diff --git a/docs/assets/KnowStreamingLogo.png b/docs/assets/KnowStreamingLogo.png
index 206c2b6a..f38dd42a 100644
Binary files a/docs/assets/KnowStreamingLogo.png and b/docs/assets/KnowStreamingLogo.png differ
diff --git a/docs/assets/readme/ZSXQ.jpeg b/docs/assets/readme/ZSXQ.jpeg
new file mode 100644
index 00000000..121bf9b1
Binary files /dev/null and b/docs/assets/readme/ZSXQ.jpeg differ
diff --git a/docs/assets/readme/ZSXQ.jpg b/docs/assets/readme/ZSXQ.jpg
deleted file mode 100644
index ff73c44c..00000000
Binary files a/docs/assets/readme/ZSXQ.jpg and /dev/null differ
diff --git a/docs/dev_guide/免登录调用接口.md b/docs/dev_guide/免登录调用接口.md
deleted file mode 100644
index cfaaf688..00000000
--- a/docs/dev_guide/免登录调用接口.md
+++ /dev/null
@@ -1,43 +0,0 @@
-
-
-
-## 登录绕过
-
-### 背景
-
-现在除了开放出来的第三方接口,其他接口都需要走登录认证。
-
-但是第三方接口不多,开放出来的能力有限,但是登录的接口又需要登录,非常的麻烦。
-
-因此,新增了一个登录绕过的功能,为一些紧急临时的需求,提供一个调用不需要登录的能力。
-
-### 使用方式
-
-步骤一:接口调用时,在header中,增加如下信息:
-```shell
-# 表示开启登录绕过
-Trick-Login-Switch : on
-
-# 登录绕过的用户, 这里可以是admin, 或者是其他的, 但是必须在运维管控->平台管理->用户管理中设置了该用户。
-Trick-Login-User : admin
-```
-
-
-
-步骤二:在运维管控->平台管理->平台配置上,设置允许了该用户以绕过的方式登录
-```shell
-# 设置的key,必须是这个
-SECURITY.TRICK_USERS
-
-# 设置的value,是json数组的格式,例如
-[ "admin", "logi"]
-```
-
-
-
-步骤三:解释说明
-
-设置完成上面两步之后,就可以直接调用需要登录的接口了。
-
-但是还有一点需要注意,绕过的用户仅能调用他有权限的接口,比如一个普通用户,那么他就只能调用普通的接口,不能去调用运维人员的接口。
-
diff --git a/docs/dev_guide/多版本兼容方案.md b/docs/dev_guide/多版本兼容方案.md
index acbde789..389d0650 100644
--- a/docs/dev_guide/多版本兼容方案.md
+++ b/docs/dev_guide/多版本兼容方案.md
@@ -1,12 +1,13 @@
-## 3.2、Kafka 多版本兼容方案
+
+## 4.2、Kafka 多版本兼容方案
当前 KnowStreaming 支持纳管多个版本的 kafka 集群,由于不同版本的 kafka 在指标采集、接口查询、行为操作上有些不一致,因此 KnowStreaming 需要一套机制来解决多 kafka 版本的纳管兼容性问题。
-### 3.2.1、整体思路
+### 4.2.1、整体思路
由于需要纳管多个 kafka 版本,而且未来还可能会纳管非 kafka 官方的版本,kafka 的版本号会存在着多种情况,所以首先要明确一个核心思想:KnowStreaming 提供尽可能多的纳管能力,但是不提供无限的纳管能力,每一个版本的 KnowStreaming 只纳管其自身声明的 kafka 版本,后续随着 KnowStreaming 自身版本的迭代,会逐步支持更多 kafka 版本的纳管接入。
-### 3.2.2、构建版本兼容列表
+### 4.2.2、构建版本兼容列表
每一个版本的 KnowStreaming 都声明一个自身支持纳管的 kafka 版本列表,并且对 kafka 的版本号进行归一化处理,后续所有 KnowStreaming 对不同 kafka 集群的操作都和这个集群对应的版本号严格相关。
@@ -14,7 +15,7 @@
对于在集群接入过程中,如果希望接入当前 KnowStreaming 不支持的 kafka 版本的集群,KnowStreaming 建议在于的过程中选择相近的版本号接入。
-### 3.2.3、构建版本兼容性字典
+### 4.2.3、构建版本兼容性字典
在构建了 KnowStreaming 支持的 kafka 版本列表的基础上,KnowStreaming 在实现过程中,还会声明自身支持的所有兼容性,构建兼容性字典。
@@ -31,7 +32,7 @@
KS-KM 根据其需要纳管的 kafka 版本,按照上述三个维度构建了完善了兼容性字典。
-### 3.2.4、兼容性问题
+### 4.2.4、兼容性问题
KS-KM 的每个版本针对需要纳管的 kafka 版本列表,事先分析各个版本的差异性和产品需求,同时 KS-KM 构建了一套专门处理兼容性的服务,来进行兼容性的注册、字典构建、处理器分发等操作,其中版本兼容性处理器是来具体处理不同 kafka 版本差异性的地方。
diff --git a/docs/dev_guide/指标说明.md b/docs/dev_guide/指标说明.md
index fe342d5f..1eb9a94b 100644
--- a/docs/dev_guide/指标说明.md
+++ b/docs/dev_guide/指标说明.md
@@ -1,10 +1,10 @@
-## 2.3、指标说明
+## 3.3、指标说明
- 当前 KnowStreaming 支持针对 kafka 集群的多维度指标的采集和展示,同时也支持多个 kafka 版本的指标进行兼容,以下是 KnowStreaming 支持的指标说明。
+当前 KnowStreaming 支持针对 kafka 集群的多维度指标的采集和展示,同时也支持多个 kafka 版本的指标进行兼容,以下是 KnowStreaming 支持的指标说明。
- 现在对当前 KnowStreaming 支持的指标从指标名称、指标单位、指标说明、kafka 版本四个维度进行说明。
+现在对当前 KnowStreaming 支持的指标从指标名称、指标单位、指标说明、kafka 版本、企业/开源版指标 五个维度进行说明。
-### 2.3.1、Cluster 指标
+### 3.3.1、Cluster 指标
| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
| ------------------------- | -------- | ------------------------------------ | ---------------- | --------------- |
@@ -73,7 +73,7 @@
| LoadReBalanceNwOut | 是/否 | BytesOut 是否均衡, 1:是;0:否 | 全部版本 | 企业版 |
| LoadReBalanceDisk | 是/否 | Disk 是否均衡, 1:是;0:否 | 全部版本 | 企业版 |
-### 2.3.2、Broker 指标
+### 3.3.2、Broker 指标
| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
| ----------------------- | -------- | ------------------------------------- | ---------- | --------------- |
@@ -105,7 +105,7 @@
| LogSize | byte | Broker 上的消息容量大小 | 全部版本 | 开源版 |
| Alive | 是/否 | Broker 是否存活,1:存活;0:没有存活 | 全部版本 | 开源版 |
-### 2.3.3、Topic 指标
+### 3.3.3、Topic 指标
| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
| --------------------- | -------- | ------------------------------------- | ---------- | --------------- |
@@ -128,7 +128,7 @@
| LogSize | byte | Topic 的大小 | 全部版本 | 开源版 |
| PartitionURP | 个 | Topic 未同步的副本数 | 全部版本 | 开源版 |
-### 2.3.4、Partition 指标
+### 3.3.4、Partition 指标
| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
| -------------- | -------- | ----------------------------------------- | ---------- | --------------- |
@@ -139,7 +139,7 @@
| BytesOut | byte/s | Partition 的每秒消息流出字节数 | 全部版本 | 开源版 |
| LogSize | byte | Partition 的大小 | 全部版本 | 开源版 |
-### 2.3.5、Group 指标
+### 3.3.5、Group 指标
| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
| ----------------- | -------- | -------------------------- | ---------- | --------------- |
diff --git a/docs/dev_guide/本地源码启动手册.md b/docs/dev_guide/本地源码启动手册.md
index 1ee63a13..ed21c3b8 100644
--- a/docs/dev_guide/本地源码启动手册.md
+++ b/docs/dev_guide/本地源码启动手册.md
@@ -20,6 +20,7 @@
- MySQL 5.7
- Idea
- Elasticsearch 7.6
+- Git
### 6.1.3、环境初始化
@@ -63,7 +64,7 @@ es.client.address: 修改为实际ES地址
**第三步:配置 IDEA**
-`Know streaming`的 Main 方法在:
+`Know Streaming`的 Main 方法在:
```java
km-rest/src/main/java/com/xiaojukeji/know/streaming/km/rest/KnowStreaming.java
@@ -71,17 +72,19 @@ km-rest/src/main/java/com/xiaojukeji/know/streaming/km/rest/KnowStreaming.java
IDEA 更多具体的配置如下图所示:
-
+
+ +
+
**第四步:启动项目**
-最后就是启动项目,在本地 console 中输出了 `KnowStreaming-KM started` 则表示我们已经成功启动 `Know streaming` 了。
+最后就是启动项目,在本地 console 中输出了 `KnowStreaming-KM started` 则表示我们已经成功启动 `Know Streaming` 了。
### 6.1.5、本地访问
-`Know streaming` 启动之后,可以访问一些信息,包括:
+`Know Streaming` 启动之后,可以访问一些信息,包括:
- 产品页面:http://localhost:8080 ,默认账号密码:`admin` / `admin2022_` 进行登录。
- 接口地址:http://localhost:8080/swagger-ui.html 查看后端提供的相关接口。
-更多信息,详见:[KnowStreaming 官网](http://116.85.24.211/)
+更多信息,详见:[KnowStreaming 官网](https://knowstreaming.com/)
\ No newline at end of file
diff --git a/docs/dev_guide/登录系统对接.md b/docs/dev_guide/登录系统对接.md
index 85046ac0..bac2b5cc 100644
--- a/docs/dev_guide/登录系统对接.md
+++ b/docs/dev_guide/登录系统对接.md
@@ -1,10 +1,6 @@

-
-
-
-
## 登录系统对接
### 前言
diff --git a/docs/install_guide/单机部署手册.md b/docs/install_guide/单机部署手册.md
index 40c9b26e..2ffd42cd 100644
--- a/docs/install_guide/单机部署手册.md
+++ b/docs/install_guide/单机部署手册.md
@@ -1,171 +1,196 @@
-## 前言
+## 2.1、单机部署
-- 本文以 Centos7 系统为例,系统基础配置要求:4 核 8G
-- 按照本文可以快速部署一套单机模式的 KnowStreaming 环境
-- 本文以 v3.0.0-bete 版本为例进行部署,如需其他版本请关注[官网](https://knowstreaming.com/)
-- 部署完成后可以通过浏览器输入 IP:PORT 进行访问,默认用户名密码: admin/admin2022\_
-- KnowStreaming 同样支持分布式集群模式,如需部署高可用集群,[请联系我们](https://knowstreaming.com/support-center)
+**风险提示**
-## 1.1、软件版本及依赖
+⚠️ 脚本全自动安装,会将所部署机器上的 MySQL、JDK、ES 等进行删除重装,请注意原有服务丢失风险。
-| 软件名 | 版本要求 | 默认端口 |
-| ------------- | -------- | -------- |
-| Mysql | v5.7+ | 3306 |
-| Elasticsearch | v6+ | 8060 |
-| JDK | v8+ | - |
-| Centos | v6+ | - |
-| Ubantu | v16+ | - |
+### 2.1.1、安装说明
-## 1.2、部署方式选择
+- 以 `v3.0.0-bete` 版本为例进行部署;
+- 以 CentOS-7 为例,系统基础配置要求 4C-8G;
+- 部署完成后,可通过浏览器:`IP:PORT` 进行访问,默认端口是 `8080`,系统默认账号密码: `admin` / `admin2022_`;
+- 本文为单机部署,如需分布式部署,[请联系我们](https://knowstreaming.com/support-center)
-- Shell 部署(单机版本)
+**软件依赖**
-- 容器化部署(需准备 K8S 环境)
+| 软件名 | 版本要求 | 默认端口 |
+| ------------- | ------------ | -------- |
+| MySQL | v5.7 或 v8.0 | 3306 |
+| ElasticSearch | v7.6+ | 8060 |
+| JDK | v8+ | - |
+| CentOS | v6+ | - |
+| Ubantu | v16+ | - |
-- 根据操作手册进行手动部署
+
-## 1.3、Shell 部署
+### 2.1.2、脚本部署
-### 1.3.1、在线方式安装
+**在线安装**
- #在服务器中下载安装脚本,脚本中会重新安装Mysql
- wget https://s3-gzpu.didistatic.com/pub/knowstreaming/deploy_KnowStreaming.sh
+```bash
+# 在服务器中下载安装脚本, 该脚本中会在当前目录下,重新安装MySQL。重装后的mysql密码存放在当前目录的mysql.password文件中。
+wget https://s3-gzpu.didistatic.com/pub/knowstreaming/deploy_KnowStreaming.sh
- #执行脚本
- sh deploy_KnowStreaming.sh
+# 执行脚本
+sh deploy_KnowStreaming.sh
- #访问测试
- 127.0.0.1:8080
+# 访问地址
+127.0.0.1:8080
+```
-### 1.3.2、离线方式安装
+**离线安装**
- #将安装包下载到本地且传输到目标服务器
- wget https://s3-gzpu.didistatic.com/pub/knowstreaming/KnowStreaming-3.0.0-beta—offline.tar.gz
+```bash
+# 将安装包下载到本地且传输到目标服务器
+wget https://s3-gzpu.didistatic.com/pub/knowstreaming/KnowStreaming-3.0.0-beta—offline.tar.gz
- #解压安装包
- tar -zxf KnowStreaming-3.0.0-beta—offline.tar.gz
+# 解压安装包
+tar -zxf KnowStreaming-3.0.0-beta—offline.tar.gz
- #执行安装脚本
- sh deploy_KnowStreaming-offline.sh
+# 执行安装脚本
+sh deploy_KnowStreaming-offline.sh
- #访问测试
- 127.0.0.1:8080
+# 访问地址
+127.0.0.1:8080
+```
-## 1.4、容器化部署
+
-### 1.4.1、环境依赖及版本要求
+### 2.1.3、容器部署
+
+**环境依赖**
- Kubernetes >= 1.14 ,Helm >= 2.17.0
-- 默认配置为全部安装(elasticsearch + mysql + knowstreaming)
+- 默认配置为全部安装( ElasticSearch + MySQL + KnowStreaming)
-- 如果使用已有的 elasticsearch(7.6.x) 和 mysql(5.7) 只需调整 values.yaml 部分参数即可
+- 如果使用已有的 ElasticSearch(7.6.x) 和 MySQL(5.7) 只需调整 values.yaml 部分参数即可
-### 1.4.2、安装方式
+**安装命令**
- #下载安装包
- wget https://s3-gzpu.didistatic.com/pub/knowstreaming/knowstreaming-3.0.0-hlem.tgz
+```bash
+# 下载安装包
+wget https://s3-gzpu.didistatic.com/pub/knowstreaming/knowstreaming-3.0.0-hlem.tgz
- #解压安装包
- tar -zxf knowstreaming-3.0.0-hlem.tgz
+# 解压安装包
+tar -zxf knowstreaming-3.0.0-hlem.tgz
- #执行命令(NAMESPACE需要更改为已存在的)
- helm install -n [NAMESPACE] knowstreaming knowstreaming-manager/
+# 执行命令(NAMESPACE需要更改为已存在的)
+helm install -n [NAMESPACE] knowstreaming knowstreaming-manager/
- #获取KnowStreaming前端ui的service. 默认nodeport方式.(http://nodeIP:nodeport,默认用户名密码:admin/admin2022_)
+# 获取KnowStreaming前端ui的service. 默认nodeport方式.
+# (http://nodeIP:nodeport,默认用户名密码:admin/admin2022_)
+```
-## 1.5、手动部署
+
-### 1.5.1、部署流程
+### 2.1.4、手动部署
-基础依赖服务部署 ——> KnowStreaming 模块
+**部署流程**
-### 1.5.2、基础依赖服务部署
+1. 安装 `JDK-11`、`MySQL`、`ElasticSearch` 等依赖服务
+2. 安装 KnowStreaming
-#### 如现有环境中已经有相关服务,可跳过对其的安装
+
-#### 基础依赖:JAVA11、Mysql、Elasticsearch
+#### 2.1.4.1、安装 MySQL 服务
-#### 1.5.2.1、安装 Mysql 服务
+**yum 方式安装**
-##### 1.5.2.1.1 yum 方式安装
+```bash
+# 配置yum源
+wget https://dev.mysql.com/get/mysql57-community-release-el7-9.noarch.rpm
+rpm -ivh mysql57-community-release-el7-9.noarch.rpm
- #配置yum源
- wget https://dev.mysql.com/get/mysql57-community-release-el7-9.noarch.rpm
- rpm -ivh mysql57-community-release-el7-9.noarch.rpm
+# 执行安装
+yum -y install mysql-server mysql-client
- #执行安装
- yum -y install mysql-server mysql-client
+# 服务启动
+systemctl start mysqld
- #服务启动
- systemctl start mysqld
+# 获取初始密码并修改
+old_pass=`grep 'temporary password' /var/log/mysqld.log | awk '{print $NF}' | tail -n 1`
- #获取初始密码并修改
- old_pass=`grep 'temporary password' /var/log/mysqld.log | awk '{print $NF}' | tail -n 1`
+mysql -NBe "alter user USER() identified by 'Didi_km_678';" --connect-expired-password -uroot -p$old_pass
+```
- mysql -NBe "alter user USER() identified by 'Didi_km_678';" --connect-expired-password -uroot -p$old_pass
+**rpm 方式安装**
-##### 1.5.2.1.2、rpm 包方式安装
+```bash
+# 下载安装包
+wget https://s3-gzpu.didistatic.com/knowsearch/mysql5.7.tar.gz
- #下载安装包
- wget https://s3-gzpu.didistatic.com/knowsearch/mysql5.7.tar.gz
+# 解压到指定目录
+tar -zxf mysql5.7.tar.gz -C /tmp/
- #解压到指定目录
- tar -zxf mysql5.7.tar.gz -C /tmp/
+# 执行安装
+yum -y localinstall /tmp/libaio-*.rpm /tmp/mysql-*.rpm
- #执行安装
- yum -y localinstall /tmp/libaio-*.rpm /tmp/mysql-*.rpm
-
- #服务启动
- systemctl start mysqld
+# 服务启动
+systemctl start mysqld
- #获取初始密码并修改
- old_pass=`grep 'temporary password' /var/log/mysqld.log | awk '{print $NF}' | tail -n 1`
+# 获取初始密码并修改
+old_pass=`grep 'temporary password' /var/log/mysqld.log | awk '{print $NF}' | tail -n 1`
- mysql -NBe "alter user USER() identified by 'Didi_km_678';" --connect-expired-pa
- ssword -uroot -p$old_pass
+mysql -NBe "alter user USER() identified by 'Didi_km_678';" --connect-expired-password -uroot -p$old_pass
-#### 1.5.2.2、配置 JAVA 环境
+```
-#下载安装包
-wget https://s3-gzpu.didistatic.com/pub/jdk11.tar.gz #解压到指定目录
-tar -zxf jdk11.tar.gz -C /usr/local/ #更改目录名
-mv /usr/local/jdk-11.0.2 /usr/local/java11 #添加到环境变量
+
+
+#### 2.1.4.2、配置 JDK 环境
+
+```bash
+# 下载安装包
+wget https://s3-gzpu.didistatic.com/pub/jdk11.tar.gz
+
+# 解压到指定目录
+tar -zxf jdk11.tar.gz -C /usr/local/
+
+# 更改目录名
+mv /usr/local/jdk-11.0.2 /usr/local/java11
+
+# 添加到环境变量
echo "export JAVA_HOME=/usr/local/java11" >> ~/.bashrc
echo "export CLASSPATH=/usr/java/java11/lib" >> ~/.bashrc
-echo "export PATH=\$JAVA_HOME/bin:\$PATH:\$HOME/bin" >> ~/.bashrc
+echo "export PATH=$JAVA_HOME/bin:$PATH:$HOME/bin" >> ~/.bashrc
+
source ~/.bashrc
-#### 1.5.2.3、Elasticsearch 实例搭建
+```
-#### Elasticsearch 元数据集群来支持平台核心指标数据的存储,如集群维度指标、节点维度指标等
+
-#### 以下安装示例为单节点模式,如需集群部署可以参考[Elasticsearch 官方文档](https://www.elastic.co/guide/en/elasticsearch/reference/7.6/elasticsearch-intro.html)
+#### 2.1.4.3、ElasticSearch 实例搭建
- #下载安装包
- wget https://s3-gzpu.didistatic.com/pub/elasticsearch.tar.gz
+- ElasticSearch 用于存储平台采集的 Kafka 指标;
+- 以下安装示例为单节点模式,如需集群部署可以参考:[Elasticsearch 官方文档](https://www.elastic.co/guide/en/elasticsearch/reference/7.6/elasticsearch-intro.html)
- #创建ES数据存储目录
- mkdir -p /data/es_data
+```bash
+# 下载安装包
+wget https://s3-gzpu.didistatic.com/pub/elasticsearch.tar.gz
- #创建ES所属用户
- useradd arius
+# 创建ES数据存储目录
+mkdir -p /data/es_data
- #配置用户的打开文件数
- echo "arius soft nofile 655350" >>/etc/security/limits.conf
- echo "arius hard nofile 655350" >>/etc/security/limits.conf
- echo "vm.max_map_count = 655360" >>/etc/sysctl.conf
- sysctl -p
+# 创建ES所属用户
+useradd arius
- #解压安装包
- tar -zxf elasticsearch.tar.gz -C /data/
+# 配置用户的打开文件数
+echo "arius soft nofile 655350" >> /etc/security/limits.conf
+echo "arius hard nofile 655350" >> /etc/security/limits.conf
+echo "vm.max_map_count = 655360" >> /etc/sysctl.conf
+sysctl -p
- #更改目录所属组
- chown -R arius:arius /data/
+# 解压安装包
+tar -zxf elasticsearch.tar.gz -C /data/
- #修改配置文件(参考以下配置)
- vim /data/elasticsearch/config/elasticsearch.yml
+# 更改目录所属组
+chown -R arius:arius /data/
+
+# 修改配置文件(参考以下配置)
+vim /data/elasticsearch/config/elasticsearch.yml
cluster.name: km_es
node.name: es-node1
node.master: true
@@ -174,64 +199,64 @@ source ~/.bashrc
http.port: 8060
discovery.seed_hosts: ["127.0.0.1:9300"]
- #修改内存配置
- vim /data/elasticsearch/config/jvm.options
+# 修改内存配置
+vim /data/elasticsearch/config/jvm.options
-Xms2g
-Xmx2g
- #启动服务
- su - arius
- export JAVA_HOME=/usr/local/java11
- sh /data/elasticsearch/control.sh start
+# 启动服务
+su - arius
+export JAVA_HOME=/usr/local/java11
+sh /data/elasticsearch/control.sh start
- #确认状态
- sh /data/elasticsearch/control.sh status
+# 确认状态
+sh /data/elasticsearch/control.sh status
+```
-### 1.5.3、KnowStreaming 服务部署
+
-#### 以 KnowStreaming 为例
+#### 2.1.4.4、KnowStreaming 实例搭建
- #下载安装包
- wget wget https://s3-gzpu.didistatic.com/pub/knowstreaming/KnowStreaming-3.0.0-beta.tar.gz
+```bash
+# 下载安装包
+wget https://s3-gzpu.didistatic.com/pub/knowstreaming/KnowStreaming-3.0.0-beta.tar.gz
- #解压安装包到指定目录
- tar -zxf KnowStreaming-3.0.0-beta.tar.gz -C /data/
+# 解压安装包到指定目录
+tar -zxf KnowStreaming-3.0.0-beta.tar.gz -C /data/
- #修改启动脚本并加入systemd管理
- cd /data/KnowStreaming/
+# 修改启动脚本并加入systemd管理
+cd /data/KnowStreaming/
- #创建相应的库和导入初始化数据
- mysql -uroot -pDidi_km_678 -e "create database know_streaming;"
- mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/ddl-ks-km.sql
- mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/ddl-logi-job.sql
- mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/ddl-logi-security.sql
- mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/dml-ks-km.sql
- mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/dml-logi.sql
+# 创建相应的库和导入初始化数据
+mysql -uroot -pDidi_km_678 -e "create database know_streaming;"
+mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/ddl-ks-km.sql
+mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/ddl-logi-job.sql
+mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/ddl-logi-security.sql
+mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/dml-ks-km.sql
+mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/dml-logi.sql
- #创建elasticsearch初始化数据
- sh ./init/template/template.sh
+# 创建elasticsearch初始化数据
+sh ./init/template/template.sh
- #修改配置文件
- vim ./conf/application.yml
+# 修改配置文件
+vim ./conf/application.yml
- #监听端口
- server:
+# 监听端口
+server:
+ port: 8080 # web 服务端口
+ tomcat:
+ accept-count: 1000
+ max-connections: 10000
-port: 8080 # web 服务端口
-tomcat:
-accept-count: 1000
-max-connections: 10000
+# ES地址
+es.client.address: 127.0.0.1:8060
- #elasticsearch地址
- es.client.address: 127.0.0.1:8060
+# 数据库配置(一共三处地方,修改正确的mysql地址和数据库名称以及用户名密码)
+jdbc-url: jdbc:mariadb://127.0.0.1:3306/know_streaming?.....
+username: root
+password: Didi_km_678
- #数据库配置(一共三处地方,修改正确的mysql地址和数据库名称以及用户名密码)
- jdbc-url: jdbc:mariadb://127.0.0.1:3306/know-streaming?.....
- username: root
- password: Didi_km_678
-
- #启动服务
- cd /data/KnowStreaming/bin/
- sh startup.sh
-
-#### 打开浏览器输入 IP 地址+端口测试(默认端口 8080),用户名密码: admin/admin2022\_
+# 启动服务
+cd /data/KnowStreaming/bin/
+sh startup.sh
+```
diff --git a/docs/install_guide/源码编译打包手册.md b/docs/install_guide/源码编译打包手册.md
index 625ce3a7..b0b20101 100644
--- a/docs/install_guide/源码编译打包手册.md
+++ b/docs/install_guide/源码编译打包手册.md
@@ -15,6 +15,7 @@
- Maven 3.6.3 (后端)
- Node v12.20.0/v14.17.3 (前端)
- Java 8+ (后端)
+- Git
## 2、编译打包
diff --git a/docs/install_guide/版本升级手册.md b/docs/install_guide/版本升级手册.md
index be117b6f..621d90bc 100644
--- a/docs/install_guide/版本升级手册.md
+++ b/docs/install_guide/版本升级手册.md
@@ -1,6 +1,6 @@
-## 版本升级说明
+## 6.2、版本升级手册
-### `2.x`版本 升级至 `3.0.0`版本
+**`2.x`版本 升级至 `3.0.0`版本**
**升级步骤:**
@@ -34,4 +34,4 @@ UPDATE ks_km_topic
AND ks_km_topic.topic_name = t.topic_name
AND ks_km_topic.id > 0
SET ks_km_topic.description = t.description;
-```
+```
\ No newline at end of file
diff --git a/docs/user_guide/faq.md b/docs/user_guide/faq.md
index 471595cc..98f21289 100644
--- a/docs/user_guide/faq.md
+++ b/docs/user_guide/faq.md
@@ -4,71 +4,68 @@
# FAQ
-- [FAQ](#faq)
- - [1、支持哪些Kafka版本?](#1支持哪些kafka版本)
- - [2、页面流量信息等无数据?](#2页面流量信息等无数据)
- - [3、`Jmx`连接失败如何解决?](#3jmx连接失败如何解决)
- - [4、有没有 API 文档?](#4有没有-api-文档)
- - [5、删除Topic成功后,为何过段时间又出现了?](#5删除topic成功后为何过段时间又出现了)
- - [6、如何在不登录的情况下,调用接口?](#6如何在不登录的情况下调用接口)
-
----
-
-## 1、支持哪些Kafka版本?
-
-- 支持 0.10+ 的Kafka版本;
-- 支持 ZK 及 Raft 运行模式的Kafka版本;
+## 8.1、支持哪些 Kafka 版本?
+- 支持 0.10+ 的 Kafka 版本;
+- 支持 ZK 及 Raft 运行模式的 Kafka 版本;
+## 8.1、2.x 版本和 3.0 版本有什么差异?
-## 2、页面流量信息等无数据?
+**全新设计理念**
+
+- 在 0 侵入、0 门槛的前提下提供直观 GUI 用于管理和观测 Apache Kafka®,帮助用户降低 Kafka CLI 操作门槛,轻松实现对原生 Kafka 集群的可管、可见、可掌控,提升 Kafka 使用体验和降低管理成本。
+- 支持海量集群一键接入,无需任何改造,即可实现集群深度纳管,真正的 0 侵入、插件化系统设计,覆盖 0.10.x-3.x.x 众多 Kafka 版本无缝纳管。
+
+**开源协议调整**
+
+- 3.x:AGPL 3.0
+- 2.x:Apache License 2.0
+
+更多具体内容见:[新旧版本对比](https://doc.knowstreaming.com/product/9-attachment#92%E6%96%B0%E6%97%A7%E7%89%88%E6%9C%AC%E5%AF%B9%E6%AF%94)
+
+
+
+## 8.3、页面流量信息等无数据?
- 1、`Broker JMX`未正确开启
-可以参看:[Jmx连接配置&问题解决说明文档](../dev_guide/解决连接JMX失败.md)
+可以参看:[Jmx 连接配置&问题解决](https://doc.knowstreaming.com/product/9-attachment#91jmx-%E8%BF%9E%E6%8E%A5%E5%A4%B1%E8%B4%A5%E9%97%AE%E9%A2%98%E8%A7%A3%E5%86%B3)
- 2、`ES` 存在问题
-建议使用`ES 7.6`版本,同时创建近7天的索引,具体见:[单机部署手册](../install_guide/单机部署手册.md) 中的ES索引模版及索引创建。
-
+建议使用`ES 7.6`版本,同时创建近 7 天的索引,具体见:[快速开始](./1-quick-start.md) 中的 ES 索引模版及索引创建。
+## 8.4、`Jmx`连接失败如何解决?
-## 3、`Jmx`连接失败如何解决?
-
-- 参看 [Jmx连接配置&问题解决说明文档](../dev_guide/解决连接JMX失败.md) 说明。
-
+- 参看 [Jmx 连接配置&问题解决](./9-attachment#jmx-连接失败问题解决) 说明。
+## 8.5、有没有 API 文档?
-## 4、有没有 API 文档?
-
-`KnowStreaming` 采用 Swagger 进行 API 说明,在启动 KnowStreaming 服务之后,就可以从下面地址看到。
-
-Swagger-API地址: [http://IP:PORT/swagger-ui.html#/](http://IP:PORT/swagger-ui.html#/)
+`KnowStreaming` 采用 Swagger 进行 API 说明,在启动 KnowStreaming 服务之后,就可以从下面地址看到。
+Swagger-API 地址: [http://IP:PORT/swagger-ui.html#/](http://IP:PORT/swagger-ui.html#/)
-
-## 5、删除Topic成功后,为何过段时间又出现了?
+## 8.6、删除 Topic 成功后,为何过段时间又出现了?
**原因说明:**
-`KnowStreaming` 会去请求Topic的endoffset信息,要获取这个信息就需要发送metadata请求,发送metadata请求的时候,如果集群允许自动创建Topic,那么当Topic不存在时,就会自动将该Topic创建出来。
-
+`KnowStreaming` 会去请求 Topic 的 endoffset 信息,要获取这个信息就需要发送 metadata 请求,发送 metadata 请求的时候,如果集群允许自动创建 Topic,那么当 Topic 不存在时,就会自动将该 Topic 创建出来。
**问题解决:**
-因为在 `KnowStreaming` 上,禁止Kafka客户端内部元信息获取这个动作非常的难做到,因此短时间内这个问题不好从 `KnowStreaming` 上解决。
+因为在 `KnowStreaming` 上,禁止 Kafka 客户端内部元信息获取这个动作非常的难做到,因此短时间内这个问题不好从 `KnowStreaming` 上解决。
-当然,对于不存在的Topic,`KnowStreaming` 是不会进行元信息请求的,因此也不用担心会莫名其妙的创建一个Topic出来。
+当然,对于不存在的 Topic,`KnowStreaming` 是不会进行元信息请求的,因此也不用担心会莫名其妙的创建一个 Topic 出来。
-但是,另外一点,对于开启允许Topic自动创建的集群,建议是关闭该功能,开启是非常危险的,如果关闭之后,`KnowStreaming` 也不会有这个问题。
+但是,另外一点,对于开启允许 Topic 自动创建的集群,建议是关闭该功能,开启是非常危险的,如果关闭之后,`KnowStreaming` 也不会有这个问题。
最后这里举个开启这个配置后,非常危险的代码例子吧:
@@ -79,12 +76,36 @@ for (int i= 0; i < 100000; ++i) {
}
```
+
+
+## 8.7、如何在不登录的情况下,调用接口?
+
+步骤一:接口调用时,在 header 中,增加如下信息:
+
+```shell
+# 表示开启登录绕过
+Trick-Login-Switch : on
+
+# 登录绕过的用户, 这里可以是admin, 或者是其他的, 但是必须在系统管理->用户管理中设置了该用户。
+Trick-Login-User : admin
+```
+步骤二:点击右上角"系统管理",选择配置管理,在页面中添加以下键值对。
-## 6、如何在不登录的情况下,调用接口?
+```shell
+# 设置的key,必须是这个
+SECURITY.TRICK_USERS
-具体见:[免登录调用接口](../dev_guide/免登录调用接口.md)
+# 设置的value,是json数组的格式,包含步骤一header中设置的用户名,例如
+[ "admin", "logi"]
+```
+
+步骤三:解释说明
+
+设置完成上面两步之后,就可以直接调用需要登录的接口了。
+
+但是还有一点需要注意,绕过的用户仅能调用他有权限的接口,比如一个普通用户,那么他就只能调用普通的接口,不能去调用运维人员的接口。
diff --git a/docs/user_guide/新旧对比手册.md b/docs/user_guide/新旧对比手册.md
index 55829033..d934e41f 100644
--- a/docs/user_guide/新旧对比手册.md
+++ b/docs/user_guide/新旧对比手册.md
@@ -1,33 +1,33 @@
-## 4.2、新旧版本对比
+## 9.2、新旧版本对比
-### 4.2.1、全新的设计理念
+### 9.2.1、全新的设计理念
- 在 0 侵入、0 门槛的前提下提供直观 GUI 用于管理和观测 Apache Kafka®,帮助用户降低 Kafka CLI 操作门槛,轻松实现对原生 Kafka 集群的可管、可见、可掌控,提升 Kafka 使用体验和降低管理成本。
- 支持海量集群一键接入,无需任何改造,即可实现集群深度纳管,真正的 0 侵入、插件化系统设计,覆盖 0.10.x-3.x.x 众多 Kafka 版本无缝纳管。
-### 4.2.2、产品名称&LOGO
+### 9.2.2、产品名称&协议
-- 4.2.2.1、Know Streaming V3.0
+- Know Streaming V3.0
- 名称:Know Streaming
- - Logo:
+ - 协议:AGPL 3.0
-- 4.2.2.2、Logi-KM V2.x
+- Logi-KM V2.x
- 名称:Logi-KM
- - Logo:
+ - 协议:Apache License 2.0
-### 4.2.3、功能架构
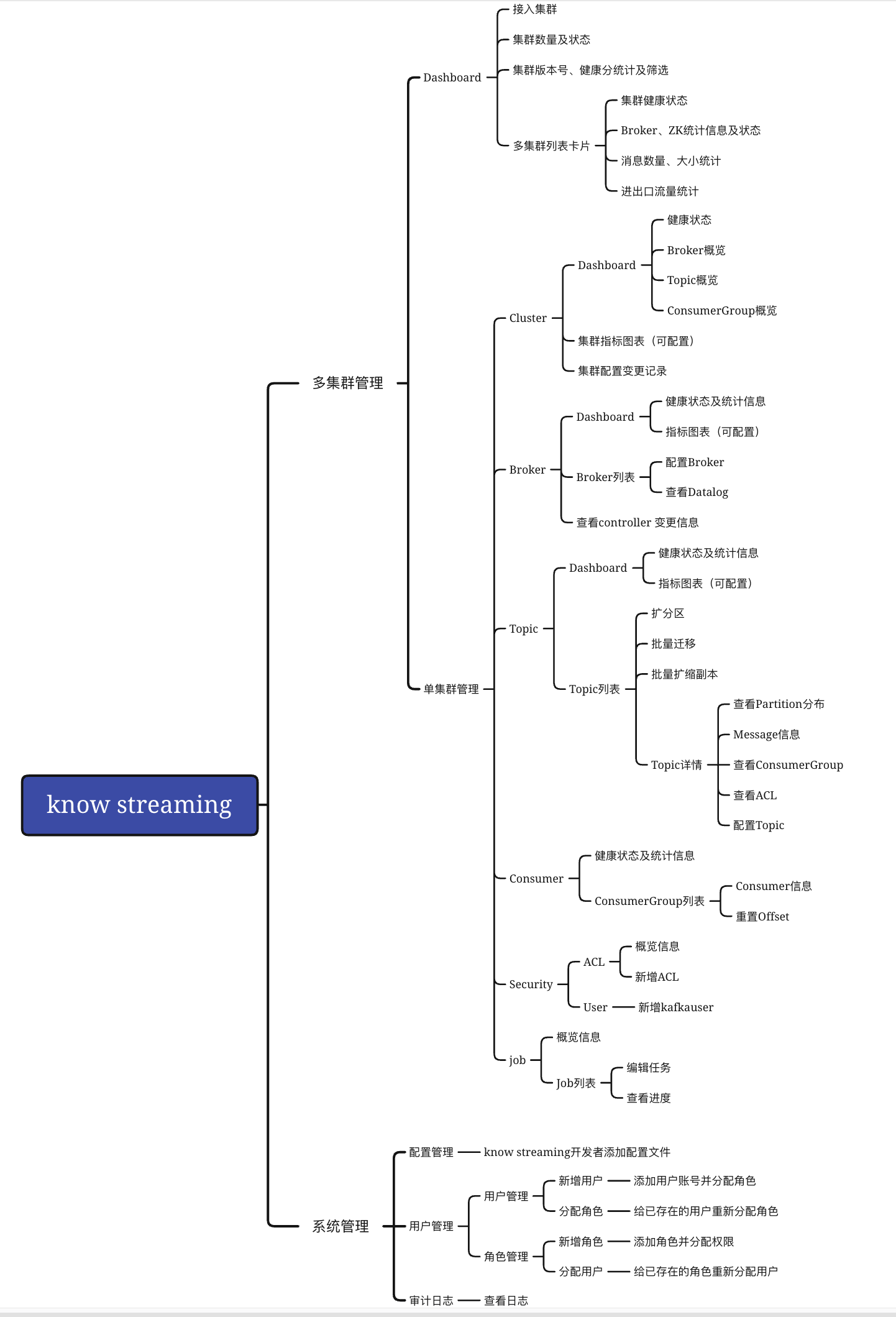
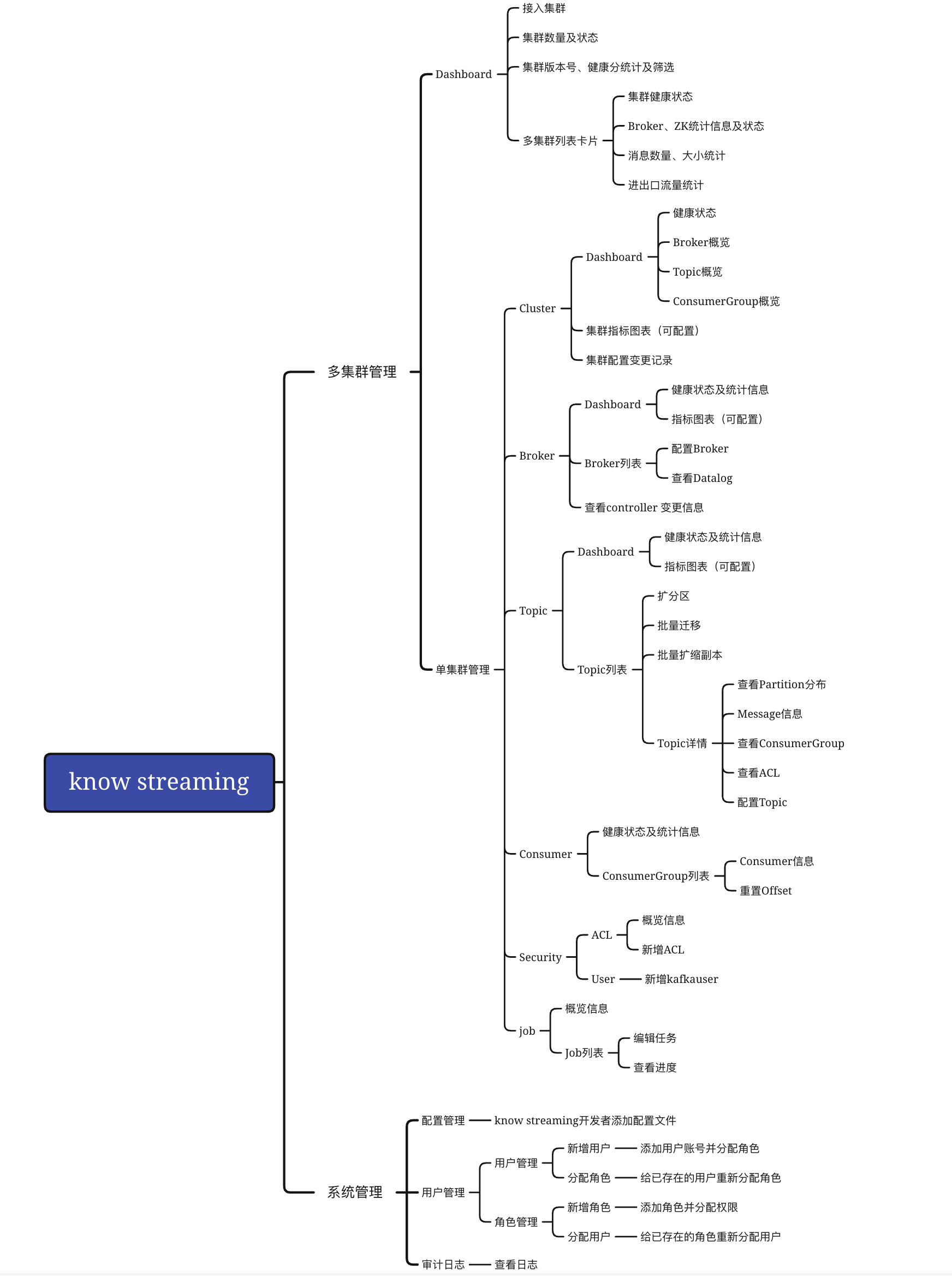
+### 9.2.3、功能架构
-- 4.2.3.1、Know Streaming V3.0
+- Know Streaming V3.0
-- 4.2.3.2、Logi-KM V2.x
+- Logi-KM V2.x
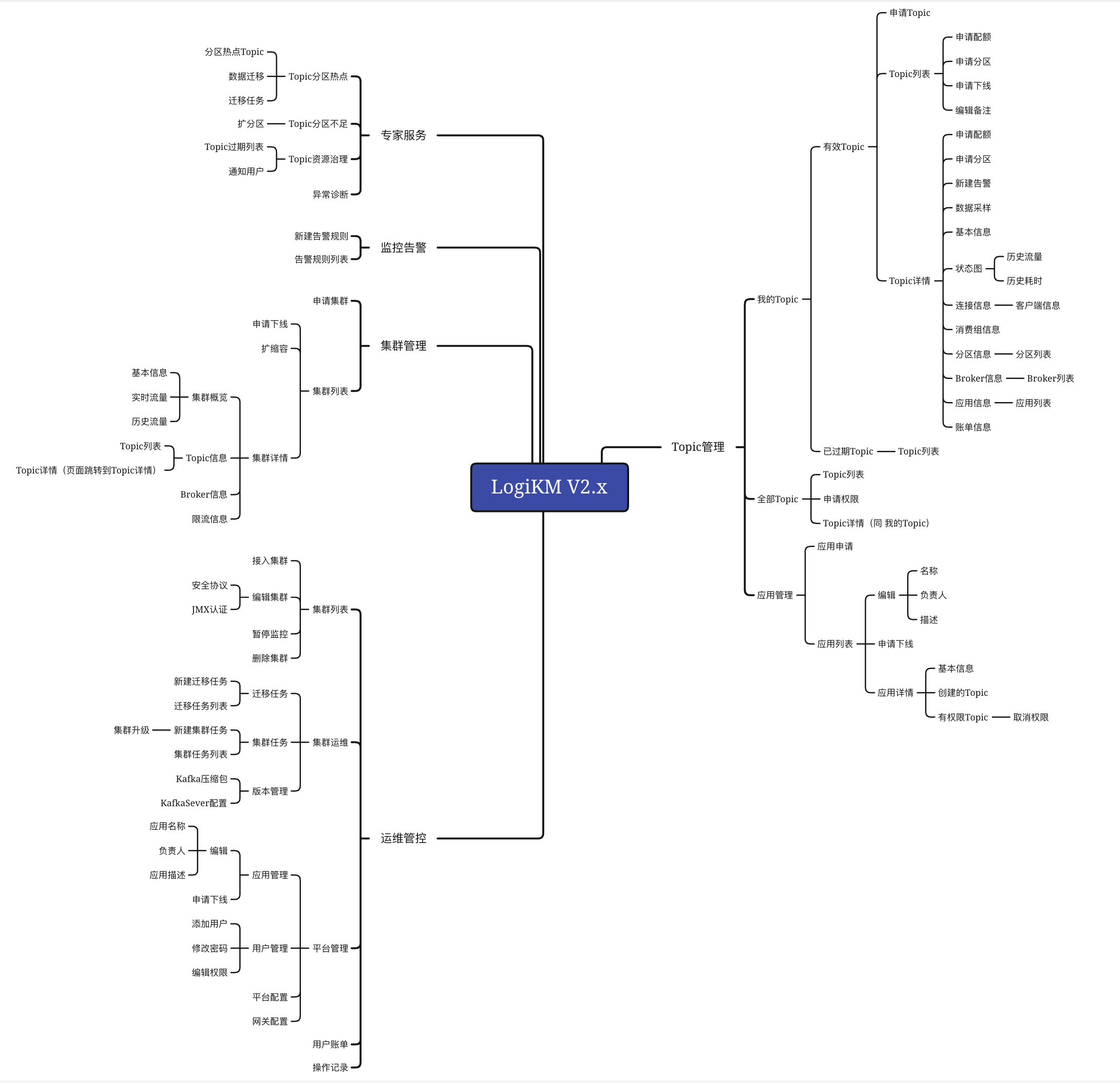
-### 4.2.4、功能变更
+### 9.2.4、功能变更
- 多集群管理
diff --git a/docs/user_guide/用户使用手册.md b/docs/user_guide/用户使用手册.md
index 189b5869..f2efc936 100644
--- a/docs/user_guide/用户使用手册.md
+++ b/docs/user_guide/用户使用手册.md
@@ -1,44 +1,21 @@
-## 5.1、简介
+## 5.0、产品简介
-Know Streaming 脱胎于众多互联网内部多年的 Kafka 运营实践经验,是面向 Kafka 用户、Kafka 运维人员打造的共享多租户 Kafka 管控平台。不会对 Apache Kafka 做侵入性改造,就可纳管 0.10.x-3.x 集群版本,帮助您提升集群管理水平;我们屏蔽了 Kafka 的复杂性,让普通运维人员都能成为 Kafka 专家。
+`Know Streaming` 是一套云原生的 Kafka 管控平台,脱胎于众多互联网内部多年的 Kafka 运营实践经验,专注于 Kafka 运维管控、监控告警、资源治理、多活容灾等核心场景,在用户体验、监控、运维管控上进行了平台化、可视化、智能化的建设,提供一系列特色的功能,极大地方便了用户和运维人员的日常使用,让普通运维人员都能成为 Kafka 专家。
-## 5.2、产品功能架构
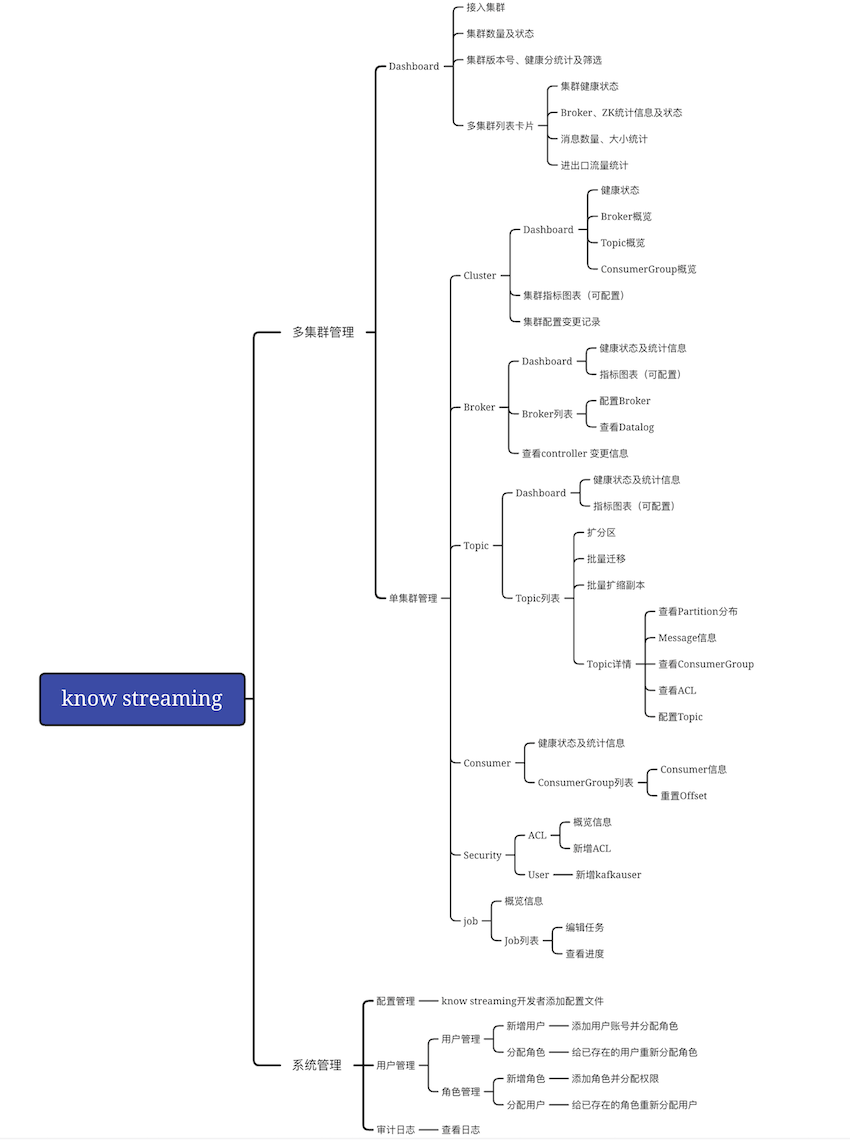
+## 5.1、功能架构
-
+
-## 5.3、产品主要特点介绍
-
-### 5.3.1、Kafka 命令行操作转化为 GUI,大大提高易用性
-
-- 更多版本适配。支持 0.10.x-3.x.x 众多主流 Kafka 版本统一纳管
-
-- 更多组件纳管。支持 Cluster、Broker、Topic、Message、Consumer、ALC 等组件 GUI 管理
-
-- 更少成本投入。支持存量集群一键接入,无需任何改造,即可实现集群深度纳管,真正的 0 侵入、插件化系统设计
-
-### 5.3.2、指标监控及可视化
-
-- 集群配置可视化。通过提供管理界面,便于用户集中查看和控制集群参数配置、Topic、Message...
