mirror of
https://github.com/didi/KnowStreaming.git
synced 2025-12-24 20:22:12 +08:00
[Init]官网文档Init
This commit is contained in:
184
study-kafka/5-implementation.md
Normal file
184
study-kafka/5-implementation.md
Normal file
@@ -0,0 +1,184 @@
|
||||
---
|
||||
title: 5.Kafka实现机制
|
||||
order: 5
|
||||
toc: menu
|
||||
---
|
||||
|
||||
## 5.1 网络层
|
||||
|
||||
网络层是一个相当简单的 NIO 服务器,不再详细介绍。`sendfile` 的实现是通过给 MessageSet 接口一个 writeTo 方法来完成的。这允许文件支持的消息集使用更有效的 transferTo 实现而不是进程内缓冲写入。线程模型是单个接受线程和 N 个处理器线程,每个线程处理固定数量的连接。这种设计已经在其他地方进行了相当彻底的测试,并且发现它易于实现且速度快。该协议保持非常简单,以允许将来以其他语言实现客户端。
|
||||
|
||||
## 5.2 消息
|
||||
|
||||
消息由一个可变长度的标头、一个可变长度的不透明键字节数组和一个可变长度的不透明值字节数组组成。标题的格式在下一节中描述。保持 key 和 value 不透明是正确的决定:序列化库目前正在取得很大进展,任何特定的选择都不太可能适合所有用途。不用说,使用 Kafka 的特定应用程序可能会要求特定的序列化类型作为其使用的一部分。该 RecordBatch 接口只是消息的迭代器,具有用于批量读取和写入 NIO 的专用方法 Channel。
|
||||
|
||||
## 5.3 消息格式
|
||||
|
||||
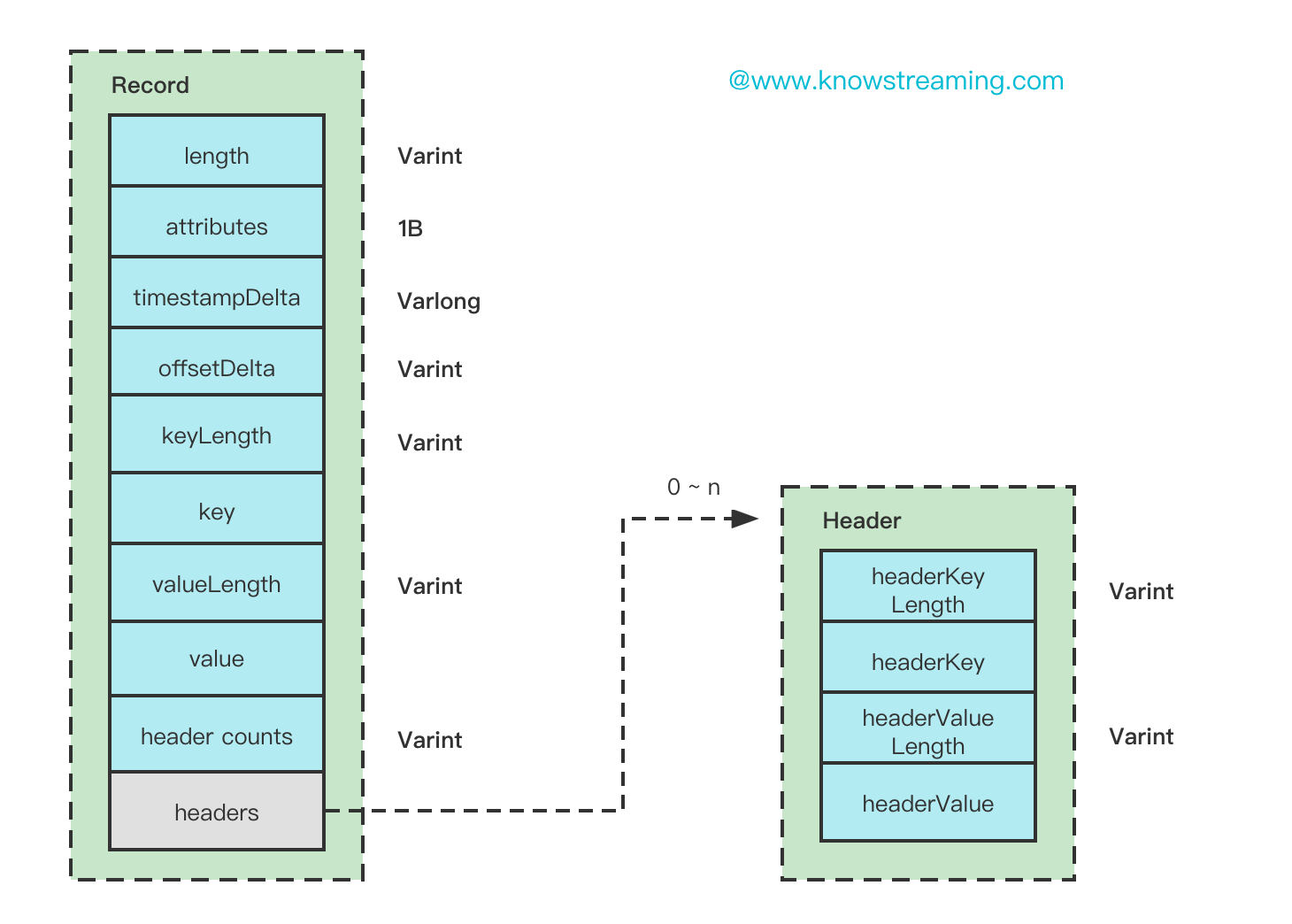
<font size=5 ><b>Record 结构图 </b></font>
|
||||
|
||||
|
||||
