36 KiB
1.脚本的使用
2.源码解析
如果阅读源码太枯燥,可以直接跳转到 源码总结和Q&A部分
2.1--generate 生成分配策略分析
配置启动类--zookeeper xxxx:2181 --topics-to-move-json-file config/move-json-file.json --broker-list "0,1,2,3" --generate
 配置
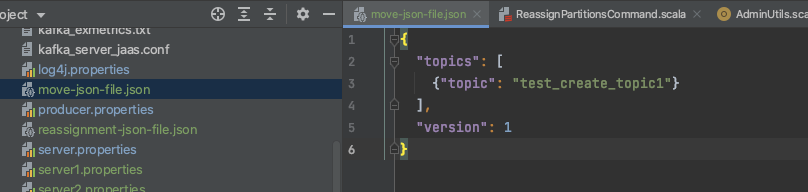
配置move-json-file.json文件
 启动,调试:
启动,调试:
ReassignPartitionsCommand.generateAssignment
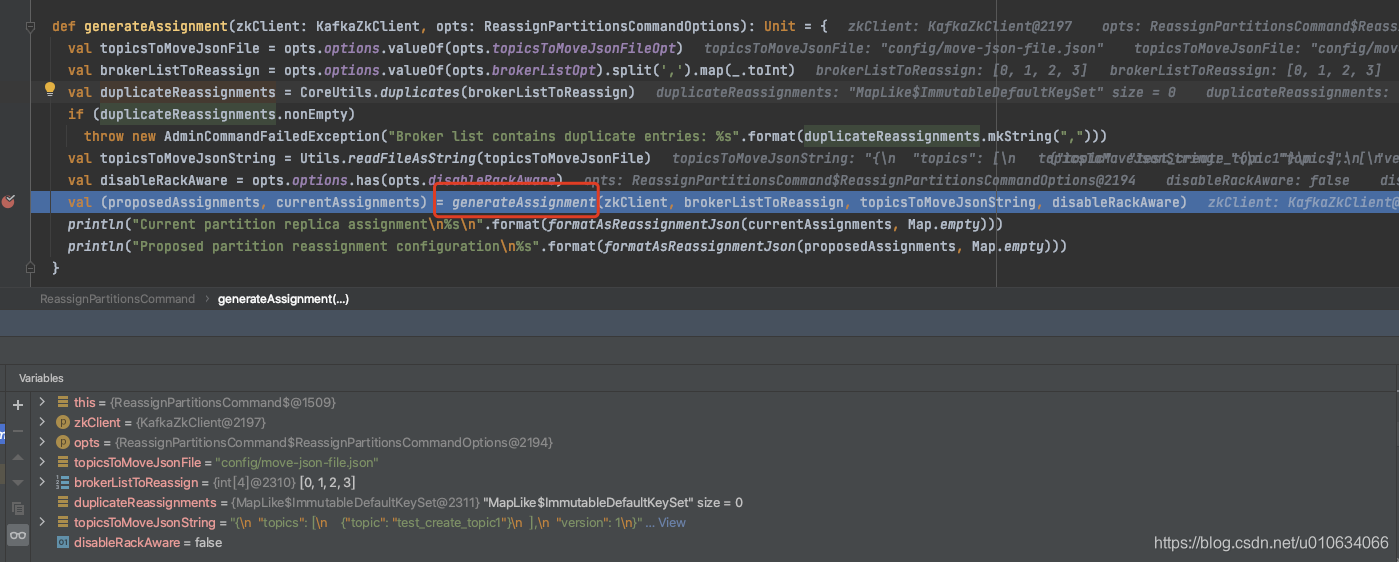
- 获取入参的数据
- 校验
--broker-list传入的BrokerId是否有重复的,重复就报错 - 开始进行分配
ReassignPartitionsCommand.generateAssignment
def generateAssignment(zkClient: KafkaZkClient, brokerListToReassign: Seq[Int], topicsToMoveJsonString: String, disableRackAware: Boolean): (Map[TopicPartition, Seq[Int]], Map[TopicPartition, Seq[Int]]) = {
//解析出游哪些Topic
val topicsToReassign = parseTopicsData(topicsToMoveJsonString)
//检查是否有重复的topic
val duplicateTopicsToReassign = CoreUtils.duplicates(topicsToReassign)
if (duplicateTopicsToReassign.nonEmpty)
throw new AdminCommandFailedException("List of topics to reassign contains duplicate entries: %s".format(duplicateTopicsToReassign.mkString(",")))
//获取topic当前的副本分配情况 /brokers/topics/{topicName}
val currentAssignment = zkClient.getReplicaAssignmentForTopics(topicsToReassign.toSet)
val groupedByTopic = currentAssignment.groupBy { case (tp, _) => tp.topic }
//机架感知模式
val rackAwareMode = if (disableRackAware) RackAwareMode.Disabled else RackAwareMode.Enforced
val adminZkClient = new AdminZkClient(zkClient)
val brokerMetadatas = adminZkClient.getBrokerMetadatas(rackAwareMode, Some(brokerListToReassign))
val partitionsToBeReassigned = mutable.Map[TopicPartition, Seq[Int]]()
groupedByTopic.foreach { case (topic, assignment) =>
val (_, replicas) = assignment.head
val assignedReplicas = AdminUtils.assignReplicasToBrokers(brokerMetadatas, assignment.size, replicas.size)
partitionsToBeReassigned ++= assignedReplicas.map { case (partition, replicas) =>
new TopicPartition(topic, partition) -> replicas
}
}
(partitionsToBeReassigned, currentAssignment)
}
- 检查是否有重复的topic,重复则抛出异常
- 从zk节点
/brokers/topics/{topicName}获取topic当前的副本分配情况 - 从zk节点
brokers/ids中获取所有在线节点,并跟--broker-list参数传入的取个交集 - 获取Brokers元数据,如果机架感知模式
RackAwareMode.Enforced(默认)&&上面3中获取到的交集列表brokers不是都有机架信息或者都没有机架信息的话就抛出异常; 因为要根据机架信息做分区分配的话,必须要么都有机架信息,要么都没有机架信息; 出现这种情况怎么办呢? 那就将机架感知模式RackAwareMode设置为RackAwareMode.Disabled;只需要加上一个参数--disable-rack-aware就行了 - 调用
AdminUtils.assignReplicasToBrokers计算分配情况;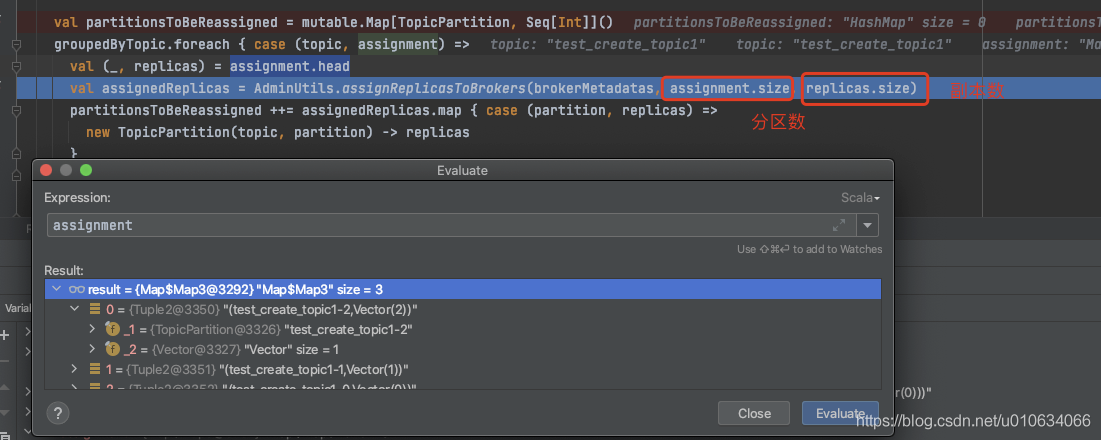 我们在【kafka源码】创建Topic的时候是如何分区和副本的分配规则里面分析过就不再赘述了,
我们在【kafka源码】创建Topic的时候是如何分区和副本的分配规则里面分析过就不再赘述了, AdminUtils.assignReplicasToBrokers(要分配的Broker们的元数据, 分区数, 副本数)需要注意的是副本数是通过assignment.head.replicas.size获取的,意思是第一个分区的副本数量,正常情况下分区副本都会相同,但是也不一定,也可能被设置为了不同
根据这条信息我们是不是就可以直接调用这个接口来实现其他功能? 比如副本的扩缩容
2.2--execute 执行阶段分析
使用脚本执行
--zookeeper xxx --reassignment-json-file config/reassignment-json-file.json --execute --throttle 10000
ReassignPartitionsCommand.executeAssignment
def executeAssignment(zkClient: KafkaZkClient, adminClientOpt: Option[Admin], reassignmentJsonString: String, throttle: Throttle, timeoutMs: Long = 10000L): Unit = {
//对json文件进行校验和解析
val (partitionAssignment, replicaAssignment) = parseAndValidate(zkClient, reassignmentJsonString)
val adminZkClient = new AdminZkClient(zkClient)
val reassignPartitionsCommand = new ReassignPartitionsCommand(zkClient, adminClientOpt, partitionAssignment.toMap, replicaAssignment, adminZkClient)
//检查是否已经存在副本重分配进程, 则尝试限流
if (zkClient.reassignPartitionsInProgress()) {
reassignPartitionsCommand.maybeLimit(throttle)
} else {
//打印当前的副本分配方式,方便回滚
printCurrentAssignment(zkClient, partitionAssignment.map(_._1.topic))
if (throttle.interBrokerLimit >= 0 || throttle.replicaAlterLogDirsLimit >= 0)