-
-- 核心指标趋势分析。通过实时采集集群关键指标,提供直观图表便于用户订阅跟踪集群健康度
-
-- 监控告警生态集成。通过基于专家规则和算法的智能警报,确保集群可用性,保持集群平稳运行
-
-### 5.3.3、高频的问题和操作沉淀形成特有的专家服务
-
-- 分区迁移&扩容。通过提供 Topic 热点迁移和弹性扩容,有效提升集群可用性和稳定性
-
-- 集群资源治理。通过分析 Topic 流量和请求,对无效 Topic 定期跟踪,提升集群资源使用率
-
-## 5.4、用户体验路径
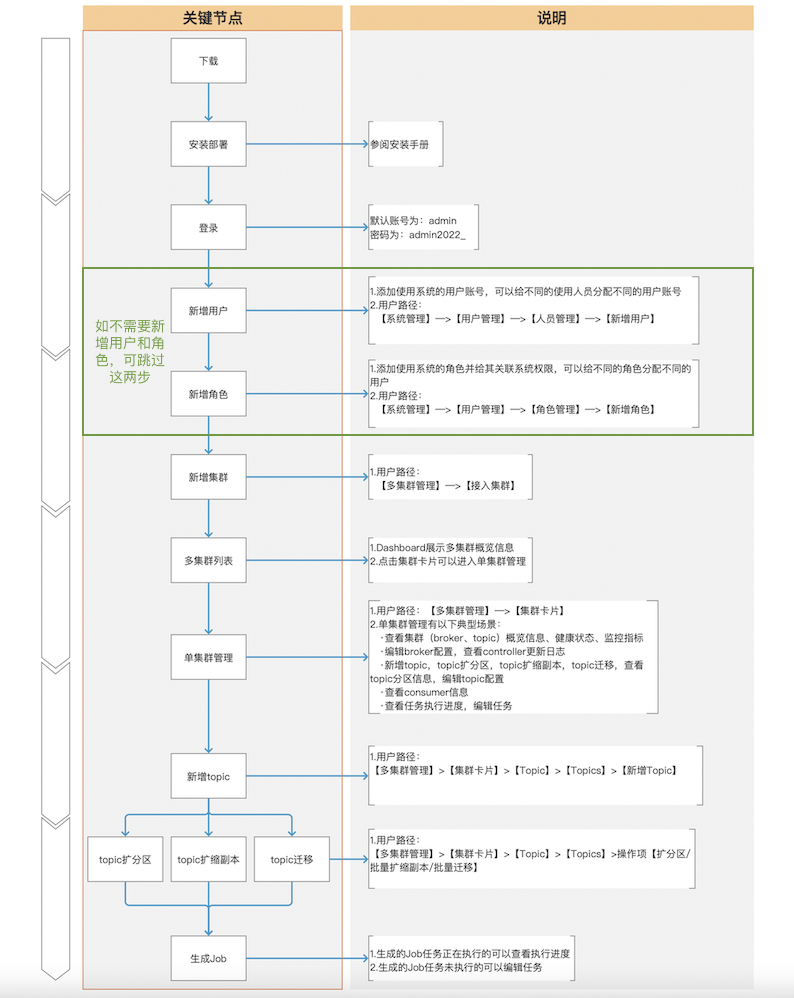
+## 5.2、体验路径
下面是用户第一次使用我们产品的典型体验路径:
-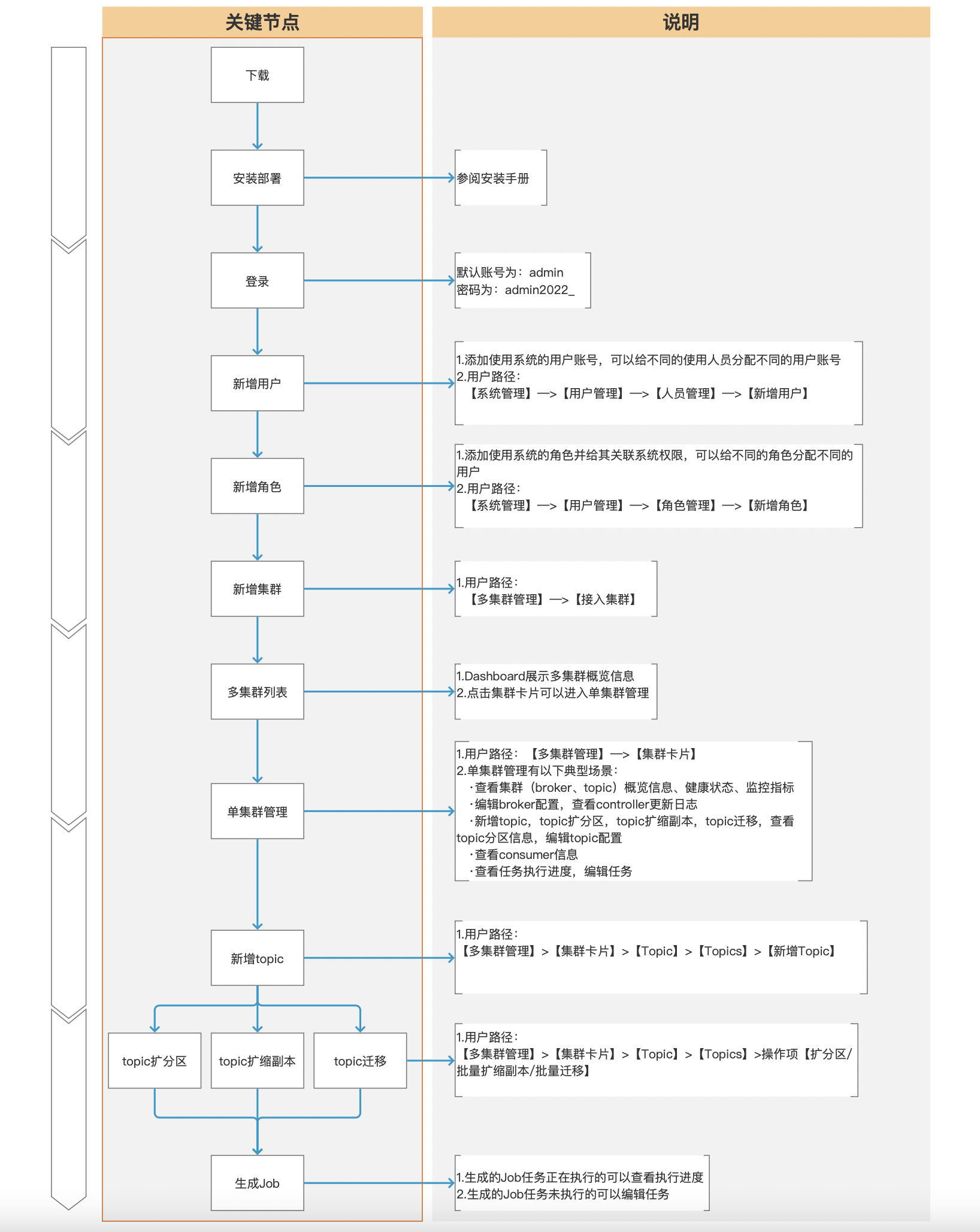
-## 5.5、典型场景
+
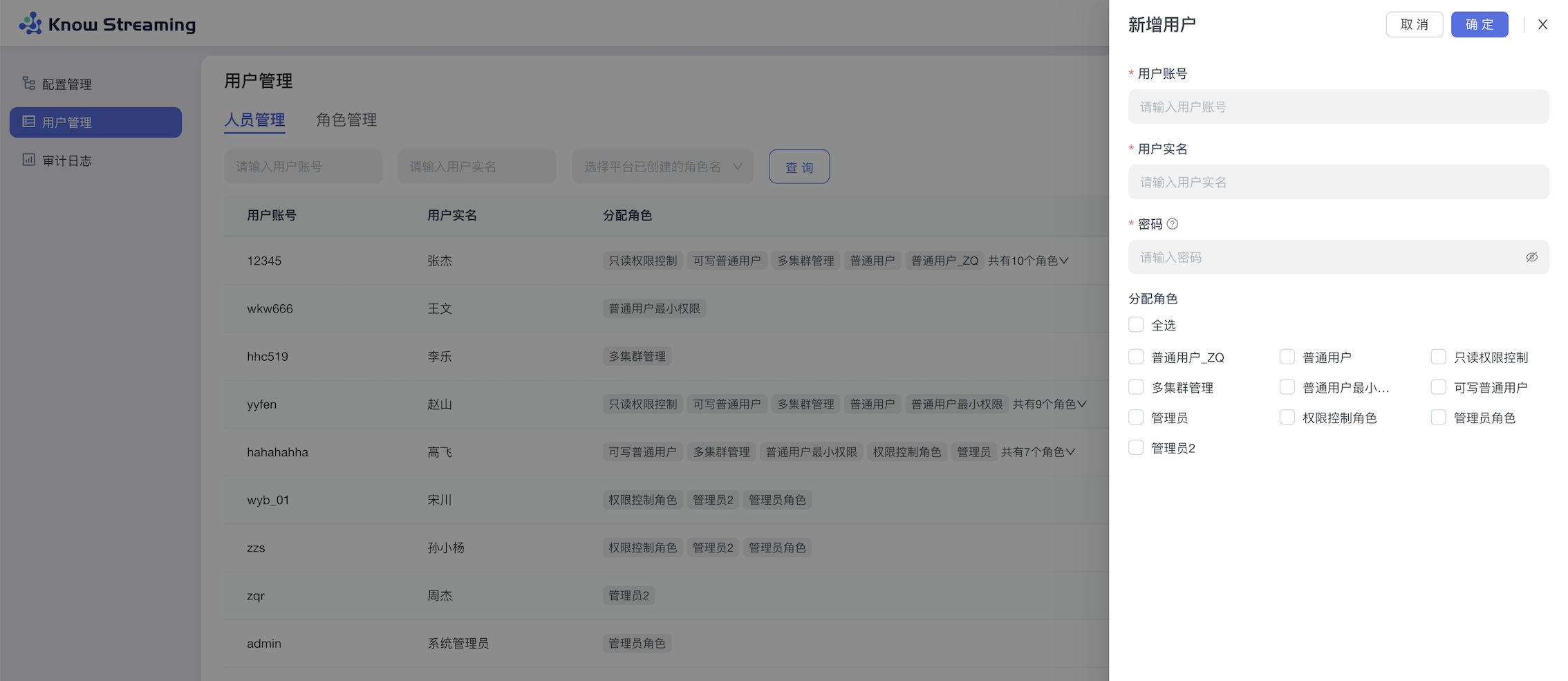
-### 5.5.1、用户管理
+## 5.3、常用功能
+
+### 5.3.1、用户管理
用户管理是提供给管理员进行人员管理和用户角色管理的功能模块,可以进行新增用户和分配角色。下面是一个典型的场景:
eg:团队加入了新成员,需要给这位成员分配一个使用系统的账号,需要以下几个步骤
@@ -50,25 +27,26 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 4:此用户账号新增成功,可以进行登录产品使用
-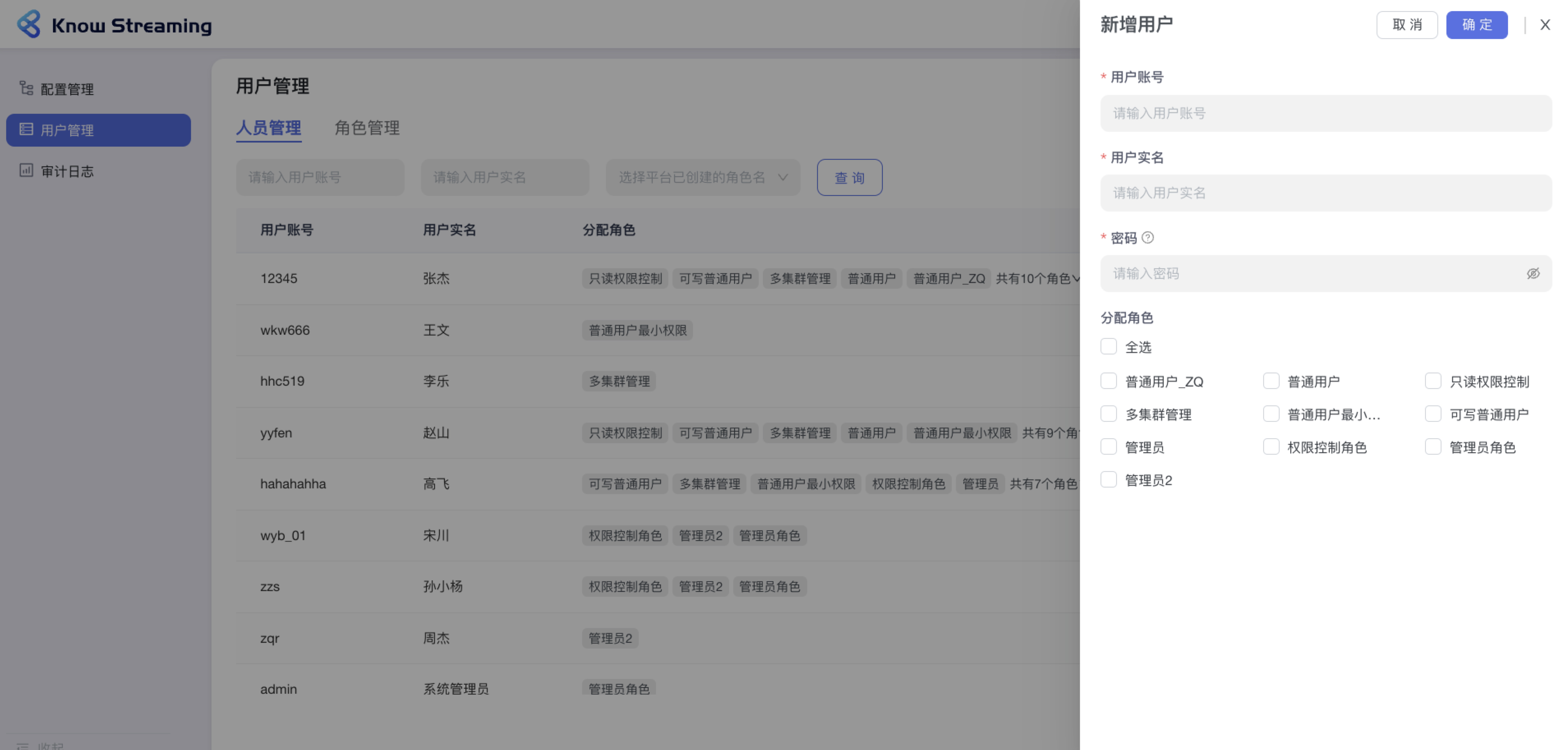
+
-### 5.5.2、接入集群
+### 5.3.2、接入集群
- 步骤 1:点击“多集群管理”>“接入集群”
- 步骤 2:填写相关集群信息
- 集群名称:支持中英文、下划线、短划线(-),最长 128 字符。平台内不能重复
- - Bootstrap Servers:输入 Bootstrap Servers 地址,不限制长度和输入内容。例如 192.168.1.1:9092,192.168.1.2:9092,192.168.1.3:9092,输入完成之后会进行连接测试,测试完成之后会给出测试结果连接成功 or 连接失败(以及失败的原因)。【备注:根据填写的 Bootstrap Servers 地址自动获取 zk 信息、mertics 信息、version 信息。若能获取成功,则自动展示。当 zk 已填写时,再次修改 bootstrap server 地址时就不再重新获取 zk 信息,按照用户维护的 zk 信息为准】
- - Zookeeper:输入 zookeeper 地址,例如:192.168.0.1:2181,192.168.0.2:2181,192.168.0.2:2181/ks-kafka,输入完成之后会进行连接测试,测试完成之后会给出测试结果连接成功 or 连接失败(以及失败的原因)【备注:根据填写的 zk 地址自动获取后续的 mertics、version 信息。若能获取成功,则自动展示】
+ - Bootstrap Servers:输入 Bootstrap Servers 地址。输入完成之后会进行连接测试,测试完成之后会给出测试结果连接成功 or 连接失败(以及失败的原因)。
+ - Zookeeper:输入 zookeeper 地址,输入完成之后会进行连接测试,测试完成之后会给出测试结果连接成功 or 连接失败(以及失败的原因)
- Metrics 选填:JMX Port,输入 JMX 端口号;MaxConn,输入服务端最大允许的连接数
- - Security:若集群有账号密码,则输入账号密码
- - Version:下拉选择所支持的 kafka 版本,如果没有匹配则可以选择相近版本
+ - Security:若有 JMX 账号密码,则输入账号密码
+ - Version:选择所支持的 kafka 版本,如果没有匹配则可以选择相近版本
- 集群配置选填:输入用户创建 kafka 客户端进行信息获取的相关配置
- - 集群描述:输入集群的描述,最多 200 字符
- 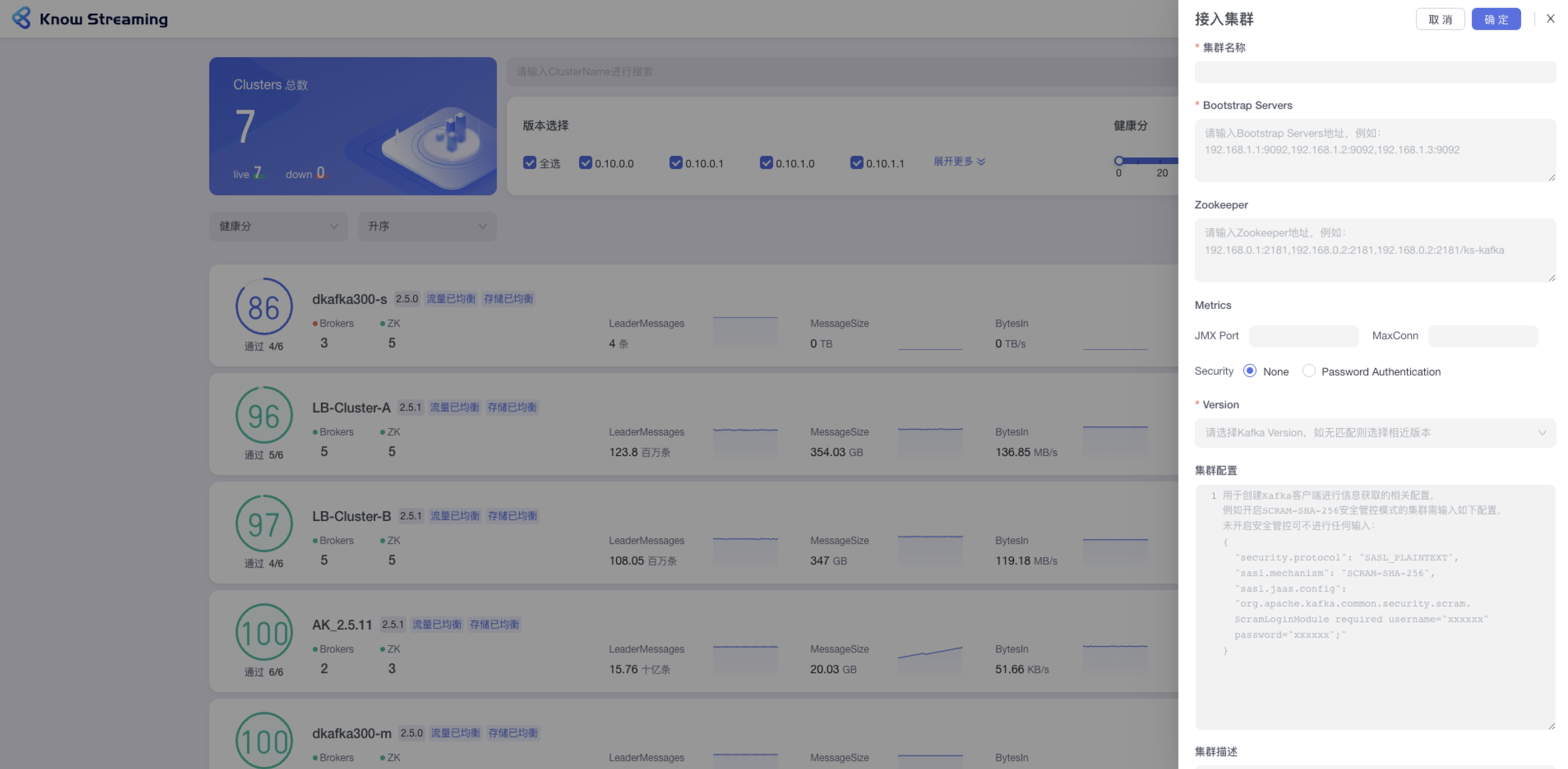
+ - 集群描述:最多 200 字符
-### 5.5.3、新增 Topic
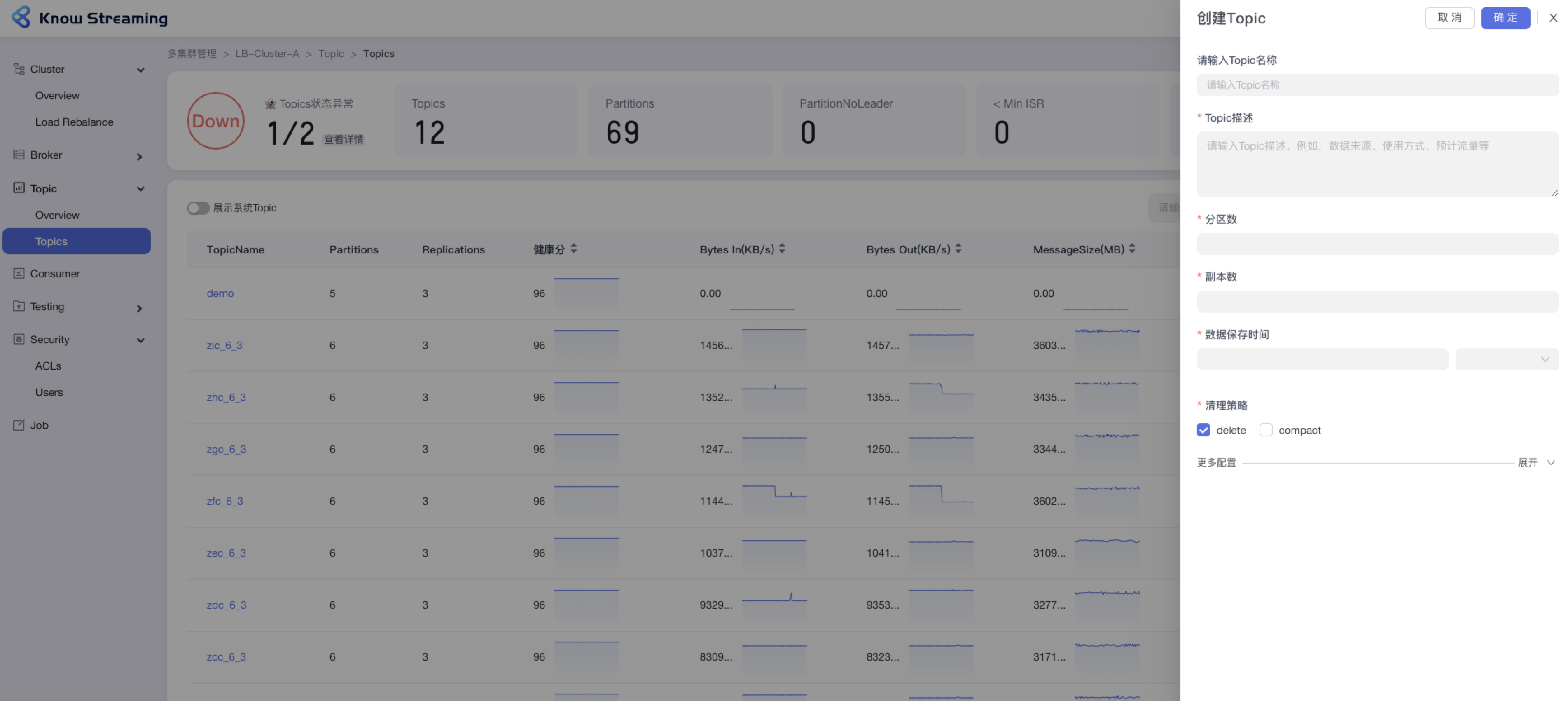
+
+
+### 5.3.3、新增 Topic
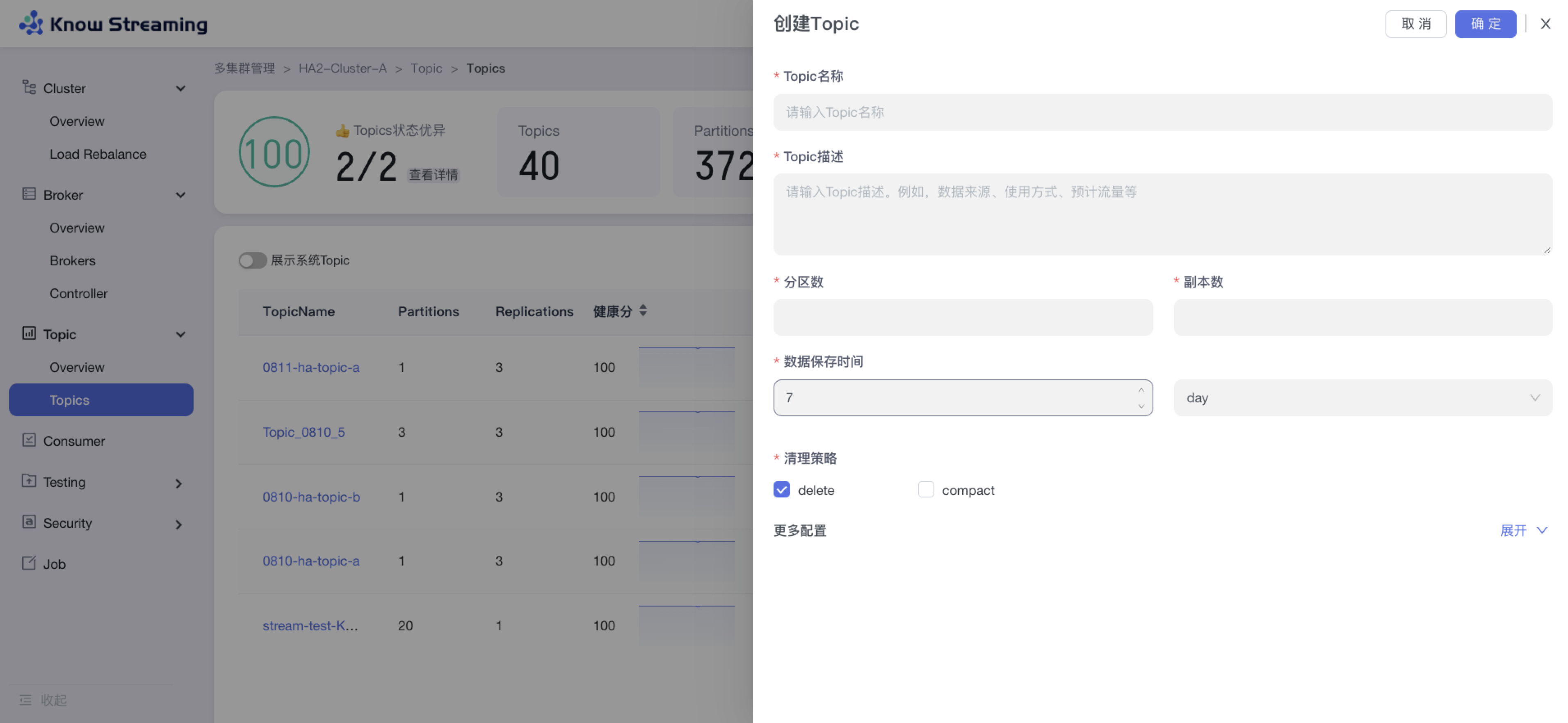
- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“新增 Topic”按钮>“创建 Topic“抽屉
@@ -77,9 +55,10 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 3:展开“更多配置”可以打开高级配置选项,根据自己需要输入相应配置参数
- 步骤 4:点击“确定”,创建 Topic 完成
- 
-### 5.5.4、Topic 扩分区
+
+
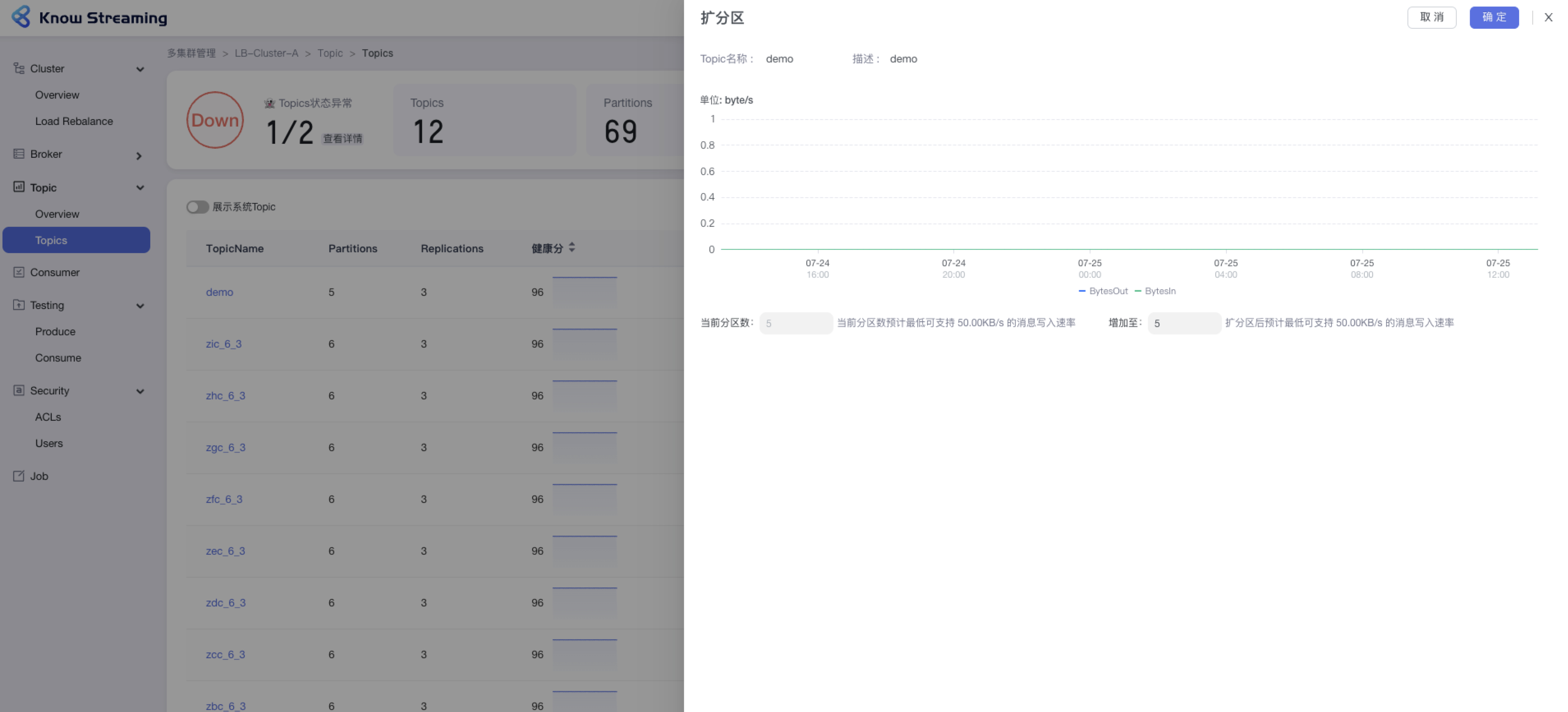
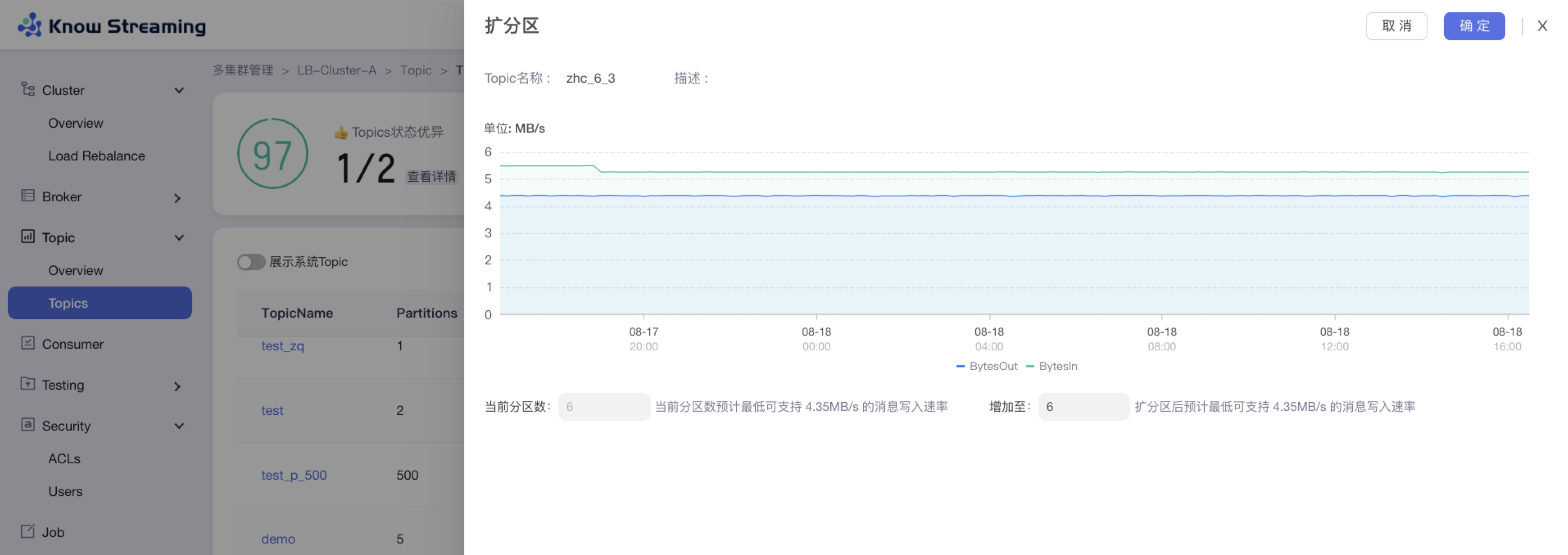
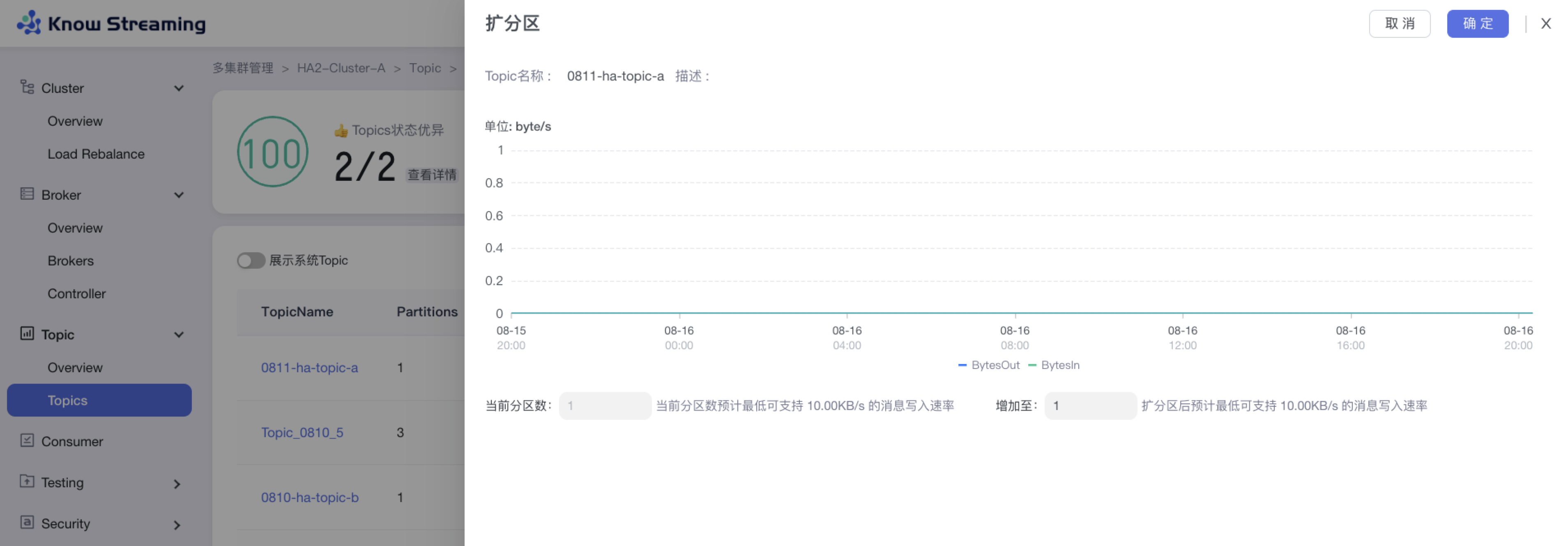
+### 5.3.4、Topic 扩分区
- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“Topic 列表“>操作项”扩分区“>“扩分区”抽屉
@@ -88,9 +67,10 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 3:输入所需的分区总数,自动计算出扩分区后支持的最低消息写入速率
- 步骤 4:点击确定,扩分区完成
- 
-### 5.5.5、Topic 批量扩缩副本
+
+
+### 5.3.5、Topic 批量扩缩副本
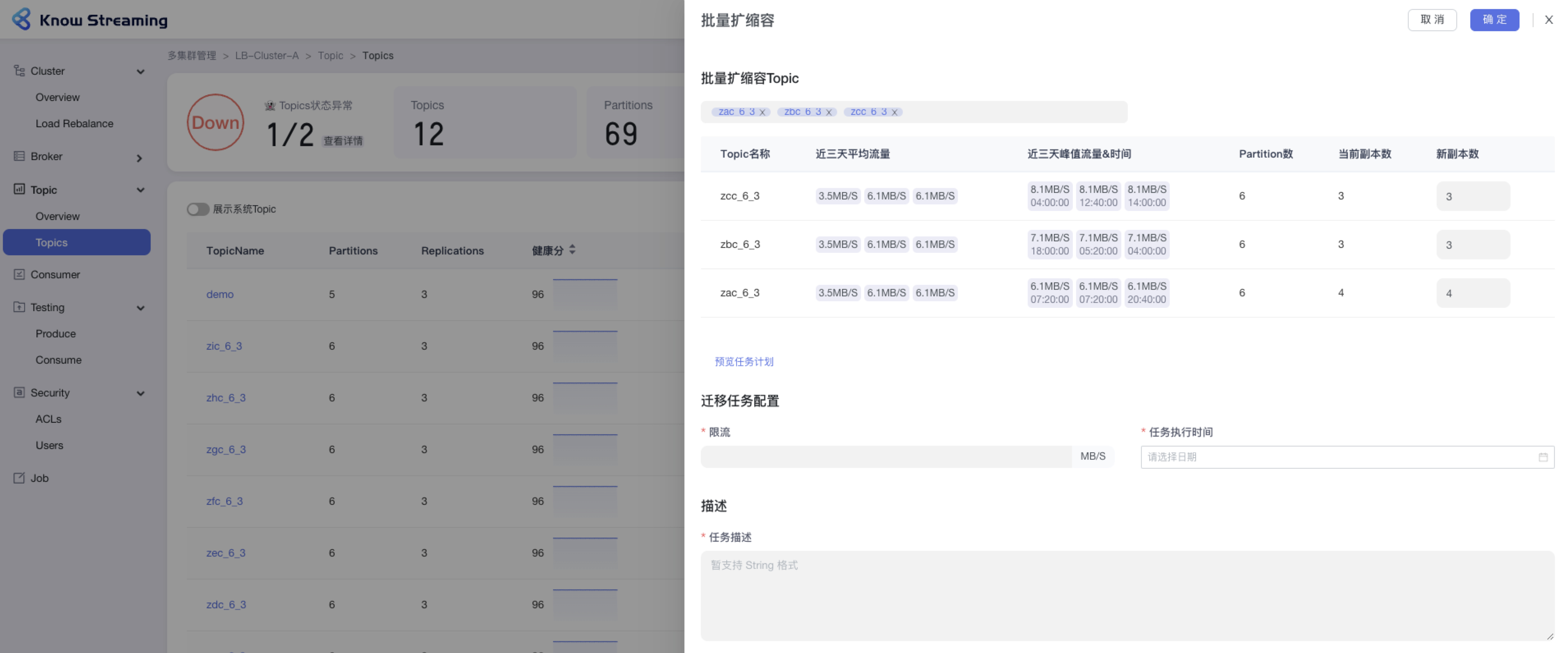
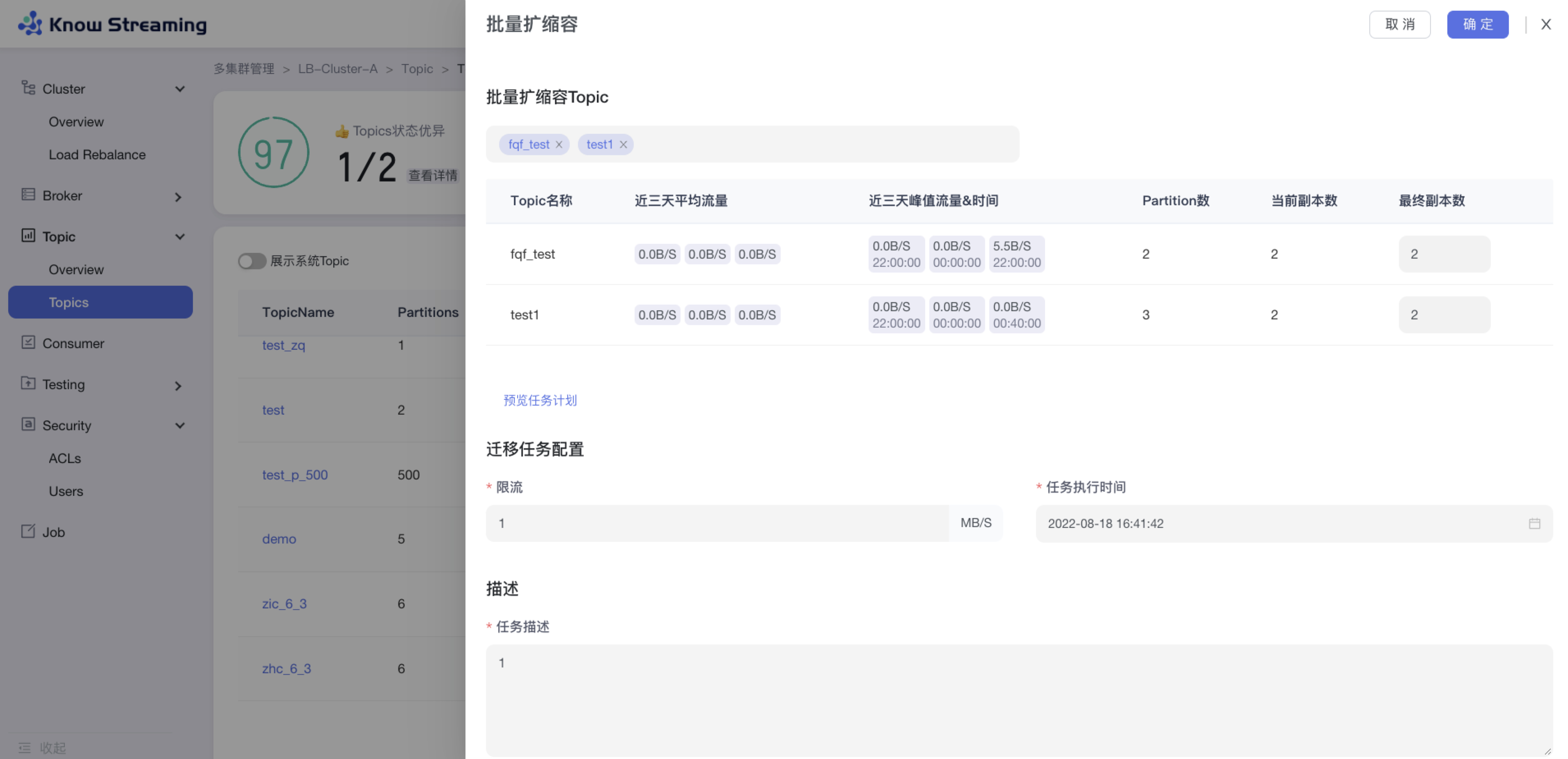
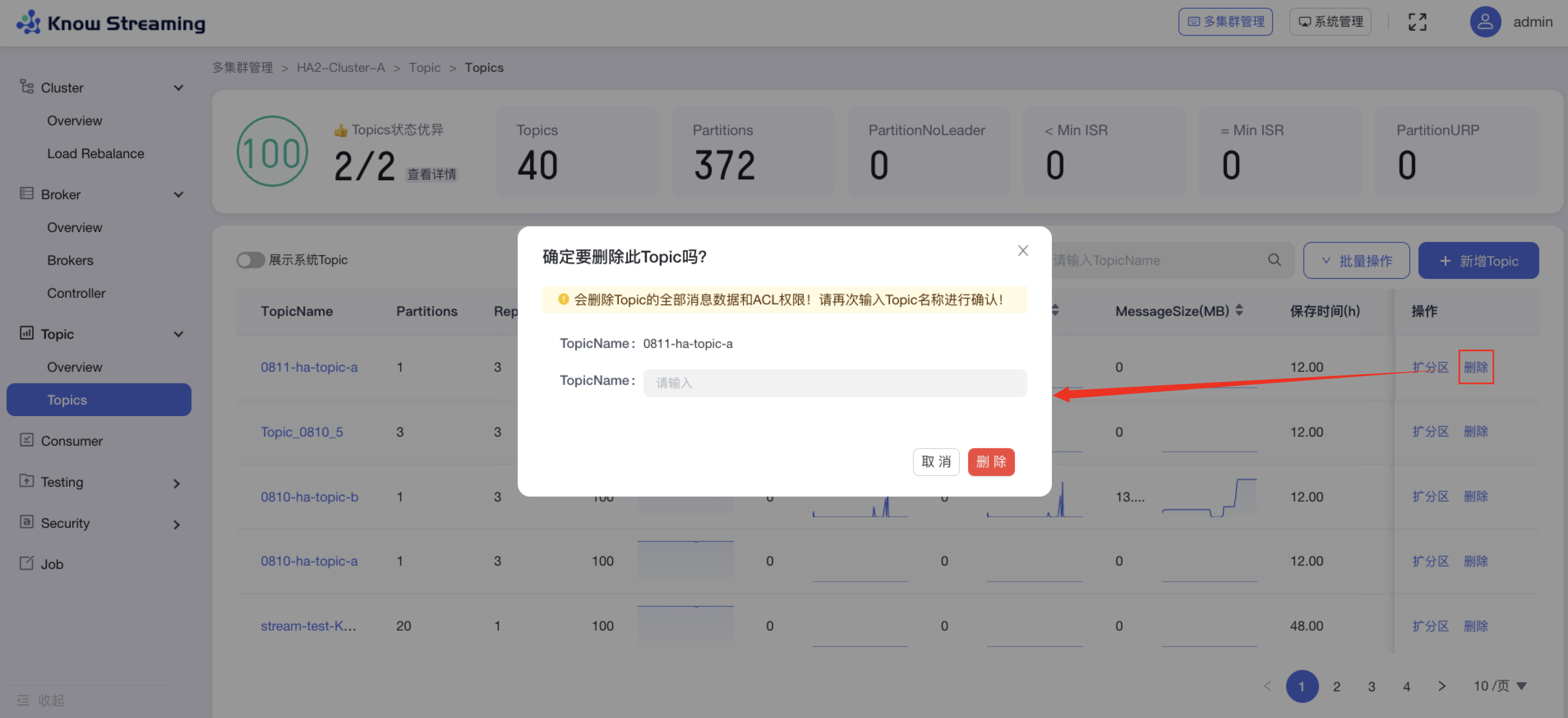
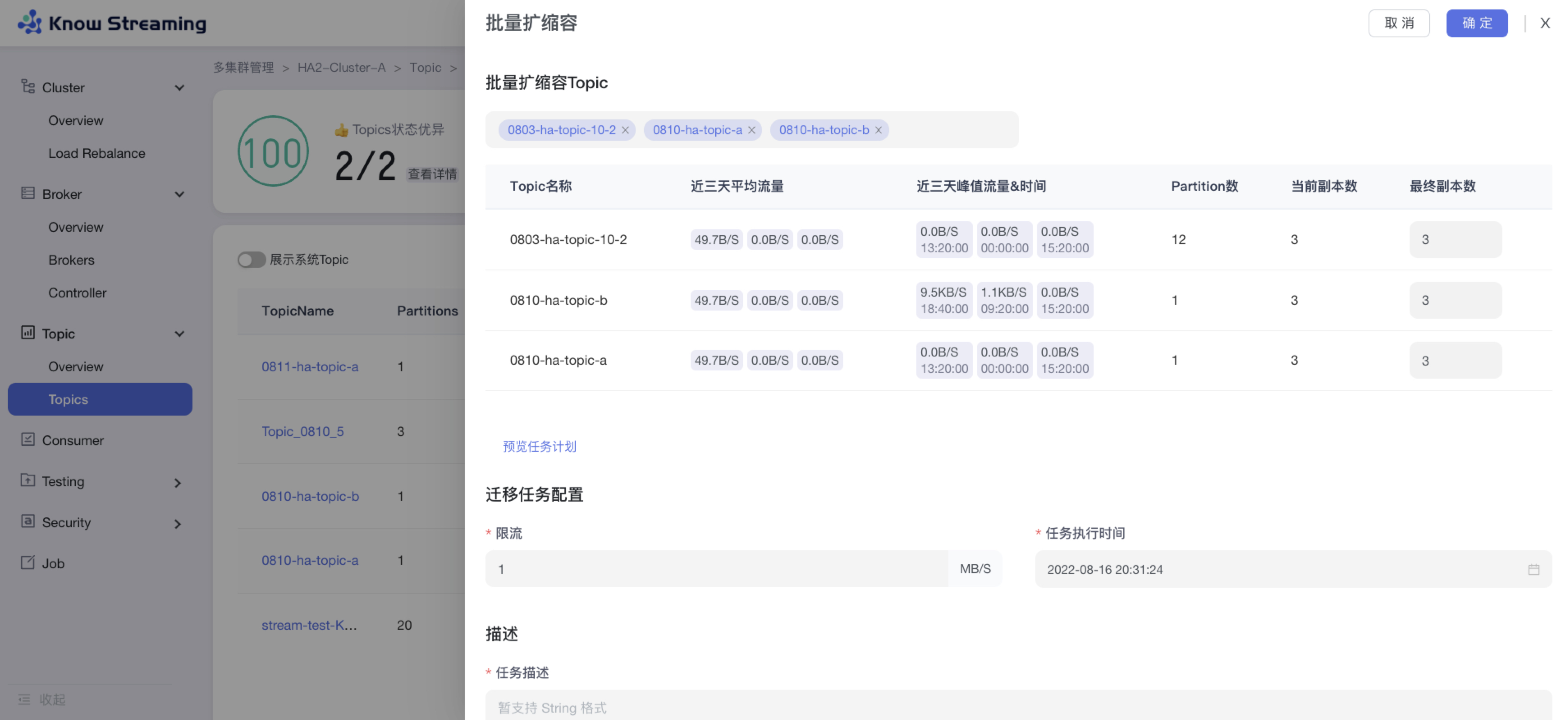
- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“批量操作下拉“>“批量扩缩副本“>“批量扩缩容”抽屉
@@ -108,9 +88,9 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 8:去“Job”模块的 Job 列表查看创建的任务,如果已经执行则可以查看执行进度;如果未开始执行则可以编辑任务
-
+
-### 5.5.6、Topic 批量迁移
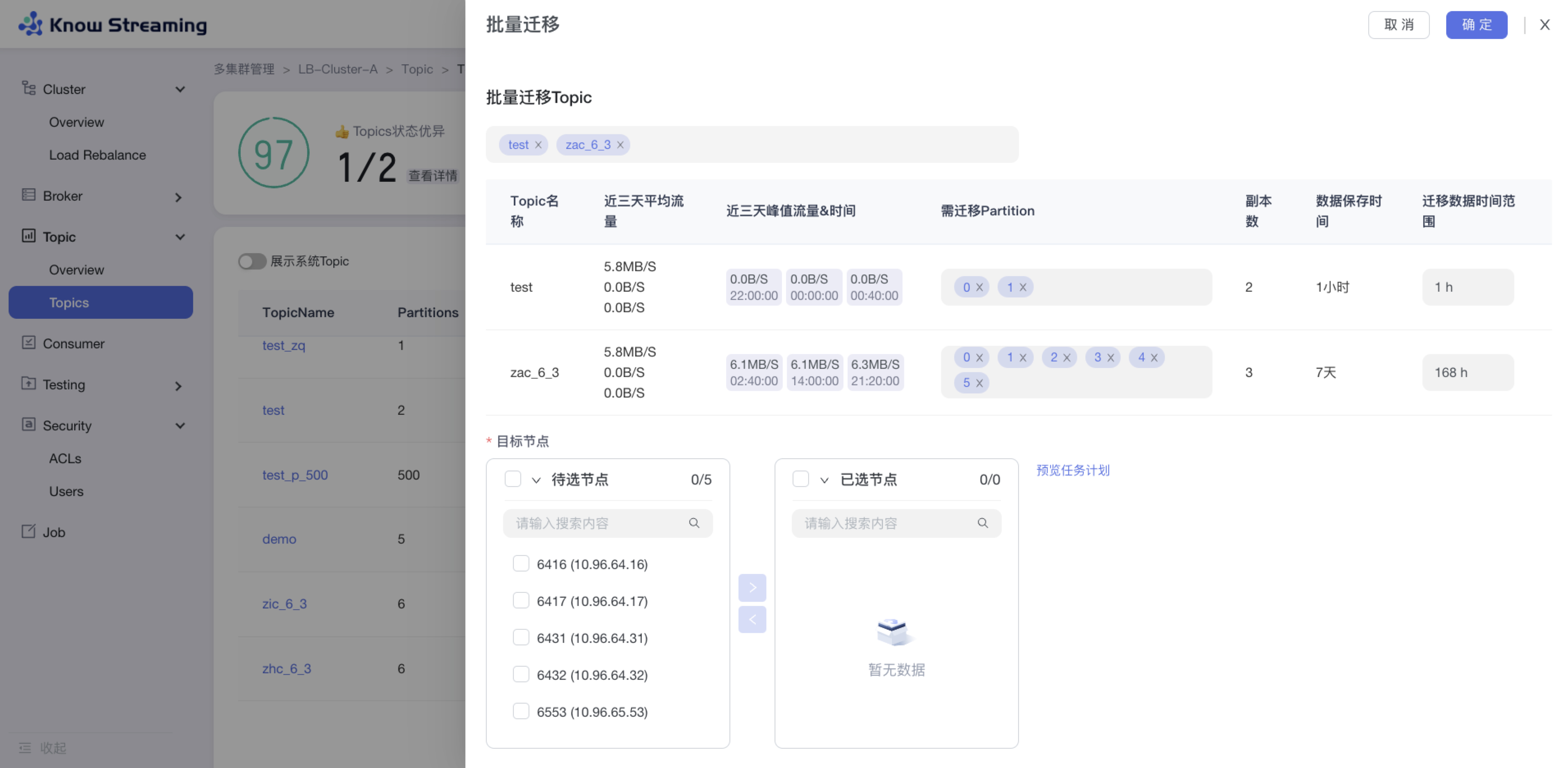
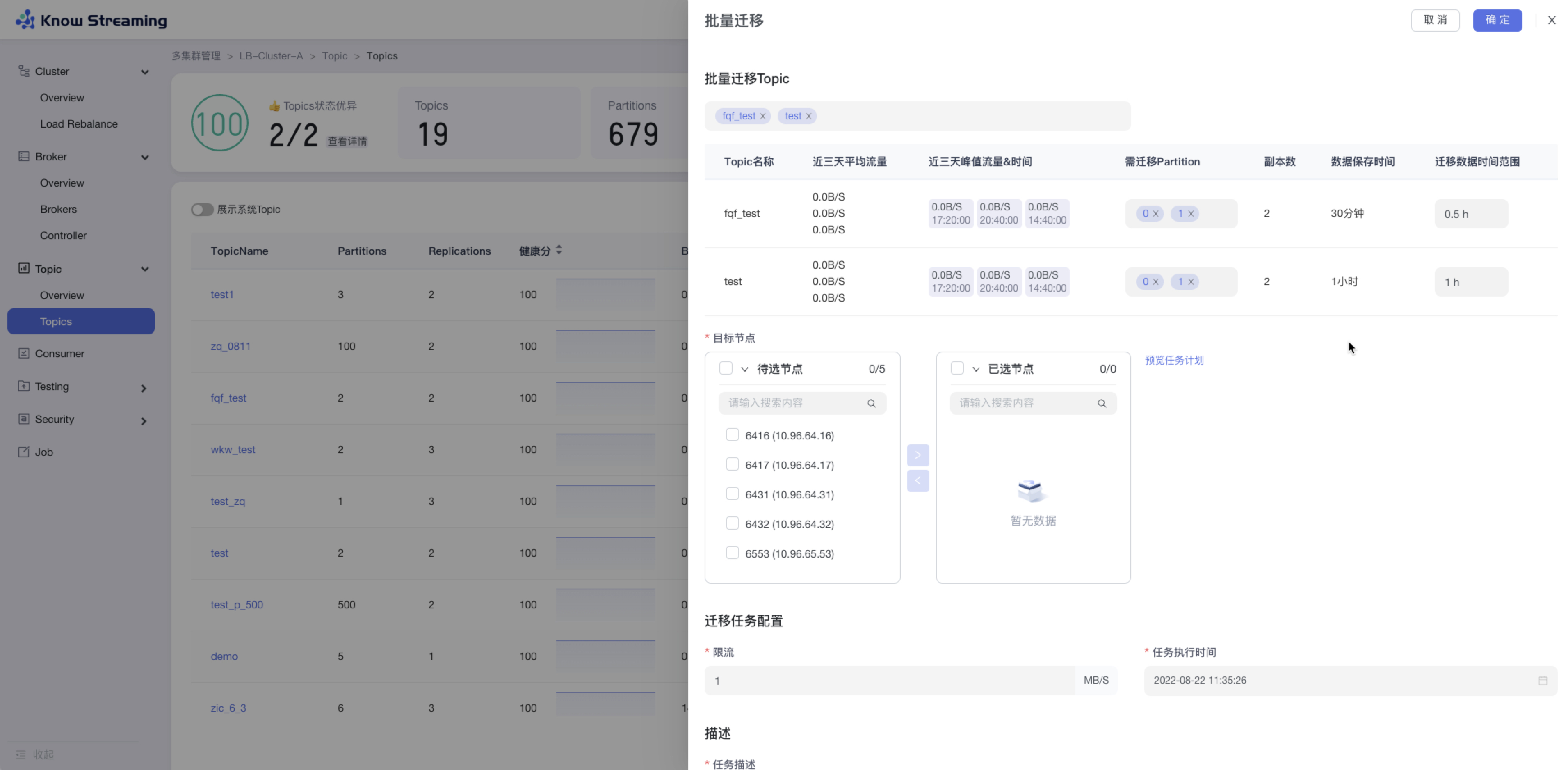
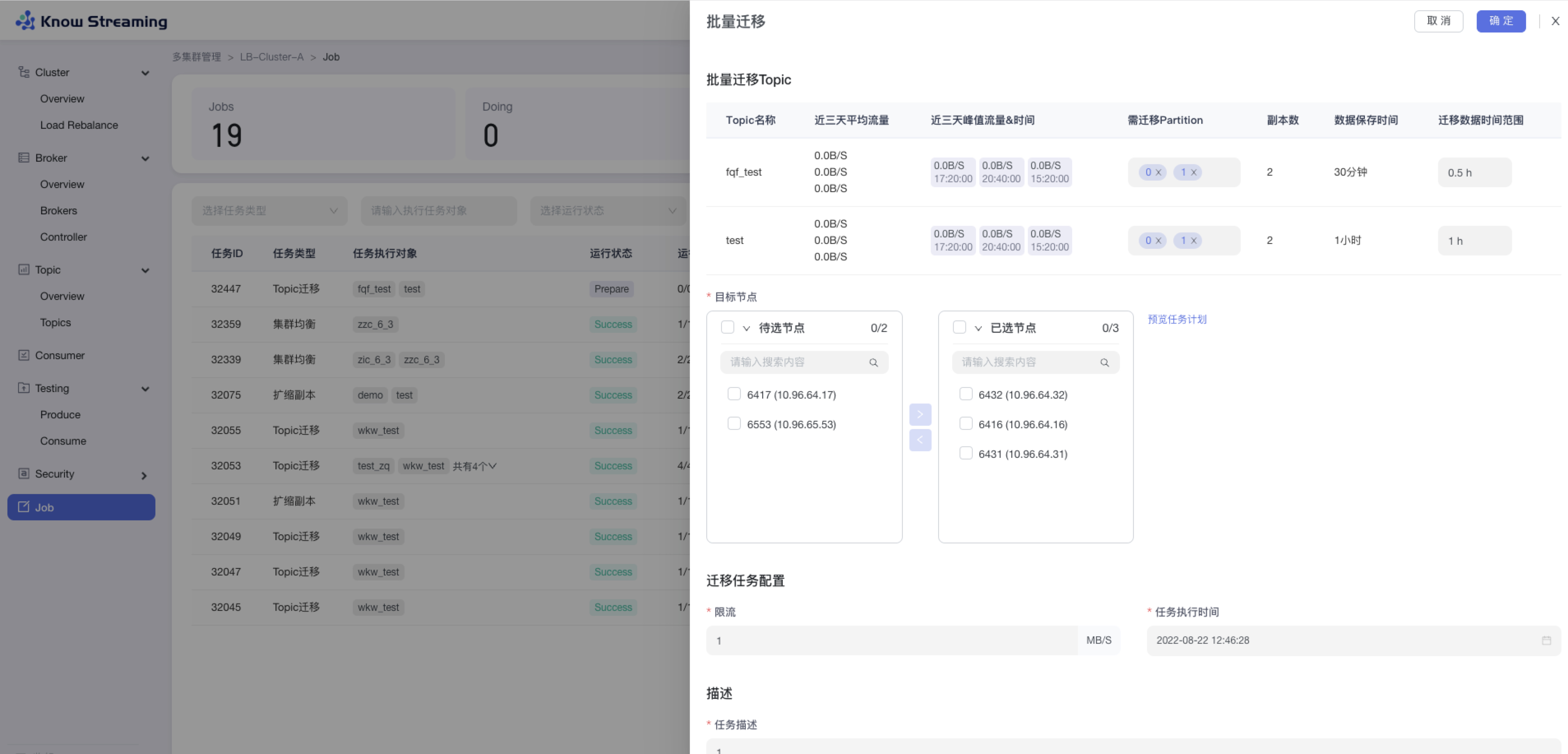
+### 5.3.6、Topic 批量迁移
- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“批量操作下拉“>“批量迁移“>“批量迁移”抽屉
@@ -130,9 +110,9 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 9:去“Job”模块的 Job 列表查看创建的任务,如果已经执行则可以查看执行进度;如果未开始执行则可以编辑任务
-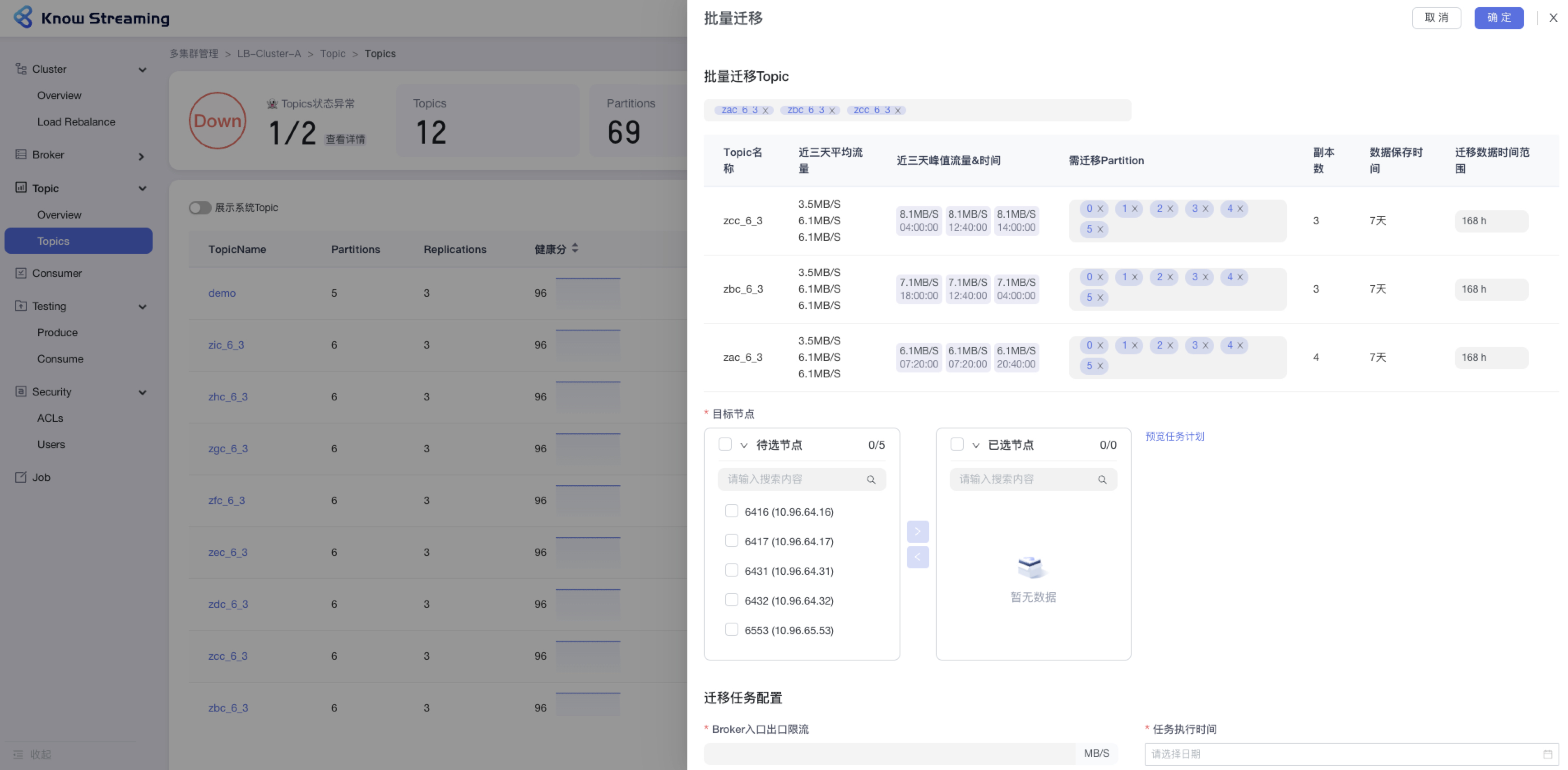
+
-### 5.5.7、设置 Cluster 健康检查规则
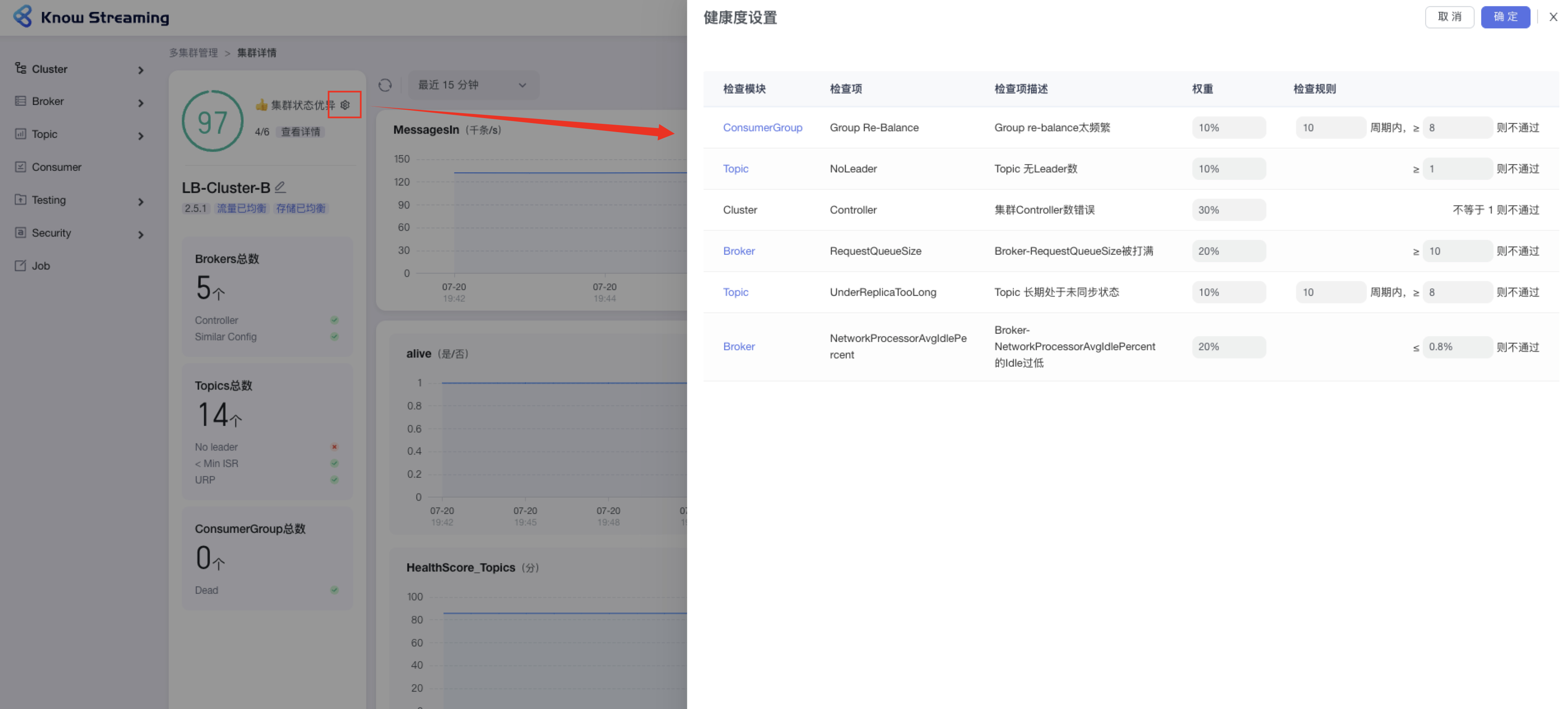
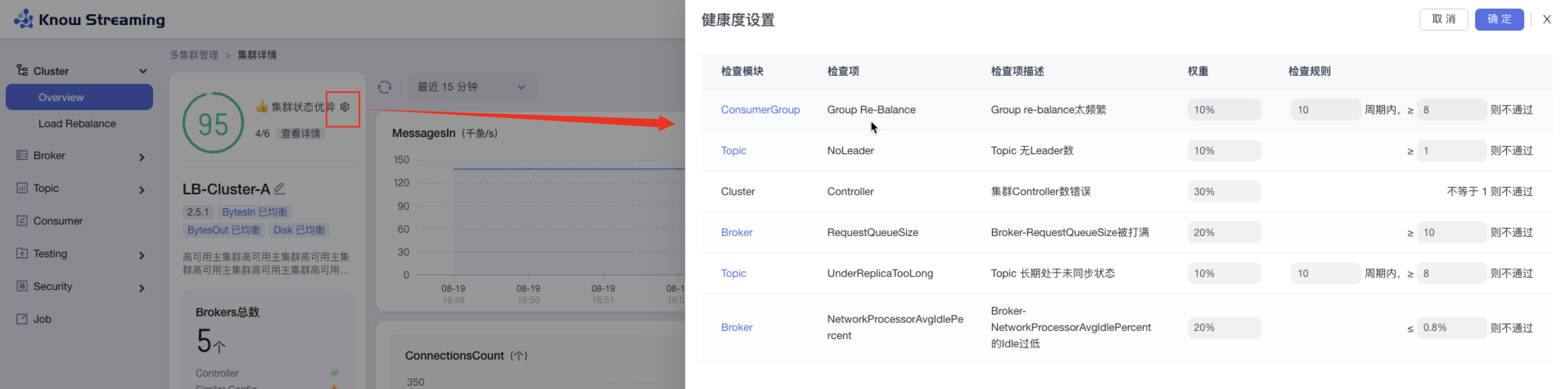
+### 5.3.7、设置 Cluster 健康检查规则
- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“集群健康状态旁边 icon”>“健康度设置抽屉”
@@ -149,9 +129,9 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 4:设置完成后,点击“确认”,健康检查规则设置成功
-
+
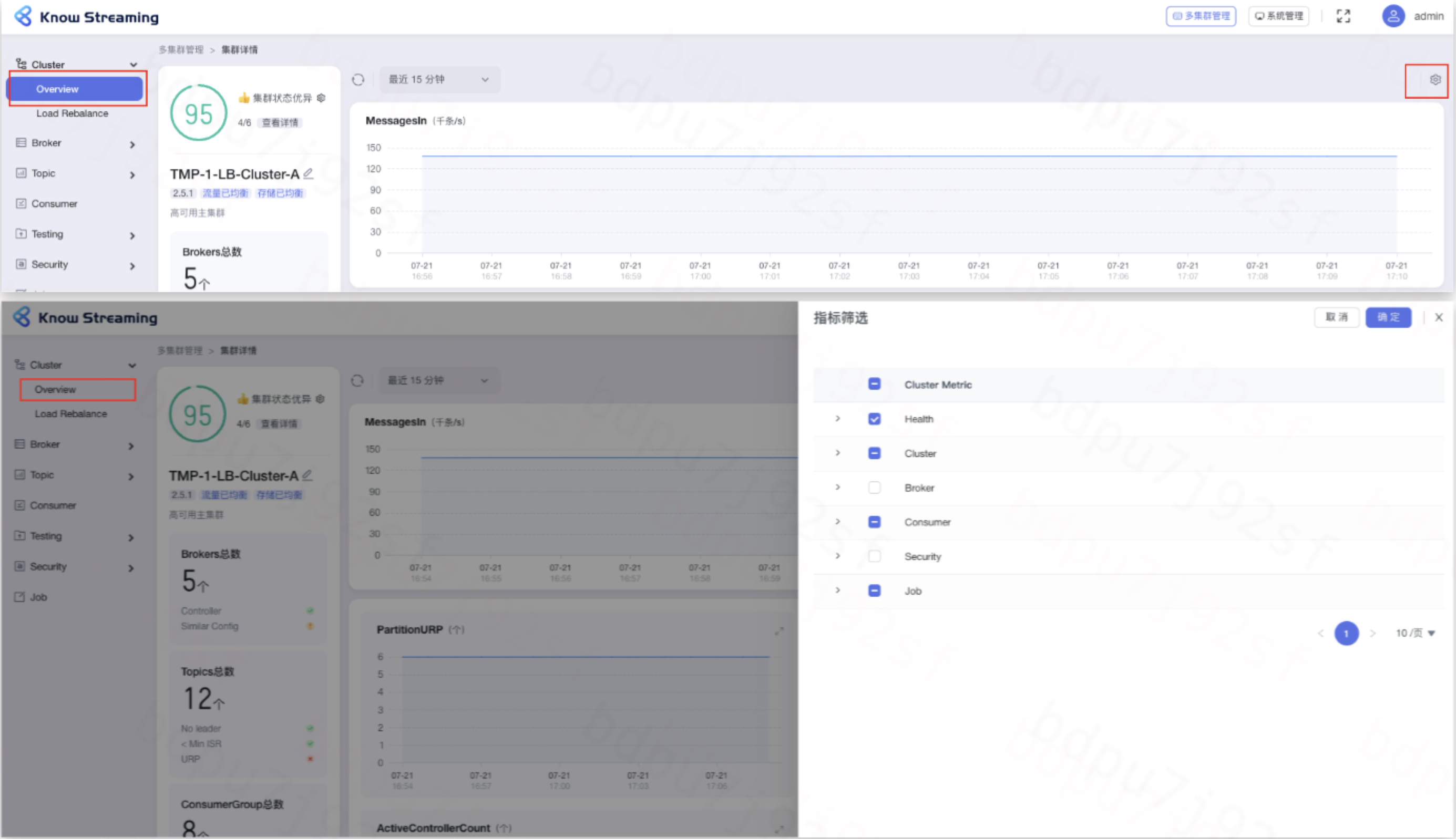
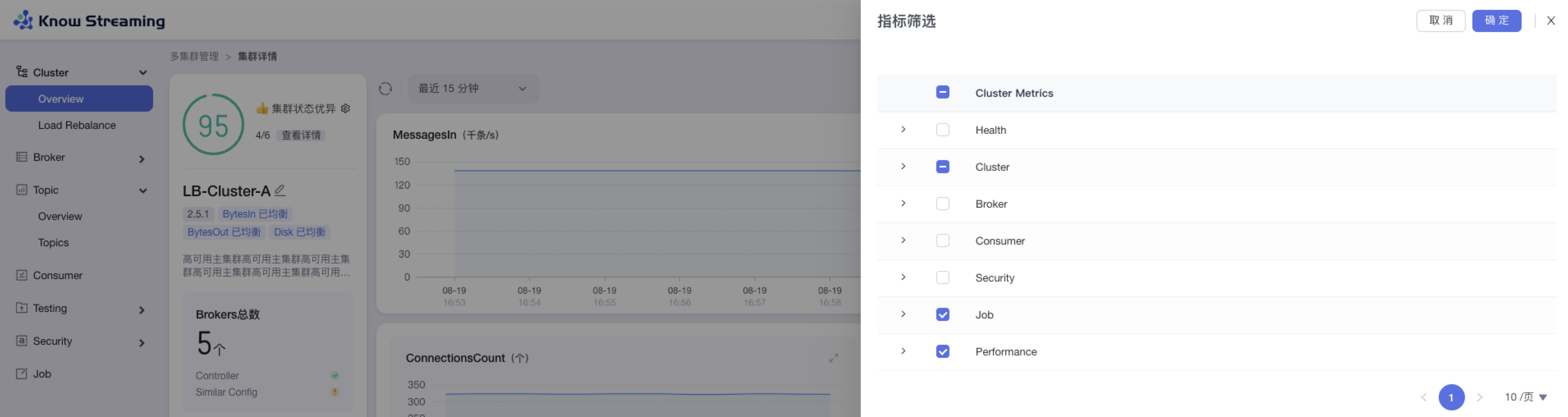
-### 5.5.8、图表指标筛选
+### 5.3.8、图表指标筛选
- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“指标筛选 icon”>“指标筛选抽屉”
@@ -159,9 +139,9 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 3:默认勾选比较重要的指标进行展示。根据需要选中/取消选中相应指标,点击”确认“,指标筛选成功,展示的图表随之变化
-
+
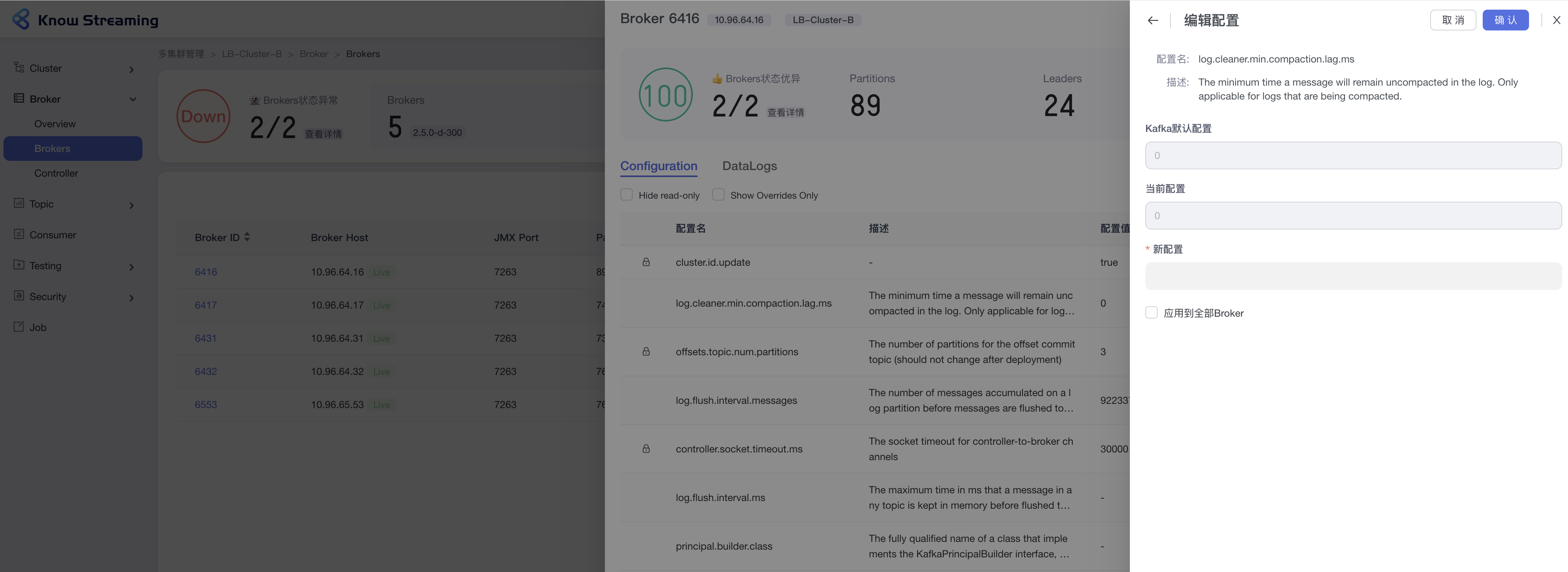
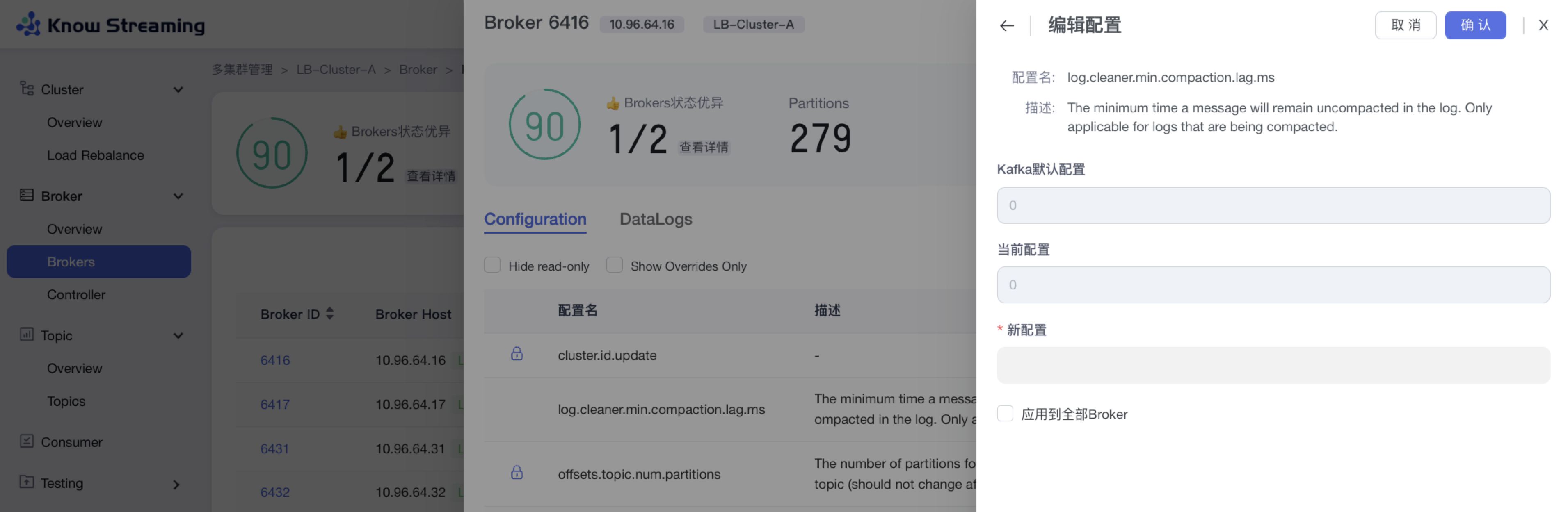
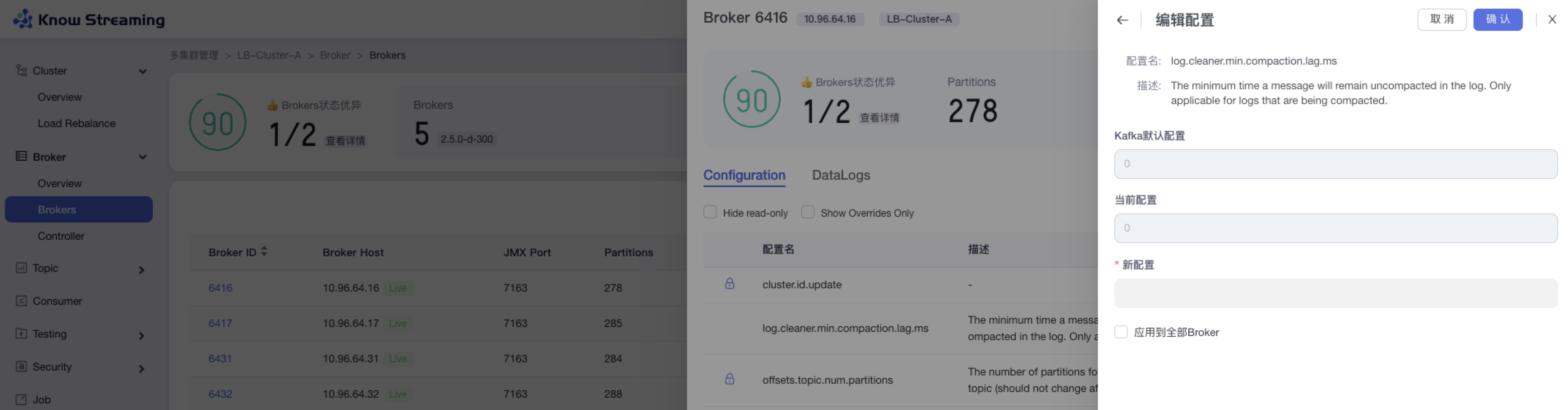
-### 5.5.9、编辑 Broker 配置
+### 5.3.9、编辑 Broker 配置
- 步骤 1:点击“多集群管理”>“集群卡片”>“Brokers”>“Broker ID”>“Configuration”TAB>“编辑”按钮
@@ -171,9 +151,9 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 4:点击“确认”,Broker 配置修改成功
-
+
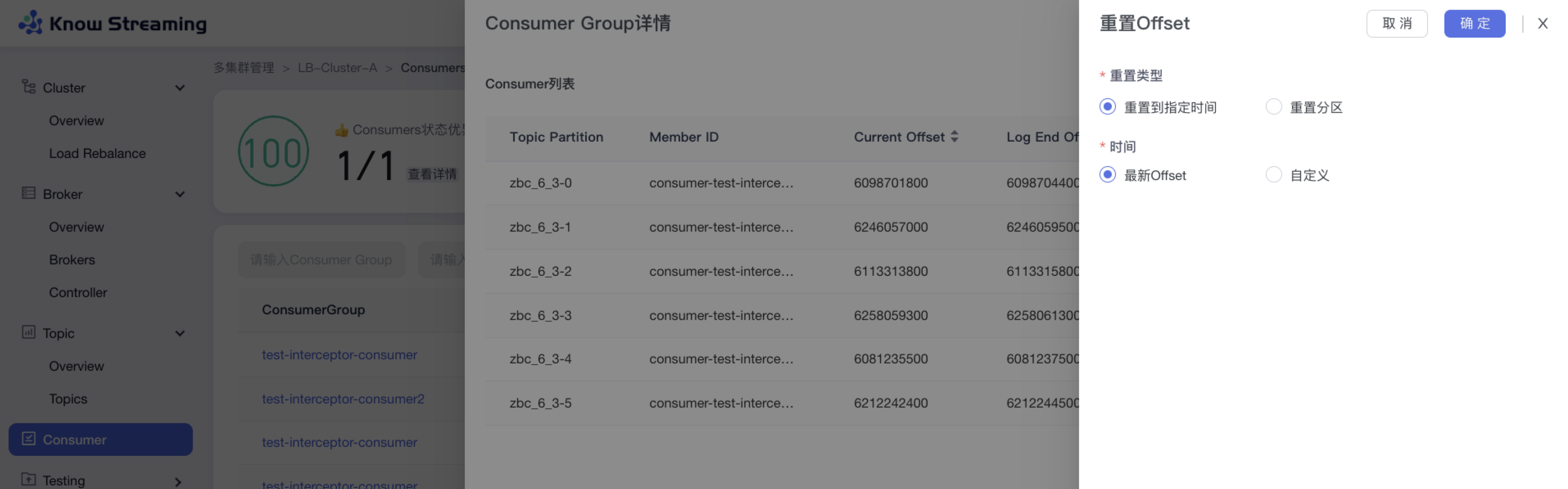
-### 5.5.10、重置 consumer Offset
+### 5.3.10、重置 consumer Offset
- 步骤 1:点击“多集群管理”>“集群卡片”>“Consumer”>“Consumer Group”名称>“Consumer Group 详情”抽屉>“重置 Offset”按钮>“重置 Offset”抽屉
@@ -185,9 +165,9 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 5:点击“确认”,重置 Offset 开始执行
