterPhy.getId());
- mirrorMakerVO.setDestKafkaClusterName(clusterPhy.getName());
- }
- }
-
- newMirrorMakerVOList.add(mirrorMakerVO);
-
- }
-
- return newMirrorMakerVOList;
- }
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/group/GroupManager.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/group/GroupManager.java
deleted file mode 100644
index 5a6d3ac6..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/group/GroupManager.java
+++ /dev/null
@@ -1,43 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.group;
-
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterGroupSummaryDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.group.GroupOffsetResetDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.pagination.PaginationBaseDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.pagination.PaginationSortDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.topic.TopicPartitionKS;
-import com.xiaojukeji.know.streaming.km.common.bean.po.group.GroupMemberPO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.group.GroupOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.group.GroupTopicConsumedDetailVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.group.GroupTopicOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.exception.AdminOperateException;
-import com.xiaojukeji.know.streaming.km.common.exception.NotExistException;
-
-import java.util.List;
-import java.util.Set;
-
-public interface GroupManager {
- PaginationResult pagingGroupMembers(Long clusterPhyId,
- String topicName,
- String groupName,
- String searchTopicKeyword,
- String searchGroupKeyword,
- PaginationBaseDTO dto);
-
- PaginationResult pagingGroupTopicMembers(Long clusterPhyId, String groupName, PaginationBaseDTO dto);
-
- PaginationResult pagingClusterGroupsOverview(Long clusterPhyId, ClusterGroupSummaryDTO dto);
-
- PaginationResult pagingGroupTopicConsumedMetrics(Long clusterPhyId,
- String topicName,
- String groupName,
- List latestMetricNames,
- PaginationSortDTO dto)throws NotExistException, AdminOperateException;
-
- Result> listClusterPhyGroupPartitions(Long clusterPhyId, String groupName, Long startTime, Long endTime);
-
- Result resetGroupOffsets(GroupOffsetResetDTO dto, String operator) throws Exception;
-
- List getGroupTopicOverviewVOList(Long clusterPhyId, List groupMemberPOList);
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/group/impl/GroupManagerImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/group/impl/GroupManagerImpl.java
deleted file mode 100644
index 17216793..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/group/impl/GroupManagerImpl.java
+++ /dev/null
@@ -1,371 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.group.impl;
-
-import com.didiglobal.logi.log.ILog;
-import com.didiglobal.logi.log.LogFactory;
-import com.xiaojukeji.know.streaming.km.biz.group.GroupManager;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterGroupSummaryDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.group.GroupOffsetResetDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.pagination.PaginationBaseDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.pagination.PaginationSortDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.partition.PartitionOffsetDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.cluster.ClusterPhy;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.group.Group;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.group.GroupTopic;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.group.GroupTopicMember;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.kafka.KSGroupDescription;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.kafka.KSMemberConsumerAssignment;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.kafka.KSMemberDescription;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.metrics.GroupMetrics;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.offset.KSOffsetSpec;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.topic.Topic;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.topic.TopicPartitionKS;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.ResultStatus;
-import com.xiaojukeji.know.streaming.km.common.bean.po.group.GroupMemberPO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.group.GroupOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.group.GroupTopicConsumedDetailVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.group.GroupTopicOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.constant.MsgConstant;
-import com.xiaojukeji.know.streaming.km.common.constant.PaginationConstant;
-import com.xiaojukeji.know.streaming.km.common.converter.GroupConverter;
-import com.xiaojukeji.know.streaming.km.common.enums.AggTypeEnum;
-import com.xiaojukeji.know.streaming.km.common.enums.OffsetTypeEnum;
-import com.xiaojukeji.know.streaming.km.common.enums.SortTypeEnum;
-import com.xiaojukeji.know.streaming.km.common.enums.group.GroupStateEnum;
-import com.xiaojukeji.know.streaming.km.common.exception.AdminOperateException;
-import com.xiaojukeji.know.streaming.km.common.exception.NotExistException;
-import com.xiaojukeji.know.streaming.km.common.utils.ConvertUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationMetricsUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.ValidateUtils;
-import com.xiaojukeji.know.streaming.km.core.service.cluster.ClusterPhyService;
-import com.xiaojukeji.know.streaming.km.core.service.group.GroupMetricService;
-import com.xiaojukeji.know.streaming.km.core.service.group.GroupService;
-import com.xiaojukeji.know.streaming.km.core.service.partition.PartitionService;
-import com.xiaojukeji.know.streaming.km.core.service.topic.TopicService;
-import com.xiaojukeji.know.streaming.km.core.service.version.metrics.kafka.GroupMetricVersionItems;
-import com.xiaojukeji.know.streaming.km.persistence.es.dao.GroupMetricESDAO;
-import org.apache.kafka.common.ConsumerGroupState;
-import org.apache.kafka.common.TopicPartition;
-import org.springframework.beans.factory.annotation.Autowired;
-import org.springframework.stereotype.Component;
-
-import java.util.*;
-import java.util.stream.Collectors;
-
-import static com.xiaojukeji.know.streaming.km.common.enums.group.GroupTypeEnum.CONNECT_CLUSTER_PROTOCOL_TYPE;
-
-@Component
-public class GroupManagerImpl implements GroupManager {
- private static final ILog log = LogFactory.getLog(GroupManagerImpl.class);
-
- @Autowired
- private TopicService topicService;
-
- @Autowired
- private GroupService groupService;
-
- @Autowired
- private PartitionService partitionService;
-
- @Autowired
- private GroupMetricService groupMetricService;
-
- @Autowired
- private GroupMetricESDAO groupMetricESDAO;
-
- @Autowired
- private ClusterPhyService clusterPhyService;
-
- @Override
- public PaginationResult pagingGroupMembers(Long clusterPhyId,
- String topicName,
- String groupName,
- String searchTopicKeyword,
- String searchGroupKeyword,
- PaginationBaseDTO dto) {
- PaginationResult paginationResult = groupService.pagingGroupMembers(clusterPhyId, topicName, groupName, searchTopicKeyword, searchGroupKeyword, dto);
-
- if (!paginationResult.hasData()) {
- return PaginationResult.buildSuc(new ArrayList<>(), paginationResult);
- }
-
- List groupTopicVOList = this.getGroupTopicOverviewVOList(clusterPhyId, paginationResult.getData().getBizData());
-
- return PaginationResult.buildSuc(groupTopicVOList, paginationResult);
- }
-
- @Override
- public PaginationResult pagingGroupTopicMembers(Long clusterPhyId, String groupName, PaginationBaseDTO dto) {
- Group group = groupService.getGroupFromDB(clusterPhyId, groupName);
-
- //没有topicMember则直接返回
- if (group == null || ValidateUtils.isEmptyList(group.getTopicMembers())) {
- return PaginationResult.buildSuc(dto);
- }
-
- //排序
- List groupTopicMembers = PaginationUtil.pageBySort(group.getTopicMembers(), PaginationConstant.DEFAULT_GROUP_TOPIC_SORTED_FIELD, SortTypeEnum.DESC.getSortType());
-
- //分页
- PaginationResult paginationResult = PaginationUtil.pageBySubData(groupTopicMembers, dto);
-
- List groupMemberPOList = paginationResult.getData().getBizData().stream().map(elem -> new GroupMemberPO(clusterPhyId, elem.getTopicName(), groupName, group.getState().getState(), elem.getMemberCount())).collect(Collectors.toList());
-
- return PaginationResult.buildSuc(this.getGroupTopicOverviewVOList(clusterPhyId, groupMemberPOList), paginationResult);
- }
-
- @Override
- public PaginationResult pagingClusterGroupsOverview(Long clusterPhyId, ClusterGroupSummaryDTO dto) {
- List groupList = groupService.listClusterGroups(clusterPhyId);
-
- // 类型转化
- List voList = groupList.stream().map(elem -> GroupConverter.convert2GroupOverviewVO(elem)).collect(Collectors.toList());
-
- // 搜索groupName
- voList = PaginationUtil.pageByFuzzyFilter(voList, dto.getSearchGroupName(), Arrays.asList("name"));
-
- //搜索topic
- if (!ValidateUtils.isBlank(dto.getSearchTopicName())) {
- voList = voList.stream().filter(elem -> {
- for (String topicName : elem.getTopicNameList()) {
- if (topicName.contains(dto.getSearchTopicName())) {
- return true;
- }
- }
- return false;
- }).collect(Collectors.toList());
- }
-
- // 分页 后 返回
- return PaginationUtil.pageBySubData(voList, dto);
- }
-
- @Override
- public PaginationResult pagingGroupTopicConsumedMetrics(Long clusterPhyId,
- String topicName,
- String groupName,
- List latestMetricNames,
- PaginationSortDTO dto) throws NotExistException, AdminOperateException {
- ClusterPhy clusterPhy = clusterPhyService.getClusterByCluster(clusterPhyId);
- if (clusterPhy == null) {
- return PaginationResult.buildFailure(MsgConstant.getClusterPhyNotExist(clusterPhyId), dto);
- }
-
- // 获取消费组消费的TopicPartition列表
- Map consumedOffsetMap = groupService.getGroupOffsetFromKafka(clusterPhyId, groupName);
- List partitionList = consumedOffsetMap.keySet()
- .stream()
- .filter(elem -> elem.topic().equals(topicName))
- .map(elem -> elem.partition())
- .collect(Collectors.toList());
- Collections.sort(partitionList);
-
- // 获取消费组当前运行信息
- KSGroupDescription groupDescription = groupService.getGroupDescriptionFromKafka(clusterPhy, groupName);
-
- // 转换存储格式
- Map tpMemberMap = new HashMap<>();
-
- //如果不是connect集群
- if (!groupDescription.protocolType().equals(CONNECT_CLUSTER_PROTOCOL_TYPE)) {
- for (KSMemberDescription description : groupDescription.members()) {
- KSMemberConsumerAssignment assignment = (KSMemberConsumerAssignment) description.assignment();
- for (TopicPartition tp : assignment.topicPartitions()) {
- tpMemberMap.put(tp, description);
- }
- }
- }
-
- // 获取指标
- PaginationResult metricsResult = this.pagingGroupTopicPartitionMetrics(clusterPhyId, groupName, topicName, partitionList, latestMetricNames, dto);
- if (metricsResult.failed()) {
- return PaginationResult.buildFailure(metricsResult, dto);
- }
-
- // 数据组装
- List voList = new ArrayList<>();
- for (GroupMetrics groupMetrics: metricsResult.getData().getBizData()) {
- GroupTopicConsumedDetailVO vo = new GroupTopicConsumedDetailVO();
- vo.setTopicName(topicName);
- vo.setPartitionId(groupMetrics.getPartitionId());
-
- KSMemberDescription ksMemberDescription = tpMemberMap.get(new TopicPartition(topicName, groupMetrics.getPartitionId()));
- if (ksMemberDescription != null) {
- vo.setMemberId(ksMemberDescription.consumerId());
- vo.setHost(ksMemberDescription.host());
- vo.setClientId(ksMemberDescription.clientId());
- }
-
- vo.setLatestMetrics(groupMetrics);
- voList.add(vo);
- }
-
- return PaginationResult.buildSuc(voList, metricsResult);
- }
-
- @Override
- public Result> listClusterPhyGroupPartitions(Long clusterPhyId, String groupName, Long startTime, Long endTime) {
- try {
- return Result.buildSuc(groupMetricESDAO.listGroupTopicPartitions(clusterPhyId, groupName, startTime, endTime));
- }catch (Exception e){
- return Result.buildFailure(e.getMessage());
- }
- }
-
- @Override
- public Result resetGroupOffsets(GroupOffsetResetDTO dto, String operator) throws Exception {
- Result rv = this.checkFieldLegal(dto);
- if (rv.failed()) {
- return rv;
- }
-
- ClusterPhy clusterPhy = clusterPhyService.getClusterByCluster(dto.getClusterId());
- if (clusterPhy == null) {
- return Result.buildFromRSAndMsg(ResultStatus.CLUSTER_NOT_EXIST, MsgConstant.getClusterPhyNotExist(dto.getClusterId()));
- }
-
- KSGroupDescription description = groupService.getGroupDescriptionFromKafka(clusterPhy, dto.getGroupName());
- if (ConsumerGroupState.DEAD.equals(description.state()) && !dto.isCreateIfNotExist()) {
- return Result.buildFromRSAndMsg(ResultStatus.KAFKA_OPERATE_FAILED, "group不存在, 重置失败");
- }
-
- if (!ConsumerGroupState.EMPTY.equals(description.state()) && !ConsumerGroupState.DEAD.equals(description.state())) {
- return Result.buildFromRSAndMsg(ResultStatus.KAFKA_OPERATE_FAILED, String.format("group处于%s, 重置失败(仅Empty | Dead 情况可重置)", GroupStateEnum.getByRawState(description.state()).getState()));
- }
-
- // 获取offset
- Result> offsetMapResult = this.getPartitionOffset(dto);
- if (offsetMapResult.failed()) {
- return Result.buildFromIgnoreData(offsetMapResult);
- }
-
- // 重置offset
- return groupService.resetGroupOffsets(dto.getClusterId(), dto.getGroupName(), offsetMapResult.getData(), operator);
- }
-
- @Override
- public List getGroupTopicOverviewVOList(Long clusterPhyId, List groupMemberPOList) {
- // 获取指标
- Result> metricsListResult = groupMetricService.listLatestMetricsAggByGroupTopicFromES(
- clusterPhyId,
- groupMemberPOList.stream().map(elem -> new GroupTopic(elem.getGroupName(), elem.getTopicName())).collect(Collectors.toList()),
- Arrays.asList(GroupMetricVersionItems.GROUP_METRIC_LAG),
- AggTypeEnum.MAX
- );
- if (metricsListResult.failed()) {
- // 如果查询失败,则输出错误信息,但是依旧进行已有数据的返回
- log.error("method=completeMetricData||clusterPhyId={}||result={}||errMsg=search es failed", clusterPhyId, metricsListResult);
- }
- return this.convert2GroupTopicOverviewVOList(groupMemberPOList, metricsListResult.getData());
- }
-
-
- /**************************************************** private method ****************************************************/
-
-
- private Result
-
-2、查看'/logi-security/api/v1/permission/tree'接口返回值,出现如下图所示乱码现象。
-
-
-3、查看logi_security_permission表,看看是否出现了中文乱码现象。
-
-根据以上几点,我们可以确定是由于数据库乱码造成的权限识别失败问题。
-
-+ 原因:由于数据库编码和我们提供的脚本不一致,数据库里的数据发生了乱码,因此出现权限识别失败问题。
-+ 解决方案:清空数据库数据,将数据库字符集调整为utf8,最后重新执行[dml-logi.sql](https://github.com/didi/KnowStreaming/blob/master/km-dist/init/sql/dml-logi.sql)脚本导入数据即可。
-
-
-## 8.13、接入开启kerberos认证的kafka集群
-
-1. 部署KnowStreaming的机器上安装krb客户端;
-2. 替换/etc/krb5.conf配置文件;
-3. 把kafka对应的keytab复制到改机器目录下;
-4. 接入集群时认证配置,配置信息根据实际情况填写;
-```json
-{
- "security.protocol": "SASL_PLAINTEXT",
- "sasl.mechanism": "GSSAPI",
- "sasl.jaas.config": "com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true keyTab=\"/etc/keytab/kafka.keytab\" storeKey=true useTicketCache=false principal=\"kafka/kafka@TEST.COM\";",
- "sasl.kerberos.service.name": "kafka"
-}
-```
-
-
-## 8.14、对接Ldap的配置
-
-```yaml
-# 需要在application.yml中增加如下配置。相关配置的信息,按实际情况进行调整
-account:
- ldap:
- url: ldap://127.0.0.1:8080/
- basedn: DC=senz,DC=local
- factory: com.sun.jndi.ldap.LdapCtxFactory
- filter: sAMAccountName
- security:
- authentication: simple
- principal: CN=search,DC=senz,DC=local
- credentials: xxxxxxx
- auth-user-registration: false # 是否注册到mysql,默认false
- auth-user-registration-role: 1677 # 1677是超级管理员角色的id,如果赋予想默认赋予普通角色,可以到ks新建一个。
-
-# 需要在application.yml中修改如下配置
-spring:
- logi-security:
- login-extend-bean-name: ksLdapLoginService # 表示使用ldap的service
-```
-
-## 8.15、测试时使用Testcontainers的说明
-1. 需要docker运行环境 [Testcontainers运行环境说明](https://www.testcontainers.org/supported_docker_environment/)
-2. 如果本机没有docker,可以使用[远程访问docker](https://docs.docker.com/config/daemon/remote-access/) [Testcontainers配置说明](https://www.testcontainers.org/features/configuration/#customizing-docker-host-detection)
\ No newline at end of file
diff --git a/docs/user_guide/新旧对比手册.md b/docs/user_guide/新旧对比手册.md
deleted file mode 100644
index d934e41f..00000000
--- a/docs/user_guide/新旧对比手册.md
+++ /dev/null
@@ -1,92 +0,0 @@
-## 9.2、新旧版本对比
-
-### 9.2.1、全新的设计理念
-
-- 在 0 侵入、0 门槛的前提下提供直观 GUI 用于管理和观测 Apache Kafka®,帮助用户降低 Kafka CLI 操作门槛,轻松实现对原生 Kafka 集群的可管、可见、可掌控,提升 Kafka 使用体验和降低管理成本。
-- 支持海量集群一键接入,无需任何改造,即可实现集群深度纳管,真正的 0 侵入、插件化系统设计,覆盖 0.10.x-3.x.x 众多 Kafka 版本无缝纳管。
-
-### 9.2.2、产品名称&协议
-
-- Know Streaming V3.0
-
- - 名称:Know Streaming
- - 协议:AGPL 3.0
-
-- Logi-KM V2.x
-
- - 名称:Logi-KM
- - 协议:Apache License 2.0
-
-### 9.2.3、功能架构
-
-- Know Streaming V3.0
-
-
-
-- Logi-KM V2.x
-
-
-
-### 9.2.4、功能变更
-
-- 多集群管理
-
- - 增加健康监测体系、关键组件&指标 GUI 展示
- - 增加 2.8.x 以上 Kafka 集群接入,覆盖 0.10.x-3.x
- - 删除逻辑集群、共享集群、Region 概念
-
-- Cluster 管理
-
- - 增加集群概览信息、集群配置变更记录
- - 增加 Cluster 健康分,健康检查规则支持自定义配置
- - 增加 Cluster 关键指标统计和 GUI 展示,支持自定义配置
- - 增加 Cluster 层 I/O、Disk 的 Load Reblance 功能,支持定时均衡任务(企业版)
- - 删除限流、鉴权功能
- - 删除 APPID 概念
-
-- Broker 管理
-
- - 增加 Broker 健康分
- - 增加 Broker 关键指标统计和 GUI 展示,支持自定义配置
- - 增加 Broker 参数配置功能,需重启生效
- - 增加 Controller 变更记录
- - 增加 Broker Datalogs 记录
- - 删除 Leader Rebalance 功能
- - 删除 Broker 优先副本选举
-
-- Topic 管理
-
- - 增加 Topic 健康分
- - 增加 Topic 关键指标统计和 GUI 展示,支持自定义配置
- - 增加 Topic 参数配置功能,可实时生效
- - 增加 Topic 批量迁移、Topic 批量扩缩副本功能
- - 增加查看系统 Topic 功能
- - 优化 Partition 分布的 GUI 展示
- - 优化 Topic Message 数据采样
- - 删除 Topic 过期概念
- - 删除 Topic 申请配额功能
-
-- Consumer 管理
-
- - 优化了 ConsumerGroup 展示形式,增加 Consumer Lag 的 GUI 展示
-
-- ACL 管理
-
- - 增加原生 ACL GUI 配置功能,可配置生产、消费、自定义多种组合权限
- - 增加 KafkaUser 功能,可自定义新增 KafkaUser
-
-- 消息测试(企业版)
-
- - 增加生产者消息模拟器,支持 Data、Flow、Header、Options 自定义配置(企业版)
- - 增加消费者消息模拟器,支持 Data、Flow、Header、Options 自定义配置(企业版)
-
-- Job
-
- - 优化 Job 模块,支持任务进度管理
-
-- 系统管理
-
- - 优化用户、角色管理体系,支持自定义角色配置页面及操作权限
- - 优化审计日志信息
- - 删除多租户体系
- - 删除工单流程
\ No newline at end of file
diff --git a/docs/user_guide/用户使用手册.md b/docs/user_guide/用户使用手册.md
deleted file mode 100644
index 6179cb3b..00000000
--- a/docs/user_guide/用户使用手册.md
+++ /dev/null
@@ -1,848 +0,0 @@
-
-## 5.0、产品简介
-
-`Know Streaming` 是一套云原生的 Kafka 管控平台,脱胎于众多互联网内部多年的 Kafka 运营实践经验,专注于 Kafka 运维管控、监控告警、资源治理、多活容灾等核心场景,在用户体验、监控、运维管控上进行了平台化、可视化、智能化的建设,提供一系列特色的功能,极大地方便了用户和运维人员的日常使用,让普通运维人员都能成为 Kafka 专家。
