Compare commits
1 Commits
v3.0.0-bet
...
v2.0.0
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
f8ca797f16 |
225
.gitignore
vendored
@@ -1,112 +1,113 @@
|
||||
### Intellij ###
|
||||
# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio and Webstorm
|
||||
|
||||
*.iml
|
||||
|
||||
## Directory-based project format:
|
||||
.idea/
|
||||
# if you remove the above rule, at least ignore the following:
|
||||
|
||||
# User-specific stuff:
|
||||
# .idea/workspace.xml
|
||||
# .idea/tasks.xml
|
||||
# .idea/dictionaries
|
||||
# .idea/shelf
|
||||
|
||||
# Sensitive or high-churn files:
|
||||
.idea/dataSources.ids
|
||||
.idea/dataSources.xml
|
||||
.idea/sqlDataSources.xml
|
||||
.idea/dynamic.xml
|
||||
.idea/uiDesigner.xml
|
||||
|
||||
|
||||
# Mongo Explorer plugin:
|
||||
.idea/mongoSettings.xml
|
||||
|
||||
## File-based project format:
|
||||
*.ipr
|
||||
*.iws
|
||||
|
||||
## Plugin-specific files:
|
||||
|
||||
# IntelliJ
|
||||
/out/
|
||||
|
||||
# mpeltonen/sbt-idea plugin
|
||||
.idea_modules/
|
||||
|
||||
# JIRA plugin
|
||||
atlassian-ide-plugin.xml
|
||||
|
||||
# Crashlytics plugin (for Android Studio and IntelliJ)
|
||||
com_crashlytics_export_strings.xml
|
||||
crashlytics.properties
|
||||
crashlytics-build.properties
|
||||
fabric.properties
|
||||
|
||||
|
||||
### Java ###
|
||||
*.class
|
||||
|
||||
# Mobile Tools for Java (J2ME)
|
||||
.mtj.tmp/
|
||||
|
||||
# Package Files #
|
||||
*.jar
|
||||
*.war
|
||||
*.ear
|
||||
*.tar.gz
|
||||
|
||||
# virtual machine crash logs, see http://www.java.com/en/download/help/error_hotspot.xml
|
||||
hs_err_pid*
|
||||
|
||||
|
||||
### OSX ###
|
||||
.DS_Store
|
||||
.AppleDouble
|
||||
.LSOverride
|
||||
|
||||
# Icon must end with two \r
|
||||
Icon
|
||||
|
||||
|
||||
# Thumbnails
|
||||
._*
|
||||
|
||||
# Files that might appear in the root of a volume
|
||||
.DocumentRevisions-V100
|
||||
.fseventsd
|
||||
.Spotlight-V100
|
||||
.TemporaryItems
|
||||
.Trashes
|
||||
.VolumeIcon.icns
|
||||
|
||||
# Directories potentially created on remote AFP share
|
||||
.AppleDB
|
||||
.AppleDesktop
|
||||
Network Trash Folder
|
||||
Temporary Items
|
||||
.apdisk
|
||||
|
||||
/target
|
||||
target/
|
||||
*.log
|
||||
*.log.*
|
||||
*.bak
|
||||
*.vscode
|
||||
*/.vscode/*
|
||||
*/.vscode
|
||||
*/velocity.log*
|
||||
*/*.log
|
||||
*/*.log.*
|
||||
node_modules/
|
||||
node_modules/*
|
||||
workspace.xml
|
||||
/output/*
|
||||
.gitversion
|
||||
out/*
|
||||
dist/
|
||||
dist/*
|
||||
km-rest/src/main/resources/templates/
|
||||
*dependency-reduced-pom*
|
||||
### Intellij ###
|
||||
# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio and Webstorm
|
||||
|
||||
*.iml
|
||||
|
||||
## Directory-based project format:
|
||||
.idea/
|
||||
# if you remove the above rule, at least ignore the following:
|
||||
|
||||
# User-specific stuff:
|
||||
# .idea/workspace.xml
|
||||
# .idea/tasks.xml
|
||||
# .idea/dictionaries
|
||||
# .idea/shelf
|
||||
|
||||
# Sensitive or high-churn files:
|
||||
.idea/dataSources.ids
|
||||
.idea/dataSources.xml
|
||||
.idea/sqlDataSources.xml
|
||||
.idea/dynamic.xml
|
||||
.idea/uiDesigner.xml
|
||||
|
||||
|
||||
# Mongo Explorer plugin:
|
||||
.idea/mongoSettings.xml
|
||||
|
||||
## File-based project format:
|
||||
*.ipr
|
||||
*.iws
|
||||
|
||||
## Plugin-specific files:
|
||||
|
||||
# IntelliJ
|
||||
/out/
|
||||
|
||||
# mpeltonen/sbt-idea plugin
|
||||
.idea_modules/
|
||||
|
||||
# JIRA plugin
|
||||
atlassian-ide-plugin.xml
|
||||
|
||||
# Crashlytics plugin (for Android Studio and IntelliJ)
|
||||
com_crashlytics_export_strings.xml
|
||||
crashlytics.properties
|
||||
crashlytics-build.properties
|
||||
fabric.properties
|
||||
|
||||
|
||||
### Java ###
|
||||
*.class
|
||||
|
||||
# Mobile Tools for Java (J2ME)
|
||||
.mtj.tmp/
|
||||
|
||||
# Package Files #
|
||||
*.jar
|
||||
*.war
|
||||
*.ear
|
||||
*.tar.gz
|
||||
|
||||
# virtual machine crash logs, see http://www.java.com/en/download/help/error_hotspot.xml
|
||||
hs_err_pid*
|
||||
|
||||
|
||||
### OSX ###
|
||||
.DS_Store
|
||||
.AppleDouble
|
||||
.LSOverride
|
||||
|
||||
# Icon must end with two \r
|
||||
Icon
|
||||
|
||||
|
||||
# Thumbnails
|
||||
._*
|
||||
|
||||
# Files that might appear in the root of a volume
|
||||
.DocumentRevisions-V100
|
||||
.fseventsd
|
||||
.Spotlight-V100
|
||||
.TemporaryItems
|
||||
.Trashes
|
||||
.VolumeIcon.icns
|
||||
|
||||
# Directories potentially created on remote AFP share
|
||||
.AppleDB
|
||||
.AppleDesktop
|
||||
Network Trash Folder
|
||||
Temporary Items
|
||||
.apdisk
|
||||
|
||||
/target
|
||||
target/
|
||||
*.log
|
||||
*.log.*
|
||||
*.bak
|
||||
*.vscode
|
||||
*/.vscode/*
|
||||
*/.vscode
|
||||
*/velocity.log*
|
||||
*/*.log
|
||||
*/*.log.*
|
||||
node_modules/
|
||||
node_modules/*
|
||||
workspace.xml
|
||||
/output/*
|
||||
.gitversion
|
||||
node_modules/*
|
||||
out/*
|
||||
dist/
|
||||
dist/*
|
||||
kafka-manager-web/src/main/resources/templates/
|
||||
.DS_Store
|
||||
|
||||
@@ -7,7 +7,7 @@ Thanks for considering to contribute this project. All issues and pull requests
|
||||
Before sending pull request to this project, please read and follow guidelines below.
|
||||
|
||||
1. Branch: We only accept pull request on `dev` branch.
|
||||
2. Coding style: Follow the coding style used in LogiKM.
|
||||
2. Coding style: Follow the coding style used in kafka-manager.
|
||||
3. Commit message: Use English and be aware of your spell.
|
||||
4. Test: Make sure to test your code.
|
||||
|
||||
|
||||
203
README.md
@@ -1,139 +1,64 @@
|
||||
|
||||
<p align="center">
|
||||
<img src="https://user-images.githubusercontent.com/71620349/185368586-aed82d30-1534-453d-86ff-ecfa9d0f35bd.png" width = "256" div align=center />
|
||||
|
||||
</p>
|
||||
|
||||
<p align="center">
|
||||
<a href="https://knowstreaming.com">产品官网</a> |
|
||||
<a href="https://github.com/didi/KnowStreaming/releases">下载地址</a> |
|
||||
<a href="https://doc.knowstreaming.com/product">文档资源</a> |
|
||||
<a href="https://demo.knowstreaming.com">体验环境</a>
|
||||
</p>
|
||||
|
||||
<p align="center">
|
||||
<!--最近一次提交时间-->
|
||||
<a href="https://img.shields.io/github/last-commit/didi/KnowStreaming">
|
||||
<img src="https://img.shields.io/github/last-commit/didi/KnowStreaming" alt="LastCommit">
|
||||
</a>
|
||||
|
||||
<!--最新版本-->
|
||||
<a href="https://github.com/didi/KnowStreaming/blob/master/LICENSE">
|
||||
<img src="https://img.shields.io/github/v/release/didi/KnowStreaming" alt="License">
|
||||
</a>
|
||||
|
||||
<!--License信息-->
|
||||
<a href="https://github.com/didi/KnowStreaming/blob/master/LICENSE">
|
||||
<img src="https://img.shields.io/github/license/didi/KnowStreaming" alt="License">
|
||||
</a>
|
||||
|
||||
<!--Open-Issue-->
|
||||
<a href="https://github.com/didi/KnowStreaming/issues">
|
||||
<img src="https://img.shields.io/github/issues-raw/didi/KnowStreaming" alt="Issues">
|
||||
</a>
|
||||
|
||||
<!--知识星球-->
|
||||
<a href="https://z.didi.cn/5gSF9">
|
||||
<img src="https://img.shields.io/badge/join-%E7%9F%A5%E8%AF%86%E6%98%9F%E7%90%83-red" alt="Slack">
|
||||
</a>
|
||||
|
||||
</p>
|
||||
|
||||
|
||||
---
|
||||
|
||||
|
||||
## `Know Streaming` 简介
|
||||
|
||||
`Know Streaming`是一套云原生的Kafka管控平台,脱胎于众多互联网内部多年的Kafka运营实践经验,专注于Kafka运维管控、监控告警、资源治理、多活容灾等核心场景。在用户体验、监控、运维管控上进行了平台化、可视化、智能化的建设,提供一系列特色的功能,极大地方便了用户和运维人员的日常使用,让普通运维人员都能成为Kafka专家。整体具有以下特点:
|
||||
|
||||
- 👀 **零侵入、全覆盖**
|
||||
- 无需侵入改造 `Apache Kafka` ,一键便能纳管 `0.10.x` ~ `3.x.x` 众多版本的Kafka,包括 `ZK` 或 `Raft` 运行模式的版本,同时在兼容架构上具备良好的扩展性,帮助您提升集群管理水平;
|
||||
|
||||
- 🌪️ **零成本、界面化**
|
||||
- 提炼高频 CLI 能力,设计合理的产品路径,提供清新美观的 GUI 界面,支持 Cluster、Broker、Zookeeper、Topic、ConsumerGroup、Message、ACL、Connect 等组件 GUI 管理,普通用户5分钟即可上手;
|
||||
|
||||
- 👏 **云原生、插件化**
|
||||
- 基于云原生构建,具备水平扩展能力,只需要增加节点即可获取更强的采集及对外服务能力,提供众多可热插拔的企业级特性,覆盖可观测性生态整合、资源治理、多活容灾等核心场景;
|
||||
|
||||
- 🚀 **专业能力**
|
||||
- 集群管理:支持一键纳管,健康分析、核心组件观测 等功能;
|
||||
- 观测提升:多维度指标观测大盘、观测指标最佳实践 等功能;
|
||||
- 异常巡检:集群多维度健康巡检、集群多维度健康分 等功能;
|
||||
- 能力增强:集群负载均衡、Topic扩缩副本、Topic副本迁移 等功能;
|
||||
|
||||
|
||||
|
||||
**产品图**
|
||||
|
||||
<p align="center">
|
||||
|
||||
<img src="http://img-ys011.didistatic.com/static/dc2img/do1_sPmS4SNLX9m1zlpmHaLJ" width = "768" height = "473" div align=center />
|
||||
|
||||
</p>
|
||||
|
||||
|
||||
|
||||
|
||||
## 文档资源
|
||||
|
||||
**`开发相关手册`**
|
||||
|
||||
- [打包编译手册](docs/install_guide/源码编译打包手册.md)
|
||||
- [单机部署手册](docs/install_guide/单机部署手册.md)
|
||||
- [版本升级手册](docs/install_guide/版本升级手册.md)
|
||||
- [本地源码启动手册](docs/dev_guide/本地源码启动手册.md)
|
||||
|
||||
**`产品相关手册`**
|
||||
|
||||
- [产品使用指南](docs/user_guide/用户使用手册.md)
|
||||
- [2.x与3.x新旧对比手册](docs/user_guide/新旧对比手册.md)
|
||||
- [FAQ](docs/user_guide/faq.md)
|
||||
|
||||
|
||||
**点击 [这里](https://doc.knowstreaming.com/product),也可以从官网获取到更多文档**
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 成为社区贡献者
|
||||
|
||||
点击 [这里](CONTRIBUTING.md),了解如何成为 Know Streaming 的贡献者
|
||||
|
||||
|
||||
|
||||
## 加入技术交流群
|
||||
|
||||
**`1、知识星球`**
|
||||
|
||||
<p align="left">
|
||||
<img src="https://user-images.githubusercontent.com/71620349/185357284-fdff1dad-c5e9-4ddf-9a82-0be1c970980d.JPG" height = "180" div align=left />
|
||||
</p>
|
||||
|
||||
<br/>
|
||||
<br/>
|
||||
<br/>
|
||||
<br/>
|
||||
<br/>
|
||||
<br/>
|
||||
<br/>
|
||||
<br/>
|
||||
|
||||
👍 我们正在组建国内最大,最权威的 **[Kafka中文社区](https://z.didi.cn/5gSF9)**
|
||||
|
||||
在这里你可以结交各大互联网的 Kafka大佬 以及 4000+ Kafka爱好者,一起实现知识共享,实时掌控最新行业资讯,期待 👏 您的加入中~ https://z.didi.cn/5gSF9
|
||||
|
||||
有问必答~! 互动有礼~!
|
||||
|
||||
PS: 提问请尽量把问题一次性描述清楚,并告知环境信息情况~!如使用版本、操作步骤、报错/警告信息等,方便大V们快速解答~
|
||||
|
||||
|
||||
|
||||
**`2、微信群`**
|
||||
|
||||
微信加群:添加`mike_zhangliang`、`PenceXie`的微信号备注KnowStreaming加群。
|
||||
|
||||
## Star History
|
||||
|
||||
[](https://star-history.com/#didi/KnowStreaming&Date)
|
||||
|
||||
---
|
||||
|
||||

|
||||
|
||||
**一站式`Apache Kafka`集群指标监控与运维管控平台**
|
||||
|
||||
---
|
||||
|
||||
## 主要功能特性
|
||||
|
||||
|
||||
### 集群监控维度
|
||||
|
||||
- 多版本集群管控,支持从`0.10.2`到`2.x`版本;
|
||||
- 集群Topic、Broker等多维度历史与实时关键指标查看;
|
||||
|
||||
|
||||
### 集群管控维度
|
||||
|
||||
- 集群运维,包括逻辑Region方式管理集群
|
||||
- Broker运维,包括优先副本选举
|
||||
- Topic运维,包括创建、查询、扩容、修改属性、数据采样及迁移等;
|
||||
- 消费组运维,包括指定时间或指定偏移两种方式进行重置消费偏移
|
||||
|
||||
|
||||
### 用户使用维度
|
||||
|
||||
- Kafka用户、Kafka研发、Kafka运维 视角区分
|
||||
- Kafka用户、Kafka研发、Kafka运维 权限区分
|
||||
|
||||
|
||||
## kafka-manager架构图
|
||||
|
||||

|
||||
|
||||
|
||||
## 相关文档
|
||||
|
||||
- [kafka-manager 安装手册](docs/install_guide/install_guide_cn.md)
|
||||
- [kafka-manager 接入集群](docs/user_guide/add_cluster/add_cluster.md)
|
||||
- [kafka-manager 用户使用手册](docs/user_guide/user_guide_cn.md)
|
||||
- [kafka-manager FAQ](docs/user_guide/faq.md)
|
||||
|
||||
## 钉钉交流群
|
||||
|
||||

|
||||
|
||||
|
||||
## 项目成员
|
||||
|
||||
### 内部核心人员
|
||||
|
||||
`iceyuhui`、`liuyaguang`、`limengmonty`、`zhangliangmike`、`nullhuangyiming`、`zengqiao`、`eilenexuzhe`、`huangjiaweihjw`
|
||||
|
||||
|
||||
### 外部贡献者
|
||||
|
||||
`fangjunyu`、`zhoutaiyang`
|
||||
|
||||
|
||||
## 协议
|
||||
|
||||
`kafka-manager`基于`Apache-2.0`协议进行分发和使用,更多信息参见[协议文件](./LICENSE)
|
||||
|
||||
@@ -1,369 +0,0 @@
|
||||
|
||||
|
||||
## v3.0.0-beta.3
|
||||
|
||||
**文档**
|
||||
- FAQ 补充权限识别失败问题的说明
|
||||
- 同步更新文档,保持与官网一致
|
||||
|
||||
|
||||
**Bug修复**
|
||||
- Offset 信息获取时,过滤掉无 Leader 的分区
|
||||
- 升级 oshi-core 版本至 5.6.1 版本,修复 Windows 系统获取系统指标失败问题
|
||||
- 修复 JMX 连接被关闭后,未进行重建的问题
|
||||
- 修复因 DB 中 Broker 信息不存在导致 TotalLogSize 指标获取时抛空指针问题
|
||||
- 修复 dml-logi.sql 中,SQL 注释错误的问题
|
||||
- 修复 startup.sh 中,识别操作系统类型错误的问题
|
||||
- 修复配置管理页面删除配置失败的问题
|
||||
- 修复系统管理应用文件引用路径
|
||||
- 修复 Topic Messages 详情提示信息点击跳转 404 的问题
|
||||
- 修复扩副本时,当前副本数不显示问题
|
||||
|
||||
|
||||
**体验优化**
|
||||
- Topic-Messages 页面,增加返回数据的排序以及按照Earliest/Latest的获取方式
|
||||
- 优化 GroupOffsetResetEnum 类名为 OffsetTypeEnum,使得类名含义更准确
|
||||
- 移动 KafkaZKDAO 类,及 Kafka Znode 实体类的位置,使得 Kafka Zookeeper DAO 更加内聚及便于识别
|
||||
- 后端补充 Overview 页面指标排序的功能
|
||||
- 前端 Webpack 配置优化
|
||||
- Cluster Overview 图表取消放大展示功能
|
||||
- 列表页增加手动刷新功能
|
||||
- 接入/编辑集群,优化 JMX-PORT,Version 信息的回显,优化JMX信息的展示
|
||||
- 提高登录页面图片展示清晰度
|
||||
- 部分样式和文案优化
|
||||
|
||||
---
|
||||
|
||||
## v3.0.0-beta.2
|
||||
|
||||
**文档**
|
||||
- 新增登录系统对接文档
|
||||
- 优化前端工程打包构建部分文档说明
|
||||
- FAQ补充KnowStreaming连接特定JMX IP的说明
|
||||
|
||||
|
||||
**Bug修复**
|
||||
- 修复logi_security_oplog表字段过短,导致删除Topic等操作无法记录的问题
|
||||
- 修复ES查询时,抛java.lang.NumberFormatException: For input string: "{"value":0,"relation":"eq"}" 问题
|
||||
- 修复LogStartOffset和LogEndOffset指标单位错误问题
|
||||
- 修复进行副本变更时,旧副本数为NULL的问题
|
||||
- 修复集群Group列表,在第二页搜索时,搜索时返回的分页信息错误问题
|
||||
- 修复重置Offset时,返回的错误信息提示不一致的问题
|
||||
- 修复集群查看,系统查看,LoadRebalance等页面权限点缺失问题
|
||||
- 修复查询不存在的Topic时,错误信息提示不明显的问题
|
||||
- 修复Windows用户打包前端工程报错的问题
|
||||
- package-lock.json锁定前端依赖版本号,修复因依赖自动升级导致打包失败等问题
|
||||
- 系统管理子应用,补充后端返回的Code码拦截,解决后端接口返回报错不展示的问题
|
||||
- 修复用户登出后,依旧可以访问系统的问题
|
||||
- 修复巡检任务配置时,数值显示错误的问题
|
||||
- 修复Broker/Topic Overview 图表和图表详情问题
|
||||
- 修复Job扩缩副本任务明细数据错误的问题
|
||||
- 修复重置Offset时,分区ID,Offset数值无限制问题
|
||||
- 修复扩缩/迁移副本时,无法选中Kafka系统Topic的问题
|
||||
- 修复Topic的Config页面,编辑表单时不能正确回显当前值的问题
|
||||
- 修复Broker Card返回数据后依旧展示加载态的问题
|
||||
|
||||
|
||||
|
||||
**体验优化**
|
||||
- 优化默认用户密码为 admin/admin
|
||||
- 缩短新增集群后,集群信息加载的耗时
|
||||
- 集群Broker列表,增加Controller角色信息
|
||||
- 副本变更任务结束后,增加进行优先副本选举的操作
|
||||
- Task模块任务分为Metrics、Common、Metadata三类任务,每类任务配备独立线程池,减少对Job模块的线程池,以及不同类任务之间的相互影响
|
||||
- 删除代码中存在的多余无用文件
|
||||
- 自动新增ES索引模版及近7天索引,减少用户搭建时需要做的事项
|
||||
- 优化前端工程打包流程
|
||||
- 优化登录页文案,页面左侧栏内容,单集群详情样式,Topic列表趋势图等
|
||||
- 首次进入Broker/Topic图表详情时,进行预缓存数据从而优化体验
|
||||
- 优化Topic详情Partition Tab的展示
|
||||
- 多集群列表页增加编辑功能
|
||||
- 优化副本变更时,迁移时间支持分钟级别粒度
|
||||
- logi-security版本升级至2.10.13
|
||||
- logi-elasticsearch-client版本升级至1.0.24
|
||||
|
||||
|
||||
**能力提升**
|
||||
- 支持Ldap登录认证
|
||||
|
||||
---
|
||||
|
||||
## v3.0.0-beta.1
|
||||
|
||||
**文档**
|
||||
- 新增Task模块说明文档
|
||||
- FAQ补充 `Specified key was too long; max key length is 767 bytes ` 错误说明
|
||||
- FAQ补充 `出现ESIndexNotFoundException报错` 错误说明
|
||||
|
||||
|
||||
**Bug修复**
|
||||
- 修复 Consumer 点击 Stop 未停止检索的问题
|
||||
- 修复创建/编辑角色权限报错问题
|
||||
- 修复多集群管理/单集群详情均衡卡片状态错误问题
|
||||
- 修复版本列表未排序问题
|
||||
- 修复Raft集群Controller信息不断记录问题
|
||||
- 修复部分版本消费组描述信息获取失败问题
|
||||
- 修复分区Offset获取失败的日志中,缺少Topic名称信息问题
|
||||
- 修复GitHub图地址错误,及图裂问题
|
||||
- 修复Broker默认使用的地址和注释不一致问题
|
||||
- 修复 Consumer 列表分页不生效问题
|
||||
- 修复操作记录表operation_methods字段缺少默认值问题
|
||||
- 修复集群均衡表中move_broker_list字段无效的问题
|
||||
- 修复KafkaUser、KafkaACL信息获取时,日志一直重复提示不支持问题
|
||||
- 修复指标缺失时,曲线出现掉底的问题
|
||||
|
||||
|
||||
**体验优化**
|
||||
- 优化前端构建时间和打包体积,增加依赖打包的分包策略
|
||||
- 优化产品样式和文案展示
|
||||
- 优化ES客户端数为可配置
|
||||
- 优化日志中大量出现的MySQL Key冲突日志
|
||||
|
||||
|
||||
**能力提升**
|
||||
- 增加周期任务,用于主动创建缺少的ES模版及索引的能力,减少额外的脚本操作
|
||||
- 增加JMX连接的Broker地址可选择的能力
|
||||
|
||||
---
|
||||
|
||||
## v3.0.0-beta.0
|
||||
|
||||
**1、多集群管理**
|
||||
|
||||
- 增加健康监测体系、关键组件&指标 GUI 展示
|
||||
- 增加 2.8.x 以上 Kafka 集群接入,覆盖 0.10.x-3.x
|
||||
- 删除逻辑集群、共享集群、Region 概念
|
||||
|
||||
**2、Cluster 管理**
|
||||
|
||||
- 增加集群概览信息、集群配置变更记录
|
||||
- 增加 Cluster 健康分,健康检查规则支持自定义配置
|
||||
- 增加 Cluster 关键指标统计和 GUI 展示,支持自定义配置
|
||||
- 增加 Cluster 层 I/O、Disk 的 Load Reblance 功能,支持定时均衡任务(企业版)
|
||||
- 删除限流、鉴权功能
|
||||
- 删除 APPID 概念
|
||||
|
||||
**3、Broker 管理**
|
||||
|
||||
- 增加 Broker 健康分
|
||||
- 增加 Broker 关键指标统计和 GUI 展示,支持自定义配置
|
||||
- 增加 Broker 参数配置功能,需重启生效
|
||||
- 增加 Controller 变更记录
|
||||
- 增加 Broker Datalogs 记录
|
||||
- 删除 Leader Rebalance 功能
|
||||
- 删除 Broker 优先副本选举
|
||||
|
||||
**4、Topic 管理**
|
||||
|
||||
- 增加 Topic 健康分
|
||||
- 增加 Topic 关键指标统计和 GUI 展示,支持自定义配置
|
||||
- 增加 Topic 参数配置功能,可实时生效
|
||||
- 增加 Topic 批量迁移、Topic 批量扩缩副本功能
|
||||
- 增加查看系统 Topic 功能
|
||||
- 优化 Partition 分布的 GUI 展示
|
||||
- 优化 Topic Message 数据采样
|
||||
- 删除 Topic 过期概念
|
||||
- 删除 Topic 申请配额功能
|
||||
|
||||
**5、Consumer 管理**
|
||||
|
||||
- 优化了 ConsumerGroup 展示形式,增加 Consumer Lag 的 GUI 展示
|
||||
|
||||
**6、ACL 管理**
|
||||
|
||||
- 增加原生 ACL GUI 配置功能,可配置生产、消费、自定义多种组合权限
|
||||
- 增加 KafkaUser 功能,可自定义新增 KafkaUser
|
||||
|
||||
**7、消息测试(企业版)**
|
||||
|
||||
- 增加生产者消息模拟器,支持 Data、Flow、Header、Options 自定义配置(企业版)
|
||||
- 增加消费者消息模拟器,支持 Data、Flow、Header、Options 自定义配置(企业版)
|
||||
|
||||
**8、Job**
|
||||
|
||||
- 优化 Job 模块,支持任务进度管理
|
||||
|
||||
**9、系统管理**
|
||||
|
||||
- 优化用户、角色管理体系,支持自定义角色配置页面及操作权限
|
||||
- 优化审计日志信息
|
||||
- 删除多租户体系
|
||||
- 删除工单流程
|
||||
|
||||
---
|
||||
|
||||
## v2.6.0
|
||||
|
||||
版本上线时间:2022-01-24
|
||||
|
||||
### 能力提升
|
||||
- 增加简单回退工具类
|
||||
|
||||
### 体验优化
|
||||
- 补充周期任务说明文档
|
||||
- 补充集群安装部署使用说明文档
|
||||
- 升级Swagger、SpringFramework、SpringBoot、EChats版本
|
||||
- 优化Task模块的日志输出
|
||||
- 优化corn表达式解析失败后退出无任何日志提示问题
|
||||
- Ldap用户接入时,增加部门及邮箱信息等
|
||||
- 对Jmx模块,增加连接失败后的回退机制及错误日志优化
|
||||
- 增加线程池、客户端池可配置
|
||||
- 删除无用的jmx_prometheus_javaagent-0.14.0.jar
|
||||
- 优化迁移任务名称
|
||||
- 优化创建Region时,Region容量信息不能立即被更新问题
|
||||
- 引入lombok
|
||||
- 更新视频教程
|
||||
- 优化kcm_script.sh脚本中的LogiKM地址为可通过程序传入
|
||||
- 第三方接口及网关接口,增加是否跳过登录的开关
|
||||
- extends模块相关配置调整为非必须在application.yml中配置
|
||||
|
||||
### bug修复
|
||||
- 修复批量往DB写入空指标数组时报SQL语法异常的问题
|
||||
- 修复网关增加配置及修改配置时,version不变化问题
|
||||
- 修复集群列表页,提示框遮挡问题
|
||||
- 修复对高版本Broker元信息协议解析失败的问题
|
||||