-
+
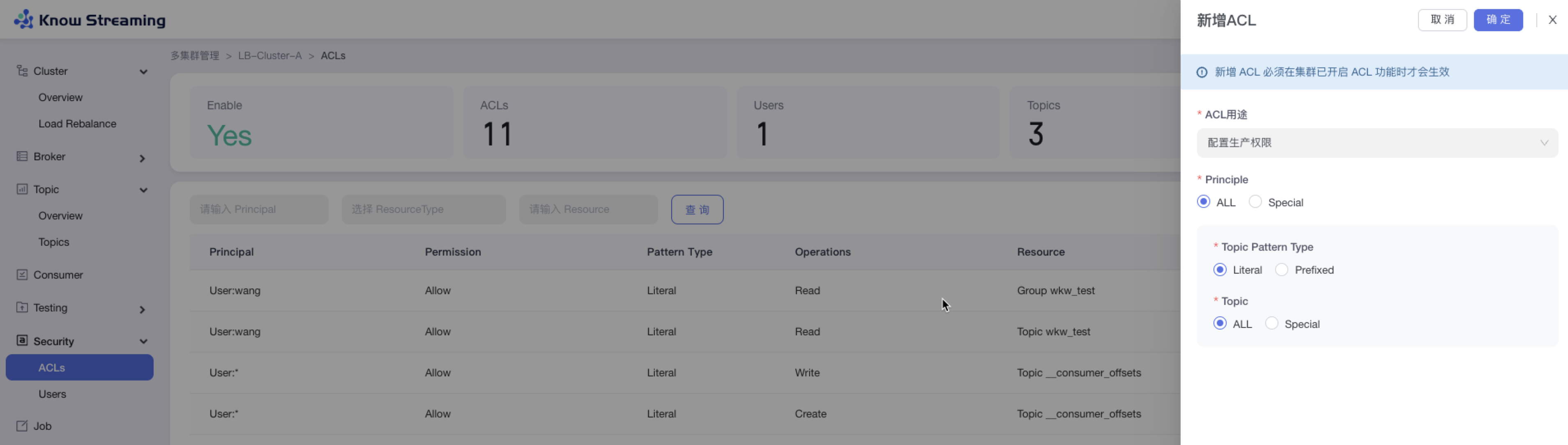
-### 5.5.11、新增 ACL
+### 5.3.11、新增 ACL
- 步骤 1:点击“多集群管理”>“集群卡片”>“Security”>“Users”>“新增 ACL”
@@ -199,26 +179,26 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 3:点击“确定”,新增 ACL 成功
-
+
-## 5.6、页面级别详细功能介绍
+## 5.4、全部功能
-### 5.6.1、登录/退出登录
+### 5.4.1、登录/退出登录
- 登录:输入账号密码,点击登录
- 退出登录:鼠标悬停右上角“头像”或者“用户名”,出现小弹窗“登出”,点击“登出”,退出登录
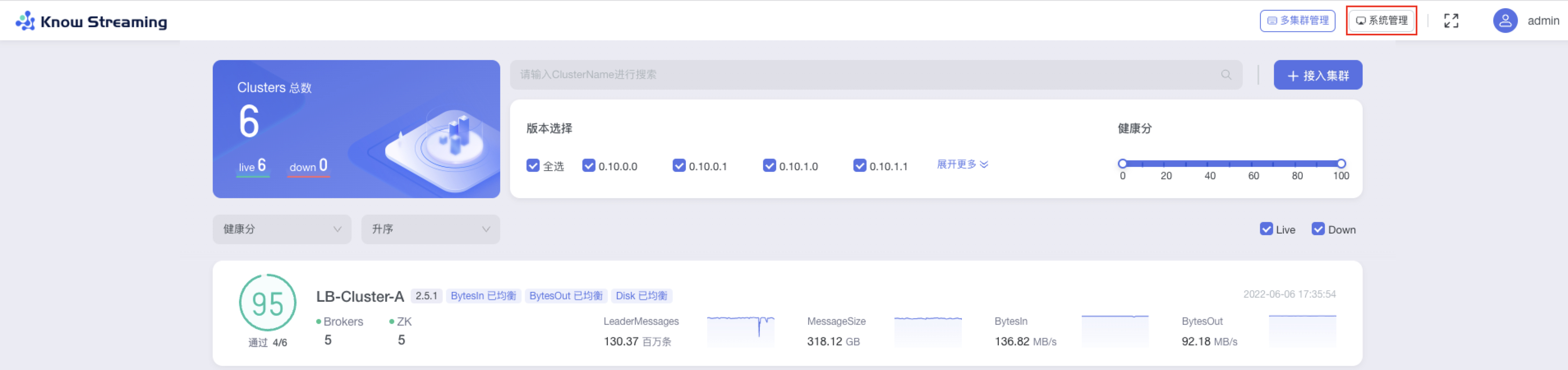
-### 5.6.2、系统管理
+### 5.4.2、系统管理
用户登录完成之后,点击页面右上角【系统管理】按钮,切换到系统管理的视角,可以进行配置管理、用户管理、审计日志查看。
-
+
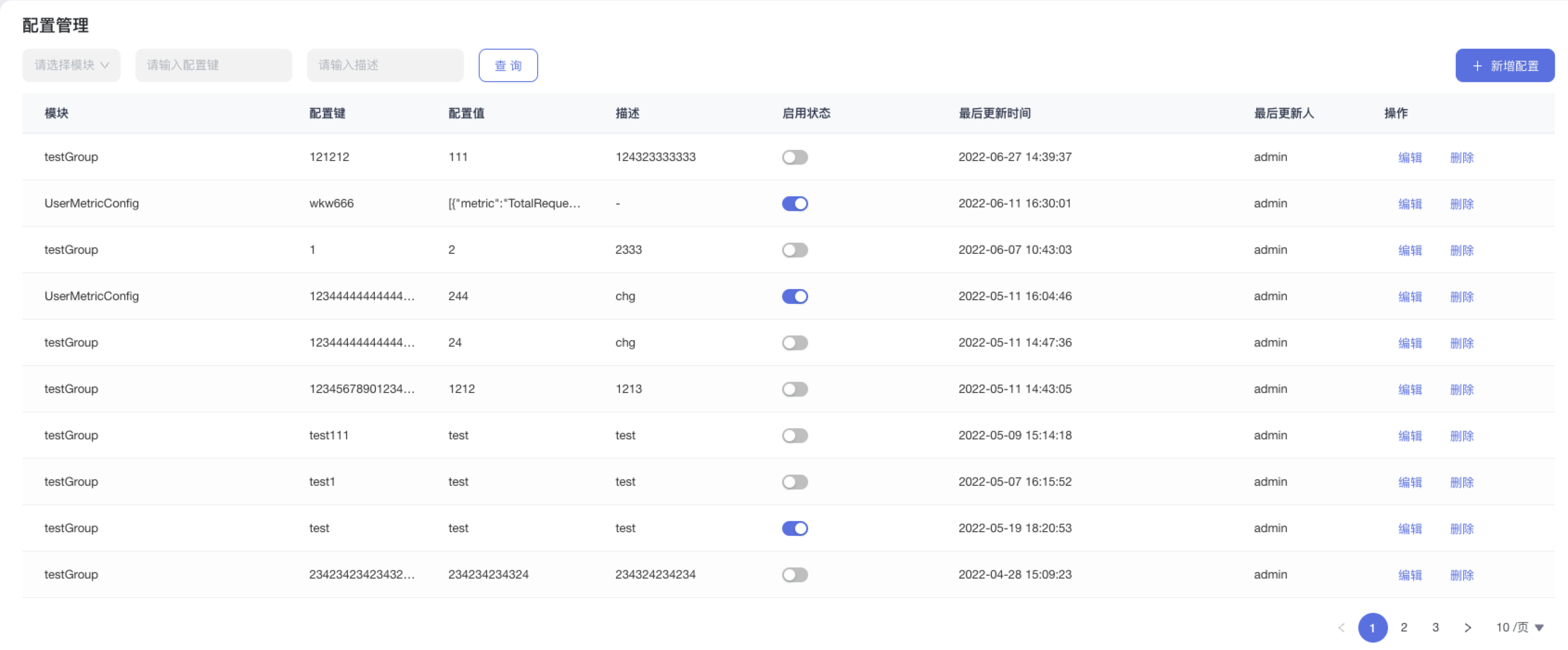
-#### 5.6.2.1、配置管理
+#### 5.4.2.1、配置管理
配置管理是提供给管理员一个快速配置配置文件的能力,所配置的配置文件将会在对应模块生效。
-#### 5.6.2.2、查看配置列表
+#### 5.4.2.2、查看配置列表
- 步骤 1:点击”系统管理“>“配置管理”
@@ -226,23 +206,23 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
-#### 5.6.2.3、新增配置
+#### 5.4.2.3、新增配置
- 步骤 1:点击“系统管理”>“配置管理”>“新增配置”
- 步骤 2:模块:下拉选择所有可配置的模块;配置键:不限制输入内容,500 字以内;配置值:代码编辑器样式,不限内容不限长度;启用状态开关:可以启用/禁用此项配置
-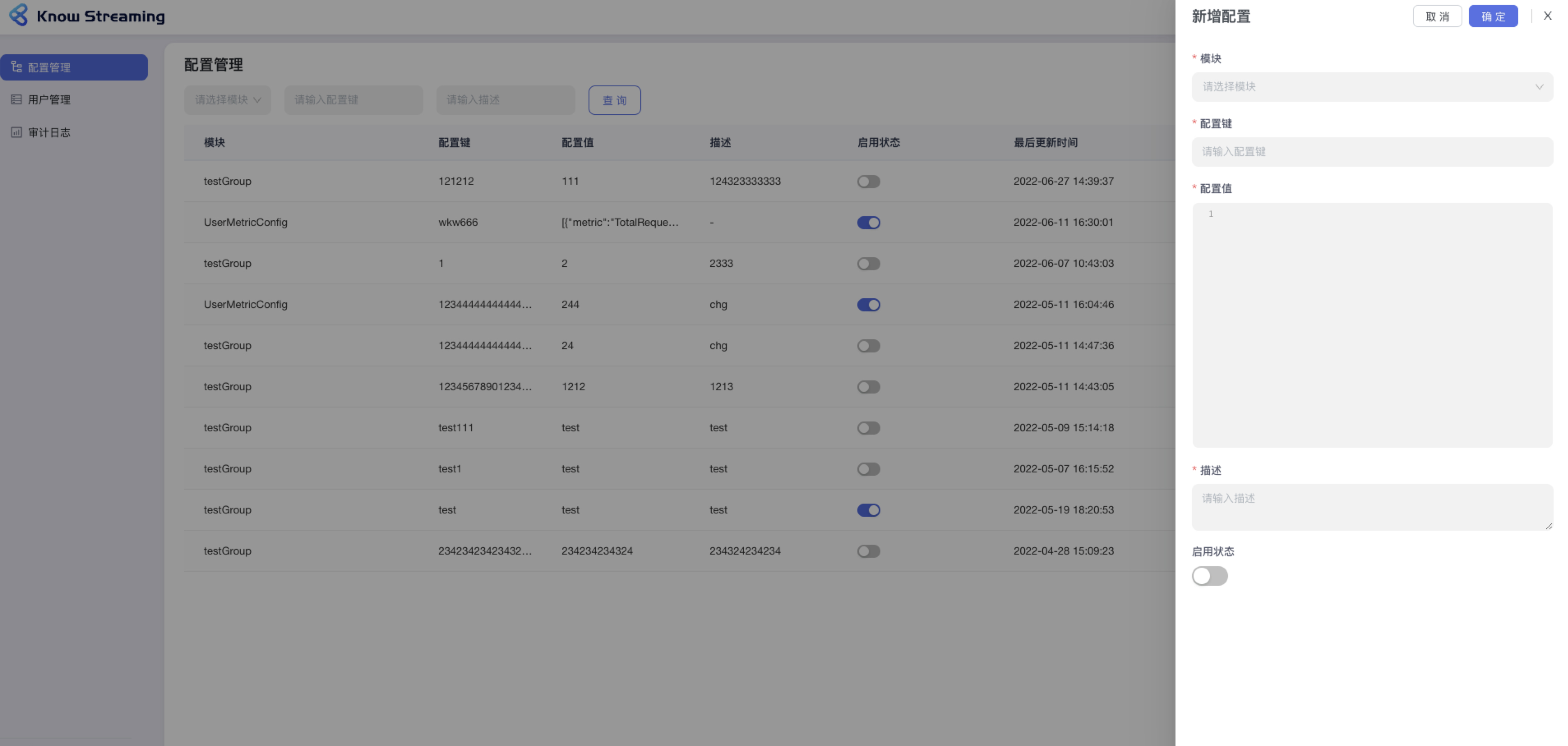
+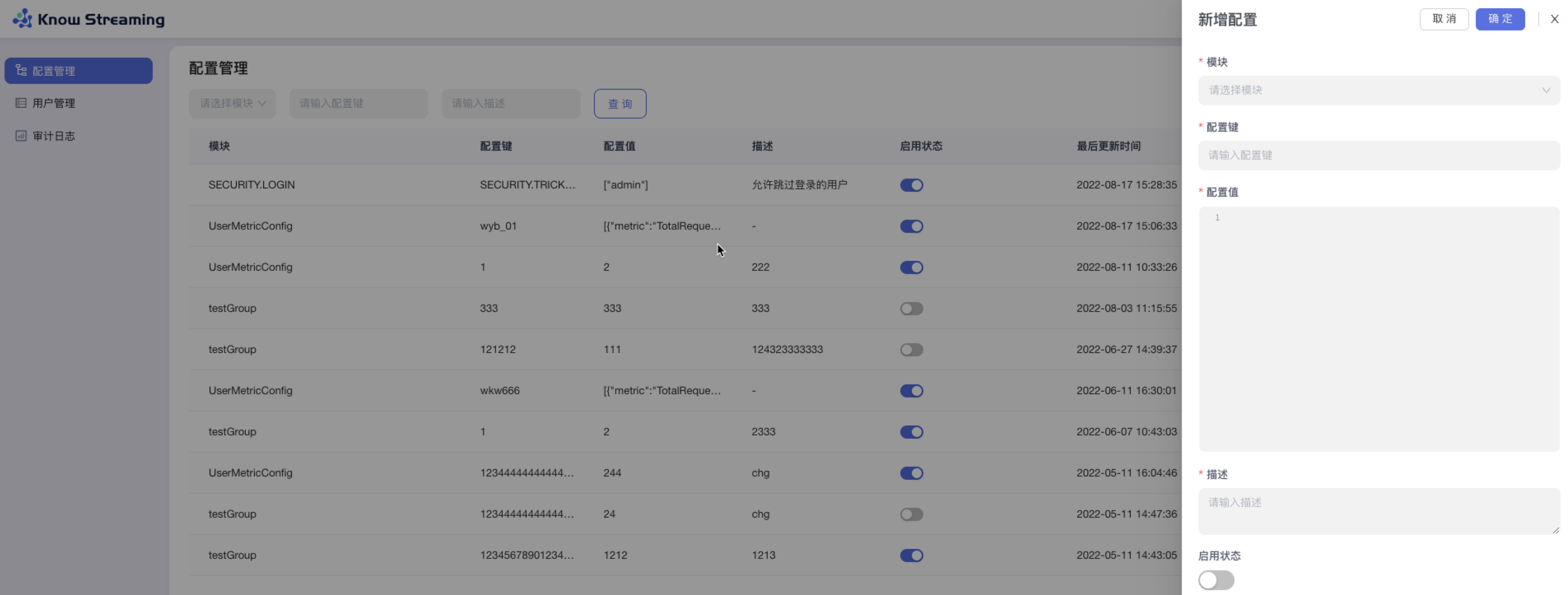
-#### 5.6.2.4、编辑配置
+#### 5.4.2.4、编辑配置
可对配置模块、配置键、配置值、描述、启用状态进行配置。
-#### 5.6.2.5、用户管理
+#### 5.4.2.5、用户管理
用户管理是提供给管理员进行人员管理和用户角色管理的功能模块,可以进行新增用户和分配角色。
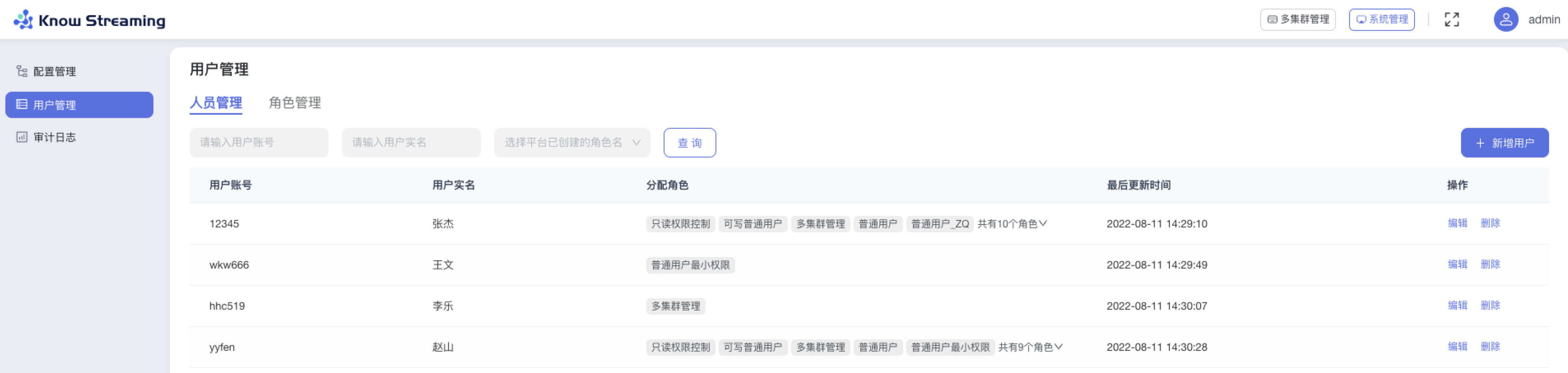
-#### 5.6.2.6、人员管理列表
+#### 5.4.2.6、人员管理列表
- 步骤 1:点击“系统管理”>“用户管理”>“人员管理”
@@ -250,25 +230,25 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 3:列表支持”用户账号“、“用户实名”、“角色名”筛选。
-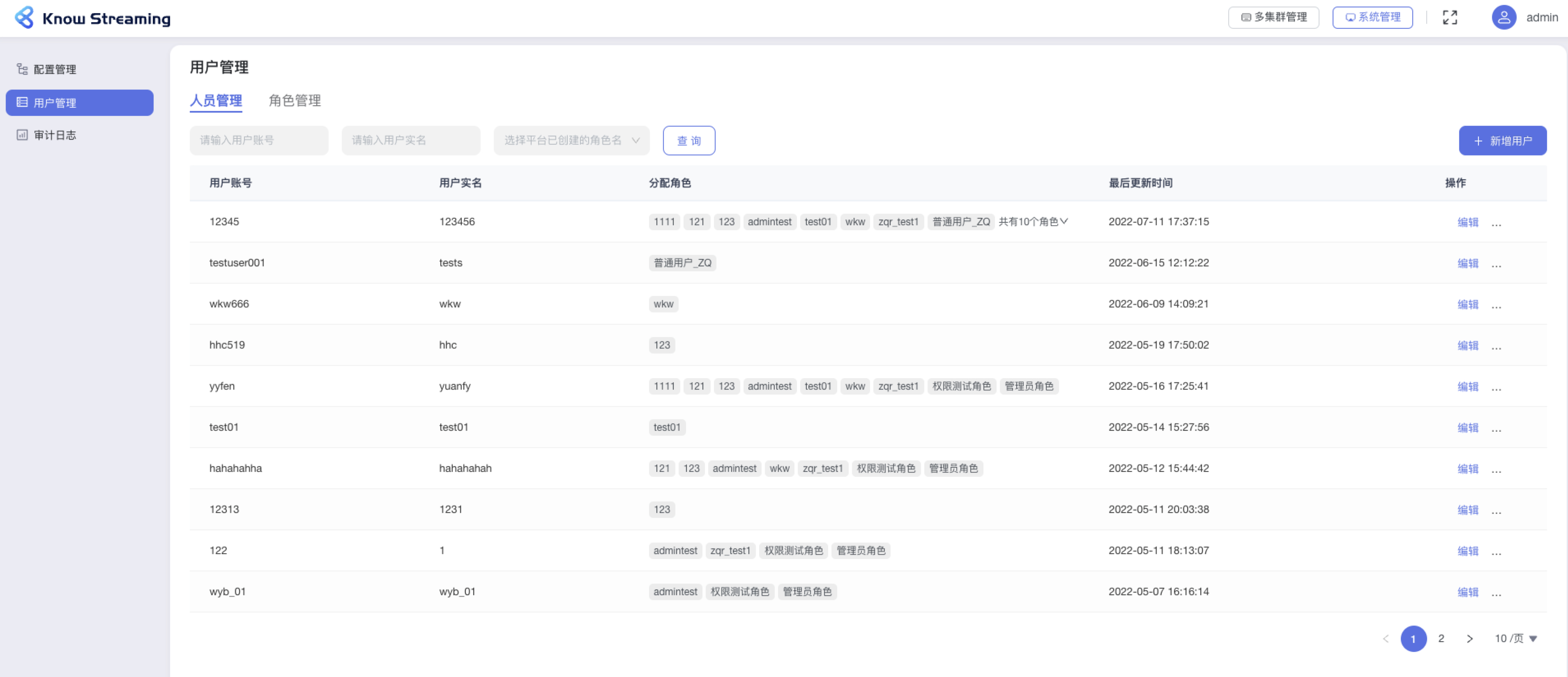
+
-#### 5.6.2.7、新增用户
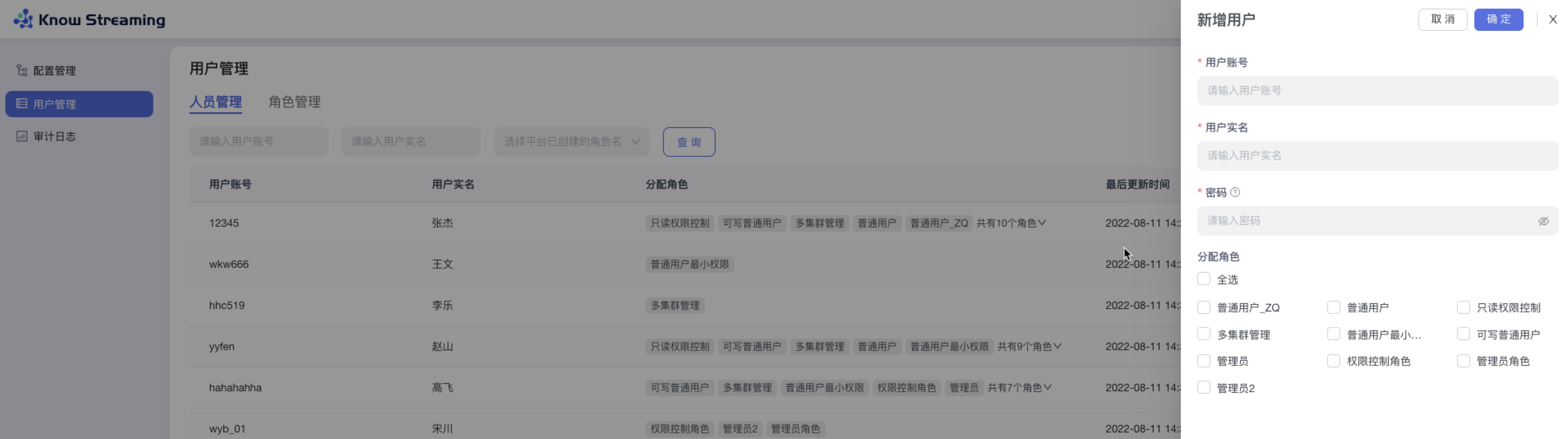
+#### 5.4.2.7、新增用户
- 步骤 1:点击“系统管理”>“用户管理”>“人员管理”>“新增用户”
- 步骤 2:填写“用户账号”、“用户实名”、“用户密码”这些必填参数,可以对此账号分配已经存在的角色。
-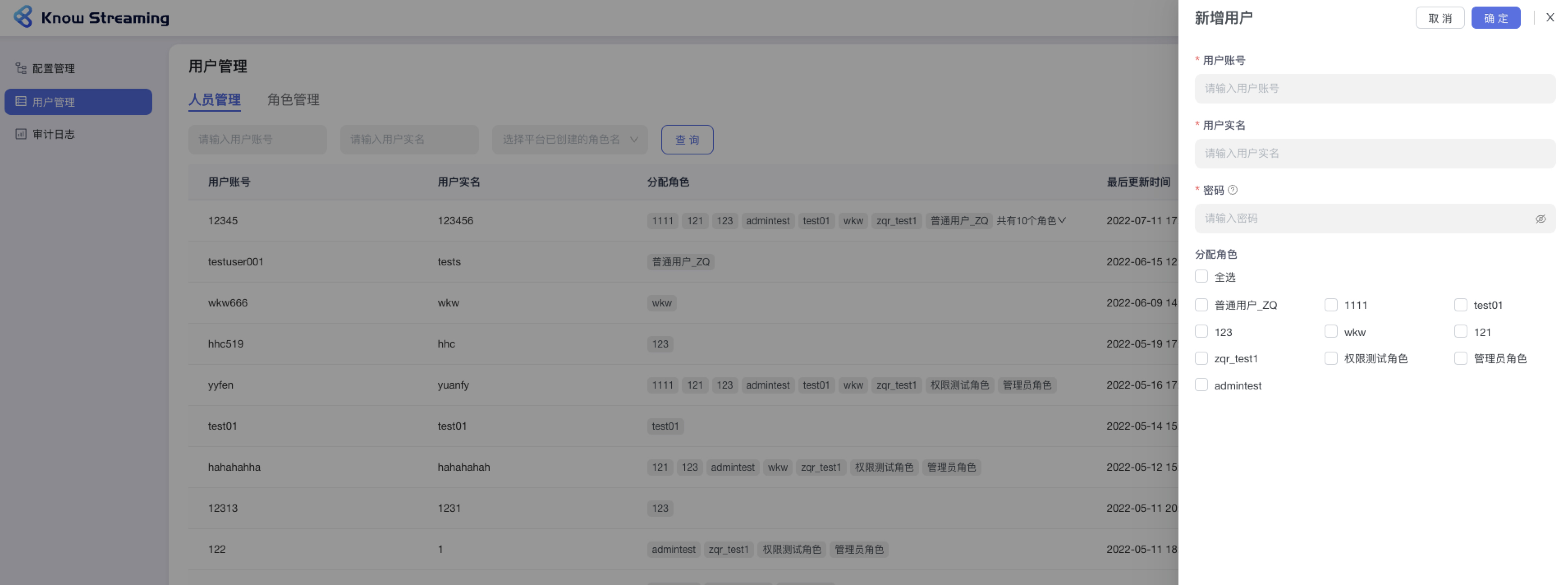
+
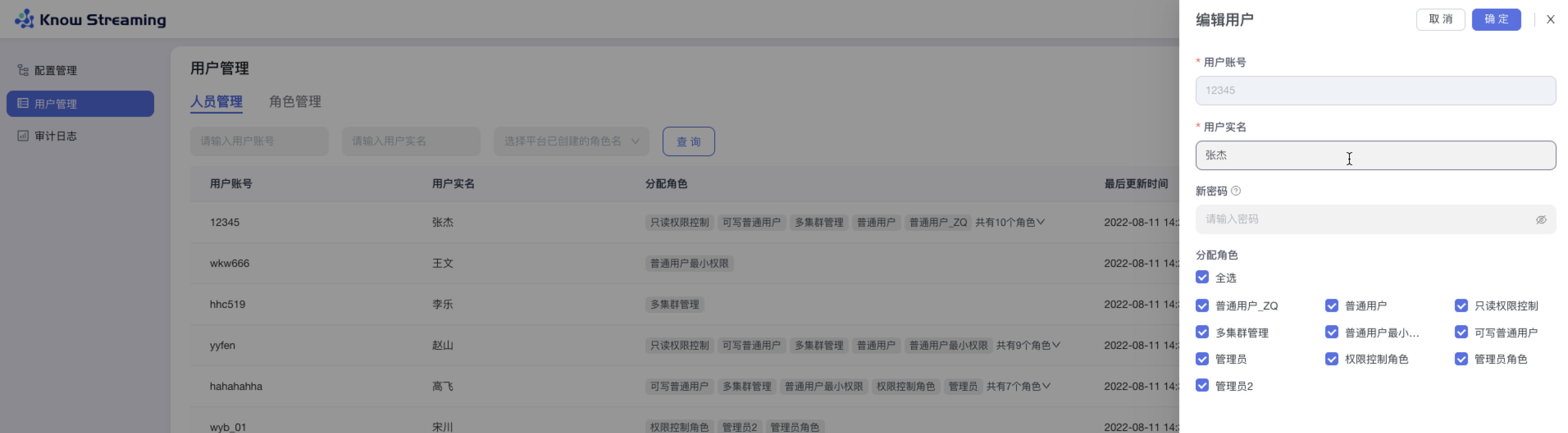
-#### 5.6.2.8、编辑用户
+#### 5.4.2.8、编辑用户
- 步骤 1:点击“系统管理”>“用户管理”>“人员管理”>列表操作项“编辑”
- 步骤 2:用户账号不可编辑;可以编辑“用户实名”,修改“用户密码”,重新分配“用户角色“
-
+
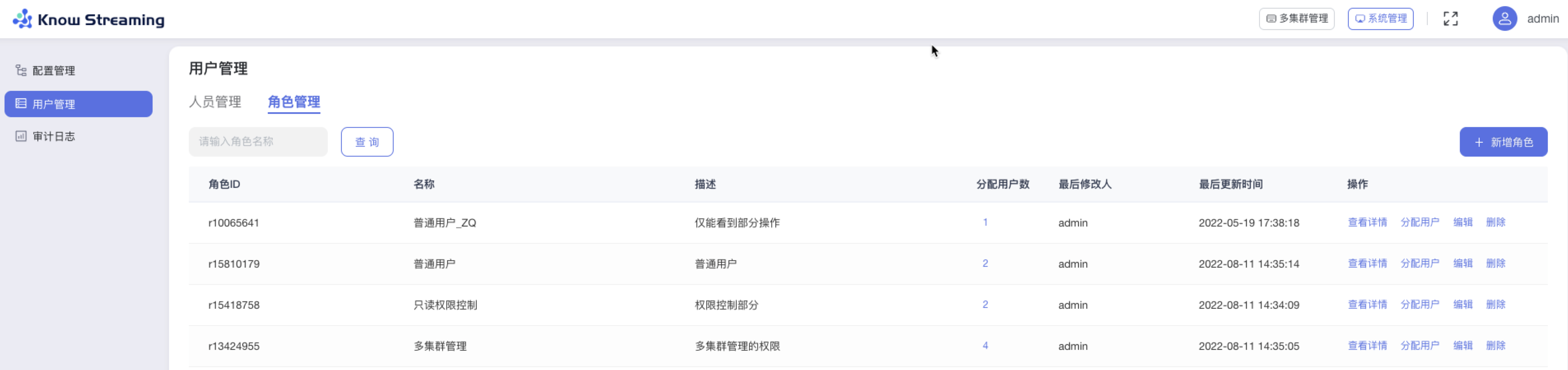
-#### 5.6.2.9、角色管理列表
+#### 5.4.2.9、角色管理列表
- 步骤 1:点击“系统管理”>“用户管理”>“角色管理”
@@ -278,17 +258,17 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 4:列表操作项,“查看详情”可查看到角色绑定的权限项,”分配用户“可对此项角色下绑定的用户进行增减
-
+
-#### 5.6.2.10、新增角色
+#### 5.4.2.10、新增角色
- 步骤 1:点击“系统管理”>“用户管理”>“角色管理”>“新增角色”
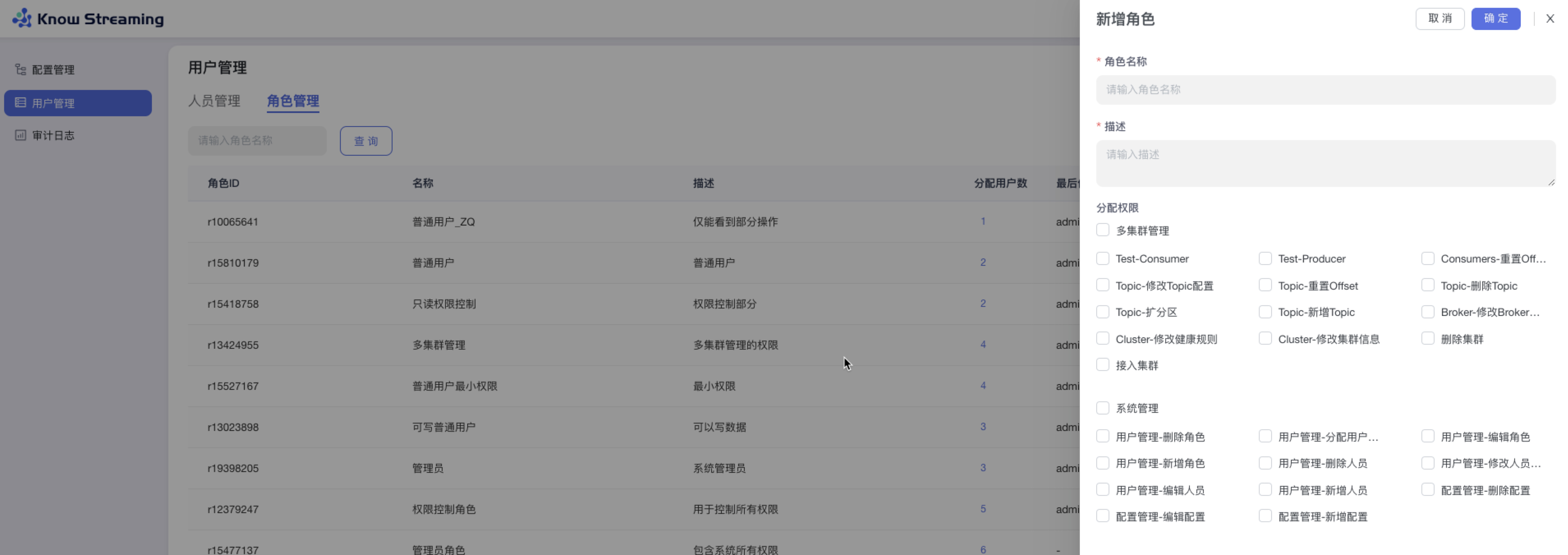
- 步骤 2:输入“角色名称”(角色名称只能由中英文大小写、数字、下划线\_组成,长度限制在 3 ~ 128 字符)、“角色描述“(不能为空)、“分配权限“(至少需要分配一项权限),点击确认,新增角色成功添加到角色列表
-
+
-#### 5.6.2.11、审计日志
+#### 5.4.2.11、审计日志
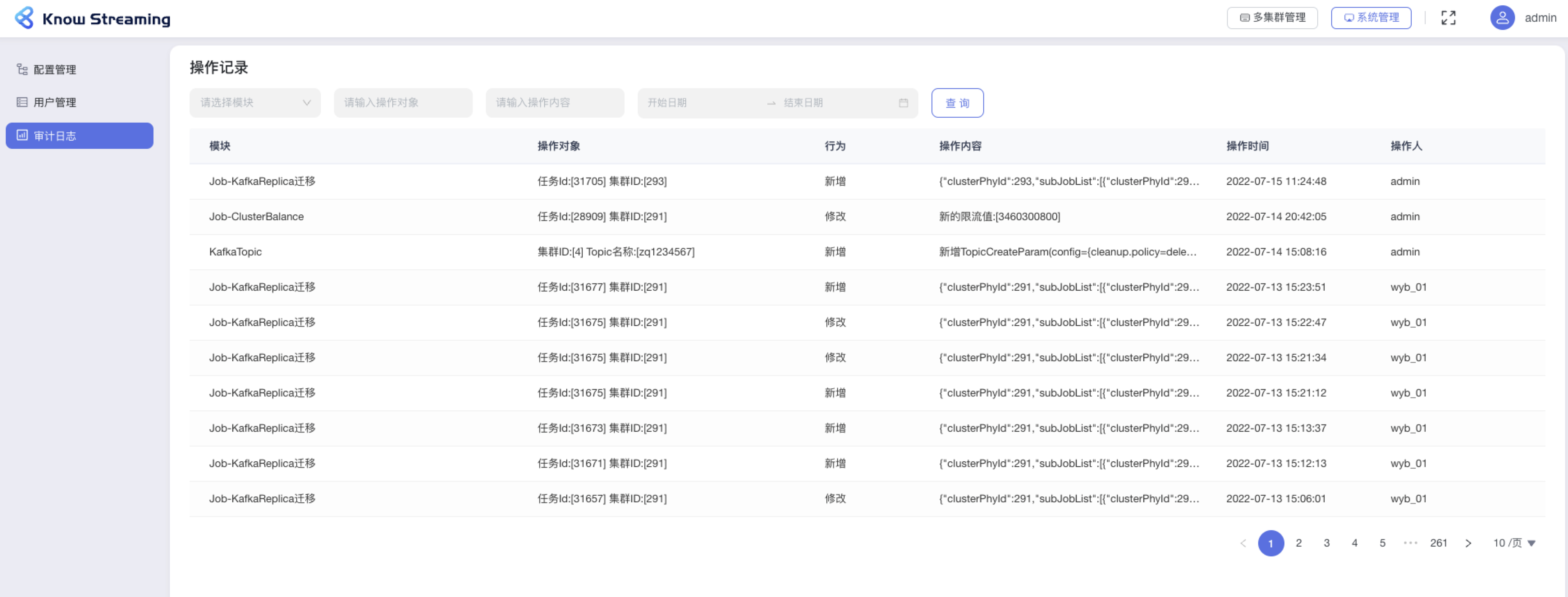
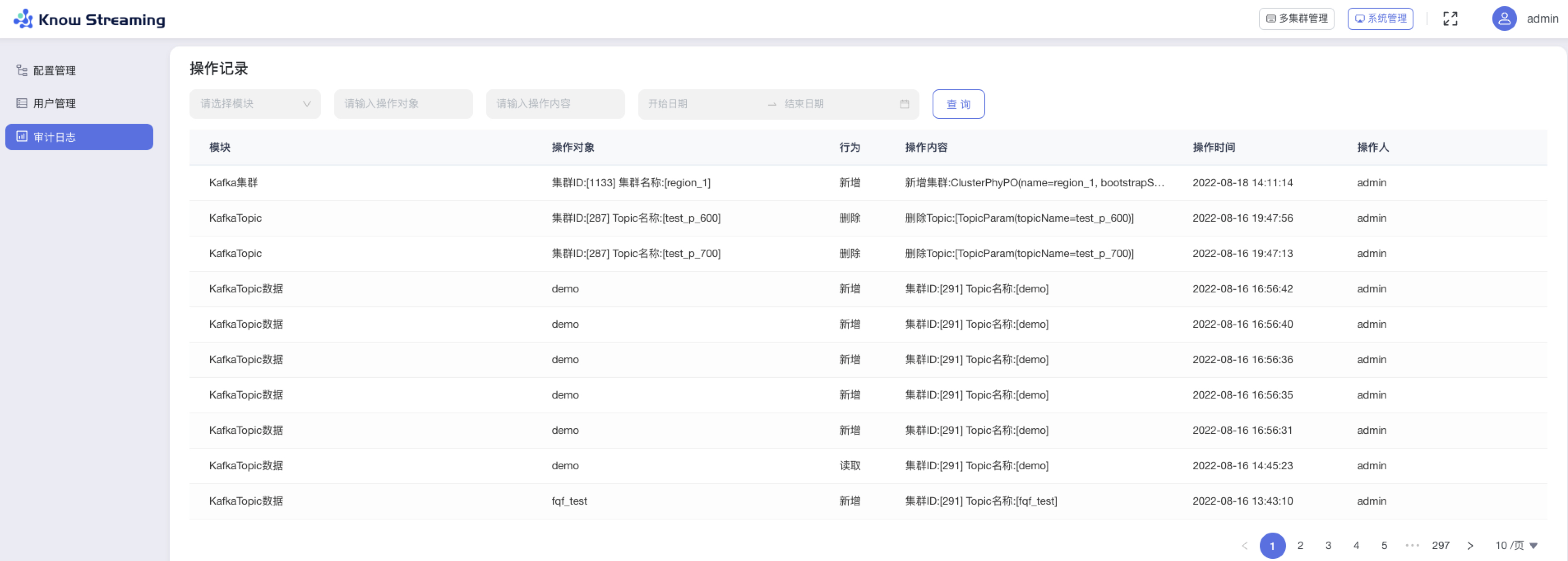
- 步骤 1:点击“系统管理”>“审计日志“
- 步骤 2:审计日志包含所有对于系统的操作记录,操作记录列表展示信息为下
@@ -302,11 +282,11 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 3:操作记录列表可以对“模块“、”操作对象“、“操作内容”、”操作时间“进行筛选
-
+
-### 5.6.3、多集群管理
+### 5.4.3、多集群管理
-#### 5.6.3.1、多集群列表
+#### 5.4.3.1、多集群列表
- 步骤 1:点击顶部导航栏“多集群管理”
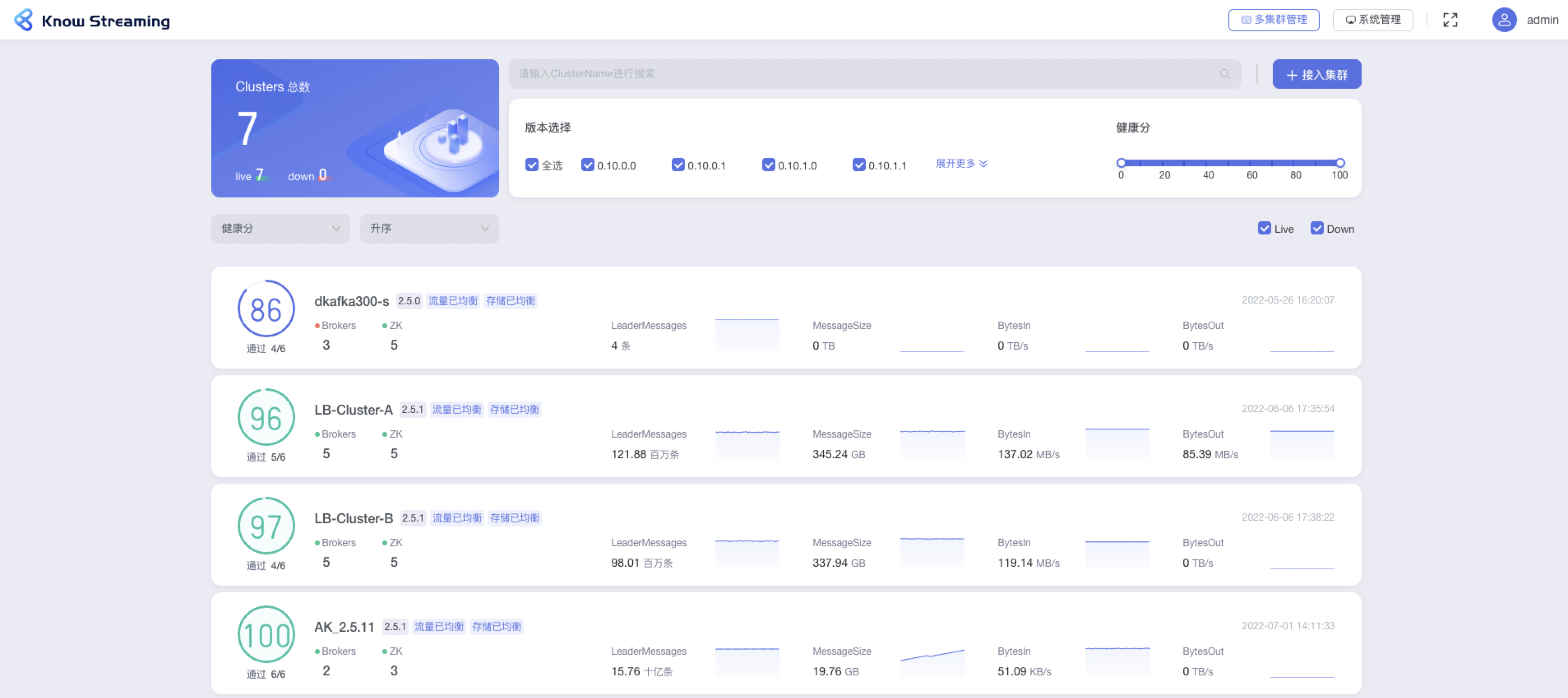
@@ -322,33 +302,34 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
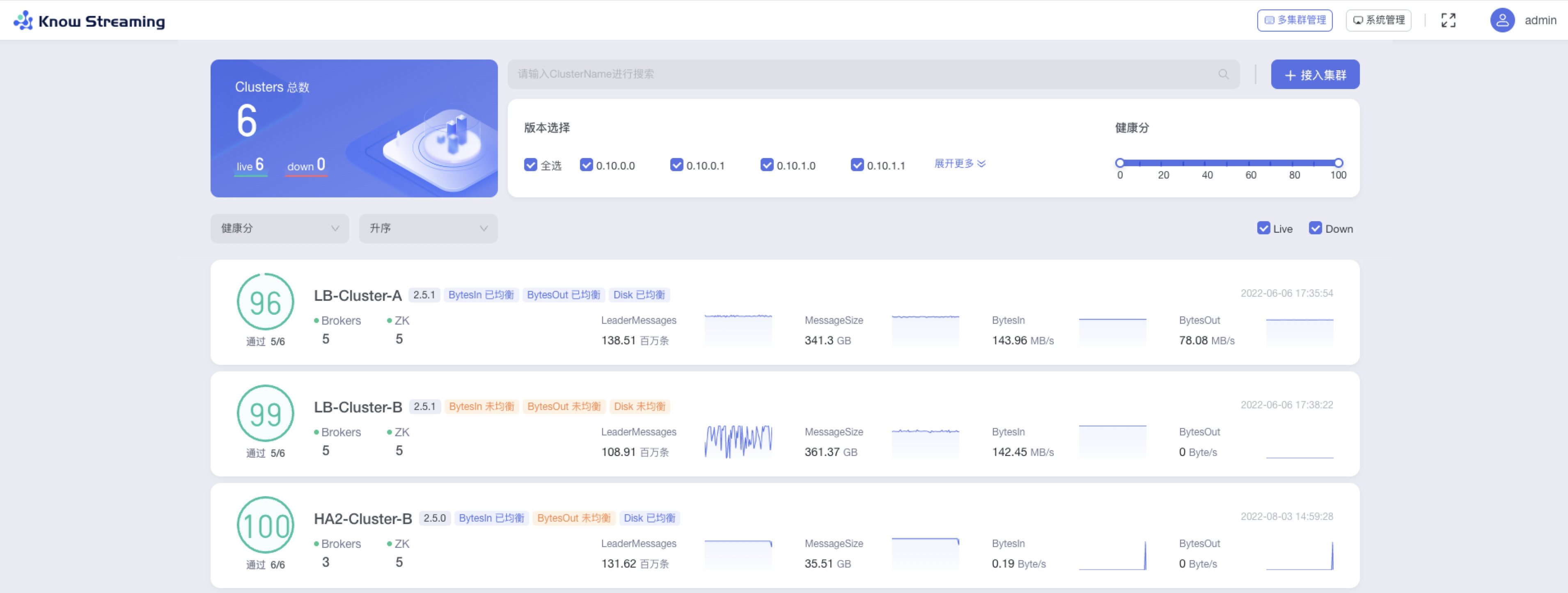
- 步骤 4:每个卡片代表一个集群,其所展示的集群概览信息包括“健康分及健康检查项通过数”、“broker 数量”、“ZK 数量”、“版本号”、“BytesIn 均衡状态”、“BytesOut 均衡状态”、“Disk 均衡状态”、”Messages“、“MessageSize”、“BytesIn”、“BytesOut”、“接入时间”
-
+
-#### 5.6.3.2、接入集群
+#### 5.4.3.2、接入集群
- 步骤 1:点击“多集群管理”>“接入集群”
- 步骤 2:填写相关集群信息
- - 集群名称:支持中英文、下划线、短划线(-),最长 128 字符。平台内不能重复
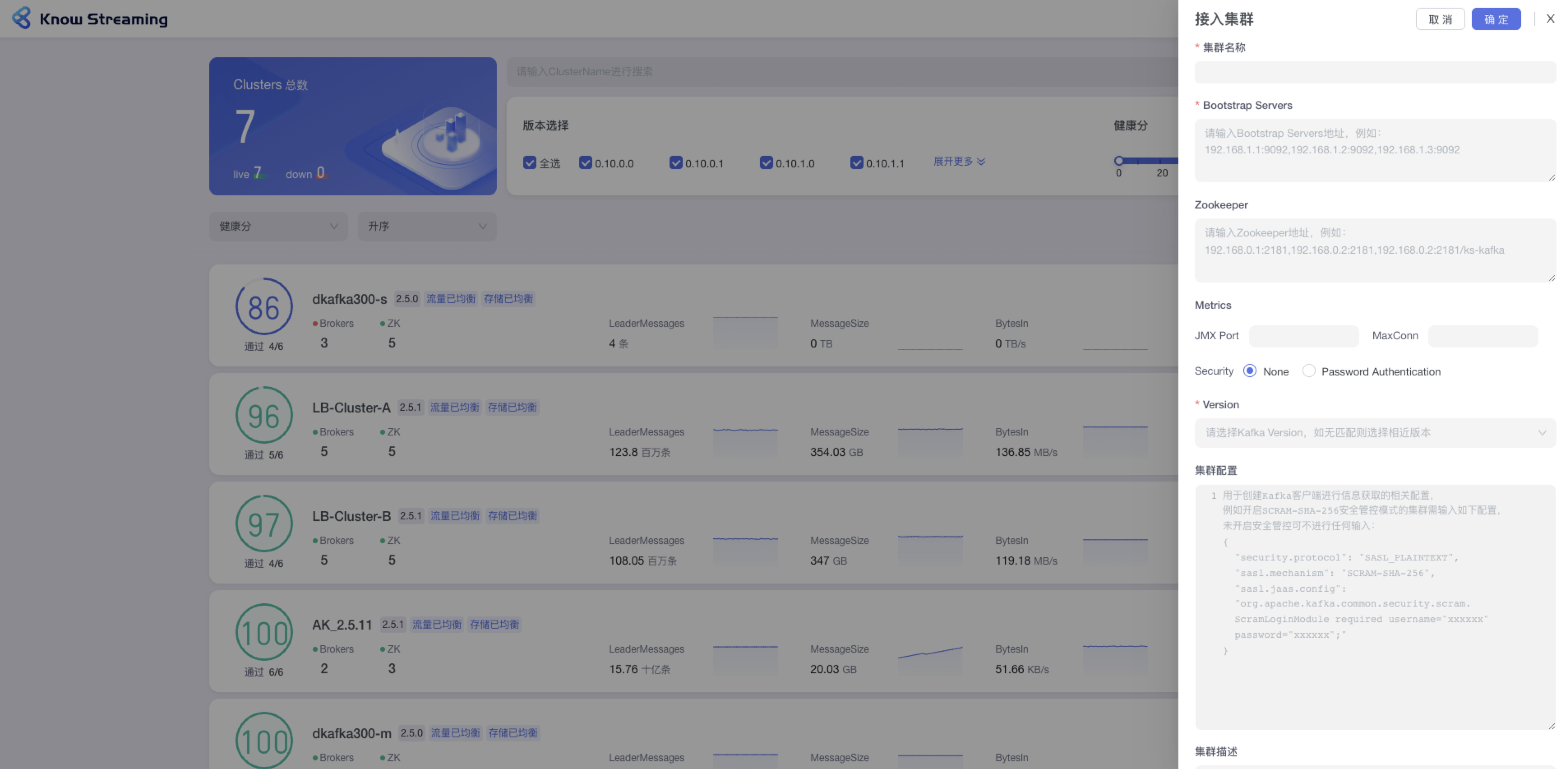
- - Bootstrap Servers:输入 Bootstrap Servers 地址,不限制长度和输入内容。例如 192.168.1.1:9092,192.168.1.2:9092,192.168.1.3:9092,输入完成之后会进行连接测试,测试完成之后会给出测试结果连接成功 or 连接失败(以及失败的原因)。【备注:根据填写的 Bootstrap Servers 地址自动获取 zk 信息、mertics 信息、version 信息。若能获取成功,则自动展示。当 zk 已填写时,再次修改 bootstrap server 地址时就不再重新获取 zk 信息,按照用户维护的 zk 信息为准】
- - Zookeeper:输入 zookeeper 地址,例如:192.168.0.1:2181,192.168.0.2:2181,192.168.0.2:2181/ks-kafka,输入完成之后会进行连接测试,测试完成之后会给出测试结果连接成功 or 连接失败(以及失败的原因)【备注:根据填写的 zk 地址自动获取后续的 mertics、version 信息。若能获取成功,则自动展示】
+ - 集群名称:平台内不能重复
+ - Bootstrap Servers:输入 Bootstrap Servers 地址,输入完成之后会进行连接测试,测试完成之后会给出测试结果连接成功 or 连接失败(以及失败的原因)。
+ - Zookeeper:输入 zookeeper 地址,输入完成之后会进行连接测试,测试完成之后会给出测试结果连接成功 or 连接失败(以及失败的原因)
- Metrics 选填:JMX Port,输入 JMX 端口号;MaxConn,输入服务端最大允许的连接数
- - Version:下拉选择所支持的 kafka 版本,如果没有匹配则可以选择相近版本
- - 集群配置选填:输入用户创建 kafka 客户端进行信息获取的相关配置
- - 集群描述:输入集群的描述,最多 200 字符
- 
+ - Security:若有 JMX 账号密码,则输入账号密码
+ - Version:kafka 版本,如果没有匹配则可以选择相近版本
+ - 集群配置选填:用户创建 kafka 客户端进行信息获取的相关配置
-#### 5.6.3.3、删除集群
+
+
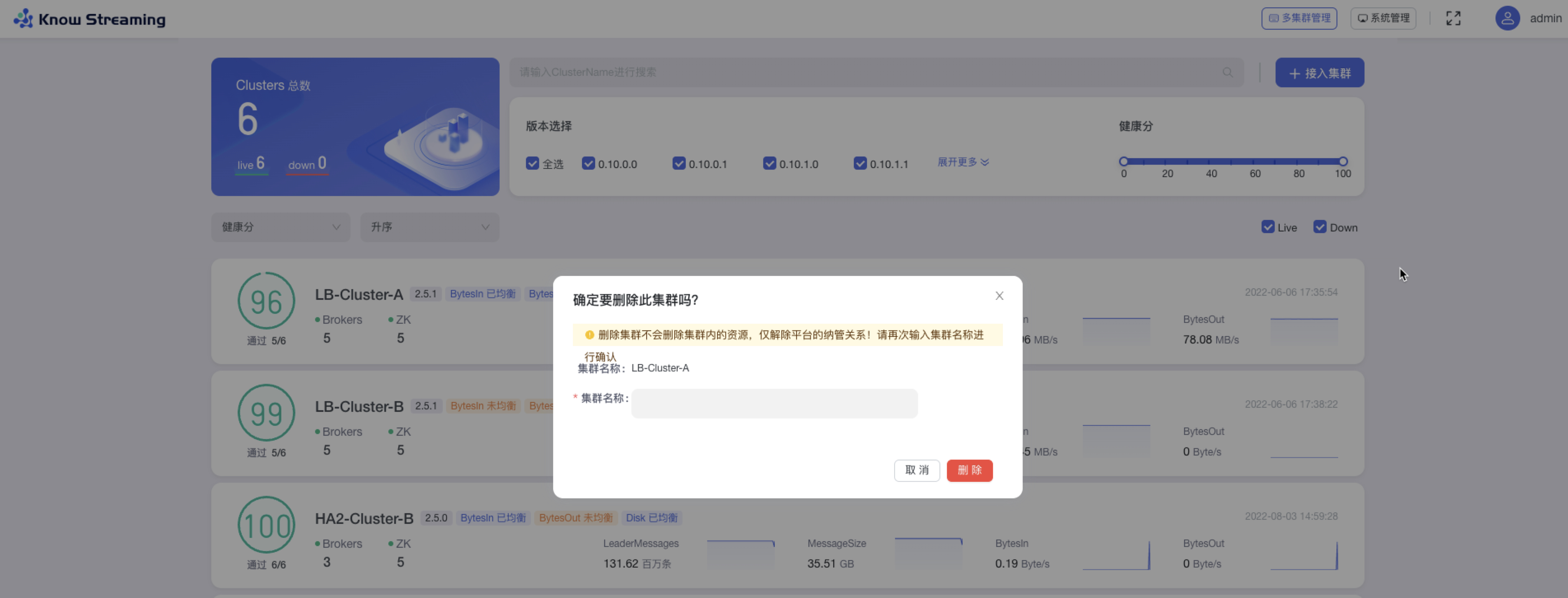
+#### 5.4.3.3、删除集群
- 步骤 1:点击“多集群管理”>鼠标悬浮集群卡片>点击卡片右上角“删除 icon”>打开“删除弹窗”
- 步骤 2:在删除弹窗中的“集群名称”输入框,输入所要删除集群的集群名称,点击“删除”,成功删除集群,解除平台的纳管关系(集群资源不会删除)
-
+
-### 5.6.4、Cluster 管理
+### 5.4.4、Cluster 管理
-#### 5.6.4.1、Cluster Overview
+#### 5.4.4.1、Cluster Overview
- 步骤 1:点击“多集群管理”>“集群卡片”>进入单集群管理界面
@@ -361,9 +342,10 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 一级导航:Testing;二级导航:Produce、Consume
- 一级导航:Security;二级导航:ACLs、Users
- 一级导航:Job
- 
