mirror of
https://github.com/didi/KnowStreaming.git
synced 2026-01-16 21:34:31 +08:00
Add km module kafka
This commit is contained in:
243
docs/zh/Kafka分享/Kafka Controller /Controller与Brokers之间的网络通信.md
Normal file
243
docs/zh/Kafka分享/Kafka Controller /Controller与Brokers之间的网络通信.md
Normal file
@@ -0,0 +1,243 @@
|
||||
|
||||
## 前言
|
||||
之前我们有解析过[【kafka源码】Controller启动过程以及选举流程源码分析](), 其中在分析过程中,Broker在当选Controller之后,需要初始化Controller的上下文中, 有关于Controller与Broker之间的网络通信的部分我没有细讲,因为这个部分我想单独来讲;所以今天 我们就来好好分析分析**Controller与Brokers之间的网络通信**
|
||||
|
||||
## 源码分析
|
||||
### 1. 源码入口 ControllerChannelManager.startup()
|
||||
调用链路
|
||||
->`KafkaController.processStartup`
|
||||
->`KafkaController.elect()`
|
||||
->`KafkaController.onControllerFailover()`
|
||||
->`KafkaController.initializeControllerContext()`
|
||||
```scala
|
||||
def startup() = {
|
||||
// 把所有存活的Broker全部调用 addNewBroker这个方法
|
||||
controllerContext.liveOrShuttingDownBrokers.foreach(addNewBroker)
|
||||
|
||||
brokerLock synchronized {
|
||||
//开启 网络请求线程
|
||||
brokerStateInfo.foreach(brokerState => startRequestSendThread(brokerState._1))
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 2. addNewBroker 构造broker的连接信息
|
||||
> 将所有存活的brokers 构造一些对象例如`NetworkClient`、`RequestSendThread` 等等之类的都封装到对象`ControllerBrokerStateInfo`中;
|
||||
> 由`brokerStateInfo`持有对象 key=brokerId; value = `ControllerBrokerStateInfo`
|
||||
|
||||
```scala
|
||||
private def addNewBroker(broker: Broker): Unit = {
|
||||
// 省略部分代码
|
||||
val threadName = threadNamePrefix match {
|
||||
case None => s"Controller-${config.brokerId}-to-broker-${broker.id}-send-thread"
|
||||
case Some(name) => s"$name:Controller-${config.brokerId}-to-broker-${broker.id}-send-thread"
|
||||
}
|
||||
|
||||
val requestRateAndQueueTimeMetrics = newTimer(
|
||||
RequestRateAndQueueTimeMetricName, TimeUnit.MILLISECONDS, TimeUnit.SECONDS, brokerMetricTags(broker.id)
|
||||
)
|
||||
|
||||
//构造请求发送线程
|
||||
val requestThread = new RequestSendThread(config.brokerId, controllerContext, messageQueue, networkClient,
|
||||
brokerNode, config, time, requestRateAndQueueTimeMetrics, stateChangeLogger, threadName)
|
||||
requestThread.setDaemon(false)
|
||||
|
||||
val queueSizeGauge = newGauge(QueueSizeMetricName, () => messageQueue.size, brokerMetricTags(broker.id))
|
||||
//封装好对象 缓存在brokerStateInfo中
|
||||
brokerStateInfo.put(broker.id, ControllerBrokerStateInfo(networkClient, brokerNode, messageQueue,
|
||||
requestThread, queueSizeGauge, requestRateAndQueueTimeMetrics, reconfigurableChannelBuilder))
|
||||
}
|
||||
```
|
||||
1. 将所有存活broker 封装成一个个`ControllerBrokerStateInfo`对象保存在缓存中; 对象中包含了`RequestSendThread` 请求发送线程 对象; 什么时候执行发送线程 ,我们下面分析
|
||||
2. `messageQueue:` 一个阻塞队列,里面放的都是待执行的请求,里面的对象`QueueItem` 封装了
|
||||
请求接口`ApiKeys`,`AbstractControlRequest`请求体对象;`AbstractResponse` 回调函数和`enqueueTimeMs`入队时间
|
||||
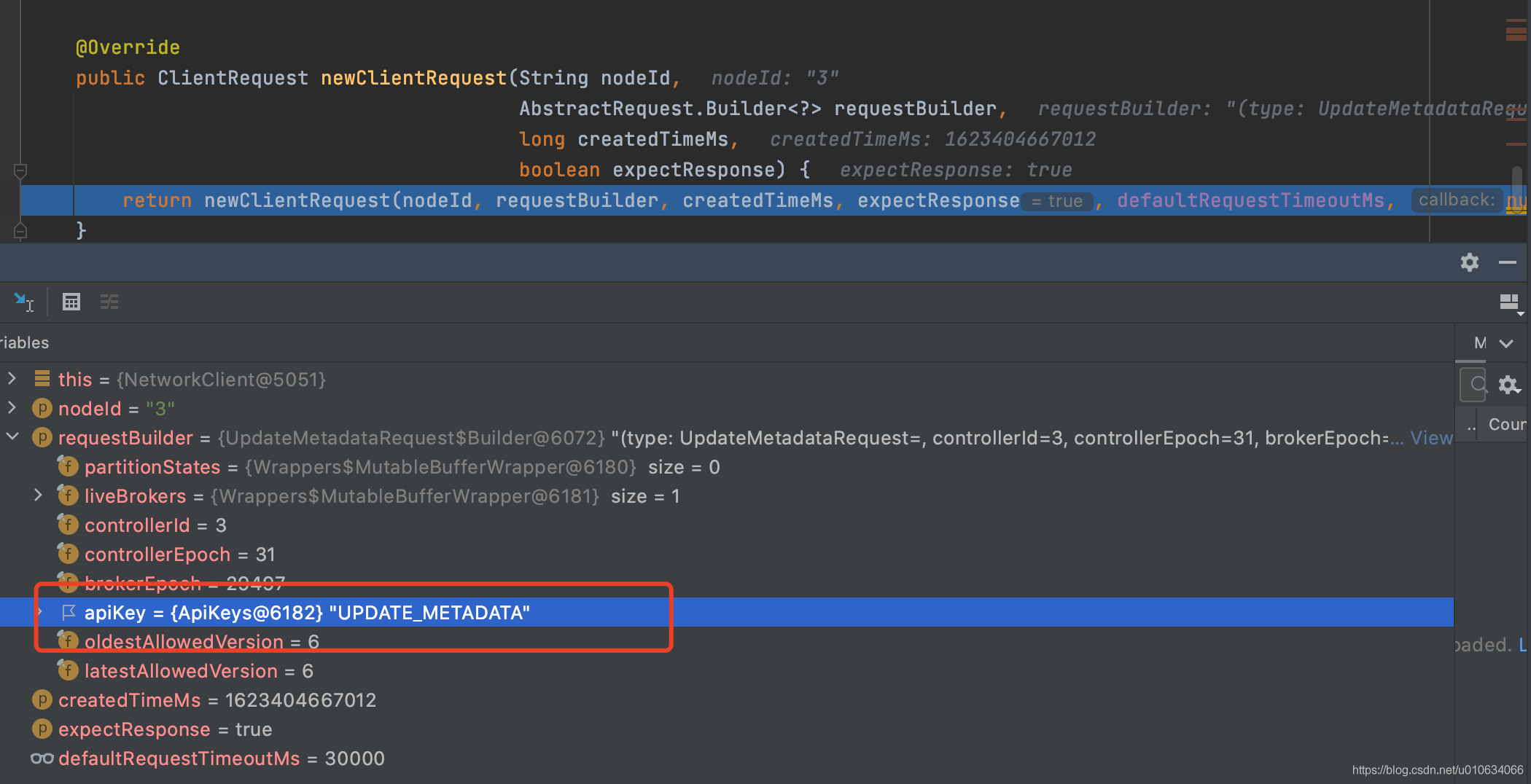
3. `RequestSendThread` 发送请求的线程 , 跟Broker们的网络连接就是通过这里进行的;比如下图中向Brokers们(当然包含自己)发送`UPDATE_METADATA`更新元数据的请求
|
||||
|
||||
|
||||
|
||||
### 3. startRequestSendThread 启动网络请求线程
|
||||
>把所有跟Broker连接的网络请求线程开起来
|
||||
```scala
|
||||
protected def startRequestSendThread(brokerId: Int): Unit = {
|
||||
val requestThread = brokerStateInfo(brokerId).requestSendThread
|
||||
if (requestThread.getState == Thread.State.NEW)
|
||||
requestThread.start()
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
线程执行代码块 ; 以下省略了部分代码
|
||||
```scala
|
||||
override def doWork(): Unit = {
|
||||
|
||||
def backoff(): Unit = pause(100, TimeUnit.MILLISECONDS)
|
||||
|
||||
//从阻塞请求队列里面获取有没有待执行的请求
|
||||
val QueueItem(apiKey, requestBuilder, callback, enqueueTimeMs) = queue.take()
|
||||
requestRateAndQueueTimeMetrics.update(time.milliseconds() - enqueueTimeMs, TimeUnit.MILLISECONDS)
|
||||
|
||||
var clientResponse: ClientResponse = null
|
||||
try {
|
||||
var isSendSuccessful = false
|
||||
while (isRunning && !isSendSuccessful) {
|
||||
// if a broker goes down for a long time, then at some point the controller's zookeeper listener will trigger a
|
||||
// removeBroker which will invoke shutdown() on this thread. At that point, we will stop retrying.
|
||||
try {
|
||||
//检查跟Broker的网络连接是否畅通,如果连接不上会重试
|
||||
if (!brokerReady()) {
|
||||
isSendSuccessful = false
|
||||
backoff()
|
||||
}
|
||||
else {
|
||||
//构建请求参数
|
||||
val clientRequest = networkClient.newClientRequest(brokerNode.idString, requestBuilder,
|
||||
time.milliseconds(), true)
|
||||
//发起网络请求
|
||||
clientResponse = NetworkClientUtils.sendAndReceive(networkClient, clientRequest, time)
|
||||
isSendSuccessful = true
|
||||
}
|
||||
} catch {
|
||||
}
|
||||
if (clientResponse != null) {
|
||||
val requestHeader = clientResponse.requestHeader
|
||||
val api = requestHeader.apiKey
|
||||
if (api != ApiKeys.LEADER_AND_ISR && api != ApiKeys.STOP_REPLICA && api != ApiKeys.UPDATE_METADATA)
|
||||
throw new KafkaException(s"Unexpected apiKey received: $apiKey")
|
||||
|
||||
if (callback != null) {
|
||||
callback(response)
|
||||
}
|
||||
}
|
||||
} catch {
|
||||
|
||||
}
|
||||
}
|
||||
```
|
||||
1. 从请求队列`queue`中take请求; 如果有的话就开始执行,没有的话就阻塞住
|
||||
2. 检查请求的目标Broker是否可以连接; 连接不通会一直进行尝试,然后在某个时候,控制器的 zookeeper 侦听器将触发一个 `removeBroker`,它将在此线程上调用 shutdown()。就不会在重试了
|
||||
3. 发起请求;
|
||||
4. 如果请求失败,则重新连接Broker发送请求
|
||||
5. 返回成功,调用回调接口
|
||||
6. 值得注意的是<font color="red"> Controller发起的请求,收到Response中的ApiKeys中如果不是 `LEADER_AND_ISR`、`STOP_REPLICA`、`UPDATE_METADATA` 三个请求,就会抛出异常; 不会进行callBack的回调; </font> 不过也是很奇怪,如果Controller限制只能发起这几个请求的话,为什么在发起请求之前去做拦截,而要在返回之后做拦截; **个人猜测 可能是Broker在Response带上ApiKeys, 在Controller 调用callBack的时候可能会根据ApiKeys的不同而处理不同逻辑吧;但是又只想对Broker开放那三个接口;**
|
||||
|
||||
|
||||
|
||||
### 4. 向RequestSendThread的请求队列queue中添加请求
|
||||
> 上面的线程启动完成之后,queue中还没有待执行的请求的,那么什么时候有添加请求呢?
|
||||
|
||||
添加请求最终都会调用接口`` ,反查一下就知道了;
|
||||
```java
|
||||
def sendRequest(brokerId: Int, request: AbstractControlRequest.Builder[_ <: AbstractControlRequest],
|
||||
callback: AbstractResponse => Unit = null): Unit = {
|
||||
brokerLock synchronized {
|
||||
val stateInfoOpt = brokerStateInfo.get(brokerId)
|
||||
stateInfoOpt match {
|
||||
case Some(stateInfo) =>
|
||||
stateInfo.messageQueue.put(QueueItem(request.apiKey, request, callback, time.milliseconds()))
|
||||
case None =>
|
||||
warn(s"Not sending request $request to broker $brokerId, since it is offline.")
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
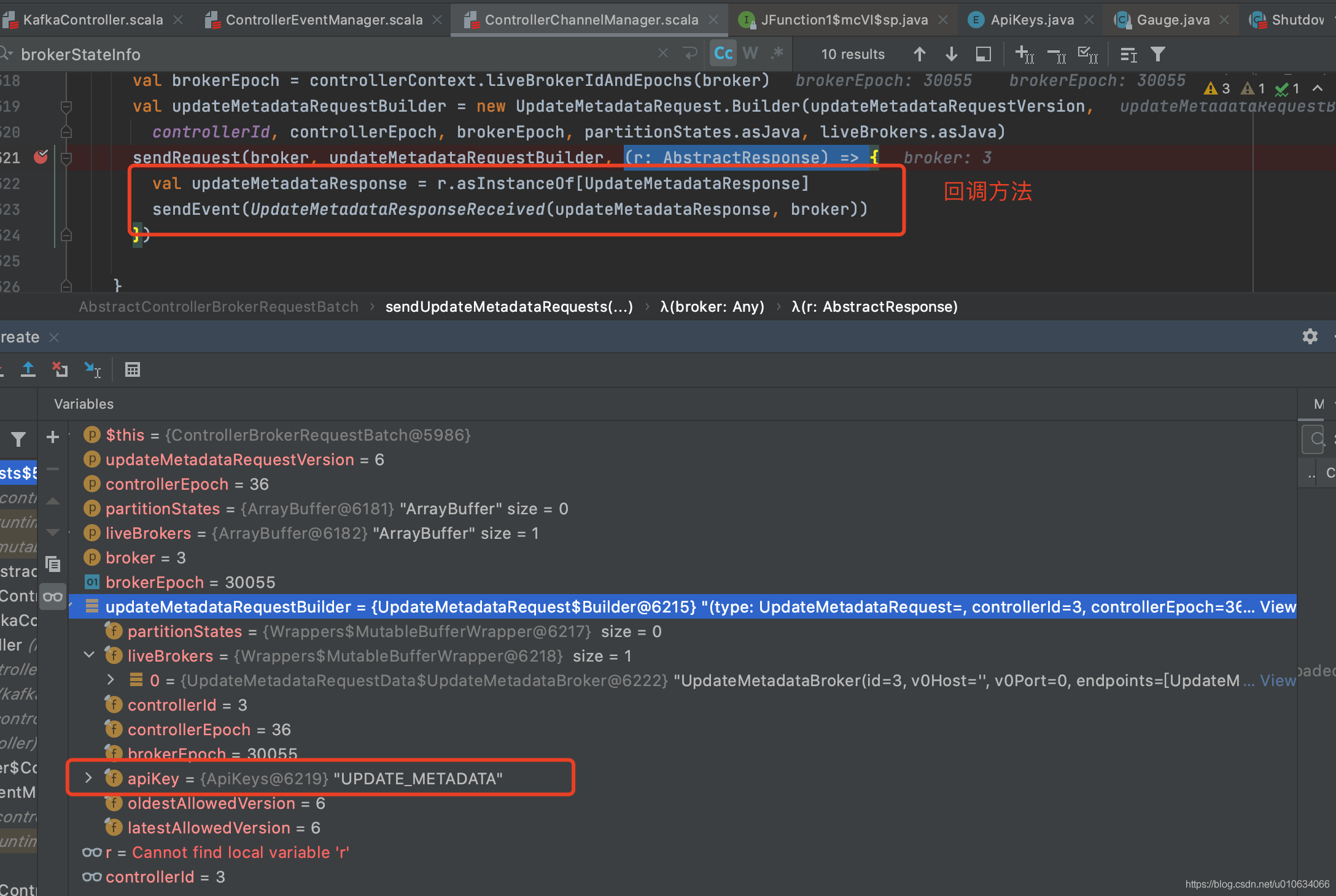
**这里举一个**🌰 ; 看看Controller向Broker发起一个`UPDATE_METADATA`请求;
|
||||

|
||||
|
||||
|
||||
1. 可以看到调用了`sendRequest`请求 ; 请求的接口ApiKey=`UPDATE_METADATA`
|
||||
2. 回调方法就是如上所示; 向事件管理器`ControllerChannelManager`中添加一个事件`UpdateMetadataResponseReceived`
|
||||
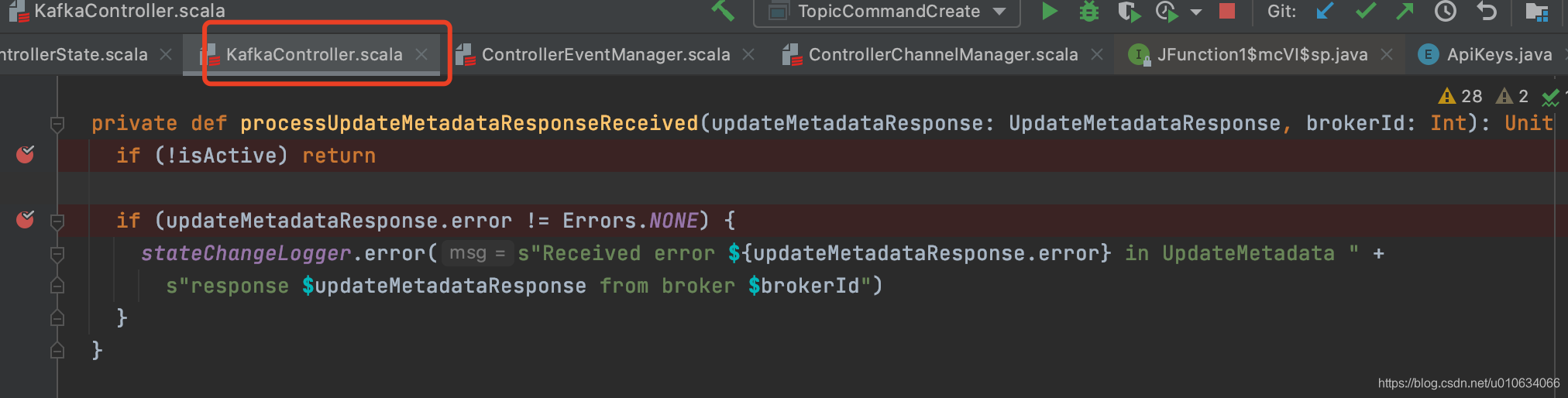
3. 当请求成功之后,调用2中的callBack, `UpdateMetadataResponseReceived`被添加到事件管理器中; 就会立马被执行(排队)
|
||||
4. 执行地方如下图所示,只不过它也没干啥,也就是如果返回异常response就打印一下日志
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 5. Broker接收Controller的请求
|
||||
> 上面说了Controller对所有Brokers(当然也包括自己)发起请求; 那么Brokers接受请求的地方在哪里呢,我们下面分析分析
|
||||
|
||||
这个部分内容我们在[【kafka源码】TopicCommand之创建Topic源码解析]() 中也分析过,处理过程都是一样的;
|
||||
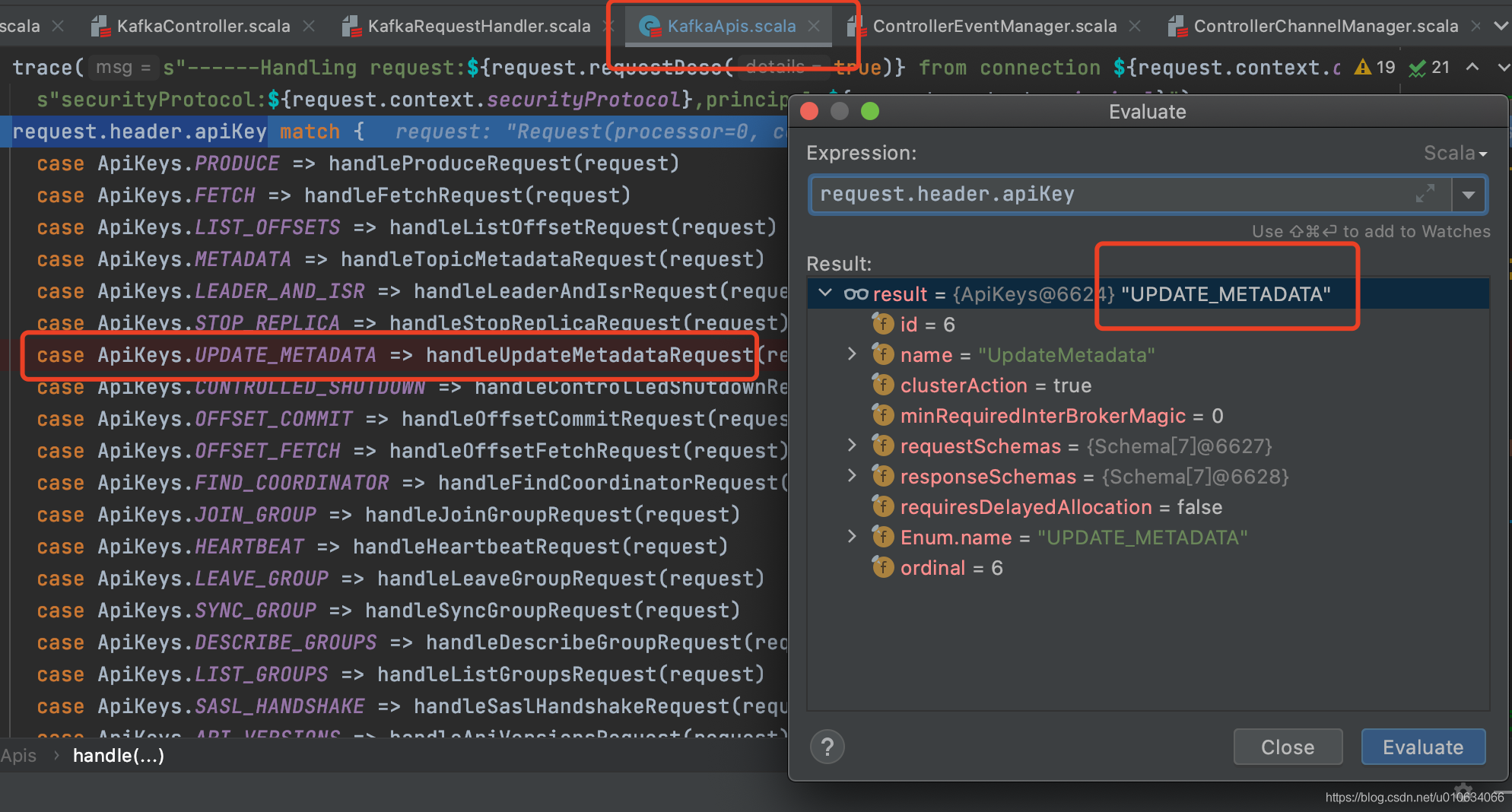
比如还是上面的例子🌰, 发起请求了之后,Broker处理的地方在`KafkaRequestHandler.run`里面的`apis.handle(request)`;
|
||||
|
||||
|
||||
可以看到这里列举了所有的接口请求;我们找到`UPDATE_METADATA`处理逻辑;
|
||||
里面的处理逻辑就不进去看了,不然超出了本篇文章的范畴;
|
||||
|
||||
|
||||
### 6. Broker服务下线
|
||||
我们模拟一下Broker宕机了, 手动把zk上的` /brokers/ids/broker节点`删除; 因为Controller是有对节点`watch`的, 就会看到Controller收到了变更通知,并且调用了 `KafkaController.processBrokerChange()`接口;
|
||||
```scala
|
||||
private def processBrokerChange(): Unit = {
|
||||
if (!isActive) return
|
||||
val curBrokerAndEpochs = zkClient.getAllBrokerAndEpochsInCluster
|
||||
val curBrokerIdAndEpochs = curBrokerAndEpochs map { case (broker, epoch) => (broker.id, epoch) }
|
||||
val curBrokerIds = curBrokerIdAndEpochs.keySet
|
||||
val liveOrShuttingDownBrokerIds = controllerContext.liveOrShuttingDownBrokerIds
|
||||
val newBrokerIds = curBrokerIds -- liveOrShuttingDownBrokerIds
|
||||
val deadBrokerIds = liveOrShuttingDownBrokerIds -- curBrokerIds
|
||||
val bouncedBrokerIds = (curBrokerIds & liveOrShuttingDownBrokerIds)
|
||||
.filter(brokerId => curBrokerIdAndEpochs(brokerId) > controllerContext.liveBrokerIdAndEpochs(brokerId))
|
||||
val newBrokerAndEpochs = curBrokerAndEpochs.filter { case (broker, _) => newBrokerIds.contains(broker.id) }
|
||||
val bouncedBrokerAndEpochs = curBrokerAndEpochs.filter { case (broker, _) => bouncedBrokerIds.contains(broker.id) }
|
||||
val newBrokerIdsSorted = newBrokerIds.toSeq.sorted
|
||||
val deadBrokerIdsSorted = deadBrokerIds.toSeq.sorted
|
||||
val liveBrokerIdsSorted = curBrokerIds.toSeq.sorted
|
||||
val bouncedBrokerIdsSorted = bouncedBrokerIds.toSeq.sorted
|
||||
info(s"Newly added brokers: ${newBrokerIdsSorted.mkString(",")}, " +
|
||||
s"deleted brokers: ${deadBrokerIdsSorted.mkString(",")}, " +
|
||||
s"bounced brokers: ${bouncedBrokerIdsSorted.mkString(",")}, " +
|
||||
s"all live brokers: ${liveBrokerIdsSorted.mkString(",")}")
|
||||
|
||||
newBrokerAndEpochs.keySet.foreach(controllerChannelManager.addBroker)
|
||||
bouncedBrokerIds.foreach(controllerChannelManager.removeBroker)
|
||||
bouncedBrokerAndEpochs.keySet.foreach(controllerChannelManager.addBroker)
|
||||
deadBrokerIds.foreach(controllerChannelManager.removeBroker)
|
||||
if (newBrokerIds.nonEmpty) {
|
||||
controllerContext.addLiveBrokersAndEpochs(newBrokerAndEpochs)
|
||||
onBrokerStartup(newBrokerIdsSorted)
|
||||
}
|
||||
if (bouncedBrokerIds.nonEmpty) {
|
||||
controllerContext.removeLiveBrokers(bouncedBrokerIds)
|
||||
onBrokerFailure(bouncedBrokerIdsSorted)
|
||||
controllerContext.addLiveBrokersAndEpochs(bouncedBrokerAndEpochs)
|
||||
onBrokerStartup(bouncedBrokerIdsSorted)
|
||||
}
|
||||
if (deadBrokerIds.nonEmpty) {
|
||||
controllerContext.removeLiveBrokers(deadBrokerIds)
|
||||
onBrokerFailure(deadBrokerIdsSorted)
|
||||
}
|
||||
|
||||
if (newBrokerIds.nonEmpty || deadBrokerIds.nonEmpty || bouncedBrokerIds.nonEmpty) {
|
||||
info(s"Updated broker epochs cache: ${controllerContext.liveBrokerIdAndEpochs}")
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
1. 这里会去zk里面获取所有的Broker信息; 并将得到的数据跟当前Controller缓存中的所有Broker信息做对比;
|
||||
2. 如果有新上线的Broker,则会执行 Broker上线的流程
|
||||
3. 如果有删除的Broker,则执行Broker下线的流程; 比如`removeLiveBrokers`
|
||||
|
||||
收到删除节点之后, Controller 会觉得Broker已经下线了,即使那台Broker服务是正常的,那么它仍旧提供不了服务
|
||||
|
||||
### 7. Broker上下线
|
||||
本篇主要讲解**Controller与Brokers之间的网络通信**
|
||||
故**Broker上下线**内容单独开一篇文章来详细讲解 [【kafka源码】Brokers的上下线流程](https://shirenchuang.blog.csdn.net/article/details/117846476)
|
||||
|
||||
## 源码总结
|
||||
本篇文章内容比较简单, Controller和Broker之间的通信就是通过 `RequestSendThread` 这个线程来进行发送请求;
|
||||
`RequestSendThread`维护的阻塞请求队列在没有任务的时候处理阻塞状态;
|
||||
当有需要发起请求的时候,直接向`queue`中添加任务就行了;
|
||||
|
||||
Controller自身也是一个Broker,所以Controller发出的请求,自己也会收到并且执行
|
||||
|
||||
|
||||
## Q&A
|
||||
### 如果Controller与Broker网络连接不通会怎么办?
|
||||
> 会一直进行重试, 直到zookeeper发现Broker通信有问题,会将这台Broker的节点移除,Controller就会收到通知,并将Controller与这台Broker的`RequestSendThread`线程shutdown;就不会再重试了; 如果zk跟Broker之间网络通信是正常的,只是发起的逻辑请求就是失败,则会一直进行重试
|
||||
|
||||
### 如果手动将zk中的 /brokers/ids/ 下的子节点删除会怎么样?
|
||||
>手动删除` /brokers/ids/Broker的ID`, Controller收到变更通知,则将该Broker在Controller中处理下线逻辑; 所有该Broker已经游离于集群之外,即使它服务还是正常的,但是它却提供不了服务了; 只能重启该Broker重新注册;
|
||||
289
docs/zh/Kafka分享/Kafka Controller /Controller中的状态机.md
Normal file
289
docs/zh/Kafka分享/Kafka Controller /Controller中的状态机.md
Normal file
@@ -0,0 +1,289 @@
|
||||
|
||||
|
||||
前言
|
||||
>Controller中有两个状态机分别是`ReplicaStateMachine 副本状态机`和`PartitionStateMachine分区状态机` ; 他们的作用是负责处理每个分区和副本在状态变更过程中要处理的事情; 并且确保从上一个状态变更到下一个状态是合法的; 源码中你能看到很多地方只是进行状态流转; 所以我们要清楚每个流转都做了哪些事情;对我们阅读源码更清晰
|
||||
>
|
||||
>----
|
||||
>在之前的文章 [【kafka源码】Controller启动过程以及选举流程源码分析]() 中,我们有分析到,
|
||||
>`replicaStateMachine.startup()` 和 `partitionStateMachine.startup()`
|
||||
>副本专状态机和分区状态机的启动; 那我们就从这里开始好好讲下两个状态机
|
||||
|
||||
|
||||
## 源码解析
|
||||
<font color="red">如果觉得阅读源码解析太枯燥,请直接看 源码总结及其后面部分</font>
|
||||
|
||||
### ReplicaStateMachine 副本状态机
|
||||
Controller 选举成功之后 调用`ReplicaStateMachine.startup`启动副本状态机
|
||||
```scala
|
||||
|
||||
def startup(): Unit = {
|
||||
//初始化所有副本的状态
|
||||
initializeReplicaState()
|
||||
val (onlineReplicas, offlineReplicas) = controllerContext.onlineAndOfflineReplicas
|
||||
handleStateChanges(onlineReplicas.toSeq, OnlineReplica)
|
||||
handleStateChanges(offlineReplicas.toSeq, OfflineReplica)
|
||||
}
|
||||
|
||||
```
|
||||
1. 初始化所有副本的状态,如果副本在线则状态变更为`OnlineReplica` ;否则变更为`ReplicaDeletionIneligible`副本删除失败状态; 判断副本是否在线的条件是 副本所在Broker需要在线&&副本没有被标记为已下线状态(Map `replicasOnOfflineDirs`用于维护副本失败在线),一般情况下这个里面是被标记为删除的Topic
|
||||
2. 执行状态变更处理器
|
||||
|
||||
#### ReplicaStateMachine状态变更处理器
|
||||
>它确保每个状态转换都发生从合法的先前状态到目标状态。有效的状态转换是:
|
||||
>1. `NonExistentReplica --> NewReplica: `-- 将 LeaderAndIsr 请求与当前领导者和 isr 发送到新副本,并将分区的 UpdateMetadata 请求发送到每个实时代理
|
||||
>2. `NewReplica -> OnlineReplica` --如果需要,将新副本添加到分配的副本列表中
|
||||
>3. `OnlineReplica,OfflineReplica -> OnlineReplica:`--将带有当前领导者和 isr 的 LeaderAndIsr 请求发送到新副本,并将分区的 UpdateMetadata 请求发送到每个实时代理
|
||||
>4. `NewReplica,OnlineReplica,OfflineReplica,ReplicaDeletionIneligible -> OfflineReplica:`:-- 向副本发送 `StopReplicaRequest` ;
|
||||
> -- 从 isr 中删除此副本并将 LeaderAndIsr 请求(带有新的 isr)发送到领导副本,并将分区的 UpdateMetadata 请求发送到每个实时代理。
|
||||
> 5. `OfflineReplica -> ReplicaDeletionStarted:` -- 向副本发送 `StopReplicaRequest` (带 删除参数);
|
||||
> 6. `ReplicaDeletionStarted -> ReplicaDeletionSuccessful:` --在状态机中标记副本的状态
|
||||
> 7. `ReplicaDeletionStarted -> ReplicaDeletionIneligible:` --在状态机中标记副本的状态
|
||||
> 8. `ReplicaDeletionSuccessful -> NonExistentReplica:`--从内存分区副本分配缓存中删除副本
|
||||
```scala
|
||||
private def doHandleStateChanges(replicaId: Int, replicas: Seq[PartitionAndReplica], targetState: ReplicaState): Unit = {
|
||||
//如果有副本没有设置状态,则初始化为`NonExistentReplica`
|
||||
replicas.foreach(replica => controllerContext.putReplicaStateIfNotExists(replica, NonExistentReplica))
|
||||
//校验状态流转是不是正确
|
||||
val (validReplicas, invalidReplicas) = controllerContext.checkValidReplicaStateChange(replicas, targetState)
|
||||
invalidReplicas.foreach(replica => logInvalidTransition(replica, targetState))
|
||||
|
||||
//代码省略,在下面细细说来
|
||||
}
|
||||
```
|
||||
```scala
|
||||
controllerBrokerRequestBatch.sendRequestsToBrokers(controllerContext.epoch)
|
||||
```
|
||||
1. 如果有副本没有设置状态,则初始化为`NonExistentReplica`
|
||||
2. 校验状态流转是不是正确
|
||||
3. 执行完了之后,还会可能尝试发一次`UPDATA_METADATA`
|
||||
|
||||
##### 先前状态 ==> OnlineReplica
|
||||
可流转的状态有
|
||||
1. `NewReplica`
|
||||
2. `OnlineReplica`
|
||||
3. `OfflineReplica`
|
||||
4. `ReplicaDeletionIneligible`
|
||||
|
||||
###### NewReplica ==》OnlineReplica
|
||||
>如果有需要,将新副本添加到分配的副本列表中;
|
||||
>比如[【kafka源码】TopicCommand之创建Topic源码解析]()
|
||||
|
||||
```scala
|
||||
case NewReplica =>
|
||||
val assignment = controllerContext.partitionFullReplicaAssignment(partition)
|
||||
if (!assignment.replicas.contains(replicaId)) {
|
||||
error(s"Adding replica ($replicaId) that is not part of the assignment $assignment")
|
||||
val newAssignment = assignment.copy(replicas = assignment.replicas :+ replicaId)
|
||||
controllerContext.updatePartitionFullReplicaAssignment(partition, newAssignment)
|
||||
}
|
||||
```
|
||||
|
||||
###### 其他状态 ==》OnlineReplica
|
||||
> 将带有当前领导者和 isr 的 LeaderAndIsr 请求发送到新副本,并将分区的 UpdateMetadata 请求发送到每个实时代理
|
||||
```scala
|
||||
case _ =>
|
||||
controllerContext.partitionLeadershipInfo.get(partition) match {
|
||||
case Some(leaderIsrAndControllerEpoch) =>
|
||||
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(Seq(replicaId),
|
||||
replica.topicPartition,
|
||||
leaderIsrAndControllerEpoch,
|
||||
controllerContext.partitionFullReplicaAssignment(partition), isNew = false)
|
||||
case None =>
|
||||
}
|
||||
```
|
||||
##### 先前状态 ==> ReplicaDeletionIneligible
|
||||
> 在内存`replicaStates`中更新一下副本状态为`ReplicaDeletionIneligible`
|
||||
##### 先前状态 ==》OfflinePartition
|
||||
>-- 向副本发送 StopReplicaRequest ;
|
||||
– 从 isr 中删除此副本并将 LeaderAndIsr 请求(带有新的 isr)发送到领导副本,并将分区的 UpdateMetadata 请求发送到每个实时代理。
|
||||
|
||||
```scala
|
||||
|
||||
case OfflineReplica =>
|
||||
// 添加构建StopReplicaRequest请求的擦书,deletePartition = false表示还不删除分区
|
||||
validReplicas.foreach { replica =>
|
||||
controllerBrokerRequestBatch.addStopReplicaRequestForBrokers(Seq(replicaId), replica.topicPartition, deletePartition = false)
|
||||
}
|
||||
val (replicasWithLeadershipInfo, replicasWithoutLeadershipInfo) = validReplicas.partition { replica =>
|
||||
controllerContext.partitionLeadershipInfo.contains(replica.topicPartition)
|
||||
}
|
||||
//尝试从多个分区的 isr 中删除副本。从 isr 中删除副本会更新 Zookeeper 中的分区状态
|
||||
//反复尝试从多个分区的 isr 中删除副本,直到没有更多剩余的分区可以重试。
|
||||
//从/brokers/topics/test_create_topic13/partitions获取分区相关数据
|
||||
//移除副本之后,重新写入到zk中
|
||||
val updatedLeaderIsrAndControllerEpochs = removeReplicasFromIsr(replicaId, replicasWithLeadershipInfo.map(_.topicPartition))
|
||||
updatedLeaderIsrAndControllerEpochs.foreach { case (partition, leaderIsrAndControllerEpoch) =>
|
||||
if (!controllerContext.isTopicQueuedUpForDeletion(partition.topic)) {
|
||||
val recipients = controllerContext.partitionReplicaAssignment(partition).filterNot(_ == replicaId)
|
||||
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(recipients,
|
||||
partition,
|
||||
leaderIsrAndControllerEpoch,
|
||||
controllerContext.partitionFullReplicaAssignment(partition), isNew = false)
|
||||
}
|
||||
val replica = PartitionAndReplica(partition, replicaId)
|
||||
val currentState = controllerContext.replicaState(replica)
|
||||
logSuccessfulTransition(replicaId, partition, currentState, OfflineReplica)
|
||||
controllerContext.putReplicaState(replica, OfflineReplica)
|
||||
}
|
||||
|
||||
replicasWithoutLeadershipInfo.foreach { replica =>
|
||||
val currentState = controllerContext.replicaState(replica)
|
||||
logSuccessfulTransition(replicaId, replica.topicPartition, currentState, OfflineReplica)
|
||||
controllerBrokerRequestBatch.addUpdateMetadataRequestForBrokers(controllerContext.liveOrShuttingDownBrokerIds.toSeq, Set(replica.topicPartition))
|
||||
controllerContext.putReplicaState(replica, OfflineReplica)
|
||||
}
|
||||
```
|
||||
1. 添加构建StopReplicaRequest请求的参数,`deletePartition = false`表示还不删除分区
|
||||
2. 反复尝试从多个分区的 isr 中删除副本,直到没有更多剩余的分区可以重试。从`/brokers/topics/{TOPICNAME}/partitions`获取分区相关数据,进过计算然后重新写入到zk中`/brokers/topics/{TOPICNAME}/partitions/state/`; 当然内存中的副本状态机的状态也会变更成 `OfflineReplica` ;
|
||||
3. 根据条件判断是否需要发送`LeaderAndIsrRequest`、`UpdateMetadataRequest`
|
||||
4. 发送`StopReplicaRequests`请求;
|
||||
|
||||
|
||||
##### 先前状态==>ReplicaDeletionStarted
|
||||
> 向指定的副本发送 [StopReplicaRequest 请求]()(带 删除参数);
|
||||
|
||||
```scala
|
||||
controllerBrokerRequestBatch.addStopReplicaRequestForBrokers(Seq(replicaId), replica.topicPartition, deletePartition = true)
|
||||
|
||||
```
|
||||
|
||||
##### 当前状态 ==> NewReplica
|
||||
>一般情况下,创建Topic的时候会触发这个流转;
|
||||
|
||||
```scala
|
||||
case NewReplica =>
|
||||
validReplicas.foreach { replica =>
|
||||
val partition = replica.topicPartition
|
||||
val currentState = controllerContext.replicaState(replica)
|
||||
|
||||
controllerContext.partitionLeadershipInfo.get(partition) match {
|
||||
case Some(leaderIsrAndControllerEpoch) =>
|
||||
if (leaderIsrAndControllerEpoch.leaderAndIsr.leader == replicaId) {
|
||||
val exception = new StateChangeFailedException(s"Replica $replicaId for partition $partition cannot be moved to NewReplica state as it is being requested to become leader")
|
||||
logFailedStateChange(replica, currentState, OfflineReplica, exception)
|
||||
} else {
|
||||
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(Seq(replicaId),
|
||||
replica.topicPartition,
|
||||
leaderIsrAndControllerEpoch,
|
||||
controllerContext.partitionFullReplicaAssignment(replica.topicPartition),
|
||||
isNew = true)
|
||||
logSuccessfulTransition(replicaId, partition, currentState, NewReplica)
|
||||
controllerContext.putReplicaState(replica, NewReplica)
|
||||
}
|
||||
case None =>
|
||||
logSuccessfulTransition(replicaId, partition, currentState, NewReplica)
|
||||
controllerContext.putReplicaState(replica, NewReplica)
|
||||
}
|
||||
}
|
||||
```
|
||||
1. 在内存中更新 副本状态;
|
||||
2. 在某些情况下,将带有当前领导者和 isr 的 LeaderAndIsr 请求发送到新副本,并将分区的 UpdateMetadata 请求发送到每个实时代理
|
||||
|
||||
##### 当前状态 ==> NonExistentPartition
|
||||
1. `OfflinePartition`
|
||||
|
||||
##### 当前状态 ==> NonExistentPartition
|
||||
|
||||
|
||||
### PartitionStateMachine分区状态机
|
||||
`PartitionStateMachine.startup`
|
||||
```scala
|
||||
def startup(): Unit = {
|
||||
initializePartitionState()
|
||||
triggerOnlinePartitionStateChange()
|
||||
}
|
||||
```
|
||||
`PartitionStateMachine.initializePartitionState()`
|
||||
> 初始化分区状态
|
||||
```scala
|
||||
/**
|
||||
* Invoked on startup of the partition's state machine to set the initial state for all existing partitions in
|
||||
* zookeeper
|
||||
*/
|
||||
private def initializePartitionState(): Unit = {
|
||||
for (topicPartition <- controllerContext.allPartitions) {
|
||||
// check if leader and isr path exists for partition. If not, then it is in NEW state
|
||||
//检查leader和isr路径是否存在
|
||||
controllerContext.partitionLeadershipInfo.get(topicPartition) match {
|
||||
case Some(currentLeaderIsrAndEpoch) =>
|
||||
if (controllerContext.isReplicaOnline(currentLeaderIsrAndEpoch.leaderAndIsr.leader, topicPartition))
|
||||
// leader is alive
|
||||
controllerContext.putPartitionState(topicPartition, OnlinePartition)
|
||||
else
|
||||
controllerContext.putPartitionState(topicPartition, OfflinePartition)
|
||||
case None =>
|
||||
controllerContext.putPartitionState(topicPartition, NewPartition)
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
1. 如果分区不存在`LeaderIsr`,则状态是`NewPartition`
|
||||
2. 如果分区存在`LeaderIsr`,就判断一下Leader是否存活
|
||||
2.1 如果存活的话,状态是`OnlinePartition`
|
||||
2.2 否则是`OfflinePartition`
|
||||
|
||||
|
||||
`PartitionStateMachine. triggerOnlinePartitionStateChange()`
|
||||
>尝试将所有处于 `NewPartition `或 `OfflinePartition `状态的分区移动到 `OnlinePartition` 状态,但属于要删除的主题的分区除外
|
||||
|
||||
```scala
|
||||
def triggerOnlinePartitionStateChange(): Unit = {
|
||||
val partitions = controllerContext.partitionsInStates(Set(OfflinePartition, NewPartition))
|
||||
triggerOnlineStateChangeForPartitions(partitions)
|
||||
}
|
||||
|
||||
private def triggerOnlineStateChangeForPartitions(partitions: collection.Set[TopicPartition]): Unit = {
|
||||
// try to move all partitions in NewPartition or OfflinePartition state to OnlinePartition state except partitions
|
||||
// that belong to topics to be deleted
|
||||
val partitionsToTrigger = partitions.filter { partition =>
|
||||
!controllerContext.isTopicQueuedUpForDeletion(partition.topic)
|
||||
}.toSeq
|
||||
|
||||
handleStateChanges(partitionsToTrigger, OnlinePartition, Some(OfflinePartitionLeaderElectionStrategy(false)))
|
||||
// TODO: If handleStateChanges catches an exception, it is not enough to bail out and log an error.