- 修复Dockerfile执行时提示缺少application.yml文件的问题
|
||||
- 修复逻辑集群更新时,会报空指针的问题
|
||||
|
||||
|
||||
## v2.5.0
|
||||
|
||||
版本上线时间:2021-07-10
|
||||
|
||||
### 体验优化
|
||||
- 更改产品名为LogiKM
|
||||
- 更新产品图标
|
||||
|
||||
|
||||
## v2.4.1+
|
||||
|
||||
版本上线时间:2021-05-21
|
||||
|
||||
### 能力提升
|
||||
- 增加直接增加权限和配额的接口(v2.4.1)
|
||||
- 增加接口调用可绕过登录的功能(v2.4.1)
|
||||
|
||||
### 体验优化
|
||||
- Tomcat 版本提升至8.5.66(v2.4.2)
|
||||
- op接口优化,拆分util接口为topic、leader两类接口(v2.4.1)
|
||||
- 简化Gateway配置的Key长度(v2.4.1)
|
||||
|
||||
### bug修复
|
||||
- 修复页面展示版本错误问题(v2.4.2)
|
||||
|
||||
|
||||
## v2.4.0
|
||||
|
||||
版本上线时间:2021-05-18
|
||||
|
||||
|
||||
### 能力提升
|
||||
|
||||
- 增加App与Topic自动化审批开关
|
||||
- Broker元信息中增加Rack信息
|
||||
- 升级MySQL 驱动,支持MySQL 8+
|
||||
- 增加操作记录查询界面
|
||||
|
||||
### 体验优化
|
||||
|
||||
- FAQ告警组说明优化
|
||||
- 用户手册共享及 独享集群概念优化
|
||||
- 用户管理界面,前端限制用户删除自己
|
||||
|
||||
### bug修复
|
||||
|
||||
- 修复op-util类中创建Topic失败的接口
|
||||
- 周期同步Topic到DB的任务修复,将Topic列表查询从缓存调整为直接查DB
|
||||
- 应用下线审批失败的功能修复,将权限为0(无权限)的数据进行过滤
|
||||
- 修复登录及权限绕过的漏洞
|
||||
- 修复研发角色展示接入集群、暂停监控等按钮的问题
|
||||
|
||||
|
||||
## v2.3.0
|
||||
|
||||
版本上线时间:2021-02-08
|
||||
|
||||
|
||||
### 能力提升
|
||||
|
||||
- 新增支持docker化部署
|
||||
- 可指定Broker作为候选controller
|
||||
- 可新增并管理网关配置
|
||||
- 可获取消费组状态
|
||||
- 增加集群的JMX认证
|
||||
|
||||
### 体验优化
|
||||
|
||||
- 优化编辑用户角色、修改密码的流程
|
||||
- 新增consumerID的搜索功能
|
||||
- 优化“Topic连接信息”、“消费组重置消费偏移”、“修改Topic保存时间”的文案提示
|
||||
- 在相应位置增加《资源申请文档》链接
|
||||
|
||||
### bug修复
|
||||
|
||||
- 修复Broker监控图表时间轴展示错误的问题
|
||||
- 修复创建夜莺监控告警规则时,使用的告警周期的单位不正确的问题
|
||||
|
||||
|
||||
|
||||
## v2.2.0
|
||||
|
||||
版本上线时间:2021-01-25
|
||||
|
||||
|
||||
|
||||
### 能力提升
|
||||
|
||||
- 优化工单批量操作流程
|
||||
- 增加获取Topic75分位/99分位的实时耗时数据
|
||||
- 增加定时任务,可将无主未落DB的Topic定期写入DB
|
||||
|
||||
### 体验优化
|
||||
|
||||
- 在相应位置增加《集群接入文档》链接
|
||||
- 优化物理集群、逻辑集群含义
|
||||
- 在Topic详情页、Topic扩分区操作弹窗增加展示Topic所属Region的信息
|
||||
- 优化Topic审批时,Topic数据保存时间的配置流程
|
||||
- 优化Topic/应用申请、审批时的错误提示文案
|
||||
- 优化Topic数据采样的操作项文案
|
||||
- 优化运维人员删除Topic时的提示文案
|
||||
- 优化运维人员删除Region的删除逻辑与提示文案
|
||||
- 优化运维人员删除逻辑集群的提示文案
|
||||
- 优化上传集群配置文件时的文件类型限制条件
|
||||
|
||||
### bug修复
|
||||
|
||||
- 修复填写应用名称时校验特殊字符出错的问题
|
||||
- 修复普通用户越权访问应用详情的问题
|
||||
- 修复由于Kafka版本升级,导致的数据压缩格式无法获取的问题
|
||||
- 修复删除逻辑集群或Topic之后,界面依旧展示的问题
|
||||
- 修复进行Leader rebalance操作时执行结果重复提示的问题
|
||||
|
||||
|
||||
## v2.1.0
|
||||
|
||||
版本上线时间:2020-12-19
|
||||
|
||||
|
||||
|
||||
### 体验优化
|
||||
|
||||
- 优化页面加载时的背景样式
|
||||
- 优化普通用户申请Topic权限的流程
|
||||
- 优化Topic申请配额、申请分区的权限限制
|
||||
- 优化取消Topic权限的文案提示
|
||||
- 优化申请配额表单的表单项名称
|
||||
- 优化重置消费偏移的操作流程
|
||||
- 优化创建Topic迁移任务的表单内容
|
||||
- 优化Topic扩分区操作的弹窗界面样式
|
||||
- 优化集群Broker监控可视化图表样式
|
||||
- 优化创建逻辑集群的表单内容
|
||||
- 优化集群安全协议的提示文案
|
||||
|
||||
### bug修复
|
||||
|
||||
- 修复偶发性重置消费偏移失败的问题
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -1,655 +0,0 @@
|
||||
esaddr=127.0.0.1
|
||||
port=8060
|
||||
curl -s --connect-timeout 10 -o /dev/null http://${esaddr}:${port}/_cat/nodes >/dev/null 2>&1
|
||||
if [ "$?" != "0" ];then
|
||||
echo "Elasticserach 访问失败, 请安装完后检查并重新执行该脚本 "
|
||||
exit
|
||||
fi
|
||||
|
||||
curl -s --connect-timeout 10 -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${esaddr}:${port}/_template/ks_kafka_broker_metric -d '{
|
||||
"order" : 10,
|
||||
"index_patterns" : [
|
||||
"ks_kafka_broker_metric*"
|
||||
],
|
||||
"settings" : {
|
||||
"index" : {
|
||||
"number_of_shards" : "10"
|
||||
}
|
||||
},
|
||||
"mappings" : {
|
||||
"properties" : {
|
||||
"brokerId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"routingValue" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"clusterPhyId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"metrics" : {
|
||||
"properties" : {
|
||||
"NetworkProcessorAvgIdle" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"UnderReplicatedPartitions" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesIn_min_15" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"HealthCheckTotal" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"RequestHandlerAvgIdle" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"connectionsCount" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesIn_min_5" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"HealthScore" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesOut" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesOut_min_15" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesIn" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesOut_min_5" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"TotalRequestQueueSize" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"MessagesIn" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"TotalProduceRequests" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"HealthCheckPassed" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"TotalResponseQueueSize" : {
|
||||
"type" : "float"
|
||||
}
|
||||
}
|
||||
},
|
||||
"key" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"timestamp" : {
|
||||
"format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
|
||||
"index" : true,
|
||||
"type" : "date",
|
||||
"doc_values" : true
|
||||
}
|
||||
}
|
||||
},
|
||||
"aliases" : { }
|
||||
}'
|
||||
|
||||
curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${esaddr}:${port}/_template/ks_kafka_cluster_metric -d '{
|
||||
"order" : 10,
|
||||
"index_patterns" : [
|
||||
"ks_kafka_cluster_metric*"
|
||||
],
|
||||
"settings" : {
|
||||
"index" : {
|
||||
"number_of_shards" : "10"
|
||||
}
|
||||
},
|
||||
"mappings" : {
|
||||
"properties" : {
|
||||
"routingValue" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"clusterPhyId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"metrics" : {
|
||||
"properties" : {
|
||||
"Connections" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"BytesIn_min_15" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"PartitionURP" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthScore_Topics" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"EventQueueSize" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"ActiveControllerCount" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"GroupDeads" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"BytesIn_min_5" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthCheckTotal_Topics" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"Partitions" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"BytesOut" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"Groups" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"BytesOut_min_15" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"TotalRequestQueueSize" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthCheckPassed_Groups" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"TotalProduceRequests" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthCheckPassed" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"TotalLogSize" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"GroupEmptys" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"PartitionNoLeader" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthScore_Brokers" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"Messages" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"Topics" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"PartitionMinISR_E" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthCheckTotal" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"Brokers" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"Replicas" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthCheckTotal_Groups" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"GroupRebalances" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"MessageIn" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthScore" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthCheckPassed_Topics" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthCheckTotal_Brokers" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"PartitionMinISR_S" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"BytesIn" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"BytesOut_min_5" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"GroupActives" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"MessagesIn" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"GroupReBalances" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthCheckPassed_Brokers" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthScore_Groups" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"TotalResponseQueueSize" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"Zookeepers" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"LeaderMessages" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthScore_Cluster" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthCheckPassed_Cluster" : {
|
||||
"type" : "double"
|
||||
},
|
||||
"HealthCheckTotal_Cluster" : {
|
||||
"type" : "double"
|
||||
}
|
||||
}
|
||||
},
|
||||
"key" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"timestamp" : {
|
||||
"format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
|
||||
"type" : "date"
|
||||
}
|
||||
}
|
||||
},
|
||||
"aliases" : { }
|
||||
}'
|
||||
|
||||
curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${esaddr}:${port}/_template/ks_kafka_group_metric -d '{
|
||||
"order" : 10,
|
||||
"index_patterns" : [
|
||||
"ks_kafka_group_metric*"
|
||||
],
|
||||
"settings" : {
|
||||
"index" : {
|
||||
"number_of_shards" : "10"
|
||||
}
|
||||
},
|
||||
"mappings" : {
|
||||
"properties" : {
|
||||
"group" : {
|
||||
"type" : "keyword"
|
||||
},
|
||||
"partitionId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"routingValue" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"clusterPhyId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"topic" : {
|
||||
"type" : "keyword"
|
||||
},
|
||||
"metrics" : {
|
||||
"properties" : {
|
||||
"HealthScore" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"Lag" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"OffsetConsumed" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"HealthCheckTotal" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"HealthCheckPassed" : {
|
||||
"type" : "float"
|
||||
}
|
||||
}
|
||||
},
|
||||
"groupMetric" : {
|
||||
"type" : "keyword"
|
||||
},
|
||||
"key" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"timestamp" : {
|
||||
"format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
|
||||
"index" : true,
|
||||
"type" : "date",
|
||||
"doc_values" : true
|
||||
}
|
||||
}
|
||||
},
|
||||
"aliases" : { }
|
||||
}'
|
||||
|
||||
curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${esaddr}:${port}/_template/ks_kafka_partition_metric -d '{
|
||||
"order" : 10,
|
||||
"index_patterns" : [
|
||||
"ks_kafka_partition_metric*"
|
||||
],
|
||||
"settings" : {
|
||||
"index" : {
|
||||
"number_of_shards" : "10"
|
||||
}
|
||||
},
|
||||
"mappings" : {
|
||||
"properties" : {
|
||||
"brokerId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"partitionId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"routingValue" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"clusterPhyId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"topic" : {
|
||||
"type" : "keyword"
|
||||
},
|
||||
"metrics" : {
|
||||
"properties" : {
|
||||
"LogStartOffset" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"Messages" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"LogEndOffset" : {
|
||||
"type" : "float"
|
||||
}
|
||||
}
|
||||
},
|
||||
"key" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"timestamp" : {
|
||||
"format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
|
||||
"index" : true,
|
||||
"type" : "date",
|
||||
"doc_values" : true
|
||||
}
|
||||
}
|
||||
},
|
||||
"aliases" : { }
|
||||
}'
|
||||
|
||||
curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${esaddr}:${port}/_template/ks_kafka_replication_metric -d '{
|
||||
"order" : 10,
|
||||
"index_patterns" : [
|
||||
"ks_kafka_partition_metric*"
|
||||
],
|
||||
"settings" : {
|
||||
"index" : {
|
||||
"number_of_shards" : "10"
|
||||
}
|
||||
},
|
||||
"mappings" : {
|
||||
"properties" : {
|
||||
"brokerId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"partitionId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"routingValue" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"clusterPhyId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"topic" : {
|
||||
"type" : "keyword"
|
||||
},
|
||||
"metrics" : {
|
||||
"properties" : {
|
||||
"LogStartOffset" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"Messages" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"LogEndOffset" : {
|
||||
"type" : "float"
|
||||
}
|
||||
}
|
||||
},
|
||||
"key" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"timestamp" : {
|
||||
"format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
|
||||
"index" : true,
|
||||
"type" : "date",
|
||||
"doc_values" : true
|
||||
}
|
||||
}
|
||||
},
|
||||
"aliases" : { }
|
||||
}[root@10-255-0-23 template]# cat ks_kafka_replication_metric
|
||||
PUT _template/ks_kafka_replication_metric
|
||||
{
|
||||
"order" : 10,
|
||||
"index_patterns" : [
|
||||
"ks_kafka_replication_metric*"
|
||||
],
|
||||
"settings" : {
|
||||
"index" : {
|
||||
"number_of_shards" : "10"
|
||||
}
|
||||
},
|
||||
"mappings" : {
|
||||
"properties" : {
|
||||
"timestamp" : {
|
||||
"format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
|
||||
"index" : true,
|
||||
"type" : "date",
|
||||
"doc_values" : true
|
||||
}
|
||||
}
|
||||
},
|
||||
"aliases" : { }
|
||||
}'
|
||||
|
||||
curl -s -o /dev/null -X POST -H 'cache-control: no-cache' -H 'content-type: application/json' http://${esaddr}:${port}/_template/ks_kafka_topic_metric -d '{
|
||||
"order" : 10,
|
||||
"index_patterns" : [
|
||||
"ks_kafka_topic_metric*"
|
||||
],
|
||||
"settings" : {
|
||||
"index" : {
|
||||
"number_of_shards" : "10"
|
||||
}
|
||||
},
|
||||
"mappings" : {
|
||||
"properties" : {
|
||||
"brokerId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"routingValue" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"topic" : {
|
||||
"type" : "keyword"
|
||||
},
|
||||
"clusterPhyId" : {
|
||||
"type" : "long"
|
||||
},
|
||||
"metrics" : {
|
||||
"properties" : {
|
||||
"BytesIn_min_15" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"Messages" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesRejected" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"PartitionURP" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"HealthCheckTotal" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"ReplicationCount" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"ReplicationBytesOut" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"ReplicationBytesIn" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"FailedFetchRequests" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesIn_min_5" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"HealthScore" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"LogSize" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesOut" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesOut_min_15" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"FailedProduceRequests" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesIn" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"BytesOut_min_5" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"MessagesIn" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"TotalProduceRequests" : {
|
||||
"type" : "float"
|
||||
},
|
||||
"HealthCheckPassed" : {
|
||||
"type" : "float"
|
||||
}
|
||||
}
|
||||
},
|
||||
"brokerAgg" : {
|
||||
"type" : "keyword"
|
||||
},
|
||||
"key" : {
|
||||
"type" : "text",
|
||||
"fields" : {
|
||||
"keyword" : {
|
||||
"ignore_above" : 256,
|
||||
"type" : "keyword"
|
||||
}
|
||||
}
|
||||
},
|
||||
"timestamp" : {
|
||||
"format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
|
||||
"index" : true,
|
||||
"type" : "date",
|
||||
"doc_values" : true
|
||||
}
|
||||
}
|
||||
},
|
||||
"aliases" : { }
|
||||
}'
|
||||
|
||||
for i in {0..6};
|
||||
do
|
||||
logdate=_$(date -d "${i} day ago" +%Y-%m-%d)
|
||||
curl -s --connect-timeout 10 -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_broker_metric${logdate} && \
|
||||
curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_cluster_metric${logdate} && \
|
||||
curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_group_metric${logdate} && \
|
||||
curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_partition_metric${logdate} && \
|
||||
curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_replication_metric${logdate} && \
|
||||
curl -s -o /dev/null -X PUT http://${esaddr}:${port}/ks_kafka_topic_metric${logdate} || \
|
||||
exit 2
|
||||
done
|
||||
@@ -1,16 +0,0 @@
|
||||
#!/bin/bash
|
||||
|
||||
cd `dirname $0`/../libs
|
||||
target_dir=`pwd`
|
||||
|
||||
pid=`ps ax | grep -i 'ks-km' | grep ${target_dir} | grep java | grep -v grep | awk '{print $1}'`
|
||||
if [ -z "$pid" ] ; then
|
||||
echo "No ks-km running."