-
-## 5.1、功能架构
-
-
-
-## 5.2、体验路径
-
-下面是用户第一次使用我们产品的典型体验路径:
-
-
-
-## 5.3、常用功能
-
-### 5.3.1、用户管理
-
-用户管理是提供给管理员进行人员管理和用户角色管理的功能模块,可以进行新增用户和分配角色。下面是一个典型的场景:
-eg:团队加入了新成员,需要给这位成员分配一个使用系统的账号,需要以下几个步骤
-
-- 步骤 1:点击“系统管理”>“用户管理”>“人员管理”>“新增用户”,输入“账号”、“实名”、“密码”,根据此账号所需要的权限,选择此账号所对应的角色。如果有满足权限的角色,则用户新增成功。如果没有满足权限的角色,则需要新增角色(步骤 2)
-- 步骤 2:点击“系统管理”>“用户管理”>“角色管理”>“新增角色”。输入角色名称和描述,给此角色分配权限,点击“确定”,角色新增成功
-
-- 步骤 3:根据此新增的角色,参考步骤 1,重新新增用户
-
-- 步骤 4:此用户账号新增成功,可以进行登录产品使用
-
-
-
-### 5.3.2、接入集群
-
-- 步骤 1:点击“多集群管理”>“接入集群”
-
-- 步骤 2:填写相关集群信息
-
-- 集群名称:支持中英文、下划线、短划线(-),最长 128 字符。平台内不能重复
- - Bootstrap Servers:输入 Bootstrap Servers 地址。输入完成之后会进行连接测试,测试完成之后会给出测试结果连接成功 or 连接失败(以及失败的原因)。
- - Zookeeper:输入 zookeeper 地址,输入完成之后会进行连接测试,测试完成之后会给出测试结果连接成功 or 连接失败(以及失败的原因)
- - Metrics 选填:JMX Port,输入 JMX 端口号;MaxConn,输入服务端最大允许的连接数
- - Security:若有 JMX 账号密码,则输入账号密码
- - Version:选择所支持的 kafka 版本,如果没有匹配则可以选择相近版本
- - 集群配置选填:输入用户创建 kafka 客户端进行信息获取的相关配置
- - 集群描述:最多 200 字符
-
-
-
-### 5.3.3、新增 Topic
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“新增 Topic”按钮>“创建 Topic“抽屉
-
-- 步骤 2:输入“Topic 名称(不能重复)”、“Topic 描述”、“分区数”、“副本数”、“数据保存时间”、“清理策略(删除或压缩)”
-
-- 步骤 3:展开“更多配置”可以打开高级配置选项,根据自己需要输入相应配置参数
-
-- 步骤 4:点击“确定”,创建 Topic 完成
-
-
-
-### 5.3.4、Topic 扩分区
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“Topic 列表“>操作项”扩分区“>“扩分区”抽屉
-
-- 步骤 2:扩分区抽屉展示内容为“流量的趋势图”、“当前分区数及支持的最低消息写入速率”、“扩分区后支持的最低消息写入速率”
-
-- 步骤 3:输入所需的分区总数,自动计算出扩分区后支持的最低消息写入速率
-
-- 步骤 4:点击确定,扩分区完成
-
-
-
-### 5.3.5、Topic 批量扩缩副本
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“批量操作下拉“>“批量扩缩副本“>“批量扩缩容”抽屉
-
-- 步骤 2:选择所需要进行扩缩容的 Topic,可多选,所选择的 Topic 出现在下方 Topic 列表中
-
-- 步骤 3:Topic 列表展示 Topic“近三天平均流量”、“近三天峰值流量及时间”、“Partition 数”、”当前副本数“、“新副本数”
-
-- 步骤 4:扩容时,选择目标节点,新增的副本会在选择的目标节点上;缩容时不需要选择目标节点,自动删除最后一个(或几个)副本
-
-- 步骤 5:输入迁移任务配置参数,包含限流值和任务执行时间
-
-- 步骤 6:输入任务描述
-
-- 步骤 7:点击“确定”,创建 Topic 扩缩副本任务
-
-- 步骤 8:去“Job”模块的 Job 列表查看创建的任务,如果已经执行则可以查看执行进度;如果未开始执行则可以编辑任务
-
-
-
-### 5.3.6、Topic 批量迁移
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“批量操作下拉“>“批量迁移“>“批量迁移”抽屉
-
-- 步骤 2:选择所需要进行迁移的 Topic,可多选,所选择的 Topic 出现在下方 Topic 列表中
-
-- 步骤 3:选择所需要迁移的 partition 和迁移数据的时间范围
-
-- 步骤 4:选择目标节点(节点数必须不小于最大副本数)
-
-- 步骤 5:点击“预览任务计划”,打开“任务计划”二次抽屉,可对目标 Broker ID 进行编辑
-
-- 步骤 6:输入迁移任务配置参数,包含限流值和任务执行时间
-
-- 步骤 7:输入任务描述
-
-- 步骤 8:点击“确定”,创建 Topic 迁移任务
-
-- 步骤 9:去“Job”模块的 Job 列表查看创建的任务,如果已经执行则可以查看执行进度;如果未开始执行则可以编辑任务
-
-
-
-### 5.3.7、设置 Cluster 健康检查规则
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“集群健康状态旁边 icon”>“健康度设置抽屉”
-
-- 步骤 2:健康度设置抽屉展示出了检查项和其对应的权重,可以修改检查项的检查规则
-
-- 步骤 3:检查规则可配置,分别为
-
- - Cluster:集群 controller 数不等于 1(数字不可配置)不通过
- - Broker:RequestQueueSize 大于等于 10(默认为 10,可配置数字)不通过
- - Broker:NetworkProcessorAvgIdlePercent 的 Idle 小于等于 0.8%(默认为 0.8%,可配置数字)不通过
- - Topic:无 leader 的 Topic 数量,大于等于 1(默认为 1,数字可配置)不通过
- - Topic:Topic 在 10(默认为 10,数字可配置)个周期内 8(默认为 8,数字可配置)个周期内处于未同步的状态则不通过
- - ConsumerGroup:Group 在 10(默认为 10,数字可配置)个周期内进行 8(默认为 8,数字可配置)次 re-balance 不通过
-
-- 步骤 4:设置完成后,点击“确认”,健康检查规则设置成功
-
-
-
-### 5.3.8、图表指标筛选
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“指标筛选 icon”>“指标筛选抽屉”
-
-- 步骤 2:指标筛选抽屉展示信息为以下几类“Health”、“Cluster”、“Broker”、“Consumer”、“Security”、“Job”
-
-- 步骤 3:默认勾选比较重要的指标进行展示。根据需要选中/取消选中相应指标,点击”确认“,指标筛选成功,展示的图表随之变化
-
-
-
-### 5.3.9、编辑 Broker 配置
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Brokers”>“Broker ID”>“Configuration”TAB>“编辑”按钮
-
-- 步骤 2:输入配置项的新配置内容
-
-- 步骤 3:(选填)点击“应用于全部 Broker”,将此配置项的修改应用于全部的 Broker
-
-- 步骤 4:点击“确认”,Broker 配置修改成功
-
-
-
-### 5.3.10、重置 consumer Offset
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Consumer”>“Consumer Group”名称>“Consumer Group 详情”抽屉>“重置 Offset”按钮>“重置 Offset”抽屉
-
-- 步骤 2:选择重置 Offset 的类型,可“重置到指定时间”或“重置分区”
-
-- 步骤 3:重置到指定时间,可选择“最新 Offset”或“自定义时间”
-
-- 步骤 4:重置分区,可选择 partition 和其重置的 offset
-
-- 步骤 5:点击“确认”,重置 Offset 开始执行
-
-
-
-### 5.3.11、新增 ACL
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Security”>“Users”>“新增 ACL”
-
-- 步骤 2:输入 ACL 配置参数
-
- - ACL 用途:生产权限、消费权限、自定义权限
- - 生产权限时:可选择应用于所有 Kafka User 或者特定 Kafka User;可选择应用于所有 Topic 或者特定 Topic
- - 消费权限时:可选择应用于所有 Kafka User 或者特定 Kafka User;可选择应用于所有 Topic 或者特定 Topic;可选择应用于所有 Consumer Group 或者特定 Consumer Group
-
-- 步骤 3:点击“确定”,新增 ACL 成功
-
-
-
-## 5.4、全部功能
-
-### 5.4.1、登录/退出登录
-
-- 登录:输入账号密码,点击登录
-
-- 退出登录:鼠标悬停右上角“头像”或者“用户名”,出现小弹窗“登出”,点击“登出”,退出登录
-
-### 5.4.2、系统管理
-
-用户登录完成之后,点击页面右上角【系统管理】按钮,切换到系统管理的视角,可以进行配置管理、用户管理、审计日志查看。
-
-
-#### 5.4.2.1、配置管理
-
-配置管理是提供给管理员一个快速配置配置文件的能力,所配置的配置文件将会在对应模块生效。
-
-#### 5.4.2.2、查看配置列表
-
-- 步骤 1:点击”系统管理“>“配置管理”
-
-- 步骤 2:列表展示配置所属模块、配置键、配置值、启用状态、更新时间、更新人。列表有操作项编辑、删除,可对配置模块、配置键、配置值、描述、启用状态进行配置,也可删除此条配置
-
-
-
-#### 5.4.2.3、新增配置
-
-- 步骤 1:点击“系统管理”>“配置管理”>“新增配置”
-
-- 步骤 2:模块:下拉选择所有可配置的模块;配置键:不限制输入内容,500 字以内;配置值:代码编辑器样式,不限内容不限长度;启用状态开关:可以启用/禁用此项配置
-
-
-
-#### 5.4.2.4、编辑配置
-
-可对配置模块、配置键、配置值、描述、启用状态进行配置。
-
-#### 5.4.2.5、用户管理
-
-用户管理是提供给管理员进行人员管理和用户角色管理的功能模块,可以进行新增用户和分配角色。
-
-#### 5.4.2.6、人员管理列表
-
-- 步骤 1:点击“系统管理”>“用户管理”>“人员管理”
-
-- 步骤 2:人员管理列表展示用户角色、用户实名、用户分配的角色、更新时间、编辑操作。
-
-- 步骤 3:列表支持”用户账号“、“用户实名”、“角色名”筛选。
-
-
-
-#### 5.4.2.7、新增用户
-
-- 步骤 1:点击“系统管理”>“用户管理”>“人员管理”>“新增用户”
-
-- 步骤 2:填写“用户账号”、“用户实名”、“用户密码”这些必填参数,可以对此账号分配已经存在的角色。
-
-
-
-#### 5.4.2.8、编辑用户
-
-- 步骤 1:点击“系统管理”>“用户管理”>“人员管理”>列表操作项“编辑”
-
-- 步骤 2:用户账号不可编辑;可以编辑“用户实名”,修改“用户密码”,重新分配“用户角色“
-
-
-
-#### 5.4.2.9、角色管理列表
-
-- 步骤 1:点击“系统管理”>“用户管理”>“角色管理”
-
-- 步骤 2:角色列表展示信息为“角色 ID”、“名称”、“描述”、“分配用户数”、“最后修改人”、“最后更新时间”、操作项“查看详情”、操作项”分配用户“
-
-- 步骤 3:列表有筛选框,可对“角色名称”进行筛选
-
-- 步骤 4:列表操作项,“查看详情”可查看到角色绑定的权限项,”分配用户“可对此项角色下绑定的用户进行增减
-
-
-
-#### 5.4.2.10、新增角色
-
-- 步骤 1:点击“系统管理”>“用户管理”>“角色管理”>“新增角色”
-
-- 步骤 2:输入“角色名称”(角色名称只能由中英文大小写、数字、下划线\_组成,长度限制在 3 ~ 128 字符)、“角色描述“(不能为空)、“分配权限“(至少需要分配一项权限),点击确认,新增角色成功添加到角色列表
-
-
-
-#### 5.4.2.11、审计日志
-
-- 步骤 1:点击“系统管理”>“审计日志“
-- 步骤 2:审计日志包含所有对于系统的操作记录,操作记录列表展示信息为下
-
- - “模块”:操作对象所属的功能模块
- - “操作对象”:具体哪一个集群、任务 ID、topic、broker、角色等
- - “行为”:操作记录的行为,包含“新增”、“替换”、“读取”、“禁用”、“修改”、“删除”、“编辑”等
- - “操作内容”:具体操作的内容是什么
- - “操作时间”:操作发生的时间
- - “操作人”:此项操作所属的用户
-
-- 步骤 3:操作记录列表可以对“模块“、”操作对象“、“操作内容”、”操作时间“进行筛选
-
-
-
-### 5.4.3、多集群管理
-
-#### 5.4.3.1、多集群列表
-
-- 步骤 1:点击顶部导航栏“多集群管理”
-
-- 步骤 2:多集群管理页面包含的信息为:”集群信息总览“、“集群列表”、“列表筛选项”、“接入集群”
-
-- 步骤 3:集群列表筛选项为
-
- - 集群信息总览:cluster 总数、live 数、down 数
- - 版本筛选:包含所有存在的集群版本
- - 健康分筛选:筛选项为 0、10、20、30、40、50、60、70、80、90、100
- - live、down 筛选:多选
- - 下拉框筛选排序,选项维度为“接入时间”、“健康分“、”Messages“、”MessageSize“、”BytesIn“、”BytesOut“、”Brokers“;可对这些维度进行“升序”、“降序”排序
-
-- 步骤 4:每个卡片代表一个集群,其所展示的集群概览信息包括“健康分及健康检查项通过数”、“broker 数量”、“ZK 数量”、“版本号”、“BytesIn 均衡状态”、“BytesOut 均衡状态”、“Disk 均衡状态”、”Messages“、“MessageSize”、“BytesIn”、“BytesOut”、“接入时间”
-
-
-
-#### 5.4.3.2、接入集群
-
-- 步骤 1:点击“多集群管理”>“接入集群”
-
-- 步骤 2:填写相关集群信息
- - 集群名称:平台内不能重复
- - Bootstrap Servers:输入 Bootstrap Servers 地址,输入完成之后会进行连接测试,测试完成之后会给出测试结果连接成功 or 连接失败(以及失败的原因)。
- - Zookeeper:输入 zookeeper 地址,输入完成之后会进行连接测试,测试完成之后会给出测试结果连接成功 or 连接失败(以及失败的原因)
- - Metrics 选填:JMX Port,输入 JMX 端口号;MaxConn,输入服务端最大允许的连接数
- - Security:若有 JMX 账号密码,则输入账号密码
- - Version:kafka 版本,如果没有匹配则可以选择相近版本
- - 集群配置选填:用户创建 kafka 客户端进行信息获取的相关配置
-
-
-
-#### 5.4.3.3、删除集群
-
-- 步骤 1:点击“多集群管理”>鼠标悬浮集群卡片>点击卡片右上角“删除 icon”>打开“删除弹窗”
-
-- 步骤 2:在删除弹窗中的“集群名称”输入框,输入所要删除集群的集群名称,点击“删除”,成功删除集群,解除平台的纳管关系(集群资源不会删除)
-
-
-
-### 5.4.4、Cluster 管理
-
-#### 5.4.4.1、Cluster Overview
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>进入单集群管理界面
-
-- 步骤 2:左侧导航栏
-
- - 一级导航:Cluster;二级导航:Overview、Load Rebalance
- - 一级导航:Broker;二级导航:Overview、Brokers、Controller
- - 一级导航:Topic;二级导航:Overview、Topics
- - 一级导航:Consumer
- - 一级导航:Testing;二级导航:Produce、Consume
- - 一级导航:Security;二级导航:ACLs、Users
- - 一级导航:Job
-
-
-
-#### 5.4.4.2、查看 Cluster 概览信息
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”
-
-- 步骤 2:cluster 概览信息包括以下内容
-
- - 集群健康分,健康检查通过项
- - Cluster 信息:包含名称、版本、均衡状态
- - Broker 信息:Broker 总数、controller 信息、similar config 信息
- - Topic 信息:Topic 总数、No Leader、“集群卡片”>“Cluster”>“Overview”>“集群健康状态旁边 icon”>“健康度设置抽屉”
-
-- 步骤 2:健康度设置抽屉展示出了检查项和其对应的权重,可以修改检查项的检查规则
-
-- 步骤 3:检查规则可配置,分别为
-
- - Cluster:集群 controller 数不等于 1(数字不可配置)不通过
- - Broker:RequestQueueSize 大于等于 10(默认为 10,可配置数字)不通过
- - Broker:NetworkProcessorAvgIdlePercent 的 Idle 小于等于 0.8%(默认为 0.8%,可配置数字)不通过
- - Topic:无 leader 的 Topic 数量,大于等于 1(默认为 1,数字可配置)不通过
- - Topic:Topic 在 10(默认为 10,数字可配置)个周期内 8(默认为 8,数字可配置)个周期内处于未同步的状态
- - ConsumerGroup:Group 在 10(默认为 10,数字可配置)个周期内进行 8(默认为 8,数字可配置)次 re-balance 不通过
-
-- 步骤 4:设置完成后,点击“确认”,健康检查规则设置成功
-
-
-
-#### 5.4.4.4、查看 Cluster 健康检查详情
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“集群健康状态旁边【查看详情】”>“健康检查详情抽屉”
-
-- 步骤 2:健康检查详情抽屉展示信息为:“检查模块”、“检查项”、“权重”、“得分”、“检查时间”、“检查结果是否通过”,若未通过会展示未通过的对象
-
-
-
-#### 5.4.4.5、编辑 Cluster 信息
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“Cluster 名称旁边编辑 icon”>“编辑集群抽屉”
-
-- 步骤 2:可编辑的信息包括“集群名称”、“Bootstrap Servers”、“Zookeeper”、“JMX Port”、“Maxconn(最大连接数)”、“Security(认证措施)”、“Version(版本号)”、“集群配置”、“集群描述”
-
-- 步骤 3:点击“确定”,成功编辑集群信息
-
-
-
-#### 5.4.4.6、图表指标筛选
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“指标筛选 icon”>“指标筛选抽屉”
-
-- 步骤 2:指标筛选抽屉展示信息为以下几类“Health”、“Cluster”、“Broker”、“Consumer”、“Security”、“Job”
-
-- 步骤 3:默认勾选比较重要的指标进行展示。根据需要选中/取消选中相应指标,点击”确认“,指标筛选成功,展示的图表随之变化
-
-
-
-#### 5.4.4.7、图表时间筛选
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“时间选择下拉框”>“时间选择弹窗”
-
-- 步骤 2:选择时间“最近 15 分钟”、“最近 1 小时”、“最近 6 小时”、“最近 12 小时”、“最近 1 天”,也可以自定义时间段范围
-
-
-
-#### 5.4.4.8、查看集群历史变更记录
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“历史变更记录”区域
-
-- 步骤 2:历史变更记录区域展示了历史的配置变更,每条记录可展开收起。包含“配置对象”、“变更时间”、“变更内容”、“配置类型”
-
-
-
-### 5.4.5、Load Rebalance(企业版)
-
-#### 5.4.5.1、查看 Load Rebalance 概览信息
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Load Rebalance”
-
-- 步骤 2:Load Rebalance 概览信息包含“均衡状态卡片”、“Disk 信息卡片”、“BytesIn 信息卡片”、“BytesOut 信息卡片”、“Broker 均衡状态列表”
-
-
-
-#### 5.4.5.2、设置集群规格
-
-提供对集群的每个节点的 Disk、BytesIn、BytesOut 的规格进行设置的功能
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Load Rebalance”>“State 卡片 icon“>”设置集群规格抽屉“
-
-- 步骤 2:穿梭框左侧展示集群中的待选节点,穿梭框右侧展示已经选中的节点,选择自己所需设置规格的节点
-
-- 步骤 3:设置“单机核数”、“单机磁盘”、“单机网络”,点击确定,完成设置
-
-
-
-#### 5.4.5.3、均衡状态列表筛选
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Load Rebalance”>“筛选列表”按钮>筛选弹窗
-
-- 步骤 2:可选择“Disk”、“BytesIn”、“BytesOut”三种维度,其各自对应“已均衡”、“未均衡”两种状态,可以组合进行筛选
-
-- 步骤 3:点击“确认”,执行筛选操作
-
-
-
-#### 5.4.5.4、立即均衡
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Load Rebalance”>“立即均衡”按钮>“立即均衡抽屉”
-
-- 步骤 2:配置均衡策略
-
- - 指标计算周期:默认近 10mins,可选择
- - 均衡维度:默认 Disk、BytesIn、BytesOut,可选择
- - 均衡区间:在表格内自定义配置均衡区间范围(单位:%,大于 0,小于 100)
- - Topic 黑名单:选择 topic 黑名单。通过穿梭框(支持模糊选择)选出目标 topic(本次均衡,略过已选的 topic)
-
-- 步骤 3:配置运行参数
-
- - 吞吐量优先:并行度 0(无限制), 策略是优先执行大小最大副本
- - 稳定性优先: 并行度 1 ,策略是优先执行大小最小副本
- - 自定义:可以自由设置并行度和优先执行的副本策略
- - 限流值:流量最大值,0-99999 自定义
-
-- 步骤 4:点击“预览计划”按钮,打开执行计划弹窗。可以看到计划概览信息、计划明细信息
-
-- 步骤 5:点击“预览计划弹窗”的“执行文件”,可以下载 json 格式的执行文件
-
-- 步骤 6:点击“预览计划弹窗”的“立即均衡”按钮,开始执行均衡任务
-
-
-
-#### 5.4.5.5、周期均衡
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Load Rebalance”>“周期均衡”按钮>“周期均衡抽屉”
-
-- 步骤 2:配置均衡策略
-
- - 指标计算周期:默认近 10mins,可选择
- - 均衡维度:默认 Disk、BytesIn、BytesOut,可选择
- - 均衡区间:在表格内自定义配置均衡区间范围(单位:%,大于 0,小于 100)
- - Topic 黑名单:选择 topic 黑名单。通过穿梭框(支持模糊选择)选出目标 topic(本次均衡,略过已选的 topic)
-
-- 步骤 3:配置运行参数
-
- - 任务并行度:每个节点同时迁移的副本数量
- - 任务周期:时间选择器,自定义选择运行周期
- - 稳定性优先: 并行度 1 ,策略是优先执行大小最小副本
- - 自定义:可以自由设置并行度和优先执行的副本策略
- - 限流值:流量最大值,0-99999 自定义
-
-- 步骤 4:点击“预览计划”按钮,打开执行计划弹窗。可以看到计划概览信息、计划明细信息
-
-- 步骤 5:点击“预览计划弹窗”的“执行文件”,可以下载 json 格式的执行文件
-
-- 步骤 6:点击“预览计划弹窗”的“立即均衡”按钮,开始执行均衡任务
-
-
-
-### 5.4.6、Broker
-
-#### 5.4.6.1、查看 Broker 概览信息
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Broker”>“Overview”
-
-- 步骤 2:Broker 概览信息包括以下内容
-
- - 集群健康分,健康检查通过项
- - Broker 信息:包含名称、版本、均衡状态
- - Broker 信息:Broker 总数、controller 信息、similar config 信息
- - Topic 信息:Topic 总数、No Leader、“集群卡片”>“Brokers”>“Broker ID”>“Configuration”TAB>“编辑”按钮
-
-- 步骤 2:输入配置项的新配置内容
-
-- 步骤 3:(选填)点击“应用于全部 Broker”,将此配置项的修改应用于全部的 Broker
-
-- 步骤 4:点击“确认”,Broker 配置修改成功
-
-
-
-#### 5.4.6.3、查看 Broker DataLogs
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Brokers”>“Broker ID”>“Data Logs”TAB>“编辑”按钮
-
-- 步骤 2:Broker DataLogs 列表展示的信息为“Folder”、“topic”、“Partition”、“Offset Lag”、“Size”
-
-- 步骤 3:输入框输入”Topic Name“可以筛选结果
-
-
-
-#### 5.4.6.4、查看 Controller 列表
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Broker”>“Controller”
-
-- 步骤 2:Controller 列表展示的信息为“Change Time”、“Broker ID”、“Broker Host”
-
-- 步骤 3:输入框输入“Broker Host“可以筛选结果
-
-- 步骤 4:点击 Broker ID 可以打开 Broker 详情,进行修改配置或者查看 DataLogs
-
-
-
-### 5.4.7、Topic
-
-#### 5.4.7.1、查看 Topic 概览信息
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Overview”
-
-- 步骤 2:Topic 概览信息包括以下内容
-
- - 集群健康分,健康检查通过项
- - Topics:Topic 总数
- - Partitions:Partition 总数
- - PartitionNoLeader:没有 leader 的 partition 个数
- - < Min ISR:同步副本数小于 Min ISR
- - =Min ISR:同步副本数等于 Min ISR
- - Topic 指标图表
-
-
-
-#### 5.4.7.2、查看 Topic 健康检查详情
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Overview”>“集群健康状态旁边【查看详情】”>“健康检查详情抽屉”
-
-- 步骤 2:健康检查详情抽屉展示信息为:“检查项”、“权重”、“得分”、“检查时间”、“检查结果是否通过”,若未通过会展示未通过的对象
-
-
-
-#### 5.4.7.3、查看 Topic 列表
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”
-
-- 步骤 2:Topic 列表展示内容为“TopicName”、“Partitions”、“Replications”、“健康分”、“BytesIn”、“BytesOut”、“MessageSize”、“保存时间”、“描述”、操作项”扩分区“、操作项”删除“
-
-- 步骤 3:筛选框输入“TopicName”可以对列表进行筛选;点击“展示系统 Topic”开关,可以筛选系统 topic
-
-
-
-#### 5.4.7.4、新增 Topic
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“新增 Topic”按钮>“创建 Topic“抽屉
-
-- 步骤 2:输入“Topic 名称(不能重复)”、“Topic 描述”、“分区数”、“副本数”、“数据保存时间”、“清理策略(删除或压缩)”
-
-- 步骤 3:展开“更多配置”可以打开高级配置选项,根据自己需要输入相应配置参数
-
-- 步骤 4:点击“确定”,创建 Topic 完成
-
-
-
-#### 5.4.7.5、Topic 扩分区
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“Topic 列表“>操作项”扩分区“>“扩分区”抽屉
-
-- 步骤 2:扩分区抽屉展示内容为“流量的趋势图”、“当前分区数及支持的最低消息写入速率”、“扩分区后支持的最低消息写入速率”
-
-- 步骤 3:输入所需的分区总数,自动计算出扩分区后支持的最低消息写入速率
-
-- 步骤 4:点击确定,扩分区完成
-
-
-
-#### 5.4.7.6、删除 Topic
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“Topic 列表“>操作项”删除“>“删除 Topic”弹窗
-
-- 步骤 2:输入“TopicName”进行二次确认
-
-- 步骤 3:点击“删除”,删除 Topic 完成
-
-
-
-#### 5.4.7.7、Topic 批量扩缩副本
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“批量操作下拉“>“批量扩缩副本“>“批量扩缩容”抽屉
-
-- 步骤 2:选择所需要进行扩缩容的 Topic,可多选,所选择的 Topic 出现在下方 Topic 列表中
-
-- 步骤 3:Topic 列表展示 Topic“近三天平均流量”、“近三天峰值流量及时间”、“Partition 数”、”当前副本数“、“新副本数”
-
-- 步骤 4:扩容时,选择目标节点,新增的副本会在选择的目标节点上;缩容时不需要选择目标节点,自动删除最后一个(或几个)副本
-
-- 步骤 5:输入迁移任务配置参数,包含限流值和任务执行时间
-
-- 步骤 6:输入任务描述
-
-- 步骤 7:点击“确定”,执行 Topic 扩缩容任务
-
-
-
-#### 5.4.7.8、Topic 批量迁移
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“批量操作下拉“>“批量迁移“>“批量迁移”抽屉
-
-- 步骤 2:选择所需要进行迁移的 Topic,可多选,所选择的 Topic 出现在下方 Topic 列表中
-
-- 步骤 3:选择所需要迁移的 partition 和迁移数据的时间范围
-
-- 步骤 4:选择目标节点(节点数必须不小于最大副本数)
-
-- 步骤 5:点击“预览任务计划”,打开“任务计划”二次抽屉,可对每个 partition 的目标 Broker ID 进行编辑,目标 broker 应该等于副本数
-
-- 步骤 6:输入迁移任务配置参数,包含限流值和任务执行时间
-
-- 步骤 7:输入任务描述
-
-- 步骤 8:点击“确定”,执行 Topic 迁移任务
-
-
-
-### 5.4.8、Consumer
-
-#### 5.4.8.1、Consumer Overview
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Consumer”
-
-- 步骤 2:Consumer 概览信息包括以下内容
-
- - 集群健康分,健康检查通过项
- - Groups:Consumer Group 总数
- - GroupsActives:活跃的 Group 总数
- - GroupsEmptys:Empty 的 Group 总数
- - GroupRebalance:进行 Rebalance 的 Group 总数
- - GroupDeads:Dead 的 Group 总数
- - Consumer Group 列表
-
-- 步骤 3:输入“Consumer Group”、“Topic Name‘,可对列表进行筛选
-
-- 步骤 4:点击列表“Consumer Group”名称,可以查看 Comsuer Group 详情
-
-
-
-#### 5.4.8.2、查看 Consumer 列表
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Consumer”>“Consumer Group”名称>“Consumer Group 详情”抽屉
-
-- 步骤 2:Consumer Group 详情有列表视图和图表视图
-
-- 步骤 3:列表视图展示信息为 Consumer 列表,包含”Topic Partition“、”Member ID“、”Current Offset“、“Log End Offset”、”Lag“、”Host“、”Client ID“
-
-
-
-#### 5.4.8.3、重置 Offset
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Consumer”>“Consumer Group”名称>“Consumer Group 详情”抽屉>“重置 Offset”按钮>“重置 Offset”抽屉
-
-- 步骤 2:选择重置 Offset 的类型,可“重置到指定时间”或“重置分区”
-
-- 步骤 3:重置到指定时间,可选择“最新 Offset”或“自定义时间”
-
-- 步骤 4:重置分区,可选择 partition 和其重置的 offset
-
-- 步骤 5:点击“确认”,重置 Offset 开始执行
-
-
-
-### 5.4.9、Testing(企业版)
-
-#### 5.4.9.1、生产测试
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Testing”>“Produce”
-
-- 步骤 2:生产配置
-
- - Data:选择数据写入的 topic,输入写入数据的 key(暂只支持 string 格式),输入写入数据的 value(暂只支持 string 格式)。其中 key 和 value 可以随机生成
- - Flow:输入单次发送的消息数量,默认为 1,可以手动修改。选择手动生产模式,代表每次点击按钮【Run】执行生产;选择周期生产模式,需要填写运行总时间和运行时间间隔。
- - Header:输入 Header 的 key,value
- - Options:选择 Froce Partition,代表消息仅发送到这些选择的 Partition。选择数据压缩格式。选择 Acks 参数,none 意思是消息发送了就认为发送成功;leader 意思是 leader 接收到消息(不管 follower 有没有同步成功)认为消息发送成功;all 意思是所有的 follower 消息同步成功认为是消息发送成功
-
-- 步骤 3:点击按钮【Run】,生产测试开始,可以从右侧看到生产测试的信息
-
-
-
-#### 5.4.9.2、消费测试
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Testing”>“Consume”
-
-- 步骤 2:消费配置
-
- - Topic:选择数据从哪个 topic 进行消费
- - Start From:选择数据从什么地方开始消费,可以根据时间选择或者根据 Offset 进行选择
- - Until:选择消费截止到什么地方,可以根据时间或者 offset 或者消息数等进行选择
- - Filter:选择过滤器的规则。包含/不包含某【key,value】;等于/大于/小于多少条消息
-
-- 步骤 3:点击按钮【Run】,消费测试开始,可以在右边看到消费的明细信息
-
-
-
-### 5.4.10、Security
-
-注意:只有在开启集群认证的情况下才能够使用 Security 功能
-
-#### 5.4.10.1、查看 ACL 概览信息
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Security”>“ACLs”
-
-- 步骤 2:ACL 概览信息包括以下内容
-
- - Enable:是否可用
- - ACLs:ACL 总数
- - Users:User 总数
- - Topics:Topic 总数
- - Consumer Groups:Consumer Group 总数
- - ACL 列表
-
-
-
-#### 5.4.10.2、新增 ACl
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Security”>“Users”>“新增 ACL”
-
-- 步骤 2:输入 ACL 配置参数
-
- - ACL 用途:生产权限、消费权限、自定义权限
- - 生产权限时:可选择应用于所有 Kafka User 或者特定 Kafka User;可选择应用于所有 Topic 或者特定 Topic
- - 消费权限时:可选择应用于所有 Kafka User 或者特定 Kafka User;可选择应用于所有 Topic 或者特定 Topic;可选择应用于所有 Consumer Group 或者特定 Consumer Group
-
-- 步骤 3:点击“确定”,新增 ACL 成功
-
-
-
-#### 5.4.10.3、查看 User 信息
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Security”>“ACLs”
-
-- 步骤 2:User 列表展示内容包括“Kafka User 名称”、“认证方式”、“passwprd”、操作项”修改密码“、”操作项“删除”
-
-- 步骤 3:筛选框输入“Kafka User”可筛选出列表中相关 Kafka User
-
-
-
-#### 5.4.10.4、新增 Kafka User
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Security”>“Users”>“新增 Kafka User”
-
-- 步骤 2:输入 Kafka User 名称、认证方式、密码
-
-- 步骤 3:点击“确定”,新增 Kafka User 成功
-
-
-
-### 5.4.11、Job
-
-#### 5.4.11.1、查看 Job 概览信息
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Job“
-
-- 步骤 2:Job 概览信息包括以下内容
-
- - Jobs:Job 总数
- - Doing:正在运行的 Job 总数
- - Prepare:准备运行的 Job 总数
- - Success:运行成功的 Job 总数
- - Fail:运行失败的 Job 总数
- - Job 列表
-
-
-
-#### 5.4.11.2、Job 查看进度
-
-Doing 状态下的任务可以查看进度
-
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Job”>“Job”列表>操作项“查看进度”>“查看进度”抽屉
-
-- 步骤 2:
-