|
||||
// It is important to trigger leader election for those partitions.
|
||||
}
|
||||
```
|
||||
|
||||
#### PartitionStateMachine 分区状态机
|
||||
|
||||
`PartitionStateMachine.doHandleStateChanges `
|
||||
` controllerBrokerRequestBatch.sendRequestsToBrokers(controllerContext.epoch)
|
||||
`
|
||||
|
||||
>它确保每个状态转换都发生从合法的先前状态到目标状态。有效的状态转换是:
|
||||
>1. `NonExistentPartition -> NewPartition:` 将分配的副本从 ZK 加载到控制器缓存
|
||||
>2. `NewPartition -> OnlinePartition:` 将第一个活动副本指定为领导者,将所有活动副本指定为 isr;将此分区的leader和isr写入ZK ;向每个实时副本发送 LeaderAndIsr 请求,向每个实时代理发送 UpdateMetadata 请求
|
||||
>3. `OnlinePartition,OfflinePartition -> OnlinePartition:` 为这个分区选择新的leader和isr以及一组副本来接收LeaderAndIsr请求,并将leader和isr写入ZK;
|
||||
> 对于这个分区,向每个接收副本发送LeaderAndIsr请求,向每个live broker发送UpdateMetadata请求
|
||||
> 4. `NewPartition,OnlinePartition,OfflinePartition -> OfflinePartition:` 将分区状态标记为 Offline
|
||||
> 5. `OfflinePartition -> NonExistentPartition:` 将分区状态标记为 NonExistentPartition
|
||||
>
|
||||
##### 先前状态==》NewPartition
|
||||
>将分配的副本从 ZK 加载到控制器缓存
|
||||
|
||||
##### 先前状态==》OnlinePartition
|
||||
> 将第一个活动副本指定为领导者,将所有活动副本指定为 isr;将此分区的leader和isr写入ZK ;向每个实时副本发送 LeaderAndIsr 请求,向每个实时Broker发送 UpdateMetadata 请求
|
||||
|
||||
创建一个新的Topic的时候,我们主要看下面这个接口`initializeLeaderAndIsrForPartitions`
|
||||
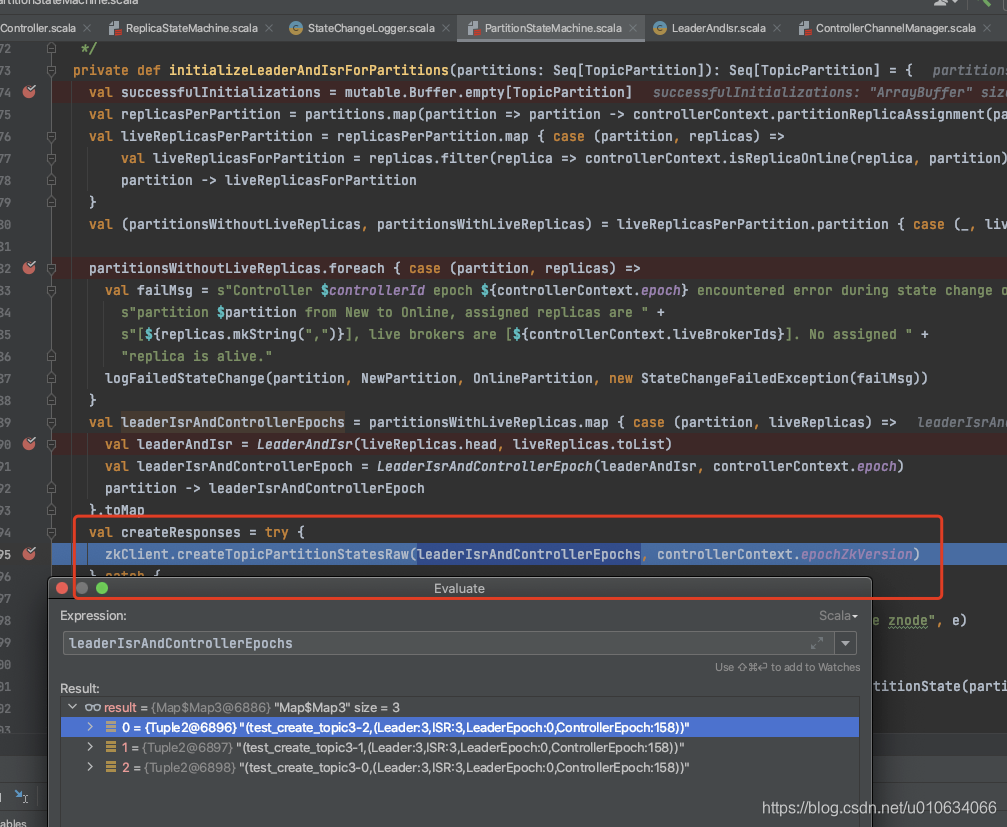
|
||||
|
||||
0. 获取`leaderIsrAndControllerEpochs`; Leader为副本的第一个;
|
||||
1. 向zk中写入`/brokers/topics/{topicName}/partitions/` 持久节点; 无数据
|
||||
2. 向zk中写入`/brokers/topics/{topicName}/partitions/{分区号}` 持久节点; 无数据
|
||||
3. 向zk中写入`/brokers/topics/{topicName}/partitions/{分区号}/state` 持久节点; 数据为`leaderIsrAndControllerEpoch`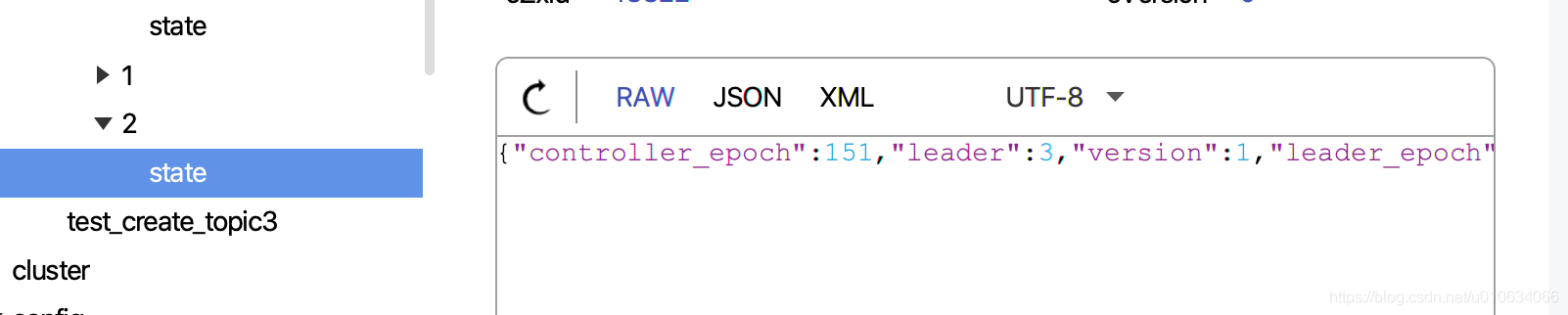
|
||||
4. 向副本所属Broker发送[`leaderAndIsrRequest`]()请求
|
||||
5. 向所有Broker发送[`UPDATE_METADATA` ]()请求
|
||||
|
||||
|
||||
##### 先前状态==》OfflinePartition
|
||||
>将分区状态标记为 Offline ; 在Map对象`partitionStates`中维护的; `NewPartition,OnlinePartition,OfflinePartition ` 可转;
|
||||
##### 先前状态==》NonExistentPartition
|
||||
|
||||
>将分区状态标记为 Offline ; 在Map对象`partitionStates`中维护的; `OfflinePartition ` 可转;
|
||||
|
||||
|
||||
|
||||
## 源码总结
|
||||
|
||||
## Q&A
|
||||
339
docs/zh/Kafka分享/Kafka Controller /Controller启动过程以及选举流程源码分析.md
Normal file
339
docs/zh/Kafka分享/Kafka Controller /Controller启动过程以及选举流程源码分析.md
Normal file
@@ -0,0 +1,339 @@
|
||||
[TOC]
|
||||
|
||||
## 前言
|
||||
>本篇文章,我们开始来分析分析Kafka的`Controller`部分的源码,Controller 作为 Kafka Server 端一个重要的组件,它的角色类似于其他分布式系统 Master 的角色,跟其他系统不一样的是,Kafka 集群的任何一台 Broker 都可以作为 Controller,但是在一个集群中同时只会有一个 Controller 是 alive 状态。Controller 在集群中负责的事务很多,比如:集群 meta 信息的一致性保证、Partition leader 的选举、broker 上下线等都是由 Controller 来具体负责。
|
||||
|
||||
## 源码分析
|
||||
老样子,我们还是先来撸一遍源码之后,再进行总结
|
||||
<font color="red">如果觉得阅读源码解析太枯燥,请直接看 **源码总结及其后面部分**</font>
|
||||
|
||||
|
||||
### 1.源码入口KafkaServer.startup
|
||||
我们在启动kafka服务的时候,最开始执行的是`KafkaServer.startup`方法; 这里面包含了kafka启动的所有流程; 我们主要看Controller的启动流程
|
||||
```scala
|
||||
def startup(): Unit = {
|
||||
try {
|
||||
//省略部分代码....
|
||||
/* start kafka controller */
|
||||
kafkaController = new KafkaController(config, zkClient, time, metrics, brokerInfo, brokerEpoch, tokenManager, threadNamePrefix)
|
||||
kafkaController.startup()
|
||||
//省略部分代码....
|
||||
}
|
||||
}
|
||||
```
|
||||
### 2. kafkaController.startup() 启动
|
||||
```scala
|
||||
/**
|
||||
每个kafka启动的时候都会调用, 注意这并不假设当前代理是控制器。
|
||||
它只是注册会话过期侦听器 并启动控制器尝试选举Controller
|
||||
*/
|
||||
def startup() = {
|
||||
//注册状态变更处理器; 这里是把`StateChangeHandler`这个处理器放到一个`stateChangeHandlers` Map中了
|
||||
zkClient.registerStateChangeHandler(new StateChangeHandler {
|
||||
override val name: String = StateChangeHandlers.ControllerHandler
|
||||
override def afterInitializingSession(): Unit = {
|
||||
eventManager.put(RegisterBrokerAndReelect)
|
||||
}
|
||||
override def beforeInitializingSession(): Unit = {
|
||||
val queuedEvent = eventManager.clearAndPut(Expire)
|
||||
|
||||
// Block initialization of the new session until the expiration event is being handled,
|
||||
// which ensures that all pending events have been processed before creating the new session
|
||||
queuedEvent.awaitProcessing()
|
||||
}
|
||||
})
|
||||
// 在事件管理器的队列里面放入 一个 Startup启动事件; 这个时候放入还不会执行;
|
||||
eventManager.put(Startup)
|
||||
//启动事件管理器,启动的是一个 `ControllerEventThread`的线程
|
||||
eventManager.start()
|
||||
}
|
||||
```
|
||||
1. `zkClient.registerStateChangeHandler` 注册一个`StateChangeHandler` 状态变更处理器; 有一个map `stateChangeHandlers`来维护这个处理器列表; 这个类型的处理器有下图三个方法,可以看到我们这里实现了`beforeInitializingSession`和`afterInitializingSession`方法,具体调用的时机,我后面再分析(监听zk的数据变更)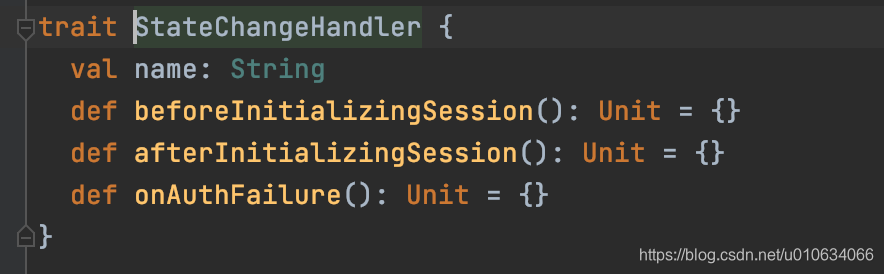
|
||||
2. `ControllerEventManager`是Controller的事件管理器; 里面维护了一个阻塞队列`queue`; 这个queue里面存放的是所有的Controller事件; 按顺序排队执行入队的事件; 上面的代码中`eventManager.put(Startup)` 在队列中放入了一个`Startup`启动事件; 所有的事件都是集成了`ControllerEvent`类的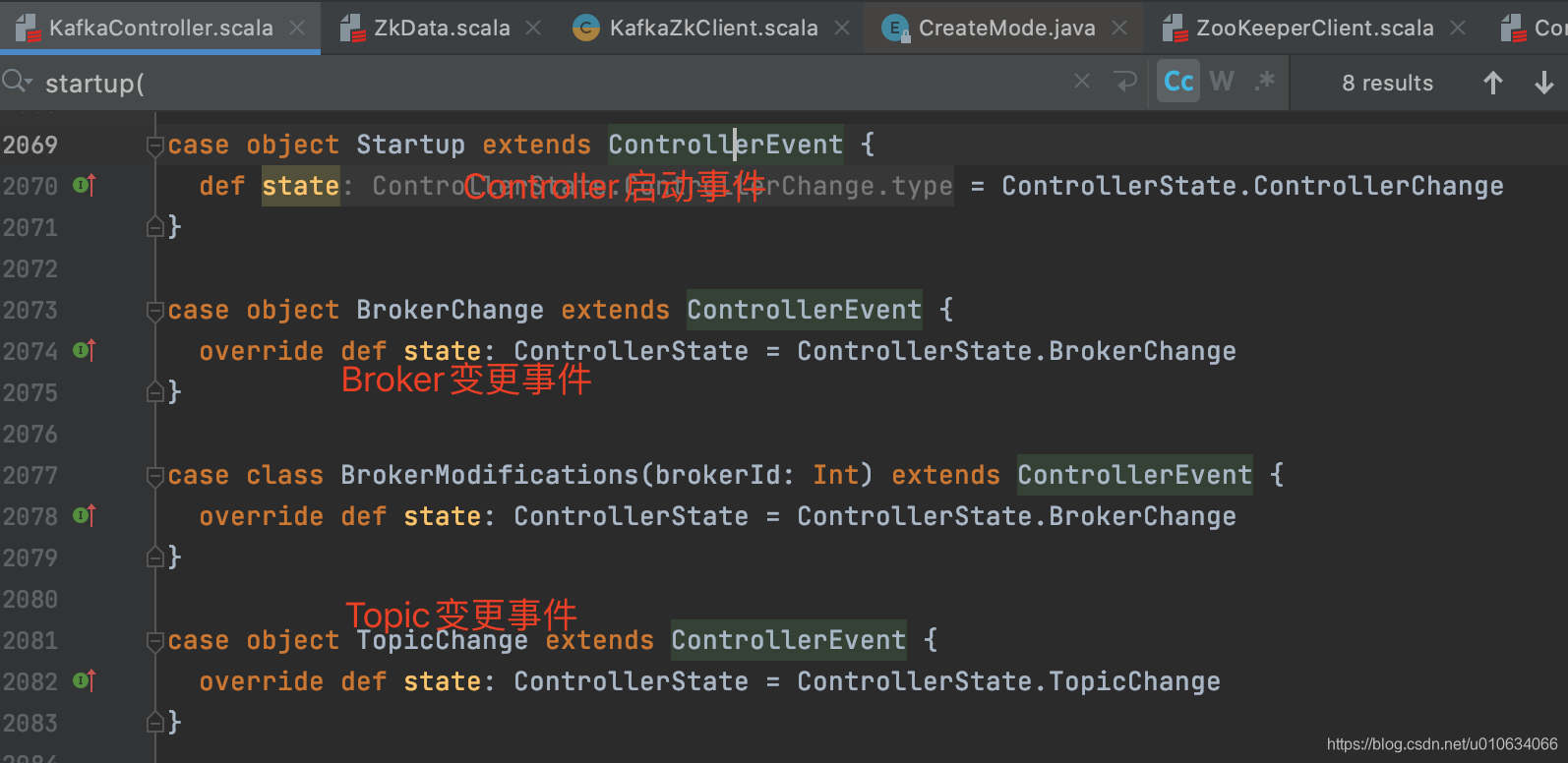
|
||||
3. 启动事件管理器, 从待执行事件队列`queue`中获取事件进行执行,刚刚不是假如了一个`StartUp`事件么,这个事件就会执行这个事件
|
||||
|
||||
### 3. ControllerEventThread 执行事件线程
|
||||
` eventManager.start()` 之后执行了下面的方法
|
||||
|
||||
```scala
|
||||
class ControllerEventThread(name: String) extends ShutdownableThread(name = name, isInterruptible = false) {
|
||||
override def doWork(): Unit = {
|
||||
//从待执行队列里面take一个事件; 没有事件的时候这里会阻塞
|
||||
val dequeued = queue.take()
|
||||
dequeued.event match {
|
||||
case ShutdownEventThread => // The shutting down of the thread has been initiated at this point. Ignore this event.
|
||||
case controllerEvent =>
|
||||
//获取事件的ControllerState值;不同事件不一样,都集成自ControllerState
|
||||
_state = controllerEvent.state
|
||||
eventQueueTimeHist.update(time.milliseconds() - dequeued.enqueueTimeMs)
|
||||
try {
|
||||
// 定义process方法; 最终执行的是 事件提供的process方法;
|
||||
def process(): Unit = dequeued.process(processor)
|
||||
|
||||
//根据state获取不同的KafkaTimer 主要是为了采集数据; 我们只要关注里面是执行了 process()方法就行了
|
||||
rateAndTimeMetrics.get(state) match {
|
||||
case Some(timer) => timer.time { process() }
|
||||
case None => process()
|
||||
}
|
||||
} catch {
|
||||
case e: Throwable => error(s"Uncaught error processing event $controllerEvent", e)
|
||||
}
|
||||
|
||||
_state = ControllerState.Idle
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
1. `val dequeued = queue.take()`从待执行队列里面take一个事件; 没有事件的时候这里会阻塞
|
||||
2. `dequeued.process(processor)`调用具体事件实现的 `process方法`如下图, 不过要注意的是这里使用了`CountDownLatch(1)`, 那肯定有个地方调用了`processingStarted.await()` 来等待这里的`process()执行完成`;上面的startUp方法就调用了; 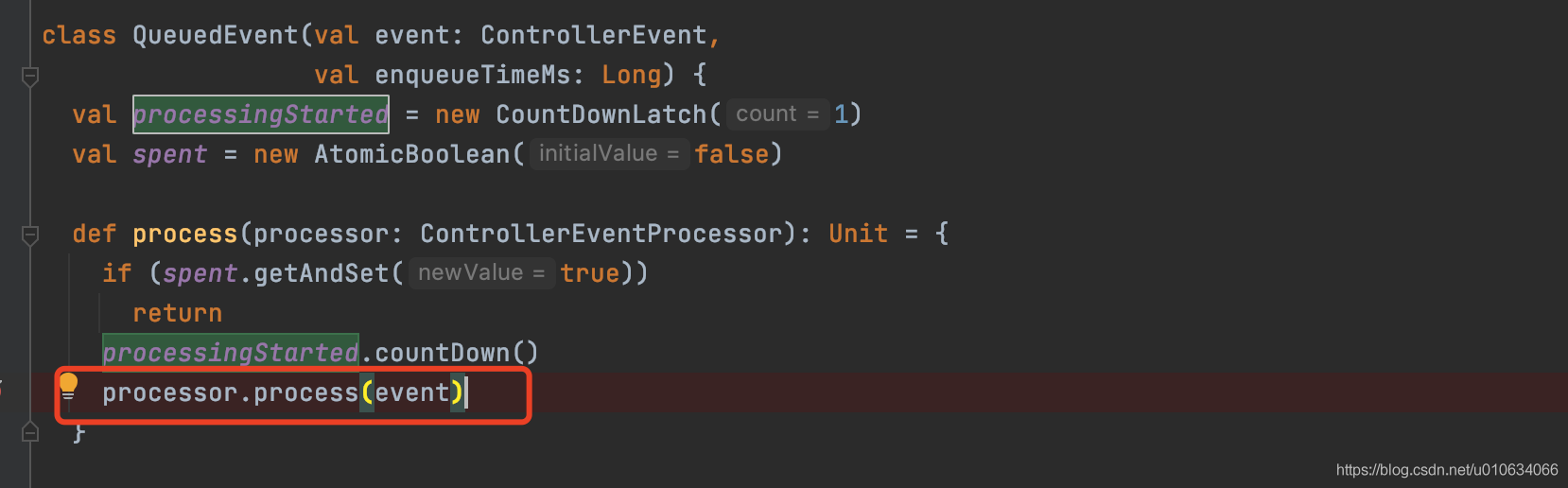
|
||||
|
||||
|
||||
### 4. processStartup 启动流程
|
||||
启动Controller的流程
|
||||
```scala
|
||||
private def processStartup(): Unit = {
|
||||
//注册znode变更事件和watch Controller节点是否在zk中存在
|
||||
zkClient.registerZNodeChangeHandlerAndCheckExistence(controllerChangeHandler)
|
||||
//选举逻辑
|
||||
elect()
|
||||
}
|
||||
|
||||
```
|
||||
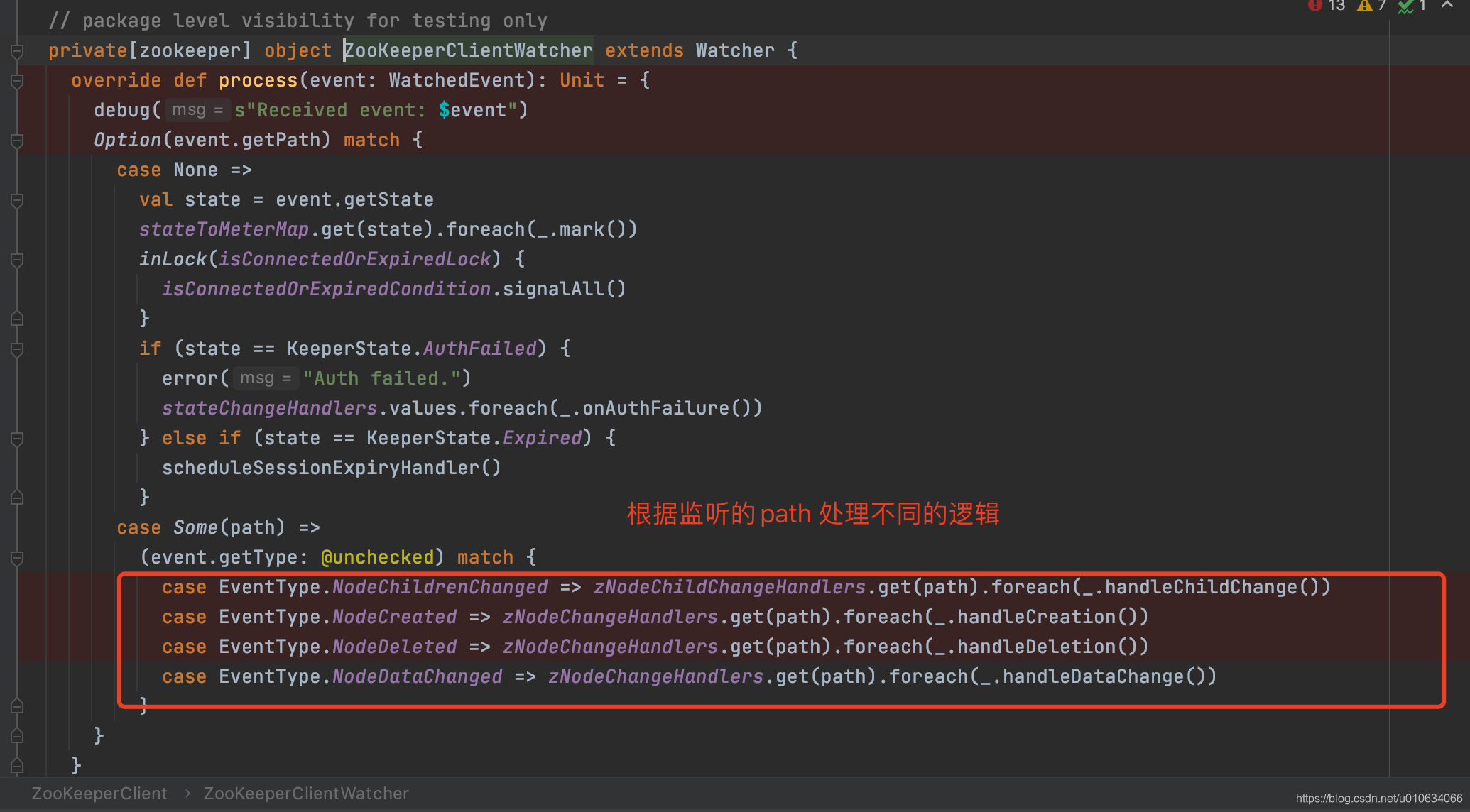
1. 注册`ZNodeChangeHandler` 节点变更事件处理器,在map `zNodeChangeHandlers`中保存了key=`/controller`;value=`ZNodeChangeHandler`的键值对; 其中`ZNodeChangeHandler`处理器有如下三个接口
|
||||
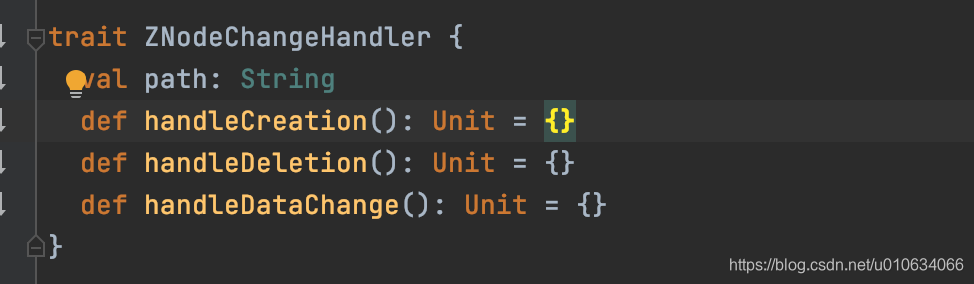
|
||||
2. 然后向zk发起一个`ExistsRequest(/controller)`的请求,去查询一下`/controller`节点是否存在; 并且如果不存在的话,就注册一个`watch` 监视这个节点;从下面的代码可以看出
|
||||
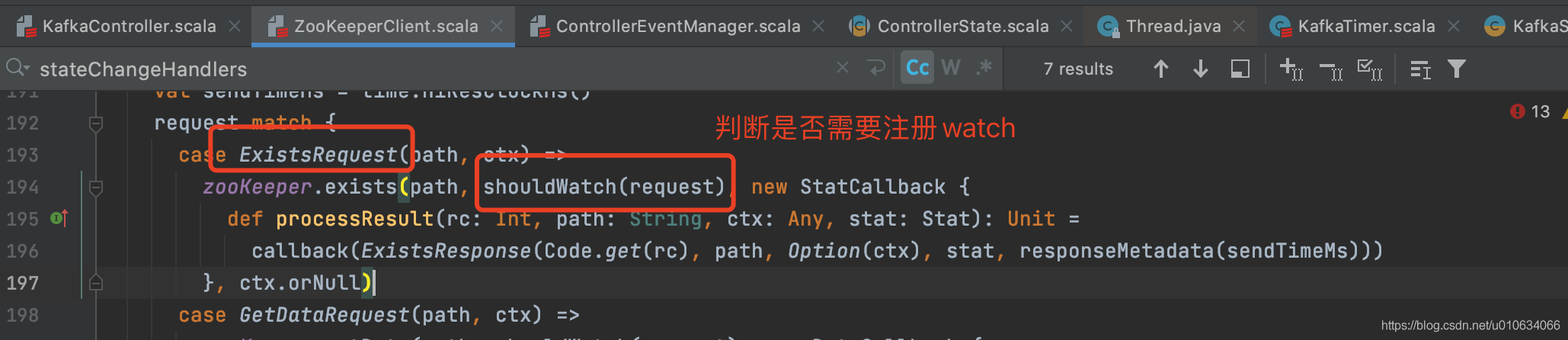
|
||||

|
||||
因为上一步中我们在map `zNodeChangeHandlers`中保存了key=`/controller`; 所以上图中可知,需要注册`watch`来进行`/controller`节点的监控;
|
||||
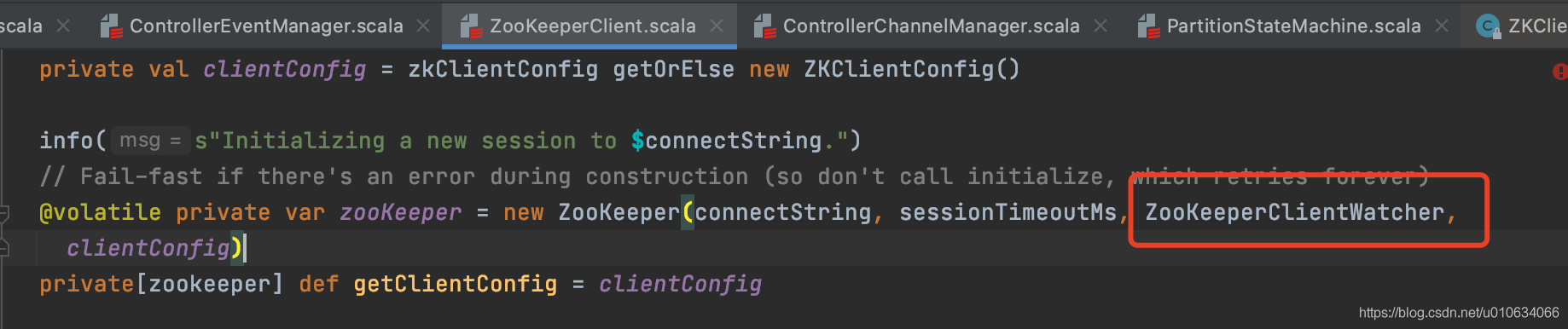
kafka是是怎实现监听的呢?`zookeeper`构建的时候传入了自定义的`WATCH`
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
3. 选举; 选举的过程其实就是几个Broker抢占式去成为Controller; 谁先创建`/controller`这个节点; 谁就成为Controller; 我们下面仔细分析以下选择
|
||||
|
||||
### 5. Controller的选举elect()
|
||||
|
||||
```scala
|
||||
private def elect(): Unit = {
|
||||
//去zk上获取 /controller 节点的数据 如果没有就赋值为-1
|
||||
activeControllerId = zkClient.getControllerId.getOrElse(-1)
|
||||
//如果获取到了数据就
|
||||
if (activeControllerId != -1) {
|
||||
debug(s"Broker $activeControllerId has been elected as the controller, so stopping the election process.")
|
||||
return
|
||||
}
|
||||
|
||||
try {
|
||||
|
||||
//尝试去zk中写入自己的Brokerid作为Controller;并且更新Controller epoch
|
||||
val (epoch, epochZkVersion) = zkClient.registerControllerAndIncrementControllerEpoch(config.brokerId)
|
||||
controllerContext.epoch = epoch
|
||||
controllerContext.epochZkVersion = epochZkVersion
|
||||
activeControllerId = config.brokerId
|
||||
//
|
||||
onControllerFailover()
|
||||
} catch {
|
||||
//尝试卸任Controller的职责
|
||||
maybeResign()
|
||||
//省略...