|
||||
exit -1;
|
||||
fi
|
||||
|
||||
echo "The ks-km (${pid}) is running..."
|
||||
|
||||
kill ${pid}
|
||||
|
||||
echo "Send shutdown request to ks-km (${pid}) OK"
|
||||
@@ -1,82 +0,0 @@
|
||||
error_exit ()
|
||||
{
|
||||
echo "ERROR: $1 !!"
|
||||
exit 1
|
||||
}
|
||||
|
||||
[ ! -e "$JAVA_HOME/bin/java" ] && JAVA_HOME=$HOME/jdk/java
|
||||
[ ! -e "$JAVA_HOME/bin/java" ] && JAVA_HOME=/usr/java
|
||||
[ ! -e "$JAVA_HOME/bin/java" ] && unset JAVA_HOME
|
||||
|
||||
if [ -z "$JAVA_HOME" ]; then
|
||||
if [ "Darwin" = "$(uname -s)" ]; then
|
||||
|
||||
if [ -x '/usr/libexec/java_home' ] ; then
|
||||
export JAVA_HOME=`/usr/libexec/java_home`
|
||||
|
||||
elif [ -d "/System/Library/Frameworks/JavaVM.framework/Versions/CurrentJDK/Home" ]; then
|
||||
export JAVA_HOME="/System/Library/Frameworks/JavaVM.framework/Versions/CurrentJDK/Home"
|
||||
fi
|
||||
else
|
||||
JAVA_PATH=`dirname $(readlink -f $(which javac))`
|
||||
if [ "x$JAVA_PATH" != "x" ]; then
|
||||
export JAVA_HOME=`dirname $JAVA_PATH 2>/dev/null`
|
||||
fi
|
||||
fi
|
||||
if [ -z "$JAVA_HOME" ]; then
|
||||
error_exit "Please set the JAVA_HOME variable in your environment, We need java(x64)! jdk8 or later is better!"
|
||||
fi
|
||||
fi
|
||||
|
||||
|
||||
|
||||
|
||||
export WEB_SERVER="ks-km"
|
||||
export JAVA_HOME
|
||||
export JAVA="$JAVA_HOME/bin/java"
|
||||
export BASE_DIR=`cd $(dirname $0)/..; pwd`
|
||||
export CUSTOM_SEARCH_LOCATIONS=file:${BASE_DIR}/conf/
|
||||
|
||||
|
||||
#===========================================================================================
|
||||
# JVM Configuration
|
||||
#===========================================================================================
|
||||
|
||||
JAVA_OPT="${JAVA_OPT} -server -Xms2g -Xmx2g -Xmn1g -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=320m"
|
||||
JAVA_OPT="${JAVA_OPT} -XX:-OmitStackTraceInFastThrow -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${BASE_DIR}/logs/java_heapdump.hprof"
|
||||
|
||||
## jdk版本高的情况 有些 参数废弃了
|
||||
JAVA_MAJOR_VERSION=$($JAVA -version 2>&1 | sed -E -n 's/.* version "([0-9]*).*$/\1/p')
|
||||
if [[ "$JAVA_MAJOR_VERSION" -ge "9" ]] ; then
|
||||
JAVA_OPT="${JAVA_OPT} -Xlog:gc*:file=${BASE_DIR}/logs/km_gc.log:time,tags:filecount=10,filesize=102400"
|
||||
else
|
||||
JAVA_OPT="${JAVA_OPT} -Djava.ext.dirs=${JAVA_HOME}/jre/lib/ext:${JAVA_HOME}/lib/ext"
|
||||
JAVA_OPT="${JAVA_OPT} -Xloggc:${BASE_DIR}/logs/km_gc.log -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=100M"
|
||||
|
||||
fi
|
||||
|
||||
JAVA_OPT="${JAVA_OPT} -jar ${BASE_DIR}/libs/${WEB_SERVER}.jar"
|
||||
JAVA_OPT="${JAVA_OPT} --spring.config.additional-location=${CUSTOM_SEARCH_LOCATIONS}"
|
||||
JAVA_OPT="${JAVA_OPT} --logging.config=${BASE_DIR}/conf/logback-spring.xml"
|
||||
JAVA_OPT="${JAVA_OPT} --server.max-http-header-size=524288"
|
||||
|
||||
|
||||
|
||||
if [ ! -d "${BASE_DIR}/logs" ]; then
|
||||
mkdir ${BASE_DIR}/logs
|
||||
fi
|
||||
|
||||
echo "$JAVA ${JAVA_OPT}"
|
||||
|
||||
# check the start.out log output file
|
||||
if [ ! -f "${BASE_DIR}/logs/start.out" ]; then
|
||||
touch "${BASE_DIR}/logs/start.out"
|
||||
fi
|
||||
|
||||
# start
|
||||
echo -e "---- 启动脚本 ------\n $JAVA ${JAVA_OPT}" > ${BASE_DIR}/logs/start.out 2>&1 &
|
||||
|
||||
|
||||
nohup $JAVA ${JAVA_OPT} >> ${BASE_DIR}/logs/start.out 2>&1 &
|
||||
|
||||
echo "${WEB_SERVER} is starting,you can check the ${BASE_DIR}/logs/start.out"
|
||||
91
build.sh
Normal file
@@ -0,0 +1,91 @@
|
||||
#!/bin/bash
|
||||
workspace=$(cd $(dirname $0) && pwd -P)
|
||||
cd $workspace
|
||||
|
||||
## constant
|
||||
app_name=kafka-manager
|
||||
output_dir=output
|
||||
|
||||
gitversion=.gitversion
|
||||
control=./control.sh
|
||||
create_mysql_table=./docs/install_guide/create_mysql_table.sql
|
||||
app_config_file=./kafka-manager-web/src/main/resources/application.yml
|
||||
|
||||
## function
|
||||
function build() {
|
||||
# 进行编译
|
||||
# # cmd 设置使用的JDK, 按需选择, 默认已安装了JDK 8
|
||||
# JVERSION=`java -version 2>&1 | awk 'NR==1{gsub(/"/,"");print $3}'`
|
||||
# major=`echo $JVERSION | awk -F. '{print $1}'`
|
||||
# mijor=`echo $JVERSION | awk -F. '{print $2}'`
|
||||
# if [ $major -le 1 ] && [ $mijor -lt 8 ]; then
|
||||
# export JAVA_HOME=/usr/local/jdk1.8.0_65 #(使用jdk8请设置)
|
||||
# export PATH=$JAVA_HOME/bin:$PATH
|
||||
# fi
|
||||
|
||||
# 编译命令
|
||||
mvn -U clean package -Dmaven.test.skip=true
|
||||
|
||||
local sc=$?
|
||||
if [ $sc -ne 0 ];then
|
||||
## 编译失败, 退出码为 非0
|
||||
echo "$app_name build error"
|
||||
exit $sc
|
||||
else
|
||||
echo -n "$app_name build ok, vsn="`gitversion`
|
||||
fi
|
||||
}
|
||||
|
||||
function make_output() {
|
||||
# 新建output目录
|
||||
rm -rf $output_dir &>/dev/null
|
||||
mkdir -p $output_dir &>/dev/null
|
||||
|
||||
# 填充output目录, output内的内容 即为 线上部署内容
|
||||
(
|
||||
# cp -rf $control $output_dir && # 拷贝 control.sh 脚本 至output目录
|
||||
cp -rf $create_mysql_table $output_dir && # 拷贝 sql 初始化脚本 至output目录
|
||||
cp -rf $app_config_file $output_dir && # 拷贝 application.yml 至output目录
|
||||
|
||||
# 拷贝程序包到output路径
|
||||
cp kafka-manager-web/target/${app_name}-*-SNAPSHOT.jar ${output_dir}/${app_name}.jar
|
||||
echo -e "make output ok."
|
||||
) || { echo -e "make output error"; exit 2; } # 填充output目录失败后, 退出码为 非0
|
||||
}
|
||||
|
||||
function make_package() {
|
||||
# 压缩output目录
|
||||
(
|
||||
tar cvzf ${app_name}.tar.gz ${output_dir}
|
||||
echo -e "make package ok."
|
||||
) || { echo -e "make package error"; exit 2; } # 压缩output目录失败后, 退出码为 非0
|
||||
}
|
||||
|
||||
## internals
|
||||
function gitversion() {
|
||||
git log -1 --pretty=%h > $gitversion
|
||||
local gv=`cat $gitversion`
|
||||
echo "$gv"
|
||||
}
|
||||
|
||||
|
||||
##########################################
|
||||
## main
|
||||
## 其中,
|
||||
## 1.进行编译
|
||||
## 2.生成部署包output
|
||||
## 3.生成tar.gz压缩包
|
||||
##########################################
|
||||
|
||||
# 1.进行编译
|
||||
build
|
||||
|
||||
# 2.生成部署包output
|
||||
make_output
|
||||
|
||||
# 3.生成tar.gz压缩包
|
||||
make_package
|
||||
|
||||
# 编译成功
|
||||
echo -e "build done"
|
||||
exit 0
|
||||
BIN
docs/assets/images/common/arch.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 73 KiB |
BIN
docs/assets/images/common/dingding_group.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 20 KiB |
BIN
docs/assets/images/common/logo_name.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 7.4 KiB |
39
docs/dev_guide/Intergration_n9e_monitor.md
Normal file
@@ -0,0 +1,39 @@
|
||||
|
||||
---
|
||||
|
||||

|
||||
|
||||
**一站式`Apache Kafka`集群指标监控与运维管控平台**
|
||||
|
||||
---
|
||||
|
||||
# 夜莺监控集成
|
||||
|
||||
- `Kafka-Manager`通过将 监控的数据 以及 监控的规则 都提交给夜莺,然后依赖夜莺的监控系统从而实现监控告警功能。
|
||||
|
||||
- 监控数据上报 & 告警规则的创建等能力已经具备。但类似查看告警历史,告警触发时的监控数据等正在集成中(暂时可以到夜莺系统进行查看),欢迎有兴趣的同学进行共建 或 贡献代码。
|
||||
|
||||
## 1、配置说明
|
||||
|
||||
```yml
|
||||
# 配置文件中关于监控部分的配置
|
||||
monitor:
|
||||
enabled: false
|
||||
n9e:
|
||||
nid: 2
|
||||
user-token: 123456
|
||||
mon:
|
||||
base-url: http://127.0.0.1:8032
|
||||
sink:
|
||||
base-url: http://127.0.0.1:8006
|
||||
rdb:
|
||||
base-url: http://127.0.0.1:80
|
||||
|
||||
# enabled: 表示是否开启监控告警的功能, true: 开启, false: 不开启
|
||||
# n9e.nid: 夜莺的节点ID
|
||||
# n9e.user-token: 用户的密钥,在夜莺的个人设置中
|
||||
# n9e.mon.base-url: 监控地址
|
||||
# n9e.sink.base-url: 数据上报地址
|
||||
# n9e.rdb.base-url: 用户资源中心地址
|
||||
```
|
||||
|
||||
@@ -1,264 +0,0 @@
|
||||
# Task模块简介
|
||||
|
||||
## 1、Task简介
|
||||
|
||||
在 KnowStreaming 中(下面简称KS),Task模块主要是用于执行一些周期任务,包括Cluster、Broker、Topic等指标的定时采集,集群元数据定时更新至DB,集群状态的健康巡检等。在KS中,与Task模块相关的代码,我们都统一存放在km-task模块中。
|
||||
|
||||
Task模块是基于 LogiCommon 中的Logi-Job组件实现的任务周期执行,Logi-Job 的功能类似 XXX-Job,它是 XXX-Job 在 KnowStreaming 的内嵌实现,主要用于简化 KnowStreaming 的部署。
|
||||
Logi-Job 的任务总共有两种执行模式,分别是:
|
||||
|
||||
+ 广播模式:同一KS集群下,同一任务周期中,所有KS主机都会执行该定时任务。
|
||||
+ 抢占模式:同一KS集群下,同一任务周期中,仅有某一台KS主机会执行该任务。
|
||||
|
||||
KS集群范围定义:连接同一个DB,且application.yml中的spring.logi-job.app-name的名称一样的KS主机为同一KS集群。
|
||||
|
||||
## 2、使用指南
|
||||
|
||||
Task模块基于Logi-Job的广播模式与抢占模式,分别实现了任务的抢占执行、重复执行以及均衡执行,他们之间的差别是:
|
||||
|
||||
+ 抢占执行:同一个KS集群,同一个任务执行周期中,仅有一台KS主机执行该任务;
|
||||
+ 重复执行:同一个KS集群,同一个任务执行周期中,所有KS主机都执行该任务。比如3台KS主机,3个Kafka集群,此时每台KS主机都会去采集这3个Kafka集群的指标;
|
||||
+ 均衡执行:同一个KS集群,同一个任务执行周期中,每台KS主机仅执行该任务的一部分,所有的KS主机共同协作完成了任务。比如3台KS主机,3个Kafka集群,稳定运行情况下,每台KS主机将仅采集1个Kafka集群的指标,3台KS主机共同完成3个Kafka集群指标的采集。
|
||||
|
||||
下面我们看一下具体例子。
|
||||
|
||||
### 2.1、抢占模式——抢占执行
|
||||
|
||||
功能说明:
|
||||
|
||||
+ 同一个KS集群,同一个任务执行周期中,仅有一台KS主机执行该任务。
|
||||
|
||||
代码例子:
|
||||
|
||||
```java
|
||||
// 1、实现Job接口,重写excute方法;
|
||||
// 2、在类上添加@Task注解,并且配置好信息,指定为随机抢占模式;
|
||||
// 效果:KS集群中,每5秒,会有一台KS主机输出 "测试定时任务运行中";
|
||||
@Task(name = "TestJob",
|
||||
description = "测试定时任务",
|
||||
cron = "*/5 * * * * ?",
|
||||
autoRegister = true,
|
||||
consensual = ConsensualEnum.RANDOM, // 这里一定要设置为RANDOM
|
||||
timeout = 6 * 60)
|
||||
public class TestJob implements Job {
|
||||
|
||||
@Override
|
||||
public TaskResult execute(JobContext jobContext) throws Exception {
|
||||
|
||||
System.out.println("测试定时任务运行中");
|
||||
return new TaskResult();
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 2.2、广播模式——重复执行
|
||||
|
||||
功能说明:
|
||||
|
||||
+ 同一个KS集群,同一个任务执行周期中,所有KS主机都执行该任务。比如3台KS主机,3个Kafka集群,此时每台KS主机都会去重复采集这3个Kafka集群的指标。
|
||||
|
||||
代码例子:
|
||||
|
||||
```java
|
||||
// 1、实现Job接口,重写excute方法;
|
||||
// 2、在类上添加@Task注解,并且配置好信息,指定为广播抢占模式;
|
||||
// 效果:KS集群中,每5秒,每台KS主机都会输出 "测试定时任务运行中";
|
||||
@Task(name = "TestJob",
|
||||
description = "测试定时任务",
|
||||
cron = "*/5 * * * * ?",
|
||||
autoRegister = true,
|
||||
consensual = ConsensualEnum.BROADCAST, // 这里一定要设置为BROADCAST
|
||||
timeout = 6 * 60)
|
||||
public class TestJob implements Job {
|
||||
|
||||
@Override
|
||||
public TaskResult execute(JobContext jobContext) throws Exception {
|
||||
|
||||
System.out.println("测试定时任务运行中");
|
||||
return new TaskResult();
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 2.3、广播模式——均衡执行
|
||||
|
||||
功能说明:
|
||||
|
||||
+ 同一个KS集群,同一个任务执行周期中,每台KS主机仅执行该任务的一部分,所有的KS主机共同协作完成了任务。比如3台KS主机,3个Kafka集群,稳定运行情况下,每台KS主机将仅采集1个Kafka集群的指标,3台KS主机共同完成3个Kafka集群指标的采集。
|
||||
|
||||
代码例子:
|
||||
|
||||
+ 该模式有点特殊,是KS基于Logi-Job的广播模式,做的一个扩展,以下为一个使用例子:
|
||||
|
||||
```java
|
||||
// 1、继承AbstractClusterPhyDispatchTask,实现processSubTask方法;
|
||||
// 2、在类上添加@Task注解,并且配置好信息,指定为广播模式;
|
||||
// 效果:在本样例中,每隔1分钟ks会将所有的kafka集群列表在ks集群主机内均衡拆分,每台主机会将分发到自身的Kafka集群依次执行processSubTask方法,实现KS集群的任务协同处理。
|
||||
@Task(name = "kmJobTask",
|
||||
description = "km job 模块调度执行任务",
|
||||
cron = "0 0/1 * * * ? *",
|
||||
autoRegister = true,
|
||||
consensual = ConsensualEnum.BROADCAST,
|
||||
timeout = 6 * 60)
|
||||
public class KMJobTask extends AbstractClusterPhyDispatchTask {
|
||||
|
||||
@Autowired
|
||||
private JobService jobService;
|
||||
|
||||
@Override
|
||||
protected TaskResult processSubTask(ClusterPhy clusterPhy, long triggerTimeUnitMs) throws Exception {
|
||||
jobService.scheduleJobByClusterId(clusterPhy.getId());
|
||||
return TaskResult.SUCCESS;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 3、原理简介
|
||||
|
||||
### 3.1、Task注解说明
|
||||
|
||||
```java
|
||||
public @interface Task {
|
||||
String name() default ""; //任务名称
|
||||
String description() default ""; //任务描述
|
||||
String owner() default "system"; //拥有者
|
||||
String cron() default ""; //定时执行的时间策略
|
||||
int retryTimes() default 0; //失败以后所能重试的最大次数
|
||||
long timeout() default 0; //在超时时间里重试
|
||||
//是否自动注册任务到数据库中
|
||||
//如果设置为false,需要手动去数据库km_task表注册定时任务信息。数据库记录和@Task注解缺一不可
|
||||
boolean autoRegister() default false;
|
||||
//执行模式:广播、随机抢占
|
||||
//广播模式:同一集群下的所有服务器都会执行该定时任务
|
||||
//随机抢占模式:同一集群下随机一台服务器执行该任务
|
||||
ConsensualEnum consensual() default ConsensualEnum.RANDOM;
|
||||
}
|
||||
```
|
||||
|
||||
### 3.2、数据库表介绍
|
||||
|
||||
+ logi_task:记录项目中的定时任务信息,一个定时任务对应一条记录。
|
||||
+ logi_job:具体任务执行信息。
|
||||
+ logi_job_log:定时任务的执行日志。
|
||||
+ logi_worker:记录机器信息,实现集群控制。
|
||||
|
||||
### 3.3、均衡执行简介
|
||||
|
||||
#### 3.3.1、类关系图
|
||||
|
||||
这里以KMJobTask为例,简单介绍KM中的定时任务实现逻辑。
|
||||
|
||||
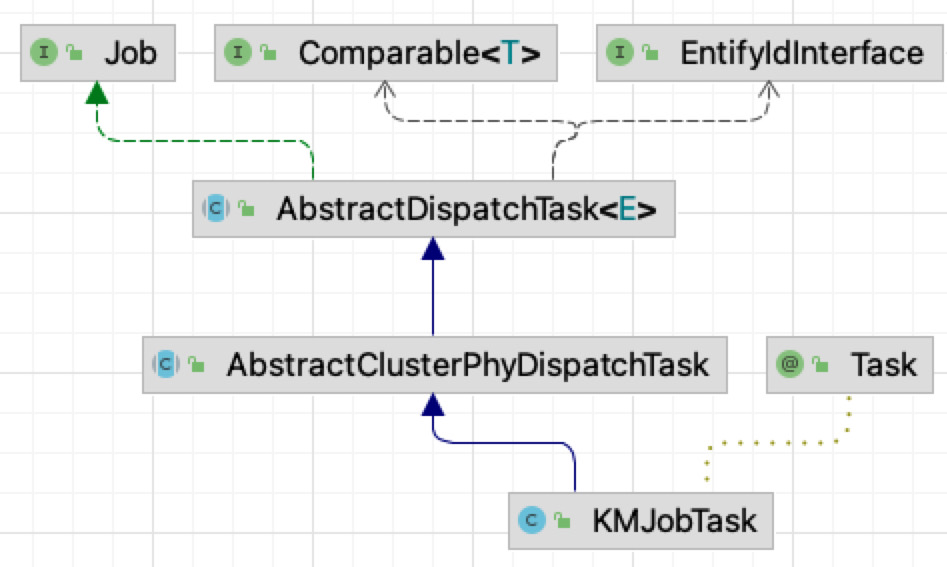
|
||||
|
||||
+ Job:使用logi组件实现定时任务,必须实现该接口。
|
||||
+ Comparable & EntufyIdInterface:比较接口,实现任务的排序逻辑。
|
||||
+ AbstractDispatchTask:实现广播模式下,任务的均衡分发。
|
||||
+ AbstractClusterPhyDispatchTask:对分发到当前服务器的集群列表进行枚举。
|
||||
+ KMJobTask:实现对单个集群的定时任务处理。
|
||||
|
||||
#### 3.3.2、关键类代码
|
||||
|
||||
+ **AbstractDispatchTask类**
|
||||
|
||||
```java
|
||||
// 实现Job接口的抽象类,进行任务的负载均衡执行
|
||||
public abstract class AbstractDispatchTask<E extends Comparable & EntifyIdInterface> implements Job {
|
||||
|
||||
// 罗列所有的任务
|
||||
protected abstract List<E> listAllTasks();
|
||||
|
||||
// 执行被分配给该KS主机的任务
|
||||
protected abstract TaskResult processTask(List<E> subTaskList, long triggerTimeUnitMs);
|
||||
|
||||
// 被Logi-Job触发执行该方法
|
||||
// 该方法进行任务的分配
|
||||
@Override
|
||||
public TaskResult execute(JobContext jobContext) {
|
||||
try {
|
||||
|
||||
long triggerTimeUnitMs = System.currentTimeMillis();
|
||||
|
||||
// 获取所有的任务
|
||||
List<E> allTaskList = this.listAllTasks();
|
||||
|
||||
// 计算当前KS机器需要执行的任务
|
||||
List<E> subTaskList = this.selectTask(allTaskList, jobContext.getAllWorkerCodes(), jobContext.getCurrentWorkerCode());
|
||||
|
||||
// 进行任务处理
|
||||
return this.processTask(subTaskList, triggerTimeUnitMs);
|
||||
} catch (Exception e) {
|
||||
// ...