|
||||
**Record 属性解释:**
|
||||
|
||||
1. length:整个 Record 的消息总大小, 使用可变字段。
|
||||
2. attributes:已经弃用,默认为 0,固定占用了 1B
|
||||
3. timestampDelta: 时间戳的增量,使用可变字段。使用增量可以有效节约内存
|
||||
4. offsetDelta: 位移的增量,使用可变字段, 使用增量可以有效节约内存
|
||||
5. keyLength: key 的长度,使用可变字段, 如果没有 key,该值为-1。
|
||||
6. key: key 的信息,正常存储。如果 key==null,则该值不存在。
|
||||
7. valueLength:value 的长度,使用可变字段, 如果没有 key,改值为-1.
|
||||
8. value: value 的信息,正常存储,如果 value==null,则该值也不存在。
|
||||
9. headers:消息头,这个字段用于支持应用级别的扩展,可以携带很多信息,例如你带一个 TraceId 也不过分。
|
||||
10. header counts : 消息头的数量,使用可变字段
|
||||
|
||||
<font color=red> Varints 是可变长自动,可以有效的节省空间</font>
|
||||
|
||||
**Header 属性解释:**
|
||||
|
||||
类似,就不再赘述了。
|
||||
|
||||
<font size=5 ><b> RecordBatchHeader 结构图 </b></font>
|
||||
|
||||

|
||||
|
||||
**RecordBatchHeader 属性解释:**
|
||||
|
||||
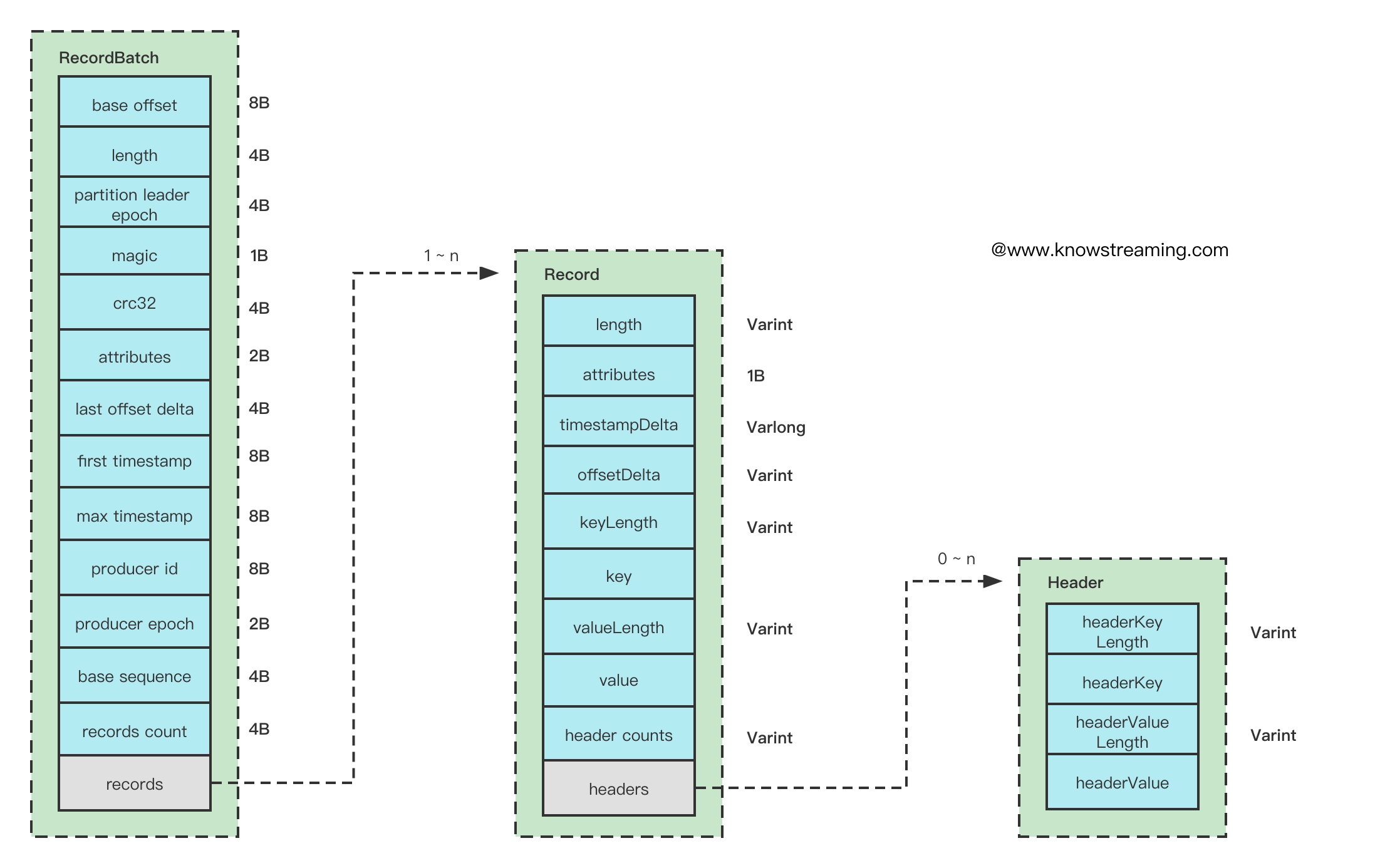
1. **baseOffset**: 当然 RecordBatch 的起始位移,一般默认为 0
|
||||
2. **length**:计算从`partition leader epoch` 字段开始到整体末尾的长度,计算的逻辑是(sizeInBytes - LOG_OVERHEAD), 这个`sizeInBytes`就是整个 RecordBatch 的长度。LOG_OVERHEAD = 12