|
||||
}
|
||||
}
|
||||
```
|
||||
1. 去zk上获取` /controller `节点的数据 如果没有就赋值为-1
|
||||
2. 如果获取到了数据说明已经有Controller注册成功了;直接结束选举流程
|
||||
3. 尝试去zk中写入自己的Brokerid作为Controller;并且更新Controller epoch
|
||||
- 获取zk节点`/controller_epoch`, 这个节点是表示Controller变更的次数,如果没有的话就创建这个节点(**持久节点**); 起始`controller_epoch=0` `ControllerEpochZkVersion=0`
|
||||
- 向zk发起一个`MultiRequest`请求;里面包含两个命令; 一个是向zk中创建`/controller`节点,节点内容是自己的brokerId;另一个命令是向`/controller_epoch`中更新数据; 数据+1 ;
|
||||
- 如果写入过程中抛出异常提示说节点已经存在,说明别的Broker已经抢先成为Controller了; 这个时候会做一个检查`checkControllerAndEpoch` 来检查是不是别的Controller抢先了; 如果是的话就抛出`ControllerMovedException`异常; 抛出了这个异常之后,当前Broker会尝试的去卸任一下Controller的职责; (因为有可能他之前是Controller,Controller转移之后都需要尝试卸任一下)
|
||||
|
||||
5. Controller确定之后,就是做一下成功之后的事情了 `onControllerFailover`
|
||||
|
||||
|
||||
### 6. 当选Controller之后的处理 onControllerFailover
|
||||
进入到`KafkaController.onControllerFailover`
|
||||
```scala
|
||||
private def onControllerFailover(): Unit = {
|
||||
|
||||
// 都是ZNodeChildChangeHandler处理器; 含有接口 handleChildChange;注册了不同事件的处理器
|
||||
// 对应的事件分别有`BrokerChange`、`TopicChange`、`TopicDeletion`、`LogDirEventNotification`
|
||||
val childChangeHandlers = Seq(brokerChangeHandler, topicChangeHandler, topicDeletionHandler, logDirEventNotificationHandler,
|
||||
isrChangeNotificationHandler)
|
||||
//把这些handle都维护在 map类型`zNodeChildChangeHandlers`中
|
||||
childChangeHandlers.foreach(zkClient.registerZNodeChildChangeHandler)
|
||||
//都是ZNodeChangeHandler处理器,含有增删改节点接口;
|
||||
//分别对应的事件 `ReplicaLeaderElection`、`ZkPartitionReassignment`、``
|
||||
val nodeChangeHandlers = Seq(preferredReplicaElectionHandler, partitionReassignmentHandler)
|
||||
//把这些handle都维护在 map类型`zNodeChangeHandlers`中
|
||||
nodeChangeHandlers.foreach(zkClient.registerZNodeChangeHandlerAndCheckExistence)
|
||||
|
||||
info("Deleting log dir event notifications")
|
||||
//删除所有日志目录事件通知。 ;获取zk中节点`/log_dir_event_notification`的值;然后把节点下面的节点全部删除
|
||||
zkClient.deleteLogDirEventNotifications(controllerContext.epochZkVersion)
|
||||
info("Deleting isr change notifications")
|
||||
// 删除节点 `/isr_change_notification`下的所有节点
|
||||
zkClient.deleteIsrChangeNotifications(controllerContext.epochZkVersion)
|
||||
info("Initializing controller context")
|
||||
initializeControllerContext()
|
||||
info("Fetching topic deletions in progress")
|
||||
val (topicsToBeDeleted, topicsIneligibleForDeletion) = fetchTopicDeletionsInProgress()
|
||||
info("Initializing topic deletion manager")
|
||||
topicDeletionManager.init(topicsToBeDeleted, topicsIneligibleForDeletion)
|
||||
|
||||
// We need to send UpdateMetadataRequest after the controller context is initialized and before the state machines
|
||||
// are started. The is because brokers need to receive the list of live brokers from UpdateMetadataRequest before
|
||||
// they can process the LeaderAndIsrRequests that are generated by replicaStateMachine.startup() and
|
||||
// partitionStateMachine.startup().
|
||||
info("Sending update metadata request")
|
||||
sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq, Set.empty)
|
||||
|
||||
replicaStateMachine.startup()
|
||||
partitionStateMachine.startup()
|
||||
|
||||
info(s"Ready to serve as the new controller with epoch $epoch")
|
||||
|
||||
initializePartitionReassignments()
|
||||
topicDeletionManager.tryTopicDeletion()
|
||||
val pendingPreferredReplicaElections = fetchPendingPreferredReplicaElections()
|
||||
onReplicaElection(pendingPreferredReplicaElections, ElectionType.PREFERRED, ZkTriggered)
|
||||
info("Starting the controller scheduler")
|
||||
kafkaScheduler.startup()
|
||||
if (config.autoLeaderRebalanceEnable) {
|
||||
scheduleAutoLeaderRebalanceTask(delay = 5, unit = TimeUnit.SECONDS)
|
||||
}
|
||||
scheduleUpdateControllerMetricsTask()
|
||||
|
||||
if (config.tokenAuthEnabled) {
|
||||
info("starting the token expiry check scheduler")
|
||||
tokenCleanScheduler.startup()
|
||||
tokenCleanScheduler.schedule(name = "delete-expired-tokens",
|
||||
fun = () => tokenManager.expireTokens,
|
||||
period = config.delegationTokenExpiryCheckIntervalMs,
|
||||
unit = TimeUnit.MILLISECONDS)
|
||||
}
|
||||
}
|
||||
```
|
||||
1. 把事件`BrokerChange`、`TopicChange`、`TopicDeletion`、`LogDirEventNotification`对应的handle处理器都维护在 map类型`zNodeChildChangeHandlers`中
|
||||
2. 把事件 `ReplicaLeaderElection`、`ZkPartitionReassignment`对应的handle处理器都维护在 map类型`zNodeChildChangeHandlers`中
|
||||
3. 删除zk中节点`/log_dir_event_notification`下的所有节点
|
||||
4. 删除zk中节点 `/isr_change_notification`下的所有节点
|
||||
5. 初始化Controller的上下文对象`initializeControllerContext()`
|
||||
- 获取`/brokers/ids`节点信息,拿到所有的存活的BrokerID; 然后获取每个Broker的信息 `/brokers/ids/对应BrokerId`的信息以及对应的节点的Epoch; 也就是`cZxid`; 然后将数据保存在内存中
|
||||
- 获取`/brokers/topics`节点信息;拿到所有Topic之后,放到Map `partitionModificationsHandlers`中,key=topicName;value=对应节点的`PartitionModificationsHandler`; 节点是`/brokers/topics/topic名称`;最终相当于是在事件处理队列`queue`中给每个Topic添加了一个`PartitionModifications`事件; 这个事件是怎么处理的,我们下面分析
|
||||
- 同时又注册一下上面的`PartitionModificationsHandler`,保存在map `zNodeChangeHandlers` 中; key= `/brokers/topics/Topic名称`,Value=`PartitionModificationsHandler`; 我们上面也说到过,这个有个功能就是判断需不需要向zk中注册`watch`; 从下图的代码中可以看出,在获取zk数据(`GetDataRequest`)的时候,会去 `zNodeChangeHandlers`判断一下存不存在对应节点key;存在的话就注册`watch`监视数据
|
||||
- zk中获取`/brokers/topics/topic名称`所有topic的分区数据; 保存在内存中
|
||||
- 给每个broker注册broker变更处理器`BrokerModificationsHandler`(也是`ZNodeChangeHandler`)它对应的事件是`BrokerModifications`; 同样的`zNodeChangeHandlers`中也保存着对应的`/brokers/ids/对应BrokerId` 同样的`watch`监控;并且map `brokerModificationsHandlers`保存对应关系 key=`brokerID` value=`BrokerModificationsHandler`
|
||||
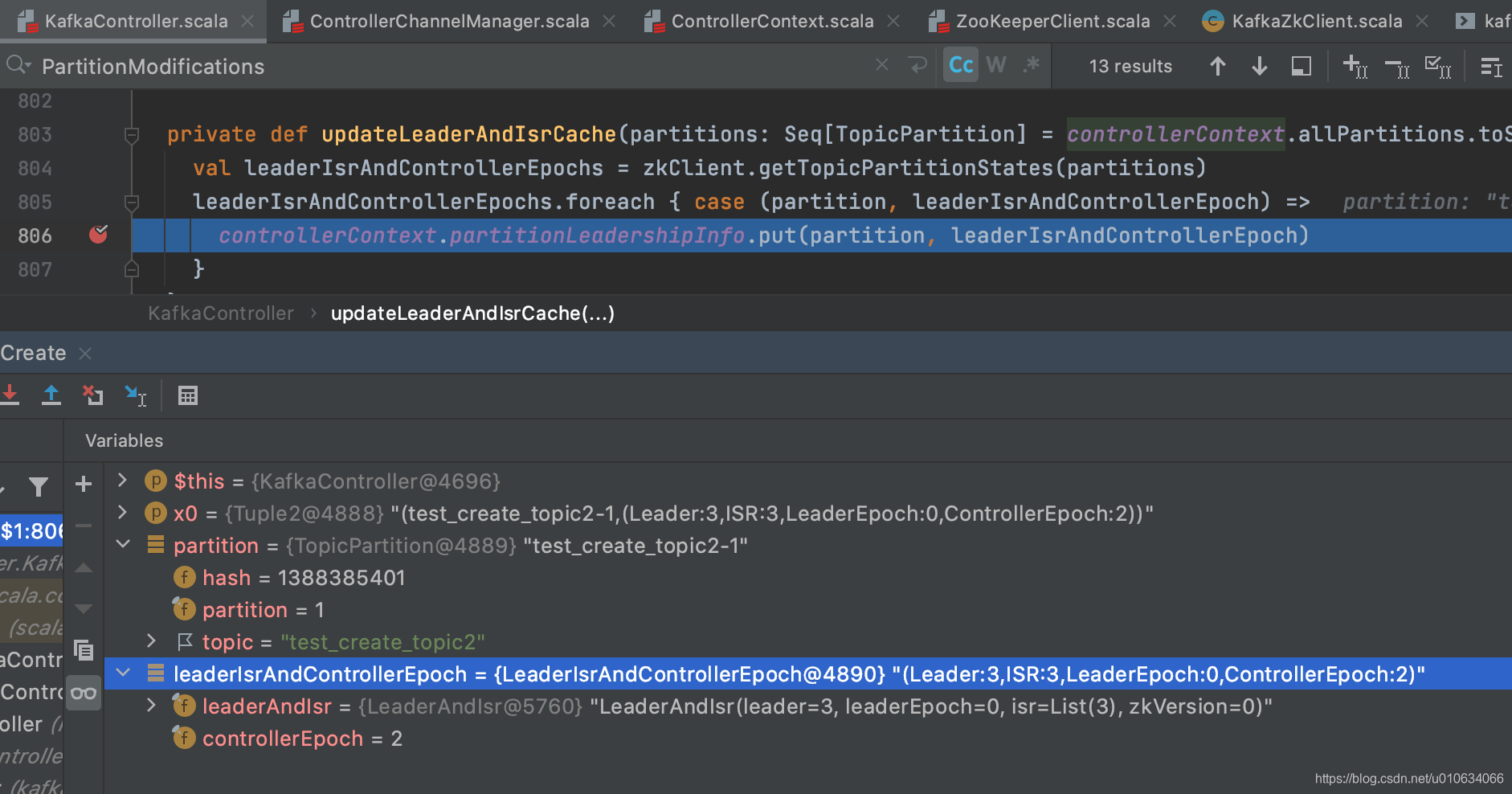
- 从zk中获取所有的topic-partition 信息; 节点: `/brokers/topics/Topic名称/partitions/分区号/state` ; 然后保存在缓存中`controllerContext.partitionLeadershipInfo`
|
||||
|
||||
- `controllerChannelManager.startup()` 这个单独开了一篇文章讲解,请看[【kafka源码】Controller与Brokers之间的网络通信](), 简单来说就是创建一个map来保存于所有Broker的发送请求线程对象`RequestSendThread`;这个对象中有一个 阻塞队列`queue`; 用来排队执行要执行的请求,没有任务时候回阻塞; Controller需要发送请求的时候只需要向这个`queue`中添加任务就行了
|
||||
|
||||
6. 初始化删除Topic管理器`topicDeletionManager.init()`
|
||||
- 读取zk节点`/admin/delete_topics`的子节点数据,表示的是标记为已经删除的Topic
|
||||
- 将被标记为删除的Topic,做一些开始删除Topic的操作;具体详情情况请看[【kafka源码】TopicCommand之删除Topic源码解析]()
|
||||
|
||||
7. `sendUpdateMetadataRequest` 给Brokers们发送`UPDATA_METADATA` 更新元数据的请求,关于更新元数据详细情况 [【kafka源码】更新元数据`UPDATA_METADATA`请求源码分析 ]()
|
||||
8. `replicaStateMachine.startup()` 启动副本状态机,获取所有在线的和不在线的副本;
|
||||
①. 将在线副本状态变更为`OnlineReplica:`将带有当前领导者和 isr 的 `LeaderAndIsr `请求发送到新副本,并将分区的 `UpdateMetadata `请求发送到每个实时代理
|
||||
②. 将不在线副本状态变更为`OfflineReplica:` 向副本发送 [StopReplicaRequest]() ; 从 isr 中删除此副本并将 [LeaderAndIsr]() 请求(带有新的 isr)发送到领导副本,并将分区的 UpdateMetadata 请求发送到每个实时代理。
|
||||
详细请看 [【kafka源码】Controller中的状态机](https://shirenchuang.blog.csdn.net/article/details/117848213)
|
||||
9. `partitionStateMachine.startup()`启动分区状态机,获取所有在线的和不在线(判断Leader是否在线)的分区;
|
||||
1. 如果分区不存在`LeaderIsr`,则状态是`NewPartition`
|
||||
2. 如果分区存在`LeaderIsr`,就判断一下Leader是否存活
|
||||
2.1 如果存活的话,状态是`OnlinePartition`
|
||||
2.2 否则是`OfflinePartition`
|
||||
3. 尝试将所有处于 `NewPartition `或 `OfflinePartition `状态的分区移动到 `OnlinePartition` 状态,但属于要删除的主题的分区除外
|
||||
|
||||
PS:如果之前创建Topic过程中,Controller发生了变更,Topic创建么有完成,那么这个状态流转的过程会继续创建下去; [【kafka源码】TopicCommand之创建Topic源码解析]()
|
||||
关于状态机 详细请看 [【kafka源码】Controller中的状态机](https://shirenchuang.blog.csdn.net/article/details/117848213)
|
||||
|
||||
11. ` initializePartitionReassignments` 初始化挂起的重新分配。这包括通过 `/admin/reassign_partitions` 发送的重新分配,它将取代任何正在进行的 API 重新分配。[【kafka源码】分区重分配 TODO..]()
|
||||
12. `topicDeletionManager.tryTopicDeletion()`尝试恢复未完成的Topic删除操作;相关情况 [【kafka源码】TopicCommand之删除Topic源码解析](https://shirenchuang.blog.csdn.net/article/details/117847877)
|
||||
13. 从`/admin/preferred_replica_election` 获取值,调用`onReplicaElection()` 尝试为每个给定分区选举一个副本作为领导者 ;相关内容请看[【kafka源码】Kafka的优先副本选举源码分析]();
|
||||
14. `kafkaScheduler.startup()`启动一些定时任务线程
|
||||
15. 如果配置了`auto.leader.rebalance.enable=true`,则启动LeaderRebalace的定时任务;线程名`auto-leader-rebalance-task`
|
||||
16. 如果配置了 `delegation.token.master.key`,则启动一些token的清理线程
|
||||
|
||||
|
||||
### 7. Controller重新选举
|
||||
当我们把zk中的节点`/controller`删除之后; 会调用下面接口;进行重新选举
|
||||
```scala
|
||||
private def processReelect(): Unit = {
|
||||
//尝试卸任一下
|
||||
maybeResign()
|
||||
//进行选举
|
||||
elect()
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
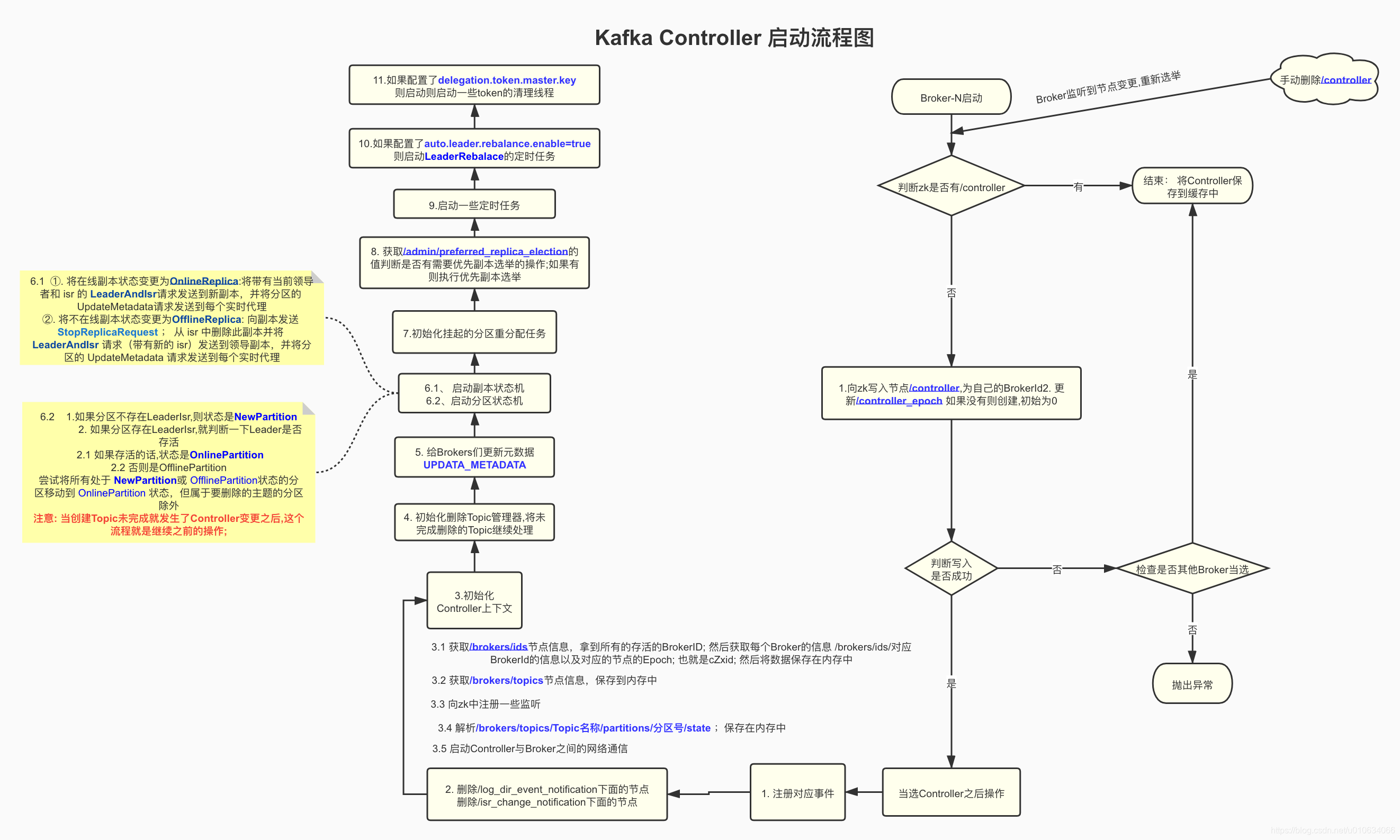
## 源码总结
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
PS: 可以看到 Broker当选Controller之后,保存了很多zk上的数据到自己的内存中, 也承担了很多责任; 如果这台Broker自身压力就挺大,那么它当选Controller之后压力会更大,所以尽量让比较空闲的Broker当选Controller,那么如何实现这样一个目标呢? 可以指定Broker作为Controller;
|
||||
这样一个功能可以在 <font color=red size=5>项目地址: [didi/Logi-KafkaManager: 一站式Apache Kafka集群指标监控与运维管控平台](https://github.com/didi/Logi-KafkaManager)</font> 里面可以实现
|
||||
|
||||
|
||||
## Q&A
|
||||
|
||||
### 直接删除zk节点`/controller`会怎么样
|
||||
>Broker之间会立马重新选举Controller;
|
||||
|
||||
### 如果修改节点`/controller/`下的数据会成功将Controller转移吗
|
||||
假如`/controller`节点数据是`{"version":1,"brokerid":3,"timestamp":"1623746563454"}` 我把BrokerId=1;Controller会直接变成Broker-1?
|
||||
>Answer: **不会成功转移,并且当前的集群中Broker是没有Controller角色的;这就是一个非常严重的问题了**
|
||||
|
||||
分析源码:
|
||||
修改`/controller/`数据在Controller执行的代码是
|
||||
```scala
|
||||
private def processControllerChange(): Unit = {
|
||||
maybeResign()
|
||||
}
|
||||
|
||||
private def maybeResign(): Unit = {
|
||||
val wasActiveBeforeChange = isActive
|
||||
zkClient.registerZNodeChangeHandlerAndCheckExistence(controllerChangeHandler)
|
||||
activeControllerId = zkClient.getControllerId.getOrElse(-1)
|
||||
if (wasActiveBeforeChange && !isActive) {
|
||||
onControllerResignation()
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
代码就非常清楚的看到, 修改数据之后,如果修改后的Broker-Id和当前的Controller的BrokerId不一致,执行`onControllerResignation` 就让当前的Controller卸任这个角色了;
|
||||
|
||||
### /log_dir_event_notification 是干啥 的
|
||||
> 当`log.dir`日志文件夹出现访问不了,磁盘损坏等等异常导致读写失败,就会触发一些异常通知事件;
|
||||
> 流程是->
|
||||
> 1. Broker检查到`log.dir`异常,做一些清理工作,然后向zk中创建持久序列节点`/log_dir_event_notification/log_dir_event_+序列号`;数据是 BrokerID;例如:
|
||||
>`/log_dir_event_notification/log_dir_event_0000000003`
|
||||
>2. Controller 监听到了zk的变更; 将从zk节点 /log_dir_event_notification/log_dir_event_序列号 中获取到的数据的Broker上的所有副本进行一个副本状态流转 ->OnlineReplica
|
||||
> 2.1 给所有broker 发送`LeaderAndIsrRequest`请求,让brokers们去查询他们的副本的状态,如果副本logDir已经离线则返回KAFKA_STORAGE_ERROR异常;
|
||||
> 2.2 完事之后会删除节点
|
||||
|
||||
### /isr_change_notification 是干啥用的
|
||||
> 当有isr变更的时候会在这个节点写入数据; Controller监听之后做一些通知
|
||||
### /admin/preferred_replica_election 是干啥用的
|
||||
>优先副本选举, 详情请戳[kafka的优先副本选举流程 .]()
|
||||
>
|
||||
|
||||
## 思考
|
||||
### 有什么办法实现Controller的优先选举?
|
||||
>既然我们知道了Controller承担了这么多的任务,又是Broker又是Controller,身兼数职压力难免会比较大;
|
||||
>所以我们很希望能够有一个功能能够知道Broker为Controller角色; 这样就可以指定压力比较小的Broker来承担Controller的角色了;
|
||||
|
||||
**那么,如何实现呢?**
|
||||
>Kafka原生目前并不支持这个功能,所以我们想要实现这个功能,就得要改源码了;
|
||||
>知道了原理, 改源码实现这个功能就很简单了; 有很多种实现方式;
|
||||
|
||||
比如说: 在zk里面设置一个节点专门用来存放候选节点; 竞选Controller的时候优先从这里面选择;
|
||||
然后Broker们启动的时候,可以判断一下自己是不是候选节点, 如果不是的话,那就让它睡个两三秒; (让候选者99米再跑)
|
||||
那么大概率的情况下,候选者肯定就会当选了;
|
||||
26
docs/zh/Kafka分享/Kafka Controller /Controller滴滴特性解读.md
Normal file
26
docs/zh/Kafka分享/Kafka Controller /Controller滴滴特性解读.md
Normal file
@@ -0,0 +1,26 @@
|
||||
|
||||
## Controller优先选举
|
||||
> 在原生的kafka中,Controller角色的选举,是每个Broker抢占式的去zk写入节点`Controller`
|
||||
> 任何一个Broker都有可能当选Controller;
|
||||
> 但是Controller角色除了是一个正常的Broker外,还承担着Controller角色的一些任务;
|
||||
> 具体情况 [【kafka源码】Controller启动过程以及选举流程源码分析]()
|
||||
> 当这台Broker本身压力很大的情况下,又当选Controller让Broker压力更大了;
|
||||
> 所以我们期望让Controller角色落在一些压力较小的Broker上;或者专门用一台机器用来当做Controller角色;
|
||||
> 基于这么一个需求,我们内部就对引擎做了些改造,用于支持`Controller优先选举`
|
||||
|
||||
|
||||
## 改造原理
|
||||
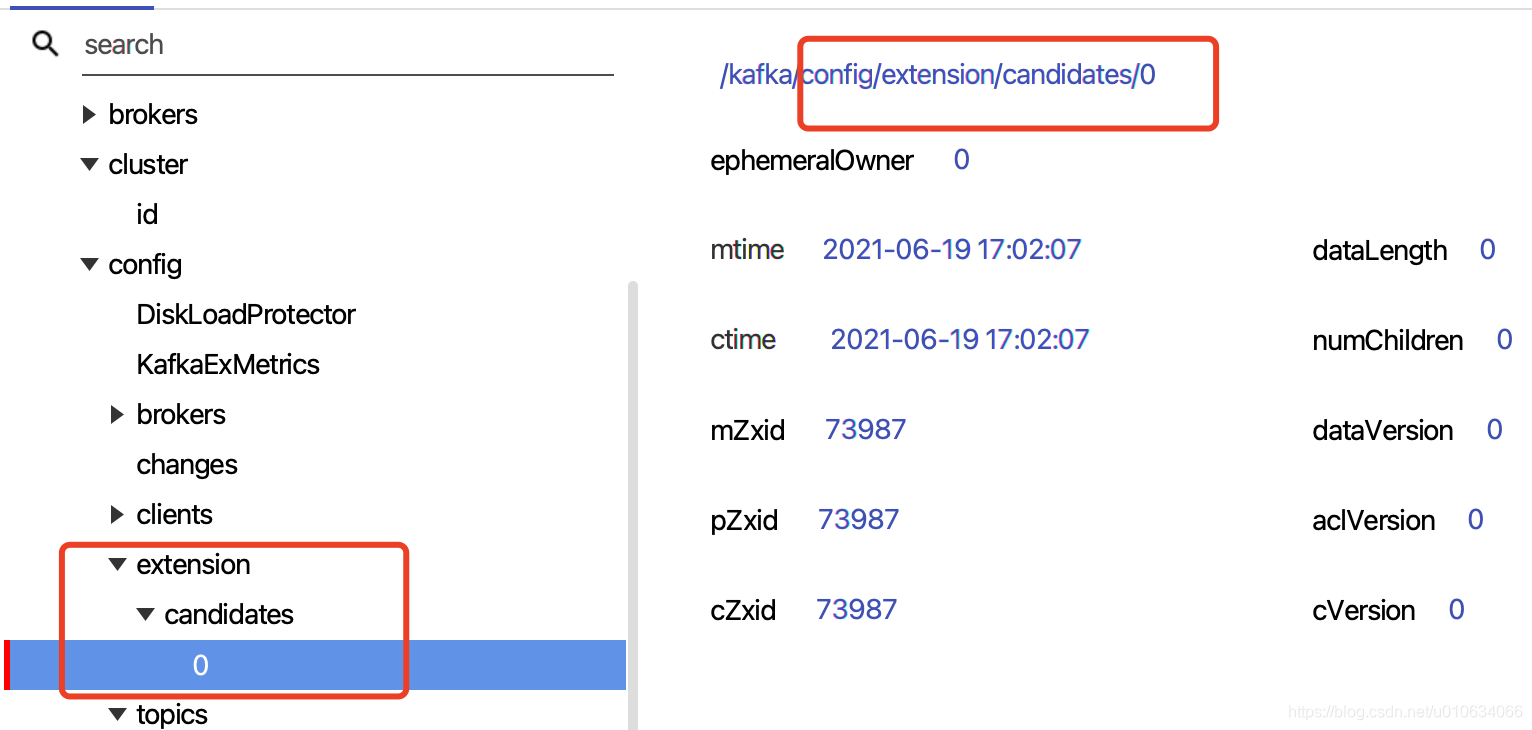
> 在`/config`节点下新增了节点`/config/extension/candidates/ `;
|
||||
> 将所有需要被优先选举的BrokerID存放到该节点下面;
|
||||
> 例如:
|
||||
> `/config/extension/candidates/0`
|
||||
> 
|
||||
|
||||
当Controller发生重新选举的时候, 每个Broker都去抢占式写入`/controller`节点, 但是会先去节点`/config/extension/candidates/`节点获取所有子节点,获取到有一个BrokerID=0; 这个时候会判断一下是否跟自己的BrokerID相等; 不相等的话就`sleep 3秒` 钟; 这样的话,那么BrokerId=0这个Broker就会大概率当选Controller; 如果这个Broker挂掉了,那么其他Broker就可能会当选
|
||||
|
||||
<font color=red>PS: `/config/extension/candidates/` 节点下可以配置多个候选Controller </font>
|
||||
|
||||
|
||||
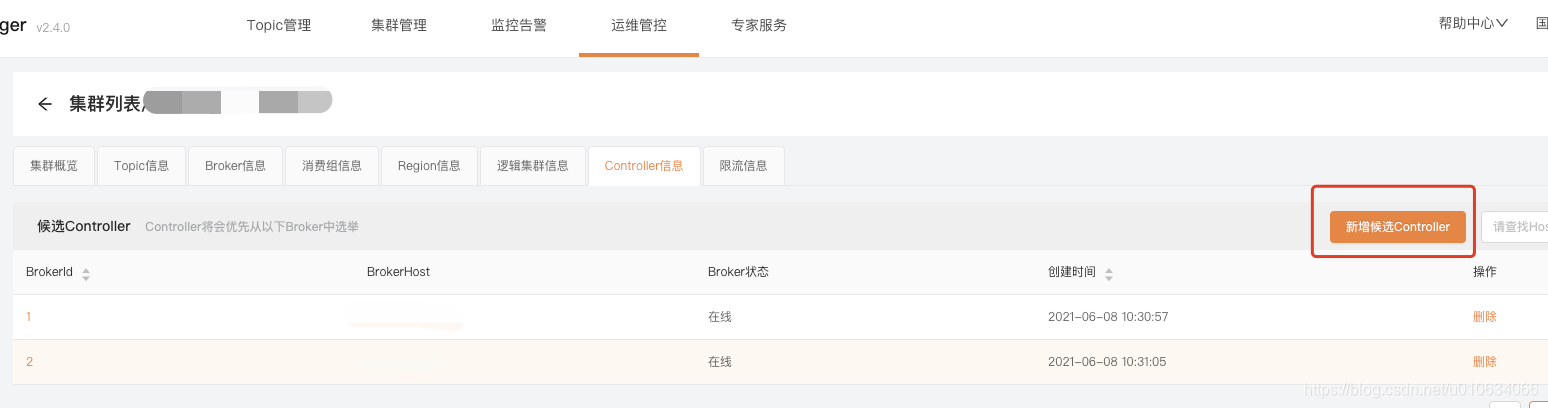
## KM管理平台操作
|
||||
|
||||
|
||||
@@ -0,0 +1,614 @@
|
||||
|
||||
|
||||
## 1.脚本的使用
|
||||
>请看 [【kafka运维】副本扩缩容、数据迁移、分区重分配]()
|
||||
|
||||
## 2.源码解析
|
||||
<font color=red>如果阅读源码太枯燥,可以直接跳转到 源码总结和Q&A部分<font>
|
||||
|
||||
### 2.1`--generate ` 生成分配策略分析
|
||||
配置启动类`--zookeeper xxxx:2181 --topics-to-move-json-file config/move-json-file.json --broker-list "0,1,2,3" --generate`
|
||||

|
||||
配置`move-json-file.json`文件
|
||||
|
||||
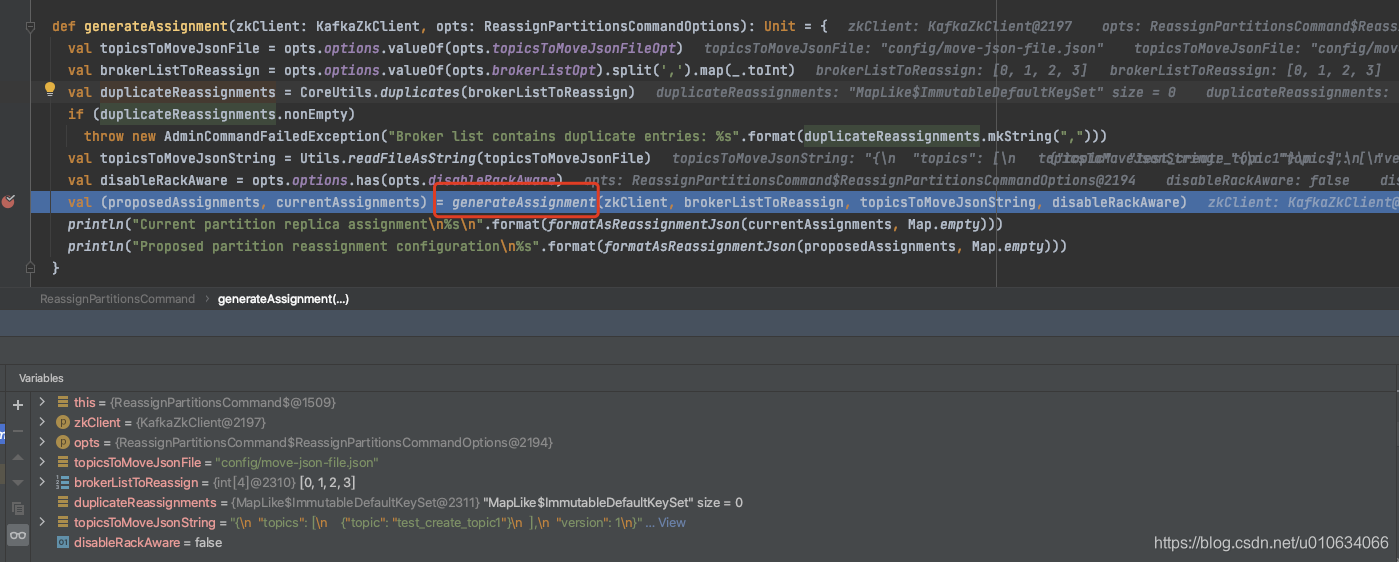
启动,调试:
|
||||
`ReassignPartitionsCommand.generateAssignment`
|
||||
|
||||
1. 获取入参的数据
|
||||
2. 校验`--broker-list`传入的BrokerId是否有重复的,重复就报错
|
||||
3. 开始进行分配
|
||||
|
||||
`ReassignPartitionsCommand.generateAssignment`
|
||||
```scala
|
||||
def generateAssignment(zkClient: KafkaZkClient, brokerListToReassign: Seq[Int], topicsToMoveJsonString: String, disableRackAware: Boolean): (Map[TopicPartition, Seq[Int]], Map[TopicPartition, Seq[Int]]) = {
|
||||
//解析出游哪些Topic
|
||||
val topicsToReassign = parseTopicsData(topicsToMoveJsonString)
|
||||
//检查是否有重复的topic
|
||||
val duplicateTopicsToReassign = CoreUtils.duplicates(topicsToReassign)
|
||||
if (duplicateTopicsToReassign.nonEmpty)
|
||||
throw new AdminCommandFailedException("List of topics to reassign contains duplicate entries: %s".format(duplicateTopicsToReassign.mkString(",")))
|
||||
//获取topic当前的副本分配情况 /brokers/topics/{topicName}
|
||||
val currentAssignment = zkClient.getReplicaAssignmentForTopics(topicsToReassign.toSet)
|
||||
|
||||
val groupedByTopic = currentAssignment.groupBy { case (tp, _) => tp.topic }
|
||||
//机架感知模式
|
||||
val rackAwareMode = if (disableRackAware) RackAwareMode.Disabled else RackAwareMode.Enforced
|
||||
val adminZkClient = new AdminZkClient(zkClient)
|
||||
val brokerMetadatas = adminZkClient.getBrokerMetadatas(rackAwareMode, Some(brokerListToReassign))
|
||||
|
||||
val partitionsToBeReassigned = mutable.Map[TopicPartition, Seq[Int]]()
|
||||
groupedByTopic.foreach { case (topic, assignment) =>
|
||||
val (_, replicas) = assignment.head
|
||||
val assignedReplicas = AdminUtils.assignReplicasToBrokers(brokerMetadatas, assignment.size, replicas.size)
|
||||
partitionsToBeReassigned ++= assignedReplicas.map { case (partition, replicas) =>
|
||||
new TopicPartition(topic, partition) -> replicas
|
||||
}
|
||||
}
|
||||
(partitionsToBeReassigned, currentAssignment)
|
||||
}
|
||||
```
|
||||
1. 检查是否有重复的topic,重复则抛出异常
|
||||
2. 从zk节点` /brokers/topics/{topicName}`获取topic当前的副本分配情况
|
||||
3. 从zk节点`brokers/ids`中获取所有在线节点,并跟`--broker-list`参数传入的取个交集
|
||||
4. 获取Brokers元数据,如果机架感知模式`RackAwareMode.Enforced`(默认)&&上面3中获取到的交集列表brokers不是都有机架信息或者都没有机架信息的话就抛出异常; 因为要根据机架信息做分区分配的话,必须要么都有机架信息,要么都没有机架信息; 出现这种情况怎么办呢? 那就将机架感知模式`RackAwareMode`设置为`RackAwareMode.Disabled` ;只需要加上一个参数`--disable-rack-aware`就行了
|
||||
5. 调用`AdminUtils.assignReplicasToBrokers` 计算分配情况;
|
||||
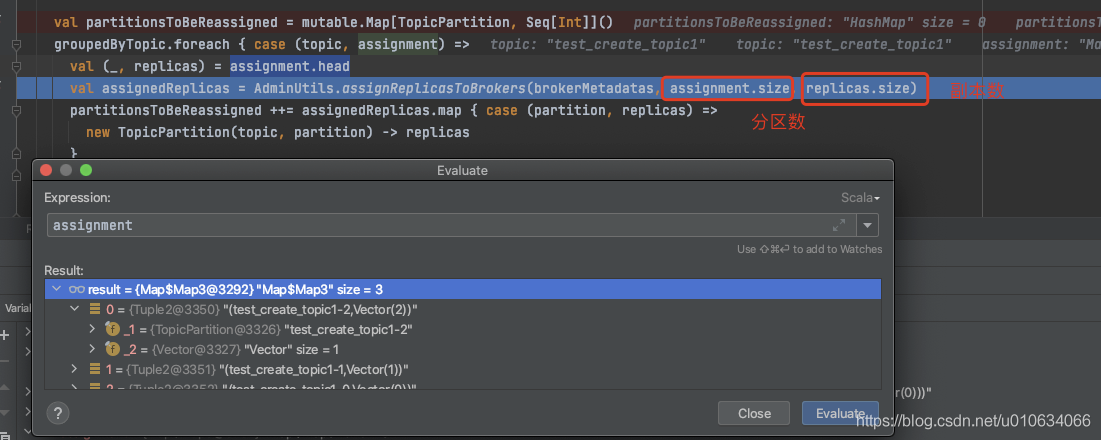
|
||||
我们在[【kafka源码】创建Topic的时候是如何分区和副本的分配规则]()里面分析过就不再赘述了, `AdminUtils.assignReplicasToBrokers(要分配的Broker们的元数据, 分区数, 副本数)`
|
||||
需要注意的是副本数是通过`assignment.head.replicas.size`获取的,意思是第一个分区的副本数量,正常情况下分区副本都会相同,但是也不一定,也可能被设置为了不同
|
||||
|
||||
<font color=red>根据这条信息我们是不是就可以直接调用这个接口来实现其他功能? **比如副本的扩缩容**</font>
|
||||
|
||||
|
||||
|
||||
|
||||
### 2.2`--execute ` 执行阶段分析
|
||||
> 使用脚本执行
|
||||
> `--zookeeper xxx --reassignment-json-file config/reassignment-json-file.json --execute --throttle 10000`
|
||||
|
||||
|
||||
|
||||
`ReassignPartitionsCommand.executeAssignment`
|
||||
```scala
|
||||
def executeAssignment(zkClient: KafkaZkClient, adminClientOpt: Option[Admin], reassignmentJsonString: String, throttle: Throttle, timeoutMs: Long = 10000L): Unit = {
|
||||
//对json文件进行校验和解析
|
||||
val (partitionAssignment, replicaAssignment) = parseAndValidate(zkClient, reassignmentJsonString)
|
||||
val adminZkClient = new AdminZkClient(zkClient)
|
||||
val reassignPartitionsCommand = new ReassignPartitionsCommand(zkClient, adminClientOpt, partitionAssignment.toMap, replicaAssignment, adminZkClient)
|
||||
|
||||
//检查是否已经存在副本重分配进程, 则尝试限流
|
||||
if (zkClient.reassignPartitionsInProgress()) {
|
||||
reassignPartitionsCommand.maybeLimit(throttle)
|
||||
} else {
|
||||
//打印当前的副本分配方式,方便回滚
|
||||
printCurrentAssignment(zkClient, partitionAssignment.map(_._1.topic))
|
||||
if (throttle.interBrokerLimit >= 0 || throttle.replicaAlterLogDirsLimit >= 0)
|
||||
println(String.format("Warning: You must run Verify periodically, until the reassignment completes, to ensure the throttle is removed. You can also alter the throttle by rerunning the Execute command passing a new value."))