- - 均衡任务:任务基本信息、均衡计划、任务执行明细信息
- - 扩缩副本:任务基本信息、任务执行明细信息、节点流量情况
- - Topic 迁移:任务基本信息、任务执行明细信息、节点流量情况
-
-
-
-#### 5.4.11.3、Job 编辑任务
-
-Prepare 状态下的任务可以进行编辑
-
-- 点击“多集群管理”>“集群卡片”>“Job”>“Job”列表>操作项“编辑”
-
-- 对任务执行的参数进行重新配置
-
- - 集群均衡:可以对指标计算周期、均衡维度、topic 黑名单、运行配置等参数重新设置
- - Topic 迁移:可以对 topic 需要迁移的 partition、迁移数据的时间范围、目标 broker 节点、限流值、执行时间、描述等参数重新配置
- - topic 扩缩副本:可以对最终副本数、限流值、任务执行时间、描述等参数重新配置
-
-- 点击“确定”,编辑任务成功
-
-
diff --git a/km-biz/pom.xml b/km-biz/pom.xml
deleted file mode 100644
index b8c3457b..00000000
--- a/km-biz/pom.xml
+++ /dev/null
@@ -1,94 +0,0 @@
-
-
- 4.0.0
- com.xiaojukeji.kafka
- km-biz
- ${km.revision}
- jar
-
-
- km
- com.xiaojukeji.kafka
- ${km.revision}
-
-
-
-
- true
- true
-
- UTF-8
- UTF-8
-
-
-
-
- com.xiaojukeji.kafka
- km-core
- ${project.parent.version}
-
-
-
-
- org.springframework
- spring-web
- ${spring.version}
-
-
- org.springframework
- spring-test
- ${spring.version}
-
-
-
-
- javax.servlet
- javax.servlet-api
-
-
- javax.annotation
- javax.annotation-api
-
-
-
- org.apache.kafka
- kafka-clients
- ${kafka-clients.version}
-
-
-
- commons-lang
- commons-lang
-
-
-
- commons-codec
- commons-codec
-
-
- org.eclipse.jetty
- jetty-util
-
-
-
- com.github.ben-manes.caffeine
- caffeine
-
-
-
-
- com.alibaba
- fastjson
-
-
- com.fasterxml.jackson.core
- jackson-databind
-
-
- org.springframework
- spring-context
-
-
-
\ No newline at end of file
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/BrokerConfigManager.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/BrokerConfigManager.java
deleted file mode 100644
index 4c583dc4..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/BrokerConfigManager.java
+++ /dev/null
@@ -1,19 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.broker;
-
-import com.xiaojukeji.know.streaming.km.common.bean.entity.param.config.KafkaBrokerConfigModifyParam;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.config.kafka.KafkaBrokerConfigVO;
-
-import java.util.List;
-
-public interface BrokerConfigManager {
- /**
- * 获取Broker配置详细信息
- * @param clusterPhyId 物理集群ID
- * @param brokerId brokerId
- * @return
- */
- Result> getBrokerConfigDetail(Long clusterPhyId, Integer brokerId);
-
- Result modifyBrokerConfig(KafkaBrokerConfigModifyParam modifyParam, String operator);
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/BrokerManager.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/BrokerManager.java
deleted file mode 100644
index e135bcd9..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/BrokerManager.java
+++ /dev/null
@@ -1,13 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.broker;
-
-import com.xiaojukeji.know.streaming.km.common.bean.dto.pagination.PaginationBaseDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.broker.BrokerBasicVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.log.LogDirVO;
-
-public interface BrokerManager {
- Result getBrokerBasic(Long clusterPhyId, Integer brokerId);
-
- PaginationResult getBrokerLogDirs(Long clusterPhyId, Integer brokerId, PaginationBaseDTO dto);
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/impl/BrokerConfigManagerImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/impl/BrokerConfigManagerImpl.java
deleted file mode 100644
index d670a8a5..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/impl/BrokerConfigManagerImpl.java
+++ /dev/null
@@ -1,97 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.broker.impl;
-
-import com.xiaojukeji.know.streaming.km.biz.broker.BrokerConfigManager;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.broker.Broker;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.config.kafkaconfig.KafkaConfigDetail;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.param.config.KafkaBrokerConfigModifyParam;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.po.broker.BrokerConfigPO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.config.kafka.KafkaBrokerConfigVO;
-import com.xiaojukeji.know.streaming.km.common.constant.KafkaConstant;
-import com.xiaojukeji.know.streaming.km.common.enums.config.ConfigDiffTypeEnum;
-import com.xiaojukeji.know.streaming.km.common.utils.ConvertUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.ValidateUtils;
-import com.xiaojukeji.know.streaming.km.core.service.broker.BrokerConfigService;
-import com.xiaojukeji.know.streaming.km.core.service.broker.BrokerService;
-import org.apache.kafka.common.config.ConfigDef;
-import org.springframework.beans.factory.annotation.Autowired;
-import org.springframework.stereotype.Component;
-
-import java.util.*;
-import java.util.function.Function;
-import java.util.stream.Collectors;
-
-@Component
-public class BrokerConfigManagerImpl implements BrokerConfigManager {
- @Autowired
- private BrokerService brokerService;
-
- @Autowired
- private BrokerConfigService brokerConfigService;
-
- @Override
- public Result> getBrokerConfigDetail(Long clusterPhyId, Integer brokerId) {
- // 获取当前broker配置
- Result> configResult = brokerConfigService.getBrokerConfigDetailFromKafka(clusterPhyId, brokerId);
- if (configResult.failed()) {
- return Result.buildFromIgnoreData(configResult);
- }
-
- // 获取差异的配置
- List diffPOList = brokerConfigService.getBrokerConfigDiffFromDB(clusterPhyId, brokerId);
-
- // 组装数据
- return Result.buildSuc(this.convert2KafkaBrokerConfigVOList(configResult.getData(), diffPOList));
- }
-
- private List convert2KafkaBrokerConfigVOList(List configList, List diffPOList) {
- if (ValidateUtils.isEmptyList(configList)) {
- return new ArrayList<>();
- }
-
- Map poMap = diffPOList.stream().collect(Collectors.toMap(BrokerConfigPO::getConfigName, Function.identity()));
-
- List voList = ConvertUtil.list2List(configList, KafkaBrokerConfigVO.class);
- for (KafkaBrokerConfigVO vo: voList) {
- BrokerConfigPO po = poMap.get(vo.getName());
- if (po != null) {
- vo.setExclusive(po.getDiffType().equals(ConfigDiffTypeEnum.ALONE_POSSESS.getCode()));
- vo.setDifferentiated(po.getDiffType().equals(ConfigDiffTypeEnum.UN_EQUAL.getCode()));
- } else {
- vo.setExclusive(false);
- vo.setDifferentiated(false);
- }
-
- ConfigDef.ConfigKey configKey = KafkaConstant.KAFKA_ALL_CONFIG_DEF_MAP.get(vo.getName());
- if (configKey == null) {
- continue;
- }
-
- try {
- vo.setDocumentation(configKey.documentation);
- vo.setDefaultValue(configKey.defaultValue.toString());
- } catch (Exception e) {
- // ignore
- }
- }
- return voList;
- }
-
- @Override
- public Result modifyBrokerConfig(KafkaBrokerConfigModifyParam modifyParam, String operator) {
- if (modifyParam.getApplyAll() == null || !modifyParam.getApplyAll()) {
- return brokerConfigService.modifyBrokerConfig(modifyParam, operator);
- }
-
- List brokerList = brokerService.listAliveBrokersFromDB(modifyParam.getClusterPhyId());
- for (Broker broker: brokerList) {
- modifyParam.setBrokerId(broker.getBrokerId());
- Result rv = brokerConfigService.modifyBrokerConfig(modifyParam, operator);
- if (rv.failed()) {
- return rv;
- }
- }
-
- return Result.buildSuc();
- }
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/impl/BrokerManagerImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/impl/BrokerManagerImpl.java
deleted file mode 100644
index 8fd9a411..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/broker/impl/BrokerManagerImpl.java
+++ /dev/null
@@ -1,75 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.broker.impl;
-
-import com.xiaojukeji.know.streaming.km.biz.broker.BrokerManager;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.pagination.PaginationBaseDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.broker.Broker;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.cluster.ClusterPhy;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.ResultStatus;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.broker.BrokerBasicVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.log.LogDirVO;
-import com.xiaojukeji.know.streaming.km.common.constant.MsgConstant;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationUtil;
-import com.xiaojukeji.know.streaming.km.core.service.broker.BrokerService;
-import com.xiaojukeji.know.streaming.km.core.service.cluster.ClusterPhyService;
-import org.apache.kafka.clients.admin.LogDirDescription;
-import org.springframework.beans.factory.annotation.Autowired;
-import org.springframework.stereotype.Component;
-
-import java.util.*;
-
-@Component
-public class BrokerManagerImpl implements BrokerManager {
- @Autowired
- private BrokerService brokerService;
-
- @Autowired
- private ClusterPhyService clusterPhyService;
-
- @Override
- public Result getBrokerBasic(Long clusterPhyId, Integer brokerId) {
- ClusterPhy clusterPhy = clusterPhyService.getClusterByCluster(clusterPhyId);
- if (clusterPhy == null) {
- return Result.buildFromRSAndMsg(ResultStatus.NOT_EXIST, MsgConstant.getClusterPhyNotExist(clusterPhyId));
- }
-
- Broker broker = brokerService.getBroker(clusterPhyId, brokerId);
- if (broker == null) {
- return Result.buildFromRSAndMsg(ResultStatus.NOT_EXIST, MsgConstant.getBrokerNotExist(clusterPhyId, brokerId));
- }
-
- return Result.buildSuc(new BrokerBasicVO(brokerId, broker.getHost(), clusterPhy.getName()));
- }
-
- @Override
- public PaginationResult getBrokerLogDirs(Long clusterPhyId, Integer brokerId, PaginationBaseDTO dto) {
- Result> dirDescResult = brokerService.getBrokerLogDirDescFromKafka(clusterPhyId, brokerId);
- if (dirDescResult.failed()) {
- return PaginationResult.buildFailure(dirDescResult, dto);
- }
-
- Map dirDescMap = dirDescResult.hasData()? dirDescResult.getData(): new HashMap<>();
-
- List voList = new ArrayList<>();
- for (Map.Entry entry: dirDescMap.entrySet()) {
- entry.getValue().replicaInfos().entrySet().stream().forEach(elem -> {
- LogDirVO vo = new LogDirVO();
- vo.setDir(entry.getKey());
- vo.setTopicName(elem.getKey().topic());
- vo.setPartitionId(elem.getKey().partition());
- vo.setOffsetLag(elem.getValue().offsetLag());
- vo.setLogSizeUnitB(elem.getValue().size());
- voList.add(vo);
- });
- }
-
- return PaginationUtil.pageBySubData(
- PaginationUtil.pageByFuzzyFilter(voList, dto.getSearchKeywords(), Arrays.asList("topicName")),
- dto
- );
- }
-
- /**************************************************** private method ****************************************************/
-
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterBrokersManager.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterBrokersManager.java
deleted file mode 100644
index 8427c1ef..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterBrokersManager.java
+++ /dev/null
@@ -1,26 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.cluster;
-
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterBrokersOverviewDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.res.ClusterBrokersOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.res.ClusterBrokersStateVO;
-
-/**
- * 多集群总体状态
- */
-public interface ClusterBrokersManager {
- /**
- * 获取缓存查询结果 & broker 表查询结果并集
- * @param clusterPhyId kafka 物理集群 id
- * @param dto 封装分页查询参数对象
- * @return 返回获取到的缓存查询结果 & broker 表查询结果并集
- */
- PaginationResult getClusterPhyBrokersOverview(Long clusterPhyId, ClusterBrokersOverviewDTO dto);
-
- /**
- * 根据物理集群id获取集群对应broker状态信息
- * @param clusterPhyId 物理集群 id
- * @return 返回根据物理集群id获取到的集群对应broker状态信息
- */
- ClusterBrokersStateVO getClusterPhyBrokersState(Long clusterPhyId);
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterConnectorsManager.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterConnectorsManager.java
deleted file mode 100644
index c20c5c77..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterConnectorsManager.java
+++ /dev/null
@@ -1,15 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.cluster;
-
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterConnectorsOverviewDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.connect.ConnectStateVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.connector.ClusterConnectorOverviewVO;
-
-/**
- * Kafka集群Connector概览
- */
-public interface ClusterConnectorsManager {
- PaginationResult getClusterConnectorsOverview(Long clusterPhyId, ClusterConnectorsOverviewDTO dto);
-
- ConnectStateVO getClusterConnectorsState(Long clusterPhyId);
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterTopicsManager.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterTopicsManager.java
deleted file mode 100644
index 928d5d36..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterTopicsManager.java
+++ /dev/null
@@ -1,12 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.cluster;
-
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterTopicsOverviewDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.res.ClusterPhyTopicsOverviewVO;
-
-/**
- * 多集群总体状态
- */
-public interface ClusterTopicsManager {
- PaginationResult getClusterPhyTopicsOverview(Long clusterPhyId, ClusterTopicsOverviewDTO dto);
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterZookeepersManager.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterZookeepersManager.java
deleted file mode 100644
index 8219cd7e..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/ClusterZookeepersManager.java
+++ /dev/null
@@ -1,19 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.cluster;
-
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterZookeepersOverviewDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.zookeeper.ClusterZookeepersOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.zookeeper.ClusterZookeepersStateVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.zookeeper.ZnodeVO;
-
-/**
- * 多集群总体状态
- */
-public interface ClusterZookeepersManager {
- Result getClusterPhyZookeepersState(Long clusterPhyId);
-
- PaginationResult getClusterPhyZookeepersOverview(Long clusterPhyId, ClusterZookeepersOverviewDTO dto);
-
- Result getZnodeVO(Long clusterPhyId, String path);
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/MultiClusterPhyManager.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/MultiClusterPhyManager.java
deleted file mode 100644
index 2d57d719..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/MultiClusterPhyManager.java
+++ /dev/null
@@ -1,33 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.cluster;
-
-import com.xiaojukeji.know.streaming.km.common.bean.entity.cluster.ClusterPhysHealthState;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.cluster.ClusterPhysState;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.MultiClusterDashboardDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.ClusterPhyBaseVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.ClusterPhyDashboardVO;
-
-import java.util.List;
-
-/**
- * 多集群总体状态
- */
-public interface MultiClusterPhyManager {
- /**
- * 获取所有集群的状态
- * @return
- */
- ClusterPhysState getClusterPhysState();
-
- ClusterPhysHealthState getClusterPhysHealthState();
-
- /**
- * 查询多集群大盘
- * @param dto 分页信息
- * @return
- */
- PaginationResult getClusterPhysDashboard(MultiClusterDashboardDTO dto);
-
- Result> getClusterPhysBasic();
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterBrokersManagerImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterBrokersManagerImpl.java
deleted file mode 100644
index ab5d6a6d..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterBrokersManagerImpl.java
+++ /dev/null
@@ -1,257 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.cluster.impl;
-
-import com.didiglobal.logi.log.ILog;
-import com.didiglobal.logi.log.LogFactory;
-import com.xiaojukeji.know.streaming.km.biz.cluster.ClusterBrokersManager;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterBrokersOverviewDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.pagination.PaginationSortDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.broker.Broker;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.cluster.ClusterPhy;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.config.JmxConfig;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.kafkacontroller.KafkaController;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.metrics.BrokerMetrics;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.topic.Topic;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.res.ClusterBrokersOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.res.ClusterBrokersStateVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.kafkacontroller.KafkaControllerVO;
-import com.xiaojukeji.know.streaming.km.common.constant.KafkaConstant;
-import com.xiaojukeji.know.streaming.km.common.enums.SortTypeEnum;
-import com.xiaojukeji.know.streaming.km.common.enums.cluster.ClusterRunStateEnum;
-import com.xiaojukeji.know.streaming.km.common.utils.ConvertUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationMetricsUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.ValidateUtils;
-import com.xiaojukeji.know.streaming.km.core.service.broker.BrokerConfigService;
-import com.xiaojukeji.know.streaming.km.core.service.broker.BrokerMetricService;
-import com.xiaojukeji.know.streaming.km.core.service.broker.BrokerService;
-import com.xiaojukeji.know.streaming.km.core.service.kafkacontroller.KafkaControllerService;
-import com.xiaojukeji.know.streaming.km.core.service.topic.TopicService;
-import com.xiaojukeji.know.streaming.km.persistence.cache.LoadedClusterPhyCache;
-import com.xiaojukeji.know.streaming.km.persistence.kafka.KafkaJMXClient;
-import org.springframework.beans.factory.annotation.Autowired;
-import org.springframework.stereotype.Service;
-
-import java.util.*;
-import java.util.function.Function;
-import java.util.stream.Collectors;
-
-
-@Service
-public class ClusterBrokersManagerImpl implements ClusterBrokersManager {
- private static final ILog log = LogFactory.getLog(ClusterBrokersManagerImpl.class);
-
- @Autowired
- private TopicService topicService;
-
- @Autowired
- private BrokerService brokerService;
-
- @Autowired
- private BrokerConfigService brokerConfigService;
-
- @Autowired
- private BrokerMetricService brokerMetricService;
-
- @Autowired
- private KafkaControllerService kafkaControllerService;
-
- @Autowired
