## 脚本参数
`sh bin/kafka-topic -help` 查看更具体参数
下面只是列出了跟` --alter` 相关的参数
| 参数 |描述 |例子|
|--|--|--|
|`--bootstrap-server ` 指定kafka服务|指定连接到的kafka服务; 如果有这个参数,则 `--zookeeper`可以不需要|--bootstrap-server localhost:9092 |
|`--replica-assignment `|副本分区分配方式;修改topic的时候可以自己指定副本分配情况; |`--replica-assignment id0:id1:id2,id3:id4:id5,id6:id7:id8 `;其中,“id0:id1:id2,id3:id4:id5,id6:id7:id8”表示Topic TopicName一共有3个Partition(以“,”分隔),每个Partition均有3个Replica(以“:”分隔),Topic Partition Replica与Kafka Broker之间的对应关系如下:
## Alert Topic脚本
## 分区扩容
**zk方式(不推荐)**
```sh
bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic topic1 --partitions 2
```
**kafka版本 >= 2.2 支持下面方式(推荐)**
**单个Topic扩容**
>`bin/kafka-topics.sh --bootstrap-server broker_host:port --alter --topic test_create_topic1 --partitions 4`
**批量扩容** (将所有正则表达式匹配到的Topic分区扩容到4个)
>`sh bin/kafka-topics.sh --topic ".*?" --bootstrap-server 172.23.248.85:9092 --alter --partitions 4`
>
`".*?"` 正则表达式的意思是匹配所有; 您可按需匹配
**PS:** 当某个Topic的分区少于指定的分区数时候,他会抛出异常;但是不会影响其他Topic正常进行;
---
相关可选参数
| 参数 |描述 |例子|
|--|--|--|
|`--replica-assignment `|副本分区分配方式;创建topic的时候可以自己指定副本分配情况; |`--replica-assignment` BrokerId-0:BrokerId-1:BrokerId-2,BrokerId-1:BrokerId-2:BrokerId-0,BrokerId-2:BrokerId-1:BrokerId-0 ; 这个意思是有三个分区和三个副本,对应分配的Broker; 逗号隔开标识分区;冒号隔开表示副本|
**PS: 虽然这里配置的是全部的分区副本分配配置,但是正在生效的是新增的分区;**
比如: 以前3分区1副本是这样的
| Broker-1 |Broker-2 |Broker-3|Broker-4|
|--|--|--|--|
|0 | 1 |2|
现在新增一个分区,`--replica-assignment` 2,1,3,4 ; 看这个意思好像是把0,1号分区互相换个Broker
| Broker-1 |Broker-2 |Broker-3|Broker-4|
|--|--|--|--|
|1 | 0 |2|3||
但是实际上不会这样做,Controller在处理的时候会把前面3个截掉; 只取新增的分区分配方式,原来的还是不会变
| Broker-1 |Broker-2 |Broker-3|Broker-4|
|--|--|--|--|
|0 | 1 |2|3||
## 源码解析
> 如果觉得源码解析过程比较枯燥乏味,可以直接如果 **源码总结及其后面部分**
因为在 [【kafka源码】TopicCommand之创建Topic源码解析]() 里面分析的比较详细; 故本文就着重点分析了;
### 1. `TopicCommand.alterTopic`
```scala
override def alterTopic(opts: TopicCommandOptions): Unit = {
val topic = new CommandTopicPartition(opts)
val topics = getTopics(opts.topic, opts.excludeInternalTopics)
//校验Topic是否存在