-#### 5.6.4.2、查看 Cluster 概览信息
+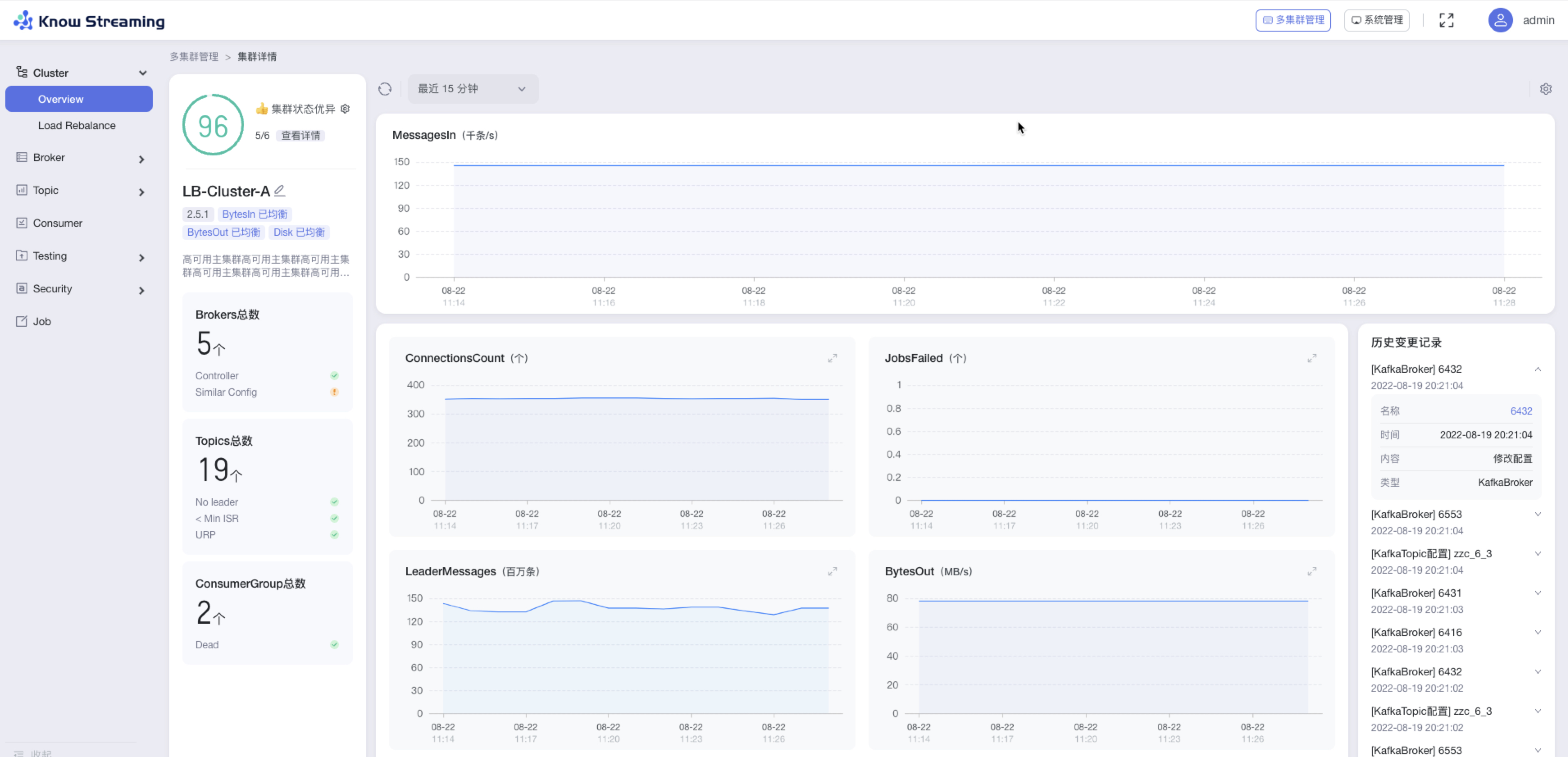
+
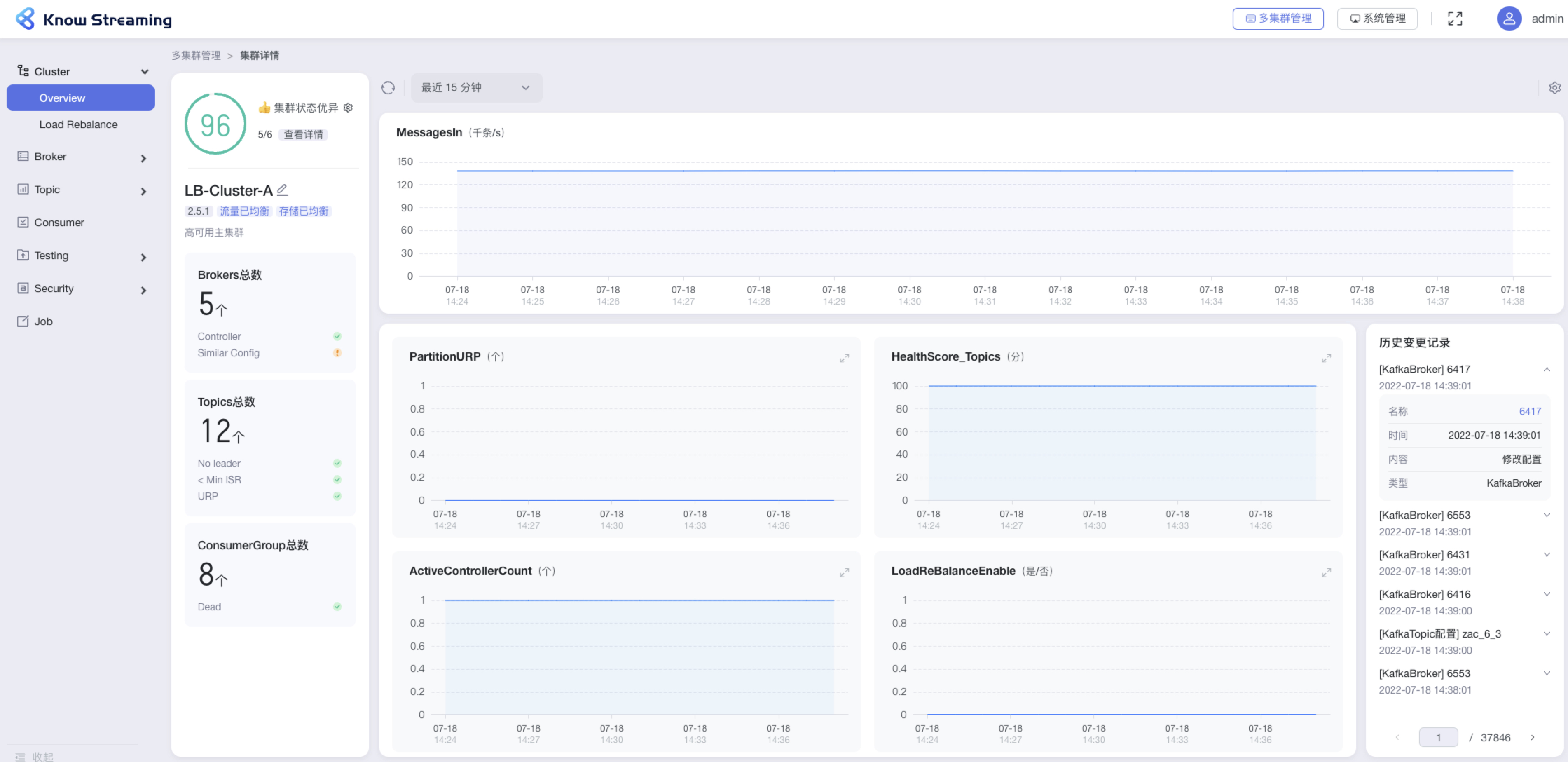
+#### 5.4.4.2、查看 Cluster 概览信息
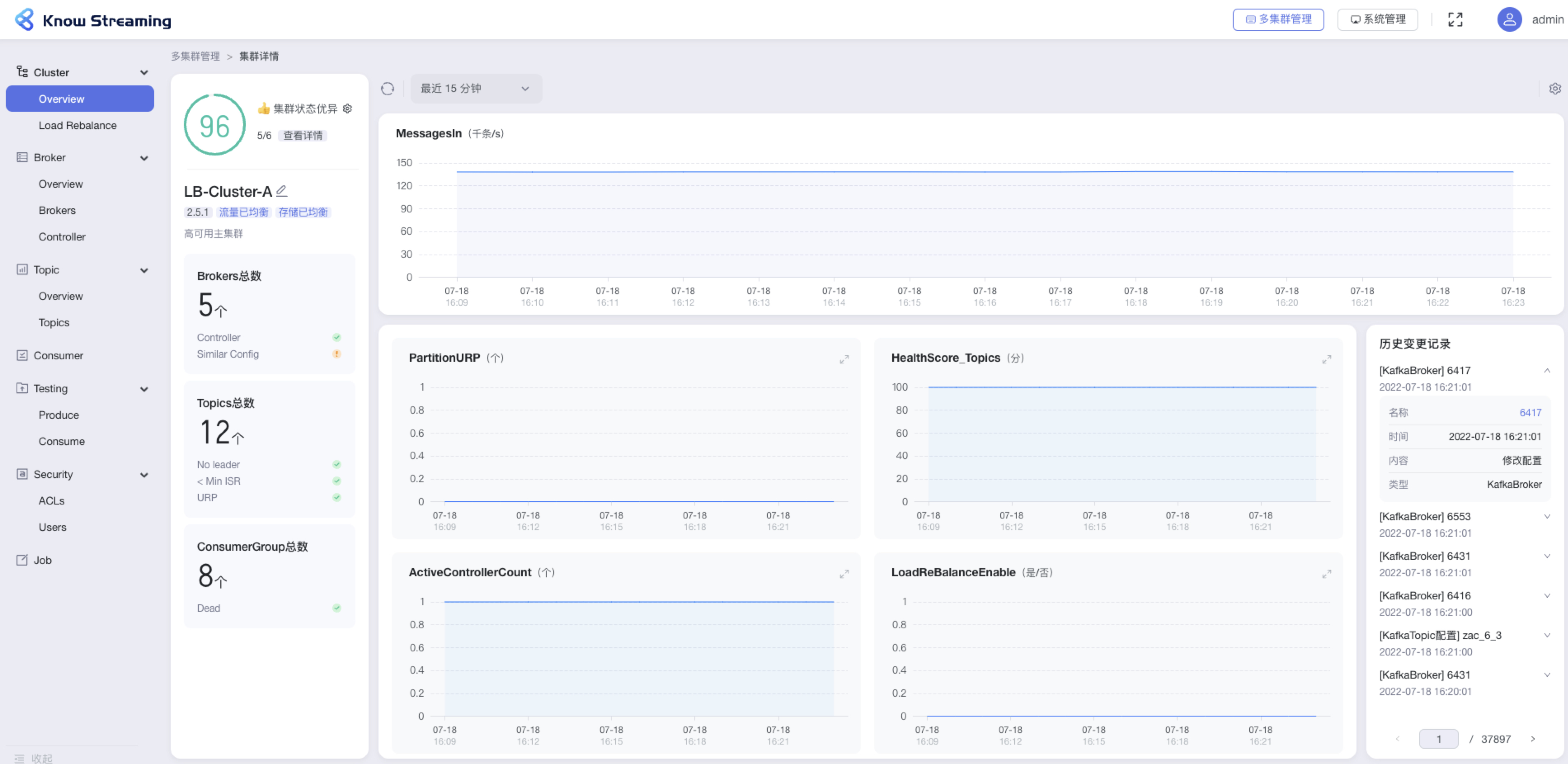
- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”
@@ -376,9 +358,10 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- Consumer Group 信息:Consumer Group 总数、是否存在 Dead 情况
- 指标图表
- 历史变更记录:名称、时间、内容、类型
- 
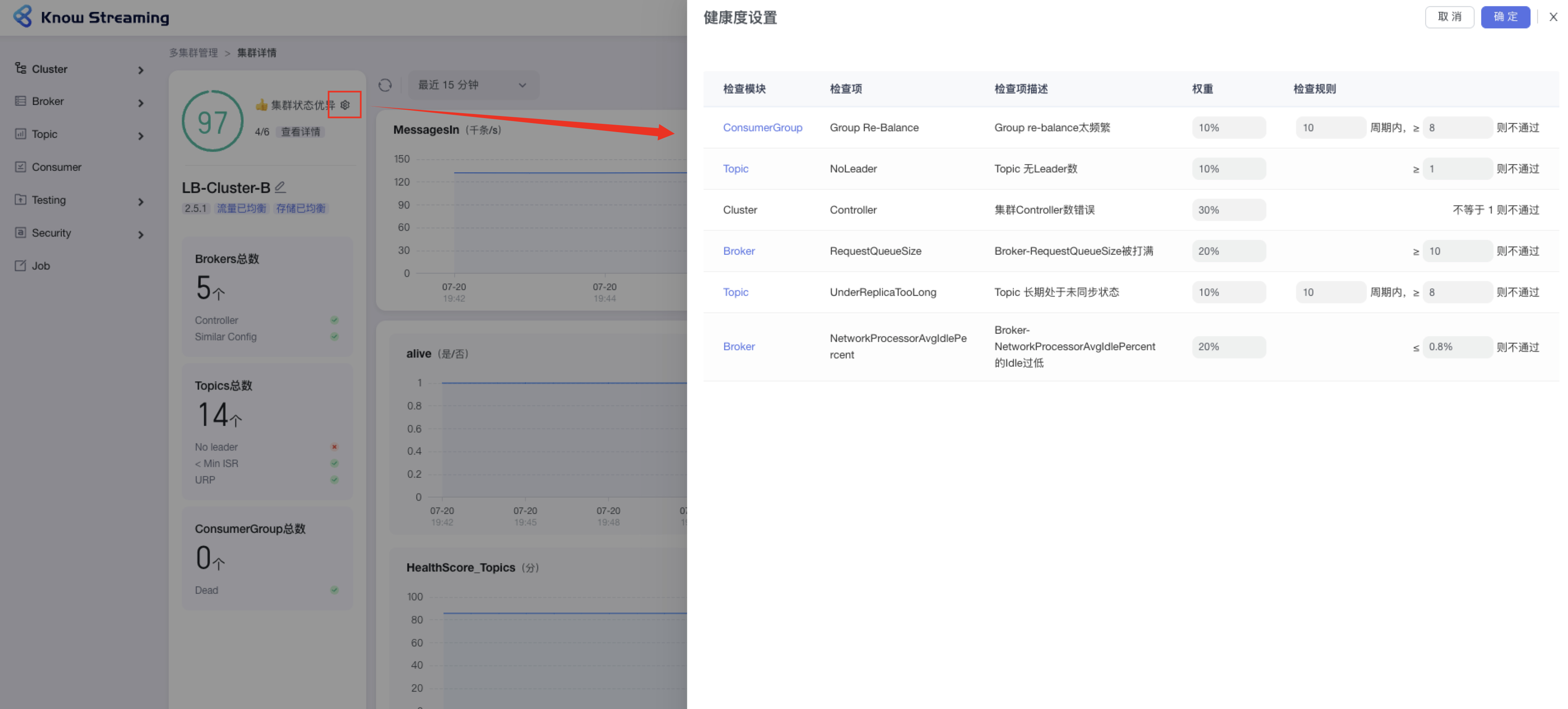
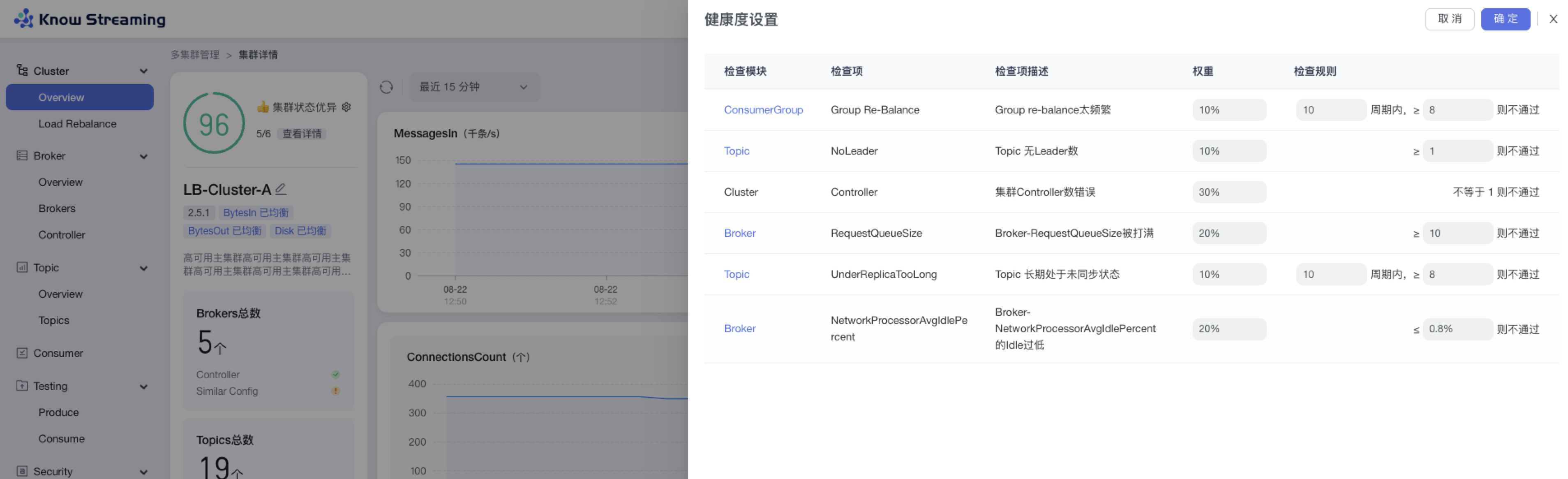
-#### 5.6.4.3、设置 Cluster 健康检查规则
+
+
+#### 5.4.4.3、设置 Cluster 健康检查规则
- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“集群健康状态旁边 icon”>“健康度设置抽屉”
@@ -395,17 +378,17 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 4:设置完成后,点击“确认”,健康检查规则设置成功
-
+
-#### 5.6.4.4、查看 Cluster 健康检查详情
+#### 5.4.4.4、查看 Cluster 健康检查详情
- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“集群健康状态旁边【查看详情】”>“健康检查详情抽屉”
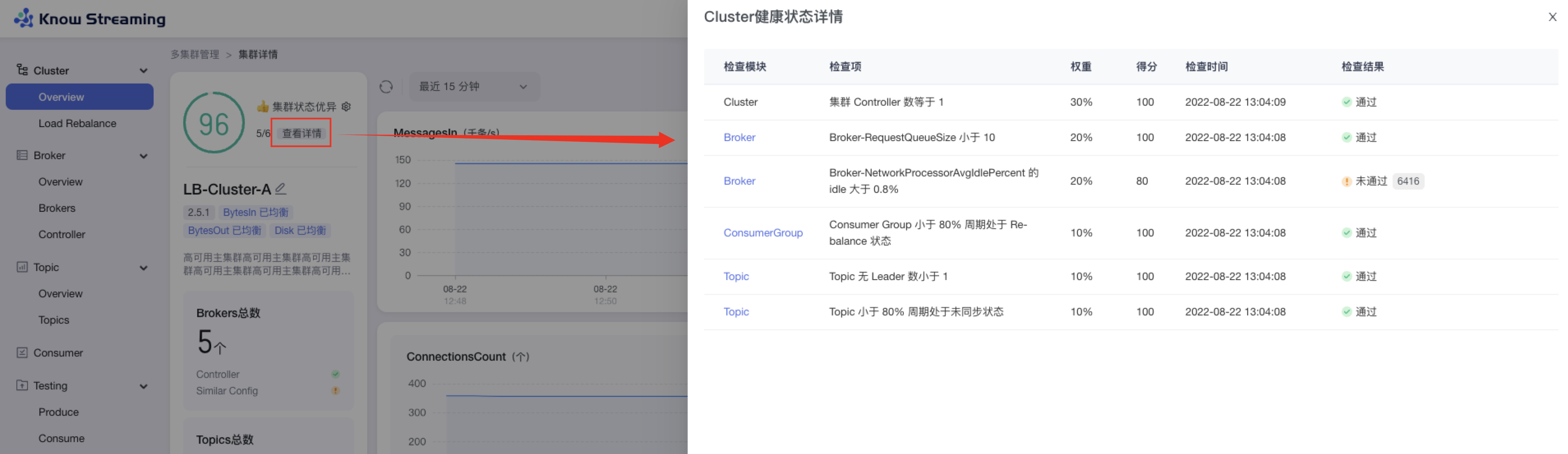
- 步骤 2:健康检查详情抽屉展示信息为:“检查模块”、“检查项”、“权重”、“得分”、“检查时间”、“检查结果是否通过”,若未通过会展示未通过的对象
-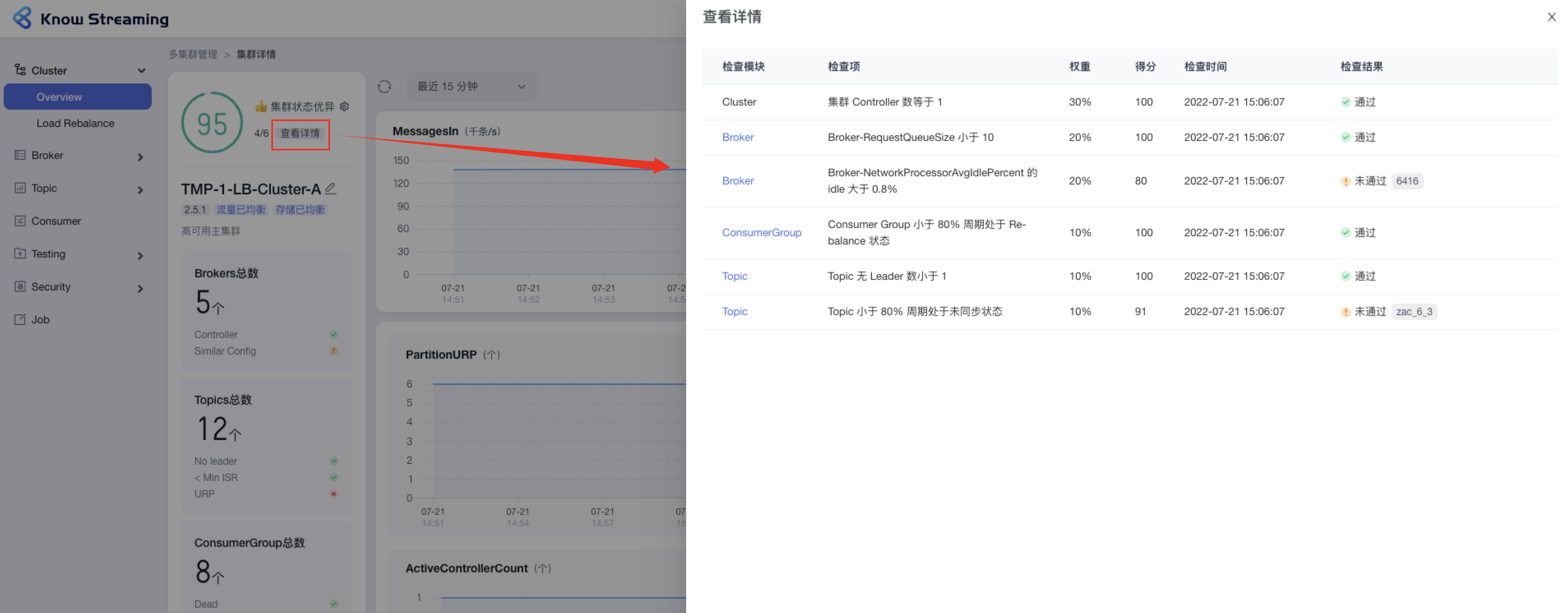
+
-#### 5.6.4.5、编辑 Cluster 信息
+#### 5.4.4.5、编辑 Cluster 信息
- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“Cluster 名称旁边编辑 icon”>“编辑集群抽屉”
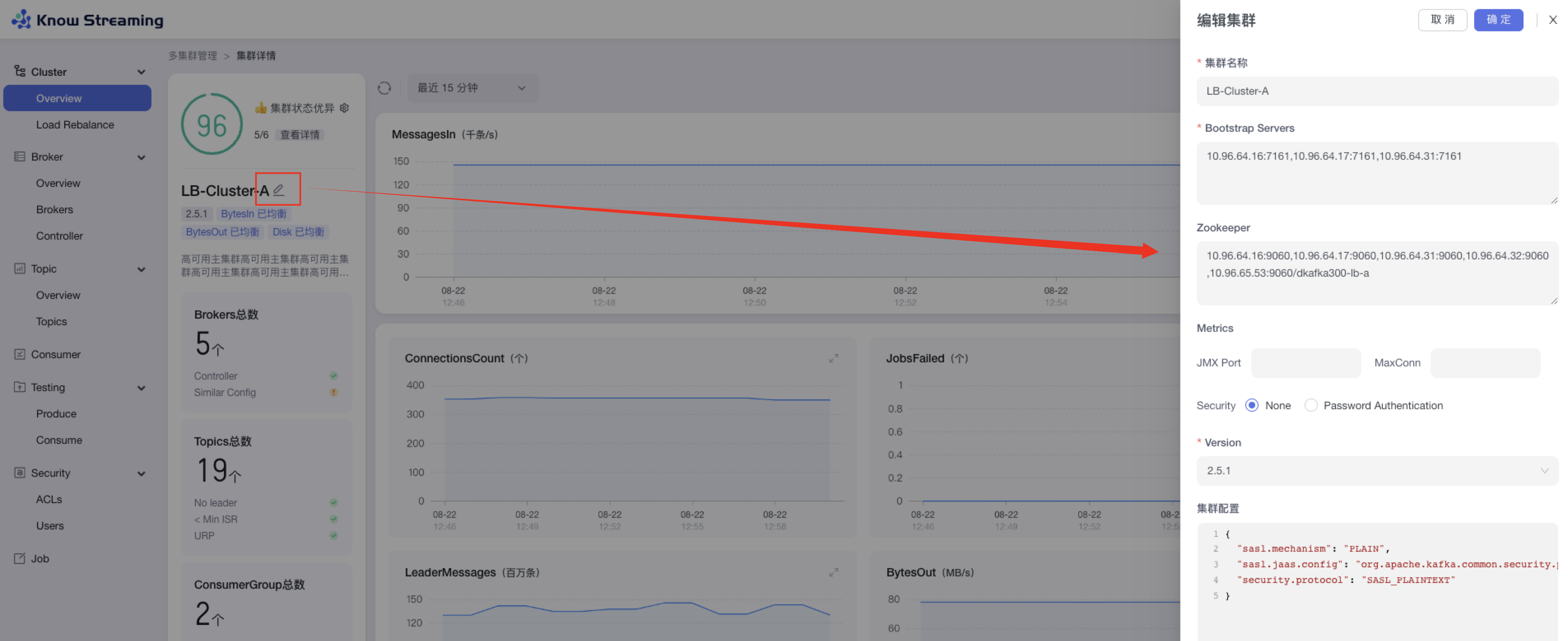
@@ -413,9 +396,9 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 3:点击“确定”,成功编辑集群信息
-
+
-#### 5.6.4.6、图表指标筛选
+#### 5.4.4.6、图表指标筛选
- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“指标筛选 icon”>“指标筛选抽屉”
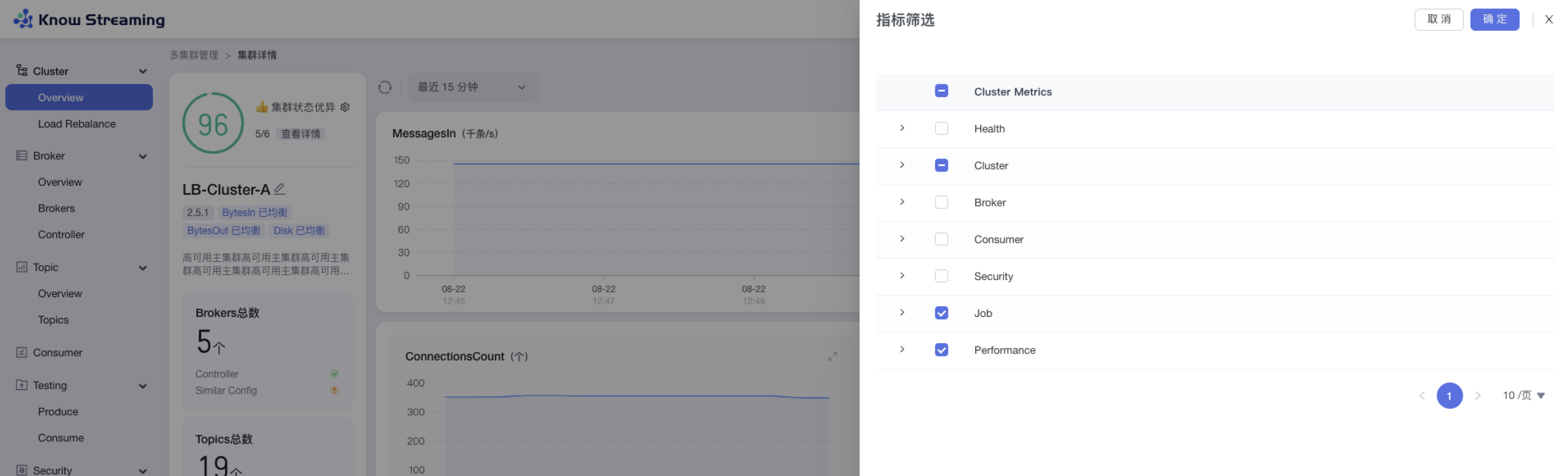
@@ -423,35 +406,35 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 3:默认勾选比较重要的指标进行展示。根据需要选中/取消选中相应指标,点击”确认“,指标筛选成功,展示的图表随之变化
-
+
-#### 5.6.4.7、图表时间筛选
+#### 5.4.4.7、图表时间筛选
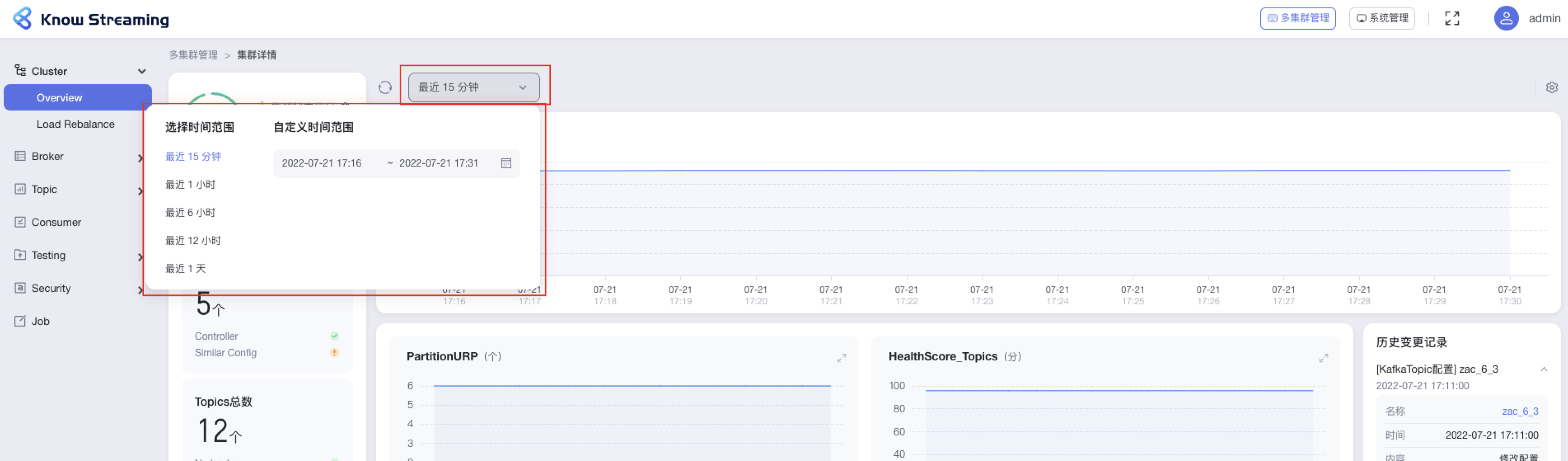
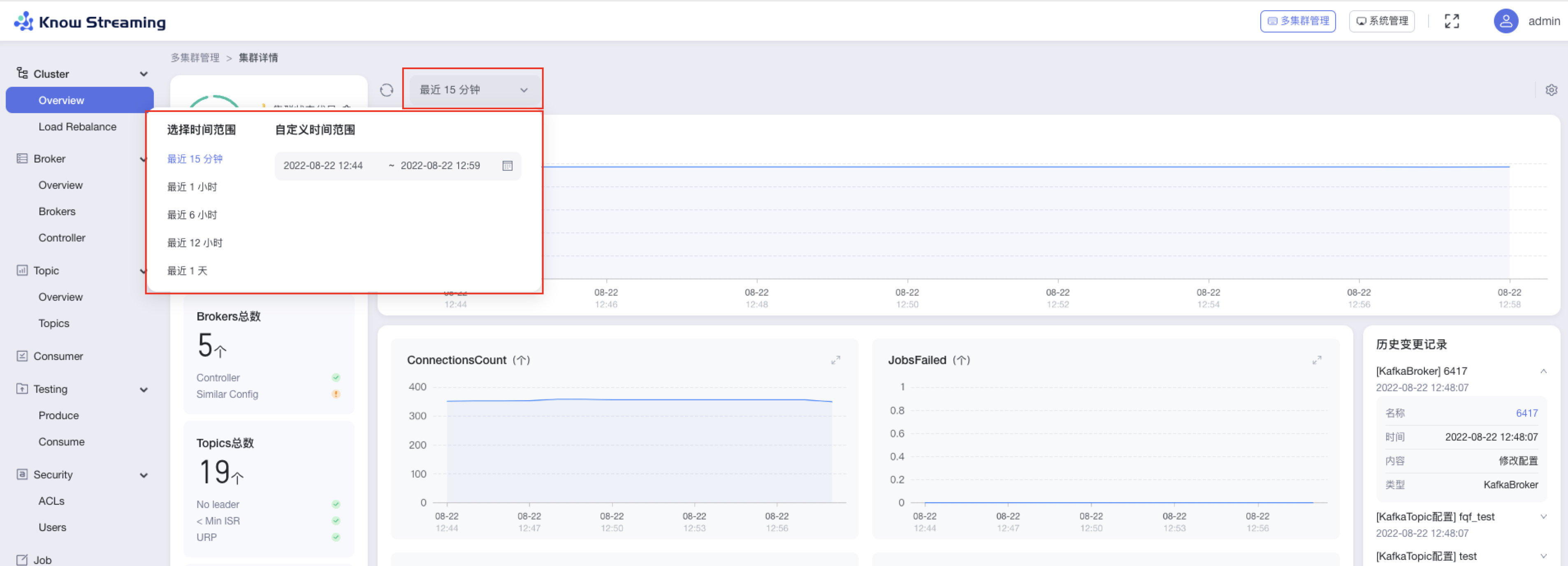
- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“时间选择下拉框”>“时间选择弹窗”
- 步骤 2:选择时间“最近 15 分钟”、“最近 1 小时”、“最近 6 小时”、“最近 12 小时”、“最近 1 天”,也可以自定义时间段范围
-
+
-#### 5.6.4.8、查看集群历史变更记录
+#### 5.4.4.8、查看集群历史变更记录
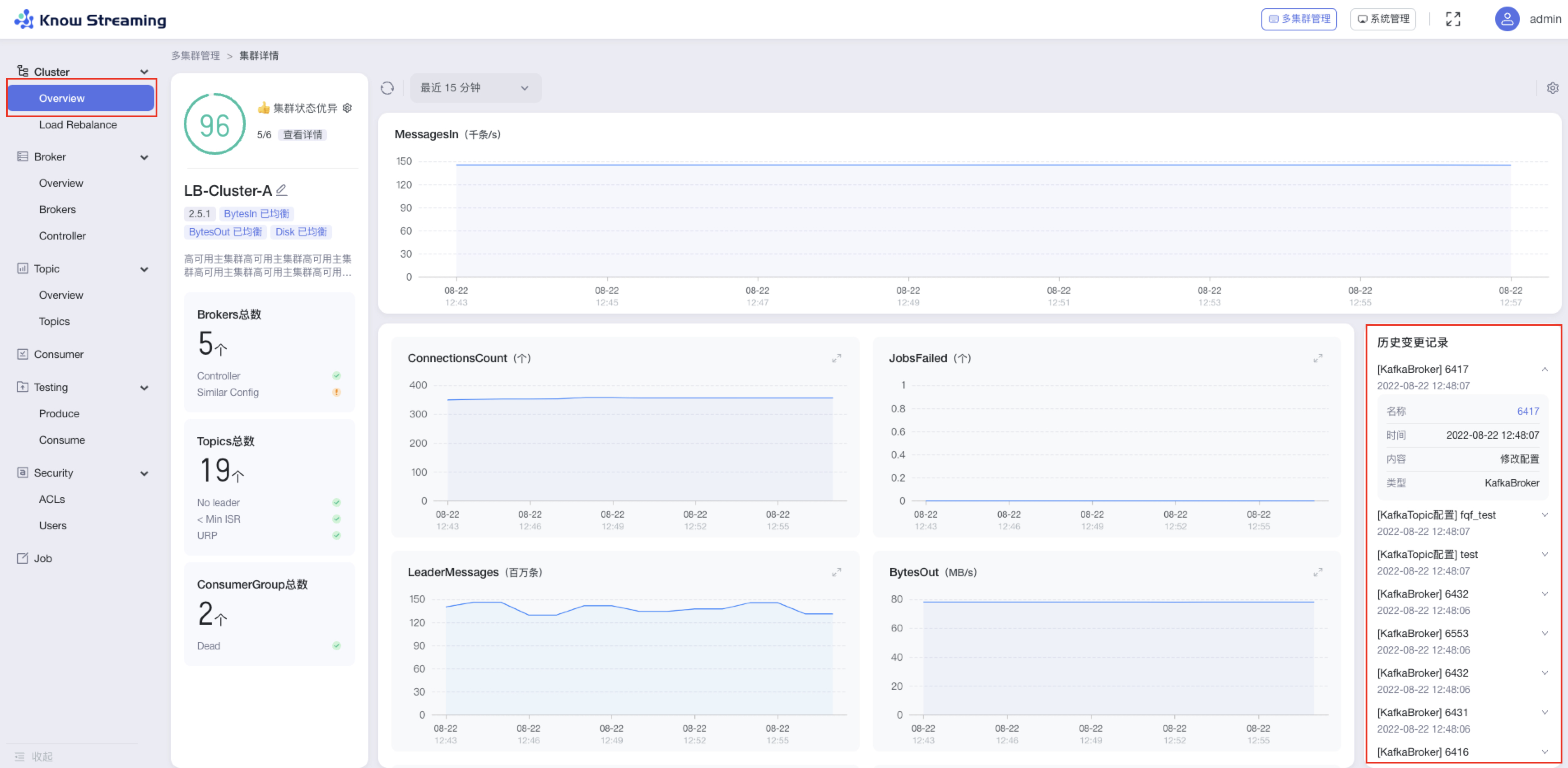
- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“历史变更记录”区域
- 步骤 2:历史变更记录区域展示了历史的配置变更,每条记录可展开收起。包含“配置对象”、“变更时间”、“变更内容”、“配置类型”
-
+
-### 5.6.5、Load Rebalance(企业版)
+### 5.4.5、Load Rebalance(企业版)
-#### 5.6.5.1、查看 Load Rebalance 概览信息
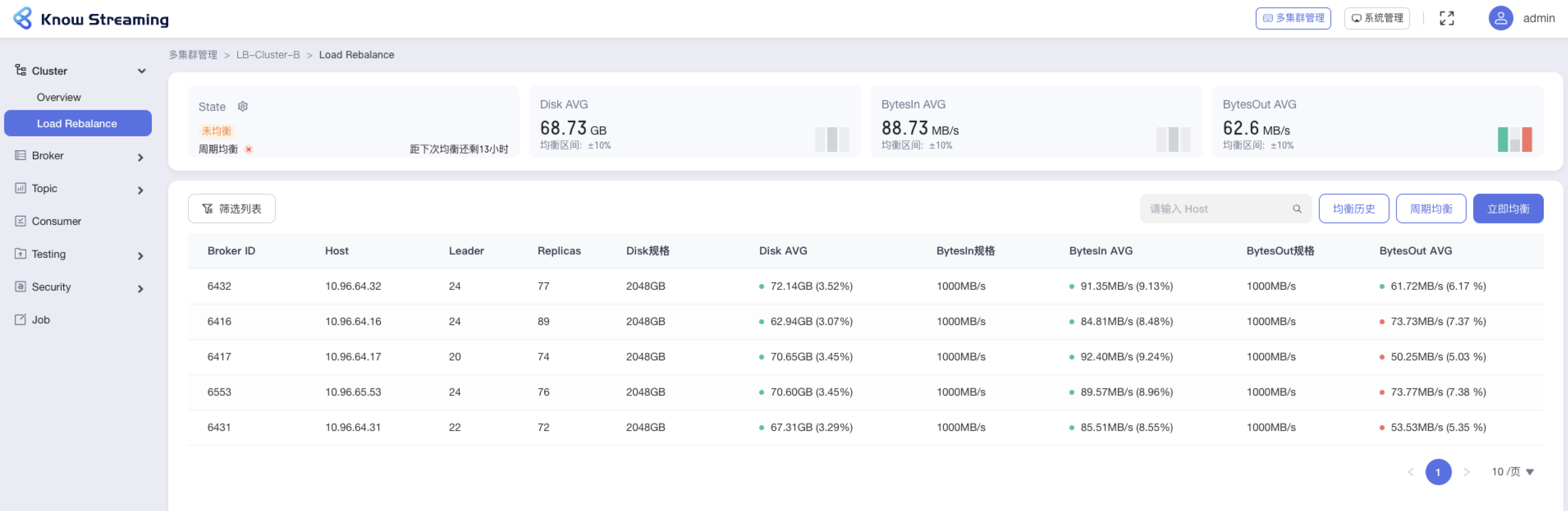
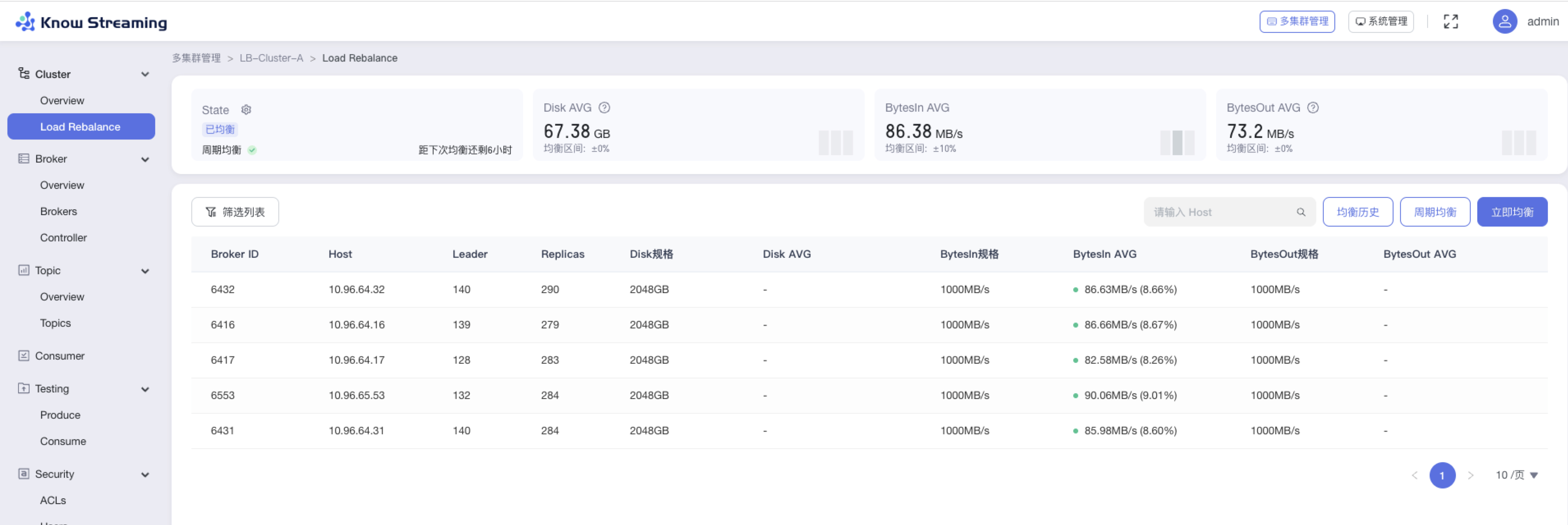
+#### 5.4.5.1、查看 Load Rebalance 概览信息
- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Load Rebalance”
- 步骤 2:Load Rebalance 概览信息包含“均衡状态卡片”、“Disk 信息卡片”、“BytesIn 信息卡片”、“BytesOut 信息卡片”、“Broker 均衡状态列表”
-
+
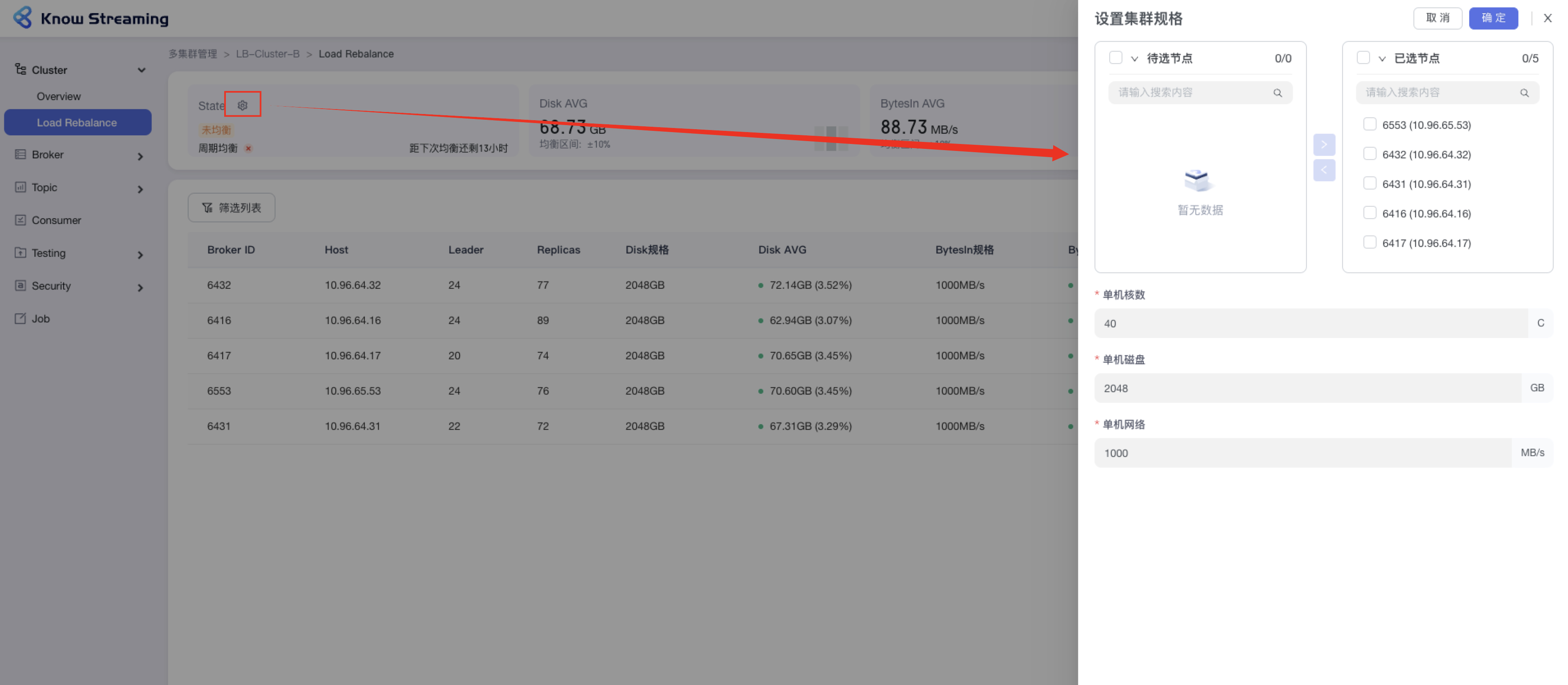
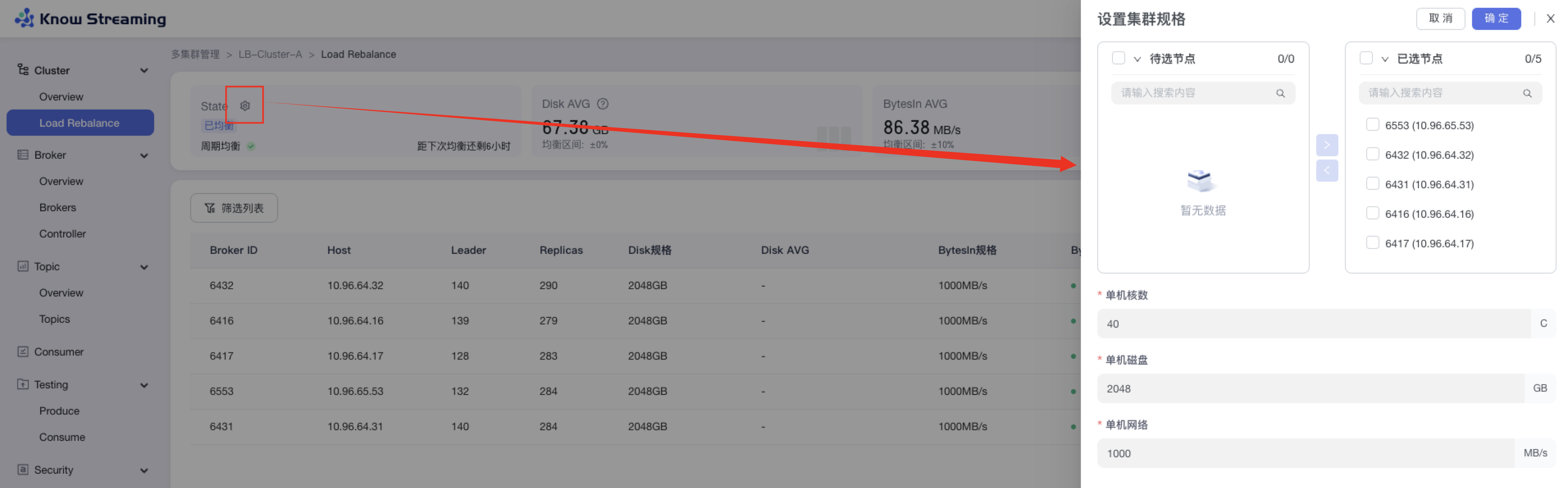
-#### 5.6.5.2、设置集群规格
+#### 5.4.5.2、设置集群规格
提供对集群的每个节点的 Disk、BytesIn、BytesOut 的规格进行设置的功能
@@ -461,9 +444,9 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 3:设置“单机核数”、“单机磁盘”、“单机网络”,点击确定,完成设置
-
+
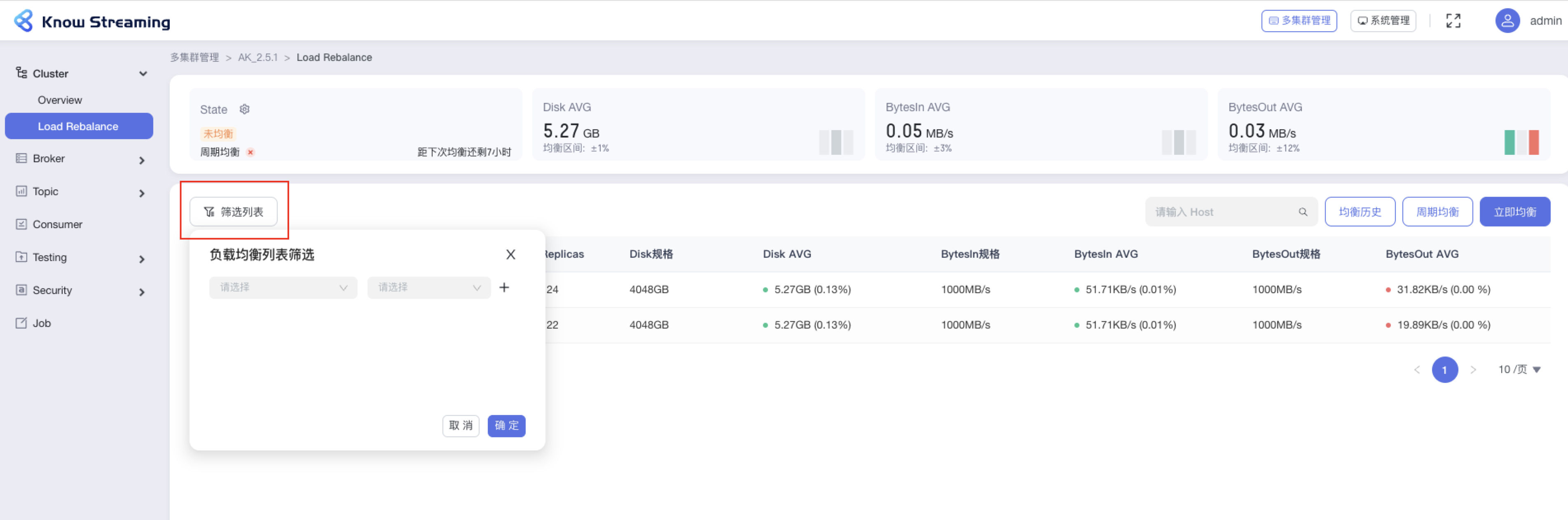
-#### 5.6.5.3、均衡状态列表筛选
+#### 5.4.5.3、均衡状态列表筛选
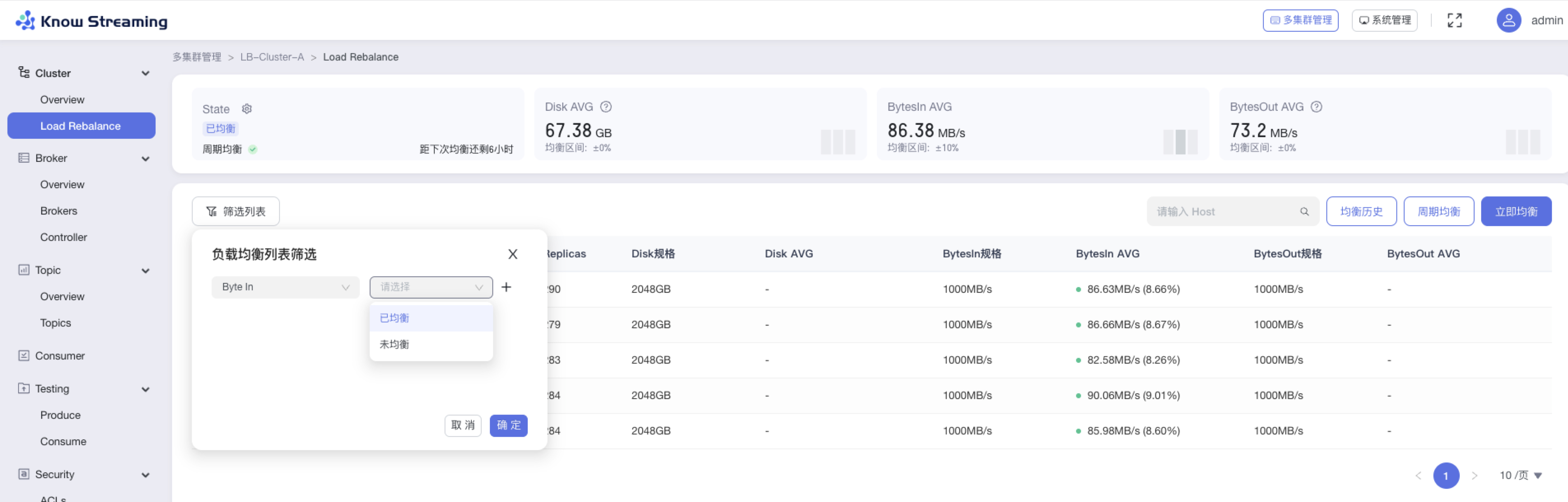
- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Load Rebalance”>“筛选列表”按钮>筛选弹窗
@@ -471,9 +454,9 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 3:点击“确认”,执行筛选操作
-
+
-#### 5.6.5.4、立即均衡
+#### 5.4.5.4、立即均衡
- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Load Rebalance”>“立即均衡”按钮>“立即均衡抽屉”
@@ -499,7 +482,7 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
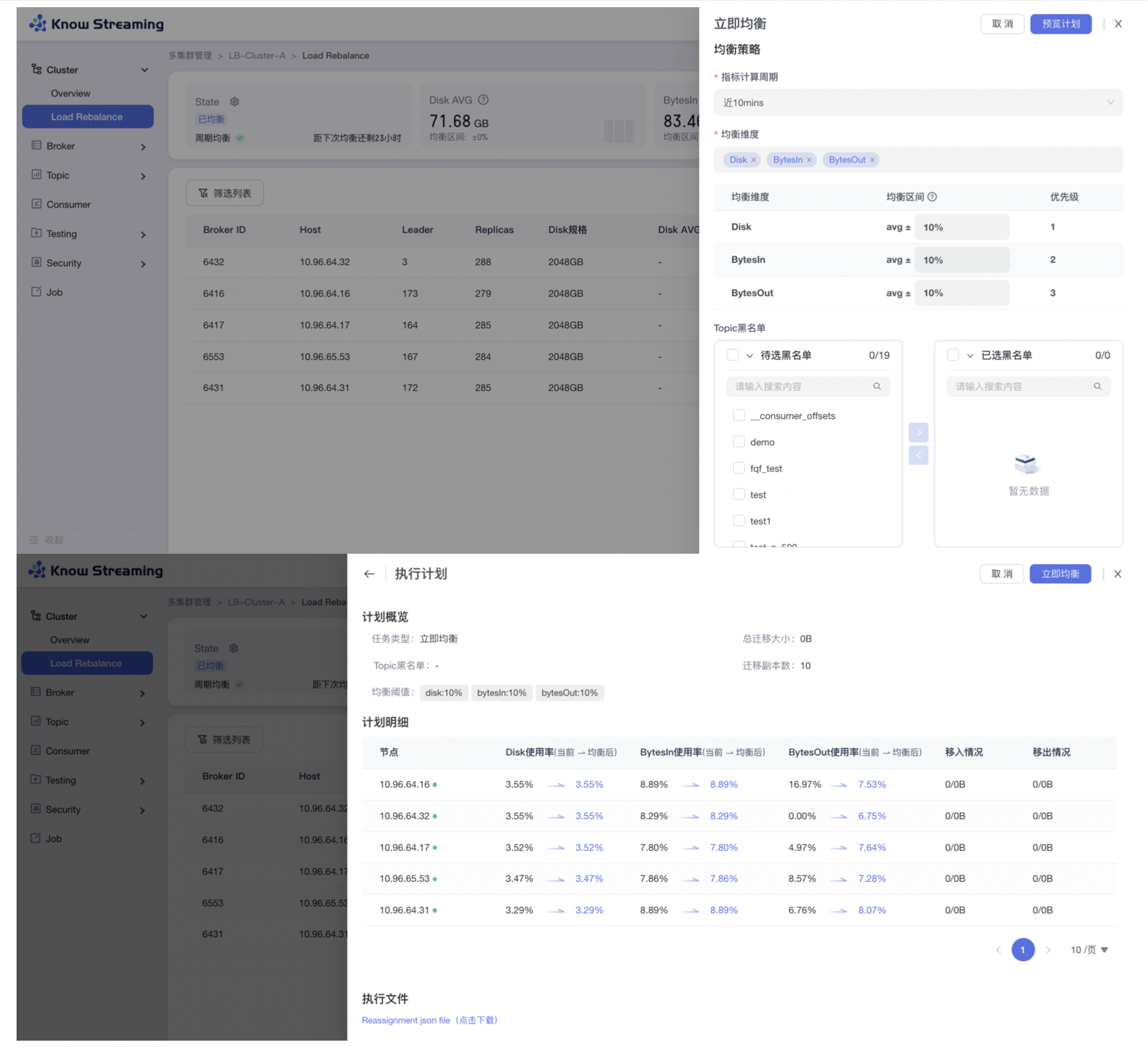
-#### 5.6.5.5、周期均衡
+#### 5.4.5.5、周期均衡
- 步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Load Rebalance”>“周期均衡”按钮>“周期均衡抽屉”
@@ -526,9 +509,9 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
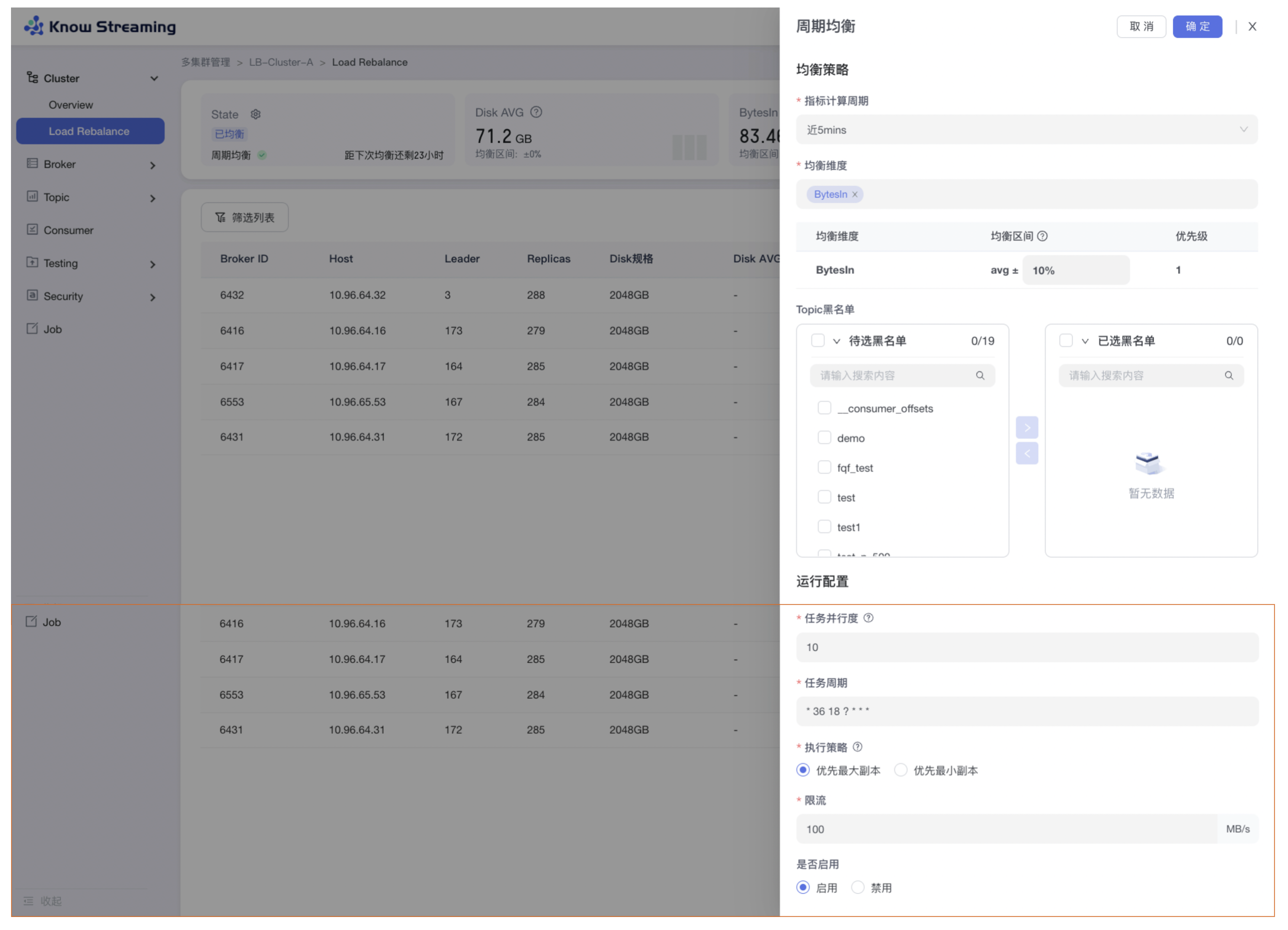
-### 5.6.6、Broker
+### 5.4.6、Broker
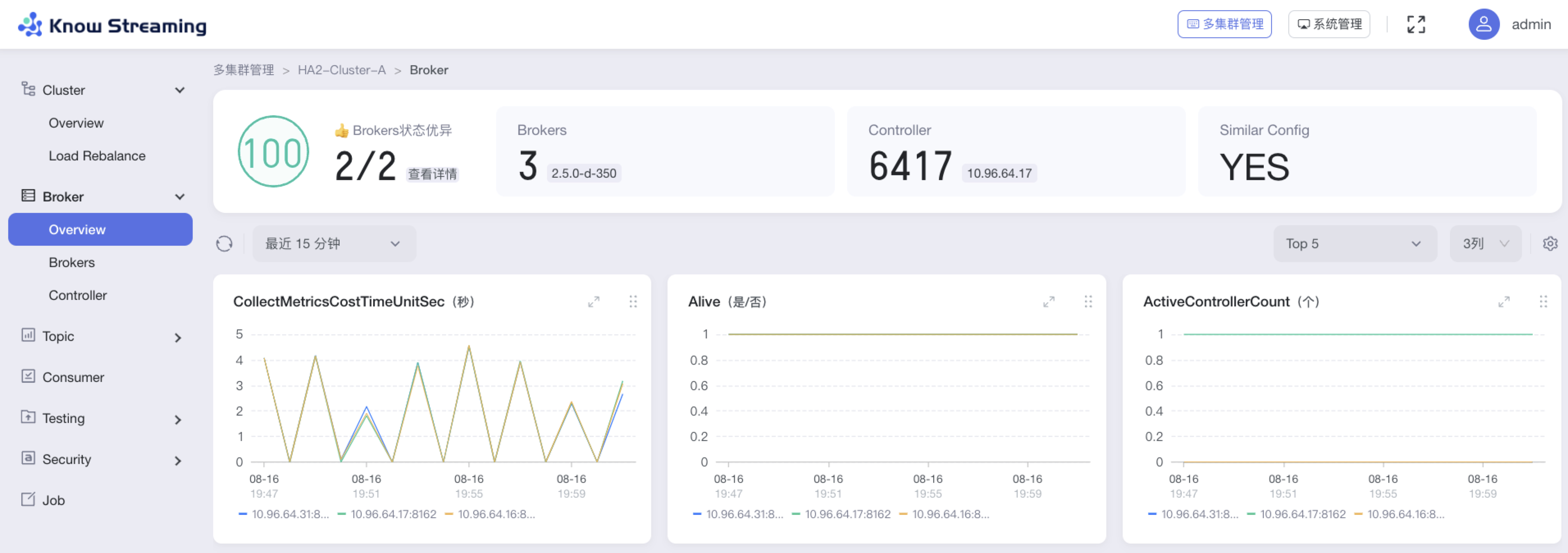
-#### 5.6.6.1、查看 Broker 概览信息
+#### 5.4.6.1、查看 Broker 概览信息
- 步骤 1:点击“多集群管理”>“集群卡片”>“Broker”>“Overview”
@@ -541,9 +524,10 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- Consumer Group 信息:Consumer Group 总数、是否存在 Dead 情况
- 指标图表
- 历史变更记录:名称、时间、内容、类型
- 
-#### 5.6.6.2、编辑 Broker 配置
+
+
+#### 5.4.6.2、编辑 Broker 配置
- 步骤 1:点击“多集群管理”>“集群卡片”>“Brokers”>“Broker ID”>“Configuration”TAB>“编辑”按钮
@@ -553,9 +537,9 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 4:点击“确认”,Broker 配置修改成功
-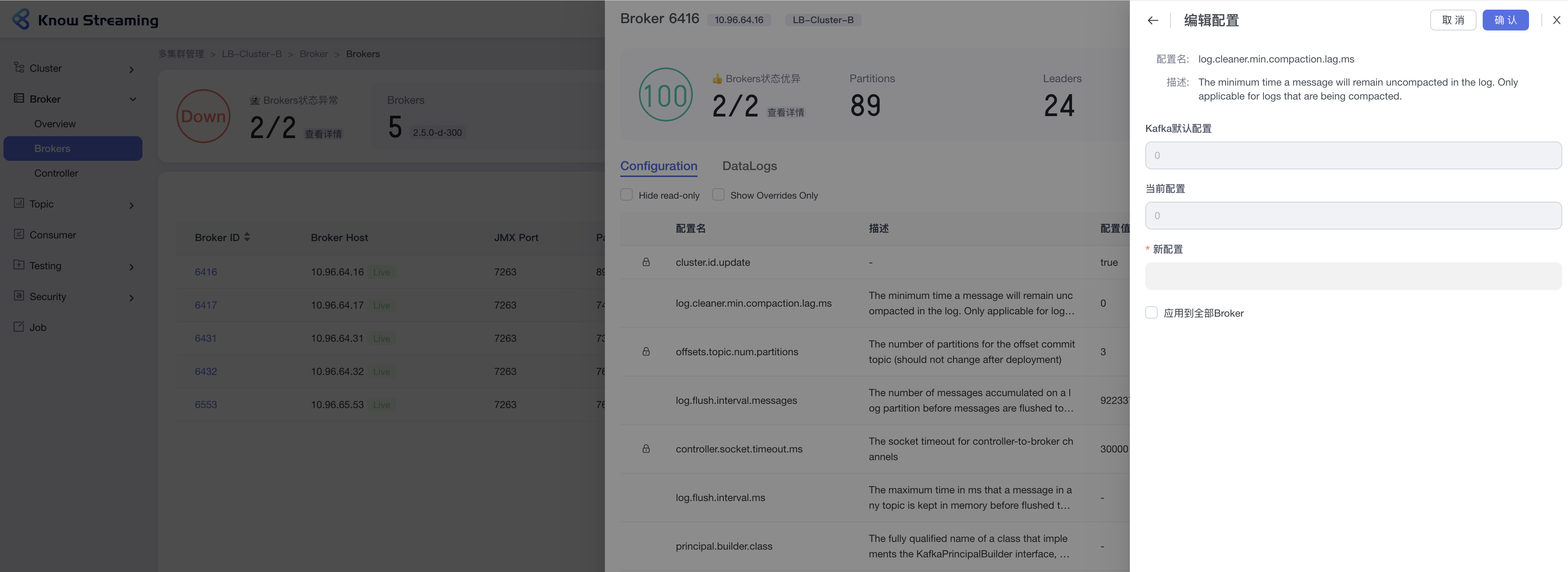
+
-#### 5.6.6.3、查看 Broker DataLogs
+#### 5.4.6.3、查看 Broker DataLogs
- 步骤 1:点击“多集群管理”>“集群卡片”>“Brokers”>“Broker ID”>“Data Logs”TAB>“编辑”按钮
@@ -565,7 +549,7 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
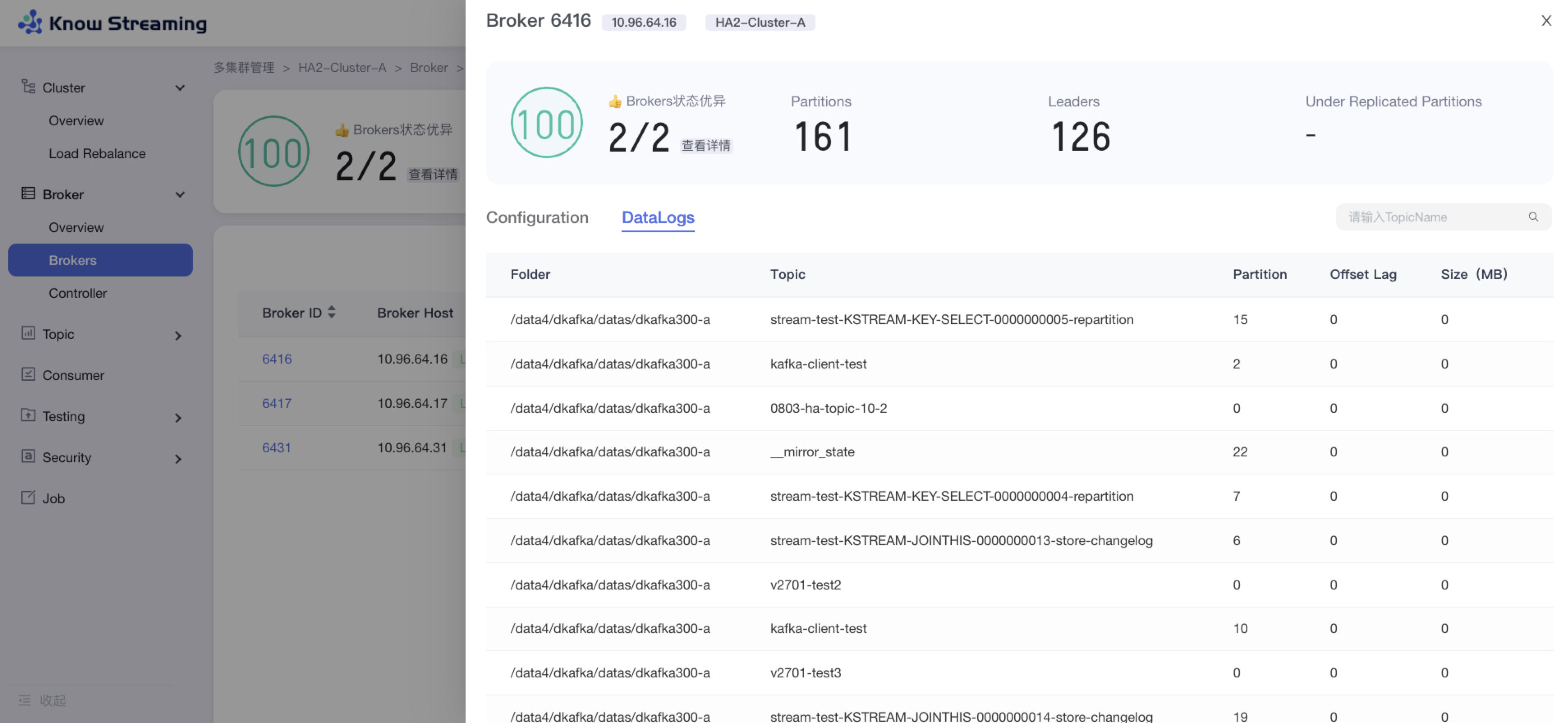
-#### 5.6.6.4、查看 Controller 列表
+#### 5.4.6.4、查看 Controller 列表
- 步骤 1:点击“多集群管理”>“集群卡片”>“Broker”>“Controller”
@@ -577,9 +561,9 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
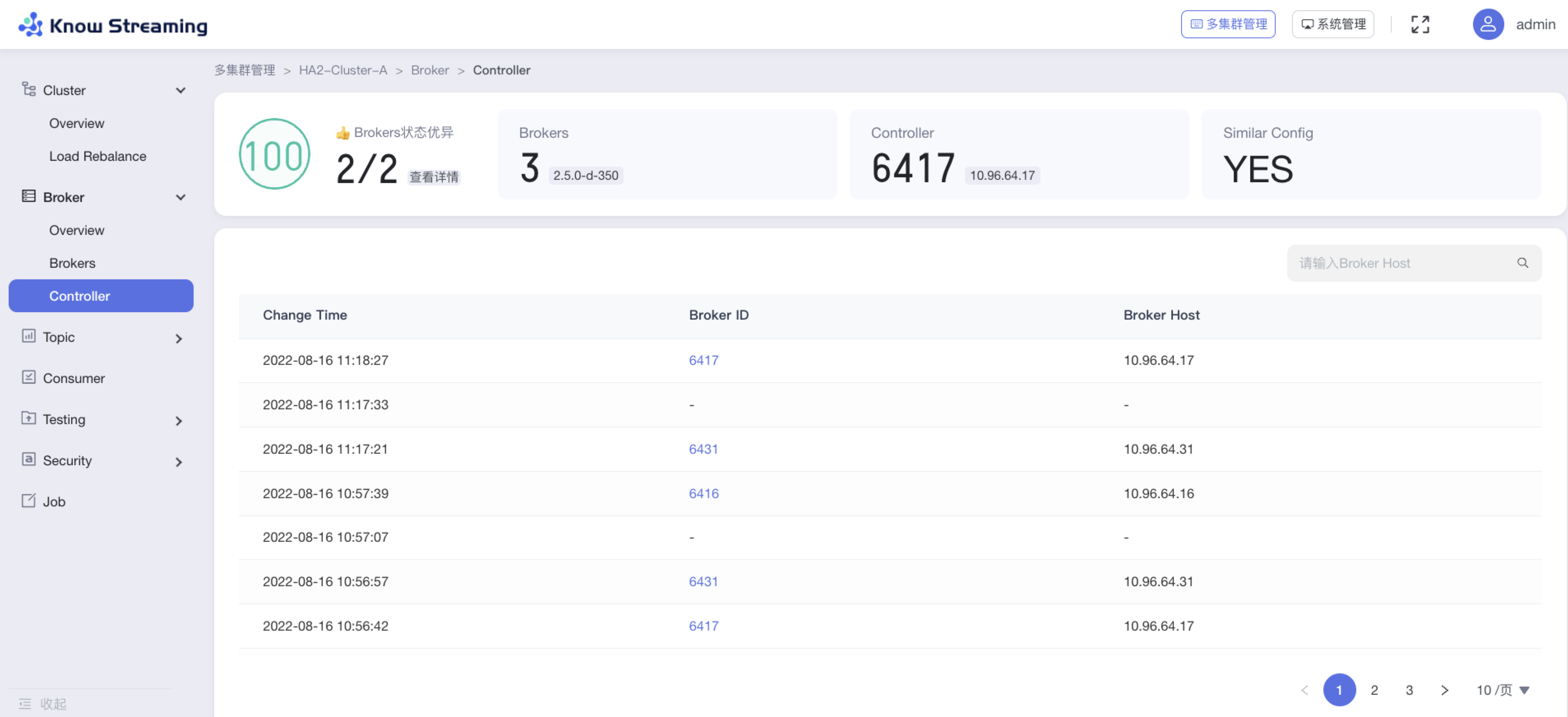
-### 5.6.7、Topic
+### 5.4.7、Topic