- private KafkaJMXClient kafkaJMXClient;
-
- @Override
- public PaginationResult getClusterPhyBrokersOverview(Long clusterPhyId, ClusterBrokersOverviewDTO dto) {
- // 获取集群Broker列表
- List brokerList = brokerService.listAllBrokersFromDB(clusterPhyId);
-
- // 搜索
- brokerList = PaginationUtil.pageByFuzzyFilter(brokerList, dto.getSearchKeywords(), Arrays.asList("host"));
-
- // 获取指标
- Result> metricsResult = brokerMetricService.getLatestMetricsFromES(
- clusterPhyId,
- brokerList.stream().filter(elem1 -> elem1.alive()).map(elem2 -> elem2.getBrokerId()).collect(Collectors.toList())
- );
-
- // 分页 + 搜索
- PaginationResult paginationResult = this.pagingBrokers(brokerList, metricsResult.hasData()? metricsResult.getData(): new ArrayList<>(), dto);
-
- // 获取__consumer_offsetsTopic的分布
- Topic groupTopic = topicService.getTopic(clusterPhyId, org.apache.kafka.common.internals.Topic.GROUP_METADATA_TOPIC_NAME);
- Topic transactionTopic = topicService.getTopic(clusterPhyId, org.apache.kafka.common.internals.Topic.TRANSACTION_STATE_TOPIC_NAME);
-
- //获取controller信息
- KafkaController kafkaController = kafkaControllerService.getKafkaControllerFromDB(clusterPhyId);
-
- //获取jmx状态信息
- Map jmxConnectedMap = new HashMap<>();
- brokerList.forEach(elem -> jmxConnectedMap.put(elem.getBrokerId(), kafkaJMXClient.getClientWithCheck(clusterPhyId, elem.getBrokerId()) != null));
-
-
- ClusterPhy clusterPhy = LoadedClusterPhyCache.getByPhyId(clusterPhyId);
-
- // 格式转换
- return PaginationResult.buildSuc(
- this.convert2ClusterBrokersOverviewVOList(
- clusterPhy,
- paginationResult.getData().getBizData(),
- brokerList,
- metricsResult.getData(),
- groupTopic,
- transactionTopic,
- kafkaController,
- jmxConnectedMap
- ),
- paginationResult
- );
- }
-
- @Override
- public ClusterBrokersStateVO getClusterPhyBrokersState(Long clusterPhyId) {
- ClusterBrokersStateVO clusterBrokersStateVO = new ClusterBrokersStateVO();
-
- // 获取集群Broker列表
- List allBrokerList = brokerService.listAllBrokersFromDB(clusterPhyId);
- if (allBrokerList == null) {
- allBrokerList = new ArrayList<>();
- }
-
- // 设置broker数
- clusterBrokersStateVO.setBrokerCount(allBrokerList.size());
-
- // 设置版本信息
- clusterBrokersStateVO.setBrokerVersionList(
- this.getBrokerVersionList(clusterPhyId, allBrokerList.stream().filter(elem -> elem.alive()).collect(Collectors.toList()))
- );
-
- // 获取controller信息
- KafkaController kafkaController = kafkaControllerService.getKafkaControllerFromDB(clusterPhyId);
-
- // 设置kafka-controller信息
- clusterBrokersStateVO.setKafkaControllerAlive(false);
- if(null != kafkaController) {
- clusterBrokersStateVO.setKafkaController(
- this.convert2KafkaControllerVO(
- kafkaController,
- brokerService.getBroker(clusterPhyId, kafkaController.getBrokerId())
- )
- );
- clusterBrokersStateVO.setKafkaControllerAlive(true);
- }
-
- clusterBrokersStateVO.setConfigSimilar(brokerConfigService.countBrokerConfigDiffsFromDB(clusterPhyId, KafkaConstant.CONFIG_SIMILAR_IGNORED_CONFIG_KEY_LIST) <= 0
- );
-
- return clusterBrokersStateVO;
- }
-
- /**************************************************** private method ****************************************************/
-
- private PaginationResult pagingBrokers(List brokerList, List metricsList, PaginationSortDTO dto) {
- if (ValidateUtils.isBlank(dto.getSortField())) {
- // 默认排序
- return PaginationUtil.pageBySubData(
- PaginationUtil.pageBySort(brokerList, "brokerId", SortTypeEnum.ASC.getSortType()).stream().map(elem -> elem.getBrokerId()).collect(Collectors.toList()),
- dto
- );
- }
- if (!brokerMetricService.isMetricName(dto.getSortField())) {
- // 非指标字段进行排序,分页
- return PaginationUtil.pageBySubData(
- PaginationUtil.pageBySort(brokerList, dto.getSortField(), dto.getSortType()).stream().map(elem -> elem.getBrokerId()).collect(Collectors.toList()),
- dto
- );
- }
-
- // 指标字段进行排序及分页
- Map metricsMap = metricsList.stream().collect(Collectors.toMap(BrokerMetrics::getBrokerId, Function.identity()));
- brokerList.stream().forEach(elem -> {
- metricsMap.putIfAbsent(elem.getBrokerId(), new BrokerMetrics(elem.getClusterPhyId(), elem.getBrokerId()));
- });
-
- // 排序
- metricsList = (List) PaginationMetricsUtil.sortMetrics(new ArrayList<>(metricsMap.values()), dto.getSortField(), "brokerId", dto.getSortType());
-
- return PaginationUtil.pageBySubData(
- metricsList.stream().map(elem -> elem.getBrokerId()).collect(Collectors.toList()),
- dto
- );
- }
-
- private List convert2ClusterBrokersOverviewVOList(ClusterPhy clusterPhy,
- List pagedBrokerIdList,
- List brokerList,
- List metricsList,
- Topic groupTopic,
- Topic transactionTopic,
- KafkaController kafkaController,
- Map jmxConnectedMap) {
- Map metricsMap = metricsList == null ? new HashMap<>() : metricsList.stream().collect(Collectors.toMap(BrokerMetrics::getBrokerId, Function.identity()));
-
- Map brokerMap = brokerList == null ? new HashMap<>() : brokerList.stream().collect(Collectors.toMap(Broker::getBrokerId, Function.identity()));
-
- List voList = new ArrayList<>(pagedBrokerIdList.size());
- for (Integer brokerId : pagedBrokerIdList) {
- Broker broker = brokerMap.get(brokerId);
- BrokerMetrics brokerMetrics = metricsMap.get(brokerId);
- Boolean jmxConnected = jmxConnectedMap.get(brokerId);
- voList.add(this.convert2ClusterBrokersOverviewVO(brokerId, broker, brokerMetrics, groupTopic, transactionTopic, kafkaController, jmxConnected));
- }
-
- //补充非zk模式的JMXPort信息
- if (!clusterPhy.getRunState().equals(ClusterRunStateEnum.RUN_ZK.getRunState())) {
- JmxConfig jmxConfig = ConvertUtil.str2ObjByJson(clusterPhy.getJmxProperties(), JmxConfig.class);
- voList.forEach(elem -> elem.setJmxPort(jmxConfig.getJmxPort() == null ? -1 : jmxConfig.getJmxPort()));
- }
-
- return voList;
- }
-
- private ClusterBrokersOverviewVO convert2ClusterBrokersOverviewVO(Integer brokerId, Broker broker, BrokerMetrics brokerMetrics, Topic groupTopic, Topic transactionTopic, KafkaController kafkaController, Boolean jmxConnected) {
- ClusterBrokersOverviewVO clusterBrokersOverviewVO = new ClusterBrokersOverviewVO();
- clusterBrokersOverviewVO.setBrokerId(brokerId);
- if (broker != null) {
- clusterBrokersOverviewVO.setHost(broker.getHost());
- clusterBrokersOverviewVO.setRack(broker.getRack());
- clusterBrokersOverviewVO.setJmxPort(broker.getJmxPort());
- clusterBrokersOverviewVO.setAlive(broker.alive());
- clusterBrokersOverviewVO.setStartTimeUnitMs(broker.getStartTimestamp());
- }
- clusterBrokersOverviewVO.setKafkaRoleList(new ArrayList<>());
-
- if (groupTopic != null && groupTopic.getBrokerIdSet().contains(brokerId)) {
- clusterBrokersOverviewVO.getKafkaRoleList().add(groupTopic.getTopicName());
- }
- if (transactionTopic != null && transactionTopic.getBrokerIdSet().contains(brokerId)) {
- clusterBrokersOverviewVO.getKafkaRoleList().add(transactionTopic.getTopicName());
- }
- if (kafkaController != null && kafkaController.getBrokerId().equals(brokerId)) {
- clusterBrokersOverviewVO.getKafkaRoleList().add(KafkaConstant.CONTROLLER_ROLE);
- }
-
- clusterBrokersOverviewVO.setLatestMetrics(brokerMetrics);
- clusterBrokersOverviewVO.setJmxConnected(jmxConnected);
- return clusterBrokersOverviewVO;
- }
-
- private KafkaControllerVO convert2KafkaControllerVO(KafkaController kafkaController, Broker kafkaControllerBroker) {
- if(null != kafkaController && null != kafkaControllerBroker) {
- KafkaControllerVO kafkaControllerVO = new KafkaControllerVO();
- kafkaControllerVO.setBrokerId(kafkaController.getBrokerId());
- kafkaControllerVO.setBrokerHost(kafkaControllerBroker.getHost());
- return kafkaControllerVO;
- }
-
- return null;
- }
-
- private List getBrokerVersionList(Long clusterPhyId, List brokerList) {
- Set brokerVersionList = new HashSet<>();
- for (Broker broker : brokerList) {
- brokerVersionList.add(brokerService.getBrokerVersionFromKafkaWithCacheFirst(broker.getClusterPhyId(),broker.getBrokerId(),broker.getStartTimestamp()));
- }
- brokerVersionList.remove("");
- return new ArrayList<>(brokerVersionList);
- }
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterConnectorsManagerImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterConnectorsManagerImpl.java
deleted file mode 100644
index e982c588..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterConnectorsManagerImpl.java
+++ /dev/null
@@ -1,152 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.cluster.impl;
-
-import com.didiglobal.logi.log.ILog;
-import com.didiglobal.logi.log.LogFactory;
-import com.xiaojukeji.know.streaming.km.biz.cluster.ClusterConnectorsManager;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterConnectorsOverviewDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.connect.ClusterConnectorDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.metrices.MetricDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.metrices.connect.MetricsConnectorsDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.ConnectCluster;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.ConnectWorker;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.WorkerConnector;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.metrics.connect.ConnectorMetrics;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.po.connect.ConnectorPO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.connect.ConnectStateVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.connector.ClusterConnectorOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.metrics.line.MetricMultiLinesVO;
-import com.xiaojukeji.know.streaming.km.common.converter.ConnectConverter;
-import com.xiaojukeji.know.streaming.km.common.utils.ConvertUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationMetricsUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationUtil;
-import com.xiaojukeji.know.streaming.km.core.service.connect.cluster.ConnectClusterService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.connector.ConnectorMetricService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.connector.ConnectorService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.worker.WorkerConnectorService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.worker.WorkerService;
-import org.apache.kafka.connect.runtime.AbstractStatus;
-import org.springframework.beans.factory.annotation.Autowired;
-import org.springframework.stereotype.Service;
-
-import java.util.ArrayList;
-import java.util.Arrays;
-import java.util.List;
-import java.util.stream.Collectors;
-
-
-@Service
-public class ClusterConnectorsManagerImpl implements ClusterConnectorsManager {
- private static final ILog LOGGER = LogFactory.getLog(ClusterConnectorsManagerImpl.class);
-
- @Autowired
- private ConnectorService connectorService;
-
- @Autowired
- private ConnectClusterService connectClusterService;
-
- @Autowired
- private ConnectorMetricService connectorMetricService;
-
- @Autowired
- private WorkerService workerService;
-
- @Autowired
- private WorkerConnectorService workerConnectorService;
-
- @Override
- public PaginationResult getClusterConnectorsOverview(Long clusterPhyId, ClusterConnectorsOverviewDTO dto) {
- List clusterList = connectClusterService.listByKafkaCluster(clusterPhyId);
-
- List poList = connectorService.listByKafkaClusterIdFromDB(clusterPhyId);
-
- // 查询实时指标
- Result> latestMetricsResult = connectorMetricService.getLatestMetricsFromES(
- clusterPhyId,
- poList.stream().map(elem -> new ClusterConnectorDTO(elem.getConnectClusterId(), elem.getConnectorName())).collect(Collectors.toList()),
- dto.getLatestMetricNames()
- );
-
- if (latestMetricsResult.failed()) {
- LOGGER.error("method=getClusterConnectorsOverview||clusterPhyId={}||result={}||errMsg=get latest metric failed", clusterPhyId, latestMetricsResult);
- return PaginationResult.buildFailure(latestMetricsResult, dto);
- }
-
- // 转换成vo
- List voList = ConnectConverter.convert2ClusterConnectorOverviewVOList(clusterList, poList,latestMetricsResult.getData());
-
- // 请求分页信息
- PaginationResult voPaginationResult = this.pagingConnectorInLocal(voList, dto);
- if (voPaginationResult.failed()) {
- LOGGER.error("method=getClusterConnectorsOverview||clusterPhyId={}||result={}||errMsg=pagination in local failed", clusterPhyId, voPaginationResult);
-
- return PaginationResult.buildFailure(voPaginationResult, dto);
- }
-
- // 查询历史指标
- Result> lineMetricsResult = connectorMetricService.listConnectClusterMetricsFromES(
- clusterPhyId,
- this.buildMetricsConnectorsDTO(
- voPaginationResult.getData().getBizData().stream().map(elem -> new ClusterConnectorDTO(elem.getConnectClusterId(), elem.getConnectorName())).collect(Collectors.toList()),
- dto.getMetricLines()
- )
- );
-
-
- return PaginationResult.buildSuc(
- ConnectConverter.supplyData2ClusterConnectorOverviewVOList(
- voPaginationResult.getData().getBizData(),
- lineMetricsResult.getData()
- ),
- voPaginationResult
- );
- }
-
- @Override
- public ConnectStateVO getClusterConnectorsState(Long clusterPhyId) {
- //获取Connect集群Id列表
- List connectClusterList = connectClusterService.listByKafkaCluster(clusterPhyId);
- List connectorPOList = connectorService.listByKafkaClusterIdFromDB(clusterPhyId);
- List workerConnectorList = workerConnectorService.listByKafkaClusterIdFromDB(clusterPhyId);
- List connectWorkerList = workerService.listByKafkaClusterIdFromDB(clusterPhyId);
-
- return convert2ConnectStateVO(connectClusterList, connectorPOList, workerConnectorList, connectWorkerList);
- }
-
- /**************************************************** private method ****************************************************/
-
- private MetricsConnectorsDTO buildMetricsConnectorsDTO(List connectorDTOList, MetricDTO metricDTO) {
- MetricsConnectorsDTO dto = ConvertUtil.obj2Obj(metricDTO, MetricsConnectorsDTO.class);
- dto.setConnectorNameList(connectorDTOList == null? new ArrayList<>(): connectorDTOList);
-
- return dto;
- }
-
- private ConnectStateVO convert2ConnectStateVO(List connectClusterList, List connectorPOList, List workerConnectorList, List connectWorkerList) {
- ConnectStateVO connectStateVO = new ConnectStateVO();
- connectStateVO.setConnectClusterCount(connectClusterList.size());
- connectStateVO.setTotalConnectorCount(connectorPOList.size());
- connectStateVO.setAliveConnectorCount(connectorPOList.stream().filter(elem -> elem.getState().equals(AbstractStatus.State.RUNNING.name())).collect(Collectors.toList()).size());
- connectStateVO.setWorkerCount(connectWorkerList.size());
- connectStateVO.setTotalTaskCount(workerConnectorList.size());
- connectStateVO.setAliveTaskCount(workerConnectorList.stream().filter(elem -> elem.getState().equals(AbstractStatus.State.RUNNING.name())).collect(Collectors.toList()).size());
- return connectStateVO;
- }
-
- private PaginationResult pagingConnectorInLocal(List connectorVOList, ClusterConnectorsOverviewDTO dto) {
- //模糊匹配
- connectorVOList = PaginationUtil.pageByFuzzyFilter(connectorVOList, dto.getSearchKeywords(), Arrays.asList("connectorName"));
-
- //排序
- if (!dto.getLatestMetricNames().isEmpty()) {
- PaginationMetricsUtil.sortMetrics(connectorVOList, "latestMetrics", dto.getSortMetricNameList(), "connectorName", dto.getSortType());
- } else {
- PaginationUtil.pageBySort(connectorVOList, dto.getSortField(), dto.getSortType(), "connectorName", dto.getSortType());
- }
-
- //分页
- return PaginationUtil.pageBySubData(connectorVOList, dto);
- }
-
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterTopicsManagerImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterTopicsManagerImpl.java
deleted file mode 100644
index 3a2b11ef..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterTopicsManagerImpl.java
+++ /dev/null
@@ -1,120 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.cluster.impl;
-
-import com.didiglobal.logi.log.ILog;
-import com.didiglobal.logi.log.LogFactory;
-import com.xiaojukeji.know.streaming.km.biz.cluster.ClusterTopicsManager;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterTopicsOverviewDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.metrices.MetricDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.metrices.MetricsTopicDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.metrics.TopicMetrics;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.topic.Topic;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.res.ClusterPhyTopicsOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.metrics.line.MetricMultiLinesVO;
-import com.xiaojukeji.know.streaming.km.common.constant.KafkaConstant;
-import com.xiaojukeji.know.streaming.km.common.converter.TopicVOConverter;
-import com.xiaojukeji.know.streaming.km.common.enums.ha.HaResTypeEnum;
-import com.xiaojukeji.know.streaming.km.common.utils.ConvertUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationMetricsUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.ValidateUtils;
-import com.xiaojukeji.know.streaming.km.core.service.ha.HaActiveStandbyRelationService;
-import com.xiaojukeji.know.streaming.km.core.service.topic.TopicMetricService;
-import com.xiaojukeji.know.streaming.km.core.service.topic.TopicService;
-import org.springframework.beans.factory.annotation.Autowired;
-import org.springframework.stereotype.Service;
-
-import java.util.*;
-import java.util.stream.Collectors;
-
-
-
-@Service
-public class ClusterTopicsManagerImpl implements ClusterTopicsManager {
- private static final ILog log = LogFactory.getLog(ClusterTopicsManagerImpl.class);
-
- @Autowired
- private TopicService topicService;
-
- @Autowired
- private TopicMetricService topicMetricService;
-
- @Autowired
- private HaActiveStandbyRelationService haActiveStandbyRelationService;
-
- @Override
- public PaginationResult getClusterPhyTopicsOverview(Long clusterPhyId, ClusterTopicsOverviewDTO dto) {
- // 获取集群所有的Topic信息
- List topicList = topicService.listTopicsFromDB(clusterPhyId);
-
- // 获取集群所有Topic的指标
- Map metricsMap = topicMetricService.getLatestMetricsFromCache(clusterPhyId);
-
- // 获取HA信息
- Set haTopicNameSet = haActiveStandbyRelationService.listByClusterAndType(clusterPhyId, HaResTypeEnum.MIRROR_TOPIC).stream().map(elem -> elem.getResName()).collect(Collectors.toSet());
