初始化3.0.0版本
226
.gitignore
vendored
@@ -1,114 +1,112 @@
|
||||
### Intellij ###
|
||||
# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio and Webstorm
|
||||
|
||||
*.iml
|
||||
|
||||
## Directory-based project format:
|
||||
.idea/
|
||||
# if you remove the above rule, at least ignore the following:
|
||||
|
||||
# User-specific stuff:
|
||||
# .idea/workspace.xml
|
||||
# .idea/tasks.xml
|
||||
# .idea/dictionaries
|
||||
# .idea/shelf
|
||||
|
||||
# Sensitive or high-churn files:
|
||||
.idea/dataSources.ids
|
||||
.idea/dataSources.xml
|
||||
.idea/sqlDataSources.xml
|
||||
.idea/dynamic.xml
|
||||
.idea/uiDesigner.xml
|
||||
|
||||
|
||||
# Mongo Explorer plugin:
|
||||
.idea/mongoSettings.xml
|
||||
|
||||
## File-based project format:
|
||||
*.ipr
|
||||
*.iws
|
||||
|
||||
## Plugin-specific files:
|
||||
|
||||
# IntelliJ
|
||||
/out/
|
||||
|
||||
# mpeltonen/sbt-idea plugin
|
||||
.idea_modules/
|
||||
|
||||
# JIRA plugin
|
||||
atlassian-ide-plugin.xml
|
||||
|
||||
# Crashlytics plugin (for Android Studio and IntelliJ)
|
||||
com_crashlytics_export_strings.xml
|
||||
crashlytics.properties
|
||||
crashlytics-build.properties
|
||||
fabric.properties
|
||||
|
||||
|
||||
### Java ###
|
||||
*.class
|
||||
|
||||
# Mobile Tools for Java (J2ME)
|
||||
.mtj.tmp/
|
||||
|
||||
# Package Files #
|
||||
*.jar
|
||||
*.war
|
||||
*.ear
|
||||
*.tar.gz
|
||||
|
||||
# virtual machine crash logs, see http://www.java.com/en/download/help/error_hotspot.xml
|
||||
hs_err_pid*
|
||||
|
||||
|
||||
### OSX ###
|
||||
.DS_Store
|
||||
.AppleDouble
|
||||
.LSOverride
|
||||
|
||||
# Icon must end with two \r
|
||||
Icon
|
||||
|
||||
|
||||
# Thumbnails
|
||||
._*
|
||||
|
||||
# Files that might appear in the root of a volume
|
||||
.DocumentRevisions-V100
|
||||
.fseventsd
|
||||
.Spotlight-V100
|
||||
.TemporaryItems
|
||||
.Trashes
|
||||
.VolumeIcon.icns
|
||||
|
||||
# Directories potentially created on remote AFP share
|
||||
.AppleDB
|
||||
.AppleDesktop
|
||||
Network Trash Folder
|
||||
Temporary Items
|
||||
.apdisk
|
||||
|
||||
/target
|
||||
target/
|
||||
*.log
|
||||
*.log.*
|
||||
*.bak
|
||||
*.vscode
|
||||
*/.vscode/*
|
||||
*/.vscode
|
||||
*/velocity.log*
|
||||
*/*.log
|
||||
*/*.log.*
|
||||
node_modules/
|
||||
node_modules/*
|
||||
workspace.xml
|
||||
/output/*
|
||||
.gitversion
|
||||
node_modules/*
|
||||
out/*
|
||||
dist/
|
||||
dist/*
|
||||
kafka-manager-web/src/main/resources/templates/
|
||||
.DS_Store
|
||||
kafka-manager-console/package-lock.json
|
||||
### Intellij ###
|
||||
# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio and Webstorm
|
||||
|
||||
*.iml
|
||||
|
||||
## Directory-based project format:
|
||||
.idea/
|
||||
# if you remove the above rule, at least ignore the following:
|
||||
|
||||
# User-specific stuff:
|
||||
# .idea/workspace.xml
|
||||
# .idea/tasks.xml
|
||||
# .idea/dictionaries
|
||||
# .idea/shelf
|
||||
|
||||
# Sensitive or high-churn files:
|
||||
.idea/dataSources.ids
|
||||
.idea/dataSources.xml
|
||||
.idea/sqlDataSources.xml
|
||||
.idea/dynamic.xml
|
||||
.idea/uiDesigner.xml
|
||||
|
||||
|
||||
# Mongo Explorer plugin:
|
||||
.idea/mongoSettings.xml
|
||||
|
||||
## File-based project format:
|
||||
*.ipr
|
||||
*.iws
|
||||
|
||||
## Plugin-specific files:
|
||||
|
||||
# IntelliJ
|
||||
/out/
|
||||
|
||||
# mpeltonen/sbt-idea plugin
|
||||
.idea_modules/
|
||||
|
||||
# JIRA plugin
|
||||
atlassian-ide-plugin.xml
|
||||
|
||||
# Crashlytics plugin (for Android Studio and IntelliJ)
|
||||
com_crashlytics_export_strings.xml
|
||||
crashlytics.properties
|
||||
crashlytics-build.properties
|
||||
fabric.properties
|
||||
|
||||
|
||||
### Java ###
|
||||
*.class
|
||||
|
||||
# Mobile Tools for Java (J2ME)
|
||||
.mtj.tmp/
|
||||
|
||||
# Package Files #
|
||||
*.jar
|
||||
*.war
|
||||
*.ear
|
||||
*.tar.gz
|
||||
|
||||
# virtual machine crash logs, see http://www.java.com/en/download/help/error_hotspot.xml
|
||||
hs_err_pid*
|
||||
|
||||
|
||||
### OSX ###
|
||||
.DS_Store
|
||||
.AppleDouble
|
||||
.LSOverride
|
||||
|
||||
# Icon must end with two \r
|
||||
Icon
|
||||
|
||||
|
||||
# Thumbnails
|
||||
._*
|
||||
|
||||
# Files that might appear in the root of a volume
|
||||
.DocumentRevisions-V100
|
||||
.fseventsd
|
||||
.Spotlight-V100
|
||||
.TemporaryItems
|
||||
.Trashes
|
||||
.VolumeIcon.icns
|
||||
|
||||
# Directories potentially created on remote AFP share
|
||||
.AppleDB
|
||||
.AppleDesktop
|
||||
Network Trash Folder
|
||||
Temporary Items
|
||||
.apdisk
|
||||
|
||||
/target
|
||||
target/
|
||||
*.log
|
||||
*.log.*
|
||||
*.bak
|
||||
*.vscode
|
||||
*/.vscode/*
|
||||
*/.vscode
|
||||
*/velocity.log*
|
||||
*/*.log
|
||||
*/*.log.*
|
||||
node_modules/
|
||||
node_modules/*
|
||||
workspace.xml
|
||||
/output/*
|
||||
.gitversion
|
||||
out/*
|
||||
dist/
|
||||
dist/*
|
||||
km-rest/src/main/resources/templates/
|
||||
*dependency-reduced-pom*
|
||||
@@ -7,7 +7,7 @@ Thanks for considering to contribute this project. All issues and pull requests
|
||||
Before sending pull request to this project, please read and follow guidelines below.
|
||||
|
||||
1. Branch: We only accept pull request on `dev` branch.
|
||||
2. Coding style: Follow the coding style used in kafka-manager.
|
||||
2. Coding style: Follow the coding style used in LogiKM.
|
||||
3. Commit message: Use English and be aware of your spell.
|
||||
4. Test: Make sure to test your code.
|
||||
|
||||
|
||||
41
Dockerfile
@@ -1,41 +0,0 @@
|
||||
ARG MAVEN_VERSION=3.8.4-openjdk-8-slim
|
||||
ARG JAVA_VERSION=8-jdk-alpine3.9
|
||||
FROM maven:${MAVEN_VERSION} AS builder
|
||||
ARG CONSOLE_ENABLE=true
|
||||
|
||||
WORKDIR /opt
|
||||
COPY . .
|
||||
COPY distribution/conf/settings.xml /root/.m2/settings.xml
|
||||
|
||||
# whether to build console
|
||||
RUN set -eux; \
|
||||
if [ $CONSOLE_ENABLE = 'false' ]; then \
|
||||
sed -i "/kafka-manager-console/d" pom.xml; \
|
||||
fi \
|
||||
&& mvn -Dmaven.test.skip=true clean install -U
|
||||
|
||||
FROM openjdk:${JAVA_VERSION}
|
||||
|
||||
RUN sed -i 's/dl-cdn.alpinelinux.org/mirrors.aliyun.com/g' /etc/apk/repositories && apk add --no-cache tini
|
||||
|
||||
ENV TZ=Asia/Shanghai
|
||||
ENV AGENT_HOME=/opt/agent/
|
||||
|
||||
COPY --from=builder /opt/kafka-manager-web/target/kafka-manager.jar /opt
|
||||
COPY --from=builder /opt/container/dockerfiles/docker-depends/config.yaml $AGENT_HOME
|
||||
COPY --from=builder /opt/container/dockerfiles/docker-depends/jmx_prometheus_javaagent-0.15.0.jar $AGENT_HOME
|
||||
COPY --from=builder /opt/distribution/conf/application-docker.yml /opt
|
||||
|
||||
WORKDIR /opt
|
||||
|
||||
ENV JAVA_AGENT="-javaagent:$AGENT_HOME/jmx_prometheus_javaagent-0.15.0.jar=9999:$AGENT_HOME/config.yaml"
|
||||
ENV JAVA_HEAP_OPTS="-Xms1024M -Xmx1024M -Xmn100M "
|
||||
ENV JAVA_OPTS="-verbose:gc \
|
||||
-XX:MaxMetaspaceSize=256M -XX:+DisableExplicitGC -XX:+UseStringDeduplication \
|
||||
-XX:+UseG1GC -XX:+HeapDumpOnOutOfMemoryError -XX:-UseContainerSupport"
|
||||
|
||||
EXPOSE 8080 9999
|
||||
|
||||
ENTRYPOINT ["tini", "--"]
|
||||
|
||||
CMD [ "sh", "-c", "java -jar $JAVA_AGENT $JAVA_HEAP_OPTS $JAVA_OPTS kafka-manager.jar --spring.config.location=application-docker.yml"]
|
||||
259
README.md
@@ -1,121 +1,138 @@
|
||||
|
||||
---
|
||||

|
||||
|
||||
**一站式`Apache Kafka`管控平台**
|
||||
|
||||
`LogiKM开源至今备受关注,考虑到开源项目应该更贴合Apache Kafka未来发展方向,经项目组慎重考虑,我们将其品牌升级成Know Streaming,新的大版本更新马上就绪,感谢大家一如既往的支持!也欢迎Kafka爱好者一起共建社区`
|
||||
|
||||
阅读本README文档,您可以了解到滴滴Know Streaming的用户群体、产品定位等信息,并通过体验地址,快速体验Kafka集群指标监控与运维管控的全流程。
|
||||
|
||||
|
||||
## 1 产品简介
|
||||
滴滴Know Streaming脱胎于滴滴内部多年的Kafka运营实践经验,是面向Kafka用户、Kafka运维人员打造的共享多租户Kafka云平台。专注于Kafka运维管控、监控告警、资源治理等核心场景,经历过大规模集群、海量大数据的考验。内部满意度高达90%的同时,还与多家知名企业达成商业化合作。
|
||||
|
||||
### 1.1 快速体验地址
|
||||
|
||||
- 体验地址(新的体验地址马上就来) http://117.51.150.133:8080 账号密码 admin/admin
|
||||
|
||||
### 1.2 体验地图
|
||||
相比较于同类产品的用户视角单一(大多为管理员视角),滴滴Logi-KafkaManager建立了基于分角色、多场景视角的体验地图。分别是:**用户体验地图、运维体验地图、运营体验地图**
|
||||
|
||||
#### 1.2.1 用户体验地图
|
||||
- 平台租户申请 :申请应用(App)作为Kafka中的用户名,并用 AppID+password作为身份验证
|
||||
- 集群资源申请 :按需申请、按需使用。可使用平台提供的共享集群,也可为应用申请独立的集群
|
||||
- Topic 申 请 :可根据应用(App)创建Topic,或者申请其他topic的读写权限
|
||||
- Topic 运 维 :Topic数据采样、调整配额、申请分区等操作
|
||||
- 指 标 监 控 :基于Topic生产消费各环节耗时统计,监控不同分位数性能指标
|
||||
- 消 费 组 运 维 :支持将消费偏移重置至指定时间或指定位置
|
||||
|
||||
#### 1.2.2 运维体验地图
|
||||
- 多版本集群管控 :支持从`0.10.2`到`2.x`版本
|
||||
- 集 群 监 控 :集群Topic、Broker等多维度历史与实时关键指标查看,建立健康分体系
|
||||
- 集 群 运 维 :划分部分Broker作为Region,使用Region定义资源划分单位,并按照业务、保障能力区分逻辑集群
|
||||
- Broker 运 维 :包括优先副本选举等操作
|
||||
- Topic 运 维 :包括创建、查询、扩容、修改属性、迁移、下线等
|
||||
|
||||
|
||||
#### 1.2.3 运营体验地图
|
||||
- 资 源 治 理 :沉淀资源治理方法。针对Topic分区热点、分区不足等高频常见问题,沉淀资源治理方法,实现资源治理专家化
|
||||
- 资 源 审 批 :工单体系。Topic创建、调整配额、申请分区等操作,由专业运维人员审批,规范资源使用,保障平台平稳运行
|
||||
- 账 单 体 系 :成本控制。Topic资源、集群资源按需申请、按需使用。根据流量核算费用,帮助企业建设大数据成本核算体系
|
||||
|
||||
### 1.3 核心优势
|
||||
- 高 效 的 问 题 定 位 :监控多项核心指标,统计不同分位数据,提供种类丰富的指标监控报表,帮助用户、运维人员快速高效定位问题
|
||||
- 便 捷 的 集 群 运 维 :按照Region定义集群资源划分单位,将逻辑集群根据保障等级划分。在方便资源隔离、提高扩展能力的同时,实现对服务端的强管控
|
||||
- 专 业 的 资 源 治 理 :基于滴滴内部多年运营实践,沉淀资源治理方法,建立健康分体系。针对Topic分区热点、分区不足等高频常见问题,实现资源治理专家化
|
||||
- 友 好 的 运 维 生 态 :与Prometheus、Grafana、滴滴夜莺监控告警系统打通,集成指标分析、监控告警、集群部署、集群升级等能力。形成运维生态,凝练专家服务,使运维更高效
|
||||
|
||||
### 1.4 滴滴Logi-KafkaManager架构图
|
||||
|
||||
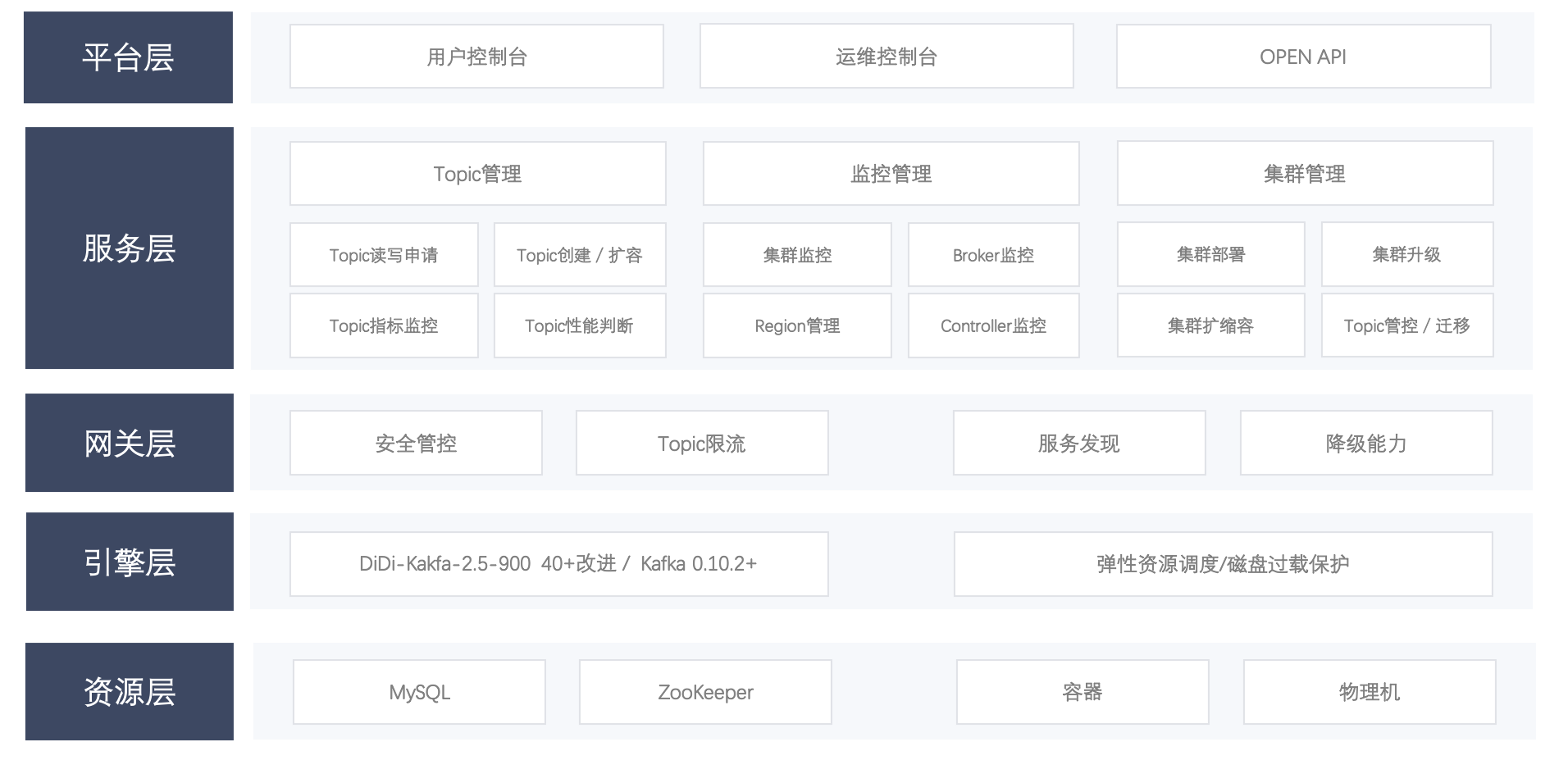
|
||||
|
||||
|
||||
## 2 相关文档
|
||||
|
||||
### 2.1 产品文档
|
||||
- [滴滴Know Streaming 安装手册](docs/install_guide/install_guide_cn.md)
|
||||
- [滴滴Know Streaming 接入集群](docs/user_guide/add_cluster/add_cluster.md)
|
||||
- [滴滴Know Streaming 用户使用手册](docs/user_guide/user_guide_cn.md)
|
||||
- [滴滴Know Streaming FAQ](docs/user_guide/faq.md)
|
||||
|
||||
### 2.2 社区文章
|
||||
- [滴滴云官网产品介绍](https://www.didiyun.com/production/logi-KafkaManager.html)
|
||||
- [7年沉淀之作--滴滴Logi日志服务套件](https://mp.weixin.qq.com/s/-KQp-Qo3WKEOc9wIR2iFnw)
|
||||
- [滴滴Know Streaming 一站式Kafka管控平台](https://mp.weixin.qq.com/s/9qSZIkqCnU6u9nLMvOOjIQ)
|
||||
- [滴滴Know Streaming 开源之路](https://xie.infoq.cn/article/0223091a99e697412073c0d64)
|
||||
- [滴滴Know Streaming 系列视频教程](https://space.bilibili.com/442531657/channel/seriesdetail?sid=571649)
|
||||
- [kafka最强最全知识图谱](https://www.szzdzhp.com/kafka/)
|
||||
- [滴滴Know Streaming新用户入门系列文章专栏 --石臻臻](https://www.szzdzhp.com/categories/LogIKM/)
|
||||
- [kafka实践(十五):滴滴开源Kafka管控平台 Know Streaming研究--A叶子叶来](https://blog.csdn.net/yezonggang/article/details/113106244)
|
||||
- [基于云原生应用管理平台Rainbond安装 滴滴Know Streaming](https://www.rainbond.com/docs/opensource-app/logikm/?channel=logikm)
|
||||
|
||||
## 3 Know Streaming开源用户交流群
|
||||
|
||||

|
||||
|
||||
想跟各个大佬交流Kafka Es 等中间件/大数据相关技术请 加微信进群。
|
||||
|
||||
微信加群:添加<font color=red>mike_zhangliang</font>、<font color=red>PenceXie</font>的微信号备注Know Streaming加群或关注公众号 云原生可观测性 回复 "Know Streaming加群"
|
||||
|
||||
## 4 知识星球
|
||||
|
||||
<img width="447" alt="image" src="https://user-images.githubusercontent.com/71620349/147314042-843a371a-48c0-4d9a-a65e-ca40236f3300.png">
|
||||
|
||||
<br>
|
||||
<center>
|
||||
✅我们正在组建国内最大最权威的
|
||||
</center>
|
||||
<br>
|
||||
<center>
|
||||
<font color=red size=5><b>【Kafka中文社区】</b></font>
|
||||
</center>
|
||||
|
||||
在这里你可以结交各大互联网Kafka大佬以及3000+Kafka爱好者,一起实现知识共享,实时掌控最新行业资讯,期待您的加入中~https://z.didi.cn/5gSF9
|
||||
|
||||
<font color=red size=5>有问必答~! </font>
|
||||
|
||||
<font color=red size=5>互动有礼~! </font>
|
||||
|
||||
PS:提问请尽量把问题一次性描述清楚,并告知环境信息情况哦~!如使用版本、操作步骤、报错/警告信息等,方便大V们快速解答~
|
||||
|
||||
## 5 项目成员
|
||||
|
||||
### 5.1 内部核心人员
|
||||
|
||||
`iceyuhui`、`liuyaguang`、`limengmonty`、`zhangliangmike`、`zhaoqingrong`、`xiepeng`、`nullhuangyiming`、`zengqiao`、`eilenexuzhe`、`huangjiaweihjw`、`zhaoyinrui`、`marzkonglingxu`、`joysunchao`、`石臻臻`
|
||||
|
||||
|
||||
### 5.2 外部贡献者
|
||||
|
||||
`fangjunyu`、`zhoutaiyang`
|
||||
|
||||
|
||||
## 6 协议
|
||||
|
||||
`Know Streaming`基于`Apache-2.0`协议进行分发和使用,更多信息参见[协议文件](./LICENSE)
|
||||
|
||||
## 7 Star History
|
||||
|
||||
[](https://star-history.com/#didi/KnowStreaming&Date)
|
||||
|
||||
|
||||
<p align="center">
|
||||
<img src="docs/assets/KnowStreamingLogo.png" width = "512" height = "129" div align=center />
|
||||
</p>
|
||||
|
||||
<p align="center">
|
||||
<a href="knowstreaming.com">产品官网</a> |
|
||||
<a href="https://github.com/didi/KnowStreaming/releases">下载地址</a> |
|
||||
<a href="doc.knowstreaming.com">文档资源</a> |
|
||||
<a href="demo.knowstreaming.com">体验环境</a>
|
||||
</p>
|
||||
|
||||
<p align="center">
|
||||
<!--最近一次提交时间-->
|
||||
<a href="https://img.shields.io/github/last-commit/didi/KnowStreaming">
|
||||
<img src="https://img.shields.io/github/last-commit/didi/KnowStreaming" alt="LastCommit">
|
||||
</a>
|
||||
|
||||
<!--最新版本-->
|
||||
<a href="https://github.com/didi/KnowStreaming/blob/master/LICENSE">
|
||||
<img src="https://img.shields.io/github/v/release/didi/KnowStreaming" alt="License">
|
||||
</a>
|
||||
|
||||
<!--License信息-->
|
||||
<a href="https://github.com/didi/KnowStreaming/blob/master/LICENSE">
|
||||
<img src="https://img.shields.io/github/license/didi/KnowStreaming" alt="License">
|
||||
</a>
|
||||
|
||||
<!--Open-Issue-->
|
||||
<a href="https://github.com/didi/KnowStreaming/issues">
|
||||
<img src="https://img.shields.io/github/issues-raw/didi/KnowStreaming" alt="Issues">
|
||||
</a>
|
||||
|
||||
<!--知识星球-->
|
||||
<a href="https://z.didi.cn/5gSF9">
|
||||
<img src="https://img.shields.io/badge/join-%E7%9F%A5%E8%AF%86%E6%98%9F%E7%90%83-red" alt="Slack">
|
||||
</a>
|
||||
|
||||
</p>
|
||||
|
||||
|
||||
---
|
||||
|
||||
|
||||
## `Know Streaming` 简介
|
||||
|
||||
|
||||
`Know Streaming`专注于Kafka运维管控、监控告警、资源治理、多活容灾等核心场景,经历大规模集群、海量大数据考验,在用户体验、监控、运维管控上进行了平台化、可视化、智能化的建设,提供一系列特色的功能,极大地方便了用户和运维人员的日常使用。与其他Kafka管控产品相比,`Know Streaming` 具有以下特点:
|
||||
|
||||
- 👀 **简单易用**:提炼高频的 CLI 能力,设计合理的产品使用路径,绘制清新美观的 GUI 页面,始终将简单易用作为产品的主要目标。
|
||||
|
||||
|
||||
- 🌪️ **功能丰富**:主要包含`多集群管理`和`系统管理`两大块,具体包含:
|
||||
1. 多集群管理:包括集群管理、Broker管理、Topic管理、Group管理、Security管理、Jobs管理等六大功能模块,几乎涵盖 CLI 的所有高频能力。
|
||||
2. 系统管理:包括配置管理、用户管理、审计日志等3大功能模块,基本满足开源用户的使用需要。
|
||||
|
||||
|
||||
- 👏 **版本兼容**:支持 0.10 及以上,**`ZK`** 或 **`Raft`** 运行模式的Kafka版本,此外在兼容架构上具备良好的扩展性。
|
||||
|
||||
|
||||
- 🚀 **专业能力**:不仅是 CLI 到 GUI 的优秀翻译,更是涵盖一系列专业能力的产品,包括但不限于:
|
||||
1. 观测提升: **`多维度指标观测大盘`**、**`观测指标最佳实践`** 等功能。
|
||||
2. 异常巡检:**`集群多维度健康巡检`**、 **`集群多维度健康分`** 等功能。
|
||||
3. 能力增强:**`Topic扩缩副本`**、**`Topic副本迁移`** 等功能。
|
||||
|
||||
|
||||
- ⚡️ **支持分布式**:具备水平扩展能力,只需要增加节点即可获取更强的采集及对外服务能力。
|
||||
|
||||
|
||||
**产品图**
|
||||
|
||||
<p align="center">
|
||||
|
||||
<img src="docs/assets/readme/KnowStreamingPageDemo.jpg" width = "768" height = "473" div align=center />
|
||||
|
||||
</p>
|
||||
|
||||
|
||||
|
||||
|
||||
## 文档资源
|
||||
|
||||
**`开发相关手册`**
|
||||
|
||||
- [打包编译手册](docs/install_guide/源码编译打包手册.md)
|
||||
- [单机部署手册](docs/install_guide/单机部署手册.md)
|
||||
- [版本升级手册](docs/install_guide/版本升级手册.md)
|
||||
- [本地源码启动手册](docs/dev_guide/本地源码启动手册.md)
|
||||
|
||||
**`产品相关手册`**
|
||||
|
||||
- [产品使用指南](docs/user_guide/用户使用手册.md)
|
||||
- [2.x与3.x新旧对比手册](docs/user_guide/新旧对比手册.md)
|
||||
- [FAQ](docs/user_guide/faq.md)
|
||||
|
||||
|
||||
**点击 [这里](https://doc.knowstreaming.com/product/1-quick-start),也可以从官网获取到更多文档**
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 成为社区贡献者
|
||||
|
||||
点击 [这里](CONTRIBUTING.md),了解如何成为 Know Streaming 的贡献者
|
||||
|
||||
|
||||
|
||||
## 加入技术交流群
|
||||
|
||||
**`1、知识星球`**
|
||||
|
||||
<p align="left">
|
||||
<img src="docs/assets/readme/ZSXQ.jpg" width = "512" height = "160" div align=left />
|
||||
</p>
|
||||
|
||||
<br/>
|
||||
<br/>
|
||||
<br/>
|
||||
<br/>
|
||||
<br/>
|
||||
<br/>
|
||||
<br/>
|
||||
<br/>
|
||||
|
||||
👍 我们正在组建国内最大,最权威的 **[Kafka中文社区](https://z.didi.cn/5gSF9)**
|
||||
|
||||
在这里你可以结交各大互联网的 Kafka大佬 以及 3000+ Kafka爱好者,一起实现知识共享,实时掌控最新行业资讯,期待 👏 您的加入中~ https://z.didi.cn/5gSF9
|
||||
|
||||
有问必答~! 互动有礼~!
|
||||
|
||||
PS: 提问请尽量把问题一次性描述清楚,并告知环境信息情况~!如使用版本、操作步骤、报错/警告信息等,方便大V们快速解答~
|
||||
|
||||
|
||||
|
||||
**`2、微信群`**
|
||||
|
||||
微信加群:添加`mike_zhangliang`、`danke-x`的微信号备注Logi加群。
|
||||
@@ -1,12 +1,13 @@
|
||||
|
||||
---
|
||||
|
||||