println(String.format("Warning: You must run Verify periodically, until the reassignment completes, to ensure the throttle is removed. You can also alter the throttle by rerunning the Execute command passing a new value."))
//开始进行重分配进程
if (reassignPartitionsCommand.reassignPartitions(throttle, timeoutMs)) {
println("Successfully started reassignment of partitions.")
} else
println("Failed to reassign partitions %s".format(partitionAssignment))
}
}
- 解析json文件并做些校验
- (partition、replica非空校验,partition重复校验)
- 校验
partition是否有不存在的分区;(新增分区请用kafka-topic) - 检查配置中的Brokers-id是否都存在
- 如果发现已经存在副本重分配进程(检查是否有节点
/admin/reassign_partitions),则检查是否需要更改限流; 如果有参数(--throttle,--replica-alter-log-dirs-throttle) 则设置限流信息; 而后不再执行下一步 - 如果当前没有执行中的副本重分配任务(检查是否有节点
/admin/reassign_partitions),则开始进行副本重分配任务;
2.2.1 已有任务,尝试限流
如果zk中有节点/admin/reassign_partitions; 则表示当前已有一个任务在进行,那么当前操作就不继续了,如果有参数
--throttle:
--replica-alter-log-dirs-throttle:
则进行限制
限制当前移动副本的节流阀。请注意,此命令可用于更改节流阀,但如果某些代理已完成重新平衡,则它可能不会更改最初设置的所有限制。所以后面需要将这个限制给移除掉 通过
--verify
maybeLimit
def maybeLimit(throttle: Throttle): Unit = {
if (throttle.interBrokerLimit >= 0 || throttle.replicaAlterLogDirsLimit >= 0) {
//当前存在的broker
val existingBrokers = existingAssignment().values.flatten.toSeq
//期望的broker
val proposedBrokers = proposedPartitionAssignment.values.flatten.toSeq ++ proposedReplicaAssignment.keys.toSeq.map(_.brokerId())
//前面broker相加去重
val brokers = (existingBrokers ++ proposedBrokers).distinct
//遍历与之相关的Brokers, 添加限流配置写入到zk节点/config/broker/{brokerId}中
for (id <- brokers) {
//获取broker的配置 /config/broker/{brokerId}
val configs = adminZkClient.fetchEntityConfig(ConfigType.Broker, id.toString)
if (throttle.interBrokerLimit >= 0) {
configs.put(DynamicConfig.Broker.LeaderReplicationThrottledRateProp, throttle.interBrokerLimit.toString)
configs.put(DynamicConfig.Broker.FollowerReplicationThrottledRateProp, throttle.interBrokerLimit.toString)
}
if (throttle.replicaAlterLogDirsLimit >= 0)
configs.put(DynamicConfig.Broker.ReplicaAlterLogDirsIoMaxBytesPerSecondProp, throttle.replicaAlterLogDirsLimit.toString)
adminZkClient.changeBrokerConfig(Seq(id), configs)
}
}
}
/config/brokers/{brokerId}节点配置是Broker端的动态配置,不需要重启Broker实时生效;
- 如果传入了参数
--throttle:则从zk节点/config/brokers/{BrokerId}节点获取Broker们的配置信息,然后再加上以下两个配置重新写入到节点/config/brokers/{BrokerId}中leader.replication.throttled.rate控制leader副本端处理FETCH请求的速率follower.replication.throttled.rate控制follower副本发送FETCH请求的速率 - 如果传入了参数
--replica-alter-log-dirs-throttle:则将如下配置也写入节点中;replica.alter.log.dirs.io.max.bytes.per.second:broker内部目录之间迁移数据流量限制功能,限制数据拷贝从一个目录到另外一个目录带宽上限
例如写入之后的数据
{"version":1,"config":{"leader.replication.throttled.rate":"1","follower.replication.throttled.rate":"1"}}
注意: 这里写入的限流配置,是写入所有与之相关的Broker的限流配置;
2.2.2 当前未有执行任务,开始执行副本重分配任务
ReassignPartitionsCommand.reassignPartitions
def reassignPartitions(throttle: Throttle = NoThrottle, timeoutMs: Long = 10000L): Boolean = {
//写入一些限流数据
maybeThrottle(throttle)
try {
//验证分区是否存在
val validPartitions = proposedPartitionAssignment.groupBy(_._1.topic())
.flatMap { case (topic, topicPartitionReplicas) =>
validatePartition(zkClient, topic, topicPartitionReplicas)
}
if (validPartitions.isEmpty) false
else {
if (proposedReplicaAssignment.nonEmpty && adminClientOpt.isEmpty)
throw new AdminCommandFailedException("bootstrap-server needs to be provided in order to reassign replica to the specified log directory")
val startTimeMs = System.currentTimeMillis()
// Send AlterReplicaLogDirsRequest to allow broker to create replica in the right log dir later if the replica has not been created yet.