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
+ **AbstractClusterPhyDispatchTask类**
|
||||
|
||||
```java
|
||||
// 继承AbstractDispatchTask的抽象类,对Kafka集群进行负载均衡执行
|
||||
public abstract class AbstractClusterPhyDispatchTask extends AbstractDispatchTask<ClusterPhy> {
|
||||
|
||||
// 执行被分配的任务,具体由子类实现
|
||||
protected abstract TaskResult processSubTask(ClusterPhy clusterPhy, long triggerTimeUnitMs) throws Exception;
|
||||
|
||||
// 返回所有的Kafka集群
|
||||
@Override
|
||||
public List<ClusterPhy> listAllTasks() {
|
||||
return clusterPhyService.listAllClusters();
|
||||
}
|
||||
|
||||
// 执行被分配给该KS主机的Kafka集群任务
|
||||
@Override
|
||||
public TaskResult processTask(List<ClusterPhy> subTaskList, long triggerTimeUnitMs) { // ... }
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
+ **KMJobTask类**
|
||||
|
||||
```java
|
||||
// 加上@Task注解,并配置任务执行信息
|
||||
@Task(name = "kmJobTask",
|
||||
description = "km job 模块调度执行任务",
|
||||
cron = "0 0/1 * * * ? *",
|
||||
autoRegister = true,
|
||||
consensual = ConsensualEnum.BROADCAST,
|
||||
timeout = 6 * 60)
|
||||
// 继承AbstractClusterPhyDispatchTask类
|
||||
public class KMJobTask extends AbstractClusterPhyDispatchTask {
|
||||
|
||||
@Autowired
|
||||
private JobService jobService;
|
||||
|
||||
// 执行该Kafka集群的Job模块的任务
|
||||
@Override
|
||||
protected TaskResult processSubTask(ClusterPhy clusterPhy, long triggerTimeUnitMs) throws Exception {
|
||||
jobService.scheduleJobByClusterId(clusterPhy.getId());
|
||||
return TaskResult.SUCCESS;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 3.3.3、均衡执行总结
|
||||
|
||||
均衡执行的实现原理总结起来就是以下几点:
|
||||
|
||||
+ Logi-Job设置为广播模式,触发所有的KS主机执行任务;
|
||||
+ 每台KS主机,被触发执行后,按照统一的规则,对任务列表,KS集群主机列表进行排序。然后按照顺序将任务列表均衡的分配给排序后的KS集群主机。KS集群稳定运行情况下,这一步保证了每台KS主机之间分配到的任务列表不重复,不丢失。
|
||||
+ 最后每台KS主机,执行被分配到的任务。
|
||||
|
||||
## 4、注意事项
|
||||
|
||||
+ 不能100%保证任务在一个周期内,且仅且执行一次,可能出现重复执行或丢失的情况,所以必须严格是且仅且执行一次的任务,不建议基于Logi-Job进行任务控制。
|
||||
+ 尽量让Logi-Job仅负责任务的触发,后续的执行建议放到自己创建的线程池中进行。
|
||||
{kind=link}
|
Before Width: | Height: | Size: 382 KiB |
41
docs/dev_guide/use_mysql_8.md
Normal file
@@ -0,0 +1,41 @@
|
||||
|
||||
---
|
||||
|
||||

|
||||
|
||||
**一站式`Apache Kafka`集群指标监控与运维管控平台**
|
||||
|
||||
---
|
||||
|
||||
# 使用`MySQL 8`
|
||||
|
||||
感谢 [herry-hu](https://github.com/herry-hu) 提供的方案。
|
||||
|
||||
|
||||
当前因为无法同时兼容`MySQL 8`与`MySQL 5.7`,因此代码中默认的版本还是`MySQL 5.7`。
|
||||
|
||||
|
||||
当前如需使用`MySQL 8`,则续按照下述流程进行简单修改代码。
|
||||
|
||||
|
||||
- Step1. 修改application.yml中的MySQL驱动类
|
||||
```shell
|
||||
|
||||
# 将driver-class-name后面的驱动类修改为:
|
||||
# driver-class-name: com.mysql.jdbc.Driver
|
||||
driver-class-name: com.mysql.cj.jdbc.Driver
|
||||
```
|
||||
|
||||
|
||||
- Step2. 修改MySQL依赖包
|
||||
```shell
|
||||
# 将根目录下面的pom.xml文件依赖的`MySQL`依赖包版本调整为
|
||||
|
||||
<dependency>
|
||||
<groupId>mysql</groupId>
|
||||
<artifactId>mysql-connector-java</artifactId>
|
||||
# <version>5.1.41</version>
|
||||
<version>8.0.20</version>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
@@ -1,43 +0,0 @@
|
||||
|
||||
## 4.2、Kafka 多版本兼容方案
|
||||
|
||||
  当前 KnowStreaming 支持纳管多个版本的 kafka 集群,由于不同版本的 kafka 在指标采集、接口查询、行为操作上有些不一致,因此 KnowStreaming 需要一套机制来解决多 kafka 版本的纳管兼容性问题。
|
||||
|
||||
### 4.2.1、整体思路
|
||||
|
||||
  由于需要纳管多个 kafka 版本,而且未来还可能会纳管非 kafka 官方的版本,kafka 的版本号会存在着多种情况,所以首先要明确一个核心思想:KnowStreaming 提供尽可能多的纳管能力,但是不提供无限的纳管能力,每一个版本的 KnowStreaming 只纳管其自身声明的 kafka 版本,后续随着 KnowStreaming 自身版本的迭代,会逐步支持更多 kafka 版本的纳管接入。
|
||||
|
||||
### 4.2.2、构建版本兼容列表
|
||||
|
||||
  每一个版本的 KnowStreaming 都声明一个自身支持纳管的 kafka 版本列表,并且对 kafka 的版本号进行归一化处理,后续所有 KnowStreaming 对不同 kafka 集群的操作都和这个集群对应的版本号严格相关。
|
||||
|
||||
  KnowStreaming 对外提供自身所支持的 kafka 版本兼容列表,用以声明自身支持的版本范围。
|
||||
|
||||
  对于在集群接入过程中,如果希望接入当前 KnowStreaming 不支持的 kafka 版本的集群,KnowStreaming 建议在于的过程中选择相近的版本号接入。
|
||||
|
||||
### 4.2.3、构建版本兼容性字典
|
||||
|
||||
  在构建了 KnowStreaming 支持的 kafka 版本列表的基础上,KnowStreaming 在实现过程中,还会声明自身支持的所有兼容性,构建兼容性字典。
|
||||
|
||||
  当前 KnowStreaming 支持的 kafka 版本兼容性字典包括三个维度:
|
||||
|
||||
- 指标采集:同一个指标在不同 kafka 版本下可能获取的方式不一样,不同版本的 kafka 可能会有不同的指标,因此对于指标采集的处理需要构建兼容性字典。
|
||||
- kafka api:同一个 kafka 的操作处理的方式在不同 kafka 版本下可能存在不一致,如:topic 的创建,因此 KnowStreaming 针对不同 kafka-api 的处理需要构建兼容性字典。
|
||||
- 平台操作:KnowStreaming 在接入不同版本的 kafka 集群的时候,在平台页面上会根据不同的 kafka 版。
|
||||
|
||||
兼容性字典的核心设计字段如下:
|
||||
|
||||
| 兼容性维度 | 兼容项名称 | 最小 Kafka 版本号(归一化) | 最大 Kafka 版本号(归一化) | 处理器 |
|
||||
| ---------- | ---------- | --------------------------- | --------------------------- | ------ |
|
||||
|
||||
KS-KM 根据其需要纳管的 kafka 版本,按照上述三个维度构建了完善了兼容性字典。
|
||||
|
||||
### 4.2.4、兼容性问题
|
||||
|
||||
  KS-KM 的每个版本针对需要纳管的 kafka 版本列表,事先分析各个版本的差异性和产品需求,同时 KS-KM 构建了一套专门处理兼容性的服务,来进行兼容性的注册、字典构建、处理器分发等操作,其中版本兼容性处理器是来具体处理不同 kafka 版本差异性的地方。
|
||||
|
||||
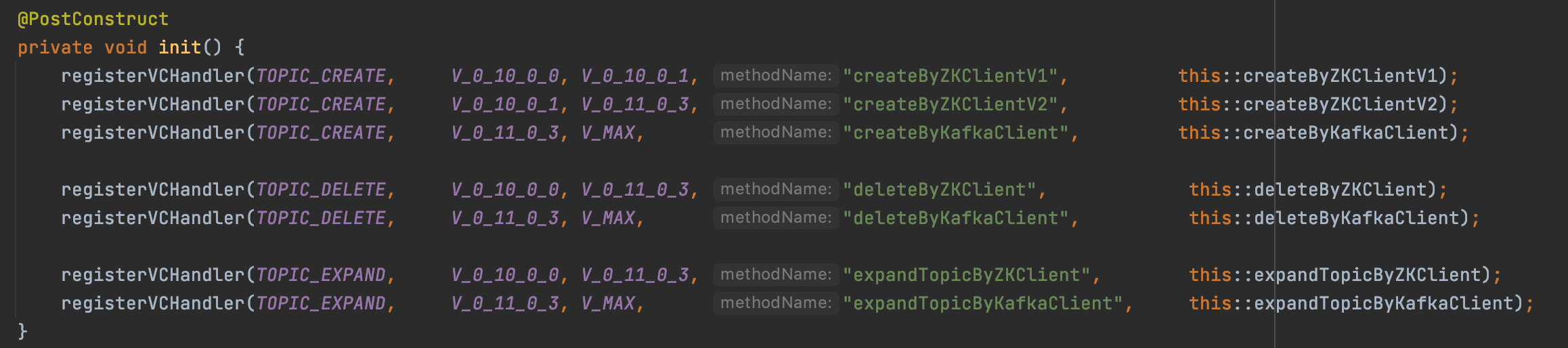
|
||||
|
||||
  如上图所示,KS-KM 的 topic 服务在面对不同 kafka 版本时,其 topic 的创建、删除、扩容由于 kafka 版本自身的差异,导致 KnowStreaming 的处理也不一样,所以需要根据不同的 kafka 版本来实现不同的兼容性处理器,同时向 KnowStreaming 的兼容服务进行兼容性的注册,构建兼容性字典,后续在 KnowStreaming 的运行过程中,针对不同的 kafka 版本即可分发到不同的处理器中执行。
|
||||
|
||||
  后续随着 KnowStreaming 产品的发展,如果有新的兼容性的地方需要增加,只需要实现新版本的处理器,增加注册项即可。
|
||||
@@ -1,152 +0,0 @@
|
||||
## 3.3、指标说明
|
||||
|
||||
当前 KnowStreaming 支持针对 kafka 集群的多维度指标的采集和展示,同时也支持多个 kafka 版本的指标进行兼容,以下是 KnowStreaming 支持的指标说明。
|
||||
|
||||
现在对当前 KnowStreaming 支持的指标从指标名称、指标单位、指标说明、kafka 版本、企业/开源版指标 五个维度进行说明。
|
||||
|
||||
### 3.3.1、Cluster 指标
|
||||
|
||||
| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
|
||||
| ------------------------- | -------- | ------------------------------------ | ---------------- | --------------- |
|
||||
| HealthScore | 分 | 集群总体的健康分 | 全部版本 | 开源版 |
|
||||
| HealthCheckPassed | 个 | 集群总体健康检查通过数 | 全部版本 | 开源版 |
|
||||
| HealthCheckTotal | 个 | 集群总体健康检查总数 | 全部版本 | 开源版 |
|
||||
| HealthScore_Topics | 分 | 集群 Topics 的健康分 | 全部版本 | 开源版 |
|
||||
| HealthCheckPassed_Topics | 个 | 集群 Topics 健康检查通过数 | 全部版本 | 开源版 |
|
||||
| HealthCheckTotal_Topics | 个 | 集群 Topics 健康检查总数 | 全部版本 | 开源版 |
|
||||
| HealthScore_Brokers | 分 | 集群 Brokers 的健康分 | 全部版本 | 开源版 |
|
||||
| HealthCheckPassed_Brokers | 个 | 集群 Brokers 健康检查通过数 | 全部版本 | 开源版 |
|
||||
| HealthCheckTotal_Brokers | 个 | 集群 Brokers 健康检查总数 | 全部版本 | 开源版 |
|
||||
| HealthScore_Groups | 分 | 集群 Groups 的健康分 | 全部版本 | 开源版 |
|
||||
| HealthCheckPassed_Groups | 个 | 集群 Groups 健康检查总数 | 全部版本 | 开源版 |
|
||||
| HealthCheckTotal_Groups | 个 | 集群 Groups 健康检查总数 | 全部版本 | 开源版 |
|
||||
| HealthScore_Cluster | 分 | 集群自身的健康分 | 全部版本 | 开源版 |
|
||||
| HealthCheckPassed_Cluster | 个 | 集群自身健康检查通过数 | 全部版本 | 开源版 |
|
||||
| HealthCheckTotal_Cluster | 个 | 集群自身健康检查总数 | 全部版本 | 开源版 |
|
||||
| TotalRequestQueueSize | 个 | 集群中总的请求队列数 | 全部版本 | 开源版 |
|
||||
| TotalResponseQueueSize | 个 | 集群中总的响应队列数 | 全部版本 | 开源版 |
|
||||
| EventQueueSize | 个 | 集群中 Controller 的 EventQueue 大小 | 2.0.0 及以上版本 | 开源版 |
|
||||
| ActiveControllerCount | 个 | 集群中存活的 Controller 数 | 全部版本 | 开源版 |
|
||||
| TotalProduceRequests | 个 | 集群中的 Produce 每秒请求数 | 全部版本 | 开源版 |
|
||||
| TotalLogSize | byte | 集群总的已使用的磁盘大小 | 全部版本 | 开源版 |
|
||||
| ConnectionsCount | 个 | 集群的连接(Connections)个数 | 全部版本 | 开源版 |
|
||||
| Zookeepers | 个 | 集群中存活的 zk 节点个数 | 全部版本 | 开源版 |
|
||||
| ZookeepersAvailable | 是/否 | ZK 地址是否合法 | 全部版本 | 开源版 |
|
||||
| Brokers | 个 | 集群的 broker 的总数 | 全部版本 | 开源版 |
|
||||
| BrokersAlive | 个 | 集群的 broker 的存活数 | 全部版本 | 开源版 |
|
||||
| BrokersNotAlive | 个 | 集群的 broker 的未存活数 | 全部版本 | 开源版 |
|
||||
| Replicas | 个 | 集群中 Replica 的总数 | 全部版本 | 开源版 |
|
||||
| Topics | 个 | 集群中 Topic 的总数 | 全部版本 | 开源版 |
|
||||
| Partitions | 个 | 集群的 Partitions 总数 | 全部版本 | 开源版 |
|
||||
| PartitionNoLeader | 个 | 集群中的 PartitionNoLeader 总数 | 全部版本 | 开源版 |
|
||||
| PartitionMinISR_S | 个 | 集群中的小于 PartitionMinISR 总数 | 全部版本 | 开源版 |
|
||||
| PartitionMinISR_E | 个 | 集群中的等于 PartitionMinISR 总数 | 全部版本 | 开源版 |
|
||||
| PartitionURP | 个 | 集群中的未同步的 Partition 总数 | 全部版本 | 开源版 |
|
||||
| MessagesIn | 条/s | 集群每条消息写入条数 | 全部版本 | 开源版 |
|
||||
| Messages | 条 | 集群总的消息条数 | 全部版本 | 开源版 |
|
||||
| LeaderMessages | 条 | 集群中 leader 总的消息条数 | 全部版本 | 开源版 |
|
||||
| BytesIn | byte/s | 集群的每秒写入字节数 | 全部版本 | 开源版 |
|
||||
| BytesIn_min_5 | byte/s | 集群的每秒写入字节数,5 分钟均值 | 全部版本 | 开源版 |
|
||||
| BytesIn_min_15 | byte/s | 集群的每秒写入字节数,15 分钟均值 | 全部版本 | 开源版 |
|
||||
| BytesOut | byte/s | 集群的每秒流出字节数 | 全部版本 | 开源版 |
|
||||
| BytesOut_min_5 | byte/s | 集群的每秒流出字节数,5 分钟均值 | 全部版本 | 开源版 |
|
||||
| BytesOut_min_15 | byte/s | 集群的每秒流出字节数,15 分钟均值 | 全部版本 | 开源版 |
|
||||
| Groups | 个 | 集群中 Group 的总数 | 全部版本 | 开源版 |
|
||||
| GroupActives | 个 | 集群中 ActiveGroup 的总数 | 全部版本 | 开源版 |
|
||||
| GroupEmptys | 个 | 集群中 EmptyGroup 的总数 | 全部版本 | 开源版 |
|
||||
| GroupRebalances | 个 | 集群中 RebalanceGroup 的总数 | 全部版本 | 开源版 |
|
||||
| GroupDeads | 个 | 集群中 DeadGroup 的总数 | 全部版本 | 开源版 |
|
||||
| Alive | 是/否 | 集群是否存活,1:存活;0:没有存活 | 全部版本 | 开源版 |
|
||||
| AclEnable | 是/否 | 集群是否开启 Acl,1:是;0:否 | 全部版本 | 开源版 |
|
||||
| Acls | 个 | ACL 数 | 全部版本 | 开源版 |
|
||||
| AclUsers | 个 | ACL-KafkaUser 数 | 全部版本 | 开源版 |
|
||||
| AclTopics | 个 | ACL-Topic 数 | 全部版本 | 开源版 |
|
||||
| AclGroups | 个 | ACL-Group 数 | 全部版本 | 开源版 |
|
||||
| Jobs | 个 | 集群任务总数 | 全部版本 | 开源版 |
|
||||
| JobsRunning | 个 | 集群 running 任务总数 | 全部版本 | 开源版 |
|
||||
| JobsWaiting | 个 | 集群 waiting 任务总数 | 全部版本 | 开源版 |
|
||||
| JobsSuccess | 个 | 集群 success 任务总数 | 全部版本 | 开源版 |
|
||||
| JobsFailed | 个 | 集群 failed 任务总数 | 全部版本 | 开源版 |
|
||||
| LoadReBalanceEnable | 是/否 | 是否开启均衡, 1:是;0:否 | 全部版本 | 企业版 |
|
||||
| LoadReBalanceCpu | 是/否 | CPU 是否均衡, 1:是;0:否 | 全部版本 | 企业版 |
|
||||
| LoadReBalanceNwIn | 是/否 | BytesIn 是否均衡, 1:是;0:否 | 全部版本 | 企业版 |
|
||||
| LoadReBalanceNwOut | 是/否 | BytesOut 是否均衡, 1:是;0:否 | 全部版本 | 企业版 |
|
||||
| LoadReBalanceDisk | 是/否 | Disk 是否均衡, 1:是;0:否 | 全部版本 | 企业版 |
|
||||
|
||||
### 3.3.2、Broker 指标
|
||||
|
||||
| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
|
||||
| ----------------------- | -------- | ------------------------------------- | ---------- | --------------- |
|
||||
| HealthScore | 分 | Broker 健康分 | 全部版本 | 开源版 |
|
||||
| HealthCheckPassed | 个 | Broker 健康检查通过数 | 全部版本 | 开源版 |
|
||||
| HealthCheckTotal | 个 | Broker 健康检查总数 | 全部版本 | 开源版 |
|
||||
| TotalRequestQueueSize | 个 | Broker 的请求队列大小 | 全部版本 | 开源版 |
|
||||
| TotalResponseQueueSize | 个 | Broker 的应答队列大小 | 全部版本 | 开源版 |
|
||||
| ReplicationBytesIn | byte/s | Broker 的副本流入流量 | 全部版本 | 开源版 |
|
||||
| ReplicationBytesOut | byte/s | Broker 的副本流出流量 | 全部版本 | 开源版 |
|
||||
| MessagesIn | 条/s | Broker 的每秒消息流入条数 | 全部版本 | 开源版 |
|
||||
| TotalProduceRequests | 个/s | Broker 上 Produce 的每秒请求数 | 全部版本 | 开源版 |
|
||||
| NetworkProcessorAvgIdle | % | Broker 的网络处理器的空闲百分比 | 全部版本 | 开源版 |
|
||||
| RequestHandlerAvgIdle | % | Broker 上请求处理器的空闲百分比 | 全部版本 | 开源版 |
|
||||
| PartitionURP | 个 | Broker 上的未同步的副本的个数 | 全部版本 | 开源版 |
|
||||
| ConnectionsCount | 个 | Broker 上网络链接的个数 | 全部版本 | 开源版 |
|
||||
| BytesIn | byte/s | Broker 的每秒数据写入量 | 全部版本 | 开源版 |
|
||||
| BytesIn_min_5 | byte/s | Broker 的每秒数据写入量,5 分钟均值 | 全部版本 | 开源版 |
|
||||
| BytesIn_min_15 | byte/s | Broker 的每秒数据写入量,15 分钟均值 | 全部版本 | 开源版 |
|
||||
| BytesOut | byte/s | Broker 的每秒数据流出量 | 全部版本 | 开源版 |
|
||||
| BytesOut_min_5 | byte/s | Broker 的每秒数据流出量,5 分钟均值 | 全部版本 | 开源版 |
|
||||
| BytesOut_min_15 | byte/s | Broker 的每秒数据流出量,15 分钟均值 | 全部版本 | 开源版 |
|
||||
| ReassignmentBytesIn | byte/s | Broker 的每秒数据迁移写入量 | 全部版本 | 开源版 |
|
||||
| ReassignmentBytesOut | byte/s | Broker 的每秒数据迁移流出量 | 全部版本 | 开源版 |
|
||||
| Partitions | 个 | Broker 上的 Partition 个数 | 全部版本 | 开源版 |
|
||||
| PartitionsSkew | % | Broker 上的 Partitions 倾斜度 | 全部版本 | 开源版 |
|
||||
| Leaders | 个 | Broker 上的 Leaders 个数 | 全部版本 | 开源版 |
|
||||
| LeadersSkew | % | Broker 上的 Leaders 倾斜度 | 全部版本 | 开源版 |
|
||||
| LogSize | byte | Broker 上的消息容量大小 | 全部版本 | 开源版 |
|
||||
| Alive | 是/否 | Broker 是否存活,1:存活;0:没有存活 | 全部版本 | 开源版 |
|
||||
|
||||
### 3.3.3、Topic 指标
|
||||
|
||||
| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
|
||||
| --------------------- | -------- | ------------------------------------- | ---------- | --------------- |
|
||||
| HealthScore | 分 | 健康分 | 全部版本 | 开源版 |