|
||||

|
||||
|
||||
**一站式`Apache Kafka`集群指标监控与运维管控平台**
|
||||
|
||||
---
|
||||
|
||||
|
||||
## v2.6.0
|
||||
|
||||
版本上线时间:2022-01-24
|
||||
@@ -40,6 +41,16 @@
|
||||
- 修复Dockerfile执行时提示缺少application.yml文件的问题
|
||||
- 修复逻辑集群更新时,会报空指针的问题
|
||||
|
||||
|
||||
## v2.5.0
|
||||
|
||||
版本上线时间:2021-07-10
|
||||
|
||||
### 体验优化
|
||||
- 更改产品名为LogiKM
|
||||
- 更新产品图标
|
||||
|
||||
|
||||
## v2.4.1+
|
||||
|
||||
版本上线时间:2021-05-21
|
||||
@@ -49,7 +60,7 @@
|
||||
- 增加接口调用可绕过登录的功能(v2.4.1)
|
||||
|
||||
### 体验优化
|
||||
- tomcat 版本提升至8.5.66(v2.4.2)
|
||||
- Tomcat 版本提升至8.5.66(v2.4.2)
|
||||
- op接口优化,拆分util接口为topic、leader两类接口(v2.4.1)
|
||||
- 简化Gateway配置的Key长度(v2.4.1)
|
||||
|
||||
|
||||
655
bin/init_es_template.sh
Normal file
@@ -0,0 +1,655 @@
|
||||
esaddr=127.0.0.1
|
||||
port=8060
|
||||
curl -s --connect-timeout 10 -o /dev/null http://${esaddr}:${port}/_cat/nodes >/dev/null 2>&1
|
||||
if [ "$?" != "0" ];then
|
||||
echo "Elasticserach 访问失败, 请安装完后检查并重新执行该脚本 "
|
||||
exit
|
||||
fi
|
||||
|
||||
curl -s --connect-timeout 10 -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${esaddr}:${port}/_template/ks_kafka_broker_metric -d '{
|
||||
"order" : 10,
|
||||
"index_patterns" : [
|
||||
"ks_kafka_broker_metric*"
|
||||
],
|
||||
"settings" : {
|
||||
"index" : {
|
||||
"number_of_shards" : "10"
|
||||
}
|
||||
},
|
||||
"mappings" : {
|
||||
"properties" : {
|
||||
"brokerId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"routingValue" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"clusterPhyId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"metrics" : {
|
||||
"properties" : {
|
||||
"NetworkProcessorAvgIdle" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"UnderReplicatedPartitions" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesIn_min_15" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"HealthCheckTotal" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"RequestHandlerAvgIdle" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"connectionsCount" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesIn_min_5" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"HealthScore" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesOut" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesOut_min_15" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesIn" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesOut_min_5" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"TotalRequestQueueSize" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"MessagesIn" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"TotalProduceRequests" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"HealthCheckPassed" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"TotalResponseQueueSize" : {
|
||||
"type" : "float"
|
||||
}
|
||||
}
|
||||
},
|
||||
"key" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"timestamp" : {
|
||||
"format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
|
||||
"index" : true,
|
||||
"type" : "date",
|
||||
"doc_values" : true
|
||||
}
|
||||
}
|
||||
},
|
||||
"aliases" : { }
|
||||
}'
|
||||
|
||||
curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${esaddr}:${port}/_template/ks_kafka_cluster_metric -d '{
|
||||
"order" : 10,
|
||||
"index_patterns" : [
|
||||
"ks_kafka_cluster_metric*"
|
||||
],
|
||||
"settings" : {
|
||||
"index" : {
|
||||
"number_of_shards" : "10"
|
||||
}
|
||||
},
|
||||
"mappings" : {
|
||||
"properties" : {
|
||||
"routingValue" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"clusterPhyId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"metrics" : {
|
||||
"properties" : {
|
||||
"Connections" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"BytesIn_min_15" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"PartitionURP" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthScore_Topics" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"EventQueueSize" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"ActiveControllerCount" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"GroupDeads" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"BytesIn_min_5" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthCheckTotal_Topics" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"Partitions" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"BytesOut" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"Groups" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"BytesOut_min_15" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"TotalRequestQueueSize" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthCheckPassed_Groups" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"TotalProduceRequests" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthCheckPassed" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"TotalLogSize" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"GroupEmptys" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"PartitionNoLeader" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthScore_Brokers" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"Messages" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"Topics" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"PartitionMinISR_E" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthCheckTotal" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"Brokers" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"Replicas" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthCheckTotal_Groups" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"GroupRebalances" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"MessageIn" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthScore" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthCheckPassed_Topics" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthCheckTotal_Brokers" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"PartitionMinISR_S" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"BytesIn" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"BytesOut_min_5" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"GroupActives" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"MessagesIn" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"GroupReBalances" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthCheckPassed_Brokers" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthScore_Groups" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"TotalResponseQueueSize" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"Zookeepers" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"LeaderMessages" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthScore_Cluster" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthCheckPassed_Cluster" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthCheckTotal_Cluster" : {
|
||||
"type" : "double"
|
||||
}
|
||||
}
|
||||
},
|
||||
"key" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"timestamp" : {
|
||||
"format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
|
||||
"type" : "date"
|
||||
}
|
||||
}
|
||||
},
|
||||
"aliases" : { }
|
||||
}'
|
||||
|
||||
curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${esaddr}:${port}/_template/ks_kafka_group_metric -d '{
|
||||
"order" : 10,
|
||||
"index_patterns" : [
|
||||
"ks_kafka_group_metric*"
|
||||
],
|
||||
"settings" : {
|
||||
"index" : {
|
||||
"number_of_shards" : "10"
|
||||
}
|
||||
},
|
||||
"mappings" : {
|
||||
"properties" : {
|
||||
"group" : {
|
||||
"type" : "keyword"
|
||||
},
|
||||
"partitionId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"routingValue" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"clusterPhyId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"topic" : {
|
||||
"type" : "keyword"
|
||||
},
|
||||
"metrics" : {
|
||||
"properties" : {
|
||||
"HealthScore" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"Lag" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"OffsetConsumed" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"HealthCheckTotal" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"HealthCheckPassed" : {
|
||||
"type" : "float"
|
||||
}
|
||||
}
|
||||
},
|
||||
"groupMetric" : {
|
||||
"type" : "keyword"
|
||||
},
|
||||
"key" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"timestamp" : {
|
||||
"format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
|
||||
"index" : true,
|
||||
"type" : "date",
|
||||
"doc_values" : true
|
||||
}
|
||||
}
|
||||
},
|
||||
"aliases" : { }
|
||||
}'
|
||||
|
||||
curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${esaddr}:${port}/_template/ks_kafka_partition_metric -d '{
|
||||
"order" : 10,
|
||||
"index_patterns" : [
|
||||
"ks_kafka_partition_metric*"
|
||||
],
|
||||
"settings" : {
|
||||
"index" : {
|
||||
"number_of_shards" : "10"
|
||||
}
|
||||
},
|
||||
"mappings" : {
|
||||
"properties" : {
|
||||
"brokerId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"partitionId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"routingValue" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"clusterPhyId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"topic" : {
|
||||
"type" : "keyword"
|
||||
},
|
||||
"metrics" : {
|
||||
"properties" : {
|
||||
"LogStartOffset" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"Messages" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"LogEndOffset" : {
|
||||
"type" : "float"
|
||||
}
|
||||
}
|
||||
},
|
||||
"key" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"timestamp" : {
|
||||
"format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
|
||||
"index" : true,
|
||||
"type" : "date",
|
||||
"doc_values" : true
|
||||
}
|
||||
}
|
||||
},
|
||||
"aliases" : { }
|
||||
}'
|
||||
|
||||
curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${esaddr}:${port}/_template/ks_kafka_replication_metric -d '{
|
||||
"order" : 10,
|
||||
"index_patterns" : [
|
||||
"ks_kafka_partition_metric*"
|
||||
],
|
||||
"settings" : {
|
||||
"index" : {
|
||||
"number_of_shards" : "10"
|
||||
}
|
||||
},
|
||||
"mappings" : {
|
||||
"properties" : {
|
||||
"brokerId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"partitionId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"routingValue" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"clusterPhyId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"topic" : {
|
||||
"type" : "keyword"
|
||||
},
|
||||
"metrics" : {
|
||||
"properties" : {
|
||||
"LogStartOffset" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"Messages" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"LogEndOffset" : {
|
||||
"type" : "float"
|
||||
}
|
||||
}
|
||||
},
|
||||
"key" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"timestamp" : {
|
||||
"format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
|
||||
"index" : true,
|
||||
"type" : "date",
|
||||
"doc_values" : true
|
||||
}
|
||||
}
|
||||
},
|
||||
"aliases" : { }
|
||||
}[root@10-255-0-23 template]# cat ks_kafka_replication_metric
|
||||
PUT _template/ks_kafka_replication_metric
|
||||
{
|
||||
"order" : 10,
|
||||
"index_patterns" : [
|
||||
"ks_kafka_replication_metric*"
|
||||
],
|
||||
"settings" : {
|
||||
"index" : {
|
||||
"number_of_shards" : "10"
|
||||
}
|
||||
},
|
||||
"mappings" : {
|
||||
"properties" : {
|
||||
"timestamp" : {
|
||||
"format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
|
||||
"index" : true,
|
||||
"type" : "date",
|
||||
"doc_values" : true
|
||||
}
|
||||
}
|
||||
},
|
||||
"aliases" : { }
|
||||
}'
|
||||
|
||||
curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${esaddr}:${port}/_template/ks_kafka_topic_metric -d '{
|
||||
"order" : 10,
|
||||
"index_patterns" : [
|
||||
"ks_kafka_topic_metric*"
|
||||
],
|
||||
"settings" : {
|
||||
"index" : {
|
||||
"number_of_shards" : "10"
|
||||
}
|
||||
},
|
||||
"mappings" : {
|
||||
"properties" : {
|
||||
"brokerId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"routingValue" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"topic" : {
|
||||
"type" : "keyword"
|
||||
},
|
||||
"clusterPhyId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"metrics" : {
|
||||
"properties" : {
|
||||
"BytesIn_min_15" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"Messages" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesRejected" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"PartitionURP" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"HealthCheckTotal" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"ReplicationCount" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"ReplicationBytesOut" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"ReplicationBytesIn" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"FailedFetchRequests" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesIn_min_5" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"HealthScore" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"LogSize" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesOut" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesOut_min_15" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"FailedProduceRequests" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesIn" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesOut_min_5" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"MessagesIn" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"TotalProduceRequests" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"HealthCheckPassed" : {
|
||||
"type" : "float"
|
||||
}
|
||||
}
|
||||
},
|
||||
"brokerAgg" : {
|
||||
"type" : "keyword"
|
||||
},
|
||||
"key" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"timestamp" : {
|
||||
"format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
|
||||
"index" : true,
|
||||
"type" : "date",
|
||||
"doc_values" : true
|
||||
}
|
||||
}
|
||||
},
|
||||
"aliases" : { }
|
||||
}'
|
||||
|
||||
for i in {0..6};
|
||||
do
|
||||
logdate=_$(date -d "${i} day ago" +%Y-%m-%d)
|
||||
curl -s --connect-timeout 10 -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_broker_metric${logdate} && \
|
||||
curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_cluster_metric${logdate} && \
|
||||
curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_group_metric${logdate} && \
|
||||
curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_partition_metric${logdate} && \
|
||||
curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_replication_metric${logdate} && \
|
||||
curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_topic_metric${logdate} || \
|
||||
exit 2
|
||||
done
|
||||
16
bin/shutdown.sh
Normal file
@@ -0,0 +1,16 @@
|
||||
#!/bin/bash
|
||||
|
||||
cd `dirname $0`/../libs
|
||||
target_dir=`pwd`
|
||||
|
||||
pid=`ps ax | grep -i 'ks-km' | grep ${target_dir} | grep java | grep -v grep | awk '{print $1}'`
|
||||
if [ -z "$pid" ] ; then
|
||||
echo "No ks-km running."
|
||||
exit -1;
|
||||
fi
|
||||
|
||||
echo "The ks-km (${pid}) is running..."
|
||||
|
||||
kill ${pid}
|
||||
|
||||
echo "Send shutdown request to ks-km (${pid}) OK"
|
||||
86
bin/standalone-deploy.sh
Normal file
@@ -0,0 +1,86 @@
|
||||
#!/bin/bash
|
||||
set -x
|
||||
|
||||
function Install_Java(){
|
||||
cd $dir
|
||||
wget https://s3-gzpu.didistatic.com/pub/jdk11.tar.gz
|
||||
tar -zxf $dir/jdk11.tar.gz -C /usr/local/
|
||||
mv -f /usr/local/jdk-11.0.2 /usr/local/java11 >/dev/null 2>&1
|
||||
echo "export JAVA_HOME=/usr/local/java11" >> ~/.bashrc
|
||||
echo "export CLASSPATH=/usr/java/java11/lib" >> ~/.bashrc
|
||||
echo "export PATH=\$JAVA_HOME/bin:\$PATH:\$HOME/bin" >> ~/.bashrc
|
||||
source ~/.bashrc
|
||||
}
|
||||
|
||||
function Install_Mysql(){
|
||||
cd $dir
|
||||
wget https://s3-gzpu.didistatic.com/pub/mysql5.7.tar.gz
|
||||
rpm -qa | grep -E "mariadb|mysql" | xargs yum -y remove >/dev/null 2>&1
|
||||
mv -f /var/lib/mysql/ /var/lib/mysqlbak$(date "+%s") >/dev/null 2>&1
|
||||
mkdir -p $dir/mysql/ && cd $dir/mysql/
|
||||
tar -zxf $dir/mysql5.7.tar.gz -C $dir/mysql/
|
||||
yum -y localinstall mysql* libaio*
|
||||
systemctl start mysqld
|
||||
systemctl enable mysqld >/dev/null 2>&1
|
||||
old_pass=`grep 'temporary password' /var/log/mysqld.log | awk '{print $NF}' | tail -n 1`
|
||||
mysql -NBe "alter user USER() identified by '$mysql_pass';" --connect-expired-password -uroot -p$old_pass
|
||||
if [ $? -eq 0 ];then
|
||||
echo "Mysql database installation completed"
|
||||
else
|
||||
echo "Mysql database configuration failed. The script exits"
|
||||
exit
|
||||
fi
|
||||
}
|
||||
|
||||
function Install_ElasticSearch(){
|
||||
kill -9 $(ps -ef | grep elasticsearch | grep -v "grep" | awk '{print $2}') >/dev/null 2>&1
|
||||
id esuser >/dev/null 2>&1
|
||||
if [ "$?" != "0" ];then
|
||||
useradd esuser
|
||||
echo "esuser soft nofile 655350" >>/etc/security/limits.conf
|
||||
echo "esuser hard nofile 655350" >>/etc/security/limits.conf
|
||||
echo "vm.max_map_count = 655360" >>/etc/sysctl.conf
|
||||
sysctl -p >/dev/null 2>&1
|
||||
fi
|
||||
mkdir -p /km_es/es_data && cd /km_es/ >/dev/null 2>&1
|
||||
wget https://s3-gzpu.didistatic.com/pub/elasticsearch.tar.gz
|
||||
tar -zxf elasticsearch.tar.gz -C /km_es/
|
||||
chown -R esuser:esuser /km_es/
|
||||
su - esuser <<-EOF
|
||||
export JAVA_HOME=/usr/local/java11
|
||||
sh /km_es/elasticsearch/control.sh start
|
||||
EOF
|
||||
sleep 5
|
||||
es_status=`sh /km_es/elasticsearch/control.sh status | grep -o "started"`
|
||||
if [ "$es_status" = "started" ];then
|
||||
echo "elasticsearch started successfully~ "
|
||||
else
|
||||
echo "Elasticsearch failed to start. The script exited"
|
||||
exit
|
||||
fi
|
||||
}
|
||||
|
||||
function Install_KnowStreaming(){
|
||||
cd $dir
|
||||
wget https://s3-gzpu.didistatic.com/pub/knowstreaming/KnowStreaming-3.0.0-beta.tar.gz
|
||||
tar -zxf KnowStreaming-3.0.0-beta.tar.gz -C $dir/
|
||||
mysql -uroot -p$mysql_pass -e "create database know_streaming;"
|
||||
mysql -uroot -p$mysql_pass know_streaming < ./KnowStreaming/init/sql/ddl-ks-km.sql
|
||||
mysql -uroot -p$mysql_pass know_streaming < ./KnowStreaming/init/sql/ddl-logi-job.sql
|
||||
mysql -uroot -p$mysql_pass know_streaming < ./KnowStreaming/init/sql/ddl-logi-security.sql
|
||||
mysql -uroot -p$mysql_pass know_streaming < ./KnowStreaming/init/sql/dml-ks-km.sql
|
||||
mysql -uroot -p$mysql_pass know_streaming < ./KnowStreaming/init/sql/dml-logi.sql
|
||||
sh ./KnowStreaming/init/template/template.sh
|
||||
sed -i "s/mysql_pass/"$mysql_pass"/g" ./KnowStreaming/conf/application.yml
|
||||
cd $dir/KnowStreaming/bin/ && sh startup.sh
|
||||
|
||||
}
|
||||
|
||||
dir=`pwd`
|
||||
mysql_pass=`date +%s |sha256sum |base64 |head -c 10 ;echo`"_Di2"
|
||||
echo "$mysql_pass" > $dir/mysql.password
|
||||
|
||||
Install_Java
|
||||
Install_Mysql
|
||||
Install_ElasticSearch
|
||||
Install_KnowStreaming
|
||||
@@ -31,7 +31,7 @@ fi
|
||||
|
||||
|
||||
|
||||
export WEB_SERVER="kafka-manager"
|
||||
export WEB_SERVER="ks-km"
|
||||
export JAVA_HOME
|
||||
export JAVA="$JAVA_HOME/bin/java"
|
||||
export BASE_DIR=`cd $(dirname $0)/..; pwd`
|
||||
@@ -55,7 +55,7 @@ else
|
||||
|
||||
fi
|
||||
|
||||
JAVA_OPT="${JAVA_OPT} -jar ${BASE_DIR}/target/${WEB_SERVER}.jar"
|
||||
JAVA_OPT="${JAVA_OPT} -jar ${BASE_DIR}/libs/${WEB_SERVER}.jar"
|
||||
JAVA_OPT="${JAVA_OPT} --spring.config.additional-location=${CUSTOM_SEARCH_LOCATIONS}"
|
||||
JAVA_OPT="${JAVA_OPT} --logging.config=${BASE_DIR}/conf/logback-spring.xml"
|
||||
JAVA_OPT="${JAVA_OPT} --server.max-http-header-size=524288"
|
||||
@@ -72,6 +72,7 @@ echo "$JAVA ${JAVA_OPT}"
|
||||
if [ ! -f "${BASE_DIR}/logs/start.out" ]; then
|
||||
touch "${BASE_DIR}/logs/start.out"
|
||||
fi
|
||||
|
||||
# start
|
||||
echo -e "---- 启动脚本 ------\n $JAVA ${JAVA_OPT}" > ${BASE_DIR}/logs/start.out 2>&1 &
|
||||
|
||||
@@ -1,5 +0,0 @@
|
||||
---
|
||||
startDelaySeconds: 0
|
||||
ssl: false
|
||||
lowercaseOutputName: false
|
||||
lowercaseOutputLabelNames: false
|
||||
@@ -1,13 +0,0 @@
|
||||
FROM mysql:5.7.37
|
||||
|
||||
COPY mysqld.cnf /etc/mysql/mysql.conf.d/
|
||||
ENV TZ=Asia/Shanghai
|
||||
ENV MYSQL_ROOT_PASSWORD=root
|
||||
|
||||
RUN apt-get update \
|
||||
&& apt -y install wget \
|
||||
&& wget https://ghproxy.com/https://raw.githubusercontent.com/didi/LogiKM/master/distribution/conf/create_mysql_table.sql -O /docker-entrypoint-initdb.d/create_mysql_table.sql
|
||||
|
||||
EXPOSE 3306
|
||||
|
||||
VOLUME ["/var/lib/mysql"]
|
||||
@@ -1,24 +0,0 @@
|
||||
[client]
|
||||
default-character-set = utf8
|
||||
|
||||
[mysqld]
|
||||
character_set_server = utf8
|
||||
pid-file = /var/run/mysqld/mysqld.pid
|
||||
socket = /var/run/mysqld/mysqld.sock
|
||||
datadir = /var/lib/mysql
|
||||
symbolic-links=0
|
||||
|
||||
max_allowed_packet = 10M
|
||||
sort_buffer_size = 1M
|
||||
read_rnd_buffer_size = 2M
|
||||
max_connections=2000
|
||||
|
||||
lower_case_table_names=1
|
||||
character-set-server=utf8
|
||||
|
||||
max_allowed_packet = 1G
|
||||
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
|
||||
group_concat_max_len = 102400
|
||||
default-time-zone = '+08:00'
|
||||
[mysql]
|
||||
default-character-set = utf8
|
||||
@@ -1,6 +0,0 @@
|
||||
dependencies:
|
||||
- name: mysql
|
||||
repository: https://charts.bitnami.com/bitnami
|
||||
version: 8.6.3
|
||||
digest: sha256:d250c463c1d78ba30a24a338a06a551503c7a736621d974fe4999d2db7f6143e
|
||||
generated: "2021-06-24T11:34:54.625217+08:00"
|
||||
@@ -1,29 +0,0 @@
|
||||
apiVersion: v2
|
||||
name: didi-km
|
||||
description: Logi-KafkaManager
|
||||
|
||||
# A chart can be either an 'application' or a 'library' chart.
|
||||
#
|
||||
# Application charts are a collection of templates that can be packaged into versioned archives
|
||||
# to be deployed.
|
||||
#
|
||||
# Library charts provide useful utilities or functions for the chart developer. They're included as
|
||||
# a dependency of application charts to inject those utilities and functions into the rendering
|
||||
# pipeline. Library charts do not define any templates and therefore cannot be deployed.
|
||||
type: application
|
||||
|
||||
# This is the chart version. This version number should be incremented each time you make changes
|
||||
# to the chart and its templates, including the app version.
|
||||
# Versions are expected to follow Semantic Versioning (https://semver.org/)
|
||||
version: 0.1.0
|
||||
|
||||
# This is the version number of the application being deployed. This version number should be
|
||||
# incremented each time you make changes to the application. Versions are not expected to
|
||||
# follow Semantic Versioning. They should reflect the version the application is using.
|
||||
# It is recommended to use it with quotes.
|
||||
appVersion: "2.4.2"
|
||||
dependencies:
|
||||
- condition: mysql.enabled
|
||||
name: mysql
|
||||
repository: https://charts.bitnami.com/bitnami
|
||||
version: 8.x.x
|
||||
@@ -1,22 +0,0 @@
|
||||
1. Get the application URL by running these commands:
|
||||
{{- if .Values.ingress.enabled }}
|
||||
{{- range $host := .Values.ingress.hosts }}
|
||||
{{- range .paths }}
|
||||
http{{ if $.Values.ingress.tls }}s{{ end }}://{{ $host.host }}{{ .path }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
{{- else if contains "NodePort" .Values.service.type }}
|
||||
export NODE_PORT=$(kubectl get --namespace {{ .Release.Namespace }} -o jsonpath="{.spec.ports[0].nodePort}" services {{ include "didi-km.fullname" . }})
|
||||
export NODE_IP=$(kubectl get nodes --namespace {{ .Release.Namespace }} -o jsonpath="{.items[0].status.addresses[0].address}")
|
||||
echo http://$NODE_IP:$NODE_PORT
|
||||
{{- else if contains "LoadBalancer" .Values.service.type }}
|
||||
NOTE: It may take a few minutes for the LoadBalancer IP to be available.
|
||||
You can watch the status of by running 'kubectl get --namespace {{ .Release.Namespace }} svc -w {{ include "didi-km.fullname" . }}'
|
||||
export SERVICE_IP=$(kubectl get svc --namespace {{ .Release.Namespace }} {{ include "didi-km.fullname" . }} --template "{{"{{ range (index .status.loadBalancer.ingress 0) }}{{.}}{{ end }}"}}")
|
||||
echo http://$SERVICE_IP:{{ .Values.service.port }}
|
||||
{{- else if contains "ClusterIP" .Values.service.type }}
|
||||
export POD_NAME=$(kubectl get pods --namespace {{ .Release.Namespace }} -l "app.kubernetes.io/name={{ include "didi-km.name" . }},app.kubernetes.io/instance={{ .Release.Name }}" -o jsonpath="{.items[0].metadata.name}")
|
||||
export CONTAINER_PORT=$(kubectl get pod --namespace {{ .Release.Namespace }} $POD_NAME -o jsonpath="{.spec.containers[0].ports[0].containerPort}")
|
||||
echo "Visit http://127.0.0.1:8080 to use your application"
|
||||
kubectl --namespace {{ .Release.Namespace }} port-forward $POD_NAME 8080:$CONTAINER_PORT
|
||||
{{- end }}
|
||||
@@ -1,62 +0,0 @@
|
||||
{{/*
|
||||
Expand the name of the chart.
|
||||
*/}}
|
||||
{{- define "didi-km.name" -}}
|
||||
{{- default .Chart.Name .Values.nameOverride | trunc 63 | trimSuffix "-" }}
|
||||
{{- end }}
|
||||
|
||||
{{/*
|
||||
Create a default fully qualified app name.
|
||||
We truncate at 63 chars because some Kubernetes name fields are limited to this (by the DNS naming spec).
|
||||
If release name contains chart name it will be used as a full name.
|
||||
*/}}
|
||||
{{- define "didi-km.fullname" -}}
|
||||
{{- if .Values.fullnameOverride }}
|
||||
{{- .Values.fullnameOverride | trunc 63 | trimSuffix "-" }}
|
||||
{{- else }}
|
||||
{{- $name := default .Chart.Name .Values.nameOverride }}
|
||||
{{- if contains $name .Release.Name }}
|
||||
{{- .Release.Name | trunc 63 | trimSuffix "-" }}
|
||||
{{- else }}
|
||||
{{- printf "%s-%s" .Release.Name $name | trunc 63 | trimSuffix "-" }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
|
||||
{{/*
|
||||
Create chart name and version as used by the chart label.
|
||||
*/}}
|
||||
{{- define "didi-km.chart" -}}
|
||||
{{- printf "%s-%s" .Chart.Name .Chart.Version | replace "+" "_" | trunc 63 | trimSuffix "-" }}
|
||||
{{- end }}
|
||||
|
||||
{{/*
|
||||
Common labels
|
||||
*/}}
|
||||
{{- define "didi-km.labels" -}}
|
||||
helm.sh/chart: {{ include "didi-km.chart" . }}
|
||||
{{ include "didi-km.selectorLabels" . }}
|
||||
{{- if .Chart.AppVersion }}
|
||||
app.kubernetes.io/version: {{ .Chart.AppVersion | quote }}
|
||||
{{- end }}
|
||||
app.kubernetes.io/managed-by: {{ .Release.Service }}
|
||||
{{- end }}
|
||||
|
||||
{{/*
|
||||
Selector labels
|
||||
*/}}
|
||||
{{- define "didi-km.selectorLabels" -}}
|
||||
app.kubernetes.io/name: {{ include "didi-km.name" . }}
|
||||
app.kubernetes.io/instance: {{ .Release.Name }}
|
||||
{{- end }}
|
||||
|
||||
{{/*
|
||||
Create the name of the service account to use
|
||||
*/}}
|
||||
{{- define "didi-km.serviceAccountName" -}}
|
||||
{{- if .Values.serviceAccount.create }}
|
||||
{{- default (include "didi-km.fullname" .) .Values.serviceAccount.name }}
|
||||
{{- else }}
|
||||
{{- default "default" .Values.serviceAccount.name }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
@@ -1,110 +0,0 @@
|
||||
{{- define "datasource.mysql" -}}
|
||||
{{- if .Values.mysql.enabled }}
|
||||
{{- printf "%s-mysql" (include "didi-km.fullname" .) -}}
|
||||
{{- else -}}
|
||||
{{- printf "%s" .Values.externalDatabase.host -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
|
||||
apiVersion: v1
|
||||
kind: ConfigMap
|
||||
metadata:
|
||||
name: {{ include "didi-km.fullname" . }}-configs
|
||||
labels:
|
||||
{{- include "didi-km.labels" . | nindent 4 }}
|
||||
data:
|
||||
application.yml: |
|
||||
server:
|
||||
port: 8080
|
||||
tomcat:
|
||||
accept-count: 1000
|
||||
max-connections: 10000
|
||||
max-threads: 800
|
||||
min-spare-threads: 100
|
||||
|
||||
spring:
|
||||
application:
|
||||
name: kafkamanager
|
||||
datasource:
|
||||
kafka-manager:
|
||||
jdbc-url: jdbc:mysql://{{ include "datasource.mysql" . }}:3306/{{ .Values.mysql.auth.database }}?characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=false
|
||||
username: {{ .Values.mysql.auth.username }}
|
||||
password: {{ .Values.mysql.auth.password }}
|
||||
driver-class-name: com.mysql.jdbc.Driver
|
||||
main:
|
||||
allow-bean-definition-overriding: true
|
||||
|
||||
profiles:
|
||||
active: dev
|
||||
servlet:
|
||||
multipart:
|
||||
max-file-size: 100MB
|
||||
max-request-size: 100MB
|
||||
|
||||
logging:
|
||||
config: classpath:logback-spring.xml
|
||||
|
||||
custom:
|
||||
idc: cn
|
||||
jmx:
|
||||
max-conn: 20
|
||||
store-metrics-task:
|
||||
community:
|
||||
broker-metrics-enabled: true
|
||||
topic-metrics-enabled: true
|
||||
didi:
|
||||
app-topic-metrics-enabled: false
|
||||
topic-request-time-metrics-enabled: false
|
||||
topic-throttled-metrics-enabled: false
|
||||
save-days: 7
|
||||
|
||||
# 任务相关的开关
|
||||
task:
|
||||
op:
|
||||
sync-topic-enabled: false # 未落盘的Topic定期同步到DB中
|
||||
|
||||
account:
|
||||
# ldap settings
|
||||
ldap:
|
||||
enabled: false
|
||||
url: ldap://127.0.0.1:389/
|
||||
basedn: dc=tsign,dc=cn
|
||||
factory: com.sun.jndi.ldap.LdapCtxFactory
|
||||
filter: sAMAccountName
|
||||
security:
|
||||
authentication: simple
|
||||
principal: cn=admin,dc=tsign,dc=cn
|
||||
credentials: admin
|
||||
auth-user-registration: false
|
||||
auth-user-registration-role: normal
|
||||
|
||||
kcm:
|
||||
enabled: false
|
||||
storage:
|
||||
base-url: http://127.0.0.1
|
||||
n9e:
|
||||
base-url: http://127.0.0.1:8004
|
||||
user-token: 12345678
|
||||
timeout: 300
|
||||
account: root
|
||||
script-file: kcm_script.sh
|
||||
|
||||
monitor:
|
||||
enabled: false
|
||||
n9e:
|
||||
nid: 2
|
||||
user-token: 1234567890
|
||||
mon:
|
||||
base-url: http://127.0.0.1:8032
|
||||
sink:
|
||||
base-url: http://127.0.0.1:8006
|
||||
rdb:
|
||||
base-url: http://127.0.0.1:80
|
||||
|
||||
notify:
|
||||
kafka:
|
||||
cluster-id: 95
|
||||
topic-name: didi-kafka-notify
|
||||
order:
|
||||
detail-url: http://127.0.0.1
|
||||
|
||||
@@ -1,64 +0,0 @@
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: {{ include "didi-km.fullname" . }}
|
||||
labels:
|
||||
{{- include "didi-km.labels" . | nindent 4 }}
|
||||
spec:
|
||||
{{- if not .Values.autoscaling.enabled }}
|
||||
replicas: {{ .Values.replicaCount }}
|
||||
{{- end }}
|
||||
selector:
|
||||
matchLabels:
|
||||
{{- include "didi-km.selectorLabels" . | nindent 6 }}
|
||||
template:
|
||||
metadata:
|
||||
{{- with .Values.podAnnotations }}
|
||||
annotations:
|
||||
{{- toYaml . | nindent 8 }}
|
||||
{{- end }}
|
||||
labels:
|
||||
{{- include "didi-km.selectorLabels" . | nindent 8 }}
|
||||
spec:
|
||||
{{- with .Values.imagePullSecrets }}
|
||||
imagePullSecrets:
|
||||
{{- toYaml . | nindent 8 }}
|
||||
{{- end }}
|
||||
serviceAccountName: {{ include "didi-km.serviceAccountName" . }}
|
||||
securityContext:
|
||||
{{- toYaml .Values.podSecurityContext | nindent 8 }}
|
||||
containers:
|
||||
- name: {{ .Chart.Name }}
|
||||
securityContext:
|
||||
{{- toYaml .Values.securityContext | nindent 12 }}
|
||||
image: "{{ .Values.image.repository }}:{{ .Values.image.tag | default .Chart.AppVersion }}"
|
||||
imagePullPolicy: {{ .Values.image.pullPolicy }}
|
||||
ports:
|
||||
- name: http
|
||||
containerPort: 8080
|
||||
protocol: TCP
|
||||
- name: jmx-metrics
|
||||
containerPort: 9999
|
||||
protocol: TCP
|
||||
resources:
|
||||
{{- toYaml .Values.resources | nindent 12 }}
|
||||
volumeMounts:
|
||||
- name: configs
|
||||
mountPath: /tmp/application.yml
|
||||
subPath: application.yml
|
||||
{{- with .Values.nodeSelector }}
|
||||
nodeSelector:
|
||||
{{- toYaml . | nindent 8 }}
|
||||
{{- end }}
|
||||
{{- with .Values.affinity }}
|
||||
affinity:
|
||||
{{- toYaml . | nindent 8 }}
|
||||
{{- end }}
|
||||
{{- with .Values.tolerations }}
|
||||
tolerations:
|
||||
{{- toYaml . | nindent 8 }}
|
||||
{{- end }}
|
||||
volumes:
|
||||
- name: configs
|
||||
configMap:
|
||||
name: {{ include "didi-km.fullname" . }}-configs
|
||||
@@ -1,28 +0,0 @@
|
||||
{{- if .Values.autoscaling.enabled }}
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
metadata:
|
||||
name: {{ include "didi-km.fullname" . }}
|
||||
labels:
|
||||
{{- include "didi-km.labels" . | nindent 4 }}
|
||||
spec:
|
||||
scaleTargetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: {{ include "didi-km.fullname" . }}
|
||||
minReplicas: {{ .Values.autoscaling.minReplicas }}
|
||||
maxReplicas: {{ .Values.autoscaling.maxReplicas }}
|
||||
metrics:
|
||||
{{- if .Values.autoscaling.targetCPUUtilizationPercentage }}
|
||||
- type: Resource
|
||||
resource:
|
||||
name: cpu
|
||||
targetAverageUtilization: {{ .Values.autoscaling.targetCPUUtilizationPercentage }}
|
||||
{{- end }}
|
||||
{{- if .Values.autoscaling.targetMemoryUtilizationPercentage }}
|
||||
- type: Resource
|
||||
resource:
|
||||
name: memory
|
||||
targetAverageUtilization: {{ .Values.autoscaling.targetMemoryUtilizationPercentage }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
@@ -1,41 +0,0 @@
|
||||
{{- if .Values.ingress.enabled -}}
|
||||
{{- $fullName := include "didi-km.fullname" . -}}
|
||||
{{- $svcPort := .Values.service.port -}}
|
||||
{{- if semverCompare ">=1.14-0" .Capabilities.KubeVersion.GitVersion -}}
|
||||
apiVersion: networking.k8s.io/v1beta1
|
||||
{{- else -}}
|
||||
apiVersion: extensions/v1beta1
|
||||
{{- end }}
|
||||
kind: Ingress
|
||||
metadata:
|
||||
name: {{ $fullName }}
|
||||
labels:
|
||||
{{- include "didi-km.labels" . | nindent 4 }}
|
||||
{{- with .Values.ingress.annotations }}
|
||||
annotations:
|
||||
{{- toYaml . | nindent 4 }}
|
||||
{{- end }}
|
||||
spec:
|
||||
{{- if .Values.ingress.tls }}
|
||||
tls:
|
||||
{{- range .Values.ingress.tls }}
|
||||
- hosts:
|
||||
{{- range .hosts }}
|
||||
- {{ . | quote }}
|
||||
{{- end }}
|
||||
secretName: {{ .secretName }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
rules:
|
||||
{{- range .Values.ingress.hosts }}
|
||||
- host: {{ .host | quote }}
|
||||
http:
|
||||
paths:
|
||||
{{- range .paths }}
|
||||
- path: {{ .path }}
|
||||
backend:
|
||||
serviceName: {{ $fullName }}
|
||||
servicePort: {{ $svcPort }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
@@ -1,15 +0,0 @@
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: {{ include "didi-km.fullname" . }}
|
||||
labels:
|
||||
{{- include "didi-km.labels" . | nindent 4 }}
|
||||
spec:
|
||||
type: {{ .Values.service.type }}
|
||||
ports:
|
||||
- port: {{ .Values.service.port }}
|
||||
targetPort: http
|
||||
protocol: TCP
|
||||
name: http
|
||||
selector:
|
||||
{{- include "didi-km.selectorLabels" . | nindent 4 }}
|
||||
@@ -1,12 +0,0 @@
|
||||
{{- if .Values.serviceAccount.create -}}
|
||||
apiVersion: v1
|
||||
kind: ServiceAccount
|
||||
metadata:
|
||||
name: {{ include "didi-km.serviceAccountName" . }}
|
||||
labels:
|
||||
{{- include "didi-km.labels" . | nindent 4 }}
|
||||
{{- with .Values.serviceAccount.annotations }}
|
||||
annotations:
|
||||
{{- toYaml . | nindent 4 }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
@@ -1,15 +0,0 @@
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
name: "{{ include "didi-km.fullname" . }}-test-connection"
|
||||
labels:
|
||||
{{- include "didi-km.labels" . | nindent 4 }}
|
||||
annotations:
|
||||
"helm.sh/hook": test
|
||||
spec:
|
||||
containers:
|
||||
- name: wget
|
||||
image: busybox
|
||||
command: ['wget']
|
||||
args: ['{{ include "didi-km.fullname" . }}:{{ .Values.service.port }}']
|
||||
restartPolicy: Never
|
||||
@@ -1,93 +0,0 @@
|
||||
# Default values for didi-km.
|
||||
# This is a YAML-formatted file.
|
||||
# Declare variables to be passed into your templates.
|
||||
|
||||
replicaCount: 1
|
||||
|
||||
image:
|
||||
repository: docker.io/fengxsong/logi-kafka-manager
|
||||
pullPolicy: IfNotPresent
|
||||
# Overrides the image tag whose default is the chart appVersion.
|
||||
tag: "v2.4.2"
|
||||
|
||||
imagePullSecrets: []
|
||||
nameOverride: ""
|
||||
# fullnameOverride must set same as release name
|
||||
fullnameOverride: "km"
|
||||
|
||||
serviceAccount:
|
||||
# Specifies whether a service account should be created
|
||||
create: true
|
||||
# Annotations to add to the service account
|
||||
annotations: {}
|
||||
# The name of the service account to use.
|
||||
# If not set and create is true, a name is generated using the fullname template
|
||||
name: ""
|
||||
|
||||
podAnnotations: {}
|
||||
|
||||
podSecurityContext: {}
|
||||
# fsGroup: 2000
|
||||
|
||||
securityContext: {}
|
||||
# capabilities:
|
||||
# drop:
|
||||
# - ALL
|
||||
# readOnlyRootFilesystem: true
|
||||
# runAsNonRoot: true
|
||||
# runAsUser: 1000
|
||||
|
||||
service:
|
||||
type: ClusterIP
|
||||
port: 8080
|
||||
|
||||
ingress:
|
||||
enabled: false
|
||||
annotations: {}
|
||||
# kubernetes.io/ingress.class: nginx
|
||||
# kubernetes.io/tls-acme: "true"
|
||||
hosts:
|
||||
- host: chart-example.local
|
||||
paths: []
|
||||
tls: []
|
||||
# - secretName: chart-example-tls
|
||||
# hosts:
|
||||
# - chart-example.local
|
||||
|
||||
resources:
|
||||
# We usually recommend not to specify default resources and to leave this as a conscious
|
||||
# choice for the user. This also increases chances charts run on environments with little
|
||||
# resources, such as Minikube. If you do want to specify resources, uncomment the following
|
||||
# lines, adjust them as necessary, and remove the curly braces after 'resources:'.
|
||||
limits:
|
||||
cpu: 500m
|
||||
memory: 2048Mi
|
||||
requests:
|
||||
cpu: 100m
|
||||
memory: 200Mi
|
||||
|
||||
autoscaling:
|
||||
enabled: false
|
||||
minReplicas: 1
|
||||
maxReplicas: 100
|
||||
targetCPUUtilizationPercentage: 80
|
||||
# targetMemoryUtilizationPercentage: 80
|
||||
|
||||
nodeSelector: {}
|
||||
|
||||
tolerations: []
|
||||
|
||||
affinity: {}
|
||||
|
||||
# more configurations are set with configmap in file template/configmap.yaml
|
||||
externalDatabase:
|
||||
host: ""
|
||||
mysql:
|
||||
# if enabled is set to false, then you should manually specified externalDatabase.host
|
||||
enabled: true
|
||||
architecture: standalone
|
||||
auth:
|
||||
rootPassword: "s3cretR00t"
|
||||
database: "logi_kafka_manager"
|
||||
username: "logi_kafka_manager"
|
||||
password: "n0tp@55w0rd"
|
||||
@@ -1,16 +0,0 @@
|
||||
#!/bin/bash
|
||||
|
||||
cd `dirname $0`/../target
|
||||
target_dir=`pwd`
|
||||
|
||||
pid=`ps ax | grep -i 'kafka-manager' | grep ${target_dir} | grep java | grep -v grep | awk '{print $1}'`
|
||||
if [ -z "$pid" ] ; then
|
||||
echo "No kafka-manager running."
|
||||
exit -1;
|
||||
fi
|
||||
|
||||
echo "The kafka-manager (${pid}) is running..."
|
||||
|
||||
kill ${pid}
|
||||
|
||||
echo "Send shutdown request to kafka-manager (${pid}) OK"
|
||||
@@ -1,28 +0,0 @@
|
||||
|
||||
## kafka-manager的配置文件,该文件中的配置会覆盖默认配置
|
||||
## 下面的配置信息基本就是jar中的 application.yml默认配置了;
|
||||
## 可以只修改自己变更的配置,其他的删除就行了; 比如只配置一下mysql
|
||||
|
||||
|
||||
server:
|
||||
port: 8080
|
||||
tomcat:
|
||||
accept-count: 1000
|
||||
max-connections: 10000
|
||||
max-threads: 800
|
||||
min-spare-threads: 100
|
||||
|
||||
spring:
|
||||
application:
|
||||
name: kafkamanager
|
||||
version: 2.6.0
|
||||
profiles:
|
||||
active: dev
|
||||
datasource:
|
||||
kafka-manager:
|
||||
jdbc-url: jdbc:mysql://${LOGI_MYSQL_HOST:mysql}:${LOGI_MYSQL_PORT:3306}/${LOGI_MYSQL_DATABASE:logi_kafka_manager}?characterEncoding=UTF-8&useSSL=false&serverTimezone=GMT%2B8
|
||||
username: ${LOGI_MYSQL_USER:root}
|
||||
password: ${LOGI_MYSQL_PASSWORD:root}
|
||||
driver-class-name: com.mysql.cj.jdbc.Driver
|
||||
main:
|
||||
allow-bean-definition-overriding: true
|
||||
@@ -1,28 +0,0 @@
|
||||
|
||||
## kafka-manager的配置文件,该文件中的配置会覆盖默认配置
|
||||
## 下面的配置信息基本就是jar中的 application.yml默认配置了;
|
||||
## 可以只修改自己变更的配置,其他的删除就行了; 比如只配置一下mysql
|
||||
|
||||
|
||||
server:
|
||||
port: 8080
|
||||
tomcat:
|
||||
accept-count: 1000
|
||||
max-connections: 10000
|
||||
max-threads: 800
|
||||
min-spare-threads: 100
|
||||
|
||||
spring:
|
||||
application:
|
||||
name: kafkamanager
|
||||
profiles:
|
||||
active: dev
|
||||
datasource:
|
||||
kafka-manager:
|
||||
jdbc-url: jdbc:mysql://localhost:3306/logi_kafka_manager?characterEncoding=UTF-8&useSSL=false&serverTimezone=GMT%2B8
|
||||
username: root
|
||||
password: 123456
|
||||
driver-class-name: com.mysql.cj.jdbc.Driver
|
||||
main:
|
||||
allow-bean-definition-overriding: true
|
||||
|
||||
@@ -1,135 +0,0 @@
|
||||
|
||||
## kafka-manager的配置文件,该文件中的配置会覆盖默认配置
|
||||
## 下面的配置信息基本就是jar中的 application.yml默认配置了;
|
||||
## 可以只修改自己变更的配置,其他的删除就行了; 比如只配置一下mysql
|
||||
|
||||
|
||||
server:
|
||||
port: 8080
|
||||
tomcat:
|
||||
accept-count: 1000
|
||||
max-connections: 10000
|
||||
max-threads: 800
|
||||
min-spare-threads: 100
|
||||
|
||||
spring:
|
||||
application:
|
||||
name: kafkamanager
|
||||
profiles:
|
||||
active: dev
|
||||
datasource:
|
||||
kafka-manager:
|
||||
jdbc-url: jdbc:mysql://localhost:3306/logi_kafka_manager?characterEncoding=UTF-8&useSSL=false&serverTimezone=GMT%2B8
|
||||
username: root
|
||||
password: 123456
|
||||
driver-class-name: com.mysql.cj.jdbc.Driver
|
||||
main:
|
||||
allow-bean-definition-overriding: true
|
||||
|
||||
servlet:
|
||||
multipart:
|
||||
max-file-size: 100MB
|
||||
max-request-size: 100MB
|
||||
|
||||
logging:
|
||||
config: classpath:logback-spring.xml
|
||||
|
||||
custom:
|
||||
idc: cn
|
||||
store-metrics-task:
|
||||
community:
|
||||
topic-metrics-enabled: true
|
||||
didi: # 滴滴Kafka特有的指标
|
||||
app-topic-metrics-enabled: false
|
||||
topic-request-time-metrics-enabled: false
|
||||
topic-throttled-metrics-enabled: false
|
||||
|
||||
# 任务相关的配置
|
||||
task:
|
||||
op:
|
||||
sync-topic-enabled: false # 未落盘的Topic定期同步到DB中
|
||||
order-auto-exec: # 工单自动化审批线程的开关
|
||||
topic-enabled: false # Topic工单自动化审批开关, false:关闭自动化审批, true:开启
|
||||
app-enabled: false # App工单自动化审批开关, false:关闭自动化审批, true:开启
|
||||
metrics:
|
||||
collect: # 收集指标
|
||||
broker-metrics-enabled: true # 收集Broker指标
|
||||
sink: # 上报指标
|
||||
cluster-metrics: # 上报cluster指标
|
||||
sink-db-enabled: true # 上报到db
|
||||
broker-metrics: # 上报broker指标
|
||||
sink-db-enabled: true # 上报到db
|
||||
delete: # 删除指标
|
||||
delete-limit-size: 1000 # 单次删除的批大小
|
||||
cluster-metrics-save-days: 14 # 集群指标保存天数
|
||||
broker-metrics-save-days: 14 # Broker指标保存天数
|
||||
topic-metrics-save-days: 7 # Topic指标保存天数
|
||||
topic-request-time-metrics-save-days: 7 # Topic请求耗时指标保存天数
|
||||
topic-throttled-metrics-save-days: 7 # Topic限流指标保存天数
|
||||
app-topic-metrics-save-days: 7 # App+Topic指标保存天数
|
||||
|
||||
thread-pool:
|
||||
collect-metrics:
|
||||
thread-num: 256 # 收集指标线程池大小
|
||||