|
||||
//开始进行重分配进程
|
||||
if (reassignPartitionsCommand.reassignPartitions(throttle, timeoutMs)) {
|
||||
println("Successfully started reassignment of partitions.")
|
||||
} else
|
||||
println("Failed to reassign partitions %s".format(partitionAssignment))
|
||||
}
|
||||
}
|
||||
```
|
||||
1. 解析json文件并做些校验
|
||||
1. (partition、replica非空校验,partition重复校验)
|
||||
3. 校验`partition`是否有不存在的分区;(新增分区请用`kafka-topic`)
|
||||
4. 检查配置中的Brokers-id是否都存在
|
||||
3. 如果发现已经存在副本重分配进程(检查是否有节点`/admin/reassign_partitions`),则检查是否需要更改限流; 如果有参数(`--throttle`,`--replica-alter-log-dirs-throttle`) 则设置限流信息; 而后不再执行下一步
|
||||
4. 如果当前没有执行中的副本重分配任务(检查是否有节点`/admin/reassign_partitions`),则开始进行副本重分配任务;
|
||||
|
||||
#### 2.2.1 已有任务,尝试限流
|
||||
如果zk中有节点`/admin/reassign_partitions`; 则表示当前已有一个任务在进行,那么当前操作就不继续了,如果有参数
|
||||
`--throttle:`
|
||||
`--replica-alter-log-dirs-throttle:`
|
||||
则进行限制
|
||||
|
||||
>限制当前移动副本的节流阀。请注意,此命令可用于更改节流阀,但如果某些代理已完成重新平衡,则它可能不会更改最初设置的所有限制。所以后面需要将这个限制给移除掉 通过`--verify`
|
||||
|
||||
`maybeLimit`
|
||||
```scala
|
||||
def maybeLimit(throttle: Throttle): Unit = {
|
||||
if (throttle.interBrokerLimit >= 0 || throttle.replicaAlterLogDirsLimit >= 0) {
|
||||
//当前存在的broker
|
||||
val existingBrokers = existingAssignment().values.flatten.toSeq
|
||||
//期望的broker
|
||||
val proposedBrokers = proposedPartitionAssignment.values.flatten.toSeq ++ proposedReplicaAssignment.keys.toSeq.map(_.brokerId())
|
||||
//前面broker相加去重
|
||||
val brokers = (existingBrokers ++ proposedBrokers).distinct
|
||||
|
||||
//遍历与之相关的Brokers, 添加限流配置写入到zk节点/config/broker/{brokerId}中
|
||||
for (id <- brokers) {
|
||||
//获取broker的配置 /config/broker/{brokerId}
|
||||
val configs = adminZkClient.fetchEntityConfig(ConfigType.Broker, id.toString)
|
||||
if (throttle.interBrokerLimit >= 0) {
|
||||
configs.put(DynamicConfig.Broker.LeaderReplicationThrottledRateProp, throttle.interBrokerLimit.toString)
|
||||
configs.put(DynamicConfig.Broker.FollowerReplicationThrottledRateProp, throttle.interBrokerLimit.toString)
|
||||
}
|
||||
if (throttle.replicaAlterLogDirsLimit >= 0)
|
||||
configs.put(DynamicConfig.Broker.ReplicaAlterLogDirsIoMaxBytesPerSecondProp, throttle.replicaAlterLogDirsLimit.toString)
|
||||
|
||||
adminZkClient.changeBrokerConfig(Seq(id), configs)
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
`/config/brokers/{brokerId}`节点配置是Broker端的动态配置,不需要重启Broker实时生效;
|
||||
1. 如果传入了参数`--throttle:` 则从zk节点`/config/brokers/{BrokerId}`节点获取Broker们的配置信息,然后再加上以下两个配置重新写入到节点`/config/brokers/{BrokerId}`中
|
||||
`leader.replication.throttled.rate` 控制leader副本端处理FETCH请求的速率
|
||||
`follower.replication.throttled.rate` 控制follower副本发送FETCH请求的速率
|
||||
2. 如果传入了参数`--replica-alter-log-dirs-throttle:` 则将如下配置也写入节点中;
|
||||
`replica.alter.log.dirs.io.max.bytes.per.second:` broker内部目录之间迁移数据流量限制功能,限制数据拷贝从一个目录到另外一个目录带宽上限
|
||||
|
||||
例如写入之后的数据
|
||||
```json
|
||||
{"version":1,"config":{"leader.replication.throttled.rate":"1","follower.replication.throttled.rate":"1"}}
|
||||
```
|
||||
|
||||
**注意: 这里写入的限流配置,是写入所有与之相关的Broker的限流配置;**
|
||||
|
||||
#### 2.2.2 当前未有执行任务,开始执行副本重分配任务
|
||||
`ReassignPartitionsCommand.reassignPartitions`
|
||||
```scala
|
||||
def reassignPartitions(throttle: Throttle = NoThrottle, timeoutMs: Long = 10000L): Boolean = {
|
||||
//写入一些限流数据
|
||||
maybeThrottle(throttle)
|
||||
try {
|
||||
//验证分区是否存在
|
||||
val validPartitions = proposedPartitionAssignment.groupBy(_._1.topic())
|
||||
.flatMap { case (topic, topicPartitionReplicas) =>
|
||||
validatePartition(zkClient, topic, topicPartitionReplicas)
|
||||
}
|
||||
if (validPartitions.isEmpty) false
|
||||
else {
|
||||
if (proposedReplicaAssignment.nonEmpty && adminClientOpt.isEmpty)
|
||||
throw new AdminCommandFailedException("bootstrap-server needs to be provided in order to reassign replica to the specified log directory")
|
||||
val startTimeMs = System.currentTimeMillis()
|
||||
|
||||
// Send AlterReplicaLogDirsRequest to allow broker to create replica in the right log dir later if the replica has not been created yet.
|
||||
if (proposedReplicaAssignment.nonEmpty)
|
||||
alterReplicaLogDirsIgnoreReplicaNotAvailable(proposedReplicaAssignment, adminClientOpt.get, timeoutMs)
|
||||
|
||||
// Create reassignment znode so that controller will send LeaderAndIsrRequest to create replica in the broker
|
||||
zkClient.createPartitionReassignment(validPartitions.map({case (key, value) => (new TopicPartition(key.topic, key.partition), value)}).toMap)
|
||||
|
||||
// Send AlterReplicaLogDirsRequest again to make sure broker will start to move replica to the specified log directory.
|
||||
// It may take some time for controller to create replica in the broker. Retry if the replica has not been created.
|
||||
var remainingTimeMs = startTimeMs + timeoutMs - System.currentTimeMillis()
|
||||
val replicasAssignedToFutureDir = mutable.Set.empty[TopicPartitionReplica]
|
||||
while (remainingTimeMs > 0 && replicasAssignedToFutureDir.size < proposedReplicaAssignment.size) {
|
||||
replicasAssignedToFutureDir ++= alterReplicaLogDirsIgnoreReplicaNotAvailable(
|
||||
proposedReplicaAssignment.filter { case (replica, _) => !replicasAssignedToFutureDir.contains(replica) },
|
||||
adminClientOpt.get, remainingTimeMs)
|
||||
Thread.sleep(100)
|
||||
remainingTimeMs = startTimeMs + timeoutMs - System.currentTimeMillis()
|
||||
}
|
||||
replicasAssignedToFutureDir.size == proposedReplicaAssignment.size
|
||||
}
|
||||
} catch {
|
||||
case _: NodeExistsException =>
|
||||
val partitionsBeingReassigned = zkClient.getPartitionReassignment()
|
||||
throw new AdminCommandFailedException("Partition reassignment currently in " +
|
||||
"progress for %s. Aborting operation".format(partitionsBeingReassigned))
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
1. `maybeThrottle(throttle)` 设置副本移动时候的限流配置,这个方法只用于任务初始化的时候
|
||||
```scala
|
||||
private def maybeThrottle(throttle: Throttle): Unit = {
|
||||
if (throttle.interBrokerLimit >= 0)
|
||||
assignThrottledReplicas(existingAssignment(), proposedPartitionAssignment, adminZkClient)
|
||||
maybeLimit(throttle)
|
||||
if (throttle.interBrokerLimit >= 0 || throttle.replicaAlterLogDirsLimit >= 0)
|
||||
throttle.postUpdateAction()
|
||||
if (throttle.interBrokerLimit >= 0)
|
||||
println(s"The inter-broker throttle limit was set to ${throttle.interBrokerLimit} B/s")
|
||||
if (throttle.replicaAlterLogDirsLimit >= 0)
|
||||
println(s"The replica-alter-dir throttle limit was set to ${throttle.replicaAlterLogDirsLimit} B/s")
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
1.1 将一些topic的限流配置写入到节点`/config/topics/{topicName}`中
|
||||
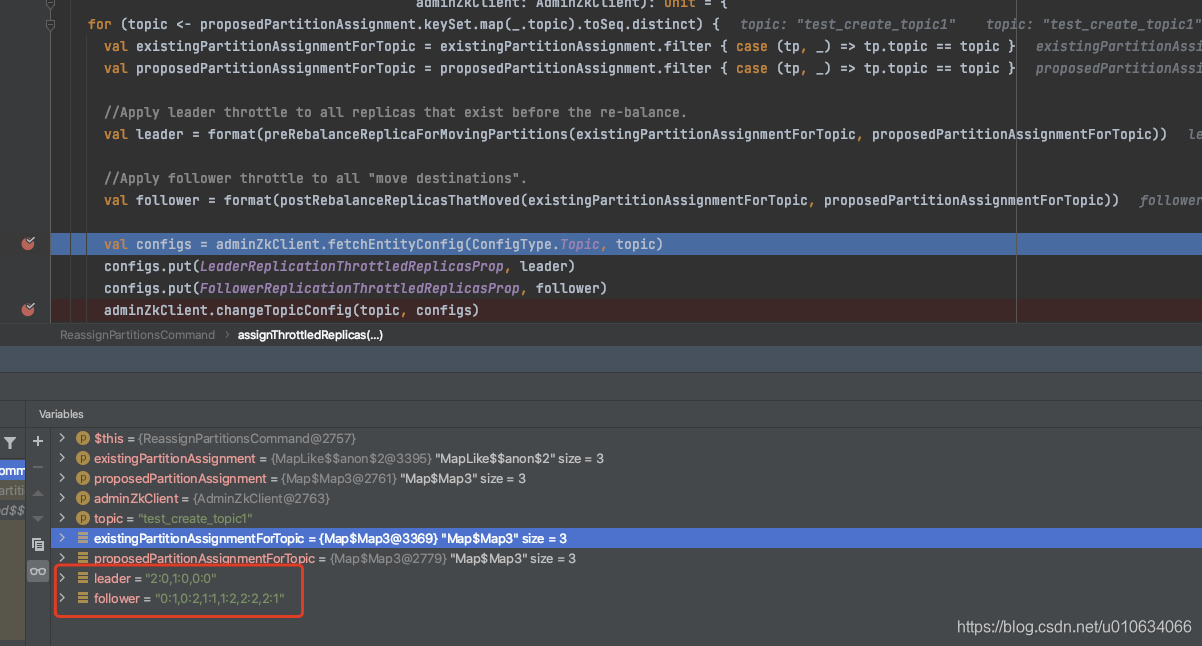
|
||||
将计算得到的leader、follower 值写入到`/config/topics/{topicName}`中
|
||||
leader: 找到 TopicPartition中有新增的副本的 那个分区;数据= 分区号:副本号,分区号:副本号
|
||||
follower: 遍历 预期 TopicPartition,副本= 预期副本-现有副本;数据= 分区号:副本号,分区号:副本号
|
||||
`leader.replication.throttled.replicas`: leader
|
||||
`follower.replication.throttled.replicas`: follower
|
||||

|
||||
1.2. 执行 《**2.2.1 已有任务,尝试限流**》流程
|
||||
|
||||
2. 从zk中获取`/broker/topics/{topicName}`数据来验证给定的分区是否存在,如果分区不存在则忽略此分区的配置,继续流程
|
||||
3. 如果尚未创建副本,则发送 `AlterReplicaLogDirsRequest` 以允许代理稍后在正确的日志目录中创建副本。这个跟 `log_dirs` 有关 TODO....
|
||||
4. 将重分配的数据写入到zk的节点`/admin/reassign_partitions`中;数据内容如:
|
||||
```
|
||||
{"version":1,"partitions":[{"topic":"test_create_topic1","partition":0,"replicas":[0,1,2,3]},{"topic":"test_create_topic1","partition":1,"replicas":[1,2,0,3]},{"topic":"test_create_topic1","partition":2,"replicas":[2,1,0,3]}]}
|
||||
```
|
||||
5. 再次发送 `AlterReplicaLogDirsRequest `以确保代理将开始将副本移动到指定的日志目录。控制器在代理中创建副本可能需要一些时间。如果尚未创建副本,请重试。
|
||||
1. 像Broker发送`alterReplicaLogDirs`请求
|
||||
|
||||
|
||||
|
||||
|
||||
#### 2.2.3 Controller监听`/admin/reassign_partitions`节点变化
|
||||
|
||||
|
||||
`KafkaController.processZkPartitionReassignment`
|
||||
```scala
|
||||
private def processZkPartitionReassignment(): Set[TopicPartition] = {
|
||||
// We need to register the watcher if the path doesn't exist in order to detect future
|
||||
// reassignments and we get the `path exists` check for free
|
||||
if (isActive && zkClient.registerZNodeChangeHandlerAndCheckExistence(partitionReassignmentHandler)) {
|
||||
val reassignmentResults = mutable.Map.empty[TopicPartition, ApiError]
|
||||
val partitionsToReassign = mutable.Map.empty[TopicPartition, ReplicaAssignment]
|
||||
|
||||
zkClient.getPartitionReassignment().foreach { case (tp, targetReplicas) =>
|
||||
maybeBuildReassignment(tp, Some(targetReplicas)) match {
|
||||
case Some(context) => partitionsToReassign.put(tp, context)
|
||||
case None => reassignmentResults.put(tp, new ApiError(Errors.NO_REASSIGNMENT_IN_PROGRESS))
|
||||
}
|
||||
}
|
||||
|
||||
reassignmentResults ++= maybeTriggerPartitionReassignment(partitionsToReassign)
|
||||
val (partitionsReassigned, partitionsFailed) = reassignmentResults.partition(_._2.error == Errors.NONE)
|
||||
if (partitionsFailed.nonEmpty) {
|
||||
warn(s"Failed reassignment through zk with the following errors: $partitionsFailed")
|
||||
maybeRemoveFromZkReassignment((tp, _) => partitionsFailed.contains(tp))
|
||||
}
|
||||
partitionsReassigned.keySet
|
||||
} else {
|
||||
Set.empty
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
1. 判断是否是Controller角色并且是否存在节点`/admin/reassign_partitions`
|
||||
2. `maybeTriggerPartitionReassignment` 重分配,如果topic已经被标记为删除了,则此topic流程终止;
|
||||
3. `maybeRemoveFromZkReassignment`将执行失败的一些分区信息从zk中删除;(覆盖信息)
|
||||
|
||||
##### onPartitionReassignment
|
||||
`KafkaController.onPartitionReassignment`
|
||||
|
||||
```scala
|
||||
private def onPartitionReassignment(topicPartition: TopicPartition, reassignment: ReplicaAssignment): Unit = {
|
||||
// 暂停一些正在删除的Topic操作
|
||||
topicDeletionManager.markTopicIneligibleForDeletion(Set(topicPartition.topic), reason = "topic reassignment in progress")
|
||||
//更新当前的分配
|
||||
updateCurrentReassignment(topicPartition, reassignment)
|
||||
|
||||
val addingReplicas = reassignment.addingReplicas
|
||||
val removingReplicas = reassignment.removingReplicas
|
||||
|
||||
if (!isReassignmentComplete(topicPartition, reassignment)) {
|
||||
// A1. Send LeaderAndIsr request to every replica in ORS + TRS (with the new RS, AR and RR).
|
||||
updateLeaderEpochAndSendRequest(topicPartition, reassignment)
|
||||
// A2. replicas in AR -> NewReplica
|
||||
startNewReplicasForReassignedPartition(topicPartition, addingReplicas)
|
||||
} else {
|
||||
// B1. replicas in AR -> OnlineReplica
|
||||
replicaStateMachine.handleStateChanges(addingReplicas.map(PartitionAndReplica(topicPartition, _)), OnlineReplica)
|
||||
// B2. Set RS = TRS, AR = [], RR = [] in memory.
|
||||
val completedReassignment = ReplicaAssignment(reassignment.targetReplicas)
|
||||
controllerContext.updatePartitionFullReplicaAssignment(topicPartition, completedReassignment)
|
||||
// B3. Send LeaderAndIsr request with a potential new leader (if current leader not in TRS) and
|
||||
// a new RS (using TRS) and same isr to every broker in ORS + TRS or TRS
|
||||
moveReassignedPartitionLeaderIfRequired(topicPartition, completedReassignment)
|
||||
// B4. replicas in RR -> Offline (force those replicas out of isr)
|
||||
// B5. replicas in RR -> NonExistentReplica (force those replicas to be deleted)
|
||||
stopRemovedReplicasOfReassignedPartition(topicPartition, removingReplicas)
|
||||
// B6. Update ZK with RS = TRS, AR = [], RR = [].
|
||||
updateReplicaAssignmentForPartition(topicPartition, completedReassignment)
|
||||
// B7. Remove the ISR reassign listener and maybe update the /admin/reassign_partitions path in ZK to remove this partition from it.
|
||||
removePartitionFromReassigningPartitions(topicPartition, completedReassignment)
|
||||
// B8. After electing a leader in B3, the replicas and isr information changes, so resend the update metadata request to every broker
|
||||
sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq, Set(topicPartition))
|
||||
// signal delete topic thread if reassignment for some partitions belonging to topics being deleted just completed
|
||||
topicDeletionManager.resumeDeletionForTopics(Set(topicPartition.topic))
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
1. 暂停一些正在删除的Topic操作
|
||||
2. 更新 Zk节点`brokers/topics/{topicName}`,和内存中的当前分配状态。如果重新分配已经在进行中,那么新的重新分配将取代它并且一些副本将被关闭。
|
||||
2.1 更新zk中的topic节点信息`brokers/topics/{topicName}`,这里会标记AR哪些副本是新增的,RR哪些副本是要删除的;例如: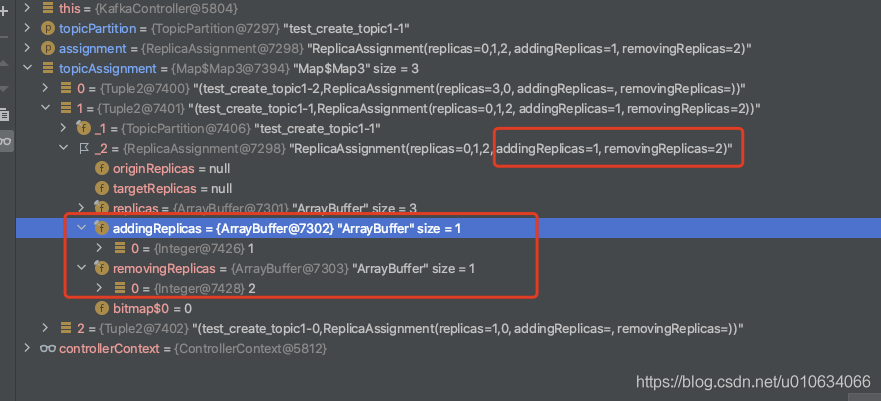
|
||||
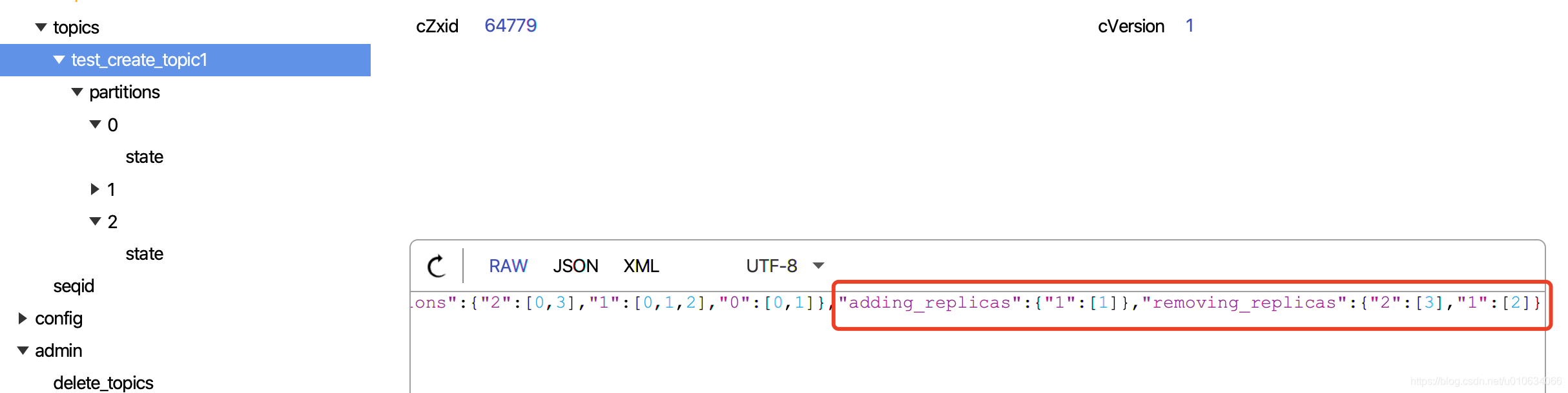
|
||||
2.2 更新当前内存
|
||||
2.3 如果**重新分配**已经在进行中,那么一些当前新增加的副本有可能被立即删除,在这种情况下,我们需要停止副本。
|
||||
2.4 注册一个监听节点`/brokers/topics/{topicName}/partitions/{分区号}/state`变更的处理器`PartitionReassignmentIsrChangeHandler`
|
||||
3. 如果该分区的重新分配还没有完成(根据`/brokers/topics/{topicName}/partitions/{分区号}/state`里面的isr来判断是否已经包含了新增的BrokerId了);则
|
||||
以下几个名称说明:
|
||||
`ORS`: OriginReplicas 原先的副本
|
||||
`TRS`: targetReplicas 将要变更成的目标副本
|
||||
`AR`: adding_replicas 正在添加的副本
|
||||
`RR`:removing_replicas 正在移除的副本
|
||||
3.1 向 ORS + TRS 中的每个副本发送` LeaderAndIsr `请求(带有新的 RS、AR 和 RR)。
|
||||
3.2 给新增加的AR副本 进行状态变更成`NewReplica` ; 这个过程有发送`LeaderAndIsrRequest`详细请看[【kafka源码】Controller中的状态机]()
|
||||
|
||||
#### 2.2.4 Controller监听节点`brokers/topics/{topicName}`变化,检查是否有新增分区
|
||||
这一个流程可以不必在意,因为在这里没有做任何事情;
|
||||
|
||||
>上面的 **2.2.3** 的第2小段中不是有将新增的和删掉的副本写入到了 zk中吗
|
||||
>例如:
|
||||
>```json
|
||||
>
|
||||
>{"version":2,"partitions":{"2":[0,1],"1":[0,1],"0":[0,1]},"adding_replicas":{"2":[1],"1":[1],"0":[1]},"removing_replicas":{}}
|
||||
>
|
||||
>```
|
||||
Controller监听到这个节点之后,执行方法`processPartitionModifications`
|
||||
`KafkaController.processPartitionModifications`
|
||||
```scala
|
||||
private def processPartitionModifications(topic: String): Unit = {
|
||||
def restorePartitionReplicaAssignment(
|
||||
topic: String,
|
||||
newPartitionReplicaAssignment: Map[TopicPartition, ReplicaAssignment]
|
||||
): Unit = {
|
||||
info("Restoring the partition replica assignment for topic %s".format(topic))
|
||||
|
||||
//从zk节点中获取所有分区
|
||||
val existingPartitions = zkClient.getChildren(TopicPartitionsZNode.path(topic))
|
||||
//找到已经存在的分区
|
||||
val existingPartitionReplicaAssignment = newPartitionReplicaAssignment
|
||||
.filter(p => existingPartitions.contains(p._1.partition.toString))
|
||||
.map { case (tp, _) =>
|
||||
tp -> controllerContext.partitionFullReplicaAssignment(tp)
|
||||
}.toMap
|
||||
|
||||
zkClient.setTopicAssignment(topic,
|
||||
existingPartitionReplicaAssignment,
|
||||
controllerContext.epochZkVersion)
|
||||
}
|
||||
|
||||
if (!isActive) return
|
||||
val partitionReplicaAssignment = zkClient.getFullReplicaAssignmentForTopics(immutable.Set(topic))
|
||||
val partitionsToBeAdded = partitionReplicaAssignment.filter { case (topicPartition, _) =>
|
||||
controllerContext.partitionReplicaAssignment(topicPartition).isEmpty
|
||||
}
|
||||
|
||||
if (topicDeletionManager.isTopicQueuedUpForDeletion(topic)) {
|
||||
if (partitionsToBeAdded.nonEmpty) {
|
||||
warn("Skipping adding partitions %s for topic %s since it is currently being deleted"
|
||||
.format(partitionsToBeAdded.map(_._1.partition).mkString(","), topic))
|
||||
|
||||
restorePartitionReplicaAssignment(topic, partitionReplicaAssignment)
|
||||
} else {
|
||||
// This can happen if existing partition replica assignment are restored to prevent increasing partition count during topic deletion
|
||||
info("Ignoring partition change during topic deletion as no new partitions are added")
|
||||
}
|
||||
} else if (partitionsToBeAdded.nonEmpty) {
|
||||
info(s"New partitions to be added $partitionsToBeAdded")
|
||||
partitionsToBeAdded.foreach { case (topicPartition, assignedReplicas) =>
|
||||
controllerContext.updatePartitionFullReplicaAssignment(topicPartition, assignedReplicas)
|
||||
}
|
||||
onNewPartitionCreation(partitionsToBeAdded.keySet)
|
||||
}
|
||||
}
|
||||
```
|
||||
1. 从`brokers/topics/{topicName}`中获取完整的分配信息,例如
|
||||
```json
|
||||
{
|
||||
"version": 2,
|
||||
"partitions": {
|
||||
"2": [0, 1],
|
||||
"1": [0, 1],
|
||||
"0": [0, 1]
|
||||
},
|
||||
"adding_replicas": {
|
||||
"2": [1],
|
||||
"1": [1],
|
||||
"0": [1]
|
||||
},
|
||||
"removing_replicas": {}
|
||||
}
|
||||
```
|
||||
2. 如果有需要新增的分区,如下操作
|
||||
2.1 如果当前Topic刚好在删掉队列中,那么就没有必要进行分区扩容了; 将zk的`brokers/topics/{topicName}`数据恢复回去
|
||||
2.2 如果不在删除队列中,则开始走新增分区的流程;关于新增分区的流程 在[【kafka源码】TopicCommand之创建Topic源码解析
|
||||
]()里面已经详细讲过了,跳转后请搜索关键词`onNewPartitionCreation`
|
||||
|
||||
3. 如果该Topic正在删除中,则跳过该Topic的处理; 并且同时如果有AR(adding_replical),则重写一下zk节点`/broker/topics/{topicName}`节点的数据; 相当于是还原数据; 移除掉里面的AR;
|
||||
|
||||
**这一步完全不用理会,因为 分区副本重分配不会出现新增分区的情况;**
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
#### 2.2.5 Controller监听zk节点`/brokers/topics/{topicName}/partitions/{分区号}/state`
|
||||
> 上面2.2.3 里面的 2.4不是有说过注册一个监听节点`/brokers/topics/{topicName}/partitions/{分区号}/state`变更的处理器`PartitionReassignmentIsrChangeHandler`
|
||||
>
|
||||
到底是什么时候这个节点有变化呢? 前面我们不是对副本们发送了`LEADERANDISR`的请求么, 当新增的副本去leader
|
||||
fetch数据开始同步的时候,当数据同步完成跟上了ISR的节奏,就会去修改这个节点; 修改之后那么下面就开始执行监听流程了
|
||||
|
||||
这里跟 **2.2.3** 中有调用同一个接口; 不过这个时候经过了`LeaderAndIsr`请求
|
||||
`kafkaController.processPartitionReassignmentIsrChange->onPartitionReassignment`
|
||||
```scala
|
||||
private def onPartitionReassignment(topicPartition: TopicPartition, reassignment: ReplicaAssignment): Unit = {
|
||||
// While a reassignment is in progress, deletion is not allowed
|
||||
topicDeletionManager.markTopicIneligibleForDeletion(Set(topicPartition.topic), reason = "topic reassignment in progress")
|
||||
|
||||
updateCurrentReassignment(topicPartition, reassignment)
|
||||
|
||||
val addingReplicas = reassignment.addingReplicas
|
||||
val removingReplicas = reassignment.removingReplicas
|
||||
|
||||
if (!isReassignmentComplete(topicPartition, reassignment)) {
|
||||
// A1. Send LeaderAndIsr request to every replica in ORS + TRS (with the new RS, AR and RR).
|
||||
updateLeaderEpochAndSendRequest(topicPartition, reassignment)
|
||||
// A2. replicas in AR -> NewReplica
|
||||
startNewReplicasForReassignedPartition(topicPartition, addingReplicas)
|
||||
} else {
|
||||
// B1. replicas in AR -> OnlineReplica
|
||||
replicaStateMachine.handleStateChanges(addingReplicas.map(PartitionAndReplica(topicPartition, _)), OnlineReplica)
|
||||
// B2. Set RS = TRS, AR = [], RR = [] in memory.
|
||||
val completedReassignment = ReplicaAssignment(reassignment.targetReplicas)
|
||||
controllerContext.updatePartitionFullReplicaAssignment(topicPartition, completedReassignment)
|
||||
// B3. Send LeaderAndIsr request with a potential new leader (if current leader not in TRS) and
|
||||
// a new RS (using TRS) and same isr to every broker in ORS + TRS or TRS
|
||||
moveReassignedPartitionLeaderIfRequired(topicPartition, completedReassignment)
|
||||
// B4. replicas in RR -> Offline (force those replicas out of isr)
|
||||
// B5. replicas in RR -> NonExistentReplica (force those replicas to be deleted)
|
||||
stopRemovedReplicasOfReassignedPartition(topicPartition, removingReplicas)
|
||||
// B6. Update ZK with RS = TRS, AR = [], RR = [].
|
||||
updateReplicaAssignmentForPartition(topicPartition, completedReassignment)
|
||||
// B7. Remove the ISR reassign listener and maybe update the /admin/reassign_partitions path in ZK to remove this partition from it.