|
||||
3. **partition leader epoch**: 分区的 Leader 纪元,也就是版本号
|
||||
4. **magic**: 消息格式版本号, V2 版本 该值为 2
|
||||
5. **crc32**: 该 RecordBatch 的校验值, 计算该值是从**attributes**的位置开始计算的。
|
||||
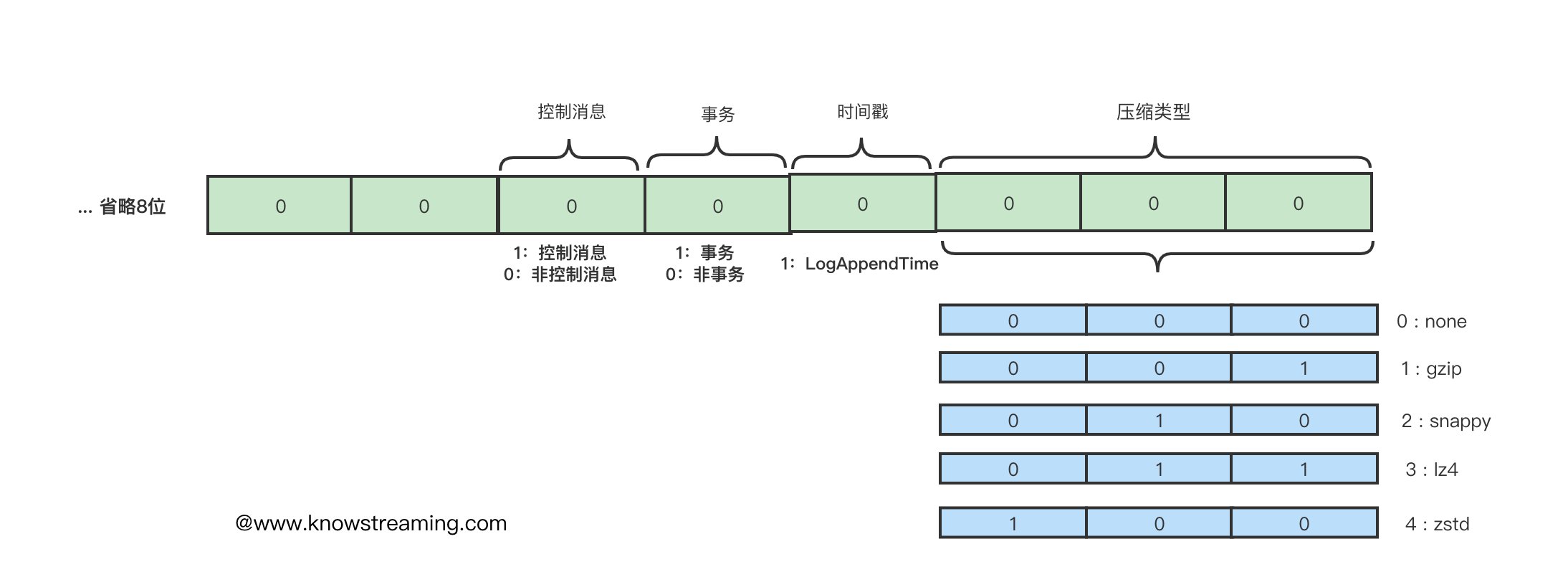
6. **attributes**:消息的属性,这里用了 2 个字节, 低 3 位表示压缩格式,第 4 位表示时间戳,第 5 位表示事务标识,第 6 位表示是否控制消息。如下图
|
||||
|
||||
|
||||
|
||||
7. **last offset delta** : RecordBatch 中最后一个 Record 的 offset 与 first offset 的差值。
|
||||
8. **first timestamp**: 第一条 Record 的时间戳。对于 Record 的时间戳的值 ,如果在构造待发送的 ProducerRecord 的时候设置了 timestamp,那么就是这个设置的值,如果没有设置那就是当前时间戳的值。
|
||||
9. **max timestamp**: RecordBatch 中最大时间戳。
|
||||
10. **producer id** : 用于支持幂等和事务的属性。
|
||||
11. **producer epoch** :用于支持幂等和事务的属性。
|
||||
12. **base sequence** :用于支持幂等和事务的属性。
|
||||
13. **record count** : 消息数量
|
||||
|
||||
<font size=5 ><b> RecordBatch 整体结构图 </b></font>
|
||||
|
||||
|
||||
|
||||
1. 在创建 RecordBatch 的时候,会先预留 61B 的位置给 BatchHeader, 实现方式就是让 buffer 的位置移动到 61 位` buffer.possition(61)`