queue-size: 5000 # 收集指标线程池的queue大小
|
||||
api-call:
|
||||
thread-num: 16 # api服务线程池大小
|
||||
queue-size: 5000 # api服务线程池的queue大小
|
||||
|
||||
client-pool:
|
||||
kafka-consumer:
|
||||
min-idle-client-num: 24 # 最小空闲客户端数
|
||||
max-idle-client-num: 24 # 最大空闲客户端数
|
||||
max-total-client-num: 24 # 最大客户端数
|
||||
borrow-timeout-unit-ms: 3000 # 租借超时时间,单位毫秒
|
||||
|
||||
account:
|
||||
jump-login:
|
||||
gateway-api: false # 网关接口
|
||||
third-part-api: false # 第三方接口
|
||||
ldap:
|
||||
enabled: false
|
||||
url: ldap://127.0.0.1:389/
|
||||
basedn: dc=tsign,dc=cn
|
||||
factory: com.sun.jndi.ldap.LdapCtxFactory
|
||||
filter: sAMAccountName
|
||||
security:
|
||||
authentication: simple
|
||||
principal: cn=admin,dc=tsign,dc=cn
|
||||
credentials: admin
|
||||
auth-user-registration: true
|
||||
auth-user-registration-role: normal
|
||||
|
||||
kcm: # 集群安装部署,仅安装broker
|
||||
enabled: false # 是否开启
|
||||
s3: # s3 存储服务
|
||||
endpoint: s3.didiyunapi.com
|
||||
access-key: 1234567890
|
||||
secret-key: 0987654321
|
||||
bucket: logi-kafka
|
||||
n9e: # 夜莺
|
||||
base-url: http://127.0.0.1:8004 # 夜莺job服务地址
|
||||
user-token: 12345678 # 用户的token
|
||||
timeout: 300 # 当台操作的超时时间
|
||||
account: root # 操作时使用的账号
|
||||
script-file: kcm_script.sh # 脚本,已内置好,在源码的kcm模块内,此处配置无需修改
|
||||
logikm-url: http://127.0.0.1:8080 # logikm部署地址,部署时kcm_script.sh会调用logikm检查部署中的一些状态
|
||||
|
||||
monitor:
|
||||
enabled: false
|
||||
n9e:
|
||||
nid: 2
|
||||
user-token: 1234567890
|
||||
mon:
|
||||
base-url: http://127.0.0.1:8000 # 夜莺v4版本,默认端口统一调整为了8000
|
||||
sink:
|
||||
base-url: http://127.0.0.1:8000 # 夜莺v4版本,默认端口统一调整为了8000
|
||||
rdb:
|
||||
base-url: http://127.0.0.1:8000 # 夜莺v4版本,默认端口统一调整为了8000
|
||||
|
||||
notify:
|
||||
kafka:
|
||||
cluster-id: 95
|
||||
topic-name: didi-kafka-notify
|
||||
order:
|
||||
detail-url: http://127.0.0.1
|
||||
@@ -1,594 +0,0 @@
|
||||
-- create database
|
||||
CREATE DATABASE logi_kafka_manager;
|
||||
|
||||
USE logi_kafka_manager;
|
||||
|
||||
--
|
||||
-- Table structure for table `account`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `account`;
|
||||
CREATE TABLE `account` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`username` varchar(128) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT '用户名',
|
||||
`password` varchar(128) NOT NULL DEFAULT '' COMMENT '密码',
|
||||
`role` tinyint(8) NOT NULL DEFAULT '0' COMMENT '角色类型, 0:普通用户 1:研发 2:运维',
|
||||
`department` varchar(256) DEFAULT '' COMMENT '部门名',
|
||||
`display_name` varchar(256) DEFAULT '' COMMENT '用户姓名',
|
||||
`mail` varchar(256) DEFAULT '' COMMENT '邮箱',
|
||||
`status` int(16) NOT NULL DEFAULT '0' COMMENT '0标识使用中,-1标识已废弃',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_username` (`username`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='账号表';
|
||||
INSERT INTO account(username, password, role) VALUES ('admin', '21232f297a57a5a743894a0e4a801fc3', 2);
|
||||
|
||||
--
|
||||
-- Table structure for table `app`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `app`;
|
||||
CREATE TABLE `app` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`app_id` varchar(128) NOT NULL DEFAULT '' COMMENT '应用id',
|
||||
`name` varchar(192) NOT NULL DEFAULT '' COMMENT '应用名称',
|
||||
`password` varchar(256) NOT NULL DEFAULT '' COMMENT '应用密码',
|
||||
`type` int(11) NOT NULL DEFAULT '0' COMMENT '类型, 0:普通用户, 1:超级用户',
|
||||
`applicant` varchar(64) NOT NULL DEFAULT '' COMMENT '申请人',
|
||||
`principals` text COMMENT '应用负责人',
|
||||
`description` text COMMENT '应用描述',
|
||||
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_name` (`name`),
|
||||
UNIQUE KEY `uniq_app_id` (`app_id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='应用信息';
|
||||
|
||||
|
||||
--
|
||||
-- Table structure for table `authority`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `authority`;
|
||||
CREATE TABLE `authority` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`app_id` varchar(128) NOT NULL DEFAULT '' COMMENT '应用id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '集群id',
|
||||
`topic_name` varchar(192) NOT NULL DEFAULT '' COMMENT 'topic名称',
|
||||
`access` int(11) NOT NULL DEFAULT '0' COMMENT '0:无权限, 1:读, 2:写, 3:读写',
|
||||
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_app_id_cluster_id_topic_name` (`app_id`,`cluster_id`,`topic_name`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='权限信息(kafka-manager)';
|
||||
|
||||
--
|
||||
-- Table structure for table `broker`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `broker`;
|
||||
CREATE TABLE `broker` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`broker_id` int(16) NOT NULL DEFAULT '-1' COMMENT 'brokerid',
|
||||
`host` varchar(128) NOT NULL DEFAULT '' COMMENT 'broker主机名',
|
||||
`port` int(16) NOT NULL DEFAULT '-1' COMMENT 'broker端口',
|
||||
`timestamp` bigint(20) NOT NULL DEFAULT '-1' COMMENT '启动时间',
|
||||
`max_avg_bytes_in` bigint(20) NOT NULL DEFAULT '-1' COMMENT '峰值的均值流量',
|
||||
`version` varchar(128) NOT NULL DEFAULT '' COMMENT 'broker版本',
|
||||
`status` int(16) NOT NULL DEFAULT '0' COMMENT '状态: 0有效,-1无效',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_cluster_id_broker_id` (`cluster_id`,`broker_id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='broker信息表';
|
||||
|
||||
--
|
||||
-- Table structure for table `broker_metrics`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `broker_metrics`;
|
||||
CREATE TABLE `broker_metrics` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`broker_id` int(16) NOT NULL DEFAULT '-1' COMMENT 'brokerid',
|
||||
`metrics` text COMMENT '指标',
|
||||
`messages_in` double(53,2) NOT NULL DEFAULT '0.00' COMMENT '每秒消息数流入',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`),
|
||||
KEY `idx_cluster_id_broker_id_gmt_create` (`cluster_id`,`broker_id`,`gmt_create`),
|
||||
KEY `idx_gmt_create` (`gmt_create`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='broker-metric信息表';
|
||||
|
||||
--
|
||||
-- Table structure for table `cluster`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `cluster`;
|
||||
CREATE TABLE `cluster` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '集群id',
|
||||
`cluster_name` varchar(128) NOT NULL DEFAULT '' COMMENT '集群名称',
|
||||
`zookeeper` varchar(512) NOT NULL DEFAULT '' COMMENT 'zk地址',
|
||||
`bootstrap_servers` varchar(512) NOT NULL DEFAULT '' COMMENT 'server地址',
|
||||
`kafka_version` varchar(32) NOT NULL DEFAULT '' COMMENT 'kafka版本',
|
||||
`security_properties` text COMMENT 'Kafka安全认证参数',
|
||||
`jmx_properties` text COMMENT 'JMX配置',
|
||||
`status` tinyint(4) NOT NULL DEFAULT '1' COMMENT ' 监控标记, 0表示未监控, 1表示监控中',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_cluster_name` (`cluster_name`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='cluster信息表';
|
||||
|
||||
--
|
||||
-- Table structure for table `cluster_metrics`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `cluster_metrics`;
|
||||
CREATE TABLE `cluster_metrics` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '集群id',
|
||||
`metrics` text COMMENT '指标',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`),
|
||||
KEY `idx_cluster_id_gmt_create` (`cluster_id`,`gmt_create`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='clustermetrics信息';
|
||||
|
||||
--
|
||||
-- Table structure for table `cluster_tasks`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `cluster_tasks`;
|
||||
CREATE TABLE `cluster_tasks` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`uuid` varchar(128) NOT NULL DEFAULT '' COMMENT '任务UUID',
|
||||
`cluster_id` bigint(128) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`task_type` varchar(128) NOT NULL DEFAULT '' COMMENT '任务类型',
|
||||
`kafka_package` text COMMENT 'kafka包',
|
||||
`kafka_package_md5` varchar(128) NOT NULL DEFAULT '' COMMENT 'kafka包的md5',
|
||||
`server_properties` text COMMENT 'kafkaserver配置',
|
||||
`server_properties_md5` varchar(128) NOT NULL DEFAULT '' COMMENT '配置文件的md5',
|
||||
`agent_task_id` bigint(128) NOT NULL DEFAULT '-1' COMMENT '任务id',
|
||||
`agent_rollback_task_id` bigint(128) NOT NULL DEFAULT '-1' COMMENT '回滚任务id',
|
||||
`host_list` text COMMENT '升级的主机',
|
||||
`pause_host_list` text COMMENT '暂停点',
|
||||
`rollback_host_list` text COMMENT '回滚机器列表',
|
||||
`rollback_pause_host_list` text COMMENT '回滚暂停机器列表',
|
||||
`operator` varchar(64) NOT NULL DEFAULT '' COMMENT '操作人',
|
||||
`task_status` int(11) NOT NULL DEFAULT '0' COMMENT '任务状态',
|
||||
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='集群任务(集群升级部署)';
|
||||
|
||||
--
|
||||
-- Table structure for table `config`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `config`;
|
||||
CREATE TABLE `config` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`config_key` varchar(128) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT '配置key',
|
||||
`config_value` text COMMENT '配置value',
|
||||
`config_description` text COMMENT '备注说明',
|
||||
`status` int(16) NOT NULL DEFAULT '0' COMMENT '0标识使用中,-1标识已废弃',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_config_key` (`config_key`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='配置表';
|
||||
|
||||
--
|
||||
-- Table structure for table `controller`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `controller`;
|
||||
CREATE TABLE `controller` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`broker_id` int(16) NOT NULL DEFAULT '-1' COMMENT 'brokerid',
|
||||
`host` varchar(256) NOT NULL DEFAULT '' COMMENT '主机名',
|
||||
`timestamp` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'controller变更时间',
|
||||
`version` int(16) NOT NULL DEFAULT '-1' COMMENT 'controller格式版本',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_cluster_id_broker_id_timestamp` (`cluster_id`,`broker_id`,`timestamp`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='controller记录表';
|
||||
|
||||
--
|
||||
-- Table structure for table `gateway_config`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `gateway_config`;
|
||||
CREATE TABLE `gateway_config` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`type` varchar(128) NOT NULL DEFAULT '' COMMENT '配置类型',
|
||||
`name` varchar(128) NOT NULL DEFAULT '' COMMENT '配置名称',
|
||||
`value` text COMMENT '配置值',
|
||||
`version` bigint(20) unsigned NOT NULL DEFAULT '1' COMMENT '版本信息',
|
||||
`description` text COMMENT '描述信息',
|
||||
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_type_name` (`type`,`name`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='gateway配置';
|
||||
INSERT INTO gateway_config(type, name, value, `version`, `description`) values('SD_QUEUE_SIZE', 'SD_QUEUE_SIZE', 100000000, 1, '任意集群队列大小');
|
||||
INSERT INTO gateway_config(type, name, value, `version`, `description`) values('SD_APP_RATE', 'SD_APP_RATE', 100000000, 1, '任意一个App限速');
|
||||
INSERT INTO gateway_config(type, name, value, `version`, `description`) values('SD_IP_RATE', 'SD_IP_RATE', 100000000, 1, '任意一个IP限速');
|
||||
INSERT INTO gateway_config(type, name, value, `version`, `description`) values('SD_SP_RATE', 'app_01234567', 100000000, 1, '指定App限速');
|
||||
INSERT INTO gateway_config(type, name, value, `version`, `description`) values('SD_SP_RATE', '192.168.0.1', 100000000, 1, '指定IP限速');
|
||||
|
||||
--
|
||||
-- Table structure for table `heartbeat`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `heartbeat`;
|
||||
CREATE TABLE `heartbeat` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`ip` varchar(128) NOT NULL DEFAULT '' COMMENT '主机ip',
|
||||
`hostname` varchar(256) NOT NULL DEFAULT '' COMMENT '主机名',
|
||||
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_ip` (`ip`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='心跳信息';
|
||||
|
||||
--
|
||||
-- Table structure for table `kafka_acl`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `kafka_acl`;
|
||||
CREATE TABLE `kafka_acl` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`app_id` varchar(128) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT '用户id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '集群id',
|
||||
`topic_name` varchar(192) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'topic名称',
|
||||
`access` int(11) NOT NULL DEFAULT '0' COMMENT '0:无权限, 1:读, 2:写, 3:读写',
|
||||
`operation` int(11) NOT NULL DEFAULT '0' COMMENT '0:创建, 1:更新 2:删除, 以最新的一条数据为准',
|
||||
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='权限信息(kafka-broker)';
|
||||
|
||||
--
|
||||
-- Table structure for table `kafka_bill`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `kafka_bill`;
|
||||
CREATE TABLE `kafka_bill` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '集群id',
|
||||
`topic_name` varchar(192) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'topic名称',
|
||||
`principal` varchar(64) NOT NULL DEFAULT '' COMMENT '负责人',
|
||||
`quota` double(53,2) NOT NULL DEFAULT '0.00' COMMENT '配额, 单位mb/s',
|
||||
`cost` double(53,2) NOT NULL DEFAULT '0.00' COMMENT '成本, 单位元',
|
||||
`cost_type` int(16) NOT NULL DEFAULT '0' COMMENT '成本类型, 0:共享集群, 1:独享集群, 2:独立集群',
|
||||
`gmt_day` varchar(64) NOT NULL DEFAULT '' COMMENT '计价的日期, 例如2019-02-02的计价结果',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_cluster_id_topic_name_gmt_day` (`cluster_id`,`topic_name`,`gmt_day`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='kafka账单';
|
||||
|
||||
--
|
||||
-- Table structure for table `kafka_file`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `kafka_file`;
|
||||
CREATE TABLE `kafka_file` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`storage_name` varchar(128) NOT NULL DEFAULT '' COMMENT '存储位置',
|
||||
`file_name` varchar(128) NOT NULL DEFAULT '' COMMENT '文件名',
|
||||
`file_md5` varchar(256) NOT NULL DEFAULT '' COMMENT '文件md5',
|
||||
`file_type` int(16) NOT NULL DEFAULT '-1' COMMENT '0:kafka压缩包, 1:kafkaserver配置',
|
||||
`description` text COMMENT '备注信息',
|
||||
`operator` varchar(64) NOT NULL DEFAULT '' COMMENT '创建用户',
|
||||
`status` int(16) NOT NULL DEFAULT '0' COMMENT '状态, 0:正常, -1:删除',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_cluster_id_file_name_storage_name` (`cluster_id`,`file_name`,`storage_name`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='文件管理';
|
||||
|
||||
--
|
||||
-- Table structure for table `kafka_user`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `kafka_user`;
|
||||
CREATE TABLE `kafka_user` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`app_id` varchar(128) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT '应用id',
|
||||
`password` varchar(256) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT '密码',
|
||||
`user_type` int(11) NOT NULL DEFAULT '0' COMMENT '0:普通用户, 1:超级用户',
|
||||
`operation` int(11) NOT NULL DEFAULT '0' COMMENT '0:创建, 1:更新 2:删除, 以最新一条的记录为准',
|
||||
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='kafka用户表';
|
||||
INSERT INTO app(app_id, name, password, type, applicant, principals, description) VALUES ('dkm_admin', 'KM管理员', 'km_kMl4N8as1Kp0CCY', 1, 'admin', 'admin', 'KM管理员应用-谨慎对外提供');
|
||||
INSERT INTO kafka_user(app_id, password, user_type, operation) VALUES ('dkm_admin', 'km_kMl4N8as1Kp0CCY', 1, 0);
|
||||
|
||||
|
||||
--
|
||||
-- Table structure for table `logical_cluster`
|
||||
--
|
||||
|
||||
CREATE TABLE `logical_cluster` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`name` varchar(192) NOT NULL DEFAULT '' COMMENT '逻辑集群名称',
|
||||
`identification` varchar(192) NOT NULL DEFAULT '' COMMENT '逻辑集群标识',
|
||||
`mode` int(16) NOT NULL DEFAULT '0' COMMENT '逻辑集群类型, 0:共享集群, 1:独享集群, 2:独立集群',
|
||||
`app_id` varchar(64) NOT NULL DEFAULT '' COMMENT '所属应用',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`region_list` varchar(256) NOT NULL DEFAULT '' COMMENT 'regionid列表',
|
||||
`description` text COMMENT '备注说明',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_name` (`name`),
|
||||
UNIQUE KEY `uniq_identification` (`identification`)
|
||||
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8 COMMENT='逻辑集群信息表';
|
||||
|
||||
|
||||
--
|
||||
-- Table structure for table `monitor_rule`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `monitor_rule`;
|
||||
CREATE TABLE `monitor_rule` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`name` varchar(192) NOT NULL DEFAULT '' COMMENT '告警名称',
|
||||
`strategy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '监控id',
|
||||
`app_id` varchar(64) NOT NULL DEFAULT '' COMMENT 'appid',
|
||||
`operator` varchar(64) NOT NULL DEFAULT '' COMMENT '操作人',
|
||||
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_name` (`name`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='监控规则';
|
||||
|
||||
--
|
||||
-- Table structure for table `operate_record`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `operate_record`;
|
||||
CREATE TABLE `operate_record` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`module_id` int(16) NOT NULL DEFAULT '-1' COMMENT '模块类型, 0:topic, 1:应用, 2:配额, 3:权限, 4:集群, -1:未知',
|
||||
`operate_id` int(16) NOT NULL DEFAULT '-1' COMMENT '操作类型, 0:新增, 1:删除, 2:修改',
|
||||
`resource` varchar(256) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'topic名称、app名称',
|
||||
`content` text COMMENT '操作内容',
|
||||
`operator` varchar(64) NOT NULL DEFAULT '' COMMENT '操作人',
|
||||
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
KEY `idx_module_id_operate_id_operator` (`module_id`,`operate_id`,`operator`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='操作记录';
|
||||
|
||||
--
|
||||
-- Table structure for table `reassign_task`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `reassign_task`;
|
||||
CREATE TABLE `reassign_task` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`task_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '任务ID',
|
||||
`name` varchar(256) NOT NULL DEFAULT '' COMMENT '任务名称',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '集群id',
|
||||
`topic_name` varchar(192) NOT NULL DEFAULT '' COMMENT 'Topic名称',
|
||||
`partitions` text COMMENT '分区',
|
||||
`reassignment_json` text COMMENT '任务参数',
|
||||
`real_throttle` bigint(20) NOT NULL DEFAULT '0' COMMENT '限流值',
|
||||
`max_throttle` bigint(20) NOT NULL DEFAULT '0' COMMENT '限流上限',
|
||||
`min_throttle` bigint(20) NOT NULL DEFAULT '0' COMMENT '限流下限',
|
||||
`begin_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '开始时间',
|
||||
`operator` varchar(64) NOT NULL DEFAULT '' COMMENT '操作人',
|
||||
`description` varchar(256) NOT NULL DEFAULT '' COMMENT '备注说明',
|
||||
`status` int(16) NOT NULL DEFAULT '0' COMMENT '任务状态',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '任务创建时间',
|
||||
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '任务修改时间',
|
||||
`original_retention_time` bigint(20) NOT NULL DEFAULT '86400000' COMMENT 'Topic存储时间',
|
||||
`reassign_retention_time` bigint(20) NOT NULL DEFAULT '86400000' COMMENT '迁移时的存储时间',
|
||||
`src_brokers` text COMMENT '源Broker',
|
||||
`dest_brokers` text COMMENT '目标Broker',
|
||||
PRIMARY KEY (`id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='topic迁移信息';
|
||||
|
||||
--
|
||||
-- Table structure for table `region`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `region`;
|
||||
CREATE TABLE `region` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`name` varchar(192) NOT NULL DEFAULT '' COMMENT 'region名称',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`broker_list` varchar(256) NOT NULL DEFAULT '' COMMENT 'broker列表',
|
||||
`capacity` bigint(20) NOT NULL DEFAULT '0' COMMENT '容量(B/s)',
|
||||
`real_used` bigint(20) NOT NULL DEFAULT '0' COMMENT '实际使用量(B/s)',
|
||||
`estimate_used` bigint(20) NOT NULL DEFAULT '0' COMMENT '预估使用量(B/s)',
|
||||
`description` text COMMENT '备注说明',
|
||||
`status` int(16) NOT NULL DEFAULT '0' COMMENT '状态,0正常,1已满',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_name` (`name`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='region信息表';
|
||||
|
||||
--
|
||||
-- Table structure for table `topic`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `topic`;
|
||||
CREATE TABLE `topic` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`topic_name` varchar(192) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'topic名称',
|
||||
`app_id` varchar(64) NOT NULL DEFAULT '' COMMENT 'topic所属appid',
|
||||
`peak_bytes_in` bigint(20) NOT NULL DEFAULT '0' COMMENT '峰值流量',
|
||||
`description` text COMMENT '备注信息',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_cluster_id_topic_name` (`cluster_id`,`topic_name`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='topic信息表';
|
||||
|
||||
--
|
||||
-- Table structure for table `topic_app_metrics`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `topic_app_metrics`;
|
||||
CREATE TABLE `topic_app_metrics` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '集群id',
|
||||
`topic_name` varchar(192) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'topic名称',
|
||||
`app_id` varchar(64) NOT NULL DEFAULT '' COMMENT 'appid',
|
||||
`metrics` text COMMENT '指标',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`),
|
||||
KEY `idx_cluster_id_topic_name_app_id_gmt_create` (`cluster_id`,`topic_name`,`app_id`,`gmt_create`),
|
||||
KEY `idx_gmt_create` (`gmt_create`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='topic app metrics';
|
||||
|
||||
--
|
||||
-- Table structure for table `topic_connections`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `topic_connections`;
|
||||
CREATE TABLE `topic_connections` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`app_id` varchar(64) NOT NULL DEFAULT '' COMMENT '应用id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '集群id',
|
||||
`topic_name` varchar(192) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'topic名称',
|
||||
`type` varchar(16) NOT NULL DEFAULT '' COMMENT 'producer or consumer',
|
||||
`ip` varchar(32) NOT NULL DEFAULT '' COMMENT 'ip地址',
|
||||
`client_version` varchar(8) NOT NULL DEFAULT '' COMMENT '客户端版本',
|
||||
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_app_id_cluster_id_topic_name_type_ip_client_version` (`app_id`,`cluster_id`,`topic_name`,`type`,`ip`,`client_version`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='topic连接信息表';
|
||||
|
||||
--
|
||||
-- Table structure for table `topic_expired`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `topic_expired`;
|
||||
CREATE TABLE `topic_expired` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`topic_name` varchar(192) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'topic名称',
|
||||
`produce_connection_num` bigint(20) NOT NULL DEFAULT '0' COMMENT '发送连接数',
|
||||
`fetch_connection_num` bigint(20) NOT NULL DEFAULT '0' COMMENT '消费连接数',
|
||||
`expired_day` bigint(20) NOT NULL DEFAULT '0' COMMENT '过期天数',
|
||||
`gmt_retain` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '保留截止时间',
|
||||
`status` int(16) NOT NULL DEFAULT '0' COMMENT '-1:可下线, 0:过期待通知, 1+:已通知待反馈',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_cluster_id_topic_name` (`cluster_id`,`topic_name`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='topic过期信息表';
|
||||
|
||||
--
|
||||
-- Table structure for table `topic_metrics`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `topic_metrics`;
|
||||
CREATE TABLE `topic_metrics` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`topic_name` varchar(192) NOT NULL DEFAULT '' COMMENT 'topic名称',
|
||||
`metrics` text COMMENT '指标数据JSON',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`),
|
||||
KEY `idx_cluster_id_topic_name_gmt_create` (`cluster_id`,`topic_name`,`gmt_create`),
|
||||
KEY `idx_gmt_create` (`gmt_create`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='topicmetrics表';
|
||||
|
||||
--
|
||||
-- Table structure for table `topic_report`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `topic_report`;
|
||||
CREATE TABLE `topic_report` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '集群id',
|
||||
`topic_name` varchar(192) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'topic名称',
|
||||
`start_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '开始上报时间',
|
||||
`end_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '结束上报时间',
|
||||
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_cluster_id_topic_name` (`cluster_id`,`topic_name`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='开启jmx采集的topic';
|
||||
|
||||
--
|
||||
-- Table structure for table `topic_request_time_metrics`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `topic_request_time_metrics`;
|
||||
CREATE TABLE `topic_request_time_metrics` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`topic_name` varchar(192) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'topic名称',
|
||||
`metrics` text COMMENT '指标',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`),
|
||||
KEY `idx_cluster_id_topic_name_gmt_create` (`cluster_id`,`topic_name`,`gmt_create`),
|
||||
KEY `idx_gmt_create` (`gmt_create`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='topic请求耗时信息';
|
||||
|
||||
--
|
||||
-- Table structure for table `topic_statistics`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `topic_statistics`;
|
||||
CREATE TABLE `topic_statistics` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`topic_name` varchar(192) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'topic名称',
|
||||
`offset_sum` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'offset和',
|
||||
`max_avg_bytes_in` double(53,2) NOT NULL DEFAULT '-1.00' COMMENT '峰值的均值流量',
|
||||
`gmt_day` varchar(64) NOT NULL DEFAULT '' COMMENT '日期2020-03-30的形式',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`max_avg_messages_in` double(53,2) NOT NULL DEFAULT '-1.00' COMMENT '峰值的均值消息条数',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_cluster_id_topic_name_gmt_day` (`cluster_id`,`topic_name`,`gmt_day`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='topic统计信息表';
|
||||
|
||||
--
|
||||
-- Table structure for table `topic_throttled_metrics`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `topic_throttled_metrics`;
|
||||
CREATE TABLE `topic_throttled_metrics` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`topic_name` varchar(192) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'topic name',
|
||||
`app_id` varchar(64) NOT NULL DEFAULT '' COMMENT 'app',
|
||||
`produce_throttled` tinyint(8) NOT NULL DEFAULT '0' COMMENT '是否是生产耗时',
|
||||
`fetch_throttled` tinyint(8) NOT NULL DEFAULT '0' COMMENT '是否是消费耗时',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`),
|
||||
KEY `idx_cluster_id_topic_name_app_id` (`cluster_id`,`topic_name`,`app_id`),
|
||||
KEY `idx_gmt_create` (`gmt_create`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='topic限流信息';
|
||||
|
||||
--
|
||||
-- Table structure for table `work_order`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `work_order`;
|
||||
CREATE TABLE `work_order` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`type` int(16) NOT NULL DEFAULT '-1' COMMENT '工单类型',
|
||||
`title` varchar(512) NOT NULL DEFAULT '' COMMENT '工单标题',
|
||||
`applicant` varchar(64) NOT NULL DEFAULT '' COMMENT '申请人',
|
||||
`description` text COMMENT '备注信息',
|
||||
`approver` varchar(64) NOT NULL DEFAULT '' COMMENT '审批人',
|
||||
`gmt_handle` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '审批时间',
|
||||
`opinion` varchar(256) NOT NULL DEFAULT '' COMMENT '审批信息',
|
||||
`extensions` text COMMENT '扩展信息',
|
||||
`status` int(16) NOT NULL DEFAULT '0' COMMENT '工单状态, 0:待审批, 1:通过, 2:拒绝, 3:取消',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='工单表';
|
||||
@@ -1,215 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<configuration scan="true" scanPeriod="10 seconds">
|
||||
<contextName>logback</contextName>
|
||||
<property name="log.path" value="./logs" />
|
||||
|
||||
<!-- 彩色日志 -->
|
||||
<!-- 彩色日志依赖的渲染类 -->
|
||||
<conversionRule conversionWord="clr" converterClass="org.springframework.boot.logging.logback.ColorConverter" />
|
||||
<conversionRule conversionWord="wex" converterClass="org.springframework.boot.logging.logback.WhitespaceThrowableProxyConverter" />
|
||||
<conversionRule conversionWord="wEx" converterClass="org.springframework.boot.logging.logback.ExtendedWhitespaceThrowableProxyConverter" />
|
||||
<!-- 彩色日志格式 -->
|
||||
<property name="CONSOLE_LOG_PATTERN" value="${CONSOLE_LOG_PATTERN:-%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}"/>
|
||||
|
||||
<!--输出到控制台-->
|
||||
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
|
||||
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
|
||||
<level>info</level>
|
||||
</filter>
|
||||
<encoder>
|
||||
<Pattern>${CONSOLE_LOG_PATTERN}</Pattern>
|
||||
<charset>UTF-8</charset>
|
||||
</encoder>
|
||||
</appender>
|
||||
|
||||
|
||||
<!--输出到文件-->
|
||||
|
||||
<!-- 时间滚动输出 level为 DEBUG 日志 -->
|
||||
<appender name="DEBUG_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
|
||||
<file>${log.path}/log_debug.log</file>
|
||||
<!--日志文件输出格式-->
|
||||
<encoder>
|
||||
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
|
||||
<charset>UTF-8</charset> <!-- 设置字符集 -->
|
||||
</encoder>
|
||||
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
|
||||
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
|
||||
<!-- 日志归档 -->
|
||||
<fileNamePattern>${log.path}/log_debug_%d{yyyy-MM-dd}.%i.log</fileNamePattern>
|
||||
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
|
||||
<maxFileSize>100MB</maxFileSize>
|
||||
</timeBasedFileNamingAndTriggeringPolicy>
|
||||
<!--日志文件保留天数-->
|
||||
<maxHistory>7</maxHistory>
|
||||
</rollingPolicy>
|
||||
<!-- 此日志文件只记录debug级别的 -->
|
||||
<filter class="ch.qos.logback.classic.filter.LevelFilter">
|
||||
<level>debug</level>
|
||||
<onMatch>ACCEPT</onMatch>
|
||||
<onMismatch>DENY</onMismatch>
|
||||
</filter>
|
||||
</appender>
|
||||
|
||||
<!-- 时间滚动输出 level为 INFO 日志 -->
|
||||
<appender name="INFO_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
|
||||
<!-- 正在记录的日志文件的路径及文件名 -->
|
||||
<file>${log.path}/log_info.log</file>
|
||||
<!--日志文件输出格式-->
|
||||
<encoder>
|
||||
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
|
||||
<charset>UTF-8</charset>
|
||||
</encoder>
|
||||
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
|
||||
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
|
||||
<!-- 每天日志归档路径以及格式 -->
|
||||
<fileNamePattern>${log.path}/log_info_%d{yyyy-MM-dd}.%i.log</fileNamePattern>
|
||||
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
|
||||
<maxFileSize>100MB</maxFileSize>
|
||||
</timeBasedFileNamingAndTriggeringPolicy>
|
||||
<!--日志文件保留天数-->
|
||||
<maxHistory>7</maxHistory>
|
||||
</rollingPolicy>
|
||||
<!-- 此日志文件只记录info级别的 -->
|
||||
<filter class="ch.qos.logback.classic.filter.LevelFilter">
|
||||
<level>info</level>
|
||||
<onMatch>ACCEPT</onMatch>
|
||||
<onMismatch>DENY</onMismatch>
|
||||
</filter>
|
||||
</appender>
|
||||
|
||||
<!-- 时间滚动输出 level为 WARN 日志 -->
|
||||
<appender name="WARN_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
|
||||
<!-- 正在记录的日志文件的路径及文件名 -->
|
||||
<file>${log.path}/log_warn.log</file>
|
||||
<!--日志文件输出格式-->
|
||||
<encoder>
|
||||
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
|
||||
<charset>UTF-8</charset> <!-- 此处设置字符集 -->
|
||||
</encoder>
|
||||
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
|
||||
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
|
||||
<fileNamePattern>${log.path}/log_warn_%d{yyyy-MM-dd}.%i.log</fileNamePattern>
|
||||
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
|
||||
<maxFileSize>100MB</maxFileSize>
|
||||
</timeBasedFileNamingAndTriggeringPolicy>
|
||||
<!--日志文件保留天数-->
|
||||
<maxHistory>7</maxHistory>
|
||||
</rollingPolicy>
|
||||
<!-- 此日志文件只记录warn级别的 -->
|
||||
<filter class="ch.qos.logback.classic.filter.LevelFilter">
|
||||
<level>warn</level>
|
||||
<onMatch>ACCEPT</onMatch>
|
||||
<onMismatch>DENY</onMismatch>
|
||||
</filter>
|
||||
</appender>
|
||||
|
||||
|
||||
<!-- 时间滚动输出 level为 ERROR 日志 -->
|
||||
<appender name="ERROR_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
|
||||
<!-- 正在记录的日志文件的路径及文件名 -->
|
||||
<file>${log.path}/log_error.log</file>
|
||||
<!--日志文件输出格式-->
|
||||
<encoder>
|
||||
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
|
||||
<charset>UTF-8</charset> <!-- 此处设置字符集 -->
|
||||
</encoder>
|
||||
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
|
||||
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
|
||||
<fileNamePattern>${log.path}/log_error_%d{yyyy-MM-dd}.%i.log</fileNamePattern>
|
||||
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
|
||||
<maxFileSize>100MB</maxFileSize>
|
||||
</timeBasedFileNamingAndTriggeringPolicy>
|
||||
<!--日志文件保留天数-->
|
||||
<maxHistory>7</maxHistory>
|
||||
</rollingPolicy>
|
||||
<!-- 此日志文件只记录ERROR级别的 -->
|
||||
<filter class="ch.qos.logback.classic.filter.LevelFilter">
|
||||
<level>ERROR</level>
|
||||
<onMatch>ACCEPT</onMatch>
|
||||
<onMismatch>DENY</onMismatch>
|
||||
</filter>
|
||||
</appender>
|
||||
|
||||
<!-- Metrics信息收集日志 -->
|
||||
<appender name="COLLECTOR_METRICS_LOGGER" class="ch.qos.logback.core.rolling.RollingFileAppender">
|
||||
<file>${log.path}/metrics/collector_metrics.log</file>
|
||||
<encoder>
|
||||
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
|
||||
<charset>UTF-8</charset>
|
||||
</encoder>
|
||||
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
|
||||
<fileNamePattern>${log.path}/metrics/collector_metrics_%d{yyyy-MM-dd}.%i.log</fileNamePattern>
|
||||
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
|
||||
<maxFileSize>100MB</maxFileSize>
|
||||
</timeBasedFileNamingAndTriggeringPolicy>
|
||||
<maxHistory>3</maxHistory>
|
||||
</rollingPolicy>
|
||||
</appender>
|
||||
|
||||
<!-- Metrics信息收集日志 -->
|
||||
<appender name="API_METRICS_LOGGER" class="ch.qos.logback.core.rolling.RollingFileAppender">
|
||||
<file>${log.path}/metrics/api_metrics.log</file>
|
||||
<encoder>
|
||||
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
|
||||
<charset>UTF-8</charset>
|
||||
</encoder>
|
||||
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
|
||||
<fileNamePattern>${log.path}/metrics/api_metrics_%d{yyyy-MM-dd}.%i.log</fileNamePattern>
|
||||
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
|
||||
<maxFileSize>100MB</maxFileSize>
|
||||
</timeBasedFileNamingAndTriggeringPolicy>
|
||||
<maxHistory>3</maxHistory>
|
||||
</rollingPolicy>
|
||||
</appender>
|
||||
|
||||
<!-- Metrics信息收集日志 -->
|
||||
<appender name="SCHEDULED_TASK_LOGGER" class="ch.qos.logback.core.rolling.RollingFileAppender">
|
||||
<file>${log.path}/metrics/scheduled_tasks.log</file>
|
||||
<encoder>
|
||||
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
|
||||
<charset>UTF-8</charset>
|
||||
</encoder>
|
||||
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
|
||||
<fileNamePattern>${log.path}/metrics/scheduled_tasks_%d{yyyy-MM-dd}.%i.log</fileNamePattern>
|
||||
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
|
||||
<maxFileSize>100MB</maxFileSize>
|
||||
</timeBasedFileNamingAndTriggeringPolicy>
|
||||
<maxHistory>5</maxHistory>
|
||||
</rollingPolicy>
|
||||
</appender>
|
||||
|
||||
<logger name="COLLECTOR_METRICS_LOGGER" level="DEBUG" additivity="false">
|
||||
<appender-ref ref="COLLECTOR_METRICS_LOGGER"/>
|
||||
</logger>
|
||||
<logger name="API_METRICS_LOGGER" level="DEBUG" additivity="false">
|
||||
<appender-ref ref="API_METRICS_LOGGER"/>
|
||||
</logger>
|
||||
<logger name="SCHEDULED_TASK_LOGGER" level="DEBUG" additivity="false">
|
||||
<appender-ref ref="SCHEDULED_TASK_LOGGER"/>
|
||||
</logger>
|
||||
|
||||
<logger name="org.apache.ibatis" level="INFO" additivity="false" />
|
||||
<logger name="org.mybatis.spring" level="INFO" additivity="false" />
|
||||
<logger name="com.github.miemiedev.mybatis.paginator" level="INFO" additivity="false" />
|
||||
|
||||
<root level="info">
|
||||
<appender-ref ref="CONSOLE" />
|
||||
<appender-ref ref="DEBUG_FILE" />
|
||||
<appender-ref ref="INFO_FILE" />
|
||||
<appender-ref ref="WARN_FILE" />
|
||||
<appender-ref ref="ERROR_FILE" />
|
||||
<!--<appender-ref ref="METRICS_LOG" />-->
|
||||
</root>
|
||||
|
||||
<!--生产环境:输出到文件-->
|
||||
<!--<springProfile name="pro">-->
|
||||
<!--<root level="info">-->
|
||||
<!--<appender-ref ref="CONSOLE" />-->
|
||||
<!--<appender-ref ref="DEBUG_FILE" />-->
|
||||
<!--<appender-ref ref="INFO_FILE" />-->
|
||||
<!--<appender-ref ref="ERROR_FILE" />-->
|
||||
<!--<appender-ref ref="WARN_FILE" />-->
|
||||
<!--</root>-->
|
||||
<!--</springProfile>-->
|
||||
</configuration>
|
||||
@@ -1,10 +0,0 @@
|
||||
<settings>
|
||||
<mirrors>
|
||||
<mirror>
|
||||
<id>aliyunmaven</id>
|
||||
<mirrorOf>*</mirrorOf>
|
||||
<name>阿里云公共仓库</name>
|
||||
<url>https://maven.aliyun.com/repository/public</url>
|
||||
</mirror>
|
||||
</mirrors>
|
||||
</settings>
|
||||
@@ -1,64 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
|
||||
<project xmlns="http://maven.apache.org/POM/4.0.0"
|
||||
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
|
||||
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
|
||||
|
||||
<parent>
|
||||
<artifactId>kafka-manager</artifactId>
|
||||
<groupId>com.xiaojukeji.kafka</groupId>
|
||||
<version>${kafka-manager.revision}</version>
|
||||
</parent>
|
||||
|
||||
<modelVersion>4.0.0</modelVersion>
|
||||
|
||||
<artifactId>distribution</artifactId>
|
||||
<name>distribution</name>
|
||||
<packaging>pom</packaging>
|
||||
|
||||
<dependencies>
|
||||
<dependency>
|
||||
<groupId>${project.groupId}</groupId>
|
||||
<artifactId>kafka-manager-web</artifactId>
|
||||
<version>${kafka-manager.revision}</version>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
|
||||
<profiles>
|
||||
|
||||
<profile>
|
||||
<id>release-kafka-manager</id>
|
||||
<dependencies>
|
||||
<dependency>
|
||||
<groupId>${project.groupId}</groupId>
|
||||
<artifactId>kafka-manager-web</artifactId>
|
||||
<version>${kafka-manager.revision}</version>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
<build>
|
||||
<plugins>
|
||||
<plugin>
|
||||
<groupId>org.apache.maven.plugins</groupId>
|
||||
<artifactId>maven-assembly-plugin</artifactId>
|
||||
<configuration>
|
||||
<descriptors>
|
||||
<descriptor>release-km.xml</descriptor>
|
||||
</descriptors>
|
||||
<tarLongFileMode>posix</tarLongFileMode>
|
||||
</configuration>
|
||||
<executions>
|
||||
<execution>
|
||||
<id>make-assembly</id>
|
||||
<phase>install</phase>
|
||||
<goals>
|
||||
<goal>single</goal>
|
||||
</goals>
|
||||
</execution>
|
||||
</executions>
|
||||
</plugin>
|
||||
</plugins>
|
||||
<finalName>kafka-manager</finalName>
|
||||
</build>
|
||||
</profile>
|
||||
</profiles>
|
||||
</project>
|
||||
@@ -1,22 +0,0 @@
|
||||
## 说明
|
||||
|
||||
### 1.创建mysql数据库文件
|
||||
> conf/create_mysql_table.sql
|
||||
|
||||
### 2. 修改配置文件
|
||||
> conf/application.yml.example
|
||||
> 请将application.yml.example 复制一份改名为application.yml;
|
||||
> 并放在同级目录下(conf/); 并修改成自己的配置
|
||||
> 这里的优先级比jar包内配置文件的默认值高;
|
||||
>
|
||||
|
||||
### 3.启动/关闭kafka-manager
|
||||
> sh bin/startup.sh 启动
|
||||
>
|
||||
> sh shutdown.sh 关闭
|
||||
>
|
||||
|
||||
|
||||
### 4.升级jar包
|
||||
> 如果是升级, 可以看看文件 `upgrade_config.md` 的配置变更历史;
|
||||
>
|
||||
@@ -1,51 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
|
||||
<assembly>
|
||||
<id>${project.version}</id>
|
||||
<includeBaseDirectory>true</includeBaseDirectory>
|
||||
<formats>
|
||||
<format>dir</format>
|
||||
<format>tar.gz</format>
|
||||
<format>zip</format>
|
||||
</formats>
|
||||
<fileSets>
|
||||
<fileSet>
|
||||
<includes>
|
||||
<include>conf/**</include>
|
||||
</includes>
|
||||
</fileSet>
|
||||
|
||||
<fileSet>
|
||||
<includes>
|
||||
<include>bin/*</include>
|
||||
</includes>
|
||||
<fileMode>0755</fileMode>
|
||||
</fileSet>
|
||||
</fileSets>
|
||||
<files>
|
||||
|
||||
|
||||
<file>
|
||||
<source>readme.md</source>
|
||||
<destName>readme.md</destName>
|
||||
</file>
|
||||
<file>
|
||||
<source>upgrade_config.md</source>
|
||||
<destName>upgrade_config.md</destName>
|
||||
</file>
|
||||
<file>
|
||||
<!--打好的jar包名称和放置目录-->
|
||||
<source>../kafka-manager-web/target/kafka-manager.jar</source>
|
||||
<outputDirectory>target/</outputDirectory>
|
||||
</file>
|
||||
</files>
|
||||
|
||||
<moduleSets>
|
||||
<moduleSet>
|
||||
<useAllReactorProjects>true</useAllReactorProjects>
|
||||
<includes>
|
||||
<include>com.xiaojukeji.kafka:kafka-manager-web</include>
|
||||
</includes>
|
||||
</moduleSet>
|
||||
</moduleSets>
|
||||
</assembly>
|
||||
@@ -1,52 +0,0 @@
|
||||
|
||||
## 版本升级配置变更
|
||||
> 本文件 从 V2.2.0 开始记录; 如果配置有变更则会填写到下文中; 如果没有,则表示无变更;
|
||||
> 当您从一个很低的版本升级时候,应该依次执行中间有过变更的sql脚本
|
||||
|
||||
|
||||
|
||||
**一站式`Apache Kafka`集群指标监控与运维管控平台**
|
||||
|
||||
---
|
||||
|
||||
### 1.升级至`V2.2.0`版本
|
||||
|
||||
#### 1.mysql变更
|
||||
|
||||
`2.2.0`版本在`cluster`表及`logical_cluster`各增加了一个字段,因此需要执行下面的sql进行字段的增加。
|
||||
|
||||
```sql
|
||||
# 往cluster表中增加jmx_properties字段, 这个字段会用于存储jmx相关的认证以及配置信息
|
||||
ALTER TABLE `cluster` ADD COLUMN `jmx_properties` TEXT NULL COMMENT 'JMX配置' AFTER `security_properties`;
|
||||
|
||||
# 往logical_cluster中增加identification字段, 同时数据和原先name数据相同, 最后增加一个唯一键.
|
||||
# 此后, name字段还是表示集群名称, 而identification字段表示的是集群标识, 只能是字母数字及下划线组成,
|
||||
# 数据上报到监控系统时, 集群这个标识采用的字段就是identification字段, 之前使用的是name字段.
|
||||
ALTER TABLE `logical_cluster` ADD COLUMN `identification` VARCHAR(192) NOT NULL DEFAULT '' COMMENT '逻辑集群标识' AFTER `name`;
|
||||
|
||||
UPDATE `logical_cluster` SET `identification`=`name` WHERE id>=0;
|
||||
|
||||
ALTER TABLE `logical_cluster` ADD INDEX `uniq_identification` (`identification` ASC);
|
||||
```
|
||||
|
||||
### 升级至`2.3.0`版本
|
||||
|
||||
#### 1.mysql变更
|
||||
`2.3.0`版本在`gateway_config`表增加了一个描述说明的字段,因此需要执行下面的sql进行字段的增加。
|
||||
|
||||
```sql
|
||||
ALTER TABLE `gateway_config`
|
||||
ADD COLUMN `description` TEXT NULL COMMENT '描述信息' AFTER `version`;
|
||||
```
|
||||
|
||||
### 升级至`2.6.0`版本
|
||||
|
||||
#### 1.mysql变更
|
||||
`2.6.0`版本在`account`表增加用户姓名,部门名,邮箱三个字段,因此需要执行下面的sql进行字段的增加。
|
||||
|
||||
```sql
|
||||
ALTER TABLE `account`
|
||||
ADD COLUMN `display_name` VARCHAR(256) NOT NULL DEFAULT '' COMMENT '用户名' AFTER `role`,
|
||||
ADD COLUMN `department` VARCHAR(256) NOT NULL DEFAULT '' COMMENT '部门名' AFTER `display_name`,
|
||||
ADD COLUMN `mail` VARCHAR(256) NOT NULL DEFAULT '' COMMENT '邮箱' AFTER `department`;
|
||||
```
|
||||
BIN
docs/assets/KnowStreamingLogo.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 41 KiB |
{kind=link}
|
Before Width: | Height: | Size: 73 KiB |
{kind=link}
|
Before Width: | Height: | Size: 7.4 KiB |
BIN
docs/assets/readme/KnowStreamingPageDemo.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 183 KiB |
BIN
docs/assets/readme/WeChat.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 50 KiB |
BIN
docs/assets/readme/ZSXQ.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 96 KiB |
@@ -1,47 +0,0 @@
|
||||
|
||||
---
|
||||
|
||||