ensureTopicExists(topics, opts.topic)
//获取一下该topic的一些基本信息
val topicsInfo = adminClient.describeTopics(topics.asJavaCollection).values()
adminClient.createPartitions(topics.map {topicName =>
//判断是否有参数 replica-assignment 指定分区分配方式
if (topic.hasReplicaAssignment) {
val startPartitionId = topicsInfo.get(topicName).get().partitions().size()
val newAssignment = {
val replicaMap = topic.replicaAssignment.get.drop(startPartitionId)
new util.ArrayList(replicaMap.map(p => p._2.asJava).asJavaCollection).asInstanceOf[util.List[util.List[Integer]]]
}
topicName -> NewPartitions.increaseTo(topic.partitions.get, newAssignment)
} else {
topicName -> NewPartitions.increaseTo(topic.partitions.get)
}}.toMap.asJava).all().get()
}
```
1. 校验Topic是否存在
2. 如果设置了`--replica-assignment `参数, 则会算出新增的分区数的分配; 这个并不会修改原本已经分配好的分区结构.从源码就可以看出来,假如我之前的分配方式是3,3,3(3分区一个副本都在BrokerId-3上)现在我传入的参数是: `3,3,3,3`(多出来一个分区),这个时候会把原有的给截取掉;只传入3,(表示在Broker3新增一个分区)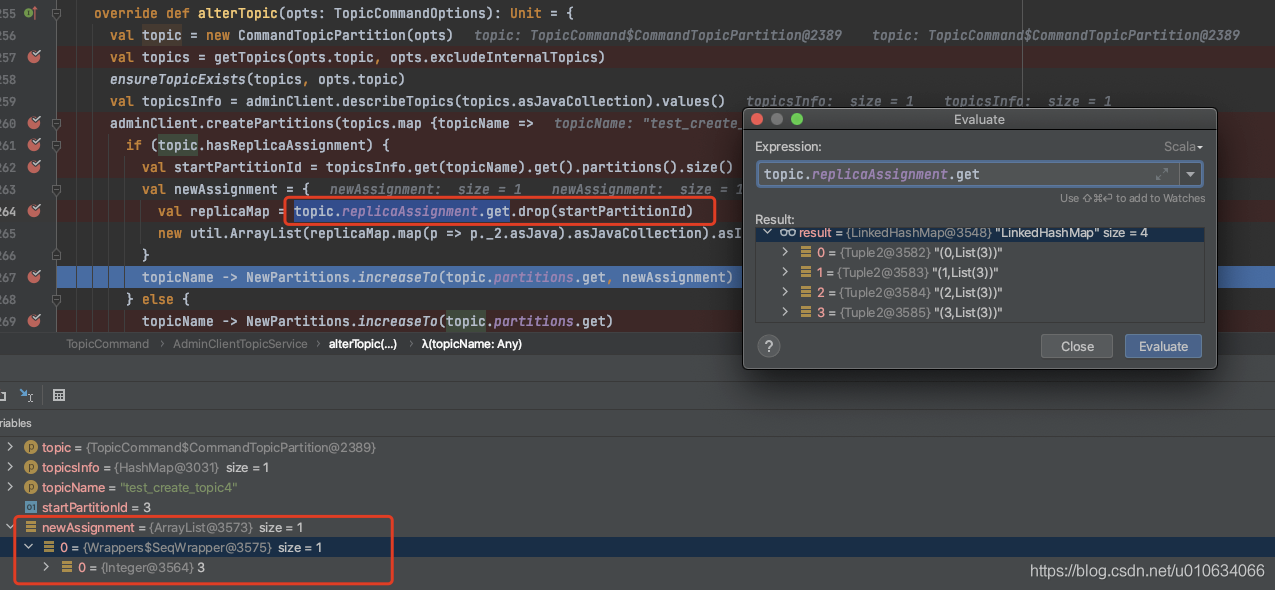
3. 如果没有传入参数`--replica-assignment`,则后面会用默认分配策略分配
#### 客户端发起请求createPartitions
`KafkaAdminClient.createPartitions` 省略部分代码
```java
@Override
public CreatePartitionsResult createPartitions(Map newPartitions,
final CreatePartitionsOptions options) {
final Map> futures = new HashMap<>(newPartitions.size());
for (String topic : newPartitions.keySet()) {
futures.put(topic, new KafkaFutureImpl<>());
}
runnable.call(new Call("createPartitions", calcDeadlineMs(now, options.timeoutMs()),
new ControllerNodeProvider()) {
//省略部分代码
@Override
void handleFailure(Throwable throwable) {
completeAllExceptionally(futures.values(), throwable);
}
}, now);
return new CreatePartitionsResult(new HashMap<>(futures));
}
```
1. 从源码中可以看到向`ControllerNodeProvider` 发起来`createPartitions`请求
### 2. Controller角色的服务端接受createPartitions请求处理逻辑
>
`KafkaApis.handleCreatePartitionsRequest`
```scala
def handleCreatePartitionsRequest(request: RequestChannel.Request): Unit = {
val createPartitionsRequest = request.body[CreatePartitionsRequest]
//部分代码省略..