|
||||
2. 消息写入的时候并不会压缩,只有等到即将发送这个 Batch 的时候,会关闭 Batch,从而进行压缩(如果配置了压缩策略的话), 压缩的知识 Records, 不包含 RecordBatchHeader
|
||||
3. 填充 RecordBatchHeader
|
||||
|
||||
## 5.4 日志
|
||||
|
||||
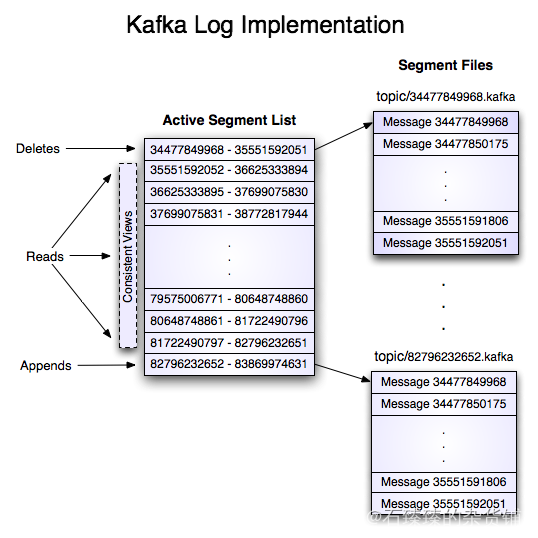
具有两个分区的名为“my_topic”的主题的日志由两个目录(即 my_topic_0 和 my_topic_1)组成,其中填充了包含该主题消息的数据文件。日志文件的格式是“日志条目”的序列;每个日志条目是一个 4 字节整数 N,存储消息长度,后跟 N 个消息字节。每条消息由一个 64 位整数偏移量唯一标识给出该消息在该分区上发送到该主题的所有消息流中开始的字节位置。下面给出了每条消息的磁盘格式。每个日志文件都以其包含的第一条消息的偏移量命名。因此,创建的第一个文件将是 00000000000.kafka,并且每个附加文件将具有一个与前一个文件大约 S 字节的整数名称,其中 S 是配置中给出的最大日志文件大小。
|
||||
|
||||
记录的确切二进制格式作为标准接口进行版本控制和维护,因此记录批次可以在生产者、代理和客户端之间传输,而无需在需要时重新复制或转换。上一节包括有关记录的磁盘格式的详细信息。
|
||||
|
||||
使用消息偏移量作为消息 ID 是不寻常的。我们最初的想法是使用生产者生成的 GUID,并在每个代理上维护从 GUID 到偏移量的映射。但是由于消费者必须为每个服务器维护一个 ID,所以 GUID 的全局唯一性没有任何价值。此外,维护从随机 id 到偏移量的映射的复杂性需要一个必须与磁盘同步的重量级索引结构,本质上需要一个完全持久的随机访问数据结构。因此,为了简化查找 结构,我们决定使用一个简单的每个分区原子计数器,它可以与分区 id 和节点 id 耦合来唯一标识一条消息;这使得查找结构更简单,尽管每个消费者请求仍然可能进行多次查找。然而,一旦我们在柜台上安顿下来,直接使用偏移量的跳转似乎很自然——毕竟两者都是分区独有的单调递增整数。由于偏移量对消费者 API 是隐藏的,所以这个决定最终是一个实现细节,我们采用了更有效的方法。