if (proposedReplicaAssignment.nonEmpty)
alterReplicaLogDirsIgnoreReplicaNotAvailable(proposedReplicaAssignment, adminClientOpt.get, timeoutMs)
// Create reassignment znode so that controller will send LeaderAndIsrRequest to create replica in the broker
zkClient.createPartitionReassignment(validPartitions.map({case (key, value) => (new TopicPartition(key.topic, key.partition), value)}).toMap)
// Send AlterReplicaLogDirsRequest again to make sure broker will start to move replica to the specified log directory.
// It may take some time for controller to create replica in the broker. Retry if the replica has not been created.
var remainingTimeMs = startTimeMs + timeoutMs - System.currentTimeMillis()
val replicasAssignedToFutureDir = mutable.Set.empty[TopicPartitionReplica]
while (remainingTimeMs > 0 && replicasAssignedToFutureDir.size < proposedReplicaAssignment.size) {
replicasAssignedToFutureDir ++= alterReplicaLogDirsIgnoreReplicaNotAvailable(
proposedReplicaAssignment.filter { case (replica, _) => !replicasAssignedToFutureDir.contains(replica) },
adminClientOpt.get, remainingTimeMs)
Thread.sleep(100)
remainingTimeMs = startTimeMs + timeoutMs - System.currentTimeMillis()
}
replicasAssignedToFutureDir.size == proposedReplicaAssignment.size
}
} catch {
case _: NodeExistsException =>
val partitionsBeingReassigned = zkClient.getPartitionReassignment()
throw new AdminCommandFailedException("Partition reassignment currently in " +
"progress for %s. Aborting operation".format(partitionsBeingReassigned))
}
}
-
maybeThrottle(throttle)设置副本移动时候的限流配置,这个方法只用于任务初始化的时候private def maybeThrottle(throttle: Throttle): Unit = { if (throttle.interBrokerLimit >= 0) assignThrottledReplicas(existingAssignment(), proposedPartitionAssignment, adminZkClient) maybeLimit(throttle) if (throttle.interBrokerLimit >= 0 || throttle.replicaAlterLogDirsLimit >= 0) throttle.postUpdateAction() if (throttle.interBrokerLimit >= 0) println(s"The inter-broker throttle limit was set to ${throttle.interBrokerLimit} B/s") if (throttle.replicaAlterLogDirsLimit >= 0) println(s"The replica-alter-dir throttle limit was set to ${throttle.replicaAlterLogDirsLimit} B/s") }1.1 将一些topic的限流配置写入到节点
/config/topics/{topicName}中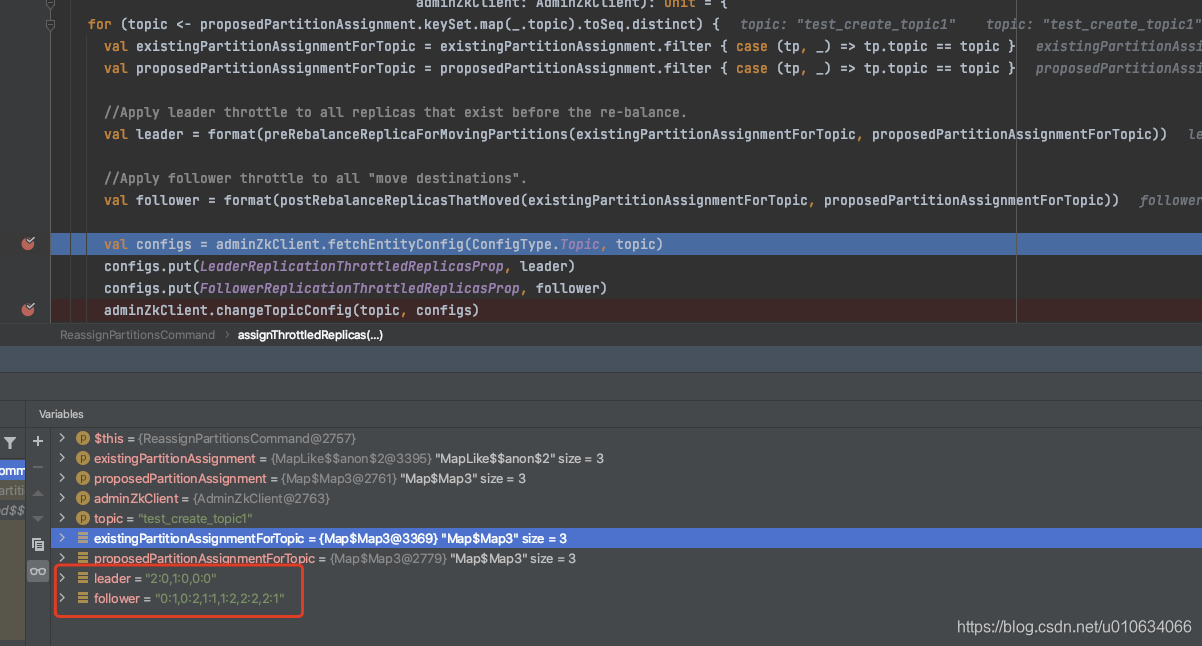 将计算得到的leader、follower 值写入到
将计算得到的leader、follower 值写入到/config/topics/{topicName}中 leader: 找到 TopicPartition中有新增的副本的 那个分区;数据= 分区号:副本号,分区号:副本号 follower: 遍历 预期 TopicPartition,副本= 预期副本-现有副本;数据= 分区号:副本号,分区号:副本号leader.replication.throttled.replicas: leaderfollower.replication.throttled.replicas: follower 1.2. 执行 《2.2.1 已有任务,尝试限流》流程
1.2. 执行 《2.2.1 已有任务,尝试限流》流程 -
从zk中获取
/broker/topics/{topicName}数据来验证给定的分区是否存在,如果分区不存在则忽略此分区的配置,继续流程 -
如果尚未创建副本,则发送
AlterReplicaLogDirsRequest以允许代理稍后在正确的日志目录中创建副本。这个跟log_dirs有关 TODO.... -
将重分配的数据写入到zk的节点
/admin/reassign_partitions中;数据内容如:{"version":1,"partitions":[{"topic":"test_create_topic1","partition":0,"replicas":[0,1,2,3]},{"topic":"test_create_topic1","partition":1,"replicas":[1,2,0,3]},{"topic":"test_create_topic1","partition":2,"replicas":[2,1,0,3]}]} -
再次发送
AlterReplicaLogDirsRequest以确保代理将开始将副本移动到指定的日志目录。控制器在代理中创建副本可能需要一些时间。如果尚未创建副本,请重试。- 像Broker发送
alterReplicaLogDirs请求
- 像Broker发送
2.2.3 Controller监听/admin/reassign_partitions节点变化
KafkaController.processZkPartitionReassignment