//如果当前不是Controller角色直接抛出异常
if (!controller.isActive) {
val result = createPartitionsRequest.data.topics.asScala.map { topic =>
(topic.name, new ApiError(Errors.NOT_CONTROLLER, null))
}.toMap
sendResponseCallback(result)
} else {
// Special handling to add duplicate topics to the response
val topics = createPartitionsRequest.data.topics.asScala
val dupes = topics.groupBy(_.name)
.filter { _._2.size > 1 }
.keySet
val notDuped = topics.filterNot(topic => dupes.contains(topic.name))
val authorizedTopics = filterAuthorized(request, ALTER, TOPIC, notDuped.map(_.name))
val (authorized, unauthorized) = notDuped.partition { topic => authorizedTopics.contains(topic.name) }
val (queuedForDeletion, valid) = authorized.partition { topic =>
controller.topicDeletionManager.isTopicQueuedUpForDeletion(topic.name)
}
val errors = dupes.map(_ -> new ApiError(Errors.INVALID_REQUEST, "Duplicate topic in request.")) ++
unauthorized.map(_.name -> new ApiError(Errors.TOPIC_AUTHORIZATION_FAILED, "The topic authorization is failed.")) ++
queuedForDeletion.map(_.name -> new ApiError(Errors.INVALID_TOPIC_EXCEPTION, "The topic is queued for deletion."))
adminManager.createPartitions(createPartitionsRequest.data.timeoutMs,
valid,
createPartitionsRequest.data.validateOnly,
request.context.listenerName, result => sendResponseCallback(result ++ errors))
}
}
```
1. 检验自身是不是Controller角色,不是的话就抛出异常终止流程
2. 鉴权
3. 调用` adminManager.createPartitions`
3.1 从zk中获取`/brokers/ids/`Brokers列表的元信息的
3.2 从zk获取`/brokers/topics/{topicName}`已经存在的副本分配方式,并判断是否有正在进行副本重分配的进程在执行,如果有的话就抛出异常结束流程
3.3 如果从zk获取`/brokers/topics/{topicName}`数据不存在则抛出异常 `The topic '$topic' does not exist`
3.4 检查修改的分区数是否比原来的分区数大,如果比原来还小或者等于原来分区数则抛出异常结束流程
3.5 如果传入的参数`--replica-assignment` 中有不存在的BrokerId;则抛出异常`Unknown broker(s) in replica assignment`结束流程
3.5 如果传入的`--partitions`数量 与`--replica-assignment`中新增的部分数量不匹配则抛出异常`Increasing the number of partitions by...` 结束流程
3.6 调用` adminZkClient.addPartitions`
#### ` adminZkClient.addPartitions` 添加分区
1. 校验`--partitions`数量是否比存在的分区数大,否则异常`The number of partitions for a topic can only be increased`
2. 如果传入了`--replica-assignment` ,则对副本进行一些简单的校验
3. 调用`AdminUtils.assignReplicasToBrokers`分配副本 ; 这个我们在[【kafka源码】TopicCommand之创建Topic源码解析]() 也分析过; 具体请看[【kafka源码】创建Topic的时候是如何分区和副本的分配规则](); 当然这里由于我们是新增的分区,只会将新增的分区进行分配计算
4. 得到分配规则只后,调用`adminZkClient.writeTopicPartitionAssignment` 写入
#### adminZkClient.writeTopicPartitionAssignment将分区信息写入zk中
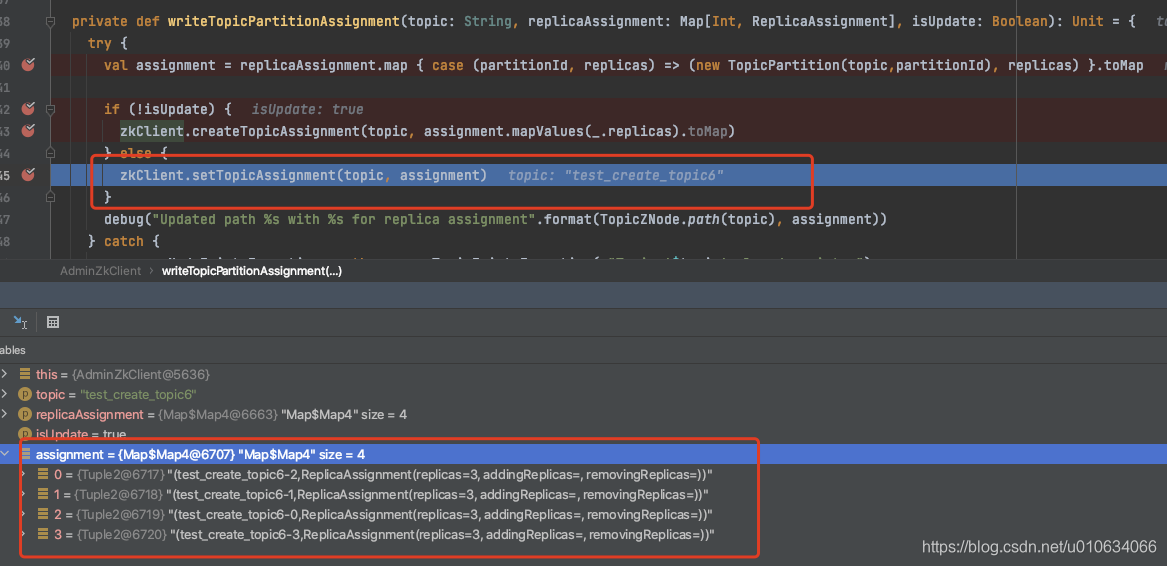
我们在 [【kafka源码】TopicCommand之创建Topic源码解析]()的时候也分析过这段代码,但是那个时候调用的是`zkClient.createTopicAssignment` 创建接口
这里我们是调用` zkClient.setTopicAssignment` 写入接口, 写入当然会覆盖掉原有的信息,所以写入的时候会把原来分区信息获取到,重新写入;