|
||||
removePartitionFromReassigningPartitions(topicPartition, completedReassignment)
|
||||
// B8. After electing a leader in B3, the replicas and isr information changes, so resend the update metadata request to every broker
|
||||
sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq, Set(topicPartition))
|
||||
// signal delete topic thread if reassignment for some partitions belonging to topics being deleted just completed
|
||||
topicDeletionManager.resumeDeletionForTopics(Set(topicPartition.topic))
|
||||
}
|
||||
}
|
||||
```
|
||||
以下几个名称说明:
|
||||
`ORS`: origin repilicas 原先的副本
|
||||
`RS`: Replicas 现在的副本
|
||||
`TRS`: targetReplicas 将要变更成的目标副本
|
||||
`AR`: adding_replicas 正在添加的副本
|
||||
`RR`:removing_replicas 正在移除的副本
|
||||
|
||||
1. 副本状态变更 -> `OnlineReplica`,将 AR 中的所有副本移动到 OnlineReplica 状态
|
||||
2. 在内存中设置 RS = TRS, AR = [], RR = []
|
||||
3. 向 ORS + TRS 或 TRS 中的每个经纪人发送带有潜在新Leader(如果当前Leader不在 TRS 中)和新 RS(使用 TRS)和相同 isr 的` LeaderAndIsr `请求
|
||||
6. 我们可能会将 `LeaderAndIsr `发送到多个 TRS 副本。将 RR 中的所有副本移动到 `OfflineReplica `状态。转换的过程中,有删除 ZooKeeper 中的 RR,并且仅向 Leader 发送一个 `LeaderAndIsr `以通知它缩小的 isr。之后,向 RR 中的副本发送一个 `StopReplica (delete = false)` 这个时候还没有正在的进行删除。
|
||||
7. 将 RR 中的所有副本移动到` NonExistentReplica `状态。这将向 RR 中的副本发送一个 `StopReplica (delete = true) `以物理删除磁盘上的副本。这里的流程可以看看文章[【kafka源码】TopicCommand之删除Topic源码解析]()
|
||||
5. 用RS=TRS, AR=[], RR=[] 更新 zk `/broker/topics/{topicName}` 节点,更新partitions并移除AR(adding_replicas)RR(removing_replicas) 例如
|
||||
```json
|
||||
{"version":2,"partitions":{"2":[0,1],"1":[0,1],"0":[0,1]},"adding_replicas":{},"removing_replicas":{}}
|
||||
|
||||
```
|
||||
|
||||
8. 删除 ISR 重新分配侦听器`/brokers/topics/{topicName}/partitions/{分区号}/state`,并可能更新 ZK 中的 `/admin/reassign_partitions `路径以从中删除此分区(如果存在)
|
||||
9. 选举leader后,replicas和isr信息发生变化。因此,向每个代理重新发送`UPDATE_METADATA`更新元数据请求。
|
||||
10. 恢复删除线程`resumeDeletions`; 该操作[【kafka源码】TopicCommand之删除Topic源码解析]()在分析过; 请移步阅读,并搜索关键字`resumeDeletions`
|
||||
|
||||
|
||||
|
||||
#### 2.2.6 Controller重新选举恢复 恢复任务
|
||||
> KafkaController.onControllerFailover() 里面 有调用接口`initializePartitionReassignments` 会恢复未完成的重分配任务
|
||||
|
||||
#### alterReplicaLogDirs请求
|
||||
> 副本跨路径迁移相关
|
||||
`KafkaApis.handleAlterReplicaLogDirsRequest`
|
||||
```scala
|
||||
def handleAlterReplicaLogDirsRequest(request: RequestChannel.Request): Unit = {
|
||||
val alterReplicaDirsRequest = request.body[AlterReplicaLogDirsRequest]
|
||||
val responseMap = {
|
||||
if (authorize(request, ALTER, CLUSTER, CLUSTER_NAME))
|
||||
replicaManager.alterReplicaLogDirs(alterReplicaDirsRequest.partitionDirs.asScala)
|
||||
else
|
||||
alterReplicaDirsRequest.partitionDirs.asScala.keys.map((_, Errors.CLUSTER_AUTHORIZATION_FAILED)).toMap
|
||||
}
|
||||
sendResponseMaybeThrottle(request, requestThrottleMs => new AlterReplicaLogDirsResponse(requestThrottleMs, responseMap.asJava))
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 2.3`--verify ` 验证结果分析
|
||||
|
||||
>校验执行情况, 顺便移除之前加过的限流配置
|
||||
>`--zookeeper xxxxx --reassignment-json-file config/reassignment-json-file.json --verify`
|
||||
>
|
||||
>
|
||||
源码在`ReassignPartitionsCommand.verifyAssignment` ,很简单 这里就不分析了
|
||||
主要就是把之前写入的配置给清理掉
|
||||
|
||||
|
||||
### 2.4 副本跨路径迁移
|
||||
>为什么线上Kafka机器各个磁盘间的占用不均匀,经常出现“一边倒”的情形? 这是因为Kafka只保证分区数量在各个磁盘上均匀分布,但它无法知晓每个分区实际占用空间,故很有可能出现某些分区消息数量巨大导致占用大量磁盘空间的情况。在1.1版本之前,用户对此毫无办法,因为1.1之前Kafka只支持分区数据在不同broker间的重分配,而无法做到在同一个broker下的不同磁盘间做重分配。1.1版本正式支持副本在不同路径间的迁移
|
||||
|
||||
**怎么在一台Broker上用多个路径存放分区呢?**
|
||||
|
||||
只需要在配置上接多个文件夹就行了
|
||||
```
|
||||
############################# Log Basics #############################
|
||||
|
||||
# A comma separated list of directories under which to store log files
|
||||
log.dirs=kafka-logs-5,kafka-logs-6,kafka-logs-7,kafka-logs-8
|
||||
|
||||
```
|
||||
|
||||
**注意同一个Broker上不同路径只会存放不同的分区,而不会将副本存放在同一个Broker; 不然那副本就没有意义了(容灾)**
|
||||
|
||||
|
||||
**怎么针对跨路径迁移呢?**
|
||||
|
||||
迁移的json文件有一个参数是`log_dirs`; 默认请求不传的话 它是`"log_dirs": ["any"]` (这个数组的数量要跟副本保持一致)
|
||||
但是你想实现跨路径迁移,只需要在这里填入绝对路径就行了,例如下面
|
||||
|
||||
迁移的json文件示例
|
||||
```json
|
||||
{
|
||||
"version": 1,
|
||||
"partitions": [{
|
||||
"topic": "test_create_topic4",
|
||||
"partition": 2,
|
||||
"replicas": [0],
|
||||
"log_dirs": ["/Users/xxxxx/work/IdeaPj/source/kafka/kafka-logs-5"]
|
||||
}, {
|
||||
"topic": "test_create_topic4",
|
||||
"partition": 1,
|
||||
"replicas": [0],
|
||||
"log_dirs": ["/Users/xxxxx/work/IdeaPj/source/kafka/kafka-logs-6"]
|
||||
}]
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
## 3.源码总结
|
||||
|
||||
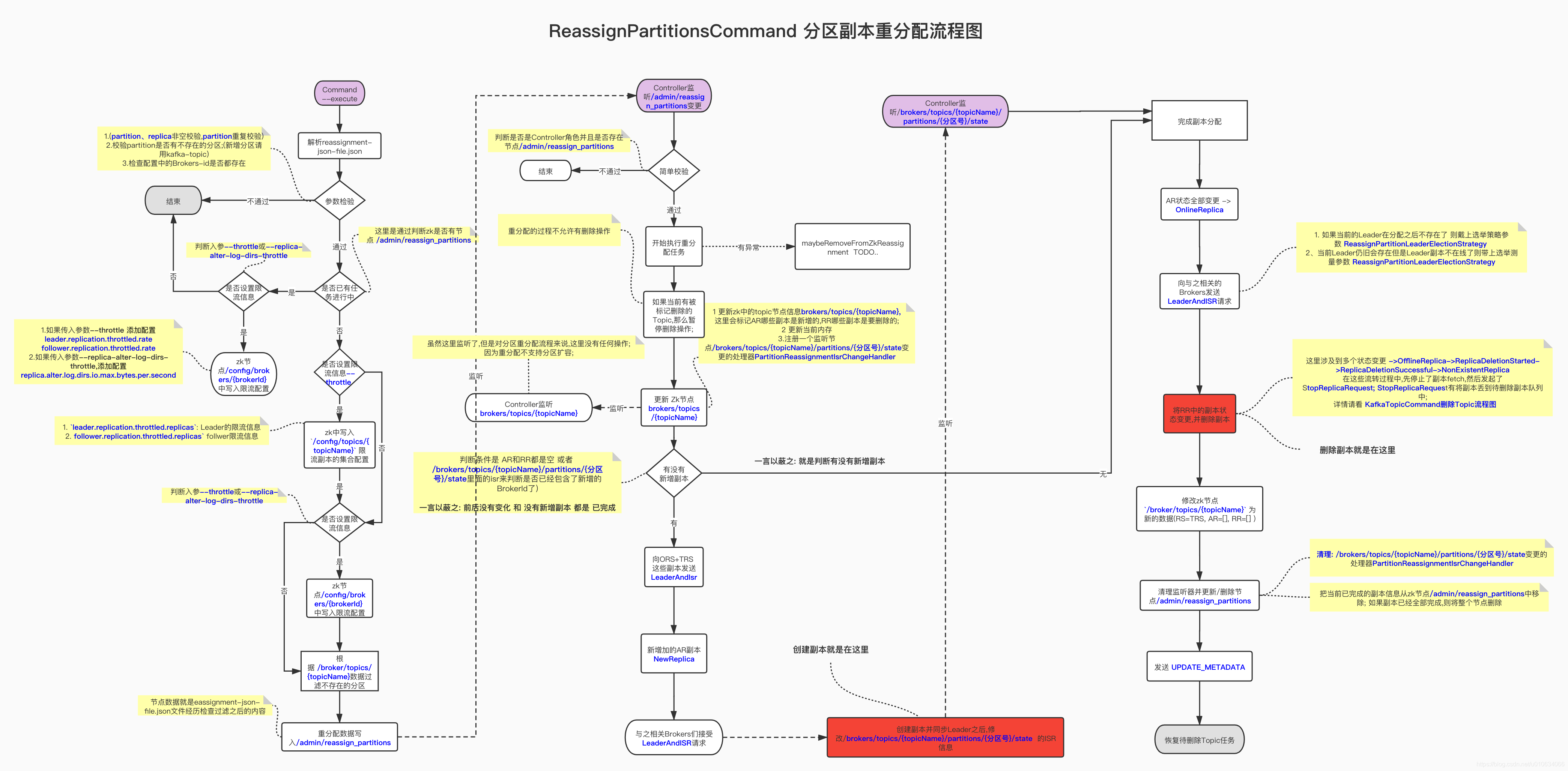
|
||||
|
||||
|
||||
|
||||
## 4.Q&A
|
||||
|
||||
### 如果新增副本之后,会触发副本重新选举吗
|
||||
>**Question:** 如果原来副本分配方式是: `"replicas": [0,1]` 重新分配方式变更成 `"replicas": [0,1,2] `或者 `"replicas": [2,0,1]` Leader会变更吗?
|
||||
> **Answer:** 不会,只要没有涉及到原来的Leader的变更,就不会触发重新选举
|
||||
### 如果删除副本之后,会触发副本重新选举吗
|
||||
>**Question:** 如果原来副本分配方式是: `"replicas": [0,1,2]` 重新分配方式变更成 `"replicas": [0,1] `或者 `"replicas": [2,0]` 或者 `"replicas": [1,2] ` Leader会变更吗?
|
||||
> **Answer:** 不会,只要没有涉及到原来的Leader的变更,就不会触发重新选举 ;
|
||||
> 但是如果是之前的Leader被删除了,那就会触发重新选举了
|
||||
> 如果触发选举了,那么选举策略是什么?策略如下图所述
|
||||
> 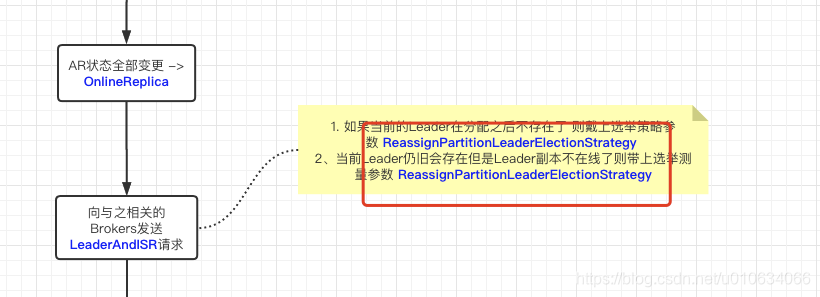
|
||||
|
||||
|
||||
|
||||
|
||||
### 在重新分配的过程中,如果执行删除操作会怎么样
|
||||
> 删除操作会等待,等待重新分配完成之后,继续进行删除操作
|
||||
> 可参考文章 [【kafka源码】TopicCommand之删除Topic源码解析]()中的 源码总结部分
|
||||
> 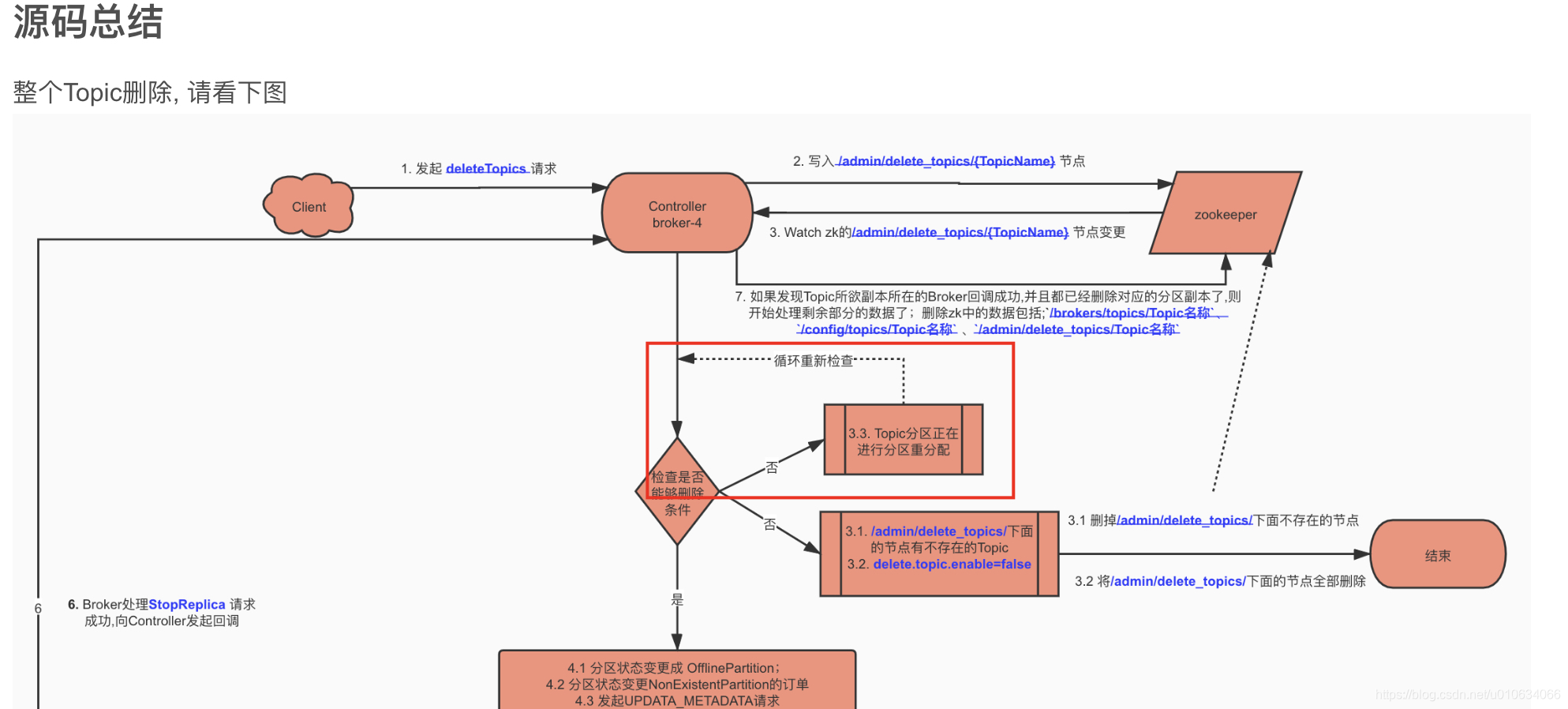
|
||||
|
||||
|
||||
|
||||
### 副本增加是在哪个时机发生的
|
||||
> 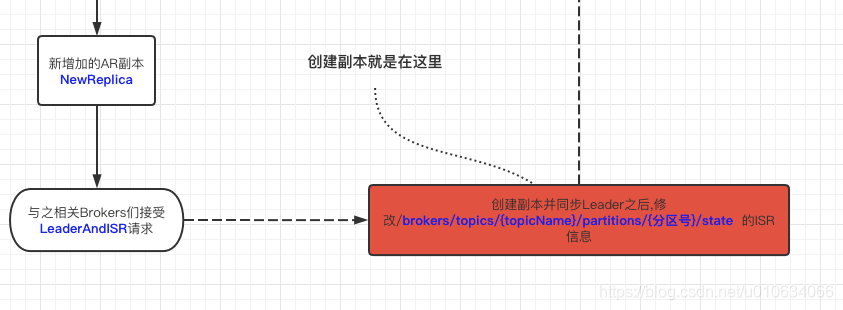
|
||||
>副本新增之后会开始与leader进行同步, 并修改节点`/brokers/topics/{topicName}/partitions/{分区号}/state` 的isr信息
|
||||
|
||||
### 副本删除是在哪个时机发生的
|
||||
>
|
||||
>副本的删除是一个副本状态转换的过程,具体请看 [【kafka源码】Controller中的状态机]()
|
||||
|
||||
|
||||
### 手动在zk中创建`/admin/reassign_partitions`节点能成功重分配吗
|
||||
> 可以但是没必要, 需要做好一些前置校验
|
||||
|
||||
### 限流配置详情
|
||||
> 里面有很多限流的配置, 关于限流相关 请看 [TODO.....]()
|
||||
|
||||
### 如果重新分配没有新增和删除副本,只是副本位置变更了
|
||||
> Q: 假设分区副本 [0,1,2] 变更为[2,1,0] 会把副本删除之后再新增吗? 会触发leader选举吗?
|
||||
> A: 不会, 副本么有增多和减少就不会有 新增和删除副本的流程; 最终只是在zk节点`/broker/topics/{topicName}` 修改了一下顺序而已, 产生影响只会在下一次进行优先副本选举的时候 让第一个副本作为了Leader;
|
||||
### 重分配过程手动写入限流信息会生效吗
|
||||
>关于限流相关 请看 [TODO.....]()
|
||||
|
||||
|
||||
### 如果Controller角色重新选举 那重新分配任务还会继续吗
|
||||
> KafkaController.onControllerFailover() 里面 有调用接口`initializePartitionReassignments` 会恢复未完成的重分配任务
|
||||
@@ -0,0 +1,411 @@
|
||||
|
||||
|
||||
## 脚本参数
|
||||
|
||||
`sh bin/kafka-topic -help` 查看更具体参数
|
||||
|
||||
下面只是列出了跟` --alter` 相关的参数
|
||||
|
||||
| 参数 |描述 |例子|
|
||||
|--|--|--|
|
||||
|`--bootstrap-server ` 指定kafka服务|指定连接到的kafka服务; 如果有这个参数,则 `--zookeeper`可以不需要|--bootstrap-server localhost:9092 |
|
||||
|`--replica-assignment `|副本分区分配方式;修改topic的时候可以自己指定副本分配情况; |`--replica-assignment id0:id1:id2,id3:id4:id5,id6:id7:id8 `;其中,“id0:id1:id2,id3:id4:id5,id6:id7:id8”表示Topic TopicName一共有3个Partition(以“,”分隔),每个Partition均有3个Replica(以“:”分隔),Topic Partition Replica与Kafka Broker之间的对应关系如下:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## Alert Topic脚本
|
||||
|
||||
|
||||
## 分区扩容
|
||||
**zk方式(不推荐)**
|
||||
```sh
|
||||
bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic topic1 --partitions 2
|
||||
```
|
||||
|
||||
**kafka版本 >= 2.2 支持下面方式(推荐)**
|
||||
**单个Topic扩容**
|
||||
>`bin/kafka-topics.sh --bootstrap-server broker_host:port --alter --topic test_create_topic1 --partitions 4`
|
||||
|
||||
**批量扩容** (将所有正则表达式匹配到的Topic分区扩容到4个)
|
||||
>`sh bin/kafka-topics.sh --topic ".*?" --bootstrap-server 172.23.248.85:9092 --alter --partitions 4`
|
||||
>
|
||||
`".*?"` 正则表达式的意思是匹配所有; 您可按需匹配
|
||||
|
||||
**PS:** 当某个Topic的分区少于指定的分区数时候,他会抛出异常;但是不会影响其他Topic正常进行;
|
||||
|
||||
---
|
||||
|
||||
相关可选参数
|
||||
| 参数 |描述 |例子|
|
||||
|--|--|--|
|
||||
|`--replica-assignment `|副本分区分配方式;创建topic的时候可以自己指定副本分配情况; |`--replica-assignment` BrokerId-0:BrokerId-1:BrokerId-2,BrokerId-1:BrokerId-2:BrokerId-0,BrokerId-2:BrokerId-1:BrokerId-0 ; 这个意思是有三个分区和三个副本,对应分配的Broker; 逗号隔开标识分区;冒号隔开表示副本|
|
||||
|
||||
**PS: 虽然这里配置的是全部的分区副本分配配置,但是正在生效的是新增的分区;**
|
||||
比如: 以前3分区1副本是这样的
|
||||
| Broker-1 |Broker-2 |Broker-3|Broker-4|
|
||||
|--|--|--|--|
|
||||
|0 | 1 |2|
|
||||
现在新增一个分区,`--replica-assignment` 2,1,3,4 ; 看这个意思好像是把0,1号分区互相换个Broker
|
||||
| Broker-1 |Broker-2 |Broker-3|Broker-4|
|
||||
|--|--|--|--|
|
||||
|1 | 0 |2|3||
|
||||
但是实际上不会这样做,Controller在处理的时候会把前面3个截掉; 只取新增的分区分配方式,原来的还是不会变
|
||||
| Broker-1 |Broker-2 |Broker-3|Broker-4|
|
||||
|--|--|--|--|
|
||||
|0 | 1 |2|3||
|
||||
|
||||
## 源码解析
|
||||
> <font color=red>如果觉得源码解析过程比较枯燥乏味,可以直接如果 **源码总结及其后面部分**</font>
|
||||
|
||||
因为在 [【kafka源码】TopicCommand之创建Topic源码解析]() 里面分析的比较详细; 故本文就着重点分析了;
|
||||
|
||||
### 1. `TopicCommand.alterTopic`
|
||||
```scala
|
||||
override def alterTopic(opts: TopicCommandOptions): Unit = {
|
||||
val topic = new CommandTopicPartition(opts)
|
||||
val topics = getTopics(opts.topic, opts.excludeInternalTopics)
|
||||
//校验Topic是否存在
|
||||
ensureTopicExists(topics, opts.topic)
|
||||
//获取一下该topic的一些基本信息
|
||||
val topicsInfo = adminClient.describeTopics(topics.asJavaCollection).values()
|
||||
adminClient.createPartitions(topics.map {topicName =>
|
||||
//判断是否有参数 replica-assignment 指定分区分配方式
|
||||
if (topic.hasReplicaAssignment) {
|
||||
val startPartitionId = topicsInfo.get(topicName).get().partitions().size()
|
||||
val newAssignment = {
|
||||
val replicaMap = topic.replicaAssignment.get.drop(startPartitionId)
|
||||
new util.ArrayList(replicaMap.map(p => p._2.asJava).asJavaCollection).asInstanceOf[util.List[util.List[Integer]]]
|
||||
}
|
||||
topicName -> NewPartitions.increaseTo(topic.partitions.get, newAssignment)
|
||||
} else {
|
||||
|
||||
topicName -> NewPartitions.increaseTo(topic.partitions.get)
|
||||
}}.toMap.asJava).all().get()
|
||||
}
|
||||
```
|
||||
1. 校验Topic是否存在
|
||||
2. 如果设置了`--replica-assignment `参数, 则会算出新增的分区数的分配; 这个并不会修改原本已经分配好的分区结构.从源码就可以看出来,假如我之前的分配方式是3,3,3(3分区一个副本都在BrokerId-3上)现在我传入的参数是: `3,3,3,3`(多出来一个分区),这个时候会把原有的给截取掉;只传入3,(表示在Broker3新增一个分区)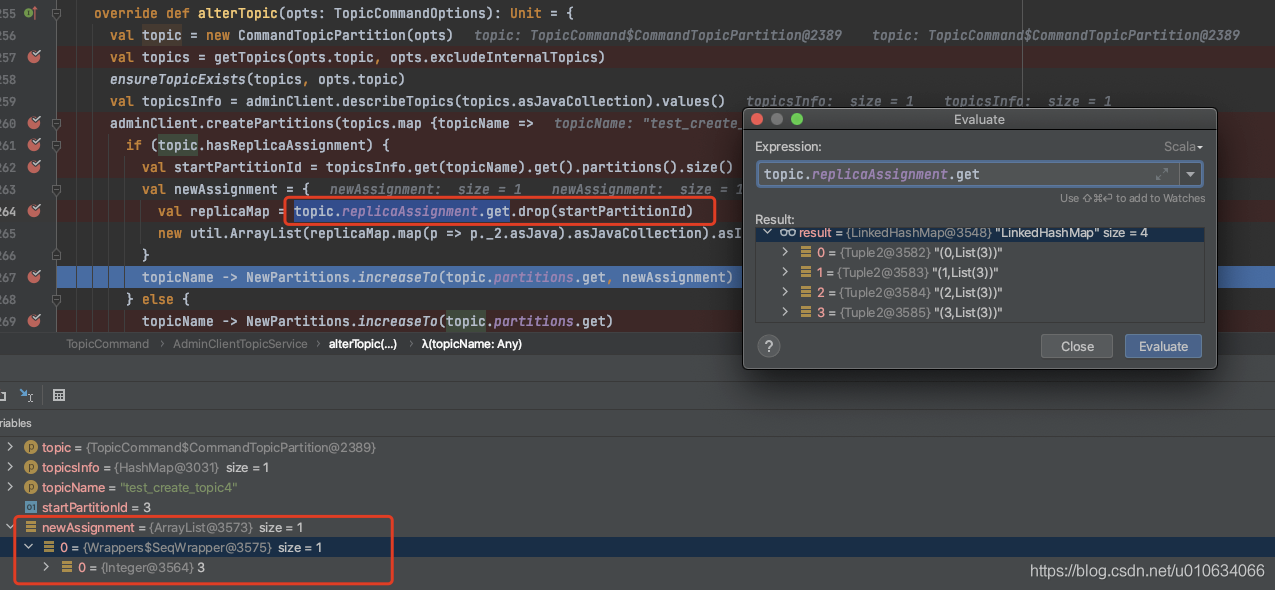
|
||||
3. 如果没有传入参数`--replica-assignment`,则后面会用默认分配策略分配
|
||||
|
||||
#### 客户端发起请求createPartitions
|
||||
|
||||
`KafkaAdminClient.createPartitions` 省略部分代码
|
||||
```java
|
||||
@Override
|
||||
public CreatePartitionsResult createPartitions(Map<String, NewPartitions> newPartitions,
|
||||
final CreatePartitionsOptions options) {
|
||||
final Map<String, KafkaFutureImpl<Void>> futures = new HashMap<>(newPartitions.size());
|
||||
for (String topic : newPartitions.keySet()) {
|
||||
futures.put(topic, new KafkaFutureImpl<>());
|
||||
}
|
||||
runnable.call(new Call("createPartitions", calcDeadlineMs(now, options.timeoutMs()),
|
||||
new ControllerNodeProvider()) {
|
||||
//省略部分代码
|
||||
@Override
|
||||
void handleFailure(Throwable throwable) {
|
||||
completeAllExceptionally(futures.values(), throwable);
|
||||
}
|
||||
}, now);
|
||||
return new CreatePartitionsResult(new HashMap<>(futures));
|
||||
}
|
||||
```
|
||||
1. 从源码中可以看到向`ControllerNodeProvider` 发起来`createPartitions`请求
|
||||
|
||||
|
||||
### 2. Controller角色的服务端接受createPartitions请求处理逻辑
|
||||
>
|
||||
`KafkaApis.handleCreatePartitionsRequest`
|
||||
```scala
|
||||
def handleCreatePartitionsRequest(request: RequestChannel.Request): Unit = {
|
||||
val createPartitionsRequest = request.body[CreatePartitionsRequest]
|
||||
|
||||
//部分代码省略..
|
||||
|
||||
//如果当前不是Controller角色直接抛出异常
|
||||
if (!controller.isActive) {
|
||||
val result = createPartitionsRequest.data.topics.asScala.map { topic =>
|
||||
(topic.name, new ApiError(Errors.NOT_CONTROLLER, null))
|
||||
}.toMap
|
||||
sendResponseCallback(result)
|
||||
} else {
|
||||
// Special handling to add duplicate topics to the response
|
||||
val topics = createPartitionsRequest.data.topics.asScala
|
||||
val dupes = topics.groupBy(_.name)
|
||||
.filter { _._2.size > 1 }
|
||||
.keySet
|
||||
val notDuped = topics.filterNot(topic => dupes.contains(topic.name))
|
||||
val authorizedTopics = filterAuthorized(request, ALTER, TOPIC, notDuped.map(_.name))
|
||||
val (authorized, unauthorized) = notDuped.partition { topic => authorizedTopics.contains(topic.name) }
|
||||
|
||||
val (queuedForDeletion, valid) = authorized.partition { topic =>
|
||||
controller.topicDeletionManager.isTopicQueuedUpForDeletion(topic.name)
|
||||
}
|
||||
|
||||
val errors = dupes.map(_ -> new ApiError(Errors.INVALID_REQUEST, "Duplicate topic in request.")) ++
|
||||
unauthorized.map(_.name -> new ApiError(Errors.TOPIC_AUTHORIZATION_FAILED, "The topic authorization is failed.")) ++
|
||||
queuedForDeletion.map(_.name -> new ApiError(Errors.INVALID_TOPIC_EXCEPTION, "The topic is queued for deletion."))
|
||||
|
||||
adminManager.createPartitions(createPartitionsRequest.data.timeoutMs,
|
||||
valid,
|
||||
createPartitionsRequest.data.validateOnly,
|
||||
request.context.listenerName, result => sendResponseCallback(result ++ errors))
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
1. 检验自身是不是Controller角色,不是的话就抛出异常终止流程
|
||||
2. 鉴权
|
||||
3. 调用` adminManager.createPartitions`
|
||||
3.1 从zk中获取`/brokers/ids/`Brokers列表的元信息的
|
||||
3.2 从zk获取`/brokers/topics/{topicName}`已经存在的副本分配方式,并判断是否有正在进行副本重分配的进程在执行,如果有的话就抛出异常结束流程
|
||||
3.3 如果从zk获取`/brokers/topics/{topicName}`数据不存在则抛出异常 `The topic '$topic' does not exist`
|
||||
3.4 检查修改的分区数是否比原来的分区数大,如果比原来还小或者等于原来分区数则抛出异常结束流程
|
||||
3.5 如果传入的参数`--replica-assignment` 中有不存在的BrokerId;则抛出异常`Unknown broker(s) in replica assignment`结束流程
|
||||
3.5 如果传入的`--partitions`数量 与`--replica-assignment`中新增的部分数量不匹配则抛出异常`Increasing the number of partitions by...` 结束流程
|
||||
3.6 调用` adminZkClient.addPartitions`
|
||||
|
||||
|
||||
#### ` adminZkClient.addPartitions` 添加分区
|
||||
|
||||
|
||||
1. 校验`--partitions`数量是否比存在的分区数大,否则异常`The number of partitions for a topic can only be increased`
|
||||
2. 如果传入了`--replica-assignment` ,则对副本进行一些简单的校验
|
||||
3. 调用`AdminUtils.assignReplicasToBrokers`分配副本 ; 这个我们在[【kafka源码】TopicCommand之创建Topic源码解析]() 也分析过; 具体请看[【kafka源码】创建Topic的时候是如何分区和副本的分配规则](); 当然这里由于我们是新增的分区,只会将新增的分区进行分配计算
|
||||
4. 得到分配规则只后,调用`adminZkClient.writeTopicPartitionAssignment` 写入
|
||||
|
||||
#### adminZkClient.writeTopicPartitionAssignment将分区信息写入zk中
|
||||
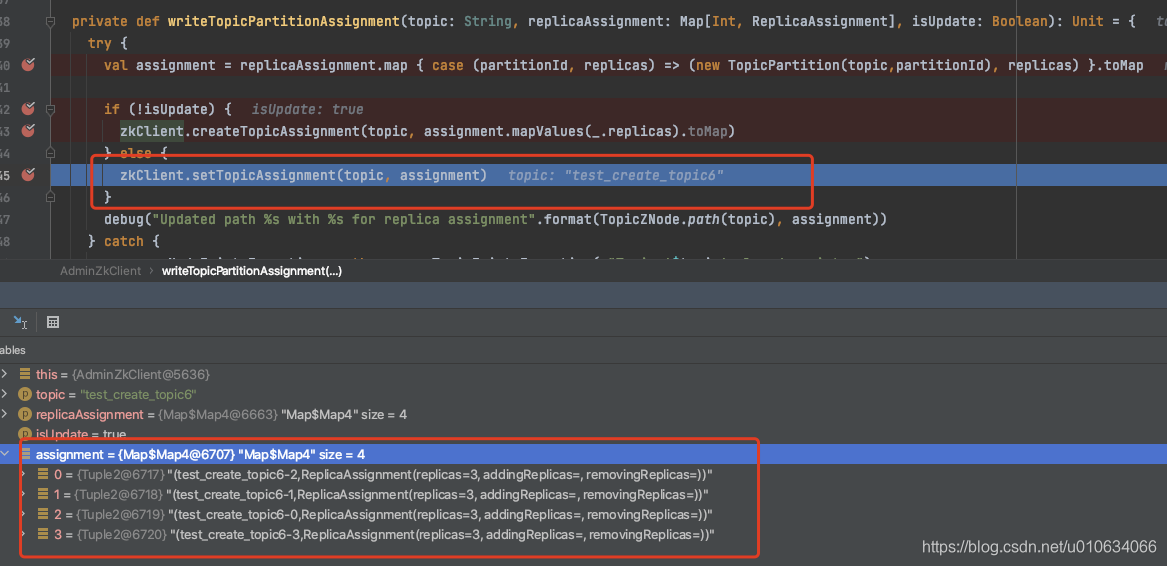
|
||||
|
||||
我们在 [【kafka源码】TopicCommand之创建Topic源码解析]()的时候也分析过这段代码,但是那个时候调用的是`zkClient.createTopicAssignment` 创建接口
|
||||
这里我们是调用` zkClient.setTopicAssignment` 写入接口, 写入当然会覆盖掉原有的信息,所以写入的时候会把原来分区信息获取到,重新写入;
|
||||
|
||||
1. 获取Topic原有分区副本分配信息
|
||||
2. 将原有的和现在要添加的组装成一个数据对象写入到zk节点`/brokers/topics/{topicName}`中
|
||||
|
||||
|
||||
### 3. Controller监控节点`/brokers/topics/{topicName}` ,真正在Broker上将分区写入磁盘
|
||||
监听到节点信息变更之后调用下面的接口;
|
||||
`KafkaController.processPartitionModifications`
|
||||
```scala
|
||||
private def processPartitionModifications(topic: String): Unit = {
|
||||
def restorePartitionReplicaAssignment(
|
||||
topic: String,
|
||||
newPartitionReplicaAssignment: Map[TopicPartition, ReplicaAssignment]
|
||||
): Unit = {
|
||||
info("Restoring the partition replica assignment for topic %s".format(topic))
|
||||
|
||||
val existingPartitions = zkClient.getChildren(TopicPartitionsZNode.path(topic))
|
||||
val existingPartitionReplicaAssignment = newPartitionReplicaAssignment
|
||||
.filter(p => existingPartitions.contains(p._1.partition.toString))
|
||||
.map { case (tp, _) =>
|
||||
tp -> controllerContext.partitionFullReplicaAssignment(tp)
|
||||
}.toMap
|
||||
|
||||
zkClient.setTopicAssignment(topic,
|
||||
existingPartitionReplicaAssignment,
|
||||
controllerContext.epochZkVersion)
|
||||
}
|
||||
|
||||
if (!isActive) return
|
||||
val partitionReplicaAssignment = zkClient.getFullReplicaAssignmentForTopics(immutable.Set(topic))
|
||||
val partitionsToBeAdded = partitionReplicaAssignment.filter { case (topicPartition, _) =>
|
||||
controllerContext.partitionReplicaAssignment(topicPartition).isEmpty
|
||||
}
|
||||
|
||||
if (topicDeletionManager.isTopicQueuedUpForDeletion(topic)) {
|
||||
if (partitionsToBeAdded.nonEmpty) {
|
||||
warn("Skipping adding partitions %s for topic %s since it is currently being deleted"
|
||||
.format(partitionsToBeAdded.map(_._1.partition).mkString(","), topic))
|
||||
|
||||
restorePartitionReplicaAssignment(topic, partitionReplicaAssignment)
|
||||
} else {
|
||||
// This can happen if existing partition replica assignment are restored to prevent increasing partition count during topic deletion
|
||||
info("Ignoring partition change during topic deletion as no new partitions are added")
|
||||
}
|
||||
} else if (partitionsToBeAdded.nonEmpty) {
|
||||
info(s"New partitions to be added $partitionsToBeAdded")
|
||||
partitionsToBeAdded.foreach { case (topicPartition, assignedReplicas) =>
|
||||
controllerContext.updatePartitionFullReplicaAssignment(topicPartition, assignedReplicas)
|
||||
}
|
||||
onNewPartitionCreation(partitionsToBeAdded.keySet)
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
1. 判断是否Controller,不是则直接结束流程
|
||||
2. 获取`/brokers/topics/{topicName}` 节点信息, 然后再对比一下当前该节点的分区分配信息; 看看有没有是新增的分区; 如果是新增的分区这个时候是还没有`/brokers/topics/{topicName}/partitions/{分区号}/state` ;
|
||||
3. 如果当前的TOPIC正在被删除中,那么就没有必要执行扩分区了
|
||||
5. 将新增加的分区信息加载到内存中
|
||||
6. 调用接口`KafkaController.onNewPartitionCreation`
|
||||
|
||||
#### KafkaController.onNewPartitionCreation 新增分区
|
||||
从这里开始 , 后面的流程就跟创建Topic的对应流程一样了;
|
||||
|
||||
> 该接口主要是针对新增分区和副本的一些状态流转过程; 在[【kafka源码】TopicCommand之创建Topic源码解析]() 也同样分析过
|
||||
|
||||
```scala
|
||||
/**
|
||||
* This callback is invoked by the topic change callback with the list of failed brokers as input.
|
||||
* It does the following -
|
||||
* 1. Move the newly created partitions to the NewPartition state
|
||||
* 2. Move the newly created partitions from NewPartition->OnlinePartition state
|
||||
*/
|
||||
private def onNewPartitionCreation(newPartitions: Set[TopicPartition]): Unit = {
|
||||
info(s"New partition creation callback for ${newPartitions.mkString(",")}")
|
||||
partitionStateMachine.handleStateChanges(newPartitions.toSeq, NewPartition)
|
||||
replicaStateMachine.handleStateChanges(controllerContext.replicasForPartition(newPartitions).toSeq, NewReplica)
|
||||
partitionStateMachine.handleStateChanges(
|
||||
newPartitions.toSeq,
|
||||
OnlinePartition,
|
||||
Some(OfflinePartitionLeaderElectionStrategy(false))
|
||||
)
|
||||
replicaStateMachine.handleStateChanges(controllerContext.replicasForPartition(newPartitions).toSeq, OnlineReplica)
|
||||
}
|
||||
```
|
||||
1. 将待创建的分区状态流转为`NewPartition`;
|
||||
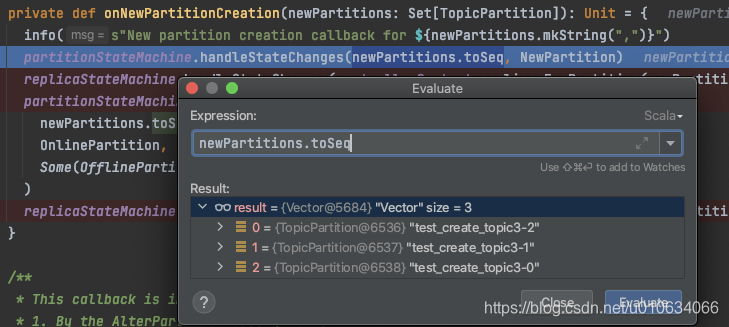
|
||||
2. 将待创建的副本 状态流转为`NewReplica`;
|
||||
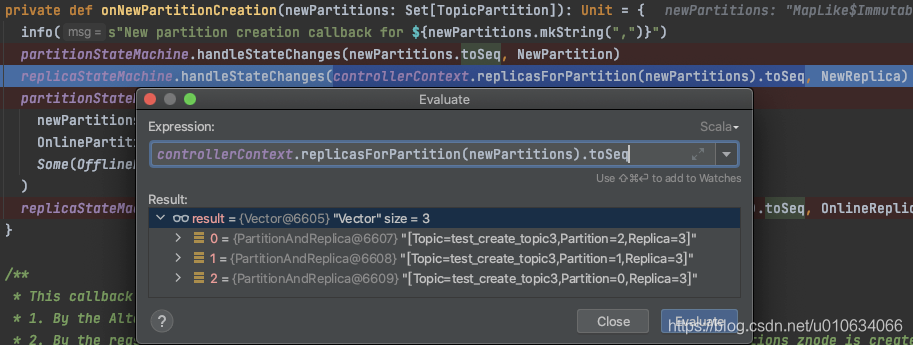
|
||||
3. 将分区状态从刚刚的`NewPartition`流转为`OnlinePartition`
|
||||
0. 获取`leaderIsrAndControllerEpochs`; Leader为副本的第一个;
|
||||
1. 向zk中写入`/brokers/topics/{topicName}/partitions/` 持久节点; 无数据
|
||||
2. 向zk中写入`/brokers/topics/{topicName}/partitions/{分区号}` 持久节点; 无数据
|
||||
3. 向zk中写入`/brokers/topics/{topicName}/partitions/{分区号}/state` 持久节点; 数据为`leaderIsrAndControllerEpoch`
|
||||
4. 向副本所属Broker发送[`leaderAndIsrRequest`]()请求
|
||||
5. 向所有Broker发送[`UPDATE_METADATA` ]()请求
|
||||
4. 将副本状态从刚刚的`NewReplica`流转为`OnlineReplica` ,更新下内存
|
||||
|
||||
关于分区状态机和副本状态机详情请看[【kafka源码】Controller中的状态机](TODO)
|
||||
|
||||
### 4. Broker收到LeaderAndIsrRequest 创建本地Log
|
||||
>上面步骤中有说到向副本所属Broker发送[`leaderAndIsrRequest`]()请求,那么这里做了什么呢
|
||||
>其实主要做的是 创建本地Log
|
||||
>
|
||||
代码太多,这里我们直接定位到只跟创建Topic相关的关键代码来分析
|
||||
`KafkaApis.handleLeaderAndIsrRequest->replicaManager.becomeLeaderOrFollower->ReplicaManager.makeLeaders...LogManager.getOrCreateLog`
|
||||
|
||||
```scala
|
||||
/**
|
||||
* 如果日志已经存在,只返回现有日志的副本否则如果 isNew=true 或者如果没有离线日志目录,则为给定的主题和给定的分区创建日志 否则抛出 KafkaStorageException
|
||||
*/
|
||||
def getOrCreateLog(topicPartition: TopicPartition, config: LogConfig, isNew: Boolean = false, isFuture: Boolean = false): Log = {
|
||||
logCreationOrDeletionLock synchronized {
|
||||
getLog(topicPartition, isFuture).getOrElse {
|
||||
// create the log if it has not already been created in another thread
|
||||
if (!isNew && offlineLogDirs.nonEmpty)
|
||||
throw new KafkaStorageException(s"Can not create log for $topicPartition because log directories ${offlineLogDirs.mkString(",")} are offline")
|
||||
|
||||
val logDirs: List[File] = {
|
||||
val preferredLogDir = preferredLogDirs.get(topicPartition)
|
||||
|
||||
if (isFuture) {
|
||||
if (preferredLogDir == null)
|
||||
throw new IllegalStateException(s"Can not create the future log for $topicPartition without having a preferred log directory")
|
||||
else if (getLog(topicPartition).get.dir.getParent == preferredLogDir)
|
||||
throw new IllegalStateException(s"Can not create the future log for $topicPartition in the current log directory of this partition")
|
||||
}
|
||||
|
||||
if (preferredLogDir != null)
|
||||
List(new File(preferredLogDir))
|
||||
else
|
||||
nextLogDirs()
|
||||
}
|
||||
|
||||
val logDirName = {
|
||||
if (isFuture)
|
||||
Log.logFutureDirName(topicPartition)
|
||||
else
|
||||
Log.logDirName(topicPartition)
|
||||
}
|
||||
|
||||
val logDir = logDirs
|
||||
.toStream // to prevent actually mapping the whole list, lazy map
|
||||
.map(createLogDirectory(_, logDirName))
|
||||
.find(_.isSuccess)
|
||||
.getOrElse(Failure(new KafkaStorageException("No log directories available. Tried " + logDirs.map(_.getAbsolutePath).mkString(", "))))
|
||||
.get // If Failure, will throw
|
||||
|
||||
val log = Log(
|
||||
dir = logDir,
|
||||
config = config,
|
||||
logStartOffset = 0L,
|
||||
recoveryPoint = 0L,
|
||||
maxProducerIdExpirationMs = maxPidExpirationMs,
|
||||
producerIdExpirationCheckIntervalMs = LogManager.ProducerIdExpirationCheckIntervalMs,
|
||||
scheduler = scheduler,
|
||||
time = time,
|
||||
brokerTopicStats = brokerTopicStats,
|
||||
logDirFailureChannel = logDirFailureChannel)
|
||||
|
||||
if (isFuture)
|
||||
futureLogs.put(topicPartition, log)
|
||||
else
|
||||
currentLogs.put(topicPartition, log)
|
||||
|
||||
info(s"Created log for partition $topicPartition in $logDir with properties " + s"{${config.originals.asScala.mkString(", ")}}.")