|
||||
|
||||
**一站式`Apache Kafka`集群指标监控与运维管控平台**
|
||||
|
||||
---
|
||||
|
||||
|
||||
# LogiKM单元测试和集成测试
|
||||
|
||||
## 1、单元测试
|
||||
### 1.1 单元测试介绍
|
||||
单元测试又称模块测试,是针对软件设计的最小单位——程序模块进行正确性检验的测试工作。
|
||||
其目的在于检查每个程序单元能否正确实现详细设计说明中的模块功能、性能、接口和设计约束等要求,
|
||||
发现各模块内部可能存在的各种错误。单元测试需要从程序的内部结构出发设计测试用例。
|
||||
多个模块可以平行地独立进行单元测试。
|
||||
|
||||
### 1.2 LogiKM单元测试思路
|
||||
LogiKM单元测试思路主要是测试Service层的方法,通过罗列方法的各种参数,
|
||||
判断方法返回的结果是否符合预期。单元测试的基类加了@SpringBootTest注解,即每次运行单测用例都启动容器
|
||||
|
||||
### 1.3 LogiKM单元测试注意事项
|
||||
1. 单元测试用例在kafka-manager-core以及kafka-manager-extends下的test包中
|
||||
2. 配置在resources/application.yml,包括运行单元测试用例启用的数据库配置等等
|
||||
3. 编译打包项目时,加上参数-DskipTests可不执行测试用例,例如使用命令行mvn -DskipTests进行打包
|
||||
|
||||
|
||||
|
||||
|
||||
## 2、集成测试
|
||||
### 2.1 集成测试介绍
|
||||
集成测试又称组装测试,是一种黑盒测试。通常在单元测试的基础上,将所有的程序模块进行有序的、递增的测试。
|
||||
集成测试是检验程序单元或部件的接口关系,逐步集成为符合概要设计要求的程序部件或整个系统。
|
||||
|
||||
### 2.2 LogiKM集成测试思路
|
||||
LogiKM集成测试主要思路是对Controller层的接口发送Http请求。
|
||||
通过罗列测试用例,模拟用户的操作,对接口发送Http请求,判断结果是否达到预期。
|
||||
本地运行集成测试用例时,无需加@SpringBootTest注解(即无需每次运行测试用例都启动容器)
|
||||
|
||||
### 2.3 LogiKM集成测试注意事项
|
||||
1. 集成测试用例在kafka-manager-web的test包下
|
||||
2. 因为对某些接口发送Http请求需要先登陆,比较麻烦,可以绕过登陆,方法可见教程见docs -> user_guide -> call_api_bypass_login
|
||||
3. 集成测试的配置在resources/integrationTest-settings.properties文件下,包括集群地址,zk地址的配置等等
|
||||
4. 如果需要运行集成测试用例,需要本地先启动LogiKM项目
|
||||
5. 编译打包项目时,加上参数-DskipTests可不执行测试用例,例如使用命令行mvn -DskipTests进行打包
|
||||
{kind=link}
|
Before Width: | Height: | Size: 270 KiB |
{kind=link}
|
Before Width: | Height: | Size: 785 KiB |
{kind=link}
|
Before Width: | Height: | Size: 2.5 MiB |
{kind=link}
|
Before Width: | Height: | Size: 69 KiB |
{kind=link}
|
Before Width: | Height: | Size: 589 KiB |
{kind=link}
|
Before Width: | Height: | Size: 652 KiB |
{kind=link}
|
Before Width: | Height: | Size: 511 KiB |
{kind=link}
|
Before Width: | Height: | Size: 672 KiB |
{kind=link}
|
After Width: | Height: | Size: 600 KiB |
BIN
docs/dev_guide/assets/startup_using_source_code/IDEA配置.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 228 KiB |
@@ -1,107 +0,0 @@
|
||||
|
||||
---
|
||||
|
||||