1. 获取Topic原有分区副本分配信息
2. 将原有的和现在要添加的组装成一个数据对象写入到zk节点`/brokers/topics/{topicName}`中
### 3. Controller监控节点`/brokers/topics/{topicName}` ,真正在Broker上将分区写入磁盘
监听到节点信息变更之后调用下面的接口;
`KafkaController.processPartitionModifications`
```scala
private def processPartitionModifications(topic: String): Unit = {
def restorePartitionReplicaAssignment(
topic: String,
newPartitionReplicaAssignment: Map[TopicPartition, ReplicaAssignment]
): Unit = {
info("Restoring the partition replica assignment for topic %s".format(topic))
val existingPartitions = zkClient.getChildren(TopicPartitionsZNode.path(topic))
val existingPartitionReplicaAssignment = newPartitionReplicaAssignment
.filter(p => existingPartitions.contains(p._1.partition.toString))
.map { case (tp, _) =>
tp -> controllerContext.partitionFullReplicaAssignment(tp)
}.toMap
zkClient.setTopicAssignment(topic,
existingPartitionReplicaAssignment,
controllerContext.epochZkVersion)
}
if (!isActive) return
val partitionReplicaAssignment = zkClient.getFullReplicaAssignmentForTopics(immutable.Set(topic))
val partitionsToBeAdded = partitionReplicaAssignment.filter { case (topicPartition, _) =>
controllerContext.partitionReplicaAssignment(topicPartition).isEmpty
}
if (topicDeletionManager.isTopicQueuedUpForDeletion(topic)) {
if (partitionsToBeAdded.nonEmpty) {
warn("Skipping adding partitions %s for topic %s since it is currently being deleted"
.format(partitionsToBeAdded.map(_._1.partition).mkString(","), topic))
restorePartitionReplicaAssignment(topic, partitionReplicaAssignment)
} else {
// This can happen if existing partition replica assignment are restored to prevent increasing partition count during topic deletion
info("Ignoring partition change during topic deletion as no new partitions are added")
}
} else if (partitionsToBeAdded.nonEmpty) {
info(s"New partitions to be added $partitionsToBeAdded")
partitionsToBeAdded.foreach { case (topicPartition, assignedReplicas) =>
controllerContext.updatePartitionFullReplicaAssignment(topicPartition, assignedReplicas)
}
onNewPartitionCreation(partitionsToBeAdded.keySet)
}
}
```
1. 判断是否Controller,不是则直接结束流程
2. 获取`/brokers/topics/{topicName}` 节点信息, 然后再对比一下当前该节点的分区分配信息; 看看有没有是新增的分区; 如果是新增的分区这个时候是还没有`/brokers/topics/{topicName}/partitions/{分区号}/state` ;
3. 如果当前的TOPIC正在被删除中,那么就没有必要执行扩分区了
5. 将新增加的分区信息加载到内存中
6. 调用接口`KafkaController.onNewPartitionCreation`
#### KafkaController.onNewPartitionCreation 新增分区
从这里开始 , 后面的流程就跟创建Topic的对应流程一样了;
> 该接口主要是针对新增分区和副本的一些状态流转过程; 在[【kafka源码】TopicCommand之创建Topic源码解析]() 也同样分析过
```scala
/**
* This callback is invoked by the topic change callback with the list of failed brokers as input.