private def processZkPartitionReassignment(): Set[TopicPartition] = {
// We need to register the watcher if the path doesn't exist in order to detect future
// reassignments and we get the `path exists` check for free
if (isActive && zkClient.registerZNodeChangeHandlerAndCheckExistence(partitionReassignmentHandler)) {
val reassignmentResults = mutable.Map.empty[TopicPartition, ApiError]
val partitionsToReassign = mutable.Map.empty[TopicPartition, ReplicaAssignment]
zkClient.getPartitionReassignment().foreach { case (tp, targetReplicas) =>
maybeBuildReassignment(tp, Some(targetReplicas)) match {
case Some(context) => partitionsToReassign.put(tp, context)
case None => reassignmentResults.put(tp, new ApiError(Errors.NO_REASSIGNMENT_IN_PROGRESS))
}
}
reassignmentResults ++= maybeTriggerPartitionReassignment(partitionsToReassign)
val (partitionsReassigned, partitionsFailed) = reassignmentResults.partition(_._2.error == Errors.NONE)
if (partitionsFailed.nonEmpty) {
warn(s"Failed reassignment through zk with the following errors: $partitionsFailed")
maybeRemoveFromZkReassignment((tp, _) => partitionsFailed.contains(tp))
}
partitionsReassigned.keySet
} else {
Set.empty
}
}
- 判断是否是Controller角色并且是否存在节点
/admin/reassign_partitions maybeTriggerPartitionReassignment重分配,如果topic已经被标记为删除了,则此topic流程终止;maybeRemoveFromZkReassignment将执行失败的一些分区信息从zk中删除;(覆盖信息)
onPartitionReassignment
KafkaController.onPartitionReassignment
private def onPartitionReassignment(topicPartition: TopicPartition, reassignment: ReplicaAssignment): Unit = {
// 暂停一些正在删除的Topic操作
topicDeletionManager.markTopicIneligibleForDeletion(Set(topicPartition.topic), reason = "topic reassignment in progress")
//更新当前的分配
updateCurrentReassignment(topicPartition, reassignment)
val addingReplicas = reassignment.addingReplicas
val removingReplicas = reassignment.removingReplicas
if (!isReassignmentComplete(topicPartition, reassignment)) {
// A1. Send LeaderAndIsr request to every replica in ORS + TRS (with the new RS, AR and RR).
updateLeaderEpochAndSendRequest(topicPartition, reassignment)
// A2. replicas in AR -> NewReplica
startNewReplicasForReassignedPartition(topicPartition, addingReplicas)
} else {
// B1. replicas in AR -> OnlineReplica
replicaStateMachine.handleStateChanges(addingReplicas.map(PartitionAndReplica(topicPartition, _)), OnlineReplica)
// B2. Set RS = TRS, AR = [], RR = [] in memory.
val completedReassignment = ReplicaAssignment(reassignment.targetReplicas)
controllerContext.updatePartitionFullReplicaAssignment(topicPartition, completedReassignment)
// B3. Send LeaderAndIsr request with a potential new leader (if current leader not in TRS) and
// a new RS (using TRS) and same isr to every broker in ORS + TRS or TRS
moveReassignedPartitionLeaderIfRequired(topicPartition, completedReassignment)
// B4. replicas in RR -> Offline (force those replicas out of isr)
// B5. replicas in RR -> NonExistentReplica (force those replicas to be deleted)
stopRemovedReplicasOfReassignedPartition(topicPartition, removingReplicas)
// B6. Update ZK with RS = TRS, AR = [], RR = [].
updateReplicaAssignmentForPartition(topicPartition, completedReassignment)
// B7. Remove the ISR reassign listener and maybe update the /admin/reassign_partitions path in ZK to remove this partition from it.