|
||||
| HealthCheckPassed | 个 | 健康项检查通过数 | 全部版本 | 开源版 |
|
||||
| HealthCheckTotal | 个 | 健康项检查总数 | 全部版本 | 开源版 |
|
||||
| TotalProduceRequests | 条/s | Topic 的 TotalProduceRequests | 全部版本 | 开源版 |
|
||||
| BytesRejected | 个/s | Topic 的每秒写入拒绝量 | 全部版本 | 开源版 |
|
||||
| FailedFetchRequests | 个/s | Topic 的 FailedFetchRequests | 全部版本 | 开源版 |
|
||||
| FailedProduceRequests | 个/s | Topic 的 FailedProduceRequests | 全部版本 | 开源版 |
|
||||
| ReplicationCount | 个 | Topic 总的副本数 | 全部版本 | 开源版 |
|
||||
| Messages | 条 | Topic 总的消息数 | 全部版本 | 开源版 |
|
||||
| MessagesIn | 条/s | Topic 每秒消息条数 | 全部版本 | 开源版 |
|
||||
| BytesIn | byte/s | Topic 每秒消息写入字节数 | 全部版本 | 开源版 |
|
||||
| BytesIn_min_5 | byte/s | Topic 每秒消息写入字节数,5 分钟均值 | 全部版本 | 开源版 |
|
||||
| BytesIn_min_15 | byte/s | Topic 每秒消息写入字节数,15 分钟均值 | 全部版本 | 开源版 |
|
||||
| BytesOut | byte/s | Topic 每秒消息流出字节数 | 全部版本 | 开源版 |
|
||||
| BytesOut_min_5 | byte/s | Topic 每秒消息流出字节数,5 分钟均值 | 全部版本 | 开源版 |
|
||||
| BytesOut_min_15 | byte/s | Topic 每秒消息流出字节数,15 分钟均值 | 全部版本 | 开源版 |
|
||||
| LogSize | byte | Topic 的大小 | 全部版本 | 开源版 |
|
||||
| PartitionURP | 个 | Topic 未同步的副本数 | 全部版本 | 开源版 |
|
||||
|
||||
### 3.3.4、Partition 指标
|
||||
|
||||
| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
|
||||
| -------------- | -------- | ----------------------------------------- | ---------- | --------------- |
|
||||
| LogEndOffset | 条 | Partition 中 leader 副本的 LogEndOffset | 全部版本 | 开源版 |
|
||||
| LogStartOffset | 条 | Partition 中 leader 副本的 LogStartOffset | 全部版本 | 开源版 |
|
||||
| Messages | 条 | Partition 总的消息数 | 全部版本 | 开源版 |
|
||||
| BytesIn | byte/s | Partition 的每秒消息流入字节数 | 全部版本 | 开源版 |
|
||||
| BytesOut | byte/s | Partition 的每秒消息流出字节数 | 全部版本 | 开源版 |
|
||||
| LogSize | byte | Partition 的大小 | 全部版本 | 开源版 |
|
||||
|
||||
### 3.3.5、Group 指标
|
||||
|
||||
| 指标名称 | 指标单位 | 指标含义 | kafka 版本 | 企业/开源版指标 |
|
||||
| ----------------- | -------- | -------------------------- | ---------- | --------------- |
|
||||
| HealthScore | 分 | 健康分 | 全部版本 | 开源版 |
|
||||
| HealthCheckPassed | 个 | 健康检查通过数 | 全部版本 | 开源版 |
|
||||
| HealthCheckTotal | 个 | 健康检查总数 | 全部版本 | 开源版 |
|
||||
| OffsetConsumed | 条 | Consumer 的 CommitedOffset | 全部版本 | 开源版 |
|
||||
| LogEndOffset | 条 | Consumer 的 LogEndOffset | 全部版本 | 开源版 |
|
||||
| Lag | 条 | Group 消费者的 Lag 数 | 全部版本 | 开源版 |
|
||||
| State | 个 | Group 组的状态 | 全部版本 | 开源版 |
|
||||
@@ -1,90 +0,0 @@
|
||||
## 6.1、本地源码启动手册
|
||||
|
||||
### 6.1.1、打包方式
|
||||
|
||||
`Know Streaming` 采用前后端分离的开发模式,使用 Maven 对项目进行统一的构建管理。maven 在打包构建过程中,会将前后端代码一并打包生成最终的安装包。
|
||||
|
||||
`Know Streaming` 除了使用安装包启动之外,还可以通过本地源码启动完整的带前端页面的项目,下面我们正式开始介绍本地源码如何启动 `Know Streaming`。
|
||||
|
||||
### 6.1.2、环境要求
|
||||
|
||||
**系统支持**
|
||||
|
||||
`windows7+`、`Linux`、`Mac`
|
||||
|
||||
**环境依赖**
|
||||
|
||||
- Maven 3.6.3
|
||||
- Node v12.20.0
|
||||
- Java 8+
|
||||
- MySQL 5.7
|
||||
- Idea
|
||||
- Elasticsearch 7.6
|
||||
- Git
|
||||
|
||||
### 6.1.3、环境初始化
|
||||
|
||||
安装好环境信息之后,还需要初始化 MySQL 与 Elasticsearch 信息,包括:
|
||||
|
||||
- 初始化 MySQL 表及数据
|
||||
- 初始化 Elasticsearch 索引
|
||||
|
||||
具体见:[单机部署手册](../install_guide/单机部署手册.md) 中的最后一步,部署 KnowStreaming 服务中的初始化相关工作。
|
||||
|
||||
### 6.1.4、本地启动
|
||||
|
||||
**第一步:本地打包**
|
||||
|
||||
执行 `mvn install` 可对项目进行前后端同时进行打包,通过该命令,除了可以对后端进行打包之外,还可以将前端相关的静态资源文件也一并打包出来。
|
||||
|
||||
**第二步:修改配置**
|
||||
|
||||
```yaml
|
||||
# 修改 km-rest/src/main/resources/application.yml 中相关的配置
|
||||
|
||||
# 修改MySQL的配置,中间省略了一些非必需修改的配置
|
||||
spring:
|
||||
datasource:
|
||||
know-streaming:
|
||||
jdbc-url: 修改为实际MYSQL地址
|
||||
username: 修改为实际MYSQL用户名
|
||||
password: 修改为实际MYSQL密码
|
||||
logi-job:
|
||||
jdbc-url: 修改为实际MYSQL地址
|
||||
username: 修改为实际MYSQL用户名
|
||||
password: 修改为实际MYSQL密码
|
||||
logi-security:
|
||||
jdbc-url: 修改为实际MYSQL地址
|
||||
username: 修改为实际MYSQL用户名
|
||||
password: 修改为实际MYSQL密码
|
||||
|
||||
# 修改ES的配置,中间省略了一些非必需修改的配置
|
||||
es.client.address: 修改为实际ES地址
|
||||
```
|
||||
|
||||
**第三步:配置 IDEA**
|
||||
|
||||
`Know Streaming`的 Main 方法在:
|
||||
|
||||
```java
|
||||
km-rest/src/main/java/com/xiaojukeji/know/streaming/km/rest/KnowStreaming.java
|
||||
```
|
||||
|
||||
IDEA 更多具体的配置如下图所示:
|
||||
|
||||
<p align="center">
|
||||
<img src="http://img-ys011.didistatic.com/static/dc2img/do1_BW1RzgEMh4n6L4dL4ncl" width = "512" height = "318" div align=center />
|
||||
</p>
|
||||
|
||||
**第四步:启动项目**
|
||||
|
||||
最后就是启动项目,在本地 console 中输出了 `KnowStreaming-KM started` 则表示我们已经成功启动 `Know Streaming` 了。
|
||||
|
||||
### 6.1.5、本地访问
|
||||
|
||||
`Know Streaming` 启动之后,可以访问一些信息,包括:
|
||||
|
||||
- 产品页面:http://localhost:8080 ,默认账号密码:`admin` / `admin2022_` 进行登录。`v3.0.0-beta.2`版本开始,默认账号密码为`admin` / `admin`;
|
||||
- 接口地址:http://localhost:8080/swagger-ui.html 查看后端提供的相关接口。
|
||||
|
||||
更多信息,详见:[KnowStreaming 官网](https://knowstreaming.com/)
|
||||
@@ -1,199 +0,0 @@
|
||||
|
||||
|
||||

|
||||
|
||||
## 登录系统对接
|
||||
|
||||
[KnowStreaming](https://github.com/didi/KnowStreaming)(以下简称KS) 除了实现基于本地MySQL的用户登录认证方式外,还已经实现了基于Ldap的登录认证。
|
||||
|
||||
但是,登录认证系统并非仅此两种。因此,为了具有更好的拓展性,KS具有自定义登陆认证逻辑,快速对接已有系统的特性。
|
||||
|
||||
在KS中,我们将登陆认证相关的一些文件放在[km-extends](https://github.com/didi/KnowStreaming/tree/master/km-extends)模块下的[km-account](https://github.com/didi/KnowStreaming/tree/master/km-extends/km-account)模块里。
|
||||
|
||||
本文将介绍KS如何快速对接自有的用户登录认证系统。
|
||||
|
||||
### 对接步骤
|
||||
|
||||
- 创建一个登陆认证类,实现[LogiCommon](https://github.com/didi/LogiCommon)的LoginExtend接口;
|
||||
- 将[application.yml](https://github.com/didi/KnowStreaming/blob/master/km-rest/src/main/resources/application.yml)中的spring.logi-security.login-extend-bean-name字段改为登陆认证类的bean名称;
|
||||
|
||||
```Java
|
||||
//LoginExtend 接口
|
||||
public interface LoginExtend {
|
||||
|
||||
/**
|
||||
* 验证登录信息,同时记住登录状态
|
||||
*/
|
||||
UserBriefVO verifyLogin(AccountLoginDTO var1, HttpServletRequest var2, HttpServletResponse var3) throws LogiSecurityException;
|
||||
|
||||
/**
|
||||
* 登出接口,清楚登录状态
|
||||
*/
|
||||
Result<Boolean> logout(HttpServletRequest var1, HttpServletResponse var2);
|
||||
|
||||
/**
|
||||
* 检查是否已经登录
|
||||
*/
|
||||
boolean interceptorCheck(HttpServletRequest var1, HttpServletResponse var2, String var3, List<String> var4) throws IOException;
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 对接例子
|
||||
|
||||
我们以Ldap对接为例,说明KS如何对接登录认证系统。
|
||||
|
||||
+ 编写[LdapLoginServiceImpl](https://github.com/didi/KnowStreaming/blob/master/km-extends/km-account/src/main/java/com/xiaojukeji/know/streaming/km/account/login/ldap/LdapLoginServiceImpl.java)类,实现LoginExtend接口。
|
||||
+ 设置[application.yml](https://github.com/didi/KnowStreaming/blob/master/km-rest/src/main/resources/application.yml)中的spring.logi-security.login-extend-bean-name=ksLdapLoginService。
|
||||
|
||||
完成上述两步即可实现KS对接Ldap认证登陆。
|
||||
|
||||
```Java
|
||||
@Service("ksLdapLoginService")
|
||||
public class LdapLoginServiceImpl implements LoginExtend {
|
||||
|
||||
|
||||
@Override
|
||||
public UserBriefVO verifyLogin(AccountLoginDTO loginDTO,
|
||||
HttpServletRequest request,
|
||||
HttpServletResponse response) throws LogiSecurityException {
|
||||
String decodePasswd = AESUtils.decrypt(loginDTO.getPw());
|
||||
|
||||
// 去LDAP验证账密
|
||||
LdapPrincipal ldapAttrsInfo = ldapAuthentication.authenticate(loginDTO.getUserName(), decodePasswd);
|
||||
if (ldapAttrsInfo == null) {
|
||||
// 用户不存在,正常来说上如果有问题,上一步会直接抛出异常
|
||||
throw new LogiSecurityException(ResultCode.USER_NOT_EXISTS);
|
||||
}
|
||||
|
||||
// 进行业务相关操作
|
||||
|
||||
// 记录登录状态,Ldap因为无法记录登录状态,因此有KnowStreaming进行记录
|
||||
initLoginContext(request, response, loginDTO.getUserName(), user.getId());
|
||||
return CopyBeanUtil.copy(user, UserBriefVO.class);
|
||||
}
|
||||
|
||||
@Override
|
||||
public Result<Boolean> logout(HttpServletRequest request, HttpServletResponse response) {
|
||||
|
||||
//清理cookie和session
|
||||
|
||||
return Result.buildSucc(Boolean.TRUE);
|
||||
}
|
||||
|
||||
@Override
|
||||
public boolean interceptorCheck(HttpServletRequest request, HttpServletResponse response, String requestMappingValue, List<String> whiteMappingValues) throws IOException {
|
||||
|
||||
// 检查是否已经登录
|
||||
String userName = HttpRequestUtil.getOperator(request);
|
||||
if (StringUtils.isEmpty(userName)) {
|
||||
// 未登录,则进行登出
|
||||
logout(request, response);
|
||||
return Boolean.FALSE;
|
||||
}
|
||||
|
||||
return Boolean.TRUE;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 实现原理
|
||||
|
||||
因为登陆和登出整体实现逻辑是一致的,所以我们以登陆逻辑为例进行介绍。
|
||||
|
||||
+ 登陆原理
|
||||
|
||||
登陆走的是[LogiCommon](https://github.com/didi/LogiCommon)自带的LoginController。
|
||||
|
||||
```java
|
||||
@RestController
|
||||
public class LoginController {
|
||||
|
||||
|
||||
//登陆接口
|
||||
@PostMapping({"/login"})
|
||||
public Result<UserBriefVO> login(HttpServletRequest request, HttpServletResponse response, @RequestBody AccountLoginDTO loginDTO) {
|
||||
try {
|
||||
//登陆认证
|
||||
UserBriefVO userBriefVO = this.loginService.verifyLogin(loginDTO, request, response);
|
||||
return Result.success(userBriefVO);
|
||||
|
||||
} catch (LogiSecurityException var5) {
|
||||
return Result.fail(var5);
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
而登陆操作是调用LoginServiceImpl类来实现,但是具体由哪个登陆认证类来执行登陆操作却由loginExtendBeanTool来指定。
|
||||
|
||||
```java
|
||||
//LoginServiceImpl类
|
||||
@Service
|
||||
public class LoginServiceImpl implements LoginService {
|
||||
|
||||
//实现登陆操作,但是具体哪个登陆类由loginExtendBeanTool来管理
|
||||
public UserBriefVO verifyLogin(AccountLoginDTO loginDTO, HttpServletRequest request, HttpServletResponse response) throws LogiSecurityException {
|
||||
|
||||
return this.loginExtendBeanTool.getLoginExtendImpl().verifyLogin(loginDTO, request, response);
|
||||
}
|
||||
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
而loginExtendBeanTool类会优先去查找用户指定的登陆认证类,如果失败则调用默认的登陆认证函数。
|
||||
|
||||
```java
|
||||
//LoginExtendBeanTool类
|
||||
@Component("logiSecurityLoginExtendBeanTool")
|
||||
public class LoginExtendBeanTool {
|
||||
|
||||
public LoginExtend getLoginExtendImpl() {
|
||||
LoginExtend loginExtend;
|
||||
//先调用用户指定登陆类,如果失败则调用系统默认登陆认证
|
||||
try {
|
||||
//调用的类由spring.logi-security.login-extend-bean-name指定
|
||||
loginExtend = this.getCustomLoginExtendImplBean();
|
||||
} catch (UnsupportedOperationException var3) {
|
||||
loginExtend = this.getDefaultLoginExtendImplBean();
|
||||
}
|
||||
|
||||
return loginExtend;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
+ 认证原理
|
||||
|
||||
认证的实现则比较简单,向Spring中注册我们的拦截器PermissionInterceptor。
|
||||
|
||||
拦截器会调用LoginServiceImpl类的拦截方法,LoginServiceImpl后续处理逻辑就和前面登陆是一致的。
|
||||
|
||||
```java
|
||||
public class PermissionInterceptor implements HandlerInterceptor {
|
||||
|
||||
|
||||
/**
|
||||
* 拦截预处理
|
||||
* @return boolean false:拦截, 不向下执行, true:放行
|
||||
*/
|
||||
@Override
|
||||
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
|
||||
|
||||
//免登录相关校验,如果验证通过,提前返回
|
||||
|
||||
//走拦截函数,进行普通用户验证
|
||||
return loginService.interceptorCheck(request, response, classRequestMappingValue, whiteMappingValues);
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
@@ -1,126 +0,0 @@
|
||||
|
||||
|
||||

|
||||
|
||||
## JMX-连接失败问题解决
|
||||
|
||||
集群正常接入`KnowStreaming`之后,即可以看到集群的Broker列表,此时如果查看不了Topic的实时流量,或者是Broker的实时流量信息时,那么大概率就是`JMX`连接的问题了。
|
||||
|
||||
下面我们按照步骤来一步一步的检查。
|
||||
|
||||
### 1、问题说明
|
||||
|
||||
**类型一:JMX配置未开启**
|
||||
|
||||
未开启时,直接到`2、解决方法`查看如何开启即可。
|
||||
|
||||
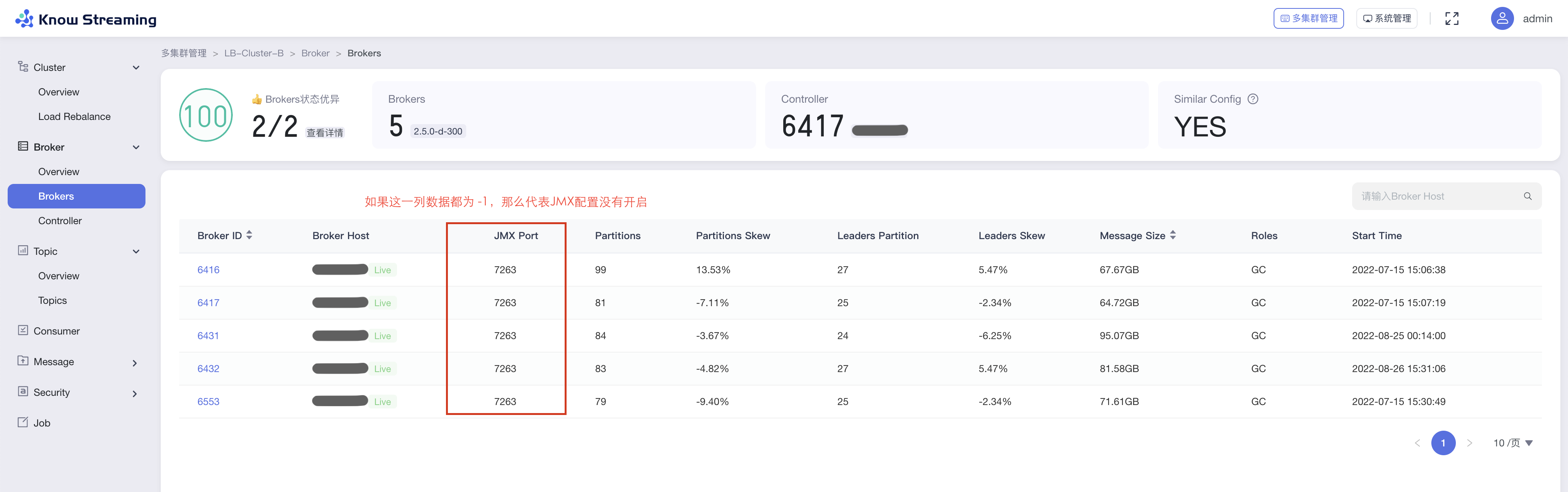
|
||||
|
||||
|
||||
**类型二:配置错误**
|
||||
|
||||
`JMX`端口已经开启的情况下,有的时候开启的配置不正确,此时也会导致出现连接失败的问题。这里大概列举几种原因:
|
||||
|
||||
- `JMX`配置错误:见`2、解决方法`。
|
||||
- 存在防火墙或者网络限制:网络通的另外一台机器`telnet`试一下看是否可以连接上。
|
||||
- 需要进行用户名及密码的认证:见`3、解决方法 —— 认证的JMX`。
|
||||
|
||||
|
||||
错误日志例子:
|
||||
```
|
||||
# 错误一: 错误提示的是真实的IP,这样的话基本就是JMX配置的有问题了。
|
||||
2021-01-27 10:06:20.730 ERROR 50901 --- [ics-Thread-1-62] c.x.k.m.c.utils.jmx.JmxConnectorWrap : JMX connect exception, host:192.168.0.1 port:9999.