* It does the following -
* 1. Move the newly created partitions to the NewPartition state
* 2. Move the newly created partitions from NewPartition->OnlinePartition state
*/
private def onNewPartitionCreation(newPartitions: Set[TopicPartition]): Unit = {
info(s"New partition creation callback for ${newPartitions.mkString(",")}")
partitionStateMachine.handleStateChanges(newPartitions.toSeq, NewPartition)
replicaStateMachine.handleStateChanges(controllerContext.replicasForPartition(newPartitions).toSeq, NewReplica)
partitionStateMachine.handleStateChanges(
newPartitions.toSeq,
OnlinePartition,
Some(OfflinePartitionLeaderElectionStrategy(false))
)
replicaStateMachine.handleStateChanges(controllerContext.replicasForPartition(newPartitions).toSeq, OnlineReplica)
}
```
1. 将待创建的分区状态流转为`NewPartition`;
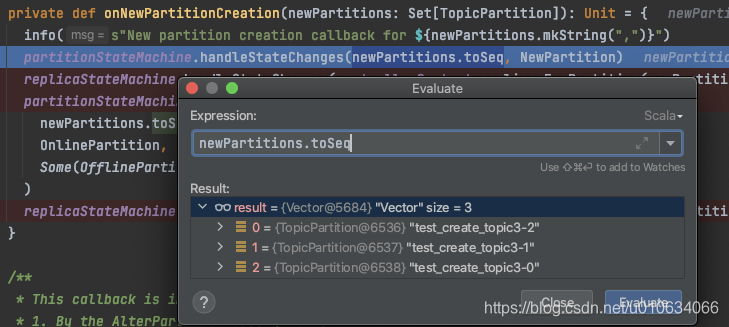
2. 将待创建的副本 状态流转为`NewReplica`;
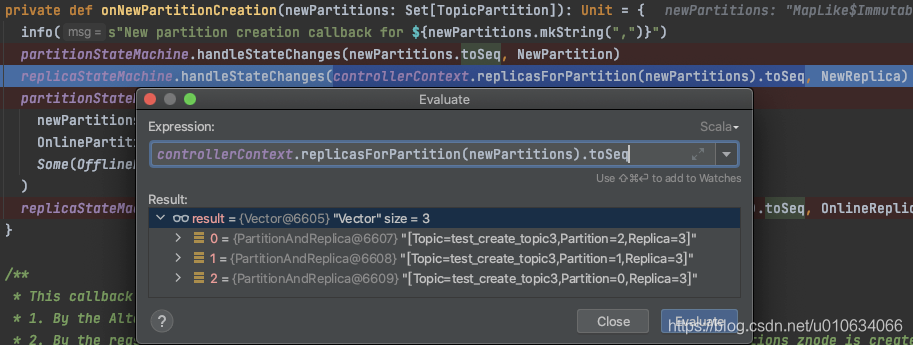
3. 将分区状态从刚刚的`NewPartition`流转为`OnlinePartition`
0. 获取`leaderIsrAndControllerEpochs`; Leader为副本的第一个;
1. 向zk中写入`/brokers/topics/{topicName}/partitions/` 持久节点; 无数据
2. 向zk中写入`/brokers/topics/{topicName}/partitions/{分区号}` 持久节点; 无数据
3. 向zk中写入`/brokers/topics/{topicName}/partitions/{分区号}/state` 持久节点; 数据为`leaderIsrAndControllerEpoch`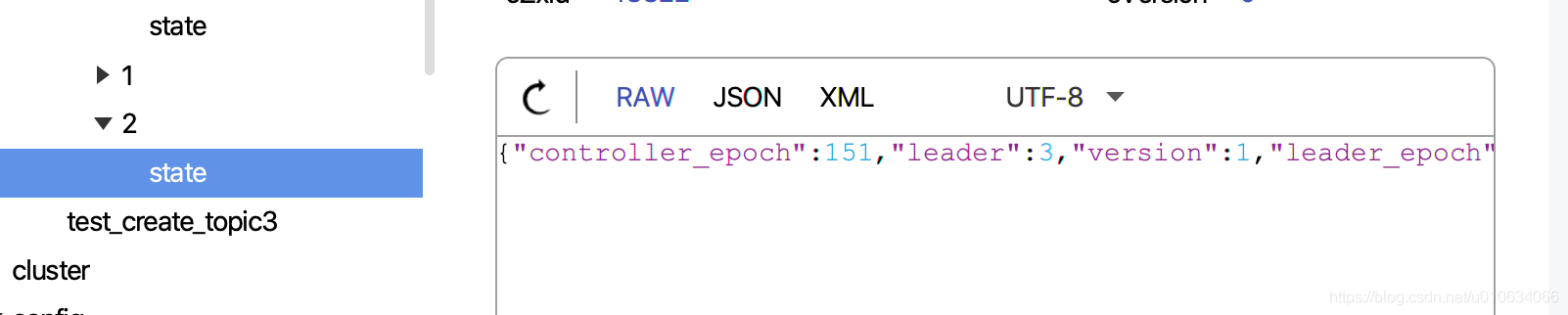
4. 向副本所属Broker发送[`leaderAndIsrRequest`]()请求
5. 向所有Broker发送[`UPDATE_METADATA` ]()请求
4. 将副本状态从刚刚的`NewReplica`流转为`OnlineReplica` ,更新下内存
关于分区状态机和副本状态机详情请看[【kafka源码】Controller中的状态机](TODO)
### 4. Broker收到LeaderAndIsrRequest 创建本地Log
>上面步骤中有说到向副本所属Broker发送[`leaderAndIsrRequest`]()请求,那么这里做了什么呢
>其实主要做的是 创建本地Log
>
代码太多,这里我们直接定位到只跟创建Topic相关的关键代码来分析
`KafkaApis.handleLeaderAndIsrRequest->replicaManager.becomeLeaderOrFollower->ReplicaManager.makeLeaders...LogManager.getOrCreateLog`
```scala
/**
* 如果日志已经存在,只返回现有日志的副本否则如果 isNew=true 或者如果没有离线日志目录,则为给定的主题和给定的分区创建日志 否则抛出 KafkaStorageException
*/