-
- // 转换成vo
- List voList = TopicVOConverter.convert2ClusterPhyTopicsOverviewVOList(topicList, metricsMap, haTopicNameSet);
-
- // 请求分页信息
- PaginationResult voPaginationResult = this.pagingTopicInLocal(voList, dto);
- if (voPaginationResult.failed()) {
- log.error("method=getClusterPhyTopicsOverview||clusterPhyId={}||result={}||errMsg=pagination in local failed", clusterPhyId, voPaginationResult);
-
- return PaginationResult.buildFailure(voPaginationResult, dto);
- }
-
- // 查询指标
- Result> metricMultiLinesResult = topicMetricService.listTopicMetricsFromES(
- clusterPhyId,
- this.buildTopicOverviewMetricsDTO(voPaginationResult.getData().getBizData().stream().map(elem -> elem.getTopicName()).collect(Collectors.toList()), dto.getMetricLines())
- );
-
- if (metricMultiLinesResult.failed()) {
- // 查询ES失败或者ES无数据,则ES可能存在问题,此时降级返回Topic的基本信息数据
- log.error("method=getClusterPhyTopicsOverview||clusterPhyId={}||result={}||errMsg=get metrics from es failed", clusterPhyId, metricMultiLinesResult);
- }
-
- return PaginationResult.buildSuc(
- TopicVOConverter.supplyMetricLines(
- voPaginationResult.getData().getBizData(),
- metricMultiLinesResult.getData() == null? new ArrayList<>(): metricMultiLinesResult.getData()
- ),
- voPaginationResult
- );
- }
-
- /**************************************************** private method ****************************************************/
-
- private MetricsTopicDTO buildTopicOverviewMetricsDTO(List topicNameList, MetricDTO metricDTO) {
- MetricsTopicDTO dto = ConvertUtil.obj2Obj(metricDTO, MetricsTopicDTO.class);
- dto.setTopics(topicNameList == null? new ArrayList<>(): topicNameList);
- return dto;
- }
-
- private PaginationResult pagingTopicInLocal(List voList, ClusterTopicsOverviewDTO dto) {
- List metricsList = voList.stream().filter(elem -> {
- if (dto.getShowInternalTopics() != null && dto.getShowInternalTopics()) {
- // 仅展示系统Topic
- return KafkaConstant.KAFKA_INTERNAL_TOPICS.contains(elem.getTopicName());
- } else {
- // 仅展示用户Topic
- return !KafkaConstant.KAFKA_INTERNAL_TOPICS.contains(elem.getTopicName());
- }
- }).collect(Collectors.toList());
-
- // 名称搜索
- metricsList = PaginationUtil.pageByFuzzyFilter(metricsList, dto.getSearchKeywords(), Arrays.asList("topicName"));
-
- if (!ValidateUtils.isBlank(dto.getSortField()) && !"createTime".equals(dto.getSortField())) {
- // 指标排序
- PaginationMetricsUtil.sortMetrics(metricsList, "latestMetrics", dto.getSortField(), "topicName", dto.getSortType());
- } else {
- // 信息排序
- PaginationUtil.pageBySort(metricsList, dto.getSortField(), dto.getSortType(), "topicName", dto.getSortType());
- }
-
- return PaginationUtil.pageBySubData(metricsList, dto);
- }
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterZookeepersManagerImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterZookeepersManagerImpl.java
deleted file mode 100644
index aca30269..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterZookeepersManagerImpl.java
+++ /dev/null
@@ -1,137 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.cluster.impl;
-
-import com.didiglobal.logi.log.ILog;
-import com.didiglobal.logi.log.LogFactory;
-import com.xiaojukeji.know.streaming.km.biz.cluster.ClusterZookeepersManager;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterZookeepersOverviewDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.cluster.ClusterPhy;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.metrics.ZookeeperMetrics;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.ResultStatus;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.zookeeper.Znode;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.zookeeper.ZookeeperInfo;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.zookeeper.ClusterZookeepersOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.zookeeper.ClusterZookeepersStateVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.zookeeper.ZnodeVO;
-import com.xiaojukeji.know.streaming.km.common.constant.MsgConstant;
-import com.xiaojukeji.know.streaming.km.common.enums.zookeeper.ZKRoleEnum;
-import com.xiaojukeji.know.streaming.km.common.utils.ConvertUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationUtil;
-import com.xiaojukeji.know.streaming.km.core.service.cluster.ClusterPhyService;
-import com.xiaojukeji.know.streaming.km.core.service.version.metrics.kafka.ZookeeperMetricVersionItems;
-import com.xiaojukeji.know.streaming.km.core.service.zookeeper.ZnodeService;
-import com.xiaojukeji.know.streaming.km.core.service.zookeeper.ZookeeperMetricService;
-import com.xiaojukeji.know.streaming.km.core.service.zookeeper.ZookeeperService;
-import org.springframework.beans.factory.annotation.Autowired;
-import org.springframework.stereotype.Service;
-import java.util.Arrays;
-import java.util.List;
-
-
-@Service
-public class ClusterZookeepersManagerImpl implements ClusterZookeepersManager {
- private static final ILog LOGGER = LogFactory.getLog(ClusterZookeepersManagerImpl.class);
-
- @Autowired
- private ClusterPhyService clusterPhyService;
-
- @Autowired
- private ZookeeperService zookeeperService;
-
- @Autowired
- private ZookeeperMetricService zookeeperMetricService;
-
- @Autowired
- private ZnodeService znodeService;
-
- @Override
- public Result getClusterPhyZookeepersState(Long clusterPhyId) {
- ClusterPhy clusterPhy = clusterPhyService.getClusterByCluster(clusterPhyId);
- if (clusterPhy == null) {
- return Result.buildFromRSAndMsg(ResultStatus.CLUSTER_NOT_EXIST, MsgConstant.getClusterPhyNotExist(clusterPhyId));
- }
-
- List infoList = zookeeperService.listFromDBByCluster(clusterPhyId);
-
- ClusterZookeepersStateVO vo = new ClusterZookeepersStateVO();
- vo.setTotalServerCount(infoList.size());
- vo.setAliveFollowerCount(0);
- vo.setTotalFollowerCount(0);
- vo.setAliveObserverCount(0);
- vo.setTotalObserverCount(0);
- vo.setAliveServerCount(0);
- for (ZookeeperInfo info: infoList) {
- if (info.getRole().equals(ZKRoleEnum.LEADER.getRole())) {
- vo.setLeaderNode(info.getHost());
- }
-
- if (info.getRole().equals(ZKRoleEnum.FOLLOWER.getRole())) {
- vo.setTotalFollowerCount(vo.getTotalFollowerCount() + 1);
- vo.setAliveFollowerCount(info.alive()? vo.getAliveFollowerCount() + 1: vo.getAliveFollowerCount());
- }
-
- if (info.getRole().equals(ZKRoleEnum.OBSERVER.getRole())) {
- vo.setTotalObserverCount(vo.getTotalObserverCount() + 1);
- vo.setAliveObserverCount(info.alive()? vo.getAliveObserverCount() + 1: vo.getAliveObserverCount());
- }
-
- if (info.alive()) {
- vo.setAliveServerCount(vo.getAliveServerCount() + 1);
- }
- }
-
- // 指标获取
- Result metricsResult = zookeeperMetricService.batchCollectMetricsFromZookeeper(
- clusterPhyId,
- Arrays.asList(
- ZookeeperMetricVersionItems.ZOOKEEPER_METRIC_WATCH_COUNT,
- ZookeeperMetricVersionItems.ZOOKEEPER_METRIC_HEALTH_STATE,
- ZookeeperMetricVersionItems.ZOOKEEPER_METRIC_HEALTH_CHECK_PASSED,
- ZookeeperMetricVersionItems.ZOOKEEPER_METRIC_HEALTH_CHECK_TOTAL
- )
-
- );
- if (metricsResult.failed()) {
- LOGGER.error(
- "method=getClusterPhyZookeepersState||clusterPhyId={}||errMsg={}",
- clusterPhyId, metricsResult.getMessage()
- );
- return Result.buildSuc(vo);
- }
-
- ZookeeperMetrics metrics = metricsResult.getData();
- vo.setWatchCount(ConvertUtil.float2Integer(metrics.getMetrics().get(ZookeeperMetricVersionItems.ZOOKEEPER_METRIC_WATCH_COUNT)));
- vo.setHealthState(ConvertUtil.float2Integer(metrics.getMetrics().get(ZookeeperMetricVersionItems.ZOOKEEPER_METRIC_HEALTH_STATE)));
- vo.setHealthCheckPassed(ConvertUtil.float2Integer(metrics.getMetrics().get(ZookeeperMetricVersionItems.ZOOKEEPER_METRIC_HEALTH_CHECK_PASSED)));
- vo.setHealthCheckTotal(ConvertUtil.float2Integer(metrics.getMetrics().get(ZookeeperMetricVersionItems.ZOOKEEPER_METRIC_HEALTH_CHECK_TOTAL)));
-
- return Result.buildSuc(vo);
- }
-
- @Override
- public PaginationResult getClusterPhyZookeepersOverview(Long clusterPhyId, ClusterZookeepersOverviewDTO dto) {
- //获取集群zookeeper列表
- List clusterZookeepersOverviewVOList = ConvertUtil.list2List(zookeeperService.listFromDBByCluster(clusterPhyId), ClusterZookeepersOverviewVO.class);
-
- //搜索
- clusterZookeepersOverviewVOList = PaginationUtil.pageByFuzzyFilter(clusterZookeepersOverviewVOList, dto.getSearchKeywords(), Arrays.asList("host"));
-
- //分页
- PaginationResult paginationResult = PaginationUtil.pageBySubData(clusterZookeepersOverviewVOList, dto);
-
- return paginationResult;
- }
-
- @Override
- public Result getZnodeVO(Long clusterPhyId, String path) {
- Result result = znodeService.getZnode(clusterPhyId, path);
- if (result.failed()) {
- return Result.buildFromIgnoreData(result);
- }
- return Result.buildSuc(ConvertUtil.obj2ObjByJSON(result.getData(), ZnodeVO.class));
- }
-
- /**************************************************** private method ****************************************************/
-
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/MultiClusterPhyManagerImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/MultiClusterPhyManagerImpl.java
deleted file mode 100644
index 7e379c99..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/MultiClusterPhyManagerImpl.java
+++ /dev/null
@@ -1,177 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.cluster.impl;
-
-import com.didiglobal.logi.log.ILog;
-import com.didiglobal.logi.log.LogFactory;
-import com.xiaojukeji.know.streaming.km.biz.cluster.MultiClusterPhyManager;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.metrices.MetricDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.metrices.MetricsClusterPhyDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.cluster.ClusterPhysHealthState;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.cluster.ClusterPhysState;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.cluster.ClusterPhy;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.MultiClusterDashboardDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.metrics.ClusterMetrics;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.ClusterPhyBaseVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.ClusterPhyDashboardVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.metrics.line.MetricMultiLinesVO;
-import com.xiaojukeji.know.streaming.km.common.converter.ClusterVOConverter;
-import com.xiaojukeji.know.streaming.km.common.enums.health.HealthStateEnum;
-import com.xiaojukeji.know.streaming.km.common.utils.ConvertUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationMetricsUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.ValidateUtils;
-import com.xiaojukeji.know.streaming.km.core.service.cluster.ClusterMetricService;
-import com.xiaojukeji.know.streaming.km.core.service.cluster.ClusterPhyService;
-import com.xiaojukeji.know.streaming.km.core.service.version.metrics.kafka.ClusterMetricVersionItems;
-import org.springframework.beans.factory.annotation.Autowired;
-import org.springframework.stereotype.Service;
-
-import java.util.*;
-import java.util.stream.Collectors;
-
-@Service
-public class MultiClusterPhyManagerImpl implements MultiClusterPhyManager {
- private static final ILog log = LogFactory.getLog(MultiClusterPhyManagerImpl.class);
-
- @Autowired
- private ClusterPhyService clusterPhyService;
-
- @Autowired
- private ClusterMetricService clusterMetricService;
-
- @Override
- public ClusterPhysState getClusterPhysState() {
- List clusterPhyList = clusterPhyService.listAllClusters();
- ClusterPhysState physState = new ClusterPhysState(0, 0, 0, clusterPhyList.size());
-
- for (ClusterPhy clusterPhy : clusterPhyList) {
- ClusterMetrics metrics = clusterMetricService.getLatestMetricsFromCache(clusterPhy.getId());
- Float state = metrics.getMetric(ClusterMetricVersionItems.CLUSTER_METRIC_HEALTH_STATE);
- if (state == null) {
- physState.setUnknownCount(physState.getUnknownCount() + 1);
- } else if (state.intValue() == HealthStateEnum.DEAD.getDimension()) {
- physState.setDownCount(physState.getDownCount() + 1);
- } else {
- physState.setLiveCount(physState.getLiveCount() + 1);
- }
- }
- return physState;
- }
-
-
- @Override
- public ClusterPhysHealthState getClusterPhysHealthState() {
- List clusterPhyList = clusterPhyService.listAllClusters();
-
- ClusterPhysHealthState physState = new ClusterPhysHealthState(clusterPhyList.size());
- for (ClusterPhy clusterPhy: clusterPhyList) {
- ClusterMetrics metrics = clusterMetricService.getLatestMetricsFromCache(clusterPhy.getId());
- Float state = metrics.getMetric(ClusterMetricVersionItems.CLUSTER_METRIC_HEALTH_STATE);
- if (state == null) {
- physState.setUnknownCount(physState.getUnknownCount() + 1);
- } else if (state.intValue() == HealthStateEnum.GOOD.getDimension()) {
- physState.setGoodCount(physState.getGoodCount() + 1);
- } else if (state.intValue() == HealthStateEnum.MEDIUM.getDimension()) {
- physState.setMediumCount(physState.getMediumCount() + 1);
- } else if (state.intValue() == HealthStateEnum.POOR.getDimension()) {
- physState.setPoorCount(physState.getPoorCount() + 1);
- } else if (state.intValue() == HealthStateEnum.DEAD.getDimension()) {
- physState.setDeadCount(physState.getDeadCount() + 1);
- } else {
- physState.setUnknownCount(physState.getUnknownCount() + 1);
- }
- }
-
- return physState;
- }
-
- @Override
- public PaginationResult getClusterPhysDashboard(MultiClusterDashboardDTO dto) {
- // 获取集群
- List clusterPhyList = clusterPhyService.listAllClusters();
-
- // 转为vo格式,方便后续进行分页筛选等
- List voList = ConvertUtil.list2List(clusterPhyList, ClusterPhyDashboardVO.class);
-
- // 本地分页过滤
- voList = this.getAndPagingDataInLocal(voList, dto);
-
- // ES分页过滤
- PaginationResult latestMetricsResult = this.getAndPagingClusterWithLatestMetricsFromCache(voList, dto);
- if (latestMetricsResult.failed()) {
- log.error("method=getClusterPhysDashboard||pagingData={}||result={}||errMsg=search es data failed.", dto, latestMetricsResult);
- return PaginationResult.buildFailure(latestMetricsResult, dto);
- }
-
- // 获取历史指标
- Result> linesMetricResult = clusterMetricService.listClusterMetricsFromES(
- this.buildMetricsClusterPhyDTO(
- latestMetricsResult.getData().getBizData().stream().map(elem -> elem.getClusterPhyId()).collect(Collectors.toList()),
- dto.getMetricLines()
- ));
-
- // 组装最终数据
- return PaginationResult.buildSuc(
- ClusterVOConverter.convert2ClusterPhyDashboardVOList(voList, linesMetricResult.getData(), latestMetricsResult.getData().getBizData()),
- latestMetricsResult
- );
- }
-
- @Override
- public Result> getClusterPhysBasic() {
- // 获取集群
- List clusterPhyList = clusterPhyService.listAllClusters();
-
- // 转为vo格式,方便后续进行分页筛选等
- return Result.buildSuc(ConvertUtil.list2List(clusterPhyList, ClusterPhyBaseVO.class));
- }
-
-
- /**************************************************** private method ****************************************************/
-
-
- private List getAndPagingDataInLocal(List voList, MultiClusterDashboardDTO dto) {
- // 时间排序
- if ("createTime".equals(dto.getSortField())) {
- voList = PaginationUtil.pageBySort(voList, "createTime", dto.getSortType(), "name", dto.getSortType());
- }
-
- // 名称搜索
- if (!ValidateUtils.isBlank(dto.getSearchKeywords())) {
- voList = PaginationUtil.pageByFuzzyFilter(voList, dto.getSearchKeywords(), Arrays.asList("name"));
- }
-
- // 精确搜索
- return PaginationUtil.pageByPreciseFilter(voList, dto.getPreciseFilterDTOList());
- }
-
- private PaginationResult getAndPagingClusterWithLatestMetricsFromCache(List voList, MultiClusterDashboardDTO dto) {
- // 获取所有的metrics
- List metricsList = new ArrayList<>();
- for (ClusterPhyDashboardVO vo: voList) {
- ClusterMetrics clusterMetrics = clusterMetricService.getLatestMetricsFromCache(vo.getId());
- clusterMetrics.getMetrics().putIfAbsent(ClusterMetricVersionItems.CLUSTER_METRIC_HEALTH_STATE, (float) HealthStateEnum.UNKNOWN.getDimension());
-
- metricsList.add(clusterMetrics);
- }
-
- // 范围搜索
- metricsList = (List) PaginationMetricsUtil.rangeFilterMetrics(metricsList, dto.getRangeFilterDTOList());
-
- // 精确搜索
- metricsList = (List) PaginationMetricsUtil.preciseFilterMetrics(metricsList, dto.getPreciseFilterDTOList());
-
- // 排序
- PaginationMetricsUtil.sortMetrics(metricsList, dto.getSortField(), "clusterPhyId", dto.getSortType());
-
- // 分页
- return PaginationUtil.pageBySubData(metricsList, dto);
- }
-
- private MetricsClusterPhyDTO buildMetricsClusterPhyDTO(List clusterIdList, MetricDTO metricDTO) {
- MetricsClusterPhyDTO dto = ConvertUtil.obj2Obj(metricDTO, MetricsClusterPhyDTO.class);
- dto.setClusterPhyIds(clusterIdList);
- return dto;
- }
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/ConnectorManager.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/ConnectorManager.java
deleted file mode 100644
index 3752504d..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/ConnectorManager.java
+++ /dev/null
@@ -1,16 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.connect.connector;
-
-import com.xiaojukeji.know.streaming.km.common.bean.dto.connect.connector.ConnectorCreateDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.connect.connector.ConnectorStateVO;
-
-import java.util.Properties;
-
-public interface ConnectorManager {
- Result updateConnectorConfig(Long connectClusterId, String connectorName, Properties configs, String operator);
-
- Result createConnector(ConnectorCreateDTO dto, String operator);
- Result createConnector(ConnectorCreateDTO dto, String heartbeatName, String checkpointName, String operator);
-
- Result getConnectorStateVO(Long connectClusterId, String connectorName);
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/WorkerConnectorManager.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/WorkerConnectorManager.java
deleted file mode 100644
index eaf82423..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/WorkerConnectorManager.java
+++ /dev/null
@@ -1,16 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.connect.connector;
-
-
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.connect.task.KCTaskOverviewVO;
-
-import java.util.List;
-
-/**
- * @author wyb
- * @date 2022/11/14
- */