-#### 5.6.7.1、查看 Topic 概览信息
+#### 5.4.7.1、查看 Topic 概览信息
- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Overview”
@@ -592,17 +576,18 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
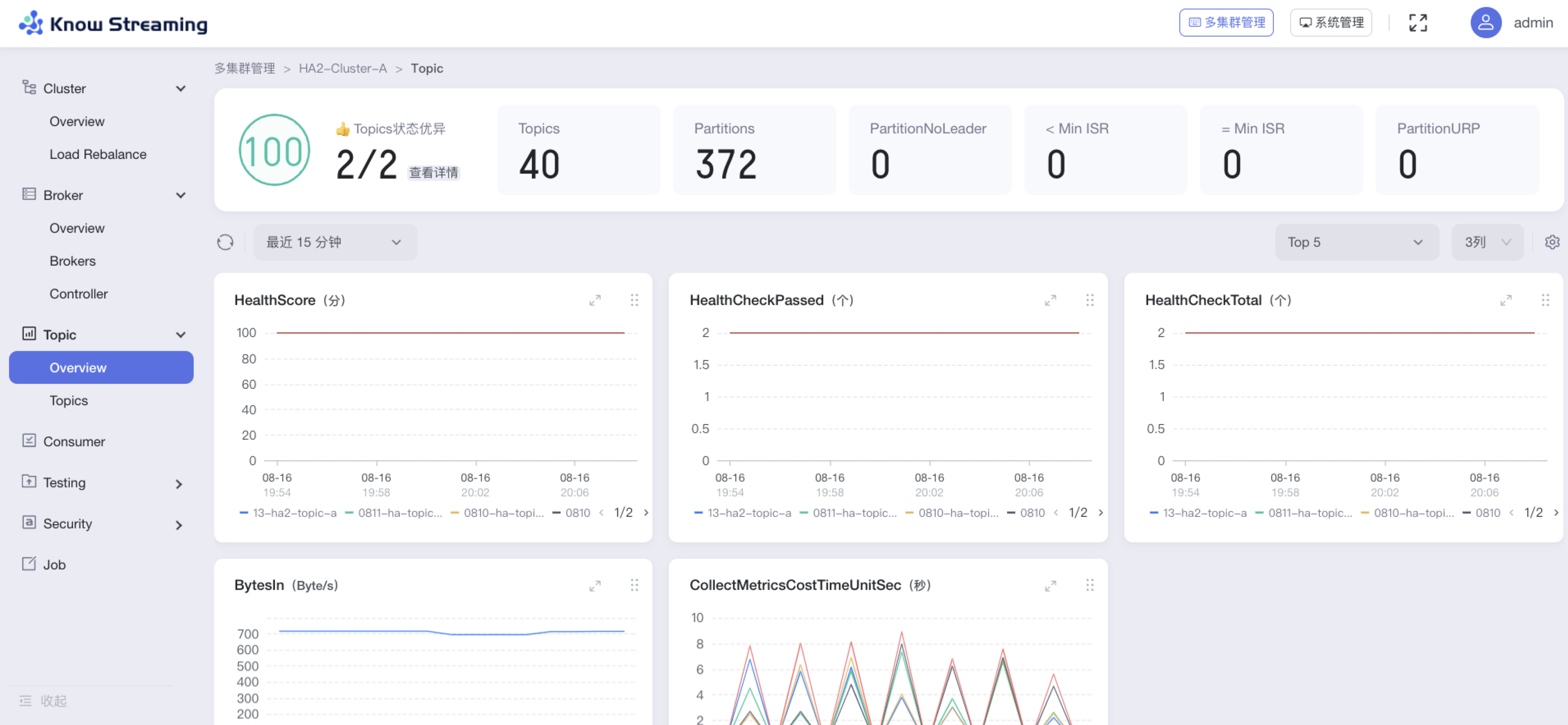
- < Min ISR:同步副本数小于 Min ISR
- =Min ISR:同步副本数等于 Min ISR
- Topic 指标图表
- 
-#### 5.6.7.2、查看 Topic 健康检查详情
+
+
+#### 5.4.7.2、查看 Topic 健康检查详情
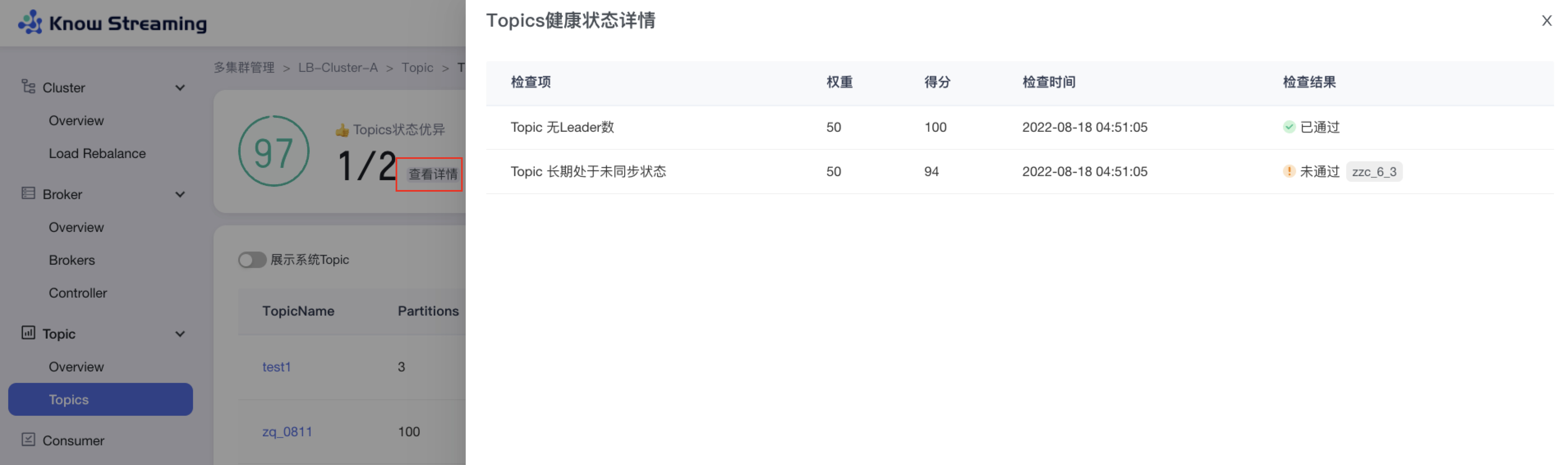
- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Overview”>“集群健康状态旁边【查看详情】”>“健康检查详情抽屉”
- 步骤 2:健康检查详情抽屉展示信息为:“检查项”、“权重”、“得分”、“检查时间”、“检查结果是否通过”,若未通过会展示未通过的对象
-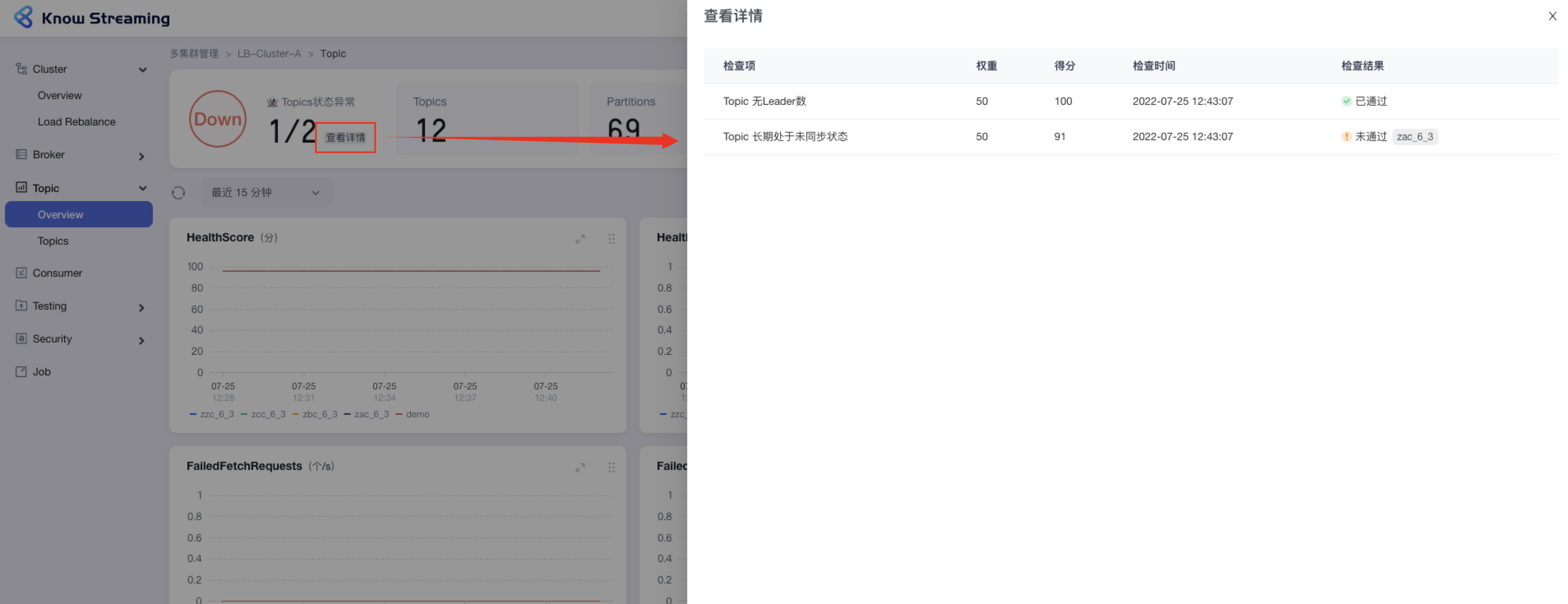
+
-#### 5.6.7.3、查看 Topic 列表
+#### 5.4.7.3、查看 Topic 列表
- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”
@@ -612,7 +597,7 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
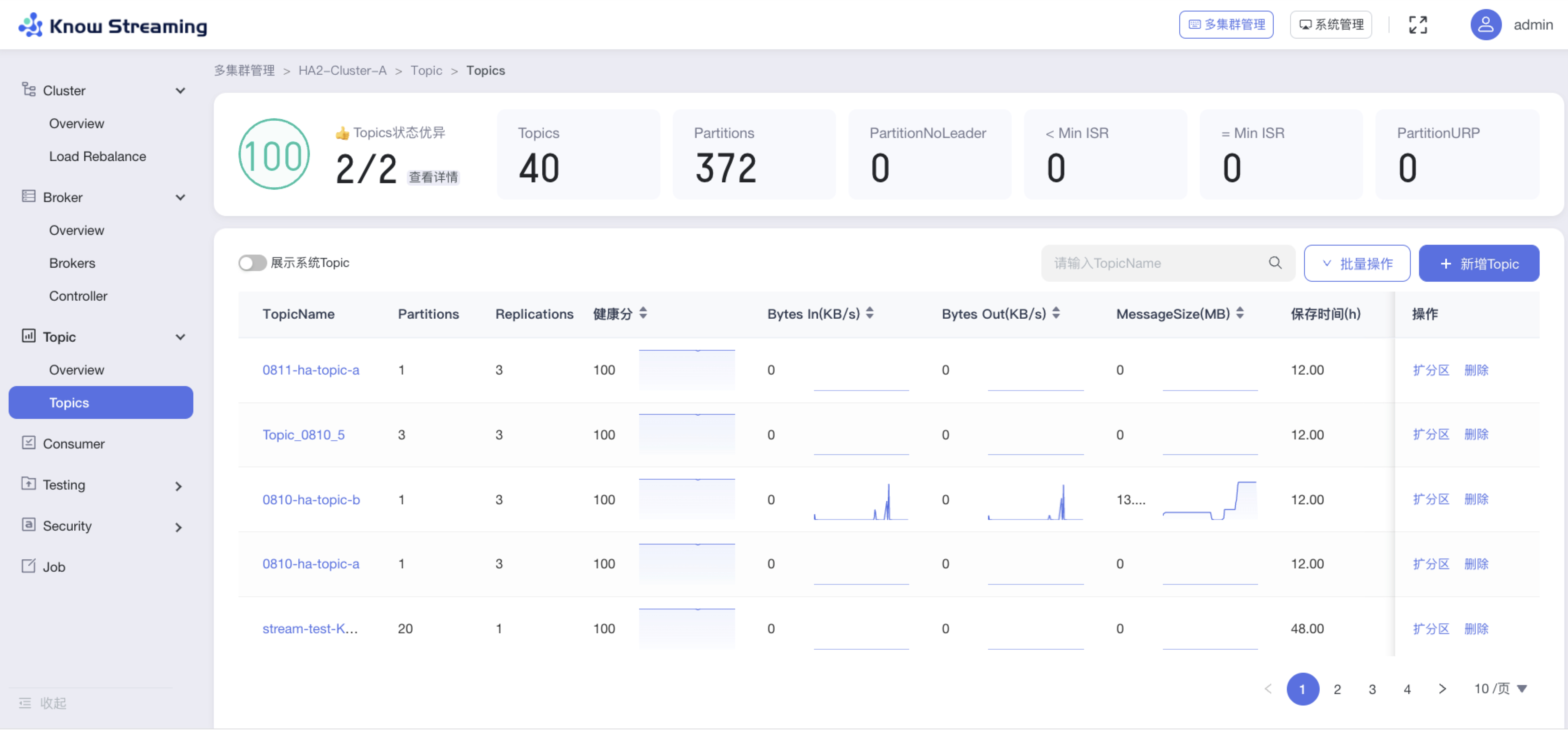
-#### 5.6.7.4、新增 Topic
+#### 5.4.7.4、新增 Topic
- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“新增 Topic”按钮>“创建 Topic“抽屉
@@ -624,7 +609,7 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
-#### 5.6.7.5、Topic 扩分区
+#### 5.4.7.5、Topic 扩分区
- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“Topic 列表“>操作项”扩分区“>“扩分区”抽屉
@@ -636,7 +621,7 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
-#### 5.6.7.6、删除 Topic
+#### 5.4.7.6、删除 Topic
- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“Topic 列表“>操作项”删除“>“删除 Topic”弹窗
@@ -646,7 +631,7 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
-#### 5.6.7.7、Topic 批量扩缩副本
+#### 5.4.7.7、Topic 批量扩缩副本
- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“批量操作下拉“>“批量扩缩副本“>“批量扩缩容”抽屉
@@ -664,7 +649,7 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
-#### 5.6.7.8、Topic 批量迁移
+#### 5.4.7.8、Topic 批量迁移
- 步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“批量操作下拉“>“批量迁移“>“批量迁移”抽屉
@@ -682,11 +667,11 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 8:点击“确定”,执行 Topic 迁移任务
-
+
-### 5.6.8、Consumer
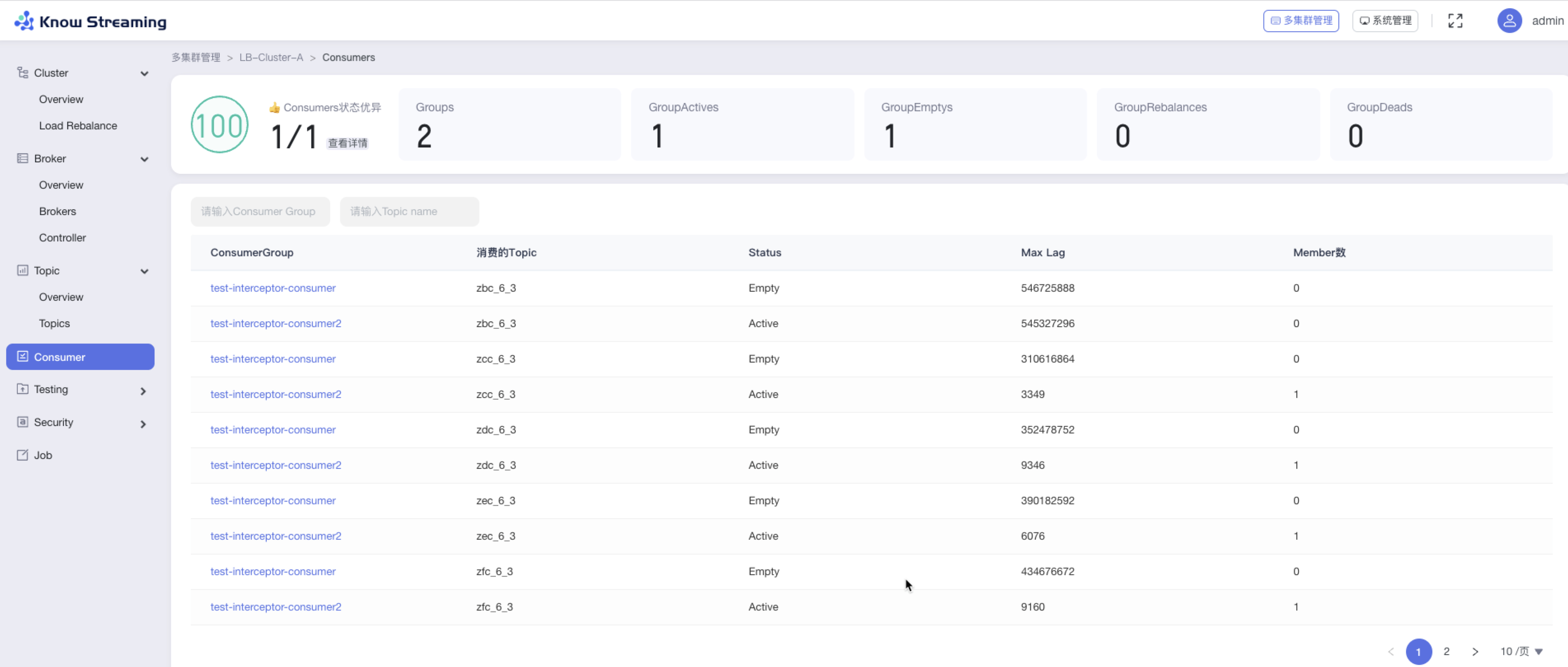
+### 5.4.8、Consumer
-#### 5.6.8.1、Consumer Overview
+#### 5.4.8.1、Consumer Overview
- 步骤 1:点击“多集群管理”>“集群卡片”>“Consumer”
@@ -700,23 +685,23 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- GroupDeads:Dead 的 Group 总数
- Consumer Group 列表
-- 操作 3:输入“Consumer Group”、“Topic Name‘,可对列表进行筛选
+- 步骤 3:输入“Consumer Group”、“Topic Name‘,可对列表进行筛选
-- 操作 4:点击列表“Consumer Group”名称,可以查看 Comsuer Group 详情
+- 步骤 4:点击列表“Consumer Group”名称,可以查看 Comsuer Group 详情
-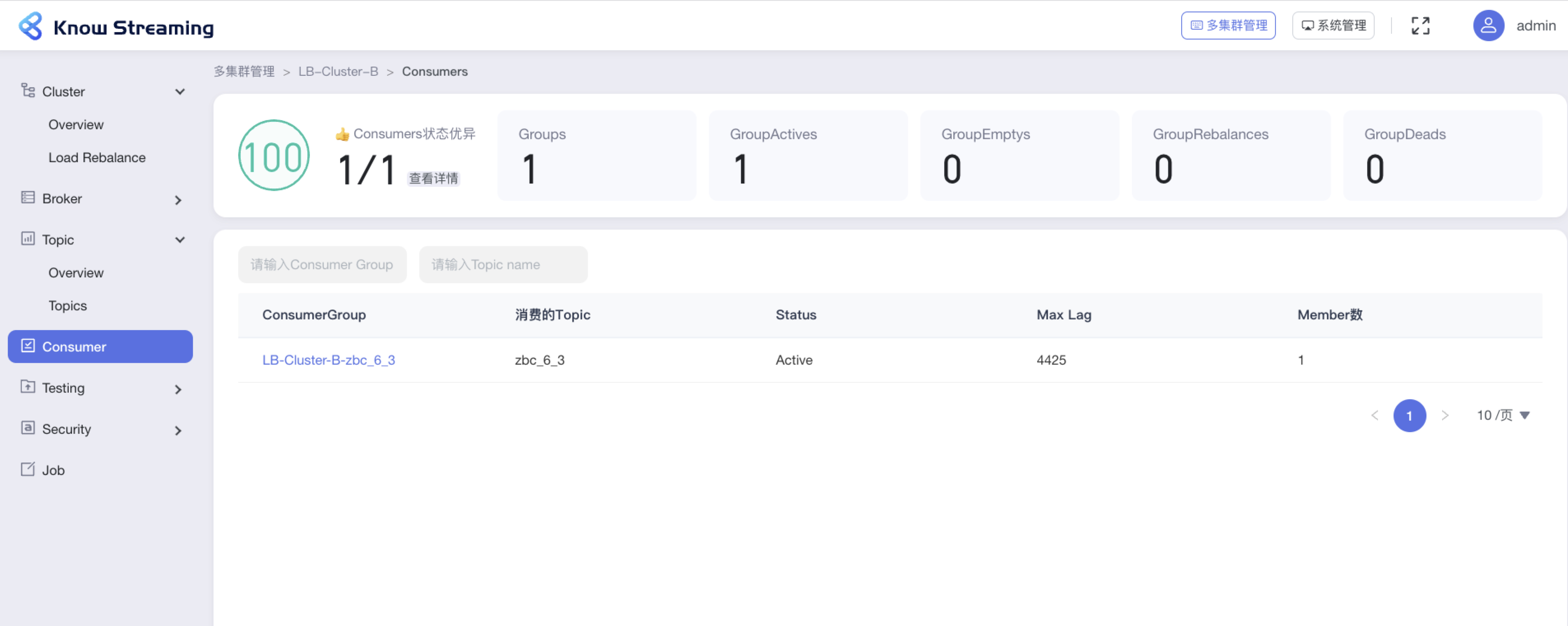
+
-#### 5.6.8.2、查看 Consumer 列表
+#### 5.4.8.2、查看 Consumer 列表
- 步骤 1:点击“多集群管理”>“集群卡片”>“Consumer”>“Consumer Group”名称>“Consumer Group 详情”抽屉
- 步骤 2:Consumer Group 详情有列表视图和图表视图
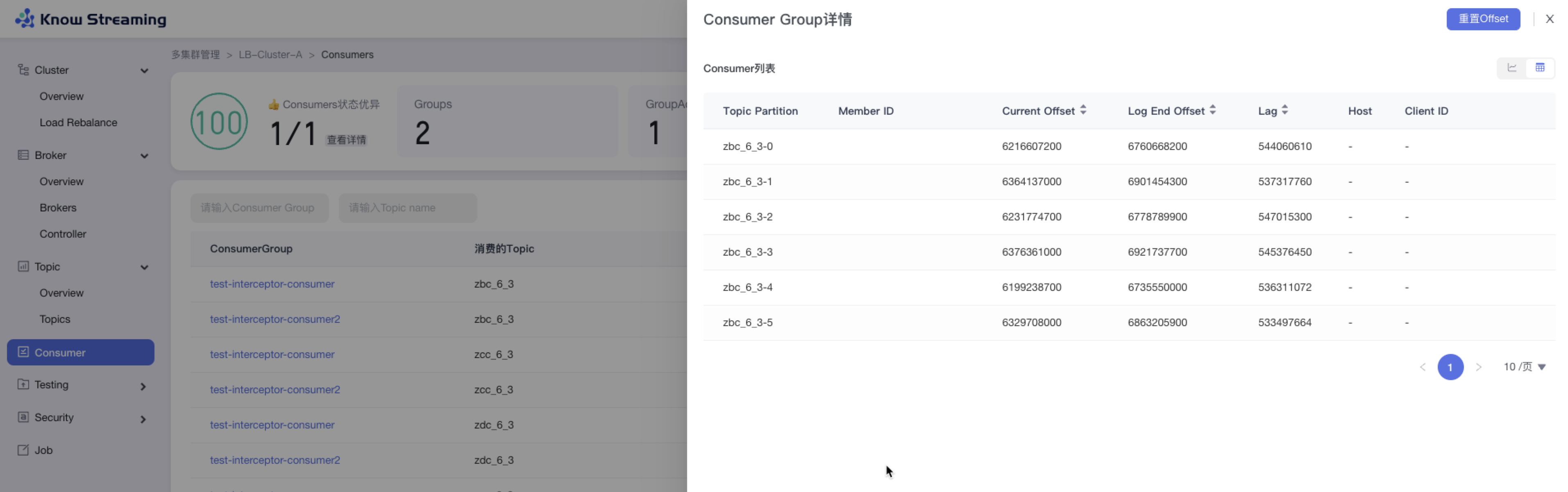
-- 操作 3:列表视图展示信息为 Consumer 列表,包含”Topic Partition“、”Member ID“、”Current Offset“、“Log End Offset”、”Lag“、”Host“、”Client ID“
+- 步骤 3:列表视图展示信息为 Consumer 列表,包含”Topic Partition“、”Member ID“、”Current Offset“、“Log End Offset”、”Lag“、”Host“、”Client ID“
-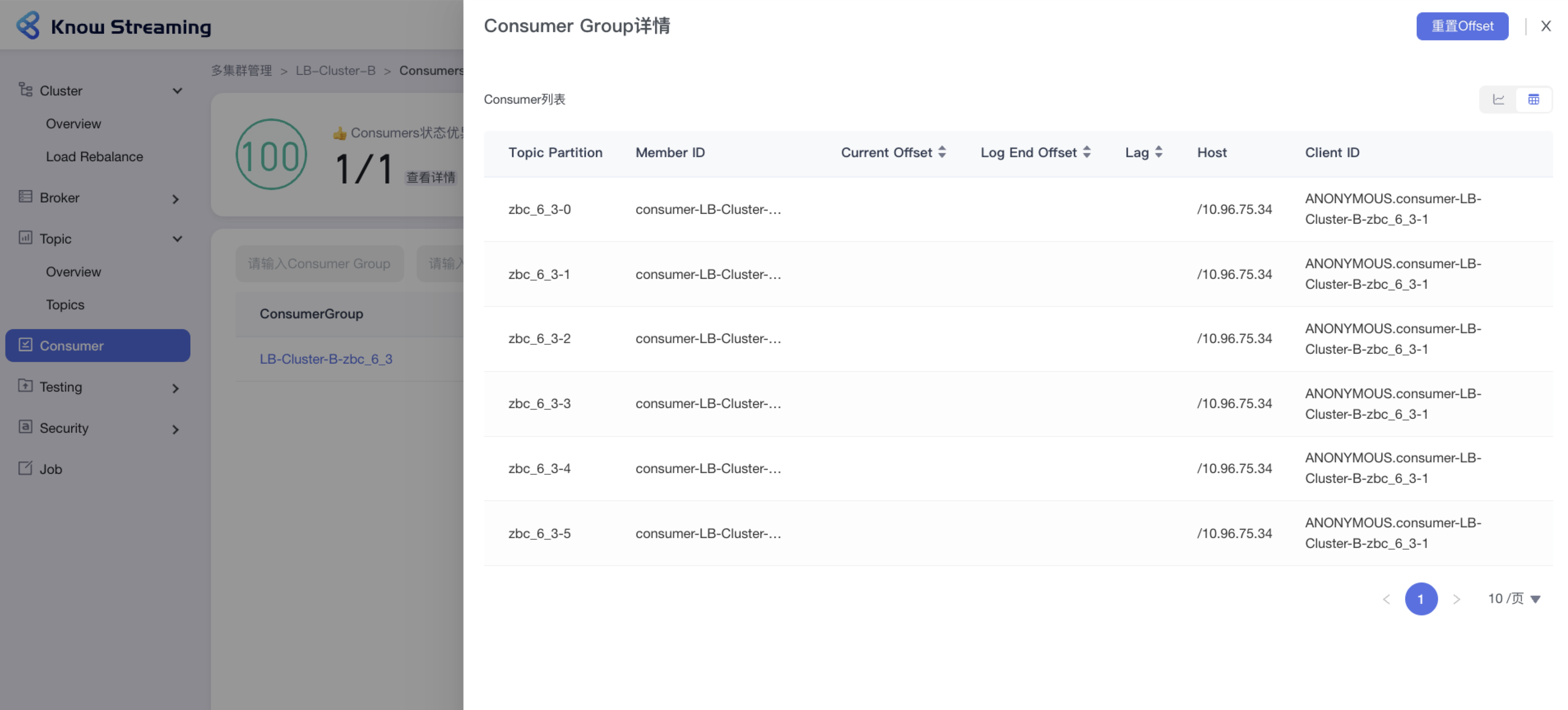
+
-#### 5.6.8.3、重置 Offset
+#### 5.4.8.3、重置 Offset
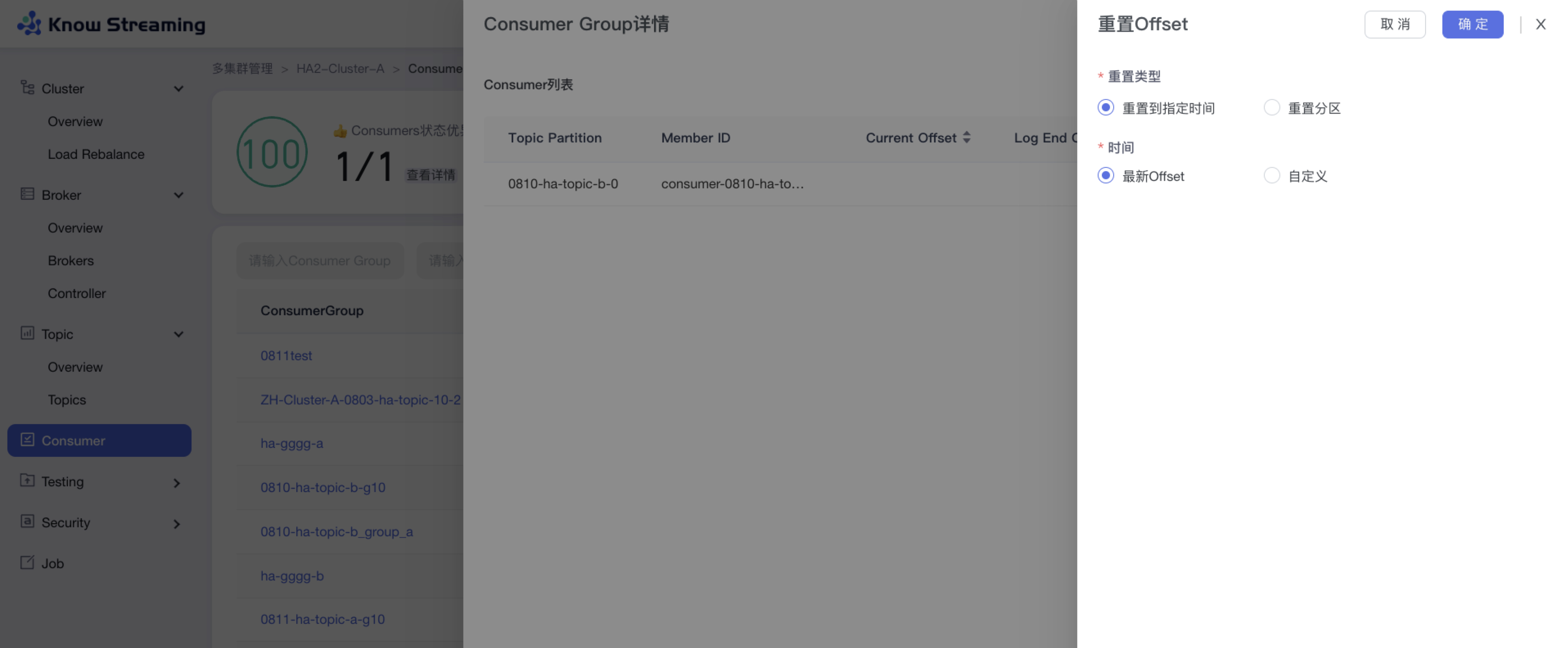
- 步骤 1:点击“多集群管理”>“集群卡片”>“Consumer”>“Consumer Group”名称>“Consumer Group 详情”抽屉>“重置 Offset”按钮>“重置 Offset”抽屉
@@ -730,9 +715,9 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
-### 5.6.9、Testing
+### 5.4.9、Testing(企业版)
-#### 5.6.9.1、生产测试
+#### 5.4.9.1、生产测试
- 步骤 1:点击“多集群管理”>“集群卡片”>“Testing”>“Produce”
@@ -745,9 +730,9 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 3:点击按钮【Run】,生产测试开始,可以从右侧看到生产测试的信息
-
+
-#### 5.6.9.2、消费测试
+#### 5.4.9.2、消费测试
- 步骤 1:点击“多集群管理”>“集群卡片”>“Testing”>“Consume”
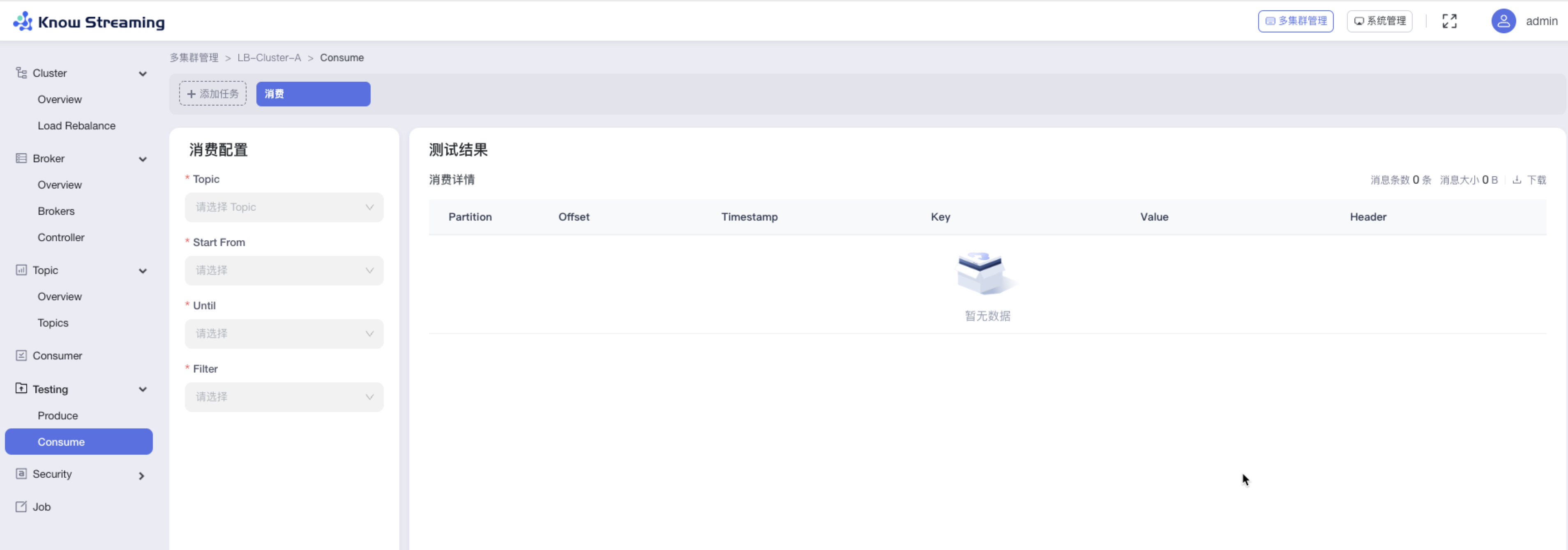
@@ -760,11 +745,13 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 3:点击按钮【Run】,消费测试开始,可以在右边看到消费的明细信息
-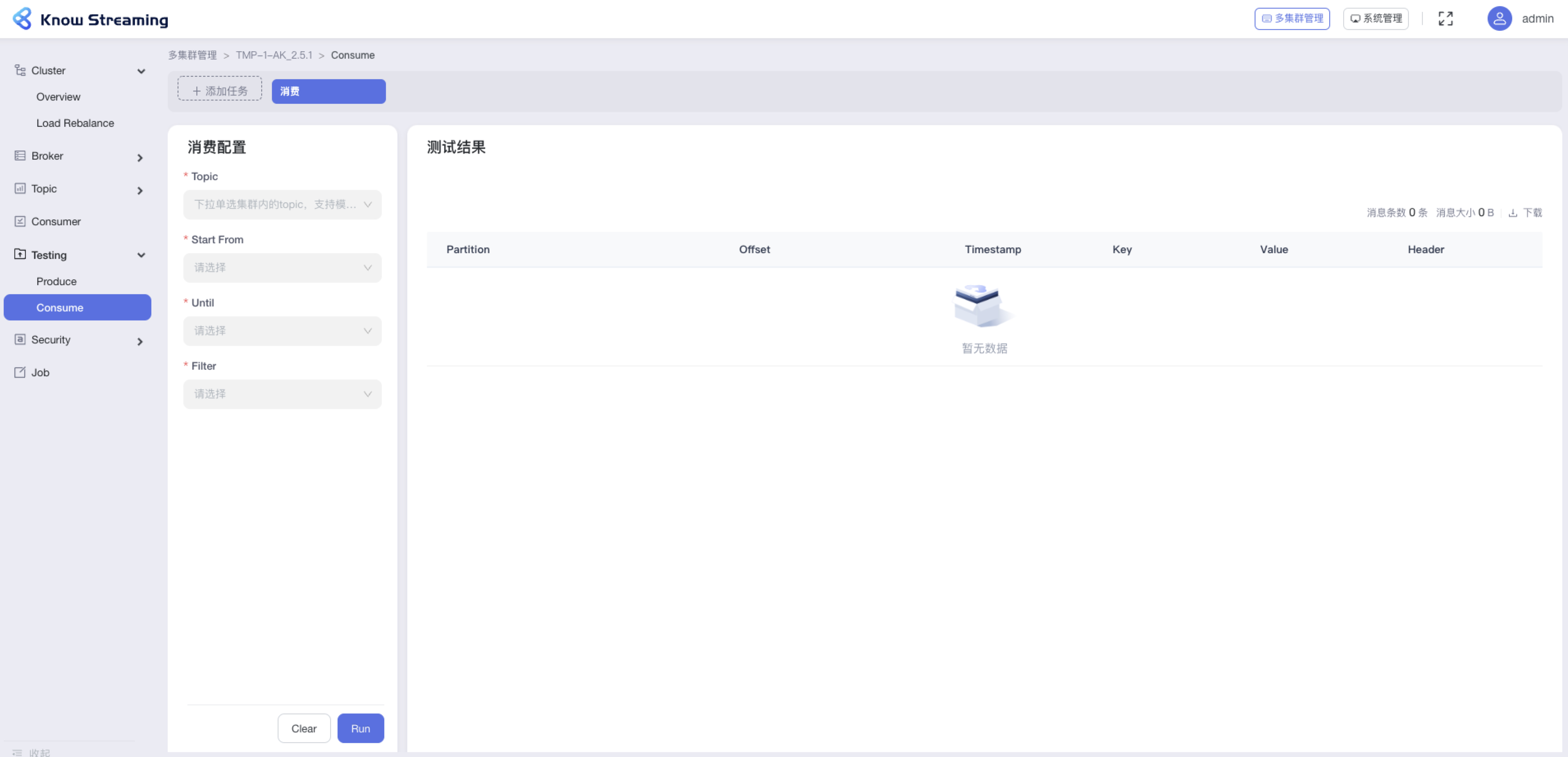
+
-### 5.6.10、Security
+### 5.4.10、Security
-#### 5.6.10.1、查看 ACL 概览信息
+注意:只有在开启集群认证的情况下才能够使用 Security 功能
+
+#### 5.4.10.1、查看 ACL 概览信息
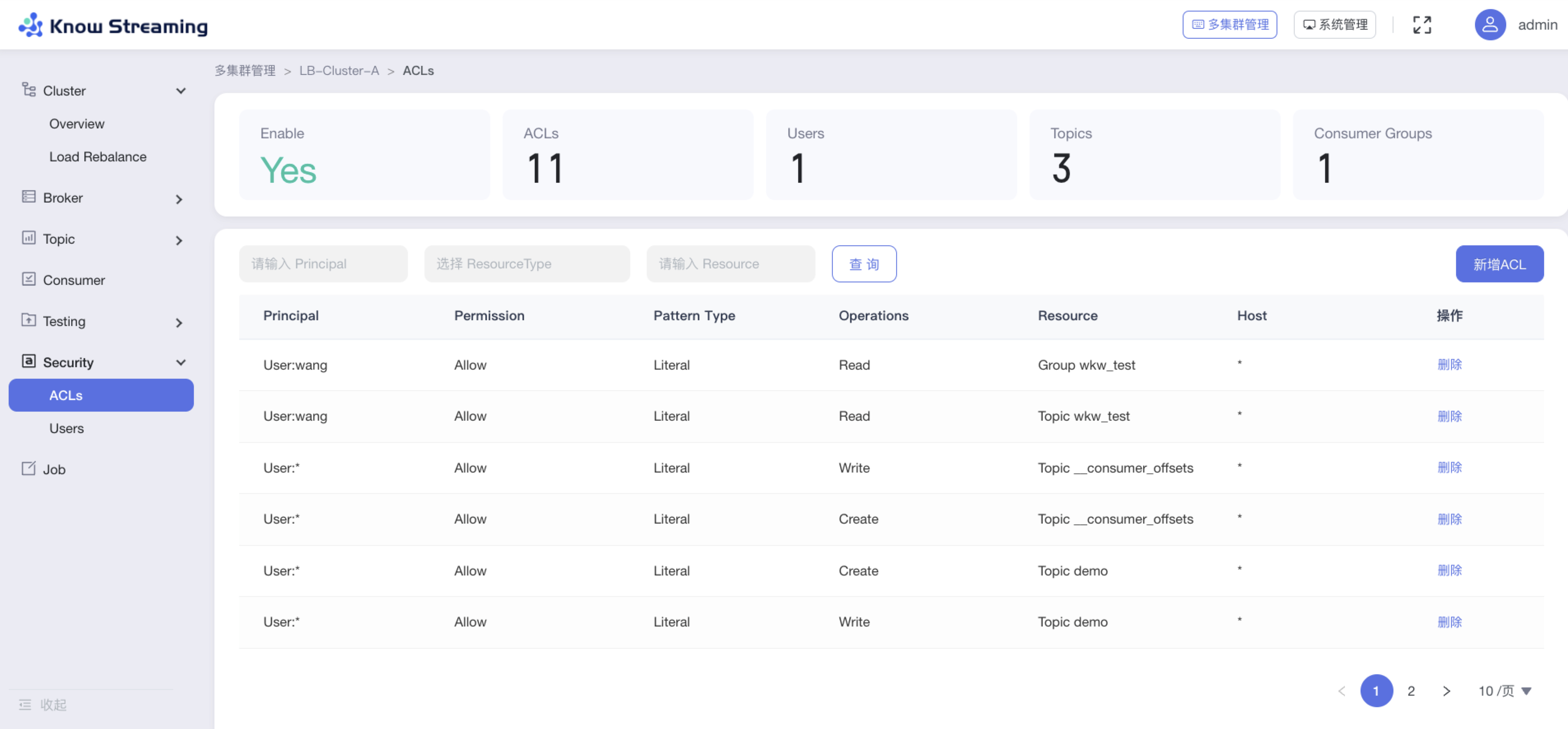
- 步骤 1:点击“多集群管理”>“集群卡片”>“Security”>“ACLs”
@@ -776,9 +763,10 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- Topics:Topic 总数
- Consumer Groups:Consumer Group 总数
- ACL 列表
- 
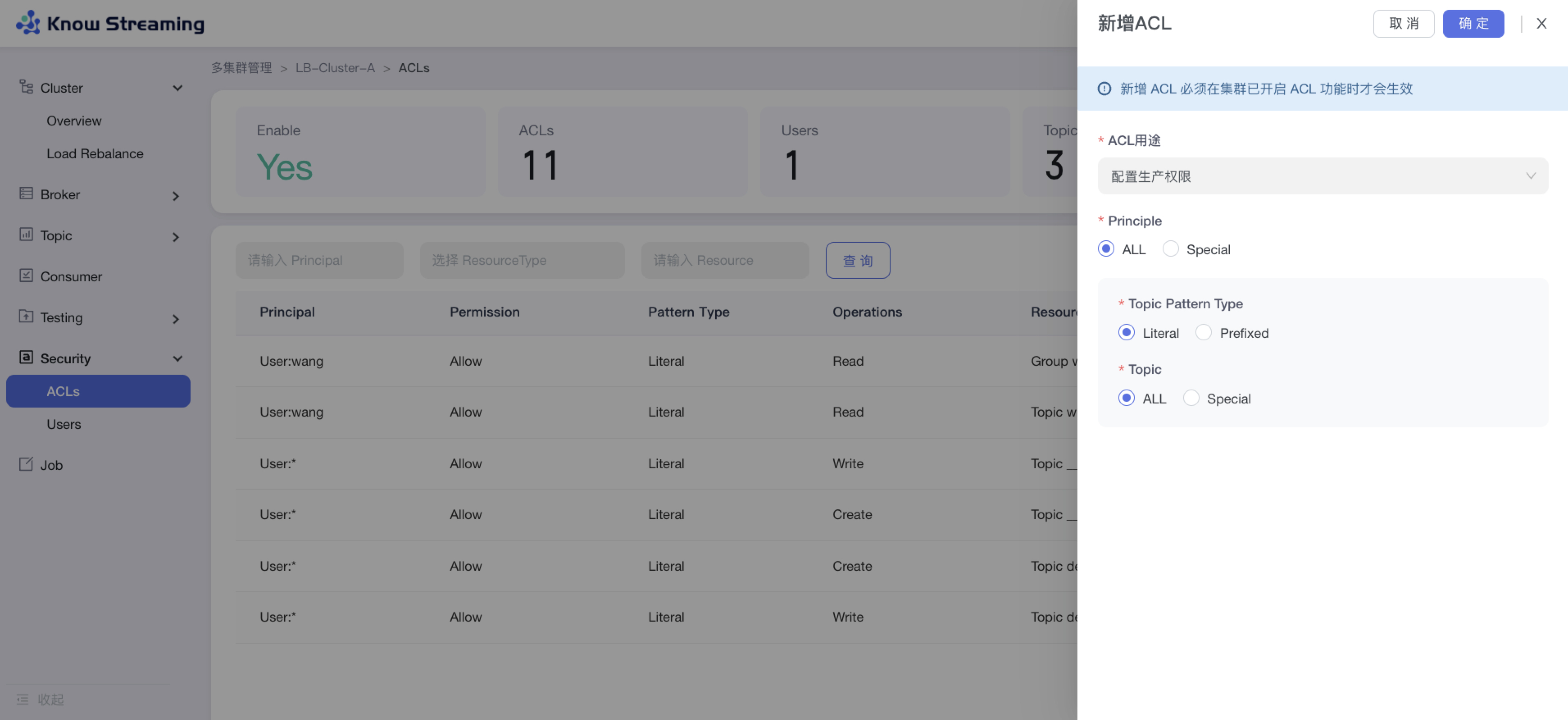
-#### 5.6.10.2、新增 ACl
+
+
+#### 5.4.10.2、新增 ACl
- 步骤 1:点击“多集群管理”>“集群卡片”>“Security”>“Users”>“新增 ACL”
@@ -792,7 +780,7 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
-#### 5.6.10.3、查看 User 信息
+#### 5.4.10.3、查看 User 信息
- 步骤 1:点击“多集群管理”>“集群卡片”>“Security”>“ACLs”
@@ -800,9 +788,9 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 3:筛选框输入“Kafka User”可筛选出列表中相关 Kafka User
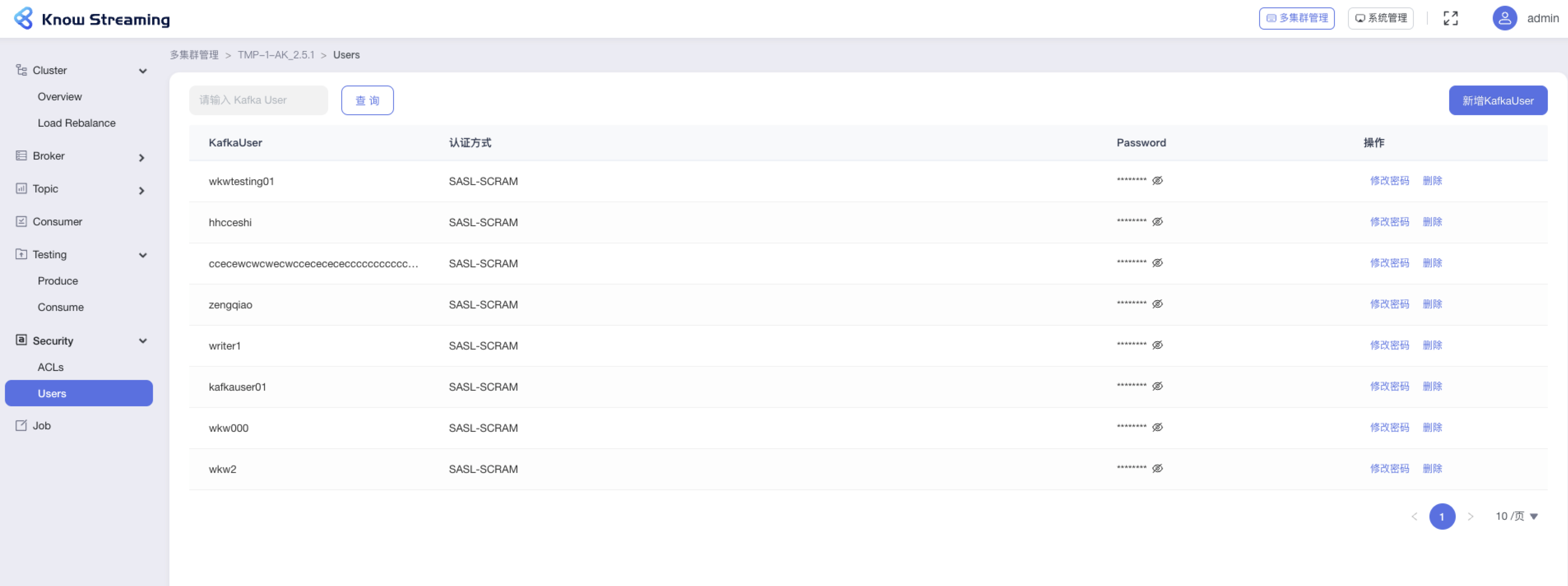
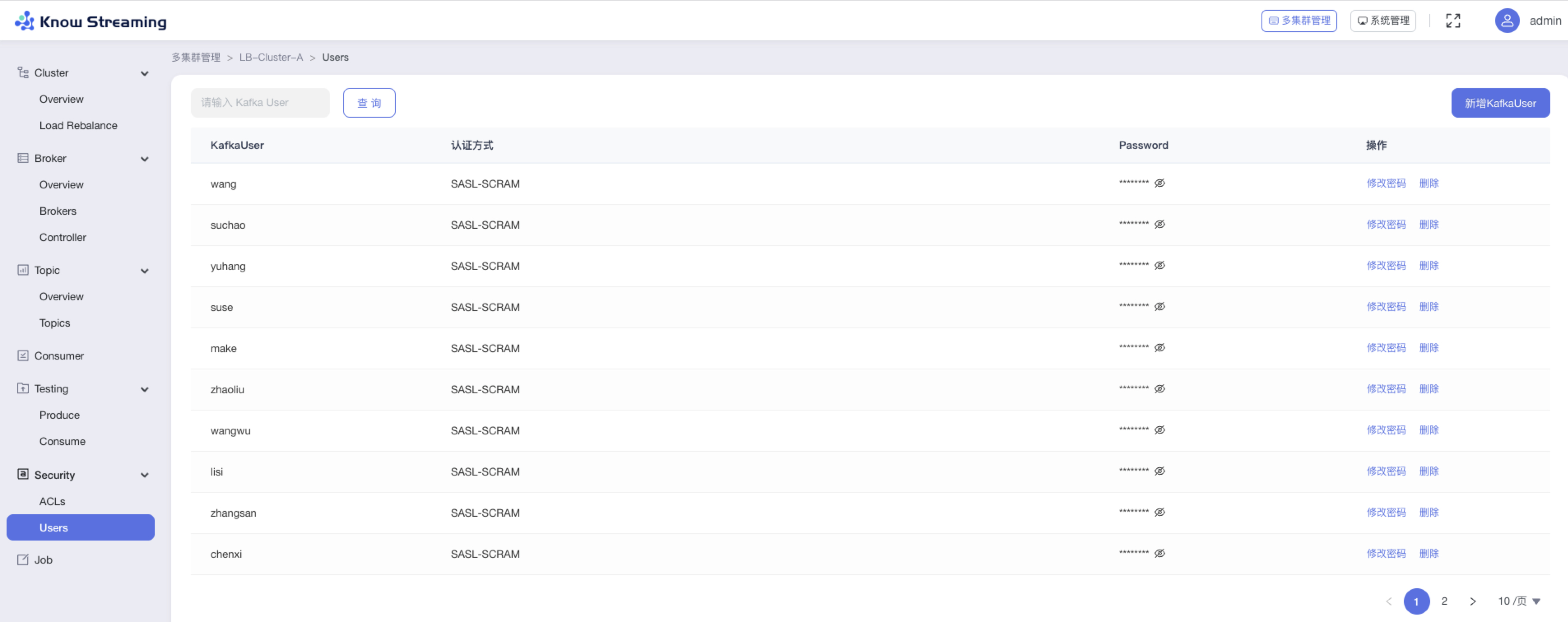
-
+
-#### 5.6.10.4、新增 Kafka User
+#### 5.4.10.4、新增 Kafka User
- 步骤 1:点击“多集群管理”>“集群卡片”>“Security”>“Users”>“新增 Kafka User”