def getOrCreateLog(topicPartition: TopicPartition, config: LogConfig, isNew: Boolean = false, isFuture: Boolean = false): Log = {
logCreationOrDeletionLock synchronized {
getLog(topicPartition, isFuture).getOrElse {
// create the log if it has not already been created in another thread
if (!isNew && offlineLogDirs.nonEmpty)
throw new KafkaStorageException(s"Can not create log for $topicPartition because log directories ${offlineLogDirs.mkString(",")} are offline")
val logDirs: List[File] = {
val preferredLogDir = preferredLogDirs.get(topicPartition)
if (isFuture) {
if (preferredLogDir == null)
throw new IllegalStateException(s"Can not create the future log for $topicPartition without having a preferred log directory")
else if (getLog(topicPartition).get.dir.getParent == preferredLogDir)
throw new IllegalStateException(s"Can not create the future log for $topicPartition in the current log directory of this partition")
}
if (preferredLogDir != null)
List(new File(preferredLogDir))
else
nextLogDirs()
}
val logDirName = {
if (isFuture)
Log.logFutureDirName(topicPartition)
else
Log.logDirName(topicPartition)
}
val logDir = logDirs
.toStream // to prevent actually mapping the whole list, lazy map
.map(createLogDirectory(_, logDirName))
.find(_.isSuccess)
.getOrElse(Failure(new KafkaStorageException("No log directories available. Tried " + logDirs.map(_.getAbsolutePath).mkString(", "))))
.get // If Failure, will throw
val log = Log(
dir = logDir,
config = config,
logStartOffset = 0L,
recoveryPoint = 0L,
maxProducerIdExpirationMs = maxPidExpirationMs,
producerIdExpirationCheckIntervalMs = LogManager.ProducerIdExpirationCheckIntervalMs,
scheduler = scheduler,
time = time,
brokerTopicStats = brokerTopicStats,
logDirFailureChannel = logDirFailureChannel)
if (isFuture)
futureLogs.put(topicPartition, log)
else
currentLogs.put(topicPartition, log)
info(s"Created log for partition $topicPartition in $logDir with properties " + s"{${config.originals.asScala.mkString(", ")}}.")