-public interface WorkerConnectorManager {
- Result> getTaskOverview(Long connectClusterId, String connectorName);
-
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/impl/ConnectorManagerImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/impl/ConnectorManagerImpl.java
deleted file mode 100644
index 5800b26f..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/impl/ConnectorManagerImpl.java
+++ /dev/null
@@ -1,115 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.connect.connector.impl;
-
-import com.xiaojukeji.know.streaming.km.biz.connect.connector.ConnectorManager;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.connect.connector.ConnectorCreateDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.WorkerConnector;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.config.ConnectConfigInfos;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.connector.KSConnector;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.connector.KSConnectorInfo;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.ResultStatus;
-import com.xiaojukeji.know.streaming.km.common.bean.po.connect.ConnectorPO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.connect.connector.ConnectorStateVO;
-import com.xiaojukeji.know.streaming.km.common.constant.connect.KafkaConnectConstant;
-import com.xiaojukeji.know.streaming.km.core.service.connect.connector.ConnectorService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.plugin.PluginService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.worker.WorkerConnectorService;
-import org.apache.kafka.connect.runtime.AbstractStatus;
-import org.springframework.beans.factory.annotation.Autowired;
-import org.springframework.stereotype.Service;
-
-import java.util.List;
-import java.util.Properties;
-import java.util.stream.Collectors;
-
-@Service
-public class ConnectorManagerImpl implements ConnectorManager {
- @Autowired
- private PluginService pluginService;
-
- @Autowired
- private ConnectorService connectorService;
-
- @Autowired
- private WorkerConnectorService workerConnectorService;
-
- @Override
- public Result updateConnectorConfig(Long connectClusterId, String connectorName, Properties configs, String operator) {
- Result infosResult = pluginService.validateConfig(connectClusterId, configs);
- if (infosResult.failed()) {
- return Result.buildFromIgnoreData(infosResult);
- }
-
- if (infosResult.getData().getErrorCount() > 0) {
- return Result.buildFromRSAndMsg(ResultStatus.PARAM_ILLEGAL, "Connector参数错误");
- }
-
- return connectorService.updateConnectorConfig(connectClusterId, connectorName, configs, operator);
- }
-
- @Override
- public Result createConnector(ConnectorCreateDTO dto, String operator) {
- dto.getConfigs().put(KafkaConnectConstant.MIRROR_MAKER_NAME_FIELD_NAME, dto.getConnectorName());
-
- Result createResult = connectorService.createConnector(dto.getConnectClusterId(), dto.getConnectorName(), dto.getConfigs(), operator);
- if (createResult.failed()) {
- return Result.buildFromIgnoreData(createResult);
- }
-
- Result ksConnectorResult = connectorService.getAllConnectorInfoFromCluster(dto.getConnectClusterId(), dto.getConnectorName());
- if (ksConnectorResult.failed()) {
- return Result.buildFromRSAndMsg(ResultStatus.SUCCESS, "创建成功,但是获取元信息失败,页面元信息会存在1分钟延迟");
- }
-
- connectorService.addNewToDB(ksConnectorResult.getData());
- return Result.buildSuc();
- }
-
- @Override
- public Result createConnector(ConnectorCreateDTO dto, String heartbeatName, String checkpointName, String operator) {
- dto.getConfigs().put(KafkaConnectConstant.MIRROR_MAKER_NAME_FIELD_NAME, dto.getConnectorName());
-
- Result createResult = connectorService.createConnector(dto.getConnectClusterId(), dto.getConnectorName(), dto.getConfigs(), operator);
- if (createResult.failed()) {
- return Result.buildFromIgnoreData(createResult);
- }
-
- Result ksConnectorResult = connectorService.getAllConnectorInfoFromCluster(dto.getConnectClusterId(), dto.getConnectorName());
- if (ksConnectorResult.failed()) {
- return Result.buildFromRSAndMsg(ResultStatus.SUCCESS, "创建成功,但是获取元信息失败,页面元信息会存在1分钟延迟");
- }
-
- KSConnector connector = ksConnectorResult.getData();
- connector.setCheckpointConnectorName(checkpointName);
- connector.setHeartbeatConnectorName(heartbeatName);
-
- connectorService.addNewToDB(connector);
- return Result.buildSuc();
- }
-
-
- @Override
- public Result getConnectorStateVO(Long connectClusterId, String connectorName) {
- ConnectorPO connectorPO = connectorService.getConnectorFromDB(connectClusterId, connectorName);
-
- if (connectorPO == null) {
- return Result.buildFailure(ResultStatus.NOT_EXIST);
- }
-
- List workerConnectorList = workerConnectorService.listFromDB(connectClusterId).stream().filter(elem -> elem.getConnectorName().equals(connectorName)).collect(Collectors.toList());
-
- return Result.buildSuc(convert2ConnectorOverviewVO(connectorPO, workerConnectorList));
- }
-
- private ConnectorStateVO convert2ConnectorOverviewVO(ConnectorPO connectorPO, List workerConnectorList) {
- ConnectorStateVO connectorStateVO = new ConnectorStateVO();
- connectorStateVO.setConnectClusterId(connectorPO.getConnectClusterId());
- connectorStateVO.setName(connectorPO.getConnectorName());
- connectorStateVO.setType(connectorPO.getConnectorType());
- connectorStateVO.setState(connectorPO.getState());
- connectorStateVO.setTotalTaskCount(workerConnectorList.size());
- connectorStateVO.setAliveTaskCount(workerConnectorList.stream().filter(elem -> elem.getState().equals(AbstractStatus.State.RUNNING.name())).collect(Collectors.toList()).size());
- connectorStateVO.setTotalWorkerCount(workerConnectorList.stream().map(elem -> elem.getWorkerId()).collect(Collectors.toSet()).size());
- return connectorStateVO;
- }
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/impl/WorkerConnectorManageImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/impl/WorkerConnectorManageImpl.java
deleted file mode 100644
index 4d0cd317..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/connector/impl/WorkerConnectorManageImpl.java
+++ /dev/null
@@ -1,37 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.connect.connector.impl;
-
-import com.didiglobal.logi.log.ILog;
-import com.didiglobal.logi.log.LogFactory;
-import com.xiaojukeji.know.streaming.km.biz.connect.connector.WorkerConnectorManager;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.ConnectCluster;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.WorkerConnector;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.connect.task.KCTaskOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.utils.ConvertUtil;
-import com.xiaojukeji.know.streaming.km.core.service.connect.worker.WorkerConnectorService;
-import com.xiaojukeji.know.streaming.km.persistence.connect.cache.LoadedConnectClusterCache;
-import org.springframework.beans.factory.annotation.Autowired;
-import org.springframework.stereotype.Service;
-
-import java.util.List;
-
-/**
- * @author wyb
- * @date 2022/11/14
- */
-@Service
-public class WorkerConnectorManageImpl implements WorkerConnectorManager {
-
- private static final ILog LOGGER = LogFactory.getLog(WorkerConnectorManageImpl.class);
-
- @Autowired
- private WorkerConnectorService workerConnectorService;
-
- @Override
- public Result> getTaskOverview(Long connectClusterId, String connectorName) {
- ConnectCluster connectCluster = LoadedConnectClusterCache.getByPhyId(connectClusterId);
- List workerConnectorList = workerConnectorService.getWorkerConnectorListFromCluster(connectCluster, connectorName);
-
- return Result.buildSuc(ConvertUtil.list2List(workerConnectorList, KCTaskOverviewVO.class));
- }
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/mm2/MirrorMakerManager.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/mm2/MirrorMakerManager.java
deleted file mode 100644
index 6851ca5e..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/mm2/MirrorMakerManager.java
+++ /dev/null
@@ -1,43 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.connect.mm2;
-
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterMirrorMakersOverviewDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.connect.mm2.MirrorMakerCreateDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.mm2.ClusterMirrorMakerOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.mm2.MirrorMakerBaseStateVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.mm2.MirrorMakerStateVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.connect.plugin.ConnectConfigInfosVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.connect.task.KCTaskOverviewVO;
-
-import java.util.List;
-import java.util.Map;
-import java.util.Properties;
-
-/**
- * @author wyb
- * @date 2022/12/26
- */
-public interface MirrorMakerManager {
- Result createMirrorMaker(MirrorMakerCreateDTO dto, String operator);
-
- Result deleteMirrorMaker(Long connectClusterId, String sourceConnectorName, String operator);
-
- Result modifyMirrorMakerConfig(MirrorMakerCreateDTO dto, String operator);
-
- Result restartMirrorMaker(Long connectClusterId, String sourceConnectorName, String operator);
- Result stopMirrorMaker(Long connectClusterId, String sourceConnectorName, String operator);
- Result resumeMirrorMaker(Long connectClusterId, String sourceConnectorName, String operator);
-
- Result getMirrorMakerStateVO(Long clusterPhyId);
-
- PaginationResult getClusterMirrorMakersOverview(Long clusterPhyId, ClusterMirrorMakersOverviewDTO dto);
-
-
- Result getMirrorMakerState(Long connectId, String connectName);
-
- Result>> getTaskOverview(Long connectClusterId, String connectorName);
- Result> getMM2Configs(Long connectClusterId, String connectorName);
-
- Result> validateConnectors(MirrorMakerCreateDTO dto);
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/mm2/impl/MirrorMakerManagerImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/mm2/impl/MirrorMakerManagerImpl.java
deleted file mode 100644
index 803daa26..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/connect/mm2/impl/MirrorMakerManagerImpl.java
+++ /dev/null
@@ -1,652 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.connect.mm2.impl;
-
-import com.didiglobal.logi.log.ILog;
-import com.didiglobal.logi.log.LogFactory;
-import com.xiaojukeji.know.streaming.km.biz.connect.connector.ConnectorManager;
-import com.xiaojukeji.know.streaming.km.biz.connect.mm2.MirrorMakerManager;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterMirrorMakersOverviewDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.connect.ClusterConnectorDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.connect.connector.ConnectorCreateDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.connect.mm2.MirrorMakerCreateDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.metrices.MetricDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.metrices.mm2.MetricsMirrorMakersDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.cluster.ClusterPhy;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.ConnectCluster;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.ConnectWorker;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.WorkerConnector;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.config.ConnectConfigInfos;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.connect.connector.KSConnectorInfo;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.metrics.mm2.MirrorMakerMetrics;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.ResultStatus;
-import com.xiaojukeji.know.streaming.km.common.bean.po.connect.ConnectorPO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.mm2.ClusterMirrorMakerOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.mm2.MirrorMakerBaseStateVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.mm2.MirrorMakerStateVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.connect.plugin.ConnectConfigInfosVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.metrics.line.MetricLineVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.metrics.line.MetricMultiLinesVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.connect.task.KCTaskOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.constant.MsgConstant;
-import com.xiaojukeji.know.streaming.km.common.utils.*;
-import com.xiaojukeji.know.streaming.km.common.constant.connect.KafkaConnectConstant;
-import com.xiaojukeji.know.streaming.km.common.utils.ConvertUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.MirrorMakerUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.ValidateUtils;
-import com.xiaojukeji.know.streaming.km.core.service.cluster.ClusterPhyService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.cluster.ConnectClusterService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.connector.ConnectorService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.mm2.MirrorMakerMetricService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.plugin.PluginService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.worker.WorkerConnectorService;
-import com.xiaojukeji.know.streaming.km.core.service.connect.worker.WorkerService;
-import com.xiaojukeji.know.streaming.km.core.utils.ApiCallThreadPoolService;
-import com.xiaojukeji.know.streaming.km.persistence.cache.LoadedClusterPhyCache;
-import org.apache.commons.lang.StringUtils;
-import org.springframework.beans.factory.annotation.Autowired;
-import org.springframework.stereotype.Service;
-
-import java.util.*;
-import java.util.function.Function;
-import java.util.stream.Collectors;
-
-import static org.apache.kafka.connect.runtime.AbstractStatus.State.RUNNING;
-import static com.xiaojukeji.know.streaming.km.common.constant.connect.KafkaConnectConstant.*;
-
-
-/**
- * @author wyb
- * @date 2022/12/26
- */
-@Service
-public class MirrorMakerManagerImpl implements MirrorMakerManager {
- private static final ILog LOGGER = LogFactory.getLog(MirrorMakerManagerImpl.class);
-
- @Autowired
- private ConnectorService connectorService;
-
- @Autowired
- private WorkerConnectorService workerConnectorService;
-
- @Autowired
- private WorkerService workerService;
-
- @Autowired
- private ConnectorManager connectorManager;
-
- @Autowired
- private ClusterPhyService clusterPhyService;
-
- @Autowired
- private MirrorMakerMetricService mirrorMakerMetricService;
-
- @Autowired
- private ConnectClusterService connectClusterService;
-
- @Autowired
- private PluginService pluginService;
-
- @Override
- public Result createMirrorMaker(MirrorMakerCreateDTO dto, String operator) {
- // 检查基本参数
- Result rv = this.checkCreateMirrorMakerParamAndUnifyData(dto);
- if (rv.failed()) {
- return rv;
- }
-
- // 创建MirrorSourceConnector
- Result sourceConnectResult = connectorManager.createConnector(
- dto,
- dto.getCheckpointConnectorConfigs() != null? MirrorMakerUtil.genCheckpointName(dto.getConnectorName()): "",
- dto.getHeartbeatConnectorConfigs() != null? MirrorMakerUtil.genHeartbeatName(dto.getConnectorName()): "",
- operator
- );
- if (sourceConnectResult.failed()) {
- // 创建失败, 直接返回
- return Result.buildFromIgnoreData(sourceConnectResult);
- }
-
- // 创建 checkpoint 任务
- Result checkpointResult = Result.buildSuc();
- if (dto.getCheckpointConnectorConfigs() != null) {
- checkpointResult = connectorManager.createConnector(
- new ConnectorCreateDTO(dto.getConnectClusterId(), MirrorMakerUtil.genCheckpointName(dto.getConnectorName()), dto.getCheckpointConnectorConfigs()),
- operator
- );
- }
-
- // 创建 heartbeat 任务
- Result heartbeatResult = Result.buildSuc();
- if (dto.getHeartbeatConnectorConfigs() != null) {
- heartbeatResult = connectorManager.createConnector(
- new ConnectorCreateDTO(dto.getConnectClusterId(), MirrorMakerUtil.genHeartbeatName(dto.getConnectorName()), dto.getHeartbeatConnectorConfigs()),
- operator
- );
- }
-
- // 全都成功
- if (checkpointResult.successful() && checkpointResult.successful()) {
- return Result.buildSuc();
- } else if (checkpointResult.failed() && checkpointResult.failed()) {
- return Result.buildFromRSAndMsg(
- ResultStatus.KAFKA_CONNECTOR_OPERATE_FAILED,
- String.format("创建 checkpoint & heartbeat 失败.\n失败信息分别为:%s\n\n%s", checkpointResult.getMessage(), heartbeatResult.getMessage())
- );
- } else if (checkpointResult.failed()) {
- return Result.buildFromRSAndMsg(
- ResultStatus.KAFKA_CONNECTOR_OPERATE_FAILED,
- String.format("创建 checkpoint 失败.\n失败信息分别为:%s", checkpointResult.getMessage())
- );
- } else{
- return Result.buildFromRSAndMsg(
- ResultStatus.KAFKA_CONNECTOR_OPERATE_FAILED,
- String.format("创建 heartbeat 失败.\n失败信息分别为:%s", heartbeatResult.getMessage())
- );
- }
- }
-
- @Override
- public Result deleteMirrorMaker(Long connectClusterId, String sourceConnectorName, String operator) {
- ConnectorPO connectorPO = connectorService.getConnectorFromDB(connectClusterId, sourceConnectorName);
- if (connectorPO == null) {
- return Result.buildFromRSAndMsg(ResultStatus.NOT_EXIST, MsgConstant.getConnectorNotExist(connectClusterId, sourceConnectorName));
- }
-
- Result rv = Result.buildSuc();
- if (!ValidateUtils.isBlank(connectorPO.getCheckpointConnectorName())) {
- rv = connectorService.deleteConnector(connectClusterId, connectorPO.getCheckpointConnectorName(), operator);
- }
- if (rv.failed()) {
- return rv;
- }
-
- if (!ValidateUtils.isBlank(connectorPO.getHeartbeatConnectorName())) {
- rv = connectorService.deleteConnector(connectClusterId, connectorPO.getHeartbeatConnectorName(), operator);
- }
- if (rv.failed()) {
- return rv;
- }
-
- return connectorService.deleteConnector(connectClusterId, sourceConnectorName, operator);
- }
-
- @Override
- public Result modifyMirrorMakerConfig(MirrorMakerCreateDTO dto, String operator) {
- ConnectorPO connectorPO = connectorService.getConnectorFromDB(dto.getConnectClusterId(), dto.getConnectorName());
- if (connectorPO == null) {
- return Result.buildFromRSAndMsg(ResultStatus.NOT_EXIST, MsgConstant.getConnectorNotExist(dto.getConnectClusterId(), dto.getConnectorName()));
- }
-
- Result rv = Result.buildSuc();
- if (!ValidateUtils.isBlank(connectorPO.getCheckpointConnectorName()) && dto.getCheckpointConnectorConfigs() != null) {