|
||||
|
||||
|
||||
|
||||
**写**
|
||||
|
||||
该日志允许串行附加总是转到最后一个文件。当这个文件达到可配置的大小(比如 1GB)时,它会滚动到一个新文件。该日志采用两个配置参数:M,它给出了在强制操作系统将文件刷新到磁盘之前要写入的消息数,以及 S,它给出了强制刷新之后的秒数。这提供了在系统崩溃 时最多丢失 M 条消息或 S 秒数据的持久性保证。
|
||||
|
||||
**读**
|
||||
|
||||
通过给出消息的 64 位逻辑偏移和 S 字节最大块大小来完成读取。这将返回 S 字节缓冲区中包含的消息的迭代器。S 旨在大于任何单个消息,但在消息异常大的情况下,可以多次重试读取,每次将缓冲区大小加倍,直到成功读取消息。可以指定最大消息和缓冲区大小以使服务器拒绝大于某个大小的消息,并为客户端提供它需要读取的最大值以获得完整消息的最大值。读取缓冲区很可能以部分消息结尾,这很容易通过大小分隔来检测。
|
||||
|
||||
从偏移量读取的实际过程需要首先找到存储数据的日志段文件,根据全局偏移量值计算文件特定的偏移量,然后从该文件偏移量中读取。搜索是针对为每个文件维护的内存范围的简单二进制搜索变体完成的。
|
||||
|
||||
该日志提供了获取最近写入消息的能力,以允许客户端从“现在”开始订阅。这在消费者未能在其 SLA 指定的天数内使用其数据的情况下也很有用。在这种情况下,当客户端尝试使用不存在的偏移量时,它会被赋予 OutOfRangeException 并且可以根据用例自行重置或失败。
|
||||
|
||||
以下是发送给消费者的结果格式。
|
||||
|
||||
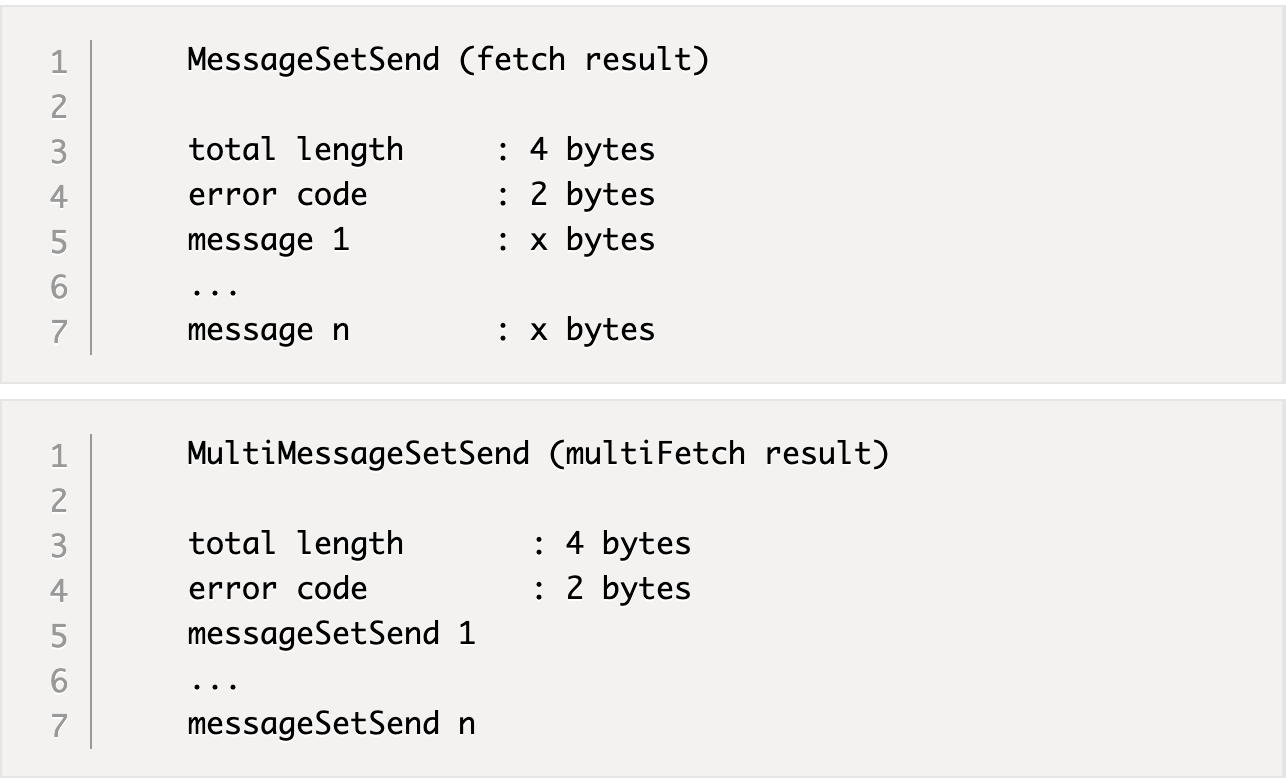
|
||||
|
||||
**删除**
|
||||
|
||||
数据一次删除一个日志段。日志管理器应用两个指标来识别符合删除条件的段:时间和大小。对于基于时间的策略,会考虑记录时间戳,段文件中的最大时间戳(记录顺序不相关)定义整个段的保留时间。默认情况下禁用基于大小的保留。启用后,日志管理器会继续删除最旧的段文件,直到分区的总大小再次在配置的限制内。如果同时启用这两个策略,则将删除由于任一策略而符合删除条件的段。