removePartitionFromReassigningPartitions(topicPartition, completedReassignment)
// B8. After electing a leader in B3, the replicas and isr information changes, so resend the update metadata request to every broker
sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq, Set(topicPartition))
// signal delete topic thread if reassignment for some partitions belonging to topics being deleted just completed
topicDeletionManager.resumeDeletionForTopics(Set(topicPartition.topic))
}
}
- 暂停一些正在删除的Topic操作
- 更新 Zk节点
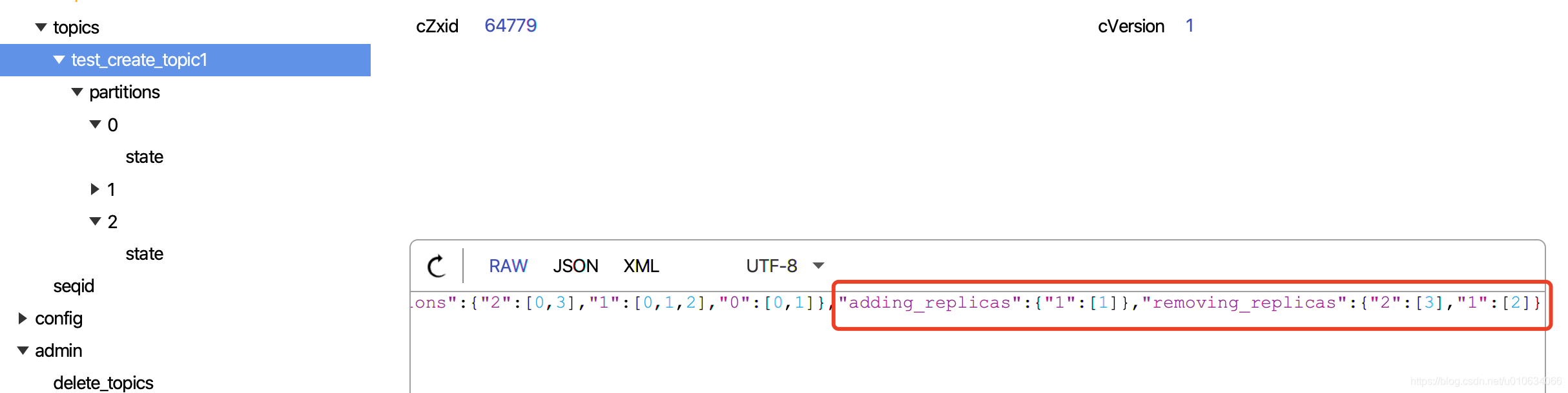
brokers/topics/{topicName},和内存中的当前分配状态。如果重新分配已经在进行中,那么新的重新分配将取代它并且一些副本将被关闭。 2.1 更新zk中的topic节点信息brokers/topics/{topicName},这里会标记AR哪些副本是新增的,RR哪些副本是要删除的;例如: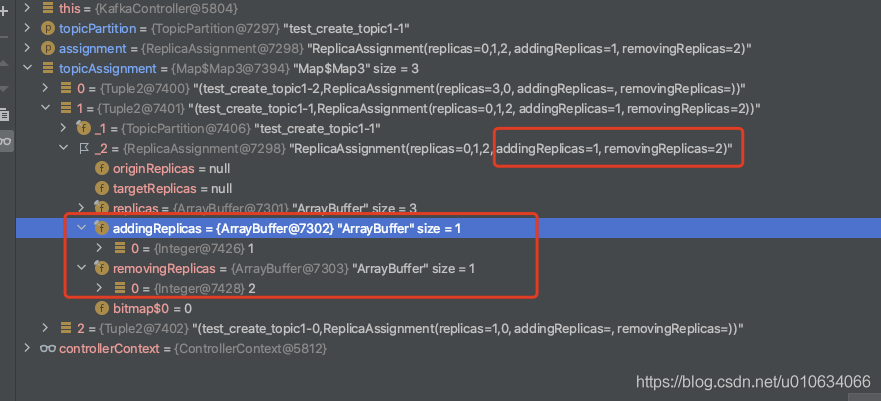
 2.2 更新当前内存
2.3 如果重新分配已经在进行中,那么一些当前新增加的副本有可能被立即删除,在这种情况下,我们需要停止副本。
2.4 注册一个监听节点
2.2 更新当前内存
2.3 如果重新分配已经在进行中,那么一些当前新增加的副本有可能被立即删除,在这种情况下,我们需要停止副本。
2.4 注册一个监听节点/brokers/topics/{topicName}/partitions/{分区号}/state变更的处理器PartitionReassignmentIsrChangeHandler - 如果该分区的重新分配还没有完成(根据
/brokers/topics/{topicName}/partitions/{分区号}/state里面的isr来判断是否已经包含了新增的BrokerId了);则 以下几个名称说明:ORS: OriginReplicas 原先的副本TRS: targetReplicas 将要变更成的目标副本AR: adding_replicas 正在添加的副本RR:removing_replicas 正在移除的副本 3.1 向 ORS + TRS 中的每个副本发送LeaderAndIsr请求(带有新的 RS、AR 和 RR)。 3.2 给新增加的AR副本 进行状态变更成NewReplica; 这个过程有发送LeaderAndIsrRequest详细请看【kafka源码】Controller中的状态机
2.2.4 Controller监听节点brokers/topics/{topicName}变化,检查是否有新增分区
这一个流程可以不必在意,因为在这里没有做任何事情;
上面的 2.2.3 的第2小段中不是有将新增的和删掉的副本写入到了 zk中吗 例如:
{"version":2,"partitions":{"2":[0,1],"1":[0,1],"0":[0,1]},"adding_replicas":{"2":[1],"1":[1],"0":[1]},"removing_replicas":{}}
Controller监听到这个节点之后,执行方法processPartitionModifications
KafkaController.processPartitionModifications
private def processPartitionModifications(topic: String): Unit = {
def restorePartitionReplicaAssignment(
topic: String,
newPartitionReplicaAssignment: Map[TopicPartition, ReplicaAssignment]
): Unit = {
info("Restoring the partition replica assignment for topic %s".format(topic))
//从zk节点中获取所有分区
val existingPartitions = zkClient.getChildren(TopicPartitionsZNode.path(topic))
//找到已经存在的分区
val existingPartitionReplicaAssignment = newPartitionReplicaAssignment
.filter(p => existingPartitions.contains(p._1.partition.toString))
.map { case (tp, _) =>
tp -> controllerContext.partitionFullReplicaAssignment(tp)
}.toMap
zkClient.setTopicAssignment(topic,
existingPartitionReplicaAssignment,
controllerContext.epochZkVersion)
}
if (!isActive) return
val partitionReplicaAssignment = zkClient.getFullReplicaAssignmentForTopics(immutable.Set(topic))
val partitionsToBeAdded = partitionReplicaAssignment.filter { case (topicPartition, _) =>
controllerContext.partitionReplicaAssignment(topicPartition).isEmpty
}
if (topicDeletionManager.isTopicQueuedUpForDeletion(topic)) {
if (partitionsToBeAdded.nonEmpty) {
warn("Skipping adding partitions %s for topic %s since it is currently being deleted"
.format(partitionsToBeAdded.map(_._1.partition).mkString(","), topic))
restorePartitionReplicaAssignment(topic, partitionReplicaAssignment)
} else {
// This can happen if existing partition replica assignment are restored to prevent increasing partition count during topic deletion
info("Ignoring partition change during topic deletion as no new partitions are added")
}
} else if (partitionsToBeAdded.nonEmpty) {
info(s"New partitions to be added $partitionsToBeAdded")
partitionsToBeAdded.foreach { case (topicPartition, assignedReplicas) =>
controllerContext.updatePartitionFullReplicaAssignment(topicPartition, assignedReplicas)
}
onNewPartitionCreation(partitionsToBeAdded.keySet)
}
}
-
从
brokers/topics/{topicName}中获取完整的分配信息,例如{ "version": 2, "partitions": { "2": [0, 1], "1": [0, 1], "0": [0, 1] }, "adding_replicas": { "2": [1], "1": [1], "0": [1] }, "removing_replicas": {} } -
如果有需要新增的分区,如下操作 2.1 如果当前Topic刚好在删掉队列中,那么就没有必要进行分区扩容了; 将zk的
brokers/topics/{topicName}数据恢复回去 2.2 如果不在删除队列中,则开始走新增分区的流程;关于新增分区的流程 在【kafka源码】TopicCommand之创建Topic源码解析 里面已经详细讲过了,跳转后请搜索关键词onNewPartitionCreation -
如果该Topic正在删除中,则跳过该Topic的处理; 并且同时如果有AR(adding_replical),则重写一下zk节点
/broker/topics/{topicName}节点的数据; 相当于是还原数据; 移除掉里面的AR;
这一步完全不用理会,因为 分区副本重分配不会出现新增分区的情况;
2.2.5 Controller监听zk节点/brokers/topics/{topicName}/partitions/{分区号}/state
上面2.2.3 里面的 2.4不是有说过注册一个监听节点
/brokers/topics/{topicName}/partitions/{分区号}/state变更的处理器PartitionReassignmentIsrChangeHandler
到底是什么时候这个节点有变化呢? 前面我们不是对副本们发送了LEADERANDISR的请求么, 当新增的副本去leader
fetch数据开始同步的时候,当数据同步完成跟上了ISR的节奏,就会去修改这个节点; 修改之后那么下面就开始执行监听流程了
这里跟 2.2.3 中有调用同一个接口; 不过这个时候经过了LeaderAndIsr请求
kafkaController.processPartitionReassignmentIsrChange->onPartitionReassignment
private def onPartitionReassignment(topicPartition: TopicPartition, reassignment: ReplicaAssignment): Unit = {