@@ -810,11 +798,11 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- 步骤 3:点击“确定”,新增 Kafka User 成功
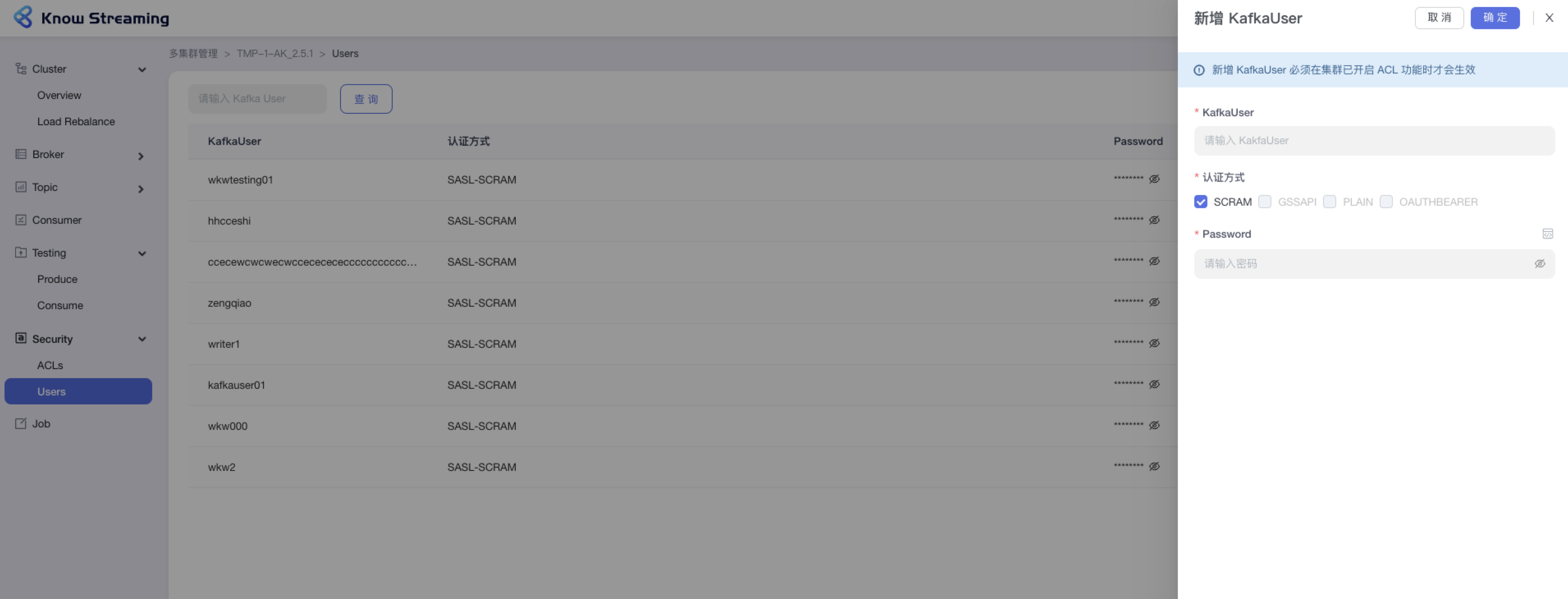
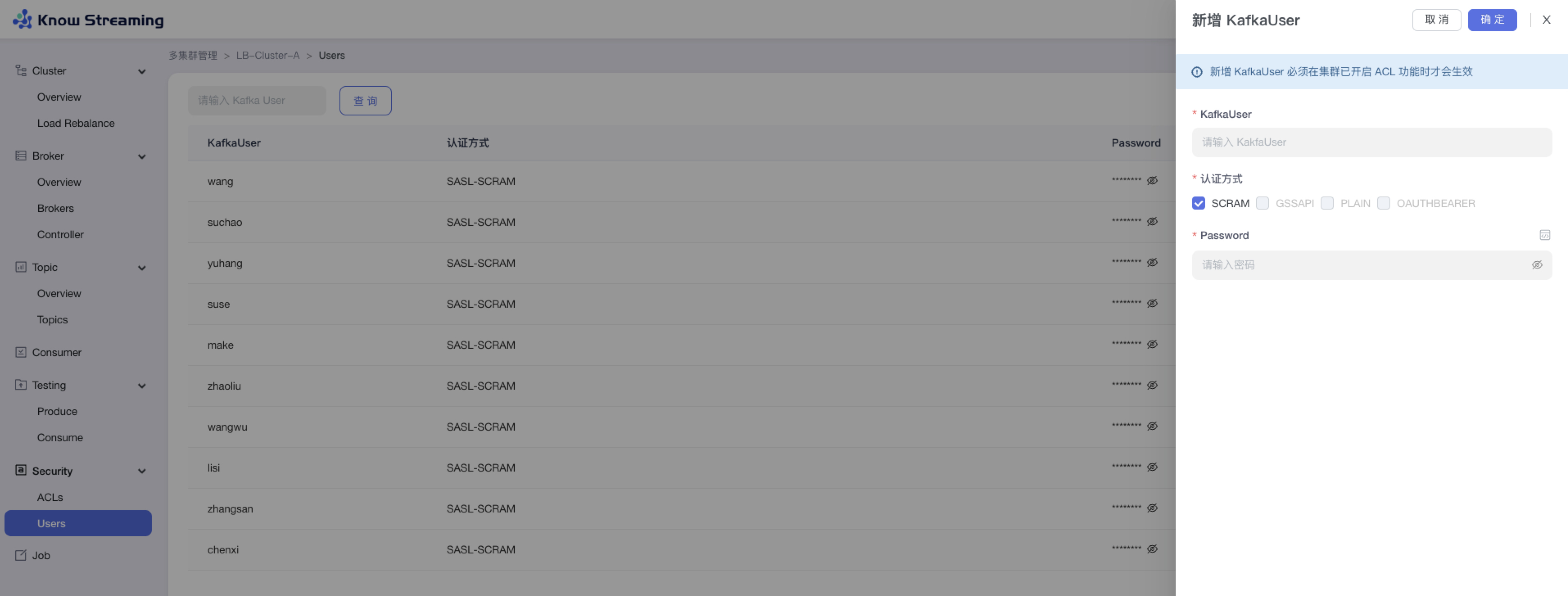
-
+
-### 5.6.11、Job
+### 5.4.11、Job
-#### 5.6.11.1、查看 Job 概览信息
+#### 5.4.11.1、查看 Job 概览信息
- 步骤 1:点击“多集群管理”>“集群卡片”>“Job“
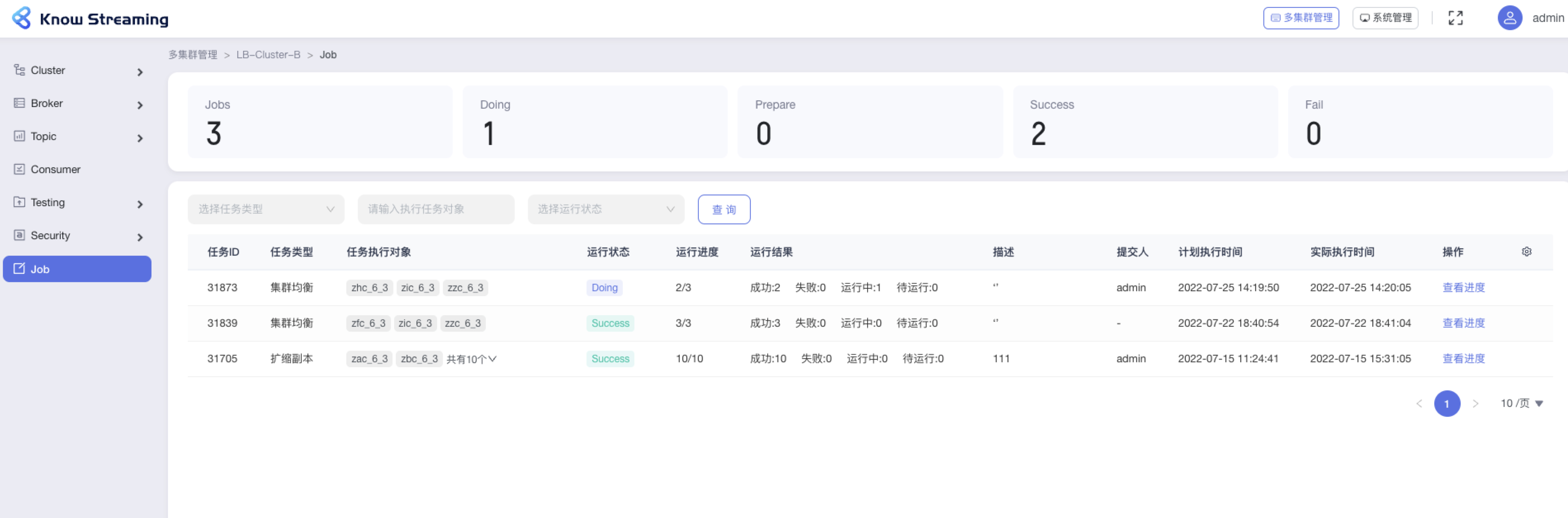
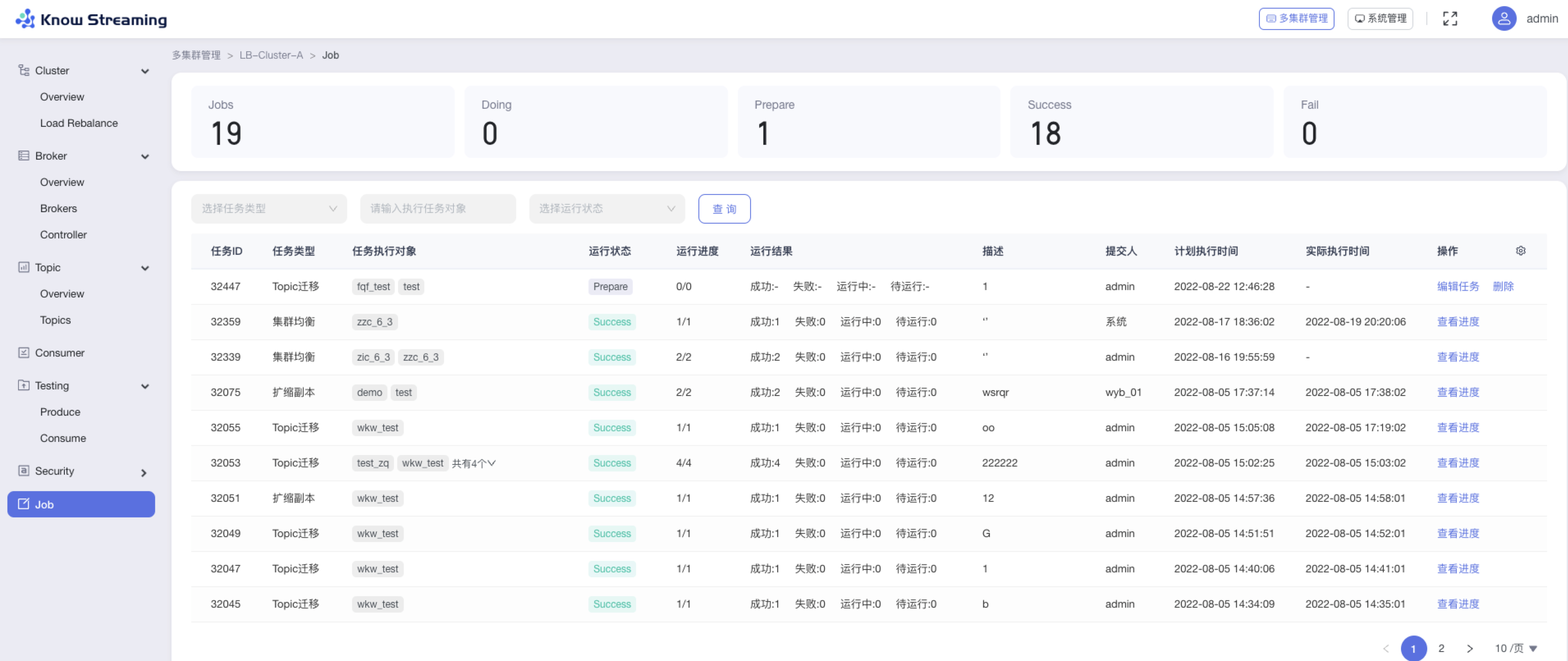
@@ -826,9 +814,10 @@ eg:团队加入了新成员,需要给这位成员分配一个使用系统的
- Success:运行成功的 Job 总数
- Fail:运行失败的 Job 总数
- Job 列表
- 
-#### 5.6.11.2、Job 查看进度
+
+
+#### 5.4.11.2、Job 查看进度
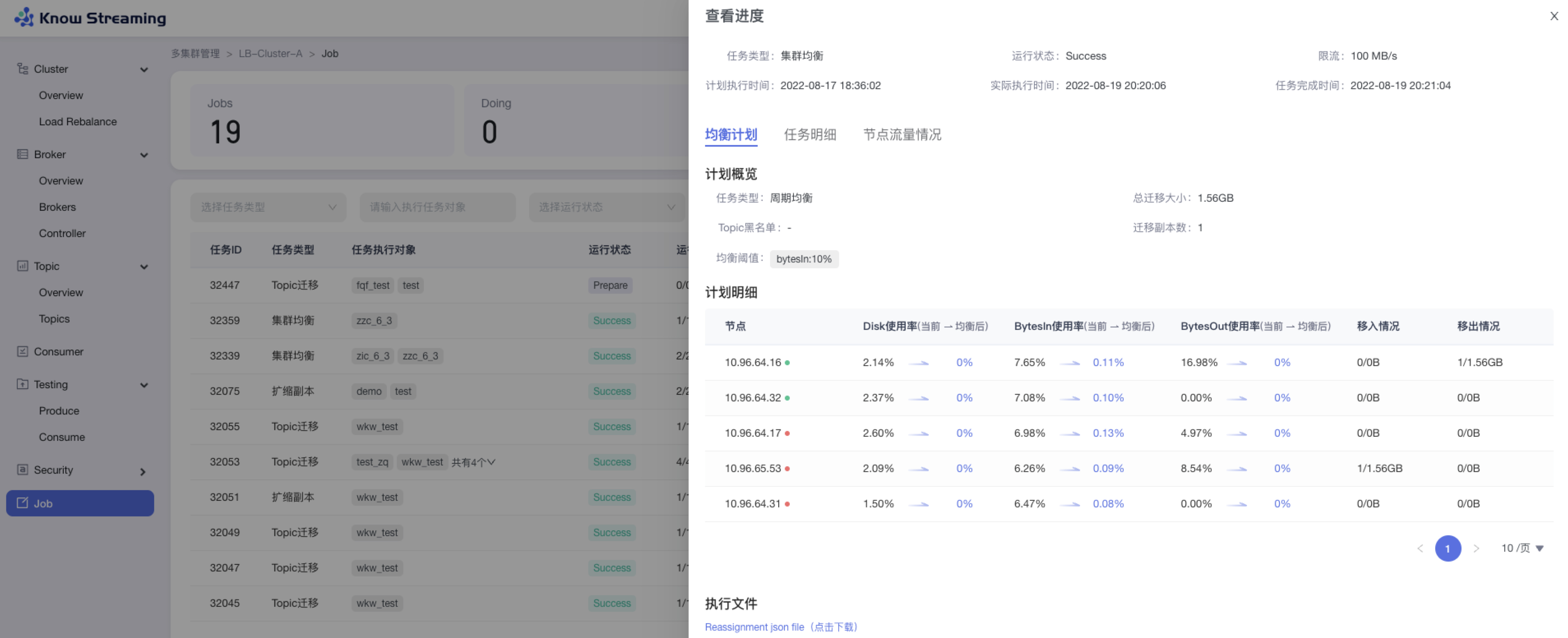
Doing 状态下的任务可以查看进度
@@ -839,20 +828,21 @@ Doing 状态下的任务可以查看进度
- 均衡任务:任务基本信息、均衡计划、任务执行明细信息
- 扩缩副本:任务基本信息、任务执行明细信息、节点流量情况
- Topic 迁移:任务基本信息、任务执行明细信息、节点流量情况
- 
-#### 5.6.11.3、Job 编辑任务
+
+
+#### 5.4.11.3、Job 编辑任务
Prepare 状态下的任务可以进行编辑
-- 步骤 1:点击“多集群管理”>“集群卡片”>“Job”>“Job”列表>操作项“编辑”
+- 点击“多集群管理”>“集群卡片”>“Job”>“Job”列表>操作项“编辑”
-- 步骤 2:对任务执行的参数进行重新配置
+- 对任务执行的参数进行重新配置
- 集群均衡:可以对指标计算周期、均衡维度、topic 黑名单、运行配置等参数重新设置
- Topic 迁移:可以对 topic 需要迁移的 partition、迁移数据的时间范围、目标 broker 节点、限流值、执行时间、描述等参数重新配置
- topic 扩缩副本:可以对最终副本数、限流值、任务执行时间、描述等参数重新配置
-- 步骤 3:点击“确定”,编辑任务成功
+- 点击“确定”,编辑任务成功
-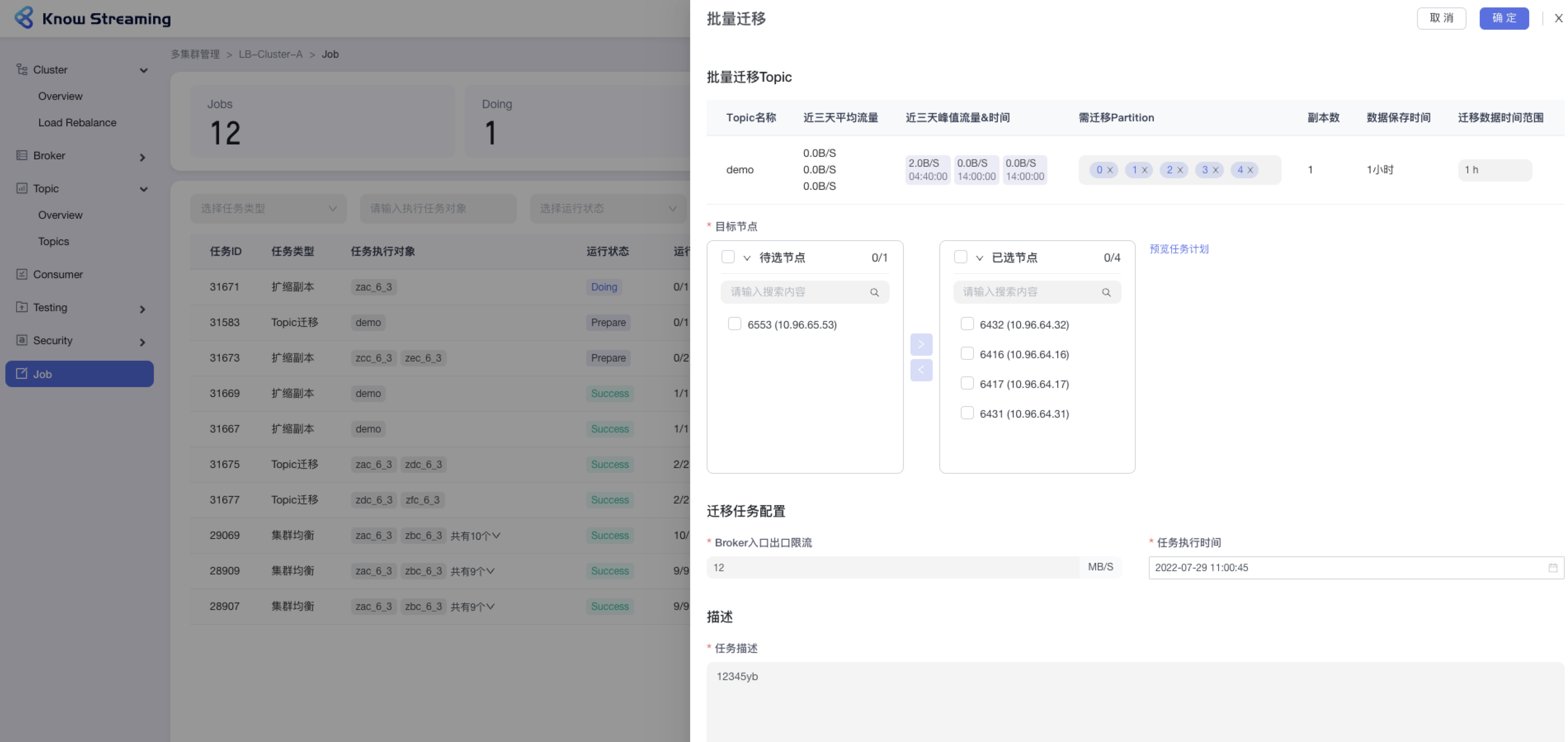
+
diff --git a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterBrokersManagerImpl.java b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterBrokersManagerImpl.java
index f8b1c309..e7a67ac7 100644
--- a/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterBrokersManagerImpl.java
+++ b/km-biz/src/main/java/com/xiaojukeji/know/streaming/km/biz/cluster/impl/ClusterBrokersManagerImpl.java
@@ -211,7 +211,7 @@ public class ClusterBrokersManagerImpl implements ClusterBrokersManager {
private List getBrokerVersionList(Long clusterPhyId, List brokerList) {
Set brokerVersionList = new HashSet<>();
for (Broker broker : brokerList) {
- brokerVersionList.add(brokerService.getBrokerVersionFromKafka(clusterPhyId, broker.getBrokerId()));
+ brokerVersionList.add(brokerService.getBrokerVersionFromKafkaWithCacheFirst(broker.getClusterPhyId(),broker.getBrokerId(),broker.getStartTimestamp()));
}
brokerVersionList.remove("");
return new ArrayList<>(brokerVersionList);
diff --git a/km-console/packages/config-manager-fe/webpack.config.js b/km-console/packages/config-manager-fe/webpack.config.js
index de57412c..9b4af39e 100644
--- a/km-console/packages/config-manager-fe/webpack.config.js
+++ b/km-console/packages/config-manager-fe/webpack.config.js
@@ -33,6 +33,7 @@ module.exports = merge(config, {
output: {
path: outPath,
+ // publicPath: isProd ? `//img-ys011.didistatic.com/static/bp_fe_daily/bigdata_cloud_KnowStreaming_FE/gn/${pkgJson.ident}/` : `http://localhost:${pkgJson.port}/${pkgJson.ident}/`,
publicPath: isProd ? `/${pkgJson.ident}/` : `http://localhost:${pkgJson.port}/${pkgJson.ident}/`,
library: pkgJson.ident,
libraryTarget: 'amd',
diff --git a/km-console/packages/layout-clusters-fe/config/d1-webpack.base.js b/km-console/packages/layout-clusters-fe/config/d1-webpack.base.js
index b1b54310..f298b2e9 100644
--- a/km-console/packages/layout-clusters-fe/config/d1-webpack.base.js
+++ b/km-console/packages/layout-clusters-fe/config/d1-webpack.base.js
@@ -58,9 +58,9 @@ module.exports = () => {
filename: cssFileName,
}),
!isProd &&
- new ReactRefreshWebpackPlugin({
- overlay: false,
- }),
+ new ReactRefreshWebpackPlugin({
+ overlay: false,
+ }),
].filter(Boolean);
const resolve = {
symlinks: false,
@@ -86,17 +86,17 @@ module.exports = () => {
},
externals: isProd
? [
- /^react$/,
- /^react\/lib.*/,
- /^react-dom$/,
- /.*react-dom.*/,
- /^single-spa$/,
- /^single-spa-react$/,
- /^moment$/,
- /^antd$/,
- /^lodash$/,
- /^echarts$/,
- ]
+ /^react$/,
+ /^react\/lib.*/,
+ /^react-dom$/,
+ /.*react-dom.*/,
+ /^single-spa$/,
+ /^single-spa-react$/,
+ /^moment$/,
+ /^antd$/,
+ /^lodash$/,
+ /^echarts$/,
+ ]
: [],
resolve,
plugins,
@@ -163,14 +163,14 @@ module.exports = () => {
},
optimization: isProd
? {
- minimizer: [
- new TerserJSPlugin({
- cache: true,
- sourceMap: true,
- }),
- new OptimizeCSSAssetsPlugin({}),
- ],
- }
+ minimizer: [
+ new TerserJSPlugin({
+ cache: true,
+ sourceMap: true,
+ }),
+ new OptimizeCSSAssetsPlugin({}),
+ ],
+ }
: {},
devtool: isProd ? 'cheap-module-source-map' : '',
node: {
diff --git a/km-console/packages/layout-clusters-fe/env.json b/km-console/packages/layout-clusters-fe/env.json
deleted file mode 100644
index 9924e0a0..00000000
--- a/km-console/packages/layout-clusters-fe/env.json
+++ /dev/null
@@ -1,56 +0,0 @@
-{
- "development": {
- "inner": {
- "proxy": {
- "/api/v2": {
- "target": "https://mock.xiaojukeji.com/mock/8739",
- "changeOrigin": true
- },
- "/sysUser": {