|
||||
|
||||
## 5.5 Zookeeper 结构
|
||||
|
||||
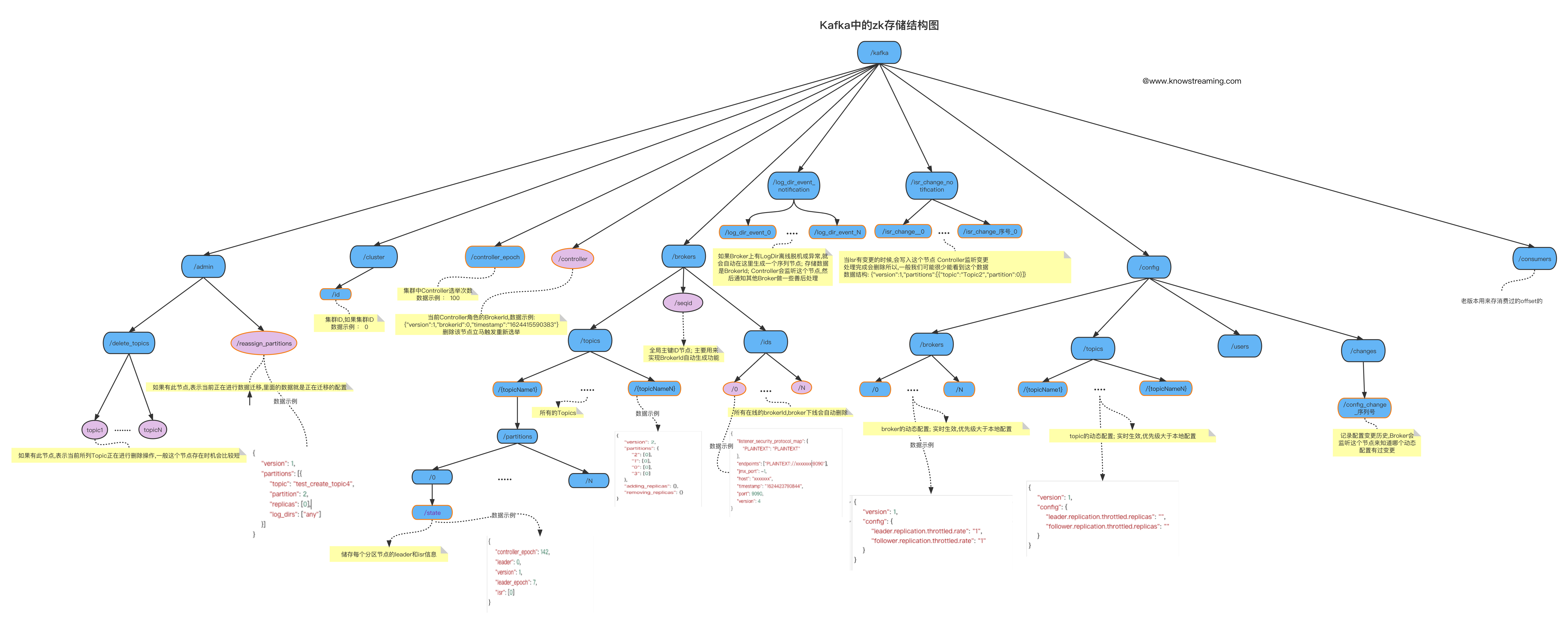
|
||||
|
||||
**/cluster/id 持久数据节点**
|
||||
|
||||
> 集群 ID
|
||||
> 当第一台 Broker 启动的时候, 发现`/cluster/id`不存在,那么它就会把自己的`cluster.id`配置写入 zk; 标记当前 zk 是属于集群哪个集群; 后面其他的 Broker 启动的时候会去获取该数据, 如果发现数据跟自己的配置不一致; 则抛出异常,加入的不是同一个集群;
|
||||
> 数据示例:`{"version":"1","id":"0"}`
|
||||
|
||||
<font size=5 ><b> /controller_epoch 持久数据节点 </b></font>
|
||||
|
||||
> Controller 选举次数;
|
||||
|
||||
<font size=5 ><b> /controller 临时数据节点 </b></font>
|
||||
|
||||
> 当前 Controller 角色的 BrokerId,数据示例:
|
||||
> `{"version":1,"brokerid":0,"timestamp":"1624415590383"}`
|
||||
> 删除该节点立马触发重新选举
|
||||
|
||||
<font size=5 ><b> /log_dir_event_notification </b></font>
|
||||
|
||||
> zk 的数据中有一个节点`/log_dir_event_notification/`,这是一个序列号持久节点
|
||||
> 这个节点在 kafka 中承担的作用是: 当某个 Broker 上的 LogDir 出现异常时(比如磁盘损坏,文件读写失败,等等异常): 向 zk 中谢增一个子节点`/log_dir_event_notification/log_dir_event_序列号` ;Controller 监听到这个节点的变更之后,会向 Brokers 们发送`LeaderAndIsrRequest`请求; 然后做一些副本脱机的善后操作