// While a reassignment is in progress, deletion is not allowed
topicDeletionManager.markTopicIneligibleForDeletion(Set(topicPartition.topic), reason = "topic reassignment in progress")
updateCurrentReassignment(topicPartition, reassignment)
val addingReplicas = reassignment.addingReplicas
val removingReplicas = reassignment.removingReplicas
if (!isReassignmentComplete(topicPartition, reassignment)) {
// A1. Send LeaderAndIsr request to every replica in ORS + TRS (with the new RS, AR and RR).
updateLeaderEpochAndSendRequest(topicPartition, reassignment)
// A2. replicas in AR -> NewReplica
startNewReplicasForReassignedPartition(topicPartition, addingReplicas)
} else {
// B1. replicas in AR -> OnlineReplica
replicaStateMachine.handleStateChanges(addingReplicas.map(PartitionAndReplica(topicPartition, _)), OnlineReplica)
// B2. Set RS = TRS, AR = [], RR = [] in memory.
val completedReassignment = ReplicaAssignment(reassignment.targetReplicas)
controllerContext.updatePartitionFullReplicaAssignment(topicPartition, completedReassignment)
// B3. Send LeaderAndIsr request with a potential new leader (if current leader not in TRS) and
// a new RS (using TRS) and same isr to every broker in ORS + TRS or TRS
moveReassignedPartitionLeaderIfRequired(topicPartition, completedReassignment)
// B4. replicas in RR -> Offline (force those replicas out of isr)
// B5. replicas in RR -> NonExistentReplica (force those replicas to be deleted)
stopRemovedReplicasOfReassignedPartition(topicPartition, removingReplicas)
// B6. Update ZK with RS = TRS, AR = [], RR = [].
updateReplicaAssignmentForPartition(topicPartition, completedReassignment)
// B7. Remove the ISR reassign listener and maybe update the /admin/reassign_partitions path in ZK to remove this partition from it.
removePartitionFromReassigningPartitions(topicPartition, completedReassignment)
// B8. After electing a leader in B3, the replicas and isr information changes, so resend the update metadata request to every broker
sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq, Set(topicPartition))
// signal delete topic thread if reassignment for some partitions belonging to topics being deleted just completed
topicDeletionManager.resumeDeletionForTopics(Set(topicPartition.topic))
}
}
以下几个名称说明:
ORS: origin repilicas 原先的副本
RS: Replicas 现在的副本
TRS: targetReplicas 将要变更成的目标副本
AR: adding_replicas 正在添加的副本
RR:removing_replicas 正在移除的副本
-
副本状态变更 ->
OnlineReplica,将 AR 中的所有副本移动到 OnlineReplica 状态 -
在内存中设置 RS = TRS, AR = [], RR = []
-
向 ORS + TRS 或 TRS 中的每个经纪人发送带有潜在新Leader(如果当前Leader不在 TRS 中)和新 RS(使用 TRS)和相同 isr 的
LeaderAndIsr请求 -
我们可能会将
LeaderAndIsr发送到多个 TRS 副本。将 RR 中的所有副本移动到OfflineReplica状态。转换的过程中,有删除 ZooKeeper 中的 RR,并且仅向 Leader 发送一个LeaderAndIsr以通知它缩小的 isr。之后,向 RR 中的副本发送一个StopReplica (delete = false)这个时候还没有正在的进行删除。 -
将 RR 中的所有副本移动到
NonExistentReplica状态。这将向 RR 中的副本发送一个StopReplica (delete = true)以物理删除磁盘上的副本。这里的流程可以看看文章【kafka源码】TopicCommand之删除Topic源码解析 -
用RS=TRS, AR=[], RR=[] 更新 zk
/broker/topics/{topicName}节点,更新partitions并移除AR(adding_replicas)RR(removing_replicas) 例如{"version":2,"partitions":{"2":[0,1],"1":[0,1],"0":[0,1]},"adding_replicas":{},"removing_replicas":{}} -
删除 ISR 重新分配侦听器
/brokers/topics/{topicName}/partitions/{分区号}/state,并可能更新 ZK 中的/admin/reassign_partitions路径以从中删除此分区(如果存在) -
选举leader后,replicas和isr信息发生变化。因此,向每个代理重新发送
UPDATE_METADATA更新元数据请求。 -
恢复删除线程
resumeDeletions; 该操作【kafka源码】TopicCommand之删除Topic源码解析在分析过; 请移步阅读,并搜索关键字resumeDeletions
2.2.6 Controller重新选举恢复 恢复任务
KafkaController.onControllerFailover() 里面 有调用接口
initializePartitionReassignments会恢复未完成的重分配任务
alterReplicaLogDirs请求
副本跨路径迁移相关
KafkaApis.handleAlterReplicaLogDirsRequest
def handleAlterReplicaLogDirsRequest(request: RequestChannel.Request): Unit = {
val alterReplicaDirsRequest = request.body[AlterReplicaLogDirsRequest]
val responseMap = {
if (authorize(request, ALTER, CLUSTER, CLUSTER_NAME))
replicaManager.alterReplicaLogDirs(alterReplicaDirsRequest.partitionDirs.asScala)
else
alterReplicaDirsRequest.partitionDirs.asScala.keys.map((_, Errors.CLUSTER_AUTHORIZATION_FAILED)).toMap
}
sendResponseMaybeThrottle(request, requestThrottleMs => new AlterReplicaLogDirsResponse(requestThrottleMs, responseMap.asJava))
}
2.3--verify 验证结果分析
校验执行情况, 顺便移除之前加过的限流配置
--zookeeper xxxxx --reassignment-json-file config/reassignment-json-file.json --verify
源码在ReassignPartitionsCommand.verifyAssignment ,很简单 这里就不分析了
主要就是把之前写入的配置给清理掉
2.4 副本跨路径迁移
为什么线上Kafka机器各个磁盘间的占用不均匀,经常出现“一边倒”的情形? 这是因为Kafka只保证分区数量在各个磁盘上均匀分布,但它无法知晓每个分区实际占用空间,故很有可能出现某些分区消息数量巨大导致占用大量磁盘空间的情况。在1.1版本之前,用户对此毫无办法,因为1.1之前Kafka只支持分区数据在不同broker间的重分配,而无法做到在同一个broker下的不同磁盘间做重分配。1.1版本正式支持副本在不同路径间的迁移
怎么在一台Broker上用多个路径存放分区呢?