// Remove the preferred log dir since it has already been satisfied
preferredLogDirs.remove(topicPartition)
log
}
}
}
```
1. 如果日志已经存在,只返回现有日志的副本否则如果 isNew=true 或者如果没有离线日志目录,则为给定的主题和给定的分区创建日志 否则抛出` KafkaStorageException`
详细请看 [【kafka源码】LeaderAndIsrRequest请求]()
## 源码总结
看图说话
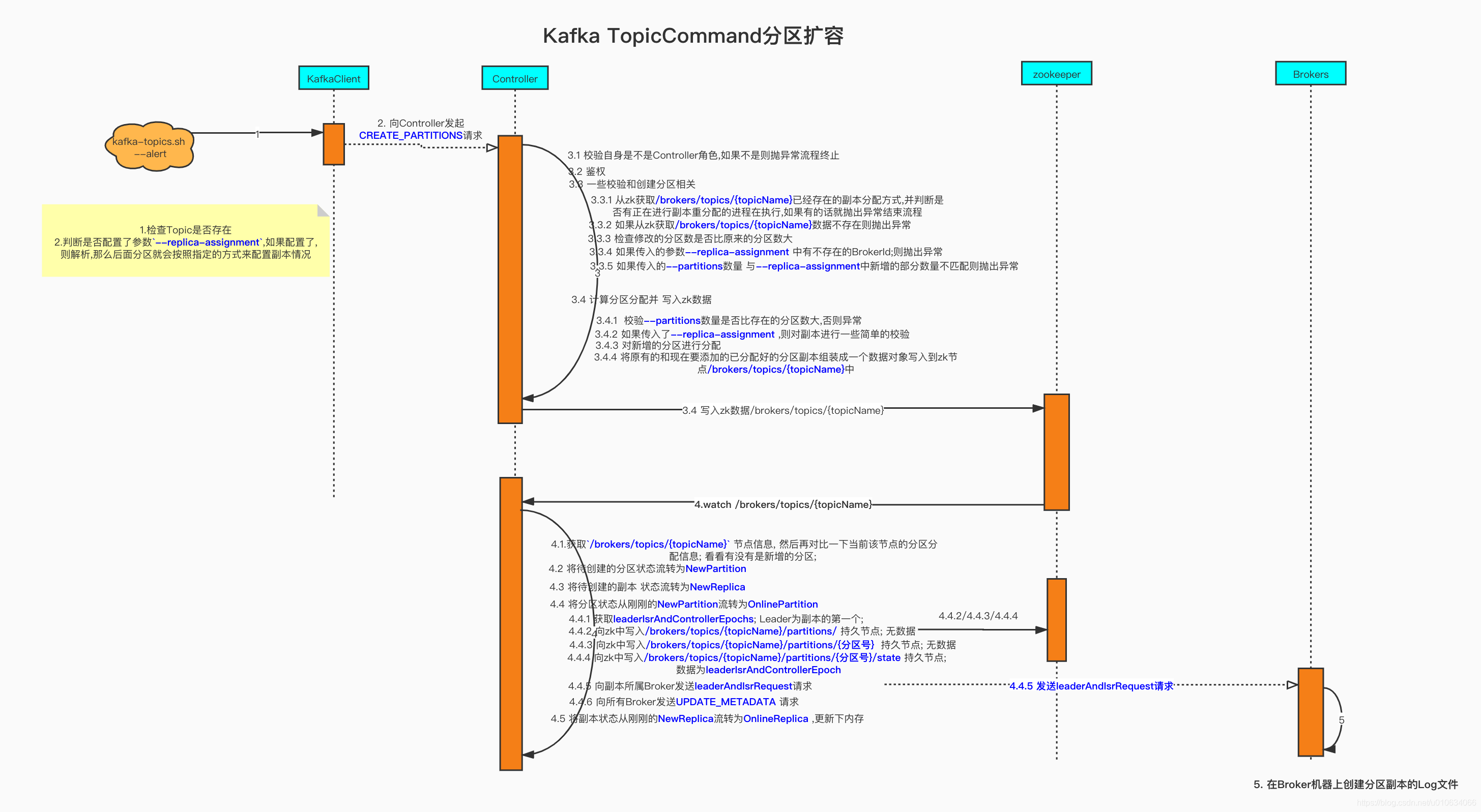
## Q&A
### 如果自定义的分配Broker不存在会怎么样
> 会抛出异常`Unknown broker(s) in replica assignment`, 因为在执行的时候会去zk获取当前的在线Broker列表,然后判断是否在线;
### 如果设置的分区数不等于 `--replica-assignment`中新增的数目会怎么样
>会抛出异常`Increasing the number of partitions by..`结束流程
### 如果写入`/brokers/topics/{topicName}`之后 Controller监听到请求正好挂掉怎么办
> Controller挂掉会发生重新选举,选举成功之后, 检查到`/brokers/topics/{topicName}`之后发现没有生成对应的分区,会自动执行接下来的流程;
### 如果我手动在zk中写入节点`/brokers/topics/{topicName}/partitions/{分区号}/state` 会怎么样
> Controller并没有监听这个节点,所以不会有变化; 但是当Controller发生重新选举的时候,
> **被删除的节点会被重新添加回来;**