|
||||
> 详情请看 [【kafka 源码】/log_dir_event_notification 的 LogDir 脱机事件通知]()
|
||||
|
||||
<font size=5 ><b> /isr*change_notification/log_dir_event*{序列号} </b></font>
|
||||
|
||||
> 当 Isr 有变更的时候,会写入这个节点 Controller 监听变更
|
||||
|
||||
<font size=5 ><b> /admin </b></font>
|
||||
|
||||
**/admin/delete_topics 待删除 Topic**
|
||||
|
||||
**/admin/delete_topics/{topicName} 持久节点,待删除 Topic**
|
||||
|
||||
> 存在此节点表示 当前 Topic 需要被删除
|
||||
|
||||
**/admin/reassign_partitions 持久数据节点**
|
||||
|
||||
> 如果有此节点,表示当前正在进行数据迁移,里面的数据就是正在迁移的配置
|
||||
> 示例数据: 
|
||||
|
||||
<font size=5 ><b> /brokers </b></font>
|
||||
|
||||
**/brokers/seqid**
|
||||
|
||||
> **`/brokers/seqid`: 全局序列号**
|
||||
> 里面没有数据,主要是用了节点的`dataVersion`信息来当全局序列号
|
||||
>
|
||||
> **在 kafka 中的作用: 自动生成 BrokerId**
|
||||
> 主要是用来自动生成 brokerId;
|
||||
> 一个集群如果特别大,配置 brokerId 的时候不能重复,一个个设置比较累; 可以让 Broker 自动生成 BrokerId
|
||||