- "target": "https://mock.xiaojukeji.com/mock/8739",
- "changeOrigin": true
- }
- },
- "loginUrl": "http://mock.xiaojukeji.com/mock/8739"
- },
- "cmb": {
- "proxy": {
- "/api/v1/uc": {
- "target": "http://cmbkafkagw-dev.paas.cmbchina.cn/",
- "pathRewrite": { "^/api/v1/uc": "/uc/api/v1" },
- "changeOrigin": true
- },
- "/api/v2": {
- "target": "http://cmbkafkagw-dev.paas.cmbchina.cn/",
- "pathRewrite": { "^/api/v2": "/acskafka/api/v2" },
- "changeOrigin": true
- }
- },
- "loginUrl": "https://oidc.idc.cmbchina.cn/authorize"
- }
- },
- "production": {
- "inner": {
- "proxy": {
- "/api/v2": "https://mock.xiaojukeji.com/mock/8739",
- "changeOrigin": true
- },
- "loginUrl": "https://mock.xiaojukeji.com/mock/8739"
- },
- "cmb": {
- "proxy": {
- "/api/v1/uc": {
- "target": "http://cmbkafkagw-dev.paas.cmbchina.cn/",
- "pathRewrite": { "^/api/v1/uc": "/uc/api/v1" },
- "changeOrigin": true
- },
- "/api/v1": {
- "target": "http://cmbkafkagw-dev.paas.cmbchina.cn/",
- "pathRewrite": { "^/api/v1": "/cmbkafka-dev" },
- "changeOrigin": true
- }
- },
- "loginUrl": "https://oidc.idc.cmbchina.cn/authorize"
- }
- }
-}
diff --git a/km-console/packages/layout-clusters-fe/webpack.config.js b/km-console/packages/layout-clusters-fe/webpack.config.js
index b11a3f1c..1c9659c7 100644
--- a/km-console/packages/layout-clusters-fe/webpack.config.js
+++ b/km-console/packages/layout-clusters-fe/webpack.config.js
@@ -85,11 +85,11 @@ module.exports = merge(config, {
proxy: {
'/ks-km/api/v3': {
changeOrigin: true,
- target: 'localhost',
+ target: 'https://api-kylin-xg02.intra.xiaojukeji.com/ks-km/',
},
'/logi-security/api/v1': {
changeOrigin: true,
- target: 'localhost',
+ target: 'https://api-kylin-xg02.intra.xiaojukeji.com/ks-km/',
},
},
},
diff --git a/km-core/src/main/java/com/xiaojukeji/know/streaming/km/core/service/broker/BrokerService.java b/km-core/src/main/java/com/xiaojukeji/know/streaming/km/core/service/broker/BrokerService.java
index d9660f37..d1f181b4 100644
--- a/km-core/src/main/java/com/xiaojukeji/know/streaming/km/core/service/broker/BrokerService.java
+++ b/km-core/src/main/java/com/xiaojukeji/know/streaming/km/core/service/broker/BrokerService.java
@@ -55,6 +55,13 @@ public interface BrokerService {
*/
String getBrokerVersionFromKafka(Long clusterPhyId, Integer brokerId);
+ /**
+ * 优先从本地缓存中获取Broker的版本信息
+ * @param
+ * @return
+ */
+ String getBrokerVersionFromKafkaWithCacheFirst(Long clusterPhyId, Integer brokerId,Long startTime);
+
/**
* 获取总的Broker数
*/
diff --git a/km-core/src/main/java/com/xiaojukeji/know/streaming/km/core/service/broker/impl/BrokerServiceImpl.java b/km-core/src/main/java/com/xiaojukeji/know/streaming/km/core/service/broker/impl/BrokerServiceImpl.java
index 6f8771f2..3ab9f3fa 100644
--- a/km-core/src/main/java/com/xiaojukeji/know/streaming/km/core/service/broker/impl/BrokerServiceImpl.java
+++ b/km-core/src/main/java/com/xiaojukeji/know/streaming/km/core/service/broker/impl/BrokerServiceImpl.java
@@ -59,7 +59,7 @@ import static com.xiaojukeji.know.streaming.km.common.jmx.JmxName.JMX_SERVER_APP
public class BrokerServiceImpl extends BaseVersionControlService implements BrokerService {
private static final ILog log = LogFactory.getLog(BrokerServiceImpl.class);
- private static final String BROKER_LOG_DIR = "getLogDir";
+ private static final String BROKER_LOG_DIR = "getLogDir";
@Autowired
private TopicService topicService;
@@ -84,6 +84,12 @@ public class BrokerServiceImpl extends BaseVersionControlService implements Brok
return SERVICE_SEARCH_BROKER;
}
+ private static final Cache brokerVersionCache = Caffeine.newBuilder()
+ .expireAfterWrite(1, TimeUnit.DAYS)
+ .maximumSize(5000)
+ .build();
+
+
private final Cache> brokersCache = Caffeine.newBuilder()
.expireAfterWrite(90, TimeUnit.SECONDS)
.maximumSize(200)
@@ -225,6 +231,22 @@ public class BrokerServiceImpl extends BaseVersionControlService implements Brok
return "";
}
+ @Override
+ public String getBrokerVersionFromKafkaWithCacheFirst(Long clusterPhyId, Integer brokerId,Long startTime) {
+ //id唯一确定一个broker
+ String id = String.valueOf(clusterPhyId) + String.valueOf(brokerId)+String.valueOf(startTime);
+ //先尝试读缓存
+ String brokerVersion = brokerVersionCache.getIfPresent(id);
+ if (brokerVersion != null) {
+ return brokerVersion;
+ }
+ String version = getBrokerVersionFromKafka(clusterPhyId, brokerId);
+ brokerVersionCache.put(id,version);
+ return version;
+ }
+
+
+
@Override
public Integer countAllBrokers() {
LambdaQueryWrapper lambdaQueryWrapper = new LambdaQueryWrapper<>();
diff --git a/km-core/src/main/java/com/xiaojukeji/know/streaming/km/core/service/cluster/ClusterPhyService.java b/km-core/src/main/java/com/xiaojukeji/know/streaming/km/core/service/cluster/ClusterPhyService.java