|
||||
// Remove the preferred log dir since it has already been satisfied
|
||||
preferredLogDirs.remove(topicPartition)
|
||||
|
||||
log
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
1. 如果日志已经存在,只返回现有日志的副本否则如果 isNew=true 或者如果没有离线日志目录,则为给定的主题和给定的分区创建日志 否则抛出` KafkaStorageException`
|
||||
|
||||
详细请看 [【kafka源码】LeaderAndIsrRequest请求]()
|
||||
|
||||
|
||||
## 源码总结
|
||||
看图说话
|
||||
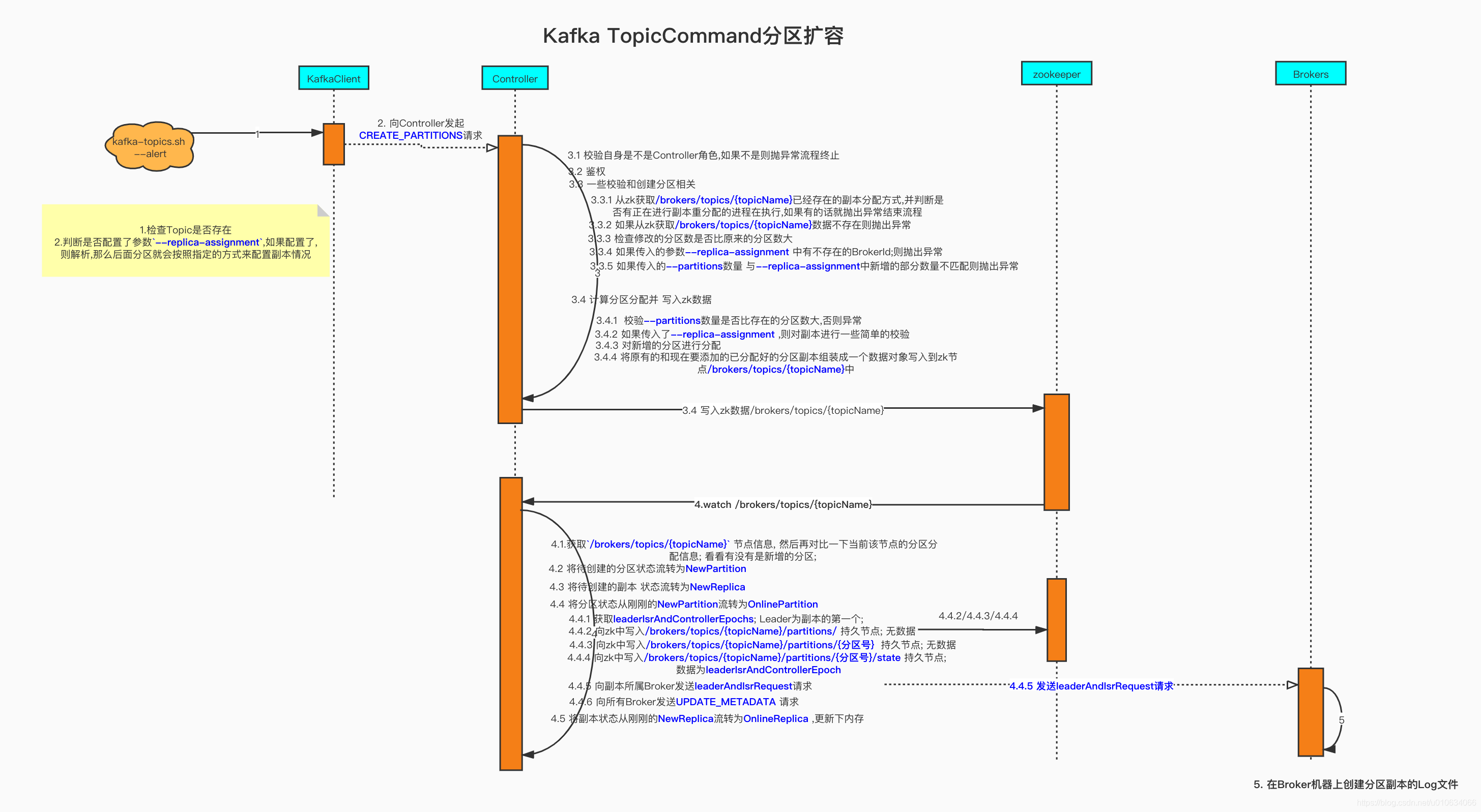
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## Q&A
|
||||
|
||||
### 如果自定义的分配Broker不存在会怎么样
|
||||
> 会抛出异常`Unknown broker(s) in replica assignment`, 因为在执行的时候会去zk获取当前的在线Broker列表,然后判断是否在线;
|
||||
|
||||
### 如果设置的分区数不等于 `--replica-assignment`中新增的数目会怎么样
|
||||
>会抛出异常`Increasing the number of partitions by..`结束流程
|
||||
|
||||
### 如果写入`/brokers/topics/{topicName}`之后 Controller监听到请求正好挂掉怎么办
|
||||
> Controller挂掉会发生重新选举,选举成功之后, 检查到`/brokers/topics/{topicName}`之后发现没有生成对应的分区,会自动执行接下来的流程;
|
||||
|
||||
|
||||
### 如果我手动在zk中写入节点`/brokers/topics/{topicName}/partitions/{分区号}/state` 会怎么样
|
||||
> Controller并没有监听这个节点,所以不会有变化; 但是当Controller发生重新选举的时候,
|
||||
> **被删除的节点会被重新添加回来;**
|
||||
>但是**写入的节点 就不会被删除了**;写入的节点信息会被保存在Controller内存中;
|
||||
>同样这会影响到分区扩容
|
||||
>
|
||||
>
|
||||
> ----
|
||||
> 例子🌰:
|
||||
> 当前分区3个,副本一个,手贱在zk上添加了一个节点如下图:
|
||||
> 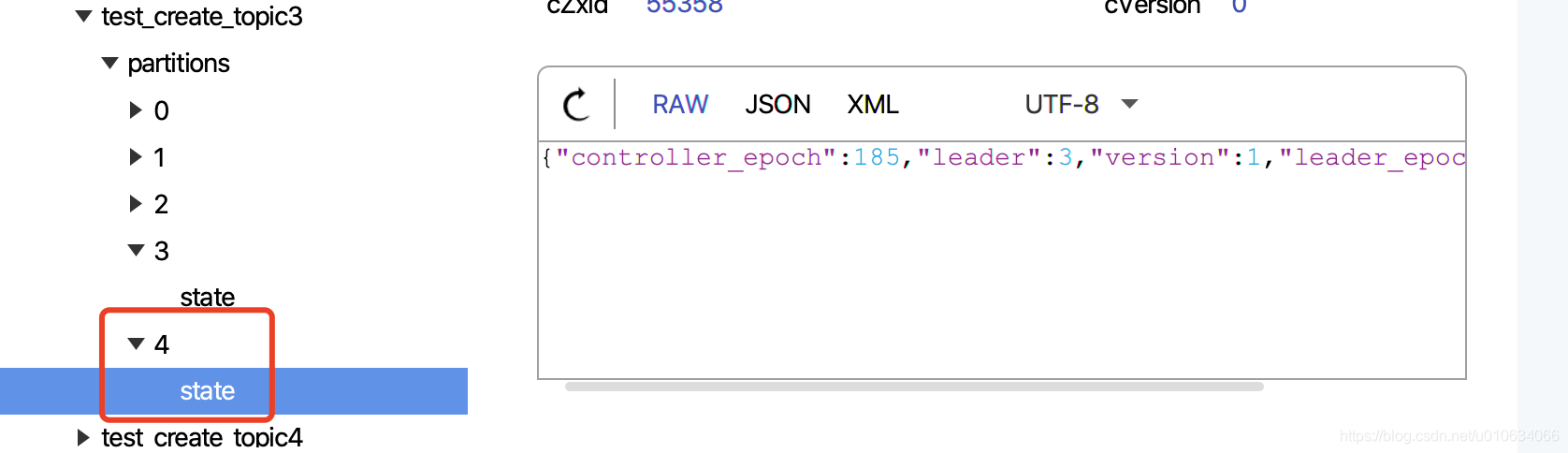
|
||||
> 这个时候我想扩展一个分区; 然后执行了脚本, 虽然`/brokers/topics/test_create_topic3`节点数据变; 但是Broker真正在`LeaderAndIsrRequest`请求里面没有执行创建本地Log文件; 这是因为源码读取到zk下面partitions的节点数量和新增之后的节点数量没有变更,那么它就认为本次请求没有变更就不会执行创建本地Log文件了;
|
||||
> 如果判断有变更,还是会去创建的;
|
||||
> 手贱zk写入N个partition节点 + 扩充N个分区 = Log文件不会被创建
|
||||
> 手贱zk写入N个partition节点 + 扩充>N个分区 = 正常扩容
|
||||
|
||||
### 如果直接修改节点/brokers/topics/{topicName}中的配置会怎么样
|
||||
>如果该节点信息是`{"version":2,"partitions":{"2":[1],"1":[1],"0":[1]},"adding_replicas":{},"removing_replicas":{}}` 看数据,说明3个分区1个副本都在Broker-1上;
|
||||
>我在zk上修改成`{"version":2,"partitions":{"2":[2],"1":[1],"0":[0]},"adding_replicas":{},"removing_replicas":{}}`
|
||||
>想将分区分配到 Broker-0,Broker-1,Broker-2上
|
||||
>TODO。。。
|
||||
|
||||
|
||||
|
||||
---
|
||||
<font color=red size=5>Tips:如果关于本篇文章你有疑问,可以在评论区留下,我会在**Q&A**部分进行解答 </font>
|
||||
|
||||
|
||||
|
||||
<font color=red size=2>PS: 文章阅读的源码版本是kafka-2.5 </font>
|
||||
597
docs/zh/Kafka分享/Kafka Controller /TopicCommand之创建Topic源码解析.md
Normal file
597
docs/zh/Kafka分享/Kafka Controller /TopicCommand之创建Topic源码解析.md
Normal file
@@ -0,0 +1,597 @@
|
||||
|
||||
## 脚本参数
|
||||
|
||||
`sh bin/kafka-topic -help` 查看更具体参数
|
||||
|
||||
下面只是列出了跟` --create` 相关的参数
|
||||
|
||||
| 参数 |描述 |例子|
|
||||
|--|--|--|
|
||||
|`--bootstrap-server ` 指定kafka服务|指定连接到的kafka服务; 如果有这个参数,则 `--zookeeper`可以不需要|--bootstrap-server localhost:9092 |
|
||||
|`--zookeeper`|弃用, 通过zk的连接方式连接到kafka集群;|--zookeeper localhost:2181 或者localhost:2181/kafka|
|
||||
|`--replication-factor `|副本数量,注意不能大于broker数量;如果不提供,则会用集群中默认配置|--replication-factor 3 |
|
||||
|`--partitions`|分区数量|当创建或者修改topic的时候,用这个来指定分区数;如果创建的时候没有提供参数,则用集群中默认值; 注意如果是修改的时候,分区比之前小会有问题|--partitions 3 |
|
||||
|`--replica-assignment `|副本分区分配方式;创建topic的时候可以自己指定副本分配情况; |`--replica-assignment` BrokerId-0:BrokerId-1:BrokerId-2,BrokerId-1:BrokerId-2:BrokerId-0,BrokerId-2:BrokerId-1:BrokerId-0 ; 这个意思是有三个分区和三个副本,对应分配的Broker; 逗号隔开标识分区;冒号隔开表示副本|
|
||||
| `--config `<String: name=value> |用来设置topic级别的配置以覆盖默认配置;**只在--create 和--bootstrap-server 同时使用时候生效**; 可以配置的参数列表请看文末附件 |例如覆盖两个配置 `--config retention.bytes=123455 --config retention.ms=600001`|
|
||||
|`--command-config` <String: command 文件路径> |用来配置客户端Admin Client启动配置,**只在--bootstrap-server 同时使用时候生效**;|例如:设置请求的超时时间 `--command-config config/producer.proterties `; 然后在文件中配置 request.timeout.ms=300000|
|
||||
|`--create`|命令方式; 表示当前请求是创建Topic|`--create`|
|
||||
|
||||
|
||||
|
||||
|
||||
## 创建Topic脚本
|
||||
**zk方式(不推荐)**
|
||||
```shell
|
||||
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 3 --topic test
|
||||
```
|
||||
<font color="red">需要注意的是--zookeeper后面接的是kafka的zk配置, 假如你配置的是localhost:2181/kafka 带命名空间的这种,不要漏掉了 </font>
|
||||
|
||||
**kafka版本 >= 2.2 支持下面方式(推荐)**
|
||||
```shell
|
||||
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 3 --partitions 3 --topic test
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
当前分析的kafka源码版本为 `kafka-2.5`
|
||||
|
||||
## 创建Topic 源码分析
|
||||
<font color="red">温馨提示: 如果阅读源码略显枯燥,你可以直接看源码总结以及后面部分</font>
|
||||
|
||||
首先我们找到源码入口处, 查看一下 `kafka-topic.sh`脚本的内容
|
||||
`exec $(dirname $0)/kafka-run-class.sh kafka.admin.TopicCommand "$@"`
|
||||
最终是执行了`kafka.admin.TopicCommand`这个类,找到这个地方之后就可以断点调试源码了,用IDEA启动
|
||||
|
||||
记得配置一下入参
|
||||
比如: `--create --bootstrap-server 127.0.0.1:9092 --partitions 3 --topic test_create_topic3`
|
||||
|
||||
|
||||
|
||||
### 1. 源码入口
|
||||
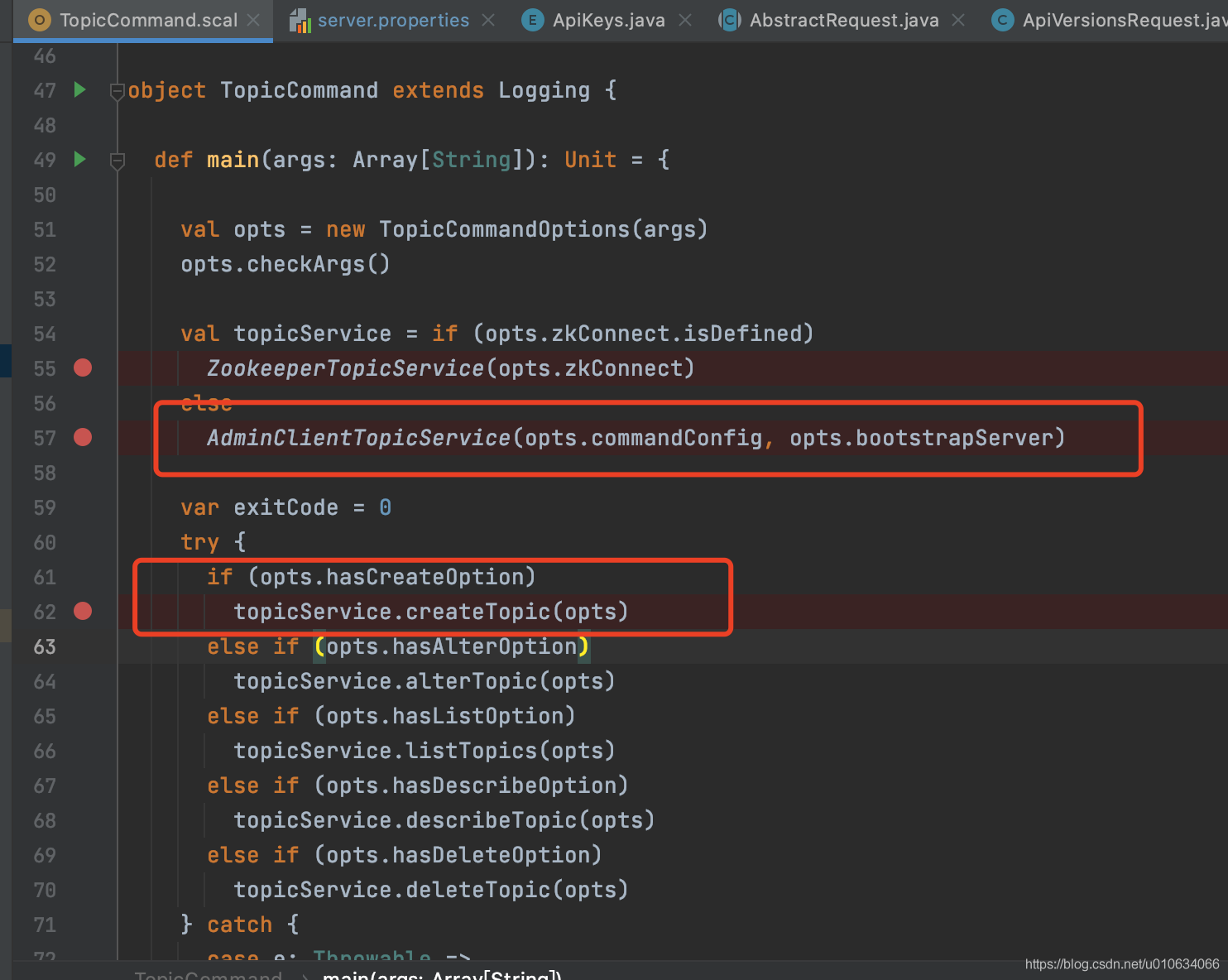
|
||||
上面的源码主要作用是
|
||||
1. 根据是否有传入参数`--zookeeper` 来判断创建哪一种 对象`topicService`
|
||||
如果传入了`--zookeeper` 则创建 类 `ZookeeperTopicService`的对象
|
||||
否则创建类`AdminClientTopicService`的对象(我们主要分析这个对象)
|
||||
2. 根据传入的参数类型判断是创建topic还是删除等等其他 判断依据是 是否在参数里传入了`--create`
|
||||
|
||||
|
||||
### 2. 创建AdminClientTopicService 对象
|
||||
> `val topicService = new AdminClientTopicService(createAdminClient(commandConfig, bootstrapServer))`
|
||||
|
||||
#### 2.1 先创建 Admin
|
||||
```scala
|
||||
object AdminClientTopicService {
|
||||
def createAdminClient(commandConfig: Properties, bootstrapServer: Option[String]): Admin = {
|
||||
bootstrapServer match {
|
||||
case Some(serverList) => commandConfig.put(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG, serverList)
|
||||
case None =>
|
||||
}
|
||||
Admin.create(commandConfig)
|
||||
}
|
||||
|
||||
def apply(commandConfig: Properties, bootstrapServer: Option[String]): AdminClientTopicService =
|
||||
new AdminClientTopicService(createAdminClient(commandConfig, bootstrapServer))
|
||||
}
|
||||
```
|
||||
|
||||
1. 如果有入参`--command-config` ,则将这个文件里面的参数都放到map `commandConfig`里面, 并且也加入`bootstrap.servers`的参数;假如配置文件里面已经有了`bootstrap.servers`配置,那么会将其覆盖
|
||||
2. 将上面的`commandConfig` 作为入参调用`Admin.create(commandConfig)`创建 Admin; 这个时候调用的Client模块的代码了, 从这里我们就可以看出,我们调用`kafka-topic.sh`脚本实际上是kafka模拟了一个客户端`Client`来创建Topic的过程;
|
||||
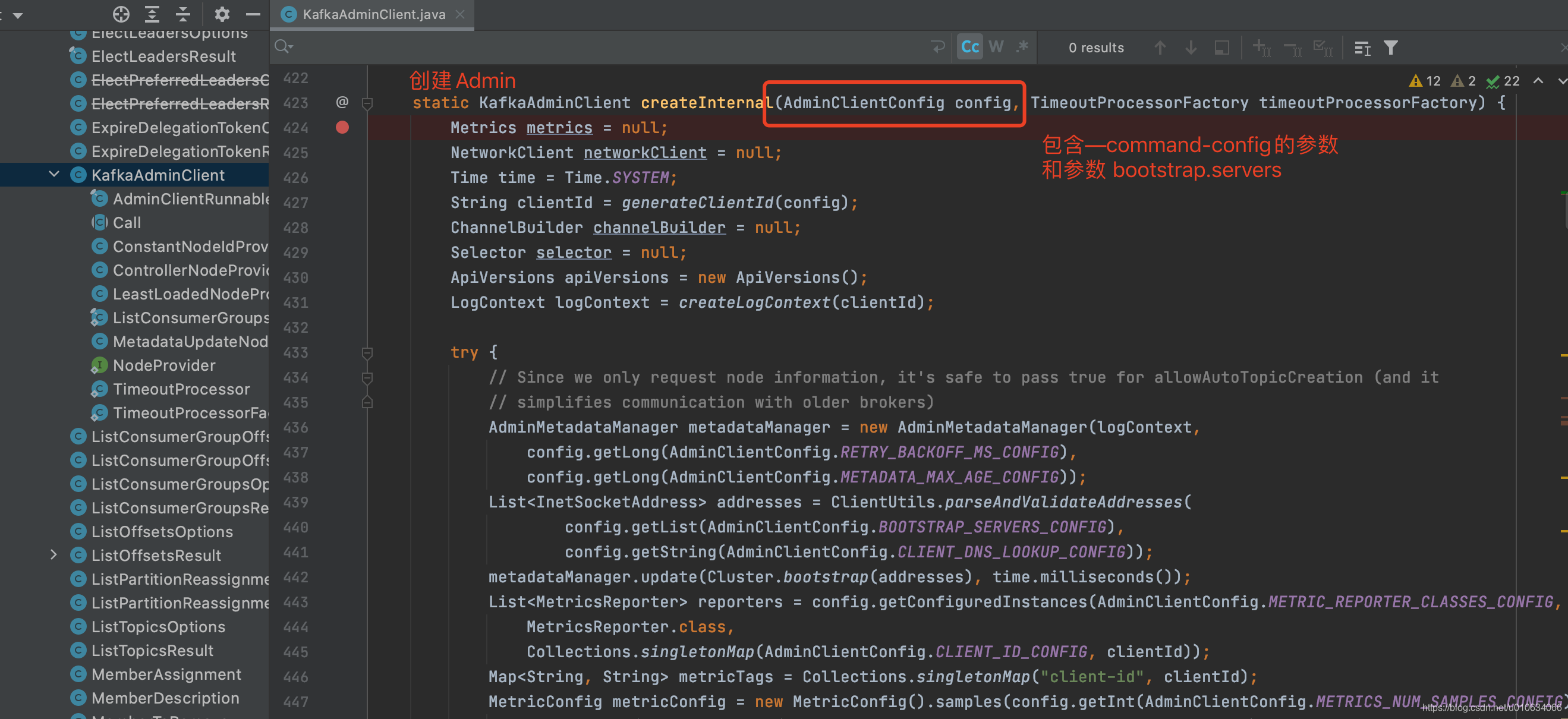
|
||||
|
||||
|
||||
|
||||
### 3. AdminClientTopicService.createTopic 创建Topic
|
||||
` topicService.createTopic(opts)`
|
||||
|
||||
```scala
|
||||
case class AdminClientTopicService private (adminClient: Admin) extends TopicService {
|
||||
|
||||
override def createTopic(topic: CommandTopicPartition): Unit = {
|
||||
//如果配置了副本副本数--replication-factor 一定要大于0
|
||||
if (topic.replicationFactor.exists(rf => rf > Short.MaxValue || rf < 1))
|
||||
throw new IllegalArgumentException(s"The replication factor must be between 1 and ${Short.MaxValue} inclusive")
|
||||
//如果配置了--partitions 分区数 必须大于0
|
||||
if (topic.partitions.exists(partitions => partitions < 1))
|
||||
throw new IllegalArgumentException(s"The partitions must be greater than 0")
|
||||
|
||||
//查询是否已经存在该Topic
|
||||
if (!adminClient.listTopics().names().get().contains(topic.name)) {
|
||||
val newTopic = if (topic.hasReplicaAssignment)
|
||||
//如果指定了--replica-assignment参数;则按照指定的来分配副本
|
||||
new NewTopic(topic.name, asJavaReplicaReassignment(topic.replicaAssignment.get))
|
||||
else {
|
||||
new NewTopic(
|
||||
topic.name,
|
||||
topic.partitions.asJava,
|
||||
topic.replicationFactor.map(_.toShort).map(Short.box).asJava)
|
||||
}
|
||||
|
||||
// 将配置--config 解析成一个配置map
|
||||
val configsMap = topic.configsToAdd.stringPropertyNames()
|
||||
.asScala
|
||||
.map(name => name -> topic.configsToAdd.getProperty(name))
|
||||
.toMap.asJava
|
||||
|
||||
newTopic.configs(configsMap)
|
||||
//调用adminClient创建Topic
|
||||
val createResult = adminClient.createTopics(Collections.singleton(newTopic))
|
||||
createResult.all().get()
|
||||
println(s"Created topic ${topic.name}.")
|
||||
} else {
|
||||
throw new IllegalArgumentException(s"Topic ${topic.name} already exists")
|
||||
}
|
||||
}
|
||||
```
|
||||
1. 检查各项入参是否有问题
|
||||
2. `adminClient.listTopics()`,然后比较是否已经存在待创建的Topic;如果存在抛出异常;
|
||||
3. 判断是否配置了参数`--replica-assignment` ; 如果配置了,那么Topic就会按照指定的方式来配置副本情况
|
||||
4. 解析配置`--config ` 配置放到` configsMap`中; `configsMap`给到`NewTopic`对象
|
||||
5. 调用`adminClient.createTopics`创建Topic; 它是如何创建Topic的呢?往下分析源码
|
||||
|
||||
#### 3.1 KafkaAdminClient.createTopics(NewTopic) 创建Topic
|
||||
|
||||
```java
|
||||
@Override
|
||||
public CreateTopicsResult createTopics(final Collection<NewTopic> newTopics,
|
||||
final CreateTopicsOptions options) {
|
||||
|
||||
//省略部分源码...
|
||||
Call call = new Call("createTopics", calcDeadlineMs(now, options.timeoutMs()),
|
||||
new ControllerNodeProvider()) {
|
||||
|
||||
@Override
|
||||
public CreateTopicsRequest.Builder createRequest(int timeoutMs) {
|
||||
return new CreateTopicsRequest.Builder(
|
||||
new CreateTopicsRequestData().
|
||||
setTopics(topics).
|
||||
setTimeoutMs(timeoutMs).
|
||||
setValidateOnly(options.shouldValidateOnly()));
|
||||
}
|
||||
|
||||
@Override
|
||||
public void handleResponse(AbstractResponse abstractResponse) {
|
||||
//省略
|
||||
}
|
||||
|
||||
@Override
|
||||
void handleFailure(Throwable throwable) {
|
||||
completeAllExceptionally(topicFutures.values(), throwable);
|
||||
}
|
||||
};
|
||||
|
||||
}
|
||||
```
|
||||
这个代码里面主要看下Call里面的接口; 先不管Kafka如何跟服务端进行通信的细节; 我们主要关注创建Topic的逻辑;
|
||||
1. `createRequest`会构造一个请求参数`CreateTopicsRequest` 例如下图
|
||||

|
||||
2. 选择ControllerNodeProvider这个节点发起网络请求
|
||||

|
||||
可以清楚的看到, 创建Topic这个操作是需要Controller来执行的;
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 4. 发起网络请求
|
||||
[==>服务端客户端网络模型 ](TODO)
|
||||
|
||||
### 5. Controller角色的服务端接受请求处理逻辑
|
||||
首先找到服务端处理客户端请求的 **源码入口** ⇒ `KafkaRequestHandler.run()`
|
||||
|
||||
|
||||
主要看里面的 `apis.handle(request)` 方法; 可以看到客户端的请求都在`request.bodyAndSize()`里面
|
||||
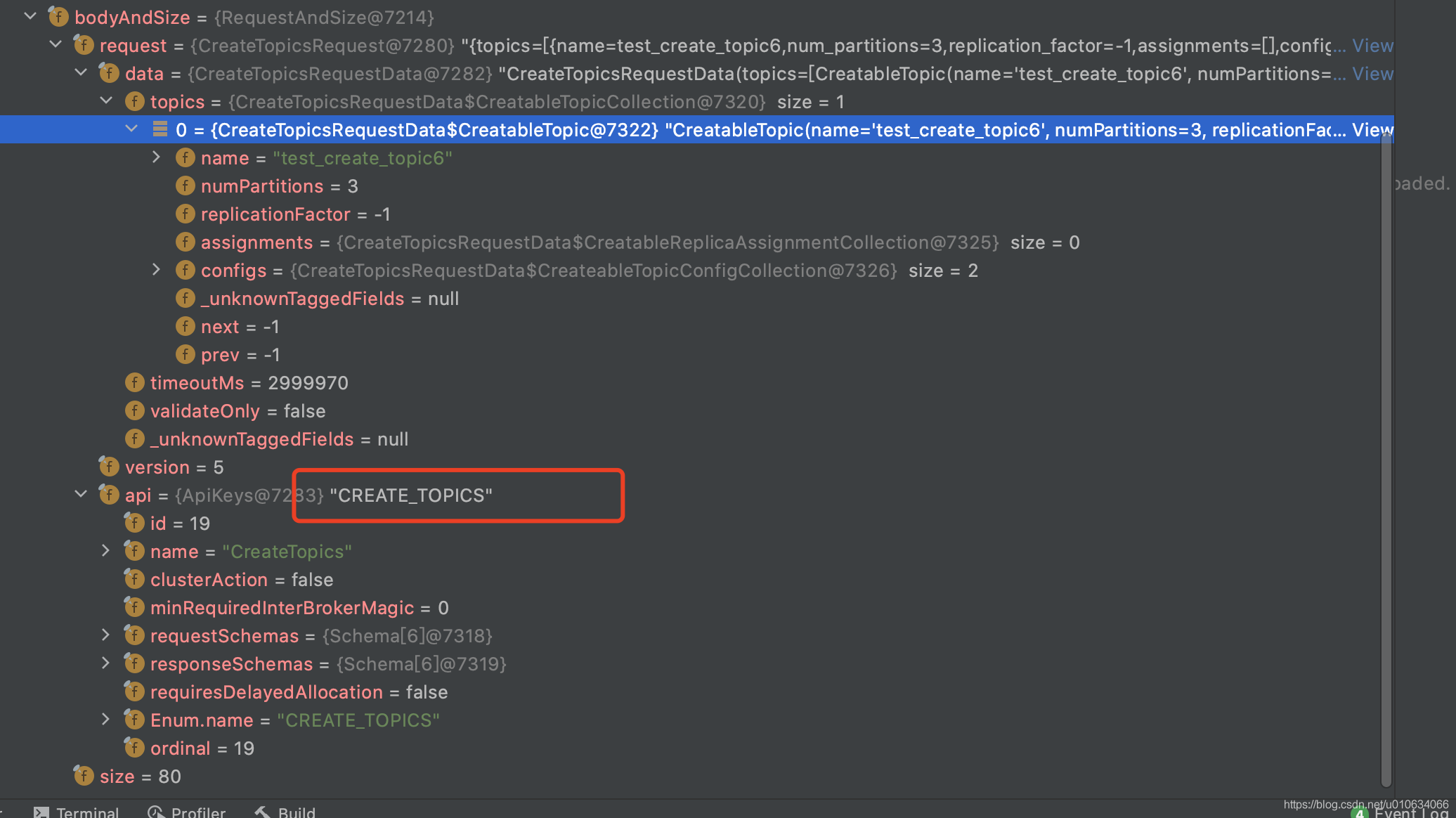
|
||||
#### 5.1 KafkaApis.handle(request) 根据请求传递Api调用不同接口
|
||||
进入方法可以看到根据`request.header.apiKey` 调用对应的方法,客户端传过来的是`CreateTopics`
|
||||
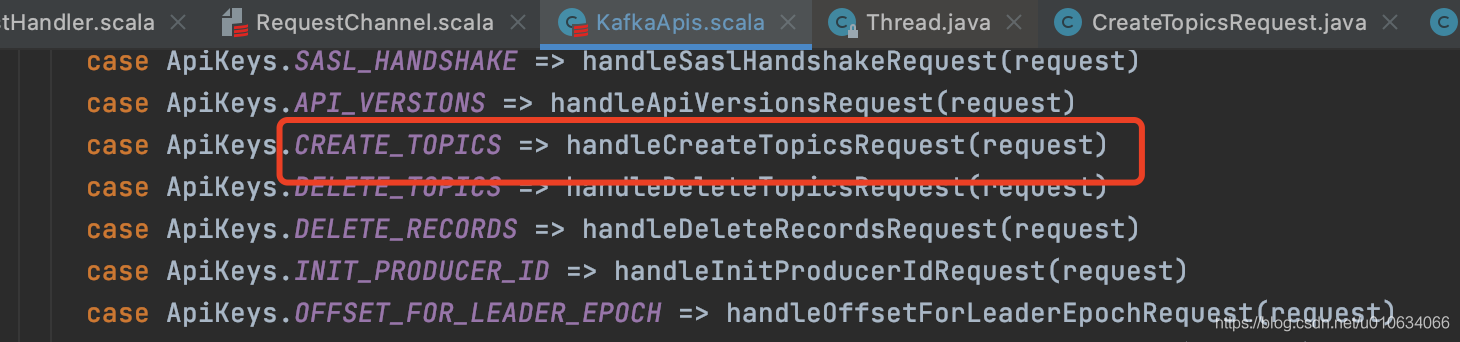
|
||||
|
||||
#### 5.2 KafkaApis.handleCreateTopicsRequest 处理创建Topic的请求
|
||||
|
||||
```java
|
||||
|
||||
def handleCreateTopicsRequest(request: RequestChannel.Request): Unit = {
|
||||
// 部分代码省略
|
||||
//如果当前Broker不是属于Controller的话,就抛出异常
|
||||
if (!controller.isActive) {
|
||||
createTopicsRequest.data.topics.asScala.foreach { topic =>
|
||||
results.add(new CreatableTopicResult().setName(topic.name).