|
||||
|
||||
**一站式`Apache Kafka`集群指标监控与运维管控平台**
|
||||
|
||||
---
|
||||
|
||||
## JMX-连接失败问题解决
|
||||
|
||||
集群正常接入Logi-KafkaManager之后,即可以看到集群的Broker列表,此时如果查看不了Topic的实时流量,或者是Broker的实时流量信息时,那么大概率就是JMX连接的问题了。
|
||||
|
||||
下面我们按照步骤来一步一步的检查。
|
||||
|
||||
### 1、问题&说明
|
||||
|
||||
**类型一:JMX配置未开启**
|
||||
|
||||
未开启时,直接到`2、解决方法`查看如何开启即可。
|
||||
|
||||

|
||||
|
||||
|
||||
**类型二:配置错误**
|
||||
|
||||
`JMX`端口已经开启的情况下,有的时候开启的配置不正确,此时也会导致出现连接失败的问题。这里大概列举几种原因:
|
||||
|
||||
- `JMX`配置错误:见`2、解决方法`。
|
||||
- 存在防火墙或者网络限制:网络通的另外一台机器`telnet`试一下看是否可以连接上。
|
||||
- 需要进行用户名及密码的认证:见`3、解决方法 —— 认证的JMX`。
|
||||
- 当logikm和kafka不在同一台机器上时,kafka的Jmx端口不允许其他机器访问:见`4、解决方法`。
|
||||
|
||||
|
||||
错误日志例子:
|
||||
```
|
||||
# 错误一: 错误提示的是真实的IP,这样的话基本就是JMX配置的有问题了。
|
||||
2021-01-27 10:06:20.730 ERROR 50901 --- [ics-Thread-1-62] c.x.k.m.c.utils.jmx.JmxConnectorWrap : JMX connect exception, host:192.168.0.1 port:9999.
|
||||
java.rmi.ConnectException: Connection refused to host: 192.168.0.1; nested exception is:
|
||||
|
||||
|
||||
# 错误二:错误提示的是127.0.0.1这个IP,这个是机器的hostname配置的可能有问题。
|
||||
2021-01-27 10:06:20.730 ERROR 50901 --- [ics-Thread-1-62] c.x.k.m.c.utils.jmx.JmxConnectorWrap : JMX connect exception, host:127.0.0.1 port:9999.
|
||||
java.rmi.ConnectException: Connection refused to host: 127.0.0.1;; nested exception is:
|
||||
```
|
||||
|
||||
### 2、解决方法
|
||||
|
||||
这里仅介绍一下比较通用的解决方式,如若有更好的方式,欢迎大家指导告知一下。
|
||||
|
||||
修改`kafka-server-start.sh`文件:
|
||||
```
|
||||
# 在这个下面增加JMX端口的配置
|
||||
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
|
||||
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
|
||||
export JMX_PORT=9999 # 增加这个配置, 这里的数值并不一定是要9999
|
||||
fi
|
||||
```
|
||||
|
||||
|
||||
|
||||
修改`kafka-run-class.sh`文件
|
||||
```
|
||||
# JMX settings
|
||||
if [ -z "$KAFKA_JMX_OPTS" ]; then
|
||||
KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=${当前机器的IP}"
|
||||
fi
|
||||
|
||||
# JMX port to use
|
||||
if [ $JMX_PORT ]; then
|
||||
KAFKA_JMX_OPTS="$KAFKA_JMX_OPTS -Dcom.sun.management.jmxremote.port=$JMX_PORT -Dcom.sun.management.jmxremote.rmi.port=$JMX_PORT"
|
||||
fi
|
||||
```
|
||||
|
||||
|
||||
### 3、解决方法 —— 认证的JMX
|
||||
|
||||
如果您是直接看的这个部分,建议先看一下上一节:`2、解决方法`以确保`JMX`的配置没有问题了。
|
||||
|
||||
在JMX的配置等都没有问题的情况下,如果是因为认证的原因导致连接不了的,此时可以使用下面介绍的方法进行解决。
|
||||
|
||||
**当前这块后端刚刚开发完成,可能还不够完善,有问题随时沟通。**
|
||||
|
||||
`Logi-KafkaManager 2.2.0+`之后的版本后端已经支持`JMX`认证方式的连接,但是还没有界面,此时我们可以往`cluster`表的`jmx_properties`字段写入`JMX`的认证信息。
|
||||
|
||||
这个数据是`json`格式的字符串,例子如下所示:
|
||||
|
||||
```json
|
||||
{
|
||||
"maxConn": 10, # KM对单台Broker的最大JMX连接数
|
||||
"username": "xxxxx", # 用户名
|
||||
"password": "xxxx", # 密码
|
||||
"openSSL": true, # 开启SSL, true表示开启ssl, false表示关闭
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
SQL的例子:
|
||||
```sql
|
||||
UPDATE cluster SET jmx_properties='{ "maxConn": 10, "username": "xxxxx", "password": "xxxx", "openSSL": false }' where id={xxx};
|
||||
```
|
||||
### 4、解决方法 —— 不允许其他机器访问
|
||||

|
||||
|
||||
该图中的127.0.0.1表明该端口只允许本机访问.
|
||||
在cdh中可以点击配置->搜索jmx->寻找broker_java_opts 修改com.sun.management.jmxremote.host和java.rmi.server.hostname为本机ip
|
||||
@@ -1,89 +0,0 @@
|
||||
<mxfile host="65bd71144e">
|
||||
<diagram id="bhaMuW99Q1BzDTtcfRXp" name="Page-1">
|
||||
<mxGraphModel dx="1138" dy="830" grid="1" gridSize="10" guides="1" tooltips="1" connect="1" arrows="1" fold="1" page="1" pageScale="1" pageWidth="1169" pageHeight="827" math="0" shadow="0">
|
||||
<root>
|
||||
<mxCell id="0"/>
|
||||
<mxCell id="1" parent="0"/>
|
||||
<mxCell id="11" value="待部署Kafka-Broker的机器" style="rounded=0;whiteSpace=wrap;html=1;absoluteArcSize=1;arcSize=14;strokeWidth=1;labelPosition=center;verticalLabelPosition=bottom;align=center;verticalAlign=top;dashed=1;" vertex="1" parent="1">
|
||||
<mxGeometry x="380" y="240" width="320" height="240" as="geometry"/>
|
||||
</mxCell>
|
||||
<mxCell id="24" value="" style="rounded=0;whiteSpace=wrap;html=1;absoluteArcSize=1;arcSize=14;strokeWidth=1;labelPosition=center;verticalLabelPosition=bottom;align=center;verticalAlign=top;dashed=1;fillColor=#eeeeee;strokeColor=#36393d;" vertex="1" parent="1">
|
||||
<mxGeometry x="410" y="310" width="260" height="160" as="geometry"/>
|
||||
</mxCell>
|
||||
<mxCell id="6" style="edgeStyle=none;html=1;entryX=0;entryY=0.5;entryDx=0;entryDy=0;" edge="1" parent="1" source="2" target="3">
|
||||
<mxGeometry relative="1" as="geometry"/>
|
||||
</mxCell>
|
||||
<mxCell id="7" value="调用夜莺接口,<br>创建集群安装部署任务" style="edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];" vertex="1" connectable="0" parent="6">
|
||||
<mxGeometry x="-0.0875" y="1" relative="1" as="geometry">
|
||||
<mxPoint x="9" y="1" as="offset"/>
|
||||
</mxGeometry>
|
||||
</mxCell>
|
||||
<mxCell id="9" style="edgeStyle=none;html=1;" edge="1" parent="1" source="2" target="4">
|
||||
<mxGeometry relative="1" as="geometry"/>
|
||||
</mxCell>
|
||||
<mxCell id="10" value="通过版本管理,将Kafka的安装包,<br>server配置上传到s3中" style="edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];" vertex="1" connectable="0" parent="9">
|
||||
<mxGeometry x="0.0125" y="2" relative="1" as="geometry">
|
||||
<mxPoint as="offset"/>
|
||||
</mxGeometry>
|
||||
</mxCell>
|
||||
<mxCell id="2" value="LogiKM" style="rounded=0;whiteSpace=wrap;html=1;absoluteArcSize=1;arcSize=14;strokeWidth=1;fillColor=#dae8fc;strokeColor=#6c8ebf;" vertex="1" parent="1">
|
||||
<mxGeometry x="40" y="100" width="120" height="40" as="geometry"/>
|
||||
</mxCell>
|
||||
<mxCell id="12" style="edgeStyle=none;html=1;exitX=0.5;exitY=1;exitDx=0;exitDy=0;entryX=0.5;entryY=0;entryDx=0;entryDy=0;" edge="1" parent="1" source="3" target="5">
|
||||
<mxGeometry relative="1" as="geometry"/>
|
||||
</mxCell>
|
||||
<mxCell id="13" value="1、下发任务脚本(kcm_script.sh);<br>2、下发任务操作命令;" style="edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];" vertex="1" connectable="0" parent="12">
|
||||
<mxGeometry x="-0.0731" y="2" relative="1" as="geometry">
|
||||
<mxPoint x="-2" y="-16" as="offset"/>
|
||||
</mxGeometry>
|
||||
</mxCell>
|
||||
<mxCell id="3" value="夜莺——任务中心" style="rounded=0;whiteSpace=wrap;html=1;absoluteArcSize=1;arcSize=14;strokeWidth=1;fillColor=#cdeb8b;strokeColor=#36393d;" vertex="1" parent="1">
|
||||
<mxGeometry x="480" y="100" width="120" height="40" as="geometry"/>
|
||||
</mxCell>
|
||||
<mxCell id="4" value="S3" style="rounded=0;whiteSpace=wrap;html=1;absoluteArcSize=1;arcSize=14;strokeWidth=1;fillColor=#ffe6cc;strokeColor=#d79b00;" vertex="1" parent="1">
|
||||
<mxGeometry x="40" y="310" width="120" height="40" as="geometry"/>
|
||||
</mxCell>
|
||||
<mxCell id="5" value="夜莺——Agent(<font color="#ff3333">代理执行kcm_script.sh脚本</font>)" style="rounded=0;whiteSpace=wrap;html=1;absoluteArcSize=1;arcSize=14;strokeWidth=1;fillColor=#d5e8d4;strokeColor=#82b366;" vertex="1" parent="1">
|
||||
<mxGeometry x="400" y="260" width="280" height="40" as="geometry"/>
|
||||
</mxCell>
|
||||
<mxCell id="22" style="edgeStyle=orthogonalEdgeStyle;html=1;entryX=1;entryY=0.5;entryDx=0;entryDy=0;fontColor=#FF3333;exitX=0;exitY=0.5;exitDx=0;exitDy=0;" edge="1" parent="1" source="14" target="4">
|
||||
<mxGeometry relative="1" as="geometry"/>
|
||||
</mxCell>
|
||||
<mxCell id="25" value="下载安装包" style="edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];fontColor=#000000;" vertex="1" connectable="0" parent="22">
|
||||
<mxGeometry x="0.2226" y="-2" relative="1" as="geometry">
|
||||
<mxPoint x="27" y="2" as="offset"/>
|
||||
</mxGeometry>
|
||||
</mxCell>
|
||||
<mxCell id="14" value="执行kcm_script.sh脚本:下载安装包" style="rounded=0;whiteSpace=wrap;html=1;absoluteArcSize=1;arcSize=14;strokeWidth=1;fillColor=#eeeeee;strokeColor=#36393d;" vertex="1" parent="1">
|
||||
<mxGeometry x="425" y="320" width="235" height="20" as="geometry"/>
|
||||
</mxCell>
|
||||
<mxCell id="18" value="执行kcm_script.sh脚本:安装" style="rounded=0;whiteSpace=wrap;html=1;absoluteArcSize=1;arcSize=14;strokeWidth=1;fillColor=#eeeeee;strokeColor=#36393d;" vertex="1" parent="1">
|
||||
<mxGeometry x="425" y="350" width="235" height="20" as="geometry"/>
|
||||
</mxCell>
|
||||
<mxCell id="19" value="执行kcm_script.sh脚本:检查安装结果" style="rounded=0;whiteSpace=wrap;html=1;absoluteArcSize=1;arcSize=14;strokeWidth=1;fillColor=#eeeeee;strokeColor=#36393d;" vertex="1" parent="1">
|
||||
<mxGeometry x="425" y="380" width="235" height="20" as="geometry"/>
|
||||
</mxCell>
|
||||
<mxCell id="23" style="edgeStyle=orthogonalEdgeStyle;html=1;entryX=0.5;entryY=0;entryDx=0;entryDy=0;fontColor=#FF3333;exitX=1;exitY=0.5;exitDx=0;exitDy=0;" edge="1" parent="1" source="20" target="2">
|
||||
<mxGeometry relative="1" as="geometry">
|
||||
<Array as="points">
|
||||
<mxPoint x="770" y="420"/>
|
||||
<mxPoint x="770" y="40"/>
|
||||
<mxPoint x="100" y="40"/>
|
||||
</Array>
|
||||
</mxGeometry>
|
||||
</mxCell>
|
||||
<mxCell id="26" value="检查副本同步状态" style="edgeLabel;html=1;align=center;verticalAlign=middle;resizable=0;points=[];fontColor=#000000;" vertex="1" connectable="0" parent="23">
|
||||
<mxGeometry x="-0.3344" relative="1" as="geometry">
|
||||
<mxPoint as="offset"/>
|
||||
</mxGeometry>
|
||||
</mxCell>
|
||||
<mxCell id="20" value="执行kcm_script.sh脚本:检查副本同步" style="rounded=0;whiteSpace=wrap;html=1;absoluteArcSize=1;arcSize=14;strokeWidth=1;fillColor=#eeeeee;strokeColor=#36393d;" vertex="1" parent="1">
|
||||
<mxGeometry x="425" y="410" width="235" height="20" as="geometry"/>
|
||||
</mxCell>
|
||||
<mxCell id="21" value="执行kcm_script.sh脚本:结束" style="rounded=0;whiteSpace=wrap;html=1;absoluteArcSize=1;arcSize=14;strokeWidth=1;fillColor=#eeeeee;strokeColor=#36393d;" vertex="1" parent="1">
|
||||
<mxGeometry x="425" y="440" width="235" height="20" as="geometry"/>
|
||||
</mxCell>
|
||||
</root>
|
||||
</mxGraphModel>
|
||||
</diagram>
|
||||
</mxfile>
|
||||
@@ -1,169 +0,0 @@
|
||||
|
||||
---
|
||||
|
||||

|
||||
|
||||
**一站式`Apache Kafka`集群指标监控与运维管控平台**
|
||||
|
||||
---
|
||||
|
||||
# 动态配置管理
|
||||
|
||||
## 0、目录
|
||||
|
||||
- 1、Topic定时同步任务
|
||||
- 2、专家服务——Topic分区热点
|
||||
- 3、专家服务——Topic分区不足
|
||||
- 4、专家服务——Topic资源治理
|
||||
- 5、账单配置
|
||||
|
||||
|
||||
## 1、Topic定时同步任务
|
||||
|
||||
### 1.1、配置的用途
|
||||
`Logi-KafkaManager`在设计上,所有的资源都是挂在应用(app)下面。 如果接入的Kafka集群已经存在Topic了,那么会导致这些Topic不属于任何的应用,从而导致很多管理上的不便。
|
||||
|
||||
因此,需要有一个方式将这些无主的Topic挂到某个应用下面。
|
||||
|
||||
这里提供了一个配置,会定时自动将集群无主的Topic挂到某个应用下面下面。
|
||||
|
||||
### 1.2、相关实现
|
||||
|
||||
就是一个定时任务,该任务会定期做同步的工作。具体代码的位置在`com.xiaojukeji.kafka.manager.task.dispatch.op`包下面的`SyncTopic2DB`类。
|
||||
|
||||
### 1.3、配置说明
|
||||
|
||||
**步骤一:开启该功能**
|
||||
|
||||
在application.yml文件中,增加如下配置,已经有该配置的话,直接把false修改为true即可
|
||||
```yml
|
||||
# 任务相关的开关
|
||||
task:
|
||||
op:
|
||||
sync-topic-enabled: true # 无主的Topic定期同步到DB中
|
||||
```
|
||||
|
||||
**步骤二:配置管理中指定挂在那个应用下面**
|
||||
|
||||
配置的位置:
|
||||
|
||||

|
||||
|
||||
配置键:`SYNC_TOPIC_2_DB_CONFIG_KEY`
|
||||
|
||||
配置值(JSON数组):
|
||||
- clusterId:需要进行定时同步的集群ID
|
||||
- defaultAppId:该集群无主的Topic将挂在哪个应用下面
|
||||
- addAuthority:是否需要加上权限, 默认是false。因为考虑到这个挂载只是临时的,我们不希望用户使用这个App,同时后续可能移交给真正的所属的应用,因此默认是不加上权限。
|
||||
|
||||
**注意,这里的集群ID,或者是应用ID不存在的话,会导致配置不生效。该任务对已经在DB中的Topic不会进行修改**
|
||||
```json
|
||||
[
|
||||
{
|
||||
"clusterId": 1234567,
|
||||
"defaultAppId": "ANONYMOUS",
|
||||
"addAuthority": false
|
||||
},
|
||||
{
|
||||
"clusterId": 7654321,
|
||||
"defaultAppId": "ANONYMOUS",
|
||||
"addAuthority": false
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 2、专家服务——Topic分区热点
|
||||
|
||||
在`Region`所圈定的Broker范围内,某个Topic的Leader数在这些圈定的Broker上分布不均衡时,我们认为该Topic是存在热点的Topic。
|
||||
|
||||
备注:单纯的查看Leader数的分布,确实存在一定的局限性,这块欢迎贡献更多的热点定义于代码。
|
||||
|
||||
|
||||
Topic分区热点相关的动态配置(页面在运维管控->平台管理->配置管理):
|
||||
|
||||
配置Key:
|
||||
```
|
||||
REGION_HOT_TOPIC_CONFIG
|
||||
```
|
||||
|
||||
配置Value:
|
||||
```json
|
||||
{
|
||||
"maxDisPartitionNum": 2, # Region内Broker间的leader数差距超过2时,则认为是存在热点的Topic
|
||||
"minTopicBytesInUnitB": 1048576, # 流量低于该值的Topic不做统计
|
||||
"ignoreClusterIdList": [ # 忽略的集群
|
||||
50
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 3、专家服务——Topic分区不足
|
||||
|
||||
总流量除以分区数,超过指定值时,则我们认为存在Topic分区不足。
|
||||
|
||||
Topic分区不足相关的动态配置(页面在运维管控->平台管理->配置管理):
|
||||
|
||||
配置Key:
|
||||
```
|
||||
TOPIC_INSUFFICIENT_PARTITION_CONFIG
|
||||
```
|
||||
|
||||
配置Value:
|
||||
```json
|
||||
{
|
||||
"maxBytesInPerPartitionUnitB": 3145728, # 单分区流量超过该值, 则认为分区不去
|
||||
"minTopicBytesInUnitB": 1048576, # 流量低于该值的Topic不做统计
|
||||
"ignoreClusterIdList": [ # 忽略的集群
|
||||
50
|
||||
]
|
||||
}
|
||||
```
|
||||
## 4、专家服务——Topic资源治理
|
||||
|
||||
首先,我们认为在一定的时间长度内,Topic的分区offset没有任何变化的Topic,即没有数据写入的Topic,为过期的Topic。
|
||||
|
||||
Topic分区不足相关的动态配置(页面在运维管控->平台管理->配置管理):
|
||||
|
||||
配置Key:
|
||||
```
|
||||
EXPIRED_TOPIC_CONFIG
|
||||
```
|
||||
|
||||
配置Value:
|
||||
```json
|
||||
{
|
||||
"minExpiredDay": 30, #过期时间大于此值才显示,
|
||||
"filterRegex": ".*XXX\\s+", #忽略符合此正则规则的Topic
|
||||
"ignoreClusterIdList": [ # 忽略的集群
|
||||
50
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
## 5、账单配置
|
||||
|
||||
Logi-KafkaManager除了作为Kafka运维管控平台之外,实际上还会有一些资源定价相关的功能。
|
||||
|
||||
当前定价方式:当月Topic的maxAvgDay天的峰值的均值流量作为Topic的使用额度。使用的额度 * 单价 * 溢价(预留buffer) 就等于当月的费用。
|
||||
详细的计算逻辑见:com.xiaojukeji.kafka.manager.task.dispatch.biz.CalKafkaTopicBill; 和 com.xiaojukeji.kafka.manager.task.dispatch.biz.CalTopicStatistics;
|
||||
|
||||
这块在计算Topic的费用的配置如下所示:
|
||||
|
||||
配置Key:
|
||||
```
|
||||
KAFKA_TOPIC_BILL_CONFIG
|
||||
```
|
||||
|
||||
配置Value:
|
||||
|
||||
```json
|
||||
{
|
||||
"maxAvgDay": 10, # 使用额度的计算规则
|
||||
"quotaRatio": 1.5, # 溢价率
|
||||
"priseUnitMB": 100 # 单价,即单MB/s流量多少钱
|
||||
}
|
||||
```
|
||||
@@ -1,10 +0,0 @@
|
||||
|
||||
---
|
||||
|
||||

|
||||
|
||||
**一站式`Apache Kafka`集群指标监控与运维管控平台**
|
||||
|
||||
---
|
||||
|
||||
# Kafka-Gateway 配置说明
|
||||
@@ -1,42 +0,0 @@
|
||||
|
||||
---
|
||||
|
||||

|
||||
|
||||
**一站式`Apache Kafka`集群指标监控与运维管控平台**
|
||||
|
||||
---
|
||||
|
||||
# 监控系统集成——夜莺
|
||||
|
||||
- `Kafka-Manager`通过将 监控的数据 以及 监控的规则 都提交给夜莺,然后依赖夜莺的监控系统从而实现监控告警功能。
|
||||
|
||||
- 监控数据上报 & 告警规则的创建等能力已经具备。但类似查看告警历史,告警触发时的监控数据等正在集成中(暂时可以到夜莺系统进行查看),欢迎有兴趣的同学进行共建 或 贡献代码。
|
||||
|
||||
## 1、配置说明
|
||||
|
||||
```yml
|
||||
# 配置文件中关于监控部分的配置
|
||||
monitor:
|
||||
enabled: false
|
||||
n9e:
|
||||
nid: 2
|
||||
user-token: 123456
|
||||
# 夜莺 mon监控服务 地址
|
||||
mon:
|
||||
base-url: http://127.0.0.1:8006
|
||||
# 夜莺 transfer上传服务 地址
|
||||
sink:
|
||||
base-url: http://127.0.0.1:8008
|
||||
# 夜莺 rdb资源服务 地址
|
||||
rdb:
|
||||
base-url: http://127.0.0.1:80
|
||||
|
||||
# enabled: 表示是否开启监控告警的功能, true: 开启, false: 不开启
|
||||
# n9e.nid: 夜莺的节点ID
|
||||
# n9e.user-token: 用户的密钥,在夜莺的个人设置中
|
||||
# n9e.mon.base-url: 监控地址
|
||||
# n9e.sink.base-url: 数据上报地址
|
||||
# n9e.rdb.base-url: 用户资源中心地址
|
||||
```
|
||||
|
||||
@@ -1,54 +0,0 @@
|
||||
|
||||
---
|
||||
|
||||