|
||||
`server.properties` 配置
|
||||
|
||||
```properties
|
||||
## 设置Brokerid能够自动生成
|
||||
broker.id.generation.enable=true
|
||||
## 设置BrokerId<0 (如果>=0则以此配置为准)
|
||||
broker.id=-1
|
||||
## 自动生成配置的起始值
|
||||
reserved.broker.max.id=20000
|
||||
```
|
||||
|
||||
BrokerId 计算方法
|
||||
|
||||
> brokerId = {reserved.broker.max.id} +` /brokers/seqid`.dataVersion
|
||||
>
|
||||
> 每次想要获取` /brokers/seqid`的 dataVersion 值的时候都是用 set 方法,set 的时候会返回 version 数据,并不是 get;每次 set 这个节点数据,版本信息就会自增;所以就实现了全局自增 ID 了;
|
||||
|
||||
**/brokers/ids/{id} 临时数据节点 : 在线 BrokerID**
|
||||
|
||||
> 在线的 Broker 都会在这里注册一个节点; 下线自动删除
|
||||
|
||||
**/brokers/topics/{topicName}持久数据节点**
|
||||
|
||||
> 存储 topic 的分区副本分配信息
|
||||
> 例如:`{"version":1,"partitions":{"0":[0]}}`
|
||||
|
||||
**/brokers/topics/{topicName}/{分区号}/state 持久数据节点**
|
||||
|
||||
> 存储指定分区的`leader`和`isr`等信息
|
||||
> 例如:`{"controller_epoch":203,"leader":0,"version":1,"leader_epoch":0,"isr":[0]}`
|
||||
Reference in New Issue
Block a user