|
||||
setErrorCode(Errors.NOT_CONTROLLER.code))
|
||||
}
|
||||
sendResponseCallback(results)
|
||||
} else {
|
||||
// 部分代码省略
|
||||
}
|
||||
adminManager.createTopics(createTopicsRequest.data.timeoutMs,
|
||||
createTopicsRequest.data.validateOnly,
|
||||
toCreate,
|
||||
authorizedForDescribeConfigs,
|
||||
handleCreateTopicsResults)
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
1. 判断当前处理的broker是不是Controller,如果不是Controller的话直接抛出异常,从这里可以看出,CreateTopic这个操作必须是Controller来进行, 出现这种情况有可能是客户端发起请求的时候Controller已经变更;
|
||||
2. 鉴权 [【Kafka源码】kafka鉴权机制]()
|
||||
3. 调用`adminManager.createTopics()`
|
||||
|
||||
#### 5.3 adminManager.createTopics()
|
||||
> 创建主题并等等主题完全创建,回调函数将会在超时、错误、或者主题创建完成时触发
|
||||
|
||||
该方法过长,省略部分代码
|
||||
```scala
|
||||
def createTopics(timeout: Int,
|
||||
validateOnly: Boolean,
|
||||
toCreate: Map[String, CreatableTopic],
|
||||
includeConfigsAndMetatadata: Map[String, CreatableTopicResult],
|
||||
responseCallback: Map[String, ApiError] => Unit): Unit = {
|
||||
|
||||
// 1. map over topics creating assignment and calling zookeeper
|
||||
val brokers = metadataCache.getAliveBrokers.map { b => kafka.admin.BrokerMetadata(b.id, b.rack) }
|
||||
val metadata = toCreate.values.map(topic =>
|
||||
try {
|
||||
//省略部分代码
|
||||
//检查Topic是否存在
|
||||
//检查 --replica-assignment参数和 (--partitions || --replication-factor ) 不能同时使用
|
||||
// 如果(--partitions || --replication-factor ) 没有设置,则使用 Broker的配置(这个Broker肯定是Controller)
|
||||
// 计算分区副本分配方式
|
||||
|
||||
createTopicPolicy match {
|
||||
case Some(policy) =>
|
||||
//省略部分代码
|
||||
adminZkClient.validateTopicCreate(topic.name(), assignments, configs)
|
||||
if (!validateOnly)
|
||||
adminZkClient.createTopicWithAssignment(topic.name, configs, assignments)
|
||||
|
||||
case None =>
|
||||
if (validateOnly)
|
||||
//校验创建topic的参数准确性
|
||||
adminZkClient.validateTopicCreate(topic.name, assignments, configs)
|
||||
else
|
||||
//把topic相关数据写入到zk中
|
||||
adminZkClient.createTopicWithAssignment(topic.name, configs, assignments)
|
||||
}
|
||||
|
||||
|
||||
}
|
||||
```
|
||||
1. 做一些校验检查
|
||||
①.检查Topic是否存在
|
||||
②. 检查` --replica-assignment`参数和 (`--partitions || --replication-factor` ) 不能同时使用
|
||||
③.如果(`--partitions || --replication-factor` ) 没有设置,则使用 Broker的配置(这个Broker肯定是Controller)
|
||||
④.计算分区副本分配方式
|
||||
|
||||
2. `createTopicPolicy` 根据Broker是否配置了创建Topic的自定义校验策略; 使用方式是自定义实现`org.apache.kafka.server.policy.CreateTopicPolicy`接口;并 在服务器配置 `create.topic.policy.class.name=自定义类`; 比如我就想所有创建Topic的请求分区数都要大于10; 那么这里就可以实现你的需求了
|
||||
3. `createTopicWithAssignment`把topic相关数据写入到zk中; 进去分析一下
|
||||
|
||||
|
||||
|
||||
#### 5.4 写入zookeeper数据
|
||||
我们进入到` adminZkClient.createTopicWithAssignment(topic.name, configs, assignments)
|
||||
`看看有哪些数据写入到了zk中;
|
||||
```scala
|
||||
def createTopicWithAssignment(topic: String,
|
||||
config: Properties,
|
||||
partitionReplicaAssignment: Map[Int, Seq[Int]]): Unit = {
|
||||
validateTopicCreate(topic, partitionReplicaAssignment, config)
|
||||
|
||||
// 将topic单独的配置写入到zk中
|
||||
zkClient.setOrCreateEntityConfigs(ConfigType.Topic, topic, config)
|
||||
|
||||
// 将topic分区相关信息写入zk中
|
||||
writeTopicPartitionAssignment(topic, partitionReplicaAssignment.mapValues(ReplicaAssignment(_)).toMap, isUpdate = false)
|
||||
}
|
||||
|
||||
```
|
||||
源码就不再深入了,这里直接详细说明一下
|
||||
|
||||
**写入Topic配置信息**
|
||||
1. 先调用`SetDataRequest`请求往节点` /config/topics/Topic名称` 写入数据; 这里
|
||||
一般这个时候都会返回 `NONODE (NoNode)`;节点不存在; 假如zk已经存在节点就直接覆盖掉
|
||||
2. 节点不存在的话,就发起`CreateRequest`请求,写入数据; 并且节点类型是**持久节点**
|
||||
|
||||
这里写入的数据,是我们入参时候传的topic配置`--config`; 这里的配置会覆盖默认配置
|
||||
|
||||
**写入Topic分区副本信息**
|
||||
1. 将已经分配好的副本分配策略写入到 `/brokers/topics/Topic名称` 中; 节点类型 **持久节点**
|
||||
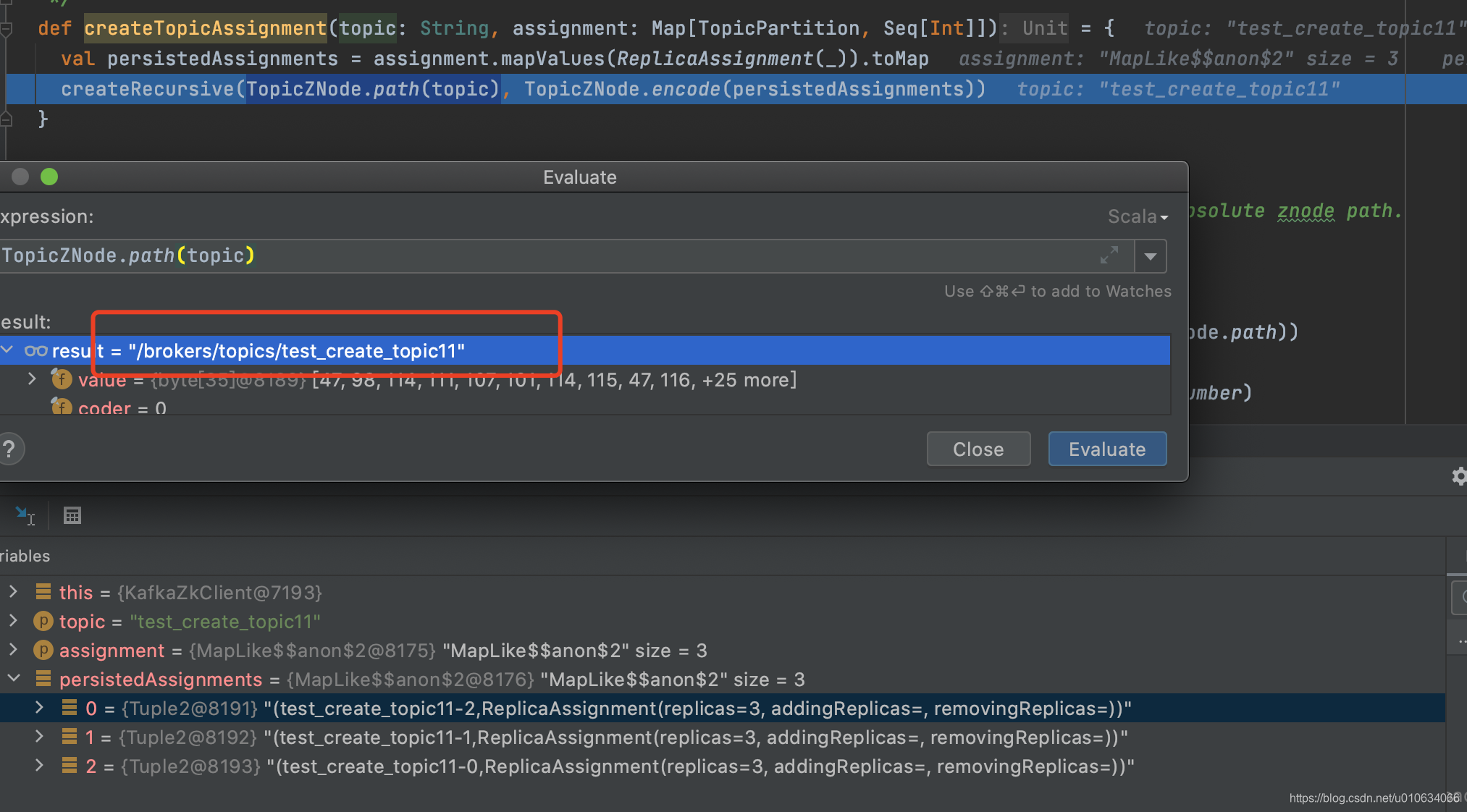
|
||||
|
||||
**具体跟zk交互的地方在**
|
||||
`ZookeeperClient.send()` 这里包装了很多跟zk的交互;
|
||||
|
||||
### 6. Controller监听 `/brokers/topics/Topic名称`, 通知Broker将分区写入磁盘
|
||||
> Controller 有监听zk上的一些节点; 在上面的流程中已经在zk中写入了 `/brokers/topics/Topic名称` ; 这个时候Controller就监听到了这个变化并相应;
|
||||
|
||||
`KafkaController.processTopicChange`
|
||||
```scala
|
||||
|
||||
private def processTopicChange(): Unit = {
|
||||
//如果处理的不是Controller角色就返回
|
||||
if (!isActive) return
|
||||
//从zk中获取 `/brokers/topics 所有Topic
|
||||
val topics = zkClient.getAllTopicsInCluster
|
||||
//找出哪些是新增的
|
||||
val newTopics = topics -- controllerContext.allTopics
|
||||
//找出哪些Topic在zk上被删除了
|
||||
val deletedTopics = controllerContext.allTopics -- topics
|
||||
controllerContext.allTopics = topics
|
||||
|
||||
|
||||
registerPartitionModificationsHandlers(newTopics.toSeq)
|
||||
val addedPartitionReplicaAssignment = zkClient.getFullReplicaAssignmentForTopics(newTopics)
|
||||
deletedTopics.foreach(controllerContext.removeTopic)
|
||||
addedPartitionReplicaAssignment.foreach {
|
||||
case (topicAndPartition, newReplicaAssignment) => controllerContext.updatePartitionFullReplicaAssignment(topicAndPartition, newReplicaAssignment)
|
||||
}
|
||||
info(s"New topics: [$newTopics], deleted topics: [$deletedTopics], new partition replica assignment " +
|
||||
s"[$addedPartitionReplicaAssignment]")
|
||||
if (addedPartitionReplicaAssignment.nonEmpty)
|
||||
onNewPartitionCreation(addedPartitionReplicaAssignment.keySet)
|
||||
}
|
||||
```
|
||||
1. 从zk中获取 `/brokers/topics` 所有Topic跟当前Broker内存中所有Broker`controllerContext.allTopics`的差异; 就可以找到我们新增的Topic; 还有在zk中被删除了的Broker(该Topic会在当前内存中remove掉)
|
||||
2. 从zk中获取`/brokers/topics/{TopicName}` 给定主题的副本分配。并保存在内存中
|
||||
|
||||
4. 执行`onNewPartitionCreation`;分区状态开始流转
|
||||
|
||||
#### 6.1 onNewPartitionCreation 状态流转
|
||||
> 关于Controller的状态机 详情请看: [【kafka源码】Controller中的状态机](TODO)
|
||||
|
||||
```scala
|
||||
/**
|
||||
* This callback is invoked by the topic change callback with the list of failed brokers as input.
|
||||
* It does the following -
|
||||
* 1. Move the newly created partitions to the NewPartition state
|
||||
* 2. Move the newly created partitions from NewPartition->OnlinePartition state
|
||||
*/
|
||||
private def onNewPartitionCreation(newPartitions: Set[TopicPartition]): Unit = {
|
||||
info(s"New partition creation callback for ${newPartitions.mkString(",")}")
|
||||
partitionStateMachine.handleStateChanges(newPartitions.toSeq, NewPartition)
|
||||
replicaStateMachine.handleStateChanges(controllerContext.replicasForPartition(newPartitions).toSeq, NewReplica)
|
||||
partitionStateMachine.handleStateChanges(
|
||||
newPartitions.toSeq,
|
||||
OnlinePartition,
|
||||
Some(OfflinePartitionLeaderElectionStrategy(false))
|
||||
)
|
||||
replicaStateMachine.handleStateChanges(controllerContext.replicasForPartition(newPartitions).toSeq, OnlineReplica)
|
||||
}
|
||||
```
|
||||
1. 将待创建的分区状态流转为`NewPartition`;
|
||||

|
||||
2. 将待创建的副本 状态流转为`NewReplica`;
|
||||

|
||||
3. 将分区状态从刚刚的`NewPartition`流转为`OnlinePartition`
|
||||
0. 获取`leaderIsrAndControllerEpochs`; Leader为副本的第一个;
|
||||
1. 向zk中写入`/brokers/topics/{topicName}/partitions/` 持久节点; 无数据
|
||||
2. 向zk中写入`/brokers/topics/{topicName}/partitions/{分区号}` 持久节点; 无数据
|
||||
3. 向zk中写入`/brokers/topics/{topicName}/partitions/{分区号}/state` 持久节点; 数据为`leaderIsrAndControllerEpoch`
|
||||
4. 向副本所属Broker发送[`leaderAndIsrRequest`]()请求
|
||||
5. 向所有Broker发送[`UPDATE_METADATA` ]()请求
|
||||
4. 将副本状态从刚刚的`NewReplica`流转为`OnlineReplica` ,更新下内存
|
||||
|
||||
关于分区状态机和副本状态机详情请看[【kafka源码】Controller中的状态机](TODO)
|
||||
|
||||
### 7. Broker收到LeaderAndIsrRequest 创建本地Log
|
||||
>上面步骤中有说到向副本所属Broker发送[`leaderAndIsrRequest`]()请求,那么这里做了什么呢
|
||||
>其实主要做的是 创建本地Log
|
||||
>
|
||||
代码太多,这里我们直接定位到只跟创建Topic相关的关键代码来分析
|
||||
`KafkaApis.handleLeaderAndIsrRequest->replicaManager.becomeLeaderOrFollower->ReplicaManager.makeLeaders...LogManager.getOrCreateLog`
|
||||
|
||||
```scala
|
||||
/**
|
||||
* 如果日志已经存在,只返回现有日志的副本否则如果 isNew=true 或者如果没有离线日志目录,则为给定的主题和给定的分区创建日志 否则抛出 KafkaStorageException
|
||||
*/
|
||||
def getOrCreateLog(topicPartition: TopicPartition, config: LogConfig, isNew: Boolean = false, isFuture: Boolean = false): Log = {
|
||||
logCreationOrDeletionLock synchronized {
|
||||
getLog(topicPartition, isFuture).getOrElse {
|
||||
// create the log if it has not already been created in another thread
|
||||
if (!isNew && offlineLogDirs.nonEmpty)
|
||||
throw new KafkaStorageException(s"Can not create log for $topicPartition because log directories ${offlineLogDirs.mkString(",")} are offline")
|
||||
|
||||
val logDirs: List[File] = {
|
||||
val preferredLogDir = preferredLogDirs.get(topicPartition)
|
||||
|
||||
if (isFuture) {
|
||||
if (preferredLogDir == null)
|
||||
throw new IllegalStateException(s"Can not create the future log for $topicPartition without having a preferred log directory")
|
||||
else if (getLog(topicPartition).get.dir.getParent == preferredLogDir)
|
||||
throw new IllegalStateException(s"Can not create the future log for $topicPartition in the current log directory of this partition")
|
||||
}
|
||||
|
||||
if (preferredLogDir != null)
|
||||
List(new File(preferredLogDir))
|
||||
else
|
||||
nextLogDirs()
|
||||
}
|
||||
|
||||
val logDirName = {
|
||||
if (isFuture)
|
||||
Log.logFutureDirName(topicPartition)
|
||||
else
|
||||
Log.logDirName(topicPartition)
|
||||
}
|
||||
|
||||
val logDir = logDirs
|
||||
.toStream // to prevent actually mapping the whole list, lazy map
|
||||
.map(createLogDirectory(_, logDirName))
|
||||
.find(_.isSuccess)
|
||||
.getOrElse(Failure(new KafkaStorageException("No log directories available. Tried " + logDirs.map(_.getAbsolutePath).mkString(", "))))
|
||||
.get // If Failure, will throw
|
||||
|
||||
val log = Log(
|
||||
dir = logDir,
|
||||
config = config,
|
||||
logStartOffset = 0L,
|
||||
recoveryPoint = 0L,
|
||||
maxProducerIdExpirationMs = maxPidExpirationMs,
|
||||
producerIdExpirationCheckIntervalMs = LogManager.ProducerIdExpirationCheckIntervalMs,
|
||||
scheduler = scheduler,
|
||||
time = time,
|
||||
brokerTopicStats = brokerTopicStats,
|
||||
logDirFailureChannel = logDirFailureChannel)
|
||||
|
||||
if (isFuture)
|
||||
futureLogs.put(topicPartition, log)
|
||||
else
|
||||
currentLogs.put(topicPartition, log)
|
||||
|
||||
info(s"Created log for partition $topicPartition in $logDir with properties " + s"{${config.originals.asScala.mkString(", ")}}.")
|
||||
// Remove the preferred log dir since it has already been satisfied
|
||||
preferredLogDirs.remove(topicPartition)
|
||||
|
||||
log
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
1. 如果日志已经存在,只返回现有日志的副本否则如果 isNew=true 或者如果没有离线日志目录,则为给定的主题和给定的分区创建日志 否则抛出` KafkaStorageException`
|
||||
|
||||
详细请看 [【kafka源码】LeaderAndIsrRequest请求]()
|
||||
|
||||
|
||||
## 源码总结
|
||||
> 如果上面的源码分析,你不想看,那么你可以直接看这里的简洁叙述
|
||||
|
||||
1. 根据是否有传入参数`--zookeeper` 来判断创建哪一种 对象`topicService`
|
||||
如果传入了`--zookeeper` 则创建 类 `ZookeeperTopicService`的对象
|
||||
否则创建类`AdminClientTopicService`的对象(我们主要分析这个对象)
|
||||
2. 如果有入参`--command-config` ,则将这个文件里面的参数都放到mapl类型 `commandConfig`里面, 并且也加入`bootstrap.servers`的参数;假如配置文件里面已经有了`bootstrap.servers`配置,那么会将其覆盖
|
||||
3. 将上面的`commandConfig `作为入参调用`Admin.create(commandConfig)`创建 Admin; 这个时候调用的Client模块的代码了, 从这里我们就可以猜测,我们调用`kafka-topic.sh`脚本实际上是kafka模拟了一个客户端Client来创建Topic的过程;
|
||||
4. 一些异常检查
|
||||
①.如果配置了副本副本数--replication-factor 一定要大于0
|
||||
②.如果配置了--partitions 分区数 必须大于0
|
||||
③.去zk查询是否已经存在该Topic
|
||||
5. 判断是否配置了参数`--replica-assignment` ; 如果配置了,那么Topic就会按照指定的方式来配置副本情况
|
||||
6. 解析配置`--config ` 配置放到`configsMap`中; configsMap给到NewTopic对象
|
||||
7. **将上面所有的参数包装成一个请求参数`CreateTopicsRequest` ;然后找到是`Controller`的节点发起请求(`ControllerNodeProvider`)**
|
||||
8. 服务端收到请求之后,开始根据`CreateTopicsRequest`来调用创建Topic的方法; 不过首先要判断一下自己这个时候是不是`Controller`; 有可能这个时候Controller重新选举了; 这个时候要抛出异常
|
||||
9. 服务端进行一下请求参数检查
|
||||
①.检查Topic是否存在
|
||||
②.检查 `--replica-assignment`参数和 (`--partitions` || `--replication-factor` ) 不能同时使用
|
||||
10. 如果(`--partitions` || `--replication-factor` ) 没有设置,则使用 Broker的默认配置(这个Broker肯定是Controller)
|
||||
11. 计算分区副本分配方式;如果是传入了 `--replica-assignment`;则会安装自定义参数进行组装;否则的话系统会自动计算分配方式; 具体详情请看 [【kafka源码】创建Topic的时候是如何分区和副本的分配规则 ]()
|
||||
12. `createTopicPolicy `根据Broker是否配置了创建Topic的自定义校验策略; 使用方式是自定义实现`org.apache.kafka.server.policy.CreateTopicPolicy`接口;并 在服务器配置 `create.topic.policy.class.name`=自定义类; 比如我就想所有创建Topic的请求分区数都要大于10; 那么这里就可以实现你的需求了
|
||||
13. **zk中写入Topic配置信息** 发起`CreateRequest`请求,这里写入的数据,是我们入参时候传的topic配置`--config`; 这里的配置会覆盖默认配置;并且节点类型是持久节点;**path** = `/config/topics/Topic名称`
|
||||
14. **zk中写入Topic分区副本信息** 发起`CreateRequest`请求 ,将已经分配好的副本分配策略 写入到 `/brokers/topics/Topic名称 `中; 节点类型 持久节点
|
||||
15. `Controller`监听zk上面的topic信息; 根据zk上变更的topic信息;计算出新增/删除了哪些Topic; 然后拿到新增Topic的 副本分配信息; 并做一些状态流转
|
||||
16. 向新增Topic所在Broker发送`leaderAndIsrRequest`请求,
|
||||
17. Broker收到`发送leaderAndIsrRequest请求`; 创建副本Log文件;
|
||||
|
||||
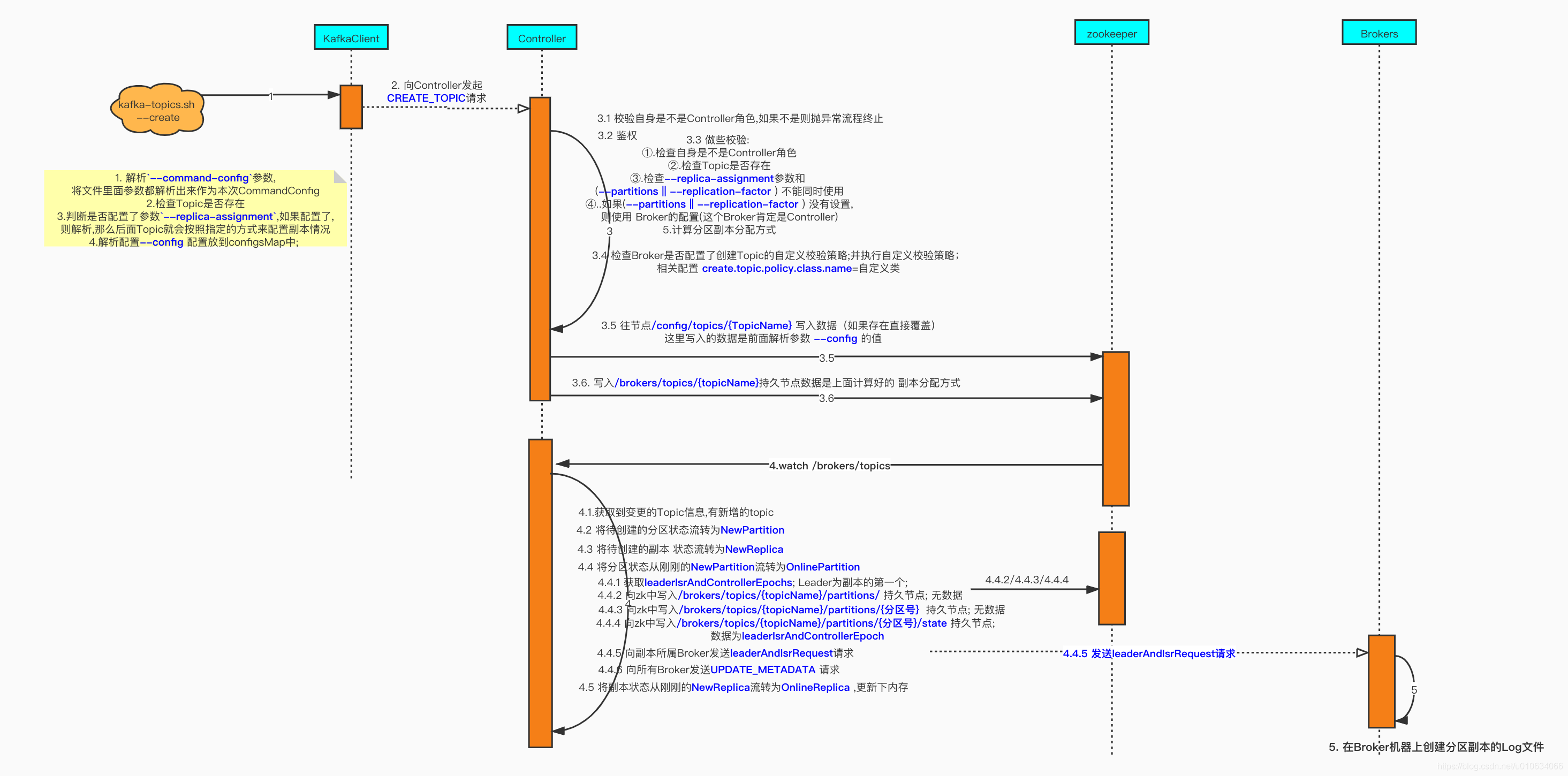
|
||||
|
||||
|
||||
## Q&A
|
||||
|
||||
|
||||
### 创建Topic的时候 在Zk上创建了哪些节点
|
||||
>接受客户端请求阶段:
|
||||
>1. topic的配置信息 ` /config/topics/Topic名称` 持久节点
|
||||
>2. topic的分区信息`/brokers/topics/Topic名称` 持久节点
|
||||
>
|
||||
>Controller监听zk节点`/brokers/topics`变更阶段
|
||||
>1. `/brokers/topics/{topicName}/partitions/ `持久节点; 无数据
|
||||
>2. 向zk中写入`/brokers/topics/{topicName}/partitions/{分区号}` 持久节点; 无数据
|
||||
>3. 向zk中写入`/brokers/topics/{topicName}/partitions/{分区号}/state` 持久节点;
|
||||
|
||||
### 创建Topic的时候 什么时候在Broker磁盘上创建的日志文件
|
||||
>当Controller监听zk节点`/brokers/topics`变更之后,将新增的Topic 解析好的分区状态流转
|
||||
>`NonExistentPartition`->`NewPartition`->`OnlinePartition` 当流转到`OnlinePartition`的时候会像分区分配到的Broker发送一个`leaderAndIsrRequest`请求,当Broker们收到这个请求之后,根据请求参数做一些处理,其中就包括检查自身有没有这个分区副本的本地Log;如果没有的话就重新创建;
|
||||
### 如果我没有指定分区数或者副本数,那么会如何创建
|
||||
>我们都知道,如果我们没有指定分区数或者副本数, 则默认使用Broker的配置, 那么这么多Broker,假如不小心默认值配置不一样,那究竟使用哪一个呢? 那肯定是哪台机器执行创建topic的过程,就是使用谁的配置;
|
||||
**所以是谁执行的?** 那肯定是Controller啊! 上面的源码我们分析到了,创建的过程,会指定Controller这台机器去进行;
|
||||
|
||||
|
||||
### 如果我手动删除了`/brokers/topics/`下的某个节点会怎么样?
|
||||
>在Controller中的内存中更新一下相关信息
|
||||
>其他Broker呢?TODO.
|
||||
|
||||
### 如果我手动在zk中添加`/brokers/topics/{TopicName}`节点会怎么样
|
||||
>**先说结论:** 根据上面分析过的源码画出的时序图可以指定; 客户端发起创建Topic的请求,本质上是去zk里面写两个数据
|
||||
>1. topic的配置信息 ` /config/topics/Topic名称` 持久节点
|
||||
>2. topic的分区信息`/brokers/topics/Topic名称` 持久节点
|
||||
>所以我们绕过这一步骤直接去写入数据,可以达到一样的效果;不过我们的数据需要保证准确
|
||||
>因为在这一步已经没有了一些基本的校验了; 假如这一步我们写入的副本Brokerid不存在会怎样,从时序图中可以看到,`leaderAndIsrRequest请求`; 就不会正确的发送的不存在的BrokerId上,那么那台机器就不会创建Log文件;
|
||||
>
|
||||
>
|
||||
>**下面不妨让我们来验证一下;**
|
||||
>创建一个节点`/brokers/topics/create_topic_byhand_zk` 节点数据为下面数据;
|
||||
>```
|
||||
>{"version":2,"partitions":{"2":[3],"1":[3],"0":[3]},"adding_replicas":{},"removing_replicas":{}}
|
||||
>```
|
||||
>
|
||||
>这里我用的工具`PRETTYZOO`手动创建的,你也可以用命令行创建;
|
||||
>创建完成之后我们再看看本地有没有生成一个Log文件
|
||||
>
|
||||
>可以看到我们指定的Broker,已经生成了对应的分区副本Log文件;
|
||||
>而且zk中也写入了其他的数据
|
||||
>`在我们写入zk数据的时候,就已经确定好了哪个每个分区的Leader是谁了,那就是第一个副本默认为Leader`
|
||||
>
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 如果写入`/brokers/topics/{TopicName}`节点之后Controller挂掉了会怎么样
|
||||
> **先说结论**:Controller 重新选举的时候,会有一些初始化的操作; 会把创建过程继续下去
|
||||
|
||||
> 然后我们来模拟这么一个过程,先停止集群,然后再zk中写入`/brokers/topics/{TopicName}`节点数据; 然后再启动一台Broker;
|
||||
> **源码分析:** 我们之前分析过[Controller的启动过程与选举]() 有提到过,这里再提一下Controller当选之后有一个地方处理这个事情
|
||||
> ```
|
||||
> replicaStateMachine.startup()
|
||||
> partitionStateMachine.startup()
|
||||
> ```
|
||||
> 启动状态机的过程是不是跟上面的**6.1 onNewPartitionCreation 状态流转** 的过程很像; 最终都把状态流转到了`OnlinePartition`; 伴随着是不发起了`leaderAndIsrRequest`请求; 是不是Broker收到请求之后,创建本地Log文件了
|
||||
>
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 附件
|
||||
|
||||
### --config 可生效参数
|
||||
请以`sh bin/kafka-topic -help` 为准
|
||||
```xml
|
||||
configurations:
|
||||
cleanup.policy
|
||||
compression.type
|
||||
delete.retention.ms
|
||||
file.delete.delay.ms
|
||||
flush.messages
|
||||
flush.ms
|
||||
follower.replication.throttled.
|
||||
replicas
|
||||
index.interval.bytes
|
||||
leader.replication.throttled.replicas
|
||||
max.compaction.lag.ms
|
||||
max.message.bytes
|
||||
message.downconversion.enable
|
||||
message.format.version
|
||||
message.timestamp.difference.max.ms
|
||||
message.timestamp.type
|
||||
min.cleanable.dirty.ratio
|
||||
min.compaction.lag.ms
|
||||
min.insync.replicas
|
||||
preallocate
|
||||
retention.bytes
|
||||
retention.ms
|
||||
segment.bytes
|
||||
segment.index.bytes
|
||||
segment.jitter.ms
|
||||
segment.ms
|
||||
unclean.leader.election.enable
|
||||
```
|
||||
|
||||
|
||||
---
|
||||
<font color=red size=5>Tips:如果关于本篇文章你有疑问,可以在评论区留下,我会在**Q&A**部分进行解答 </font>
|
||||
|
||||
|
||||
|
||||
<font color=red size=2>PS: 文章阅读的源码版本是kafka-2.5 </font>
|
||||
|
||||
420
docs/zh/Kafka分享/Kafka Controller /TopicCommand之删除Topic源码解析.md
Normal file
420
docs/zh/Kafka分享/Kafka Controller /TopicCommand之删除Topic源码解析.md
Normal file
@@ -0,0 +1,420 @@
|
||||
|
||||
|
||||
## 删除Topic命令
|
||||
>bin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic test
|
||||
|
||||
|
||||
|
||||
支持正则表达式匹配Topic来进行删除,只需要将topic 用双引号包裹起来
|
||||
例如: 删除以`create_topic_byhand_zk`为开头的topic;
|
||||
>>bin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic "create_topic_byhand_zk.*"
|
||||
> `.`表示任意匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 \. 。
|
||||
`·*·`:匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \*。
|
||||
`.*` : 任意字符
|
||||
|
||||
**删除任意Topic (慎用)**
|
||||
> bin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic ".*?"
|
||||
>
|
||||
更多的用法请[参考正则表达式](https://www.runoob.com/regexp/regexp-syntax.html)
|
||||
|
||||
## 源码解析
|
||||
<font color="red">如果觉得阅读源码解析太枯燥,请直接看 **源码总结及其后面部分**</font>
|
||||
### 1. 客户端发起删除Topic的请求
|
||||
在[【kafka源码】TopicCommand之创建Topic源码解析]() 里面已经分析过了整个请求流程; 所以这里就不再详细的分析请求的过程了,直接看重点;
|
||||
|
||||
**向Controller发起 `deleteTopics`请求**
|
||||
|
||||
### 2. Controller处理deleteTopics的请求
|
||||
`KafkaApis.handle`
|
||||
`AdminManager.deleteTopics`
|
||||
```scala
|
||||
/**
|
||||
* Delete topics and wait until the topics have been completely deleted.
|
||||
* The callback function will be triggered either when timeout, error or the topics are deleted.
|
||||
*/
|
||||
def deleteTopics(timeout: Int,
|
||||
topics: Set[String],
|
||||
responseCallback: Map[String, Errors] => Unit): Unit = {
|
||||
|
||||
// 1. map over topics calling the asynchronous delete
|
||||
val metadata = topics.map { topic =>
|
||||
try {
|
||||
// zk中写入数据 标记要被删除的topic /admin/delete_topics/Topic名称
|
||||
adminZkClient.deleteTopic(topic)
|
||||
DeleteTopicMetadata(topic, Errors.NONE)
|
||||
} catch {
|
||||
case _: TopicAlreadyMarkedForDeletionException =>
|
||||
// swallow the exception, and still track deletion allowing multiple calls to wait for deletion
|
||||
DeleteTopicMetadata(topic, Errors.NONE)
|
||||
case e: Throwable =>
|
||||
error(s"Error processing delete topic request for topic $topic", e)
|
||||
DeleteTopicMetadata(topic, Errors.forException(e))
|
||||
}
|
||||
}
|
||||
|
||||
// 2. 如果客户端传过来的timeout<=0或者 写入zk数据过程异常了 则执行下面的,直接返回异常
|
||||
if (timeout <= 0 || !metadata.exists(_.error == Errors.NONE)) {
|
||||
val results = metadata.map { deleteTopicMetadata =>
|
||||
// ignore topics that already have errors
|
||||
if (deleteTopicMetadata.error == Errors.NONE) {
|
||||
(deleteTopicMetadata.topic, Errors.REQUEST_TIMED_OUT)
|
||||
} else {
|
||||
(deleteTopicMetadata.topic, deleteTopicMetadata.error)
|
||||
}
|
||||
}.toMap
|
||||
responseCallback(results)
|
||||
} else {
|
||||
// 3. else pass the topics and errors to the delayed operation and set the keys
|
||||
val delayedDelete = new DelayedDeleteTopics(timeout, metadata.toSeq, this, responseCallback)
|
||||
val delayedDeleteKeys = topics.map(new TopicKey(_)).toSeq
|
||||
// try to complete the request immediately, otherwise put it into the purgatory
|
||||
topicPurgatory.tryCompleteElseWatch(delayedDelete, delayedDeleteKeys)
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
1. zk中写入数据topic` /admin/delete_topics/Topic名称`; 标记要被删除的Topic
|
||||
2. 如果客户端传过来的timeout<=0或者 写入zk数据过程异常了 则直接返回异常
|
||||
|
||||
|
||||
### 3. Controller监听zk变更 执行删除Topic流程
|
||||
`KafkaController.processTopicDeletion`
|
||||
|
||||
```scala
|
||||
private def processTopicDeletion(): Unit = {
|
||||
if (!isActive) return
|
||||
var topicsToBeDeleted = zkClient.getTopicDeletions.toSet
|
||||
val nonExistentTopics = topicsToBeDeleted -- controllerContext.allTopics
|
||||
if (nonExistentTopics.nonEmpty) {
|
||||
warn(s"Ignoring request to delete non-existing topics ${nonExistentTopics.mkString(",")}")
|
||||
zkClient.deleteTopicDeletions(nonExistentTopics.toSeq, controllerContext.epochZkVersion)
|
||||
}
|
||||
topicsToBeDeleted --= nonExistentTopics
|
||||
if (config.deleteTopicEnable) {
|
||||
if (topicsToBeDeleted.nonEmpty) {
|
||||
info(s"Starting topic deletion for topics ${topicsToBeDeleted.mkString(",")}")
|
||||
// 标记暂时不可删除的Topic
|
||||
topicsToBeDeleted.foreach { topic =>
|
||||
val partitionReassignmentInProgress =
|
||||
controllerContext.partitionsBeingReassigned.map(_.topic).contains(topic)
|
||||
if (partitionReassignmentInProgress)
|
||||
topicDeletionManager.markTopicIneligibleForDeletion(Set(topic),
|
||||
reason = "topic reassignment in progress")
|
||||
}
|
||||
// add topic to deletion list
|
||||
topicDeletionManager.enqueueTopicsForDeletion(topicsToBeDeleted)
|
||||
}
|
||||
} else {
|
||||
// If delete topic is disabled remove entries under zookeeper path : /admin/delete_topics
|
||||
info(s"Removing $topicsToBeDeleted since delete topic is disabled")
|
||||
zkClient.deleteTopicDeletions(topicsToBeDeleted.toSeq, controllerContext.epochZkVersion)
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
1. 如果`/admin/delete_topics/`下面的节点有不存在的Topic,则清理掉
|
||||
2. 如果配置了`delete.topic.enable=false`不可删除Topic的话,则将`/admin/delete_topics/`下面的节点全部删除,然后流程结束
|
||||
3. `delete.topic.enable=true`; 将主题标记为不符合删除条件,放到`topicsIneligibleForDeletion`中; 不符合删除条件的是:**Topic分区正在进行分区重分配**
|
||||
4. 将Topic添加到删除Topic列表`topicsToBeDeleted`中;
|
||||
5. 然后调用`TopicDeletionManager.resumeDeletions()`方法执行删除操作
|
||||
|
||||
#### 3.1 resumeDeletions 执行删除方法
|
||||
`TopicDeletionManager.resumeDeletions()`
|
||||
|
||||
```scala
|
||||
private def resumeDeletions(): Unit = {
|
||||
val topicsQueuedForDeletion = Set.empty[String] ++ controllerContext.topicsToBeDeleted
|
||||
val topicsEligibleForRetry = mutable.Set.empty[String]
|
||||
val topicsEligibleForDeletion = mutable.Set.empty[String]
|
||||
|
||||
if (topicsQueuedForDeletion.nonEmpty)
|
||||
topicsQueuedForDeletion.foreach { topic =>
|
||||
// if all replicas are marked as deleted successfully, then topic deletion is done
|
||||
//如果所有副本都被标记为删除成功了,然后执行删除Topic成功操作;
|
||||
if (controllerContext.areAllReplicasInState(topic, ReplicaDeletionSuccessful)) {
|
||||
// clear up all state for this topic from controller cache and zookeeper
|
||||
//执行删除Topic成功之后的操作;
|
||||
completeDeleteTopic(topic)
|
||||
info(s"Deletion of topic $topic successfully completed")
|
||||
} else if (!controllerContext.isAnyReplicaInState(topic, ReplicaDeletionStarted)) {
|
||||
// if you come here, then no replica is in TopicDeletionStarted and all replicas are not in
|
||||
// TopicDeletionSuccessful. That means, that either given topic haven't initiated deletion
|
||||
// or there is at least one failed replica (which means topic deletion should be retried).