|
||||
|
||||
**一站式`Apache Kafka`集群指标监控与运维管控平台**
|
||||
|
||||
---
|
||||
|
||||
# 监控系统集成
|
||||
|
||||
- 监控系统默认与 [夜莺] (https://github.com/didi/nightingale) 进行集成;
|
||||
- 对接自有的监控系统需要进行简单的二次开发,即实现部分监控告警模块的相关接口即可;
|
||||
- 集成会有两块内容,一个是指标数据上报的集成,还有一个是监控告警规则的集成;
|
||||
|
||||
## 1、指标数据上报集成
|
||||
|
||||
仅完成这一步的集成之后,即可将监控数据上报到监控系统中,此时已能够在自己的监控系统进行监控告警规则的配置了。
|
||||
|
||||
**步骤一:实现指标上报的接口**
|
||||
|
||||
- 按照自己内部监控系统的数据格式要求,将数据进行组装成符合自己内部监控系统要求的数据进行上报,具体的可以参考夜莺集成的实现代码。
|
||||
- 至于会上报哪些指标,可以查看有哪些地方调用了该接口。
|
||||
|
||||

|
||||
|
||||
**步骤二:相关配置修改**
|
||||
|
||||

|
||||
|
||||
**步骤三:开启上报任务**
|
||||
|
||||

|
||||
|
||||
|
||||
## 2、监控告警规则集成
|
||||
|
||||
完成**1、指标数据上报集成**之后,即可在自己的监控系统进行监控告警规则的配置了。完成该步骤的集成之后,可以在`Logi-KafkaManager`中进行监控告警规则的增删改查等等。
|
||||
|
||||
大体上和**1、指标数据上报集成**一致,
|
||||
|
||||
**步骤一:实现相关接口**
|
||||
|
||||

|
||||
|
||||
实现完成步骤一之后,接下来的步骤和**1、指标数据上报集成**中的步骤二、步骤三一致,都需要进行相关配置的修改即可。
|
||||
|
||||
|
||||
## 3、总结
|
||||
|
||||
简单介绍了一下监控告警的集成,嫌麻烦的同学可以仅做 **1、指标数据上报集成** 这一节的内容即可满足一定场景下的需求。
|
||||
|
||||
|
||||
**集成过程中,有任何觉得文档没有说清楚的地方或者建议,欢迎入群交流,也欢迎贡献代码,觉得好也辛苦给个star。**
|
||||
@@ -1,41 +0,0 @@
|
||||
|
||||
---
|
||||
|
||||

|
||||
|
||||
**一站式`Apache Kafka`集群指标监控与运维管控平台**
|
||||
|
||||
---
|
||||
|
||||
# 使用`MySQL 8`
|
||||
|
||||
感谢 [herry-hu](https://github.com/herry-hu) 提供的方案。
|
||||
|
||||
|
||||
当前因为无法同时兼容`MySQL 8`与`MySQL 5.7`,因此代码中默认的版本还是`MySQL 5.7`。
|
||||
|
||||
|
||||
当前如需使用`MySQL 8`,则需按照下述流程进行简单修改代码。
|
||||
|
||||
|
||||
- Step1. 修改application.yml中的MySQL驱动类
|
||||
```shell
|
||||
|
||||
# 将driver-class-name后面的驱动类修改为:
|
||||
# driver-class-name: com.mysql.jdbc.Driver
|
||||
driver-class-name: com.mysql.cj.jdbc.Driver
|
||||
```
|
||||
|
||||
|
||||
- Step2. 修改MySQL依赖包
|
||||
```shell
|
||||
# 将根目录下面的pom.xml文件依赖的`MySQL`依赖包版本调整为
|
||||
|
||||
<dependency>
|
||||
<groupId>mysql</groupId>
|
||||
<artifactId>mysql-connector-java</artifactId>
|
||||
# <version>5.1.41</version>
|
||||
<version>8.0.20</version>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
98
docs/dev_guide/健康巡检.md
Normal file
@@ -0,0 +1,98 @@
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
# 健康巡检
|
||||
|
||||
## 1、前言
|
||||
|
||||
|
||||
|
||||
---
|
||||
|
||||
## 2、已有巡检
|
||||
|
||||
### 2.1、Cluster健康巡检(1个)
|
||||
|
||||
#### 2.1.1、集群Controller数错误
|
||||
|
||||
**说明**
|
||||
|
||||
- 集群Controller数不等于1,表明集群集群无Controller或者出现了多个Controller,该
|
||||
|
||||
|
||||
**配置**
|
||||
|
||||
---
|
||||
|
||||
### 2.2、Broker健康巡检(2个)
|
||||
|
||||
#### 2.2.1、Broker-RequestQueueSize被打满
|
||||
|
||||
**说明**
|
||||
|
||||
- Broker的RequestQueueSize,被打满;
|
||||
|
||||
|
||||
**配置**
|
||||
|
||||
---
|
||||
|
||||
|
||||
#### 2.2.2、Broker-NetworkProcessorAvgIdle过低
|
||||
|
||||
**说明**
|
||||
|
||||
- Broker的NetworkProcessorAvgIdle指标,当前过低;
|
||||
|
||||
|
||||
**配置**
|
||||
|
||||
---
|
||||
|
||||
### 2.3、Topic健康巡检(2个)
|
||||
|
||||
|
||||
#### 2.3.1、Topic 无Leader数
|
||||
|
||||
**说明**
|
||||
|
||||
- 当前Topic的无Leader分区数超过一定值;
|
||||
|
||||
|
||||
**配置**
|
||||
|
||||
|
||||
#### 2.3.1、Topic 长期处于未同步状态
|
||||
|
||||
**说明**
|
||||
|
||||
- 指定的一段时间内,Topic一直处于未同步的状态;
|
||||
|
||||
|
||||
**配置**
|
||||
|
||||
---
|
||||
|
||||
### 2.4、Group健康巡检(1个)
|
||||
|
||||
|
||||
#### 2.4.1、Group Re-Balance太频繁
|
||||
|
||||
**说明**
|
||||
|
||||
- 指定的一段时间内,Group Re-Balance的次数是否过多;
|
||||
|
||||
|
||||
**配置**
|
||||
|
||||
|
||||
|
||||
---
|
||||
|
||||
## 3、自定义增强
|
||||
|
||||
如何增加想要的巡检?
|
||||
|
||||
43
docs/dev_guide/免登录调用接口.md
Normal file
@@ -0,0 +1,43 @@
|
||||
|
||||

|
||||
|
||||
## 登录绕过
|
||||
|
||||
### 背景
|
||||
|
||||
现在除了开放出来的第三方接口,其他接口都需要走登录认证。
|
||||
|
||||
但是第三方接口不多,开放出来的能力有限,但是登录的接口又需要登录,非常的麻烦。
|
||||
|
||||
因此,新增了一个登录绕过的功能,为一些紧急临时的需求,提供一个调用不需要登录的能力。
|
||||
|
||||
### 使用方式
|
||||
|
||||
步骤一:接口调用时,在header中,增加如下信息:
|
||||
```shell
|
||||
# 表示开启登录绕过
|
||||
Trick-Login-Switch : on
|
||||
|
||||
# 登录绕过的用户, 这里可以是admin, 或者是其他的, 但是必须在运维管控->平台管理->用户管理中设置了该用户。
|
||||
Trick-Login-User : admin
|
||||
```
|
||||
|
||||
|
||||
|
||||
步骤二:在运维管控->平台管理->平台配置上,设置允许了该用户以绕过的方式登录
|
||||
```shell
|
||||
# 设置的key,必须是这个
|
||||
SECURITY.TRICK_USERS
|
||||
|
||||
# 设置的value,是json数组的格式,例如
|
||||
[ "admin", "logi"]
|
||||
```
|
||||
|
||||
|
||||
|
||||
步骤三:解释说明
|
||||
|
||||
设置完成上面两步之后,就可以直接调用需要登录的接口了。
|
||||
|
||||
但是还有一点需要注意,绕过的用户仅能调用他有权限的接口,比如一个普通用户,那么他就只能调用普通的接口,不能去调用运维人员的接口。
|
||||
|
||||
@@ -1,39 +0,0 @@
|
||||
---
|
||||
|
||||

|
||||
|
||||
**一站式`Apache Kafka`集群指标监控与运维管控平台**
|
||||
|
||||
---
|
||||
|
||||
|
||||
| 定时任务名称或方法名 | 所在类 | 详细说明 | cron | cron说明 | 线程数量 |
|
||||
| -------------------------------------- | -------------------------------------- | ------------------------------------------ | --------------- | --------------------------------------- | -------- |
|
||||
| calKafkaBill | CalKafkaTopicBill | 计算Kafka使用账单 | 0 0 1 * * ? | 每天凌晨1点执行一次 | 1 |
|
||||
| calRegionCapacity | CalRegionCapacity | 计算Region容量 | 0 0 0/12 * * ? | 每隔12小时执行一次,在0分钟0秒时触发 | 1 |
|
||||
| calTopicStatistics | CalTopicStatistics | 定时计算Topic统计数据 | 0 0 0/4 * * ? | 每隔4小时执行一次,在0分钟0秒时触发 | 5 |
|
||||
| flushBrokerTable | FlushBrokerTable | 定时刷新BrokerTable数据 | 0 0 0/1 * * ? | 每隔1小时执行一次,在0分钟0秒时触发 | 1 |
|
||||
| flushExpiredTopic | FlushExpiredTopic | 定期更新过期Topic | 0 0 0/5 * * ? | 每隔5小时执行一次,在0分钟0秒时触发 | 1 |
|
||||
| syncClusterTaskState | SyncClusterTaskState | 同步更新集群任务状态 | 0 0/1 * * * ? | 每隔1分钟执行一次,在每分钟的0秒时触发 | 1 |
|
||||
| newCollectAndPublishCGData | CollectAndPublishCGData | 收集并发布消费者指标数据 | 30 0/1 * * * ? | 每隔1分钟执行一次,在每分钟的30秒时触发 | 10 |
|
||||
| collectAndPublishCommunityTopicMetrics | CollectAndPublishCommunityTopicMetrics | Topic社区指标收集 | 31 0/1 * * * ? | 每隔1分钟执行一次,在每分钟的30秒时触发 | 5 |
|
||||
| collectAndPublishTopicThrottledMetrics | CollectAndPublishTopicThrottledMetrics | 收集和发布Topic限流信息 | 11 0/1 * * * ? | 每隔1分钟执行一次,在每分钟的11秒时触发 | 5 |
|
||||
| deleteMetrics | DeleteMetrics | 定期删除Metrics信息 | 0 0/2 * * * ? | 每隔2分钟执行一次,在每分钟的0秒时触发 | 1 |
|
||||
| storeDiDiAppTopicMetrics | StoreDiDiAppTopicMetrics | JMX中获取appId维度的流量信息存DB | 41 0/1 * * * ? | 每隔1分钟执行一次,在每分钟的41秒时触发 | 5 |
|
||||
| storeDiDiTopicRequestTimeMetrics | StoreDiDiTopicRequestTimeMetrics | JMX中获取的TopicRequestTimeMetrics信息存DB | 51 0/1 * * * ? | 每隔1分钟执行一次,在每分钟的51秒时触发 | 5 |
|
||||
| autoHandleTopicOrder | AutoHandleTopicOrder | 定时自动处理Topic相关工单 | 0 0/1 * * * ? | 每隔1分钟执行一次,在每分钟的0秒时触发 | 1 |
|
||||
| automatedHandleOrder | AutomatedHandleOrder | 工单自动化审批 | 0 0/1 * * * ? | 每隔1分钟执行一次,在每分钟的0秒时触发 | 1 |
|
||||
| flushReassignment | FlushReassignment | 定时处理分区迁移任务 | 0 0/1 * * * ? | 每隔1分钟执行一次,在每分钟的0秒时触发 | 1 |
|
||||
| syncTopic2DB | SyncTopic2DB | 定期将未落盘的Topic刷新到DB中 | 0 0/2 * * * ? | 每隔2分钟执行一次,在每分钟的0秒时触发 | 1 |
|
||||
| sinkCommunityTopicMetrics2Monitor | SinkCommunityTopicMetrics2Monitor | 定时上报Topic监控指标 | 1 0/1 * * * ? | 每隔1分钟执行一次,在每分钟的1秒时触发 | 5 |
|
||||
| flush方法 | LogicalClusterMetadataManager | 定时刷新逻辑集群元数据到缓存中 | 0/30 * * * * ? | 每隔30秒执行一次 | 1 |
|
||||
| flush方法 | AccountServiceImpl | 定时刷新account信息到缓存中 | 0/5 * * * * ? | 每隔5秒执行一次 | 1 |
|
||||
| ipFlush方法 | HeartBeat | 定时获取管控平台所在机器IP等信息到DB | 0/10 * * * * ? | 每隔10秒执行一次 | 1 |
|
||||
| flushTopicMetrics方法 | FlushTopicMetrics | 定时刷新topic指标到缓存中 | 5 0/1 * * * ? | 每隔1分钟执行一次,在每分钟的5秒时触发 | 1 |
|
||||
| schedule方法 | FlushBKConsumerGroupMetadata | 定时刷新broker上消费组信息到缓存中 | 15 0/1 * * * ? | 每隔1分钟执行一次,在每分钟的15秒时触发 | 1 |
|
||||
| flush方法 | FlushClusterMetadata | 定时刷新物理集群元信息到缓存中 | 0/30 * * * * ? | 每隔30秒执行一次 | 1 |
|
||||
| flush方法 | FlushTopicProperties | 定时刷新物理集群配置到缓存中 | 25 0/1 * * * ? | 每隔1分钟执行一次,在每分钟的25秒时触发 | 1 |
|
||||
| schedule方法 | FlushZKConsumerGroupMetadata | 定时刷新zk上的消费组信息到缓存中 | 35 0/1 * * * ? | 每隔1分钟执行一次,在每分钟的35秒时触发 | 1 |
|
||||
|
||||
|
||||
|
||||
42
docs/dev_guide/多版本兼容方案.md
Normal file
@@ -0,0 +1,42 @@
|
||||
## 3.2、Kafka 多版本兼容方案
|
||||
|
||||
  当前 KnowStreaming 支持纳管多个版本的 kafka 集群,由于不同版本的 kafka 在指标采集、接口查询、行为操作上有些不一致,因此 KnowStreaming 需要一套机制来解决多 kafka 版本的纳管兼容性问题。
|
||||
|
||||
### 3.2.1、整体思路
|
||||
|
||||
  由于需要纳管多个 kafka 版本,而且未来还可能会纳管非 kafka 官方的版本,kafka 的版本号会存在着多种情况,所以首先要明确一个核心思想:KnowStreaming 提供尽可能多的纳管能力,但是不提供无限的纳管能力,每一个版本的 KnowStreaming 只纳管其自身声明的 kafka 版本,后续随着 KnowStreaming 自身版本的迭代,会逐步支持更多 kafka 版本的纳管接入。
|
||||
|
||||
### 3.2.2、构建版本兼容列表
|
||||
|
||||
  每一个版本的 KnowStreaming 都声明一个自身支持纳管的 kafka 版本列表,并且对 kafka 的版本号进行归一化处理,后续所有 KnowStreaming 对不同 kafka 集群的操作都和这个集群对应的版本号严格相关。
|
||||
|
||||
  KnowStreaming 对外提供自身所支持的 kafka 版本兼容列表,用以声明自身支持的版本范围。
|
||||
|
||||
  对于在集群接入过程中,如果希望接入当前 KnowStreaming 不支持的 kafka 版本的集群,KnowStreaming 建议在于的过程中选择相近的版本号接入。
|
||||
|
||||
### 3.2.3、构建版本兼容性字典
|
||||
|
||||
  在构建了 KnowStreaming 支持的 kafka 版本列表的基础上,KnowStreaming 在实现过程中,还会声明自身支持的所有兼容性,构建兼容性字典。
|
||||
|
||||
  当前 KnowStreaming 支持的 kafka 版本兼容性字典包括三个维度:
|
||||
|
||||
- 指标采集:同一个指标在不同 kafka 版本下可能获取的方式不一样,不同版本的 kafka 可能会有不同的指标,因此对于指标采集的处理需要构建兼容性字典。
|
||||
- kafka api:同一个 kafka 的操作处理的方式在不同 kafka 版本下可能存在不一致,如:topic 的创建,因此 KnowStreaming 针对不同 kafka-api 的处理需要构建兼容性字典。
|
||||
- 平台操作:KnowStreaming 在接入不同版本的 kafka 集群的时候,在平台页面上会根据不同的 kafka 版。
|
||||
|
||||
兼容性字典的核心设计字段如下:
|
||||
|
||||
| 兼容性维度 | 兼容项名称 | 最小 Kafka 版本号(归一化) | 最大 Kafka 版本号(归一化) | 处理器 |
|
||||
| ---------- | ---------- | --------------------------- | --------------------------- | ------ |
|
||||
|
||||
KS-KM 根据其需要纳管的 kafka 版本,按照上述三个维度构建了完善了兼容性字典。
|
||||
|
||||
### 3.2.4、兼容性问题
|
||||
|
||||
  KS-KM 的每个版本针对需要纳管的 kafka 版本列表,事先分析各个版本的差异性和产品需求,同时 KS-KM 构建了一套专门处理兼容性的服务,来进行兼容性的注册、字典构建、处理器分发等操作,其中版本兼容性处理器是来具体处理不同 kafka 版本差异性的地方。
|
||||
|
||||

|
||||
|
||||
  如上图所示,KS-KM 的 topic 服务在面对不同 kafka 版本时,其 topic 的创建、删除、扩容由于 kafka 版本自身的差异,导致 KnowStreaming 的处理也不一样,所以需要根据不同的 kafka 版本来实现不同的兼容性处理器,同时向 KnowStreaming 的兼容服务进行兼容性的注册,构建兼容性字典,后续在 KnowStreaming 的运行过程中,针对不同的 kafka 版本即可分发到不同的处理器中执行。
|
||||
|
||||
  后续随着 KnowStreaming 产品的发展,如果有新的兼容性的地方需要增加,只需要实现新版本的处理器,增加注册项即可。
|
||||
@@ -1,89 +0,0 @@
|
||||
|
||||
---
|
||||
|
||||

|
||||
|
||||
**一站式`Apache Kafka`集群指标监控与运维管控平台**
|
||||
|
||||
---
|
||||
|
||||
# 如何使用集群安装部署功能?
|
||||
|
||||
[TOC]
|
||||
|
||||
## 1、实现原理
|
||||
|
||||

|
||||
|
||||
- LogiKM上传安装包到S3服务;
|
||||
- LogiKM调用夜莺-Job服务接口,创建执行[kcm_script.sh](https://github.com/didi/LogiKM/blob/master/kafka-manager-extends/kafka-manager-kcm/src/main/resources/kcm_script.sh)脚本的任务,kcm_script.sh脚本是安装部署Kafka集群的脚本;
|
||||
- 夜莺将任务脚本下发到具体的机器上,通过夜莺Agent执行该脚本;
|
||||
- kcm_script.sh脚本会进行Kafka-Broker的安装部署;
|
||||
|
||||
|
||||
---
|
||||
|
||||
## 2、使用方式
|
||||
|
||||
### 2.1、第一步:修改配置
|
||||
|
||||
**配置application.yml文件**
|
||||
```yaml
|
||||
#
|
||||
kcm:
|
||||
enabled: false # 是否开启,将其修改为true
|
||||
s3: # s3 存储服务
|
||||
endpoint: s3.didiyunapi.com
|
||||
access-key: 1234567890
|
||||
secret-key: 0987654321
|
||||
bucket: logi-kafka
|
||||
n9e: # 夜莺
|
||||
base-url: http://127.0.0.1:8004 # 夜莺job服务地址
|
||||
user-token: 12345678 # 用户的token
|
||||
timeout: 300 # 单台操作的超时时间
|
||||
account: root # 操作时使用的账号
|
||||
script-file: kcm_script.sh # 脚本,已内置好,在源码的kcm模块内,此处配置无需修改
|
||||
logikm-url: http://127.0.0.1:8080 # logikm部署地址,部署时kcm_script.sh会调用logikm检查部署中的一些状态,这里只需要填写 http://IP:PORT 就可以了
|
||||
|
||||
|
||||
account:
|
||||
jump-login:
|
||||
gateway-api: false # 网关接口
|
||||
third-part-api: false # 第三方接口,将其修改为true,即允许未登录情况下调用开放的第三方接口
|
||||
```
|
||||
|
||||
### 2.2、第二步:检查服务
|
||||
|
||||
**检查s3服务**
|
||||
- 测试 "运维管控-》集群运维-》版本管理" 页面的上传,查看等功能是否都正常。如果存在不正常,则需要查看s3的配置是否正确;
|
||||
- 如果都没有问题,则上传Kafka的以.tgz结尾的安装包以及server.properties文件;
|
||||
|
||||
**检查夜莺Job服务**
|
||||
- 创建一个job任务,机器选择需要安装Kafka集群的机器,然后执行的命令是echo "Hello LogiKM",看能否被成功执行。如果不行,则需要检查夜莺的安装;
|
||||
- 如果没有问题则表示夜莺和所需部署的机器之间的交互是没有问题的;
|
||||
|
||||
### 2.3、第三步:接入集群
|
||||
|
||||
在LogiKM的 “运维管控-》集群列表” 中接入需要安装部署的集群,**PS:此时是允许接入一个没有任何Broker的空的Kafka集群**,其中对的bootstrapServers配置搭建完成后的Kafka集群地址就可以了,而ZK地址必须和集群的server.properties中的ZK地址保持一致;
|
||||
|
||||
### 2.4、第四步:部署集群
|
||||
|
||||
- 打开LogiKM的 “运维管控-》集群运维-》集群任务” 页面,点击 “新建集群任务” 按钮;
|
||||
- 选择集群、任务类型、包版本、server配置及填写主机列表,然后点击确认,即可在夜莺的Job服务中心中创建一个任务出来。**PS:如果创建失败,可以看一下日志我为什么创建失败**;
|
||||
- 随后可以点击详情及状态对任务进行操作;
|
||||
|
||||
### 2.5、可能问题
|
||||
|
||||
#### 2.5.1、问题一:任务执行超时、失败等
|
||||
|
||||
进入夜莺Job服务中心,查看对应的任务的相关日志;
|
||||
|
||||
- 提示安装包下载失败,则需要查看对应的s3服务是否可以直接wget下载安装包,如果不可以则需要对kcm_script.sh脚本进行修改;
|
||||
- 提示调用LogiKM失败,则可以使用postman手动测试一下kcm_script.sh脚本调用LogiKM的那个接口是否有问题,如果存在问题则进行相应的修改;PS:具体接口见kcm_script.sh脚本
|
||||
|
||||
|
||||
## 3、备注说明
|
||||
|
||||
- 集群安装部署,仅安装部署Kafka-Broker,不安装Kafka的ZK服务;
|
||||
- 安装部署中,有任何定制化的需求,例如修改安装的目录等,可以通过修改kcm_script.sh脚本实现;
|
||||
- kcm_script.sh脚本位置:[kcm_script.sh](https://github.com/didi/LogiKM/blob/master/kafka-manager-extends/kafka-manager-kcm/src/main/resources/kcm_script.sh);
|
||||
@@ -1,53 +0,0 @@
|
||||
|
||||
---
|
||||
|
||||

|
||||
|
||||
**一站式`Apache Kafka`集群指标监控与运维管控平台**
|
||||
|
||||
---
|
||||
|
||||
# 如何增加上报监控系统指标?
|
||||
|
||||
## 0、前言
|
||||
|
||||
LogiKM是 **一站式`Apache Kafka`集群指标监控与运维管控平台** ,当前会将消费Lag,Topic流量等指标上报到监控系统中,从而方便用户在监控系统中对这些指标配置监控告警规则,进而达到监控自身客户端是否正常的目的。
|
||||
|
||||
那么,如果我们想增加一个新的监控指标,应该如何做呢,比如我们想监控Broker的流量,监控Broker的存活信息,监控集群Controller个数等等。
|
||||
|
||||
在具体介绍之前,我们大家都知道,Kafka监控相关的信息,基本都存储于Broker、Jmx以及ZK中。当前LogiKM也已经具备从这三个地方获取数据的基本能力,因此基于LogiKM我们再获取其他指标,总体上还是非常方便的。
|
||||
|
||||
这里我们就以已经获取到的Topic流量信息为例,看LogiKM如何实现Topic指标的获取并上报的。
|
||||
|
||||
---
|
||||
|
||||
## 1、确定指标位置
|
||||
|
||||
基于对Kafka的了解,我们知道Topic流量信息这个指标是存储于Jmx中的,因此我们需要从Jmx中获取。大家如果对于自己所需要获取的指标存储在何处不太清楚的,可以加入我们维护的Kafka中文社区(README中有二维码)中今天沟通交流。
|
||||
|
||||
---
|
||||
|
||||
## 2、指标获取
|
||||
|
||||
Topic流量指标的获取详细见图中说明。
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
## 3、指标上报
|
||||
|
||||
上一步我们已经采集到Topic流量指标了,下一步就是将该指标上报到监控系统,这块只需要按照监控系统要求的格式,将数据上报即可。
|
||||
|
||||
LogiKM中有一个monitor模块,具体的如下图所示:
|
||||
|
||||

|
||||
|
||||
|
||||
## 4、补充说明
|
||||
|
||||
监控系统对接的相关内容见:
|
||||
|
||||
[监控系统集成](./monitor_system_integrate_with_self.md)
|
||||
|
||||
[监控系统集成例子——集成夜莺](./monitor_system_integrate_with_n9e.md)
|
||||
152
docs/dev_guide/指标说明.md
Normal file
@@ -0,0 +1,152 @@
|
||||
## 2.3、指标说明
|
||||
|
||||
  当前 KnowStreaming 支持针对 kafka 集群的多维度指标的采集和展示,同时也支持多个 kafka 版本的指标进行兼容,以下是 KnowStreaming 支持的指标说明。
|
||||
|
||||
  现在对当前 KnowStreaming 支持的指标从指标名称、指标单位、指标说明、kafka 版本四个维度进行说明。
|
||||
|
||||
### 2.3.1、Cluster 指标
|
||||
|
||||
| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
|
||||
| ------------------------- | -------- | ------------------------------------ | ---------------- | --------------- |
|
||||
| HealthScore | 分 | 集群总体的健康分 | 全部版本 | 开源版 |
|
||||
| HealthCheckPassed | 个 | 集群总体健康检查通过数 | 全部版本 | 开源版 |
|
||||
| HealthCheckTotal | 个 | 集群总体健康检查总数 | 全部版本 | 开源版 |
|
||||
| HealthScore_Topics | 分 | 集群 Topics 的健康分 | 全部版本 | 开源版 |
|
||||
| HealthCheckPassed_Topics | 个 | 集群 Topics 健康检查通过数 | 全部版本 | 开源版 |
|
||||
| HealthCheckTotal_Topics | 个 | 集群 Topics 健康检查总数 | 全部版本 | 开源版 |
|
||||
| HealthScore_Brokers | 分 | 集群 Brokers 的健康分 | 全部版本 | 开源版 |
|
||||
| HealthCheckPassed_Brokers | 个 | 集群 Brokers 健康检查通过数 | 全部版本 | 开源版 |
|
||||
| HealthCheckTotal_Brokers | 个 | 集群 Brokers 健康检查总数 | 全部版本 | 开源版 |
|
||||
| HealthScore_Groups | 分 | 集群 Groups 的健康分 | 全部版本 | 开源版 |
|
||||
| HealthCheckPassed_Groups | 个 | 集群 Groups 健康检查总数 | 全部版本 | 开源版 |
|
||||
| HealthCheckTotal_Groups | 个 | 集群 Groups 健康检查总数 | 全部版本 | 开源版 |
|
||||
| HealthScore_Cluster | 分 | 集群自身的健康分 | 全部版本 | 开源版 |
|
||||
| HealthCheckPassed_Cluster | 个 | 集群自身健康检查通过数 | 全部版本 | 开源版 |
|
||||
| HealthCheckTotal_Cluster | 个 | 集群自身健康检查总数 | 全部版本 | 开源版 |
|
||||
| TotalRequestQueueSize | 个 | 集群中总的请求队列数 | 全部版本 | 开源版 |
|
||||
| TotalResponseQueueSize | 个 | 集群中总的响应队列数 | 全部版本 | 开源版 |
|
||||
| EventQueueSize | 个 | 集群中 Controller 的 EventQueue 大小 | 2.0.0 及以上版本 | 开源版 |
|
||||
| ActiveControllerCount | 个 | 集群中存活的 Controller 数 | 全部版本 | 开源版 |
|
||||
| TotalProduceRequests | 个 | 集群中的 Produce 每秒请求数 | 全部版本 | 开源版 |
|
||||
| TotalLogSize | byte | 集群总的已使用的磁盘大小 | 全部版本 | 开源版 |
|
||||
| ConnectionsCount | 个 | 集群的连接(Connections)个数 | 全部版本 | 开源版 |
|
||||
| Zookeepers | 个 | 集群中存活的 zk 节点个数 | 全部版本 | 开源版 |
|
||||
| ZookeepersAvailable | 是/否 | ZK 地址是否合法 | 全部版本 | 开源版 |
|
||||
| Brokers | 个 | 集群的 broker 的总数 | 全部版本 | 开源版 |
|
||||
| BrokersAlive | 个 | 集群的 broker 的存活数 | 全部版本 | 开源版 |
|
||||
| BrokersNotAlive | 个 | 集群的 broker 的未存活数 | 全部版本 | 开源版 |
|
||||
| Replicas | 个 | 集群中 Replica 的总数 | 全部版本 | 开源版 |
|
||||
| Topics | 个 | 集群中 Topic 的总数 | 全部版本 | 开源版 |
|
||||
| Partitions | 个 | 集群的 Partitions 总数 | 全部版本 | 开源版 |
|
||||
| PartitionNoLeader | 个 | 集群中的 PartitionNoLeader 总数 | 全部版本 | 开源版 |
|
||||
| PartitionMinISR_S | 个 | 集群中的小于 PartitionMinISR 总数 | 全部版本 | 开源版 |
|
||||
| PartitionMinISR_E | 个 | 集群中的等于 PartitionMinISR 总数 | 全部版本 | 开源版 |
|
||||
| PartitionURP | 个 | 集群中的未同步的 Partition 总数 | 全部版本 | 开源版 |
|
||||
| MessagesIn | 条/s | 集群每条消息写入条数 | 全部版本 | 开源版 |
|
||||
| Messages | 条 | 集群总的消息条数 | 全部版本 | 开源版 |
|
||||
| LeaderMessages | 条 | 集群中 leader 总的消息条数 | 全部版本 | 开源版 |
|
||||
| BytesIn | byte/s | 集群的每秒写入字节数 | 全部版本 | 开源版 |
|
||||
| BytesIn_min_5 | byte/s | 集群的每秒写入字节数,5 分钟均值 | 全部版本 | 开源版 |
|
||||
| BytesIn_min_15 | byte/s | 集群的每秒写入字节数,15 分钟均值 | 全部版本 | 开源版 |
|
||||
| BytesOut | byte/s | 集群的每秒流出字节数 | 全部版本 | 开源版 |
|
||||
| BytesOut_min_5 | byte/s | 集群的每秒流出字节数,5 分钟均值 | 全部版本 | 开源版 |
|
||||
| BytesOut_min_15 | byte/s | 集群的每秒流出字节数,15 分钟均值 | 全部版本 | 开源版 |
|
||||
| Groups | 个 | 集群中 Group 的总数 | 全部版本 | 开源版 |
|
||||
| GroupActives | 个 | 集群中 ActiveGroup 的总数 | 全部版本 | 开源版 |
|
||||
| GroupEmptys | 个 | 集群中 EmptyGroup 的总数 | 全部版本 | 开源版 |
|
||||
| GroupRebalances | 个 | 集群中 RebalanceGroup 的总数 | 全部版本 | 开源版 |
|
||||
| GroupDeads | 个 | 集群中 DeadGroup 的总数 | 全部版本 | 开源版 |
|
||||
| Alive | 是/否 | 集群是否存活,1:存活;0:没有存活 | 全部版本 | 开源版 |
|
||||
| AclEnable | 是/否 | 集群是否开启 Acl,1:是;0:否 | 全部版本 | 开源版 |
|
||||
| Acls | 个 | ACL 数 | 全部版本 | 开源版 |
|
||||
| AclUsers | 个 | ACL-KafkaUser 数 | 全部版本 | 开源版 |
|
||||
| AclTopics | 个 | ACL-Topic 数 | 全部版本 | 开源版 |
|
||||
| AclGroups | 个 | ACL-Group 数 | 全部版本 | 开源版 |
|
||||
| Jobs | 个 | 集群任务总数 | 全部版本 | 开源版 |
|
||||
| JobsRunning | 个 | 集群 running 任务总数 | 全部版本 | 开源版 |
|
||||
| JobsWaiting | 个 | 集群 waiting 任务总数 | 全部版本 | 开源版 |
|
||||
| JobsSuccess | 个 | 集群 success 任务总数 | 全部版本 | 开源版 |
|
||||
| JobsFailed | 个 | 集群 failed 任务总数 | 全部版本 | 开源版 |
|
||||
| LoadReBalanceEnable | 是/否 | 是否开启均衡, 1:是;0:否 | 全部版本 | 企业版 |
|
||||
| LoadReBalanceCpu | 是/否 | CPU 是否均衡, 1:是;0:否 | 全部版本 | 企业版 |
|
||||
| LoadReBalanceNwIn | 是/否 | BytesIn 是否均衡, 1:是;0:否 | 全部版本 | 企业版 |
|
||||
| LoadReBalanceNwOut | 是/否 | BytesOut 是否均衡, 1:是;0:否 | 全部版本 | 企业版 |
|
||||
| LoadReBalanceDisk | 是/否 | Disk 是否均衡, 1:是;0:否 | 全部版本 | 企业版 |
|
||||
|
||||
### 2.3.2、Broker 指标
|
||||
|
||||
| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
|
||||
| ----------------------- | -------- | ------------------------------------- | ---------- | --------------- |
|
||||
| HealthScore | 分 | Broker 健康分 | 全部版本 | 开源版 |
|
||||
| HealthCheckPassed | 个 | Broker 健康检查通过数 | 全部版本 | 开源版 |
|
||||
| HealthCheckTotal | 个 | Broker 健康检查总数 | 全部版本 | 开源版 |
|
||||
| TotalRequestQueueSize | 个 | Broker 的请求队列大小 | 全部版本 | 开源版 |
|
||||
| TotalResponseQueueSize | 个 | Broker 的应答队列大小 | 全部版本 | 开源版 |
|
||||
| ReplicationBytesIn | byte/s | Broker 的副本流入流量 | 全部版本 | 开源版 |
|
||||
| ReplicationBytesOut | byte/s | Broker 的副本流出流量 | 全部版本 | 开源版 |
|
||||
| MessagesIn | 条/s | Broker 的每秒消息流入条数 | 全部版本 | 开源版 |
|
||||
| TotalProduceRequests | 个/s | Broker 上 Produce 的每秒请求数 | 全部版本 | 开源版 |
|
||||
| NetworkProcessorAvgIdle | % | Broker 的网络处理器的空闲百分比 | 全部版本 | 开源版 |
|
||||
| RequestHandlerAvgIdle | % | Broker 上请求处理器的空闲百分比 | 全部版本 | 开源版 |
|
||||
| PartitionURP | 个 | Broker 上的未同步的副本的个数 | 全部版本 | 开源版 |
|
||||
| ConnectionsCount | 个 | Broker 上网络链接的个数 | 全部版本 | 开源版 |
|
||||
| BytesIn | byte/s | Broker 的每秒数据写入量 | 全部版本 | 开源版 |
|
||||
| BytesIn_min_5 | byte/s | Broker 的每秒数据写入量,5 分钟均值 | 全部版本 | 开源版 |
|
||||
| BytesIn_min_15 | byte/s | Broker 的每秒数据写入量,15 分钟均值 | 全部版本 | 开源版 |
|
||||
| BytesOut | byte/s | Broker 的每秒数据流出量 | 全部版本 | 开源版 |
|
||||
| BytesOut_min_5 | byte/s | Broker 的每秒数据流出量,5 分钟均值 | 全部版本 | 开源版 |
|
||||
| BytesOut_min_15 | byte/s | Broker 的每秒数据流出量,15 分钟均值 | 全部版本 | 开源版 |
|
||||
| ReassignmentBytesIn | byte/s | Broker 的每秒数据迁移写入量 | 全部版本 | 开源版 |
|
||||
| ReassignmentBytesOut | byte/s | Broker 的每秒数据迁移流出量 | 全部版本 | 开源版 |
|
||||
| Partitions | 个 | Broker 上的 Partition 个数 | 全部版本 | 开源版 |
|
||||
| PartitionsSkew | % | Broker 上的 Partitions 倾斜度 | 全部版本 | 开源版 |
|
||||
| Leaders | 个 | Broker 上的 Leaders 个数 | 全部版本 | 开源版 |
|
||||
| LeadersSkew | % | Broker 上的 Leaders 倾斜度 | 全部版本 | 开源版 |
|
||||
| LogSize | byte | Broker 上的消息容量大小 | 全部版本 | 开源版 |
|
||||
| Alive | 是/否 | Broker 是否存活,1:存活;0:没有存活 | 全部版本 | 开源版 |
|
||||
|
||||
### 2.3.3、Topic 指标
|
||||
|
||||
| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
|
||||
| --------------------- | -------- | ------------------------------------- | ---------- | --------------- |
|
||||
| HealthScore | 分 | 健康分 | 全部版本 | 开源版 |
|
||||
| HealthCheckPassed | 个 | 健康项检查通过数 | 全部版本 | 开源版 |
|
||||
| HealthCheckTotal | 个 | 健康项检查总数 | 全部版本 | 开源版 |
|
||||
| TotalProduceRequests | 条/s | Topic 的 TotalProduceRequests | 全部版本 | 开源版 |
|
||||
| BytesRejected | 个/s | Topic 的每秒写入拒绝量 | 全部版本 | 开源版 |
|
||||
| FailedFetchRequests | 个/s | Topic 的 FailedFetchRequests | 全部版本 | 开源版 |
|
||||
| FailedProduceRequests | 个/s | Topic 的 FailedProduceRequests | 全部版本 | 开源版 |
|
||||
| ReplicationCount | 个 | Topic 总的副本数 | 全部版本 | 开源版 |
|
||||
| Messages | 条 | Topic 总的消息数 | 全部版本 | 开源版 |
|
||||
| MessagesIn | 条/s | Topic 每秒消息条数 | 全部版本 | 开源版 |
|
||||
| BytesIn | byte/s | Topic 每秒消息写入字节数 | 全部版本 | 开源版 |
|
||||
| BytesIn_min_5 | byte/s | Topic 每秒消息写入字节数,5 分钟均值 | 全部版本 | 开源版 |
|
||||
| BytesIn_min_15 | byte/s | Topic 每秒消息写入字节数,15 分钟均值 | 全部版本 | 开源版 |
|
||||
| BytesOut | byte/s | Topic 每秒消息流出字节数 | 全部版本 | 开源版 |
|
||||
| BytesOut_min_5 | byte/s | Topic 每秒消息流出字节数,5 分钟均值 | 全部版本 | 开源版 |
|
||||
| BytesOut_min_15 | byte/s | Topic 每秒消息流出字节数,15 分钟均值 | 全部版本 | 开源版 |
|
||||
| LogSize | byte | Topic 的大小 | 全部版本 | 开源版 |
|
||||
| PartitionURP | 个 | Topic 未同步的副本数 | 全部版本 | 开源版 |
|
||||
|
||||
### 2.3.4、Partition 指标
|
||||
|
||||
| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
|
||||
| -------------- | -------- | ----------------------------------------- | ---------- | --------------- |
|
||||
| LogEndOffset | 条 | Partition 中 leader 副本的 LogEndOffset | 全部版本 | 开源版 |
|
||||
| LogStartOffset | 条 | Partition 中 leader 副本的 LogStartOffset | 全部版本 | 开源版 |
|
||||
| Messages | 条 | Partition 总的消息数 | 全部版本 | 开源版 |
|
||||
| BytesIn | byte/s | Partition 的每秒消息流入字节数 | 全部版本 | 开源版 |
|
||||
| BytesOut | byte/s | Partition 的每秒消息流出字节数 | 全部版本 | 开源版 |
|
||||
| LogSize | byte | Partition 的大小 | 全部版本 | 开源版 |
|
||||
|
||||
### 2.3.5、Group 指标
|
||||
|
||||
| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
|
||||
| ----------------- | -------- | -------------------------- | ---------- | --------------- |
|
||||
| HealthScore | 分 | 健康分 | 全部版本 | 开源版 |
|
||||
| HealthCheckPassed | 个 | 健康检查通过数 | 全部版本 | 开源版 |
|
||||
| HealthCheckTotal | 个 | 健康检查总数 | 全部版本 | 开源版 |
|
||||
| OffsetConsumed | 条 | Consumer 的 CommitedOffset | 全部版本 | 开源版 |
|
||||
| LogEndOffset | 条 | Consumer 的 LogEndOffset | 全部版本 | 开源版 |
|
||||
| Lag | 条 | Group 消费者的 Lag 数 | 全部版本 | 开源版 |
|
||||
| State | 个 | Group 组的状态 | 全部版本 | 开源版 |
|
||||
87
docs/dev_guide/本地源码启动手册.md
Normal file
@@ -0,0 +1,87 @@
|
||||
## 6.1、本地源码启动手册
|
||||
|
||||
### 6.1.1、打包方式
|
||||
|
||||
`Know Streaming` 采用前后端分离的开发模式,使用 Maven 对项目进行统一的构建管理。maven 在打包构建过程中,会将前后端代码一并打包生成最终的安装包。
|
||||
|
||||
`Know Streaming` 除了使用安装包启动之外,还可以通过本地源码启动完整的带前端页面的项目,下面我们正式开始介绍本地源码如何启动 `Know Streaming`。
|
||||
|
||||
### 6.1.2、环境要求
|
||||
|
||||
**系统支持**
|
||||
|
||||
`windows7+`、`Linux`、`Mac`
|
||||
|
||||
**环境依赖**
|
||||
|
||||
- Maven 3.6.3
|
||||
- Node v12.20.0
|
||||
- Java 8+
|
||||
- MySQL 5.7
|
||||
- Idea
|
||||
- Elasticsearch 7.6
|
||||
|
||||
### 6.1.3、环境初始化
|
||||
|
||||
安装好环境信息之后,还需要初始化 MySQL 与 Elasticsearch 信息,包括:
|
||||
|
||||
- 初始化 MySQL 表及数据
|
||||
- 初始化 Elasticsearch 索引
|
||||
|
||||
具体见:[快速开始](./1-quick-start.md) 中的最后一步,部署 KnowStreaming 服务中的初始化相关工作。
|
||||
|
||||
### 6.1.4、本地启动
|
||||
|
||||
**第一步:本地打包**
|
||||
|
||||
执行 `mvn install` 可对项目进行前后端同时进行打包,通过该命令,除了可以对后端进行打包之外,还可以将前端相关的静态资源文件也一并打包出来。
|
||||
|
||||
**第二步:修改配置**
|
||||
|
||||
```yaml
|
||||
# 修改 km-rest/src/main/resources/application.yml 中相关的配置
|
||||
|
||||
# 修改MySQL的配置,中间省略了一些非必需修改的配置
|
||||
spring:
|
||||
datasource:
|
||||
know-streaming:
|
||||
jdbc-url: 修改为实际MYSQL地址
|
||||
username: 修改为实际MYSQL用户名
|
||||
password: 修改为实际MYSQL密码
|
||||
logi-job:
|
||||
jdbc-url: 修改为实际MYSQL地址
|
||||
username: 修改为实际MYSQL用户名
|
||||
password: 修改为实际MYSQL密码
|
||||
logi-security:
|
||||
jdbc-url: 修改为实际MYSQL地址
|
||||
username: 修改为实际MYSQL用户名
|
||||
password: 修改为实际MYSQL密码
|
||||
|
||||
# 修改ES的配置,中间省略了一些非必需修改的配置
|
||||
es.client.address: 修改为实际ES地址
|
||||
```
|
||||
|
||||
**第三步:配置 IDEA**
|
||||
|
||||
`Know streaming`的 Main 方法在:
|
||||
|
||||
```java
|
||||
km-rest/src/main/java/com/xiaojukeji/know/streaming/km/rest/KnowStreaming.java
|
||||
```
|
||||
|
||||
IDEA 更多具体的配置如下图所示:
|
||||
|
||||

|
||||
|
||||
**第四步:启动项目**
|
||||
|
||||
最后就是启动项目,在本地 console 中输出了 `KnowStreaming-KM started` 则表示我们已经成功启动 `Know streaming` 了。
|
||||
|
||||
### 6.1.5、本地访问
|
||||
|
||||
`Know streaming` 启动之后,可以访问一些信息,包括:
|
||||
|
||||
- 产品页面:http://localhost:8080 ,默认账号密码:`admin` / `admin2022_` 进行登录。
|
||||
- 接口地址:http://localhost:8080/swagger-ui.html 查看后端提供的相关接口。
|
||||
|
||||
更多信息,详见:[KnowStreaming 官网](http://116.85.24.211/)
|
||||
114
docs/dev_guide/登录系统对接.md
Normal file
@@ -0,0 +1,114 @@
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 登录系统对接
|
||||
|
||||
### 前言
|
||||
|
||||
KnowStreaming 除了实现基于本地MySQL的用户登录认证方式外,还实现了基于Ldap的登录认证。
|
||||
|
||||
但是,登录认证系统并非仅此两种,因此本文将介绍 KnowStreaming 如何对接自有的用户登录认证系统。
|
||||
|
||||
下面我们正式开始介绍登录系统的对接。
|
||||
|
||||
### 如何对接?
|
||||
|
||||
- 实现Log-Common中的LoginService的三个接口即可;
|
||||
|
||||
```Java
|
||||
// LoginService三个方法
|
||||
public interface LoginService {
|
||||
/**
|
||||
* 验证登录信息,同时记住登录状态
|
||||
*/
|
||||
UserBriefVO verifyLogin(AccountLoginDTO loginDTO, HttpServletRequest request, HttpServletResponse response) throws LogiSecurityException;
|
||||
|
||||
/**
|
||||
* 登出接口,清楚登录状态
|
||||
*/
|
||||
Result<Boolean> logout(HttpServletRequest request, HttpServletResponse response);
|
||||
|
||||
/**
|
||||
* 检查是否已经登录
|
||||
*/
|
||||
boolean interceptorCheck(HttpServletRequest request, HttpServletResponse response,
|
||||
String requestMappingValue,
|
||||
List<String> whiteMappingValues) throws IOException;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
没错,登录就是如此的简单,仅仅只需要实现上述的三个接口即可。说了半天,具体如何做呢,能不能给个例子?
|
||||
|
||||
|
||||
### 有没有例子?
|
||||
|
||||
我们以Ldap对接为例,说明KnowStreaming如何对接登录认证系统。
|
||||
|
||||
```Java
|
||||
// 继承 LoginService 接口
|
||||
public class LdapLoginServiceImpl implements LoginService {
|
||||
private static final Logger LOGGER = LoggerFactory.getLogger(LdapLoginServiceImpl.class);
|
||||
|
||||
// Ldap校验
|
||||
@Autowired
|
||||
private LdapAuthentication ldapAuthentication;
|
||||
|
||||
@Override
|
||||
public UserBriefVO verifyLogin(AccountLoginDTO loginDTO,
|
||||
HttpServletRequest request,
|
||||
HttpServletResponse response) throws LogiSecurityException {
|
||||
String decodePasswd = AESUtils.decrypt(loginDTO.getPw());
|
||||
|
||||
// 去LDAP验证账密
|
||||
LdapPrincipal ldapAttrsInfo = ldapAuthentication.authenticate(loginDTO.getUserName(), decodePasswd);
|
||||
if (ldapAttrsInfo == null) {
|
||||
// 用户不存在,正常来说上如果有问题,上一步会直接抛出异常
|
||||
throw new LogiSecurityException(ResultCode.USER_NOT_EXISTS);
|
||||
}
|
||||
|
||||
// 进行业务相关操作
|
||||
|
||||
// 记录登录状态,Ldap因为无法记录登录状态,因此有KnowStreaming进行记录
|
||||
initLoginContext(request, response, loginDTO.getUserName(), user.getId());
|
||||
return CopyBeanUtil.copy(user, UserBriefVO.class);
|
||||
}
|
||||
|
||||
@Override
|
||||
public Result<Boolean> logout(HttpServletRequest request, HttpServletResponse response) {
|
||||
request.getSession().invalidate();
|
||||
response.setStatus(REDIRECT_CODE);
|
||||
return Result.buildSucc(Boolean.TRUE);
|
||||
}
|
||||
|
||||
@Override
|
||||
public boolean interceptorCheck(HttpServletRequest request, HttpServletResponse response, String requestMappingValue, List<String> whiteMappingValues) throws IOException {
|
||||
// 其他处理
|
||||
|
||||
// 检查是否已经登录
|
||||
String userName = HttpRequestUtil.getOperator(request);
|
||||
if (StringUtils.isEmpty(userName)) {
|
||||
// 未登录,则进行登出
|
||||
logout(request, response);
|
||||
return Boolean.FALSE;
|
||||
}
|
||||
|
||||
// 其他业务处理
|
||||
|
||||
return Boolean.TRUE;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
### 背后原理是?
|
||||
|
||||
- KnowStreaming 会拦截所有的接口请求;
|
||||
- 拦截到请求之后,如果是登录的请求,则调用LoginService.verifyLogin();
|
||||
- 拦截到请求之后,如果是登出的请求,则调用LoginService.logout();
|
||||
- 拦截到请求之后,如果是其他请求,则调用LoginService.interceptorCheck();
|
||||
101
docs/dev_guide/解决连接JMX失败.md
Normal file
@@ -0,0 +1,101 @@
|
||||
|
||||

|
||||
|
||||
|
||||
## JMX-连接失败问题解决
|
||||
|
||||
- [JMX-连接失败问题解决](#jmx-连接失败问题解决)
|
||||
- [1、问题&说明](#1问题说明)
|
||||
- [2、解决方法](#2解决方法)
|
||||
- [3、解决方法 —— 认证的JMX](#3解决方法--认证的jmx)
|
||||
|
||||
集群正常接入Logi-KafkaManager之后,即可以看到集群的Broker列表,此时如果查看不了Topic的实时流量,或者是Broker的实时流量信息时,那么大概率就是JMX连接的问题了。
|
||||
|
||||
下面我们按照步骤来一步一步的检查。
|
||||
|
||||
### 1、问题&说明
|
||||
|
||||
**类型一:JMX配置未开启**
|
||||
|
||||
未开启时,直接到`2、解决方法`查看如何开启即可。
|
||||
|
||||

|
||||
|
||||
|
||||
**类型二:配置错误**
|
||||
|
||||
`JMX`端口已经开启的情况下,有的时候开启的配置不正确,此时也会导致出现连接失败的问题。这里大概列举几种原因:
|
||||
|
||||
- `JMX`配置错误:见`2、解决方法`。
|
||||
- 存在防火墙或者网络限制:网络通的另外一台机器`telnet`试一下看是否可以连接上。
|
||||
- 需要进行用户名及密码的认证:见`3、解决方法 —— 认证的JMX`。
|
||||
|
||||
|
||||
错误日志例子:
|
||||
```
|
||||
# 错误一: 错误提示的是真实的IP,这样的话基本就是JMX配置的有问题了。
|
||||
2021-01-27 10:06:20.730 ERROR 50901 --- [ics-Thread-1-62] c.x.k.m.c.utils.jmx.JmxConnectorWrap : JMX connect exception, host:192.168.0.1 port:9999.
|
||||
java.rmi.ConnectException: Connection refused to host: 192.168.0.1; nested exception is:
|
||||
|
||||
|
||||
# 错误二:错误提示的是127.0.0.1这个IP,这个是机器的hostname配置的可能有问题。
|
||||
2021-01-27 10:06:20.730 ERROR 50901 --- [ics-Thread-1-62] c.x.k.m.c.utils.jmx.JmxConnectorWrap : JMX connect exception, host:127.0.0.1 port:9999.
|
||||
java.rmi.ConnectException: Connection refused to host: 127.0.0.1;; nested exception is:
|
||||
```
|
||||
|
||||
### 2、解决方法
|
||||
|
||||
这里仅介绍一下比较通用的解决方式,如若有更好的方式,欢迎大家指导告知一下。
|
||||
|
||||
修改`kafka-server-start.sh`文件:
|
||||
```
|
||||
# 在这个下面增加JMX端口的配置
|
||||
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
|
||||
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
|
||||
export JMX_PORT=9999 # 增加这个配置, 这里的数值并不一定是要9999
|
||||
fi
|
||||
```
|
||||
|
||||
|
||||
|
||||
修改`kafka-run-class.sh`文件
|
||||
```
|
||||
# JMX settings
|
||||
if [ -z "$KAFKA_JMX_OPTS" ]; then
|
||||
KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=${当前机器的IP}"
|
||||
fi
|
||||
|
||||
# JMX port to use
|
||||
if [ $JMX_PORT ]; then
|
||||
KAFKA_JMX_OPTS="$KAFKA_JMX_OPTS -Dcom.sun.management.jmxremote.port=$JMX_PORT -Dcom.sun.management.jmxremote.rmi.port=$JMX_PORT"
|
||||
fi
|
||||
```
|
||||
|
||||
|
||||
### 3、解决方法 —— 认证的JMX
|
||||
|
||||
如果您是直接看的这个部分,建议先看一下上一节:`2、解决方法`以确保`JMX`的配置没有问题了。
|
||||
|
||||
在JMX的配置等都没有问题的情况下,如果是因为认证的原因导致连接不了的,此时可以使用下面介绍的方法进行解决。
|
||||
|
||||
**当前这块后端刚刚开发完成,可能还不够完善,有问题随时沟通。**
|
||||
|
||||
`Logi-KafkaManager 2.2.0+`之后的版本后端已经支持`JMX`认证方式的连接,但是还没有界面,此时我们可以往`cluster`表的`jmx_properties`字段写入`JMX`的认证信息。
|
||||
|
||||
这个数据是`json`格式的字符串,例子如下所示:
|
||||
|
||||
```json
|
||||
{
|
||||
"maxConn": 10, # KM对单台Broker的最大JMX连接数
|
||||
"username": "xxxxx", # 用户名
|
||||
"password": "xxxx", # 密码
|
||||
"openSSL": true, # 开启SSL, true表示开启ssl, false表示关闭
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
SQL的例子:
|
||||
```sql
|
||||
UPDATE cluster SET jmx_properties='{ "maxConn": 10, "username": "xxxxx", "password": "xxxx", "openSSL": false }' where id={xxx};
|
||||
```
|
||||
@@ -1,107 +0,0 @@
|
||||
|
||||
---
|
||||
|
||||