|
||||
java.rmi.ConnectException: Connection refused to host: 192.168.0.1; nested exception is:
|
||||
|
||||
|
||||
# 错误二:错误提示的是127.0.0.1这个IP,这个是机器的hostname配置的可能有问题。
|
||||
2021-01-27 10:06:20.730 ERROR 50901 --- [ics-Thread-1-62] c.x.k.m.c.utils.jmx.JmxConnectorWrap : JMX connect exception, host:127.0.0.1 port:9999.
|
||||
java.rmi.ConnectException: Connection refused to host: 127.0.0.1;; nested exception is:
|
||||
```
|
||||
|
||||
**类型三:连接特定IP**
|
||||
|
||||
Broker 配置了内外网,而JMX在配置时,可能配置了内网IP或者外网IP,此时 `KnowStreaming` 需要连接到特定网络的IP才可以进行访问。
|
||||
|
||||
比如:
|
||||
|
||||
Broker在ZK的存储结构如下所示,我们期望连接到 `endpoints` 中标记为 `INTERNAL` 的地址,但是 `KnowStreaming` 却连接了 `EXTERNAL` 的地址,此时可以看 `4、解决方法 —— JMX连接特定网络` 进行解决。
|
||||
|
||||
```json
|
||||
{
|
||||
"listener_security_protocol_map": {"EXTERNAL":"SASL_PLAINTEXT","INTERNAL":"SASL_PLAINTEXT"},
|
||||
"endpoints": ["EXTERNAL://192.168.0.1:7092","INTERNAL://192.168.0.2:7093"],
|
||||
"jmx_port": 8099,
|
||||
"host": "192.168.0.1",
|
||||
"timestamp": "1627289710439",
|
||||
"port": -1,
|
||||
"version": 4
|
||||
}
|
||||
```
|
||||
|
||||
### 2、解决方法
|
||||
|
||||
这里仅介绍一下比较通用的解决方式,如若有更好的方式,欢迎大家指导告知一下。
|
||||
|
||||
修改`kafka-server-start.sh`文件:
|
||||
```
|
||||
# 在这个下面增加JMX端口的配置
|
||||
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
|
||||
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
|
||||
export JMX_PORT=9999 # 增加这个配置, 这里的数值并不一定是要9999
|
||||
fi
|
||||
```
|
||||
|
||||
|
||||
|
||||
修改`kafka-run-class.sh`文件
|
||||
```
|
||||
# JMX settings
|
||||
if [ -z "$KAFKA_JMX_OPTS" ]; then
|
||||
KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=${当前机器的IP}"
|
||||
fi
|
||||
|
||||
# JMX port to use
|
||||
if [ $JMX_PORT ]; then
|
||||
KAFKA_JMX_OPTS="$KAFKA_JMX_OPTS -Dcom.sun.management.jmxremote.port=$JMX_PORT -Dcom.sun.management.jmxremote.rmi.port=$JMX_PORT"
|
||||
fi
|
||||
```
|
||||
|
||||
|
||||
### 3、解决方法 —— 认证的JMX
|
||||
|
||||
如果您是直接看的这个部分,建议先看一下上一节:`2、解决方法`以确保`JMX`的配置没有问题了。
|
||||
|
||||
在`JMX`的配置等都没有问题的情况下,如果是因为认证的原因导致连接不了的,可以在集群接入界面配置你的`JMX`认证信息。
|
||||
|
||||
<img src='http://img-ys011.didistatic.com/static/dc2img/do1_EUU352qMEX1Jdp7pxizp' width=350>
|
||||
|
||||
|
||||
|
||||
### 4、解决方法 —— JMX连接特定网络
|
||||
|
||||
可以手动往`ks_km_physical_cluster`表的`jmx_properties`字段增加一个`useWhichEndpoint`字段,从而控制 `KnowStreaming` 连接到特定的JMX IP及PORT。
|
||||
|
||||
`jmx_properties`格式:
|
||||
```json
|
||||
{
|
||||
"maxConn": 100, # KM对单台Broker的最大JMX连接数
|
||||
"username": "xxxxx", # 用户名,可以不填写
|
||||
"password": "xxxx", # 密码,可以不填写
|
||||
"openSSL": true, # 开启SSL, true表示开启ssl, false表示关闭
|
||||
"useWhichEndpoint": "EXTERNAL" #指定要连接的网络名称,填写EXTERNAL就是连接endpoints里面的EXTERNAL地址
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
SQL例子:
|
||||
```sql
|
||||
UPDATE ks_km_physical_cluster SET jmx_properties='{ "maxConn": 10, "username": "xxxxx", "password": "xxxx", "openSSL": false , "useWhichEndpoint": "xxx"}' where id={xxx};
|
||||
```
|
||||
|
||||
注意:
|
||||
|
||||
+ 目前此功能只支持采用 `ZK` 做分布式协调的kafka集群。
|
||||
|
||||
|
||||
582
docs/install_guide/create_mysql_table.sql
Normal file
@@ -0,0 +1,582 @@
|
||||
--
|
||||
-- Table structure for table `account`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `account`;
|
||||
CREATE TABLE `account` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`username` varchar(128) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT '用户名',
|
||||
`password` varchar(128) NOT NULL DEFAULT '' COMMENT '密码',
|
||||
`role` tinyint(8) NOT NULL DEFAULT '0' COMMENT '角色类型, 0:普通用户 1:研发 2:运维',
|
||||
`status` int(16) NOT NULL DEFAULT '0' COMMENT '0标识使用中,-1标识已废弃',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_username` (`username`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='账号表';
|
||||
INSERT INTO account(username, password, role) VALUES ('admin', '21232f297a57a5a743894a0e4a801fc3', 2);
|
||||
|
||||
--
|
||||
-- Table structure for table `app`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `app`;
|
||||
CREATE TABLE `app` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`app_id` varchar(128) NOT NULL DEFAULT '' COMMENT '应用id',
|
||||
`name` varchar(192) NOT NULL DEFAULT '' COMMENT '应用名称',
|
||||
`password` varchar(256) NOT NULL DEFAULT '' COMMENT '应用密码',
|
||||
`type` int(11) NOT NULL DEFAULT '0' COMMENT '类型, 0:普通用户, 1:超级用户',
|
||||
`applicant` varchar(64) NOT NULL DEFAULT '' COMMENT '申请人',
|
||||
`principals` text COMMENT '应用负责人',
|
||||
`description` text COMMENT '应用描述',
|
||||
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_name` (`name`),
|
||||
UNIQUE KEY `uniq_app_id` (`app_id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='应用信息';
|
||||
|
||||
|
||||
--
|
||||
-- Table structure for table `authority`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `authority`;
|
||||
CREATE TABLE `authority` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`app_id` varchar(128) NOT NULL DEFAULT '' COMMENT '应用id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '集群id',
|
||||
`topic_name` varchar(192) NOT NULL DEFAULT '' COMMENT 'topic名称',
|
||||
`access` int(11) NOT NULL DEFAULT '0' COMMENT '0:无权限, 1:读, 2:写, 3:读写',
|
||||
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_app_id_cluster_id_topic_name` (`app_id`,`cluster_id`,`topic_name`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='权限信息(kafka-manager)';
|
||||
|
||||
--
|
||||
-- Table structure for table `broker`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `broker`;
|
||||
CREATE TABLE `broker` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`broker_id` int(16) NOT NULL DEFAULT '-1' COMMENT 'brokerid',
|
||||
`host` varchar(128) NOT NULL DEFAULT '' COMMENT 'broker主机名',
|
||||
`port` int(16) NOT NULL DEFAULT '-1' COMMENT 'broker端口',
|
||||
`timestamp` bigint(20) NOT NULL DEFAULT '-1' COMMENT '启动时间',
|
||||
`max_avg_bytes_in` bigint(20) NOT NULL DEFAULT '-1' COMMENT '峰值的均值流量',
|
||||
`version` varchar(128) NOT NULL DEFAULT '' COMMENT 'broker版本',
|
||||
`status` int(16) NOT NULL DEFAULT '0' COMMENT '状态: 0有效,-1无效',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_cluster_id_broker_id` (`cluster_id`,`broker_id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='broker信息表';
|
||||
|
||||
--
|
||||
-- Table structure for table `broker_metrics`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `broker_metrics`;
|
||||
CREATE TABLE `broker_metrics` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`broker_id` int(16) NOT NULL DEFAULT '-1' COMMENT 'brokerid',
|
||||
`metrics` text COMMENT '指标',
|
||||
`messages_in` double(53,2) NOT NULL DEFAULT '0.00' COMMENT '每秒消息数流入',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`),
|
||||
KEY `idx_cluster_id_broker_id_gmt_create` (`cluster_id`,`broker_id`,`gmt_create`),
|
||||
KEY `idx_gmt_create` (`gmt_create`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='broker-metric信息表';
|
||||
|
||||
--
|
||||
-- Table structure for table `cluster`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `cluster`;
|
||||
CREATE TABLE `cluster` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '集群id',
|
||||
`cluster_name` varchar(128) NOT NULL DEFAULT '' COMMENT '集群名称',
|
||||
`zookeeper` varchar(512) NOT NULL DEFAULT '' COMMENT 'zk地址',
|
||||
`bootstrap_servers` varchar(512) NOT NULL DEFAULT '' COMMENT 'server地址',
|
||||
`kafka_version` varchar(32) NOT NULL DEFAULT '' COMMENT 'kafka版本',
|
||||
`security_properties` text COMMENT '安全认证参数',
|
||||
`status` tinyint(4) NOT NULL DEFAULT '1' COMMENT ' 监控标记, 0表示未监控, 1表示监控中',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_cluster_name` (`cluster_name`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='cluster信息表';
|
||||
|
||||
--
|
||||
-- Table structure for table `cluster_metrics`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `cluster_metrics`;
|
||||
CREATE TABLE `cluster_metrics` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '集群id',
|
||||
`metrics` text COMMENT '指标',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`),
|
||||
KEY `idx_cluster_id_gmt_create` (`cluster_id`,`gmt_create`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='clustermetrics信息';
|
||||
|
||||
--
|
||||
-- Table structure for table `cluster_tasks`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `cluster_tasks`;
|
||||
CREATE TABLE `cluster_tasks` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`uuid` varchar(128) NOT NULL DEFAULT '' COMMENT '任务UUID',
|
||||
`cluster_id` bigint(128) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`task_type` varchar(128) NOT NULL DEFAULT '' COMMENT '任务类型',
|
||||
`kafka_package` text COMMENT 'kafka包',
|
||||
`kafka_package_md5` varchar(128) NOT NULL DEFAULT '' COMMENT 'kafka包的md5',
|
||||
`server_properties` text COMMENT 'kafkaserver配置',
|
||||
`server_properties_md5` varchar(128) NOT NULL DEFAULT '' COMMENT '配置文件的md5',
|
||||
`agent_task_id` bigint(128) NOT NULL DEFAULT '-1' COMMENT '任务id',
|
||||
`agent_rollback_task_id` bigint(128) NOT NULL DEFAULT '-1' COMMENT '回滚任务id',
|
||||
`host_list` text COMMENT '升级的主机',
|
||||
`pause_host_list` text COMMENT '暂停点',
|
||||
`rollback_host_list` text COMMENT '回滚机器列表',
|
||||
`rollback_pause_host_list` text COMMENT '回滚暂停机器列表',
|
||||
`operator` varchar(64) NOT NULL DEFAULT '' COMMENT '操作人',
|
||||
`task_status` int(11) NOT NULL DEFAULT '0' COMMENT '任务状态',
|
||||
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='集群任务(集群升级部署)';
|
||||
|
||||
--
|
||||
-- Table structure for table `config`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `config`;
|
||||
CREATE TABLE `config` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`config_key` varchar(128) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT '配置key',
|
||||
`config_value` text COMMENT '配置value',
|
||||
`config_description` text COMMENT '备注说明',
|
||||
`status` int(16) NOT NULL DEFAULT '0' COMMENT '0标识使用中,-1标识已废弃',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_config_key` (`config_key`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='配置表';
|
||||
|
||||
--
|
||||
-- Table structure for table `controller`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `controller`;
|
||||
CREATE TABLE `controller` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`broker_id` int(16) NOT NULL DEFAULT '-1' COMMENT 'brokerid',
|
||||
`host` varchar(256) NOT NULL DEFAULT '' COMMENT '主机名',
|
||||
`timestamp` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'controller变更时间',
|
||||
`version` int(16) NOT NULL DEFAULT '-1' COMMENT 'controller格式版本',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_cluster_id_broker_id_timestamp` (`cluster_id`,`broker_id`,`timestamp`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='controller记录表';
|
||||
|
||||
--
|
||||
-- Table structure for table `gateway_config`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `gateway_config`;
|
||||
CREATE TABLE `gateway_config` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`type` varchar(128) NOT NULL DEFAULT '' COMMENT '配置类型',
|
||||
`name` varchar(128) NOT NULL DEFAULT '' COMMENT '配置名称',
|
||||
`value` text COMMENT '配置值',
|
||||
`version` bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '版本信息',
|
||||
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_type_name` (`type`,`name`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='gateway配置';
|
||||
INSERT INTO gateway_config(type, name, value, `version`) values('SERVICE_DISCOVERY_QUEUE_SIZE', 'SERVICE_DISCOVERY_QUEUE_SIZE', 100000000, 1);
|
||||
INSERT INTO gateway_config(type, name, value, `version`) values('SERVICE_DISCOVERY_APPID_RATE', 'SERVICE_DISCOVERY_APPID_RATE', 100000000, 1);
|
||||
INSERT INTO gateway_config(type, name, value, `version`) values('SERVICE_DISCOVERY_IP_RATE', 'SERVICE_DISCOVERY_IP_RATE', 100000000, 1);
|
||||
INSERT INTO gateway_config(type, name, value, `version`) values('SERVICE_DISCOVERY_SP_RATE', 'app_01234567', 100000000, 1);
|
||||
INSERT INTO gateway_config(type, name, value, `version`) values('SERVICE_DISCOVERY_SP_RATE', '192.168.0.1', 100000000, 1);
|
||||
|
||||
--
|
||||
-- Table structure for table `heartbeat`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `heartbeat`;
|
||||
CREATE TABLE `heartbeat` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`ip` varchar(128) NOT NULL DEFAULT '' COMMENT '主机ip',
|
||||
`hostname` varchar(256) NOT NULL DEFAULT '' COMMENT '主机名',
|
||||
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_ip` (`ip`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='心跳信息';
|
||||
|
||||
--
|
||||
-- Table structure for table `kafka_acl`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `kafka_acl`;
|
||||
CREATE TABLE `kafka_acl` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`app_id` varchar(128) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT '用户id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '集群id',
|
||||
`topic_name` varchar(192) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'topic名称',
|
||||
`access` int(11) NOT NULL DEFAULT '0' COMMENT '0:无权限, 1:读, 2:写, 3:读写',
|
||||
`operation` int(11) NOT NULL DEFAULT '0' COMMENT '0:创建, 1:更新 2:删除, 以最新的一条数据为准',
|
||||
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='权限信息(kafka-broker)';
|
||||
|
||||
--
|
||||
-- Table structure for table `kafka_bill`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `kafka_bill`;
|
||||
CREATE TABLE `kafka_bill` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '集群id',
|
||||
`topic_name` varchar(192) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'topic名称',
|
||||
`principal` varchar(64) NOT NULL DEFAULT '' COMMENT '负责人',
|
||||
`quota` double(53,2) NOT NULL DEFAULT '0.00' COMMENT '配额, 单位mb/s',
|
||||
`cost` double(53,2) NOT NULL DEFAULT '0.00' COMMENT '成本, 单位元',
|
||||
`cost_type` int(16) NOT NULL DEFAULT '0' COMMENT '成本类型, 0:共享集群, 1:独享集群, 2:独立集群',
|
||||
`gmt_day` varchar(64) NOT NULL DEFAULT '' COMMENT '计价的日期, 例如2019-02-02的计价结果',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_cluster_id_topic_name_gmt_day` (`cluster_id`,`topic_name`,`gmt_day`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='kafka账单';
|
||||
|
||||
--
|
||||
-- Table structure for table `kafka_file`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `kafka_file`;
|
||||
CREATE TABLE `kafka_file` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`storage_name` varchar(128) NOT NULL DEFAULT '' COMMENT '存储位置',
|
||||
`file_name` varchar(128) NOT NULL DEFAULT '' COMMENT '文件名',
|
||||
`file_md5` varchar(256) NOT NULL DEFAULT '' COMMENT '文件md5',
|
||||
`file_type` int(16) NOT NULL DEFAULT '-1' COMMENT '0:kafka压缩包, 1:kafkaserver配置',
|
||||
`description` text COMMENT '备注信息',
|
||||
`operator` varchar(64) NOT NULL DEFAULT '' COMMENT '创建用户',
|
||||
`status` int(16) NOT NULL DEFAULT '0' COMMENT '状态, 0:正常, -1:删除',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_cluster_id_file_name_storage_name` (`cluster_id`,`file_name`,`storage_name`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='文件管理';
|
||||
|
||||
--
|
||||
-- Table structure for table `kafka_user`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `kafka_user`;
|
||||
CREATE TABLE `kafka_user` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`app_id` varchar(128) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT '应用id',
|
||||
`password` varchar(256) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT '密码',
|
||||
`user_type` int(11) NOT NULL DEFAULT '0' COMMENT '0:普通用户, 1:超级用户',
|
||||
`operation` int(11) NOT NULL DEFAULT '0' COMMENT '0:创建, 1:更新 2:删除, 以最新一条的记录为准',
|
||||
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='kafka用户表';
|
||||
INSERT INTO app(app_id, name, password, type, applicant, principals, description) VALUES ('dkm_admin', 'KM管理员', 'km_kMl4N8as1Kp0CCY', 1, 'admin', 'admin', 'KM管理员应用-谨慎对外提供');
|
||||
INSERT INTO kafka_user(app_id, password, user_type, operation) VALUES ('dkm_admin', 'km_kMl4N8as1Kp0CCY', 1, 0);
|
||||
|
||||
|
||||
--
|
||||
-- Table structure for table `logical_cluster`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `logical_cluster`;
|
||||
CREATE TABLE `logical_cluster` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`name` varchar(192) NOT NULL DEFAULT '' COMMENT '逻辑集群名称',
|
||||
`mode` int(16) NOT NULL DEFAULT '0' COMMENT '逻辑集群类型, 0:共享集群, 1:独享集群, 2:独立集群',
|
||||
`app_id` varchar(64) NOT NULL DEFAULT '' COMMENT '所属应用',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`region_list` varchar(256) NOT NULL DEFAULT '' COMMENT 'regionid列表',
|
||||
`description` text COMMENT '备注说明',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_name` (`name`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='逻辑集群信息表';
|
||||
|
||||
--
|
||||
-- Table structure for table `monitor_rule`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `monitor_rule`;
|
||||
CREATE TABLE `monitor_rule` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`name` varchar(192) NOT NULL DEFAULT '' COMMENT '告警名称',
|
||||
`strategy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '监控id',
|
||||
`app_id` varchar(64) NOT NULL DEFAULT '' COMMENT 'appid',
|
||||
`operator` varchar(64) NOT NULL DEFAULT '' COMMENT '操作人',
|
||||
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_name` (`name`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='监控规则';
|
||||
|
||||
--
|
||||
-- Table structure for table `operate_record`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `operate_record`;
|
||||
CREATE TABLE `operate_record` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`module_id` int(16) NOT NULL DEFAULT '-1' COMMENT '模块类型, 0:topic, 1:应用, 2:配额, 3:权限, 4:集群, -1:未知',
|
||||
`operate_id` int(16) NOT NULL DEFAULT '-1' COMMENT '操作类型, 0:新增, 1:删除, 2:修改',
|
||||
`resource` varchar(256) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'topic名称、app名称',
|
||||
`content` text COMMENT '操作内容',
|
||||
`operator` varchar(64) NOT NULL DEFAULT '' COMMENT '操作人',
|
||||
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
KEY `idx_module_id_operate_id_operator` (`module_id`,`operate_id`,`operator`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='操作记录';
|
||||
|
||||
--
|
||||
-- Table structure for table `reassign_task`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `reassign_task`;
|
||||
CREATE TABLE `reassign_task` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`task_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '任务ID',
|
||||
`name` varchar(256) NOT NULL DEFAULT '' COMMENT '任务名称',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '集群id',
|
||||
`topic_name` varchar(192) NOT NULL DEFAULT '' COMMENT 'Topic名称',
|
||||
`partitions` text COMMENT '分区',
|
||||
`reassignment_json` text COMMENT '任务参数',
|
||||
`real_throttle` bigint(20) NOT NULL DEFAULT '0' COMMENT '限流值',
|
||||
`max_throttle` bigint(20) NOT NULL DEFAULT '0' COMMENT '限流上限',
|
||||
`min_throttle` bigint(20) NOT NULL DEFAULT '0' COMMENT '限流下限',
|
||||
`begin_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '开始时间',
|
||||
`operator` varchar(64) NOT NULL DEFAULT '' COMMENT '操作人',
|
||||
`description` varchar(256) NOT NULL DEFAULT '' COMMENT '备注说明',
|
||||
`status` int(16) NOT NULL DEFAULT '0' COMMENT '任务状态',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '任务创建时间',
|
||||
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '任务修改时间',
|
||||
`original_retention_time` bigint(20) NOT NULL DEFAULT '86400000' COMMENT 'Topic存储时间',
|
||||
`reassign_retention_time` bigint(20) NOT NULL DEFAULT '86400000' COMMENT '迁移时的存储时间',
|
||||
`src_brokers` text COMMENT '源Broker',
|
||||
`dest_brokers` text COMMENT '目标Broker',
|
||||
PRIMARY KEY (`id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='topic迁移信息';