>但是**写入的节点 就不会被删除了**;写入的节点信息会被保存在Controller内存中;
>同样这会影响到分区扩容
>
>
> ----
> 例子🌰:
> 当前分区3个,副本一个,手贱在zk上添加了一个节点如下图:
> 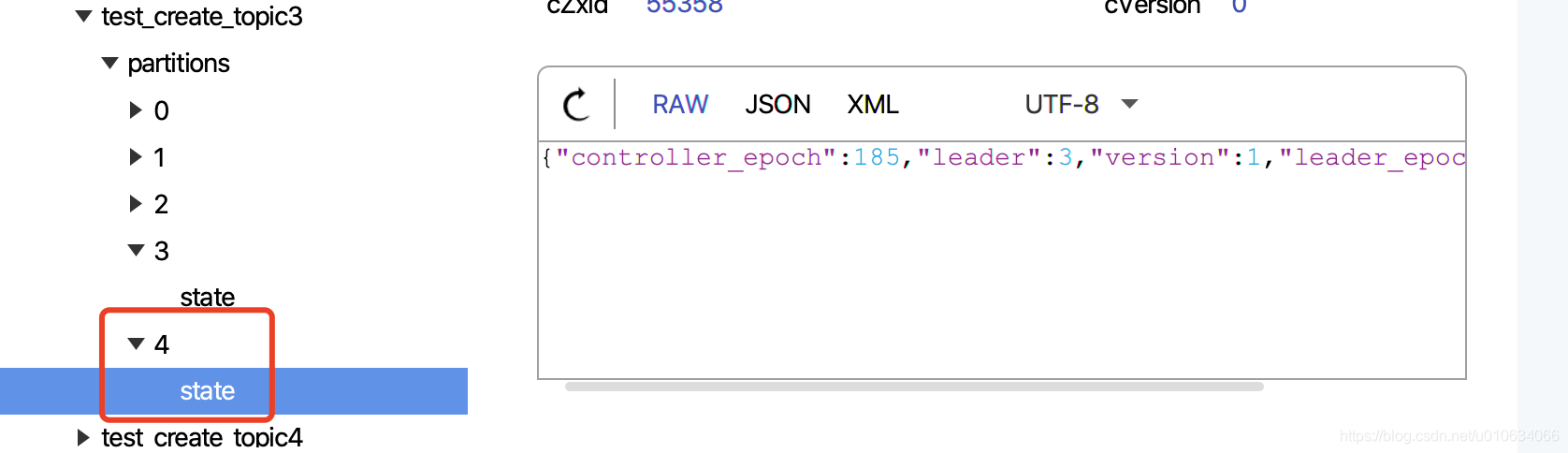
> 这个时候我想扩展一个分区; 然后执行了脚本, 虽然`/brokers/topics/test_create_topic3`节点数据变; 但是Broker真正在`LeaderAndIsrRequest`请求里面没有执行创建本地Log文件; 这是因为源码读取到zk下面partitions的节点数量和新增之后的节点数量没有变更,那么它就认为本次请求没有变更就不会执行创建本地Log文件了;
> 如果判断有变更,还是会去创建的;
> 手贱zk写入N个partition节点 + 扩充N个分区 = Log文件不会被创建
> 手贱zk写入N个partition节点 + 扩充>N个分区 = 正常扩容
### 如果直接修改节点/brokers/topics/{topicName}中的配置会怎么样
>如果该节点信息是`{"version":2,"partitions":{"2":[1],"1":[1],"0":[1]},"adding_replicas":{},"removing_replicas":{}}` 看数据,说明3个分区1个副本都在Broker-1上;
>我在zk上修改成`{"version":2,"partitions":{"2":[2],"1":[1],"0":[0]},"adding_replicas":{},"removing_replicas":{}}`
>想将分区分配到 Broker-0,Broker-1,Broker-2上
>TODO。。。
---
Tips:如果关于本篇文章你有疑问,可以在评论区留下,我会在**Q&A**部分进行解答
PS: 文章阅读的源码版本是kafka-2.5