|
||||
|
||||
**一站式`Apache Kafka`集群指标监控与运维管控平台**
|
||||
|
||||
---
|
||||
|
||||
# 配置说明
|
||||
|
||||
```yaml
|
||||
server:
|
||||
port: 8080 # 服务端口
|
||||
tomcat:
|
||||
accept-count: 1000
|
||||
max-connections: 10000
|
||||
max-threads: 800
|
||||
min-spare-threads: 100
|
||||
|
||||
spring:
|
||||
application:
|
||||
name: kafkamanager
|
||||
datasource:
|
||||
kafka-manager: # 数据库连接配置
|
||||
jdbc-url: jdbc:mysql://127.0.0.1:3306/kafka_manager?characterEncoding=UTF-8&serverTimezone=GMT%2B8 #数据库的地址
|
||||
username: admin # 用户名
|
||||
password: admin # 密码
|
||||
driver-class-name: com.mysql.jdbc.Driver
|
||||
main:
|
||||
allow-bean-definition-overriding: true
|
||||
|
||||
profiles:
|
||||
active: dev # 启用的配置
|
||||
servlet:
|
||||
multipart:
|
||||
max-file-size: 100MB
|
||||
max-request-size: 100MB
|
||||
|
||||
logging:
|
||||
config: classpath:logback-spring.xml
|
||||
|
||||
custom:
|
||||
idc: cn # 部署的数据中心, 忽略该配置, 后续会进行删除
|
||||
jmx:
|
||||
max-conn: 10 # 和单台 broker 的最大JMX连接数
|
||||
store-metrics-task:
|
||||
community:
|
||||
broker-metrics-enabled: true # 社区部分broker metrics信息收集开关, 关闭之后metrics信息将不会进行收集及写DB
|
||||
topic-metrics-enabled: true # 社区部分topic的metrics信息收集开关, 关闭之后metrics信息将不会进行收集及写DB
|
||||
didi:
|
||||
app-topic-metrics-enabled: false # 滴滴埋入的指标, 社区AK不存在该指标,因此默认关闭
|
||||
topic-request-time-metrics-enabled: false # 滴滴埋入的指标, 社区AK不存在该指标,因此默认关闭
|
||||
topic-throttled-metrics-enabled: false # 滴滴埋入的指标, 社区AK不存在该指标,因此默认关闭
|
||||
save-days: 7 #指标在DB中保持的天数,-1表示永久保存,7表示保存近7天的数据
|
||||
|
||||
# 任务相关的开关
|
||||
task:
|
||||
op:
|
||||
sync-topic-enabled: false # 未落盘的Topic定期同步到DB中
|
||||
order-auto-exec: # 工单自动化审批线程的开关
|
||||
topic-enabled: false # Topic工单自动化审批开关, false:关闭自动化审批, true:开启
|
||||
app-enabled: false # App工单自动化审批开关, false:关闭自动化审批, true:开启
|
||||
|
||||
account: # ldap相关的配置, 社区版本暂时支持不够完善,可以先忽略,欢迎贡献代码对这块做优化
|
||||
ldap:
|
||||
|
||||
kcm: # 集群升级部署相关的功能,需要配合夜莺及S3进行使用,这块我们后续专门补充一个文档细化一下,牵扯到kcm_script.sh脚本的修改
|
||||
enabled: false # 默认关闭
|
||||
storage:
|
||||
base-url: http://127.0.0.1 # 存储地址
|
||||
n9e:
|
||||
base-url: http://127.0.0.1:8004 # 夜莺任务中心的地址
|
||||
user-token: 12345678 # 夜莺用户的token
|
||||
timeout: 300 # 集群任务的超时时间,单位秒
|
||||
account: root # 集群任务使用的账号
|
||||
script-file: kcm_script.sh # 集群任务的脚本
|
||||
|
||||
monitor: # 监控告警相关的功能,需要配合夜莺进行使用
|
||||
enabled: false # 默认关闭,true就是开启
|
||||
n9e:
|
||||
nid: 2
|
||||
user-token: 1234567890
|
||||
mon:
|
||||
# 夜莺 mon监控服务 地址
|
||||
base-url: http://127.0.0.1:8032
|
||||
sink:
|
||||
# 夜莺 transfer上传服务 地址
|
||||
base-url: http://127.0.0.1:8006
|
||||
rdb:
|
||||
# 夜莺 rdb资源服务 地址
|
||||
base-url: http://127.0.0.1:80
|
||||
|
||||
# enabled: 表示是否开启监控告警的功能, true: 开启, false: 不开启
|
||||
# n9e.nid: 夜莺的节点ID
|
||||
# n9e.user-token: 用户的密钥,在夜莺的个人设置中
|
||||
# n9e.mon.base-url: 监控地址
|
||||
# n9e.sink.base-url: 数据上报地址
|
||||
# n9e.rdb.base-url: 用户资源中心地址
|
||||
|
||||
notify: # 通知的功能
|
||||
kafka: # 默认通知发送到kafka的指定Topic中
|
||||
cluster-id: 95 # Topic的集群ID
|
||||
topic-name: didi-kafka-notify # Topic名称
|
||||
order: # 部署的KM的地址
|
||||
detail-url: http://127.0.0.1
|
||||
```
|
||||
@@ -1,93 +0,0 @@
|
||||
|
||||
---
|
||||
|
||||