index f8741c92..b55594b1 100644
--- a/km-core/src/main/java/com/xiaojukeji/know/streaming/km/core/service/cluster/ClusterPhyService.java
+++ b/km-core/src/main/java/com/xiaojukeji/know/streaming/km/core/service/cluster/ClusterPhyService.java
@@ -9,6 +9,7 @@ import com.xiaojukeji.know.streaming.km.common.exception.NotExistException;
import com.xiaojukeji.know.streaming.km.common.exception.ParamErrorException;
import java.util.List;
+import java.util.Set;
/**
* @author didi
@@ -67,4 +68,10 @@ public interface ClusterPhyService {
DuplicateException,
NotExistException,
AdminOperateException;
+
+ /**
+ * 获取系统已存在的kafka版本列表
+ * @return
+ */
+ Set getClusterVersionSet();
}
diff --git a/km-core/src/main/java/com/xiaojukeji/know/streaming/km/core/service/cluster/impl/ClusterPhyServiceImpl.java b/km-core/src/main/java/com/xiaojukeji/know/streaming/km/core/service/cluster/impl/ClusterPhyServiceImpl.java
index 9ac13bf7..562645c0 100644
--- a/km-core/src/main/java/com/xiaojukeji/know/streaming/km/core/service/cluster/impl/ClusterPhyServiceImpl.java
+++ b/km-core/src/main/java/com/xiaojukeji/know/streaming/km/core/service/cluster/impl/ClusterPhyServiceImpl.java
@@ -25,6 +25,8 @@ import org.springframework.dao.DuplicateKeyException;
import org.springframework.stereotype.Service;
import java.util.List;
+import java.util.Set;
+import java.util.stream.Collectors;
/**
* @author didi
@@ -201,4 +203,11 @@ public class ClusterPhyServiceImpl implements ClusterPhyService {
throw new AdminOperateException("modify cluster failed", e, ResultStatus.MYSQL_OPERATE_FAILED);
}
}
+
+ @Override
+ public Set getClusterVersionSet() {
+ List clusterPhyList = listAllClusters();
+ Set versionSet = clusterPhyList.stream().map(elem -> elem.getKafkaVersion()).collect(Collectors.toSet());
+ return versionSet;
+ }
}
diff --git a/km-dist/helm/charts/knowstreaming-web/templates/configMap.yaml b/km-dist/helm/charts/knowstreaming-web/templates/configMap.yaml
index 34cf58f4..86d6e5eb 100644
--- a/km-dist/helm/charts/knowstreaming-web/templates/configMap.yaml
+++ b/km-dist/helm/charts/knowstreaming-web/templates/configMap.yaml
@@ -39,7 +39,7 @@ data:
location ~ ^/ks-km/api/v3 {
#rewrite ^/ks-km/api/v3/(.*)$ /ks-km/ks-km/api/v3/$1 break;
proxy_pass http://{{ .Release.Name }}-knowstreaming-manager;
- #proxy_pass localhost;
+ #proxy_pass https://api-kylin-xg02.intra.xiaojukeji.com;
#proxy_cookie_path /ks-km/ /;
#proxy_set_header Host $host;
#proxy_set_header Referer $http_referer;
@@ -50,7 +50,7 @@ data:
location ~ ^/logi-security/api/v1 {
#rewrite ^/logi-security/api/v1/(.*)$ /ks-km/logi-security/api/v1/$1 break;
proxy_pass http://{{ .Release.Name }}-knowstreaming-manager;
- #proxy_pass localhost;
+ #proxy_pass https://api-kylin-xg02.intra.xiaojukeji.com;
}
location ~ ^/(401|403|404|500){
rewrite ^.*$ /;
diff --git a/km-rest/src/main/java/com/xiaojukeji/know/streaming/km/rest/api/v3/cluster/MultiClusterPhyController.java b/km-rest/src/main/java/com/xiaojukeji/know/streaming/km/rest/api/v3/cluster/MultiClusterPhyController.java
index 568f1410..d443bcac 100644
--- a/km-rest/src/main/java/com/xiaojukeji/know/streaming/km/rest/api/v3/cluster/MultiClusterPhyController.java
+++ b/km-rest/src/main/java/com/xiaojukeji/know/streaming/km/rest/api/v3/cluster/MultiClusterPhyController.java
@@ -9,12 +9,15 @@ import com.xiaojukeji.know.streaming.km.common.bean.vo.cluster.ClusterPhyDashboa
import com.xiaojukeji.know.streaming.km.common.constant.ApiPrefix;
import com.xiaojukeji.know.streaming.km.common.constant.Constant;
import com.xiaojukeji.know.streaming.km.common.utils.ConvertUtil;
+import com.xiaojukeji.know.streaming.km.core.service.cluster.ClusterPhyService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.validation.annotation.Validated;
import org.springframework.web.bind.annotation.*;
+import java.util.Set;
+
/**
* @author zengqiao
@@ -27,6 +30,9 @@ public class MultiClusterPhyController {
@Autowired
private MultiClusterPhyManager multiClusterPhyManager;
+ @Autowired
+ private ClusterPhyService clusterPhyService;
+
@ApiOperation(value = "多物理集群-大盘", notes = "")
@PostMapping(value = "physical-clusters/dashboard")
@ResponseBody
@@ -40,4 +46,10 @@ public class MultiClusterPhyController {
public Result getClusterPhysState() {
return Result.buildSuc(ConvertUtil.obj2Obj(multiClusterPhyManager.getClusterPhysState(), ClusterPhysStateVO.class));
}
+
+ @ApiOperation(value = "多物理集群-已存在kafka版本", notes = "")
+ @GetMapping(value = "physical-clusters/exist-version")
+ public Result> getClusterPhysVersion() {
+ return Result.buildSuc(clusterPhyService.getClusterVersionSet());
+ }
}