- rv = connectorService.updateConnectorConfig(dto.getConnectClusterId(), connectorPO.getCheckpointConnectorName(), dto.getCheckpointConnectorConfigs(), operator);
- }
- if (rv.failed()) {
- return rv;
- }
-
- if (!ValidateUtils.isBlank(connectorPO.getHeartbeatConnectorName()) && dto.getHeartbeatConnectorConfigs() != null) {
- rv = connectorService.updateConnectorConfig(dto.getConnectClusterId(), connectorPO.getHeartbeatConnectorName(), dto.getHeartbeatConnectorConfigs(), operator);
- }
- if (rv.failed()) {
- return rv;
- }
-
- return connectorService.updateConnectorConfig(dto.getConnectClusterId(), dto.getConnectorName(), dto.getConfigs(), operator);
- }
-
- @Override
- public Result restartMirrorMaker(Long connectClusterId, String sourceConnectorName, String operator) {
- ConnectorPO connectorPO = connectorService.getConnectorFromDB(connectClusterId, sourceConnectorName);
- if (connectorPO == null) {
- return Result.buildFromRSAndMsg(ResultStatus.NOT_EXIST, MsgConstant.getConnectorNotExist(connectClusterId, sourceConnectorName));
- }
-
- Result rv = Result.buildSuc();
- if (!ValidateUtils.isBlank(connectorPO.getCheckpointConnectorName())) {
- rv = connectorService.restartConnector(connectClusterId, connectorPO.getCheckpointConnectorName(), operator);
- }
- if (rv.failed()) {
- return rv;
- }
-
- if (!ValidateUtils.isBlank(connectorPO.getHeartbeatConnectorName())) {
- rv = connectorService.restartConnector(connectClusterId, connectorPO.getHeartbeatConnectorName(), operator);
- }
- if (rv.failed()) {
- return rv;
- }
-
- return connectorService.restartConnector(connectClusterId, sourceConnectorName, operator);
- }
-
- @Override
- public Result stopMirrorMaker(Long connectClusterId, String sourceConnectorName, String operator) {
- ConnectorPO connectorPO = connectorService.getConnectorFromDB(connectClusterId, sourceConnectorName);
- if (connectorPO == null) {
- return Result.buildFromRSAndMsg(ResultStatus.NOT_EXIST, MsgConstant.getConnectorNotExist(connectClusterId, sourceConnectorName));
- }
-
- Result rv = Result.buildSuc();
- if (!ValidateUtils.isBlank(connectorPO.getCheckpointConnectorName())) {
- rv = connectorService.stopConnector(connectClusterId, connectorPO.getCheckpointConnectorName(), operator);
- }
- if (rv.failed()) {
- return rv;
- }
-
- if (!ValidateUtils.isBlank(connectorPO.getHeartbeatConnectorName())) {
- rv = connectorService.stopConnector(connectClusterId, connectorPO.getHeartbeatConnectorName(), operator);
- }
- if (rv.failed()) {
- return rv;
- }
-
- return connectorService.stopConnector(connectClusterId, sourceConnectorName, operator);
- }
-
- @Override
- public Result resumeMirrorMaker(Long connectClusterId, String sourceConnectorName, String operator) {
- ConnectorPO connectorPO = connectorService.getConnectorFromDB(connectClusterId, sourceConnectorName);
- if (connectorPO == null) {
- return Result.buildFromRSAndMsg(ResultStatus.NOT_EXIST, MsgConstant.getConnectorNotExist(connectClusterId, sourceConnectorName));
- }
-
- Result rv = Result.buildSuc();
- if (!ValidateUtils.isBlank(connectorPO.getCheckpointConnectorName())) {
- rv = connectorService.resumeConnector(connectClusterId, connectorPO.getCheckpointConnectorName(), operator);
- }
- if (rv.failed()) {
- return rv;
- }
-
- if (!ValidateUtils.isBlank(connectorPO.getHeartbeatConnectorName())) {
- rv = connectorService.resumeConnector(connectClusterId, connectorPO.getHeartbeatConnectorName(), operator);
- }
- if (rv.failed()) {
- return rv;
- }
-
- return connectorService.resumeConnector(connectClusterId, sourceConnectorName, operator);
- }
-
- @Override
- public Result getMirrorMakerStateVO(Long clusterPhyId) {
- List connectorPOList = connectorService.listByKafkaClusterIdFromDB(clusterPhyId);
- List workerConnectorList = workerConnectorService.listByKafkaClusterIdFromDB(clusterPhyId);
- List workerList = workerService.listByKafkaClusterIdFromDB(clusterPhyId);
-
- return Result.buildSuc(convert2MirrorMakerStateVO(connectorPOList, workerConnectorList, workerList));
- }
-
- @Override
- public PaginationResult getClusterMirrorMakersOverview(Long clusterPhyId, ClusterMirrorMakersOverviewDTO dto) {
- List mirrorMakerList = connectorService.listByKafkaClusterIdFromDB(clusterPhyId).stream().filter(elem -> elem.getConnectorClassName().equals(MIRROR_MAKER_SOURCE_CONNECTOR_TYPE)).collect(Collectors.toList());
- List connectClusterList = connectClusterService.listByKafkaCluster(clusterPhyId);
-
-
- Result> latestMetricsResult = mirrorMakerMetricService.getLatestMetricsFromES(clusterPhyId,
- mirrorMakerList.stream().map(elem -> new Tuple<>(elem.getConnectClusterId(), elem.getConnectorName())).collect(Collectors.toList()),
- dto.getLatestMetricNames());
-
- if (latestMetricsResult.failed()) {
- LOGGER.error("method=getClusterMirrorMakersOverview||clusterPhyId={}||result={}||errMsg=get latest metric failed", clusterPhyId, latestMetricsResult);
- return PaginationResult.buildFailure(latestMetricsResult, dto);
- }
-
- List mirrorMakerOverviewVOList = this.convert2ClusterMirrorMakerOverviewVO(mirrorMakerList, connectClusterList, latestMetricsResult.getData());
-
- List mirrorMakerVOList = this.completeClusterInfo(mirrorMakerOverviewVOList);
-
- PaginationResult voPaginationResult = this.pagingMirrorMakerInLocal(mirrorMakerVOList, dto);
-
- if (voPaginationResult.failed()) {
- LOGGER.error("method=ClusterMirrorMakerOverviewVO||clusterPhyId={}||result={}||errMsg=pagination in local failed", clusterPhyId, voPaginationResult);
-
- return PaginationResult.buildFailure(voPaginationResult, dto);
- }
-
- // 查询历史指标
- Result> lineMetricsResult = mirrorMakerMetricService.listMirrorMakerClusterMetricsFromES(
- clusterPhyId,
- this.buildMetricsConnectorsDTO(
- voPaginationResult.getData().getBizData().stream().map(elem -> new ClusterConnectorDTO(elem.getConnectClusterId(), elem.getConnectorName())).collect(Collectors.toList()),
- dto.getMetricLines()
- ));
-
- return PaginationResult.buildSuc(
- this.supplyData2ClusterMirrorMakerOverviewVOList(
- voPaginationResult.getData().getBizData(),
- lineMetricsResult.getData()
- ),
- voPaginationResult
- );
- }
-
- @Override
- public Result getMirrorMakerState(Long connectClusterId, String connectName) {
- //mm2任务
- ConnectorPO connectorPO = connectorService.getConnectorFromDB(connectClusterId, connectName);
- if (connectorPO == null){
- return Result.buildFrom(ResultStatus.NOT_EXIST);
- }
-
- List workerConnectorList = workerConnectorService.listFromDB(connectClusterId).stream()
- .filter(workerConnector -> workerConnector.getConnectorName().equals(connectorPO.getConnectorName())
- || (!StringUtils.isBlank(connectorPO.getCheckpointConnectorName()) && workerConnector.getConnectorName().equals(connectorPO.getCheckpointConnectorName()))
- || (!StringUtils.isBlank(connectorPO.getHeartbeatConnectorName()) && workerConnector.getConnectorName().equals(connectorPO.getHeartbeatConnectorName())))
- .collect(Collectors.toList());
-
- MirrorMakerBaseStateVO mirrorMakerBaseStateVO = new MirrorMakerBaseStateVO();
- mirrorMakerBaseStateVO.setTotalTaskCount(workerConnectorList.size());
- mirrorMakerBaseStateVO.setAliveTaskCount(workerConnectorList.stream().filter(elem -> elem.getState().equals(RUNNING.name())).collect(Collectors.toList()).size());
- mirrorMakerBaseStateVO.setWorkerCount(workerConnectorList.stream().collect(Collectors.groupingBy(WorkerConnector::getWorkerId)).size());
- return Result.buildSuc(mirrorMakerBaseStateVO);
- }
-
- @Override
- public Result>> getTaskOverview(Long connectClusterId, String connectorName) {
- ConnectorPO connectorPO = connectorService.getConnectorFromDB(connectClusterId, connectorName);
- if (connectorPO == null){
- return Result.buildFrom(ResultStatus.NOT_EXIST);
- }
-
- Map> listMap = new HashMap<>();
- List workerConnectorList = workerConnectorService.listFromDB(connectClusterId);
- if (workerConnectorList.isEmpty()){
- return Result.buildSuc(listMap);
- }
- workerConnectorList.forEach(workerConnector -> {
- if (workerConnector.getConnectorName().equals(connectorPO.getConnectorName())){
- listMap.putIfAbsent(KafkaConnectConstant.MIRROR_MAKER_SOURCE_CONNECTOR_TYPE, new ArrayList<>());
- listMap.get(MIRROR_MAKER_SOURCE_CONNECTOR_TYPE).add(ConvertUtil.obj2Obj(workerConnector, KCTaskOverviewVO.class));
- } else if (workerConnector.getConnectorName().equals(connectorPO.getCheckpointConnectorName())) {
- listMap.putIfAbsent(KafkaConnectConstant.MIRROR_MAKER_HEARTBEAT_CONNECTOR_TYPE, new ArrayList<>());
- listMap.get(MIRROR_MAKER_HEARTBEAT_CONNECTOR_TYPE).add(ConvertUtil.obj2Obj(workerConnector, KCTaskOverviewVO.class));
- } else if (workerConnector.getConnectorName().equals(connectorPO.getHeartbeatConnectorName())) {
- listMap.putIfAbsent(KafkaConnectConstant.MIRROR_MAKER_CHECKPOINT_CONNECTOR_TYPE, new ArrayList<>());
- listMap.get(MIRROR_MAKER_CHECKPOINT_CONNECTOR_TYPE).add(ConvertUtil.obj2Obj(workerConnector, KCTaskOverviewVO.class));
- }
-
- });
-
- return Result.buildSuc(listMap);
- }
-
- @Override
- public Result> getMM2Configs(Long connectClusterId, String connectorName) {
- ConnectorPO connectorPO = connectorService.getConnectorFromDB(connectClusterId, connectorName);
- if (connectorPO == null){
- return Result.buildFrom(ResultStatus.NOT_EXIST);
- }
-
- List propList = new ArrayList<>();
-
- // source
- Result connectorResult = connectorService.getConnectorInfoFromCluster(connectClusterId, connectorPO.getConnectorName());
- if (connectorResult.failed()) {
- return Result.buildFromIgnoreData(connectorResult);
- }
-
- Properties props = new Properties();
- props.putAll(connectorResult.getData().getConfig());
- propList.add(props);
-
- // checkpoint
- if (!ValidateUtils.isBlank(connectorPO.getCheckpointConnectorName())) {
- connectorResult = connectorService.getConnectorInfoFromCluster(connectClusterId, connectorPO.getCheckpointConnectorName());
- if (connectorResult.failed()) {
- return Result.buildFromIgnoreData(connectorResult);
- }
-
- props = new Properties();
- props.putAll(connectorResult.getData().getConfig());
- propList.add(props);
- }
-
-
- // heartbeat
- if (!ValidateUtils.isBlank(connectorPO.getHeartbeatConnectorName())) {
- connectorResult = connectorService.getConnectorInfoFromCluster(connectClusterId, connectorPO.getHeartbeatConnectorName());
- if (connectorResult.failed()) {
- return Result.buildFromIgnoreData(connectorResult);
- }
-
- props = new Properties();
- props.putAll(connectorResult.getData().getConfig());
- propList.add(props);
- }
-
- return Result.buildSuc(propList);
- }
-
- @Override
- public Result> validateConnectors(MirrorMakerCreateDTO dto) {
- List voList = new ArrayList<>();
-
- Result infoResult = pluginService.validateConfig(dto.getConnectClusterId(), dto.getConfigs());
- if (infoResult.failed()) {
- return Result.buildFromIgnoreData(infoResult);
- }
-
- voList.add(ConvertUtil.obj2Obj(infoResult.getData(), ConnectConfigInfosVO.class));
-
- if (dto.getHeartbeatConnectorConfigs() != null) {
- infoResult = pluginService.validateConfig(dto.getConnectClusterId(), dto.getHeartbeatConnectorConfigs());
- if (infoResult.failed()) {
- return Result.buildFromIgnoreData(infoResult);
- }
-
- voList.add(ConvertUtil.obj2Obj(infoResult.getData(), ConnectConfigInfosVO.class));
- }
-
- if (dto.getCheckpointConnectorConfigs() != null) {
- infoResult = pluginService.validateConfig(dto.getConnectClusterId(), dto.getCheckpointConnectorConfigs());
- if (infoResult.failed()) {
- return Result.buildFromIgnoreData(infoResult);
- }
-
- voList.add(ConvertUtil.obj2Obj(infoResult.getData(), ConnectConfigInfosVO.class));
- }
-
- return Result.buildSuc(voList);
- }
-
-
- /**************************************************** private method ****************************************************/
-
- private MetricsMirrorMakersDTO buildMetricsConnectorsDTO(List connectorDTOList, MetricDTO metricDTO) {
- MetricsMirrorMakersDTO dto = ConvertUtil.obj2Obj(metricDTO, MetricsMirrorMakersDTO.class);
- dto.setConnectorNameList(connectorDTOList == null? new ArrayList<>(): connectorDTOList);
-
- return dto;
- }
-
- public Result checkCreateMirrorMakerParamAndUnifyData(MirrorMakerCreateDTO dto) {
- ClusterPhy sourceClusterPhy = clusterPhyService.getClusterByCluster(dto.getSourceKafkaClusterId());
- if (sourceClusterPhy == null) {
- return Result.buildFromRSAndMsg(ResultStatus.CLUSTER_NOT_EXIST, MsgConstant.getClusterPhyNotExist(dto.getSourceKafkaClusterId()));
- }
-
- ConnectCluster connectCluster = connectClusterService.getById(dto.getConnectClusterId());
- if (connectCluster == null) {
- return Result.buildFromRSAndMsg(ResultStatus.CLUSTER_NOT_EXIST, MsgConstant.getConnectClusterNotExist(dto.getConnectClusterId()));
- }
-
- ClusterPhy targetClusterPhy = clusterPhyService.getClusterByCluster(connectCluster.getKafkaClusterPhyId());
- if (targetClusterPhy == null) {
- return Result.buildFromRSAndMsg(ResultStatus.CLUSTER_NOT_EXIST, MsgConstant.getClusterPhyNotExist(connectCluster.getKafkaClusterPhyId()));
- }
-
- if (!dto.getConfigs().containsKey(CONNECTOR_CLASS_FILED_NAME)) {
- return Result.buildFromRSAndMsg(ResultStatus.PARAM_ILLEGAL, "SourceConnector缺少connector.class");
- }
-
- if (!MIRROR_MAKER_SOURCE_CONNECTOR_TYPE.equals(dto.getConfigs().getProperty(CONNECTOR_CLASS_FILED_NAME))) {
- return Result.buildFromRSAndMsg(ResultStatus.PARAM_ILLEGAL, "SourceConnector的connector.class类型错误");
- }
-
- if (dto.getCheckpointConnectorConfigs() != null) {
- if (!dto.getCheckpointConnectorConfigs().containsKey(CONNECTOR_CLASS_FILED_NAME)) {
- return Result.buildFromRSAndMsg(ResultStatus.PARAM_ILLEGAL, "CheckpointConnector缺少connector.class");
- }
-
- if (!MIRROR_MAKER_CHECKPOINT_CONNECTOR_TYPE.equals(dto.getCheckpointConnectorConfigs().getProperty(CONNECTOR_CLASS_FILED_NAME))) {
- return Result.buildFromRSAndMsg(ResultStatus.PARAM_ILLEGAL, "Checkpoint的connector.class类型错误");
- }
- }
-
- if (dto.getHeartbeatConnectorConfigs() != null) {
- if (!dto.getHeartbeatConnectorConfigs().containsKey(CONNECTOR_CLASS_FILED_NAME)) {
- return Result.buildFromRSAndMsg(ResultStatus.PARAM_ILLEGAL, "HeartbeatConnector缺少connector.class");
- }
-
- if (!MIRROR_MAKER_HEARTBEAT_CONNECTOR_TYPE.equals(dto.getHeartbeatConnectorConfigs().getProperty(CONNECTOR_CLASS_FILED_NAME))) {
- return Result.buildFromRSAndMsg(ResultStatus.PARAM_ILLEGAL, "Heartbeat的connector.class类型错误");
- }
- }
-
- dto.unifyData(
- sourceClusterPhy.getId(), sourceClusterPhy.getBootstrapServers(), ConvertUtil.str2ObjByJson(sourceClusterPhy.getClientProperties(), Properties.class),
- targetClusterPhy.getId(), targetClusterPhy.getBootstrapServers(), ConvertUtil.str2ObjByJson(targetClusterPhy.getClientProperties(), Properties.class)
- );
-
- return Result.buildSuc();
- }
-
- private MirrorMakerStateVO convert2MirrorMakerStateVO(List connectorPOList,List workerConnectorList,List workerList){
- MirrorMakerStateVO mirrorMakerStateVO = new MirrorMakerStateVO();
-
- List sourceSet = connectorPOList.stream().filter(elem -> elem.getConnectorClassName().equals(MIRROR_MAKER_SOURCE_CONNECTOR_TYPE)).collect(Collectors.toList());
- mirrorMakerStateVO.setMirrorMakerCount(sourceSet.size());
-
- Set connectClusterIdSet = sourceSet.stream().map(ConnectorPO::getConnectClusterId).collect(Collectors.toSet());
- mirrorMakerStateVO.setWorkerCount(workerList.stream().filter(elem -> connectClusterIdSet.contains(elem.getConnectClusterId())).collect(Collectors.toList()).size());
-
- List mirrorMakerConnectorList = new ArrayList<>();
- mirrorMakerConnectorList.addAll(sourceSet);
- mirrorMakerConnectorList.addAll(connectorPOList.stream().filter(elem -> elem.getConnectorClassName().equals(MIRROR_MAKER_CHECKPOINT_CONNECTOR_TYPE)).collect(Collectors.toList()));
- mirrorMakerConnectorList.addAll(connectorPOList.stream().filter(elem -> elem.getConnectorClassName().equals(MIRROR_MAKER_HEARTBEAT_CONNECTOR_TYPE)).collect(Collectors.toList()));
- mirrorMakerStateVO.setTotalConnectorCount(mirrorMakerConnectorList.size());
- mirrorMakerStateVO.setAliveConnectorCount(mirrorMakerConnectorList.stream().filter(elem -> elem.getState().equals(RUNNING.name())).collect(Collectors.toList()).size());
-
- Set connectorNameSet = mirrorMakerConnectorList.stream().map(elem -> elem.getConnectorName()).collect(Collectors.toSet());
- List taskList = workerConnectorList.stream().filter(elem -> connectorNameSet.contains(elem.getConnectorName())).collect(Collectors.toList());
- mirrorMakerStateVO.setTotalTaskCount(taskList.size());
- mirrorMakerStateVO.setAliveTaskCount(taskList.stream().filter(elem -> elem.getState().equals(RUNNING.name())).collect(Collectors.toList()).size());
-
- return mirrorMakerStateVO;
- }
-
- private List convert2ClusterMirrorMakerOverviewVO(List mirrorMakerList, List connectClusterList, List latestMetric) {
- List clusterMirrorMakerOverviewVOList = new ArrayList<>();
- Map metricsMap = latestMetric.stream().collect(Collectors.toMap(elem -> elem.getConnectClusterId() + "@" + elem.getConnectorName(), Function.identity()));
- Map connectClusterMap = connectClusterList.stream().collect(Collectors.toMap(elem -> elem.getId(), Function.identity()));
-
- for (ConnectorPO mirrorMaker : mirrorMakerList) {
- ClusterMirrorMakerOverviewVO clusterMirrorMakerOverviewVO = new ClusterMirrorMakerOverviewVO();
- clusterMirrorMakerOverviewVO.setConnectClusterId(mirrorMaker.getConnectClusterId());
- clusterMirrorMakerOverviewVO.setConnectClusterName(connectClusterMap.get(mirrorMaker.getConnectClusterId()).getName());
- clusterMirrorMakerOverviewVO.setConnectorName(mirrorMaker.getConnectorName());
- clusterMirrorMakerOverviewVO.setState(mirrorMaker.getState());
- clusterMirrorMakerOverviewVO.setCheckpointConnector(mirrorMaker.getCheckpointConnectorName());
- clusterMirrorMakerOverviewVO.setTaskCount(mirrorMaker.getTaskCount());
- clusterMirrorMakerOverviewVO.setHeartbeatConnector(mirrorMaker.getHeartbeatConnectorName());
- clusterMirrorMakerOverviewVO.setLatestMetrics(metricsMap.getOrDefault(mirrorMaker.getConnectClusterId() + "@" + mirrorMaker.getConnectorName(), new MirrorMakerMetrics(mirrorMaker.getConnectClusterId(), mirrorMaker.getConnectorName())));