|
||||
|
||||
**一站式`Apache Kafka`集群指标监控与运维管控平台**
|
||||
|
||||
---
|
||||
|
||||
# 安装手册
|
||||
|
||||
## 1、环境依赖
|
||||
|
||||
如果是以Release包进行安装的,则仅安装`Java`及`MySQL`即可。如果是要先进行源码包进行打包,然后再使用,则需要安装`Maven`及`Node`环境。
|
||||
|
||||
- `Java 8+`(运行环境需要)
|
||||
- `MySQL 5.7`(数据存储)
|
||||
- `Maven 3.5+`(后端打包依赖)
|
||||
- `Node 10+`(前端打包依赖)
|
||||
|
||||
---
|
||||
|
||||
## 2、获取安装包
|
||||
|
||||
**1、Release直接下载**
|
||||
|
||||
这里如果觉得麻烦,然后也不想进行二次开发,则可以直接下载Release包,下载地址:[Github Release包下载地址](https://github.com/didi/Logi-KafkaManager/releases)
|
||||
|
||||
如果觉得Github的下载地址太慢了,也可以进入`Logi-KafkaManager`的用户群获取,群地址在README中。
|
||||
|
||||
|
||||
**2、源代码进行打包**
|
||||
|
||||
下载好代码之后,进入`Logi-KafkaManager`的主目录,执行`mvn -Prelease-kafka-manager -Dmaven.test.skip=true clean install -U `命令即可,
|
||||
执行完成之后会在`distribution/target`目录下面生成一个`kafka-manager-*.tar.gz`。
|
||||
和一个`kafka-manager-*.zip` 文件,随便任意一个压缩包都可以;
|
||||
当然此时同级目录有一个已经解压好的文件夹;
|
||||
|
||||
|
||||
|
||||
---
|
||||
|
||||
## 3. 解压安装包
|
||||
解压完成后; 在文件目录中可以看到有`kafka-manager/conf/create_mysql_table.sql` 有个mysql初始化文件
|
||||
先初始化DB
|
||||
|
||||
|
||||
## 4、MySQL-DB初始化
|
||||
|
||||
执行[create_mysql_table.sql](../../distribution/conf/create_mysql_table.sql)中的SQL命令,从而创建所需的MySQL库及表,默认创建的库名是`logi_kafka_manager`。
|
||||
|
||||
```
|
||||
# 示例:
|
||||
mysql -uXXXX -pXXX -h XXX.XXX.XXX.XXX -PXXXX < ./create_mysql_table.sql
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 5.修该配置
|
||||
请将`conf/application.yml.example` 文件复制一份出来命名为`application.yml` 放在同级目录:conf/application.yml ;
|
||||
并且修改配置; 当然不修改的话 就会用默认的配置;
|
||||
至少 mysql配置成自己的吧
|
||||
|
||||
|
||||
## 6、启动/关闭
|
||||
解压包中有启动和关闭脚本
|
||||
`kafka-manager/bin/shutdown.sh`
|
||||
`kafka-manager/bin/startup.sh`
|
||||
|
||||
执行 sh startup.sh 启动
|
||||
执行 sh shutdown.sh 关闭
|
||||
|
||||
|
||||
|
||||
### 6、使用
|
||||
|
||||
本地启动的话,访问`http://localhost:8080`,输入帐号及密码(默认`admin/admin`)进行登录。更多参考:[kafka-manager 用户使用手册](../user_guide/user_guide_cn.md)
|
||||
|
||||
### 7. 升级
|
||||
|
||||
如果是升级版本,请查看文件 [kafka-manager 升级手册](../../distribution/upgrade_config.md)
|
||||
在您下载的启动包(V2.5及其后)中也有记录,在 kafka-manager/upgrade_config.md 中
|
||||
|
||||
|
||||
### 8. 在IDE中启动
|
||||
> 如果想参与开发或者想在IDE中启动的话
|
||||
> 先执行 `mvn -Dmaven.test.skip=true clean install -U `
|
||||
>
|
||||
> 然后这个时候可以选择去 [pom.xml](../../pom.xml) 中将`kafka-manager-console`模块注释掉;
|
||||
> 注释是因为每次install的时候都会把前端文件`kafka-manager-console`重新打包进`kafka-manager-web`
|
||||
>
|
||||
> 完事之后,只需要直接用IDE启动运行`kafka-manager-web`模块中的
|
||||
> com.xiaojukeji.kafka.manager.web.MainApplication main方法就行了
|
||||
@@ -1,132 +0,0 @@
|
||||
---
|
||||
|
||||

|
||||
|
||||
**一站式`Apache Kafka`集群指标监控与运维管控平台**
|
||||
|
||||
---
|
||||
|
||||
|
||||
## 基于Docker部署Logikm
|
||||
|
||||
为了方便用户快速的在自己的环境搭建Logikm,可使用docker快速搭建
|
||||
|
||||
### 部署Mysql
|
||||
|
||||
```shell
|
||||
docker run --name mysql -p 3306:3306 -d registry.cn-hangzhou.aliyuncs.com/zqqq/logikm-mysql:5.7.37
|
||||
```
|
||||
|
||||
可选变量参考[文档](https://hub.docker.com/_/mysql)
|
||||
|
||||
默认参数
|
||||
|
||||
* MYSQL_ROOT_PASSWORD:root
|
||||
|
||||
|
||||
|
||||
### 部署Logikm Allinone
|
||||
|
||||
> 前后端部署在一起
|
||||
|
||||
```shell
|
||||
docker run --name logikm -p 8080:8080 --link mysql -d registry.cn-hangzhou.aliyuncs.com/zqqq/logikm:2.6.0
|
||||
```
|
||||
|
||||
参数详解:
|
||||
|
||||
* -p 映射容器8080端口至宿主机的8080
|
||||
* --link 连接mysql容器
|
||||
|
||||
|
||||
|
||||
### 部署前后端分离
|
||||
|
||||
#### 部署后端 Logikm-backend
|
||||
|
||||
```shell
|
||||
docker run --name logikm-backend --link mysql -d registry.cn-hangzhou.aliyuncs.com/zqqq/logikm-backend:2.6.0
|
||||
```
|
||||
|
||||
可选参数:
|
||||
|
||||
* -e LOGI_MYSQL_HOST mysql连接地址,默认mysql
|
||||
* -e LOGI_MYSQL_PORT mysql端口,默认3306
|
||||
* -e LOGI_MYSQL_DATABASE 数据库,默认logi_kafka_manager
|
||||
* -e LOGI_MYSQL_USER mysql用户名,默认root
|
||||
* -e LOGI_MYSQL_PASSWORD mysql密码,默认root
|
||||
|
||||
#### 部署前端 Logikm-front
|
||||
|
||||
```shell
|
||||
docker run --name logikm-front -p 8088:80 --link logikm-backend -d registry.cn-hangzhou.aliyuncs.com/zqqq/logikm-front:2.6.0
|
||||
```
|
||||
|
||||
|
||||
|
||||
### Logi后端可配置参数
|
||||
|
||||
docker run 运行参数 -e 可指定环境变量如下
|
||||
|
||||
| 环境变量 | 变量解释 | 默认值 |
|
||||
| ------------------- | ------------- | ------------------ |
|
||||
| LOGI_MYSQL_HOST | mysql连接地址 | mysql |
|
||||
| LOGI_MYSQL_PORT | mysql端口 | 3306 |
|
||||
| LOGI_MYSQL_DATABASE | 数据库 | logi_kafka_manager |
|
||||
| LOGI_MYSQL_USER | mysql用户名 | root |
|
||||
| LOGI_MYSQL_PASSWORD | mysql密码 | root |
|
||||
|
||||
|
||||
|
||||
|
||||
## 基于Docker源码构建
|
||||
|
||||
根据此文档用户可自行通过Docker 源码构建 Logikm
|
||||
|
||||
### 构建Mysql
|
||||
|
||||
```shell
|
||||
docker build -t mysql:{TAG} -f container/dockerfiles/mysql/Dockerfile container/dockerfiles/mysql
|
||||
```
|
||||
|
||||
### 构建Allinone
|
||||
|
||||
将前后端打包在一起
|
||||
|
||||
```shell
|
||||
docker build -t logikm:{TAG} .
|
||||
```
|
||||
|
||||
可选参数 --build-arg :
|
||||
|
||||
* MAVEN_VERSION maven镜像tag
|
||||
* JAVA_VERSION java镜像tag
|
||||
|
||||
|
||||
|
||||
### 构建前后端分离
|
||||
|
||||
前后端分离打包
|
||||
|
||||
#### 构建后端
|
||||
|
||||
```shell
|
||||
docker build --build-arg CONSOLE_ENABLE=false -t logikm-backend:{TAG} .
|
||||
```
|
||||
|
||||
参数:
|
||||
|
||||
* MAVEN_VERSION maven镜像tag
|
||||
* JAVA_VERSION java镜像tag
|
||||
|
||||
* CONSOLE_ENABLE=false 不构建console模块
|
||||
|
||||
#### 构建前端
|
||||
|
||||
```shell
|
||||
docker build -t logikm-front:{TAG} -f kafka-manager-console/Dockerfile kafka-manager-console
|
||||
```
|
||||
|
||||
可选参数:
|
||||
|
||||
* --build-arg:OUTPUT_PATH 修改默认打包输出路径,默认当前目录下的dist
|
||||
@@ -1,94 +0,0 @@
|
||||
---
|
||||
|
||||

|
||||
|
||||
**一站式`Apache Kafka`集群指标监控与运维管控平台**
|
||||
|
||||
---
|
||||
|
||||
## nginx配置-安装手册
|
||||
|
||||
# 一、独立部署
|
||||
|
||||
请参考参考:[kafka-manager 安装手册](install_guide_cn.md)
|
||||
|
||||
# 二、nginx配置
|
||||
|
||||
## 1、独立部署配置
|
||||
|
||||
```
|
||||
#nginx 根目录访问配置如下
|
||||
location / {
|
||||
proxy_pass http://ip:port;
|
||||
}
|
||||
```
|
||||
|
||||
## 2、前后端分离&配置多个静态资源
|
||||
|
||||
以下配置解决`nginx代理多个静态资源`,实现项目前后端分离,版本更新迭代。
|
||||
|
||||
### 1、源码下载
|
||||
|
||||
根据所需版本下载对应代码,下载地址:[Github 下载地址](https://github.com/didi/Logi-KafkaManager)
|
||||
|
||||
### 2、修改webpack.config.js 配置文件
|
||||
|
||||
修改`kafka-manager-console`模块 `webpack.config.js`
|
||||
以下所有<font color='red'>xxxx</font>为nginx代理路径和打包静态文件加载前缀,<font color='red'>xxxx</font>可根据需求自行更改。
|
||||
|
||||
```
|
||||
cd kafka-manager-console
|
||||
vi webpack.config.js
|
||||
|
||||
# publicPath默认打包方式根目录下,修改为nginx代理访问路径。
|
||||
let publicPath = '/xxxx';
|
||||
```
|
||||
|
||||
### 3、打包
|
||||
|
||||
```
|
||||
|
||||
npm cache clean --force && npm install
|
||||
|
||||
```
|
||||
|
||||
ps:如果打包过程中报错,运行`npm install clipboard@2.0.6`,相反请忽略!
|
||||
|
||||
### 4、部署
|
||||
|
||||
#### 1、前段静态文件部署
|
||||
|
||||
静态资源 `../kafka-manager-web/src/main/resources/templates`
|
||||
|
||||
上传到指定目录,目前以`root目录`做demo
|
||||
|
||||
#### 2、上传jar包并启动,请参考:[kafka-manager 安装手册](install_guide_cn.md)
|
||||
|
||||
#### 3、修改nginx 配置
|
||||
|
||||
```
|
||||
location /xxxx {
|
||||
# 静态文件存放位置
|
||||
alias /root/templates;
|
||||
try_files $uri $uri/ /xxxx/index.html;
|
||||
index index.html;
|
||||
}
|
||||
|
||||
location /api {
|
||||
proxy_pass http://ip:port;
|
||||
}
|
||||
#后代端口建议使用/api,如果冲突可以使用以下配置
|
||||
#location /api/v2 {
|
||||
# proxy_pass http://ip:port;
|
||||
#}
|
||||
#location /api/v1 {
|
||||
# proxy_pass http://ip:port;
|
||||
#}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
237
docs/install_guide/单机部署手册.md
Normal file
@@ -0,0 +1,237 @@
|
||||
## 前言
|
||||
|
||||
- 本文以 Centos7 系统为例,系统基础配置要求:4 核 8G
|
||||
- 按照本文可以快速部署一套单机模式的 KnowStreaming 环境
|
||||
- 本文以 v3.0.0-bete 版本为例进行部署,如需其他版本请关注[官网](https://knowstreaming.com/)
|
||||
- 部署完成后可以通过浏览器输入 IP:PORT 进行访问,默认用户名密码: admin/admin2022\_
|
||||
- KnowStreaming 同样支持分布式集群模式,如需部署高可用集群,[请联系我们](https://knowstreaming.com/support-center)
|
||||
|
||||
## 1.1、软件版本及依赖
|
||||
|
||||
| 软件名 | 版本要求 | 默认端口 |
|
||||
| ------------- | -------- | -------- |
|
||||
| Mysql | v5.7+ | 3306 |
|
||||
| Elasticsearch | v6+ | 8060 |
|
||||
| JDK | v8+ | - |
|
||||
| Centos | v6+ | - |
|
||||
| Ubantu | v16+ | - |
|
||||
|
||||
## 1.2、部署方式选择
|
||||
|
||||
- Shell 部署(单机版本)
|
||||
|
||||
- 容器化部署(需准备 K8S 环境)
|
||||
|
||||
- 根据操作手册进行手动部署
|
||||
|
||||
## 1.3、Shell 部署
|
||||
|
||||
### 1.3.1、在线方式安装
|
||||
|
||||
#在服务器中下载安装脚本,脚本中会重新安装Mysql
|
||||
wget https://s3-gzpu.didistatic.com/pub/knowstreaming/deploy_KnowStreaming.sh
|
||||
|
||||
#执行脚本
|
||||
sh deploy_KnowStreaming.sh
|
||||
|
||||
#访问测试
|
||||
127.0.0.1:8080
|
||||
|
||||
### 1.3.2、离线方式安装
|
||||
|
||||
#将安装包下载到本地且传输到目标服务器
|
||||
wget https://s3-gzpu.didistatic.com/pub/knowstreaming/KnowStreaming-3.0.0-beta—offline.tar.gz
|
||||
|
||||
#解压安装包
|
||||
tar -zxf KnowStreaming-3.0.0-beta—offline.tar.gz
|
||||
|
||||
#执行安装脚本
|
||||
sh deploy_KnowStreaming-offline.sh
|
||||
|
||||
#访问测试
|
||||
127.0.0.1:8080
|
||||
|
||||
## 1.4、容器化部署
|
||||
|
||||
### 1.4.1、环境依赖及版本要求
|
||||
|
||||
- Kubernetes >= 1.14 ,Helm >= 2.17.0
|
||||
|
||||
- 默认配置为全部安装(elasticsearch + mysql + knowstreaming)
|
||||
|
||||
- 如果使用已有的 elasticsearch(7.6.x) 和 mysql(5.7) 只需调整 values.yaml 部分参数即可
|
||||
|
||||
### 1.4.2、安装方式
|
||||
|
||||
#下载安装包
|
||||
wget https://s3-gzpu.didistatic.com/pub/knowstreaming/knowstreaming-3.0.0-hlem.tgz
|
||||
|
||||
#解压安装包
|
||||
tar -zxf knowstreaming-3.0.0-hlem.tgz
|
||||
|
||||
#执行命令(NAMESPACE需要更改为已存在的)
|
||||
helm install -n [NAMESPACE] knowstreaming knowstreaming-manager/
|
||||
|
||||
#获取KnowStreaming前端ui的service. 默认nodeport方式.(http://nodeIP:nodeport,默认用户名密码:admin/admin2022_)
|
||||
|
||||
## 1.5、手动部署
|
||||
|
||||
### 1.5.1、部署流程
|
||||
|
||||
基础依赖服务部署 ——> KnowStreaming 模块
|
||||
|
||||
### 1.5.2、基础依赖服务部署
|
||||
|
||||
#### 如现有环境中已经有相关服务,可跳过对其的安装
|
||||
|
||||
#### 基础依赖:JAVA11、Mysql、Elasticsearch
|
||||
|
||||
#### 1.5.2.1、安装 Mysql 服务
|
||||
|
||||
##### 1.5.2.1.1 yum 方式安装
|
||||
|
||||
#配置yum源
|
||||
wget https://dev.mysql.com/get/mysql57-community-release-el7-9.noarch.rpm
|
||||
rpm -ivh mysql57-community-release-el7-9.noarch.rpm
|
||||
|
||||
#执行安装
|
||||
yum -y install mysql-server mysql-client
|
||||
|
||||
#服务启动
|
||||
systemctl start mysqld
|
||||
|
||||
#获取初始密码并修改
|
||||
old_pass=`grep 'temporary password' /var/log/mysqld.log | awk '{print $NF}' | tail -n 1`
|
||||
|
||||
mysql -NBe "alter user USER() identified by 'Didi_km_678';" --connect-expired-password -uroot -p$old_pass
|
||||
|
||||
##### 1.5.2.1.2、rpm 包方式安装
|
||||
|
||||
#下载安装包
|
||||
wget https://s3-gzpu.didistatic.com/knowsearch/mysql5.7.tar.gz
|
||||
|
||||
#解压到指定目录
|
||||
tar -zxf mysql5.7.tar.gz -C /tmp/
|
||||
|
||||
#执行安装
|
||||
yum -y localinstall /tmp/libaio-*.rpm /tmp/mysql-*.rpm
|
||||
|
||||
#服务启动
|
||||
systemctl start mysqld
|
||||
|
||||
|
||||
#获取初始密码并修改
|
||||
old_pass=`grep 'temporary password' /var/log/mysqld.log | awk '{print $NF}' | tail -n 1`
|
||||
|
||||
mysql -NBe "alter user USER() identified by 'Didi_km_678';" --connect-expired-pa
|
||||
ssword -uroot -p$old_pass
|
||||
|
||||
#### 1.5.2.2、配置 JAVA 环境
|
||||
|
||||
#下载安装包
|
||||
wget https://s3-gzpu.didistatic.com/pub/jdk11.tar.gz #解压到指定目录
|
||||
tar -zxf jdk11.tar.gz -C /usr/local/ #更改目录名
|
||||
mv /usr/local/jdk-11.0.2 /usr/local/java11 #添加到环境变量
|
||||
echo "export JAVA_HOME=/usr/local/java11" >> ~/.bashrc
|
||||
echo "export CLASSPATH=/usr/java/java11/lib" >> ~/.bashrc
|
||||
echo "export PATH=\$JAVA_HOME/bin:\$PATH:\$HOME/bin" >> ~/.bashrc
|
||||
source ~/.bashrc
|
||||
|
||||
#### 1.5.2.3、Elasticsearch 实例搭建
|
||||
|
||||
#### Elasticsearch 元数据集群来支持平台核心指标数据的存储,如集群维度指标、节点维度指标等
|
||||
|
||||
#### 以下安装示例为单节点模式,如需集群部署可以参考[Elasticsearch 官方文档](https://www.elastic.co/guide/en/elasticsearch/reference/7.6/elasticsearch-intro.html)
|
||||
|
||||
#下载安装包
|
||||
wget https://s3-gzpu.didistatic.com/pub/elasticsearch.tar.gz
|
||||
|
||||
#创建ES数据存储目录
|
||||
mkdir -p /data/es_data
|
||||
|
||||
#创建ES所属用户
|
||||
useradd arius
|
||||
|
||||
#配置用户的打开文件数
|
||||
echo "arius soft nofile 655350" >>/etc/security/limits.conf
|
||||
echo "arius hard nofile 655350" >>/etc/security/limits.conf
|
||||
echo "vm.max_map_count = 655360" >>/etc/sysctl.conf
|
||||
sysctl -p
|
||||
|
||||
#解压安装包
|
||||
tar -zxf elasticsearch.tar.gz -C /data/
|
||||
|
||||
#更改目录所属组
|
||||
chown -R arius:arius /data/
|
||||
|
||||
#修改配置文件(参考以下配置)
|
||||
vim /data/elasticsearch/config/elasticsearch.yml
|
||||
cluster.name: km_es
|
||||
node.name: es-node1
|
||||
node.master: true
|
||||
node.data: true
|
||||
path.data: /data/es_data
|
||||
http.port: 8060
|
||||
discovery.seed_hosts: ["127.0.0.1:9300"]
|
||||
|
||||
#修改内存配置
|
||||
vim /data/elasticsearch/config/jvm.options
|
||||
-Xms2g
|
||||
-Xmx2g
|
||||
|
||||
#启动服务
|
||||
su - arius
|
||||
export JAVA_HOME=/usr/local/java11
|
||||
sh /data/elasticsearch/control.sh start
|
||||
|
||||
#确认状态
|
||||
sh /data/elasticsearch/control.sh status
|
||||
|
||||
### 1.5.3、KnowStreaming 服务部署
|
||||
|
||||
#### 以 KnowStreaming 为例
|
||||
|
||||
#下载安装包
|
||||
wget wget https://s3-gzpu.didistatic.com/pub/knowstreaming/KnowStreaming-3.0.0-beta.tar.gz
|
||||
|
||||
#解压安装包到指定目录
|
||||
tar -zxf KnowStreaming-3.0.0-beta.tar.gz -C /data/
|
||||
|
||||
#修改启动脚本并加入systemd管理
|
||||
cd /data/KnowStreaming/
|
||||
|
||||
#创建相应的库和导入初始化数据
|
||||
mysql -uroot -pDidi_km_678 -e "create database know_streaming;"
|
||||
mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/ddl-ks-km.sql
|
||||
mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/ddl-logi-job.sql
|
||||
mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/ddl-logi-security.sql
|
||||
mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/dml-ks-km.sql
|
||||
mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/dml-logi.sql
|
||||
|
||||
#创建elasticsearch初始化数据
|
||||
sh ./init/template/template.sh
|
||||
|
||||
#修改配置文件
|
||||
vim ./conf/application.yml
|
||||
|
||||
#监听端口
|
||||
server:
|
||||
|
||||
port: 8080 # web 服务端口
|
||||
tomcat:
|
||||
accept-count: 1000
|
||||
max-connections: 10000
|
||||
|
||||
#elasticsearch地址
|
||||
es.client.address: 127.0.0.1:8060
|
||||
|
||||
#数据库配置(一共三处地方,修改正确的mysql地址和数据库名称以及用户名密码)
|
||||
jdbc-url: jdbc:mariadb://127.0.0.1:3306/know-streaming?.....
|
||||
username: root
|
||||
password: Didi_km_678
|
||||
|
||||
#启动服务
|
||||
cd /data/KnowStreaming/bin/
|
||||
sh startup.sh
|
||||
|
||||
#### 打开浏览器输入 IP 地址+端口测试(默认端口 8080),用户名密码: admin/admin2022\_
|
||||
70
docs/install_guide/源码编译打包手册.md
Normal file
@@ -0,0 +1,70 @@
|
||||
|
||||

|
||||
|
||||
|
||||
# `Know Streaming` 源码编译打包手册
|
||||
|
||||
## 1、环境信息
|
||||
|
||||
**系统支持**
|
||||
|
||||
`windows7+`、`Linux`、`Mac`
|
||||
|
||||
**环境依赖**
|
||||
|
||||
- Maven 3.6.3 (后端)
|
||||
- Node v12.20.0/v14.17.3 (前端)
|
||||
- Java 8+ (后端)
|
||||
|
||||
## 2、编译打包
|
||||
|
||||
整个工程中,除了`km-console`为前端模块之外,其他模块都是后端工程相关模块。
|
||||
|
||||
因此,如果前后端合并打包,则打对整个工程进行打包;如果前端单独打包,则仅打包 `km-console` 中的代码;如果是仅需要后端打包,则在顶层 `pom.xml` 中去掉 `km-console`模块,然后进行打包。
|
||||
|
||||
具体见下面描述。
|
||||
|
||||
|
||||
|
||||
### 2.1、前后端合并打包
|
||||
|
||||
1. 下载源码;
|
||||
2. 进入 `KS-KM` 工程目录,执行 `mvn -Prelease-package -Dmaven.test.skip=true clean install -U` 命令;
|
||||
3. 打包命令执行完成后,会在 `km-dist/target` 目录下面生成一个 `KnowStreaming-*.tar.gz` 的安装包。
|
||||
|
||||
|
||||
### 2.2、前端单独打包
|
||||
|
||||
1. 下载源码;
|
||||
2. 进入 `KS-KM/km-console` 工程目录;
|
||||
3. 执行 `npm run build`命令,会在 `KS-KM/km-console` 目录下生成一个名为 `pub` 的前端静态资源包;
|
||||
|
||||
|
||||
|
||||
### 2.3、后端单独打包
|
||||
|
||||
1. 下载源码;
|
||||
2. 修改顶层 `pom.xml` ,去掉其中的 `km-console` 模块,如下所示;
|
||||
```xml
|
||||
<modules>
|
||||
<!-- <module>km-console</module>-->
|
||||
<module>km-common</module>
|
||||
<module>km-persistence</module>
|
||||
<module>km-core</module>
|
||||
<module>km-biz</module>
|
||||
<module>km-extends/km-account</module>
|
||||
<module>km-extends/km-monitor</module>
|
||||
<module>km-extends/km-license</module>
|
||||
<module>km-extends/km-rebalance</module>
|
||||
<module>km-task</module>
|
||||
<module>km-collector</module>
|
||||
<module>km-rest</module>
|
||||
<module>km-dist</module>
|
||||
</modules>
|
||||
```
|
||||
3. 执行 `mvn -U clean package -Dmaven.test.skip=true`命令;
|
||||
4. 执行完成之后会在 `KS-KM/km-rest/target` 目录下面生成一个 `ks-km.jar` 即为KS的后端部署的Jar包,也可以执行 `mvn -Prelease-package -Dmaven.test.skip=true clean install -U` 生成的tar包也仅有后端服务的功能;
|
||||
|
||||
|
||||
|
||||
|
||||
37
docs/install_guide/版本升级手册.md
Normal file
@@ -0,0 +1,37 @@
|
||||
## 版本升级说明
|
||||
|
||||
### `2.x`版本 升级至 `3.0.0`版本
|
||||
|
||||
**升级步骤:**
|
||||
|
||||
1. 依旧使用**`2.x 版本的 DB`**,在上面初始化 3.0.0 版本所需数据库表结构及数据;
|
||||
2. 将 2.x 版本中的集群,在 3.0.0 版本,手动逐一接入;
|
||||
3. 将 Topic 业务数据,迁移至 3.0.0 表中,详见下方 SQL;
|
||||
|
||||
**注意事项**
|
||||
|
||||
- 建议升级 3.0.0 版本过程中,保留 2.x 版本的使用,待 3.0.0 版本稳定使用后,再下线 2.x 版本;
|
||||
- 3.0.0 版本仅需要`集群信息`及`Topic的描述信息`。2.x 版本的 DB 的其他数据 3.0.0 版本都不需要;
|
||||
- 部署 3.0.0 版本之后,集群、Topic 等指标数据都为空,3.0.0 版本会周期进行采集,运行一段时间之后就会有该数据了,因此不会将 2.x 中的指标数据进行迁移;
|
||||
|
||||
**迁移数据**
|
||||
|
||||
```sql
|
||||
-- 迁移Topic的备注信息。
|
||||
-- 需在 3.0.0 部署完成后,再执行该SQL。
|
||||
-- 考虑到 2.x 版本中还存在增量数据,因此建议改SQL周期执行,是的增量数据也能被迁移至 3.0.0 版本中。
|
||||
|
||||
UPDATE ks_km_topic
|
||||
INNER JOIN
|
||||
(SELECT
|
||||
topic.cluster_id AS cluster_id,
|
||||
topic.topic_name AS topic_name,
|
||||
topic.description AS description
|
||||
FROM topic WHERE description != ''
|
||||
) AS t
|
||||
|
||||
ON ks_km_topic.cluster_phy_id = t.cluster_id
|
||||
AND ks_km_topic.topic_name = t.topic_name
|
||||
AND ks_km_topic.id > 0
|
||||
SET ks_km_topic.description = t.description;
|
||||
```
|
||||
@@ -1,49 +0,0 @@
|
||||
|
||||
---
|
||||
|
||||

|
||||
|
||||
**一站式`Apache Kafka`集群指标监控与运维管控平台**
|
||||
|
||||
|
||||
---
|
||||
|
||||
# 集群接入
|
||||
|
||||
## 主要概念讲解
|
||||
面对大规模集群、业务场景复杂的情况,引入Region、逻辑集群的概念
|
||||
- Region:划分部分Broker作为一个 Region,用Region定义资源划分的单位,提高扩展性和隔离性。如果部分Topic异常也不会影响大面积的Broker
|
||||
- 逻辑集群:逻辑集群由部分Region组成,便于对大规模集群按照业务划分、保障能力进行管理
|
||||

|
||||
|
||||
集群的接入总共需要三个步骤,分别是:
|
||||
1. 接入物理集群:填写机器地址、安全协议等配置信息,接入真实的物理集群
|
||||
2. 创建Region:将部分Broker划分为一个Region
|
||||
3. 创建逻辑集群:逻辑集群由部分Region组成,可根据业务划分、保障等级来创建相应的逻辑集群
|
||||
|
||||

|
||||
|
||||
|
||||
**备注:接入集群需要2、3两步是因为普通用户的视角下,看到的都是逻辑集群,如果没有2、3两步,那么普通用户看不到任何信息。**
|
||||
|
||||
|
||||
## 1、接入物理集群
|
||||
|
||||

|
||||
|
||||
如上图所示,填写集群信息,然后点击确定,即可完成集群的接入。因为考虑到分布式部署,添加集群之后,需要稍等**`1分钟`**才可以在界面上看到集群的详细信息。
|
||||
|
||||
## 2、创建Region
|
||||
|
||||

|
||||
|
||||
如上图所示,填写Region信息,然后点击确定,即可完成Region的创建。
|
||||
|
||||
备注:Region即为Broker的集合,可以按照业务需要,将Broker归类,从而创建相应的Region。
|
||||
|
||||
## 3、创建逻辑集群
|
||||
|
||||

|
||||
|
||||
|
||||
如上图所示,填写逻辑集群信息,然后点击确定,即可完成逻辑集群的创建。
|
||||
{kind=link}
|
Before Width: | Height: | Size: 261 KiB |
{kind=link}
|
Before Width: | Height: | Size: 240 KiB |
{kind=link}
|
Before Width: | Height: | Size: 195 KiB |
{kind=link}
|
Before Width: | Height: | Size: 124 KiB |
{kind=link}
|
Before Width: | Height: | Size: 105 KiB |
{kind=link}
|
Before Width: | Height: | Size: 94 KiB |
{kind=link}
|
Before Width: | Height: | Size: 181 KiB |
{kind=link}
|
Before Width: | Height: | Size: 65 KiB |
{kind=link}
|
Before Width: | Height: | Size: 166 KiB |
{kind=link}
|
Before Width: | Height: | Size: 30 KiB |
{kind=link}
|
Before Width: | Height: | Size: 78 KiB |
{kind=link}
|
Before Width: | Height: | Size: 48 KiB |
{kind=link}
|
Before Width: | Height: | Size: 55 KiB |
{kind=link}
|
Before Width: | Height: | Size: 16 KiB |
{kind=link}
|
Before Width: | Height: | Size: 297 KiB |
{kind=link}
|
Before Width: | Height: | Size: 189 KiB |
{kind=link}
|
Before Width: | Height: | Size: 173 KiB |
{kind=link}
|
Before Width: | Height: | Size: 197 KiB |
{kind=link}
|
Before Width: | Height: | Size: 244 KiB |
{kind=link}
|
Before Width: | Height: | Size: 118 KiB |