|
||||
|
||||
--
|
||||
-- Table structure for table `region`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `region`;
|
||||
CREATE TABLE `region` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`name` varchar(192) NOT NULL DEFAULT '' COMMENT 'region名称',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`broker_list` varchar(256) NOT NULL DEFAULT '' COMMENT 'broker列表',
|
||||
`capacity` bigint(20) NOT NULL DEFAULT '0' COMMENT '容量(B/s)',
|
||||
`real_used` bigint(20) NOT NULL DEFAULT '0' COMMENT '实际使用量(B/s)',
|
||||
`estimate_used` bigint(20) NOT NULL DEFAULT '0' COMMENT '预估使用量(B/s)',
|
||||
`description` text COMMENT '备注说明',
|
||||
`status` int(16) NOT NULL DEFAULT '0' COMMENT '状态,0正常,1已满',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_name` (`name`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='region信息表';
|
||||
|
||||
--
|
||||
-- Table structure for table `topic`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `topic`;
|
||||
CREATE TABLE `topic` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`topic_name` varchar(192) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'topic名称',
|
||||
`app_id` varchar(64) NOT NULL DEFAULT '' COMMENT 'topic所属appid',
|
||||
`peak_bytes_in` bigint(20) NOT NULL DEFAULT '0' COMMENT '峰值流量',
|
||||
`description` text COMMENT '备注信息',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_cluster_id_topic_name` (`cluster_id`,`topic_name`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='topic信息表';
|
||||
|
||||
--
|
||||
-- Table structure for table `topic_app_metrics`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `topic_app_metrics`;
|
||||
CREATE TABLE `topic_app_metrics` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '集群id',
|
||||
`topic_name` varchar(192) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'topic名称',
|
||||
`app_id` varchar(64) NOT NULL DEFAULT '' COMMENT 'appid',
|
||||
`metrics` text COMMENT '指标',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`),
|
||||
KEY `idx_cluster_id_topic_name_app_id_gmt_create` (`cluster_id`,`topic_name`,`app_id`,`gmt_create`),
|
||||
KEY `idx_gmt_create` (`gmt_create`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='topic app metrics';
|
||||
|
||||
--
|
||||
-- Table structure for table `topic_connections`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `topic_connections`;
|
||||
CREATE TABLE `topic_connections` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`app_id` varchar(64) NOT NULL DEFAULT '' COMMENT '应用id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '集群id',
|
||||
`topic_name` varchar(192) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'topic名称',
|
||||
`type` varchar(16) NOT NULL DEFAULT '' COMMENT 'producer or consumer',
|
||||
`ip` varchar(32) NOT NULL DEFAULT '' COMMENT 'ip地址',
|
||||
`client_version` varchar(8) NOT NULL DEFAULT '' COMMENT '客户端版本',
|
||||
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_app_id_cluster_id_topic_name_type_ip_client_version` (`app_id`,`cluster_id`,`topic_name`,`type`,`ip`,`client_version`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='topic连接信息表';
|
||||
|
||||
--
|
||||
-- Table structure for table `topic_expired`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `topic_expired`;
|
||||
CREATE TABLE `topic_expired` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`topic_name` varchar(192) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'topic名称',
|
||||
`produce_connection_num` bigint(20) NOT NULL DEFAULT '0' COMMENT '发送连接数',
|
||||
`fetch_connection_num` bigint(20) NOT NULL DEFAULT '0' COMMENT '消费连接数',
|
||||
`expired_day` bigint(20) NOT NULL DEFAULT '0' COMMENT '过期天数',
|
||||
`gmt_retain` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '保留截止时间',
|
||||
`status` int(16) NOT NULL DEFAULT '0' COMMENT '-1:可下线, 0:过期待通知, 1+:已通知待反馈',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_cluster_id_topic_name` (`cluster_id`,`topic_name`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='topic过期信息表';
|
||||
|
||||
--
|
||||
-- Table structure for table `topic_metrics`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `topic_metrics`;
|
||||
CREATE TABLE `topic_metrics` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`topic_name` varchar(192) NOT NULL DEFAULT '' COMMENT 'topic名称',
|
||||
`metrics` text COMMENT '指标数据JSON',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`),
|
||||
KEY `idx_cluster_id_topic_name_gmt_create` (`cluster_id`,`topic_name`,`gmt_create`),
|
||||
KEY `idx_gmt_create` (`gmt_create`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='topicmetrics表';
|
||||
|
||||
--
|
||||
-- Table structure for table `topic_report`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `topic_report`;
|
||||
CREATE TABLE `topic_report` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '集群id',
|
||||
`topic_name` varchar(192) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'topic名称',
|
||||
`start_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '开始上报时间',
|
||||
`end_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '结束上报时间',
|
||||
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_cluster_id_topic_name` (`cluster_id`,`topic_name`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='开启jmx采集的topic';
|
||||
|
||||
--
|
||||
-- Table structure for table `topic_request_time_metrics`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `topic_request_time_metrics`;
|
||||
CREATE TABLE `topic_request_time_metrics` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`topic_name` varchar(192) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'topic名称',
|
||||
`metrics` text COMMENT '指标',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`),
|
||||
KEY `idx_cluster_id_topic_name_gmt_create` (`cluster_id`,`topic_name`,`gmt_create`),
|
||||
KEY `idx_gmt_create` (`gmt_create`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='topic请求耗时信息';
|
||||
|
||||
--
|
||||
-- Table structure for table `topic_statistics`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `topic_statistics`;
|
||||
CREATE TABLE `topic_statistics` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`topic_name` varchar(192) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'topic名称',
|
||||
`offset_sum` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'offset和',
|
||||
`max_avg_bytes_in` double(53,2) NOT NULL DEFAULT '-1.00' COMMENT '峰值的均值流量',
|
||||
`gmt_day` varchar(64) NOT NULL DEFAULT '' COMMENT '日期2020-03-30的形式',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`max_avg_messages_in` double(53,2) NOT NULL DEFAULT '-1.00' COMMENT '峰值的均值消息条数',
|
||||
PRIMARY KEY (`id`),
|
||||
UNIQUE KEY `uniq_cluster_id_topic_name_gmt_day` (`cluster_id`,`topic_name`,`gmt_day`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='topic统计信息表';
|
||||
|
||||
--
|
||||
-- Table structure for table `topic_throttled_metrics`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `topic_throttled_metrics`;
|
||||
CREATE TABLE `topic_throttled_metrics` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
|
||||
`topic_name` varchar(192) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'topic name',
|
||||
`app_id` varchar(64) NOT NULL DEFAULT '' COMMENT 'app',
|
||||
`produce_throttled` tinyint(8) NOT NULL DEFAULT '0' COMMENT '是否是生产耗时',
|
||||
`fetch_throttled` tinyint(8) NOT NULL DEFAULT '0' COMMENT '是否是消费耗时',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
PRIMARY KEY (`id`),
|
||||
KEY `idx_cluster_id_topic_name_app_id` (`cluster_id`,`topic_name`,`app_id`),
|
||||
KEY `idx_gmt_create` (`gmt_create`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='topic限流信息';
|
||||
|
||||
--
|
||||
-- Table structure for table `work_order`
|
||||
--
|
||||
|
||||
-- DROP TABLE IF EXISTS `work_order`;
|
||||
CREATE TABLE `work_order` (
|
||||
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
|
||||
`type` int(16) NOT NULL DEFAULT '-1' COMMENT '工单类型',
|
||||
`title` varchar(512) NOT NULL DEFAULT '' COMMENT '工单标题',
|
||||
`applicant` varchar(64) NOT NULL DEFAULT '' COMMENT '申请人',
|
||||
`description` text COMMENT '备注信息',
|
||||
`approver` varchar(64) NOT NULL DEFAULT '' COMMENT '审批人',
|
||||
`gmt_handle` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '审批时间',
|
||||
`opinion` varchar(256) NOT NULL DEFAULT '' COMMENT '审批信息',
|
||||
`extensions` text COMMENT '扩展信息',
|
||||
`status` int(16) NOT NULL DEFAULT '0' COMMENT '工单状态, 0:待审批, 1:通过, 2:拒绝, 3:取消',
|
||||
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
|
||||
`gmt_modify` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
|
||||
PRIMARY KEY (`id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='工单表';
|
||||
58
docs/install_guide/install_guide_cn.md
Normal file
@@ -0,0 +1,58 @@
|
||||
|
||||
---
|
||||
|
||||

|
||||
|
||||
**一站式`Apache Kafka`集群指标监控与运维管控平台**
|
||||
|
||||
---
|
||||
|
||||
# 安装手册
|
||||
|
||||
|
||||
## 环境依赖
|
||||
|
||||
- `Maven 3.5+`(后端打包依赖)
|
||||
- `node 10+`(前端打包依赖)
|
||||
- `Java 8+`(运行环境需要)
|
||||
- `MySQL 5.7`(数据存储)
|
||||
|
||||
---
|
||||
|
||||
## 环境初始化
|
||||
|
||||
执行[create_mysql_table.sql](create_mysql_table.sql)中的SQL命令,从而创建所需的MySQL库及表,默认创建的库名是`kafka_manager`。
|
||||
|
||||
```
|
||||
# 示例:
|
||||
mysql -uXXXX -pXXX -h XXX.XXX.XXX.XXX -PXXXX < ./create_mysql_table.sql
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 打包
|
||||
|
||||
```bash
|
||||
|
||||
# 一次性打包
|
||||
cd ..
|
||||
mvn install
|
||||
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 启动
|
||||
|
||||
```
|
||||
# application.yml 是配置文件
|
||||
|
||||
cp kafka-manager-web/src/main/resources/application.yml kafka-manager-web/target/
|
||||
cd kafka-manager-web/target/
|
||||
nohup java -jar kafka-manager-web-2.0.0-SNAPSHOT.jar --spring.config.location=./application.yml > /dev/null 2>&1 &
|
||||
```
|
||||
|
||||
## 使用
|
||||
|
||||
本地启动的话,访问`http://localhost:8080`,输入帐号及密码(默认`admin/admin`)进行登录。更多参考:[kafka-manager 用户使用手册](../user_guide/user_guide_cn.md)
|
||||
|
||||
@@ -1,364 +0,0 @@
|
||||
## 2.1、单机部署
|
||||
|
||||
**风险提示**
|
||||
|
||||
⚠️ 脚本全自动安装,会将所部署机器上的 MySQL、JDK、ES 等进行删除重装,请注意原有服务丢失风险。
|
||||
|
||||
### 2.1.1、安装说明
|
||||
|
||||
- 以 `v3.0.0-beta.1` 版本为例进行部署;
|
||||
- 以 CentOS-7 为例,系统基础配置要求 4C-8G;
|
||||
- 部署完成后,可通过浏览器:`IP:PORT` 进行访问,默认端口是 `8080`,系统默认账号密码: `admin` / `admin2022_`。
|
||||
- `v3.0.0-beta.2`版本开始,默认账号密码为`admin` / `admin`;
|
||||
- 本文为单机部署,如需分布式部署,[请联系我们](https://knowstreaming.com/support-center)
|
||||
|
||||
**软件依赖**
|
||||
|
||||
| 软件名 | 版本要求 | 默认端口 |
|
||||
| ------------- | ------------ | -------- |
|
||||
| MySQL | v5.7 或 v8.0 | 3306 |
|
||||
| ElasticSearch | v7.6+ | 8060 |
|
||||
| JDK | v8+ | - |
|
||||
| CentOS | v6+ | - |
|
||||
| Ubuntu | v16+ | - |
|
||||
|
||||
|
||||
|
||||
### 2.1.2、脚本部署
|
||||
|
||||
**在线安装**
|
||||
|
||||
```bash
|
||||
# 在服务器中下载安装脚本, 该脚本中会在当前目录下,重新安装MySQL。重装后的mysql密码存放在当前目录的mysql.password文件中。
|
||||
wget https://s3-gzpu.didistatic.com/pub/knowstreaming/deploy_KnowStreaming-3.0.0-beta.1.sh
|
||||
|
||||
# 执行脚本
|
||||
sh deploy_KnowStreaming.sh
|
||||
|
||||
# 访问地址
|
||||
127.0.0.1:8080
|
||||
```
|
||||
|
||||
**离线安装**
|
||||
|
||||
```bash
|
||||
# 将安装包下载到本地且传输到目标服务器
|
||||
wget https://s3-gzpu.didistatic.com/pub/knowstreaming/KnowStreaming-3.0.0-beta.1-offline.tar.gz
|
||||
|
||||
# 解压安装包
|
||||
tar -zxf KnowStreaming-3.0.0-beta.1-offline.tar.gz
|
||||
|
||||
# 执行安装脚本
|
||||
sh deploy_KnowStreaming-offline.sh
|
||||
|
||||
# 访问地址
|
||||
127.0.0.1:8080
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 2.1.3、容器部署
|
||||
|
||||
#### 2.1.3.1、Helm
|
||||
|
||||
**环境依赖**
|
||||
|
||||
- Kubernetes >= 1.14 ,Helm >= 2.17.0
|
||||
|
||||
- 默认依赖全部安装,ElasticSearch(3 节点集群模式) + MySQL(单机) + KnowStreaming-manager + KnowStreaming-ui
|
||||
|
||||
- 使用已有的 ElasticSearch(7.6.x) 和 MySQL(5.7) 只需调整 values.yaml 部分参数即可
|
||||
|
||||
**安装命令**
|
||||
|
||||
```bash
|
||||
# 相关镜像在Docker Hub都可以下载
|
||||
# 快速安装(NAMESPACE需要更改为已存在的,安装启动需要几分钟初始化请稍等~)
|
||||
helm install -n [NAMESPACE] [NAME] http://download.knowstreaming.com/charts/knowstreaming-manager-0.1.3.tgz
|
||||
|
||||
# 获取KnowStreaming前端ui的service. 默认nodeport方式.
|
||||
# (http://nodeIP:nodeport,默认用户名密码:admin/admin2022_)
|
||||
# `v3.0.0-beta.2`版本开始,默认账号密码为`admin` / `admin`;
|
||||
|
||||
# 添加仓库
|
||||
helm repo add knowstreaming http://download.knowstreaming.com/charts
|
||||
|
||||
# 拉取最新版本
|
||||
helm pull knowstreaming/knowstreaming-manager
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 2.1.3.2、Docker Compose
|
||||
```yml
|
||||
version: "3"
|
||||
|
||||
services:
|
||||
|
||||
knowstreaming-manager:
|
||||
image: knowstreaming/knowstreaming-manager:0.2.0-test
|
||||
container_name: knowstreaming-manager
|
||||
privileged: true
|
||||
restart: always
|
||||
depends_on:
|
||||
- elasticsearch-single
|
||||
- knowstreaming-mysql
|
||||
expose:
|
||||
- 80
|
||||
command:
|
||||
- /bin/sh
|
||||
- /ks-start.sh
|
||||
environment:
|
||||
TZ: Asia/Shanghai
|
||||
|
||||
SERVER_MYSQL_ADDRESS: knowstreaming-mysql:3306
|
||||
SERVER_MYSQL_DB: know_streaming
|
||||
SERVER_MYSQL_USER: root
|
||||
SERVER_MYSQL_PASSWORD: admin2022_
|
||||
|
||||
SERVER_ES_ADDRESS: elasticsearch-single:9200
|
||||
|
||||
JAVA_OPTS: -Xmx1g -Xms1g
|
||||
|
||||
# extra_hosts:
|
||||
# - "hostname:x.x.x.x"
|
||||
# volumes:
|
||||
# - /ks/manage/log:/logs
|
||||
knowstreaming-ui:
|
||||
image: knowstreaming/knowstreaming-ui:0.2.0-test1
|
||||
container_name: knowstreaming-ui
|
||||
restart: always
|
||||
ports:
|
||||
- '18092:80'
|
||||
environment:
|
||||
TZ: Asia/Shanghai
|
||||
depends_on:
|
||||
- knowstreaming-manager
|
||||
# extra_hosts:
|
||||
# - "hostname:x.x.x.x"
|
||||
|
||||
elasticsearch-single:
|
||||
image: docker.io/library/elasticsearch:7.6.2
|
||||
container_name: elasticsearch-single
|
||||
restart: always
|
||||
expose:
|
||||
- 9200
|
||||
- 9300
|
||||
# ports:
|
||||
# - '9200:9200'
|
||||
# - '9300:9300'
|
||||
environment:
|
||||
TZ: Asia/Shanghai
|
||||
ES_JAVA_OPTS: -Xms512m -Xmx512m
|
||||
discovery.type: single-node
|
||||
# volumes:
|
||||
# - /ks/es/data:/usr/share/elasticsearch/data
|
||||
|
||||
knowstreaming-init:
|
||||
image: knowstreaming/knowstreaming-manager:0.2.0-test
|
||||
container_name: knowstreaming_init
|
||||
depends_on:
|
||||
- elasticsearch-single
|
||||
command:
|
||||
- /bin/bash
|
||||
- /es_template_create.sh
|
||||
environment:
|
||||
TZ: Asia/Shanghai
|
||||
SERVER_ES_ADDRESS: elasticsearch-single:9200
|
||||
|
||||
|
||||
knowstreaming-mysql:
|
||||
image: knowstreaming/knowstreaming-mysql:0.2.0-test
|
||||
container_name: knowstreaming-mysql
|
||||
restart: always
|
||||
environment:
|
||||
TZ: Asia/Shanghai
|
||||
MYSQL_ROOT_PASSWORD: admin2022_
|
||||
MYSQL_DATABASE: know_streaming
|
||||
MYSQL_ROOT_HOST: '%'
|
||||
expose:
|
||||
- 3306
|
||||
# ports:
|
||||
# - '3306:3306'
|
||||
# volumes:
|
||||
# - /ks/mysql/data:/data/mysql
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 2.1.4、手动部署
|
||||
|
||||
**部署流程**
|
||||
|
||||
1. 安装 `JDK-11`、`MySQL`、`ElasticSearch` 等依赖服务
|
||||
2. 安装 KnowStreaming
|
||||
|
||||
|
||||
|
||||
#### 2.1.4.1、安装 MySQL 服务
|
||||
|
||||
**yum 方式安装**
|
||||
|
||||
```bash
|
||||
# 配置yum源
|
||||
wget https://dev.mysql.com/get/mysql57-community-release-el7-9.noarch.rpm
|
||||
rpm -ivh mysql57-community-release-el7-9.noarch.rpm
|
||||
|
||||
# 执行安装
|
||||
yum -y install mysql-server mysql-client
|
||||
|
||||
# 服务启动
|
||||
systemctl start mysqld
|
||||
|
||||
# 获取初始密码并修改
|
||||
old_pass=`grep 'temporary password' /var/log/mysqld.log | awk '{print $NF}' | tail -n 1`
|
||||
|
||||
mysql -NBe "alter user USER() identified by 'Didi_km_678';" --connect-expired-password -uroot -p$old_pass
|
||||
```
|
||||
|
||||
**rpm 方式安装**
|
||||
|
||||
```bash
|
||||
# 下载安装包
|
||||
wget https://s3-gzpu.didistatic.com/knowsearch/mysql5.7.tar.gz
|
||||
|
||||
# 解压到指定目录
|
||||
tar -zxf mysql5.7.tar.gz -C /tmp/
|
||||
|
||||
# 执行安装
|
||||
yum -y localinstall /tmp/libaio-*.rpm /tmp/mysql-*.rpm
|
||||
|
||||
# 服务启动
|
||||
systemctl start mysqld
|
||||
|
||||
|
||||
# 获取初始密码并修改
|
||||
old_pass=`grep 'temporary password' /var/log/mysqld.log | awk '{print $NF}' | tail -n 1`
|
||||
|
||||
mysql -NBe "alter user USER() identified by 'Didi_km_678';" --connect-expired-password -uroot -p$old_pass
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 2.1.4.2、配置 JDK 环境
|
||||
|
||||
```bash
|
||||
# 下载安装包
|
||||
wget https://s3-gzpu.didistatic.com/pub/jdk11.tar.gz
|
||||
|
||||
# 解压到指定目录
|
||||
tar -zxf jdk11.tar.gz -C /usr/local/
|
||||
|
||||
# 更改目录名
|
||||
mv /usr/local/jdk-11.0.2 /usr/local/java11
|
||||
|
||||
# 添加到环境变量
|
||||
echo "export JAVA_HOME=/usr/local/java11" >> ~/.bashrc
|
||||
echo "export CLASSPATH=/usr/java/java11/lib" >> ~/.bashrc
|
||||
echo "export PATH=$JAVA_HOME/bin:$PATH:$HOME/bin" >> ~/.bashrc
|
||||
|
||||
source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 2.1.4.3、ElasticSearch 实例搭建
|
||||
|
||||
- ElasticSearch 用于存储平台采集的 Kafka 指标;
|
||||
- 以下安装示例为单节点模式,如需集群部署可以参考:[Elasticsearch 官方文档](https://www.elastic.co/guide/en/elasticsearch/reference/7.6/elasticsearch-intro.html)
|
||||
|
||||
```bash
|
||||
# 下载安装包
|
||||
wget https://s3-gzpu.didistatic.com/pub/elasticsearch.tar.gz
|
||||
|
||||
# 创建ES数据存储目录
|
||||
mkdir -p /data/es_data
|
||||
|
||||
# 创建ES所属用户
|
||||
useradd arius
|
||||
|
||||
# 配置用户的打开文件数
|
||||
echo "arius soft nofile 655350" >> /etc/security/limits.conf
|
||||
echo "arius hard nofile 655350" >> /etc/security/limits.conf
|
||||
echo "vm.max_map_count = 655360" >> /etc/sysctl.conf
|
||||
sysctl -p
|
||||
|
||||
# 解压安装包
|
||||
tar -zxf elasticsearch.tar.gz -C /data/
|
||||
|
||||
# 更改目录所属组
|
||||
chown -R arius:arius /data/
|
||||
|
||||
# 修改配置文件(参考以下配置)
|
||||
vim /data/elasticsearch/config/elasticsearch.yml
|
||||
cluster.name: km_es
|
||||
node.name: es-node1
|
||||
node.master: true
|
||||
node.data: true
|
||||
path.data: /data/es_data
|
||||
http.port: 8060
|
||||
discovery.seed_hosts: ["127.0.0.1:9300"]
|
||||
|
||||
# 修改内存配置
|
||||
vim /data/elasticsearch/config/jvm.options
|
||||
-Xms2g
|
||||
-Xmx2g
|
||||
|
||||
# 启动服务
|
||||
su - arius
|
||||
export JAVA_HOME=/usr/local/java11
|
||||
sh /data/elasticsearch/control.sh start
|
||||
|
||||
# 确认状态
|
||||
sh /data/elasticsearch/control.sh status
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 2.1.4.4、KnowStreaming 实例搭建
|
||||
|
||||
```bash
|
||||
# 下载安装包
|
||||
wget https://s3-gzpu.didistatic.com/pub/knowstreaming/KnowStreaming-3.0.0-beta.1.tar.gz
|
||||
|
||||
# 解压安装包到指定目录
|
||||
tar -zxf KnowStreaming-3.0.0-beta.1.tar.gz -C /data/
|
||||
|
||||
# 修改启动脚本并加入systemd管理
|
||||
cd /data/KnowStreaming/
|
||||
|
||||
# 创建相应的库和导入初始化数据
|
||||
mysql -uroot -pDidi_km_678 -e "create database know_streaming;"
|
||||
mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/ddl-ks-km.sql
|
||||
mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/ddl-logi-job.sql
|
||||
mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/ddl-logi-security.sql
|
||||
mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/dml-ks-km.sql
|
||||
mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/dml-logi.sql
|
||||
|
||||
# 创建elasticsearch初始化数据
|
||||
sh ./bin/init_es_template.sh
|
||||
|
||||
# 修改配置文件
|
||||
vim ./conf/application.yml
|
||||
|
||||
# 监听端口
|
||||
server:
|
||||
port: 8080 # web 服务端口
|
||||
tomcat:
|
||||
accept-count: 1000
|
||||
max-connections: 10000
|
||||
|
||||
# ES地址
|
||||
es.client.address: 127.0.0.1:8060
|
||||
|
||||
# 数据库配置(一共三处地方,修改正确的mysql地址和数据库名称以及用户名密码)
|
||||
jdbc-url: jdbc:mariadb://127.0.0.1:3306/know_streaming?.....