- clusterMirrorMakerOverviewVOList.add(clusterMirrorMakerOverviewVO);
- }
- return clusterMirrorMakerOverviewVOList;
- }
-
- PaginationResult pagingMirrorMakerInLocal(List mirrorMakerOverviewVOList, ClusterMirrorMakersOverviewDTO dto) {
- List mirrorMakerVOList = PaginationUtil.pageByFuzzyFilter(mirrorMakerOverviewVOList, dto.getSearchKeywords(), Arrays.asList("connectorName"));
-
- //排序
- if (!dto.getLatestMetricNames().isEmpty()) {
- PaginationMetricsUtil.sortMetrics(mirrorMakerVOList, "latestMetrics", dto.getSortMetricNameList(), "connectorName", dto.getSortType());
- } else {
- PaginationUtil.pageBySort(mirrorMakerVOList, dto.getSortField(), dto.getSortType(), "connectorName", dto.getSortType());
- }
-
- //分页
- return PaginationUtil.pageBySubData(mirrorMakerVOList, dto);
- }
-
- public static List supplyData2ClusterMirrorMakerOverviewVOList(List voList,
- List metricLineVOList) {
- Map> metricLineMap = new HashMap<>();
- if (metricLineVOList != null) {
- for (MetricMultiLinesVO metricMultiLinesVO : metricLineVOList) {
- metricMultiLinesVO.getMetricLines()
- .forEach(metricLineVO -> {
- String key = metricLineVO.getName();
- List metricLineVOS = metricLineMap.getOrDefault(key, new ArrayList<>());
- metricLineVOS.add(metricLineVO);
- metricLineMap.put(key, metricLineVOS);
- });
- }
- }
-
- voList.forEach(elem -> {
- elem.setMetricLines(metricLineMap.get(elem.getConnectClusterId() + "#" + elem.getConnectorName()));
- });
-
- return voList;
- }
-
- private List completeClusterInfo(List mirrorMakerVOList) {
-
- Map connectorInfoMap = new HashMap<>();
-
- for (ClusterMirrorMakerOverviewVO mirrorMakerVO : mirrorMakerVOList) {
- ApiCallThreadPoolService.runnableTask(String.format("method=completeClusterInfo||connectClusterId=%d||connectorName=%s||getMirrorMakerInfo", mirrorMakerVO.getConnectClusterId(), mirrorMakerVO.getConnectorName()),
- 3000
- , () -> {
- Result connectorInfoRet = connectorService.getConnectorInfoFromCluster(mirrorMakerVO.getConnectClusterId(), mirrorMakerVO.getConnectorName());
- if (connectorInfoRet.hasData()) {
- connectorInfoMap.put(mirrorMakerVO.getConnectClusterId() + mirrorMakerVO.getConnectorName(), connectorInfoRet.getData());
- }
-
- return connectorInfoRet.getData();
- });
- }
-
- ApiCallThreadPoolService.waitResult(1000);
-
- List newMirrorMakerVOList = new ArrayList<>();
- for (ClusterMirrorMakerOverviewVO mirrorMakerVO : mirrorMakerVOList) {
- KSConnectorInfo connectorInfo = connectorInfoMap.get(mirrorMakerVO.getConnectClusterId() + mirrorMakerVO.getConnectorName());
- if (connectorInfo == null) {
- continue;
- }
-
- String sourceClusterAlias = connectorInfo.getConfig().get(MIRROR_MAKER_SOURCE_CLUSTER_ALIAS_FIELD_NAME);
- String targetClusterAlias = connectorInfo.getConfig().get(MIRROR_MAKER_TARGET_CLUSTER_ALIAS_FIELD_NAME);
- //先默认设置为集群别名
- mirrorMakerVO.setSourceKafkaClusterName(sourceClusterAlias);
- mirrorMakerVO.setDestKafkaClusterName(targetClusterAlias);
-
- if (!ValidateUtils.isBlank(sourceClusterAlias) && CommonUtils.isNumeric(sourceClusterAlias)) {
- ClusterPhy clusterPhy = LoadedClusterPhyCache.getByPhyId(Long.valueOf(sourceClusterAlias));
- if (clusterPhy != null) {
- mirrorMakerVO.setSourceKafkaClusterId(clusterPhy.getId());
- mirrorMakerVO.setSourceKafkaClusterName(clusterPhy.getName());
- }
- }
-
- if (!ValidateUtils.isBlank(targetClusterAlias) && CommonUtils.isNumeric(targetClusterAlias)) {
- ClusterPhy clusterPhy = LoadedClusterPhyCache.getByPhyId(Long.valueOf(targetClusterAlias));
- if (clusterPhy != null) {
- mirrorMakerVO.setDestKafkaClusterId(clusterPhy.getId());
- mirrorMakerVO.setDestKafkaClusterName(clusterPhy.getName());
- }
- }
-
- newMirrorMakerVOList.add(mirrorMakerVO);
-
- }
-
- return newMirrorMakerVOList;
- }
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/group/GroupManager.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/group/GroupManager.java
deleted file mode 100644
index 5a6d3ac6..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/group/GroupManager.java
+++ /dev/null
@@ -1,43 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.group;
-
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterGroupSummaryDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.group.GroupOffsetResetDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.pagination.PaginationBaseDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.pagination.PaginationSortDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.topic.TopicPartitionKS;
-import com.xiaojukeji.know.streaming.km.common.bean.po.group.GroupMemberPO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.group.GroupOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.group.GroupTopicConsumedDetailVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.group.GroupTopicOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.exception.AdminOperateException;
-import com.xiaojukeji.know.streaming.km.common.exception.NotExistException;
-
-import java.util.List;
-import java.util.Set;
-
-public interface GroupManager {
- PaginationResult pagingGroupMembers(Long clusterPhyId,
- String topicName,
- String groupName,
- String searchTopicKeyword,
- String searchGroupKeyword,
- PaginationBaseDTO dto);
-
- PaginationResult pagingGroupTopicMembers(Long clusterPhyId, String groupName, PaginationBaseDTO dto);
-
- PaginationResult pagingClusterGroupsOverview(Long clusterPhyId, ClusterGroupSummaryDTO dto);
-
- PaginationResult pagingGroupTopicConsumedMetrics(Long clusterPhyId,
- String topicName,
- String groupName,
- List latestMetricNames,
- PaginationSortDTO dto)throws NotExistException, AdminOperateException;
-
- Result> listClusterPhyGroupPartitions(Long clusterPhyId, String groupName, Long startTime, Long endTime);
-
- Result resetGroupOffsets(GroupOffsetResetDTO dto, String operator) throws Exception;
-
- List getGroupTopicOverviewVOList(Long clusterPhyId, List groupMemberPOList);
-}
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/group/impl/GroupManagerImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/group/impl/GroupManagerImpl.java
deleted file mode 100644
index 17216793..00000000
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/group/impl/GroupManagerImpl.java
+++ /dev/null
@@ -1,371 +0,0 @@
-package com.xiaojukeji.know.streaming.km.biz.group.impl;
-
-import com.didiglobal.logi.log.ILog;
-import com.didiglobal.logi.log.LogFactory;
-import com.xiaojukeji.know.streaming.km.biz.group.GroupManager;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.cluster.ClusterGroupSummaryDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.group.GroupOffsetResetDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.pagination.PaginationBaseDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.pagination.PaginationSortDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.dto.partition.PartitionOffsetDTO;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.cluster.ClusterPhy;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.group.Group;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.group.GroupTopic;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.group.GroupTopicMember;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.kafka.KSGroupDescription;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.kafka.KSMemberConsumerAssignment;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.kafka.KSMemberDescription;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.metrics.GroupMetrics;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.offset.KSOffsetSpec;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.PaginationResult;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.Result;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.topic.Topic;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.topic.TopicPartitionKS;
-import com.xiaojukeji.know.streaming.km.common.bean.entity.result.ResultStatus;
-import com.xiaojukeji.know.streaming.km.common.bean.po.group.GroupMemberPO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.group.GroupOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.group.GroupTopicConsumedDetailVO;
-import com.xiaojukeji.know.streaming.km.common.bean.vo.group.GroupTopicOverviewVO;
-import com.xiaojukeji.know.streaming.km.common.constant.MsgConstant;
-import com.xiaojukeji.know.streaming.km.common.constant.PaginationConstant;
-import com.xiaojukeji.know.streaming.km.common.converter.GroupConverter;
-import com.xiaojukeji.know.streaming.km.common.enums.AggTypeEnum;
-import com.xiaojukeji.know.streaming.km.common.enums.OffsetTypeEnum;
-import com.xiaojukeji.know.streaming.km.common.enums.SortTypeEnum;
-import com.xiaojukeji.know.streaming.km.common.enums.group.GroupStateEnum;
-import com.xiaojukeji.know.streaming.km.common.exception.AdminOperateException;
-import com.xiaojukeji.know.streaming.km.common.exception.NotExistException;
-import com.xiaojukeji.know.streaming.km.common.utils.ConvertUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationMetricsUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.PaginationUtil;
-import com.xiaojukeji.know.streaming.km.common.utils.ValidateUtils;
-import com.xiaojukeji.know.streaming.km.core.service.cluster.ClusterPhyService;
-import com.xiaojukeji.know.streaming.km.core.service.group.GroupMetricService;
-import com.xiaojukeji.know.streaming.km.core.service.group.GroupService;
-import com.xiaojukeji.know.streaming.km.core.service.partition.PartitionService;
-import com.xiaojukeji.know.streaming.km.core.service.topic.TopicService;
-import com.xiaojukeji.know.streaming.km.core.service.version.metrics.kafka.GroupMetricVersionItems;
-import com.xiaojukeji.know.streaming.km.persistence.es.dao.GroupMetricESDAO;
-import org.apache.kafka.common.ConsumerGroupState;
-import org.apache.kafka.common.TopicPartition;
-import org.springframework.beans.factory.annotation.Autowired;
-import org.springframework.stereotype.Component;
-
-import java.util.*;
-import java.util.stream.Collectors;
-
-import static com.xiaojukeji.know.streaming.km.common.enums.group.GroupTypeEnum.CONNECT_CLUSTER_PROTOCOL_TYPE;
-
-@Component
-public class GroupManagerImpl implements GroupManager {
- private static final ILog log = LogFactory.getLog(GroupManagerImpl.class);
-
- @Autowired
- private TopicService topicService;
-
- @Autowired
- private GroupService groupService;
-
- @Autowired
- private PartitionService partitionService;
-
- @Autowired
- private GroupMetricService groupMetricService;
-
- @Autowired
- private GroupMetricESDAO groupMetricESDAO;
-
- @Autowired
- private ClusterPhyService clusterPhyService;
-
- @Override
- public PaginationResult pagingGroupMembers(Long clusterPhyId,
- String topicName,
- String groupName,
- String searchTopicKeyword,
- String searchGroupKeyword,
- PaginationBaseDTO dto) {
- PaginationResult paginationResult = groupService.pagingGroupMembers(clusterPhyId, topicName, groupName, searchTopicKeyword, searchGroupKeyword, dto);
-
- if (!paginationResult.hasData()) {
- return PaginationResult.buildSuc(new ArrayList<>(), paginationResult);
- }
-
- List groupTopicVOList = this.getGroupTopicOverviewVOList(clusterPhyId, paginationResult.getData().getBizData());
-
- return PaginationResult.buildSuc(groupTopicVOList, paginationResult);
- }
-
- @Override
- public PaginationResult pagingGroupTopicMembers(Long clusterPhyId, String groupName, PaginationBaseDTO dto) {
- Group group = groupService.getGroupFromDB(clusterPhyId, groupName);
-
- //没有topicMember则直接返回
- if (group == null || ValidateUtils.isEmptyList(group.getTopicMembers())) {
- return PaginationResult.buildSuc(dto);
- }
-
- //排序
- List groupTopicMembers = PaginationUtil.pageBySort(group.getTopicMembers(), PaginationConstant.DEFAULT_GROUP_TOPIC_SORTED_FIELD, SortTypeEnum.DESC.getSortType());
-
- //分页
- PaginationResult paginationResult = PaginationUtil.pageBySubData(groupTopicMembers, dto);
-
- List groupMemberPOList = paginationResult.getData().getBizData().stream().map(elem -> new GroupMemberPO(clusterPhyId, elem.getTopicName(), groupName, group.getState().getState(), elem.getMemberCount())).collect(Collectors.toList());
-
- return PaginationResult.buildSuc(this.getGroupTopicOverviewVOList(clusterPhyId, groupMemberPOList), paginationResult);
- }
-
- @Override
- public PaginationResult pagingClusterGroupsOverview(Long clusterPhyId, ClusterGroupSummaryDTO dto) {
- List groupList = groupService.listClusterGroups(clusterPhyId);
-
- // 类型转化
- List voList = groupList.stream().map(elem -> GroupConverter.convert2GroupOverviewVO(elem)).collect(Collectors.toList());
-
- // 搜索groupName
- voList = PaginationUtil.pageByFuzzyFilter(voList, dto.getSearchGroupName(), Arrays.asList("name"));
-
- //搜索topic
- if (!ValidateUtils.isBlank(dto.getSearchTopicName())) {
- voList = voList.stream().filter(elem -> {
- for (String topicName : elem.getTopicNameList()) {
- if (topicName.contains(dto.getSearchTopicName())) {
- return true;
- }
- }
- return false;
- }).collect(Collectors.toList());
- }
-
- // 分页 后 返回
- return PaginationUtil.pageBySubData(voList, dto);
- }
-
- @Override
- public PaginationResult pagingGroupTopicConsumedMetrics(Long clusterPhyId,
- String topicName,
- String groupName,
- List latestMetricNames,
- PaginationSortDTO dto) throws NotExistException, AdminOperateException {
- ClusterPhy clusterPhy = clusterPhyService.getClusterByCluster(clusterPhyId);
- if (clusterPhy == null) {
- return PaginationResult.buildFailure(MsgConstant.getClusterPhyNotExist(clusterPhyId), dto);
- }
-
- // 获取消费组消费的TopicPartition列表
- Map consumedOffsetMap = groupService.getGroupOffsetFromKafka(clusterPhyId, groupName);
- List partitionList = consumedOffsetMap.keySet()
- .stream()
- .filter(elem -> elem.topic().equals(topicName))
- .map(elem -> elem.partition())
- .collect(Collectors.toList());
- Collections.sort(partitionList);
-
- // 获取消费组当前运行信息
- KSGroupDescription groupDescription = groupService.getGroupDescriptionFromKafka(clusterPhy, groupName);
-
- // 转换存储格式
- Map tpMemberMap = new HashMap<>();
-
- //如果不是connect集群
- if (!groupDescription.protocolType().equals(CONNECT_CLUSTER_PROTOCOL_TYPE)) {
- for (KSMemberDescription description : groupDescription.members()) {
- KSMemberConsumerAssignment assignment = (KSMemberConsumerAssignment) description.assignment();
- for (TopicPartition tp : assignment.topicPartitions()) {
- tpMemberMap.put(tp, description);
- }
- }
- }
-
- // 获取指标
- PaginationResult metricsResult = this.pagingGroupTopicPartitionMetrics(clusterPhyId, groupName, topicName, partitionList, latestMetricNames, dto);
- if (metricsResult.failed()) {
- return PaginationResult.buildFailure(metricsResult, dto);
- }
-
- // 数据组装
- List voList = new ArrayList<>();
- for (GroupMetrics groupMetrics: metricsResult.getData().getBizData()) {
- GroupTopicConsumedDetailVO vo = new GroupTopicConsumedDetailVO();
- vo.setTopicName(topicName);
- vo.setPartitionId(groupMetrics.getPartitionId());
-
- KSMemberDescription ksMemberDescription = tpMemberMap.get(new TopicPartition(topicName, groupMetrics.getPartitionId()));
- if (ksMemberDescription != null) {
- vo.setMemberId(ksMemberDescription.consumerId());
- vo.setHost(ksMemberDescription.host());
- vo.setClientId(ksMemberDescription.clientId());
- }
-
- vo.setLatestMetrics(groupMetrics);
- voList.add(vo);
- }
-
- return PaginationResult.buildSuc(voList, metricsResult);
- }
-
- @Override
- public Result> listClusterPhyGroupPartitions(Long clusterPhyId, String groupName, Long startTime, Long endTime) {
- try {
- return Result.buildSuc(groupMetricESDAO.listGroupTopicPartitions(clusterPhyId, groupName, startTime, endTime));
- }catch (Exception e){
- return Result.buildFailure(e.getMessage());
- }
- }
-
- @Override
- public Result resetGroupOffsets(GroupOffsetResetDTO dto, String operator) throws Exception {
- Result rv = this.checkFieldLegal(dto);
- if (rv.failed()) {
- return rv;
- }
-
- ClusterPhy clusterPhy = clusterPhyService.getClusterByCluster(dto.getClusterId());
- if (clusterPhy == null) {
- return Result.buildFromRSAndMsg(ResultStatus.CLUSTER_NOT_EXIST, MsgConstant.getClusterPhyNotExist(dto.getClusterId()));
- }
-
- KSGroupDescription description = groupService.getGroupDescriptionFromKafka(clusterPhy, dto.getGroupName());
- if (ConsumerGroupState.DEAD.equals(description.state()) && !dto.isCreateIfNotExist()) {
- return Result.buildFromRSAndMsg(ResultStatus.KAFKA_OPERATE_FAILED, "group不存在, 重置失败");
- }
-
- if (!ConsumerGroupState.EMPTY.equals(description.state()) && !ConsumerGroupState.DEAD.equals(description.state())) {
- return Result.buildFromRSAndMsg(ResultStatus.KAFKA_OPERATE_FAILED, String.format("group处于%s, 重置失败(仅Empty | Dead 情况可重置)", GroupStateEnum.getByRawState(description.state()).getState()));
- }
-
- // 获取offset
- Result> offsetMapResult = this.getPartitionOffset(dto);
- if (offsetMapResult.failed()) {
- return Result.buildFromIgnoreData(offsetMapResult);
- }
-
- // 重置offset
- return groupService.resetGroupOffsets(dto.getClusterId(), dto.getGroupName(), offsetMapResult.getData(), operator);
- }
-
- @Override
- public List getGroupTopicOverviewVOList(Long clusterPhyId, List groupMemberPOList) {
- // 获取指标
- Result> metricsListResult = groupMetricService.listLatestMetricsAggByGroupTopicFromES(
- clusterPhyId,
- groupMemberPOList.stream().map(elem -> new GroupTopic(elem.getGroupName(), elem.getTopicName())).collect(Collectors.toList()),
- Arrays.asList(GroupMetricVersionItems.GROUP_METRIC_LAG),
- AggTypeEnum.MAX
- );
- if (metricsListResult.failed()) {
- // 如果查询失败,则输出错误信息,但是依旧进行已有数据的返回
- log.error("method=completeMetricData||clusterPhyId={}||result={}||errMsg=search es failed", clusterPhyId, metricsListResult);
- }
- return this.convert2GroupTopicOverviewVOList(groupMemberPOList, metricsListResult.getData());
- }
-
-
- /**************************************************** private method ****************************************************/
-
-
- private Result