只需要在配置上接多个文件夹就行了
############################# Log Basics #############################
# A comma separated list of directories under which to store log files
log.dirs=kafka-logs-5,kafka-logs-6,kafka-logs-7,kafka-logs-8
注意同一个Broker上不同路径只会存放不同的分区,而不会将副本存放在同一个Broker; 不然那副本就没有意义了(容灾)
怎么针对跨路径迁移呢?
迁移的json文件有一个参数是log_dirs; 默认请求不传的话 它是"log_dirs": ["any"] (这个数组的数量要跟副本保持一致)
但是你想实现跨路径迁移,只需要在这里填入绝对路径就行了,例如下面
迁移的json文件示例
{
"version": 1,
"partitions": [{
"topic": "test_create_topic4",
"partition": 2,
"replicas": [0],
"log_dirs": ["/Users/xxxxx/work/IdeaPj/source/kafka/kafka-logs-5"]
}, {
"topic": "test_create_topic4",
"partition": 1,
"replicas": [0],
"log_dirs": ["/Users/xxxxx/work/IdeaPj/source/kafka/kafka-logs-6"]
}]
}
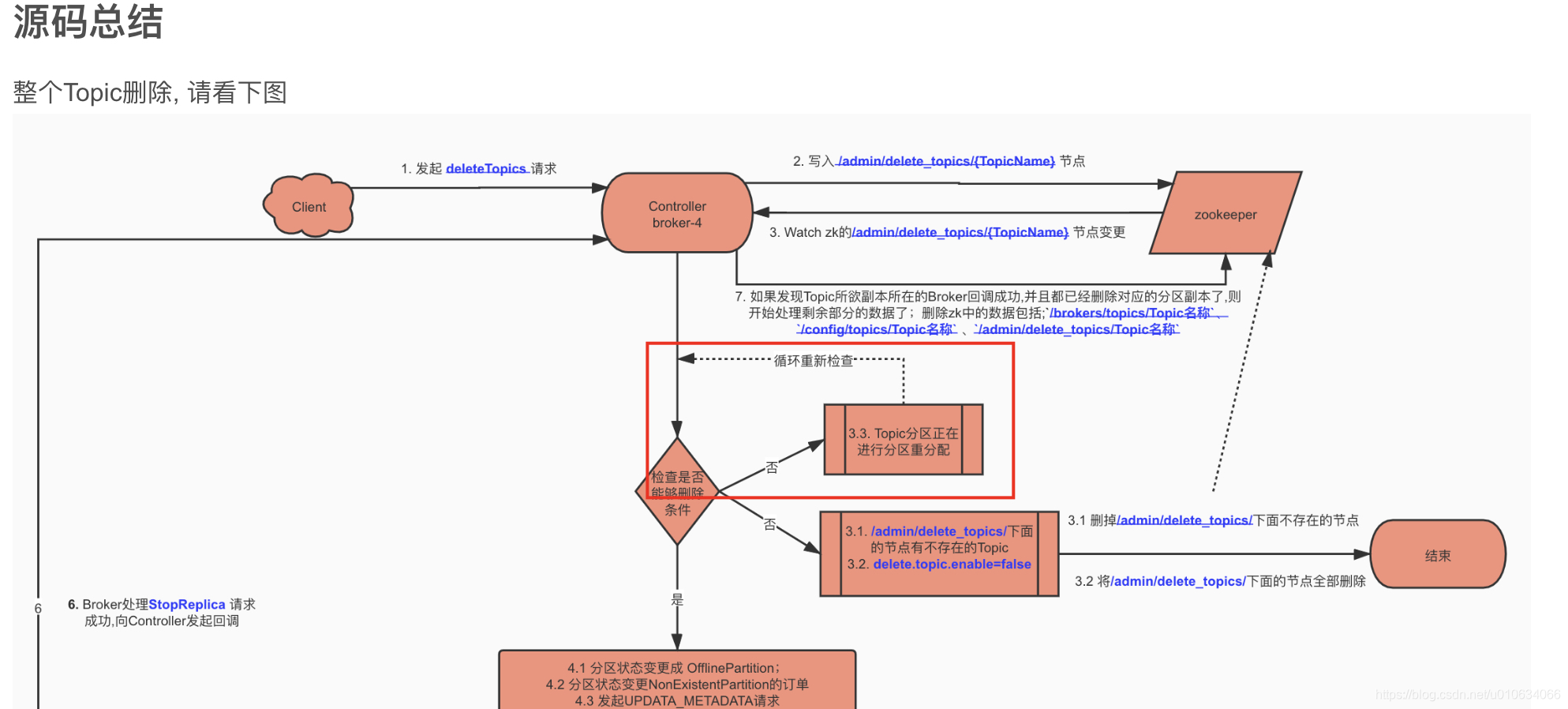
3.源码总结
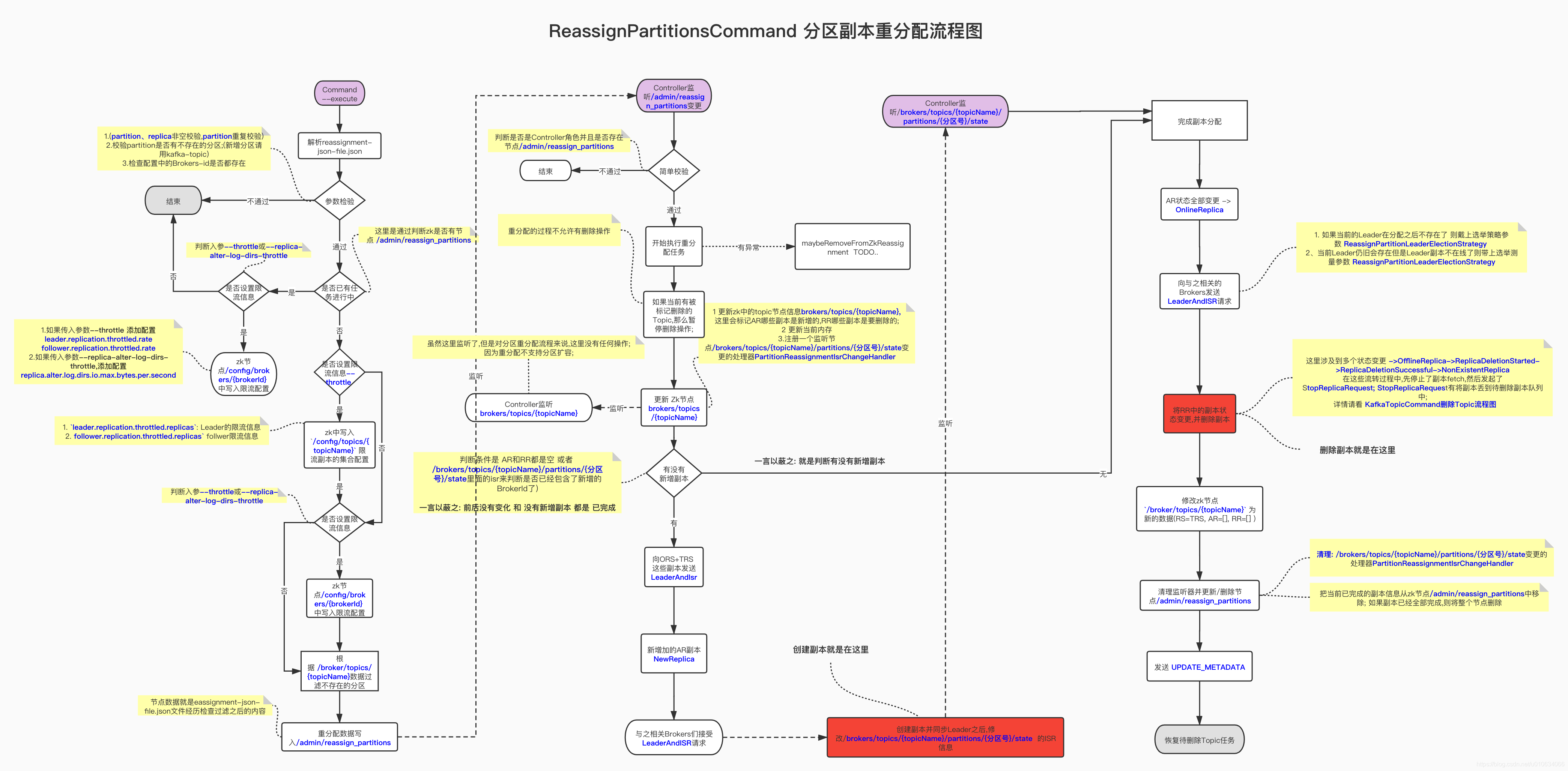
4.Q&A
如果新增副本之后,会触发副本重新选举吗
Question: 如果原来副本分配方式是:
"replicas": [0,1]重新分配方式变更成"replicas": [0,1,2]或者"replicas": [2,0,1]Leader会变更吗? Answer: 不会,只要没有涉及到原来的Leader的变更,就不会触发重新选举
如果删除副本之后,会触发副本重新选举吗