|
||||
username: root
|
||||
password: Didi_km_678
|
||||
|
||||
# 启动服务
|
||||
cd /data/KnowStreaming/bin/
|
||||
sh startup.sh
|
||||
```
|
||||
@@ -1,62 +0,0 @@
|
||||

|
||||
|
||||
# `Know Streaming` 源码编译打包手册
|
||||
|
||||
## 1、环境信息
|
||||
|
||||
**系统支持**
|
||||
|
||||
`windows7+`、`Linux`、`Mac`
|
||||
|
||||
**环境依赖**
|
||||
|
||||
- Maven 3.6.3 (后端)
|
||||
- Node v12.20.0/v14.17.3 (前端)
|
||||
- Java 8+ (后端)
|
||||
- Git
|
||||
|
||||
## 2、编译打包
|
||||
|
||||
整个工程中,除了`km-console`为前端模块之外,其他模块都是后端工程相关模块。
|
||||
|
||||
因此,如果前后端合并打包,则打对整个工程进行打包;如果前端单独打包,则仅打包 `km-console` 中的代码;如果是仅需要后端打包,则在顶层 `pom.xml` 中去掉 `km-console`模块,然后进行打包。
|
||||
|
||||
具体见下面描述。
|
||||
|
||||
### 2.1、前后端合并打包
|
||||
|
||||
1. 下载源码;
|
||||
2. 进入 `KS-KM` 工程目录,执行 `mvn -Prelease-package -Dmaven.test.skip=true clean install -U` 命令;
|
||||
3. 打包命令执行完成后,会在 `km-dist/target` 目录下面生成一个 `KnowStreaming-*.tar.gz` 的安装包。
|
||||
|
||||
### 2.2、前端单独打包
|
||||
|
||||
1. 下载源码;
|
||||
2. 跳转到 [前端打包构建文档](https://github.com/didi/KnowStreaming/blob/master/km-console/README.md) 按步骤进行。打包成功后,会在 `km-rest/src/main/resources` 目录下生成名为 `templates` 的前端静态资源包;
|
||||
3. 如果上一步过程中报错,请查看 [FAQ](https://github.com/didi/KnowStreaming/blob/master/docs/user_guide/faq.md) 第 8.10 条;
|
||||
|
||||
### 2.3、后端单独打包
|
||||
|
||||
1. 下载源码;
|
||||
2. 修改顶层 `pom.xml` ,去掉其中的 `km-console` 模块,如下所示;
|
||||
|
||||
```xml
|
||||
<modules>
|
||||
<!-- <module>km-console</module>-->
|
||||
<module>km-common</module>
|
||||
<module>km-persistence</module>
|
||||
<module>km-core</module>
|
||||
<module>km-biz</module>
|
||||
<module>km-extends/km-account</module>
|
||||
<module>km-extends/km-monitor</module>
|
||||
<module>km-extends/km-license</module>
|
||||
<module>km-extends/km-rebalance</module>
|
||||
<module>km-task</module>
|
||||
<module>km-collector</module>
|
||||
<module>km-rest</module>
|
||||
<module>km-dist</module>
|
||||
</modules>
|
||||
```
|
||||
|
||||
3. 执行 `mvn -U clean package -Dmaven.test.skip=true`命令;
|
||||
4. 执行完成之后会在 `KS-KM/km-rest/target` 目录下面生成一个 `ks-km.jar` 即为 KS 的后端部署的 Jar 包,也可以执行 `mvn -Prelease-package -Dmaven.test.skip=true clean install -U` 生成的 tar 包也仅有后端服务的功能;
|
||||
@@ -1,133 +0,0 @@
|
||||
## 6.2、版本升级手册
|
||||
|
||||
注意:如果想升级至具体版本,需要将你当前版本至你期望使用版本的变更统统执行一遍,然后才能正常使用。
|
||||
|
||||
### 6.2.0、升级至 `master` 版本
|
||||
|
||||
暂无
|
||||
|
||||
### 6.2.1、升级至 `v3.0.0-beta.2`版本
|
||||
|
||||
**配置变更**
|
||||
|
||||
```yaml
|
||||
|
||||
# 新增配置
|
||||
spring:
|
||||
logi-security: # know-streaming 依赖的 logi-security 模块的数据库的配置,默认与 know-streaming 的数据库配置保持一致即可
|
||||
login-extend-bean-name: logiSecurityDefaultLoginExtendImpl # 使用的登录系统Service的Bean名称,无需修改
|
||||
|
||||
# 线程池大小相关配置,在task模块中,新增了三类线程池,
|
||||
# 从而减少不同类型任务之间的相互影响,以及减少对logi-job内的线程池的影响
|
||||
thread-pool:
|
||||
task: # 任务模块的配置
|
||||
metrics: # metrics采集任务配置
|
||||
thread-num: 18 # metrics采集任务线程池核心线程数
|
||||
queue-size: 180 # metrics采集任务线程池队列大小
|
||||
metadata: # metadata同步任务配置
|
||||
thread-num: 27 # metadata同步任务线程池核心线程数
|
||||
queue-size: 270 # metadata同步任务线程池队列大小
|
||||
common: # 剩余其他任务配置
|
||||
thread-num: 15 # 剩余其他任务线程池核心线程数
|
||||
queue-size: 150 # 剩余其他任务线程池队列大小
|
||||
|
||||
# 删除配置,下列配置将不再使用
|
||||
thread-pool:
|
||||
task: # 任务模块的配置
|
||||
heaven: # 采集任务配置
|
||||
thread-num: 20 # 采集任务线程池核心线程数
|
||||
queue-size: 1000 # 采集任务线程池队列大小
|
||||
|
||||
```
|
||||
|
||||
**SQL 变更**
|
||||
|
||||
```sql
|
||||
-- 多集群管理权限2022-09-06新增
|
||||
INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2000', '多集群管理查看', '1593', '1', '2', '多集群管理查看', '0', 'know-streaming');
|
||||
INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2002', 'Topic-迁移副本', '1593', '1', '2', 'Topic-迁移副本', '0', 'know-streaming');
|
||||
INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2004', 'Topic-扩缩副本', '1593', '1', '2', 'Topic-扩缩副本', '0', 'know-streaming');
|
||||
INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2006', 'Cluster-LoadReBalance-周期均衡', '1593', '1', '2', 'Cluster-LoadReBalance-周期均衡', '0', 'know-streaming');
|
||||
INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2008', 'Cluster-LoadReBalance-立即均衡', '1593', '1', '2', 'Cluster-LoadReBalance-立即均衡', '0', 'know-streaming');
|
||||
INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2010', 'Cluster-LoadReBalance-设置集群规格', '1593', '1', '2', 'Cluster-LoadReBalance-设置集群规格', '0', 'know-streaming');
|
||||
|
||||
|
||||
-- 系统管理权限2022-09-06新增
|
||||
INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('3000', '系统管理查看', '1595', '1', '2', '系统管理查看', '0', 'know-streaming');
|
||||
|
||||
|
||||
INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2000', '0', 'know-streaming');
|
||||
INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2002', '0', 'know-streaming');
|
||||
INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2004', '0', 'know-streaming');
|
||||
INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2006', '0', 'know-streaming');
|
||||
INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2008', '0', 'know-streaming');
|
||||
INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2010', '0', 'know-streaming');
|
||||
INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '3000', '0', 'know-streaming');
|
||||
|
||||
-- 修改字段长度
|
||||
ALTER TABLE `logi_security_oplog`
|
||||
CHANGE COLUMN `operator_ip` `operator_ip` VARCHAR(64) NOT NULL COMMENT '操作者ip' ,
|
||||
CHANGE COLUMN `operator` `operator` VARCHAR(64) NULL DEFAULT NULL COMMENT '操作者账号' ,
|
||||
CHANGE COLUMN `operate_page` `operate_page` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '操作页面' ,
|
||||
CHANGE COLUMN `operate_type` `operate_type` VARCHAR(64) NOT NULL COMMENT '操作类型' ,
|
||||
CHANGE COLUMN `target_type` `target_type` VARCHAR(64) NOT NULL COMMENT '对象分类' ,
|
||||
CHANGE COLUMN `target` `target` VARCHAR(1024) NOT NULL COMMENT '操作对象' ,
|
||||
CHANGE COLUMN `operation_methods` `operation_methods` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '操作方式' ;
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 6.2.2、升级至 `v3.0.0-beta.1`版本
|
||||
|
||||
**SQL 变更**
|
||||
|
||||
1、在`ks_km_broker`表增加了一个监听信息字段。
|
||||
2、为`logi_security_oplog`表 operation_methods 字段设置默认值''。
|
||||
因此需要执行下面的 sql 对数据库表进行更新。
|
||||
|
||||
```sql
|
||||
ALTER TABLE `ks_km_broker`
|
||||
ADD COLUMN `endpoint_map` VARCHAR(1024) NOT NULL DEFAULT '' COMMENT '监听信息' AFTER `update_time`;
|
||||
|
||||
ALTER TABLE `logi_security_oplog`
|
||||
ALTER COLUMN `operation_methods` set default '';
|
||||
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 6.2.3、`2.x`版本 升级至 `v3.0.0-beta.0`版本
|
||||
|
||||
**升级步骤:**
|
||||
|
||||
1. 依旧使用**`2.x 版本的 DB`**,在上面初始化 3.0.0 版本所需数据库表结构及数据;
|
||||
2. 将 2.x 版本中的集群,在 3.0.0 版本,手动逐一接入;
|
||||
3. 将 Topic 业务数据,迁移至 3.0.0 表中,详见下方 SQL;
|
||||
|
||||
**注意事项**
|
||||
|
||||
- 建议升级 3.0.0 版本过程中,保留 2.x 版本的使用,待 3.0.0 版本稳定使用后,再下线 2.x 版本;
|
||||
- 3.0.0 版本仅需要`集群信息`及`Topic的描述信息`。2.x 版本的 DB 的其他数据 3.0.0 版本都不需要;
|
||||
- 部署 3.0.0 版本之后,集群、Topic 等指标数据都为空,3.0.0 版本会周期进行采集,运行一段时间之后就会有该数据了,因此不会将 2.x 中的指标数据进行迁移;
|
||||
|
||||
**迁移数据**
|
||||
|
||||
```sql
|
||||
-- 迁移Topic的备注信息。
|
||||
-- 需在 3.0.0 部署完成后,再执行该SQL。
|
||||
-- 考虑到 2.x 版本中还存在增量数据,因此建议改SQL周期执行,是的增量数据也能被迁移至 3.0.0 版本中。
|
||||
|
||||
UPDATE ks_km_topic
|
||||
INNER JOIN
|
||||
(SELECT
|
||||
topic.cluster_id AS cluster_id,
|
||||
topic.topic_name AS topic_name,
|
||||
topic.description AS description
|
||||
FROM topic WHERE description != ''
|
||||
) AS t
|
||||
|
||||
ON ks_km_topic.cluster_phy_id = t.cluster_id
|
||||
AND ks_km_topic.topic_name = t.topic_name
|
||||
AND ks_km_topic.id > 0
|
||||
SET ks_km_topic.description = t.description;
|
||||
```
|
||||
39
docs/user_guide/add_cluster/add_cluster.md
Normal file
@@ -0,0 +1,39 @@
|
||||
|
||||
---
|
||||
|
||||

|
||||
|
||||
**一站式`Apache Kafka`集群指标监控与运维管控平台**
|
||||
|
||||
---
|
||||
|
||||
# 集群接入
|
||||
|
||||
集群的接入总共需要三个步骤,分别是:
|
||||
1. 接入物理集群
|
||||
2. 创建Region
|
||||
3. 创建逻辑集群
|
||||
|
||||
备注:接入集群需要2、3两步是因为普通用户的视角下,看到的都是逻辑集群,如果没有2、3两步,那么普通用户看不到任何信息。
|
||||
|
||||
|
||||
## 1、接入物理集群
|
||||
|
||||

|
||||
|
||||
如上图所示,填写集群信息,然后点击确定,即可完成集群的接入。因为考虑到分布式部署,添加集群之后,需要稍等**`1分钟`**才可以在界面上看到集群的详细信息。
|
||||
|
||||
## 2、创建Region
|
||||
|
||||

|
||||
|
||||
如上图所示,填写Region信息,然后点击确定,即可完成Region的创建。
|
||||
|
||||
备注:Region即为Broker的集合,可以按照业务需要,将Broker归类,从而创建相应的Region。
|
||||
|
||||
## 3、创建逻辑集群
|
||||
|
||||

|
||||
|
||||
|
||||
如上图所示,填写逻辑集群信息,然后点击确定,即可完成逻辑集群的创建。
|
||||
BIN
docs/user_guide/add_cluster/assets/op_add_cluster.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 261 KiB |
BIN
docs/user_guide/add_cluster/assets/op_add_logical_cluster.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 240 KiB |
BIN
docs/user_guide/add_cluster/assets/op_add_region.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 195 KiB |
BIN
docs/user_guide/assets/LeaderRebalance.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 94 KiB |
BIN
docs/user_guide/assets/Versionmanagement.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 181 KiB |
BIN
docs/user_guide/assets/alarmhistory.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 65 KiB |
BIN
docs/user_guide/assets/alarmruledetail.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 166 KiB |
BIN
docs/user_guide/assets/alarmruleex.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 30 KiB |
BIN
docs/user_guide/assets/alarmruleforbidden.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 78 KiB |
BIN
docs/user_guide/assets/alarmruleforbiddenhistory.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 48 KiB |
BIN
docs/user_guide/assets/alarmrulesent.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 55 KiB |
BIN
docs/user_guide/assets/alarmruletime.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 16 KiB |
BIN
docs/user_guide/assets/appdetailop.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 297 KiB |
BIN
docs/user_guide/assets/applyapp.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 189 KiB |
BIN
docs/user_guide/assets/applycluster.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 173 KiB |
BIN
docs/user_guide/assets/applylocated.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 197 KiB |
BIN
docs/user_guide/assets/applytopicright.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 244 KiB |
BIN
docs/user_guide/assets/appmanager.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 118 KiB |
BIN
docs/user_guide/assets/appmanagerop.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 150 KiB |
BIN
docs/user_guide/assets/appoffline.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 177 KiB |
BIN
docs/user_guide/assets/apprighttopic.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 276 KiB |
BIN
docs/user_guide/assets/apptopic.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 257 KiB |
BIN
docs/user_guide/assets/billdata.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 153 KiB |
BIN
docs/user_guide/assets/brokerinfo.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 189 KiB |
BIN
docs/user_guide/assets/brokerinfolist.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 187 KiB |
BIN
docs/user_guide/assets/brokerpartition.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 92 KiB |
BIN
docs/user_guide/assets/brokerpartitionop.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 116 KiB |
BIN
docs/user_guide/assets/brokerrask.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 166 KiB |
BIN
docs/user_guide/assets/brokerraskop.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 158 KiB |
BIN
docs/user_guide/assets/brokerregion.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 124 KiB |
BIN
docs/user_guide/assets/brokertable.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 209 KiB |
BIN
docs/user_guide/assets/brokertopic.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 127 KiB |
BIN
docs/user_guide/assets/brokertopicana.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 162 KiB |
BIN
docs/user_guide/assets/cancelright.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 102 KiB |
BIN
docs/user_guide/assets/clusterbroker.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 189 KiB |
BIN
docs/user_guide/assets/clusterbrokerdetail.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 281 KiB |
BIN
docs/user_guide/assets/clusterbrokerdetailop.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 185 KiB |
BIN
docs/user_guide/assets/clusterbrokermo.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 170 KiB |
BIN
docs/user_guide/assets/clusterbrokerop.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 252 KiB |
BIN
docs/user_guide/assets/clusterdetail.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 238 KiB |
BIN
docs/user_guide/assets/clusterinfobrief.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 252 KiB |
BIN
docs/user_guide/assets/clustertask.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 278 KiB |
BIN
docs/user_guide/assets/clustertaskdetail.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 238 KiB |
BIN
docs/user_guide/assets/clustertopic.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 233 KiB |
BIN
docs/user_guide/assets/clustertopicop.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 208 KiB |
BIN
docs/user_guide/assets/configuremanager.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 395 KiB |
BIN
docs/user_guide/assets/consumergroup.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 235 KiB |
BIN
docs/user_guide/assets/consumeroffset.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 157 KiB |
BIN
docs/user_guide/assets/consumertopic.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 141 KiB |
BIN
docs/user_guide/assets/createalarmrule.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 150 KiB |
BIN
docs/user_guide/assets/createclustertask.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 168 KiB |
BIN
docs/user_guide/assets/createregion.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 91 KiB |
BIN
docs/user_guide/assets/createtask.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 120 KiB |
BIN
docs/user_guide/assets/createusers.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 120 KiB |
BIN
docs/user_guide/assets/datacenter.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 119 KiB |
BIN
docs/user_guide/assets/dealtask.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 168 KiB |
BIN
docs/user_guide/assets/deletcluster.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 41 KiB |
BIN
docs/user_guide/assets/deleteconfigure.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 211 KiB |
BIN
docs/user_guide/assets/deleteregion.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 136 KiB |
BIN
docs/user_guide/assets/editapp.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 215 KiB |
BIN
docs/user_guide/assets/editcluster.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 206 KiB |
BIN
docs/user_guide/assets/editconfigure.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 150 KiB |
BIN
docs/user_guide/assets/editregion.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 127 KiB |
BIN
docs/user_guide/assets/editroom.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 99 KiB |
BIN
docs/user_guide/assets/edittopic.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 92 KiB |
BIN
docs/user_guide/assets/edituser.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 69 KiB |
BIN
docs/user_guide/assets/errordiagnosis.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 110 KiB |
BIN
docs/user_guide/assets/expiredtopic.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 121 KiB |
BIN
docs/user_guide/assets/faq/jmx_check.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 266 KiB |
BIN
docs/user_guide/assets/helpcenter.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 143 KiB |
BIN
docs/user_guide/assets/hotpointtopic.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 332 KiB |
BIN
docs/user_guide/assets/limit.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 63 KiB |
BIN
docs/user_guide/assets/logicclusterdele.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 117 KiB |