|
||||
if (controllerContext.isAnyReplicaInState(topic, ReplicaDeletionIneligible)) {
|
||||
topicsEligibleForRetry += topic
|
||||
}
|
||||
}
|
||||
|
||||
// Add topic to the eligible set if it is eligible for deletion.
|
||||
if (isTopicEligibleForDeletion(topic)) {
|
||||
info(s"Deletion of topic $topic (re)started")
|
||||
topicsEligibleForDeletion += topic
|
||||
}
|
||||
}
|
||||
|
||||
// topic deletion retry will be kicked off
|
||||
if (topicsEligibleForRetry.nonEmpty) {
|
||||
retryDeletionForIneligibleReplicas(topicsEligibleForRetry)
|
||||
}
|
||||
|
||||
// topic deletion will be kicked off
|
||||
if (topicsEligibleForDeletion.nonEmpty) {
|
||||
//删除Topic,发送UpdataMetaData请求
|
||||
onTopicDeletion(topicsEligibleForDeletion)
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
1. 重点看看`onTopicDeletion`方法,标记所有待删除分区;向Brokers发送`updateMetadataRequest`请求,告知Brokers这个主题正在被删除,并将Leader设置为`LeaderAndIsrLeaderDuringDelete`;
|
||||
1. 将待删除的Topic的所有分区,执行分区状态机的转换 ;当前状态-->`OfflinePartition`->`NonExistentPartition` ; 这两个状态转换只是在当前Controller内存中更新了一下状态; 关于状态机请看 [【kafka源码】Controller中的状态机TODO....]();
|
||||
2. `client.sendMetadataUpdate(topics.flatMap(controllerContext.partitionsForTopic))` 向待删除Topic分区发送`UpdateMetadata`请求; 这个时候更新了什么数据呢? 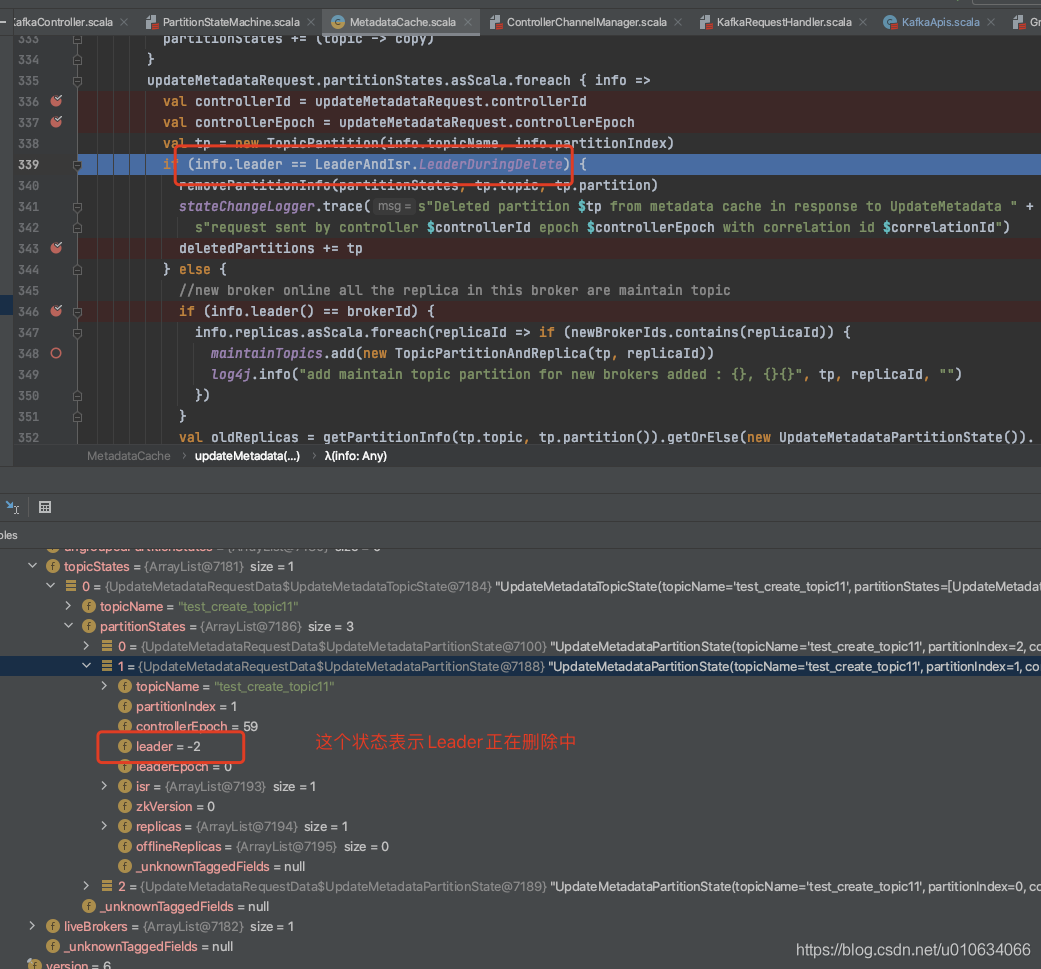
|
||||
看上面图片源码, 发送`UpdateMetadata`请求的时候把分区的Leader= -2; 表示这个分区正在被删除;那么所有正在被删除的分区就被找到了;拿到这些待删除分区之后干嘛呢?
|
||||
1. 更新一下限流相关信息
|
||||
2. 调用`groupCoordinator.handleDeletedPartitions(deletedPartitions)`: 清除给定的`deletedPartitions`的组偏移量以及执行偏移量删除的函数;就是现在该分区不能提供服务啦,不能被消费啦
|
||||
|
||||
详细请看 [Kafka的元数据更新UpdateMetadata]()
|
||||
|
||||
4. 调用`TopicDeletionManager.onPartitionDeletion`接口如下;
|
||||
|
||||
#### 3.2 TopicDeletionManager.onPartitionDeletion
|
||||
1. 将所有Dead replicas 副本直接移动到`ReplicaDeletionIneligible`状态,如果某些副本已死,也将相应的主题标记为不适合删除,因为它无论如何都不会成功完成
|
||||
2. 副本状态转换成`OfflineReplica`; 这个时候会对该Topic的所有副本所在Broker发起[`StopReplicaRequest` ]()请求;(参数`deletePartitions = false`,表示还不执行删除操作); 以便他们停止向`Leader`发送`fetch`请求; 关于状态机请看 [【kafka源码】Controller中的状态机TODO....]();
|
||||
3. 副本状态转换成 `ReplicaDeletionStarted`状态,这个时候会对该Topic的所有副本所在Broker发起[`StopReplicaRequest` ]()请求;(参数`deletePartitions = true`,表示执行删除操作)。这将发送带有 deletePartition=true 的 [`StopReplicaRequest` ]()。并将删除相应分区的所有副本中的所有持久数据
|
||||
|
||||
|
||||
### 4. Brokers 接受StopReplica请求
|
||||
最终调用的是接口
|
||||
`ReplicaManager.stopReplica` ==> `LogManager.asyncDelete`
|
||||
|
||||
>将给定主题分区“logdir”的目录重命名为“logdir.uuid.delete”,并将其添加到删除队列中
|
||||
>例如 :
|
||||
>
|
||||
|
||||
```scala
|
||||
def asyncDelete(topicPartition: TopicPartition, isFuture: Boolean = false): Log = {
|
||||
val removedLog: Log = logCreationOrDeletionLock synchronized {
|
||||
//将待删除的partition在 Logs中删除掉
|
||||
if (isFuture)
|
||||
futureLogs.remove(topicPartition)
|
||||
else
|
||||
currentLogs.remove(topicPartition)
|
||||
}
|
||||
if (removedLog != null) {
|
||||
//我们需要等到要删除的日志上没有更多的清理任务,然后才能真正删除它。
|
||||
if (cleaner != null && !isFuture) {
|
||||
cleaner.abortCleaning(topicPartition)
|
||||
cleaner.updateCheckpoints(removedLog.dir.getParentFile)
|
||||
}
|
||||
//重命名topic副本文件夹 命名规则 topic-uuid-delete
|
||||
removedLog.renameDir(Log.logDeleteDirName(topicPartition))
|
||||
checkpointRecoveryOffsetsAndCleanSnapshot(removedLog.dir.getParentFile, ArrayBuffer.empty)
|
||||
checkpointLogStartOffsetsInDir(removedLog.dir.getParentFile)
|
||||
//将Log添加到待删除Log队列中,等待删除
|
||||
addLogToBeDeleted(removedLog)
|
||||
|
||||
} else if (offlineLogDirs.nonEmpty) {
|
||||
throw new KafkaStorageException(s"Failed to delete log for ${if (isFuture) "future" else ""} $topicPartition because it may be in one of the offline directories ${offlineLogDirs.mkString(",")}")
|
||||
}
|
||||
removedLog
|
||||
}
|
||||
```
|
||||
#### 4.1 日志清理定时线程
|
||||
>上面我们知道最终是将待删除的Log添加到了`logsToBeDeleted`这个队列中; 这个队列就是待删除Log队列,有一个线程 `kafka-delete-logs`专门来处理的;我们来看看这个线程怎么工作的
|
||||
|
||||
`LogManager.startup` 启动的时候 ,启动了一个定时线程
|
||||
```scala
|
||||
scheduler.schedule("kafka-delete-logs", // will be rescheduled after each delete logs with a dynamic period
|
||||
deleteLogs _,
|
||||
delay = InitialTaskDelayMs,
|
||||
unit = TimeUnit.MILLISECONDS)
|
||||
```
|
||||
|
||||
**删除日志的线程**
|
||||
```scala
|
||||
/**
|
||||
* Delete logs marked for deletion. Delete all logs for which `currentDefaultConfig.fileDeleteDelayMs`
|
||||
* has elapsed after the delete was scheduled. Logs for which this interval has not yet elapsed will be
|
||||
* considered for deletion in the next iteration of `deleteLogs`. The next iteration will be executed
|
||||
* after the remaining time for the first log that is not deleted. If there are no more `logsToBeDeleted`,
|
||||
* `deleteLogs` will be executed after `currentDefaultConfig.fileDeleteDelayMs`.
|
||||
* 删除标记为删除的日志文件;
|
||||
* file.delete.delay.ms 文件延迟删除时间 默认60000毫秒
|
||||
*
|
||||
*/
|
||||
private def deleteLogs(): Unit = {
|
||||
var nextDelayMs = 0L
|
||||
try {
|
||||
def nextDeleteDelayMs: Long = {
|
||||
if (!logsToBeDeleted.isEmpty) {
|
||||
val (_, scheduleTimeMs) = logsToBeDeleted.peek()
|
||||
scheduleTimeMs + currentDefaultConfig.fileDeleteDelayMs - time.milliseconds()
|
||||
} else
|
||||
currentDefaultConfig.fileDeleteDelayMs
|
||||
}
|
||||
|
||||
while ({nextDelayMs = nextDeleteDelayMs; nextDelayMs <= 0}) {
|
||||
val (removedLog, _) = logsToBeDeleted.take()
|
||||
if (removedLog != null) {
|
||||
try {
|
||||
//立即彻底删除此日志目录和文件系统中的所有内容
|
||||
removedLog.delete()
|
||||
info(s"Deleted log for partition ${removedLog.topicPartition} in ${removedLog.dir.getAbsolutePath}.")
|
||||
} catch {
|
||||
case e: KafkaStorageException =>
|
||||
error(s"Exception while deleting $removedLog in dir ${removedLog.dir.getParent}.", e)
|
||||
}
|
||||
}
|
||||
}
|
||||
} catch {
|
||||
case e: Throwable =>
|
||||
error(s"Exception in kafka-delete-logs thread.", e)
|
||||
} finally {
|
||||
try {
|
||||
scheduler.schedule("kafka-delete-logs",
|
||||
deleteLogs _,
|
||||
delay = nextDelayMs,
|
||||
unit = TimeUnit.MILLISECONDS)
|
||||
} catch {
|
||||
case e: Throwable =>
|
||||
if (scheduler.isStarted) {
|
||||
// No errors should occur unless scheduler has been shutdown
|
||||
error(s"Failed to schedule next delete in kafka-delete-logs thread", e)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
`file.delete.delay.ms` 决定延迟多久删除
|
||||
|
||||
|
||||
### 5.StopReplica 请求成功 执行回调接口
|
||||
> Topic删除完成, 清理相关信息
|
||||
触发这个接口的地方是: 每个Broker执行删除`StopReplica`成功之后,都会执行一个回调函数;`TopicDeletionStopReplicaResponseReceived` ; 当然调用方是Controller,回调到的也就是Controller;
|
||||
|
||||
传入回调函数的地方
|
||||
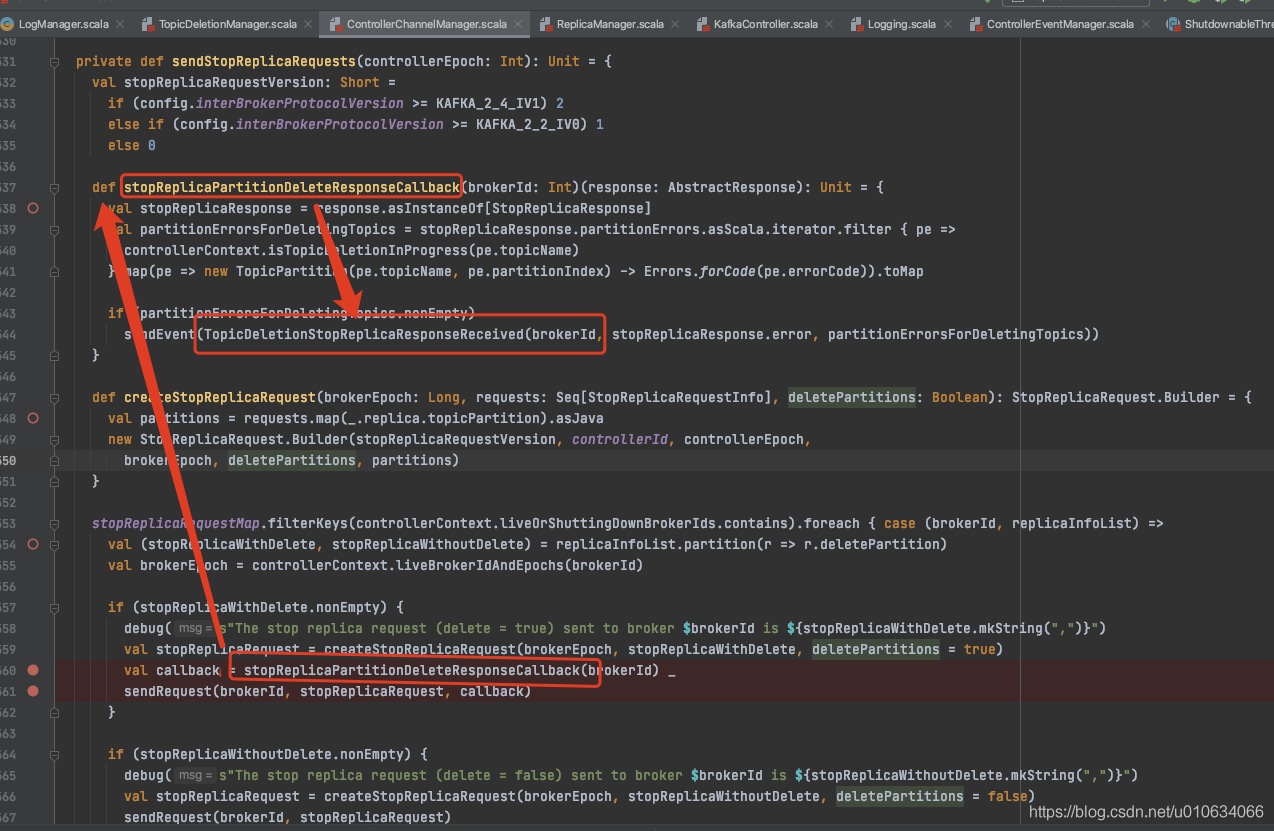
|
||||
|
||||
|
||||
|
||||
执行回调函数 `KafkaController.processTopicDeletionStopReplicaResponseReceived`
|
||||
|
||||
1. 如果回调有异常,删除失败则将副本状态转换成==》`ReplicaDeletionIneligible`,并且重新执行`resumeDeletions`方法;
|
||||
2. 如果回调正常,则变更状态 `ReplicaDeletionStarted`==》`ReplicaDeletionSuccessful`;并且重新执行`resumeDeletions`方法;
|
||||
3. `resumeDeletions`方法会判断所有副本是否均被删除,如果全部删除了就会执行下面的`completeDeleteTopic`代码;否则会继续删除未被成功删除的副本
|
||||
```scala
|
||||
private def completeDeleteTopic(topic: String): Unit = {
|
||||
// deregister partition change listener on the deleted topic. This is to prevent the partition change listener
|
||||
// firing before the new topic listener when a deleted topic gets auto created
|
||||
client.mutePartitionModifications(topic)
|
||||
val replicasForDeletedTopic = controllerContext.replicasInState(topic, ReplicaDeletionSuccessful)
|
||||
// controller will remove this replica from the state machine as well as its partition assignment cache
|
||||
replicaStateMachine.handleStateChanges(replicasForDeletedTopic.toSeq, NonExistentReplica)
|
||||
controllerContext.topicsToBeDeleted -= topic
|
||||
controllerContext.topicsWithDeletionStarted -= topic
|
||||
client.deleteTopic(topic, controllerContext.epochZkVersion)
|
||||
controllerContext.removeTopic(topic)
|
||||
}
|
||||
```
|
||||
|
||||
1. 清理内存中相关信息
|
||||
2. 取消注册被删除Topic的相关节点监听器;节点是`/brokers/topics/Topic名称`
|
||||
3. 删除zk中的数据包括;`/brokers/topics/Topic名称`、`/config/topics/Topic名称` 、`/admin/delete_topics/Topic名称`
|
||||
|
||||
|
||||
|
||||
|
||||
### 6. Controller启动时候 尝试继续处理待删除的Topic
|
||||
我们之前分析Controller上线的时候有看到
|
||||
`KafkaController.onControllerFailover`
|
||||
以下省略部分代码
|
||||
```scala
|
||||
private def onControllerFailover(): Unit = {
|
||||
// 获取哪些Topic需要被删除,哪些暂时还不能删除
|
||||
val (topicsToBeDeleted, topicsIneligibleForDeletion) = fetchTopicDeletionsInProgress()
|
||||
|
||||
info("Initializing topic deletion manager")
|
||||
//Topic删除管理器初始化
|
||||
topicDeletionManager.init(topicsToBeDeleted, topicsIneligibleForDeletion)
|
||||
|
||||
//Topic删除管理器 尝试开始删除Topi
|
||||
topicDeletionManager.tryTopicDeletion()
|
||||
|
||||
```
|
||||
#### 6.1 获取需要被删除的Topic和暂时不能删除的Topic
|
||||
` fetchTopicDeletionsInProgress`
|
||||
1. `topicsToBeDeleted`所有需要被删除的Topic从zk中`/admin/delete_topics` 获取
|
||||
2. `topicsIneligibleForDeletion`有一部分Topic还暂时不能被删除:
|
||||
①. Topic任意分区正在进行副本重分配
|
||||
②. Topic任意分区副本存在不在线的情况(只有topic有一个副本所在的Broker异常就不能能删除)
|
||||
3. 将得到的数据存在在`controllerContext`内存中
|
||||
|
||||
|
||||
#### 6.2 topicDeletionManager.init初始化删除管理器
|
||||
1. 如果服务器配置`delete.topic.enable=false`不允许删除topic的话,则删除`/admin/delete_topics` 中的节点; 这个节点下面的数据是标记topic需要被删除的意思;
|
||||
|
||||
#### 6.3 topicDeletionManager.tryTopicDeletion尝试恢复删除
|
||||
这里又回到了上面分析过的`resumeDeletions`啦;恢复删除操作
|
||||
```scala
|
||||
def tryTopicDeletion(): Unit = {
|
||||
if (isDeleteTopicEnabled) {
|
||||
resumeDeletions()
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## 源码总结
|
||||
整个Topic删除, 请看下图
|
||||
|
||||
|
||||
|
||||
几个注意点:
|
||||
1. Controller 也是Broker
|
||||
2. Controller发起删除请求的时候,只是跟相关联的Broker发起删除请求;
|
||||
3. Broker不在线或者删除失败,Controller会持续进行删除操作; 或者Broker上线之后继续进行删除操作
|
||||
|
||||
|
||||
## Q&A
|
||||
<font color="red">列举在此主题下比较常见的问题; 如果读者有其他问题可以在评论区评论, 博主会不定期更新</font>
|
||||
|
||||
|
||||
|
||||
### 什么时候在/admin/delete_topics写入节点的
|
||||
>客户端发起删除操作deleteTopics的时候,Controller响应deleteTopics请求, 这个时候Controller就将待删除Topic写入了zk的`/admin/delete_topics/Topic名称`节点中了;
|
||||
### 什么时候真正执行删除Topic磁盘日志
|
||||
>Controller监听到zk节点`/admin/delete_topics`之后,向所有存活的Broker发送删除Topic的请求; Broker收到请求之后将待删除副本标记为--delete后缀; 然后会有专门日志清理现场来进行真正的删除操作; 延迟多久删除是靠`file.delete.delay.ms`来决定的;默认是60000毫秒 = 一分钟
|
||||
|
||||
### 为什么正在重新分配的Topic不能被删除
|
||||
> 正在重新分配的Topic,你都不知道它具体会落在哪个地方,所以肯定也就不知道啥时候删除啊;
|
||||
> 等分配完毕之后,就会继续删除流程
|
||||
|
||||
|
||||
### 如果在`/admin/delete_topics/`中手动写入一个节点会不会正常删除
|
||||
> 如果写入的节点,并不是一个真实存在的Topic;则将会直接被删除
|
||||
> 当然要注意如果配置了`delete.topic.enable=false`不可删除Topic的话,则将`/admin/delete_topics/`下面的节点全部删除,然后流程结束
|
||||
> 如果写入的节点是一个真实存在的Topic; 则将会执行删除Topic的流程; 本质上跟用Kafka客户端执行删除Topic操作没有什么不同
|
||||
|
||||
|
||||
|
||||
### 如果直接删除ZK上的`/brokers/topics/{topicName}`节点会怎样
|
||||
>TODO...
|
||||
|
||||
### Controller通知Brokers 执行StopReplica是通知所有的Broker还是只通知跟被删除Topic有关联的Broker?
|
||||
> **只是通知跟被删除Topic有关联的Broker;**
|
||||
> 请看下图源码,可以看到所有需要被`StopReplica`的副本都是被过滤了一遍,获取它们所在的BrokerId; 最后调用的时候也是`sendRequest(brokerId, stopReplicaRequest)` ;根据获取到的BrokerId发起的请求
|
||||
> 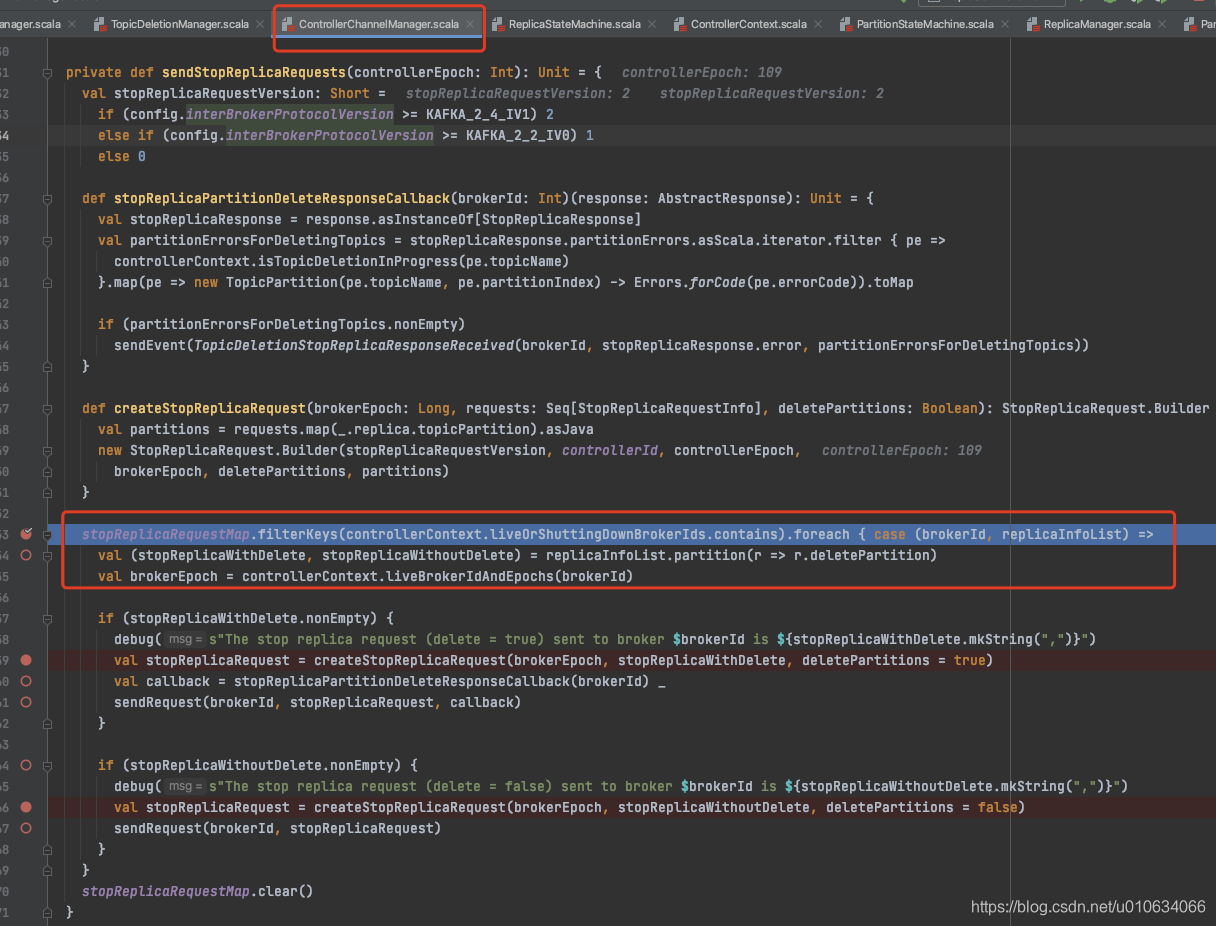
|
||||
|
||||
### 删除过程有Broker不在线 或者执行失败怎么办
|
||||
>Controller会继续删除操作;或者等Broker上线然后继续删除操作; 反正就是一定会保证所有的分区都被删除(被标记了--delete)之后才会把zk上的数据清理掉;
|
||||
|
||||
### ReplicaStateMachine 副本状态机
|
||||
> 请看 [【kafka源码】Controller中的状态机TODO]()
|
||||
|
||||
### 在重新分配的过程中,如果执行删除操作会怎么样
|
||||
> 删除操作会等待,等待重新分配完成之后,继续进行删除操作
|
||||
> 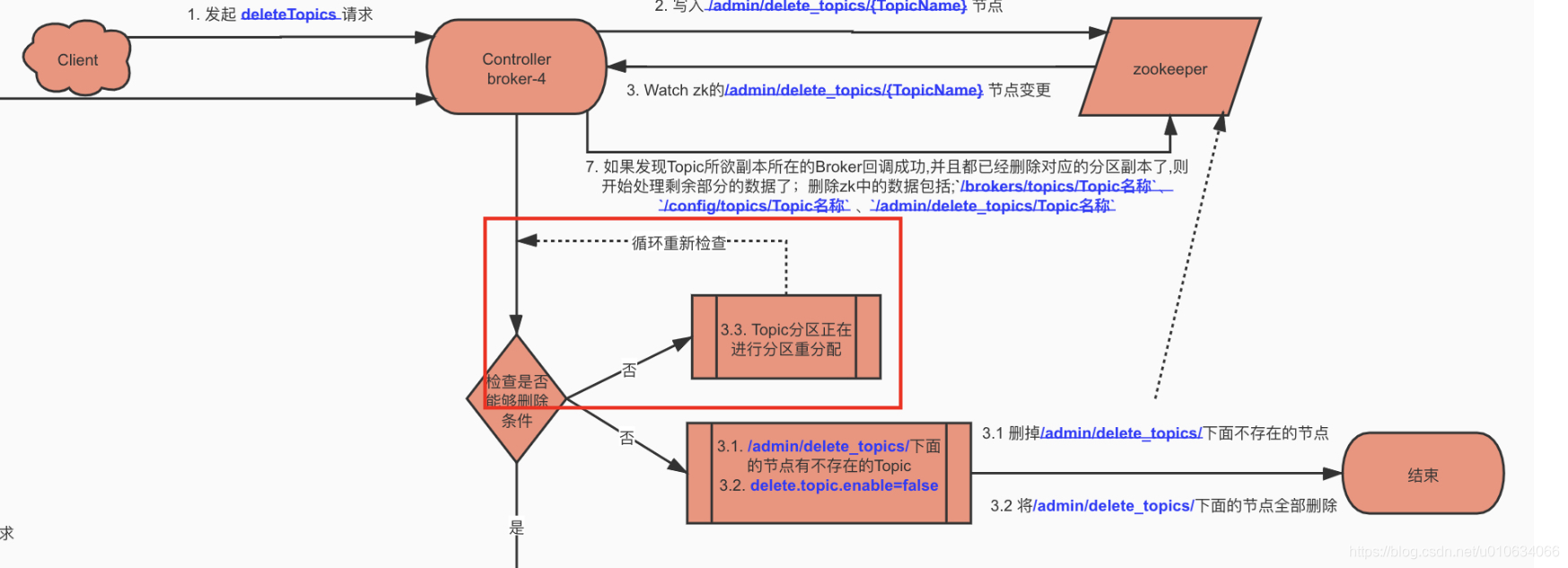
|
||||
|
||||
|
||||
Finally: 本文阅读源码为 `Kafka-2.5`
|
||||
149
docs/zh/Kafka分享/Kafka Controller /分区和副本的分配规则.md
Normal file
149
docs/zh/Kafka分享/Kafka Controller /分区和副本的分配规则.md
Normal file
@@ -0,0 +1,149 @@
|
||||
|
||||
我们有分析过[TopicCommand之创建Topic源码解析]();
|
||||
因为篇幅太长所以 关于分区分配的问题单独开一篇文章写;
|
||||
|
||||
|
||||
## 源码分析
|
||||
**创建Topic的源码入口 `AdminManager.createTopics()`**
|
||||
|
||||
以下只列出了分区分配相关代码其他省略
|
||||
```java
|
||||
|
||||
def createTopics(timeout: Int,
|
||||
validateOnly: Boolean,
|
||||
toCreate: Map[String, CreatableTopic],
|
||||
includeConfigsAndMetatadata: Map[String, CreatableTopicResult],
|
||||
responseCallback: Map[String, ApiError] => Unit): Unit = {
|
||||
|
||||
// 1. map over topics creating assignment and calling zookeeper
|
||||
val brokers = metadataCache.getAliveBrokers.map { b => kafka.admin.BrokerMetadata(b.id, b.rack) }
|
||||
|
||||
val metadata = toCreate.values.map(topic =>
|
||||
try {
|
||||
val assignments = if (topic.assignments().isEmpty) {
|
||||
AdminUtils.assignReplicasToBrokers(
|
||||
brokers, resolvedNumPartitions, resolvedReplicationFactor)
|
||||
} else {
|
||||
val assignments = new mutable.HashMap[Int, Seq[Int]]
|
||||
// Note: we don't check that replicaAssignment contains unknown brokers - unlike in add-partitions case,
|
||||
// this follows the existing logic in TopicCommand
|
||||
topic.assignments.asScala.foreach {
|
||||
case assignment => assignments(assignment.partitionIndex()) =
|
||||
assignment.brokerIds().asScala.map(a => a: Int)
|
||||
}
|
||||
assignments
|
||||
}
|
||||
trace(s"Assignments for topic $topic are $assignments ")
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
1. 以上有两种方式,一种是我们没有指定分区分配的情况也就是没有使用参数`--replica-assignment`;一种是自己指定了分区分配
|
||||
|
||||
### 1. 自己指定了分区分配规则
|
||||
从源码中得知, 会把我们指定的规则进行了包装,**注意它并没有去检查你指定的Broker是否存在;**
|
||||
|
||||
### 2. 自动分配 AdminUtils.assignReplicasToBrokers
|
||||
|
||||
1. 参数检查: 分区数>0; 副本数>0; 副本数<=Broker数 (如果自己未定义会直接使用Broker中个配置)
|
||||
2. 根据是否有 机架信息来进行不同方式的分配;
|
||||
3. 要么整个集群都有机架信息,要么整个集群都没有机架信息; 否则抛出异常
|
||||
|
||||
|
||||
#### 无机架方式分配
|
||||
`AdminUtils.assignReplicasToBrokersRackUnaware`
|
||||
```scala
|
||||
/**
|
||||
* 副本分配时,有三个原则:
|
||||
* 1. 将副本平均分布在所有的 Broker 上;
|
||||
* 2. partition 的多个副本应该分配在不同的 Broker 上;
|
||||
* 3. 如果所有的 Broker 有机架信息的话, partition 的副本应该分配到不同的机架上。
|
||||
*
|
||||
* 为实现上面的目标,在没有机架感知的情况下,应该按照下面两个原则分配 replica:
|
||||
* 1. 从 broker.list 随机选择一个 Broker,使用 round-robin 算法分配每个 partition 的第一个副本;
|
||||
* 2. 对于这个 partition 的其他副本,逐渐增加 Broker.id 来选择 replica 的分配。
|
||||
*/
|
||||
|
||||
private def assignReplicasToBrokersRackUnaware(nPartitions: Int,
|
||||
replicationFactor: Int,
|
||||
brokerList: Seq[Int],
|
||||
fixedStartIndex: Int,
|
||||
startPartitionId: Int): Map[Int, Seq[Int]] = {
|
||||
val ret = mutable.Map[Int, Seq[Int]]()
|
||||
// 这里是上一层传递过了的所有 存活的Broker列表的ID
|
||||
val brokerArray = brokerList.toArray
|
||||
//默认随机选一个index开始
|
||||
val startIndex = if (fixedStartIndex >= 0) fixedStartIndex else rand.nextInt(brokerArray.length)
|
||||
//默认从0这个分区号开始
|
||||
var currentPartitionId = math.max(0, startPartitionId)
|
||||
var nextReplicaShift = if (fixedStartIndex >= 0) fixedStartIndex else rand.nextInt(brokerArray.length)
|
||||
for (_ <- 0 until nPartitions) {
|
||||
if (currentPartitionId > 0 && (currentPartitionId % brokerArray.length == 0))
|
||||
nextReplicaShift += 1
|
||||
val firstReplicaIndex = (currentPartitionId + startIndex) % brokerArray.length
|
||||
val replicaBuffer = mutable.ArrayBuffer(brokerArray(firstReplicaIndex))
|
||||
for (j <- 0 until replicationFactor - 1)
|
||||
replicaBuffer += brokerArray(replicaIndex(firstReplicaIndex, nextReplicaShift, j, brokerArray.length))
|
||||
ret.put(currentPartitionId, replicaBuffer)
|
||||
currentPartitionId += 1
|
||||
}
|
||||
ret
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
#### 有机架方式分配
|
||||
|
||||
```java
|
||||
private def assignReplicasToBrokersRackAware(nPartitions: Int,
|
||||
replicationFactor: Int,
|
||||
brokerMetadatas: Seq[BrokerMetadata],
|
||||
fixedStartIndex: Int,
|
||||
startPartitionId: Int): Map[Int, Seq[Int]] = {
|
||||
val brokerRackMap = brokerMetadatas.collect { case BrokerMetadata(id, Some(rack)) =>
|
||||
id -> rack
|
||||
}.toMap
|
||||
val numRacks = brokerRackMap.values.toSet.size
|
||||
val arrangedBrokerList = getRackAlternatedBrokerList(brokerRackMap)
|
||||
val numBrokers = arrangedBrokerList.size
|
||||
val ret = mutable.Map[Int, Seq[Int]]()
|
||||
val startIndex = if (fixedStartIndex >= 0) fixedStartIndex else rand.nextInt(arrangedBrokerList.size)
|
||||
var currentPartitionId = math.max(0, startPartitionId)
|
||||
var nextReplicaShift = if (fixedStartIndex >= 0) fixedStartIndex else rand.nextInt(arrangedBrokerList.size)
|
||||
for (_ <- 0 until nPartitions) {
|
||||
if (currentPartitionId > 0 && (currentPartitionId % arrangedBrokerList.size == 0))
|
||||
nextReplicaShift += 1
|
||||
val firstReplicaIndex = (currentPartitionId + startIndex) % arrangedBrokerList.size
|
||||
val leader = arrangedBrokerList(firstReplicaIndex)
|
||||
val replicaBuffer = mutable.ArrayBuffer(leader)
|
||||
val racksWithReplicas = mutable.Set(brokerRackMap(leader))
|
||||
val brokersWithReplicas = mutable.Set(leader)
|
||||
var k = 0
|
||||
for (_ <- 0 until replicationFactor - 1) {
|
||||
var done = false
|
||||
while (!done) {
|
||||
val broker = arrangedBrokerList(replicaIndex(firstReplicaIndex, nextReplicaShift * numRacks, k, arrangedBrokerList.size))
|
||||
val rack = brokerRackMap(broker)
|
||||
// Skip this broker if
|
||||
// 1. there is already a broker in the same rack that has assigned a replica AND there is one or more racks
|
||||
// that do not have any replica, or
|
||||
// 2. the broker has already assigned a replica AND there is one or more brokers that do not have replica assigned
|
||||
if ((!racksWithReplicas.contains(rack) || racksWithReplicas.size == numRacks)
|
||||
&& (!brokersWithReplicas.contains(broker) || brokersWithReplicas.size == numBrokers)) {
|
||||
replicaBuffer += broker
|
||||
racksWithReplicas += rack
|
||||
brokersWithReplicas += broker
|
||||
done = true
|
||||
}
|
||||
k += 1
|
||||
}
|
||||
}
|
||||
ret.put(currentPartitionId, replicaBuffer)
|
||||
currentPartitionId += 1
|
||||
}
|
||||
ret
|
||||
}
|
||||
```
|
||||
|
||||
## 源码总结
|
||||
|
||||
Reference in New Issue
Block a user