Question: 如果原来副本分配方式是:
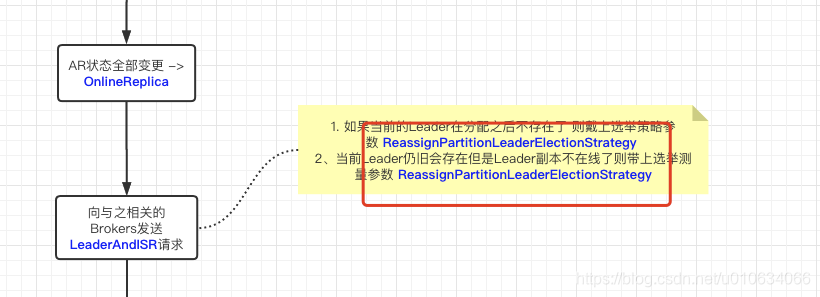
"replicas": [0,1,2]重新分配方式变更成"replicas": [0,1]或者"replicas": [2,0]或者"replicas": [1,2]Leader会变更吗? Answer: 不会,只要没有涉及到原来的Leader的变更,就不会触发重新选举 ; 但是如果是之前的Leader被删除了,那就会触发重新选举了 如果触发选举了,那么选举策略是什么?策略如下图所述
在重新分配的过程中,如果执行删除操作会怎么样
删除操作会等待,等待重新分配完成之后,继续进行删除操作 可参考文章 【kafka源码】TopicCommand之删除Topic源码解析中的 源码总结部分
副本增加是在哪个时机发生的
副本新增之后会开始与leader进行同步, 并修改节点
/brokers/topics/{topicName}/partitions/{分区号}/state的isr信息
副本删除是在哪个时机发生的
副本的删除是一个副本状态转换的过程,具体请看 【kafka源码】Controller中的状态机
手动在zk中创建/admin/reassign_partitions节点能成功重分配吗
可以但是没必要, 需要做好一些前置校验
限流配置详情
里面有很多限流的配置, 关于限流相关 请看 TODO.....
如果重新分配没有新增和删除副本,只是副本位置变更了
Q: 假设分区副本 [0,1,2] 变更为[2,1,0] 会把副本删除之后再新增吗? 会触发leader选举吗? A: 不会, 副本么有增多和减少就不会有 新增和删除副本的流程; 最终只是在zk节点
/broker/topics/{topicName}修改了一下顺序而已, 产生影响只会在下一次进行优先副本选举的时候 让第一个副本作为了Leader;
重分配过程手动写入限流信息会生效吗
关于限流相关 请看 TODO.....
如果Controller角色重新选举 那重新分配任务还会继续吗
KafkaController.onControllerFailover() 里面 有调用接口
initializePartitionReassignments会恢复未完成的重分配任务